#aws api gateway http endpoint
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr is available in 18 languages.
Text
Ultimate Checklist for Web App Security in the Cloud Era

As businesses increasingly migrate their applications and data to the cloud, the landscape of cyber threats has evolved significantly. The flexibility and scalability offered by cloud platforms are game-changers, but they also come with new security risks. Traditional security models no longer suffice. In the cloud web app security era, protecting your web applications requires a modern, proactive, and layered approach. This article outlines the ultimate security checklist for web apps hosted in the cloud, helping you stay ahead of threats and safeguard your digital assets.
1. Use HTTPS Everywhere
Secure communication is fundamental. Always use HTTPS with TLS encryption to ensure data transferred between clients and servers remains protected. Never allow any part of your web app to run over unsecured HTTP.
Checklist Tip:
Install and renew SSL/TLS certificates regularly.
Use HSTS (HTTP Strict Transport Security) headers.
2. Implement Identity and Access Management (IAM)
Cloud environments demand strict access control. Implement robust IAM policies to define who can access your application resources and what actions they can perform.
Checklist Tip: - Use role-based access control (RBAC). - Enforce multi-factor authentication (MFA). - Apply the principle of least privilege.
3. Secure APIs and Endpoints
Web applications often rely heavily on APIs to exchange data. These APIs can become a major attack vector if not secured properly.
Checklist Tip: - Authenticate and authorize all API requests. -Use API gateways to manage and monitor API traffic. - Rate-limit API requests to prevent abuse.
4. Patch and Update Regularly
Outdated software is a common entry point for attackers. Ensure that your application, dependencies, frameworks, and server environments are always up to date.
Checklist Tip: - Automate updates and vulnerability scans. - Monitor security advisories for your tech stack. - Remove unused libraries and components.
5. Encrypt Data at Rest and in Transit
To meet compliance requirements and protect user privacy, data encryption is non-negotiable. In the cloud, this applies to storage systems, databases, and backup services.
Checklist Tip: - Use encryption standards like AES-256. - Store passwords using secure hashing algorithms like bcrypt or Argon2. - Encrypt all sensitive data before saving it.
6. Configure Secure Storage and Databases
Misconfigured cloud storage (e.g., public S3 buckets) has led to many major data breaches. Ensure all data stores are properly secured.
Checklist Tip: - Set access permissions carefully—deny public access unless necessary. - Enable logging and alerting for unauthorized access attempts. - Use database firewalls and secure credentials.
7. Conduct Regular Security Testing
Routine testing is essential in identifying and fixing vulnerabilities before they can be exploited. Use both automated tools and manual assessments.
Checklist Tip: - Perform penetration testing and vulnerability scans. - Use tools like OWASP ZAP or Burp Suite. - Test code for SQL injection, XSS, CSRF, and other common threats.
8. Use a Web Application Firewall (WAF)
A WAF protects your application by filtering out malicious traffic and blocking attacks such as XSS, SQL injection, and DDoS attempts.
Checklist Tip: - Deploy a WAF provided by your cloud vendor or a third-party provider. - Customize WAF rules based on your application’s architecture. - Monitor logs and update rule sets regularly.
9. Enable Real-Time Monitoring and Logging
Visibility is key to rapid response. Continuous monitoring helps detect unusual behavior and potential breaches early.
Checklist Tip: - Use centralized logging tools (e.g., ELK Stack, AWS CloudWatch). - Set up real-time alerts for anomalies. - Monitor user activities, login attempts, and API calls.
10. Educate and Train Development Teams
Security should be baked into your development culture. Ensure your team understands secure coding principles and cloud security best practices.
Checklist Tip: - Provide regular security training for developers. - Integrate security checks into the CI/CD pipeline. - Follow DevSecOps practices from day one.
Final Thoughts
In the cloud web app security era, businesses can no longer afford to treat security as an afterthought. Threats are evolving, and the attack surface is growing. By following this security checklist, you ensure that your web applications remain secure, compliant, and resilient against modern cyber threats. From identity management to encrypted storage and real-time monitoring, every step you take now strengthens your defense tomorrow. Proactivity, not reactivity, is the new gold standard in cloud security.
#web application development company india#web application development agency#web application development firm#web application and development#web app development in india#custom web application development
0 notes
Text
How to Secure API Endpoints in Web Development
APIs are the backbone of modern web applications, letting different systems talk to each other seamlessly. But with great power comes great responsibility—securing API endpoints is critical to protect sensitive data and keep your application safe from attackers. Whether you're working with a website designing company in India or building your own app, securing APIs doesn’t have to be overwhelming. Let’s break down practical, beginner-friendly steps to lock down your API endpoints, all in a conversational tone to keep things approachable.
Why API Security Matters
APIs often handle sensitive information like user data, payment details, or authentication tokens. If left unsecured, they can be an open door for hackers to exploit, leading to data breaches or system crashes. Think of your API as a bank vault—without a strong lock, anyone could waltz in. By securing your endpoints, you protect your users and maintain trust, which is especially important for businesses, including those partnering with a website designing company in India to build robust applications.
1. Use HTTPS for Encrypted Communication
First things first: always use HTTPS. It encrypts data sent between the client (like a browser or app) and your server, making it unreadable to anyone snooping on the network. Without HTTPS, sensitive info like passwords or API keys could be intercepted. Most hosting providers offer free SSL certificates through services like Let’s Encrypt, so there’s no excuse not to enable it. Check your server configuration (e.g., Nginx or Apache) to enforce HTTPS and redirect any HTTP requests.
2. Authenticate Every Request
Never let unauthenticated users access your API. Authentication ensures only authorized users or systems can make requests. A simple way to do this is with API keys—unique strings assigned to users or apps. For stronger security, use OAuth 2.0, which provides access tokens that expire after a set time. Store these keys or tokens securely (never hardcode them in your code!) and validate them on every request. For example, in a Node.js app, you can check the API key in the request header before processing it.
3. Implement Rate Limiting
Ever heard of a denial-of-service attack? It’s when someone floods your API with requests to crash it. Rate limiting caps how many requests a user can make in a given time (e.g., 100 requests per minute). This protects your server from overload and abuse. Tools like Express Rate Limit for Node.js or built-in features in API gateways (like AWS API Gateway) make this easy to set up. You can also block suspicious IPs if you notice unusual activity.
4. Validate and Sanitize Input
Hackers love trying to sneak malicious data into your API through inputs, like SQL injection or cross-site scripting (XSS). Always validate user inputs to ensure they match expected formats (e.g., an email field contains a valid email). Sanitize inputs to strip out dangerous characters. Libraries like Joi for JavaScript or Django’s form validation in Python can help. For example, if your API expects a numeric ID, reject anything that’s not a number to avoid surprises.
5. Use Strong Authorization
Authentication says, “You’re allowed in.” Authorization says, “Here’s what you can do.” Use role-based access control (RBAC) to limit what each user can access. For instance, a regular user shouldn’t be able to delete another user’s data. Define roles (like admin, user, or guest) and check permissions for every request. Frameworks like Spring Security (Java) or Laravel (PHP) have built-in tools to manage this efficiently.
6. Protect Against Common Vulnerabilities
APIs are prime targets for attacks like injection, broken authentication, or data exposure. Follow the OWASP API Security Top 10 to stay ahead. For example, avoid exposing sensitive data (like passwords) in API responses. Use secure HTTP headers like Content-Security-Policy (CSP) to prevent XSS attacks. Regularly test your API with tools like Postman or automated scanners like OWASP ZAP to catch weaknesses early.
7. Log and Monitor API Activity
Keep an eye on what’s happening with your API. Logging tracks who’s making requests, what they’re asking for, and any errors that pop up. Use tools like ELK Stack or cloud-based solutions like AWS CloudWatch to store and analyze logs. Set up alerts for suspicious activity, like repeated failed login attempts. Monitoring helps you spot issues fast and respond before they escalate.
8. Use an API Gateway
An API gateway acts like a bouncer, managing and securing traffic to your endpoints. It can handle authentication, rate limiting, and logging in one place, saving you from coding these features yourself. Popular gateways like Kong or Amazon API Gateway also offer analytics to track usage patterns. This is especially handy for scaling applications built by teams, including those at a professional web development firm.
Keep Learning and Testing
Securing APIs isn’t a one-and-done task. As threats evolve, so should your defenses. Regularly update your dependencies to patch vulnerabilities (tools like Dependabot can help). Conduct penetration testing to simulate attacks and find weak spots. If you’re new to this, consider working with experts who specialize in secure development—they can guide you through best practices.
By following these steps, you can make your API endpoints a tough target for attackers. It’s all about layering defenses: encrypt communication, authenticate users, limit access, and stay vigilant. Whether you’re a solo developer or collaborating with a web development team, these practices will help keep your application safe and your users happy.
