#webscrapingservices
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
In 2020, Tumblr had 29.4 million users in the US.
Text
Screwfix.com Product Listings Scraping: Extract Valuable Data for Business Growth

Screwfix.com Product Listings Scraping: Extract Valuable Data for Business Growth
In the digital era, data is a powerful tool that helps businesses optimize operations, monitor competitors, and enhance decision-making. Screwfix.com Product Listings Scraping is a process that allows businesses to extract real-time, structured product data from Screwfix.com, one of the leading retailers for tools, hardware, and construction supplies. By leveraging web scraping, businesses can track pricing trends, update their product catalogs, and gain insights into market demands.
What is Screwfix.com Product Listings Scraping?
Screwfix.com Product Listings Scraping by DataScrapingServices.com is an automated data extraction process that collects product-related information from the website. This data can include product names, prices, stock availability, descriptions, and customer reviews. Retailers, e-commerce businesses, suppliers, and market analysts can use this data to gain a competitive edge in the hardware and construction supply industry.
Key Data Fields Extracted from Screwfix.com
Product Name – The exact name of the product listed on Screwfix.com.
Category – The specific product category (e.g., tools, plumbing, electrical, or safety equipment).
Price – The current price of the product, including any discounts or special offers.
Stock Availability – Information on whether the product is in stock, out of stock, or available for pre-order.
Brand – The manufacturer or brand associated with the product.
Product Description – Detailed specifications, features, and technical details of the product.
Customer Ratings & Reviews – Aggregated feedback from users to understand customer satisfaction.
Product Images – High-resolution images available on Screwfix.com.
SKU & Product Code – Unique identifiers assigned to each product.
Shipping & Delivery Information – Estimated delivery times and shipping options.
Benefits of Screwfix.com Product Listings Scraping
1. Competitive Pricing Analysis
Extracting product pricing from Screwfix.com enables businesses to monitor competitor prices and adjust their pricing strategies accordingly.
2. Product Catalog Management
For e-commerce platforms and resellers, regularly scraping Screwfix.com ensures that product catalogs remain up-to-date, improving customer experience and sales conversions.
3. Enhanced Market Research
By analyzing product trends, businesses can identify high-demand products, new arrivals, and seasonal offers, helping them stay ahead of the competition.
4. Customer Sentiment Analysis
Scraping customer reviews allows businesses to gather feedback, understand consumer behavior, and improve product offerings.
5. Inventory & Supply Chain Optimization
Monitoring stock availability and demand trends helps retailers and suppliers manage inventory efficiently, reducing overstocking and stockouts.
Why Choose Professional Screwfix.com Scraping Services?
Manual data extraction from Screwfix.com is time-consuming and inefficient. Automated Screwfix.com Product Listings Scraping Services from DataScrapingServices.com offer accurate, real-time, and structured data to help businesses make informed decisions.
Best eCommerce Data Scraping Services Provider
Macys.com Product Listings Scraping
Extracting Product Reviews from Walgreens.com
Extracting Amazon Product Listings
Scraping Woolworths.com.au Product Prices Daily
Scraping Argos.co.uk Home and Furniture Product Listings
Coles.com.au Product Information Extraction
Target.com Product Prices Extraction
Zalando.it Product Details Scraping
Overstock.com Product Listings Extraction
G2 Product Details Extraction
Best Screwfix.com Product Listings Scraping Services in USA:
Columbus, Milwaukee, Fort Worth, Washington, Orlando, Fresno, Austin, Denver, Fresno, Bakersfield, Mesa, Long Beach, Chicago, San Francisco, Omaha, New Orleans, Colorado, Tulsa, Philadelphia, Louisville, Wichita, San Antonio, Oklahoma City, Seattle, Memphis, Jacksonville, Sacramento, Charlotte, Indianapolis, Atlanta, Houston, San Jose, Dallas, Las Vegas, El Paso, Virginia Beach, Raleigh, Nashville, Boston, Tucson and New York.
Get Started Today!
Leverage Screwfix.com Product Listings Scraping to optimize your business strategy.
Contact us at: [email protected]
Visit: DataScrapingServices.com
#screwfixproductlistingsscraping#screwfixproductdetailsscraping#ecommercedatascraping#productdetailsextraction#leadgeneration#datadrivenmarketing#webscrapingservices#businessinsights#digitalgrowth#datascrapingexperts
0 notes
Text
Real Estate Property Data Scraping for Market Insights

Introduction
The real estate industry is evolving rapidly, making data-driven decisions essential for success. With changing market dynamics, investors, agents, and businesses must stay ahead by leveraging Real Estate Property Data Scraping to gain valuable insights.
Web Scraping Real Estate Data enables businesses to extract, analyze, and utilize key property information, including pricing trends, demand fluctuations, and competitor strategies. By Extracting Real Estate Property Datasets, professionals can make informed investment decisions and optimize market strategies.
At ArcTechnolabs, we specialize in AI-powered Real Estate Data Extraction, offering advanced solutions for Web Scraping for Real Estate. Our services help investors, realtors, and businesses access structured and real-time real estate data to maximize opportunities and minimize risks.
With the right data extraction strategies, real estate professionals can make smarter, data-backed investment choices.
What is Real Estate Data Scraping?

Definition
Real Estate Data Scraping is the automated extraction of property data from various online sources, including real estate listing websites, MLS platforms, property portals, and public records. This technique allows real estate investors, agencies, and businesses to gather valuable insights on market trends, pricing, rental demand, and competitive strategies in real-time.
By leveraging Commercial Real Estate Data Scraping, businesses can analyze pricing fluctuations, track investment hotspots, and evaluate competitor strategies, leading to more informed decision-making.
How It Works?
Web Scraping for Real Estate Property involves using specialized software and APIs to extract structured datasets from multiple sources. This data is then processed, cleaned, and analyzed to identify valuable trends in the real estate market.
Data Sources for Real Estate Scraping
MLS (Multiple Listing Services) – Comprehensive property listings
Real Estate Portals – Zillow, Realtor.com, Redfin, etc.
Public Property Records – Ownership history, property valuations
Rental Market Data – Airbnb, VRBO, and rental listing sites
Key Data Extracted
Real Estate Price Monitoring – Tracks historical and real-time price changes for better pricing strategies.
Scraping Rental Property Datasets – Extracts rental trends, occupancy rates, and average rental yields.
Competitive Intelligence for Realtors – Compares listings, agent strategies, and market positioning.
Real Estate Data Growth Trends (2025-2030)
YearAI & Data Analytics Usage (%)Real Estate Firms Using Web Scraping (%)202550%60%202770%75%203090%85%
Fact: 80% of real estate businesses now rely on Big Data insights for decision-making. (Source: Market Trends 2025)
Why Use Real Estate Data Scraping Services?

In today’s data-driven real estate industry, having accurate, real-time market data is essential for making informed investment decisions. Real Estate Property Data Scraping enabl es businesses to extract crucial property insights, track pricing trends, and gain a competitive advantage.
With advanced Web Scraping Services, real estate professionals can automate data collection from multiple sources, including MLS platforms, real estate portals, and public records. This helps investors, agents, and businesses optimize their strategies and mitigate investment risks.
Key Benefits of Real Estate Data Scraping Services
Accurate, Real-Time Market Data
Stay updated on property prices, rental rates, and emerging investment opportunities.
Utilize Web Scraping API Services to access structured real estate data seamlessly.
Better Investment Decision-Making
Extract and analyze historical and live market data for data-driven property investments.
Leverage Extracting Real Estate Property Datasets to identify profitable properties.
Competitive Market Analysis
Use Web Scraping Real Estate Data to monitor competitor pricing strategies.
Analyze trends in high-demand locations for better property positioning.
Risk Mitigation and Trend Prediction
Identify market fluctuations before they impact investment decisions.
Utilize AI-powered insights to predict property appreciation and rental yield trends.
Market Statistics: Real Estate Data Scraping Trends (2025-2030)
YearFirms Using Web Scraping (%)Data-Driven Decision Making (%)Automated Market Analysis (%)202560%55%50%202775%70%65%203085%90%80%
Fact: By 2030, 85% of real estate companies will integrate Web Scraping for Real Estate to improve market research and property valuation. (Source: FutureTech Real Estate 2025)
Why Choose Professional Web Scraping Services?

