#Correlation and Regression Analysis Training
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr was the first site to host the blog for President Barack Obama in 2011.
Text
Develop a strong foundation in basic statistics for data analysis and decision-making. Enhance your analytical skills. Enroll in our training program today!
0 notes
Text
Covid and 9/11 made people further suspect they’re being lied to about childhood injections (Updated 10/16/24)
James Hill, MD
Oct 15, 2024
Transcript
An October 2024 Substack article entitled Here are The True Intentions Behind Vaccinations! posits reasons vaccines are strongly coerced and mandated in developed nations without full informed consent, placebo-controlled safety testing, or manufacturer liability.
Get vaccinated!
James Hill, MD
November 3, 2022
Read full story
These reasons might relate to the absurd demand you obtain a religious exemption to avoid potentially deadly shots.
How exemptions to injection mandates train you to submit to deadly religious laws
James Hill, MD
May 4
Read full story
I’m reposting the article below with added commentary.Disclaimer: As an American physician, I’m supposed to tell people to follow the CDC’s vaccine recommendatons. The article’s reposting below is for public consideration and repudiation where appropriate and does not imply endorsement or agreement with its content.
Here is the article:
Using logic, evidence, and facts, one can reasonably argue that the true intents of vaccinations are: 1. To create chronic health conditions - such as diabetes, food allergies, asthma, thyroid issues, intestinal disease, etc., all of which have skyrocketed in recent years - thereby ensuring customers for life for Big Pharma. All vaccine package inserts state that their products are capable of causing a wide range of chronic health conditions, and, if you were born after 1990 - the year the vaccine schedule dramatically increased - your chances of having a chronic health condition are 54%. This generation of intensively vaccinated children is the most chronically ill in history and is not expected to outlive their parents.
Please post any arguments against this in the comments below.
Although a strong correlation between vaccinations and chronic diseases does not necessarily indicate a causal relationship, do any studies with transparent data permit us to dismiss vaccines as a contributing cause of these conditions?
Unjabbed children are healthier: studies
Credit: James Lyons-Weiler PhD and Paul Thomas MD
Here are six studies suggesting unvaccinated children are significantly healthier than vaccinated ones:
Ewing GE. What is regressive autism and why does it occur? Is it the consequence of multi-systemic dysfunction affecting the elimination of heavy metals and the ability to regulate neural temperature? N Am J Med Sci. 2009 Jul;1(2):28-47.“Sudden Infant Death Syndrome has been largely eradicated following withdrawal of pertussis vaccine in Sweden and Japan.”
Mawson AR, Ray BD, Bhuiyan AR, Jacob B (2017). Pilot comparative study on the health of vaccinated and unvaccinated 6- to 12-year old U.S. children. Journal of Translational Science, 3(3).“While vaccination remained significantly associated with NDD [neurodevelopmental disorders] after controlling for other factors, preterm birth coupled with vaccination was associated with an apparent synergistic increase in the odds of NDD.”
Hooker BS, Miller NZ. Analysis of health outcomes in vaccinated and unvaccinated children: Developmental delays, asthma, ear infections and gastrointestinal disorders. SAGE Open Med. 2020 May 27;8:2050312120925344.“In this study, which only allowed for the calculation of unadjusted observational associations, higher ORs [odds ratios] were observed within the vaccinated versus unvaccinated group for developmental delays, asthma and ear infections. Further study is necessary to understand the full spectrum of health effects associated with childhood vaccination.”
Goldman GS, Miller NZ (2023) Reaffirming a Positive Correlation Between Number of Vaccine Doses and Infant Mortality Rates: A Response to Critics. Cureus 15(2): e34566.“A positive correlation between the number of vaccine doses and IMRs [infant mortality rates] is detectable in the most highly developed nations but attenuated in the background noise of nations with heterogeneous socioeconomic variables that contribute to high rates of infant mortality, such as malnutrition, poverty, and substandard health care.”
Correction: Lyons-Weiler J, Thomas P. Relative Incidence of Office Visits and Cumulative Rates of Billed Diagnoses along the Axis of Vaccination. Int. J. Environ. Res. Public Health 2020, 17, 8674 (article corrected, then retracted)“The data indicate that unvaccinated children in the practice are not unhealthier than the vaccinated and indeed the overall results may indicate that the unvaccinated pediatric patients in this practice are healthier overall than the vaccinated.“
Geier, et al. A two-phase study evaluating the relationship between Thimerosal-containing vaccine administration and the risk for an autism spectrum disorder diagnosis in the United States. Translational Neurodegeneration 2013, 2:25.“[T]he present study provides new epidemiological evidence supporting an association between increasing organic-Hg [mercury] exposure from Thimerosal-containing childhood vaccines and the subsequent risk of an ASD diagnosis.“
3 notes
·
View notes
Text
From Curious Novice to Data Enthusiast: My Data Science Adventure
I've always been fascinated by data science, a field that seamlessly blends technology, mathematics, and curiosity. In this article, I want to take you on a journey—my journey—from being a curious novice to becoming a passionate data enthusiast. Together, let's explore the thrilling world of data science, and I'll share the steps I took to immerse myself in this captivating realm of knowledge.

The Spark: Discovering the Potential of Data Science
The moment I stumbled upon data science, I felt a spark of inspiration. Witnessing its impact across various industries, from healthcare and finance to marketing and entertainment, I couldn't help but be drawn to this innovative field. The ability to extract critical insights from vast amounts of data and uncover meaningful patterns fascinated me, prompting me to dive deeper into the world of data science.
Laying the Foundation: The Importance of Learning the Basics
To embark on this data science adventure, I quickly realized the importance of building a strong foundation. Learning the basics of statistics, programming, and mathematics became my priority. Understanding statistical concepts and techniques enabled me to make sense of data distributions, correlations, and significance levels. Programming languages like Python and R became essential tools for data manipulation, analysis, and visualization, while a solid grasp of mathematical principles empowered me to create and evaluate predictive models.
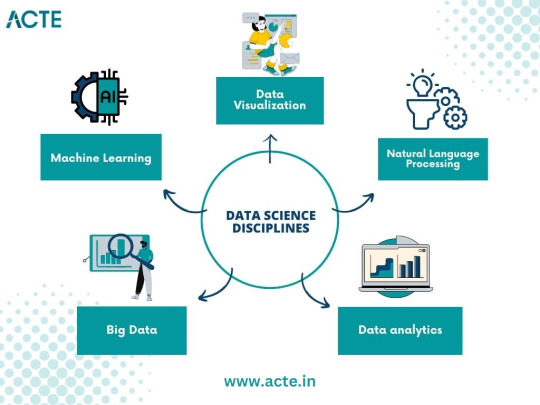
The Quest for Knowledge: Exploring Various Data Science Disciplines
A. Machine Learning: Unraveling the Power of Predictive Models
Machine learning, a prominent discipline within data science, captivated me with its ability to unlock the potential of predictive models. I delved into the fundamentals, understanding the underlying algorithms that power these models. Supervised learning, where data with labels is used to train prediction models, and unsupervised learning, which uncovers hidden patterns within unlabeled data, intrigued me. Exploring concepts like regression, classification, clustering, and dimensionality reduction deepened my understanding of this powerful field.
B. Data Visualization: Telling Stories with Data
In my data science journey, I discovered the importance of effectively visualizing data to convey meaningful stories. Navigating through various visualization tools and techniques, such as creating dynamic charts, interactive dashboards, and compelling infographics, allowed me to unlock the hidden narratives within datasets. Visualizations became a medium to communicate complex ideas succinctly, enabling stakeholders to understand insights effortlessly.
