#connection cache subsystem
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The most popular pages on Tumblr are about Minecraft, GIFs, and David J. Peterson.
Text
Micron 9400 NVMe SSDs Offer Big Rapid Memory!

Micron 9400 NVMe SSDs with NVIDIA
Training dataset sizes are approaching billions of parameters. Larger models cannot fit entirely in system memory, however some models can. Data loaders in this scenario must use a variety of techniques to access models stored on flash storage. An SSD-stored memory-mapped file is one such technique. This makes the file accessible to the data loader as if it were in memory, but the training system’s speed is significantly decreased due to the CPU and software stack overhead. This is where the GPU-Initiated Direct Storage (GIDS) data loader and Big Accelerator Memory (BaM) come in.
What are GIDS and BaM?
BaM is a system architecture that makes use of SSDs’ fast speed, big density, low latency, and durability. In contrast to systems that need CPU(s) to supply storage requests in order to service GPUs, BaM aims to offer efficient abstractions that allow GPU threads to conduct fine-grained accesses to datasets on SSDs and achieve substantially greater performance. BaM acceleration makes use of a unique storage driver created especially to make direct storage device access possible thanks to GPUs’ built-in parallelism. Unlike NVIDIA Magnum IO GPUDirect Storage (GDS), BaM uses the GPU to prepare the connection with the SSD, while GDS depends on the CPU.
Note: NVIDIA Research’s prototype projects, the NVIDIA Big Accelerator Memory (BaM) and the NVIDIA GPU Initiated Direct Storage (GIDS) dataloader, are not intended for public release.
As shown below, Micron has previously worked with NVIDIA GDS:
The Performance of the Micron 9400 NVMe SSDs Using NVIDIA Magnum IO GPUDirect Storage Platform
Micron and Magnum IO GPUDirect Storage Partner to Deliver AI & ML With Industry-Disruptive Innovation
Based on the BaM subsystem, the GIDS dataloader hides storage delay and satisfies memory capacity needs for GPU-accelerated Graph Neural Network (GNN) training. Since feature data makes up the majority of the entire graph dataset for large-scale graphs, GIDS accomplishes this by storing the graph’s feature data on the SSD. To facilitate fast GPU graph sampling, the graph structure data which is usually considerably smaller than the feature data is pinned into system memory. Finally, to minimize storage accesses, the GIDS dataloader sets aside a software-defined cache for recently accessed nodes on the GPU memory.
Training graph neural networks using GIDS
They used the heterogeneous complete dataset from the Illinois Graph Benchmark (IGB) for GNN training in order to demonstrate the advantages of BaM and GIDS. With a size of 2.28 TB, this dataset is too big to fit in the system memory of most systems. As illustrated in Figure 1 and Table 1, they changed the number of SSDs and timed the training for 100 iterations using a single NVIDIA A 100 80 GB Tensor Core GPU to provide a wide variety of outcomes.
The GPU performs graph sampling in the initial phase of training by accessing the graph structure data stored in system memory (shown in blue). The structure that is kept in system memory does not change across these tests, hence this number fluctuates very little across the various test settings.
The real training time is another component (seen in green on the far right). They can see that, as would be anticipated given its strong GPU dependence, there is little variation in this component across the various test setups.
The most significant area, where the most disparity is seen, is feature aggregation (highlighted in gold). They observe that scaling from 1 to 4 Micron 9400 NVMe SSDs significantly improves (reduces) the feature aggregation processing time since the feature data for this system is stored on the SSDs. As they increase from 1 SSD to 4 SSDs, feature aggregation becomes better by 3.68x.
They also incorporated a baseline computation that accesses the feature data using the Deep Graph Library (DGL) data loader and a memory map abstraction. They can see how ineffective the CPU software stack is at keeping the GPU saturated during training since this way of accessing the feature data necessitates using the CPU software stock rather than direct access by the GPU. With 1 Micron 9400 NVMe SSDs employing GIDS, the feature abstraction increase over baseline is 35.76x, while with 4 Micron 9400 NVMe SSDs , it is 131.87x. Table 2, which display the effective bandwidth and IOPs during these testing, provide an additional perspective on this data.
They recognize that a paradigm change is required to train these models quickly and to take advantage of the advancements offered by top GPUs as datasets continue to expand. They think that BaM and GIDS are excellent places to start, and they want to collaborate with more of these kinds of systems in the future.
Read more on Govindhtech.com
0 notes
Text
Well, uh... I have no idea what the deal with this one is, but I guess I should try to document it for the for future reference tag?
Apparently if your Mac (running 10.14, in my case) freezes every few seconds, notably when opening apps, but the problem goes away completely when you disconnect from the internet, the solution is to ensure your network connection is the top entry in network preferences, then change ipv6 from “automatically” to “manually,” restart [some subset of things or just the entire PC], then change it back.
Possibly included in this fix are clearing the DNS cache and some other subset of the 35 things I probably did before that, but probably not.
This makes absolutely no sense and the fact that some part of the ipv6 handling in MacOS has apparently been broken since like 2010 (if the Google results and random forum posts are to be believed) and yet it is documented by someone with any understanding of the relevant subsystems exactly nowhere is a terrible sign for the OS.
1 note
·
View note
Text
Ninite teamviewer 9


Anyway, there are two versions of however it is pronounced: a free version and a Pro version with additional features that is also, or so it is claimed, faster due to enhanced caching. Will people remember the name? Still seems somewhat random. The company website contends that it should be pronounced "nin-ite" but, in my humble opinion, that's not actually better and it isn't how most people will pronounce it when they see the name for the first time. I have to mention the product name, "Ninite.

Ninite was released 18 months ago and, since I first looked at it about a year ago, has matured and has been expanded in terms of the number of software titles it can manage. Click to see: Ninite Web site installer configuration. I've just been testing a really impressive solution to the problem of installing these tools and keeping them updated. That set typically includes one or more Web browsers along with messaging, media and imaging utilities, and runtimes for subsystems such as Java, Flash and Air. These features are only available in Ninite Pro Classic.Without doubt, there is a core set of applications and tools you need on all PCs, whether it's your own machine or those of users. In install mode, there are many different potential messages, so it's probably best to use the following approach: "OK" means the update or install succeeded "Skipped up to date " means the app is up to date All other messages indicate some kind of error condition Pro Classic only. We highly recommend that you specify a file that will receive a report, for example: NinitePro. We're working on documentation for the new Pro web interface.įor now the available help for that is inline in the interface. In install mode, there are many different potential messages, so it's probably best to use the following approach. To summarize, in audit mode, the message is always one of the five listed messages. Means Ninite failed to install Chrome, or at least it could not find it after running the installer. It is impossible to list them all because some of them can contain error codes from the operating system or from the installer programs. With remote mode it is in comma separated value CSV format and can be viewed in Excel. When run on a single machine the report will be a text file. If you are behind a proxy server that needs a user name and password, use the following switch in combination with the silent switch. By default, Ninite skips the installation of applications that are already up to date on the system. Without this there will be no indication of failure or debugging information, apart from the return code of the installer. and you would need to download & install the software as described in Step 2 of the tutorial, i.e.We highly recommend that you specify a file that will receive a report, for example. I would need to download & install the full Teamviewer package software onto my PC. should be on the lower left of your keyboard) to enlarge the text on the document that will open from the above link. (Remember that you can press the CTRL key and + key (. Please have a look at the link below (open the link using your browser) and read through it to get a basic understanding of what you need to do to enable me to connect to your laptop. I think it is time I was able to connect to your PC, and check settings, etc., so that I can fix some of the issues you are having.
Which software is recommended to take control over his laptop, from my laptop in South Africa?.
Whose data allowance will be used if I find he needs many apps / programs updated or installed? Will it use his data connection in the UK, or my (expensive & limited) data connection in South Africa?.
If (and it's a big IF) I can coach him into downloading and properly installing software such as LogMeIn or Teamviewer or equivalent. I usually achieve DL speeds of around 3 Mbps for download, and uploads of only 0.4 Mbps here in South Africa, data is slow, and expensive! I only have a 4 Mbps ADSL line, which is the max our exchange supports, and I have a 20GB per month capped data allowance.
Checking that he has latest OS & program updates.
I'm going to suggest he downloads & installs a program like LogMeIn (or perhaps some other equivalent), so that I will be able to remotely take control of of his laptop, and perform the simple maintenance tasks such as: I'm on Skype with him almost daily, and every day he has a new problem that he expects me to solve, but his very limited knowledge of PC settings, and PC maintenance, together with his lack of ability to properly define the issues he has with his laptop, and to explain to me exactly what problems he experiences, frustrates both of us. He uses his laptop mainly for e-mail, and creating MS Word documents, and web browsing, and Skype My 93-year-old Father is in the UK and has a HP laptop running Win 8.1 64-bit I am in South Africa, and have an ASUS Win 8.1 64-bit laptop.
0 notes
Text
Configure forward and reverse lookup zones ubuntu 16.04

