#Data Analysis with Python
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
69% of Tumblr users are millennials.
Text
Introduction to Data Analysis with Python
Embarking on Data Analysis with Python
In the dynamic landscape of data analysis, Python serves as a versatile and powerful tool, empowering analysts to derive meaningful insights from vast datasets. This introduction aims to illuminate the journey into data analysis with Python, providing a gateway for both novices and seasoned professionals to harness the language's capabilities for exploring, understanding, and interpreting data.
Unveiling Python's Significance in Data Analysis
Python's prominence in data analysis arises from its rich ecosystem of libraries and tools specifically tailored for this purpose. This article delves into the fundamental aspects of utilizing Python for data analysis, offering a roadmap for individuals seeking to leverage Python's capabilities in extracting valuable information from diverse datasets.
Libraries and Tools at Your Fingertips
Python boasts a myriad of libraries that significantly enhance the data analysis process. From Pandas for efficient data manipulation to Matplotlib and Seaborn for compelling visualizations, this introduction explores the essential tools at your disposal and how they contribute to a seamless data analysis workflow.
Hands-On Exploration with Python
A distinctive feature of Python in data analysis lies in its practicality. This article guides you through hands-on exploration, demonstrating how to load, clean, and analyze data using Python.
Unlocking the Potential of Python in Data Analysis
As you delve deeper into the realms of data analysis with Python, discover the language's potential to uncover patterns, trends, and correlations within datasets. Python's versatility enables analysts to approach complex data scenarios with confidence, fostering a deeper understanding of the information at hand.
Conclusion: Your Gateway to Data Exploration
In conclusion, this introduction serves as your gateway to the exciting world of data analysis with Python. Whether you're a beginner or an experienced professional, LearNowx Python Training Course accessibility and robust capabilities make it an invaluable tool for unraveling the stories hidden within datasets. Get ready to embark on a journey of discovery, where Python becomes your ally in transforming raw data into actionable insights.
0 notes
Text
Hey everyone! enjoying my (two) week break of uni, so I've been lazy and playing games. Today, working on Python, I'm just doing repetition of learning the basics; Variables, Data types, Logic statements, etc. Hope everyone has a good week!
#codeblr#coding#python#university#uni life#studying#datascience#data analytics#data analysis#studyblr#student life#study motivation#study blog#student
77 notes
·
View notes
Link
Bioinformatics sits at the fascinating intersection of biology, computer science, and data analysis, with Python as a powerful language that drives groundbreaking research and computational discoveries. As biological datasets continue to grow exponentially in complexity and size, researchers and computational biologists increasingly rely on Python’s robust ecosystem of specialized libraries to process genomic data, analyze protein structures, model genetic interactions, and unravel the intricate mysteries of life at a molecular level. From handling massive genetic sequencing datasets to performing sophisticated machine learning predictions, Python libraries have become indispensable tools that transform raw biological information into meaningful scientific insights. In this article, we deep dive into the top 30 Python libraries revolutionizing bioinformatics and making complex biological data analysis a breeze.
Python Libraries for Bioinformatics
Core Libraries for Data Manipulation and Data Analysis:
NumPy: Perhaps the most essential tool every AI/ML enthusiast uses, NumPy is Python’s fundamental package for scientific computing. This Python library offers a multidimensional array of objects, various derived objects, mathematical, logical, shape manipulation, sorting, selecting, I/O, discrete Fourier transforms, basic linear algebra, basic statistical operations, and random simulations. NumPy can perform efficient numerical computations on large datasets of gene expression levels.
Continue Reading
8 notes
·
View notes
Text
Python Libraries to Learn Before Tackling Data Analysis
To tackle data analysis effectively in Python, it's crucial to become familiar with several libraries that streamline the process of data manipulation, exploration, and visualization. Here's a breakdown of the essential libraries:
1. NumPy
- Purpose: Numerical computing.
- Why Learn It: NumPy provides support for large multi-dimensional arrays and matrices, along with a collection of mathematical functions to operate on these arrays efficiently.
- Key Features:
- Fast array processing.
- Mathematical operations on arrays (e.g., sum, mean, standard deviation).
- Linear algebra operations.
2. Pandas
- Purpose: Data manipulation and analysis.
- Why Learn It: Pandas offers data structures like DataFrames, making it easier to handle and analyze structured data.
- Key Features:
- Reading/writing data from CSV, Excel, SQL databases, and more.
