#Data Fabric
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr Inc. is using 66 technologies for its website.
Text
Data Fabric: A Unified Approach to Data Management
Data fabric is an emerging architectural approach that aims to create a unified, integrated data landscape. By breaking down data silos and establishing a cohesive data fabric, organizations can improve data governance, quality, and privacy. What is a Data Fabric?Key characteristics of a data fabric:Benefits of Data Fabric:So how does a data fabric affect data management fundamentals?Unified…
0 notes
Text
Rising Data Volumes Propel Global Data Fabric Market Growth
According to the latest market research study published by P&S Intelligence, the data fabric market is experiencing significant growth, with its size standing at USD 2,981.9 million in 2024. Projections indicate a robust compound annual growth rate (CAGR) of 22.1% from 2024 to 2030, aiming to reach USD 9,874 million by 2030. This surge is primarily driven by the exponential increase in data…

View On WordPress
0 notes
Text
Why Gartner's Data Fabric Graphic Puts The Horse Before The Cart
How does the old technology phrase "garbage-in, garbage-out" apply to Gartner's Data Fabric post?
Here is the link to today’s Gartner post on LinkedIn regarding the Data Fabric graphic. My comment is below. I will use these three terms: agent-based model, metaprise, and then – only then, as you call it, data fabric. Without the first two being in place, the data fabric map described above is incomplete and has limited value. Everything begins at the point of new data inputs. A major flaw is…
0 notes
Text
https://saxon.ai/blogs/turning-ai-aspirations-into-reality-with-microsoft-fabric-azure-ai/
0 notes
Text

Data fabric and data lake are two different but compatible ways of processing and storing data. This blog explains the benefits and use cases of each approach, how they relate to each other, and how to choose the best data management approach for your business.
0 notes
Text
Data Fabric Market Size, Growth Opportunities and Forecast
According to a recent report published by Allied Market Research, titled, “Data Fabric Market by Deployment, Type, Enterprise Size, and Industry Vertical: Global Opportunity Analysis and Industry Forecast, 2019–2026,” the data fabric market size was valued at $812.6 million in 2018, and is projected to reach $4,546.9 million by 2026, growing at a CAGR of 23.8% from 2019 to 2026.
Data fabric is a converged platform with an architecture and set of data services that provision diverse data management needs to deliver accurate IT service levels across unstructured data sources and infrastructure types. In the digital transformation era, data analytics has become a vital process that allows seamless flow of information and enables new customer touchpoints through technology. Therefore, data fabric has emerged as an innovative opportunity to enhance business agility.

Growth in cloud space have compelled services providers to rearchitect its storage platform. The rearchitected storage was opted to meet the demands of the services providers enterprise customers for high capacity, durability, performance, and availability, while still preserving their security posture of data storage and transfer. Data fabric is highly adopted as a rearchitect solution in form of infrastructure-as-a-service (IaaS) platform, owing to its benefits such as flexibility, scalability, replication, and others. This is a major factor that drives the growth of the global data fabric market during the forecast period.
Based on deployment, the cloud segment dominated the overall data fabric market in 2018, and is expected to continue this trend during the forecast period. This is attributed to rise in number of cloud deployment across the globe among various industry verticals as a scalable and on-demand data storage option. As data fabric can encompass a wide variety of data sources on disparate locations the deployment of data fabric solutions for cloud data is expected to rise significantly in the coming years among cloud service providers. This is expected to boost the data fabric market growth.
Banking, financial services, and insurance (BFSI) is a dominating sector in terms of technological adoption to gain highest competitive advantage. With rise in need to make smart decisions on the basis of heterogeneous data analysis which is gathered from a variety of sources, such as smartphones, IoT devices, social networks, rich media, and transaction systems, BFSI are embracing innovative solutions that deliver services at ease and speed. This has proliferated the demand for data fabric as it is capable to fulfill the needs of modern analytic, applications, and operational use cases that incorporates data from diverse sources such as files; tables; streams; logs; messaging; rich media, i.e., images, audio and video, and containers. Moreover, retail sector is expected to embrace the modern architecture functionality that offers scalable data analysis as the e-commerce activities are increasing the volume of data silos generated by these activities. This in turn creates lucrative opportunities for the players operating in the data fabric market trends.