C. Big Data: Mastering the Analysis of Vast Amounts of Information
The advent of big data challenged traditional data analysis approaches. To conquer this challenge, I dived into the world of big data, understanding its nuances and exploring techniques for efficient analysis. Uncovering the intricacies of distributed systems, parallel processing, and data storage frameworks empowered me to handle massive volumes of information effectively. With tools like Apache Hadoop and Spark, I was able to mine valuable insights from colossal datasets.
D. Natural Language Processing: Extracting Insights from Textual Data
Textual data surrounds us in the digital age, and the realm of natural language processing fascinated me. I delved into techniques for processing and analyzing unstructured text data, uncovering insights from tweets, customer reviews, news articles, and more. Understanding concepts like sentiment analysis, topic modeling, and named entity recognition allowed me to extract valuable information from written text, revolutionizing industries like sentiment analysis, customer service, and content recommendation systems.
Building the Arsenal: Acquiring Data Science Skills and Tools
Acquiring essential skills and familiarizing myself with relevant tools played a crucial role in my data science journey. Programming languages like Python and R became my companions, enabling me to manipulate, analyze, and model data efficiently. Additionally, I explored popular data science libraries and frameworks such as TensorFlow, Scikit-learn, Pandas, and NumPy, which expedited the development and deployment of machine learning models. The arsenal of skills and tools I accumulated became my assets in the quest for data-driven insights.
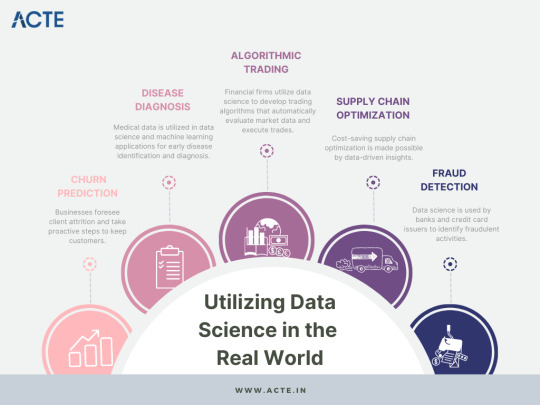
The Real-World Challenge: Applying Data Science in Practice
Data science is not just an academic pursuit but rather a practical discipline aimed at solving real-world problems. Throughout my journey, I sought to identify such problems and apply data science methodologies to provide practical solutions. From predicting customer churn to optimizing supply chain logistics, the application of data science proved transformative in various domains. Sharing success stories of leveraging data science in practice inspires others to realize the power of this field.
Cultivating Curiosity: Continuous Learning and Skill Enhancement
Embracing a growth mindset is paramount in the world of data science. The field is rapidly evolving, with new algorithms, techniques, and tools emerging frequently. To stay ahead, it is essential to cultivate curiosity and foster a continuous learning mindset. Keeping abreast of the latest research papers, attending data science conferences, and engaging in data science courses nurtures personal and professional growth. The journey to becoming a data enthusiast is a lifelong pursuit.
Joining the Community: Networking and Collaboration
Being part of the data science community is a catalyst for growth and inspiration. Engaging with like-minded individuals, sharing knowledge, and collaborating on projects enhances the learning experience. Joining online forums, participating in Kaggle competitions, and attending meetups provides opportunities to exchange ideas, solve challenges collectively, and foster invaluable connections within the data science community.
Overcoming Obstacles: Dealing with Common Data Science Challenges
Data science, like any discipline, presents its own set of challenges. From data cleaning and preprocessing to model selection and evaluation, obstacles arise at each stage of the data science pipeline. Strategies and tips to overcome these challenges, such as building reliable pipelines, conducting robust experiments, and leveraging cross-validation techniques, are indispensable in maintaining motivation and achieving success in the data science journey.
Balancing Act: Building a Career in Data Science alongside Other Commitments
For many aspiring data scientists, the pursuit of knowledge and skills must coexist with other commitments, such as full-time jobs and personal responsibilities. Effectively managing time and developing a structured learning plan is crucial in striking a balance. Tips such as identifying pockets of dedicated learning time, breaking down complex concepts into manageable chunks, and seeking mentorships or online communities can empower individuals to navigate the data science journey while juggling other responsibilities.
Ethical Considerations: Navigating the World of Data Responsibly
As data scientists, we must navigate the world of data responsibly, being mindful of the ethical considerations inherent in this field. Safeguarding privacy, addressing bias in algorithms, and ensuring transparency in data-driven decision-making are critical principles. Exploring topics such as algorithmic fairness, data anonymization techniques, and the societal impact of data science encourages responsible and ethical practices in a rapidly evolving digital landscape.
Embarking on a data science adventure from a curious novice to a passionate data enthusiast is an exhilarating and rewarding journey. By laying a foundation of knowledge, exploring various data science disciplines, acquiring essential skills and tools, and engaging in continuous learning, one can conquer challenges, build a successful career, and have a good influence on the data science community. It's a journey that never truly ends, as data continues to evolve and offer exciting opportunities for discovery and innovation. So, join me in your data science adventure, and let the exploration begin!
#data science#data analytics#data visualization#big data#machine learning#artificial intelligence#education#information
17 notes
·
View notes
Text
Optimizing Business Operations with Advanced Machine Learning Services
Machine learning has gained popularity in recent years thanks to the adoption of the technology. On the other hand, traditional machine learning necessitates managing data pipelines, robust server maintenance, and the creation of a model for machine learning from scratch, among other technical infrastructure management tasks. Many of these processes are automated by machine learning service which enables businesses to use a platform much more quickly.
What do you understand of Machine learning?
Deep learning and neural networks applied to data are examples of machine learning, a branch of artificial intelligence focused on data-driven learning. It begins with a dataset and gains the ability to extract relevant data from it.
Machine learning technologies facilitate computer vision, speech recognition, face identification, predictive analytics, and more. They also make regression more accurate.
For what purpose is it used?
Many use cases, such as churn avoidance and support ticket categorization make use of MLaaS. The vital thing about MLaaS is it makes it possible to delegate machine learning's laborious tasks. This implies that you won't need to install software, configure servers, maintain infrastructure, and other related tasks. All you have to do is choose the column to be predicted, connect the pertinent training data, and let the software do its magic.
Natural Language Interpretation
By examining social media postings and the tone of consumer reviews, natural language processing aids businesses in better understanding their clientele. the ml services enable them to make more informed choices about selling their goods and services, including providing automated help or highlighting superior substitutes. Machine learning can categorize incoming customer inquiries into distinct groups, enabling businesses to allocate their resources and time.
Predicting
Another use of machine learning is forecasting, which allows businesses to project future occurrences based on existing data. For example, businesses that need to estimate the costs of their goods, services, or clients might utilize MLaaS for cost modelling.
Data Investigation
Investigating variables, examining correlations between variables, and displaying associations are all part of data exploration. Businesses may generate informed suggestions and contextualize vital data using machine learning.
Data Inconsistency
Another crucial component of machine learning is anomaly detection, which finds anomalous occurrences like fraud. This technology is especially helpful for businesses that lack the means or know-how to create their own systems for identifying anomalies.
Examining And Comprehending Datasets
Machine learning provides an alternative to manual dataset searching and comprehension by converting text searches into SQL queries using algorithms trained on millions of samples. Regression analysis use to determine the correlations between variables, such as those affecting sales and customer satisfaction from various product attributes or advertising channels.
Recognition Of Images
One area of machine learning that is very useful for mobile apps, security, and healthcare is image recognition. Businesses utilize recommendation engines to promote music or goods to consumers. While some companies have used picture recognition to create lucrative mobile applications.
Your understanding of AI will drastically shift. They used to believe that AI was only beyond the financial reach of large corporations. However, thanks to services anyone may now use this technology.
