#LastPage
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr is available in 18 languages.
Photo

the last page of my sketchbook is the backdoor exit i take to meetup with the new sketchbook.
11 notes
·
View notes
Text
youtube
"Last Page" is a powerful pop-rock anthem that explores the emotional aftermath of a love that has come to an end. With anthemic choruses and a haunting melody, the song reflects on the quiet, painful moments of a breakup. The lyrics convey a sense of nostalgia and reflection, while the intensity of the music builds, expressing the raw emotion of the final goodbye. From shattered dreams to the winds of change, this track invites listeners to embrace both the heartbreak and the hope for healing in the aftermath of love.
#poprock#emotionalrock#powerfulanthem#lastpage#heartbreaksong#finalgoodbye#rockballad#breakupsong#anthemicpop#lovelost#healingmusic#emotionalballad#rockmusic#popmusic#powerfulchorus#heartfeltmusic#loveandloss#musicforhealing#goodbyesong#rockanthem#emotionaljourney#songaboutlove#passionandpain#poprockanthem#endoflove#brokenheart#musicwithmeaning#LastPage#HeartbreakSong#EmotionalRock
1 note
·
View note
Photo

Sketching - 11/03/2023 . . . . . . . #sketchbook #sketch #dailysketch #dailydrawing #dailypractice #wedding #marriage #lastpage #drawingpractice #bluepencil #inking #ink #alcoholmarker #drawing #scribbling https://www.instagram.com/p/CpqoqbeKPE6/?igshid=NGJjMDIxMWI=
#sketchbook#sketch#dailysketch#dailydrawing#dailypractice#wedding#marriage#lastpage#drawingpractice#bluepencil#inking#ink#alcoholmarker#drawing#scribbling
0 notes
Text
diy ao3 wrapped: how to get your data!
so i figured out how to do this last year, and spotify wrapped season got me thinking about it again. a couple people in discord asked how to do it so i figured i'd write up a little guide! i'm not quite done with mine for this year yet because i wanted to do some graphics, but this is the post i made last year, for reference!
this got long! i tried to go into as much detail as possible to make it as easy as possible, but i am a web developer, so if there's anything i didn't explain enough (or if you have any other questions) don't hesitate to send me an ask!!
references
i used two reddit posts as references for this:
basic instructions (explains the browser extension; code gets title, word count, and author)
expanded instructions (code gets title, word count, and author, as well as category, date posted, last visited, warnings, rating, fandom, relationship, summary, and completion status, and includes instructions for how to include tags and switch fandoms/relationships to multiple—i will include notes on that later)
both use the extension webscraper.io which is available for both firefox and chrome (and maybe others, but i only use firefox/chrome personally so i didn't check any others, sorry. firefox is better anyway)
scraping your basic/expanded data
first, install the webscraper plugin/extension.
once it's installed, press ctrl+shift+i on pc or cmd+option+i on mac to open your browser's dev tools and navigate to the Web Scraper tab

from there, click "Create New Site Map" > "Import Sitemap"

it will open a screen with a field to input json code and a field for name—you don't need to manually input the name, it will fill in automatically based on the json you paste in. if you want to change it after, changing one will change the other.
i've put the codes i used on pastebin here: basic // expanded

once you've pasted in your code, you will want to update the USERNAME (highlighted in yellow) to your ao3 username, and the LASTPAGE (highlighted in pink) to the last page you want to scrape. to find this, go to your history page on ao3, and click back until you find your first fic of 2024! make sure you go by the "last visited" date instead of the post date.

if you do want to change the id, you can update the value (highlighted in blue) and it will automatically update the sitemap name field, or vice versa. everything else can be left as is.
once you're done, click import, and it'll show you the sitemap. on the top bar, click the middle tab, "Sitemap [id of sitemap]" and choose Scrape. you'll see a couple of options—the defaults worked fine for me, but you can mess with them if you need to. as far as i understand it, it just sets how much time it takes to scrape each page so ao3 doesn't think it's getting attacked by a bot. now click "start scraping"!


once you've done that, it will pop up with a new window which will load your history. let it do its thing. it will start on the last page and work its way back to the first, so depending on how many pages you have, it could take a while. i have 134 pages and it took about 10-12 minutes to get through them all.
once the scrape is done, the new window will close and you should be back at your dev tools window. you can click on the "Sitemap [id of sitemap]" tab again and choose Export data.