Inquiry Before Buying: https://www.alliedmarketresearch.com/purchase-enquiry/6230
Key Findings of the Data Fabric Market :
By deployment, the cloud segment dominated the data fabric market. However, the On-premise segment is expected to exhibit significant growth during the forecast period in the data fabric industry.
Based on type, the disk-based data fabric segment accounted for the highest revenue dominated the data fabric market share in 2018.
Depending on enterprise size, the large enterprises generated the highest revenue in 2018. However, small and medium enterprises segment is expected to witness considerable growth in the near future.
Based on industry vertical, the BFSI segment generated the highest revenue in 2018. However, manufacturing is expected to witness considerable growth in the near future.
Region wise, Asia-Pacific is expected to witness significant growth in terms of CAGR in the upcoming years.
Some of the major players profiled in the data fabric market analysis include Denodo Technologies, Global IDs., Hewlett Packard Enterprise Company, IBM Corporation, NetApp, Oracle Corporation, SAP SE, Software AG, Splunk Inc., and Talend. Major players operating in this market have witnessed high growth in demand for cross-platform data management solutions especially due to growing disparate data sources in digital era.
About Us: Allied Market Research (AMR) is a full-service market research and business-consulting wing of Allied Analytics LLP based in Portland, Oregon. Allied Market Research provides global enterprises as well as medium and small businesses with unmatched quality of “Market Research Reports Insights” and “Business Intelligence Solutions.” AMR has a targeted view to provide business insights and consulting to assist its clients to make strategic business decisions and achieve sustainable growth in their respective market domain.
0 notes
Text
Data Management Trends for 2025
The data landscape is constantly evolving, driven by technological advancements and changing business needs. As we move into 2025, several key trends are shaping the future of data management. 1. AI-Powered Data Management Automated Data Processes: AI-driven automation will streamline tasks like data cleaning, classification, and governance. Enhanced Data Insights: AI-powered analytics will…
0 notes
Text
[Fabric] Entre Archivos y Tablas de Lakehouse - SQL Notebooks
Ya conocemos un panorama de Fabric y por donde empezar. La Data Web nos mostró unos artículos sobre esto. Mientras más veo Fabric más sorprendido estoy sobre la capacidad SaaS y low code que generaron para todas sus estapas de proyecto.
Un ejemplo sobre la sencillez fue copiar datos con Data Factory. En este artículo veremos otro ejemplo para que fanáticos de SQL puedan trabajar en ingeniería de datos o modelado dimensional desde un notebook.
Arquitectura Medallón
Si nunca escuchaste hablar de ella te sugiero que pronto leas. La arquitectura es una metodología que describe una capas de datos que denotan la calidad de los datos almacenados en el lakehouse. Las capas son carpetas jerárquicas que nos permiten determinar un orden en el ciclo de vida del datos y su proceso de transformaciones.
Los términos bronce (sin procesar), plata (validado) y oro (enriquecido/agrupado) describen la calidad de los datos en cada una de estas capas.
Ésta metodología es una referencia o modo de trabajo que puede tener sus variaciones dependiendo del negocio. Por ejemplo, en un escenario sencillo de pocos datos, probablemente no usaríamos gold, sino que luego de dejar validados los datos en silver podríamos construir el modelado dimensional directamente en el paso a "Tablas" de Lakehouse de Fabric.
NOTAS: Recordemos que "Tablas" en Lakehouse es un spark catalog también conocido como Metastore que esta directamente vinculado con SQL Endpoint y un PowerBi Dataset que viene por defecto.
¿Qué son los notebooks de Fabric?
Microsoft los define como: "un elemento de código principal para desarrollar trabajos de Apache Spark y experimentos de aprendizaje automático, es una superficie interactiva basada en web que usan los científicos de datos e ingenieros de datos para escribir un código que se beneficie de visualizaciones enriquecidas y texto en Markdown."
Dicho de manera más sencilla, es un espacio que nos permite ejecutar bloques de código spark que puede ser automatizado. Hoy por hoy es una de las formas más populares para hacer transformaciones y limpieza de datos.