#CONFIGURE FORWARD AND REVERSE LOOKUP ZONES UBUNTU 16.04 UPDATE#
#CONFIGURE FORWARD AND REVERSE LOOKUP ZONES UBUNTU 16.04 WINDOWS 10#
The DNS servers can be pinged successfully in WSL terminal by ICMP. 202 is the IP address of secondary DNS server. It’s originally developed … Ubuntu – DNS Resolve is not working on 18. For a long time, this file allowed quick and easy configuration of DNS nameservers, as can be seen in an example resolv. Ubuntu by default runs its own copy of dnsmasq locally to do name resolution, so the inherited configuration doesn't work (the kube cluster dnsmasq would need use the ubuntu instance of dnsmasq, which is not possible as it is bound on the lo … This means that if a local installation already uses 3 nameservers or uses more than 3 searches while your glibc version is in the affected list, some of those settings will be lost. The config for DHCP is all in one file and a little less verbose. If you are not using Ubuntu and using some other Linux, then you can also use nscd. But I think this circumvents entries in /etc/hosts/ and it seems to revert to default after reboot anyways. conf is the main configuration file for the DNS name resolver library. Open a terminal and run the below command.
#CONFIGURE FORWARD AND REVERSE LOOKUP ZONES UBUNTU 16.04 UPDATE#
To make sure the system is using dnsmasq, you have to update the /etc/resolv.
#CONFIGURE FORWARD AND REVERSE LOOKUP ZONES UBUNTU 16.04 WINDOWS 10#
The DNS servers and suffixes configured for VPN connections are used in Windows 10 to resolve names using DNS in the Force Tunneling mode (“Use default gateway on remote network” option enabled) if your VPN connection is active. This is wokring for local server perfectly. In this way, DNS alleviates the need to remember IP addresses. You can restart the nscd service on Ubuntu 16. "Ubuntu" and "Debian" Set one to WSL version 1, and the other to WSL version 2 wsl -set-version Ubuntu 1 wsl -set-version Debian 2 Comments: Threaded Linear. 1 and the DNS settings on the router point to 192. (for multiple DNS addresses, a comma-separated list should be used) The forward dns servers can also be altered after enabling the addon. ip link set dev enp0s25 up ip link set dev enp0s25 down. conf”, which will limit the binding to the local interface (lo) so it does not interfere with the libvirt bindings on other interfaces. BIND is the Berkeley Internet Name Domain, DNS server. Ping the IP address of the host you are trying to get to (if it is known) A quick way to prove that it is a DNS issue and not a network issue is to ping the IP address of the host that you are trying to get to. To fix this, create file Add content … If you encounter a network issue in Linux OS such as Ubuntu, the first thing you need to do is to check whether your network configuration is correct or not. The domain controller is acting as an authoritative DNS server for the domain. MulticastDNS is implemented by nss-mdns4_minimal and Avahi. The Nameserver fields are looking for a Domain Name Server (DNS) entry, and not your AD IP. com It should respond with a result similar to the one below. Alter Avahi's configuration to change the mDNS domain from. 04 changed to use systemd-resolved to generate /etc/resolv. Usually flushing the DNS cache can help resolve most of the issues but if it is not working for you then changing the DNS settings might help you because changing the DNS settings in Ubuntu can help us resolve a lot of errors. I have a piHole set up on my network with address 192. In this case, you cannot resolve DNS names in your local network or have Internet access using your internal LAN. local, which is included … Setting DNS Nameservers on Ubuntu Desktop # Setting up DNS nameservers on Ubuntu 18. As I stated - for the most part this works. I find it really weird that a stable release has … B. DHCP subsystem: Provide support for DHCPv4, DHCPv6, BOTP and PXE. PageKite is an open-source tunneled reverse proxy that is capable of bypassing NATs (network address translation), firewalls and making local web servers and SSH servers visible to … About Ubuntu Not Working Dns Wsl. So all my devices couldn´t resolve the other local addresses. Perfect ping response when pinging within local. The configuration of DNS nameservers in Linux were the same for many years, but all things change. Changing local DNS settings does not work as WSL2 has no route to any of the DNS servers I set. 04, add the following repositories to your sources. conf) and I can access the website from the local network but not from the internet. That should display the DNS statistics showing you all the cache in its database.
0 notes
Text
IMS Service has stopped? — How to fix the error of the IMS Service Stop in Android phones?
Have you ever encountered the error message: Unfortunately IMS Service has stopped on your Android smartphone? If your answer is yes, then you have come to the right place. But, what is the Android IMS service? The IMS service is defined as the IP Multimedia Subsystem service. This service is pre-installed on your Android device and helps it to communicate with the service provider effectively, without interruptions. The IMS service is responsible for enabling text messages, phone calls, and multimedia files to be transferred to the correct IP destination on the network. This is made possible by establishing a seamless connection between the IMS service and the carrier or service provider. In this guide, we will help you fix Unfortunately, IMS Service has stopped the issue.
How to Fix Unfortunately, IMS Service has stopped on Android
Many users mistakenly assume that uninstalling the application will sort this error, which is not true. There are several reasons behind the Unfortunately, IMS Service has stopped on Android, as listed below:
Corrupt App Cache: Cache decreases the loading time of an application or a webpage whenever you open it. This is because the cache acts as a temporary memory space that stores the frequently visited & frequently accessed data thereby, fastening the surfing process. As days pass by, the cache bulges in size and may get corrupt over time. The corrupt cache might disturb the normal functioning of several applications, especially messaging apps, on your device. It might also result in IMS Service stopped error message.
Default Messaging Applications: In a few circumstances, it was observed that a few configuration files were interfering with the default applications on your Android phone. These files are provided by your network provider and are used to establish a network connection, essential for calls and messages. Such files vary depending on factors like the place where you live and the network you use, etc. Although these files too may get corrupt and prevent the default messaging applications from working correctly leading, Unfortunately, IMS Service has stopped errors.
Third-Party Messaging Applications: Whenever the default messaging service is blocked or disabled on your device intentionally or unknowingly, the third-party messaging applications automatically, assume the charge of the default messaging app. In this case, several problems may arise including, IMS Service stopped the issue.
Outdated Applications: Always ensure that the applications installed on your phone are compatible with the version of the Android operating system. Outdated applications will not work correctly with the updated Android version and cause such issues.
Outdated Android OS: An updated Android Operating System will fix bugs and errors. If you fail to update it, several errors might occur.
Now, with a clear view of the issue at hand, let us begin problem fixing.
Method 1: Update Android OS
An issue with the device software will lead to the malfunctioning of your device. Moreover, many features will be disabled, if the device operating software is not updated to its latest version. Hence, update Android OS as follows:
Unlock the device by entering the pin or pattern.
Navigate to the Settings application on your device.
Tap on System update, as shown.
A. If your device is already updated to its latest version, The system is already the latest version message is displayed, as depicted. In this case, move straight to the next method.
4. B. If your device is not updated to its latest version, then tap the Download button.
5. Wait for a while until the software is downloaded. Then, tap Verify and Install.
6. You will be asked To install upgrades, you need to restart your phone. Do you want to continue? Tap the OK option.
Now, the Android device will restart, and new software will be installed.
More Ways: How to fix IMS service has stopped?
0 notes
Text
How to distinguish optical access network OLT, ONU, ODN and ONT?
An optical access network is an access network using optical media that replace the copper wires used to access each ethnic group. An optical access network usually consists of three components: an optical line terminal (OLT), an optical network unit (ONU) and an optical transmission network (ODN). ONT and ONU are the main components of an optical access network.

What is OLT?
The full name of OLT is optical line terminal. OLT is an optical line terminal, which is the office end equipment of telecommunications. It is used to communicate with fiber optic lines. This corresponds to a switch or a router on a traditional communication network. Equipment used for access to the external network and the intranet. The most important executive functions of desktop terminals are business planning, buffering, custom configuration of fiber optic wireless interfaces, and bandwidth allocation. To put it simply, it is to realize two functions. For the upstream, it completes the uplink access of PON network; For the downstream, the obtained data is sent and distributed to all ONU user terminal devices through ODN network.
What is ONU?
ONU is optical network unit. ONU has two functions: selective reception of broadcasts sent by OLT, and reception response to OLT if necessary; Collect and cache the Ethernet data that the user needs to send, and send the cached data to the OLT end according to the allocated sending window.
In FTTx networks, different deployment ONU access methods are also different. For example, FTTC (fiber to the cube): onus are placed in the central machine room of the cell; FTTB (fiber to the building): the ONU is placed in the junction box in the corridor; FTTH (fiber to the home): onus are placed in home users.
What is ODN?
ODN is optical distribution network, and ODN is FTTH Optical Cable Network Based on PON equipment. It is the physical optical transmission channel between OLT and ONU. Its main function is to complete the two-way transmission of optical signals. It is usually composed of optical fiber and cable, optical connector, optical splitter and supporting equipment for installing and connecting these devices. The most important component is the splitter.
Functionally, ODN can be divided into four parts: feeder optical cable subsystem, distribution optical cable subsystem, home line optical cable subsystem and optical fiber terminal subsystem.
What is ONT?
ONT is optical network terminal, commonly known as "optical cat", which is similar to xDSL electric cat. ONT is an optical network terminal, which is applied to end users, while ONU refers to an optical network unit, which may have other networks with end users. ONT is an integral part of ONU.
What is the relationship between ONU and OLT?
OLT is the management end and ONU is the terminal; ONU services are issued through OLT, which is a master-slave relationship. Multiple ONUs can be connected through the beam splitter under an OLT.
The above is a brief introduction about OLT, ONU, ODN and ONT, if you want to know the optical network unit price, welcome to contact us!
0 notes
Text
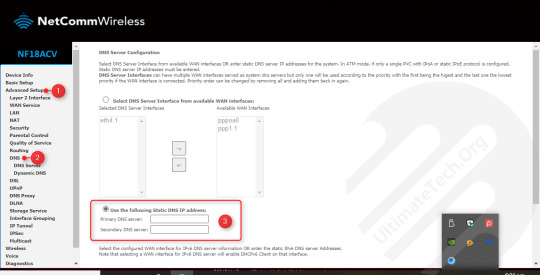
Primary Dns Server Address

Scroll up the information in the window to the 'DNS Servers' item on the left side. To the right you will see your computer's primary DNS server address as well as its secondary one (if your.
Optimum DNS Servers. Primary DNS: 167.206.112.138. Secondary DNS: 167.206.7.4.
According to this link and the Windows Server 2008 R2 Best Practices Analyzer, the loopback address should be in the list, but never as the primary DNS server. In certain situations like a topology change, this could break replication and cause a server to be 'on an island' as far as replication is concerned.
Primary And Secondary Dns Server Address
What Is My Dns Server
You may see a DNS server referred to by other names, such as a name server or nameserver, and a domain name system server. The Purpose of DNS Servers It's easier to remember a domain or hostname like lifewire.com than it is to remember the site's IP address numbers 151.101.2.114.
Nslookup (name server lookup) is a command-line tool that is used to diagnose and validate DNS servers and records, and to find name resolution problems in the DNS subsystem. The nslookup tool was originally developed as a part of the BIND package and ported to Windows by Microsoft. Nslookup is currently a built-in tool in all supported versions of Windows.


How to Use Nslookup to Check DNS Records?
Using the nslookup utility, you can determine the IP address of any server by its DNS name, perform the reverse DNS lookup, and get information about the various DNS records for a specific domain name.
When running, Nslookup sends queries to the DNS server that is specified in your network connection settings. This address is considered the default (preferred) DNS server. My phone ip. The user can specify the address of any other available DNS server. As a result, all subsequent DNS requests will be sent to it.
You can view or change your preferred and alternative DNS server IP addresses in the network connection properties.
Or you can get your DNS server setting from the CLI prompt using the ipconfig command:
You can use the nslookup tool in interactive or non-interactive mode.
To run a DNS query using nslookup tool in non-interactive mode, open a Command prompt, and run the command:
In this example, we requested the IP address of theitbros.com domain. The nslookup utility queries the DNS server (it is specified in the Server line) and it returned that this name matches the IP address 37.1.214.145 (A and AAAA records are shown by default).
This response indicates that your DNS server is available, works properly, and processes requests for resolving DNS names.
If you received such an answer:
Server: dns1.contoso.com
Address: хх.хх.хх.хх
*** dns1.contoso.com can’t find theitbros.com: Non-existent domain
This means that no entries were found for this domain name on the DNS server.
If your DNS server is unavailable or not responding, you will receive a DNS request timed out error.
In this case, check if you have specified the correct DNS server address and whether there is a problem with the network connection from the IS provider.
Plugin de autotune para fl studio 20. GSnap – (Windows) GSnap gives you the ability to control the notes that it snaps to through MIDI. Antares Auto-Tune Pro (Paid) Auto-Tune is the original pitch correction software. It’s so popular that. Download Auto Tune 8 For Fl Studio 20 Free Download; Download Auto Tune 8 For Fl Studio 2015; Auto-Tune Pro is the most complete and advanced edition of Auto-Tune. It includes Auto Mode, for real-time correction and effects, Graph Mode, for detailed pitch and time editing, and the Auto-Key plug.
READ ALSOFixing DNS Server Not Responding Error on Windows 10
The Non-authoritative answer means that the DNS server that executed the request is not the owner of the theitbros.com zone (there are no records about this domain in its database) and to perform name resolution a recursive query to another DNS server was used.
You can enable and disable the recursive nslookup mode using the commands (by default, recursive DNS queries are enabled):
You can access an authoritative DNS server by specifying its address directly in the parameters of the nslookup utility. For example, to resolve a name on the authoritative DNS server (that contains this domain) use the command:
When you run nslookup without parameters, the utility switches to the interactive mode. In this mode, you can execute various commands. A complete list of available internal commands of the nslookup utility can be displayed by typing a question.