i downloaded the data as .xlsx and uploaded to my google drive. and now you can close your dev tools window!
from here on out my instructions are for google sheets; i'm sure most of the queries and calculations will be similar in other programs, but i don't really know excel or numbers, sorry!
setting up your spreadsheet
once it's opened, the first thing i do is sort the "viewed" column A -> Z and get rid of the rows for any deleted works. they don't have any data so no need to keep them. next, i select the columns for "web-scraper-order" and "web-scraper-start-url" (highlighted in pink) and delete them; they're just default data added by the scraper and we don't need them, so it tidies it up a little.

this should leave you with category, posted, viewed, warning, rating, fandom, relationship, title, author, wordcount, and completion status if you used the expanded code. if there are any of these you don't want, you can go ahead and delete those columns also!
next, i add blank columns to the right of the data i want to focus on. this just makes it easier to do my counts later. in my case these will be rating, fandom, relationship, author, and completion status.
one additional thing you should do, is checking the "viewed" column. you'll notice that it looks like this:
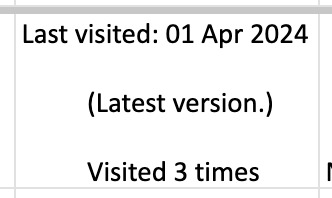
you can't really sort by this since it's text, not formatted as a date, so it'll go alphabetically by month rather than sorting by date. but, you'll want to be able to get rid of any entries that were viewed in 2023 (there could be none, but likely there are some because the scraper got everything on your last page even if it was viewed in 2023). what i did here was use the "find" dialog to search the "viewed" column for 2023, and deleted those rows manually.
ctrl/cmd+f, click the 3 dots for "more options". you want to choose "Specific range", then "C2:C#". replace C with the letter of your viewed column (remember i deleted a bunch, so yours may be different) and replace # with the number of the last row of your spreadsheet. then find 2023, select the rows containing it, right click > delete rows.
it isn't super necessary to do this, it will only add at most 19 fics to your count, but the option is there!

alright, with all that done, your sheet should look something like this:

exposing myself for having read stardew valley fic i guess
now for the fun part!!!
the math
yes, the math is the fun part.
scroll all the way down to the bottom of your sheet. i usually add 100 blank rows at the bottom just so i have some space to play with.
most of these will basically be the same query, just updating for the relevant column. i've put it in a pastebin here, but here's a screenshot so i can walk you through it:

you'll want to use lines 3-10, select the cell you want to put your data into, and paste the query into the formula bar (highlighted in green)

so, we're starting with rating, which is column E for me. if yours is a different letter you'll need to replace all the E's with the relevant letter.
what this does is it goes through the entire column, starting with row 2 (highlighted in yellow) and ending with your final row (highlighted in blue, you'll want to change this number to reflect how many rows you have). note that row 2 is your first actual data row, because of the header row.
it checks each row that has a value (line 5), groups by unique value (row 6), and arranges in descending order (row 7) by how many there are of each value (row 8). finally, row 10 determines how many rows of results you'll have; for rating, i put 5 because that's how many ratings there are, but you can increase the number of results (highlighted in pink) for other columns depending on how many you want. this is why i added the 100 extra rows!
next to make the actual number visible, go to the cell one column over. this is why we added the empty columns! next to your first result, add the second query from the pastebin:

your first and second cell numbers (highlighted in yellow and blue) should match the numbers from your query above, and the third number (highlighted in pink) should be the number of the cell with your first value. what this does is go through your column and count how many times the value occurs.
repeat this for the rest of the rows and you should end up with something like this! don't judge me and my reading habits please

now you can go ahead and repeat for the rest of your columns! as i mentioned above, you can increase the amount of result rows you get; i set it to 25 for fandom, relationship, and author, just because i was curious, and only two for completion status because it's either complete or not complete.
you should end up with something like this!

you may end up with some multiples (not sure why this happens, tagging issues maybe?) and up to you if you want to manually fix them! i just ended up doing a find and replace for the two that i didn't want and replaced with the correct tag.
now for the total wordcount! this one is pretty simple, it just adds together your entire column. first i selected the column (N for me) and went to Format > Number > 0 so it stripped commas etc. then at the bottom of the column, add the third query from the pastebin. as usual, your first number is the first data row, and the second is the last data row.

