#data scraping companies
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
70% of Tumblr users say the Dashboard is their favorite place to spend time online.
Text
Emerging Trends and Innovation in Web Scraping Services

Collecting data from various sources is a headache for many organizations, especially from the vast pool of information—the Internet. To ease the task, web scraping services allow businesses to extract data from various sources efficiently and quickly. However, the emerging trends in web scraping will transform the approach with more benefits. Check which trends are going to impact web scraping services.
#web scraping services#data scraping services#database scraping service#web scraping company#data scraping service#data scraping company#data scraping companies#web scraping companies#web scraping services usa#web data scraping services#web scraping services india
1 note
·
View note
Note
your last reblog might have some misinfo
genuinely, thanks for caring, but can you be more specific?
because if you mean the post about nightshade and glaze being ineffective and you're referencing the "debunk" in the notes from someone who clearly doesn't understand the technology involved and only cites the devs themselves (who obviously wouldnt be advertising the many ways in which the tech they're pushing fails to perform as intended), you're just mistaken I'm afraid.
also like. i know the op of that post and trust their knowledge on the subject a lot more than some rando misusing buzzwords
#look i hate the way ai companies indiscriminately scrape data and the way it has INSTANTLY oversaturated everything too#but the uninformed reactionary bullshit it's spawned is VERY unhelpful#not enabling reblogging on this either bc i dont want people to be annoying at me
37 notes
·
View notes
Text
Can someone explain to me why the idea of Automattic selling data to Midjourney is so awful?
I get that people don't want their posts and art being used to train generative models but... they already are being used to train generative models. If you make something public on the internet, then you can't stop anyone from scraping it and add it to a training set (there's no such thing as DRM that works against a well-funded opponent), and as I understand it all the big "AI" companies are already doing this.
So it seems like Tumblr is basically telling Midjourney etc. "Hey, wouldn't you like to get this data without having to process out the noise from webscraping? We'll give you cleaner data if you A) pay us and B) don't mind that we're going to let users opt out of it."
Shouldn't this be strictly better than the alternative, which is "Midjourney etc. just keep scraping all publicly available data regardless of what users want and also Tumblr doesn't have enough money to cover its operating expenses"? What am I missing here?
#like if a company is turning over private data that's one thing#but 'we take the data you were going to scrape anyway and sell it to you minus the users who opted out' seems like a step forwards#inasmuch as it becomes possible to opt out#which is not currently a thing you can do except by making your blog private#metatumblr
35 notes
·
View notes
Text
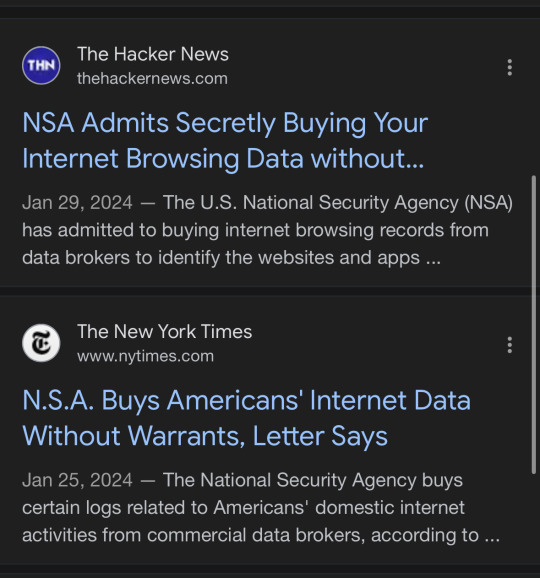
Like come on guys
26 notes
·
View notes
Text
observation-wise i do think it's interesting how enraged people were about how a giant query that returned pretty much everything ever posted (and unposted. drafts and unanswered asks and whatnot) on the site was done (which. to my knowledge. STILL doesn't have an answer regarding the question of whether or not the data included in that query was already sold) and that tumblr was going to start partnering with AI companies to train their models and then a couple of posts went around like "okie dokie guys NOW after that query was done we implemented an opt-out toggle <3 and we trust in Good Faith that the companies will respect this toggle <3" and then everyone was like Oh Okay <3 Yay <3 and suddenly everyone's fine again. 10/10 example of a collective sunk cost fallacy mentality. at this point it's kind of free entertainment to watch
#obviously if you post anything online you are implicitly acknowledging the risk of it being scraped. that isn't the point#the point is that a REALLY shitty dick move was pulled and like. nobody cares about it. at all#despite the fact that if this happened a year ago to another site like half the people posting about it would've been saying shit like#'haha that's what those idiots get for staying on a site that just wants to mine them for data. companies don't care about their users.#thank god tumblr is different <3' when it's like. guys. you realize tumblr hasn't been different for at least 6 years now. right.#you realize that the 'hellsite (affectionate)' marketing ploy was just that. a marketing ploy.#i realize some people will read this and go 'get off your high horse you're literally posting this on tumblr'#and i mean. yeah. that's the point HAHA
2 notes
·
View notes
Text