#digital marketing agency bhubaneswar#website development companies in bhubaneswar#best digital marketing company in bhubaneswar#digital marketing services in bhubaneswar#web development services in bhubaneswar#digital marketing agency in bhubaneswar
0 notes
Text
Enhancing Security in Backend Development: Best Practices for Developers
In today’s rapidly evolving digital environment, security in backend systems is paramount. As the backbone of web applications, the backend handles sensitive data processing, storage, and communication. Any vulnerabilities in this layer can lead to catastrophic breaches, affecting user trust and business integrity. This article highlights essential best practices to ensure your backend development meets the highest security standards.
1. Implement Strong Authentication and Authorization
One of the primary steps in securing backend development services is implementing robust authentication and authorization protocols. Password-based systems alone are no longer sufficient. Modern solutions like OAuth 2.0 and JSON Web Tokens (JWT) offer secure ways to manage user sessions. Multi-factor authentication (MFA) adds another layer of protection, requiring users to verify their identity using multiple methods, such as a password and a one-time code.
Authorization should be handled carefully to ensure users only access resources relevant to their role. By limiting privileges, you reduce the risk of sensitive data falling into the wrong hands. This practice is particularly crucial for applications that involve multiple user roles, such as administrators, managers, and end-users.
2. Encrypt Data in Transit and at Rest
Data encryption is a non-negotiable aspect of backend security. When data travels between servers and clients, it is vulnerable to interception. Implement HTTPS to secure this communication channel using SSL/TLS protocols. For data stored in databases, use encryption techniques that prevent unauthorized access. Even if an attacker gains access to the storage, encrypted data remains unreadable without the decryption keys.
Managing encryption keys securely is equally important. Store keys in hardware security modules (HSMs) or use services like AWS Key Management Service (KMS) to ensure they are well-protected. Regularly rotate keys to further reduce the risk of exposure.
3. Prevent SQL Injection and Other Injection Attacks
Injection attacks, particularly SQL injections, remain one of the most common threats to backend technologies for web development. Attackers exploit poorly sanitized input fields to execute malicious SQL queries. This can lead to unauthorized data access or even complete control of the database.
To mitigate this risk, always validate and sanitize user inputs. Use parameterized queries or prepared statements, which ensure that user-provided data cannot alter the intended database commands. Additionally, educate developers on the risks of injection attacks and implement static code analysis tools to identify vulnerabilities during the development process.
4. Employ Secure API Design
APIs are integral to backend development but can also serve as entry points for attackers if not secured properly. Authentication tokens, input validation, and rate limiting are essential to preventing unauthorized access and abuse. Moreover, all API endpoints should be designed with security-first principles.
For example, avoid exposing sensitive information in API responses. Error messages should be generic and not reveal the backend structure. Consider using tools like API gateways to enforce security policies, including data masking, IP whitelisting, and token validation.
5. Keep Dependencies Updated and Patched
Third-party libraries and frameworks streamline development but can introduce vulnerabilities if not updated regularly. Outdated software components are a common attack vector. Perform routine dependency checks and integrate automated vulnerability scanners like Snyk or Dependabot into your CI/CD pipeline.
Beyond updates, consider using tools to analyze your application for known vulnerabilities. For instance, dependency management tools can identify and notify you of outdated libraries, helping you stay ahead of potential risks.
6. Adopt Role-Based Access Control (RBAC)
Access management is a critical component of secure backend systems. Role-Based Access Control (RBAC) ensures users and applications have access only to what they need. Define roles clearly and assign permissions at a granular level. For example, a customer service representative may only access user profile data, while an admin might have permissions to modify backend configurations.
Implementing RBAC reduces the potential damage of a compromised user account. For added security, monitor access logs for unusual patterns, such as repeated failed login attempts or unauthorized access to restricted resources.
7. Harden Your Database Configurations
Databases are at the heart of backend systems, making them a prime target for attackers. Properly configuring your database is essential. Start by disabling unnecessary services and default accounts that could be exploited. Enforce strong password policies and ensure that sensitive data, such as passwords, is hashed using secure algorithms like bcrypt or Argon2.
Database permissions should also be restricted. Grant the least privilege necessary to applications interacting with the database. Regularly audit these permissions to identify and eliminate unnecessary access.
8. Monitor and Log Backend Activities
Real-time monitoring and logging are critical for detecting and responding to security threats. Implement tools like Logstash, Prometheus, and Kibana to track server activity and identify anomalies. Logs should include information about authentication attempts, database queries, and API usage.
However, ensure that logs themselves are secure. Store them in centralized, access-controlled environments and avoid exposing them to unauthorized users. Use log analysis tools to proactively identify patterns that may indicate an ongoing attack.
9. Mitigate Cross-Site Scripting (XSS) Risks
Cross-site scripting attacks can compromise your backend security through malicious scripts. To prevent XSS attacks, validate and sanitize all inputs received from the client side. Implement Content Security Policies (CSP) that restrict the types of scripts that can run within the application.
Another effective measure is to encode output data before rendering it in the user’s browser. For example, HTML encoding ensures that malicious scripts cannot execute, even if injected.
10. Secure Cloud Infrastructure
As businesses increasingly migrate to the cloud, backend developers must adapt to the unique challenges of cloud security. Use Identity and Access Management (IAM) features provided by cloud platforms like AWS, Google Cloud, and Azure to define precise permissions.
Enable encryption for all data stored in the cloud and use virtual private clouds (VPCs) to isolate your infrastructure from external threats. Regularly audit your cloud configuration to ensure compliance with security best practices.
11. Foster a Culture of Security
Security isn’t a one-time implementation — it’s an ongoing process. Regularly train your development team on emerging threats, secure coding practices, and compliance standards. Encourage developers to follow a security-first approach at every stage of development.
Conduct routine penetration tests and code audits to identify weaknesses. Establish a response plan to quickly address breaches or vulnerabilities. By fostering a security-conscious culture, your organization can stay ahead of evolving threats.
Thus, Backend security is an ongoing effort requiring vigilance, strategic planning, and adherence to best practices. Whether you’re managing APIs, databases, or cloud integrations, securing backend development services ensures the reliability and safety of your application.
0 notes
Text
The Role of Telegram Bots in Modern Digital Ecosystems: A Technical Perspective
In the ever-evolving landscape of digital communication, Telegram bots have emerged as a powerful tool for automating tasks, enhancing user engagement, and integrating services. These bots, which are essentially software applications running on the Telegram platform, leverage the Telegram Bot API to interact with users and perform a wide range of functions. From customer support to content delivery, Telegram bots are reshaping how businesses and individuals interact with technology.
The development of Telegram bots is deeply rooted in web development practices, requiring a solid understanding of APIs, server-side programming, and database management. The Telegram Bot API, which serves as the backbone of bot development, is a RESTful interface that allows developers to send and receive data in JSON format. This API supports a variety of methods, such as sending messages, managing user interactions, and even handling payments, making it a versatile tool for creating dynamic and interactive bots.
To build a Telegram bot, developers typically start by setting up a webhook—a mechanism that allows the bot to receive real-time updates from Telegram. Webhooks are configured using HTTPS endpoints, ensuring secure communication between the bot and Telegram’s servers. Once the webhook is in place, the bot can process incoming messages, execute commands, and send responses back to users. This process often involves the use of server-side programming languages like Python, Node.js, or PHP, along with frameworks such as Flask, Express.js, or Laravel to streamline development.
One of the most intriguing aspects of Telegram bot development is the integration of external APIs and services. For instance, a bot designed for weather updates might fetch data from a third-party weather API, process it, and deliver the information to the user in a concise format. Similarly, e-commerce bots can integrate with payment gateways like Stripe or PayPal to facilitate seamless transactions. This ability to connect with external systems makes Telegram bots a valuable asset in creating end-to-end solutions for various industries.
User experience (UX) plays a crucial role in the success of a Telegram bot. Developers must ensure that the bot’s interface is intuitive and easy to navigate. This often involves the use of inline keyboards, custom reply markup, and rich media such as images, videos, and documents. Additionally, developers can employ Natural Language Processing (NLP) techniques to enable more sophisticated interactions. Libraries like Dialogflow or Rasa can be integrated to allow the bot to understand and respond to user queries in a conversational manner.
Scalability and performance are also critical considerations in bot development. As the number of users grows, the bot must be able to handle increased traffic without compromising on response times. This is where cloud-based solutions like AWS, Google Cloud, or Heroku come into play. By deploying the bot on a scalable infrastructure, developers can ensure that it remains responsive and reliable, even under heavy load.
Security is another vital aspect that cannot be overlooked. Since bots often handle sensitive user data, developers must implement robust security measures. This includes using HTTPS for secure communication, encrypting sensitive data, and adhering to best practices for authentication and authorization. Regular security audits and updates are essential to protect the bot from potential vulnerabilities.
In conclusion, the development of Telegram bots is a multidisciplinary endeavor that combines web development, API integration, UX design, and security practices. As the digital ecosystem continues to evolve, Telegram bots are poised to play an increasingly important role in automating tasks, enhancing user experiences, and driving innovation. Whether you’re a developer looking to build your first bot or a business exploring new ways to engage with customers, the possibilities are virtually limitless.
