#Data Engineering Aws
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr was created by web developers David Karp and Marco Arment.
Text
Aretove Technologies specializes in data science consulting and predictive analytics, particularly in healthcare. We harness advanced data analytics to optimize patient care, operational efficiency, and strategic decision-making. Our tailored solutions empower healthcare providers to leverage data for improved outcomes and cost-effectiveness. Trust Aretove Technologies for cutting-edge predictive analytics and data-driven insights that transform healthcare delivery.
#Data Science Consulting#Predictive Analytics in Healthcare#Sap Predictive Analytics#Ai Predictive Analytics#Data Engineering Consulting Firms#Power Bi Predictive Analytics#Data Engineering Consulting#Data Engineering Aws#Data Engineering Company#Predictive and Prescriptive Analytics#Data Science and Analytics Consulting
0 notes
Text
AWS Data Analytics Training | AWS Data Engineering Training in Bangalore
What’s the Most Efficient Way to Ingest Real-Time Data Using AWS?
AWS provides a suite of services designed to handle high-velocity, real-time data ingestion efficiently. In this article, we explore the best approaches and services AWS offers to build a scalable, real-time data ingestion pipeline.

Understanding Real-Time Data Ingestion
Real-time data ingestion involves capturing, processing, and storing data as it is generated, with minimal latency. This is essential for applications like fraud detection, IoT monitoring, live analytics, and real-time dashboards. AWS Data Engineering Course
Key Challenges in Real-Time Data Ingestion
Scalability – Handling large volumes of streaming data without performance degradation.
Latency – Ensuring minimal delay in data processing and ingestion.
Data Durability – Preventing data loss and ensuring reliability.
Cost Optimization – Managing costs while maintaining high throughput.
Security – Protecting data in transit and at rest.
AWS Services for Real-Time Data Ingestion
1. Amazon Kinesis
Kinesis Data Streams (KDS): A highly scalable service for ingesting real-time streaming data from various sources.
Kinesis Data Firehose: A fully managed service that delivers streaming data to destinations like S3, Redshift, or OpenSearch Service.
Kinesis Data Analytics: A service for processing and analyzing streaming data using SQL.
Use Case: Ideal for processing logs, telemetry data, clickstreams, and IoT data.
2. AWS Managed Kafka (Amazon MSK)
Amazon MSK provides a fully managed Apache Kafka service, allowing seamless data streaming and ingestion at scale.
Use Case: Suitable for applications requiring low-latency event streaming, message brokering, and high availability.
3. AWS IoT Core
For IoT applications, AWS IoT Core enables secure and scalable real-time ingestion of data from connected devices.
Use Case: Best for real-time telemetry, device status monitoring, and sensor data streaming.
4. Amazon S3 with Event Notifications
Amazon S3 can be used as a real-time ingestion target when paired with event notifications, triggering AWS Lambda, SNS, or SQS to process newly added data.
Use Case: Ideal for ingesting and processing batch data with near real-time updates.
5. AWS Lambda for Event-Driven Processing
AWS Lambda can process incoming data in real-time by responding to events from Kinesis, S3, DynamoDB Streams, and more. AWS Data Engineer certification
Use Case: Best for serverless event processing without managing infrastructure.
6. Amazon DynamoDB Streams
DynamoDB Streams captures real-time changes to a DynamoDB table and can integrate with AWS Lambda for further processing.
Use Case: Effective for real-time notifications, analytics, and microservices.
Building an Efficient AWS Real-Time Data Ingestion Pipeline
Step 1: Identify Data Sources and Requirements
Determine the data sources (IoT devices, logs, web applications, etc.).
Define latency requirements (milliseconds, seconds, or near real-time?).
Understand data volume and processing needs.
Step 2: Choose the Right AWS Service
For high-throughput, scalable ingestion → Amazon Kinesis or MSK.
For IoT data ingestion → AWS IoT Core.
For event-driven processing → Lambda with DynamoDB Streams or S3 Events.
Step 3: Implement Real-Time Processing and Transformation
Use Kinesis Data Analytics or AWS Lambda to filter, transform, and analyze data.