2 notes
·
View notes
Text
Essential Predictive Analytics Techniques
With the growing usage of big data analytics, predictive analytics uses a broad and highly diverse array of approaches to assist enterprises in forecasting outcomes. Examples of predictive analytics include deep learning, neural networks, machine learning, text analysis, and artificial intelligence.
Predictive analytics trends of today reflect existing Big Data trends. There needs to be more distinction between the software tools utilized in predictive analytics and big data analytics solutions. In summary, big data and predictive analytics technologies are closely linked, if not identical.
Predictive analytics approaches are used to evaluate a person's creditworthiness, rework marketing strategies, predict the contents of text documents, forecast weather, and create safe self-driving cars with varying degrees of success.
Predictive Analytics- Meaning
By evaluating collected data, predictive analytics is the discipline of forecasting future trends. Organizations can modify their marketing and operational strategies to serve better by gaining knowledge of historical trends. In addition to the functional enhancements, businesses benefit in crucial areas like inventory control and fraud detection.
Machine learning and predictive analytics are closely related. Regardless of the precise method, a company may use, the overall procedure starts with an algorithm that learns through access to a known result (such as a customer purchase).
The training algorithms use the data to learn how to forecast outcomes, eventually creating a model that is ready for use and can take additional input variables, like the day and the weather.
Employing predictive analytics significantly increases an organization's productivity, profitability, and flexibility. Let us look at the techniques used in predictive analytics.
Techniques of Predictive Analytics
Making predictions based on existing and past data patterns requires using several statistical approaches, data mining, modeling, machine learning, and artificial intelligence. Machine learning techniques, including classification models, regression models, and neural networks, are used to make these predictions.
Data Mining
To find anomalies, trends, and correlations in massive datasets, data mining is a technique that combines statistics with machine learning. Businesses can use this method to transform raw data into business intelligence, including current data insights and forecasts that help decision-making.
Data mining is sifting through redundant, noisy, unstructured data to find patterns that reveal insightful information. A form of data mining methodology called exploratory data analysis (EDA) includes examining datasets to identify and summarize their fundamental properties, frequently using visual techniques.
EDA focuses on objectively probing the facts without any expectations; it does not entail hypothesis testing or the deliberate search for a solution. On the other hand, traditional data mining focuses on extracting insights from the data or addressing a specific business problem.
Data Warehousing
Most extensive data mining projects start with data warehousing. An example of a data management system is a data warehouse created to facilitate and assist business intelligence initiatives. This is accomplished by centralizing and combining several data sources, including transactional data from POS (point of sale) systems and application log files.
A data warehouse typically includes a relational database for storing and retrieving data, an ETL (Extract, Transfer, Load) pipeline for preparing the data for analysis, statistical analysis tools, and client analysis tools for presenting the data to clients.
Clustering
One of the most often used data mining techniques is clustering, which divides a massive dataset into smaller subsets by categorizing objects based on their similarity into groups.
When consumers are grouped together based on shared purchasing patterns or lifetime value, customer segments are created, allowing the company to scale up targeted marketing campaigns.
Hard clustering entails the categorization of data points directly. Instead of assigning a data point to a cluster, soft clustering gives it a likelihood that it belongs in one or more clusters.
Classification
A prediction approach called classification involves estimating the likelihood that a given item falls into a particular category. A multiclass classification problem has more than two classes, unlike a binary classification problem, which only has two types.
Classification models produce a serial number, usually called confidence, that reflects the likelihood that an observation belongs to a specific class. The class with the highest probability can represent a predicted probability as a class label.
Spam filters, which categorize incoming emails as "spam" or "not spam" based on predetermined criteria, and fraud detection algorithms, which highlight suspicious transactions, are the most prevalent examples of categorization in a business use case.
Regression Model
When a company needs to forecast a numerical number, such as how long a potential customer will wait to cancel an airline reservation or how much money they will spend on auto payments over time, they can use a regression method.
For instance, linear regression is a popular regression technique that searches for a correlation between two variables. Regression algorithms of this type look for patterns that foretell correlations between variables, such as the association between consumer spending and the amount of time spent browsing an online store.
Neural Networks
Neural networks are data processing methods with biological influences that use historical and present data to forecast future values. They can uncover intricate relationships buried in the data because of their design, which mimics the brain's mechanisms for pattern recognition.
They have several layers that take input (input layer), calculate predictions (hidden layer), and provide output (output layer) in the form of a single prediction. They are frequently used for applications like image recognition and patient diagnostics.
Decision Trees
A decision tree is a graphic diagram that looks like an upside-down tree. Starting at the "roots," one walks through a continuously narrowing range of alternatives, each illustrating a possible decision conclusion. Decision trees may handle various categorization issues, but they can resolve many more complicated issues when used with predictive analytics.
An airline, for instance, would be interested in learning the optimal time to travel to a new location it intends to serve weekly. Along with knowing what pricing to charge for such a flight, it might also want to know which client groups to cater to. The airline can utilize a decision tree to acquire insight into the effects of selling tickets to destination x at price point y while focusing on audience z, given these criteria.
Logistics Regression
It is used when determining the likelihood of success in terms of Yes or No, Success or Failure. We can utilize this model when the dependent variable has a binary (Yes/No) nature.
Since it uses a non-linear log to predict the odds ratio, it may handle multiple relationships without requiring a linear link between the variables, unlike a linear model. Large sample sizes are also necessary to predict future results.
Ordinal logistic regression is used when the dependent variable's value is ordinal, and multinomial logistic regression is used when the dependent variable's value is multiclass.
Time Series Model
Based on past data, time series are used to forecast the future behavior of variables. Typically, a stochastic process called Y(t), which denotes a series of random variables, are used to model these models.
A time series might have the frequency of annual (annual budgets), quarterly (sales), monthly (expenses), or daily (daily expenses) (Stock Prices). It is referred to as univariate time series forecasting if you utilize the time series' past values to predict future discounts. It is also referred to as multivariate time series forecasting if you include exogenous variables.
The most popular time series model that can be created in Python is called ARIMA, or Auto Regressive Integrated Moving Average, to anticipate future results. It's a forecasting technique based on the straightforward notion that data from time series' initial values provides valuable information.
In Conclusion-
Although predictive analytics techniques have had their fair share of critiques, including the claim that computers or algorithms cannot foretell the future, predictive analytics is now extensively employed in virtually every industry. As we gather more and more data, we can anticipate future outcomes with a certain level of accuracy. This makes it possible for institutions and enterprises to make wise judgments.
Implementing Predictive Analytics is essential for anybody searching for company growth with data analytics services since it has several use cases in every conceivable industry. Contact us at SG Analytics if you want to take full advantage of predictive analytics for your business growth.
2 notes
·
View notes
Text

In today’s data-driven world, businesses rely heavily on data analytics to make informed decisions, forecast trends, and gain competitive advantages. With industries generating vast amounts of data, the demand for skilled data analysts is skyrocketing. If you're seeking to build a future-proof career, enrolling in the best Data Analytics course is your first step. And when it comes to quality education, the best Data Analytics institute in Laxmi Nagar is setting benchmarks in delivering industry-oriented training.
Why Choose Data Analytics as a Career?
Data Analytics is not just a trend—it's the backbone of decision-making across industries like finance, healthcare, e-commerce, logistics, and marketing. The ability to analyze, interpret, and visualize data can open doors to high-paying job roles like Data Analyst, Business Analyst, Data Scientist, and Data Engineer. As the field continues to evolve with AI and machine learning, professionals with data expertise are in constant demand.
What Makes the Best Data Analytics Course in Laxmi Nagar Stand Out?
The best Data Analytics course in Laxmi Nagar is designed to provide practical, hands-on learning with real-world projects. The course is structured for beginners as well as working professionals looking to upskill. Delivered by certified trainers, the program focuses on building analytical thinking, tool proficiency, and business understanding.
