#RedShift Training
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
In February 2021, Tumblr had 518.6 million blog accounts.
Text
Amazon Redshift Courses Online | Amazon Redshift Certification Training
What is Amazon (AWS) Redshift? - Cloud Data Warehouse
Amazon Redshift is a fully managed cloud data warehouse service provided by Amazon Web Services (AWS). It is designed to handle large-scale data storage and analysis, making it a powerful tool for businesses looking to manage and analyse vast amounts of data efficiently. Amazon Redshift Courses Online

Key Features of Amazon Redshift
Scalability:
Redshift allows you to scale your data warehouse up or down based on your needs. You can start with a small amount of storage and expand as your data grows without significant downtime or complexity.
Performance:
Redshift uses columnar storage and advanced compression techniques, which optimize query performance. It also utilizes parallel processing, enabling faster query execution.
Fully Managed:
As a fully managed service, Redshift takes care of administrative tasks such as hardware provisioning, setup, configuration, monitoring, backups, and patching. This allows users to focus on their data and queries rather than maintenance.
Integration with AWS Services:
Redshift integrates seamlessly with other AWS services like Amazon S3 (for storage), Amazon RDS (for relational databases), Amazon EMR (for big data processing), and Amazon Quick Sight (for business intelligence and visualization).
Security:
Redshift provides robust security features, including encryption at rest and in transit, VPC (Virtual Private Cloud) for network isolation, and IAM (Identity and Access Management) for fine-grained access control.
Cost-Effective:
Redshift offers a pay-as-you-go pricing model and reserved instance pricing, which can significantly reduce costs. Users only pay for the resources they use, and the reserved instance option provides discounts for longer-term commitments. Amazon Redshift Certification
Advanced Query Features:
Redshift supports complex queries and joins, window functions, and nested queries. It is compatible with standard SQL, making it accessible for users familiar with SQL-based querying.
Data Sharing:
Redshift allows data sharing between different Redshift clusters without the need to copy or move data, enabling seamless collaboration and data access across teams and departments.
Use Cases for Amazon Redshift
Business Intelligence and Reporting: Companies use Redshift to run complex queries and generate reports that provide insights into business operations and performance.
Data Warehousing: Redshift serves as a central repository where data from various sources can be consolidated, stored, and analysed.
Big Data Analytics: Redshift can handle petabyte-scale data analytics, making it suitable for big data applications.
ETL Processes: Redshift is often used in ETL (Extract, Transform, and Load) processes to clean, transform, and load data into the warehouse for further analysis.
Visualpath is one of the Best Amazon RedShift Online Training institute in Hyderabad. Providing Live Instructor-Led Online Classes delivered by experts from Our Industry. Will provide AWS Redshift Course in Hyderabad. Enroll Now!! Contact us +91-9989971070
WhatsApp: https://www.whatsapp.com/catalog/919989971070/
Blog link: https://visualpathblogs.com/
Visit us https://visualpath.in/amazon-redshift-online-training.html
#Amazon Redshift Online Training#Redshift Training in Hyderabad#AWS Redshift Online Training Institute in Hyderabad#Amazon Redshift Certification Online Training#AWS Redshift training Courses in Hyderabad#Amazon Redshift Courses Online#Amazon Redshift Training in Hyderabad#Amazon RedShift Training#Amazon RedShift Training in Ameerpet#Amazon RedShift Training Online#AWS Redshift Training in Hyderabad
0 notes
Text
In Stars and Time: Axis Masterpost
Axis is a post-game au for the game "In Stars and Time" where I explore ideas and themes from the game and the impact from it's events ~ Beware, spoilers of the whole game!

ORBITAL (Act 3 Comic) - Nothing seem out of ordinary that day: the party takes a break from their long journey to save Vanguarde from the King like usually, but then Bonnie runs into a strong Sadness.
SOLAR WIND - A week passed since Siffrin broke out of loops, but the wounds on his heart are bleeding still and about to get worse for everyone involved.
GRAVITATIONAL WAVES - Siffrin and Isabeau are trying to figure out their feelings, but it not an easy task when the defender is reeling after seeing what loops did to Siffrin.
REDSHIFT - The Party takes the train to the next city to get to Bambouche. Siffrin and Odile have a talk about heritage, but it seems this gonna be less peaceful as Sadnesses still roaming around after King's defeat.
CEPHEIDS - Mirabelle and Siffrin spend time together as "Feeling Buddies".
ROCHE LIMIT - The Party finally reaches Bambouche and Bonnie retunited with their beloved sister. But things went rough as Nille finds out details about what happened when Siffrin was trapped in the timeloop.
ACCRETION DISK - The Party visits Dormont before traveling all over the world, Siffrin is coping well enough, but there is hidden danger lurks in the House of Dormont once again.
234 notes
·
View notes
Note
Might be a mid take tbh but my take is: Soda is far too harsh on the wrong side of the fandom. Or, well, the fandom at all but my point stands.
She seems outright offended by.. headcanons and jokes, it feels. Like the Shuriken eating bugs thing? I'm pretty sure that was a joke/bit. Soda's reaction felt odd, like she didn't quite get that it's just.. the fandom doing as a fandom does.
Overall Soda is very critical of the fandom for. Being a fandom. She frequently posts (on bluesky, at least, the only social of hers I follow) about how the fandom mischaracterises, misconstrues, and generally fudges lore and characterization. And yet... she makes no effort to fix it! The lore is kept locked up tight, an active dialogue rewrite means our mischaracterisations are accidental in the first place, and seriously, what are we meant to make of the vague mess tossed at us that loops back and contradicts itself and fudges itself?
I love phighting. The lore is (probably) amazing. The characters are all plenty fascinating and fun to explore. But damn, getting told I'm plain wrong for putting my own condiments on the nothing burger of proper explanation we have currently is getting tiring.
~ redshift anon (claiming that or smth in case I ever drop a take in here again)
I think it boils down to the fact that, to my knowledge, none of the devs are writers, [In a sense that they've had specialized schooling for it.] Nor have experience with being responsible for a fandom.
It can be hard to tell the story you want even with training, it can get infuriating when people misunderstand and misconstrue your work despite your best efforts. I've had instances in workshops where my pieces have been so horribly misunderstood that it physically hurts.
Even if people are just being silly and joking, it can suck to see something you poured your soul into so mischaracterized–even if you recognize and understand that other people don't have the same knowledge of the characters like you do.