Make order Tg Bot or Mobile app from us: @ChimeraFlowAssistantBot
Our portfolio: https://www.linkedin.com/company/chimeraflow
1 note
·
View note
Text
A Beginner's Guide to AWS Web Application Firewall (WAF)
A Beginner's Guide to AWS Web Application Firewall (WAF) is the perfect starting point for anyone looking to secure their web applications from common threats. This guide introduces the fundamentals of AWS WAF, explaining how it protects against attacks like SQL injection, cross-site scripting (XSS), and DDoS. It walks you through the core features, including customizable rules, IP blocking, and traffic monitoring, enabling you to create a robust defense tailored to your application’s needs. You'll also learn about integration with other AWS services, such as CloudFront and Application Load Balancer, for enhanced security and performance. Whether you're a developer, IT professional, or business owner, this guide equips you with the knowledge to safeguard your applications with AWS WAF.
What is AWS WAF and Why It Matters?
AWS Web Application Firewall (WAF) is a cloud-based security service that helps protect your web applications from common threats, such as SQL injection, cross-site scripting (XSS), and DDoS attacks. By analyzing incoming traffic and applying customizable rules, AWS WAF ensures your applications are secure and compliant with best practices. It is crucial for maintaining high application availability, minimizing downtime, and safeguarding sensitive data.
Key Features of AWS WAF
AWS WAF offers powerful features tailored to protect your applications: with aws web application firewall,
Customizable Rules: Create rules specific to your security needs, such as IP blocking or rate limiting.
Predefined Managed Rules: Use AWS Managed Rules to shield against known vulnerabilities.
Real-Time Traffic Monitoring: View application traffic patterns to detect unusual activity.
Integration with AWS Services: Seamlessly integrates with services like Amazon CloudFront, API Gateway, and Application Load Balancer.
How AWS WAF Works ?
AWS WAF works by applying web access control lists (WebACLs) to monitor and filter HTTP/HTTPS requests. These WebACLs contain rules that evaluate incoming traffic based on specified criteria, such as IP addresses, HTTP headers, query strings, and geographical locations. By rejecting malicious traffic and allowing legitimate requests, AWS WAF ensures the integrity of your web application.
Benefits of Using AWS WAF
Implementing AWS WAF offers a wide range of advantages:
Enhanced Security: Protects your application from web exploits and bots.
Cost-Efficiency: Pay-as-you-go pricing ensures scalability without overspending.
Simplified Management: Easy-to-use console for managing rules and monitoring traffic.
Improved Performance: Minimizes disruptions caused by malicious attacks.
Steps to Set Up AWS WAF
Setting up AWS WAF involves a straightforward process:
Create a WebACL: Define your rules and set action types (allow, block, or count).
Associate Resources: Attach the WebACL to your CloudFront distribution, API Gateway, or Load Balancer.
Add Rules: Configure managed or custom rules to address specific threats.
Test and Monitor: Use AWS WAF’s real-time traffic monitoring to ensure effectiveness.
Common Use Cases for AWS WAF
Aws web application firewall is ideal for various scenarios:
Preventing DDoS Attacks: Mitigate volumetric attacks with rate-limiting rules.
Securing APIs: Protect API endpoints from malicious traffic and abuse.
Blocking Malicious Bots: Stop harmful bots using AWS WAF’s bot control feature.
Complying with Security Standards: Maintain regulatory compliance with predefined security rules.
Best Practices for Optimizing AWS WAF
To maximize AWS WAF’s effectiveness, follow these best practices:
Leverage Managed Rules: Start with AWS Managed Rules for quick deployment.
Use Rate Limiting: Prevent abuse by setting request rate limits.
Regularly Update Rules: Keep custom rules up to date with emerging threats.
Monitor and Analyze Traffic: Utilize AWS WAF’s logging features for ongoing threat analysis.
Test Configurations: Ensure rules do not inadvertently block legitimate traffic.
Conclusion
aws web application firewall is an essential tool for securing web applications in today's threat-prone digital environment. With features like customizable rules, seamless integration with AWS services, and real-time monitoring, it empowers businesses to protect their applications effectively. By following this beginner’s guide, you can enhance your application’s security posture, improve performance, and gain peace of mind knowing your digital assets are safe. Start implementing AWS WAF today to build a secure and scalable web infrastructure.
0 notes
Text
How to Build a Secure Backend: Common Security Practices for Developers

How to Build a Secure Backend:
Common Security Practices for Developers Building a secure backend is critical for protecting user data, ensuring application integrity, and maintaining trust.
Cyberattacks and data breaches can have severe consequences, so implementing robust security practices is non-negotiable for developers.
This blog will cover essential security measures every backend developer should follow.
Secure Authentication and Authorization
Authentication and authorization are foundational to backend security. Weak implementations can expose your application to unauthorized access.
Best Practices: Use strong password policies (e.g., minimum length, complexity).
Hash passwords with algorithms like bcrypt, Argon2, or PBKDF2. Implement multi-factor authentication (MFA) for added security.
Use access control mechanisms like Role-Based Access Control (RBAC).
Pro Tip: Avoid storing passwords in plaintext and always use secure hash functions.
2. Validate and Sanitize Inputs
Unchecked user inputs can lead to injection attacks like SQL injection, command injection, or cross-site scripting (XSS).
Best Practices: Validate all inputs for expected formats, lengths, and data types. Sanitize inputs to remove malicious characters.
Use parameterized queries or Object-Relational Mapping (ORM) to prevent SQL injection.
Example
(SQL Injection Prevention):
python
# Using parameterized queries
cursor.execute
(“SELECT * FROM users WHERE email = %s”, (user_email,))
3. Secure APIs APIs are often targeted by attackers, making their security paramount.
Best Practices:
Require authentication for all API endpoints.
Use HTTPS to encrypt data in transit.
Implement rate limiting and throttling to prevent abuse.
Validate API inputs to ensure only valid data is processed.
Use API gateways for centralized security and monitoring.
Pro Tip: Avoid exposing sensitive information in API responses.
4. Protect Against Cross-Site Request Forgery (CSRF) CSRF attacks trick authenticated users into performing unwanted actions.
Best Practices: Use CSRF tokens for all state-changing operations. Set SameSite attributes on cookies to prevent cross-origin requests. Require user re-authentication for sensitive operations.
5. Encrypt Data Encryption ensures that sensitive data remains secure, even if intercepted.
Best Practices:
Use TLS (HTTPS) for data in transit.
Encrypt sensitive data at rest using AES-256 or similar algorithms. Rotate encryption keys periodically.
6. Implement Logging and Monitoring Regular logging and monitoring can help detect and respond to security incidents promptly.
Best Practices: Log user activities, authentication events, and errors.
Use centralized logging systems like ELK Stack or Splunk. Monitor logs for suspicious activities with tools like SIEM (Security Information and Event Management).
7. Keep Dependencies Updated Outdated libraries and frameworks are common attack vectors.
Best Practices: Regularly update dependencies to their latest stable versions.
Use tools like Dependabot or npm audit to detect vulnerabilities.
Avoid unnecessary dependencies to reduce the attack surface.
8. Secure Configuration Management Misconfigured servers or applications can lead to severe security issues.
Best Practices: Disable unused services and ports.
Restrict sensitive environment variables (e.g., API keys, database credentials).
Store secrets securely using vaults like HashiCorp Vault or AWS Secrets Manager.
9. Conduct Regular Security Testing Testing helps identify and fix vulnerabilities before they are exploited.
Best Practices: Perform static application security testing (SAST) and dynamic application security testing (DAST).
Conduct regular penetration testing. Use automated tools like OWASP ZAP or Burp Suite for vulnerability scanning.
Conclusion
A secure backend is the backbone of any robust application.
By following these security practices, developers can minimize vulnerabilities and safeguard their applications against attacks.
Remember, security is not a one-time task; it’s an ongoing process that requires constant vigilance and updates.
Building a secure backend is both an art and a science — start implementing these practices today to ensure your application remains secure and trustworthy.
0 notes
Text

AWS Ultimate Guide: From Beginners to Advanced by SK Singh
This is a very comprehensive book on AWS, from beginners to advanced. The book has extensive diagrams to help understand topics much easier way.