Tip. Note that nslookup commands are case sensitive.
To close the interactive nslookup session, type exit and press Enter.
To find the DNS servers that are responsible for a specific domain (Name Server authoritative servers), run the following commands:
You can perform reverse lookups (get DNS name by IP address). Just type the IP address in the nslookup interactive prompt and press Enter.
Using Nslookup to Get Different DNS Record Types
The default nslookup resource records type is A and AAAA, but you can use different types of resource records:
A
ANY
CNAME
GID
HINFO:
MB
MG
MINF
MR
MX
NS
PTR
SOA
TXT
UID
UINFO
WKS
You can set specific record types to lookup using the nslookup parameter:
For example, to list all mail servers configured for a specific domain (MX, Mail eXchange records), run the command:
Non-authoritative answer:
theitbros.com MX preference = 10, mail exchanger = mail.theitbros.com
theitbros.com MX preference = 20, mail exchanger = mail.theitbros.com
mail.theitbros.com internet address = 37.1.214.145
mail.theitbros.com internet address = 37.1.214.145
As you can see, this domain has 2 MX records with priorities 10 and 20 (the lower the number, the higher the priority of the MX address). If you don’t see MX records, they probably just aren’t configured for that domain.
READ ALSOHow to Configure DHCP Conflict Resolution?
To list all DNS records in the domain zone, run the command:
Non-authoritative answer:
theitbros.com internet address = 37.1.214.145
theitbros.com nameserver = ns2.theitbros.com
theitbros.com nameserver = ns1.theitbros.com
theitbros.com MX preference = 10, mail exchanger = mail.theitbros.com
theitbros.com MX preference = 20, mail exchanger = mail.theitbros.com
ns2.theitbros.com internet address = 74.80.224.189
ns1.theitbros.com internet address = 37.1.214.145
mail.theitbros.com internet address = 37.1.214.145
mail.theitbros.com internet address = 37.1.214.145
To get the SOA record (Start of Authority – start DNS zone record, which contains information about the domain zone, its administrator’s address, serial number, etc.), use the option -type=soa:
theitbros.com
primary name server = pdns1.registrar-servers.com
responsible mail addr = hostmaster.registrar-servers.com
serial = 1601449549
refresh = 43200 (12 hours)
retry = 3600 (1 hour)
expire = 604800 (7 days)
default TTL = 3601 (1 hour 1 sec)
pdns1.registrar-servers.com internet address = 156.154.130.200
pdns1.registrar-servers.com AAAA IPv6 address = 2610:a1:1022::200
primary name server;
responsible mail addr — domain administrator email address ([email protected]). Since the @ symbol in the zone description has its own meaning, it is replaced by a dot in this field);
serial — the serial number of the zone file, used to record changes. The following format is usually used: YYYYMMDDHH;
refresh — the period of time (in seconds) after which the secondary DNS server will send a request to the primary one to check if the serial number has changed;
retry — specifies the interval for reconnecting to the primary DNS server if for some reason it was unable to respond to the request;
expire — specifies how long the DNS cache is kept by the secondary DNS server, after which it will be considered expired;
default TTL — “Time to Live” seconds. Refers to how long your DNS settings must be cached before they are automatically refreshed.
If you want to list the TXT records of a domain (for example, when viewing SPF settings), run the command:
The debug option allows you to get additional information contained in the headers of client DNS requests and server responses (lifetime, flags, record types, etc.):
You can view the current values for all specified nslookup options with the command:
READ ALSOTo Sign in Remotely, You Need the Right to Sign in Through Remote Desktop Service
> set all
Default Server: ns1.theitbros.com
Address: 192.168.1.11
Set options:
nodebug
defname
search
recurse
nod2
novc
noignoretc
port=53
type=A+AAAA
class=IN
timeout=2
retry=1
root=A.ROOT-SERVERS.NET.
domain=xxx
MSxfr
IXFRversion=1
srchlist=xxx
By default, DNS servers listen on UDP port 53, but you can specify a different port number if necessary using the -port option:
or interactively:
You can change the interval to wait for a response from the DNS server. This is usually necessary on slow or unstable network links. By default, if no response comes within 5 seconds, the request is repeated, increasing the waiting time by two times. But you can manually set this value in seconds using the -timeout option:
So, in this article, we covered the basics of working with the nslookup command on Windows.
If the directory is removed from IIS, but remains in AD, you must first remove the directory from AD using the Remove-XXXVirtualDirectory cmdlet (where XXX is the name of the directory: ECP, OWA, etc.).
If the directory is still in IIS but is not present in the Active Directory configuration, you must remove it from the IIS configuration. To do this, we need the Metabase Explorer tool from the IIS 6 Resource Kit (requires Net Framework 3.5 Feature).
Launch IIS Metabase Explorer, go to Exchange > LM > W3SVC > 1 > ROOT. Delete the directory you want by right-clicking on it and choosing Delete.
Restart IIS:
Now attempt to create the virtual directory again using the New-EcpVirtualDirectory, New-OwaVirtualDirectory, or New-WebApplication cmdlets
AuthorRecent Posts
Primary And Secondary Dns Server Address
Cyril KardashevskyI enjoy technology and developing websites. Since 2012 I'm running a few of my own websites, and share useful content on gadgets, PC administration and website promotion.

Latest posts by Cyril Kardashevsky (see all)
How to Truncate SQL Server Transaction Logs? - May 6, 2021What to Do if Outlook Cannot Connect to Gmail Account? - May 5, 2021How to Check Active Directory Replication? - May 1, 2021=' font-size:14px=''>='font-size:14px>
What Is My Dns Server
FacebookTwitterWhatsAppTelegramLinkedInEmail =' tzss-text=''>='tzss-button>=tzss-share-item>=tzss-share-buttons-list>
0 notes
Text
With its most recent development, the C-DAC AUM CPU, India's Centre for Development of Advanced Computing (C-DAC) has set its eyes on developing the high-performance computing (HPC) industry. This cutting-edge CPU, code-named Zeus, is based on the ARM Neoverse V1 core architecture and promises to transform HPC's capabilities in the digital era. Let's examine this revolutionary development in further detail. C-DAC is committed to meeting a variety of computing needs, including those for data centres, augmented reality/virtual reality (AR/VR) applications, and smart devices and the Internet of Things (IoT). The entry-level market for low-power and reasonably priced processors will be especially targeted by the Vega CPU family, which has two and quad-core architectures. In order to provide companies with effective computing solutions, C-DAC plans to meet at least 10% of India's chip demand. The business also intends to launch octa-core chips within the following three years as a replacement for the popular Dhruv and Dhanush Plus processors. National Supercomputing Mission with Power-Efficient HPC C-DAC is assiduously developing a power-efficient HPC processor to aid the National Supercomputing Mission (NSM) programme. This chip, known as the C-DAC AUM, is made especially to efficiently manage heavy workloads. The AUM CPU has an impressive 96 cores and uses the ARM Neoverse V1 core architecture. These cores are split across two chiplets, each of which contains 48 V1 cores. For difficult HPC workloads, its novel architecture offers optimum performance and improved scalability.. Architecture of the C-DAC AUM CPU The C-DAC AUM CPU is distinguished by its outstanding architectural characteristics, which offer a solid basis for high-performance computation. The memory, I/O, C2C/D2D interface, cache, security, and MSCP sub-systems are all included in every AUM CPU chiplet. The two A48Z-based chiplets work together effortlessly thanks to a D2D chiplet connection on the same interposer, which boosts productivity and data transfer speeds. Notably, the CPU has a 96 MB L2 cache and a 96 MB system cache, which improves its speed even further. Memory Configuration A unique triple-memory subsystem is used by the C-DAC AUM CPU, combining on-die, inter-poser, and off-chip memory options. The AUM CPU has outstanding memory bandwidth thanks to its 64 GB of HBM3-5600 memory and an extra 96 GB of HBM3 memory on-die. Additionally, its 8-channel DDR5-5200 memory, which scales up to 16 channels for a maximum total bandwidth of 332.8 GB/s, provides efficient data processing for even the most difficult computing operations. the Power: Performance and Scalability With clock rates ranging from 3.0 to 3.5 GHz, the C-DAC AUM CPU displays its performance capability. The performance of a single CPU-only node with the C-DAC AUM can reach up to 10 TFLOPs. This extraordinary CPU can handle up to four industry-standard GPU accelerators in a dual-socket server configuration and offers an astonishing 4.6+ TFLOPs per socket. The AUM CPU enables easy integration and extension opportunities for many computing environments by supporting 64/128 PCIe Gen 5 lanes and being CXL compatible. Source:negd.in
0 notes
Text
What is Full-Stack Development?

What is Full Stack Development, Definition?
Full-stack development refers to the development of both front-end and back-end portions of an application. This web development process involves all three-layer- The presentation layer (front end part that deals with the user interface), Business Logic Layer (back end part that deals with data validation), and the Database Layer. It takes care of all the steps from the conception of an idea to the actual finished product.
Having a specialist work on each of the different subsystems of the web development process proves quite complex and expensive. Companies are demanding full-stack developers who are proficient in working across multiple stacks.
Read More: What to Choose between Native or Hybrid Development

What is a full-stack developer?
A Full-Stack Web Developer is a web developer or engineer who works on both the front-end and back-end of a website or application — meaning they can tackle projects that involve databases, building user-facing websites, or even work with clients during the planning phase of projects. Being a Full-Stack Developer doesn’t mean that you have necessarily mastered everything required to work with the front-end or back-end, but it means that you are able to work on both sides and understand what is going on when building an application.
In fact, “full-stack” refers to the collection of a series of technologies needed to complete a project. “Stack” refers to a collection of sub-modules. These software sub-modules or components combined together to achieve the established function while without the need for other modules.
Technology related to full-stack development:
There are some essential technologies that you must learn in order to call yourself a full-stack developer. Here is a quick guide to what technologies you must learn.