and just because i was curious, i wanted the average wordcount also, so in another cell i did this (fourth query from the pastebin), where the first number is the cell where your total is, and the second number is the total number of fics (total # of data rows minus 1 for the header row).

which gives me this:

tadaaaa!
getting multiple values
so, as i mentioned above, by default the scraper will only get the first value for relationships and fandoms. "but sarah," you may say, "what if i want an accurate breakdown of ALL the fandoms and relationships if there's multiples?"
here's the problem with that: if you want to be able to query and count them properly, each fandom or relationship needs to be its own row, which would skew all the other data. for me personally, it didn't bother me too much; i don't read a lot of crossovers, and typically if i'm reading a fic it's for the primary pairing, so i think the counts (for me) are pretty accurate. if you want to get multiples, i would suggest doing a secondary scrape to get those values separately.
if you want to edit the scrape to get multiples, navigate to one of your history pages (preferably one that has at least one work with multiple fandoms and/or relationships so you can preview) then hit ctrl+shift+i/cmd+option+i, open web scraper, and open your sitemap. expand the row and you should see all your values. find the one you want to edit and hit the "edit" button (highlighted in pink)

on the next screen, you should be good to just check the "Multiple" checkbox (highlighted in pink):

you can then hit "data preview" (highlighted in blue) to get a preview which should show you all the relationships on the page (which is why i said to find a page that has the multiples you are looking for, so you can confirm).

voila! now you can go back to the sitemap and scrape as before.
getting tag data
now, on the vein of multiples, i also wanted to get my most-read tags.
as i mentioned above, if you want to get ALL the tags, it'll skew the regular count data, so i did the tags in a completely separate query, which only grabs the viewed date and the tags. that code is here. you just want to repeat the scraping steps using that as a sitemap. save and open that spreadsheet.
the first thing you'll notice is that this one is a LOT bigger. for context i had 2649 fics in the first spreadsheet; the tags spreadsheet had 31,874 rows.
you can go ahead and repeat a couple of the same steps from before: remove the extra scraper data columns, and then we included the "viewed" column for the same reason as before, to remove any entries from 2023.
then you're just using the same basic query again!
replace the E with whatever your column letter is, and then change your limit to however many tags you want to see. i changed the limit to 50, again just for curiosity.
if you made it this far, congratulations! now that you have all that info, you can do whatever you want with it!
and again, if you have any questions please reach out!
56 notes
·
View notes
Text
YSH Activity game book
So finally I got this korean YSH book from handcarry service, it's about game activity and there's also sticker for the game and lastly coloring pages
last pic of this paragraflh is one and the lastpage of the colorig page (it goes hard)





now there's also clearer alt artworks of the heroes she + jinpei










anyway the white stickers are i already use it for the game lol, some stickers i use for my laptop decor haha. the last one is like a printing thingy like coin
dont wanna show the other activity pages but all i want to show are these it looks cool. but for some reason despite mist shadow is on the back cover, he doesnt appear here, and also mataro SB form seems not classified as an *actual* hero if that make sense. and also no chiaki nozu kuka, pretty much only focused to the prior main characters
8 notes
·
View notes
Text
Poesia di https://www.tumblr.com/lastpage-after
Ti Voglio[…]
“Ti voglio. Qui. Ora. Nel mio letto, a viziarmi. I baci sul collo, le mani addosso, il tuo odore intorno. Tu che sorridi , io che mi drogo, di Te.”

4 notes
·
View notes
Text

Grazie @lastpage-after e tutti coloro che mi hanno portato a 5 reblog!
2 notes
·
View notes
Text
VeryDOC Postscript to PDF Converter Command Line for Windows 10 & 11
Use VeryDOC Postscript to PDF Converter Command Line to streamline your document conversion tasks on Windows 10 and 11 systems. This powerful command-line tool allows you to batch convert Postscript files to PDF files directly on your local system, eliminating the need to send any sensitive files to an external web server. With this local processing capability, you can ensure the confidentiality and security of your documents while enjoying the convenience of efficient batch conversions. Whether you are an individual user or part of a larger organization, this feature makes VeryDOC's Postscript to PDF Converter Command Line a secure and reliable choice for handling your document conversion needs.
In the realm of document conversion, VeryDOC has developed an efficient solution to seamlessly convert Postscript files to PDF with their Postscript to PDF Converter Command Line software. This standalone application eliminates the need for Ghostscript and Acrobat Distiller, providing a hassle-free conversion experience. Whether you're an individual user or part of an organization, this tool proves to be an indispensable asset for handling Postscript and PDF files effectively.