Course Modules Covered in Data Analytics Training:
Introduction to Data Analytics
Basics of data analysis and its importance
Career scope in analytics
Excel for Data Analytics
Data formatting, functions, pivot tables, charts
Statistical analysis using Excel
SQL for Data Handling
Database concepts
Query writing, joins, subqueries, and functions
Python for Data Analytics
Data types, loops, functions
Libraries like NumPy, Pandas, Matplotlib, Seaborn
Statistics & Probability
Descriptive & inferential statistics
Hypothesis testing, correlation, regression
Data Visualization Tools
Power BI or Tableau
Creating dashboards and interactive reports
Machine Learning Basics
Supervised vs unsupervised learning
Introduction to algorithms like linear regression, clustering, and decision trees
Capstone Project
Hands-on project based on real-time datasets
End-to-end analysis and reporting
Soft Skills & Interview Preparation
Resume building, mock interviews, and case studies
Why Choose the Best Data Analytics Institute in Laxmi Nagar?
Laxmi Nagar has emerged as a hub for IT and analytics training. The best Data Analytics institute in Laxmi Nagar offers flexible batch timings, expert mentorship, modern labs, and placement assistance. Institutes like DICS prioritize practical exposure, industry certifications, and grooming sessions to ensure you’re job-ready from day one.
#DataAnalyticsCourse#BestDataAnalyticsInstitute#DataScienceTraining#AnalyticsCareer#PythonForDataAnalytics#PowerBITraining
0 notes
Link
1 note
·
View note
Text
What is Data Science and Why Is It a Growing Field?
In today’s fast-paced digital world, data has become one of the most valuable resources. From social media clicks to online purchases, every digital interaction generates data. But raw data alone holds no value unless it’s analyzed and transformed into meaningful insights. This is where Data Science comes in—a powerful, interdisciplinary field that is reshaping the future of decision-making, automation, and innovation across industries.
What is Data Science?
Data Science is the art and science of extracting knowledge and actionable insights from structured and unstructured data using a combination of mathematics, statistics, computer science, artificial intelligence, and domain expertise.
At its core, data science is about solving real-world problems by:
Collecting the right data,
Organizing and cleaning that data,
Analyzing patterns,
Building models to make predictions,
And finally, communicating results to stakeholders in an understandable way.
Whether it’s predicting customer behavior, detecting fraud, optimizing supply chains, or recommending movies—you’ll find data science working behind the scenes.
Core Components of Data Science
Data Collection & Acquisition Data scientists gather data from various sources such as databases, APIs, web scraping, sensors, mobile apps, and even social media platforms.
Data Cleaning & Preprocessing Real-world data is often messy—incomplete, inconsistent, or filled with errors. Preprocessing helps clean, structure, and convert this raw data into a usable format.
Exploratory Data Analysis (EDA) Using visualization tools like matplotlib, seaborn, or Tableau, analysts explore trends, correlations, and anomalies to understand the data’s story.
Model Building & Machine Learning Using algorithms and statistical techniques, data scientists build predictive models. These can be simple regressions or advanced deep learning neural networks.
Interpretation & Reporting The final step involves translating technical findings into business language, often through dashboards, reports, or presentations. This is crucial for informed decision-making.
Why is Data Science a Growing Field?
1. Unprecedented Growth of Data
With over 2.5 quintillion bytes of data generated daily, businesses and governments are sitting on a goldmine. However, without data science, this information remains underutilized. The surge in big data has created a pressing need for professionals who can manage and interpret it effectively.
2. Demand Across Industries
Data science isn’t limited to tech companies. Today, almost every industry—healthcare, finance, education, marketing, logistics, agriculture, and even sports—relies on data for strategic decisions. For example:
Hospitals use it for early disease detection.
Banks use it for credit scoring and fraud prevention.
Retailers use it for customer behavior analysis.
3. Rise of Artificial Intelligence & Automation
Data science fuels AI systems like recommendation engines (Netflix, Amazon), voice assistants (Siri, Alexa), self-driving cars, chatbots, and more. As AI adoption increases, so does the demand for data science professionals.
4. Shortage of Skilled Professionals
According to reports by LinkedIn and IBM, data science is among the top emerging careers, with millions of job openings globally. However, the talent gap is wide. This makes it a highly lucrative field, with strong salary packages and fast career growth.
5. Innovation & Competitive Advantage
Companies using data effectively outperform their competitors. Data science enables personalized marketing, accurate demand forecasting, efficient inventory management, and better customer service—giving organizations a crucial edge.
6. Accessible Learning Resources
With the rise of online learning platforms like ONLEI Technologies and others, aspiring professionals can now access world-class training from anywhere. These platforms offer affordable, job-oriented programs that prepare students for real-world projects.
Career Paths in Data Science
Data science is a broad domain with several specialized roles, such as:
Data Analyst
Data Scientist
Machine Learning Engineer
Business Intelligence Analyst
Data Engineer
AI/ML Researcher Each of these roles requires a unique combination of skills and offers diverse opportunities across industries.
Skills Required to Become a Data Scientist
Programming: Python, R, SQL
Statistics & Mathematics: Probability, linear algebra, hypothesis testing
Machine Learning: Regression, classification, clustering, deep learning
Data Visualization: Tableau, Power BI, Matplotlib
Big Data Tools: Hadoop, Spark
Communication & Problem Solving
Soft skills like curiosity, critical thinking, storytelling, and collaboration are equally important for a successful data science career.
Conclusion
Data Science is more than just a buzzword—it's the backbone of modern innovation and decision-making. As industries continue to digitize and automation becomes the norm, the importance of data-driven solutions will only grow. Whether you're a student, a professional looking to switch careers, or a business leader—understanding data science can unlock new opportunities and transform your future.
Investing in data science is not just about learning a skill; it's about stepping into the future of technology, analytics, and intelligence.
#onlei#like4likes#education#onleitechnologiesindia#follow4followback#onleitechnologies#followformore#course
0 notes
Text
Quantum Support Vector Machines In Prostate Cancer Detection

Quantum SVMs
Recent studies show that Quantum Machine Learning (QML) techniques, particularly Quantum Support Vector Machines (QSVMs), can improve disease detection, especially in complex and unbalanced healthcare datasets. In datasets for diabetes, heart failure, and prostate cancer, quantum models outperform conventional machine learning methods in key areas.
Modern medicine struggles to accurately and earlyly diagnose diseases. Unbalanced datasets in medicine, where there are often many more positive examples than negative cases, are a key impediment. This imbalance makes standard machine learning algorithms perform worse. Scientists are investigating whether quantum computing, which uses entanglement and superposition, can improve pattern recognition in these tough scenarios.
A comparative analysis by Tudisco et al. and published by Quantum Zeitgeist compared QNNs and QSVMs to classical algorithms like Logistic Regression, Decision Trees, Random Forests, and classical SVMs. Quantum methods were tested on prostate cancer, heart failure, and diabetic healthcare datasets to overcome unbalanced data.
QSVMs outperform QNNs and classical models on all datasets. This suggests quantum models excel at difficult categorisation problems. This superiority was notably evident in datasets with significant imbalance, a common healthcare issue. The Heart Failure dataset is severely imbalanced, and standard methods often fail to achieve high recall. Quantum models did better. Quantum models, particularly QSVMs, performed better at detecting positive examples (high recall) in these situations, implying improved diagnosis accuracy in complex clinical scenarios. Quantum models look more beneficial with class difference.