In the fast-evolving real estate industry, staying ahead of market trends requires accurate, real-time data. Professional Web Scraping Services provide businesses with structured and actionable insights, helping investors, realtors, and property managers make data-driven decisions.
By leveraging Commercial Real Estate Data Scraping, businesses can extract key property details, market trends, and competitor insights from various sources, including MLS platforms, real estate portals, and rental listings.
Key Advantages of Professional Web Scraping Services
Web Scraping API Services – Instant Access to Structured Real Estate Data
Automates data extraction from multiple sources, ensuring real-time updates.
Helps businesses track property prices, rental yields, and demand trends.
Supports Real Estate Data Scraping Services with seamless integration.
Mobile App Scraping Services – Extract Data from Real Estate Mobile Applications
Enables data collection from real estate apps like Zillow, Realtor.com, and Redfin.
Helps in Scraping Rental Property Datasets to monitor rental price fluctuations.
Essential for tracking user engagement and emerging property listings.
Customized Scraping Solutions – Tailored Data Extraction Based on Investment Strategies
Extracts data specific to commercial and residential real estate needs.
Supports Web Scraping for Real Estate Property to gain competitive intelligence.
Allows investors to analyze market demand, property appreciation rates, and ROI potential.
Real Estate Data Scraping Trends (2025-2030)
YearReal Estate Firms Using Data Scraping (%)AI & Automation Adoption (%)Market Insights Gained from Scraping (%)202562%50%55%202778%70%73%203090%85%88%
Fact: By 2030, 90% of real estate firms will rely on Real Estate Data Scraping Services for market research and investment decisions. (Source: Future Real Estate Insights 2025-2030)
Why Choose Professional Web Scraping Services?
Automated & Scalable Solutions – Large-scale data extraction for real-time insights
Compliance & Data Accuracy – Ensures legal, structured, and reliable data collection
Competitive Market Intelligence – Track competitor pricing, listings, and agent strategies
By adopting Professional Web Scraping Services, businesses can stay ahead of market fluctuations, track property trends, and maximize investment returns.
Key Benefits of Real Estate Data Scraping

In today's fast-paced real estate market, making data-driven decisions is crucial for maximizing investment returns. Real Estate Property Data Scraping enables businesses to extract valuable insights from multiple sources, allowing for smarter pricing, investment risk mitigation, and competitive analysis.
By utilizing Web Scraping Real Estate Data , investors, realtors, and analysts can gain a real-time understanding of market dynamics, ensuring better decision-making and strategic investments.
Top Benefits of Real Estate Data Scraping
Data-Driven Pricing Decisions – Analyze pricing trends to make smarter investment choices.
Tracking Market Demand & Supply – Identify emerging opportunities in high-demand areas.
Investment Risk Mitigation – Detect potential downturns before they impact investments.
Competitor Analysis – Gain insights into other realtors’ pricing strategies and listings.
Accurate Property Insights – Extract high-quality, structured data for market forecasting and valuation.
Market Trend Analysis: The Impact of Real Estate Data Scraping
Data TypeBusiness ImpactProperty PricesHelps determine optimal buy/sell timingRental DemandIdentifies high-yield rental marketsCompetitor PricingHelps refine competitive pricing strategiesMarket TrendsSupports long-term investment planningBuyer BehaviorProvides insights into purchasing trends
Fact: Companies using AI-driven property data analysis increase their ROI by 35%. (Source: PropertyTech Report 2027)
How Businesses Benefit from Extracting Real Estate Property Datasets?

In the fast-evolving real estate industry, accessing accurate, real-time data is essential for making informed investment decisions. Extracting Real Estate Property Datasets provides businesses with valuable market insights, allowing them to analyze pricing trends, demand fluctuations, and investment risks.
With Web Scraping for Real Estate , businesses can gather structured data from various sources, including MLS listings, property portals, rental databases, and public records. This information is crucial for identifying profitable investment opportunities, tracking property appreciation rates, and mitigating risks.
Key Advantages of Real Estate Data Scraping
Market Trend Monitoring – Stay ahead of property price fluctuations and rental demand shifts.
Accurate Property Valuation – Use historical and real-time data to determine fair market prices.
Investment Risk Analysis – Identify high-growth areas and minimize investment risks.
Competitive Intelligence – Analyze real estate market trends and competitor pricing strategies.
How Real Estate Professionals Use Data Scraping?
Web Scraping for Real Estate enables investors to track property valuation fluctuations over time.
Extracting Real Estate Property Datasets helps forecast property appreciation rates for better investment planning.
AI-powered analysis enhances real estate investment strategies with accurate, data-driven market insights.
Fact: Businesses leveraging Real Estate Property Data Scraping experience a 30% increase in investment accuracy and higher returns on real estate assets. (Source: Real Estate Tech Report 2027)
Maximizing Real Estate Investments with Data Scraping
By integrating Real Estate Property Data Scraping into their strategies, real estate professionals can enhance decision-making, optimize pricing models, and maximize profitability. As technology continues to shape the real estate market, data-driven insights will be the key to staying ahead of market trends and achieving long-term success.
How to Use Real Estate Data Scraping Effectively?

With the increasing reliance on data-driven decision-making, Real Estate Data Scraping has become essential for investors, realtors, and businesses looking to gain a competitive edge. By leveraging AI-powered data extraction, businesses can track market trends, predict pricing shifts, and make informed investment decisions.
Here’s a step-by-step guide to effectively utilizing Real Estate Data Scraping for maximum returns.
Step 1: Select the Right Scraping Tools
Choosing the right Web Scraping Real Estate Data tools ensures accurate, high-quality insights.
Use AI-driven scraping solutions like ArcTechnolabs for automated, real-time data extraction.
Leverage Realtor API Integration for seamless access to property listings, pricing, and historical trends.
Scraping MLS Data provides a comprehensive view of available properties, helping in better decision-making.
Step 2: Analyze Historical & Real-Time Data
Extracting Real Estate Property Datasets allows businesses to understand market fluctuations and predict investment opportunities.
Track price movements and demand shifts across different locations.
Monitor rental trends to identify high-yield rental markets.
Spot emerging investment hotspots before they become highly competitive.
Fact: 85% of real estate firms are expected to integrate Big Data analytics into their operations by 2028. (Source: Business Analytics 2025)
Step 3: Integrate Data into Your Strategy
After collecting data, the next step is to use it effectively for investment forecasting and market analysis.
AI-Powered Real Estate Insights help in predicting price fluctuations and demand trends.
Big Data in Real Estate enables investors to forecast property appreciation rates.
Competitive Intelligence for Realtors helps in analyzing other realtors' pricing strategies and market positioning.
Step 4: Ensure Legal Compliance
While Real Estate Data Scraping Services provide valuable data, businesses must adhere to ethical data collection practices.
Follow legal Scraping MLS Data guidelines to ensure compliance with data regulations.
Extract data from public and legally available sources to avoid any legal risks.
Unlock the Power of Real Estate Data Scraping
By integrating Web Scraping for Real Estate, businesses can gain actionable insights, reduce risks, and maximize profits. Whether you're an investor, agent, or real estate business, using data scraping effectively can help you stay ahead of market trends and optimize your investment strategies.
The Future of Real Estate Data Scraping