Luego de crear un notebook (dentro de servicio data engineering o data science) podemos abrir en el panel izquierdo un Lakehouse para tener referencia de la estructura en la cual estamos trabajando y el tipo de Spark deseado.
Spark
Spark se ha convertido en el indiscutible lenguaje de lectura de datos en un lake. Así como SQL lo fue por años sobre un motor de base de datos, ahora Spark lo es para Lakehouse. Lo bueno de spark es que permite usar más de un lenguaje según nuestro comodidad.

Creo que es inegable que python está ocupando un lugar privilegiado junto a SQL que ha ganado suficiente popularidad como para encontrarse con ingenieros de datos que no conocen SQL pero son increíbles desarrolladores en python. En este artículo quiero enfocarlo en SQL puesto que lo más frecuente de uso es Python y podríamos charlar de SQL para aportar a perfiles más antiguos como DBAs o Data Analysts que trabajaron con herramientas de diseño y Bases de Datos.
Lectura de archivos de Lakehouse con SQL
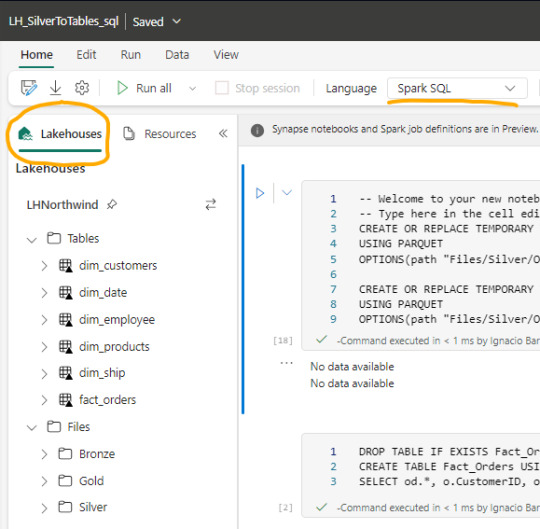
Lo primero que debemos saber es que para trabajar en comodidad con notebooks, creamos tablas temporales que nacen de un esquema especificado al momento de leer la información. Para el ejemplo veremos dos escenarios, una tabla Customers con un archivo parquet y una tabla Orders que fue particionada por año en distintos archivos parquet según el año.
CREATE OR REPLACE TEMPORARY VIEW Dim_Customers_Temp USING PARQUET OPTIONS ( path "Files/Silver/Customers/*.parquet", header "true", mode "FAILFAST" ) ;
CREATE OR REPLACE TEMPORARY VIEW Orders USING PARQUET OPTIONS ( path "Files/Silver/Orders/Year=*", header "true", mode "FAILFAST" ) ;
Vean como delimitamos la tabla temporal, especificando el formato parquet y una dirección super sencilla de Files. El "*" nos ayuda a leer todos los archivos de una carpeta o inclusive parte del nombre de las carpetas que componen los archivos. Para el caso de orders tengo carpetas "Year=1998" que podemos leerlas juntas reemplazando el año por asterisco. Finalmente, especificamos que tenga cabeceras y falle rápido en caso de un problema.
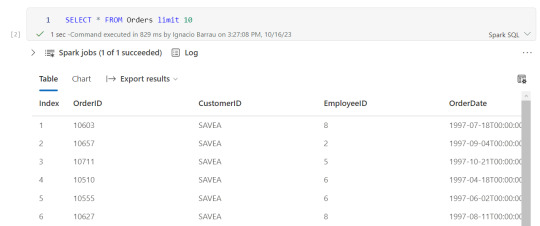
Consultas y transformaciones
Una vez creada la tabla temporal, podremos ejecutar en la celda de un notebook una consulta como si estuvieramos en un motor de nuestra comodidad como DBeaver.
Escritura de tablas temporales a las Tablas de Lakehouse
Realizadas las transformaciones, joins y lo que fuera necesario para construir nuestro modelado dimensional, hechos y dimensiones, pasaremos a almacenarlo en "Tablas".