Store processed data in Amazon S3, Redshift, or OpenSearch Service for further analysis.
Step 4: Optimize for Performance and Cost
Enable auto-scaling in Kinesis or MSK to handle traffic spikes.
Use Kinesis Firehose to buffer and batch data before storing it in S3, reducing costs.
Implement data compression and partitioning strategies in storage. AWS Data Engineering online training
Step 5: Secure and Monitor the Pipeline
Use AWS Identity and Access Management (IAM) for fine-grained access control.
Monitor ingestion performance with Amazon CloudWatch and AWS X-Ray.
Best Practices for AWS Real-Time Data Ingestion
Choose the Right Service: Select an AWS service that aligns with your data velocity and business needs.
Use Serverless Architectures: Reduce operational overhead with Lambda and managed services like Kinesis Firehose.
Enable Auto-Scaling: Ensure scalability by using Kinesis auto-scaling and Kafka partitioning.
Minimize Costs: Optimize data batching, compression, and retention policies.
Ensure Security and Compliance: Implement encryption, access controls, and AWS security best practices. AWS Data Engineer online course
Conclusion
AWS provides a comprehensive set of services to efficiently ingest real-time data for various use cases, from IoT applications to big data analytics. By leveraging Amazon Kinesis, AWS IoT Core, MSK, Lambda, and DynamoDB Streams, businesses can build scalable, low-latency, and cost-effective data pipelines. The key to success is choosing the right services, optimizing performance, and ensuring security to handle real-time data ingestion effectively.
Would you like more details on a specific AWS service or implementation example? Let me know!
Visualpath is Leading Best AWS Data Engineering training.Get an offering Data Engineering course in Hyderabad.With experienced,real-time trainers.And real-time projects to help students gain practical skills and interview skills.We are providing 24/7 Access to Recorded Sessions ,For more information,call on +91-7032290546
For more information About AWS Data Engineering training
Call/WhatsApp: +91-7032290546
Visit: https://www.visualpath.in/online-aws-data-engineering-course.html
#AWS Data Engineering Course#AWS Data Engineering training#AWS Data Engineer certification#Data Engineering course in Hyderabad#AWS Data Engineering online training#AWS Data Engineering Training Institute#AWS Data Engineering training in Hyderabad#AWS Data Engineer online course#AWS Data Engineering Training in Bangalore#AWS Data Engineering Online Course in Ameerpet#AWS Data Engineering Online Course in India#AWS Data Engineering Training in Chennai#AWS Data Analytics Training
0 notes
Text
AWS Data Engineering online training | AWS Data Engineer
AWS Data Engineering: An Overview and Its Importance
Introduction
AWS Data Engineering plays a significant role in handling and transforming raw data into valuable insights using Amazon Web Services (AWS) tools and technologies. This article explores AWS Data Engineering, its components, and why it is essential for modern enterprises. In today's data-driven world, organizations generate vast amounts of data daily. Effectively managing, processing, and analyzing this data is crucial for decision-making and business growth. AWS Data Engineering Training
What is AWS Data Engineering?
AWS Data Engineering refers to the process of designing, building, and managing scalable and secure data pipelines using AWS cloud services. It involves the extraction, transformation, and loading (ETL) of data from various sources into a centralized storage or data warehouse for analysis and reporting. Data engineers leverage AWS tools such as AWS Glue, Amazon Redshift, AWS Lambda, Amazon S3, AWS Data Pipeline, and Amazon EMR to streamline data processing and management.

Key Components of AWS Data Engineering
AWS offers a comprehensive set of tools and services to support data engineering. Here are some of the essential components:
Amazon S3 (Simple Storage Service): A scalable object storage service used to store raw and processed data securely.
AWS Glue: A fully managed ETL (Extract, Transform, Load) service that automates data preparation and transformation.
Amazon Redshift: A cloud data warehouse that enables efficient querying and analysis of large datasets. AWS Data Engineering Training
AWS Lambda: A serverless computing service used to run functions in response to events, often used for real-time data processing.