QNNs had good precision scores but overfitted training data, limiting their usefulness. Overfitting occurs when a model learns the training data too well and catches noise and features instead of essential patterns, reducing generalisation performance on unseen data. However, QSVMs were more resilient and reliable. QSVM's high recall across all datasets shows its ability to dependably identify positive cases in various clinical scenarios. Avoiding overfitting in QNNs may require studying alternate circuit design and hyperparameter tuning.
A study called “Quantum Support Vector Machine for Prostate Cancer Detection: A Performance Analysis” examined how QSVM could improve prostate cancer detection over regular SVM. Early identification improves prostate cancer treatment and results. Classical SVMs increase biomedical data interpretation, but large, high-dimensional datasets limit them. QSVMs, which use quantum notions like superposition and entanglement, can manage multidimensional data and speed up operations.
The prostate cancer technique used the Kaggle Prostate Cancer Dataset, which initially comprised 100 observations with 9 variables, including clinical and diagnostic data. The dataset's initial class imbalance was corrected using RandomOverSampler during preparation. The data was normalised and normalised using MinMaxScaler and StandardScaler to increase feature comparability and prepare for quantum encoding. Oversampled to 124 samples, processed data was divided into training (80%) and testing (20%) subsets.
The QSVM approach relied on a quantum feature map architecture, the ZZFeatureMap with full entanglement, carefully selected and tested to match the dataset. This feature map encodes conventional data into quantum states, allowing the quantum system to express complex data correlations in high-dimensional regions using entanglement. QSVM estimates the inner product (overlap) of quantum states that represent data points to generate the kernel function for SVM classification. This estimator measures the likelihood of witnessing the starting state using a quantum circuit.
Prostate cancer experiments provide compelling evidence:
Kernel matrix analysis revealed different patterns. The RBF kernel of the classical SVM showed high similarity values across data points, suggesting a strongly connected feature space. However, QSVM's ZZFeatureMap produced a more dispersed feature space with fewer high off-diagonal values. This implies that the quantum feature space's unique properties boosted class distinguishability.
QSVM outperformed classical SVM (87.89% accuracy, 85.42% sensitivity) on the training dataset with 100% accuracy and sensitivity. As shown, the quantum feature map distinguishes classes without overlap during training.
On the test dataset, both models were 92% accurate. QSVM surpassed SVM in essential medical diagnostic measures, with 100% sensitivity and 93.33% F1-Score on test data, compared to 92.86% and 92.86% for SVM.
Importantly, the QSVM model had no False Negatives (missing malignant cases) in the test data. Only one False Negative occurred in the SVM model. QSVM's great sensitivity is vital in medical circumstances when a false negative could lead to an ailment going undiagnosed and untreated. Quantum feature mapping increases class separation and allows more complex representations.
Cross-validation studies demonstrated that the SVM model was more stable across data subsets than the QSVM, suggesting that the QSVM model overfitted to the training data despite its great performance on the test set. We discuss how QSVM's improved sensitivity and F1-Score aid medical diagnosis. Quantum feature mapping's ability to create a unique, dispersed feature space, especially when separating complex data points, improves performance. QSVM was used to categorise prostate cancer datasets for the first time.
#QuantumSupportVectorMachines#machinelearning#QuantumMachineLearning#quantumcomputing#QuantumNeuralNetworks#QSVM#News#Technews#Technology#Technologynews#Technologytrends#govindhtech
0 notes
Text
The Intersection of Mathematics and Market Strategy in High-Level Trading
Success depends on more than intuition and quick decision-making at the highest trading levels. It relies heavily on a rigorous understanding of mathematical principles and their real-world applications. Sophisticated trading firms have long recognized that complex mathematical models can provide crucial insights into market dynamics, helping traders identify patterns, assess risk, and make data-driven decisions. These models don’t just crunch numbers; they translate abstract theories into practical tools that power some of the world’s most profitable trading strategies.
At its core, quantitative or quant trading uses statistical and mathematical techniques to analyze large data sets. This includes everything from basic descriptive statistics to advanced calculus and stochastic processes. By breaking down price movements and trading volumes into mathematical relationships, traders can uncover patterns that would otherwise go unnoticed. These models have become indispensable in modern trading rooms, from predicting short-term price fluctuations to managing long-term portfolio risks.
Risk Management: A Mathematical Approach
One of the most critical aspects of high-level trading is risk management. In volatile markets, even the most promising opportunities can quickly become losses if risk isn’t properly understood and controlled. Here, mathematics plays a central role. Advanced risk models use probability theory and statistical techniques to quantify potential losses under various scenarios. For example, value-at-risk (VaR) models estimate how much a portfolio might lose over time, helping traders and firms set appropriate capital reserves.
These models also help identify correlations between assets—an essential insight for managing diversified portfolios. By understanding how different investments might move about one another, traders can design hedging strategies that protect against market shocks. Mathematical techniques like covariance matrices and Monte Carlo simulations allow for more precise risk assessment, enabling traders to make informed decisions in the face of uncertainty.
But risk management isn’t just about avoiding losses. It’s also about understanding the relationship between risk and reward. Mathematical models help traders find the optimal balance—pushing the boundaries to capture opportunities while staying within acceptable risk limits. In this way, math becomes a tool for survival and strategic growth.
Algorithmic Trading and Speed
In today’s fast-paced markets, speed is a decisive advantage. Algorithmic trading, driven by sophisticated mathematical models, has revolutionized how trading decisions are made and executed. Algorithms can process vast amounts of data in milliseconds, identifying profitable trades and executing them before human traders even have time to react.
These algorithms rely on a combination of statistical models, calculus, and computer science. Techniques like regression analysis help identify relationships between variables, while differential equations model how prices evolve. Machine learning, an advanced field that merges mathematics with computer programming, is also becoming increasingly important in this domain. Traders can uncover subtle signals that drive market behavior by training algorithms on historical data.
Beyond speed, algorithms bring consistency and discipline to trading. Human emotions and biases can often cloud judgment, leading to irrational decisions. But mathematical models operate without emotion, sticking to the logic of the data and the parameters they’re given. This discipline is essential in high-frequency trading, where decisions must be made and executed in fractions of a second.
Mathematics as a Strategic Tool
While the technical side of math is critical, its strategic applications are equally important. High-level traders use mathematical models not just to analyze data but to develop new trading strategies. For instance, game theory, which uses mathematical models to study strategic interactions, can inform how traders position themselves in competitive markets. By anticipating the actions of other market participants, traders can devise tactics that give them an edge.
Options pricing models, like the Black-Scholes model, have also become essential tools for traders working with derivatives. These models use differential equations and statistical methods to calculate fair prices for options, allowing traders to capitalize on discrepancies between market prices and theoretical values. Similarly, the concept of arbitrage—profiting from price differences across markets—relies on mathematical principles to identify and exploit inefficiencies.
The strategic integration of mathematics doesn’t end there. In portfolio management, optimization models help traders allocate assets to maximize returns while minimizing risk. Linear programming and other optimization techniques offer systematic frameworks for making these complex decisions. The result is a trading approach combining scientific rigor with creative problem-solving, ensuring every move is grounded in a clear, logical rationale.
The Future of Trading: Where Math Meets Innovation
As markets evolve and technology advances, the intersection of mathematics and market strategy is only set to deepen. The rise of artificial intelligence and machine learning is creating new opportunities for traders to harness the power of data. These fields are fundamentally built on mathematical concepts—linear algebra, calculus, and probability theory, to name a few—and they’re opening up unprecedented avenues for innovation in trading.
Moreover, as markets become more interconnected and complex, the ability to model and predict interactions is becoming even more valuable. This means that traders who understand the math and how to apply it strategically will be best positioned to thrive. Collaboration between mathematicians, computer scientists, and market strategists is already reshaping the landscape of high-level trading.