- Handling missing data.
- Powerful group-by operations.
- Data filtering and transformation.
3. Matplotlib
- Purpose: Data visualization.
- Why Learn It: Matplotlib is one of the most widely used plotting libraries in Python, allowing for a wide range of static, animated, and interactive plots.
- Key Features:
- Line plots, bar charts, histograms, scatter plots.
- Customizable charts (labels, colors, legends).
- Integration with Pandas for quick plotting.
4. Seaborn
- Purpose: Statistical data visualization.
- Why Learn It: Built on top of Matplotlib, Seaborn simplifies the creation of attractive and informative statistical graphics.
- Key Features:
- High-level interface for drawing attractive statistical graphics.
- Easier to use for complex visualizations like heatmaps, pair plots, etc.
- Visualizations based on categorical data.
5. SciPy
- Purpose: Scientific and technical computing.
- Why Learn It: SciPy builds on NumPy and provides additional functionality for complex mathematical operations and scientific computing.
- Key Features:
- Optimized algorithms for numerical integration, optimization, and more.
- Statistics, signal processing, and linear algebra modules.
6. Scikit-learn
- Purpose: Machine learning and statistical modeling.
- Why Learn It: Scikit-learn provides simple and efficient tools for data mining, analysis, and machine learning.
- Key Features:
- Classification, regression, and clustering algorithms.
- Dimensionality reduction, model selection, and preprocessing utilities.
7. Statsmodels
- Purpose: Statistical analysis.
- Why Learn It: Statsmodels allows users to explore data, estimate statistical models, and perform tests.
- Key Features:
- Linear regression, logistic regression, time series analysis.
- Statistical tests and models for descriptive statistics.
8. Plotly
- Purpose: Interactive data visualization.
- Why Learn It: Plotly allows for the creation of interactive and web-based visualizations, making it ideal for dashboards and presentations.
- Key Features:
- Interactive plots like scatter, line, bar, and 3D plots.
- Easy integration with web frameworks.
- Dashboards and web applications with Dash.
9. TensorFlow/PyTorch (Optional)
- Purpose: Machine learning and deep learning.
- Why Learn It: If your data analysis involves machine learning, these libraries will help in building, training, and deploying deep learning models.
- Key Features:
- Tensor processing and automatic differentiation.
- Building neural networks.
10. Dask (Optional)
- Purpose: Parallel computing for data analysis.
- Why Learn It: Dask enables scalable data manipulation by parallelizing Pandas operations, making it ideal for big datasets.
- Key Features:
- Works with NumPy, Pandas, and Scikit-learn.
- Handles large data and parallel computations easily.
Focusing on NumPy, Pandas, Matplotlib, and Seaborn will set a strong foundation for basic data analysis.
6 notes
·
View notes
Text
Understanding Outliers in Machine Learning and Data Science

In machine learning and data science, an outlier is like a misfit in a dataset. It's a data point that stands out significantly from the rest of the data. Sometimes, these outliers are errors, while other times, they reveal something truly interesting about the data. Either way, handling outliers is a crucial step in the data preprocessing stage. If left unchecked, they can skew your analysis and even mess up your machine learning models.
In this article, we will dive into:
1. What outliers are and why they matter.
2. How to detect and remove outliers using the Interquartile Range (IQR) method.
3. Using the Z-score method for outlier detection and removal.
4. How the Percentile Method and Winsorization techniques can help handle outliers.
This guide will explain each method in simple terms with Python code examples so that even beginners can follow along.
1. What Are Outliers?
An outlier is a data point that lies far outside the range of most other values in your dataset. For example, in a list of incomes, most people might earn between $30,000 and $70,000, but someone earning $5,000,000 would be an outlier.
Why Are Outliers Important?
Outliers can be problematic or insightful:
Problematic Outliers: Errors in data entry, sensor faults, or sampling issues.
Insightful Outliers: They might indicate fraud, unusual trends, or new patterns.
Types of Outliers
1. Univariate Outliers: These are extreme values in a single variable.
Example: A temperature of 300°F in a dataset about room temperatures.
2. Multivariate Outliers: These involve unusual combinations of values in multiple variables.
Example: A person with an unusually high income but a very low age.
3. Contextual Outliers: These depend on the context.
Example: A high temperature in winter might be an outlier, but not in summer.
2. Outlier Detection and Removal Using the IQR Method
The Interquartile Range (IQR) method is one of the simplest ways to detect outliers. It works by identifying the middle 50% of your data and marking anything that falls far outside this range as an outlier.