HTML and CSS-
To begin your career in web development you must have the fundamental knowledge of HTML and CSS. They are the basic building blocks of the web that enable you to add content and styles to your web pages. So start your journey of becoming a full-stack developer by gaining a sound understanding of these front-end concepts.
JavaScript-
The fact that JavaScript can be used both in front-end and back-end development makes it very popular. It is one of the hottest technologies in the market where continuous innovations take place. With new tools and frameworks getting released every year, one needs a piece of sound knowledge in this area. Knowledge of JS frameworks like AngularJS and ReactJS would help one to write long codes with ease. A solid understanding of jQuery would be an added advantage.
Backend Programming Languages–
After gaining a strong foothold in the front-end arena next comes backend languages like Ruby, Python, PHP, etc. which handle application logic, user authentication, and data operations. Start with a language that is easier to learn. Whatever language you choose, just make sure you are thorough with its nuances. You may learn Node.JS which is based on JavaScript that you would have already learned before reaching this point.
Database & Web Storage-
In order to design and develop dynamic websites, one should surely know how database-driven websites store and access data. Learn the benefits of relational database management systems like SQL. Understand how to connect a backend language with a database. Gain knowledge about web storage so that you know how to store cookies, sessions, and cached data in the browser.
HTTP and REST-
You must gain insights into HTTP- that is the protocol required to facilitate communication between the client and server. You must also know how REST is important to the HTTP protocol and web applications. Knowledge of Chrome DevOps Tools and SSL certificates would be advantageous.
Read more: The Fundamentals of Front End and Back End Development
Additional skills set to adopt as full-stack developers are as follows.
Application Architecture-
Developing complex applications would require a deep knowledge of how the code should be structured, how the data needs to be structured in the database, how to separate files, where to perform computational tasks, and where to host large media files. So a full stack web developer surely needs a deep knowledge of web application architecture.
Version Control System-
A full-stack web developer needs to be well versed with a version control system. An understanding of GIT will help you keep track of any changes that you make to the code base.
Acquiring expertise in so many technologies and becoming an expert in all the layers of web development may seem like a daunting task in the beginning. It’ll be hard work learning all of this, but it’s rewarding in the end and Full-Stack Development is fun!
https://www.charterglobal.com/understanding-full-stack-development/
0 notes
Text
Exploring the .NET open source hybrid ORM library RepoDB
It's nice to explore alternatives, especially in open source software. Just because there's a way, or an "official" way doesn't mean it's the best way.
Today I'm looking at RepoDb. It says it's "a hybrid ORM library for .NET. It is your best alternative ORM to both Dapper and Entity Framework." Cool, let's take a look.
Michael Pendon, the author puts his micro-ORM in the same category as Dapper and EF. He says "RepoDb is a new hybrid micro-ORM for .NET designed to cater the missing pieces of both micro-ORMs and macro-ORMs (aka full-ORMs). Both are fast, efficient and easy-to-use. They are also addressing different use-cases."
Dapper is a great and venerable library that is great if you love SQL. Repo is a hybrid ORM and offers more than one way to query, and support a bunch of popular databases:
SqlServer
SqLite
MySql
PostgreSql
Here's some example code:
/* Dapper */ using (var connection = new SqlConnection(ConnectionString)) { var customers = connection.Query<Customer>("SELECT Id, Name, DateOfBirth, CreatedDateUtc FROM [dbo].[Customer];"); } /* RepoDb - Raw */ using (var connection = new SqlConnection(ConnectionString)) { var customers = connection.ExecuteQuery<Customer>("SELECT Id, Name, DateOfBirth, CreatedDateUtc FROM [dbo].[Customer];"); } /* RepoDb - Fluent */ using (var connection = new SqlConnection(ConnectionString)) { var customers = connection.QueryAll<Customer>(); }
I like RepoDB's strongly typed Fluent insertion syntax:
/* RepoDb - Fluent */ using (var connection = new SqlConnection(connectionString)) { var id = connection.Insert<Customer, int>(new Customer { Name = "John Doe", DateOfBirth = DateTime.Parse("1970/01/01"), CreatedDateUtc = DateTime.UtcNow }); }
Speaking of inserts, it's BulkInsert (my least favorite thing to do) is super clean:
using (var connection = new SqlConnection(ConnectionString)) { var customers = GenerateCustomers(1000); var insertedRows = connection.BulkInsert(customers); }
The most interesting part of RepoDB is that it formally acknowledges 2nd layer caches and has a whole section on caching in the excellent RepoDB official documentation. I have a whole LazyCache subsystem behind my podcast site that is super fast but added some complexity to the code with more Func<T> that I would have preferred.
This is super clean, just passing in an ICache when you start the connection and then mention the key when querying.
var cache = CacheFactory.GetMemoryCache(); using (var connection = new SqlConnection(connectionString).EnsureOpen()) { var products = connection.QueryAll<Product>(cacheKey: "products", cache: cache); } using (var repository = new DbRepository<Product, SqlConnection>(connectionString)) { var products = repository.QueryAll(cacheKey: "products"); }
It also shows how to do generated cache keys...also clean:
// An example of the second cache key convention: var cache = CacheFactory.GetMemoryCache(); using (var connection = new SqlConnection(connectionString).EnsureOpen()) { var productId = 5; Query<Product>(product => product.Id == productId, cacheKey: $"product-id-{productId}", cache: cache); }
And of course, if you like to drop into SQL directly for whatever reason, you can .ExecuteQuery() and call sprocs or use inline SQL as you like. So far I'm enjoying RepoDB very much. It's thoughtfully designed and well documented and fast. Give it a try and see if you like it to?
Why don't you head over to https://github.com/mikependon/RepoDb now and GIVE THEM A STAR. Encourage open source. Try it on your own project and go tweet the author and share your thoughts!
Sponsor: Have you tried developing in Rider yet? This fast and feature-rich cross-platform IDE improves your code for .NET, ASP.NET, .NET Core, Xamarin, and Unity applications on Windows, Mac, and Linux.
© 2020 Scott Hanselman. All rights reserved.





Exploring the .NET open source hybrid ORM library RepoDB published first on https://deskbysnafu.tumblr.com/
0 notes
Text
Exploring the .NET open source hybrid ORM library RepoDB
It's nice to explore alternatives, especially in open source software. Just because there's a way, or an "official" way doesn't mean it's the best way.
Today I'm looking at RepoDb. It says it's "a hybrid ORM library for .NET. It is your best alternative ORM to both Dapper and Entity Framework." Cool, let's take a look.
Michael Pendon, the author puts his micro-ORM in the same category as Dapper and EF. He says "RepoDb is a new hybrid micro-ORM for .NET designed to cater the missing pieces of both micro-ORMs and macro-ORMs (aka full-ORMs). Both are fast, efficient and easy-to-use. They are also addressing different use-cases."
Dapper is a great and venerable library that is great if you love SQL. Repo is a hybrid ORM and offers more than one way to query, and support a bunch of popular databases:
SqlServer
SqLite
MySql
PostgreSql
Here's some example code:
/* Dapper */ using (var connection = new SqlConnection(ConnectionString)) { var customers = connection.Query<Customer>("SELECT Id, Name, DateOfBirth, CreatedDateUtc FROM [dbo].[Customer];"); } /* RepoDb - Raw */ using (var connection = new SqlConnection(ConnectionString)) { var customers = connection.ExecuteQuery<Customer>("SELECT Id, Name, DateOfBirth, CreatedDateUtc FROM [dbo].[Customer];"); } /* RepoDb - Fluent */ using (var connection = new SqlConnection(ConnectionString)) { var customers = connection.QueryAll<Customer>(); }
I like RepoDB's strongly typed Fluent insertion syntax:
/* RepoDb - Fluent */ using (var connection = new SqlConnection(connectionString)) { var id = connection.Insert<Customer, int>(new Customer { Name = "John Doe", DateOfBirth = DateTime.Parse("1970/01/01"), CreatedDateUtc = DateTime.UtcNow }); }
Speaking of inserts, it's BulkInsert (my least favorite thing to do) is super clean:
using (var connection = new SqlConnection(ConnectionString)) { var customers = GenerateCustomers(1000); var insertedRows = connection.BulkInsert(customers); }
The most interesting part of RepoDB is that it formally acknowledges 2nd layer caches and has a whole section on caching in the excellent RepoDB official documentation. I have a whole LazyCache subsystem behind my podcast site that is super fast but added some complexity to the code with more Func<T> that I would have preferred.
This is super clean, just passing in an ICache when you start the connection and then mention the key when querying.
var cache = CacheFactory.GetMemoryCache(); using (var connection = new SqlConnection(connectionString).EnsureOpen()) { var products = connection.QueryAll<Product>(cacheKey: "products", cache: cache); } using (var repository = new DbRepository<Product, SqlConnection>(connectionString)) { var products = repository.QueryAll(cacheKey: "products"); }
It also shows how to do generated cache keys...also clean:
// An example of the second cache key convention: var cache = CacheFactory.GetMemoryCache(); using (var connection = new SqlConnection(connectionString).EnsureOpen()) { var productId = 5; Query<Product>(product => product.Id == productId, cacheKey: $"product-id-{productId}", cache: cache); }
And of course, if you like to drop into SQL directly for whatever reason, you can .ExecuteQuery() and call sprocs or use inline SQL as you like. So far I'm enjoying RepoDB very much. It's thoughtfully designed and well documented and fast. Give it a try and see if you like it to?
Why don't you head over to https://github.com/mikependon/RepoDb now and GIVE THEM A STAR. Encourage open source. Try it on your own project and go tweet the author and share your thoughts!
Sponsor: Have you tried developing in Rider yet? This fast and feature-rich cross-platform IDE improves your code for .NET, ASP.NET, .NET Core, Xamarin, and Unity applications on Windows, Mac, and Linux.
© 2020 Scott Hanselman. All rights reserved.





