#apache kafka training
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
If you dial 1-866-584-6757, you can leave an audio post for your followers.
Text
Does Apache Kafka handle schema?
Apache Kafka does not natively handle schema enforcement or validation, but it provides a flexible and extensible architecture that allows users to implement schema management if needed. Kafka itself is a distributed streaming platform designed to handle large-scale event streaming and data integration, providing high throughput, fault tolerance, and scalability. While Kafka is primarily concerned with the storage and movement of data, it does not impose any strict schema requirements on the messages it processes. As a result, Kafka is often referred to as a "schema-agnostic" or "schema-less" system.
However, the lack of schema enforcement may lead to challenges when processing data from diverse sources or integrating with downstream systems that expect well-defined schemas. To address this, users often implement external schema management solutions or rely on schema serialization formats like Apache Avro, JSON Schema, or Protocol Buffers when producing and consuming data to impose a degree of structure on the data. Apart from it by obtaining Apache Kafka Certification, you can advance your career as a Apache Kafka. With this course, you can demonstrate your expertise in the basics of afka architecture, configuring Kafka cluster, working with Kafka APIs, performance tuning and, many more fundamental concepts.
By using these serialization formats and associated schema registries, producers can embed schema information into the messages they produce, allowing consumers to interpret the data correctly based on the schema information provided. Schema registries can store and manage the evolution of schemas, ensuring backward and forward compatibility when data formats change over time.
Moreover, some Kafka ecosystem tools and platforms, like Confluent Schema Registry, provide built-in support for schema management, making it easier to handle schema evolution, validation, and compatibility checks in a distributed and standardized manner. This enables developers to design robust, extensible, and interoperable data pipelines using Kafka, while also ensuring that data consistency and compatibility are maintained across the ecosystem. Overall, while Apache Kafka does not handle schema enforcement by default, it provides the flexibility and extensibility needed to incorporate schema management solutions that align with specific use cases and requirements.
0 notes
Text


This week was a productive one. I've been studying microservices to better understand distributed systems. At the bus company where I work, we use a monolithic system—an old-school setup style with MySQL, PHP, some Java applications, localhost server and a mix of other technologies. However, we've recently started implementing some features that require scalability, and this book has been instrumental in helping me understand the various scenarios involved.
In the first chapters, I've gained a clearer understanding of monolithic systems and the considerations for transitioning to a distributed system, including the pros and cons.
I've also been studying Java and Apache Kafka for event-driven architecture, a topic that has captured my full attention. In this case, the Confluent training platform offers excellent test labs, and I've been running numerous tests there. Additionally, I have my own Kafka cluster set up using Docker for most configurations.
With all that said, I've decided to update this blog weekly since daily updates it's not gonna work.
#coding#developer#linux#programming#programmer#software#software development#student#study blog#study aesthetic#studyblr#self improvement#study#software engineering#study motivation#studyblr community#studying#studynotes#learning#university#student life#university student#study inspiration#brazil#booklr#book#learn#self study#java#apachekafka
21 notes
·
View notes
Text
How can you optimize the performance of machine learning models in the cloud?
Optimizing machine learning models in the cloud involves several strategies to enhance performance and efficiency. Here’s a detailed approach:

Choose the Right Cloud Services:
Managed ML Services:
Use managed services like AWS SageMaker, Google AI Platform, or Azure Machine Learning, which offer built-in tools for training, tuning, and deploying models.
Auto-scaling:
Enable auto-scaling features to adjust resources based on demand, which helps manage costs and performance.
Optimize Data Handling:
Data Storage:
Use scalable cloud storage solutions like Amazon S3, Google Cloud Storage, or Azure Blob Storage for storing large datasets efficiently.
Data Pipeline:
Implement efficient data pipelines with tools like Apache Kafka or AWS Glue to manage and process large volumes of data.
Select Appropriate Computational Resources:
Instance Types:
Choose the right instance types based on your model’s requirements. For example, use GPU or TPU instances for deep learning tasks to accelerate training.
Spot Instances:
Utilize spot instances or preemptible VMs to reduce costs for non-time-sensitive tasks.
Optimize Model Training:
Hyperparameter Tuning:
Use cloud-based hyperparameter tuning services to automate the search for optimal model parameters. Services like Google Cloud AI Platform’s HyperTune or AWS SageMaker’s Automatic Model Tuning can help.
Distributed Training:
Distribute model training across multiple instances or nodes to speed up the process. Frameworks like TensorFlow and PyTorch support distributed training and can take advantage of cloud resources.
Monitoring and Logging:
Monitoring Tools:
Implement monitoring tools to track performance metrics and resource usage. AWS CloudWatch, Google Cloud Monitoring, and Azure Monitor offer real-time insights.
Logging:
Maintain detailed logs for debugging and performance analysis, using tools like AWS CloudTrail or Google Cloud Logging.
Model Deployment:
Serverless Deployment:
Use serverless options to simplify scaling and reduce infrastructure management. Services like AWS Lambda or Google Cloud Functions can handle inference tasks without managing servers.
Model Optimization:
Optimize models by compressing them or using model distillation techniques to reduce inference time and improve latency.
Cost Management:
Cost Analysis:
Regularly analyze and optimize cloud costs to avoid overspending. Tools like AWS Cost Explorer, Google Cloud’s Cost Management, and Azure Cost Management can help monitor and manage expenses.
By carefully selecting cloud services, optimizing data handling and training processes, and monitoring performance, you can efficiently manage and improve machine learning models in the cloud.
2 notes
·
View notes
Text
The Future is Data-Driven: Top Analytics Trends You Should Know in 2025
In today's digital era, one thing is clear — data is at the center of everything. Whether it’s tracking consumer behavior, improving supply chains, or developing AI algorithms, data is powering innovation across industries. As we step into 2025, the demand for smarter, faster, and more efficient analytics is reshaping the landscape.
With the explosion of big data and AI technologies, organizations are increasingly relying on data analytics not just for insight, but for actionable intelligence. This blog explores the top data analytics trends in 2025 that are driving transformation and redefining the future of business, technology, and decision-making.

1. Augmented Analytics Is Taking Over
Augmented Analytics combines artificial intelligence (AI), machine learning (ML), and natural language processing (NLP) to automate data preparation, insight discovery, and sharing.
In 2025, this trend is becoming mainstream. Tools like Power BI, Tableau, and Google Cloud Looker are integrating AI capabilities that allow users to ask questions in natural language and get instant insights.
Why it matters:
Reduces dependence on data science teams
Empowers non-technical users with advanced analytics
Accelerates decision-making with real-time insights
2. Real-Time Analytics Is the New Norm
Gone are the days when companies could wait hours—or days—for reports. In 2025, real-time analytics is essential for agility.
From retail stock management to fraud detection in banking, organizations are using real-time data to respond instantly to events. Technologies like Apache Kafka, Spark Streaming, and Google BigQuery are driving this evolution.
Real-world example: E-commerce companies track user behavior in real-time to personalize product recommendations on the spot, increasing sales and user engagement.
3. Predictive and Prescriptive Analytics Are Growing Smarter
While descriptive analytics explains what happened, predictive analytics forecasts what might happen, and prescriptive analytics recommends what should be done.
In 2025, with the support of AI and vast cloud computing power, predictive and prescriptive analytics are more accessible than ever.
Industries using it:
Healthcare: Predicting disease outbreaks
Finance: Forecasting stock prices
Manufacturing: Predicting machine failures
Companies that master these analytics forms gain a competitive edge by staying proactive instead of reactive.
4. Data Democratization Is Driving Business Culture
The rise of self-service BI tools means data is no longer just for analysts or IT departments. Data democratization empowers every employee to access, understand, and act on data.
In 2025, training employees to be data-literate is a top priority. Companies are investing in upskilling programs and making data tools part of daily workflows.
Key benefits:
Faster decision-making
Increased accountability
Organization-wide innovation
5. Data Governance and Privacy Are in the Spotlight
With growing concerns around data privacy, compliance, and ethics, data governance is more important than ever. In 2025, businesses must ensure that data is accurate, secure, and used responsibly.
Frameworks like GDPR, CCPA, and India’s DPDP Act demand transparent handling of user data. Organizations are adopting tools that offer robust governance features like auditing, access control, and automated compliance reporting.
