#Data backup
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
In 2020, Tumblr had 29.4 million users in the US.
Text

I know we all already know this, but this is a good point: tis the season to buy electronics cheap.
14 notes
·
View notes
Text
Secure Configurations on your Technology

Ensuring secure configurations on your technology is crucial to protect against cyber threats and vulnerabilities. Here are some tips to make sure your configurations are secure:
-Change Default Settings: Always change default usernames and passwords on your devices.
-Enable Firewalls: Use firewalls to block unauthorized access to your network.
-Regular Updates: Keep your software and firmware up to date to patch any security holes.
-Strong Passwords: Use complex and unique passwords for all your accounts and devices.
-Disable Unnecessary Services: Turn off services and features you don't use to reduce potential entry points for attackers.
-Monitor and Audit: Regularly monitor and audit your configurations to ensure they remain secure.
Stay vigilant and keep your technology secure! #CyberSecurity #SecureConfigurations #StaySafe – www.centurygroup.net
#Cybersecurity#managed it services#data backup#Secured Configuration#cloud technology services#phishing
3 notes
·
View notes
Text
The Most Dangerous Data Blind Spots in Healthcare and How to Successfully Fix Them
New Post has been published on https://thedigitalinsider.com/the-most-dangerous-data-blind-spots-in-healthcare-and-how-to-successfully-fix-them/
The Most Dangerous Data Blind Spots in Healthcare and How to Successfully Fix Them

Data continues to be a significant sore spot for the healthcare industry, with increasing security breaches, cumbersome systems, and data redundancies undermining the quality of care delivered.
Adding to the pressure, the US Department of Health and Human Services (HSS) is set to introduce more stringent regulations around interoperability and handling of electronic health records (EHRs), with transparency a top priority.
However, it’s clear that technology has played a crucial role in streamlining and organizing information-sharing in the industry, which is a significant advantage when outstanding services heavily rely on speed and accuracy.
Healthcare organizations have been turning to emerging technologies to alleviate growing pressures, which could possibly save them $360 billion annually. In fact, 85% of companies are investing or planning to invest in AI to streamline operations and reduce delays in patient care. Technology is cited as a top strategic priority in healthcare for 56% of companies versus 34% in 2022, according to insights from Bain & Company and KLAS Research.
Yet there are a number of factors healthcare providers should be mindful of when looking to deploy advanced technology, especially considering that AI solutions are only as good as the information used to train them.
Let’s take a look at the biggest data pain points in healthcare and technology’s role in alleviating them.
Enormous Amounts of Data
It’s no secret that healthcare organizations have to deal with a massive amount of data, and it’s only growing in size: By next year, healthcare data is expected to hit 10 trillion gigabytes.
The sheer volume of data that needs to be stored is a driving force behind cloud storage popularity, although this isn’t a problem-free answer, especially when it comes to security and interoperability. That’s why 69% of healthcare organizations prefer localized cloud storage (i.e., private clouds on-premises).
However, this can easily become challenging to manage for a number of reasons. In particular, this huge amount of data has to be stored for years in order to be HHS-compliant.
AI is helping providers tackle this challenge by automating processes that are otherwise resource-exhaustive in terms of manpower and time. There are a plethora of solutions on the market designed to ease data management, whether that’s in the form of tracking patient data via machine learning integrations with big data analytics or utilizing generative AI to speed up diagnostics.
For AI to do its job well, organizations must ensure they’re keeping their digital ecosystems as interoperable as possible to minimize disruptions in data exchanges that have devastating repercussions for their patients’ well-being.
Moreover, it’s crucial that these solutions are scalable according to an organization’s fluctuating needs in terms of performance and processing capabilities. Upgrading and replacing solutions because they fail to scale is a time-consuming and expensive process that few healthcare providers can afford. That’s because it means further training, realigning processes, and ensuring interoperability hasn’t been compromised with the introduction of a new technology.
Data Redundancies
With all that data to manage and track, it’s no surprise that things slip through the cracks, and in an industry where lives are on the line, data redundancies are a worst-case scenario that only serves to undermine the quality of patient care. Shockingly, 24% of patient records are duplicates, and this challenge is worsened when consolidating information across multiple electronic medical records (EMR).
AI has a big role to play in handling data redundancies, helping companies streamline operations and minimize data errors. Automation solutions are especially useful in this context, speeding up data entry processes in Health Information Management Systems (HIMS), lowering the risk of human error in creating and maintaining more accurate EHRs, and slashing risks of duplicated or incorrect information.
However, these solutions aren’t always flawless, and organizations need to prioritize fault tolerance when integrating them into their systems. It’s vital to have certain measures in place so that when a component fails, the software can continue functioning properly.