Exploring the .NET open source hybrid ORM library RepoDB published first on http://7elementswd.tumblr.com/
0 notes
Text
Radeon RX 6600 XT Review: Test ( Proven) Specs| Hashrate | Overclocking | Testing

Radeon RX 6600 XT Review: Test ( Proven) Specs| Hashrate | Overclocking| Benchmark| Testing: New solution on RDNA2 for Full HD with maximum settings. The video cards of the Radeon RX 6000 family have brought back competition in the discrete GPU market, albeit nominally, since the market suffers greatly all year due to the situation with increased demand from cryptocurrency miners and, accordingly, greatly inflated prices. Radeon RX 6600 XT Review AMD has turned out to be a solid family that competes well with the GeForce RTX 30 line in different price ranges. At first, AMD announced three models that came out at the end of last year, but then a less expensive model appeared - the Radeon RX 6700 XT, which we have already reviewed. Many Read This as well - AMD Radeon RX 6800 vs RX 6800 XT: Hashrate | Specs | Test | Config | Profit We will not write much about how everything changed due to the mining boom and insufficient production of semiconductor crystals, but these factors led to a severe shortage and a rise in market prices by two, or even three times! It is not surprising that manufacturers do not have much motivation to bring new solutions to the market, because miners are already grabbing everything that is produced, and even at exorbitant prices. But the planned additions to the line were supposed to happen, and in August AMD rolled out the most budgetary (if you can say so now) solution of the new line. Brief History - Radeon RX 6600 XT Radeon RX 6600 XT The Radeon RX 6600 XT complements previously released GPUs in the lower mid-range (MSRP terms). It offers performance sufficient for any graphics setting at 1920 × 1080 in rasterized games and ray traced games under some conditions. The new GPU incorporates all the advantages of the new RDNA 2 architecture - high-performance computing units with support for hardware ray tracing, a new type of Infinity Cache, albeit a reduced size in the version of the Navi 23 chip, on which the RX 6600 XT model is based, but all the same helping to improve effective memory bandwidth, and much more. Who needs this video card and why? The answer is simple - to the most massive user. According to researchers from IDC, about two-thirds of monitors sold in the past year have a resolution of only Full HD (1920 × 1080). But there are quite a few models of such monitors with an increased screen refresh rate - up to 244-270 Hz, and all of them are intended mainly for gamers. The number of such fast gaming monitors on the market has grown dozens of times in recent years. And the power of the most common video cards of past generations, such as the GeForce GTX 1060 and Radeon RX 480, is no longer enough to provide even 60 FPS in the most modern games at maximum quality settings. These solutions from AMD and Nvidia give only about 30 FPS in games such as Cyberpunk 2077, Godfall and Red Dead Redemption 2. And it is the owners of such GPUs that AMD offers an upgrade option to the Radeon RX 6600 XT model, which will provide 2- 2.5 times better performance in many games. And the solutions of the previous generation AMD Radeon RX 5600 XT and RX 5700 can be replaced by the RX 6600 XT, because the new product provides 30% -40% higher performance compared to similar options from the previous family. And even if we take into account not the best situation on the market, the Radeon RX 6600 XT may well become one of the successful options in this price segment. After all, improvements in the RDNA 2 architecture have significantly increased the energy efficiency of the new product, and also new opportunities have appeared: hardware ray tracing and other DX12 Ultimate features that video cards of the past cannot boast. Specifications - Radeon RX 6600 XT graphics card The core of the Radeon RX 6600 XT model we are reviewing today is the new Navi 23 graphics processor, which is based on the second generation RDNA architecture, and it is closely related to both RDNA 1 and the latest generations of GCN. And before reading the article, it will be useful to familiarize yourself with our previous materials on AMD video cards: Radeon RX 6600 XT Review hashrate Graphics Accelerator Radeon RX 6600 XTChip codenameNavi 23Production technology7 нм TSMCNumber of transistors11.1 billion (Navi 22 - 17.2 billion)Core area237 mm (Navi 22 - 336 mm)Architectureunified, with an array of processors for streaming processing of any kind of data: vertices, pixels, etc.DirectX hardware supportDirectX 12 Ultimate, with Feature Level 12_2 supportMemory bus128-bit: 2 independent 64-bit memory controllers with GDDR6 supportGPU frequency1968 (base) to 2589 MHz (turbo)Computing units32 CUs with a total of 2048 ALUs for integer and floating point calculations (INT4, INT8, INT16, FP16, FP32 and FP64 formats are supported)Ray tracing blocks32 Ray Accelerator blocks to calculate the intersection of rays with triangles and BVH bounding volumesTexturing blocks128 texture addressing and filtering units with support for FP16 / FP32 components and support for trilinear and anisotropic filtering for all texture formatsRaster Operation Blocks (ROPs)8 wide 64-pixel ROPs with support for various anti-aliasing modes, including programmable and FP16 / FP32 framebuffer formatsMonitor supportsupport for up to six monitors connected via HDMI 2.1 and DisplayPort 1.4a Specifications of the reference Radeon RX 6600 XT graphics cardCore frequency (game / peak)2359/2589 MHzNumber of universal processors2048Number of texture units128Number of blending blocks64Effective memory frequency16 GHzMemory typeGDDR6Memory busPage 128Memory8 GBMemory bandwidth256 GB / sComputational Performance (FP16)to 21.2 teraflopsComputational Performance (FP32)to 10.6 teraflopsTheoretical maximum fill rate165.7 gigapixels / sTheoretical texture sampling rate331.4 gigatexels / sTirePCI Express 4.0 x8Connectorsone HDMI 2.1, three DisplayPort 1.4aEnergy consumptionup to 160 wattsAdditional food8 pin connectorThe number of slots occupied in the system chassis2Recommended price$ 379 (33 260 rubles) The name of the new video card model fully corresponds to the basic principle of naming for AMD solutions adopted several years ago - compared to the Radeon RX 5600 XT, only the generation number has changed. The XT suffix remained, and so far no other models of video cards based on the same chip have been released. And in comparison with the Radeon RX 6700 XT, the new video card is one step lower, and everything looks logical here. The recommended price for the Radeon RX 6600 XT is $ 379 - a hundred less than that of the Radeon RX 6700 XT, and the price recommendation for the Russian market is 33 260 rubles, which looks like a slightly overpriced offer against the background of the GeForce RTX 3060 model, which seems to be cost less, despite the fact that the RTX 3060 Ti is only slightly more expensive. But all these reflections are purely theoretical, since the real retail prices are determined by the deficit, the efficiency of mining and the demand on the part of the participants in this business. Interestingly, AMD does not have a reference version of the Radeon RX 6600 XT, we only saw it in renders. So there is no point in describing the cooling and power supply system, they will all be different. Note that the power consumption of the entire video card is 160 W, which is noticeably less than 230 W of the Radeon RX 6700 XT. Therefore, many cards use only one 8-pin power connector for additional power supply, although AMD partners may well decide the issue differently. Many variants of the Radeon RX 6600 XT from different companies with their own PCB design and cooling systems have already entered the market. Unlike the RX 6700 XT, there are also very compact video cards, but there are also three-fan monsters, which for the budget RX 6600 XT seem to be a bit overkill. Ready-made systems with the installed Radeon RX 6600 XT are already available for sale from Acer, Alienware, Dell and HP, and the corresponding video cards of the new model have been released by all AMD partners: ASRock, Asus, Biostar, Gigabyte, MSI, PowerColor, Sapphire, XFX and others - all of them are available for sale from August 11 in various versions, with their own options for printed circuit boards and cooling systems. Architectural features The Navi 23 GPU is a junior model compared to the Navi 22 chip, and it is also based on the RDNA 2 architecture, the main task in the development of which was to achieve the highest possible energy efficiency, as well as to implement the missing functionality that the competitor and which are included in the DirectX 12 Ultimate specifications - we have already talked about them in detail in the reviews of the Radeon RX 6800 and Radeon RX 6800 XT. The basic blocks of any modern AMD chip are Compute Units (CUs), each of which has its own local storage for exchanging data or expanding the local register stack, as well as cache memory and a full-fledged texture pipeline with texture sampling and filtering units. Each of these CUs independently scheduling and scheduling work. Overall, the architecture of RDNA 2 is very similar to RDNA 1, although it has been heavily redesigned. We draw the block diagram of Navi 23 in our head again on our own - the new chip contains 32 computational CUs, consisting of 2048 ALUs, 128 TMUs and 64 ROPs. The Radeon RX 6600 XT version uses the full version of Navi 23 in which all the chip blocks are active. Interestingly, the number of all execution units does not differ that much from their number of units in the full version of the older Navi 22 chip. There is much more difference between these GPUs in the memory and data caching subsystem, the older chip has a 192-bit bus, while the Navi 23 has only a 128-bit bus. As you know, to improve the efficiency of using relatively narrow memory buses and compensate for the relatively low bandwidth of GDDR6, AMD came up with a large data cache - Infinity Cache, which really helps to improve the position of chips with low memory bandwidth. This global cache allows you to accelerate access to any data received by the GPU, and serves as an intermediary between the GPU and the slow video memory. But if in the older Navi 22 this cache memory was as much as 96 MB, which is slightly less than 128 MB for top solutions, then in Navi 23 it was left quite a bit - only 32 MB. That is, Navi 23 has only 20% fewer computing units compared to Navi 22, but the memory bandwidth is noticeably lower, and the amount of cache memory is generally reduced by three times. So we won't be surprised if the performance of the RX 6600 XT is more limited by the memory subsystem, especially when it comes to resolutions higher than Full HD. To improve energy efficiency, AMD specialists redesigned all blocks in RDNA 2, rebalanced the pipeline, found and eliminated all bottlenecks, reworked data lines, processing geometry inside the chip, and also used the experience of designing CPUs with a high operating frequency. The result turned out to be the most impressive in terms of energy efficiency gain, but from the point of view of logic circuits, the roots of the previous version of the architecture are clearly visible in the computational units of RDNA 2. Radeon RX 6600 XT has 8 GB of local memory, and at the moment this amount can be considered the right decision. It provides some margin for the future, because games are becoming more demanding, using more and more resources, and the same hardware ray tracing imposes additional requirements on the amount of memory. A fairly large number of modern games already take up more than 8 GB of memory at maximum graphics settings. It's also useful because modern consoles have a lot of memory and fast SSDs, and future multiplatform and ported games may well start requiring 8GB of local video memory in the future. Read the rest of the details about all the changes and innovations of the new graphics processor in the big review of the Radeon RX 6800 XT, where it is written about the new Infinity Cache, and about improved access to Smart Access Memory, and about changes in support for video codecs and input port standards -Output. The junior model of the RDNA 2 architecture is no different from the older GPUs in terms of functionality, although the chips are different, they can do all the same. For example, the capabilities for hardware encoding and decoding of video data in the Radeon RX 6600 XT are very wide, the new solution supports all common codecs: H.264 (4K at 180 FPS decoding and 4K at 90 FPS encoding), H.265 (decoding 4K resolution at 90 FPS or 8K @ 24 FPS and encoding 4K @ 60 FPS and 8K @ 24 FPS), and the chip can decode VP9 (4K @ 90 FPS and 8K @ 24 FPS) and AV1 (4K @ 120 FPS or 8K @ 30 FPS) formats ... As for the performance of the new product, it must be remembered that the Radeon RX 6600 XT is designed for mid-range systems, the most common on the market. The new solution provides a sufficient level of performance for Full HD resolution in all modern games, including the ability to enable some effects using ray tracing. It is strange to demand more from the new GPU. And if we compare the Radeon RX 6600 XT model we are considering today with the similarly priced GeForce RTX 3060, then the AMD video card is up to 15% faster than the competitor, judging by the measurements of the company itself: Even with tracing turned on in Dirt 5 and Godfall. To be fair, AMD admits that their solution is inferior to the competitor in such games with ray tracing as Battlefield V, Doom Eternal, Metro Exodus, Shadow of the Tomb Raider and other games that use ray tracing more actively - most often these games were created for competitor graphics cards, which have a clear advantage due to dedicated hardware units dedicated to the task of ray tracing. But in competitive online games, the new solution of the Radeon RX 6000 line should be slightly faster than the competing Nvidia video card, which is important for owners of the very high refresh rate gaming monitors that we talked about at the beginning of the article. We will definitely check all the comparative performance data in the practical part of the article, and now let's talk about the company's technologies. AMD software technologies We will also tell you about the software improvements and innovations associated with the announcement of the new solution. Introduced in August, the AMD graphics card supports all of the company's modern technologies, such as Radeon Boost and Radeon Anti-Lag , which are useful for esports players in that the former increases FPS in dynamic scenes, and the latter reduces latency when playing online. Improvements to Radeon Boost allow variable rate shading (VRS) to be used in some games, which can be useful in multiplayer battles. AMD is also proud of its Smart Access Memory technology , which is nothing more than the Resizable BAR feature available for modern Nvidia graphics cards. But AMD claims that it is their implementation of the GPU access technology to a part of the RAM that works much more efficiently - at least in their selected games. However, in other games with a significant impact of RBAR / SAM inclusion, the advantage of the new AMD solution over the RTX 3060 will be somewhat more modest - 6% -8%, but this is enough to proclaim a clear victory over the rival. Of the new useful technologies, we note FidelityFX Super Resolution , which allows you to increase performance with a slight decrease in picture quality, which is almost imperceptible in dynamics at a sufficiently high output resolution. The technology works in part similar to DLSS of rival Nvidia, although it does not use data from previous frames and does not process it using a neural network. Rather, FSR is simply an advanced technique for improving the display of an image rendered at a lower rendering resolution. But even in such a simple form, it allows you to significantly increase performance with a sufficiently high-quality picture, and even makes it possible to play with ray tracing (not always and only in a relatively low Full HD resolution). Well, without tracing, even the most modern and demanding games in Full HD just start to fly! And not the most demanding ones - they generally show 200 FPS and more: FidelityFX technology is open source and available to everyone as part of the GPUOpen initiative, which simplifies its implementation in game projects and the corresponding optimization. Previously, one of the components of this technology was known to us as FidelityFX Contrast Adaptive Sharpening (CAS) - this part is responsible for increasing the clarity of the picture, but the FSR includes another important part that is involved in scaling a low-resolution image to a higher one, with high-quality restoration of details. There are four FSR quality modes: - Ultra Quality is the highest quality mode, rendering the picture with the quality that is as close as possible to rendering at full resolution, with a slight improvement in performance. - Quality - good quality of restoration of image details and a decent increase in rendering speed - perhaps, it can be recommended in most cases. - Balanced - a mode with a balanced increase in performance and still a fairly good quality of the final image, sometimes inferior to the native rendering resolution. - Performance is the most productive mode with a high increase in speed, but with obvious losses in rendering quality, so it should be chosen only when there is a big lack of smoothness. The good thing about FSR technology is that it works on a wide range of hardware, including older graphics cards, and not even just AMD. Yes, the technology is optimized for RDNA 1 and RDNA 2 architectures (Radeon RX 5000 and RX 6000), but it also works well on Radeon RX 500 and RX 400, and RX Vega with integrated graphics in AMD Ryzen processors. Also, importantly, FSR is supported on competing solutions - Nvidia GeForce RTX 30 and RTX 20 series graphics cards, as well as GeForce GTX 16 and GTX 10. The new software technology is very easy to implement into the code, since it does not require access to the data of previous frames. In fact, it works like another post-filter, but it increases the output resolution, and in theory it can even be screwed onto old games if they require more performance. FSR is already available for the most common game engines Unity and Unreal Engine, so it is not surprising that almost since the announcement, FSR technology has been supported in several games at once, and their list is only expanding. So, with all the theoretical data and potential capabilities of the new AMD video card, we got acquainted, it's time to take a look at it before proceeding with the tests. Features of the AMD Radeon RX 6600 XT graphics card Manufacturer Information : Sapphire Technology (Sapphire trademark) was founded in 2001 in Hong Kong as a subsidiary of the largest concern for the production of PC components - PC Partner. Focused on the release of products based on cores (graphics processors) ATI (later became part of AMD). Headquartered in Hong Kong, production in China. The largest manufacturer of accelerators in the Radeon series. It also manufactures mini-PCs and other products. ... Subject of research : 3D graphics accelerator (video card) Sapphire Pulse Radeon RX 6600 XT 8 GB 128-bit GDDR6 Card characteristics Sapphire Pulse Radeon RX 6600 XT 8GB 128-bit GDDR6GPURadeon RX 6600 XT (Navi 23)InterfacePCI Express x8 4.0GPU Read the full article
0 notes
Link
(Via: Lobsters)
Configuring a connection pool is something that developers often get wrong. There are several, possibly counter-intuitive for some, principles that need to be understood when configuring the pool.
10,000 Simultaneous Front-End Users
Imagine that you have a website that while maybe not Facebook-scale still often has 10,000 users making database requests simultaneously -- accounting for some 20,000 transactions per second. How big should your connection pool be? You might be surprised that the question is not how big but rather how small!
Watch this short video from the Oracle Real-World Performance group for an eye-opening demonstration (~10 min.):