The real estate industry is rapidly evolving, with AI, machine learning, and predictive analytics transforming how property data is collected and analyzed. As technology advances, Real Estate Data Scraping Services are becoming more automated, intelligent, and essential for investors, realtors, and businesses.
AI & Machine Learning for Advanced Market Insights
AI-powered Web Scraping for Real Estate enhances data accuracy and identifies emerging investment opportunities.
Machine learning algorithms help analyze Big Data in Real Estate, enabling investors to make data-driven decisions.
Predictive Analytics for Smarter Investments
Extracting Real Estate Property Datasets allows businesses to forecast property value appreciation.
Real Estate Price Monitoring helps investors predict price fluctuations before they happen.
Rental Market Data Extraction provides insights into occupancy rates and rental demand.
Fact: By 2030, 90% of real estate platforms will integrate AI-powered insights for strategic decision-making. (Source: Future Real Estate Trends 2025)
Automated Data Scraping for Real-Time Market Tracking
Realtor API Integration allows businesses to access real-time market data.
Scraping MLS Data enables investors to compare listings and track property pricing trends.
Competitive Intelligence for Realtors helps businesses stay ahead of market shifts and competitor strategies.
Real Estate Data Analytics Growth (2025-2030)
YearAI Adoption (%)Market Analysis Accuracy (%)202545%80%202765%85%203090%92%
With AI-driven Web Scraping Real Estate Data , businesses can enhance decision-making, reduce risks, and maximize profitability. As we move towards 2030, automation and data intelligence will continue to shape the future of real estate investments.
How ArcTechnolabs Can Help?
ArcTechnolabs specializes in Real Estate Property Data Scraping, helping businesses access accurate, real-time market insights to make informed investment decisions. Our AI-powered Web Scraping Services provide customized data extraction solutions tailored to real estate investors, developers, and market analysts.
Custom Real Estate Web Scraping Solutions
Web Scraping Real Estate Data to collect structured property listings, pricing trends, and demand fluctuations.
Extracting Real Estate Property Datasets for comprehensive market research and investment forecasting.
AI-Powered Market Insights
AI-driven Commercial Real Estate Data Scraping enhances decision-making by analyzing historical and real-time data.
Real Estate Data Scraping Services provide predictive analytics for property valuation and market demand.
Real-Time & Historical Data Extraction
Web Scraping for Real Estate Property enables tracking of rental yields, property prices, and occupancy rates.
Scraping Rental Property Datasets helps real estate businesses identify profitable locations.
Compliant & Reliable Data Scraping Services
Web Scraping API Services ensure seamless integration with existing real estate platforms.
Mobile App Scraping Services extract property data from real estate apps while maintaining data security and compliance.
By leveraging ArcTechnolabs' expertise, businesses can gain a competitive advantage in the real estate market, enhance investment strategies, and maximize returns.
Conclusion
In today’s competitive market, Real Estate Property Data Scraping is essential for making informed investment decisions. By leveraging Web Scraping Real Estate Data , businesses can track pricing trends, rental demand, and competitor strategies with AI-powered insights.
At ArcTechnolabs, we offer custom Web Scraping Services , including Mobile App Scraping Services and Web Scraping API Services , ensuring real-time, compliant, and accurate data extraction.
Read More >> https://www.arctechnolabs.com/real-estate-property-data-scraping-for-market-insights.php
#RealEstatePropertyDataScraping#RealEstateDataScrapingTrends#WebScrapingServices#WebScrapingRealEstateData#CompetitorAnalysis#MarketTrendAnalysis
0 notes
Text
Scaling e-commerce data scraping comes with challenges like IP bans, CAPTCHA restrictions, and dynamic websites. Overcome these obstacles with rotating proxies, headless browsers, and AI-driven parsing. Implement anti-detection techniques and leverage cloud-based scraping for efficiency. Optimize your data extraction process to ensure seamless and scalable e-commerce insights.
0 notes
Text
How to Choose the Best Web Scraping Services Provider in 2025?

How can organizations maintain market positions when data has become the foundation for key decisions and a key differentiator that separates leaders from laggards? Yes, organizations that use data build a competitive moat around them. However, getting quality data, that too in a required form, is the key to successful data analysis. This is where web scraping services providers come to the rescue.
Web scraping services become the solution for businesses seeking data extraction services for market analysis, competitive advantage, pricing strategies, and more. Whether you require Python web scraping, advanced web scraping or mobile app scraping, selecting a reliable web data scraping company guarantees high-speed and qualitative data extraction, data accuracy, and adherence to legal and regulatory compliance.
Companies looking to outshine the competition need to select a suitable web scraping service for 2025.
This guide outlines key factors to consider in choosing the best web scraping services provider for 2025, which helps your business find optimal solutions.
Why Businesses Need Web Scraping Services?

The forecast shows that the Web Scraper Software Market will expand to USD 2.49 Billion by 2032.
Data is the backbone for businesses in fulfilling their goals and achieving success. Businesses use data to evaluate market trends, monitor their market rivals, and get real-time info about their customers and their preferences. However, getting the data is the real task. Organizations should choose their data scraping services with extreme care because numerous companies provide these services, but a very few live up to the expectations for quality and reliability. To avail of the full benefits that data extraction provides. Businesses must choose reliable web scraping services providers.
Let’s have a look at why web scraping is essential for your business.
Data-driven Decision-making
Organizations that use insights obtained from structured and unstructured data analysis for their operations tend to have better performance than their competitors. Quality web scraping services let businesses retrieve important data from multiple databases so they can make decisions based on current and accurate information.
Competitive Intelligence
For a competitive market advantage, a complete understanding of competitor approaches- their pricing strategy, product info, and industry position is required. Businesses get competitive advantages by using data scraping services to gain important insights like changing industry trends or the inventory of a specific product of their competitor.
Price Monitoring & Market Research
Price monitoring of various product assortments and competitor product listings provides businesses with insights to price their products rationally. Retail outlets and e-commerce platforms depend highly on pricing data. With data extraction services, businesses can track prices of products on multiple online stores. Businesses use this capability to optimize their pricing approaches in real-time and stay competitive in the market.
Lead Generation
Data can be used for automated lead generation. Sales and marketing teams can gain success through web scraping services as they extract contact details, emails, as well as prospect information from online directories, social media platforms, and business listings. Web scraping enables automated lead acquisition which provides businesses with an advantage during their outreach activities.
Real-Time Data Update
Real-time data updates help businesses such as e-commerce, stock trading, and finance obtain better decision-making capabilities. Python web scraping and web scraping API solutions give businesses automatic access to updated data streams without human intervention, and create continuous information flow.
Market Trend Predictions
By analysing large quantities of data, businesses can anticipate upcoming market shifts as well as forecast emerging market developments. Companies use web data scraping solutions to collect past data, analyze it, and generate predictions for new trends. This helps businesses to adjust tactics and strategies ahead of time.
Optimize Business Operations
Business operations can be improved by studying data. How? Data can tell which operations are redundant, slow, or not efficient. Businesses can gain advantages from mobile app scraping and web scraping tools to make data-driven decisions for decreasing operational expenses.
Enhance Customer Experience
A business will succeed only when it has a proper understanding of customer preferences. Web scraping services enable you to obtain crucial customer data like customer reviews or shopping data (from POS). This data, when analyzed, can provide key insights to improve customer services, products, and shopping experiences for customers.
Selection of the leading web scraping services provider for 2025 depends on evaluating the combined expertise of the team, the technology platform they use to scrape data, costs, and scalability capabilities. The decision of a trusted web scraping company propels organizations towards greater success in this data-centric environment.
What Industries Can Leverage Web Scraping Solutions?