✅ POSTSCRIPT TO PDF CONVERTER COMMAND LINE KEY FEATURES
Standalone Operation
No Dependencies: Postscript to PDF Converter is a standalone application, eliminating the need for Ghostscript and Acrobat Distiller.
Printer Driver Independence: It doesn't rely on any Printer Driver products, ensuring independence and reliability in the conversion process.
Direct Conversion
Postscript to PDF: Convert Postscript files to Acrobat PDF files directly, ensuring accuracy and preserving the integrity of the original documents.
Advanced Functionality
PDF Merging: Merge several PDF files into one cohesive PDF file, streamlining document organization and accessibility.
PDF to Postscript: Convert Acrobat PDF files back to Postscript files, allowing flexibility in document format.
Burst PDF: Burst a PDF file into single-page PDF files, facilitating individual page extraction and manipulation.
Document Management
Document Summary: Set document summary information, including title, subject, author, and keywords for output PDF files.
Encryption Options: Set encryption options to secure output PDF files, providing password protection with 40 or 128-bit encryption.
Empty Page Removal: Automatically remove empty pages from PDF files during conversion, optimizing file size and content relevance.
Rotation: Rotate PDF pages during conversion at angles of 0, 90, 180, or 270 degrees, allowing for customized orientation.
Language Support
Multi-language Support: Postscript to PDF Converter supports various languages, including English, French, German, Italian, Chinese (Simplified and Traditional), Czech, Danish, Dutch, Japanese, Korean, Norwegian, Polish, Portuguese, Russian, Spanish, Swedish, Thai, and more.
✅ Command Line Usage Users can leverage the command line to perform efficient conversions:
ps2pdf.exe C:\input.ps: Convert a Postscript file to PDF.
ps2pdf.exe C:\input.ps C:\output.pdf: Specify input and output files for conversion.
ps2pdf.exe -firstpage 1 -lastpage 20 C:\input.ps C:\output.pdf: Convert specific pages within a range.
ps2pdf.exe -subject "subject" C:\in.ps C:\out.pdf: Set the subject of the output PDF file.
✅ Custom Development Services VeryDOC offers custom development services based on the Postscript to PDF Converter Command Line, ensuring the software aligns perfectly with unique requirements. This tailored approach reflects VeryDOC's commitment to providing solutions that cater to diverse user needs.
✅ CONCLUSION VeryDOC Postscript to PDF Converter Command Line stands out as a reliable and feature-rich tool for converting Postscript files to PDF. Its standalone operation, advanced functionalities, and language support make it an ideal choice for users looking to streamline their document conversion processes. Whether you are a single user or part of a large organization, this command line tool offers efficiency and versatility in handling Postscript and PDF files. Download the trial version from VeryDOC's website and explore the capabilities of this powerful conversion tool.
0 notes
Photo

“Last Page” is the last page in my 11” x 14” sketchbook. (Hey, when you paint every day, you run out of creative titles sometimes!😂) #abstractart #abstractpainting #abstracts #artwork #acrylicpainting #artoftheday #colorfulabstract #fineartamericaartist #intuitiveart #lastpage #makeart #newartwork #painting #painteveryday #prolific #sandiegoartist #tiffanyarpdaleo #womenartists #2023 (at San Diego, California) https://www.instagram.com/p/CnfHtWHvvnz/?igshid=NGJjMDIxMWI=
#abstractart#abstractpainting#abstracts#artwork#acrylicpainting#artoftheday#colorfulabstract#fineartamericaartist#intuitiveart#lastpage#makeart#newartwork#painting#painteveryday#prolific#sandiegoartist#tiffanyarpdaleo#womenartists#2023
26 notes
·
View notes
Photo