Key mechanisms of fault tolerance include guaranteed delivery of data and information in instances of system failure, data backup and recovery, load balancing across multiple workflows, and redundancy management.
This essentially ensures that the wheels keep turning until a system administrator is available to manually address the problem and prevent disruptions from bringing the entire system to a screeching halt. Fault tolerance is a great feature to look out for when selecting a solution, so it can help narrow down the product search for healthcare organizations.
Additionally, it’s crucial for organizations to make sure they’ve got the right framework in place for redundancy and error occurrences. That’s where data modeling comes in as it helps organizations map out requirements and data processes to maximize success.
A word of caution though: building the best data models entails analyzing all the optional information derived from pre-existing data. That’s because this enables the accurate identification of a patient and delivers timely and relevant information about them for swift, insight-driven intervention. An added bonus of data modeling is that it’s easier to pinpoint APIs and curate these for automatically filtering and addressing redundancies like data duplications.
Fragmented and Siloed Data
We know there are a lot of moving parts in data management, but compound this with the high-paced nature of healthcare and it’s easily a recipe for disaster. Data silos are among the most dangerous blind spots in this industry, and in life-or-death situations where practitioners aren’t able to access a complete picture of a patient’s record, the consequences are beyond catastrophic.
While AI and technology are helping organizations manage and process data, integrating a bunch of APIs and new software isn’t always smooth sailing, particularly if it requires outsourcing help whenever a new change or update is made. Interoperability and usability are at the crux of maximizing technology’s role in healthcare data handling and should be prioritized by organizations.
Most platforms are developer-centric, involving high levels of coding with complex tools that are beyond most people’s skill sets. This limits the changes that can be made within a system and means that every time an organization wants to make an update, they have to outsource a trained developer.
That’s a significant headache for people operating in an industry that really can’t sacrifice more time and energy to needlessly complicated processes. Technology should facilitate instant action, not hinder it, which is why healthcare providers and organizations need to opt for solutions that can be rapidly and seamlessly integrated into their existing digital ecosystem.
What to Look for in a Solution
Opt for platforms that can be templatized so they can be imported and implemented easily without having to build and write complex code from scratch, like Enterprise Integration Platform as a Service (EiPaaS) solutions. Specifically, these services use drag-and-drop features that are user-friendly so that changes can be made without the need to code.
This means that because they’re so easy to use, they democratize access for continuous efficiency so team members from across departments can implement changes without fear of causing massive disruptions.
Another vital consideration is auditing, which helps providers ensure they’re maintaining accountability and consistently connecting the dots so data doesn’t go missing. Actions like tracking transactions, logging data transformations, documenting system interactions, monitoring security controls, measuring performance, and flagging failure points should be non-negotiable for tackling these data challenges.
In fact, audit trails serve to set organizations up for continuous success in data management. Not only do they strengthen the safety of a system to ensure better data handling, but they are also valuable for enhancing business logic so operations and process workflows are as airtight as possible.
Audit trails also empower teams to be as proactive and alert as possible and to keep abreast of data in terms of where it comes from, when it was logged, and where it is sent. This bolsters the bottom line of accountability in the entire processing stage to minimize the risk of errors in data handling as much as possible.
The best healthcare solutions are designed to cover all bases in data management, so no stone is left unturned. AI isn’t perfect, but keeping these risks and opportunities in mind will help providers make the most of it in the healthcare landscape.
#2022#ai#amp#Analytics#APIs#as a service#audit#automation#backup#backup and recovery#bases#Big Data#big data analytics#billion#Building#Business#challenge#change#Cloud#cloud storage#clouds#code#coding#Companies#continuous#data#data analytics#data backup#Data Management#data modeling
0 notes
Text
Understanding Cloud Outages: Causes, Consequences, and Mitigation Strategies

Cloud computing has transformed business operations, providing unmatched scalability, flexibility, and cost-effectiveness. However, even leading cloud platforms are vulnerable to cloud outages.
Cloud outages can severely disrupt service delivery, jeopardizing business continuity and causing substantial financial setbacks. When a vendor’s servers experience downtime or fail to meet SLA commitments, the consequences can be far-reaching.
During a cloud outage, organizations often lose access to critical applications and data, rendering essential operations inoperable. This unavailability halts productivity, delays decision-making, and undermines customer trust.
Although cloud technology promises high reliability, no system is entirely immune to disruptions. Even the most reputable cloud service providers occasionally face interruptions due to unforeseen issues. These outages highlight the inherent challenges of cloud computing and the necessity for businesses to prepare for such contingencies.
While cloud computing offers transformative benefits, the risks of cloud outages demand proactive strategies. Organizations must adopt robust mitigation plans to ensure resilience and sustain operations during these inevitable disruptions.
Key Takeaways:
Cloud outages occur when services become unavailable. These disruptions impact businesses by affecting operations, causing financial loss, and harming reputation.