The story of mathematics in trading is about turning theory into action. Equations and formulas, on their own, are just symbols on a page. But when combined with a deep understanding of markets and a strategic mindset, they become powerful tools that drive growth, manage risk, and uncover hidden opportunities. As long as markets exist, the language of mathematics will continue to be one of the most important ways to understand and navigate them—proving that, in the world of trading, numbers do speak louder than words.
0 notes
Text
Excel-Based Statistical Assignment Help – Introduction
Statistics plays a vital role in academic research, business forecasting, and data analysis. Excel is widely used for statistical operations due to its flexibility and functionality. However, many students find it challenging to complete statistical assignments using Excel due to its complexity. That's where our Excel-Based Statistical Assignment Help comes into play For More...
We offer fast, accurate, and easy solutions for all types of Excel-based statistical tasks. Whether you are dealing with data visualization, regression analysis, or probability calculations, our experts are ready to guide you step-by-step. Our service connects students directly with professional tutors who not only help you complete your assignments but also ensure you understand the concepts behind the solutions.
About Gritty Tech Academy
Gritty Tech Academy is a leading online learning platform focused on technical excellence. Our mission is to support students worldwide by offering personalized tutoring and academic help. We specialize in Excel, data science, and applied statistics, making us the perfect destination for Excel-Based Statistical Assignment Help.
Our academy hosts a team of qualified experts with advanced degrees and real-world experience in analytics, research, and academic support. Students who use our services receive more than just assignment completion—they gain valuable skills in using Excel for practical, data-driven decision-making. Gritty Tech Academy has earned trust for its high standards, confidentiality, and student-friendly approach.
Why Choose Us for Excel-Based Statistical Assignment Help
Choosing the right platform for your academic needs makes a big difference. Here’s why thousands of students prefer our Excel-Based Statistical Assignment Help:
Expert Tutors: Our tutors hold master’s and PhDs in statistics, mathematics, and data analytics. They are proficient in Excel and trained to handle assignments of any complexity.
Customized Solutions: Every assignment is solved from scratch based on your unique requirements.
Fast Turnaround: We understand deadlines. Our team delivers accurate work quickly without compromising quality.
Learning-Focused Approach: We explain every step so you learn while completing your assignment.
24/7 Availability: Reach out anytime you need help.
Plagiarism-Free Work: Each assignment is checked thoroughly to ensure originality.
Affordable Pricing: Quality help doesn’t have to be expensive. We provide value-driven pricing with no hidden charges.
Tutors’ Experience
Our team includes seasoned professionals with hands-on experience in:
Advanced Excel functions for statistics
Time series and trend analysis
Correlation and regression
ANOVA and hypothesis testing
Probability distributions
Descriptive and inferential statistics
With over 10 years of combined experience in Excel-based statistical tutoring, our tutors have helped students from various academic levels and backgrounds. They understand the common mistakes students make and focus on building strong foundations.
What Our Students Say – Testimonials
John M. – Business Student (USA) "I was struggling with my Excel statistics assignment, and Gritty Tech Academy saved me. The tutor walked me through every function used. Best Excel-Based Statistical Assignment Help I've received!"
Priya S. – Data Science Graduate (India) "I needed urgent help with hypothesis testing in Excel. Not only did I submit my assignment on time, but I also finally understood the logic. Truly expert-level support!"
Carlos R. – Economics Major (UK) "This service made Excel so much easier. Now I know how to create data models and charts for analysis. Highly recommended for any Excel-Based Statistical Assignment Help."
Frequently Asked Questions (FAQs)
1. What is Excel-Based Statistical Assignment Help? Excel-Based Statistical Assignment Help refers to expert assistance in completing statistics assignments using Excel functions, formulas, and data tools.
2. Who provides Excel-Based Statistical Assignment Help? Our experienced tutors, who specialize in both statistics and Excel, provide personalized help for your assignments.
3. Can I get help with urgent Excel-based statistics tasks? Yes, we offer fast and reliable Excel-Based Statistical Assignment Help even for tight deadlines without compromising quality.
4. Is the Excel-Based Statistical Assignment Help plagiarism-free? Absolutely. We ensure each assignment is custom-written, original, and free from any plagiarism.
5. Will I learn while getting Excel-Based Statistical Assignment Help? Yes, we believe in learning by doing. Our tutors explain every concept so you gain knowledge as well as solutions.
6. What topics are covered under Excel-Based Statistical Assignment Help? We cover all statistical topics including regression, probability, descriptive stats, ANOVA, forecasting, and more.
7. How do I get started with Excel-Based Statistical Assignment Help? Simply contact us with your assignment details, and we’ll assign a tutor who fits your needs. Quick and easy.
Conclusion
Statistics using Excel can be challenging, but with the right help, it becomes manageable and even enjoyable. Our Excel-Based Statistical Assignment Help service ensures that you not only submit your assignments on time but also develop the confidence to work independently in the future.
At Gritty Tech Academy, we bridge the gap between academic theory and practical application. Whether you’re a beginner or an advanced learner, our expert tutors are here to assist. Connect with us today and experience the difference in how Excel-based assignments can be completed with clarity and speed.
Excel-Based Statistical Assignment Help is not just about getting answers; it’s about understanding, efficiency, and growth. Trust Gritty Tech Academy to deliver quality you can rely on.
0 notes
Text
Unlock Your Future: Learn Data Science Using Python A-Z for ML

Are you ready to take a deep dive into one of the most in-demand skills of the decade? Whether you're looking to switch careers, boost your resume, or just want to understand how machine learning shapes the world, learning Data Science using Python A-Z for ML is one of the smartest moves you can make today.
With Python becoming the universal language of data, combining it with data science and machine learning gives you a major edge. But here’s the best part—you don’t need to be a math genius or have a computer science degree to get started. Thanks to online learning platforms, anyone can break into the field with the right course and guidance.
If you’re ready to explore the world of predictive analytics, AI, and machine learning through Python, check out this powerful Data Science using Python A-Z for ML course that’s crafted to take you from beginner to expert.
Let’s break down what makes this learning journey so valuable—and how it can change your future.
Why Data Science with Python Is a Game-Changer
Python is known for its simplicity, readability, and versatility. That's why it’s the preferred language of many data scientists and machine learning engineers. It offers powerful libraries like:
Pandas for data manipulation
NumPy for numerical computing
Matplotlib and Seaborn for data visualization
Scikit-learn for machine learning
TensorFlow and Keras for deep learning
When you combine these tools with real-world applications, the possibilities become endless—from building recommendation engines to predicting customer churn, from detecting fraud to automating data analysis.
The key is learning the skills in the right order with hands-on practice. That’s where a well-structured course can help you move from confusion to clarity.
What You’ll Learn in This A-Z Course on Data Science with Python
The course isn’t just a theory dump—it’s an actionable, practical, hands-on bootcamp. It covers:
1. Python Programming Basics
Even if you’ve never written a line of code, you’ll be walked through Python syntax, data types, loops, functions, and more. It’s like learning a new language with a supportive tutor guiding you.
2. Data Cleaning and Preprocessing
Raw data is messy. You’ll learn how to clean, transform, and prepare datasets using Pandas, making them ready for analysis or training machine learning models.
3. Data Visualization
A picture is worth a thousand rows. Learn how to use Matplotlib and Seaborn to create powerful charts, graphs, and plots that reveal patterns in your data.
4. Exploratory Data Analysis (EDA)
Before jumping to models, EDA helps you understand your dataset. You’ll learn how to identify trends, outliers, and relationships between features.
5. Statistics for Data Science
Understand probability, distributions, hypothesis testing, and correlation. These concepts are the foundation of many ML algorithms.
6. Machine Learning Algorithms
You’ll cover essential algorithms like:
Linear Regression
Logistic Regression
Decision Trees
Random Forests
Support Vector Machines
k-Nearest Neighbors
Naïve Bayes
Clustering (K-Means)
All with practical projects!