What this means for analytics:
Trustworthy data
Reduced legal risk
Improved user confidence
6. The Rise of Edge Analytics
As IoT devices become more widespread, data is increasingly being processed at the edge—near the source rather than in centralized data centers.
In 2025, industries like automotive, smart cities, and manufacturing are deploying edge analytics to gain insights in real time, reduce latency, and maintain data privacy.
Example: Self-driving cars rely on edge analytics to make split-second decisions without waiting for cloud processing.
7. DataOps Is the New DevOps
In 2025, organizations are applying DevOps principles to analytics workflows—a practice called DataOps. This involves automating data pipelines, version control for datasets, and continuous integration for analytics code.
DataOps boosts agility, consistency, and speed in deploying analytics solutions, making it a must-have in modern analytics teams.
Advantages of DataOps:
Faster data pipeline development
Improved data quality
Better collaboration between teams
8. Cloud-Native Analytics Platforms Are Dominating
As more companies migrate to the cloud, cloud-native analytics platforms are becoming the standard. Solutions like AWS Redshift, Google BigQuery, Azure Synapse, and Snowflake offer high performance, scalability, and integration with other cloud services.
In 2025, expect to see:
Hybrid and multi-cloud strategies
Serverless analytics environments
Lower costs for big data analysis
9. Natural Language Processing (NLP) for Data Analysis
With advancements in natural language processing, users can now interact with data using everyday language.
BI platforms like Microsoft Power BI, Qlik Sense, and Tableau are integrating NLP so users can type (or speak) questions like “What were our top 5 selling products in Q1 2025?” and get visual answers.
This trend enhances accessibility, productivity, and user experience in data analytics.
10. Ethical AI and Responsible Analytics
As AI-driven analytics becomes more influential, 2025 emphasizes ethical AI practices and bias-free analytics. Organizations are being held accountable for decisions made by algorithms.
From transparent models to explainable AI (XAI), the future of data analytics will focus not just on performance—but on fairness, equity, and societal impact.
Final Thoughts
The future of analytics is not just about technology—it’s about transformation. As these trends evolve, they are not only changing how organizations operate but also reshaping entire industries.
Whether you're a business leader, aspiring data analyst, or tech enthusiast, understanding these top data analytics trends in 2025 will help you stay ahead of the curve and make smarter, data-driven decisions.
#dataanalytics#analytics2025#futureofdata#datatrends#realtimeanalytics#augmentedanalytics#predictiveanalytics#dataops#cloudanalytics#edgeanalytics#ethicalai#businessintelligence#datadriven#bigdata#nschoolacademy
0 notes
Text
Implementing AI: Step-by-step integration guide for hospitals: Specifications Breakdown, FAQs, and More
Implementing AI: Step-by-step integration guide for hospitals: Specifications Breakdown, FAQs, and More

The healthcare industry is experiencing a transformative shift as artificial intelligence (AI) technologies become increasingly sophisticated and accessible. For hospitals looking to modernize their operations and improve patient outcomes, implementing AI systems represents both an unprecedented opportunity and a complex challenge that requires careful planning and execution.
This comprehensive guide provides healthcare administrators, IT directors, and medical professionals with the essential knowledge needed to successfully integrate AI technologies into hospital environments. From understanding technical specifications to navigating regulatory requirements, we’ll explore every aspect of AI implementation in healthcare settings.
Understanding AI in Healthcare: Core Applications and Benefits
Artificial intelligence in healthcare encompasses a broad range of technologies designed to augment human capabilities, streamline operations, and enhance patient care. Modern AI systems can analyze medical imaging with remarkable precision, predict patient deterioration before clinical symptoms appear, optimize staffing schedules, and automate routine administrative tasks that traditionally consume valuable staff time.
The most impactful AI applications in hospital settings include diagnostic imaging analysis, where machine learning algorithms can detect abnormalities in X-rays, CT scans, and MRIs with accuracy rates that often exceed human radiologists. Predictive analytics systems monitor patient vital signs and electronic health records to identify early warning signs of sepsis, cardiac events, or other critical conditions. Natural language processing tools extract meaningful insights from unstructured clinical notes, while robotic process automation handles insurance verification, appointment scheduling, and billing processes.
Discover the exclusive online health & beauty, designed for people who want to stay healthy and look young.
Technical Specifications for Hospital AI Implementation
Infrastructure Requirements
Successful AI implementation demands robust technological infrastructure capable of handling intensive computational workloads. Hospital networks must support high-bandwidth data transfer, with minimum speeds of 1 Gbps for imaging applications and 100 Mbps for general clinical AI tools. Storage systems require scalable architecture with at least 50 TB initial capacity for medical imaging AI, expandable to petabyte-scale as usage grows.
Server specifications vary by application type, but most AI systems require dedicated GPU resources for machine learning processing. NVIDIA Tesla V100 or A100 cards provide optimal performance for medical imaging analysis, while CPU-intensive applications benefit from Intel Xeon or AMD EPYC processors with minimum 32 cores and 128 GB RAM per server node.
Data Integration and Interoperability
AI systems must seamlessly integrate with existing Electronic Health Record (EHR) platforms, Picture Archiving and Communication Systems (PACS), and Laboratory Information Systems (LIS). HL7 FHIR (Fast Healthcare Interoperability Resources) compliance ensures standardized data exchange between systems, while DICOM (Digital Imaging and Communications in Medicine) standards govern medical imaging data handling.
Database requirements include support for both structured and unstructured data formats, with MongoDB or PostgreSQL recommended for clinical data storage and Apache Kafka for real-time data streaming. Data lakes built on Hadoop or Apache Spark frameworks provide the flexibility needed for advanced analytics and machine learning model training.
Security and Compliance Specifications
Healthcare AI implementations must meet stringent security requirements including HIPAA compliance, SOC 2 Type II certification, and FDA approval where applicable. Encryption standards require AES-256 for data at rest and TLS 1.3 for data in transit. Multi-factor authentication, role-based access controls, and comprehensive audit logging are mandatory components.
Network segmentation isolates AI systems from general hospital networks, with dedicated VLANs and firewall configurations. Regular penetration testing and vulnerability assessments ensure ongoing security posture, while backup and disaster recovery systems maintain 99.99% uptime requirements.
Step-by-Step Implementation Framework
Phase 1: Assessment and Planning (Months 1–3)
The implementation journey begins with comprehensive assessment of current hospital infrastructure, workflow analysis, and stakeholder alignment. Form a cross-functional implementation team including IT leadership, clinical champions, department heads, and external AI consultants. Conduct thorough evaluation of existing systems, identifying integration points and potential bottlenecks.
Develop detailed project timelines, budget allocations, and success metrics. Establish clear governance structures with defined roles and responsibilities for each team member. Create communication plans to keep all stakeholders informed throughout the implementation process.
Phase 2: Infrastructure Preparation (Months 2–4)
Upgrade network infrastructure to support AI workloads, including bandwidth expansion and latency optimization. Install required server hardware and configure GPU clusters for machine learning processing. Implement security measures including network segmentation, access controls, and monitoring systems.
Establish data integration pipelines connecting AI systems with existing EHR, PACS, and laboratory systems. Configure backup and disaster recovery solutions ensuring minimal downtime during transition periods. Test all infrastructure components thoroughly before proceeding to software deployment.
Phase 3: Software Deployment and Configuration (Months 4–6)
Deploy AI software platforms in staged environments, beginning with development and testing systems before production rollout. Configure algorithms and machine learning models for specific hospital use cases and patient populations. Integrate AI tools with clinical workflows, ensuring seamless user experiences for medical staff.
Conduct extensive testing including functionality verification, performance benchmarking, and security validation. Train IT support staff on system administration, troubleshooting procedures, and ongoing maintenance requirements. Establish monitoring and alerting systems to track system performance and identify potential issues.
Phase 4: Clinical Integration and Training (Months 5–7)
Develop comprehensive training programs for clinical staff, tailored to specific roles and responsibilities. Create user documentation, quick reference guides, and video tutorials covering common use cases and troubleshooting procedures. Implement change management strategies to encourage adoption and address resistance to new technologies.
Begin pilot programs with select departments or use cases, gradually expanding scope as confidence and competency grow. Establish feedback mechanisms allowing clinical staff to report issues, suggest improvements, and share success stories. Monitor usage patterns and user satisfaction metrics to guide optimization efforts.