#phighting!#phighting roblox#roblox phighting#phighting#phighting hot takes#hot take#☕ mod cocoagraft ☕#I get the feeling I lost the point there#redshift anon
26 notes
·
View notes
Text

Evangeline Newton - X-Men OC
~ General~
Full Name: Evangeline Gertrude Newton
Nicknames: Eva, Evie
Birthdate: March 31st, 1973
Species: Mutant
Residence: Hartford, Connecticut | Westchester, New York
~ Physical Appearance ~
Hair Colour: Red
Eye Colour: Blue
Skin Tone: Pale
Body Type: Ectomorph
Height: 5’10
Faceclaim: Nicole Kidman
~ Background ~
Hometown: Hartford, Connecticut
Evangeline Newton was born to a perfectly normal family, in a perfectly normal house, in a perfectly normal neighbourhood. However, she was the complete opposite of normal. When objects around the house started floated, or becoming impossibly heavy when Evangeline was around, her parents were disconcerted. When Evangeline’s substitute teacher ended up in the hospital with a pencil in her hand after slapping Evangeline, her parents pulled her out of school. When Professor Charles Xavier informed them that Evangeline had been accepted into Xavier’s School for Gifted Youngsters, they were all too ready to send her off.
~ Family ~
Mother: Marlene Newton (née Marks)
Marlene Newton wanted nothing more than a perfectly normal life. And for a while, she had it. A loving husband, a healthy, adorable baby girl, a beautiful home and a stable job. Until her daughter turned nine and things started floating. Marlene, horrifed that her daughter was a freak, pulled her from school after an incident involved a pencil, Evangeline and a particularly irritating substitute teacher.
Father: Jonathan Newton
When Professor Charles Xavier collected Evangeline from her home in Hartford, Connecticut, Jonathan and Marlene Newton were relieved. Finally, they could be normal. They could start over. Within a year, the Newtons had packed up and moved to Arizona. Within two, Marlene was pregnant. They had a second child, a son, and it was like Evangeline never existed.
Younger Brother: Malcolm Newton
Malcolm Newton never knew he had a sister. His parents didn’t speak about her. When he was eight, Malcolm found a lone photograph of a red haired girl in the attic. His mother confiscated the picture and scolded him for poking his nose into things that he shouldn’t. Five years later, Evangeline Newton showed up on his doorstep, with Professor Charles Xavier in tow, to inform the Newtons that Malcolm had been accepted into the Xavier School for Gifted Youngsters.
~ Mutation & X-Men ~
Code Name: Redshift
Allegiance: X-Men
Class: Alpha
Mutation: Gravity Manipulation
Evangeline possesses the mutation of gravity manipulation. This ability allows her to control the gravitational fields of objects, people or places. Evangeline is able to form gravitational fields to protect herself or her allies and can even change her own gravitational weight to provide advantages in battle. Evangeline can “see” organisms or orbjects based on their gravitational field and even move them by changing the gravity around them. She can also manipulate her own gravitational field to enhance her physical attributes by changing the pull of gravity. Finally, Evangeline can create black holes that absorb everything in their path, including people or objects. Hypothetically, Evangeline could alter the universe and the space-time continuum.
Job: Librarian at Xaviar’s School for Gifted Youngsters
~ Personality & Traits ~
Personality: A spiritual yet grounded individual, Evangeline places great importance on her time for contemplation and meditation. Although introverted, she is close with many students and teachers at the school. A strong believer in balance and the universe’s way of making everything equal, Evangeline can often come off as superstitious. Evangeline has a strong intuition and often acts on gut instinct. Despite her spiritual, superstitious nature, Evangeline is a rock for the team, rarely, if ever, becoming involved in spats or disagreements between members.
Likes: Meditation, nature, calm, reading, physics, the outdoors, flying, the students, training, quiet
Dislikes: Isolation, waking up early, hot weather, public speaking, sour things, bugs, being late
~ Relationships ~
Best Friend: Jean Grey
Friends:
Scott Summers
Ororo Monroe
Charles Xavier
Anna Marie LaBeau
Warren Worthington III
Allies:
Hank McCoy
Logan Howlett
Kurt Wagner
Piotr Rasputin
Enemies:
Magneto
Mistique
~ Misc. & Notes
Evangeline is a strong believer in the saying “early is on time and on time is late”.
She’s allergic to cats and gets itchy eyes and a stuffy nose.
Evangeline’s favourite colour is green. Specifically, sage green.
Her favourite meal is breakfast, and her favourite food is french toast. Evangeline makes the best french toast.
Her guiltiest pleasure is a cheesy 80’s movie and a pint of mint chocolate chip ice cream.
Evangeline really dislikes busy traffic, she finds driving in general nerve-wracking, and having about 500 other people crammed down the same highway is positively panic-inducing.
She has an affinity for collecting vinyls.
Evangeline hates humid weather. It makes her hair frizzy.
She does the crossword every morning. It’s one of her rituals, alongside having a cup of tea and, if it’s a good day, some french toast.
Her favourite musician of all time is Joni Mitchell.
#oc: evangeline newton#original character#x men movies#x men oc#x men original character#marvel oc#marvel#marvel mcu#mcu oc#gravity manipulation#mutant oc#x men mutant oc#xmen oc
8 notes
·
View notes
Text
Allow me to introduce myself!
My name is Kaylee! I am a Parafeminie Lesbian and my pronouns are She/They/Nix.
I am a artist and writer. My requests are open! Feel free to submit any characters/ocs from the fandoms below ^^
My interests include:
Warrior Cats
Wings of Fire
Percy Jackson
Hades
Star Trek
Star Wars
Supernatural
FNaF
Horizon
Lucifer (The show)
The Edge of Sleep
The Inheritance Cycle
How to Train Your Dragon
Slay the Princess
I plan to start posting some more art eventually. Here is some to start you off!