#web scraping#data extraction#web scraper#web scraping services#data extraction company#Lensnure#Lensnure Solutions#USA
2 notes
·
View notes
Text
Boost Business Prominence with Data Scraping Services

Data scraping technology has gained popularity in recent years as the demand for new data. Businesses now mostly rely on data which can be used further for analysis and create new strategies. As technology advances, businesses extract desired information to stay ahead in the competitive market, hence to achieve that, data extraction or web data scraping services efficiently provide the collected information. UniquesData provides data scraping with cutting-edge technology and expert skills.
#data scraping services#web scraping services#data scraping company#web scraping company#data scraping companies#database scraping service#web scraping services usa#web data scraping services#data scraping services india#web scraping services uk#web scraping service provider#web and data scraping services
0 notes
Text
Get the best web scraping services to help you collect data automatically! Our simple solutions save you time and make it easy to get the information you need. Check out our services today. Get in touch with us visit: https://outsourcebigdata.com/data-automation/web-scraping-services/
0 notes
Text
If you don't want to read the whole ao3 article here's the relevant part -
Because we haven’t developed a mobile app ourselves, we are okay with individuals creating unofficial apps, provided that these apps clearly state they are unofficial, refrain from using our logos, and do not charge users for their usage. Forcing people to pay to use those apps is a violation of the AO3 Terms of Service section 1.D.5.
the worst thing that could possibly happen to ao3 is it being put on the app store so please stop asking for it because you don't understand what would happen if that went through. ao3's whole deal is it archives EVERYTHING, while the apple app store's whole deal is keeping everything clean and safe. so if ao3 were to have an app all of the 'bad' stuff, including nsfw in general, would have to be censored at best or would be purged at worse. the google play store is more lax but who fucking knows what GOOGLE would police if they got their hands on the archive. do not ask for an app. do not use third party apps. it's on mobile browser functioning perfectly, just fucking use that before you ruin everything for everyone please.
#ao3#terms of service#on fandom#fandom history#apps scrape your data#because phones have more loopholes in security#its why every company wants you to have their app#you're basically paying them to steal your information
62K notes
·
View notes
Text
Leverage AI-powered web scraping to fuel your business with real-time data and insights. By automating data extraction, companies can make faster, smarter decisions with accurate information from diverse sources. This advanced technology enhances efficiency, reduces human error, and empowers informed strategies for growth. With AI-driven web scraping, businesses gain a competitive edge by accessing critical market trends and customer insights. Discover how this powerful tool can streamline operations and transform decision-making for better business outcomes.
0 notes
Text
"why are art blogs such crybabies about AI" idk maybe the people who are most directly and materially affected by image generation models aren't going to express the most favorable and nuanced takes on the thing that's ruining their careers
#and yes i mean MATERIALLY#i'm not referring to the ethics of training data#i'm talking about the palpable and immediate loss off money for people who were already scraping by on commissions#and the increased barrier to entry for professional art because companies just want to use AI
0 notes
Text
i havent written all week FUCK MY JOB