The Secret Defenders V1 #14 (April 1994) - Ron Marz - Tom Grindberg - Don Hudson - John Kalisz - John Costanza
#tom grindberg#don hudson#john kalisz#silversurfer#silver surfer#john costanza#lastpage#ron marz#rhino#covers#nebulaeunfolding#marvel#comic#pages#artists
64 notes
·
View notes
Text
Testo di https://www.tumblr.com/lastpage-after
Tutto cambia. Ciò che oggi ritieni giusto, domani potrai considerare sbagliato…ciò che oggi approvi, domani potrai disapprovare. Ciò che oggi ti piace tanto, domani potrà disgustarti…ciò che oggi scansi come dannoso, domani potrai cercare come vantaggioso. Ciò che oggi ami, domani potrai odiare. Non dare mai niente per certo. Finché vivi niente resta immutato. Ciò che non cambia muore. Se vuoi vivere, cambia.
Lastpage

3 notes
·
View notes
Photo

1 note
·
View note
Photo
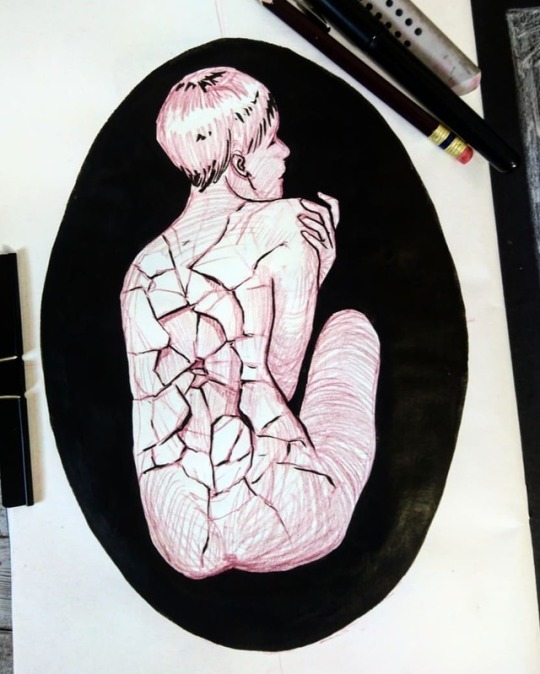
Last page in this sketchbook! 🎉✨🎈 I'll have a sketchbook tour up on YouTube next week I think 😊 I still want to paint on the cover, I like the feeling of having used every single page in a sketchbook 😁 . Yes, I know, the ellipse is wonky 😂 I tried freehanding it and that was an ordeal, hahaha. . ➡️SWIPE➡️ I uploaded prints of Kindling to my shop! Link to my print store is in my Insta bio. 📌 . I hope you all had a good week end and that this Monday wasn't too much of a shock! ❤ . . . . . #sketch #Sketchbook #pencilsketch #pencildrawing #darkart #strangeart #surrealism #surrealart #handdrawn #illo #instaart #artistoninstagram #myriamtillson #broken #lastpage #pencilonpaper #coloredpencil #myart #artprints #fineart #artshop #drawart #artdrawing #inspiration https://www.instagram.com/p/Bz8ujsaBS_I/?igshid=4voo249a52h3
#sketch#sketchbook#pencilsketch#pencildrawing#darkart#strangeart#surrealism#surrealart#handdrawn#illo#instaart#artistoninstagram#myriamtillson#broken#lastpage#pencilonpaper#coloredpencil#myart#artprints#fineart#artshop#drawart#artdrawing#inspiration
26 notes
·
View notes
Photo

#lastpage https://www.instagram.com/p/B72O-2uFOhr/?igshid=wwg50xsbs6lg
1 note
·
View note
Photo


First page Vs. Last page
#sharkduffer#traditional art#pencil#lineart#ocs#sketchbook#6thsketchbook#girl#girls#girl drawing#ohlookitme#myself#lastpage
2 notes
·
View notes
Photo

Time to use another program... and get in the habit of backing up my data... #drawingaday #lastpage #timetomoveon #digitalart https://www.instagram.com/p/BwYem6fnnxp/?utm_source=ig_tumblr_share&igshid=1prbkvwm8mp2k
2 notes
·
View notes