Steps:
1. Calculate the 25th percentile (Q1) and 75th percentile (Q3) of your data.
2. Compute the IQR:
{IQR} = Q3 - Q1
Q1 - 1.5 \times \text{IQR}
Q3 + 1.5 \times \text{IQR} ] 4. Anything below the lower bound or above the upper bound is an outlier.
Python Example:
import pandas as pd
# Sample dataset
data = {'Values': [12, 14, 18, 22, 25, 28, 32, 95, 100]}
df = pd.DataFrame(data)
# Calculate Q1, Q3, and IQR
Q1 = df['Values'].quantile(0.25)
Q3 = df['Values'].quantile(0.75)
IQR = Q3 - Q1
# Define the bounds
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
# Identify and remove outliers
outliers = df[(df['Values'] < lower_bound) | (df['Values'] > upper_bound)]
print("Outliers:\n", outliers)
filtered_data = df[(df['Values'] >= lower_bound) & (df['Values'] <= upper_bound)]
print("Filtered Data:\n", filtered_data)
Key Points:
The IQR method is great for univariate datasets.
It works well when the data isn’t skewed or heavily distributed.
3. Outlier Detection and Removal Using the Z-Score Method
The Z-score method measures how far a data point is from the mean, in terms of standard deviations. If a Z-score is greater than a certain threshold (commonly 3 or -3), it is considered an outlier.
Formula:
Z = \frac{(X - \mu)}{\sigma}
is the data point,
is the mean of the dataset,
is the standard deviation.
Python Example:
import numpy as np
# Sample dataset
data = {'Values': [12, 14, 18, 22, 25, 28, 32, 95, 100]}
df = pd.DataFrame(data)
# Calculate mean and standard deviation
mean = df['Values'].mean()
std_dev = df['Values'].std()
# Compute Z-scores
df['Z-Score'] = (df['Values'] - mean) / std_dev
# Identify and remove outliers
threshold = 3
outliers = df[(df['Z-Score'] > threshold) | (df['Z-Score'] < -threshold)]
print("Outliers:\n", outliers)
filtered_data = df[(df['Z-Score'] <= threshold) & (df['Z-Score'] >= -threshold)]
print("Filtered Data:\n", filtered_data)
Key Points:
The Z-score method assumes the data follows a normal distribution.
It may not work well with skewed datasets.
4. Outlier Detection Using the Percentile Method and Winsorization
Percentile Method:
In the percentile method, we define a lower percentile (e.g., 1st percentile) and an upper percentile (e.g., 99th percentile). Any value outside this range is treated as an outlier.
Winsorization:
Winsorization is a technique where outliers are not removed but replaced with the nearest acceptable value.
Python Example:
from scipy.stats.mstats import winsorize
import numpy as np
Sample data
data = [12, 14, 18, 22, 25, 28, 32, 95, 100]
Calculate percentiles
lower_percentile = np.percentile(data, 1)
upper_percentile = np.percentile(data, 99)
Identify outliers
outliers = [x for x in data if x < lower_percentile or x > upper_percentile]
print("Outliers:", outliers)
# Apply Winsorization
winsorized_data = winsorize(data, limits=[0.01, 0.01])
print("Winsorized Data:", list(winsorized_data))
Key Points:
Percentile and Winsorization methods are useful for skewed data.
Winsorization is preferred when data integrity must be preserved.
Final Thoughts
Outliers can be tricky, but understanding how to detect and handle them is a key skill in machine learning and data science. Whether you use the IQR method, Z-score, or Wins
orization, always tailor your approach to the specific dataset you’re working with.
By mastering these techniques, you’ll be able to clean your data effectively and improve the accuracy of your models.
#science#skills#programming#bigdata#books#machinelearning#artificial intelligence#python#machine learning#data centers#outliers#big data#data analysis#data analytics#data scientist#database#datascience#data
3 notes
·
View notes
Text
This is a shameless pitch for my field of work but if you like biology and you like coding...consider bioinformatics as a career 👀 Especially if you live in the US, as it's well-known for its bionformatics scene.