Power failures disrupt data centers, cybersecurity threats like DDoS attacks can compromise services, and human errors or technical failures can lead to downtime. Network problems and scheduled maintenance can also cause outages.
Outages have significant consequences; these include financial loss from service interruptions, reputational damage due to loss of customer trust, and legal implications from data breaches or non-compliance.
Distributing workloads across multiple regions, implementing strong security protocols, and continuously monitoring systems help prevent outages. Planning maintenance and having disaster recovery protocols ensure quick recovery from disruptions.
Businesses should focus on minimizing risks to ensure service availability and protect against potential disruptions.
What are Cloud Outages?

Cloud outages are periods when cloud-hosted applications and services become temporarily inaccessible. During these downtimes, users face slow response times, connectivity issues, or complete service disruptions. These interruptions can severely impact businesses across multiple dimensions.
The financial repercussions of cloud outages are immediate and far-reaching. When services go offline, organizations lose revenue as customers are unable to complete transactions. Additionally, businesses cannot track critical performance metrics, which can lead to operational inefficiencies and delayed decision-making.
Beyond monetary losses, cloud outages also cause reputational damage. Frustrated customers often perceive these disruptions as a sign of unreliability. A lack of transparent communication during downtime further exacerbates customer dissatisfaction. Over time, this can erode trust and push clients toward competitors offering more dependable solutions.
Another critical concern during cloud outages is the potential for legal consequences. If an outage leads to data loss, breaches, or compromised privacy, businesses may face litigation, regulatory penalties, and increased scrutiny. The fallout from such incidents can add both financial and reputational burdens.
Long-term consequences of cloud outages include reduced customer satisfaction, loss of client loyalty, and ongoing revenue declines. Organizations may also incur significant costs to restore affected systems and prevent future outages. Inadequate cloud infrastructure increases the risk of repeated disruptions, making businesses more vulnerable to prolonged downtimes.
To mitigate these risks, organizations must proactively invest in robust backup and recovery systems. Reliable disaster recovery plans and redundancies help minimize downtime, ensuring business continuity during unforeseen cloud outages. This strategic approach safeguards revenue streams, protects customer trust, and fortifies operational resilience.
Common Causes of Cloud Outages
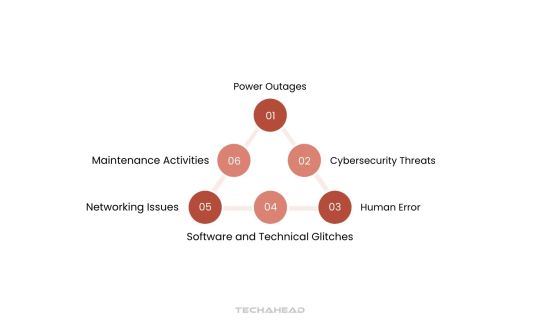
Cloud outages can stem from various factors, both within and beyond the control of cloud vendors. These challenges must be addressed to ensure cloud services meet Service Level Agreements (SLAs) with optimal performance and reliability.
Power Outages
Power disruptions are one of the most prevalent causes of cloud outages. Data centers operate on an enormous scale, consuming anywhere from tens to hundreds of megawatts of electricity. These facilities often rely on national power grids or third-party-operated power plants.
Consistently maintaining sufficient electricity supply becomes increasingly difficult as demand surges alongside market growth. Limited power scalability can leave cloud infrastructure vulnerable to sudden disruptions, impacting the availability of hosted services. To address this, cloud vendors invest heavily in backup solutions like on-site generators and alternative energy sources.
Cybersecurity Threats
Cyber attacks, such as Distributed Denial of Service (DDoS) attacks, overwhelm data centers with malicious traffic, disrupting legitimate access to cloud services. Despite robust security measures, attackers continuously identify loopholes to exploit. These intrusions may trigger automated protective mechanisms that mistakenly block legitimate users, leading to unexpected downtime.
In severe cases, breaches result in data leaks, service shutdowns, or prolonged outages. Cloud vendors constantly refine their defense systems to combat these evolving threats and ensure service continuity despite rising cybersecurity challenges.
Human Error
Human errors, though rare, can have catastrophic effects on cloud infrastructure. A single misconfiguration or incorrect command may trigger a chain reaction, causing widespread outages. Even leading cloud providers have experienced significant disruptions due to human oversight.
For instance, a human error at an AWS data center in 2017 led to widespread Internet outages globally. Although anomaly detection systems can identify such issues early, complete restoration often requires system-wide restarts, prolonging the recovery period. Cloud vendors mitigate this risk through rigorous protocols, automation tools, and comprehensive staff training.