Phase 5: Optimization and Scaling (Months 6–12)
Analyze performance data and user feedback to identify optimization opportunities. Fine-tune algorithms and workflows based on real-world usage patterns and clinical outcomes. Expand AI implementation to additional departments and use cases following proven success patterns.
Develop long-term maintenance and upgrade strategies ensuring continued system effectiveness. Establish partnerships with AI vendors for ongoing support, feature updates, and technology evolution. Create internal capabilities for algorithm customization and performance monitoring.
Regulatory Compliance and Quality Assurance
Healthcare AI implementations must navigate complex regulatory landscapes including FDA approval processes for diagnostic AI tools, HIPAA compliance for patient data protection, and Joint Commission standards for patient safety. Establish quality management systems documenting all validation procedures, performance metrics, and clinical outcomes.
Implement robust testing protocols including algorithm validation on diverse patient populations, bias detection and mitigation strategies, and ongoing performance monitoring. Create audit trails documenting all AI decisions and recommendations for regulatory review and clinical accountability.
Cost Analysis and Return on Investment
AI implementation costs vary significantly based on scope and complexity, with typical hospital projects ranging from $500,000 to $5 million for comprehensive deployments. Infrastructure costs including servers, storage, and networking typically represent 30–40% of total project budgets, while software licensing and professional services account for the remainder.
Expected returns include reduced diagnostic errors, improved operational efficiency, decreased length of stay, and enhanced staff productivity. Quantifiable benefits often justify implementation costs within 18–24 months, with long-term savings continuing to accumulate as AI capabilities expand and mature.
Discover the exclusive online health & beauty, designed for people who want to stay healthy and look young.
Frequently Asked Questions (FAQs)
1. How long does it typically take to implement AI systems in a hospital setting?
Complete AI implementation usually takes 12–18 months from initial planning to full deployment. This timeline includes infrastructure preparation, software configuration, staff training, and gradual rollout across departments. Smaller implementations focusing on specific use cases may complete in 6–9 months, while comprehensive enterprise-wide deployments can extend to 24 months or longer.
2. What are the minimum technical requirements for AI implementation in healthcare?
Minimum requirements include high-speed network connectivity (1 Gbps for imaging applications), dedicated server infrastructure with GPU support, secure data storage systems with 99.99% uptime, and integration capabilities with existing EHR and PACS systems. Most implementations require initial storage capacity of 10–50 TB and processing power equivalent to modern server-grade hardware with minimum 64 GB RAM per application.
3. How do hospitals ensure AI systems comply with HIPAA and other healthcare regulations?
Compliance requires comprehensive security measures including end-to-end encryption, access controls, audit logging, and regular security assessments. AI vendors must provide HIPAA-compliant hosting environments with signed Business Associate Agreements. Hospitals must implement data governance policies, staff training programs, and incident response procedures specifically addressing AI system risks and regulatory requirements.
4. What types of clinical staff training are necessary for AI implementation?
Training programs must address both technical system usage and clinical decision-making with AI assistance. Physicians require education on interpreting AI recommendations, understanding algorithm limitations, and maintaining clinical judgment. Nurses need training on workflow integration and alert management. IT staff require technical training on system administration, troubleshooting, and performance monitoring. Training typically requires 20–40 hours per staff member depending on their role and AI application complexity.
5. How accurate are AI diagnostic tools compared to human physicians?
AI diagnostic accuracy varies by application and clinical context. In medical imaging, AI systems often achieve accuracy rates of 85–95%, sometimes exceeding human radiologist performance for specific conditions like diabetic retinopathy or skin cancer detection. However, AI tools are designed to augment rather than replace clinical judgment, providing additional insights that physicians can incorporate into their diagnostic decision-making process.
6. What ongoing maintenance and support do AI systems require?
AI systems require continuous monitoring of performance metrics, regular algorithm updates, periodic retraining with new data, and ongoing technical support. Hospitals typically allocate 15–25% of initial implementation costs annually for maintenance, including software updates, hardware refresh cycles, staff training, and vendor support services. Internal IT teams need specialized training to manage AI infrastructure and troubleshoot common issues.
7. How do AI systems integrate with existing hospital IT infrastructure?
Modern AI platforms use standard healthcare interoperability protocols including HL7 FHIR and DICOM to integrate with EHR systems, PACS, and laboratory information systems. Integration typically requires API development, data mapping, and workflow configuration to ensure seamless information exchange. Most implementations use middleware solutions to manage data flow between AI systems and existing hospital applications.
8. What are the potential risks and how can hospitals mitigate them?
Primary risks include algorithm bias, system failures, data security breaches, and over-reliance on AI recommendations. Mitigation strategies include diverse training data sets, robust testing procedures, comprehensive backup systems, cybersecurity measures, and continuous staff education on AI limitations. Hospitals should maintain clinical oversight protocols ensuring human physicians retain ultimate decision-making authority.
9. How do hospitals measure ROI and success of AI implementations?
Success metrics include clinical outcomes (reduced diagnostic errors, improved patient safety), operational efficiency (decreased processing time, staff productivity gains), and financial impact (cost savings, revenue enhancement). Hospitals typically track key performance indicators including diagnostic accuracy rates, workflow efficiency improvements, patient satisfaction scores, and quantifiable cost reductions. ROI calculations should include both direct cost savings and indirect benefits like improved staff satisfaction and reduced liability risks.
10. Can smaller hospitals implement AI, or is it only feasible for large health systems?
AI implementation is increasingly accessible to hospitals of all sizes through cloud-based solutions, software-as-a-service models, and vendor partnerships. Smaller hospitals can focus on specific high-impact applications like radiology AI or clinical decision support rather than comprehensive enterprise deployments. Cloud platforms reduce infrastructure requirements and upfront costs, making AI adoption feasible for hospitals with 100–300 beds. Many vendors offer scaled pricing models and implementation support specifically designed for smaller healthcare organizations.
Discover the exclusive online health & beauty, designed for people who want to stay healthy and look young.
Conclusion: Preparing for the Future of Healthcare
AI implementation in hospitals represents a strategic investment in improved patient care, operational efficiency, and competitive positioning. Success requires careful planning, adequate resources, and sustained commitment from leadership and clinical staff. Hospitals that approach AI implementation systematically, with proper attention to technical requirements, regulatory compliance, and change management, will realize significant benefits in patient outcomes and organizational performance.
The healthcare industry’s AI adoption will continue accelerating, making early implementation a competitive advantage. Hospitals beginning their AI journey today position themselves to leverage increasingly sophisticated technologies as they become available, building internal capabilities and organizational readiness for the future of healthcare delivery.
As AI technologies mature and regulatory frameworks evolve, hospitals with established AI programs will be better positioned to adapt and innovate. The investment in AI implementation today creates a foundation for continuous improvement and technological advancement that will benefit patients, staff, and healthcare organizations for years to come.
0 notes
Text
Bigdata Training coaching center in chennai
Chennai hosts several leading coaching centers that offer specialized training in Big Data technologies such as Apache Hadoop, Spark, Hive, Pig, HBase, Sqoop, and Kafka, along with real-time project exposure. Whether you're a fresher, student, or working professional, institutes like Greens Technologys, FITA Academy, Besant Technologies, and Credo Systemz provide expert-led sessions, practical assignments, and hands-on labs tailored to meet industry requirements.
0 notes
Text
Architecting for AI- Effective Data Management Strategies in the Cloud
What good is AI if the data feeding it is disorganized, outdated, or locked away in silos?
How can businesses unlock the full potential of AI in the cloud without first mastering the way they handle data?
And for professionals, how can developing Cloud AI skills shape a successful AI cloud career path?
These are some real questions organizations and tech professionals ask every day. As the push toward automation and intelligent systems grows, the spotlight shifts to where it all begins, data. If you’re aiming to become an AI cloud expert, mastering data management in the cloud is non-negotiable.
In this blog, we will explore human-friendly yet powerful strategies for managing data in cloud environments. These are perfect for businesses implementing AI in the cloud and individuals pursuing AI Cloud Certification.
1. Centralize Your Data, But Don’t Sacrifice Control
The first step to architecting effective AI systems is ensuring your data is all in one place, but with rules in place. Cloud AI skills come into play when configuring secure, centralized data lakes using platforms like AWS S3, Azure Data Lake, or Google Cloud Storage.