Amazon EMR (Elastic MapReduce): A service for processing big data using frameworks like Apache Spark and Hadoop.
AWS Data Pipeline: A managed service for automating data movement and transformation between AWS services and on-premise data sources.
AWS Kinesis: A real-time data streaming service that allows businesses to collect, process, and analyze data in real time.
Why is AWS Data Engineering Important?
AWS Data Engineering is essential for businesses due to several key reasons: AWS Data Engineering Training Institute
Scalability and Performance AWS provides scalable solutions that allow organizations to handle large volumes of data efficiently. Services like Amazon Redshift and EMR ensure high-performance data processing and analysis.
Cost-Effectiveness AWS offers pay-as-you-go pricing models, eliminating the need for large upfront investments in infrastructure. Businesses can optimize costs by only using the resources they need.
Security and Compliance AWS provides robust security features, including encryption, identity and access management (IAM), and compliance with industry standards like GDPR and HIPAA. AWS Data Engineering online training
Seamless Integration AWS services integrate seamlessly with third-party tools and on-premise data sources, making it easier to build and manage data pipelines.
Real-Time Data Processing AWS supports real-time data processing with services like AWS Kinesis and AWS Lambda, enabling businesses to react to events and insights instantly.
Data-Driven Decision Making With powerful data engineering tools, organizations can transform raw data into actionable insights, leading to improved business strategies and customer experiences.
Conclusion
AWS Data Engineering is a critical discipline for modern enterprises looking to leverage data for growth and innovation. By utilizing AWS's vast array of services, organizations can efficiently manage data pipelines, enhance security, reduce costs, and improve decision-making. As the demand for data engineering continues to rise, businesses investing in AWS Data Engineering gain a competitive edge in the ever-evolving digital landscape.
Visualpath is the Best Software Online Training Institute in Hyderabad. Avail complete AWS Data Engineering Training worldwide. You will get the best course at an affordable cost
Visit: https://www.visualpath.in/online-aws-data-engineering-course.html
Visit Blog: https://visualpathblogs.com/category/aws-data-engineering-with-data-analytics/
WhatsApp: https://www.whatsapp.com/catalog/919989971070/
#AWS Data Engineering Course#AWS Data Engineering Training#AWS Data Engineer Certification#Data Engineering course in Hyderabad#AWS Data Engineering online training#AWS Data Engineering Training Institute#AWS Data Engineering Training in Hyderabad#AWS Data Engineer online course
0 notes
Text
Data Engineering with AWS: Building Next-Gen Data Architectures on AWS
Price: (as of – Details) “Data Engineering with AWS: Building Next-Gen Data Architectures on AWS” is your comprehensive guide to mastering data engineering in the cloud. This book delves into the full spectrum of data engineering on the AWS platform, from foundational concepts to advanced techniques, enabling you to build, optimize, and scale data pipelines with confidence. Designed for data…

View On WordPress
0 notes
Text
Shaktiman Mall, Principal Product Manager, Aviatrix – Interview Series
New Post has been published on https://thedigitalinsider.com/shaktiman-mall-principal-product-manager-aviatrix-interview-series/
Shaktiman Mall, Principal Product Manager, Aviatrix – Interview Series
Shaktiman Mall is Principal Product Manager at Aviatrix. With more than a decade of experience designing and implementing network solutions, Mall prides himself on ingenuity, creativity, adaptability and precision. Prior to joining Aviatrix, Mall served as Senior Technical Marketing Manager at Palo Alto Networks and Principal Infrastructure Engineer at MphasiS.
Aviatrix is a company focused on simplifying cloud networking to help businesses remain agile. Their cloud networking platform is used by over 500 enterprises and is designed to provide visibility, security, and control for adapting to changing needs. The Aviatrix Certified Engineer (ACE) Program offers certification in multicloud networking and security, aimed at supporting professionals in staying current with digital transformation trends.
What initially attracted you to computer engineering and cybersecurity?