Software and Technical Glitches
Cloud infrastructure relies on a complex interplay of hardware and software components. Even minor bugs or glitches within this ecosystem can trigger unexpected cloud outages. Technical faults may remain undetected during routine monitoring until they manifest as critical service disruptions. When these incidents occur, identifying and resolving the root cause can take time, leaving end-users unable to access essential services. Cloud vendors implement automated monitoring, rigorous testing, and proactive maintenance to identify vulnerabilities before they impact operations.
Networking Issues
Networking failures are other significant contributor to cloud outages. Cloud vendors often rely on telecommunications providers and government-operated networks for global connectivity. Issues in these external networks, such as damaged infrastructure or cross-border disruptions, are beyond the vendor’s direct control. To mitigate these risks, leading cloud providers operate data centers across geographically diverse regions. Dynamic workload balancing allows cloud vendors to shift operations to unaffected regions, ensuring uninterrupted service delivery even during network failures.
Maintenance Activities
Scheduled and unscheduled maintenance is essential for improving cloud infrastructure performance and cloud security. Cloud vendors routinely conduct upgrades, fixes, and system optimizations to enhance service delivery. However, these maintenance activities may require temporary service interruptions, workload transfers, or full system restarts.
During this period, end-users may experience service disruptions classified as cloud outages. Vendors strive to minimize downtime through well-planned maintenance windows, redundancy systems, and real-time communication with customers.
Global Cloud Outage Statistics and Notable Cases

Cloud outages remain a critical challenge for organizations worldwide, often disrupting essential operations. Below are significant real-world examples and insights drawn from these incidents to uncover key lessons.
Oracle Cloud Outage (February 2023)
In February 2023, Oracle Cloud Infrastructure encountered a severe outage triggered by an erroneous DNS configuration update. This impacted Oracle’s Ashburn data center, causing widespread service interruptions. The outage affected Oracle’s internal systems and global customers, highlighting the importance of robust change management protocols in cloud operations.
AWS Cloud Outage (June 2023)
AWS faced an extensive service disruption in June 2023, affecting prominent services, including the New York Metropolitan Transportation Authority and the Boston Globe. The root cause was a subsystem failure managing AWS Lambda’s capacity, revealing the need for stronger subsystem reliability in serverless environments.
Cloudflare Outage (June 2022)
A network configuration change caused an unplanned outage at Cloudflare in June 2022. The incident lasted 90 minutes and disrupted major platforms like Discord, Shopify, and Peloton. This outage underscores the necessity for rigorous testing of configuration updates, especially in global networks.
Atlassian Outage (April 2022)
Atlassian suffered one of its most prolonged outages in April 2022, lasting up to two weeks for some users. The disruption was due to underlying cloud infrastructure problems compounded by ineffective communication. This case emphasizes the importance of clear communication strategies during extended outages.
iCloud Outage (March 2022)
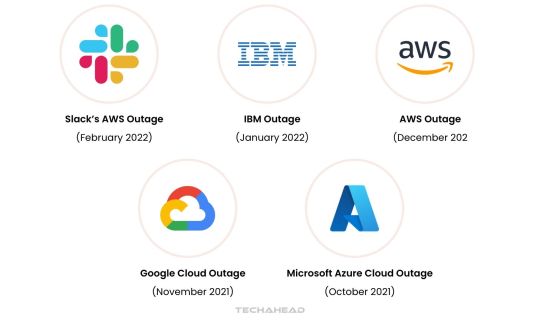
Slack’s AWS Outage (February 2022)
In February 2022, Slack users faced a five-hour disruption due to a configuration error in its AWS cloud infrastructure. Over 11,000 users experienced issues like message failures and file upload problems. The outage highlights the need for quick troubleshooting processes to minimize downtime.
IBM Outage (January 2022)
IBM encountered two significant outages in January 2022, the first lasting five hours in the Dallas region. A second, one-hour outage impacted virtual private cloud services globally due to a remediation misstep. These incidents highlight the importance of precision during issue resolution.
AWS Outage (December 2021)
AWS’s December 2021 outage disrupted key services, including API Gateway and EC2 instances, for nearly 11 hours. The issue stemmed from an automated error in the “us-east-1” region, causing network congestion akin to a DDoS attack. This underscores the necessity for robust automated system safeguards.
Google Cloud Outage (November 2021)
A two-hour outage impacted Google Cloud in November 2021, disrupting platforms like Spotify, Etsy, and Snapchat. The root cause was a load-balancing network configuration issue. This incident highlights the role of advanced network architecture in maintaining service availability.
Microsoft Azure Cloud Outage (October 2021)
Microsoft Azure experienced a six-hour service disruption in October 2021 due to a software issue during a VM architecture migration. Users faced difficulties deploying virtual machines and managing basic services. This case stresses the need for meticulous oversight during major architectural changes.