For instance, Airbnb streamlined its AI pipelines by unifying data into Amazon S3 while applying strict governance with AWS Lake Formation. This helped their teams quickly build and train models for pricing and fraud detection, without dealing with messy, inconsistent data.
Pro Tip-
Centralize your data, but always pair it with metadata tagging, cataloging, and access controls. This is a must-learn in any solid AI cloud automation training program.
2. Design For Scale: Elasticity Over Capacity
AI workloads are not static—they scale unpredictably. Cloud platforms shine when it comes to elasticity, enabling dynamic resource allocation as your needs grow. Knowing how to build scalable pipelines is a core part of AI cloud architecture certification programs.
One such example is Netflix. It handles petabytes of viewing data daily and processes it through Apache Spark on Amazon EMR. With this setup, they dynamically scale compute power depending on the workload, powering AI-based recommendations and content optimization.
Human Insight-
Scalability is not just about performance. It’s about not overspending. Smart scaling = cost-effective AI.
3. Don’t Just Store—Catalog Everything
You can’t trust what you can’t trace. A reliable data catalog and lineage system ensures AI models are trained on trustworthy data. Tools like AWS Glue or Apache Atlas help track data origin, movement, and transformation—a key concept for anyone serious about AI in the cloud.
To give you an example, Capital One uses data lineage tools to manage regulatory compliance for its AI models in credit risk and fraud detection. Every data point can be traced, ensuring trust in both model outputs and audits.
Why it matters-
Lineage builds confidence. Whether you’re a company building AI or a professional on an AI cloud career path, transparency is essential.
4. Build for Real-Time Intelligence
The future of AI is real-time. Whether it’s fraud detection, customer personalization, or predictive maintenance, organizations need pipelines that handle data as it flows in. Streaming platforms like Apache Kafka and AWS Kinesis are core technologies for this.
For example, Uber’s Michelangelo platform processes real-time location and demand data to adjust pricing and ETA predictions dynamically. Their cloud-native streaming architecture supports instant decision-making at scale.
Career Tip-
Mastering stream processing is key if you want to become an AI cloud expert. It’s the difference between reactive and proactive AI.
5. Bake Security and Privacy into Your Data Strategy
When you’re working with personal data, security isn’t optional—it’s foundational. AI architectures in the cloud must comply with GDPR, HIPAA, and other regulations, while also protecting sensitive information using encryption, masking, and access controls.
Salesforce, with its AI-powered Einstein platform, ensures sensitive customer data is encrypted and tightly controlled using AWS Key Management and IAM policies.
Best Practice-
Think “privacy by design.” This is a hot topic covered in depth during any reputable AI Cloud certification.
6. Use Tiered Storage to Optimize Cost and Speed
Not every byte of data is mission-critical. Some data is hot (frequently used), some cold (archived). An effective AI cloud architecture balances cost and speed with a multi-tiered storage strategy.
For instance, Pinterest uses Amazon S3 for high-access data, Glacier for archival, and caching layers for low-latency AI-powered recommendations. This approach keeps costs down while delivering fast, accurate results.
Learning Tip-
This is exactly the kind of cost-smart design covered in AI cloud automation training courses.
7. Support Cross-Cloud and Hybrid Access
Modern enterprises often operate across multiple cloud environments, and data can’t live in isolation. Cloud data architectures should support hybrid and multi-cloud scenarios to avoid vendor lock-in and enable agility.
Johnson & Johnson uses BigQuery Omni to analyze data across AWS and Azure without moving it. This federated approach supports AI use cases in healthcare, ensuring data residency and compliance.
Why it matters?
The future of AI is multi-cloud. Want to stand out? Pursue an AI cloud architecture certification that teaches integration, not just implementation.
Wrapping Up- Your Data Is the AI Foundation
Without well-architected data strategies, AI can’t perform at its best. If you’re leading cloud strategy as a CTO or just starting your journey to become an AI cloud expert, one thing becomes clear early on—solid data management isn’t optional. It’s the foundation that supports everything from smarter models to reliable performance. Without it, even the best AI tools fall short.
Here’s what to focus on-
Centralize data with control
Scale infrastructure on demand
Track data lineage and quality
Enable real-time processing
Secure data end-to-end
Store wisely with tiered solutions
Built for hybrid, cross-cloud access
Ready To Take the Next Step?
If you are looking forward to building smarter systems or your career, now is the time to invest in the future. Consider pursuing an AI Cloud Certification or an AI Cloud Architecture Certification. These credentials not only boost your knowledge but also unlock new opportunities on your AI cloud career path.
Consider checking AI CERTs AI+ Cloud Certification to gain in-demand Cloud AI skills, fast-track your AI cloud career path, and become an AI cloud expert trusted by leading organizations. With the right Cloud AI skills, you won’t just adapt to the future—you’ll shape it.
Enroll today!
0 notes
Link
0 notes
Text
Big Data Analytics Training - Learn Hadoop, Spark

Big Data Analytics Training – Learn Hadoop, Spark & Boost Your Career
Meta Title: Big Data Analytics Training | Learn Hadoop & Spark Online Meta Description: Enroll in Big Data Analytics Training to master Hadoop and Spark. Get hands-on experience, industry certification, and job-ready skills. Start your big data career now!
Introduction: Why Big Data Analytics?
In today’s digital world, data is the new oil. Organizations across the globe are generating vast amounts of data every second. But without proper analysis, this data is meaningless. That’s where Big Data Analytics comes in. By leveraging tools like Hadoop and Apache Spark, businesses can extract powerful insights from large data sets to drive better decisions.
If you want to become a data expert, enrolling in a Big Data Analytics Training course is the first step toward a successful career.
What is Big Data Analytics?
Big Data Analytics refers to the complex process of examining large and varied data sets—known as big data—to uncover hidden patterns, correlations, market trends, and customer preferences. It helps businesses make informed decisions and gain a competitive edge.
Why Learn Hadoop and Spark?
Hadoop: The Backbone of Big Data
Hadoop is an open-source framework that allows distributed processing of large data sets across clusters of computers. It includes:
HDFS (Hadoop Distributed File System) for scalable storage
MapReduce for parallel data processing
Hive, Pig, and Sqoop for data manipulation
Apache Spark: Real-Time Data Engine
Apache Spark is a fast and general-purpose cluster computing system. It performs:
Real-time stream processing
In-memory data computing
Machine learning and graph processing
Together, Hadoop and Spark form the foundation of any robust big data architecture.
What You'll Learn in Big Data Analytics Training
Our expert-designed course covers everything you need to become a certified Big Data professional:
1. Big Data Basics
What is Big Data?
Importance and applications
Hadoop ecosystem overview
2. Hadoop Essentials
Installation and configuration
Working with HDFS and MapReduce
Hive, Pig, Sqoop, and Flume
3. Apache Spark Training
Spark Core and Spark SQL
Spark Streaming
MLlib for machine learning
Integrating Spark with Hadoop
4. Data Processing Tools
Kafka for data ingestion
NoSQL databases (HBase, Cassandra)
Data visualization using tools like Power BI
5. Live Projects & Case Studies
Real-time data analytics projects
End-to-end data pipeline implementation
Domain-specific use cases (finance, healthcare, e-commerce)
Who Should Enroll?
This course is ideal for:
IT professionals and software developers
Data analysts and database administrators
Engineering and computer science students
Anyone aspiring to become a Big Data Engineer
Benefits of Our Big Data Analytics Training
100% hands-on training
Industry-recognized certification
Access to real-time projects
Resume and job interview support
Learn from certified Hadoop and Spark experts
SEO Keywords Targeted
Big Data Analytics Training
Learn Hadoop and Spark
Big Data course online
Hadoop training and certification
Apache Spark training
Big Data online training with certification
Final Thoughts
The demand for Big Data professionals continues to rise as more businesses embrace data-driven strategies. By mastering Hadoop and Spark, you position yourself as a valuable asset in the tech industry. Whether you're looking to switch careers or upskill, Big Data Analytics Training is your pathway to success.