TiredCorvid077 on Toyhouse owns Apostate
Click is @redshift-rambles 's oc
Ash is @crystalshifer 's oc
And WildfireKitKat on Toyhouse owns Tegrodera




#intro post#introduction#pinned intro#introductory post#kay's art#artists on tumblr#wings of fire#how to train your dragon#star trek#star wars#the inheritance cycle#the edge of sleep#lucifer show#hfw#hzd#fnaf#hades#warrior cats#percy jackson#slay the princess#supernatural
4 notes
·
View notes
Note
Im in dire need of some bottom Izzy or just would you be able to rec us your favourite izzy fics can be any ship any time just want to know your fave izzy fics
HMM i always love reccing fics but had no idea where to start, so i just stuck with bottom/sub izzy and edizzy (+ some side pairings) to narrow it down lol. also there are a lot of izzy-centric fics out there i rly love that have little/no smut at all, but these r just explicit-rated works since that's what i assume ur looking 4
to force his hand by alex51324
under the seams runs the pain by ajaxthegreat
we two boys together clinging by rimbaudofficial
new tricks by wrizard
burn and be forgiven by poppyinabreeze
plump, sweet, and begging for cream by nothingtoseehere4
filthy impetuous soul (I wanna give it to you) by shatteredhourglass
release in sodomy (one sweet moment) by izzyspussy
sing like a good canary by heizhands
cut the chord, overboard by anonymous
love is not like anything (especially a fucking knife) by redshift
take the pain, take the pleasure by shatteredhourglass
and I've prayed to appear fed by higgsbosonblues
doldrums by xylodemon
it's not like you got somewhere to be by robinade
training by spinelessdragon
crying in the shower by drool_kitten
what he needs by soiboi69
man on fire by ajaxthegreat
oblivion by cloudspassmeby
you're so transparent by goresmores
oh, we're in the in between by hymn
don't ask me by sweveris
bury the hatchet by unlovedhands
never did care for arithmetic by sushiowl
look closely by mossydreamz
shape of suffering by shatteredhourglass
want it, take it by redshift
coldest form of war by sandpapersnowman
we've built an altar in the clouds by hymns
dressing down by schmirius
freezing hands and bloodless veins by givemebaretrees
cry for me by sweveris
muscle (into your bad dreams) by bitethehands
gomorrah by marcos_the_transfag
love the rush by exsanguinate
full to the brim by xylodemon
a prize for claiming by spookygenderfuck
just wait a little more by achilles_is_gay
employer offered workplace benefits by antimonicacid
gotta love a facial by leaveanote
desire is hunger by anonymous
devotion, I'm a slave onto the mercy of your love by plunderheavenblind
inconceivable by darkhedgehog
active listening by unlovedhands
renewing wedding vows in blood and bone by unlovedhands
bore into marrow by way_visceral
rock the boat by unlovedhands
#idk if read mores still work on this website but hopefully they do bc this is insanely long#and I still feel like I forgot some nfjkdskf ok whatever. cheers
49 notes
·
View notes
Text
When discussing special relativity, sometimes the way a clock slows down on a fast-moving train or spaceship or w/e is framed as what the situation of the distant clock "looks like" to a stationary observer. But of course it's not just that time seems to slow down as you approach the speed of light--time does in fact move differently for different observers! It "looks like" the clock is moving slower, because it is. When talking about black holes, and what you perceive as you fall into them vs what an outside observer perceives, I'm not always entirely sure how much the explainer is talking about "illusory" effects vs real ones. For instance, the fact an outside observer never sees you cross the event horizon--I assume this is not just a matter of perspective (i.e., the outside observer can in fact be confident you do eventually cross the event horizon in finite time) because otherwise it seems like the black hole information paradox wouldn't be a thing (because if you didn't eventually cross the event horizon, then from the perspective of outside observers black holes only cause matter to pile up on their event horizons and that information isn't ever truly "lost"). That ScienceClic video also intimated you wouldn't see as much time contraction in the outside universe as you might expect while falling, because of Doppler effects on the infalling light, but presumably that time contraction is still occurring?
Something even that ScienceClic video doesn't really explain in detail (though some numbers in the bottom corner of the screen help a little bit) is the scale all this is happening at--would be nice to state how far away we're starting, what the total falling time is, and what the relative degree of time dilation/contraction is like at different points on the journey.
Also, if the difference in brightness of the accretion disk on one side vs the other is due to the Doppler effect, shouldn't there also be a degree of redshift/blueshift in the color of the accretion disk, too? No one ever seems to include that so I guess maybe not?
14 notes
·
View notes
Text
The upside to our very efficient ion engines that can get our ships to arbitrarily close to the speed of light is pretty obvious: you get to your destination a lot faster. In fact due to time dilation your ten-thousand light year trip might feel like only a few weeks, and most of that time is going to be speeding up and slowing down. That means you can do away with generation ships entirely. Saves a lot on resources and training.
Some of the downsides are also obvious, for instance suddenly being ten thousand years in the future and everyone you left back home being long dead can be kind of a shock. Of course usually there isn't a return trip on those kinds of missions so no one usually gets too upset. There are also the technical risks. Computers have to be really accurate about their simulations so you don't smear yourself on something at relativistic speeds and the difference between a top speed of 99.9998% the speed of light and 99.9999% the speed of light is the difference between arriving safely and, again, turning the ship and yourself and everyone on the ship into a relativistic bullet.
There's also the risk of getting even closer to the speed of light and missing the target. Physicists are saying that might cause you to end up infinitely far away and forever in the future, buuuut also you might just redshift out of existence instead. As far as being alive goes that's about the same as colliding with something, so it's probably better than leaving relativistic speeds and finding yourself in a dark universe.
2 notes
·
View notes
Text
AWS Security 101: Protecting Your Cloud Investments
In the ever-evolving landscape of technology, few names resonate as strongly as Amazon.com. This global giant, known for its e-commerce prowess, has a lesser-known but equally influential arm: Amazon Web Services (AWS). AWS is a powerhouse in the world of cloud computing, offering a vast and sophisticated array of services and products. In this comprehensive guide, we'll embark on a journey to explore the facets and features of AWS that make it a driving force for individuals, companies, and organizations seeking to utilise cloud computing to its fullest capacity.

Amazon Web Services (AWS): A Technological Titan
At its core, AWS is a cloud computing platform that empowers users to create, deploy, and manage applications and infrastructure with unparalleled scalability, flexibility, and cost-effectiveness. It's not just a platform; it's a digital transformation enabler. Let's dive deeper into some of the key components and features that define AWS:
1. Compute Services: The Heart of Scalability
AWS boasts services like Amazon EC2 (Elastic Compute Cloud), a scalable virtual server solution, and AWS Lambda for serverless computing. These services provide users with the capability to efficiently run applications and workloads with precision and ease. Whether you need to host a simple website or power a complex data-processing application, AWS's compute services have you covered.
2. Storage Services: Your Data's Secure Haven
In the age of data, storage is paramount. AWS offers a diverse set of storage options. Amazon S3 (Simple Storage Service) caters to scalable object storage needs, while Amazon EBS (Elastic Block Store) is ideal for block storage requirements. For archival purposes, Amazon Glacier is the go-to solution. This comprehensive array of storage choices ensures that diverse storage needs are met, and your data is stored securely.