These examples serve as critical reminders of vulnerabilities in cloud systems. Businesses can minimize the impact of cloud outages through proactive measures like redundancy, real-time monitoring, and advanced disaster recovery planning.
Ways to Manage Cloud Outages

While natural disasters are unavoidable, strategic measures can help you mitigate and overcome cloud outages effectively.
Adopt Hybrid and Multi-Cloud Solutions
Redundancy is key to minimizing cloud outages. Relying on a single provider introduces a single point of failure, which can disrupt your operations. Implementing failover mechanisms ensures continuous service delivery during an outage.
Hybrid cloud solutions combine private and public cloud infrastructure. Critical workloads remain operational on the private cloud even when the public cloud fails. This approach not only safeguards core business functions but also ensures compliance with data regulations.
According to Cisco’s 2022 survey of 2,577 IT decision-makers, 73% of respondents utilized hybrid cloud for backup and disaster recovery. This demonstrates its effectiveness in reducing downtime risks.
Multi-cloud solutions utilize multiple public cloud providers simultaneously. By distributing workloads across diverse cloud platforms, businesses eliminate single points of failure. If one service provider experiences downtime, another provider ensures service continuity.
Deploy Advanced Monitoring Systems
Cloud outages do not always cause full system failures. They can manifest as delayed responses, missed queries, or slower performance. Such anomalies, if ignored, can impact user experience before they escalate into major outages.
Implementing cloud monitoring systems helps you proactively detect irregularities in performance. These tools identify early warning signs, allowing you to resolve potential disruptions before they affect end users. Real-time monitoring ensures seamless operations and reduces the risk of unplanned outages.
Leverage Global Infrastructure for Resilience
Natural disasters and regional disruptions are inevitable, but you can minimize their impact. Distributing IT infrastructure across multiple geographical locations provides a robust solution against localized cloud outages.
Instead of relying on a single data center, consider global redundancy strategies. Deploy backup systems in geographically diverse regions, such as U.S. Central, U.S. West, or European data centers. This ensures uninterrupted service delivery, even if one location goes offline.
For businesses operating in Europe, adopting multi-region solutions also supports GDPR compliance. This way, customer data remains protected, and operations continue seamlessly, regardless of cloud disruptions.
By leveraging global infrastructure, businesses can enhance reliability, improve redundancy, and build resilience against unforeseen cloud outages.
Additional Preventive Measures for Businesses
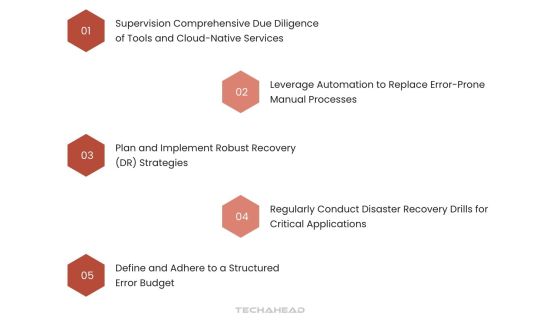
To effectively mitigate the risk of cloud outages, CIOs can adopt a multi-faceted approach that enhances resilience and ensures business continuity:
Supervision Comprehensive Due Diligence of Tools and Cloud-Native Services
Conduct a thorough evaluation of cloud-native services, ensuring they meet organizational requirements for scalability, security, and performance. This involves reviewing vendor capabilities, compatibility with existing infrastructure, and potential vulnerabilities that could lead to cloud outages. Regular audits help identify gaps early, preventing disruptions.
Leverage Automation to Replace Error-Prone Manual Processes
Automating operational tasks, such as provisioning, monitoring, and patch management, minimizes the human errors often linked to cloud outages. Automation tools also enhance efficiency by streamlining workflows, allowing IT teams to focus on proactive system improvements rather than reactive troubleshooting.
Plan and Implement Robust Recovery (DR) Strategies
A well-structured DR strategy is critical to quickly recover from cloud outages. This involves identifying mission-critical applications, determining acceptable recovery time objectives (RTOs), and creating recovery workflows. Comprehensive planning ensures minimal data loss and rapid resumption of services, even during large-scale disruptions.
Regularly Conduct Disaster Recovery Drills for Critical Applications
Testing DR plans through realistic drills allows organizations to simulate cloud outages and measure the effectiveness of their recovery protocols. These exercises reveal weaknesses in existing plans, providing actionable insights for improvement. Frequent testing also builds confidence in the system’s ability to handle unexpected disruptions.
Define and Adhere to a Structured Error Budget
An error budget establishes a clear threshold for acceptable service disruptions, balancing innovation and stability. It quantifies the permissible level of failure, enabling organizations to implement risk management frameworks effectively. This approach ensures proactive maintenance, minimizing the chances of severe cloud outages while allowing room for improvement.