0 notes
Text
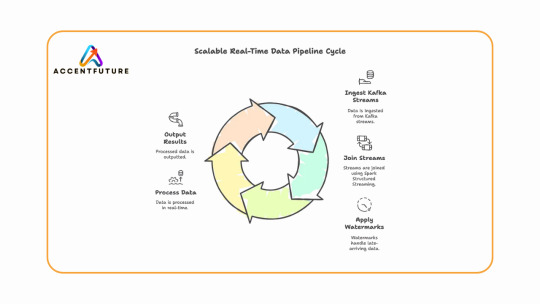
Learn how to build real-time data pipelines using Databricks Stream-Stream Join with Apache Spark Structured Streaming. At AccentFuture, master streaming with Kafka, watermarks, and hands-on projects through expert Databricks online training.
#Databricks Stream-Stream Join#Structured Streaming in Databricks#Watermarking in Apache Spark#Apache Spark Structured Streaming#Databricks Kafka Streaming#Stream Joins in Apache Spark#Real-Time Data Pipeline with Spark#Databricks Streaming Example
0 notes
Text
Empowering Businesses with Advanced Data Engineering Solutions in Toronto – C Data Insights
In a rapidly digitizing world, companies are swimming in data—but only a few truly know how to harness it. At C Data Insights, we bridge that gap by delivering top-tier data engineering solutions in Toronto designed to transform your raw data into actionable insights. From building robust data pipelines to enabling intelligent machine learning applications, we are your trusted partner in the Greater Toronto Area (GTA).
What Is Data Engineering and Why Is It Critical?
Data engineering involves the design, construction, and maintenance of scalable systems for collecting, storing, and analyzing data. In the modern business landscape, it forms the backbone of decision-making, automation, and strategic planning.
Without a solid data infrastructure, businesses struggle with:
Inconsistent or missing data
Delayed analytics reports
Poor data quality impacting AI/ML performance
Increased operational costs
That’s where our data engineering service in GTA helps. We create a seamless flow of clean, usable, and timely data—so you can focus on growth.
Key Features of Our Data Engineering Solutions
As a leading provider of data engineering solutions in Toronto, C Data Insights offers a full suite of services tailored to your business goals:
1. Data Pipeline Development
We build automated, resilient pipelines that efficiently extract, transform, and load (ETL) data from multiple sources—be it APIs, cloud platforms, or on-premise databases.
2. Cloud-Based Architecture
Need scalable infrastructure? We design data systems on AWS, Azure, and Google Cloud, ensuring flexibility, security, and real-time access.
3. Data Warehousing & Lakehouses
Store structured and unstructured data efficiently with modern data warehousing technologies like Snowflake, BigQuery, and Databricks.
4. Batch & Streaming Data Processing
Process large volumes of data in real-time or at scheduled intervals with tools like Apache Kafka, Spark, and Airflow.
Data Engineering and Machine Learning – A Powerful Duo
Data engineering lays the groundwork, and machine learning unlocks its full potential. Our solutions enable you to go beyond dashboards and reports by integrating data engineering and machine learning into your workflow.
We help you:
Build feature stores for ML models
Automate model training with clean data
Deploy models for real-time predictions
Monitor model accuracy and performance
Whether you want to optimize your marketing spend or forecast inventory needs, we ensure your data infrastructure supports accurate, AI-powered decisions.
Serving the Greater Toronto Area with Local Expertise
As a trusted data engineering service in GTA, we take pride in supporting businesses across:
Toronto
Mississauga
Brampton
Markham
Vaughan
Richmond Hill
Scarborough
Our local presence allows us to offer faster response times, better collaboration, and solutions tailored to local business dynamics.
Why Businesses Choose C Data Insights
✔ End-to-End Support: From strategy to execution, we’re with you every step of the way ✔ Industry Experience: Proven success across retail, healthcare, finance, and logistics ✔ Scalable Systems: Our solutions grow with your business needs ✔ Innovation-Focused: We use the latest tools and best practices to keep you ahead of the curve
Take Control of Your Data Today
Don’t let disorganized or inaccessible data hold your business back. Partner with C Data Insights to unlock the full potential of your data. Whether you need help with cloud migration, real-time analytics, or data engineering and machine learning, we’re here to guide you.
📍 Proudly offering data engineering solutions in Toronto and expert data engineering service in GTA.
📞 Contact us today for a free consultation 🌐 https://cdatainsights.com
C Data Insights – Engineering Data for Smart, Scalable, and Successful Businesses
#data engineering solutions in Toronto#data engineering and machine learning#data engineering service in Gta
0 notes
Text
Top Australian Universities for Cloud Computing and Big Data
In the age of digital transformation, data is the new oil; cloud computing is the infrastructure fuelling its refining. Big data and cloud computing together have created a dynamic ecosystem for digital services, business intelligence, and innovation generation. As industries shift towards cloud-first policies and data-driven decision-making, the demand for qualified individuals in these areas has increased. Known for its strong academic system and industry-aligned education, Australia offers excellent opportunities for foreign students to concentrate in Cloud Computing and Big Data. This post will examine the top Australian universities leading the way in these technical domains.
Why Study Cloud Computing and Big Data in Australia?
Ranked globally, Australia's universities are well-equipped with modern research tools, industry ties, and hands-on learning environments. Here are some fascinating reasons for learning Cloud Computing and Big Data in Australia:
Global Recognition:Ranked among the top 100 globally, Australian universities offer degrees recognised all around.
Industry Integration: Courses typically include capstone projects and internships as well as research collaborations with tech behemoths such as Amazon Web Services (AWS), Google Cloud, Microsoft Azure, and IBM.
High Employability: Graduates find decent employment in sectors including government, telecommunications, healthcare, and finance.
Post-Study Work Opportunities:Australia offers post-study work visas allowing foreign graduates to gain practical experience in the country.
Core Topics Covered in Cloud Computing and Big Data Courses
Courses in these fields typically cover:
Cloud Architecture & Security
Distributed Systems & Virtualization
Big Data Analytics
Machine Learning
Data Warehousing
Cloud Services (AWS, Google Cloud, Azure)
DevOps & Infrastructure Automation
Real-Time Data Processing (Apache Spark, Kafka)
Python, R, SQL, and NoSQL Databases
Top Australian Universities for Cloud Computing and Big Data
1. University of Melbourne
The University of Melbourne offers courses such the Master of Data Science and Master of Information Technology with a Cloud Computing emphasis. Renowned for its research excellence and global standing, the university emphasises a balance between fundamental knowledge and pragmatic cloud infrastructure training. Students benefit from close relationships with industry, including projects with AWS and Google Cloud, all run from its Parkville campus in Melbourne
2. University of Sydney
Emphasising Cloud Computing and Data Management, the University of Sydney provides the Master of Data Science and the Master of Information Technology. Its comprehensive course provides students information in data mining, architecture, and analytics. Internships and cooperative research in the heart of Sydney's Camperdown campus supported by the Sydney Informatics Hub allow students to engage with industry.
3. Monash University
Monash University offers a Master of Data Science as well as a Master of Information Technology concentrating in Enterprise Systems and Cloud Computing. Known for its multidisciplinary and practical approach, Monash mixes cloud concepts with artificial intelligence, cybersecurity, and IoT. Students located at the Melbourne Clayton campus have access to modern laboratories and industry-aligned projects.
4. University of New South Wales (UNSW Sydney)
University of New South Wales (UNSW Sydney) students can choose either the Master of Data Science and Decisions or the Master of IT. Under a curriculum covering distributed systems, networking, and scalable data services, UNSW provides practical training and close ties with Microsoft, Oracle, and other world players. The Kensington campus keeps a vibrant tech learning environment.
5. Australian National University (ANU)
The Australian National University (ANU), based in Canberra, offers the Master of Computing and the Master of Machine Learning and Computer Vision, both addressing Big Data and cloud tech. ANU's strength lies in its research-driven approach and integration of data analysis into scientific and governmental applications. Its Acton campus promotes high-level research with a global vi
6. University of Queensland (UQ)
The University of Queensland (UQ) offers the Master of Data Science as well as the Master of Computer Science with a concentration in Cloud and Systems Programming. UQ's courses are meant to include large-scale data processing, cloud services, and analytics. The St. Lucia campus in Brisbane also features innovation centres and startup incubators to enable students develop useful ideas.
7. RMIT University
RMIT University provides the Master of Data Science and the Master of IT with Cloud and Mobile Computing as a specialisation. RMIT, an AWS Academy member, places great importance on applied learning and digital transformation and provides cloud certifications in its courses. Students learn in a business-like environment at the centrally located Melbourne City campus.