To make understanding the subject a smoother experience, the book is divided into the following sections:
Cloud Computing
AWS Fundamentals (What is AWS, AWS Account, AWS Free Tier, AWS Cost & Billing Management, AWS Global Cloud Infrastructure (part I)), IAM, EC2)
AWS Advanced (EC2 Advanced, ELB, Advanced S3, Route 53, AWS Global Cloud Infrastructure (part II), Advanced Storage on AWS, AWS Monitoring, Audit, and Performance),
AWS RDS and Databases (AWS RDS and Cache, AWS Databases)
Serverless (Serverless Computing, AWS Integration, and Messaging)
Container & CI/CD (Container, AWS CI/CD services)
Data & Analytics (Data & Analytics)
Machine Learning (AWS ML/AI Services)
Security (AWS Security & Encryption, AWS Shared Responsibility Model, How to get Support on AWS, Advanced Identity)
Networking (AWS Networking)
Disaster Management (Backup, Recovery & Migrations)
Solutions Architecture (Cloud Architecture Key Design Principles, AWS Well-Architected Framework, Classic Solutions Architecture)
Includes AWS services/features such as IAM, S3, EC2, EC2 purchasing options, EC2 placement groups, Load Balancers, Auto Scaling, S3 Glacier, S3 Storage classes, Route 53 Routing policies, CloudFront, Global Accelerator, EFS, EBS, Instance Store, AWS Snow Family, AWS Storage Gateway, AWS Transfer Family, Amazon CloudWatch, EventBridge, CloudWatch Insights, AWS CloudTrail, AWS Config, Amazon RDS, Amazon Aurora, Amazon ElatiCache, Amazon DocumentDB, Amazon Keyspaces, Amazon Quantum Ledger Database, Amazon Timestream, Amazon Managed Blockchain, AWS Lambda, Amazon DynamoDB, Amazon API Gateway, SQS, SNS, SES, Amazon Kinesis, Amazon Kinesis Firehose, Amazon Kinesis Data Analytics, Amazon Kinesis Data Streams, Amazon Kinesis ECS, Amazon Kinesis ECR, Amazon EKS, AWS CloudFormation, AWS Elastic Beanstalk, AWS CodeBuild, AWS OpsWorks, AWS CodeGuru, AWS CodeCommit, Amazon Athena, Amazon Redshift, Amazon EMR, Amazon QuickSight, AWS Glue, AWS Lake Formation, Amazon MSK, Amazon Rekognition, Amazon Transcribe, Amazon Polly, Amazon Translate, Amazon Lex, Amazon Connect, Amazon Comprehend, Amazon Comprehend Medical, Amazon SageMaker, Amazon Forecast, Amazon Kendra, Amazon Personalize, Amazon Textract, Amazon Fraud Detector, Amazon Sumerian, AWS WAF, AWS Shield Standard, AWS Shield Advanced, AWS Firewall Manager, AWS GuardDuty, Amazon Inspector, Amazon Macie, Amazon Detective, SSM Session Manager, AWS Systems Manager, S3 Replication & Encryption, AWS Organization, AWS Control Tower, AWS SSO, Amazon Cognito, AWS VPC, NAT Gateway, VPC Endpoints, VPC Peering, AWS Transit Gateway, AWS Site-to-Site VPC, Database Management Service (DMS), and many others.
Order YOUR Copy NOW: https://amzn.to/4bfoHQy via @amazon
1 note
·
View note
Text
AWS API Gateway Tutorial for Cloud API Developer | AWS API Gateway Explained with Examples
Full Video Link https://youtube.com/shorts/A-DsF8mbF7U Hi, a new #video on #aws #apigateway #cloud is published on #codeonedigest #youtube channel. @java #java #awscloud @awscloud #aws @AWSCloudIndia #Cloud #CloudComputing @YouTube #you
Amazon AWS API Gateway is an AWS service for creating, publishing, maintaining, monitoring, and securing REST, HTTP, and WebSocket APIs. API developers can create APIs that access AWS or other web services, as well as data stored in the AWS Cloud. As an API Gateway API developer, you can create APIs for use in your own client applications. You can also make your APIs available to third-party…

View On WordPress
#amazon api gateway#amazon web services#api gateway#aws#aws api gateway#aws api gateway http api#aws api gateway http endpoint#aws api gateway http proxy example#aws api gateway http tutorial#aws api gateway http vs rest#aws api gateway lambda#aws api gateway rest api#aws api gateway rest api example#aws api gateway rest api lambda#aws api gateway rest vs http#aws api gateway websocket#aws api gateway websocket tutorial#aws api gatway tutorial
0 notes
Text
아마존 웹 서비스 최준승 외
1. AWS의 기본 알기 클라우드 컴퓨팅과 AWS Cloud Computing, 그리고 AWS AWS의 특징 AWS의 주요 서비스 AWS의 물리 인프라(Region, AZ, Edge) AWS 과금 방식 이해하기 AWS 과금 요소 AWS 과금 원칙 따라하기 - AWS 서비스 시작하기 AWS 계정 생성 AWS Management Console 로그인 목표 아키텍처 소개 목표 아키텍처 네트워크 구성 2. 리소스를 제어할 수 있는 권한을 관리합니다 - IAM IAM은 어떤 서비스인가요? AWS API, 그리고 IAM AWS API를 사용하는 방법 IAM에서 사용하는 객체들 루트 계정과 IAM 객체 IAM User, Group, Role IAM Policy 따라하기 - 계정 보안 향상을 위한 설정 Cloudtrail 설정 보안/감사를 위한 Config 설정 루트 계정 MFA 설정 패스워드 정책 설정 따라하기 - IAM IAM User 생성 IAM Group 생성 IAM Role 생성 IAM Policy 생성 3. 무제한 용량의 객체 스토리지 - S3 S3는 어떤 서비스인가요? Object Storage, 그리고 S3 Bucket과 Object S3의 접근제어 S3의 Storage Class S3는 어떤 추가기능을 제공하나요? Static Website Hosting Versioning Lifecycle 따라하기 - S3 S3 Bucket 생성 S3 Properties 설정 S3 정적 웹호스팅 설정 S3 Bucket에 객체 업로드 및 다운로드 S3 비용 알기 4. 나만의 Private한 네트워크를 구성해보자 - VPC VPC는 어떤 서비스인가요? Network Topology, 그리고 VPC VPC와 VPC Subnet VPC에서 관리하는 객체 Public Subnet과 Private Subnet VPC는 어떤 기능을 제공하나요? VPC Peering NAT Gateway VPC Endpoint Security Group과 Network ACL 따라하기 - VPC VPC 객체 생성 VPC Subnet 생성 Internet Gateway 생성 및 설정 Route Table 생성 및 설정 Network ACL 정책 설정 Security Group 정책 설정 VPC 비용 알기 5. 모든 서비스의 근본이 되는 Computing Unit - EC2 EC2는 어떤 서비스인가요? Host, Hypervisor, Guest, 그리고 EC2 Instance Type EC2 Action EC2에서 사용하는 Storage Instance Store EBS(Elastic Block Store) 따라하기 - EC2 EC2 Instance 생성 Elastic IP(고정 IP) 설정 EC2 Instance에 SSH 접속 AWS CLI 사용 EC2 meta-data 확인 EC2 비용 알기 6. 귀찮은 DB 관리 부탁드립니다 - RDS RDS는 어떤 서비스인가요? Managed DB Service, 그리고 RDS RDS가 지원하는 DB 엔진 RDS는 어떤 기능을 제공하나요? Multi-AZ Read Replica Backup Maintenance 따라하기 - RDS DB Subnet Group 생성 RDS Parameter Group 생성 RDS Option Group 생성 RDS Instance 생성 RDS Instance 접속 RDS 비용 알기 B. Bridge WordPress 설치 브라우저에서 접속 WordPress AWS Plugin 설치 및 설정 WordPress에 샘플 페이지 포스팅 7. VPC에 특화된 Elastic LoadBalancer - ELB ELB는 어떤 서비스인가요? LB, 그리고 ELB Classic Load Balancer와 Application Load Balancer External ELB와 Internal ELB ELB는 어떤 기능을 제공하나요? Health Check SSL Termination Sticky Session ELB의 기타 기능 따라하기 - ELB ELB 생성하기 ELB 정보 확인 및 기타 설정 ELB 비용 알기 8. 인프라 규모를 자동으로 조절하는 마법 - Auto Scaling Auto Scaling��� 어떤 서비스인가요? 인프라 규모의 자동화, Auto Scaling Scale In과 Scale Out Auto Scaling 구성 절차 Launch Configuration Auto Scaling Group Scaling Policy 따라하기 - Auto Scaling 기준 AMI 생성 Launch Configuration 구성 Auto Scaling Group 생성 9. 70여 개의 글로벌 엣지를 클릭 몇 번만으로 사용 - CloudFront CloudFront는 어떤 서비스인가요? CDN, 그리고 CloudFront CloudFront 동작 방식 CloudFront의 원본(Origin) CloudFront는 어떤 기능을 제공하나요? 웹(HTTP/S), 미디어(RTMP) 서비스 동적 콘텐츠 캐싱 보안(Signed URL/Cookie, 국가별 서비스 제한, WAF) 전용 통계 서비스 따라하기 - CloudFront CloudFront 신규 배포 생성하기 CloudFront Origin, Behavior 추가 객체 캐싱 무효화(Invalidation)시키기 CloudFront 비용 알기 10. SLA 100%의 글로벌 DNS 서비스 - Route53 Route53은 어떤 서비스인가요? DNS 서비스, 그리고 Route53 Route53에서 지원하는 레코드 형식 Public, Private Hosted Zone Route53의 특성 Route53은 어떤 기능을 제공하나요? Routing Policy Health Check Alias 레코드 따라하기 - Route53 서비스 도메인 구입 Route53 Hosted Zone 생성 Alias 레코드 생성 및 확인 Route53 비용 알기 11. 모니터링으로부터 시작되는 자동화 - CloudWatch CloudWatch는 어떤 서비스인가요? 모니터링, 그리고 CloudWatch CloudWatch 객체 주요 단위 CloudWatch는 어떤 기능을 제공하나요? Metric Alarm Logs Events Dashboard 따라하기 - CloudWatch 기본 Metric 확인 Custom Metric 생성 Alarm 생성 Logs 생성 Event를 이용한 EBS 백업 CloudWatch 비용 알기
2 notes
·
View notes
Text
Going Serverless: how to run your first AWS Lambda function in the cloud
A decade ago, cloud servers abstracted away physical servers. And now, “Serverless” is abstracting away cloud servers.