By combining these preventive measures with ongoing monitoring and optimization, CIOs can significantly reduce the likelihood and impact of cloud outages, safeguarding critical operations and maintaining customer trust.
Conclusion
Although cloud outages are unavoidable when depending on cloud services, understanding their causes and consequences is crucial. Organizations can mitigate the risks of cloud outages by proactively adopting best practices that ensure operational resilience.
Key strategies include implementing redundancy to eliminate single points of failure, enabling continuous monitoring to detect issues early, and scheduling regular backups to safeguard critical data. Robust security measures are also essential to protect against vulnerabilities that could exacerbate outages.
In today’s cloud-reliant environment, being proactive is vital. Businesses that anticipate potential disruptions are better positioned to maintain seamless operations and customer trust. Proactive planning not only minimizes the operational impact of cloud outages but also reinforces long-term business continuity.
For better seamless cloud computing you should go for a proud partner like TechAhead. We can help you in migrating and consulting for your cloud environment.
Source URL: https://www.techaheadcorp.com/blog/understanding-cloud-outages-causes-consequences-and-mitigation-strategies/
0 notes
Text

#Oracle EBS Cloning#oracle database cloning#database cloning#erp cloning#data protection#data backup#Oracle EBS snapshot
0 notes
Text
https://www.bloglovin.com/@vastedge/hybrid-cloud-backup-strategy-specifics-benefits
Learn how to create a resilient hybrid cloud backup strategy that combines the best of both private and public clouds. Explore key considerations such as data security, cost management, and disaster recovery to ensure your data is protected and accessible at all times.
#hybrid cloud#cloud backup strategy#data backup#cloud security#disaster recovery#hybrid cloud benefits#cloud storage solutions.
0 notes
Text
Back. Up. Everything.
You cannot trust the internet, you cannot trust the cloud, you need to have physical backups of your data, because sometimes computer components fry and sometimes huge-arse corporations decide they can't be fucked storing people's data any more.
Get an external hard drive. Set up your own network-attached storage (NAS; like your own little cloud). Burn important files to DVDs is another one that came up when I had this rant on Twitter. The Wayback Machine is great, but if you're deadset on keeping videos, download them. I use the extension Video DownloadHelper; it's how I managed to archive a ton of stuff off a site that's since vanished off the internet over stupid copyright reasons.
Keep the 3-2-1 data backup strategy in mind:
Keep at least three copies of your data.
Store two backup copies of your data on different storage devices.
Store one backup copy off-site or on the cloud.
This is not always going to be feasible if you (like me) have found yourself babysitting terabytes of video that a company won't (not can't; won't) release on YouTube just because it was paywalled content in 2018, but I have it on an external drive and some of it in the cloud... but the cloud in question is my Google Drive, so if my account goes inactive, that's not safe either.

doing this with anything is an awful hit, but god, there are so many youtube accounts that serve as the last existing records of so many dead people's voices. feels especially perverse
35K notes
·
View notes
Text
How to Create a Data Backup and Recovery Plan
Data disaster recovery is in place to get critical information and systems back up quickly following a serious event. It is the use of predefined strategies, tools, and processes to quickly restore data after a disaster without incurring significant downtime or losses.

Disaster Recovery and Data Backup
If we want to make a break from the inherent negativity around disaster recovery, then you can simplify it yes — in that data backup) is simply about copying your archived data and backing this up where as DR (Disaster Recovery) relates more at restoring these pieces of information post-catastrophic event. Working hand in hand, they help maintain the state of business and data during an unplanned scenario.
When Does the Disaster Recovery Plan Get Put into Motion?
An organization will deploy a Disaster Recovery Plan (DRP) the moment an event strikes causing disruption / disaster in key operation of business! This may potentially happen by natural disasters, cyber attackes or system failure and other emergencies. When the disruption is confirmed, and it is determined that systems need to be restored with critical data in order for operations to continue uninterrupted — then go! You must follow the standard steps that we defined in DRP to reduce downtime and smooth recovery. With swift, thoughtful action the business should be able to return normal operations with little effect on customers and stakeholders.
You May Also Like:
How to Create a Data Backup and Recovery Plan
1 note
·
View note
Text
Key Metrics for Your Data Backup and Disaster Recovery Plan
When creating a data backup and disaster recovery plan, there are three key metrics to focus on:

Recovery Time Objective (RTO): RTO is the maximum amount of time an organization can afford to be without access to data and systems after a disaster. It represents the time it takes to restore data and services to operational status. A well-defined RTO ensures that the impact on business operations is minimized.
Recovery Point Objective (RPO): RPO refers to the maximum age of files or data that an organization must recover from backups to resume normal operations. In other words, it indicates how much data (in terms of time) can be lost since the last backup. A low RPO ensures minimal data loss.