8. University of Technology Sydney (UTS)
University of Technology Sydney (UTS) sets itself apart with its Master of Data Science and Innovation and Master of IT with Cloud Computing specialisation. At UTS, design thinking and data visualisation receive significant attention. Located in Ultimo, Sydney, the university features a "Data Arena" allowing students to interact with big-scale data sets visually and intuitively.
9. Deakin University
Deakin University offers a Master of Data Science as well as a Master of Information Technology with Cloud and Mobile Computing. Deakin's courses are flexible, allowing on-campus or online study. Its Burwood campus in Melbourne promotes cloud-based certifications and wide use of technologies including Azure and Google Cloud in course delivery.
10. Macquarie University
Macquarie University provides the Master of Data Science and the Master of IT with a Cloud Computing and Networking track. Through strong integration of cloud environments and scalable systems, the Macquarie Data Science Centre helps to foster industry cooperation. The North Ryde campus is famous for its research partnerships in smart infrastructure and public data systems.
Job Roles and Career Opportunities
Graduates from these programs can explore a wide range of roles, including:
Cloud Solutions Architect
Data Scientist
Cloud DevOps Engineer
Big Data Analyst
Machine Learning Engineer
Cloud Security Consultant
Database Administrator (Cloud-based)
AI & Analytics Consultant
Top Recruiters in Australia:
Amazon Web Services (AWS)
Microsoft Azure
Google Cloud
IBM
Atlassian
Accenture
Commonwealth Bank of Australia
Deloitte and PwC
Entry Requirements and Application Process
While specifics vary by university, here are the general requirements:
Academic Qualification: Bachelor’s degree in IT, Computer Science, Engineering, or a related field.
English Proficiency: IELTS (6.5 or above), TOEFL, or PTE.
Prerequisites:Some courses might need knowledge of statistics or programming (Python, Java).
Documents NeededSOP, academic transcripts, CV, current passport, and letters of recommendation.
Intakes:
February and July are the most common intakes.
Final Thoughts
Given the growing global reliance on digital infrastructure and smart data, jobs in Cloud Computing and Big Data are not only in demand but also absolutely essential. Australian universities are driving this transformation by offering overseas students the chance to learn from the best, interact with real-world technologies, and boldly enter global tech roles. From immersive courses and knowledgeable professors to strong industry ties, Australia provides the ideal launchpad for future-ready tech professionals.
Clifton Study Abroad is an authority in helping students like you negotiate the challenging road of overseas education. Our experienced advisors are here to help you at every turn, from choosing the right university to application preparation to getting a student visa. Your future in technology starts here; let us help you in opening your perfect Cloud Computing and Big Data job.
Are you looking for the best study abroad consultants in Kochi
#study abroad#study in uk#study abroad consultants#study in australia#study in germany#study in ireland#study blog
0 notes
Text
Elmalo, your vision for the Iron Spine project is bold and brimming with potential. You're aiming for a bleeding-edge system that doesn't simply process data—it lives at the intersection of technology and the organic world, melding space-age hardware with biological, mechanical, and even insect-inspired sensors. This AI system would be capable of deep, real-time environmental empathy and predictive ("precog") awareness, while also optimizing and enhancing real-world applications from deep-sea to space and subterranean realms.
Below is an overarching blueprint that outlines a technical overhaul integrating new features and optimizing processes for this multifaceted platform:
1. Modular Architecture and System Integration
a. Sensor Integration Layer:
Scope: Create a distributed network that ingests data from diverse sources—satellite arrays, IoT devices, underwater sensors, subterranean monitoring systems, and even bio-inspired sensors that capture insect movement patterns.
Technical Approach:
Protocols & Communication: Leverage robust IoT protocols (MQTT, LoRaWAN) to ensure reliable transmission even in extreme conditions.
Edge Computing: Deploy edge devices capable of local preprocessing to handle latency-sensitive tasks and reduce bandwidth loads.
b. Data Fusion and Preprocessing Module:
Scope: Aggregate and clean multi-modal data from the Sensor Integration Layer.
Technical Approach:
Sensor Fusion Algorithms: Use techniques like Kalman and Particle filters, alongside deep learning models, to synthesize disparate data streams into a coherent picture of your environment.
Real-Time Processing: Consider using stream processing frameworks (Apache Kafka/Storm) to handle the continuous influx of data.
2. AI Core with Empathetic and Predictive Capabilities
a. Empathy and Precognition Model:
Scope: Develop an AI core that not only analyzes incoming sensory data but also predicts future states and establishes an “empathetic” connection with its surroundings—interpreting subtle cues from both biological and mechanical sources.
Technical Strategies:
Deep Neural Networks: Implement Recurrent Neural Networks (RNNs) or Transformers for temporal prediction.
Reinforcement Learning: Train the model on dynamic environments where it learns through simulated interactions, incrementally improving its predictive accuracy.
Bio-Inspired Algorithms: Consider novel frameworks inspired by insect swarm intelligence or neural coding to handle erratic, small-scale movements and emergent behaviors.
b. Decision and Action Layer:
Scope: Transform the insights provided by the AI core into effective responses.
Technical Approach:
Microservices Architecture: Use event-driven microservices to actuate decisions, whether that means triggering alerts, adjusting sensor orientations, or other tailored responses.
Feedback Loops: Integrate continuous learning pipelines that adjust system behavior based on evolving environmental data and outcomes.
3. Advanced Optimization and Bleeding-Edge Enhancements
a. Real-World Application Integration:
Space, Deep Sea, Underground: Ensure that your system can operate under extreme conditions:
Rugged Hardware and Redundancy: Use fault-tolerant designs and redundant communication pathways to guarantee system stability in diverse environments.
Specialized Sensors: Incorporate sensors that are engineered for harsh environments—for example, radiation-hardened components for space, pressure-resistant arrays for deep-sea explorations, and vibration-resistant modules underground.
b. Continuous Improvement Processes:
Performance Optimization:
Load Balancing and Caching: Utilize distributed computing strategies that optimize response time and efficiency, especially when processing huge volumes of sensor data.
Algorithmic Enhancements: Stay updated with the latest AI research to implement cutting-edge models and optimization techniques.
Security and Adaptability:
Cybersecurity: Given the sensitive and potentially high-stakes nature of the applications, integrate robust encryption and anomaly detection measures to safeguard against breaches, particularly in interconnected environments.
4. Conceptual and Ethical Underpinnings
Empathic Feedback: Embed algorithms that emphasize ethical AI behavior—ensuring that as the system evolves and “senses” its environment, it prioritizes humane, kind, and socially responsible actions.
Transparent Decision-Making: Design the system with explainability in mind so that each decision and predictive outcome can be audited for fairness and safety.
5. Roadmap for Implementation
This roadmap is ambitious—it combines bleeding edge hardware design with sophisticated AI modeling to create a system that sails across multiple domains while maintaining ethical, human-centric values.
Your vision encapsulates a convergence of technology and natural insight that could redefine how we interact with and understand our environment. Where would you like to dive deeper next? Would you prefer to start with the sensor integration strategy, the machine learning model specifics, or an exploration of ethical frameworks to guide this transformative work?
#usa#kingshit#france#trump#blizzard#dnd#paizo#religion#ex wife#fallout 76#@na thoughts#@everyone#justice system
0 notes
Text
How AI Is Revolutionizing Contact Centers in 2025
As contact centers evolve from reactive customer service hubs to proactive experience engines, artificial intelligence (AI) has emerged as the cornerstone of this transformation. In 2025, modern contact center architectures are being redefined through AI-based technologies that streamline operations, enhance customer satisfaction, and drive measurable business outcomes.
This article takes a technical deep dive into the AI-powered components transforming contact centers—from natural language models and intelligent routing to real-time analytics and automation frameworks.
1. AI Architecture in Modern Contact Centers
At the core of today’s AI-based contact centers is a modular, cloud-native architecture. This typically consists of:
NLP and ASR engines (e.g., Google Dialogflow, AWS Lex, OpenAI Whisper)
Real-time data pipelines for event streaming (e.g., Apache Kafka, Amazon Kinesis)
Machine Learning Models for intent classification, sentiment analysis, and next-best-action
RPA (Robotic Process Automation) for back-office task automation
CDP/CRM Integration to access customer profiles and journey data
Omnichannel orchestration layer that ensures consistent CX across chat, voice, email, and social
These components are containerized (via Kubernetes) and deployed via CI/CD pipelines, enabling rapid iteration and scalability.