Las transformaciones pueden irse guardando en otras tablas temporales o podemos almacenar el resultado de la consulta directamente sobre Tablas. Por ejemplo, queremos crear una tabla de hechos Orders a partir de Orders y Order details:
CREATE TABLE Fact_Orders USING delta AS SELECT od.*, o.CustomerID, o.EmployeeID, o.OrderDate, o.Freight, o.ShipName FROM OrdersDetails od LEFT JOIN Orders o ON od.OrderID = o.OrderID
Al realizar el Create Table estamos oficialmente almacenando sobre el Spark Catalog. Fíjense el tipo de almacenamiento porque es muy importante que este en DELTA para mejor funcionamiento puesto que es nativo para Fabric.
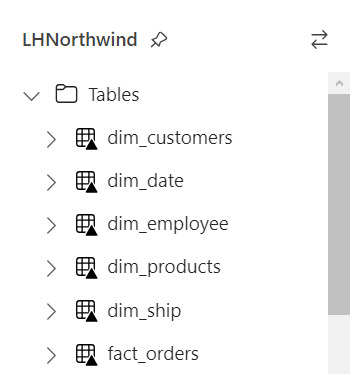
Resultado
Si nuestro proceso fue correcto, veremos la tabla en la carpeta Tables con una flechita hacia arriba sobre la tabla. Esto significa que la tabla es Delta y todo está en orden. Si hubieramos tenido una complicación, se crearía una carpeta "Undefinied" en Tables la cual impide la lectura de nuevas tablas y transformaciones por SQL Endpoint y Dataset. Mucho cuidado y siempre revisar que todo quede en orden:
Pensamientos
Así llegamos al final del recorrido donde podemos apreciar lo sencillo que es leer, transformar y almacenar nuestros modelos dimensionales con SQL usando Notebooks en Fabric. Cabe aclarar que es un simple ejemplo sin actualizaciones incrementales pero si con lectura de particiones de tiempo ya creadas por un data engineering en capa Silver.
¿Qué hay de Databricks?
Podemos usar libremente databricks para todo lo que sean notebooks y procesamiento tal cual lo venimos usando. Lo que no tendríamos al trabajar de ésta manera sería la sencillez para leer y escribir tablas sin tener que especificar todo el ABFS y la característica de Data Wrangler. Dependerá del poder de procesamiento que necesitamos para ejecutar el notebooks si nos alcanza con el de Fabric o necesitamos algo particular de mayor potencia. Para más información pueden leer esto: https://learn.microsoft.com/en-us/fabric/onelake/onelake-azure-databricks
Espero que esto los ayude a introducirse en la construcción de modelados dimensionales con clásico SQL en un Lakehouse como alternativa al tradicional Warehouse usando Fabric. Pueden encontrar el notebook completo en mi github que incluye correr una celda en otro lenguaje y construcción de tabla fecha en notebook.
#power bi#ladataweb#fabric#microsoft fabric#fabric argentina#fabric cordoba#fabric jujuy#fabric tips#fabric training#fabric tutorial#fabric notebooks#data engineering#SQL#spark#data fabric#lakehouse#fabric lakehouse
0 notes
Text
0 notes
Text
https://saxon.ai/services/microsoft-fabric-consulting-services/
#microsoft fabric#data fabric#microsoft fabric consulting service#data fabric consulting service#data analytics#data consulting service
0 notes
Text
Oh thank god I’m ok 🙏. I thought my whole website had to be turned in today but all I need is to turn in the url and I can keep editing it until next Saturday. I love when life works out
#doing a website about the technology of data fabric how it makes it easier to sort a lot of data for those who are unfamiliar#it’s a lot of me bullshitting tho I don’t know what I’m talking about#it just had a lot of papers about it so I chose it#if it’s true or not I’m not sure but dang I’m building a good website about it and I will get a good grade gosh darn it
8 notes
·
View notes
Text
Evaluating Data Fabric and Data Lake Architectures

Choosing a data management approach can be challenging, especially when you have to compare data lake and data fabric. Go through the blog to learn to understand the key differences between them and make an informed decision.
0 notes
Text
What is data fabric?
CXO Spice Talk - Data Fabric with Beate Porst at IBM [Episode 7]
youtube
1 note
·
View note