Technically, the servers are still there. You just don’t need to manage them anymore.
Another advantage of going serverless is that you no longer need to keep a server running all the time. The “server” suddenly appears when you need it, then disappears when you’re done with it. Now you can think in terms of functions instead of servers, and all your business logic can now live within these functions.
In the case of AWS Lambda Functions, this is called a trigger. Lambda Functions can be triggered in different ways: an HTTP request, a new document upload to S3, a scheduled Job, an AWS Kinesis data stream, or a notification from AWS Simple Notification Service (SNS).
In this tutorial, I’ll show you how to set up your own Lambda Function and, as a bonus, show you how to set up a REST API all in the AWS Cloud, while writing minimal code.
Note that the Pros and Cons of Serverless depend on your specific use case. So in this article, I’m not going to tell you whether Serverless is right for your particular application — I’m just going to show you how to use it.
First, you’ll need an AWS account. If you don’t have one yet, start by opening a free AWS account here. AWS has a free tier that’s more than enough for what you will need for this tutorial.
We’ll be writing the function isPalindrome, which checks whether a passed string is a palindrome or not.
Above is an example implementation in JavaScript. Here is the link for gist on Github.
A palindrome is a word, phrase, or sequence that reads the same backward as forward, for the sake of simplicity we will limit the function to words only.
As we can see in the snippet above, we take the string, split it, reverse it and then join it. if the string and its reverse are equal the string is a Palindrome otherwise the string is not a Palindrome.
Creating the isPalindrome Lambda Function
In this step we will be heading to the AWS Console to create the Lambda Function:
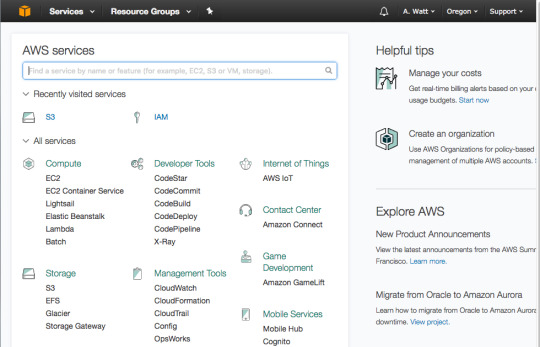
In the AWS Console go to Lambda.

And then press “Get Started Now.”
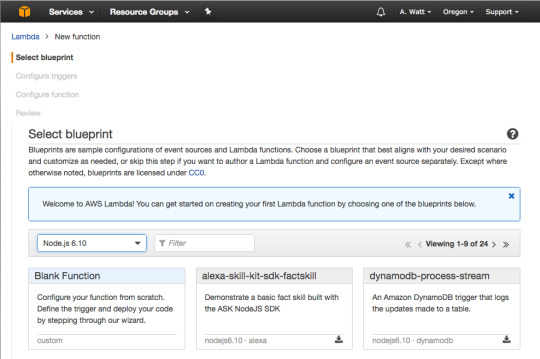
For runtime select Node.js 6.10 and then press “Blank Function.”
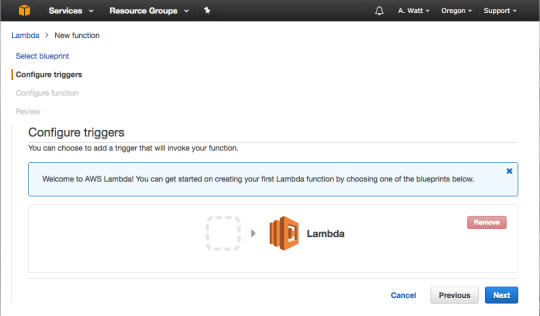
Skip this step and press “Next.”
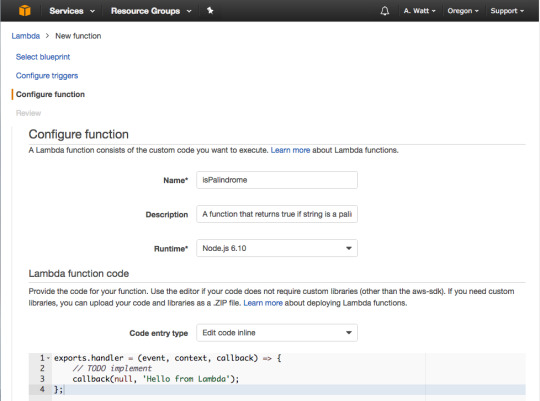
For Name type in isPalindrome, for description type in a description of your new Lambda Function, or leave it blank.
As you can see in the gist above a Lambda function is just a function we are exporting as a module, in this case, named handler. The function takes three parameters: event, context and a callback function.
The callback will run when the Lambda function is done and will return a response or an error message.For the Blank Lambda blueprint response is hard-coded as the string ‘Hello from Lambda’. For this tutorial since there will be no error handling, you will just use Null. We will look closely at the event parameter in the next few slides.
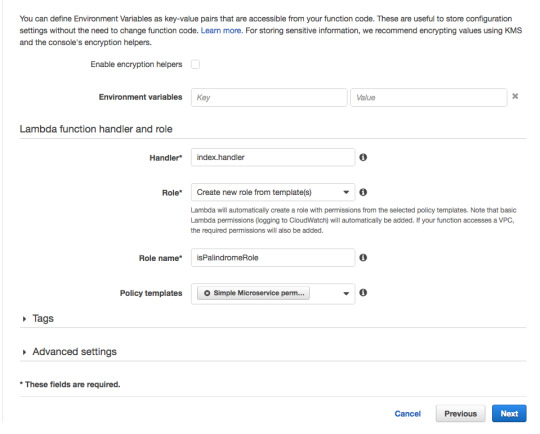
Scroll down. For Role choose “Create new Role from template”, and for Role name use isPalindromeRole or any name, you like.
For Policy templates, choose “Simple Microservice” permissions.
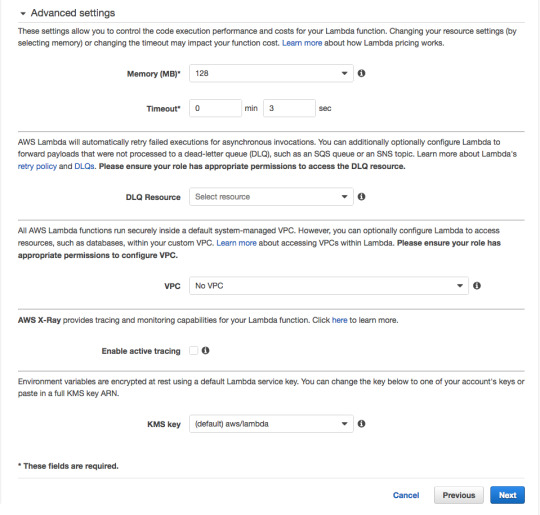
For Memory, 128 megabytes is more than enough for our simple function.
As for the 3 second timeout, this means that — should the function not return within 3 seconds — AWS will shut it down and return an error. Three seconds is also more than enough.
Leave the rest of the advanced settings unchanged.

Press “Create function.”
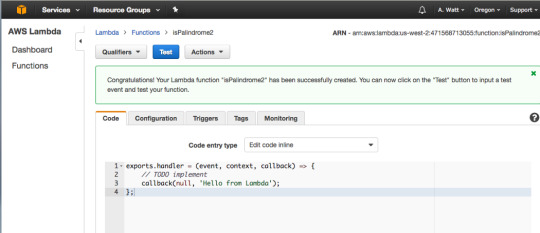
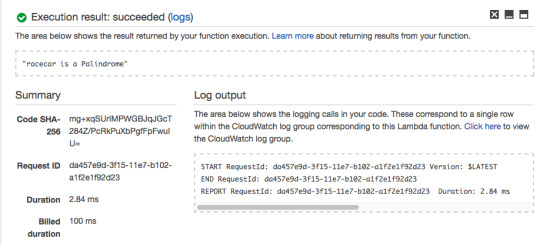
Congratulations — you’ve created your first Lambda Function. To test it press “Test.”
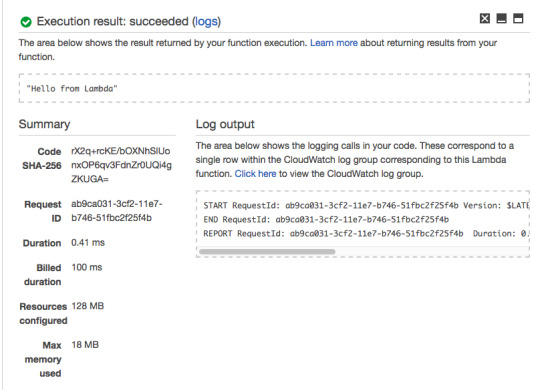
As you can see, your Lambda Function returns the hard-coded response of “Hello from Lambda.”