As a student, I was initially more interested in studying medicine and wanted to pursue a degree in biotechnology. However, I decided to switch to computer science after having conversations with my classmates about technological advancements over the preceding decade and emerging technologies on the horizon.
Could you describe your current role at Aviatrix and share with us what your responsibilities are and what an average day looks like?
I’ve been with Aviatrix for two years and currently serve as a principal product manager in the product organization. As a product manager, my responsibilities include building product vision, conducting market research, and consulting with the sales, marketing and support teams. These inputs combined with direct customer engagement help me define and prioritize features and bug fixes.
I also ensure that our products align with customers’ requirements. New product features should be easy to use and not overly or unnecessarily complex. In my role, I also need to be mindful of the timing for these features – can we put engineering resources toward it today, or can it wait six months? To that end, should the rollout be staggered or phased into different versions? Most importantly, what is the projected return on investment?
An average day includes meetings with engineering, project planning, customer calls, and meetings with sales and support. Those discussions allow me to get an update on upcoming features and use cases while understanding current issues and feedback to troubleshoot before a release.
What are the primary challenges IT teams face when integrating AI tools into their existing cloud infrastructure?
Based on real-world experience of integrating AI into our IT technology, I believe there are four challenges companies will encounter:
Harnessing data & integration: Data enriches AI, but when data is across different places and resources in an organization, it can be difficult to harness it properly.
Scaling: AI operations can be CPU intensive, making scaling challenging.
Training and raising awareness: A company could have the most powerful AI solution, but if employees don’t know how to use it or don’t understand it, then it will be underutilized.
Cost: For IT especially, a quality AI integration will not be cheap, and businesses must budget accordingly.
Security: Make sure that the cloud infrastructure meets security standards and regulatory requirements relevant to AI applications
How can businesses ensure their cloud infrastructure is robust enough to support the heavy computing needs of AI applications?
There are multiple factors to running AI applications. For starters, it’s critical to find the right type and instance for scale and performance.
Also, there needs to be adequate data storage, as these applications will draw from static data available within the company and build their own database of information. Data storage can be costly, forcing businesses to assess different types of storage optimization.
Another consideration is network bandwidth. If every employee in the company uses the same AI application at once, the network bandwidth needs to scale – otherwise, the application will be so slow as to be unusable. Likewise, companies need to decide if they will use a centralized AI model where computing happens in a single place or a distributed AI model where computing happens closer to the data sources.
With the increasing adoption of AI, how can IT teams protect their systems from the heightened risk of cyberattacks?
There are two main aspects to security every IT team must consider. First, how do we protect against external risks? Second, how do we ensure data, whether it is the personally identifiable information (PII) of customers or proprietary information, remains within the company and is not exposed? Businesses must determine who can and cannot access certain data. As a product manager, I need sensitive information others are not authorized to access or code.
At Aviatrix, we help our customers protect against attacks, allowing them to continue adopting technologies like AI that are essential for being competitive today. Recall network bandwidth optimization: because Aviatrix acts as the data plane for our customers, we can manage the data going through their network, providing visibility and enhancing security enforcement.
Likewise, our distributed cloud firewall (DCF) solves the challenges of a distributed AI model where data gets queried in multiple places, spanning geographical boundaries with different laws and compliances. Specifically, a DCF supports a single set of security compliance enforced across the globe, ensuring the same set of security and networking architecture is supported. Our Aviatrix Networks Architecture also allows us to identify choke points, where we can dynamically update the routing table or help customers create new connections to optimize AI requirements.
How can businesses optimize their cloud spending while implementing AI technologies, and what role does the Aviatrix platform play in this?
One of the main practices that will help businesses optimize their cloud spending when implementing AI is minimizing egress spend.
Cloud network data processing and egress fees are a material component of cloud costs. They are both difficult to understand and inflexible. These cost structures not only hinder scalability and data portability for enterprises, but also provide decreasing returns to scale as cloud data volume increases which can impact organizations’ bandwidth.
Aviatrix designed our egress solution to give the customer visibility and control. Not only do we perform enforcement on gateways through DCF, but we also do native orchestration, enforcing control at the network interface card level for significant cost savings. In fact, after crunching the numbers on egress spend, we had customers report savings between 20% and 40%.