3. Database Services: Managing Complexity with Ease
AWS provides managed database services that simplify the complexity of database management. Amazon RDS (Relational Database Service) is perfect for relational databases, while Amazon DynamoDB offers a seamless solution for NoSQL databases. Amazon Redshift, on the other hand, caters to data warehousing needs. These services take the headache out of database administration, allowing you to focus on innovation.
4. Networking Services: Building Strong Connections
Network isolation and robust networking capabilities are made easy with Amazon VPC (Virtual Private Cloud). AWS Direct Connect facilitates dedicated network connections, and Amazon Route 53 takes care of DNS services, ensuring that your network needs are comprehensively addressed. In an era where connectivity is king, AWS's networking services rule the realm.
5. Security and Identity: Fortifying the Digital Fortress
In a world where data security is non-negotiable, AWS prioritizes security with services like AWS IAM (Identity and Access Management) for access control and AWS KMS (Key Management Service) for encryption key management. Your data remains fortified, and access is strictly controlled, giving you peace of mind in the digital age.
6. Analytics and Machine Learning: Unleashing the Power of Data
In the era of big data and machine learning, AWS is at the forefront. Services like Amazon EMR (Elastic MapReduce) handle big data processing, while Amazon SageMaker provides the tools for developing and training machine learning models. Your data becomes a strategic asset, and innovation knows no bounds.
7. Application Integration: Seamlessness in Action
AWS fosters seamless application integration with services like Amazon SQS (Simple Queue Service) for message queuing and Amazon SNS (Simple Notification Service) for event-driven communication. Your applications work together harmoniously, creating a cohesive digital ecosystem.
8. Developer Tools: Powering Innovation
AWS equips developers with a suite of powerful tools, including AWS CodeDeploy, AWS CodeCommit, and AWS CodeBuild. These tools simplify software development and deployment processes, allowing your teams to focus on innovation and productivity.
9. Management and Monitoring: Streamlined Resource Control
Effective resource management and monitoring are facilitated by AWS CloudWatch for monitoring and AWS CloudFormation for infrastructure as code (IaC) management. Managing your cloud resources becomes a streamlined and efficient process, reducing operational overhead.
10. Global Reach: Empowering Global Presence
With data centers, known as Availability Zones, scattered across multiple regions worldwide, AWS enables users to deploy applications close to end-users. This results in optimal performance and latency, crucial for global digital operations.

In conclusion, Amazon Web Services (AWS) is not just a cloud computing platform; it's a technological titan that empowers organizations and individuals to harness the full potential of cloud computing. Whether you're an aspiring IT professional looking to build a career in the cloud or a seasoned expert seeking to sharpen your skills, understanding AWS is paramount.
In today's technology-driven landscape, AWS expertise opens doors to endless opportunities. At ACTE Institute, we recognize the transformative power of AWS, and we offer comprehensive training programs to help individuals and organizations master the AWS platform. We are your trusted partner on the journey of continuous learning and professional growth. Embrace AWS, embark on a path of limitless possibilities in the world of technology, and let ACTE Institute be your guiding light. Your potential awaits, and together, we can reach new heights in the ever-evolving world of cloud computing. Welcome to the AWS Advantage, and let's explore the boundless horizons of technology together!
8 notes
·
View notes
Text
Navigating the Cloud Landscape: Unleashing Amazon Web Services (AWS) Potential
In the ever-evolving tech landscape, businesses are in a constant quest for innovation, scalability, and operational optimization. Enter Amazon Web Services (AWS), a robust cloud computing juggernaut offering a versatile suite of services tailored to diverse business requirements. This blog explores the myriad applications of AWS across various sectors, providing a transformative journey through the cloud.

Harnessing Computational Agility with Amazon EC2
Central to the AWS ecosystem is Amazon EC2 (Elastic Compute Cloud), a pivotal player reshaping the cloud computing paradigm. Offering scalable virtual servers, EC2 empowers users to seamlessly run applications and manage computing resources. This adaptability enables businesses to dynamically adjust computational capacity, ensuring optimal performance and cost-effectiveness.
Redefining Storage Solutions
AWS addresses the critical need for scalable and secure storage through services such as Amazon S3 (Simple Storage Service) and Amazon EBS (Elastic Block Store). S3 acts as a dependable object storage solution for data backup, archiving, and content distribution. Meanwhile, EBS provides persistent block-level storage designed for EC2 instances, guaranteeing data integrity and accessibility.
Streamlined Database Management: Amazon RDS and DynamoDB
Database management undergoes a transformation with Amazon RDS, simplifying the setup, operation, and scaling of relational databases. Be it MySQL, PostgreSQL, or SQL Server, RDS provides a frictionless environment for managing diverse database workloads. For enthusiasts of NoSQL, Amazon DynamoDB steps in as a swift and flexible solution for document and key-value data storage.
Networking Mastery: Amazon VPC and Route 53
AWS empowers users to construct a virtual sanctuary for their resources through Amazon VPC (Virtual Private Cloud). This virtual network facilitates the launch of AWS resources within a user-defined space, enhancing security and control. Simultaneously, Amazon Route 53, a scalable DNS web service, ensures seamless routing of end-user requests to globally distributed endpoints.
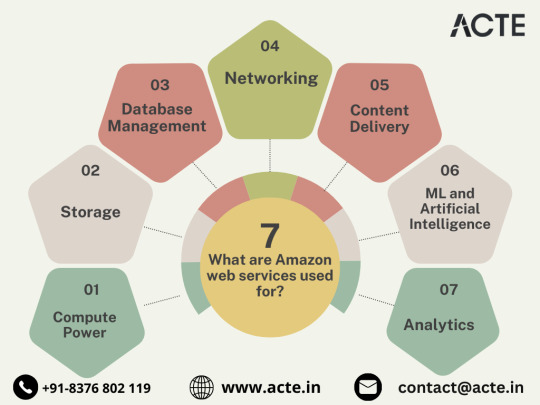
Global Content Delivery Excellence with Amazon CloudFront
Amazon CloudFront emerges as a dynamic content delivery network (CDN) service, securely delivering data, videos, applications, and APIs on a global scale. This ensures low latency and high transfer speeds, elevating user experiences across diverse geographical locations.
AI and ML Prowess Unleashed
AWS propels businesses into the future with advanced machine learning and artificial intelligence services. Amazon SageMaker, a fully managed service, enables developers to rapidly build, train, and deploy machine learning models. Additionally, Amazon Rekognition provides sophisticated image and video analysis, supporting applications in facial recognition, object detection, and content moderation.