7. Model Evaluation
Accuracy isn’t everything. You’ll explore precision, recall, F1-score, confusion matrices, and cross-validation to truly assess your models.
8. Real-World Projects
Theory only goes so far. You’ll build actual projects that simulate what data scientists do in the real world—from data collection to deploying predictions.
Who Is This Course Perfect For?
You don’t need a Ph.D. to start learning. This course is designed for:
Beginners with zero coding or data science background
Students looking to enhance their resume
Professionals switching careers to tech
Entrepreneurs wanting to use data for smarter decisions
Marketers & Analysts who want to work with predictive analytics
Whether you're 18 or 48, this course makes learning Data Science using Python A-Z for ML accessible and exciting.
What Makes This Course Stand Out?
Let’s be real: there are hundreds of data science courses online. So what makes this one different?
✅ Structured Learning Path
Everything is organized from A to Z. You don’t jump into machine learning without learning data types first.
✅ Hands-On Projects
You’ll work on mini-projects throughout the course, so you never lose the connection between theory and practice.
✅ Friendly Teaching Style
No dry lectures or overwhelming jargon. The instructor talks to you like a friend—not a robot.
✅ Lifetime Access
Once you enroll, it’s yours forever. Come back to lessons any time you need a refresher.
✅ Real-World Applications
You’ll build models you can actually talk about in job interviews—or even show on your portfolio.
Want to start now? Here’s your shortcut to mastering the field: 👉 Data Science using Python A-Z for ML
Why Data Science Skills Matter in 2025 and Beyond
Companies today are drowning in data—and they’re willing to pay handsomely for people who can make sense of it.
In 2025 and beyond, businesses will use AI to:
Automate decisions
Understand customer behavior
Forecast market trends
Detect fraud
Personalize services
To do any of this, they need data scientists who can write Python code, manipulate data, and train predictive models.
That could be you.
From Learner to Data Scientist: Your Roadmap
Here’s how your transformation might look after taking the course:
Month 1: You understand Python and basic data structures Month 2: You clean and explore datasets with Pandas and Seaborn Month 3: You build your first ML model Month 4: You complete a full project—ready for your resume Month 5: You start applying for internships, freelance gigs, or even full-time roles!
It’s not a pipe dream. It’s real, and it’s happening to people every day. All you need is to take the first step.
Your Investment? Just a Few Hours a Week
You don’t need to quit your job or study 12 hours a day. With just 4–5 hours a week, you can master the foundations within a few months.
And remember: this isn’t just a skill. It’s an asset. The return on your time is massive—financially and intellectually.
Final Thoughts: The Future Belongs to the Data-Literate
If you've been waiting for a sign to jump into data science, this is it.
The tools are beginner-friendly. The job market is exploding. And this course gives you everything you need to start building your skills today.
Don’t let hesitation hold you back.
Start your journey with Data Science using Python A-Z for ML, and see how far you can go.
0 notes
Text
Computer Science and Engineering Internship – Gain Real-World Skills with Li-Mat Soft Solutions
If you're pursuing Computer Science and Engineering (CSE) and looking to enhance your technical skills, the right internship can set the foundation for your career. Li-Mat Soft Solutions offers industry-oriented Computer Science and Engineering Internship programs that combine practical training with expert mentorship.
We understand that today’s tech industry demands more than just theoretical knowledge. That’s why our internships are designed to bridge the gap between academics and industry by offering hands-on training in the most in-demand technologies.
Why Choose Li-Mat Soft Solutions?
Real-time project exposure
Training from industry experts
Internship certificate for resume enhancement
Flexible batch timings
Career guidance and placement support
Courses Offered During Internship:
Machine Learning
Java Programming
Web Development
Cyber Security
Frequently Asked Questions
Q1: What are the steps in a Data Science project? Answer: A typical data science project follows these key steps:
Problem Understanding – Define the business problem you want to solve.
Data Collection – Gather relevant data from various sources.
Data Cleaning – Handle missing values, outliers, and remove noise.
Exploratory Data Analysis (EDA) – Understand patterns and correlations.
Feature Engineering – Select and transform variables for model training.
Model Building – Choose algorithms and train models.
Model Evaluation – Use metrics (accuracy, precision, recall) to test performance.
Deployment – Integrate the model into a production environment.
Monitoring & Maintenance – Continuously track model performance over time.
Q2: Explain the difference between data normalization and standardization. Answer:
Normalization scales the data between a fixed range (usually 0 to 1). It's useful when features have different units or scales.
Formula: (X - Xmin) / (Xmax - Xmin)
Standardization transforms data to have a mean of 0 and standard deviation of 1, making it a standard normal distribution. It’s often used in algorithms like SVM and logistic regression.
Formula: (X - mean) / standard deviation
Key Difference:
Use normalization when you want all values on the same scale.
Use standardization when your data needs to follow a normal distribution or when outliers are present.
Ready to Kickstart Your Tech Career?
Join the top-rated Computer Science and Engineering Internship program at Li-Mat Soft Solutions and gain hands-on experience that aligns with your career goals. Whether you’re aiming for a job, research, or entrepreneurship, our training equips you with the skills to thrive in any path.
Register now and transform your knowledge into real-world expertise!
0 notes
Text
Comprehensive Analysis of Global Socio-Economic Indicators: Insights from the World Bank Data
Sample
Population: The sample was drawn from the World Bank dataset, which includes global data on various socio-economic indicators. The population consists of countries worldwide, with data spanning multiple years.
Sample Selection Criteria: The data was filtered to include countries with complete entries for critical variables such as GDP, population, health expenditure, and education expenditure. This ensures a comprehensive analysis of the selected indicators.
Sample Size: The dataset contains 248 observations, representing different countries and regions.
Description of the Sample: The sample includes countries from various geographical regions such as North America, Europe, Asia-Pacific, and Africa. Demographic characteristics include variables like population density, age distribution, and gender ratio.
Measures
Description of Variables:
Economic Indicators: GDP at market prices, GDP growth, GDP per capita, gross domestic savings, adjusted net national income, foreign direct investment, and inflation.
Health Indicators: Health expenditure per capita, mortality rates (infant, neonatal, under-5), life expectancy at birth (female, male, total), incidence of tuberculosis, and out-of-pocket health expenditure.
Education Indicators: Education expenditure, percentage of students in primary education who are female.
Environmental Indicators: Forest area, renewable electricity output, PM2.5 air pollution exposure, adjusted savings for carbon dioxide damage, energy depletion, and natural resources depletion.
Social Indicators: Internet users, mobile cellular subscriptions, improved sanitation facilities, improved water source, labor force participation (female), and proportion of seats held by women in national parliaments.
Management of Variables:
Composite Scores: Variables such as health expenditure and education expenditure may be combined to create a composite score representing overall investment in human capital.
Binning: Quantitative variables like GDP growth and inflation rates can be binned into categories (e.g., low, medium, high) to facilitate categorical analysis.
Normalization: Variables such as population density and GDP per capita may be normalized to ensure comparability across countries with different sizes and economic scales.
Analyses
Statistical Methods:
Descriptive Statistics: To summarize the central tendencies, dispersion, and distribution of the variables.
Correlation Analysis: To identify relationships between different indicators, such as the correlation between health expenditure and life expectancy.
Regression Analysis: To model the impact of various predictors (e.g., GDP, health expenditure) on outcomes like life expectancy and education levels.
Cluster Analysis: To group countries with similar socio-economic profiles and identify patterns in the data.
Data Splitting:
Training and Test Sets: The data will be split into training and test sets to validate the models. Typically, 70% of the data will be used for training, and 30% for testing.