We’re also building auto-rightsizing capabilities to automatically detect high resource utilization and automatically schedule upgrades as needed.
Lastly, we ensure optimal network performance with advanced networking capabilities like intelligent routing, traffic engineering and secure connectivity across multi-cloud environments.
How does Aviatrix CoPilot enhance operational efficiency and provide better visibility and control over AI deployments in multicloud environments?
Aviatrix CoPilot’s topology view provides real-time network latency and throughput, allowing customers to see the number of VPC/VNets. It also displays different cloud resources, accelerating problem identification. For example, if the customer sees a latency issue in a network, they will know which assets are getting affected. Also, Aviatrix CoPilot helps customers identify bottlenecks, configuration issues, and improper connections or network mapping. Furthermore, if a customer needs to scale up one of its gateways into the node to accommodate more AI capabilities, Aviatrix CoPilot can automatically detect, scale, and upgrade as necessary.
Can you explain how dynamic topology mapping and embedded security visibility in Aviatrix CoPilot assist in real-time troubleshooting of AI applications?
Aviatrix CoPilot’s dynamic topology mapping also facilitates robust troubleshooting capabilities. If a customer must troubleshoot an issue between different clouds (requiring them to understand where traffic was getting blocked), CoPilot can find it, streamlining resolution. Not only does Aviatrix CoPilot visualize network aspects, but it also provides security visualization components in the form of our own threat IQ, which performs security and vulnerability protection. We help our customers map the networking and security into one comprehensive visualization solution.
We also help with capacity planning for both cost with costIQ, and performance with auto right sizing and network optimization.
How does Aviatrix ensure data security and compliance across various cloud providers when integrating AI tools?
AWS and its AI engine, Amazon Bedrock, have different security requirements from Azure and Microsoft Copilot. Uniquely, Aviatrix can help our customers create an orchestration layer where we can automatically align security and network requirements to the CSP in question. For example, Aviatrix can automatically compartmentalize data for all CSPs irrespective of APIs or underlying architecture.
It is important to note that all of these AI engines are inside a public subnet, which means they have access to the internet, creating additional vulnerabilities because they consume proprietary data. Thankfully, our DCF can sit on a public and private subnet, ensuring security. Beyond public subnets, it can also sit across different regions and CSPs, between data centers and CSPs or VPC/VNets and even between a random site and the cloud. We establish end-to-end encryption across VPC/VNets and regions for secure transfer of data. We also have extensive auditing and logging for tasks performed on the system, as well as integrated network and policy with threat detection and deep packet inspection.
What future trends do you foresee in the intersection of AI and cloud computing, and how is Aviatrix preparing to address these trends?
I see the interaction of AI and cloud computing birthing incredible automation capabilities in key areas such as networking, security, visibility, and troubleshooting for significant cost savings and efficiency.
It could also analyze the different types of data entering the network and recommend the most suitable policies or security compliances. Similarly, if a customer needed to enforce HIPAA, this solution could scan through the customer’s networks and then recommend a corresponding strategy.
Troubleshooting is a major investment because it requires a call center to assist customers. However, most of these issues don’t necessitate human intervention.
Generative AI (GenAI) will also be a game changer for cloud computing. Today, a topology is a day-zero decision – once an architecture or networking topology gets built, it is difficult to make changes. One potential use case I believe is on the horizon is a solution that could recommend an optimal topology based on certain requirements. Another problem that GenAI could solve is related to security policies, which quickly become outdated after a few years. AGenAI solution could help users routinely create new security stacks per new laws and regulations.
Aviatrix can implement the same security architecture for a datacenter with our edge solution, given that more AI will sit close to the data sources. We can help connect branches and sites to the cloud and edge with AI computes running.
We also help in B2B integration with different customers or entities in the same company with separate operating models.
AI is driving new and exciting computing trends that will impact how infrastructure is built. At Aviatrix, we’re looking forward to seizing the moment with our secure and seamless cloud networking solution.