#**** **** I HOPE YOU DIE#SO ANGRY I CONVINCED SOMEONE TO JOIN OUR UNION. GRRRRAH!!!!!!!!!!!!#2 40-hour weeks in a row because of a ‘data backlog’ but SURPRISE!!!!! THERES NO FUCKING WORK FOR US TO DO NOW BECAUSE YOU PRESSURED US TO#WORK FT AND GET IT ALL DONE QUICKER SO NOW THERES NOTHING#EASY 32+HRS AT MY COMPUTER. BARELY SCRAPED TOGETHER 20 BILLABLES HRS#i complain about working actively but at least i can switch tabs or look at my phone or WRITE but when im stuck refreshing for 12 hours#to get 6.5hrs paid. i cant do anything else. im so mad im so mad im so mad i hate this stupid dogshit company so fucking MUCH!!!!!!!!!
1 note
·
View note
Text

A new tool lets artists add invisible changes to the pixels in their art before they upload it online so that if it’s scraped into an AI training set, it can cause the resulting model to break in chaotic and unpredictable ways.
The tool, called Nightshade, is intended as a way to fight back against AI companies that use artists’ work to train their models without the creator’s permission. Using it to “poison” this training data could damage future iterations of image-generating AI models, such as DALL-E, Midjourney, and Stable Diffusion, by rendering some of their outputs useless—dogs become cats, cars become cows, and so forth. MIT Technology Review got an exclusive preview of the research, which has been submitted for peer review at computer security conference Usenix.
AI companies such as OpenAI, Meta, Google, and Stability AI are facing a slew of lawsuits from artists who claim that their copyrighted material and personal information was scraped without consent or compensation. Ben Zhao, a professor at the University of Chicago, who led the team that created Nightshade, says the hope is that it will help tip the power balance back from AI companies towards artists, by creating a powerful deterrent against disrespecting artists’ copyright and intellectual property. Meta, Google, Stability AI, and OpenAI did not respond to MIT Technology Review’s request for comment on how they might respond.
Zhao’s team also developed Glaze, a tool that allows artists to “mask” their own personal style to prevent it from being scraped by AI companies. It works in a similar way to Nightshade: by changing the pixels of images in subtle ways that are invisible to the human eye but manipulate machine-learning models to interpret the image as something different from what it actually shows.
Continue reading article here
#Ben Zhao and his team are absolute heroes#artificial intelligence#plagiarism software#more rambles#glaze#nightshade#ai theft#art theft#gleeful dancing
22K notes
·
View notes
Text
The process of gathering information from multiple sources—including websites, databases, spreadsheets, documents, text files, and more—is known as data scraping. Data integration, migration, analysis, and information retrieval are just a few of the uses for data scraping.
#data scraping#data scraping service providers#data scraping company#data scraping services company#data scraping services company in india#data scraping services#web scraper in india#Data integration
1 note
·
View note
Text
Mastering Data Collection in Machine Learning: A Comprehensive Guide -
Artificial intelligence, mastering the art of data collection is paramount to unlocking the full potential of machine learning algorithms. By adopting systematic methods, overcoming challenges, and adopting best practices, organizations can harness the power of data to drive innovation, gain competitive advantage, and provide transformative solutions across various domains. Through careful data collection, Globose Technology Solutions remains at the forefront of AI innovation, enabling clients to harness the power of data-driven insights for sustainable growth and success.
#Data Collection#Machine Learning#Artificial Intelligence#Data Quality#Data Privacy#Web Scraping#Sensor Data Acquisition#Data Labeling#Bias in Data#Data Analysis#Public Datasets#Data-driven Decision Making#Data Mining#Data Visualization#data collection company#dataset
1 note
·
View note
Text

Unlock Ecommerce Success with Codeperk Solutions
1 note
·
View note