Industries that can use web scraping solutions are:
Technology and SaaS: Web scraping technology enables technological companies to generate leads and provide information on software prices, competitive evaluations, etc.
Analyse software price data and product specifications.
Gather product development feedback from users.
Automate the process of obtaining business leads.
Retail Industry: The retail industry uses web scraping solutions to gain insights into the performance of their stores, customers, goods, vendors, and track competitor prices and reviews. The common uses are:
Monitoring Prices and Reviews.
Conducting Market research.
Review e-commerce listings.
Monitoring rival businesses.
Read article: Role of Web Scraping in Modern Retail Industry
Finance and Investment: Web scraping helps financial institutions and investors to make informed investment decisions by extracting updated and relevant information.
Obtain up-to-date stock information.
Track global financial developments and economic performance indicators.
Track cryptocurrency and forex market fluctuations.
Detect fraudulent actions.
Read article: How Web Scraping Can Help in the Financial Industry?
Marketing and Advertising: Marketing and advertising industries implement web scraping API solutions and analyze consumer behavior data, competitors’ strategies while optimizing digital marketing campaigns.
Extract customer behavioral data.
Analyze competitors’ digital advertising strategies.
Monitor search engine optimization keywords.
Track platform reviews and company reputation.
Enhance their marketing campaign precision.
Hospitality and Travel: The travel industry uses web scraping functions to analyze flight costs and hotel rates and develop advanced pricing tactics.
Monitor hotel rates and flight prices.
Assess customer feedback through reviews.
Obtain information related to travel market trends.
Analyze competitor travel package offerings.
Extracts real-time availability and pricing updates.
Read article: Revolutionize Travel Industry: Use Cases of Web Scraping
Real Estate: Real estate organizations require web data scraping procedures to identify property listings, analyze market behavior, and establish proper pricing methods.
Gather property records and sales price information.
Analyze ongoing changes to property prices, rental rates.
Investigate customer review data.
Evaluate real estate agent operational success.
Develop specific property acquisition decisions.
Read article: How Does Web Scraping Help the Real Estate Portals in Staying Ahead in the Competition?
Key Factors to Consider When Choosing a Web Scraping Services Provider

Experience and expertise in different industries
A reliable web scraping services provider must have extensive business experience in multiple industries (Saas, finance, travel, retail, real estate, social media, e-commerce, etc.). A web scraping services provider offers specialized expertise in industries, data extraction processes, as well as regulatory compliance understanding. Select a web data scraping company that delivers unique solutions that fulfill your business requirements effectively.
Ability to handle large-scale data extraction
Businesses that need to extract large datasets should select a provider that efficiently handles high-volume data. An outstanding data scraping services provider has a strong infrastructure coupled with cloud-based solutions that enable quick processing of millions of records without facing system performance problems.
Compliance with legal and ethical standards
Your data extraction by web scraping services must be legal and ethical, so make sure your provider upholds all necessary laws. The top web scraping service providers make GDPR, CCPA, and other industry regulatory compliance their highest priority. The implementation of ethical scraping practices by the service must include protection against unauthorized data access.
Data accuracy and quality assurance
A reliable data infrastructure is essential in the decision-making process of businesses. The reliability of web scraping data depends on data validation tools, deduplication, and error-handling systems from trusted API or service providers. Web scraping service providers should explain their quality assurance processes for data extraction and methods of data cleaning to deliver the best quality results.
Pricing and scalability
The selection of a web scraping services provider also depends on cost-effectiveness. You should inspect data scraping price structures to discover ones that match your financial resources and data collection requirements. Check that your chosen web scraping services provider can handle future business expansion through affordable scalable options.
Advanced tools and technologies
Efficient and dependable data extraction mainly depends on technology implementation. Leading data extraction service providers achieve their work with Python web scraping frameworks, AI processing, and cloud automation systems. The provider must have APIs that enable simple data integration for your systems and provide mobile app scraping functions as requested.
Common Challenges in Web Scraping and How a Good Services Provider Overcomes Them?

Dealing with anti-bot mechanisms
Websites adopt several anti-bot systems that include CAPTCHA reviews, IP blocking, and rate-limiting methods to stop scraping automation. A professional web scraping services company addresses these issues through the combination of:
Detection and prevention through proxy pools of multiple IP addresses.
Simulating human-like interactions to evade detection.
Implementation of AI-based or third-party CAPTCHA solving services.
Using human-like data patterns to avoid limit restrictions.
Maintaining data consistency
Business decisions require accurate and consistent extracted data to be reliable. A top web data scraping company provides data consistency through:
Implementing scripts to validate extracted data against target formats through automated procedures.
Using error handling mechanisms to detect and fix data extraction anomalies.
Alert features which detect errors in real-time for fast resolution of discrepancies.
Handling website structure changes
The HTML structure of websites is frequently updated, which results in scraped data failure. The data extraction service operation protects against structural changes by:
XPath or CSS selectors to maintain adaptation to small HTML structure modifications.
Machine learning models to detect new patterns and adapt parsing operations.
Actively monitoring the target site and updating their scraping tools regularly.
Data compliances
The process of extracting website data must comply with regulatory standards (like, GDPR, CCPA, etc.) and other prevailing website terms of service rules. A dependable web scraping API solution maintains regulations through the following features:
Following all Robots.txt File rules for permissible data extraction.
Protecting privacy of users by removing privacy-identifying information (PII).
Obtaining required permissions by seeking explicit consent or using public data.
Implementing strict security measures to safeguard scraped information.
Real-life Use cases of Data Scraping
DHL, the logistics giant, uses data to achieve operational excellence in their supply chains. By analyzing package tracking, weather, and traffic data, the company enhances route optimization and delivery time predictions. This data-driven approach enables accurate delivery estimates and swift responses to supply chain disruptions.
Amazon extensively uses data science across its operations. The e-commerce giant analyzes customer behavior and purchasing patterns for personalized recommendations. Its data-driven strategy encompasses demand forecasting, inventory management, and dynamic pricing, while also optimizing warehouse and delivery operations.
Netflix transforms entertainment through data-driven content creation and recommendations. By analyzing viewing history and user behavior, it delivers personalized suggestions and informs content production decisions. The company's A/B testing for thumbnails demonstrates its commitment to data-based engagement optimization.
Walmart utilizes data analytics for inventory management, demand prediction, and shopping experience personalization. Data science helps optimize product placement, pricing strategies, and supply chain operations, enabling Walmart to maintain competitiveness in the evolving retail landscape.
Unilever operates People Data Centres (PDCs) worldwide to collect consumer information through data analysis. Unilever uses mobile app scraping and web data scraping to retrieve customer reviews from Amazon, Walmart, and other social media networks. Natural Language Processing (NLP) models evaluate collected data through their algorithms to discover market patterns and both negative and positive customer emotions and essential customer complaints.
Top Data Scraping Services Provider Companies

We have compiled this list after a thorough analysis of various factors like expertise, experience, prices, service delivery, data compilation competencies, scalability, quality metrics, industry-specific services, and many more. The below web scraping services providers top the list on multiple metrics and performance indicators.
Conclusion
Through data extraction services, your business can access efficient collection and structuring of vast online data. However, collaborating with trusted web scraping providers is an essential requirement for collecting the data. The above article tries to ease your selection process for a top web service provider.
At Web Screen Scraping, we have a skilled team that provides high-quality data scraping services based on your requirements. Our Python web scraping is along, mobile app scraping, and web scraping API integrations deliver precise results.
Source: How to Choose the Best Web Scraping Services Provider in 2025?
#webscraping#datascraping#webscrapingservices#webscrapingservicesprovider#dataextraction#scrapewebsitedata#extractwebsitedata#bestwebscrapingservices#professionalwebscrapingservices#datascrapingcompany#webscrapingcompany#datacollection#webscreenscraping#webscrapingapi#mobileappscraping#webscrapingserviceprovider#webscrapingusecases#pythonwebscraping#websitedatascraping#webdatascraping
1 note
·
View note
Text
How does Travel Scraping API Service Transform Travel Data from Booking & Expedia?