Thank you for the great interview, readers who wish to learn more should visit Aviatrix.
#agile#ai#AI and cloud#AI and cloud computing#AI engines#AI integration#ai model#ai tools#Amazon#amp#APIs#applications#architecture#assets#automation#Aviatrix#awareness#AWS#azure#B2B#biotechnology#bug#Building#call center#certification#Cloud#cloud computing#cloud data#cloud infrastructure#cloud network
1 note
·
View note
Text
Lack of Success in the AWS Data Engineer Job Market
Wow! Talk about disappointment, the job market is definitely tough right now for AWS Data Engineers. Or, Data Engineers overall. The oddest part though, ~85% of the emails/calls I receive, they are for Senior or Lead Data Engineer and/or Data Scientist roles. When I am trying to break in at the mid-level Data Engineer role because I know I do not yet have the Senior level experience yet. But…
#acloudguru#aws certified data engineer#aws cloud#aws machine learning specialist#aws ml specialist#cloudacademy#cognitive diversity#communication skills#data engineer#data engineering essentials#diplomacy skills#drive#drive and sacrifice#gcp pro data engineer#google cloud platform data engineer#sacrifice
0 notes
Text
Unleash the power of the cloud. Our cloud consulting strategy helps you design a secure, scalable, and cost-effective cloud roadmap aligned with your business goals.
#cloud transformation service#cloud transformation consulting#cloud transformation strategy#cloud services#cloud transformation#cloud based services#cloud solutions#cloud company#cloud consulting companies#cloud consulting#Cloud Data Warehouse Services Provider#GCP data Engieer#AWS data engineer
0 notes
Text

How to create a Redshift Cluster? Learn how to create a Redshift cluster effortlessly. Explore the process of setting up a Redshift cluster through the AWS console, managing Redshift Processing Units (RPUs), and optimizing cluster performance.
#Redshift#AWS cloud#Cloud Data#AWS#Amazon Web Services#Fintech#Technology#Tech videos#Learning Videos#Trending#data analytics#data engineering#decisionmaking#youtube
0 notes
Text
This blog will delve into the benefits of cloud data engineering, its significance in our data-driven world, key factors to consider during its implementation, and the pivotal role of Google-certified professional data engineers in this domain.
0 notes
Text
Various services provided by Aretove includes Data Science, Predictive Analytics, Applied AI, Business Intelligence, Data Engineering, Big Data & Analytics
#Data Science Consulting#Predictive Analytics in Healthcare#Sap Predictive Analytics#Ai Predictive Analytics#Data Engineering Consulting Firms#Power Bi Predictive Analytics#Data Engineering Consulting#Data Engineering Aws#Data Engineering Company#Predictive and Prescriptive Analytics#Data Science and Analytics Consulting
0 notes
Text

In today's fast-paced digital landscape, cloud technology has emerged as a transformative force that empowers organizations to innovate, scale and adapt like never before. Learn more about our services, go through our blogs, study materials, case studies - https://bit.ly/463FjrO
#engineering#technology#software#softwaredevelopment#cloud#data#itservice#engineeringservices#Nitorinfotech#ascendion#softwareservices#itconsultancycompany#itcompany#cloud pillar#what is cloud data storage#aws cloud migration services#cloud engineering services#pillars of cloud#gcp cloud vision#google cloud#google cloud platform#google cloud console#cloud computing trends#cloud storage services#cloud storage
0 notes
Text
Serverless-native Data Engineering with AWS in Bangalore — Antstack
Modernize your applications for the digital age. Embrace cloud-native and serverless architecture and advanced technologies for increased scalability and flexibility. We transform conventional applications into a modern architecture that leverages serverless computing. Our data engineering with AWS effort doesn’t become a ‘legacy’ when we complete it!