{Spoiler Alert} if you didn't watch the video. Oh come on! Watch it then come back here.
You can see from the video that reducing the connection pool size alone, in the absence of any other change, decreased the response times of the application from ~100ms to ~2ms -- over 50x improvement.
But why?
We seem to have understood in other parts of computing recently that less is more. Why is it that with only 4-threads an nginx web-server can substantially out-perform an Apache web-server with 100 processes? Isn't it obvious if you think back to Computer Science 101?
Even a computer with one CPU core can "simultaneously" support dozens or hundreds of threads. But we all [should] know that this is merely a trick by the operating system though the magic of time-slicing. In reality, that single core can only execute one thread at a time; then the OS switches contexts and that core executes code for another thread, and so on. It is a basic Law of Computing that given a single CPU resource, executing A and B sequentially will always be faster than executing A and B "simultaneously" through time-slicing. Once the number of threads exceeds the number of CPU cores, you're going slower by adding more threads, not faster.
That is almost true...
Limited Resources
It is not quite as simple as stated above, but it's close. There are a few other factors at play. When we look at what the major bottlenecks for a database are, they can be summarized as three basic categories: CPU, Disk, Network. We could add Memory in there, but compared to Disk and Network there are several orders of magnitude difference in bandwidth.
If we ignored Disk and Network it would be simple. On a server with 8 computing cores, setting the number of connections to 8 would provide optimal performance, and anything beyond this would start slowing down due to the overhead of context switching. But we cannot ignore Disk and Network. Databases typically store data on a Disk, which traditionally is comprised of spinning plates of metal with read/write heads mounted on a stepper-motor driven arm. The read/write heads can only be in one place at a time (reading/writing data for a single query) and must "seek" to a new location to read/write data for a different query. So there is a seek-time cost, and also a rotational cost whereby the disk has to wait for the data to "come around again" on the platter to be read/written. Caching of course helps here, but the principle still applies.
During this time ("I/O wait"), the connection/query/thread is simply "blocked" waiting for the disk. And it is during this time that the OS could put that CPU resource to better use by executing some more code for another thread. So, because threads become blocked on I/O, we can actually get more work done by having a number of connections/threads that is greater than the number of physical computing cores.
How many more? We shall see. The question of how many more also depends on the disk subsystem, because newer SSD drives do not have a "seek time" cost or rotational factors to deal with. Don't be tricked into thinking, "SSDs are faster and therefore I can have more threads". That is exactly 180 degrees backwards. Faster, no seeks, no rotational delays means less blocking and therefore fewer threads [closer to core count] will perform better than more threads. More threads only perform better when blocking creates opportunities for executing.
Network is similar to disk. Writing data out over the wire, through the ethernet interface, can also introduce blocking when the send/receive buffers fill up and stall. A 10-Gig interface is going to stall less than Gigabit ethernet, which will stall less than a 100-megabit. But network is a 3rd place runner in terms of resource blocking and some people often omit it from their calculations.
Here's another chart to break up the wall of text.
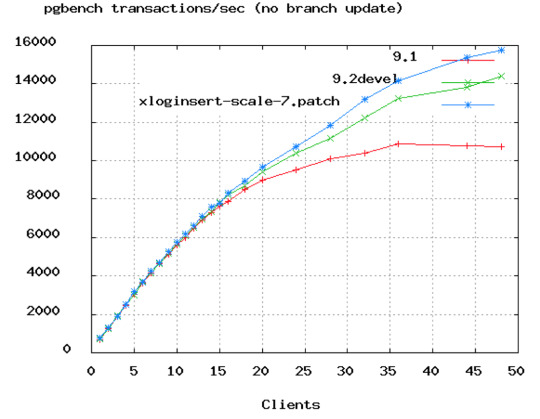
You can see in the above PostgreSQL benchmark that TPS rates start to flatten out at around 50 connections. And in Oracle's video above they showed dropping the connections from 2048 down to just 96. We would say that even 96 is probably too high, unless you're looking at a 16 or 32-core box.
The Formula
The formula below is provided by the PostgreSQL project as a starting point, but we believe it will be largely applicable across databases. You should test your application, i.e. simulate expected load, and try different pool settings around this starting point:
connections = ((core_count * 2) + effective_spindle_count)
A formula which has held up pretty well across a lot of benchmarks for years is that for optimal throughput the number of active connections should be somewhere near ((core_count * 2) + effective_spindle_count). Core count should not include HT threads, even if hyperthreading is enabled. Effective spindle count is zero if the active data set is fully cached, and approaches the actual number of spindles as the cache hit rate falls. ... There hasn't been any analysis so far regarding how well the formula works with SSDs.
Guess what that means? Your little 4-Core i7 server with one hard disk should be running a connection pool of: 9 = ((4 * 2) + 1). Call it 10 as a nice round number. Seem low? Give it a try, we'd wager that you could easily handle 3000 front-end users running simple queries at 6000 TPS on such a setup. If you run load tests, you will probably see TPS rates starting to fall, and front-end response times starting to climb, as you push the connection pool much past 10 (on that given hardware).
Axiom: You want a small pool, saturated with threads waiting for connections.
If you have 10,000 front-end users, having a connection pool of 10,000 would be shear insanity. 1000 still horrible. Even 100 connections, overkill. You want a small pool of a few dozen connections at most, and you want the rest of the application threads blocked on the pool awaiting connections. If the pool is properly tuned it is set right at the limit of the number of queries the database is capable of processing simultaneously -- which is rarely much more than (CPU cores * 2) as noted above.
We never cease to amaze at the in-house web applications we've encountered, with a few dozen front-end users performing periodic activity, and a connection pool of 100 connections. Don't over-provision your database.
"Pool-locking"
The prospect of "pool-locking" has been raised with respect to single actors that acquire many connections. This is largely an application-level issue. Yes, increasing the pool size can alleviate lockups in these scenarios, but we would urge you to examine first what can be done at the application level before enlarging the pool.
The calculation of pool size in order to avoid deadlock is a fairly simple resource allocation formula:
pool size = Tn x (Cm - 1) + 1
Where Tn is the maximum number of threads, and Cm is the maximum number of simultaneous connections held by a single thread.
For example, imagine three threads (Tn=3), each of which requires four connections to perform some task (Cm=4). The pool size required to ensure that deadlock is never possible is:
pool size = 3 x (4 - 1) + 1 = 10
Another example, you have a maximum of eight threads (Tn=8), each of which requires three connections to perform some task (Cm=3). The pool size required to ensure that deadlock is never possible is:
pool size = 8 x (3 - 1) + 1 = 17
👉 This is not necessarily the optimal pool size, but the minimum required to avoid deadlock.
👉 In some environments, using a JTA (Java Transaction Manager) can dramatically reduce the number of connections required by returning the same Connection from getConnection() to a thread that is already holding a Connection in the current transaction.
Caveat Lector
Pool sizing is ultimately very specific to deployments.
For example, systems with a mix of long running transactions and very short transactions are generally the most difficult to tune with any connection pool. In those cases, creating two pool instances can work well (eg. one for long-running jobs, another for "realtime" queries).
In systems with primarily long running transactions, there is often an "outside" constraint on the number of connections needed -- such as a job execution queue that only allows a certain number of jobs to run at once. In these cases, the job queue size should be "right-sized" to match the pool (rather than the other way around).
0 notes
Text
SSD performance and value ranked
We utilize Windows 10 Pro installed on a Samsung 960 Evo since the boot drive, AHCI is empowered, and all drives are connected to the motherboard's SATA III ports (except NVMe drives, which use the second M.2 slot). We utilize a combination of artificial and follow benchmarks, in addition to real-world file copying. Including AS SSD, CrystalDiskMark, and PCMark 8.
This is when you're really hitting on the storage subsystem, needless to say. If you're not operating benchmarks, the real-world differences are hard to detect. However, in precisely the exact same test package, a fantastic hard drive scores around 10-15. Yeah, it's that big of a leap, and you absolutely will observe the gap between any contemporary SSD and an HDD.
The single specific advantage that makes an SSD much faster than a hard disk is access times that are orders of magnitude faster. A tough disk is dependent upon a mechanical arm going into position to read information out of a platter, whereas with an SSD, information is stored and accessed electronically. Although modern hard disks are surprisingly fast at obtaining data, they're no match for an SSD; the fastest HDD access times are still around 10ms, while any good SSD will usually have access times beneath 0.1ms.
An SSD is a physically simple apparatus. It is made from an array of flash memory chips and a controller, which includes a processor, memory cache, and firmware. However, like most things in computing, it begins to get complicated when you consider it in detail. NAND flash chips shop binary values as voltage differences in non-volatile memory, meaning that they retain their state when power is cut off. In order to modify the state of a single cell (ie writing for it), a strong voltage is required. But because of the way the cells are laid out, it can not be done on a cell-by-cell foundation: an whole row needs to be erased at once.
Each mobile is insulated from its neighbors to preserve the value it holds, however every time a cell is programmed, the insulator gets slightly less reliable. Eventually, after a certain amount of writes, the mobile becomes unable to hold any values, which is why SSDs have a limited lifespan. From the first days of flash memory, this limited number of writes proved to be an issue, but clever tricks, enhanced technologies, and applications improvements mean it is not a real problem.
A given quantity of bodily flash memory cells may be programmed to hold either one, two, or three bits of data. A driveway where each cell holds one bit is called SLC (Single-Level Mobile). Each cell can only be in one or two states, off or on, and just needs to be sensitive to two voltages. Its endurance and endurance will be incredible, but a large quantity of flash memory is needed to supply a given capacity, therefore SLC drives have never really taken off beyond expensive server and workstation setups.
2-bit MLC (Multi-Level Mobile) memory is currently the most popular type employed in consumer SSDs. Each cell holds two bits, with four binary states (00, 01, 10 and 11), so the cell has to be sensitive to four voltages. The same quantity of flash memory provides double the total amount of space as SLC, so less is needed and the SSD is less expensive.
3-bit TLC (Triple-Level Cell) memory goes even further, with three pieces per cell. Since each cell should differentiate between eight voltage values, reading them faithfully requires more accuracy, and tear and wear reduces the amount of write cycles. The plus side is that you get even more power from precisely the exact same amount of flash memory, resulting in even cheaper SSDs, which is something everyone wants.
Whenever you read about an SSD or look at a review, the first figure you will usually notice is a headline-grabbing transfer speed. Imagine write and read rates up to 550MB/sec, or even faster in the case of PCIe SSDs. These numbers always seem very remarkable, and it generally represents the best-case performance you'll see from a driveway. It normally entails large sequential file transfers, which means all of the blocks are laid out one after another and caching along with other advantages are in their peak.
In the actual world, most software programs handle both large and tiny files, and sometimes a program may be waiting for input until it carries on, so you'll rarely get the most sequential rate of your SSD. You might see these speeds when composing or reading a massive 10GB movie document, but items will be a lot slower when copying a folder full of 10,000 jpeg images, HTML files, or even a game directory.
2 notes
·
View notes
Text
How to install Nginx + php + MySQL on WSL Windows 10