Backup Frequency and Retention: This metric focuses on how often backups are created and how long they are retained. Determining the appropriate backup frequency depends on the organization's data creation rate and the importance of the data. Additionally, the retention period should align with regulatory and legal requirements, as well as business needs.
By monitoring and optimizing these three key metrics, organizations can establish a robust data backup and disaster recovery plan that ensures data protection and business continuity in the event of unexpected disruptions.
FOLLOW US ON TWITTER - https://twitter.com/micro_pc_tech
0 notes
Text
This HP Compaq desktop arrived at www.fix-ya-pc.co.uk with no power.
Unfortunately in this case the motherboard had blown and was not economically worth repairing. We were able to help the customer by backing up all of their data onto a portable drive that they supplied.
Find us on bento.me/fix-ya-pc where with one click you can access all of our social media, visit our website, contact us, leave a review and see a showcase of our work.
Alternatively visit www.fix-ya-pc.co.uk drop us a message 📩 via the socials or email 📧 [email protected] and we will be happy to help.
#hewlett packard#hpcompaq#powersupply#power failure#data backup#datarecovery#motherboard#wickford#billericay#rayleigh#basildon#essexbusiness#essexsmallbusiness#lovelocalessex#fixyapc
0 notes
Text
What is Zero Trust Architecture?

Zero Trust Architecture (ZTA) is a security model that operates on the principle "never trust, always verify." Unlike traditional security models that assume everything within a network is trustworthy, ZTA requires verification for every access request, regardless of whether it originates inside or outside the network.
Why is it Important?
In today's digital landscape, cyber threats are becoming increasingly sophisticated. Zero Trust Architecture helps mitigate risks by continuously verifying every user and device, ensuring that only authorized entities can access sensitive information.
How Does It Protect You?
1. Enhanced Security: By requiring strict verification, ZTA minimizes the risk of unauthorized access and data breaches.
2. Reduced Attack Surface: Limiting access to only what is necessary decreases potential entry points for attackers.
3. Real-time Monitoring: Continuous monitoring and verification help detect and respond to threats promptly.
Adopt Zero Trust Architecture with Century Solutions Group to fortify your cybersecurity defenses and protect your business from evolving cyber threats! #ZeroTrust #CyberSecurity #CenturySolutionsGroup
Learn More:https://centurygroup.net/cloud-computing/cyber-security/
3 notes
·
View notes
Text
Cybersecurity in Personal Finance Management: Essential Strategies for Digital Safety
In today’s digital age, where a staggering 76% of Americans engage in online banking (Pew Research Center), the importance of cybersecurity in managing personal finances cannot be overstated. This comprehensive guide explores the essential strategies for protecting your online banking, investment, and transaction activities from cyber threats. Fortifying Online Banking and Investments: An…
View On WordPress
#cyberattack statistics#cybercrime prevention#Cybersecurity#data backup#data protection#digital finance management#digital transactions#expert cybersecurity advice#financial cybersecurity guide#financial data encryption#global cybercrime costs#hard drive failure risks#investment security#online banking#personal finance#phishing scams#phishing threat awareness#public Wi-Fi security#robust passwords#secure financial apps#secure online investments#SSL certificates#two-factor authentication#VPN usage#Wi-Fi safety
0 notes
Text
6 Advantages of Faster Internet Speed at Home - Technology Org
New Post has been published on https://thedigitalinsider.com/6-advantages-of-faster-internet-speed-at-home-technology-org/
6 Advantages of Faster Internet Speed at Home - Technology Org
A high-speed Internet connection has several advantages. Using high-speed Internet allows users to work remotely, learn online, and watch movies without buffering failed uploads, or poor-quality video chats. In the end, the faster your connection is, the easier it will be for everyone in your home to watch, download, and play games. High-speed Internet opens up a whole new world of Internet interaction. Here are a few other advantages of high-speed Internet:
Using internet on a tablet computer – illustrative photo. Image credit: Towfiqu Barbhuiya via Unsplash, free license
Reliable Connection and Speeds
Reliability is critical in many applications of high-speed Internet. The reliability of a connection minimizes the chance of missing phone or video conversations when remote working or studying, and constant speeds reduce the risk of streaming video buffering during peak times. Although a high-speed connection is not required to load a single website or app, it does make things simpler. A fast connection refreshes your social media feed, loads sites quickly, and reduces video buffering times.