Big Data Mastery: Amazon Redshift and Athena
For organizations grappling with massive datasets, AWS offers Amazon Redshift, a fully managed data warehouse service. It facilitates the execution of complex queries on large datasets, empowering informed decision-making. Simultaneously, Amazon Athena allows users to analyze data in Amazon S3 using standard SQL queries, unlocking invaluable insights.
In conclusion, Amazon Web Services (AWS) stands as an all-encompassing cloud computing platform, empowering businesses to innovate, scale, and optimize operations. From adaptable compute power and secure storage solutions to cutting-edge AI and ML capabilities, AWS serves as a robust foundation for organizations navigating the digital frontier. Embrace the limitless potential of cloud computing with AWS – where innovation knows no bounds.
3 notes
·
View notes
Text
Exclusive Training institute for AWS and many courses | Wiculty
Wiculty’s AWS training and certification will help you master skills like AWS Cloud, Lambda, Redshift, EC2, IAM, S3, Global Accelerator and more. Also, in this AWS course, you will work on various tools of AWS cloud platform and create highly scalable SaaS application. Learn AWS from AWS certified experts to become an AWS solutions architect.Download CurriculumFree Linux & Shell Scripting Course
2 notes
·
View notes
Text
Data Engineering Concepts, Tools, and Projects
All the associations in the world have large amounts of data. If not worked upon and anatomized, this data does not amount to anything. Data masterminds are the ones. who make this data pure for consideration. Data Engineering can nominate the process of developing, operating, and maintaining software systems that collect, dissect, and store the association’s data. In modern data analytics, data masterminds produce data channels, which are the structure armature.
How to become a data engineer:
While there is no specific degree requirement for data engineering, a bachelor's or master's degree in computer science, software engineering, information systems, or a related field can provide a solid foundation. Courses in databases, programming, data structures, algorithms, and statistics are particularly beneficial. Data engineers should have strong programming skills. Focus on languages commonly used in data engineering, such as Python, SQL, and Scala. Learn the basics of data manipulation, scripting, and querying databases.
Familiarize yourself with various database systems like MySQL, PostgreSQL, and NoSQL databases such as MongoDB or Apache Cassandra.Knowledge of data warehousing concepts, including schema design, indexing, and optimization techniques.
Data engineering tools recommendations:
Data Engineering makes sure to use a variety of languages and tools to negotiate its objects. These tools allow data masterminds to apply tasks like creating channels and algorithms in a much easier as well as effective manner.
1. Amazon Redshift: A widely used cloud data warehouse built by Amazon, Redshift is the go-to choice for many teams and businesses. It is a comprehensive tool that enables the setup and scaling of data warehouses, making it incredibly easy to use.
One of the most popular tools used for businesses purpose is Amazon Redshift, which provides a powerful platform for managing large amounts of data. It allows users to quickly analyze complex datasets, build models that can be used for predictive analytics, and create visualizations that make it easier to interpret results. With its scalability and flexibility, Amazon Redshift has become one of the go-to solutions when it comes to data engineering tasks.
2. Big Query: Just like Redshift, Big Query is a cloud data warehouse fully managed by Google. It's especially favored by companies that have experience with the Google Cloud Platform. BigQuery not only can scale but also has robust machine learning features that make data analysis much easier. 3. Tableau: A powerful BI tool, Tableau is the second most popular one from our survey. It helps extract and gather data stored in multiple locations and comes with an intuitive drag-and-drop interface. Tableau makes data across departments readily available for data engineers and managers to create useful dashboards. 4. Looker: An essential BI software, Looker helps visualize data more effectively. Unlike traditional BI tools, Looker has developed a LookML layer, which is a language for explaining data, aggregates, calculations, and relationships in a SQL database. A spectacle is a newly-released tool that assists in deploying the LookML layer, ensuring non-technical personnel have a much simpler time when utilizing company data.
5. Apache Spark: An open-source unified analytics engine, Apache Spark is excellent for processing large data sets. It also offers great distribution and runs easily alongside other distributed computing programs, making it essential for data mining and machine learning. 6. Airflow: With Airflow, programming, and scheduling can be done quickly and accurately, and users can keep an eye on it through the built-in UI. It is the most used workflow solution, as 25% of data teams reported using it. 7. Apache Hive: Another data warehouse project on Apache Hadoop, Hive simplifies data queries and analysis with its SQL-like interface. This language enables MapReduce tasks to be executed on Hadoop and is mainly used for data summarization, analysis, and query. 8. Segment: An efficient and comprehensive tool, Segment assists in collecting and using data from digital properties. It transforms, sends, and archives customer data, and also makes the entire process much more manageable. 9. Snowflake: This cloud data warehouse has become very popular lately due to its capabilities in storing and computing data. Snowflake’s unique shared data architecture allows for a wide range of applications, making it an ideal choice for large-scale data storage, data engineering, and data science. 10. DBT: A command-line tool that uses SQL to transform data, DBT is the perfect choice for data engineers and analysts. DBT streamlines the entire transformation process and is highly praised by many data engineers.
Data Engineering Projects:
Data engineering is an important process for businesses to understand and utilize to gain insights from their data. It involves designing, constructing, maintaining, and troubleshooting databases to ensure they are running optimally. There are many tools available for data engineers to use in their work such as My SQL, SQL server, oracle RDBMS, Open Refine, TRIFACTA, Data Ladder, Keras, Watson, TensorFlow, etc. Each tool has its strengths and weaknesses so it’s important to research each one thoroughly before making recommendations about which ones should be used for specific tasks or projects.
Smart IoT Infrastructure:
As the IoT continues to develop, the measure of data consumed with high haste is growing at an intimidating rate. It creates challenges for companies regarding storehouses, analysis, and visualization.
Data Ingestion:
Data ingestion is moving data from one or further sources to a target point for further preparation and analysis. This target point is generally a data storehouse, a unique database designed for effective reporting.
Data Quality and Testing:
Understand the importance of data quality and testing in data engineering projects. Learn about techniques and tools to ensure data accuracy and consistency.
Streaming Data:
Familiarize yourself with real-time data processing and streaming frameworks like Apache Kafka and Apache Flink. Develop your problem-solving skills through practical exercises and challenges.
Conclusion:
Data engineers are using these tools for building data systems. My SQL, SQL server and Oracle RDBMS involve collecting, storing, managing, transforming, and analyzing large amounts of data to gain insights. Data engineers are responsible for designing efficient solutions that can handle high volumes of data while ensuring accuracy and reliability. They use a variety of technologies including databases, programming languages, machine learning algorithms, and more to create powerful applications that help businesses make better decisions based on their collected data.