#musings#bioinformatics#stem#computer science#python#biology#i was just thinking about how not a lot of people know that a career like bioinformatics exists#hence my little post#most people i tell my job too just look at me confused like they didnt realize you could mix these fields#and a lot of people studying biology forget about how important it is to have a quantitative skill like math or computer science or physics#simply because the programs dont teach those skills#to do any sort of custom data analysis its important to have quantitative skills#and if you're passionate about genomics especially...and dna and the genome...then this may be the field for you!#good money especially in the states#of course a graduate degree is needed#masters minimum phd preferred#i have a masters
57 notes
·
View notes
Text
What Are the Qualifications for a Data Scientist?
In today's data-driven world, the role of a data scientist has become one of the most coveted career paths. With businesses relying on data for decision-making, understanding customer behavior, and improving products, the demand for skilled professionals who can analyze, interpret, and extract value from data is at an all-time high. If you're wondering what qualifications are needed to become a successful data scientist, how DataCouncil can help you get there, and why a data science course in Pune is a great option, this blog has the answers.
The Key Qualifications for a Data Scientist
To succeed as a data scientist, a mix of technical skills, education, and hands-on experience is essential. Here are the core qualifications required:
1. Educational Background
A strong foundation in mathematics, statistics, or computer science is typically expected. Most data scientists hold at least a bachelor’s degree in one of these fields, with many pursuing higher education such as a master's or a Ph.D. A data science course in Pune with DataCouncil can bridge this gap, offering the academic and practical knowledge required for a strong start in the industry.
2. Proficiency in Programming Languages
Programming is at the heart of data science. You need to be comfortable with languages like Python, R, and SQL, which are widely used for data analysis, machine learning, and database management. A comprehensive data science course in Pune will teach these programming skills from scratch, ensuring you become proficient in coding for data science tasks.
3. Understanding of Machine Learning
Data scientists must have a solid grasp of machine learning techniques and algorithms such as regression, clustering, and decision trees. By enrolling in a DataCouncil course, you'll learn how to implement machine learning models to analyze data and make predictions, an essential qualification for landing a data science job.
4. Data Wrangling Skills
Raw data is often messy and unstructured, and a good data scientist needs to be adept at cleaning and processing data before it can be analyzed. DataCouncil's data science course in Pune includes practical training in tools like Pandas and Numpy for effective data wrangling, helping you develop a strong skill set in this critical area.
5. Statistical Knowledge
Statistical analysis forms the backbone of data science. Knowledge of probability, hypothesis testing, and statistical modeling allows data scientists to draw meaningful insights from data. A structured data science course in Pune offers the theoretical and practical aspects of statistics required to excel.
6. Communication and Data Visualization Skills
Being able to explain your findings in a clear and concise manner is crucial. Data scientists often need to communicate with non-technical stakeholders, making tools like Tableau, Power BI, and Matplotlib essential for creating insightful visualizations. DataCouncil’s data science course in Pune includes modules on data visualization, which can help you present data in a way that’s easy to understand.
7. Domain Knowledge
Apart from technical skills, understanding the industry you work in is a major asset. Whether it’s healthcare, finance, or e-commerce, knowing how data applies within your industry will set you apart from the competition. DataCouncil's data science course in Pune is designed to offer case studies from multiple industries, helping students gain domain-specific insights.
Why Choose DataCouncil for a Data Science Course in Pune?
If you're looking to build a successful career as a data scientist, enrolling in a data science course in Pune with DataCouncil can be your first step toward reaching your goals. Here’s why DataCouncil is the ideal choice:
Comprehensive Curriculum: The course covers everything from the basics of data science to advanced machine learning techniques.
Hands-On Projects: You'll work on real-world projects that mimic the challenges faced by data scientists in various industries.
Experienced Faculty: Learn from industry professionals who have years of experience in data science and analytics.
100% Placement Support: DataCouncil provides job assistance to help you land a data science job in Pune or anywhere else, making it a great investment in your future.
Flexible Learning Options: With both weekday and weekend batches, DataCouncil ensures that you can learn at your own pace without compromising your current commitments.
Conclusion
Becoming a data scientist requires a combination of technical expertise, analytical skills, and industry knowledge. By enrolling in a data science course in Pune with DataCouncil, you can gain all the qualifications you need to thrive in this exciting field. Whether you're a fresher looking to start your career or a professional wanting to upskill, this course will equip you with the knowledge, skills, and practical experience to succeed as a data scientist.