Introduction
The travel industry is inundated with vast amounts of data in the modern digital landscape. This information is crucial for making informed business decisions, from hotel prices and flight schedules to customer reviews and seasonal trends. However, retrieving and analyzing data from leading platforms like Booking.com and Expedia.com can be complex without the appropriate tools. This is where a Travel Scraping API Service proves invaluable, transforming how businesses extract, process, and utilize travel data to maintain a competitive advantage.
Understanding the Power of Travel Data
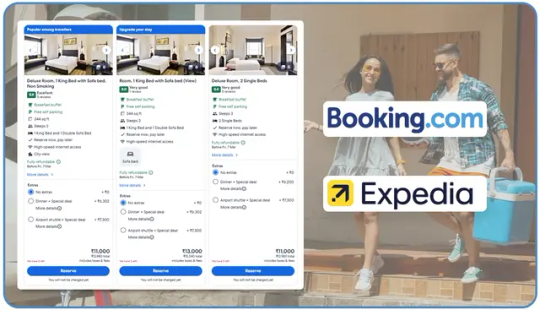
The travel industry generates an enormous volume of data every day. Every search, booking, and review contributes to this expanding information pool. For businesses in this sector, effectively accessing and analyzing this data is essential for:
Gaining more profound insights into market dynamics and consumer behavior.
Tracking pricing trends and assessing competitive positioning.
Identifying new market opportunities.
Refining revenue management strategies for maximum profitability.
Elevating the customer experience through advanced personalization.
Leading online travel agencies (OTAs) such as Booking.com and Expedia.com hold valuable data. However, obtaining this information isn’t always straightforward, as official channels often limit access. As a result, data extraction becomes a critical strategy for businesses aiming to maintain a competitive edge.
What is a Travel Scraping API Service?
A Travel Scraping API Service is a powerful solution that efficiently extracts data from major travel platforms like Booking.com and Expedia.com. By leveraging advanced data collection techniques, this service gathers, organizes, and delivers valuable travel-related data in a structured format for businesses.
Unlike traditional manual data collection, which can be slow and prone to errors, a Travel Scraping API Service automates the process, ensuring real-time access to critical insights,
Including:
Hotel availability and pricing
Flight schedules and fares
Vacation rental options
Customer reviews and ratings
Destination popularity
Seasonal booking patterns
These services function through APIs (Application Programming Interfaces), enabling smooth integration with business systems and applications and ensuring companies have the latest travel data at their fingertips.
The Transformation Journey: From Raw Data to Actionable Insights
This process involves extracting, processing, and analyzing raw data from travel platforms to generate meaningful insights that drive strategic decision-making.
Data Extraction from Major Travel Platforms
The journey begins with Booking.com API Scraping and Expedia.com Data Scraping, leveraging advanced techniques to ensure seamless data retrieval.
This process involves:
Automated collection of both structured and unstructured data.
Managing dynamic content loaded via JavaScript.
Navigating pagination and complex site architectures.
Implementing strategies to avoid detection and IP blocks.
Handling session cookies and authentication for continuous access.
Professional Travel Industry Data Scraping services utilize sophisticated algorithms and proxy solutions to guarantee reliable and consistent data extraction without disrupting the source websites.
Data Processing and Structuring
Once the raw data is collected, it must be transformed into a structured, usable format.
This involves:
Cleaning and normalizing data for accuracy.
Eliminating duplicates and irrelevant entries.
Standardizing formats such as dates and currencies.
Categorizing and tagging data for better organization.
Building relational data structures for in-depth analysis.
For instance, Hotel Price Data Scraping results must be standardized across various room types and occupancy levels, and amenities must be included, ensuring precise and meaningful comparisons.
Data Analysis and Insight Generation
With processed data in place, the next step is extracting actionable insights to drive informed decision-making.
This includes:
Analyzing price trends across different booking windows.
Assessing competitive positioning in key markets.
Identifying demand patterns for popular destinations.
Examining customer sentiment through review analysis.
Understanding the correlation between pricing strategies and booking volumes.
Leading Travel Scraping API Service providers integrate AI and machine learning algorithms to refine data analysis further. These technologies uncover hidden patterns and trends, offering deeper intelligence beyond traditional analytical methods.
Key Data Types Extracted from Travel Websites

Essential travel data categories gathered from online sources for market insights and strategic decisions.
Hotel Data Extraction
Collecting real-time hotel-related data, including pricing, availability, reviews, and amenities, to analyze market trends and improve decision-making.
Hotel Price Data Scraping provides critical insights, including:
Room rates across various dates and booking periods.
Availability trends and demand fluctuations.
Discount strategies and promotional offers.
Package deals and bundled services.
The loyalty program benefits frequent guests.
Amenity offerings and service comparisons.
Guest reviews and ratings shaping consumer perception.
This data enables hotels to refine pricing models, track competitor strategies, and identify emerging market opportunities.
Flight Information
Essential travel data covering flight schedules, pricing, availability, and airline details, helping businesses optimize travel strategies.
Flight Data Extraction uncovers key insights such as:
Fare variations across different booking windows.
Route popularity and demand trends.
Airline competitive positioning and pricing strategies.
Schedule changes and operational adjustments.
Seasonal demand patterns affecting ticket pricing.
Ancillary service offerings like baggage fees and seat selection.
Airlines and travel agencies leverage this data for strategic route planning, optimized pricing, and targeted marketing.
Vacation Rentals
Short-term lodging options, such as apartments, houses, or villas, are listed on platforms like Airbnb and Vrbo, catering to travelers seeking flexible accommodations.
Vacation Rental Data Scraping delivers valuable insights into:
Property availability and booking trends.
Pricing strategies are based on demand and seasonality.
Location popularity among travelers.
Amenity preferences shape guest expectations.
Host ratings and service reliability.
Booking patterns across platforms.
Seasonal trends affecting rental demand.
This intelligence is essential for property managers, investors, and vacation rental platforms to optimize pricing, enhance guest experiences, and improve occupancy rates.
Optimizing Travel Data Extraction with Advanced Web Scraping Services
Access to accurate, real-time data is crucial in the competitive travel industry. Businesses leverage Travel Data Scraping Services to extract and analyze key information from top travel platforms. This includes tracking airfare trends, monitoring hotel availability, and analyzing customer sentiment for informed decision-making.
A primary use of web scraping in travel is Dynamic Pricing Data Extraction. Airlines, hotels, and OTAs adjust prices based on demand and competition. Real-time data extraction helps businesses optimize pricing, develop competitive strategies, and boost revenue.
Selecting the Best Web Scraping Tools For Travel Websites is essential for handling complex site structures, dynamic content, and anti-scraping defenses. These tools ensure efficient data retrieval from Booking.com, Expedia.com, and Airbnb.
To maintain efficiency, businesses must follow Travel Industry Data Scraping Best Practices, like rotating proxies, AI-driven parsing, and automated scraping schedules. Ethical data collection ensures compliance with regulations and platform terms.
For tailored solutions, Custom API Scraping Solutions For Travel Websites provide real-time structured data, benefiting travel aggregators, comparison websites, and analytics firms seeking to enhance their offerings.
Extracting Hotel And Flight Prices From APIs
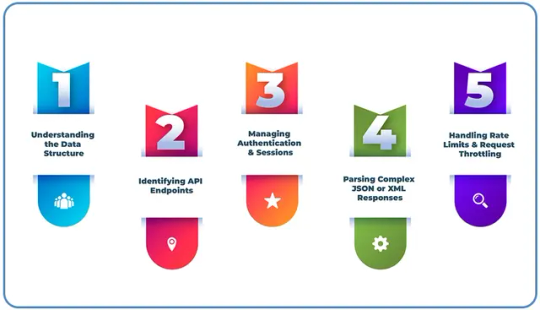
Extracting Hotel And Flight Prices From APIs requires a strategic approach to ensure accuracy and efficiency.
Here’s a breakdown of key considerations:
Understanding the Data Structure: Analyzing how travel websites organize and present hotel and flight pricing information.
Identifying API Endpoints: Using browser developer tools to locate and access relevant API endpoints.
Managing Authentication & Sessions: Implement authentication mechanisms and handle session persistence to maintain seamless data retrieval.
Parsing Complex JSON or XML Responses: Structuring and processing intricate data formats to extract relevant pricing details.
Handling Rate Limits & Request Throttling: Optimizing request frequency to comply with API restrictions and prevent access blocks.
Businesses can automate these processes by leveraging professional services for seamless and scalable data extraction, even as travel websites update their security protocols and data structures.
Web Scraping for Market Trend Analysis in Travel
Leveraging Web Scraping For Market Trend Analysis In Travel allows businesses to systematically gather vast amounts of data over time, unveiling critical patterns and industry shifts.
By extracting and analyzing real-time travel-related data, companies can gain valuable insights, including:
Tracking price fluctuations across booking windows to optimize pricing strategies and maximize revenue.
Monitoring seasonal demand variations to align marketing efforts with peak travel periods.
Identifying emerging destinations to stay ahead of shifting traveler preferences.
Analyzing competitor promotional strategies to refine offers and enhance competitive positioning.
Assessing the impact of external events on travel demand to make informed, data-driven decisions.
By harnessing these insights, businesses can proactively adapt to market changes, ensuring they remain competitive and responsive rather than reactive.
How Web Data Crawler Can Help You?