4 notes
·
View notes
Text
Terms like big data, data science, and machine learning are the buzzwords of this time. It is not for nothing that data is also referred to as the oil of the 21st century. But first, the right data of the right quality must be available so that something becomes possible here. It must firstly be extracted to be processed further, e.g. into business analyses, statistical models, or even a new data-driven service. This is where the data engineer comes into play. In this article, you'll find out everything about their field of work, training, and how you can enter this specific work area.Tasks of a Data EngineerData engineers are responsible for building data pipelines, data warehouses and lakes, data services, data products, and the whole architecture that uses this data within a company. They are also responsible for selecting the optimal data infrastructure, and monitoring and maintaining it. Of course, this means that data engineers also need to know a lot about the systems in a company—only then can they correctly and efficiently connect ERP and CRM systems.The data engineer must also know the data itself. Only then can correct ETL/ELT processes be implemented in data pipelines from source systems to end destinations like cloud data warehouses. In this process, the data is often transformed, e.g. summarized, cleaned, or brought into a new structure. It is also important that they work well with related areas, because only then can good results be delivered together with data scientists, machine learning engineers, or business analysts. In this regard, one can see that data teams often share their data transformation responsibilities amongst themselves. Within this context, data engineers take up slightly different tasks than the other teams. However, one can say that this is the exact same transformation process as in the field of software development where multiple teams have their own responsibilities.How to Become a Data EngineerThere is no specific degree program in data engineering. However, a lot of (online) courses and training programs exist for one to specialise in it. Often, data engineers have skills and knowledge from other areas like:(Business) informaticsComputer or software engineeringStatistics and data scienceTraining with a focus on trending topics like business intelligence, databases, data processes, cloud data science, or data analytics can make it easier for one to enter the profession. Also, they can then expect a higher salary. Environment of a Data Engineer: SourceSkills and Used Technologies Like other professions in the field of IT and data, the data engineer requires a general as well as a deep technical understanding. It is important for data engineers to be familiar with certain technologies in the field. These include:Programming languages like Python, Scala, or C#Database languages like SQLData storage/processing systemsMachine learning toolsExperience in cloud technologies like Google, Amazon, or AzureData modeling and structuring methodsExamples of Tools and Languages used in Data Engineering - SourceIt is important to emphasize that the trend in everything is running towards the cloud. In addition to SaaS and cloud data warehouse technologies such as Google BigQuery or Amazon Redshift, DaaS (data as a service) is also becoming increasingly popular. In this case, data integration tools with their respective data processes are all completely implemented and stored in the cloud.Data Engineer vs. Data ScientistThe terms “data scientist” and “data engineer” are often used interchangeably. However, their roles are quite different. As already said, data engineers work closely with other data experts like data scientists and data analysts. When working with big data, each profession focuses on different phases. While both professions are related to each other and have many points of contact, overarching (drag and drop) data analysis tools ensure that data engineers can also take on data science tasks and vice versa.
The core tasks of a data engineer lie in the integration of data. They obtain data, monitor the processes for it, and prepare it for data scientists and data analysts. On the other side, the data scientist is more concerned with analyzing this data and building dashboards, statistical analyses, or machine learning models.SummaryIn conclusion, one can say that data engineers are becoming more and more important in today’s working world, since companies do have to work with vast amounts of data. There is no specific program that must be undergone prior to working as a data engineer. However, skills and knowledge from other fields such as informatics, software engineering, and machine learning are often required. In this regard, it is important to say that a data engineer should have a specific amount of knowledge in programming and database languages to do their job correctly. Finally, one must state that data engineers are not the same as data scientists. Both professions have different tasks and work in slightly different areas within a company. While data engineers are mostly concerned with the integration of data, data scientists are focusing on analyzing the data and creating visualizations such as dashboard or machine learning models.
0 notes
Text
Soham Mazumdar, Co-Founder & CEO of WisdomAI – Interview Series
New Post has been published on https://thedigitalinsider.com/soham-mazumdar-co-founder-ceo-of-wisdomai-interview-series/
Soham Mazumdar, Co-Founder & CEO of WisdomAI – Interview Series

Soham Mazumdar is the Co-Founder and CEO of WisdomAI, a company at the forefront of AI-driven solutions. Prior to founding WisdomAI in 2023, he was Co-Founder and Chief Architect at Rubrik, where he played a key role in scaling the company over a 9-year period. Soham previously held engineering leadership roles at Facebook and Google, where he contributed to core search infrastructure and was recognized with the Google Founder’s Award. He also co-founded Tagtile, a mobile loyalty platform acquired by Facebook. With two decades of experience in software architecture and AI innovation, Soham is a seasoned entrepreneur and technologist based in the San Francisco Bay Area.
WisdomAI is an AI-native business intelligence platform that helps enterprises access real-time, accurate insights by integrating structured and unstructured data through its proprietary “Knowledge Fabric.” The platform powers specialized AI agents that curate data context, answer business questions in natural language, and proactively surface trends or risks—without generating hallucinated content. Unlike traditional BI tools, WisdomAI uses generative AI strictly for query generation, ensuring high accuracy and reliability. It integrates with existing data ecosystems and supports enterprise-grade security, with early adoption by major firms like Cisco and ConocoPhillips.
You co-founded Rubrik and helped scale it into a major enterprise success. What inspired you to leave in 2023 and build WisdomAI—and was there a particular moment that clarified this new direction?
The enterprise data inefficiency problem was staring me right in the face. During my time at Rubrik, I witnessed firsthand how Fortune 500 companies were drowning in data but starving for insights. Even with all the infrastructure we built, less than 20% of enterprise users actually had the right access and know-how to use data effectively in their daily work. It was a massive, systemic problem that no one was really solving.
I’m also a builder by nature – you can see it in my path from Google to Tagtile to Rubrik and now WisdomAI. I get energized by taking on fundamental challenges and building solutions from the ground up. After helping scale Rubrik to enterprise success, I felt that entrepreneurial pull again to tackle something equally ambitious.
Last but not least, the AI opportunity was impossible to ignore. By 2023, it became clear that AI could finally bridge that gap between data availability and data usability. The timing felt perfect to build something that could democratize data insights for every enterprise user, not just the technical few.
The moment of clarity came when I realized we could combine everything I’d learned about enterprise data infrastructure at Rubrik with the transformative potential of AI to solve this fundamental inefficiency problem.
WisdomAI introduces a “Knowledge Fabric” and a suite of AI agents. Can you break down how this system works together to move beyond traditional BI dashboards?
We’ve built an agentic data insights platform that works with data where it is – structured, unstructured, and even “dirty” data. Rather than asking analytics teams to run reports, business managers can directly ask questions and drill into details. Our platform can be trained on any data warehousing system by analyzing query logs.