Explore DataCouncil’s offerings today and take the first step toward unlocking a rewarding career in data science! Looking for the best data science course in Pune? DataCouncil offers comprehensive data science classes in Pune, designed to equip you with the skills to excel in this booming field. Our data science course in Pune covers everything from data analysis to machine learning, with competitive data science course fees in Pune. We provide job-oriented programs, making us the best institute for data science in Pune with placement support. Explore online data science training in Pune and take your career to new heights!
#In today's data-driven world#the role of a data scientist has become one of the most coveted career paths. With businesses relying on data for decision-making#understanding customer behavior#and improving products#the demand for skilled professionals who can analyze#interpret#and extract value from data is at an all-time high. If you're wondering what qualifications are needed to become a successful data scientis#how DataCouncil can help you get there#and why a data science course in Pune is a great option#this blog has the answers.#The Key Qualifications for a Data Scientist#To succeed as a data scientist#a mix of technical skills#education#and hands-on experience is essential. Here are the core qualifications required:#1. Educational Background#A strong foundation in mathematics#statistics#or computer science is typically expected. Most data scientists hold at least a bachelor’s degree in one of these fields#with many pursuing higher education such as a master's or a Ph.D. A data science course in Pune with DataCouncil can bridge this gap#offering the academic and practical knowledge required for a strong start in the industry.#2. Proficiency in Programming Languages#Programming is at the heart of data science. You need to be comfortable with languages like Python#R#and SQL#which are widely used for data analysis#machine learning#and database management. A comprehensive data science course in Pune will teach these programming skills from scratch#ensuring you become proficient in coding for data science tasks.#3. Understanding of Machine Learning
3 notes
·
View notes
Text

Unlock your potential in programming with the exceptional Python Course in Delhi, offered by Brillica Services. This Python Programming Course in Delhi is designed for both beginners and experienced programmers, ensuring top-notch Python Coaching in Delhi. Whether you aim to launch a career in software development, enhance your skills, or explore specialized areas like data science and web development, our course is the perfect starting point.
Our Python Course in Delhi emphasizes practical, hands-on learning. At Brillica Services, we believe in learning by doing. Our Python Classes in Delhi revolve around real-world projects and case studies, allowing you to apply theoretical knowledge to practical scenarios. Guided by industry experts, our Python Training Institute in Delhi ensures you gain valuable insights and skills that are highly regarded in the job market.
2 notes
·
View notes
Text
First time that I'm seeing in practice why Python is so widely used in Data Analysis. I have an Excel sheet with 8 million rows, that's impossible to open. I can't analyze anything without the program crashing.
I have even more respect for Python now.
35 notes
·
View notes
Text

🚀 Ready to become a Data Science pro? Join our comprehensive Data Science Course and unlock the power of data! 📊💡
🔍 Learn: Excel PowerBi Python & R Machine Learning Data Visualization Real-world Projects
👨🏫 Taught by industry experts 💼 Career support & networking
3 notes
·
View notes
Text
Girl wake up, new project idea just dropped.
Source: etymologynerd on Instagram
#data science#python#sentiment analysis#coding#code project#projects#engineering#stem#dating#relatable
2 notes
·
View notes
Text

Learn Python To Secure Your Future In Data Science
Python is one of the most important coding or programming languages that is used by more than 8 million programmers as their main programming language.Now let's talk about how to learn Python. Python language is the basic and the easiest language compared to any other language.
To more info Visit us :- https://www.sssi.in/blog/engineering/learn-python-to-secure-your-future
#learn python#online training python#python developers#python basics#learn python for data analysis#python programming#coding python for beginners
2 notes
·
View notes
Text
Hey! and welcome back!
As Uni is about to begin in a few days....I upgraded to a third monitor! Also!! I job a Data entry job! Big things moving forward :)
Let me introduce myself;
I'm Mick, (she/her) and I currently study Data Analytics. I'll be 26 in July and I love to read and play video games in my free time. I also like to watch football (LIVERPOOL xx)
Im currently taking the time to learn Excel and Python. However, I know for school I'll be learning Python, SQL and maybe some other things.
FOLLOW me along on this journey and if you have any questions please ask!