We specialize in delivering comprehensive data extraction solutions tailored for the travel industry. With a blend of technical expertise and industry knowledge, our team ensures high-quality, reliable data that empowers businesses to make informed decisions and drive growth.
Our Services Include:
Customized scraping solutions designed to meet your unique business requirements
Regular data delivery via API or structured reports for seamless access
Comprehensive data cleaning and normalization to ensure accuracy and consistency
Integration support to align with your existing systems effortlessly
Ongoing maintenance to guarantee uninterrupted data flow
Unlike standard Web Scraping API providers, we recognize the complexities of travel data and the challenges of extracting information from platforms like Booking.com and Expedia.com.
Our solutions are crafted to deliver:
Superior data quality through advanced validation techniques
Exceptional reliability with built-in redundancy for uninterrupted service
Customizable data formats tailored to your specific business needs
Scalable infrastructure that evolves as your requirements grow
Expert support from professionals with deep technical and industry expertise
With us, you gain a trusted partner dedicated to providing actionable insights and scalable solutions that fuel business success.
Conclusion
In today’s competitive travel industry, data is the key to success. An influential Travel Scraping API Service converts raw information into actionable insights, helping businesses make informed decisions across operations.
From refining pricing strategies to spotting emerging market opportunities, data from platforms like Booking.com and Expedia.com fuels sustainable growth and a competitive edge.
Unlock the potential of travel data with us. Our experts will craft a customized solution tailored to your data needs while ensuring compliance with industry standards. Don’t let valuable insights go untapped.
Contact Web Data Crawler today to transform data into your most powerful asset and drive success in the travel industry.
Originally published at https://www.webdatacrawler.com.
#APIScrapingServices#BookingComAPIScraping#ExpediaComDataScraping#TravelIndustryDataScraping#HotelPriceDataScraping#FlightDataExtraction#VacationRentalDataScraping#WebScrapingServices#TravelDataScrapingServices#DynamicPricingDataExtraction#BestWebScrapingToolsForTravelWebsites#HowToScrapeBookingComAndExpediaData#ExtractingHotelAndFlightPricesFromAPIs#WebScrapingForMarketTrendAnalysisInTravel#TravelIndustryDataScrapingBestPractices#CustomAPIScrapingSolutionsForTravelWebsites#WebDataCrawler#WebScrapingAPI
0 notes
Text
Web Scraping Uber Eats Food Data with Real Data API empowers businesses across the USA, UK, UAE, Germany, Australia, and Spain to extract valuable information like restaurant names, locations, menus, and reviews. Our Uber Eats Food data scraping services automate the process of extracting restaurant and menu data, offering real-time insights into menu trends, pricing, and customer preferences in these countries. With Uber Eats Food restaurant data extraction, businesses can optimize food delivery services, enhance pricing strategies, and gain a competitive advantage. Partner with Real Data API for efficient and accurate Uber Eats Food data scraping tailored to your business needs globally.
0 notes
Text
Discover how web scraping services are revolutionizing the FinTech industry by providing real-time access to crucial financial data, market trends, and customer insights. This blog explores how FinTech companies can leverage data scraping to drive innovation, improve decision-making, and stay ahead of competitors. Read now to unlock the power of automated data extraction!
#web scraping services#salesforce#WebScraping#DataExtraction#WebData#DataMining#WebScrapingServices#DataAnalysis#BigData#DataScience#Automation#DataVisualization#MachineLearning#BusinessIntelligence#DataDriven#WebAutomation#ScrapingSolutions#DataCollection#APIs#DataIntegration#TechSolutions#DigitalTransformation#WebCrawling#InformationRetrieval#DataManagement#DataQuality#MarketResearch#CompetitiveAnalysis#WebScrapingTools#CustomScraping
0 notes
Text
Web Scraping Services That Deliver Fast and Accurate Data for Smarter Decisions
In today’s digital age, data is the foundation of smarter decision-making. Businesses rely on timely, accurate, and comprehensive information to adapt to market trends, outpace competitors, and cater to customer demands. However, obtaining high-quality data efficiently can be a challenging task. This is where web scraping services play a pivotal role, enabling organizations to extract valuable insights from vast online sources quickly and accurately.

The Growing Importance of Web Scraping
Web scraping is the process of extracting data from websites and converting it into structured formats that are easy to analyze.
Organizations across industries—from e-commerce and finance to healthcare and real estate—are leveraging web scraping to stay informed and competitive. Whether tracking product prices, analyzing customer sentiment, or monitoring market trends, web scraping delivers the necessary data for actionable insights.
Key Benefits of Web Scraping Services
1. Speed and Efficiency
Manual data collection is not only time-consuming but also prone to errors. Web scraping automates the entire process, enabling businesses to gather large volumes of data in a fraction of the time it would take otherwise. This speed ensures that decision-makers always have access to the latest information.
2. Accuracy and Reliability
Inaccurate data can lead to misguided decisions, potentially costing businesses valuable time and resources. Professional web scraping services are designed to deliver high-accuracy results, ensuring that the data extracted is clean, complete, and free from errors.
3. Scalability
As business needs evolve, the volume and complexity of required data often increase. Web scraping services are scalable, capable of handling growing data demands without compromising on quality or speed.
4. Customizability
Different businesses have different data needs. Professional web scraping solutions can be customized to target specific websites, extract particular data points, and deliver results in preferred formats. This flexibility makes web scraping a valuable tool for diverse industries.
5. Cost-Effectiveness
Investing in web scraping services eliminates the need for extensive manual labor and reduces operational costs. By automating data collection, businesses can allocate resources to more strategic tasks, maximizing productivity and profitability.
Use Cases of Web Scraping Services
1. E-Commerce and Retail
E-commerce companies use web scraping to monitor competitor pricing, track product availability, and gather customer reviews. This data helps businesses optimize their pricing strategies and improve their product offerings to meet customer demands effectively.
2. Market Research and Analysis
Businesses leverage web scraping to gather data on industry trends, competitor performance, and consumer behavior. This information empowers companies to make informed decisions and develop data-driven strategies.
3. Lead Generation
For sales and marketing teams, web scraping helps extract valuable lead information, such as contact details and company profiles, from various online directories. This enables efficient and targeted outreach efforts.
4. Financial Services
In the finance sector, web scraping is used to collect stock market data, news articles, and financial reports. This data is essential for making investment decisions and conducting risk assessments.
5. Real Estate Insights
Real estate firms use web scraping to analyze property listings, rental trends, and market demand. This information aids in identifying lucrative investment opportunities and understanding market dynamics.
6. Academic and Scientific Research
Researchers use web scraping to gather data for academic studies, surveys, and experiments. The ability to extract and organize large datasets supports in-depth analysis and informed conclusions.
Choosing the Right Web Scraping Service
1. Expertise and Experience
Choose a provider with a proven track record in delivering web scraping solutions across various industries. Experienced providers are better equipped to handle complex data requirements.
2. Customizable Solutions
Every business has unique data needs. Ensure the provider offers customizable web scraping tailored to your specific goals and objectives.
3. Data Quality and Accuracy
High-quality data is essential for effective decision-making. Look for providers that prioritize accuracy and offer robust data cleaning and validation processes.
4. Scalability
As your business grows, so will your data requirements. Opt for a provider capable of scaling their services to meet your evolving needs.
5. Compliance and Security
Ensure the provider follows ethical practices and complies with legal regulations. Additionally, robust data security measures are essential to protect sensitive information.
Realizing the Impact of Web Scraping
Case in Point: Enhancing E-Commerce Strategies
Consider an e-commerce retailer aiming to optimize their pricing strategy. By using web scraping to monitor competitor prices and analyze market demand, the retailer can adjust their pricing dynamically, attract more customers, and increase revenue.
Case in Point: Improving Financial Forecasting
A financial firm can use web scraping to track stock prices, economic indicators, and industry news in real time. This data enables the firm to forecast trends accurately and provide clients with actionable investment advice.
Embrace Smarter Decision-Making with Web Scraping
In a world driven by data, the ability to collect and analyze information efficiently is a game-changer.
Conclusion
Are you ready to make smarter decisions with fast and accurate data? Discover how our professional Web scraping services can transform your business. Contact us today to learn more and take the first step toward a data-driven future.
Visit Us, https://www.tagxdata.com/
0 notes
Text
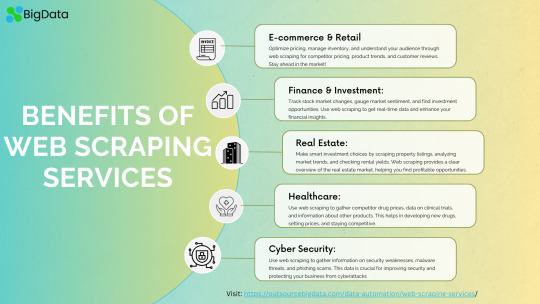
Get the best web scraping services to help you collect data automatically! Our simple solutions save you time and make it easy to get the information you need. Check out our services today. Get in touch with us visit: https://outsourcebigdata.com/data-automation/web-scraping-services/
0 notes
Text