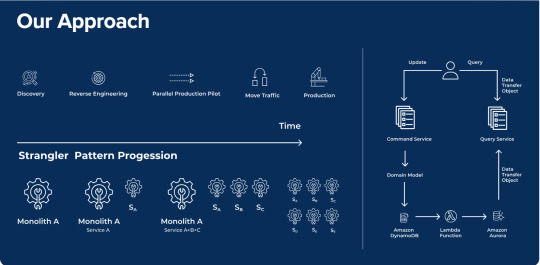
0 notes
Text
AWS Data Engineering | AWS Data Engineer online course
Key AWS Services Used in Data Engineering
AWS data engineering solutions are essential for organizations looking to process, store, and analyze vast datasets efficiently in the era of big data. Amazon Web Services (AWS) provides a wide range of cloud services designed to support data engineering tasks such as ingestion, transformation, storage, and analytics. These services are crucial for building scalable, robust data pipelines that handle massive datasets with ease. Below are the key AWS services commonly utilized in data engineering: AWS Data Engineer Certification

1. AWS Glue
AWS Glue is a fully managed extract, transform, and load (ETL) service that helps automate data preparation for analytics. It provides a serverless environment for data integration, allowing engineers to discover, catalog, clean, and transform data from various sources. Glue supports Python and Scala scripts and integrates seamlessly with AWS analytics tools like Amazon Athena and Amazon Redshift.
2. Amazon S3 (Simple Storage Service)
Amazon S3 is a highly scalable object storage service used for storing raw, processed, and structured data. It supports data lakes, enabling data engineers to store vast amounts of unstructured and structured data. With features like versioning, lifecycle policies, and integration with AWS Lake Formation, S3 is a critical component in modern data architectures. AWS Data Engineering online training
3. Amazon Redshift
Amazon Redshift is a fully managed, petabyte-scale data warehouse solution designed for high-performance analytics. It allows organizations to execute complex queries and perform real-time data analysis using SQL. With features like Redshift Spectrum, users can query data directly from S3 without loading it into the warehouse, improving efficiency and reducing costs.
4. Amazon Kinesis
Amazon Kinesis provides real-time data streaming and processing capabilities. It includes multiple services:
Kinesis Data Streams for ingesting real-time data from sources like IoT devices and applications.
Kinesis Data Firehose for streaming data directly into AWS storage and analytics services.
Kinesis Data Analytics for real-time analytics using SQL.
Kinesis is widely used for log analysis, fraud detection, and real-time monitoring applications.
5. AWS Lambda
AWS Lambda is a serverless computing service that allows engineers to run code in response to events without managing infrastructure. It integrates well with data pipelines by processing and transforming incoming data from sources like Kinesis, S3, and DynamoDB before storing or analyzing it. AWS Data Engineering Course
6. Amazon DynamoDB
Amazon DynamoDB is a NoSQL database service designed for fast and scalable key-value and document storage. It is commonly used for real-time applications, session management, and metadata storage in data pipelines. Its automatic scaling and built-in security features make it ideal for modern data engineering workflows.
7. AWS Data Pipeline
AWS Data Pipeline is a data workflow orchestration service that automates the movement and transformation of data across AWS services. It supports scheduled data workflows and integrates with S3, RDS, DynamoDB, and Redshift, helping engineers manage complex data processing tasks.
8. Amazon EMR (Elastic MapReduce)
Amazon EMR is a cloud-based big data platform that allows users to run large-scale distributed data processing frameworks like Apache Hadoop, Spark, and Presto. It is used for processing large datasets, performing machine learning tasks, and running batch analytics at scale.
9. AWS Step Functions
AWS Step Functions help in building serverless workflows by coordinating AWS services such as Lambda, Glue, and DynamoDB. It simplifies the orchestration of data processing tasks and ensures fault-tolerant, scalable workflows for data engineering pipelines. AWS Data Engineering Training
10. Amazon Athena
Amazon Athena is an interactive query service that allows users to run SQL queries on data stored in Amazon S3. It eliminates the need for complex ETL jobs and is widely used for ad-hoc querying and analytics on structured and semi-structured data.
Conclusion
AWS provides a powerful ecosystem of services that cater to different aspects of data engineering. From data ingestion with Kinesis to transformation with Glue, storage with S3, and analytics with Redshift and Athena, AWS enables scalable and cost-efficient data solutions. By leveraging these services, data engineers can build resilient, high-performance data pipelines that support modern analytics and machine learning workloads.