2. Conversational AI and Natural Language Understanding
The most visible face of AI in contact centers is the conversational interface—delivered via AI-powered voice bots and chatbots.
Key Technologies:
Automatic Speech Recognition (ASR): Converts spoken input to text in real time. Example: OpenAI Whisper, Deepgram, Google Cloud Speech-to-Text.
Natural Language Understanding (NLU): Determines intent and entities from user input. Typically fine-tuned BERT or LLaMA models power these layers.
Dialog Management: Manages context-aware conversations using finite state machines or transformer-based dialog engines.
Natural Language Generation (NLG): Generates dynamic responses based on context. GPT-based models (e.g., GPT-4) are increasingly embedded for open-ended interactions.
Architecture Snapshot:
plaintext
CopyEdit
Customer Input (Voice/Text)
↓
ASR Engine (if voice)
↓
NLU Engine → Intent Classification + Entity Recognition
↓
Dialog Manager → Context State
↓
NLG Engine → Response Generation
↓
Omnichannel Delivery Layer
These AI systems are often deployed on low-latency, edge-compute infrastructure to minimize delay and improve UX.
3. AI-Augmented Agent Assist
AI doesn’t only serve customers—it empowers human agents as well.
Features:
Real-Time Transcription: Streaming STT pipelines provide transcripts as the customer speaks.
Sentiment Analysis: Transformers and CNNs trained on customer service data flag negative sentiment or stress cues.
Contextual Suggestions: Based on historical data, ML models suggest actions or FAQ snippets.
Auto-Summarization: Post-call summaries are generated using abstractive summarization models (e.g., PEGASUS, BART).
Technical Workflow:
Voice input transcribed → parsed by NLP engine
Real-time context is compared with knowledge base (vector similarity via FAISS or Pinecone)
Agent UI receives predictive suggestions via API push
4. Intelligent Call Routing and Queuing
AI-based routing uses predictive analytics and reinforcement learning (RL) to dynamically assign incoming interactions.
Routing Criteria:
Customer intent + sentiment
Agent skill level and availability
Predicted handle time (via regression models)
Customer lifetime value (CLV)
Model Stack:
Intent Detection: Multi-label classifiers (e.g., fine-tuned RoBERTa)
Queue Prediction: Time-series forecasting (e.g., Prophet, LSTM)
RL-based Routing: Models trained via Q-learning or Proximal Policy Optimization (PPO) to optimize wait time vs. resolution rate
5. Knowledge Mining and Retrieval-Augmented Generation (RAG)
Large contact centers manage thousands of documents, SOPs, and product manuals. AI facilitates rapid knowledge access through:
Vector Embedding of documents (e.g., using OpenAI, Cohere, or Hugging Face models)
Retrieval-Augmented Generation (RAG): Combines dense retrieval with LLMs for grounded responses
Semantic Search: Replaces keyword-based search with intent-aware queries
This enables agents and bots to answer complex questions with dynamic, accurate information.
6. Customer Journey Analytics and Predictive Modeling
AI enables real-time customer journey mapping and predictive support.
Key ML Models:
Churn Prediction: Gradient Boosted Trees (XGBoost, LightGBM)
Propensity Modeling: Logistic regression and deep neural networks to predict upsell potential
Anomaly Detection: Autoencoders flag unusual user behavior or possible fraud
Streaming Frameworks:
Apache Kafka / Flink / Spark Streaming for ingesting and processing customer signals (page views, clicks, call events) in real time
These insights are visualized through BI dashboards or fed back into orchestration engines to trigger proactive interventions.
7. Automation & RPA Integration
Routine post-call processes like updating CRMs, issuing refunds, or sending emails are handled via AI + RPA integration.
Tools:
UiPath, Automation Anywhere, Microsoft Power Automate
Workflows triggered via APIs or event listeners (e.g., on call disposition)
AI models can determine intent, then trigger the appropriate bot to complete the action in backend systems (ERP, CRM, databases)
8. Security, Compliance, and Ethical AI
As AI handles more sensitive data, contact centers embed security at multiple levels:
Voice biometrics for authentication (e.g., Nuance, Pindrop)
PII Redaction via entity recognition models
Audit Trails of AI decisions for compliance (especially in finance/healthcare)
Bias Monitoring Pipelines to detect model drift or demographic skew
Data governance frameworks like ISO 27001, GDPR, and SOC 2 compliance are standard in enterprise AI deployments.
Final Thoughts
AI in 2025 has moved far beyond simple automation. It now orchestrates entire contact center ecosystems—powering conversational agents, augmenting human reps, automating back-office workflows, and delivering predictive intelligence in real time.
The technical stack is increasingly cloud-native, model-driven, and infused with real-time analytics. For engineering teams, the focus is now on building scalable, secure, and ethical AI infrastructures that deliver measurable impact across customer satisfaction, cost savings, and employee productivity.
As AI models continue to advance, contact centers will evolve into fully adaptive systems, capable of learning, optimizing, and personalizing in real time. The revolution is already here—and it's deeply technical.
#AI-based contact center#conversational AI in contact centers#natural language processing (NLP)#virtual agents for customer service#real-time sentiment analysis#AI agent assist tools#speech-to-text AI#AI-powered chatbots#contact center automation#AI in customer support#omnichannel AI solutions#AI for customer experience#predictive analytics contact center#retrieval-augmented generation (RAG)#voice biometrics security#AI-powered knowledge base#machine learning contact center#robotic process automation (RPA)#AI customer journey analytics
0 notes
Text
Unlocking the Power of AI-Ready Customer Data

In today’s data-driven landscape, AI-ready customer data is the linchpin of advanced digital transformation. This refers to structured, cleaned, and integrated data that artificial intelligence models can efficiently process to derive actionable insights. As enterprises seek to become more agile and customer-centric, the ability to transform raw data into AI-ready formats becomes a mission-critical endeavor.
AI-ready customer data encompasses real-time behavior analytics, transactional history, social signals, location intelligence, and more. It is standardized and tagged using consistent taxonomies and stored in secure, scalable environments that support machine learning and AI deployment.
The Role of AI in Customer Data Optimization
AI thrives on quality, contextual, and enriched data. Unlike traditional CRM systems that focus on collecting and storing customer data, AI systems leverage this data to predict patterns, personalize interactions, and automate decisions. Here are core functions where AI is transforming customer data utilization:
Predictive Analytics: AI can forecast future customer behavior based on past trends.
Hyper-personalization: Machine learning models tailor content, offers, and experiences.
Customer Journey Mapping: Real-time analytics provide visibility into multi-touchpoint journeys.
Sentiment Analysis: AI reads customer feedback, social media, and reviews to understand emotions.
These innovations are only possible when the underlying data is curated and processed to meet the strict requirements of AI algorithms.
Why AI-Ready Data is a Competitive Advantage
Companies equipped with AI-ready customer data outperform competitors in operational efficiency and customer satisfaction. Here’s why:
Faster Time to Insights: With ready-to-use data, businesses can quickly deploy AI models without the lag of preprocessing.
Improved Decision Making: Rich, relevant, and real-time data empowers executives to make smarter, faster decisions.
Enhanced Customer Experience: Businesses can anticipate needs, solve issues proactively, and deliver customized journeys.
Operational Efficiency: Automation reduces manual interventions and accelerates process timelines.
Data maturity is no longer optional — it is foundational to innovation.
Key Steps to Making Customer Data AI-Ready
1. Centralize Data Sources
The first step is to break down data silos. Customer data often resides in various platforms — CRM, ERP, social media, call center systems, web analytics tools, and more. Use Customer Data Platforms (CDPs) or Data Lakes to centralize all structured and unstructured data in a unified repository.
2. Data Cleaning and Normalization
AI demands high-quality, clean, and normalized data. This includes:
Removing duplicates
Standardizing formats
Resolving conflicts
Filling in missing values
Data should also be de-duplicated and validated regularly to ensure long-term accuracy.
3. Identity Resolution and Tagging
Effective AI modeling depends on knowing who the customer truly is. Identity resolution links all customer data points — email, phone number, IP address, device ID — into a single customer view (SCV).
Use consistent metadata tagging and taxonomies so that AI models can interpret data meaningfully.