Web Scraping will extract data from websites and generate website pages using HTML scripting scripts for market monitoring, analysis, research, key comparisons, and data collection.🎯
🔮Common tools include Scrappy and Selenium, and programming languages such as Python, Java Script, etc.✨
👉So can you give me the responsibility I will check the website status for all website issues using a browser request agent and handle exceptions and errors gracefully Can you give me the responsibility as a powerful tool for collecting web scraping data?
💠Then get in touch today👇
🪩Humayera Sultana Himu ✅
0 notes
Text
Scraping Woolworths.com.au Product Prices Daily

Scraping Woolworths.com.au Product Prices Daily
In today’s competitive retail environment, businesses must stay ahead of price fluctuations, discounts, and product availability. Woolworths.com.au, one of Australia’s largest supermarket chains, frequently updates its pricing and promotions, making daily product price scraping essential for retailers, e-commerce stores, and market analysts. Scraping Woolworths.com.au product prices daily helps businesses track pricing trends, optimize strategies, and stay competitive.
At DataScrapingServices.com, we specialize in extracting real-time product price data from Woolworths.com.au, enabling businesses to make informed pricing and marketing decisions.
Key Data Fields Extracted from Woolworths.com.au
Our daily price scraping service extracts the following crucial data fields:
Product Name – The official product title listed on Woolworths.
Brand – The manufacturer or brand name of the product.
Category – Classification such as dairy, beverages, frozen foods, etc.
Current Price – The latest product price displayed on the website.
Discounts & Promotions – Special offers, bundle deals, or limited-time discounts.
Stock Availability – Whether the product is in stock or out of stock.
Product URL – Direct link to the product page.
Unit Pricing – Price per kilogram, liter, or unit.
Customer Ratings & Reviews – Consumer feedback and star ratings.
Product Description – Details, ingredients, and specifications.
Benefits of Scraping Woolworths.com.au Product Prices Daily
1. Competitive Price Monitoring
For e-commerce businesses and retailers, tracking daily price changes at Woolworths.com.au helps in setting competitive prices. Businesses can compare their product pricing with Woolworths’ offerings and adjust accordingly to attract more customers.
2. Retail & E-Commerce Price Optimization
By analyzing price trends, businesses can strategize their discounts, deals, and promotions. Understanding pricing patterns enables retailers to make informed decisions about inventory management and profit margins.
3. Real-Time Market Insights for Brands
Manufacturers and suppliers can use daily scraped data to monitor how their products are priced at Woolworths. This helps in tracking retail compliance, ensuring fair pricing, and optimizing distribution strategies.
4. Enhanced Marketing & Consumer Engagement
Marketers can use daily price data to identify trending products, popular discounts, and best-selling categories. This information enables targeted advertising and promotional campaigns tailored to consumer demand.
5. Better Decision-Making for Grocery & FMCG Businesses
For businesses in the grocery, FMCG (Fast-Moving Consumer Goods), and retail sectors, having daily price updates from Woolworths.com.au is essential for forecasting sales, managing supply chains, and improving profitability.
6. Automated Price Tracking & Alerts
With automated daily scraping, businesses can receive real-time price updates and alerts when Woolworths.com.au makes pricing changes, ensuring that they always stay updated without manual monitoring.
Best eCommerce Data Scraping Services Provider
Extracting Product Reviews from Walgreens.com
Extracting Amazon Product Listings
Amazon Reviews Scraping
Web Scraping eBay.co.uk Product Listings
Overstock Product Information Scraping
Target Product Details Scraping
Walmart Product Price Scraping
Mexico eCommerce Websites Scraping
Lazada.co.th Product Detail Extraction
Capterra Product Information Scraping
Best Woolworths.com.au Product Prices Scraping Services in Australia:
Sydney, Mackay, Albury, Coffs Harbour, Wagga Wagga, Cairns, Darwin, Adelaide, Wollongong, Logan City, Bunbury, Bundaberg, Brisbane, Perth, Toowoomba, Launceston, Townsville, Ballarat, Bendigo, Rockhampton, Melbourne, Newcastle, Geelong, Hervey Bay, Gold Coast, Hobart, Canberra, Mildura, Shepparton and Gladstone.
Why Choose DataScrapingServices.com for Woolworths.com.au Price Scraping?
✔ Accurate & Real-Time Data Extraction – Get fresh, updated pricing information daily. ✔ Customizable Data Solutions – Tailored data fields to meet business needs. ✔ Scalable & Fast Scraping Services – Suitable for businesses of all sizes. ✔ Ethical & Legal Data Extraction – We follow industry best practices.
Start Scraping Woolworths.com.au Product Prices Today!
Stay ahead in the retail market with daily Woolworths product price extraction. Contact us at [email protected] or visit DataScrapingServices.com to get started with our automated price scraping services today!
#scrapingwoolworthsauproductpricesdaily#woolworthsauproductdetailsscraping#ecommercedatascraping#productdetailsextraction#leadgeneration#datadrivenmarketing#webscrapingservices#businessinsights#digitalgrowth#datascrapingexperts
0 notes
Text

Real Estate Property Data Scraping for Market Insights
Learn how real estate data scraping helps track market trends, pricing, and investment opportunities for smarter, data-driven decisions.
Read More >> https://www.arctechnolabs.com/real-estate-property-data-scraping-for-market-insights.php
#RealEstatePropertyDataScraping#RealEstateDataScrapingTrends#WebScrapingServices#WebScrapingRealEstateData#CompetitorAnalysis#MarketTrendAnalysis
0 notes
Text