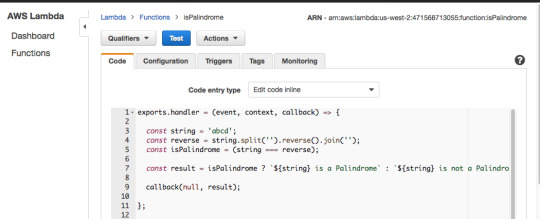
Now add the code from isPalindrome.js to your Lambda Function, but instead of return result use callback(null, result). Then add a hard-coded string value of abcd on line 3 and press “Test.”
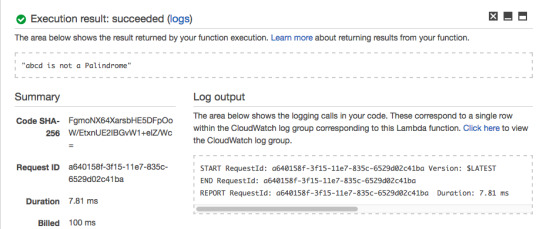
The Lambda Function should return “abcd is not a Palindrome.”
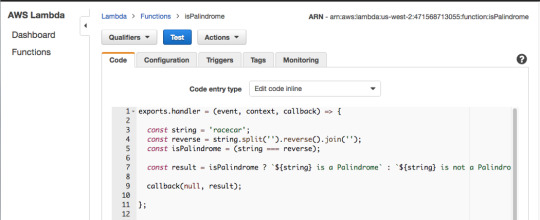
For the hard-coded string value of “racecar”, The Lambda Function returns “racecar is a Palindrome.”
So far, the Lambda Function we created is behaving as expected.
In the next steps, I’ll show you how to trigger it and pass it a string argument using an HTTP request.
If you’ve built REST APIs from scratch before using a tool like Express.js, the snippet above should make sense to you. You first create a server, and then define all your routes one-by-one.
In this section, I’ll show you how to do the same thing using the AWS API Gateway.
Creating the API Gateway
Go to your AWS Console and press “API Gateway.”

And then press “Get Started.”
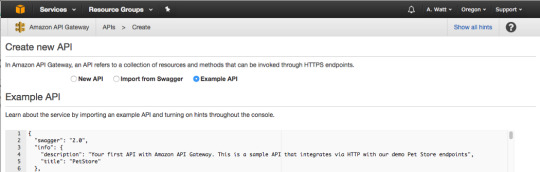
In Create new API dashboard select “New API.”
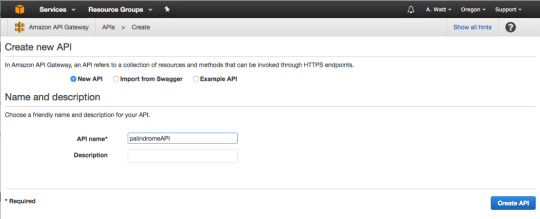
For API name, use “palindromeAPI.” For description, type in a description of your new API or just leave it blank.
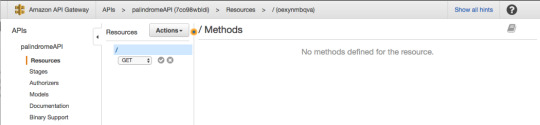
Our API will be a simple one, and will only have one GET method that will be used to communicate with the Lambda Function.
In the Actions menu, select “Create Method.” A small sub-menu will appear. Go ahead and select GET, and click on the checkmark to the right.
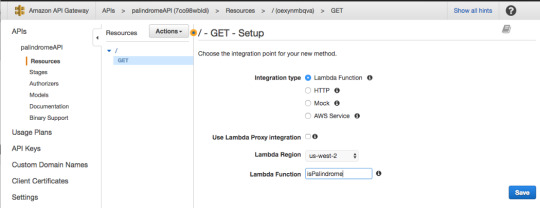
For Integration type, select Lambda Function.
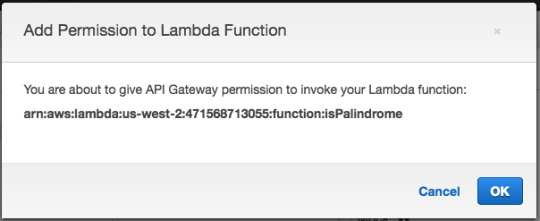
Then press “OK.”
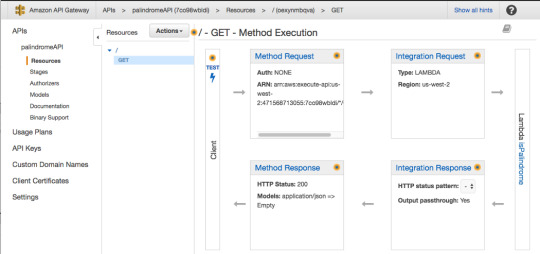
In the GET — Method Execution screen press “Integration Request.”
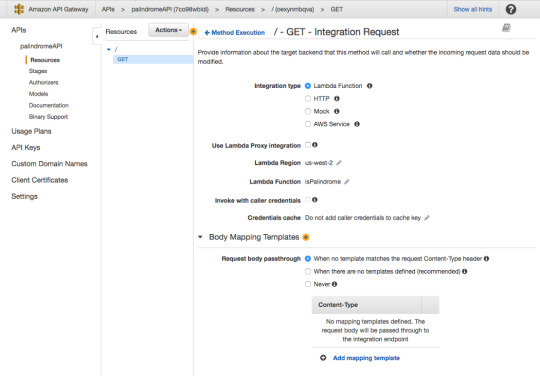
For Integration type, make sure Lambda Function is selected.
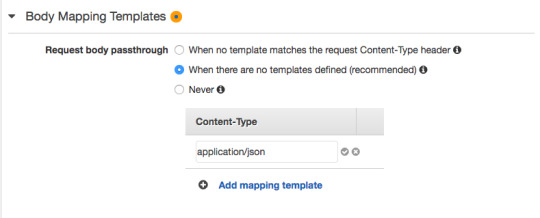
For request body passthrough, select “When there are no templates defined” and then for Content-Type enter “application/json”.
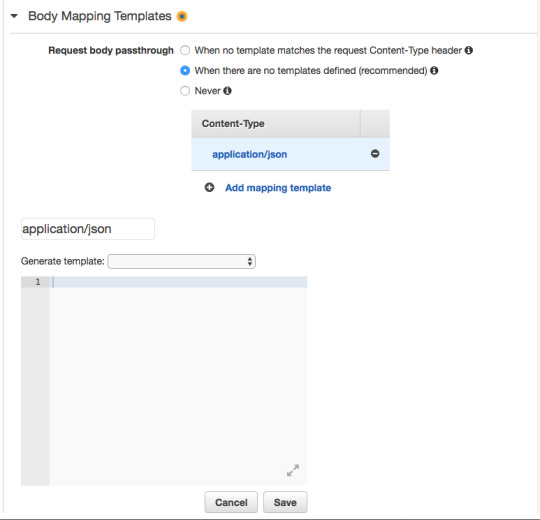
In the blank space add the JSON object shown below. This JSON object defines the parameter “string” that will allow us to pass through string values to the Lambda Function using an HTTP GET request. This is similar to using req.params in Express.js.
In the next steps, we’ll look at how to pass the string value to the Lambda Function, and how to access the passed value from within the function.

The API is now ready to be deployed. In the Actions menu click “Deploy API.”
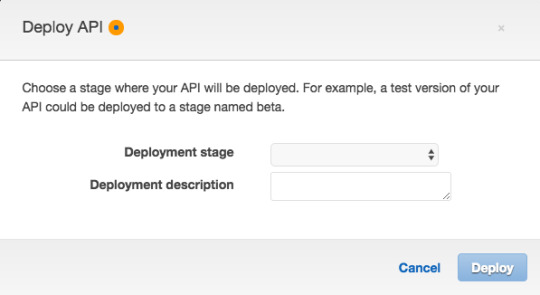
For Deployment Stage select “[New Stage]”.
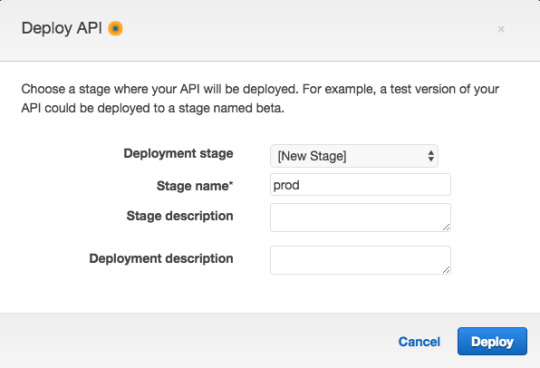
And for Stage name use “prod” (which is short for “production”).