#codeblr#python#coding#data analytics#study blog#study motivation#studyblr#student life#excel#student#physics#maths#pc setup#data analysis#data entry work#data entry projects#data scientist#study aesthetic
28 notes
·
View notes
Text
Next Generation Sequencing (NGS) Data Analysis Online Training
🚀 Unlock the power of Next Generation Sequencing (NGS) and elevate your bioinformatics skills with our upcoming training course! ⭐ Why join us? In today’s rapidly evolving world of life sciences, mastering NGS data analysis is essential for cutting-edge research. Our comprehensive training programs are designed to equip you with the skills needed to excel in bioinformatics, whether you’re a beginner or looking to advance your expertise. Registrations Open: ✅ Next-Generation Sequencing Data Analysis ✅ Python & Biopython for Bioinformatics 🗓 Dates NGS Data Analysis: September 17 - October 17, 2024 Python & Biopython: September 17 - October 03, 2024 ⏰ Time: 7:00 PM - 8:00 PM IST 🗓 Registration Closes: September 15, 2024 💻 Mode: Online 🎯 Ready to make a difference in your research? Don't miss out on this opportunity to enhance your bioinformatics skills and open new doors in your career. 👉 𝐒𝐞𝐜𝐮𝐫𝐞 𝐘𝐨𝐮𝐫 𝐒𝐩𝐨𝐭 𝐓𝐨𝐝𝐚𝐲: https://lnkd.in/grUEakiP For more details/queries, contact: [email protected] Feel free to reach out with any questions! #Bioinformatics#NGSDataAnalysis#Python hashtag#Biopython #TrainingCourses#CareerGrowth#BioinformaticsEducation#Students #OnlineCourses #BioinformaticsTools #ComputationalBiology #ScienceInnovation

#bioinformatics#next generation sequencing#ngs#genomics!#transcriptomics#omics#online courses#handsontraining#python#data analysis
2 notes
·
View notes
Text
Hyperparameter tuning in machine learning
The performance of a machine learning model in the dynamic world of artificial intelligence is crucial, we have various algorithms for finding a solution to a business problem. Some algorithms like linear regression , logistic regression have parameters whose values are fixed so we have to use those models without any modifications for training a model but there are some algorithms out there where the values of parameters are not fixed.
Here's a complete guide to Hyperparameter tuning in machine learning in Python!
#datascience #dataanalytics #dataanalysis #statistics #machinelearning #python #deeplearning #supervisedlearning #unsupervisedlearning
#machine learning#data analysis#data science#artificial intelligence#data analytics#deep learning#python#statistics#unsupervised learning#feature selection
3 notes
·
View notes
Text
Speechy Research Devlog: Some New Tools & New Discoveries
Hey everyone, so it is about 8:30pm and I am sure that by the time I write this it will be nearly 9 but I wanted to update everyone who is following my Speechy research on here. I programmed 2 new programs today, a Prosodic Pitch Analyzer (PPA), and an RMS Energy Analyzer using my handy-dandy new favorite library librosa.
Prosodic Pitch Analyzer

The PPA calculates the fundamental frequency (F0) or pitch of an audio signal and visualizes it using a line plot. This is a useful tool for analyzing prosodic features of speech such as intonation, stress, and emphasis.
The code takes an audio file as input, processes it using the librosa library to extract the fundamental frequency / pitch, and then plots the pitch contour using matplotlib.
The output plot shows the pitch contour of the audio signal over time, with changes in pitch represented by changes in the vertical position of the line. The plot can be used to identify patterns in the pitch contour, such as rising or falling intonation, and to compare the pitch contour of different audio signals. The prosodic pitch analyzer can be used to detect changes in pitch, which can be indicative of a neurological speech disorder. For example, a person with ataxic dysarthria, which is caused by damage to the cerebellum, may have difficulty controlling the pitch and loudness of their voice, resulting in variations in pitch that are not typical of normal speech. By analyzing changes in pitch using a tool like the prosodic pitch analyzer, it is possible to identify patterns that are indicative of certain neurological disorders. This information can be used by clinicians to diagnose and treat speech disorders, and to monitor progress in speech therapy.
RMS Energy Analyzer
The program that calculates the energy of a person's speech processes an audio file and calculates the energy of the signal at each time frame. This can be useful for analyzing changes in a person's speech over time, as well as for detecting changes in the intensity or loudness of the speech.
The program uses the librosa library to load and process the audio file, and then calculates the energy of each frame using the root-mean-square (RMS) energy of the signal. The energy values are then plotted over time using the matplotlib library, allowing you to visualize changes in the energy of the speech.
By analyzing changes in energy over time, you can gain insight into how the speech patterns of people with these disorders may differ from those without.
Analysis with PPA
The research that I've been focused on today primarily looked at the speech recording of myself, the mid-stage HD patient with chorea, the late-stage HD patient (EOL), and a young girl with aphasia.