Although Nginx is available for Windows 10/8/7, however, to really understand, experience, build or test web application around, I recommend to use it on Linux. And the Windows 10 WSL is the best option to run Linux+Nginx+PHP+MySQL stack to get a complete Linux based web server without really installing a separate Linux distro. Thus, let's see how to install Linux+Nginx+PHP+MySQL stack on Windows 10 WSL (Windows Subsystem for Linux). What is Nginx? Nginx (engine x) is a high-performance HTTP and reverse proxy web server that also provides IMAP/pop3/smtp services. It is distributed under a BSD-like agreement and characterized by less memory and strong concurrent power. Nginx can be compiled and run on most Unix & Linux os and has a Windows port too. In the case of high concurrency, Nginx is a good alternative to the Apache service: Nginx is one of the software platforms that bosses web hosting business supporting responses up to 50 000 concurrent connections thanks to Nginx for choosing Epoll and Kqueue as the development model. The Nginx code is written entirely from the c language and has been ported to many architectures and operating systems including Linux, FreeBSD, Solaris, mac os x, AIX and Microsoft windows. Nginx has its own library of functions, and in addition to zlib, PCRE, and OpenSSL, standard modules only use system C library functions. Also, these third-party libraries may not be used if you do not need or consider potential authorization conflicts.
Step 1: Install Windows 10 WSL for Nginx + php
If you don't have Windows 10 WSL (Windows Subsystem for Linux) enabled on your system yet, then simply go to the search section of Windows 10 and type "Turn Windows feature on or off" after that scroll and look for Windows subsystem for Linux option, check it and click on the OK button. This will enable it on your system. For step by step guide see this: How to enable WSL on Windows 10.
Step 2: Choose Linux Distro App for WIndows 10 WSL
Once you enabled WSL on your system, the next step is to procure some Linux distro app from Microsoft store. Here we are installing and using Ubuntu app on Windows 10 WSL. Just search for Microsoft store on your Windows 10 system and then in the search box type: Run Linux on Windows. The instructions of installing Nginx stack will be the same for Debian and Kali Linux WSL images. And select Ubuntu and then Get it.
Step 3: Run Ubuntu to install Nginx + php on Windows 10 WSL
Once you open the Linux Ubuntu 18.04 WSL on your Windows 10 system it will exactly look and behave like any other Linux command terminal. The first thing which we do is to update the Ubuntu Wsl, use the below-given command: sudo apt-get update sudo apt-get upgrade Second is running of commands to install Nginx on Windows 10 Ubuntu WSL: sudo add-apt-repository ppa:nginx/stable sudo apt-get update sudo apt-get install -y nginx
Step 4: Start Nginx web server service on WSL
We have successfully installed the Nginx on our Windows 10 WSL Linux app, now the thing which we have to do is starting off its service. For that use the below command sudo service nginx start

Step 5: Test Nginx Webserver
Open your Windows 10 browser and type http:localhost:80 It will show the welcome screen of this web server as shown below in the screenshot. "Welcome to nginx! If you see this page, the nginx web server is successfully installed and working. Further configuration is required. For online documentation and support please refer to nginx.org. Commercial support is available at nginx.com. Thank you for using nginx."

Step 6: Installing PHP for Nginx on Windows 10 WSL
The Webserver is ready now we have to install and configure PHP to use with Nginx open-source web server. Here we install modules PHP-FPM and PHP-MySQL to use PHP with both Nginx and MySQL. Add repo: sudo add-apt-repository ppa:ondrej/php Check latest PHP version available to install sudo apt-cache show php According to the available version, install the following PHP modules, in our case the latest version was php7.2 sudo apt-get install php7.2-cli php7.2-fpm php7.2-curl php7.2-gd php7.2-mysql php7.2-mbstring zip unzip Check the installed version php --version Output: h2s@DESKTOP-9OOKS69:~$ php --version PHP 7.2.19-0ubuntu0.18.04.2 (cli) (built: Aug 12 2019 19:34:28) ( NTS ) Copyright (c) 1997-2018 The PHP Group Zend Engine v3.2.0, Copyright (c) 1998-2018 Zend Technologies with Zend OPcache v7.2.19-0ubuntu0.18.04.2, Copyright (c) 1999-2018, by Zend Technologies