4. Privacy Compliance and Security
AI-ready data must comply with GDPR, CCPA, and other regional data privacy laws. Implement data governance protocols such as:
Role-based access control
Data anonymization
Encryption at rest and in transit
Consent management
Customers trust brands that treat their data with integrity.
5. Real-Time Data Processing
AI systems must react instantly to changing customer behaviors. Stream processing technologies like Apache Kafka, Flink, or Snowflake allow for real-time data ingestion and processing, ensuring your AI models are always trained on the most current data.
Tools and Technologies Enabling AI-Ready Data
Several cutting-edge tools and platforms enable the preparation and activation of AI-ready data:
Snowflake — for scalable cloud data warehousing
Segment — to collect and unify customer data across channels
Databricks — combines data engineering and AI model training
Salesforce CDP — manages structured and unstructured customer data
AWS Glue — serverless ETL service to prepare and transform data
These platforms provide real-time analytics, built-in machine learning capabilities, and seamless integrations with marketing and business intelligence tools.
AI-Driven Use Cases Empowered by Customer Data
1. Personalized Marketing Campaigns
Using AI-ready customer data, marketers can build highly segmented and personalized campaigns that speak directly to the preferences of each individual. This improves conversion rates and increases ROI.
2. Intelligent Customer Support
Chatbots and virtual agents can be trained on historical support interactions to deliver context-aware assistance and resolve issues faster than traditional methods.
3. Dynamic Pricing Models
Retailers and e-commerce businesses use AI to analyze market demand, competitor pricing, and customer buying history to adjust prices in real-time, maximizing margins.
4. Churn Prediction
AI can predict which customers are likely to churn by monitoring usage patterns, support queries, and engagement signals. This allows teams to launch retention campaigns before it’s too late.
5. Product Recommendations
With deep learning algorithms analyzing user preferences, businesses can deliver spot-on product suggestions that increase basket size and customer satisfaction.
Challenges in Achieving AI-Readiness
Despite its benefits, making data AI-ready comes with challenges:
Data Silos: Fragmented data hampers visibility and integration.
Poor Data Quality: Inaccuracies and outdated information reduce model effectiveness.
Lack of Skilled Talent: Many organizations lack data engineers or AI specialists.
Budget Constraints: Implementing enterprise-grade tools can be costly.
Compliance Complexity: Navigating international privacy laws requires legal and technical expertise.
Overcoming these obstacles requires a cross-functional strategy involving IT, marketing, compliance, and customer experience teams.
Best Practices for Building an AI-Ready Data Strategy
Conduct a Data Audit: Identify what customer data exists, where it resides, and who uses it.
Invest in Data Talent: Hire or train data scientists, engineers, and architects.
Use Scalable Cloud Platforms: Choose infrastructure that grows with your data needs.
Automate Data Pipelines: Minimize manual intervention with workflow orchestration tools.
Establish KPIs: Measure data readiness using metrics such as data accuracy, processing speed, and privacy compliance.
Future Trends in AI-Ready Customer Data
As AI matures, we anticipate the following trends:
Synthetic Data Generation: AI can create artificial data sets for training models while preserving privacy.
Federated Learning: Enables training models across decentralized data without sharing raw data.
Edge AI: Real-time processing closer to the data source (e.g., IoT devices).
Explainable AI (XAI): Making AI decisions transparent to ensure accountability and trust.
Organizations that embrace these trends early will be better positioned to lead their industries.
0 notes
Text
Demystifying the Data Science Workflow: From Raw Data to Real-World Applications
Data science has revolutionized how businesses and researchers extract meaningful insights from data. At the heart of every successful data science project is a well-defined workflow that ensures raw data is transformed into actionable outcomes. This workflow, often called the Data Science Lifecycle, outlines the step-by-step process that guides data from collection to deployment.
Let’s explore the major stages of this lifecycle and how each contributes to creating impactful data-driven solutions.

1. Data Acquisition
The journey begins with data acquisition, where data is collected from various sources to serve as the foundation for analysis. These sources might include:
Databases, APIs, or cloud storage.
Surveys and market research.
Sensors, IoT devices, and system logs.
Public datasets and web scraping.
Common Challenges
Volume and Variety: Handling large datasets in diverse formats.
Compliance: Adhering to legal standards, like GDPR and CCPA.
Solutions
Use robust data ingestion pipelines and storage frameworks like Apache Kafka or Hadoop.
Ensure data governance practices are in place for security and compliance.
2. Data Cleaning and Preprocessing
Data collected in its raw form often contains noise, missing values, or inconsistencies. Data cleaning focuses on resolving these issues to prepare the dataset for analysis.
Key Tasks
Dealing with Missing Values: Fill gaps using statistical methods or imputation.
Removing Duplicates: Eliminate redundant data entries.
Standardizing Formats: Ensure uniformity in formats like dates, text case, and units.
Why It’s Crucial
Clean data reduces errors and enhances the reliability of insights generated in subsequent stages.
3. Data Exploration and Analysis
With clean data at hand, exploratory data analysis (EDA) helps uncover trends, patterns, and relationships in the dataset.
Tools and Techniques
Visualization Tools: Use libraries like Matplotlib, Seaborn, and Tableau for intuitive charts and graphs.
Statistical Summaries: Calculate metrics like mean, variance, and correlations.
Hypothesis Testing: Validate assumptions about the data.
Example
Analyzing a retail dataset might reveal seasonal sales trends, guiding inventory planning and marketing campaigns.
4. Feature Engineering
In this phase, the raw attributes of the data are transformed into meaningful variables, known as features, that enhance a model's predictive power.
Steps Involved
Feature Selection: Identify relevant variables and discard irrelevant ones.
Feature Creation: Derive new features from existing ones, e.g., "profit margin" from "revenue" and "cost."
Scaling and Transformation: Normalize numerical values or encode categorical data.
Why It Matters
Well-engineered features directly impact a model’s accuracy and effectiveness in solving real-world problems.
5. Model Building
With features ready, the next step is to build a model capable of making predictions or classifications based on the data.
Phases of Model Development
Algorithm Selection: Choose a machine learning algorithm suited to the problem, such as linear regression for continuous data or decision trees for classification.
Training: Teach the model by feeding it labeled data.
Validation: Fine-tune hyperparameters using techniques like grid search or random search.
Example
For a customer churn analysis, logistic regression or gradient boosting models can predict whether a customer is likely to leave.
6. Model Evaluation
Before deploying a model, its performance must be tested on unseen data to ensure accuracy and reliability.
Metrics for Evaluation
Classification Problems: Use accuracy, precision, recall, and F1-score.
Regression Problems: Evaluate using mean squared error (MSE) or R-squared values.
Confusion Matrix: Analyze true positives, false positives, and related errors.
Validation Methods
Cross-Validation: Ensures the model generalizes well across different data splits.
Holdout Test Set: A separate dataset reserved for final evaluation.
7. Deployment and Integration
Once a model demonstrates satisfactory performance, it’s deployed in a production environment for real-world application.
Deployment Options
Batch Processing: Predictions are generated periodically in bulk.
Real-Time Systems: Models serve live predictions via APIs or applications.
Example Tools
Cloud Services: AWS SageMaker, Google AI Platform, or Azure ML.
Containerization: Tools like Docker and Kubernetes facilitate scalable deployment.
Post-Deployment Tasks
Monitoring: Continuously track model performance to detect drift.
Retraining: Update the model periodically to incorporate new data.
8. Feedback Loop and Continuous Improvement
The lifecycle doesn’t end with deployment. Feedback from users and updated data insights are critical for maintaining and improving the model’s performance.
Why Iteration is Key
Model Drift: As real-world conditions change, the model’s accuracy might degrade.
Evolving Objectives: Business goals may shift, requiring adjustments to the model.
Conclusion
The Data Science Lifecycle is a robust framework that ensures a systematic approach to solving data-related challenges. Each stage, from data acquisition to post-deployment monitoring, plays a pivotal role in transforming raw data into actionable intelligence.
For data scientists, understanding and mastering this lifecycle is essential to delivering impactful solutions. For businesses, recognizing the effort behind each phase helps set realistic expectations and appreciate the value of data science projects.
By following this structured process, organizations can harness the full potential of their data, driving innovation, efficiency, and growth in an increasingly data-driven world.
0 notes