The patient with aphasia had slurred speech and varied rising and falling much like an AD patient. Earlier I saw her ROS and was surprised at the differences between my rate of speech and hers (aphasia v AD)

My rate of speech
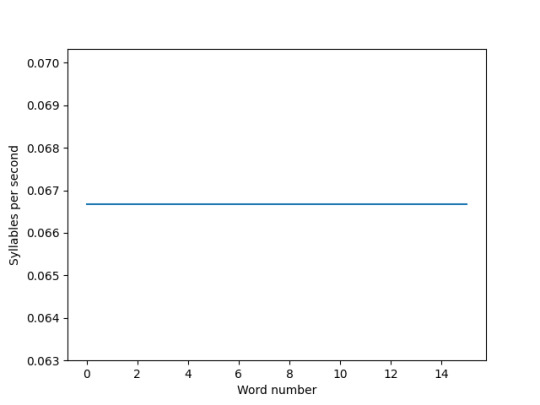
The girl with aphasia's rate of speech
So I decided to compare our speech pitches as well and this is what ours looked like side-by-side.
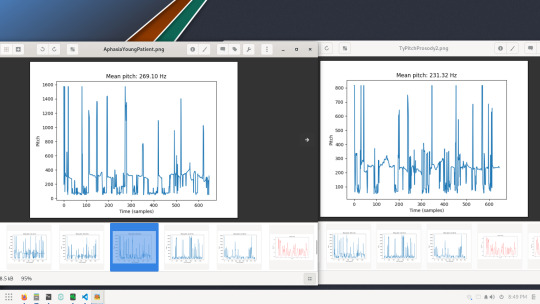
Hers is on the left, mine on the right.
Her pitch seemed to start off higher (unstable though) like mine, but mine fell during my recording and wobbled for a while. She had some drastic pitch differences but mine had around 16 peaks, where hers had around 18-19. Her latter peaks weren't as high frequency as mine, as my frequency peaks ended up mostly very high in the 1600hz or around 1000hz. There is quite a bit of instability in both our pitches though.
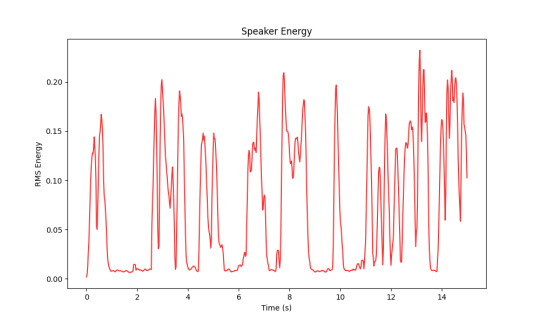
Her energy levels in the 15 seconds of speech started off at high-mid energy, then dropped around 1 second in until almost 3 seconds, shot back up and varied in high, high-mid energy, then had several "dips, and higher moments of energy. At the end around 13 seconds she got a huge boost of "gusto" (well.. energy). She had around 7 breaths (noted by the dips / flatlines)

This was mine. It seems like as the 15 seconds went on I started to run out of steam. I wasn't able to keep my energy higher. Mine had around 11 breaths so I was running out of breath eg having a breathier voice more than she was.
Research Conclusion for Today
Although we have quite a bit in common with our speech energy and pitches, our rate of speaking isn't. She used more syllables at a constant rate which made it pretty obvious she had a lot of slurring / overshooting, mine was a lot less syllables and rate of speech was quite slow and varied more than hers. This illustrates my cognitive difficulties and use of placeholder words along with slight slurring.
As far as pitch, seems that we had similar issues with pitch throughout the 15 second clips, mine spiked in the latter when I was getting "wore out" and hers spiked earlier when she had more energy.
Our energy levels differ because although she had moments of energy, I tuckered out pretty quickly.
I hope this helps shed some insight into both aphasia patients and ataxic dysarthria / HD patients speech / some cognitive differences.
Will update again tomorrow when I am done with another day of programming and research!
#python#python developer#python development#data science#data scientist#data processing#data scraping#web scraping#speech pathology#speech disorder#ataxic dysarthria#ataxia#huntingtons disease#stroke#dementia#aphasia#data analyst#data analysis#medical research#medical technology#medical#biotechnology#artificial intelligence#sound processing#sound engineering#machine learning#ai#cognitive issues
12 notes
·
View notes