Step 7: Start PHP-fpm service
Here is the command to start the installed PHP-fpm service sudo service php7.2-fpm start
Step 8: Configure PHP-fpm for Nginx on Windows 10 WSL
We have to configure PHP-fpm for Nginx otherwise PHP would not be able to contact Nginx and it through an error such as: "502 Bad Gateway” “502 Bad Gateway NGINX” “502 Proxy Error” “502 Service Temporarily Overloaded” “Error 502” “HTTP Error 502 – Bad Gateway” “HTTP 502 Bad Gateway” Thus, open the php-fpm configuration file sudo nano /etc/php/7.2/fpm/pool.d/www.conf In the file find the php-fpm listening socket path In our case, it was like given below and might be same in yours too. /run/php/php7.2-fpm.sock Copy it.
Now, open Nginx Default site configuration sudo nano/etc/nginx/sites-available/default Here find: If we want to use PHP with Nginx, first we have to add index.php in the Nginx configuration file... # Add index.php to the list if you are using PHP index index.html index.htm index.nginx-debian.html; # Add index.php to the list if you are using PHP index index.php index.html index.htm index.nginx-debian.html; Now find the below lines and do editing as mentioned below: #location ~ \.php$ { # include snippets/fastcgi-php.conf; # # # With php-fpm (or other unix sockets): # fastcgi_pass unix:/var/run/php/php7.0-fpm.sock; # # With php-cgi (or other tcp sockets): # fastcgi_pass 127.0.0.1:9000; #} Remove the # or uncomment the following things which are in yellow colour and also change the socket path from /var/run/php/php7.0-fpm.sock; to /run/php/php7.2-fpm.sock; location ~ \.php$ { include snippets/fastcgi-php.conf; # # # With php-fpm (or other unix sockets): fastcgi_pass unix:/run/php/php7.2-fpm.sock; # # With php-cgi (or other tcp sockets): # fastcgi_pass 127.0.0.1:9000; }
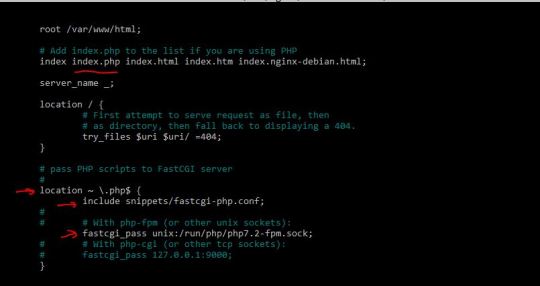
After all the changes press CTRL+X and type Y and then press the Enter button to save the changes. Restart Nginx and PHP-FPM services sudo service nginx reload sudo service php7.2-fpm restart
Step 9: Create a test PHP file
Create an index.php file sudo touch /var/www/html/index.php Open it: sudo nano /var/www/html/index.php And add the following lines in that ] Read the full article
#LinuxTutorial#nginx#nginxphpmysqlwindows#nginxphpwindows#nginxserver#nginxstackwindows#phpmysql#phpserverhost#tutorial#windows10
0 notes
Text
How Apple could replace iOS jailbreaking features without compromising too much on security
With the difficulty of jailbreaking iOS increasing to the point where iOS vulnerabilities are extremely valuable, many have been posting ideas on how Apple could replace jailbreaking. I thought I’d give my view on it, as someone who has a general idea of how iOS’s internals work (on a userland level).
The order of items in this list starts with those that impact security the least (and are most likely for Apple to accept if they were listening to user suggestions) to those that could impact security to a certain level (although I explain how the security concerns may be mitigated)
These ideas build on existing iOS functionality (such as sandboxing, XPC and Remote Views) as well as on existing UNIX functionality (chroot) to show how iOS may be expanded with its existing security features.
Small iOS feature enhancements
External Storage support in Files app (iOS 11+) and 3rd party apps
The Files app (on iOS 11+) and Document picker should allow access to external storage (either SD cards or USB flash drives/hard drives) that are plugged into the device via the Camera Connection Kits. This would greatly improve the iPad’s versatility.
More App Extensions
Lock Screen Replacements
Lock Screen replacements are a fairly popular category of tweaks. Being able to replace the lock screen will allow a vast amount of customization, considering the lock screen is the first thing a user sees when the device is turned on/woken up from sleep. Based on how Apple implemented some other extension categories in iOS 8, it is a no-brainer how this may be implemented.
SpringBoard can load a remote view controller so the lock screen runs out of process, loading in a view from a plugin provided by an app. This would allow the plugin to be sandboxed, and would prevent it from leaking information on notifications to another app or to a remote server.
Notifications and alarm information can be delivered to the plugin via XPC, allowing it to display them in its custom view without having to load any code into SpringBoard.
APIs should also be added for the plugin to be able to query basic information (should the plugin hide the status bar), such as carrier name, cell signal strength, and wifi signal strength. (APIs already exist for querying bluetooth status and battery percentage)
Weather information, etc. may be accessed by these plugins via read-only access to its parent app. The parent app may refresh weather information (using Background App Refresh introduced on iOS 7) and provide it to the plugin, although the plugin may not send any information back to the app.
Multitasking switcher and control center replacements
The multitasking switcher and control center may both load remote views from app plugins similar to how the custom lock screen implementation would work. These plugins would be sandboxed so they can't write out information to their parent app or connect to external servers. These would only run when the app switcher or control center are open and on screen.
The control center plugins would get APIs to toggle settings, as well as the ability to launch apps and get a list of apps installed.
The multitasking switcher plugins would get APIs to query a list of display items (either an app or 2 split viewed apps) open, the list of apps installed, screenshots of the display items, and have the ability to switch to display items, or quit out of display items.
As these plugins would be sandboxed, they can't leak any of this information out or change settings when requested to by a remote server.
System-wide accessible shared app files
An app, should it decide to, should be able to share a folder system-wide with other plugins or apps. This would work similarly to document storage providers introduced with iOS 8, but would have special properties.
This folder may be written to only by the app that is sharing the files
Other apps and plugins will only be able to read from this folder
The parent app may also set a property that will indicate to whether they should or shouldn’t display the files in a docoument picker (if they’re meant for internal use in a plugin only)
LaunchServices icon providers (Theming Engines)
Apps should be able to register a plugin with LaunchServices as an “icon provider��. This would allow a plugin to provide icons to LaunchServices to replace app icons on the home screen, document providers, settings app, etc. (Basically enabling theming engines). When enabled, the plugin will receive a dictionary of app bundle ID’s and the app’s icons (and alternate icons). The plugin can then go through the dictionary and either run render stages or simply replace the icons outright, and return the dictionary to launchservices when its done. Plugins may be stacked in this way to allow multiple themes. Icons will then be cached on disk so they don’t need to be rendered again unless either an app is installed (where just that app icon will be rendered) or another icon provider is installed (where icons will be re-rendered).
Icon provider plugins will only have read access to their parent app, thus preventing them from possibly leaking information about the apps installed on the device.
Developer features that can be accessible to everyone
XCode for iPad
Apple has been touting the iPad (especially the iPad Pro) as a device that can replace a laptop. However, to be able to replace laptops for everyone, the iPad needs to be able to build apps for iPhone and itself. When paired with either a bluetooth or smart keyboard, split view, and Apple pencil, XCode should be a good experience on the iPad.
Terminal w/ chroot
A terminal with a bash shell may be provided for iOS devices so traditional UNIX tools may run on iOS devices, especially iPads, to go alongside XCode. This shell may run inside a chroot that is distributed via the app store (similar to how Windows Subsystem for Linux gets its chroot). Code-signing rules may be relaxed within this chroot, as executables running inside the chroot can’t access anything outside it (thus not compromising the rest of the device’s security). However, sandbox may be used on top of the chroot to prevent direct hardware access within the chroot. This chroot, however, may be browsed as a folder from the Files app. Should anything go wrong with the chroot, the entire chroot may be deleted and redownloaded without affecting any apps running on the device.
Changes to iOS to facilitate tweak security
Before I go into how tweaks can be implemented on iOS, here’s some aspects of iOS that can be hardened to enhance security.
App Transport Security
App Transport Security was introduced in iOS 9 where apps should specify which domains they require access to, and whether they need just HTTPS access or if they really need HTTP access.
The App Store should check apps going through it and enforce that apps specify domains rather than allowing access to all domains (unless there is a very, very specific reason to allow all domains)
Sandbox SpringBoard
SpringBoard may be sandboxed so it may not access the network, and that it may not access app sandboxes (except read-only access to the folders designated by apps as accessible system-wide)
Tweak Store/Unsigned code Toggle
The following ideas will probably never be accepted by Apple, but we can dream right?
Tweak Store
A setting may be enabled to allow access to a special section of the App Store called the “Tweak Store”
Unlike regular apps or plugins, these will come with no guarantee from Apple of working, and the user will install them following an agreement to a disclaimer and a device wipe + reactivation. When tweaks are enabled on the device, a warning screen with text should be displayed on boot.
This warning screen screen on boot will either time out in 10 seconds, where the device beeps and then boots, or the user may press both volume buttons immediately to acknowledge the warning and boot (similar to Chrome OS’s verified boot). The device will then boot with a differently colored apple logo (not white, black or red – red is reserved for the next mode).
However, the root filesystem will still be read-only, and secure boot, KPP/memprot, code-signing and sandbox are still in effect, and the root filesystem may not be browsed from the Files app. Data protection will still be provided by the SEP.
Also, should the phone have any issues, these tweaks may be the first thing disabled or removed by Apple Support.
Load dylibs into processes
Dylibs may be loaded into SpringBoard (which is now sandboxed), or App Processes (which should be protected by App Transport Security). Sandboxing and App Transport security is in effect, so these dylibs will only get read access to the folder that was made accessible system-wide by their parent app.
A filter plist may be provided alongside these dylibs (similar to Cydia Substrate) to specify which processes these dylibs should be loaded into.
These dylibs may swizzle Objective-C methods, use Swift reflections, or may interpose C functions to modify SpringBoard’s or App processes. However, they may not leak any information out, as they will be prevented from writing to their parent app from processes other than their parent app, and will be domain restricted from accessing the dylib’s author’s servers from most apps (including SpringBoard).
These dylibs are still signed, however, and must pass approval through Apple before being allowed to install (unless a 7-day free cert or 1 year dev cert is used for the specific device, like normal app signing).
Almost all functionality missing, if any, from the plugins mentioned previously may be implemented using these dylibs.
Root Access + Code Signing Disable + Relaxed Sandbox
Should the above not be enough, a 2nd toggle may be accessible to enable full access. Similar to enabling the tweak store, this will require an agreement to a disclaimer acknowledging no warranty will be provided on the software, followed by a device wipe + reactivation.
Similar to the tweak store being enabled, this mode also displays a warning screen on boot, however the auto-boot timeout should be increased to 30 seconds, and the Apple logo on boot should be red. If a device in this mode is taken in to Apple Support, the device should be wiped and reset back to stock iOS before service.
Secure boot, KPP/memprot and sandboxing are still in effect. Code signing is still in effect, but any signature should be allowed, regardless of executable location on the filesystem. The root filesystem will be mounted as read/write, and the Files app will display and be able to read/write to the root filesystem. (Although the kernel and bootloader may not be changed or the device will stop booting outright).
Sandboxing rules, however, will be relaxed slightly, to allow XPC services to be hosted from SpringBoard, and a special folder will be created on the filesystem which any app or plugin may read and write to.
Also, in this mode, tweaks may hook any process, and terminal may access the root filesystem rather than a chroot.
This mode is basically the equivalent of a jailbroken device, and will satisfy any jailbreaking needs.
20 notes
·
View notes