Visualpath is the Best Software Online Training Institute in Hyderabad. Avail complete AWS Data Engineering Training worldwide. You will get the best course at an affordable cost.
#AWS Data Engineering Course#AWS Data Engineering Training#AWS Data Engineer Certification#Data Engineering course in Hyderabad#AWS Data Engineering online training#AWS Data Engineering Training Institute#AWS Data Engineering Training in Hyderabad#AWS Data Engineer online course
0 notes
Note
congrats on 1k!!! could i request a hot cocoa for oscar piastri with ever seen?
your event is so so cute <33
the prettiest eyes he's ever seen ⟡ ݁₊ . - oscar piastri

a/n: okay normally i would've wanted a more detailed req but as soon as i read this i instantly had an idea so u get off this time <333 hope u enjoy
this is part of my 1k event - check out the rules here!!

"My gosh, this is uncomfortable," you laugh from the seat of Oscar's race car.
"Well, I only have to sit in there for about an hour and a half at a time," he explains matter-of-factly.
Around you, the McLaren garage is alive with people hurrying around - engineers making sure the last parts are in place before the race, strategists going over data, and even a couple media crew snapping photos. And then there was you and your boyfriend, who had decided that your visit to the garage would be incomplete without sitting in his car.
"It's digging into my butt," you complain, "how do you even do this."
"Well it is my job, baby" he laughs, watching you with an endeared look.
"Yeah, and there's a reason it isn't mine, can I get out now?"
"Wait, wait!" he stops you right as you're about to pull yourself out, rushing off into the distance to grab something. When he appears again, he's holding his helmet for the weekend and donning a mischievous smile.
"You have to try it on," he laughs - and you're so enamoured by the sound of Oscar Piastri laughing that you have no choice outside of obliging. Obediently, you sit in place as he pushes the helmet down onto your head, and you let out a soft grunt at the feeling.
"How do you feel?" he asks.
"Squashed," you reply, voice muffled by the helmet.
"Oh, hold on," he lets out a soft laugh as he reaches towards you, flipping up the visor, "there you are."
"Thanks," you let out, but he doesn't lean back, instead leaning in even closer to the point where his nose almost touches the helmet.
"You have the prettiest eyes I've ever seen," he breathes in awe, just above a whisper. You feel your eyes widen, and you feel slightly grateful for the fact that the helmet covers up most of your face - which you're sure is bright red by now.
"Wh- sorry?" is all you can muster out as your boyfriend straightens back up with a smirk at your reaction, already whipping out his phone to snap a photo of you. "Hey!"
"You're so cute," he laughs, "this one's going in the race weekend photo dump for sure."
#oscar piastri#op81#oscar piastri x reader#oscar piastri x you#oscar piastri oneshot#oscar piastri imagine#oscar piastri fanfic#oscar piastri fic#mclaren#formula 1#fanfic#purinfelix#jet writes ★#jet's 1k event ᝰ.ᐟ
1K notes
·
View notes
Text
Achieving the AWS Data Engineer Associate Certification
DAWG GONE IT!!!! AGAIN – SUCCESS…!!! I’ve SUCCESSFULLY obtained my SECOND Data Engineering certification: AWS Data Engineering Associate cert after studying my little hiney off for months. This is after studying for months and successfully gaining the Google Cloud Platform (GCP) Pro Data Engineer (Sept 2023). This amount of time spent is because I had no previous Data Engineer…
View On WordPress
#acloudguru#aws certified data engineer#cloudacademy#data engineer#data engineering essentials#gcp pro data engineer#google cloud platform data engineer#ITVersity#maruchin tech#Sundog Education by Frank Kane#thomas haas#udemy#udemy maarek
0 notes
Photo

(via GIPHY) Takeo Boorcamp
#giphy#transparent#tech#bootcamp#programmer#data scientist#full stack developer#java developer#data engineering#frontend developer#aws python developer
1 note
·
View note