Support Multiple Users and Devices
High-speed Internet means more than simply rapid speeds for a single user. The goal is to get fast, consistent speeds no matter whether you’re multitasking or if everyone in your network is. High download and upload rates are required for Ultra HD and 4K video streaming, as well as live streaming. A high-speed Internet subscription allows you to enjoy high-quality streaming. A faster network allows multiple devices to stream video, access applications, play games, and perform other activities without interruptions
Upgrade your Smart Home
Smart home gadgets are always connected to the internet and are always on. A high speed plan allows you to connect all the devices you need without slowing down your network, such as smart thermostats, doorbell cameras, and voice assistants.
Work From Home
If you work remotely or manage a company from home, a high-speed Internet connection is important. It allows you to download a large amount of work data i.e. PowerPoint presentations, engage in video conferencing, and operate SaaS seamlessly. A poor Internet connection causes every online job to take longer, making things more difficult for you, your employer, and/or your clients.
Facilitate a Learning Environment
Whether your family member is just starting in school or is about to graduate from college, they will need the Internet to research projects, submit reports, and learn remotely. A fast internet connection allows you to keep up with your studies so you can research more efficiently and quickly and stay ahead of the class. Additionally, you can verify your internet speed to ensure a dependable connection for academic assignments and projects. You can utilize this speedtest to measure the speed of your home connection.
Quicker Cloud Access
If you use cloud-based software to back up your phone or computer’s images, movies, music, and other files, you’ll need a fast internet connection to view those files and upload more. Therefore, Data backup can be done quickly and securely with a fast internet connection.
#4K#app#applications#back up#backup#Cameras#Cloud#college#computer#data#data backup#devices#Environment#gadgets#games#images#interaction#Internet#it#Learn#learning#matter#measure#media#movies#multitasking#Music#network#Other#Other posts
0 notes
Text
Safeguarding Success: A Guide to Enterprise Data Backup and Recovery Services
In the dynamic world of business, where information reigns supreme, the security and integrity of data stand as crucial pillars for success. Imagine the chaos that could ensue if critical business data were to disappear unexpectedly. This is where the importance of enterprise data backup and recovery services becomes crystal clear.

Understanding the Importance of Data Backup and Recovery:
At its core, enterprise data backup and recovery involve safeguarding essential information and devising strategies to retrieve it in the event of loss. The aim is to ensure business continuity, preventing the potentially disastrous consequences of data loss. In an era where data is akin to gold, the cost of losing it can be staggering, affecting both finances and reputation.
Key Components of a Robust Backup and Recovery Strategy:
Regular Backups: Regular, automated backups are the backbone of any data protection strategy. By consistently preserving data, businesses can minimize the risk of information loss.
Data Encryption: To add an extra layer of security, data encryption plays a vital role. It ensures that even if data falls into the wrong hands, it remains unintelligible without the proper decryption keys.
Offsite Storage: Storing backups in geographically separate locations provides a safety net against disasters like floods or fires, ensuring data availability even in the face of physical damage.
Versioning and Retention Policies: Managing data efficiently involves implementing versioning and retention policies, allowing businesses to keep track of changes and control the lifespan of different data versions.
Types of Enterprise Data Backup and Recovery Services:
On-Premises Solutions: Traditional on-premises solutions offer control but come with the challenge of infrastructure maintenance and scalability concerns.
Cloud-Based Solutions: Cloud-based solutions, on the other hand, provide scalability, accessibility, and the flexibility to adapt to changing business needs.
Hybrid Solutions: The hybrid approach, blending on-premises and cloud elements, is gaining popularity, allowing businesses to enjoy the benefits of both worlds.
Best Practices for Implementing Data Backup and Recovery Services:
Risk Assessment: Begin by conducting a thorough risk assessment to tailor backup strategies to the specific needs of your business.
Testing and Validation: Regularly test and validate your backup and recovery processes to ensure they function as intended when the need arises.
Employee Training: Acknowledge the role of human error in data loss and invest in training employees to reduce the likelihood of such incidents.
Conclusion:
In conclusion, enterprise data backup and recovery services are not just technical necessities; they are the guardians of a business's lifeline—its data. By adopting comprehensive strategies, leveraging technological advancements, and learning from others' experiences, businesses can fortify themselves against the unpredictable tides of the digital landscape.
#data backup#data recovery#data recovery and backup#data backup and recovery services#data backup solution#data backup recovery
0 notes
Text
Exploring the Cloud with cloudHQ: A New User's Perspective
Introduction: Are you juggling multiple cloud services and feeling overwhelmed? That was me until I discovered cloudHQ. As a new user, I want to share how this powerful tool is simplifying my digital life. What is cloudHQ? cloudHQ is a cloud-based service offering comprehensive synchronization and integration solutions for various online platforms. It’s designed for individuals and businesses…
View On WordPress
#Cloud Integration#Cloud Management#Cloud Storage#CloudHQ#Data Backup#Data Synchronization#Digital Workflow#Online Collaboration#Productivity Tools#Tech Solutions
1 note
·
View note