We’re compatible with major cloud data services like Snowflake, Microsoft Fabric, Google’s BigQuery, Amazon’s Redshift, Databricks, and Postgres and also just document formats like excel, PDF, powerpoint etc.
Unlike conventional tools designed primarily for analysts, our conversational interface empowers business users to get answers directly, while our multi-agent architecture enables complex queries across diverse data systems.
You’ve emphasized that WisdomAI avoids hallucinations by separating GenAI from answer generation. Can you explain how your system uses GenAI differently—and why that matters for enterprise trust?
Our AI-Ready Context Model trains on the organization’s data to create a universal context understanding that answers questions with high semantic accuracy while maintaining data privacy and governance. Furthermore, we use generative AI to formulate well-scoped queries that allow us to extract data from the different systems, as opposed to feeding raw data into the LLMs. This is crucial for addressing hallucination and safety concerns with LLMs.
You coined the term “Agentic Data Insights Platform.” How is agentic intelligence different from traditional analytics tools or even standard LLM-based assistants?
Traditional BI stacks slow decision-making because every question has to fight its way through disconnected data silos and a relay team of specialists. When a chief revenue officer needs to know how to close the quarter, the answer typically passes through half a dozen hands—analysts wrangling CRM extracts, data engineers stitching files together, and dashboard builders refreshing reports—turning a simple query into a multi-day project.
Our platform breaks down those silos and puts the full depth of data one keystroke away, so the CRO can drill from headline metrics all the way to row-level detail in seconds.
No waiting in the analyst queue, no predefined dashboards that can’t keep up with new questions—just true self-service insights delivered at the speed the business moves.
How do you ensure WisdomAI adapts to the unique data vocabulary and structure of each enterprise? What role does human input play in refining the Knowledge Fabric?
Working with data where and how it is – that’s essentially the holy grail for enterprise business intelligence. Traditional systems aren’t built to handle unstructured data or “dirty” data with typos and errors. When information exists across varied sources – databases, documents, telemetry data – organizations struggle to integrate this information cohesively.
Without capabilities to handle these diverse data types, valuable context remains isolated in separate systems. Our platform can be trained on any data warehousing system by analyzing query logs, allowing it to adapt to each organization’s unique data vocabulary and structure.
You’ve described WisdomAI’s development process as ‘vibe coding’—building product experiences directly in code first, then iterating through real-world use. What advantages has this approach given you compared to traditional product design?
“Vibe coding” is a significant shift in how software is built where developers leverage the power of AI tools to generate code simply by describing the desired functionality in natural language. It’s like an intelligent assistant that does what you want the software to do, and it writes the code for you. This dramatically reduces the manual effort and time traditionally required for coding.
For years, the creation of digital products has largely followed a familiar script: meticulously plan the product and UX design, then execute the development, and iterate based on feedback. The logic was clear because investing in design upfront minimizes costly rework during the more expensive and time-consuming development phase. But what happens when the cost and time to execute that development drastically shrinks? This capability flips the traditional development sequence on its head. Suddenly, developers can start building functional software based on a high-level understanding of the requirements, even before detailed product and UX designs are finalized.
With the speed of AI code generation, the effort involved in creating exhaustive upfront designs can, in certain contexts, become relatively more time-consuming than getting a basic, functional version of the software up and running. The new paradigm in the world of vibe coding becomes: execute (code with AI), then adapt (design and refine).
This approach allows for incredibly early user validation of the core concepts. Imagine getting feedback on the actual functionality of a feature before investing heavily in detailed visual designs. This can lead to more user-centric designs, as the design process is directly informed by how users interact with a tangible product.
At WisdomAI, we actively embrace AI code generation. We’ve found that by embracing rapid initial development, we can quickly test core functionalities and gather invaluable user feedback early in the process, live on the product. This allows our design team to then focus on refining the user experience and visual design based on real-world usage, leading to more effective and user-loved products, faster.
From sales and marketing to manufacturing and customer success, WisdomAI targets a wide spectrum of business use cases. Which verticals have seen the fastest adoption—and what use cases have surprised you in their impact?
We’ve seen transformative results with multiple customers. For F500 oil and gas company, ConocoPhillips, drilling engineers and operators now use our platform to query complex well data directly in natural language. Before WisdomAI, these engineers needed technical help for even basic operational questions about well status or job performance. Now they can instantly access this information while simultaneously comparing against best practices in their drilling manuals—all through the same conversational interface. They evaluated numerous AI vendors in a six-month process, and our solution delivered a 50% accuracy improvement over the closest competitor.
At a hyper growth Cyber Security company Descope, WisdomAI is used as a virtual data analyst for Sales and Finance. We reduced report creation time from 2-3 days to just 2-3 hours—a 90% decrease. This transformed their weekly sales meetings from data-gathering exercises to strategy sessions focused on actionable insights. As their CRO notes, “Wisdom AI brings data to my fingertips. It really democratizes the data, bringing me the power to go answer questions and move on with my day, rather than define your question, wait for somebody to build that answer, and then get it in 5 days.” This ability to make data-driven decisions with unprecedented speed has been particularly crucial for a fast-growing company in the competitive identity management market.
A practical example: A chief revenue officer asks, “How am I going to close my quarter?” Our platform immediately offers a list of pending deals to focus on, along with information on what’s delaying each one – such as specific questions customers are waiting to have answered. This happens with five keystrokes instead of five specialists and days of delay.
Many companies today are overloaded with dashboards, reports, and siloed tools. What are the most common misconceptions enterprises have about business intelligence today?
Organizations sit on troves of information yet struggle to leverage this data for quick decision-making. The challenge isn’t just about having data, but working with it in its natural state – which often includes “dirty” data not cleaned of typos or errors. Companies invest heavily in infrastructure but face bottlenecks with rigid dashboards, poor data hygiene, and siloed information. Most enterprises need specialized teams to run reports, creating significant delays when business leaders need answers quickly. The interface where people consume data remains outdated despite advancements in cloud data engines and data science.
Do you view WisdomAI as augmenting or eventually replacing existing BI tools like Tableau or Looker? How do you fit into the broader enterprise data stack?
We’re compatible with major cloud data services like Snowflake, Microsoft Fabric, Google’s BigQuery, Amazon’s Redshift, Databricks, and Postgres and also just document formats like excel, PDF, powerpoint etc. Our approach transforms the interface where people consume data, which has remained outdated despite advancements in cloud data engines and data science.