The API is now deployed, and the invoke URL will be used to communicate via HTTP request with Lambda. If you recall, in addition to a callback, Lambda takes two parameters: event and context.
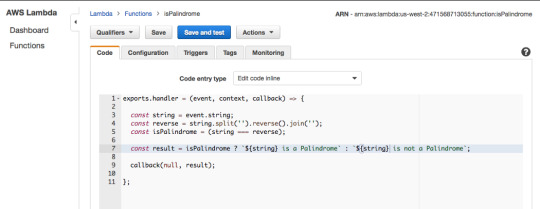
To send a string value to Lambda you take your function’s invoke URL and add to it ?string=someValue and then the passed value can be accessed from within the function using event.string.
Modify code by removing the hard-coded string value and replacing it with event.string as shown below.
Now in the browser take your function’s invoke URL and add ?string=abcd to test your function via the browser.
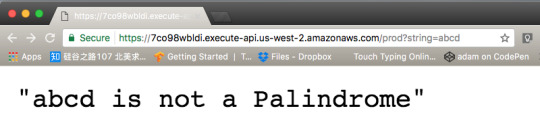
As you can see Lambda replies that abcd is not a Palindrome. Now do the same for racecar.
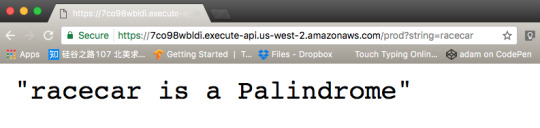
If you prefer you can use Postman as well to test your new isPalindrome Lambda Function. Postman is a great tool for testing your API endpoints, you can learn more about it here.
To verify it works, here’s a Palindrome:
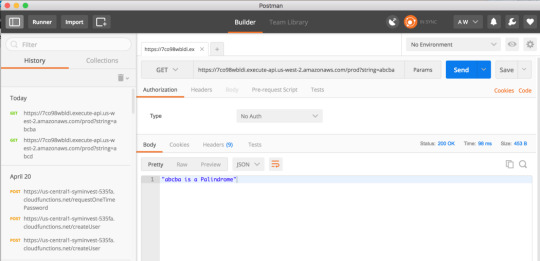
And here’s a non-palindrome:
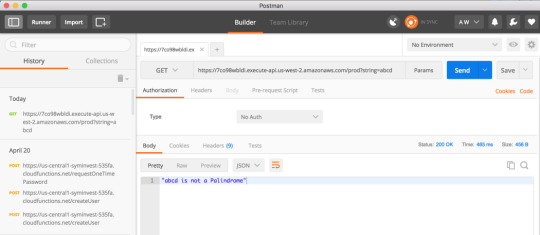
Congratulations — you have just set up and deployed your own Lambda Function!
Thanks for reading!
5 notes
·
View notes
Text
How to install maven on api linux aws

#How to install maven on api linux aws zip#
Mvn -versionIf it works, hooray! you have successfully installed the latest Apache Maven on your computer. Logout and login to the computer and check the Maven version using the following command. Sudo wget -output-document /etc/bash_completion.d/mvn Credits to Juven Xu: maven-bash-completion Sudo update-alternatives -set mvn /opt/apache-maven-$maven_version/bin/mvnĪdd Bash completion to mvn so that you can complete complex Maven commands by hitting Tab multiple times. Sudo update-alternatives -install "/usr/bin/mvn" "mvn" "/opt/apache-maven-$maven_version/bin/mvn" 0 The utility only requires Python to execute, so that's the only. It's a great tool for managing everything in AWS. M2_HOME="/opt/apache-maven-$maven_version"After the modification, press Ctrl + O to save the changes and Ctrl + X to exit nano. AWS CLI allows users to control different AWS services via the command line. PATH="/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/usr/lib/jvm/jdk-10.0.2/bin:/opt/apache-maven-$maven_version/bin"
#How to install maven on api linux aws zip#
Notice the end of PATH variable and the M2_HOME variable. &0183 &32 Select the Link option apache apache-maven-3.6.0-bin.zip to download the zip file. The data passes from the API endpoint to the Lambda function and is handled by the API-Gateway. It makes it super easy for the developers to create https endpoints and integrate it with Lambda function. My Maven installation is located at /opt/apache-maven-3.5.4, so to add that to my /. &0183 &32 Amazon API-Gateway is one of a networking service provided by AWS that allows developers to easily build and deploy API endpoints. This will override any of these environment variables set system wide by /etc/environment. The framework allows to work with applications that engage the following AWS services: API Gateway. sudo nano /etc/environment WARNING: Do not replace your environment file with the following content because you may already have different environment variables which are required by other applications to function properly. &0183 &32 First of all, to have M2HOME set between terminal restarts youll have to add the export statement to /.bashrc (assuming your shell is bash). aws-syndicate is an Amazon Web Services deployment framework written in Python, which allows to easily deploy serverless applications using resource descriptions. Execute the following command and modify the content as given below. You can use nano to edit the file in the terminal itself.
0 notes
Text
AWS Lambda 可以直接有 HTTPS Endpoint 了
AWS Lambda 可以直接有 HTTPS Endpoint 了
AWS 宣佈 AWS Lambda 可以直接有一個 HTTPS Endpoint 了:「Announcing AWS Lambda Function URLs: Built-in HTTPS Endpoints for Single-Function Microservices」。 如同文章裡面提到的,先前得透過 API Gateway 或是 ALB 才能掛上 Lambda: Each function is mapped to API endpoints, methods, and resources using services such as Amazon API Gateway and Application Load Balancer. 現在則是提供像 verylongid.lambda-url.us-east-1.on.aws…
View On WordPress
0 notes
Text
Amazon Elastic File System (EFS) Brain dump
Có bài viết học luyện thi AWS mới nhất tại https://cloudemind.com/efs/ - Cloudemind.com
Amazon Elastic File System (EFS) Brain dump

Amazon EFS
Scalable, elastic, cloud-native NFS file system
Provide simple, scalable, fully managed NFS file system for use with AWS Services and on-premises resources.
Build to scale on-demand to petabytes without interrupting applications. Eliminate to manage provision the storage, it is automatically scale your storage as needed.
EFS has 2 types: EFS standard and EFS Infrequent Access (IA).
EFS has lifecycle management (like S3 lifecycle manage) to help move files into EFS IA automatically.
EFS IA is cheaper file system.
Shared access to thousands of Amazon EC2 instances, enabling high level of aggregate throughput and IOPS with consistent low latencies.
Common use cases: Big data analytics, web serving and content management, application development & testing, database backups, containers storage…
EFS is Regional service storing data within and cross Available Zone for high availability and durability.
Amazon EC2 instances can access cross Available Zone, On-premises resources can access EFS via AWS DX and AWS VPN.
EFS can support over 10GB/s, more than 500,000 IOPS.
Using EFS Lifecycle management can reduce cost up to 92%.
Amazon EFS is compatible with all Linux-based AMIs for Amazon EC2.
You do not need to manage storage procurement and provisioning. EFS will grow and shrink automatically as you add or remove files.
AWS DataSync provides fast and secure way to sync existing file system to Amazon EFS, even from on-premise over any network connection, including AWS Direct Connect or AWS VPN.
Moving files to EFS IA by enabling Lifecycle management and choose age-off policy.
Files smaller than 128KB will remain on EFS standard storage, will not move to EFS IA even it is enabled.
Speed: EFS Standard storage is single-digit latencies, EFS IA storage is double-digit latencies.
Throughput:
50MB/s baseline performance per TB of storage.
100MB/s burst for 1TB
More than 1TB stored, storage can burst 100MB/s per TB.
Can have Amazon EFS Provisioned Throughput to provide higher throughput.
EFS’s objects are redundantly across Available Zone.
You can use AWS Backup to incremental backup your EFS.
Access to EFS:
Amazon EC2 instances inside VPC: access directly
Amazon EC2 Classic instance: via ClassicLink
Amazon EC2 instances in other VPCs: using VPC Peering Connection or VPC Transit Gateway.
EFS can store petabytes of storage. With EFS, you dont need to provision in advance, EFS will automatically grow and shrink as files added or removed from the storage.
Mount EFS via NFS v4
Access Points
EFS Access points to simplify application access to shared datasets on EFS. EFS Access points can work with AWS IAM to enforce an user or group, and a directory for every file system request made through the access point.
You can create multiple access points and provide to some specific applications.
Encryption
EFS support encryption in transit and at rest.
You can configure the encryption at rest when creating EFS via console, api or CLI.
Encrypting your data is minimal effect on I/O latency and throughput.
EFS and On-premise access
To access EFS from on-premise, you have to have AWS DX or AWS VPN.
Standard tools like GNU to allow you copy data from on-premise parallel. It can help faster copy. https://www.gnu.org/software/parallel/
Amazon FSx Windows workload
Window file server for Windows based application such as: CRM, ERP, .NET…
Backed by Native Windows file system.
Build on SSD storage.
Can access by thousands of Amazon EC2 at the same time, also provide connectivity to on-premise data center via AWS VPN or AWS DX.