Web scraping plays a crucial role in marketing and advertising by collecting vast amounts of data from competitor websites, customer reviews, and social media platforms. This data helps businesses analyze market trends, track competitors, personalize campaigns, and make data-driven decisions to enhance their marketing strategies.
#webscraping#WebScrapingServices#collectlargeamountsofdata#WebScrapinginMarketing#AI-poweredwebscraping
0 notes
Text
Web Scraping Meesho Product Data for Enhanced Market Insights - A Case Study to Analyze Consumer Behavior

Client Overview
Real Data API provides businesses with robust data scraping solutions to drive decision-making. The client aimed to extract actionable insights from Meesho, one of India’s leading e-commerce platforms for small-scale sellers, to improve competitive analysis, pricing strategies, and inventory management.
Objective
Meesho Data Scraping Services: Extract comprehensive product data, including prices, descriptions, and categories.
Meesho Product Data Extraction: Enable real-time access to product details for trend analysis.
Scrape Meesho Product Prices and Details: Collect pricing information for market comparisons.
Meesho API Data Scraping Solutions: Provide scalable scraping through API integration for continuous data updates.
Scrape Meesho App Product Listings: Extract product data directly from the mobile app interface.
Challenges
Dynamic Content: Meesho uses JavaScript-heavy pages, requiring advanced web scraping tool techniques to handle dynamic data.
Frequent Updates: The platform changes product listings, categories, and prices.
Data Volume: Scraping millions of SKUs from multiple categories and regions demanded a scalable and robust solution.
Approach
Real Data API implemented a multi-layered solution leveraging the latest web scraping and API integration tools:
Meesho Inventory Data Collection: Automated scripts extracted inventory levels for each product.
Extract Product Reviews from Meesho: Sentiment analysis on customer reviews to gauge product popularity.
Meesho Price Comparison Data Scraping: Compared prices with competing platforms for optimized pricing strategies.
Web Scraping for Meesho Sellers: Identified top-performing sellers and their bestselling products.
Scrape Meesho Product Categories: Organized data into well-defined categories for detailed analysis.
Key Features of the Solution
Meesho Discount and Offer Extraction: Identified time-sensitive promotions to monitor consumer behavior.
Meesho Bestselling Products Data Extraction: Highlighted top-selling items for trend analysis.
Extract Meesho Sales and Inventory: Monitored sales patterns and stock availability for demand forecasting.
Results (2025)
Enhanced Market Insights: The client achieved a 20% increase in revenue by implementing optimized pricing strategies.
Real-Time Data Access: Successfully scraped and analyzed over 2 million product listings and 500,000 customer reviews.
Cost Savings: Automated data collection reduced manual research costs by 30%.
Improved Inventory Management: Analyzed Meesho inventory trends, ensuring a 15% stock-out reduction.
Competitor Benchmarking: Gained critical insights into competitor pricing and discount strategies, boosting market competitiveness.
Conclusion
Real Data API’s Meesho Data Scraping Services provided the client with precise and actionable data. The client enhanced its market positioning by leveraging advanced scraping solutions like Meesho API Data Scraping Solutions and Scrape Meesho App Product Listings. This case study demonstrates how businesses can extract meaningful insights from platforms like Meesho to drive growth, efficiency, and competitive advantage.
Ready to gain a competitive edge? Contact Real Data API today for reliable data scraping solutions tailored to your needs!
0 notes
Text
Ever wondered how to uncover the secrets behind Amazon's top-selling products?
Our new post on scraping Amazon Bestsellers is here to help you dive deep into the world of web scraping. Whether you're a coding newbie or a seasoned data nerd, this guide is packed with tips and tricks to help you get the most out of your scraping adventures.
0 notes
Text
Transform Your Business with Advanced Web Scraping Services
In today data-driven world, information is the new currency. Businesses across all industries are increasingly relying on data to make informed decisions, drive growth, and gain a competitive edge. However, with the vast amount of information available online, manually gathering and processing data is no longer feasible. This is where web scraping services come into play.
Web scraping is a powerful technique that involves extracting data from websites and converting it into a structured format, such as spreadsheets or databases. Whether it's for market research, competitive analysis, price monitoring, or lead generation, web scraping allows businesses to access the data they need, when they need it. In this blog, we'll explore the various applications, benefits, and considerations of web scraping services, as well as how they can transform your business.
Understanding Web Scraping
Web scraping is the automated process of extracting data from websites. This process involves using software tools known as "scrapers" to navigate web pages, identify relevant information, and collect it for further analysis. Scrapers can capture a wide range of data, including text, images, URLs, and even metadata. Once the data is collected, it can be organized into a format that is easily accessible and analyzable.
Applications of Web Scraping Services
Market Research and Competitive Analysis
In today fast-paced business environment, staying ahead of the competition requires a deep understanding of market trends and competitors' strategies. Web scraping services can provide businesses with real-time access to data on competitors' pricing, product offerings, customer reviews, and more. This information can be used to adjust pricing strategies, improve product offerings, and identify new market opportunities.
Price Monitoring
For e-commerce businesses, price monitoring is crucial for maintaining a competitive edge. Web scraping allows companies to track prices across multiple websites, compare them with their own, and adjust pricing strategies accordingly. By regularly monitoring competitors' prices, businesses can ensure they remain competitive and maximize their profit margins.
Lead Generation
Generating high-quality leads is essential for any business looking to grow its customer base. Web scraping can automate the process of collecting contact information, such as email addresses and phone numbers, from websites, directories, and social media platforms. This enables businesses to build targeted lists of potential customers and streamline their outreach efforts.
Real Estate Data Collection
In the real estate industry, data is key to making informed investment decisions. Web scraping services can be used to gather data on property listings, sales history, rental prices, and neighborhood demographics. This data can be analyzed to identify trends, assess property values, and make data-driven investment decisions.
Financial and Investment Analysis
Investors and financial analysts rely on a wealth of online data to make informed decisions. Web scraping can be used to collect data from financial news sites, stock exchanges, company websites, and social media to gain insights into market trends, company performance, and investor sentiment. This information can be used to make more informed investment decisions and minimize risks.
Benefits of Web Scraping Services
Time and Cost Efficiency
Manually collecting data from websites is time-consuming and labor-intensive. Web scraping automates this process, allowing businesses to gather large volumes of data quickly and efficiently. This not only saves time but also reduces the costs associated with manual data collection.
Access to Real-Time Data
In today fast-paced business environment, having access to real-time data is crucial. Web scraping services enable businesses to collect up-to-date information from websites, ensuring they have the latest insights to make informed decisions.
Scalability
Web scraping services are highly scalable, allowing businesses to collect data from multiple websites simultaneously. Whether you need data from a handful of websites or thousands, web scraping can handle the task efficiently.
Customization
Web scraping services can be tailored to meet the specific needs of your business. Whether you need data from a specific industry, region, or type of website, scraping tools can be customized to target the exact data you require.
Conclusion
Web scraping services offer businesses a powerful tool to access and analyze vast amounts of data, enabling them to make data-driven decisions, stay ahead of the competition, and drive growth. From market research and competitive analysis to price monitoring and lead generation, the applications of web scraping are virtually limitless.
However, to truly harness the power of web scraping, it's essential to partner with a trusted provider that understands your unique needs and can deliver high-quality, compliant, and ethical web scraping solutions. That is where TagX comes in.
TagX specializes in providing cutting-edge web scraping services tailored to the specific needs of businesses across various industries. With a commitment to data quality, accuracy, and ethical practices, TagX is your go-to partner for unlocking the full potential of web scraping. Whether you're looking to gain a competitive edge, optimize your pricing strategies, or generate high-quality leads, TagX has the expertise and experience to deliver the results you need.
Partner with TagX today and take the first step towards data-driven success.
Visit Us, https://www.tagxdata.com/
0 notes