Looking ahead, where do you see WisdomAI in five years—and how do you see the concept of “agentic intelligence” evolving across the enterprise landscape?
The future of analytics is moving from specialist-driven reports to self-service intelligence accessible to everyone. BI tools have been around for 20+ years, but adoption hasn’t even reached 20% of company employees. Meanwhile, in just twelve months, 60% of workplace users adopted ChatGPT, many using it for data analysis. This dramatic difference shows the potential for conversational interfaces to increase adoption.
We’re seeing a fundamental shift where all employees can directly interrogate data without technical skills. The future will combine the computational power of AI with natural human interaction, allowing insights to find users proactively rather than requiring them to hunt through dashboards.
Thank you for the great interview, readers who wish to learn more should visit WisdomAI.
#2023#adoption#agent#agents#ai#AI AGENTS#ai code generation#AI innovation#ai tools#Amazon#Analysis#Analytics#approach#architecture#assistants#bi#bi tools#bigquery#bridge#Building#Business#Business Intelligence#CEO#challenge#chatGPT#Cisco#Cloud#cloud data#code#code generation
0 notes
Text
What’s the function of Tableau Prep?
Tableau Prep is a data preparation tool from Tableau that helps users clean, shape, and organize data before it is analyzed or visualized. It is especially useful for data analysts and business intelligence professionals who need to prepare data quickly and efficiently without writing complex code.
The core function of Tableau Prep is to simplify the data preparation process through an intuitive, visual interface. Users can drag and drop datasets, apply filters, rename fields, split or combine columns, handle null values, pivot data, and even join or union multiple data sources. These actions are displayed in a clear, step-by-step workflow, which makes it easy to understand how data is transformed at each stage.
Tableau Prep includes two main components: Prep Builder, used to create and edit data preparation workflows, and Prep Conductor, which automates the running of flows and integrates with Tableau Server or Tableau Cloud for scheduled data refreshes. This automation is a major advantage, especially in dynamic environments where data updates regularly.
Another significant benefit is real-time previews. As users manipulate data, they can instantly see the effects of their actions, allowing for better decisions and error checking. It supports connections to various data sources such as Excel, SQL databases, and cloud platforms like Google BigQuery or Amazon Redshift.
Tableau Prep’s seamless integration with Tableau Desktop means that once data is prepped, it can be directly pushed into visualization dashboards without exporting and re-importing files.
In short, Tableau Prep helps streamline the otherwise time-consuming process of cleaning and preparing data, making it more accessible to analysts without deep programming knowledge.
If you’re looking to master tools like Tableau Prep and enter the analytics field, consider enrolling in a data analyst course with placement for hands-on training and career support.
0 notes
Text
Powering Innovation with Data Engineering Solutions in Toronto – cdatainsights
In an era where every click, transaction, and interaction creates data, the ability to harness that information has become a competitive necessity. Businesses across industries are turning to data engineering solutions in Toronto to turn complex, unstructured data into usable insights. At cdatainsights, we deliver advanced data engineering and machine learning services designed to help organizations make smarter, faster decisions.
Whether you are building a new analytics infrastructure from the ground up or optimizing an existing one, our specialized data engineering service in GTA ensures your systems are scalable, secure, and insight-ready.
What is Data Engineering and Why It’s Crucial
Data engineering is the critical first step in the data lifecycle. It involves the architecture and development of pipelines that collect, process, and store data in formats suitable for analytics, dashboards, and machine learning models. Without well-designed data systems, your business risks relying on outdated or inaccurate information.
cdatainsights provides complete data engineering solutions in Toronto — ensuring that your data ecosystem is not just functional but future-proof. We build robust data frameworks that support:
Real-time and batch data ingestion
Data normalization and transformation
Centralized data lakes and warehouses
Monitoring and logging for data reliability
Seamless integration with BI tools and ML models
Bridging the Gap: Data Engineering and Machine Learning
Machine learning is only as effective as the data it's trained on. That’s why we focus on the intersection of data engineering and machine learning to deliver holistic, outcome-focused solutions.
Our experts help you:
Prepare and label training datasets
Automate data workflows for continuous ML model training
Deploy models into production with minimal latency
Ensure feedback loops for real-time model improvement
From sentiment analysis and predictive modeling to personalized recommendations, we help you use ML in ways that directly impact your KPIs.
Custom Data Engineering Service in GTA – Tailored for Your Industry
As a Toronto-based company, we understand the unique challenges and opportunities facing local businesses. Our data engineering service in GTA is customized to meet industry-specific needs, including:
➤ Finance & Fintech
Build systems for fraud detection, real-time transaction processing, and customer behavior analysis.
➤ Healthcare & Life Sciences
Enable data-driven patient care with EHR integration, medical device data pipelines, and secure data governance.
➤ Retail & E-Commerce
Power your customer experience with real-time product recommendations, demand forecasting, and supply chain visibility.
➤ Manufacturing & IoT
Use IoT sensor data to optimize operations, monitor equipment, and drive predictive maintenance.
Why Businesses Trust cdatainsights
We’re not just a service provider — we’re your strategic partner in digital transformation. Here's why businesses choose cdatainsights for data engineering solutions in Toronto:
✅ Toronto-Based, GTA-Focused Local expertise means quicker turnarounds, onsite collaboration, and deep knowledge of regional regulations and market trends.
✅ Full-Stack Data Capabilities From data lakes and stream processing to advanced ML integrations — we cover it all.
✅ Cloud-Native & Scalable We build cloud-agnostic solutions using AWS, Azure, or GCP, ensuring flexibility and performance.
✅ Security-First Approach Data privacy and compliance are core to every solution we deliver — including HIPAA, PIPEDA, and SOC standards.
Technologies We Use
Our tech stack includes the latest in data and cloud innovation:
Data Processing: Apache Spark, Airflow, Kafka, dbt
Storage & Warehousing: Snowflake, BigQuery, Redshift, Delta Lake
Cloud Platforms: AWS, Azure, Google Cloud
Orchestration & DevOps: Docker, Kubernetes, Terraform
ML & AI: TensorFlow, Scikit-Learn, PyTorch, MLFlow
Get Started with cdatainsights Today
If you're looking for reliable, expert-driven data engineering service in GTA, cdatainsights is your go-to partner. Our team is ready to help you organize, optimize, and activate your data to drive real business value.
🚀 Take the next step in your data transformation journey.
📞 Contact cdatainsights today to schedule your free consultation.
cdatainsights – Engineering Data. Empowering Decisions.
#data engineering solutions in Toronto#data engineering and machine learning#data engineering service in Gta
1 note
·
View note