Support multiple access from VPC, Available Zone, regions using VPC Peering and AWS Transit gateway.
High level throughput & sub-millisecond latency.
Amazon FSx for Windows File Server support: SMB, Windows NFS, Active Directory (AD) Integration, Distributed File System (DFS)
Amazon FSx also can mount to Amazon EC2 Linux based instances.
Amazon FSx for Lustre
Fully managed file system that is optimized for HPC (high performance computing), machine learning, and media processing workloads.
Hundreds of GB per second of throughput at sub-millisecond latencies.
Can be integrated with Amazon S3, so you can join long-term datasets with a high performance system. Data can be automatically copied to and from Amazon S3 to Amazon FSx for Lustre.
Amazon FSx for Lustra is POSIX-compliant, you can use your current Linux-based applications without having to make any changes.
Support read-after-write consistency and support File locking.
Amazon Lustre can also be mounted to an Amazon EC2 instance.
Connect to onpremise via AWS DX, or AWS VPN.
Data Transfer
EFS Data transfers between Region using AWS DataSync
EFS Data transfer within Region using AWS Transfer Family endpoint
Limitations
EFS per Regions: 1,000
Pricing
Pay for storage
Pay for read and write to files (EFS IA)
Xem thêm: https://cloudemind.com/efs/
0 notes
Text
Use Amazon ElastiCache for Redis as a near-real-time feature store
Customers often use Amazon ElastiCache for real-time transactional and analytical use cases. It provides high throughout and low latencies, while meeting a variety of business needs. Because it uses in-memory data structures, typical use cases include database and session caching, as well as leaderboards, gaming and financial trading platforms, social media, and sharing economy apps. Incorporating ElastiCache alongside AWS Lambda and Amazon SageMaker batch processing provides an end-to-end architecture to develop, update, and consume custom-built recommendations for each of your customers. In this post, we walk through a use case in which we set up SageMaker to develop and generate custom personalized products and media recommendations, trigger machine learning (ML) inference in batch mode, store the recommendations in Amazon Simple Storage Service (Amazon S3), and use Amazon ElastiCache for Redis to quickly return recommendations to app and web users. In effect, ElastiCache stores ML features processed asynchronously via batch processing. Lambda functions are the architecture glue that connects individual users to the newest recommendations while balancing cost, performance efficiency, and reliability. Use case In our use case, we need to develop personalized recommendations that don’t need to be updated very frequently. We can use SageMaker to develop an ML-driven set of recommendations for each customer in batch mode (every night, or every few hours), and store the individual recommendations in an S3 bucket. For customers with specific requirements, having an in-memory data store provides access to data elements with sub-millisecond latencies. For our use case, we use a Lambda function to fetch key-value data when a customer logs on to the application or website. In-memory data access provides sub-millisecond latency, which allows the application to deliver relevant ML-driven recommendations without disrupting the user experience. Architecture overview The following diagram illustrates our architecture for accessing ElastiCache for Redis using Lambda. The architecture contains the following steps: SageMaker trains custom recommendations for customer web sessions. ML batch processing generates nightly recommendations. User predictions are stored in Amazon S3 as a JSON file. A Lambda function populates predictions from Amazon S3 to ElastiCache for Redis. A second Lambda function gets predictions based on user ID and prediction rank from ElastiCache for Redis. Amazon API Gateway invokes Lambda with the user ID and prediction rank. The user queries API Gateway to get more recommendations by providing the user ID and prediction rank. Prerequisites To deploy the solution in this post, you need the following requirements: The AWS Command Line Interface (AWS CLI) configured. For instructions, see Installing, updating, and uninstalling the AWS CLI version 2. The AWS Serverless Application Model (AWS SAM) CLI already configured. For instructions, see Install the AWS SAM CLI. Python 3.7 installed. Solution deployment To deploy the solution, you complete the following high-level steps: Prepare the data using SageMaker. Access recommendations using ElastiCache for Redis. Prepare the data using SageMaker For this post, we refer to Building a customized recommender system in Amazon SageMaker for instructions to train a custom recommendation engine. After running through the setup, you get a list of model predictions. With this predictions data, upload a JSON file batchpredictions.json to an S3 bucket. Copy the ARN of this bucket to use later in this post. If you want to skip this SageMaker setup, you can also download the batchpredictions.json file. Access recommendations using ElastiCache for Redis In this section, you create the following resources using the AWS SAM CLI: An AWS Identity and Access Management (IAM) role to provide required permissions for Lambda An API Gateway to provide access to user recommendations An ElastiCache for Redis cluster with cluster mode on to store and retrieve movie recommendations An Amazon S3 gateway endpoint for Amazon VPC The PutMovieRecommendations Lambda function to fetch the movie predictions from the S3 file and insert them into the cluster The GetMovieRecommendations Lambda function to integrate with API Gateway to return recommendations based on user ID and rank Run the following commands to deploy the application into your AWS account. Run sam init --location https://github.com/aws-samples/amazon-elasticache-samples.git --no-input to download the solution code from the aws-samples GitHub repo. Run cd lambda-feature-store to navigate to code directory. Run sam build to build your package. Run sam deploy --guided to deploy the packaged template to your AWS account. The following screenshot shows an example of your output. Test your solution To test your solution, complete the following steps: Run the PutMovieRecommendations Lambda function to put movie recommendations in the Redis cluster: aws lambda invoke --function-name PutMovieRecommendations result.json Copy your API’s invoke URL, enter it in a web browser, and append ?userId=1&rank=1 to your invoke URL (for example, https://12345678.execute-api.us-west-2.amazonaws.com?userId=1&rank=1). You should receive a result like the following: The number 1 recommended movie for user 1 is 2012 Monitor the Redis cluster By default, Amazon CloudWatch provides metrics to monitor your Redis cluster. On the CloudWatch console, choose Metrics in the navigation pane and open the ElastiCache metrics namespace to filter by your cluster name. You should see all the metrics provided for your Redis cluster. Monitoring and creating alarms on metrics can help you detect and prevent issues. For example, a Redis node can connect to a maximum of 65,000 clients at one time, so you can avoid reaching this limit by creating an alarm on the metric NewConnections. In the navigation pane on the CloudWatch console, choose Alarms. Choose Create Alarm. Choose Select Metric and filter the metrics by NewConnections. Under ElastiCache to Cache Node Metrics, select the Redis cluster you created. Choose Select metric. Under Graph attributes, for Statistic, choose Maximum. For Period, choose 1 minute. Under Conditions, define the threshold as 1000. Leave the remaining settings at their default and choose Next. Enter an email list to get notifications and continue through the steps to create an alarm. As a best practice, any applications you create should reuse existing connections to avoid the extra cost of creating a new connection. Redis provides libraries to implement connection pooling, which allows you to pull from a pool of connections instead creating a new one. For more information about monitoring, see Monitoring best practices with Amazon ElastiCache for Redis using Amazon CloudWatch. Clean up your resources You can now delete the resources that you created for this post. By deleting AWS resources that you’re no longer using, you prevent unnecessary charges to your AWS account. To delete the resources, delete the stack via the AWS CloudFormation console. Conclusion In this post, we demonstrated how ElastiCache can serve as the focal point for a custom-trained ML model to present recommendations to app and web users. We used Lambda functions to facilitate the interactions between ElastiCache for Redis and Amazon S3 as well as between the front end and a custom-built ML recommendation engine. For use cases that require a more robust set of features that leverage a managed ML service, you may want to consider Amazon Personalize. For more information, see Amazon Personalize Features. For more details about configuring event sources and examples, see Using AWS Lambda with other services. To receive notifications on the performance of your ElastiCache cluster, you can configure Amazon Simple Notification Service (Amazon SNS) notifications for your CloudWatch alarms. For more information about ElastiCache features, see Amazon ElastiCache Documentation. About the author Kalhan Vundela is a Software Development Engineer who is passionate about identifying and developing solutions to solve customer challenges. Kalhan enjoys hiking, skiing, and cooking. https://aws.amazon.com/blogs/database/use-amazon-elasticache-for-redis-as-a-near-real-time-feature-store/
0 notes
Text
Interactivity Using Amazon API Gateway
AWS API Gateway may be a fully managed service that creates it easy for developers to publish, maintain, monitor, and secure APIs at any scale
It handles all of the tasks involved in accepting and processing up to many thousands of concurrent API calls, including traffic management, authorization, and access control, monitoring, and API version management.
It has no minimum fees or startup costs and charges just for the API calls received and therefore the amount of knowledge transferred out.
API Gateway also acts as a proxy to the configured backend operations.
It can scale automatically to handle the quantity of traffic the API receives
API Gateway exposes HTTPS endpoints only for all the APIs created. It does not support unencrypted (HTTP) endpoints
APIs built on Amazon API Gateway can accept any payloads sent over HTTP with typical data formats include JSON, XML, query string parameters, and request headers.
AWS API Gateway can communicate to multiple backends services
Lambda functions
AWS Step functions state machines
HTTP endpoints through Elastic Beanstalk, ELB, or EC2 servers
Non-AWS hosted HTTP based operations accessible via the public Internet
0 notes