Cross-Validation: K-fold cross-validation will be used to ensure the robustness of the models. This involves dividing the data into k subsets and using each subset as a test set while the remaining k-1 subsets are used for training.
Cross-Validation:
K-Fold Cross-Validation: This method will be employed to assess the performance of the statistical models. It helps in minimizing overfitting and provides a more accurate estimate of model performance.
1 note
·
View note
Text
Predictive Analytics in Software Testing: The Future of Quality Assurance

Introduction
The software development lifecycle (SDLC) is evolving rapidly, with increasing demands for faster releases, higher quality, and more efficient testing processes. Traditional testing methods, while effective, often rely on reactive approaches — identifying and fixing defects after they occur. However, with the rise of predictive analytics, quality assurance (QA) teams can now anticipate defects, optimize testing efforts, and enhance software reliability before issues impact end-users.
Predictive analytics leverages historical data, machine learning (ML), and artificial intelligence (AI) to forecast potential risks, prioritize test cases, and improve decision-making in QA. By integrating predictive analytics into software testing, organizations can shift from a detective to a preventive approach, reducing costs, accelerating releases, and ensuring superior product quality.
In this article, we will explore:
What predictive analytics is and its role in QA
Key components of predictive analytics in software testing
Different predictive analytics models
Real-world use cases in quality assurance
Benefits and challenges of adopting predictive analytics
What is Predictive Analytics?
Predictive analytics is a branch of data science that uses statistical algorithms, machine learning, and historical data to predict future outcomes. Unlike descriptive analytics (which explains what happened) or diagnostic analytics (which explains why it happened), predictive analytics focuses on what is likely to happen next.
In software testing, predictive analytics helps:
Identify high-risk areas prone to defects
Optimize test case selection and prioritization
Forecast testing timelines and resource needs
Reduce manual effort through intelligent automation
Predictive Analytics in QA: Key Components
To implement predictive analytics in software testing, several core components work together:
1. Data Collection
Source Data: Historical test logs, defect reports, code changes, CI/CD pipeline data, and user feedback.
Data Quality: Clean, structured, and relevant data ensures accurate predictions.
2. Data Analysis
Examines patterns, trends, and anomalies in past testing cycles.
Helps identify correlations between code changes and defect rates.
3. Statistical Modeling
Uses regression analysis, probability distributions, and hypothesis testing to predict outcomes.
4. Machine Learning (ML) & AI
Trains models to recognize defect patterns and predict future failures.
AI enhances adaptability by learning from new data continuously.
5. Risk Analysis
Evaluates the probability and impact of potential defects.
Helps prioritize testing efforts on high-risk modules.
6. Forecasting
Estimates future defect rates, test coverage, and release readiness.
Process of Predictive Analytics in Software Testing
Define Objectives — Determine what needs prediction (e.g., defect hotspots, test efficiency).
Gather Historical Data — Collect past test results, bug reports, and development metrics.
Preprocess Data — Clean, normalize, and structure data for analysis.
Select Predictive Models — Choose appropriate algorithms (classification, clustering, etc.).
Train & Validate Models — Use historical data to train ML models and validate accuracy.
Deploy & Monitor — Integrate models into testing workflows and refine based on real-time feedback.
Types of Predictive Analytics Models in Software Testing
Different predictive models serve unique purposes in QA:
1. Classification Models
Predicts categorical outcomes (e.g., “defect-prone” or “stable”).
Example: Identifying which code modules are most likely to fail.
2. Clustering Models
Groups similar test cases or defects for targeted testing.
Example: Categorizing bugs by root cause (UI, backend, integration).
3. Outlier Detection Models
Identifies unusual patterns that may indicate defects.
Example: Detecting abnormal test execution times.
4. Decision Trees
Uses branching logic to predict outcomes based on input variables.
Example: Deciding whether a build is release-ready based on test results.
5. Time Series Models
Analyzes trends over time (e.g., defect rates across sprints).
Example: Predicting future defect density based on past releases.
6. Forecasting Models
Estimates future metrics (e.g., test coverage, execution time).
Example: Predicting how many test cases are needed for a new feature.
Use Cases of Predictive Analytics in QA
1. Predicting Bug Occurrences
Analyzes past defects to forecast where new bugs may appear.
Helps developers focus on high-risk areas early.
2. Test Case Prioritization
Ranks test cases based on predicted failure likelihood.
Maximizes test efficiency by running high-impact tests first.
3. Estimating Test Coverage
Predicts gaps in test coverage before release.
Ensures critical functionalities are adequately tested.
4. Resource Optimization
Forecasts testing effort, reducing bottlenecks.
Allocates QA resources more effectively.
5. Identifying Regression Risks
Predicts which code changes are most likely to introduce regressions.
Focuses regression testing on vulnerable areas.
6. Continuous Monitoring & Improvement
Tracks testing trends and refines models over time.
Enhances accuracy with ongoing feedback.
7. Risk Management
Evaluates project risks (e.g., delay probabilities).
Supports data-driven decision-making for releases.
8. Improving Test Automation Efficiency
Predicts which tests should be automated for maximum ROI.
Reduces redundant manual testing.
9. Managing Test Environments
Forecasts infrastructure needs (e.g., cloud load during testing).
Prevents environment-related delays.
Benefits of Predictive Analytics in Software Testing
��� Proactive Defect Prevention — Catches issues before they reach production. ✅ Faster Releases — Optimizes testing efforts, reducing cycle times. ✅ Cost Savings — Minimizes late-stage bug fixes. ✅ Higher Test Accuracy — Reduces false positives/negatives. ✅ Data-Driven Decisions — Replaces guesswork with analytics.
Challenges & Considerations
⚠ Data Quality & Availability — Requires clean, comprehensive historical data. ⚠ Model Accuracy — Predictions depend on algorithm selection and training. ⚠ Integration Complexity — Must align with existing CI/CD pipelines. ⚠ Skill Gaps — Teams need data science expertise for implementation.
Conclusion
Predictive analytics is transforming software testing from a reactive process into a strategic, forward-looking discipline. By leveraging historical data, AI, and statistical modeling, QA teams can anticipate defects, optimize test efforts, and enhance software reliability like never before.
As technology advances, predictive analytics will become even more integral to QA, enabling smarter automation, risk-based testing, and continuous improvement. Organizations that adopt these techniques early will gain a competitive edge — delivering higher-quality software faster and more efficiently.
The future of software testing isn’t just about finding bugs — it’s about preventing them before they happen. Are you ready to embrace predictive analytics in your QA strategy?
0 notes
Text
Predicting GDP Per Capita Using Development Indicators
Methods
Sample: The sample consists of data from the World Bank, covering 248 countries for the years 2012 and 2013. Only data from 2012 was used for the primary analysis, with 2013 data reserved for validation. The dataset includes national, regional, and global estimates, with valid observations for a minimum of 190 countries per variable.
Measures:
Response Variable: GDP per capita (current US$)
Predictors:
Fixed broadband subscriptions (per 100 people)
Access to improved water sources (% of population)
Internet users (per 100 people)
Mortality rate for under-5-year-olds (per 1,000)
Proportion of seats held by women in national parliaments (%)
Rural population rate (% of total population)
Urban population rate (% of total population)
Birth rate (crude, per 1,000 people)
Statistical Analyses:
Descriptive Statistics: Calculated mean, standard deviation, minimum, and maximum for all variables.
Bivariate Analyses: Used Pearson correlation to test associations between predictors and GDP per capita. Log transformations were applied where necessary to linearize relationships.
Multivariable Analyses: Employed lasso regression with least angle regression selection algorithm to identify the best subset of predictors. Cross-validation with 10 folds was used to determine the optimal model. Predictive accuracy was assessed using mean squared error rates on training and test datasets.
0 notes