#CSRF Token with Ajax Request
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr Inc. has $15.1M in annual revenue.
Text
Best Practices for Ruby on Rails Website Security

Ruby on Rails (RoR) has emerged as a popular framework for web development due to its simplicity, flexibility, and productivity. However, like any other web application, Ruby on Rails websites are vulnerable to security threats such as SQL injection, cross-site scripting (XSS), and unauthorized access. In this article, we will explore best practices for ensuring the security of Ruby on Rails websites, with a focus on mitigating common vulnerabilities and protecting sensitive data. As a leading ruby on rails web development company usa, it is crucial to prioritize website security to safeguard client interests and maintain trust.
Secure Authentication and Authorization
Authentication and authorization are fundamental aspects of website security, especially for applications that handle sensitive user data or require user authentication. In Ruby on Rails, developers can leverage the built-in authentication mechanisms provided by gems like Devise or implement custom authentication solutions using the has_secure_password method. It is essential to use strong cryptographic algorithms for password hashing and enforce secure password policies to prevent brute-force attacks. Additionally, implementing role-based access control (RBAC) ensures that users only have access to the resources they are authorized to access, reducing the risk of unauthorized data access.
Input Sanitization and Parameterized Queries
One of the most common security vulnerabilities in web applications is SQL injection, which occurs when malicious SQL queries are inserted into input fields and executed by the database. To prevent SQL injection attacks in Ruby on Rails applications, developers should employ input sanitization techniques and use parameterized queries when interacting with the database. By sanitizing user input and using placeholders for dynamic values in SQL queries, developers can mitigate the risk of SQL injection attacks and ensure the integrity of the database.
Cross-Site Scripting (XSS) Prevention
Cross-Site Scripting (XSS) is another prevalent security vulnerability that can compromise the integrity and confidentiality of web applications. XSS attacks occur when malicious scripts are injected into web pages and executed in the context of unsuspecting users, allowing attackers to steal sensitive information or perform unauthorized actions on behalf of the user. To prevent XSS attacks in Ruby on Rails applications, developers should implement input validation and output encoding techniques to sanitize user input and escape special characters that could be interpreted as HTML or JavaScript code. Additionally, leveraging Content Security Policy (CSP) headers can help mitigate the impact of XSS attacks by restricting the execution of inline scripts and external resources.
Cross-Site Request Forgery (CSRF) Protection
Cross-Site Request Forgery (CSRF) attacks exploit the trust between a user and a website to execute unauthorized actions on behalf of the user without their knowledge. To prevent CSRF attacks in Ruby on Rails applications, developers should implement CSRF protection mechanisms such as CSRF tokens or SameSite cookies. By generating unique tokens for each user session and validating them with each form submission or AJAX request, developers can ensure that requests originate from legitimate sources and mitigate the risk of CSRF attacks.
Secure Session Management
Session management is a critical aspect of website security, as it involves maintaining the state of user authentication and authorization across multiple requests. In Ruby on Rails applications, developers should ensure that session cookies are encrypted and signed to prevent tampering or session hijacking attacks. Additionally, it is essential to implement proper session expiration policies and invalidate sessions after a specified period of inactivity to reduce the risk of unauthorized access.
Conclusion: Prioritizing Ruby on Rails Website Security
In conclusion, ensuring the security of Ruby on Rails websites is essential for protecting sensitive data, maintaining user trust, and mitigating the risk of security breaches. By following best practices such as secure authentication and authorization, input sanitization, XSS prevention, CSRF protection, and secure session management, ruby on rails website development company usa, can build robust and resilient web applications that withstand common security threats. By prioritizing website security from the outset of the development process and staying abreast of emerging threats and vulnerabilities, developers can create secure and reliable Ruby on Rails applications that meet the highest standards of security and compliance.
#ruby on rails web development company usa#ruby on rails website development company usa#ruby on rails web development services usa
0 notes
Text
Why Should You Hire Laravel Developers That Are The Best?

Hiring a Laravel developer can be a challenging task. It would help if you had someone skilled in this popular PHP framework, but you also need to ensure they have the right skills and qualifications. In this article, we'll provide you with a list of reasons why you should hire Laravel developers who are the best.
Here are some of the main advantages that Laravel Development offers users. So read on to learn more about the benefits that hiring the best Laravel developers can provide your business! We'll also give you tips on identifying and finding these developers for your project.
Maximum Stability
Laravel often creates chips, specifically CSRF Tokens, that prevent security breaches by ensuring that other parties do not produce fraudulent requests. Consequently, a successful token gets combined with an incoming request, whereby an AJAX call is made to a form to enable the connection of an exemplary receipt with a user request.
Performance Improvement
A webpage that uses the Laravel framework promises both quality and speed. Additionally, it enables the installation of current features to speed up the operation. It is evident when creating code that it is simpler than other frameworks. Applications may be made agile with Laravel Development.
Excellent for Managing Internet or Application Revenue
Working jobs automatically ensures that site speed gets not influenced by traffic. A website that receives a lot of traffic and is regularly visited tends to collapse, gradually affecting how search engines rank online profiles. Furthermore, Laravel offers several tools to websites that manage web application traffic.
Optimized connectors
Utilizing Laravel has several benefits, one of which is how simple it is to integrate with applications like Redis, Memcached, and the cache backend. These enable the system's settings to store the cached documents on the backside. As a result of the integration's achievement, the user's efficiency has increased.
Quick, easy, and adaptable
Since it is a fully accessible programming environment, Laravel get thought to be dependable and simply understandable. It recycles pre-existing features from many frameworks that help with application design.
Do You Need Laravel Development for Your Project?
Understanding the advantages of Laravel programming and the types of results you can guarantee your consumers
WordPress vs. Laravel
When comparing the Laravel framework to WordPress, one of its best features is information transfer, which is quicker with Laravel than with WordPress. However, WordPress plugins may slow down the website's performance, while Laravel runs more quickly thanks to its systematic, manageable components. When comparing security, Laravel offers security protection by eliminating third-party engagement, while WordPress focuses on third-party upgrades and management.
Angular vs. Laravel
Laravel handles web application development, while Angular is a JavaScript library typically used to create websites. Angular is challenging to master because it gets filled with codes and complexities, whereas Laravel's simple principles and efficient procedures are far more challenging. Laravel can get utilized for large and small projects. However, Angular is not the best choice for tiny apps.
Laravel v/s. React
Typically, front-end development with React is frequently employed. Laravel is a more widely used framework for quick application prototypes and supporting business solutions than react. React is only capable of creating intricate solitary web services. Beginning with Laravel infrastructure development, if you need web apps or solutions that could use the many advantages Laravel provides.
Employing Laravel Developers: A Guide!
A Laravel programmer is simple to find. How do you see, inspire, and hire the best individuals to ensure your internet project is a huge success? Here are some great suggestions if this question has you stumped.
Collaborate with an IT staffing firm.
The easiest way to find a talented Laravel developer is to work with a professional aware of your needs and market demands. Working with a reputable IT recruiting firm may find the best personnel for your Laravel development company.
When you seek a recruiting service, you can always hire the most qualified Laravel developers by working with a top IT recruiter. The hiring agency will assist you in selecting a hiring strategy that best meets your skill and financial requirements.
Obtain the best consulting assistance for creating the appropriate HR models and techniques.
The hiring process gets based on the demand for talent, including the frequency and duration of the need (in hours, days, months, or years). Thousands of businesses seeking app development experts have worked with a knowledgeable provider. We swiftly ascertain how much of an employee's selection and skill levels are appropriate for a specific business plan or circumstance.
Find trustworthy freelancers through our network of freelancers.
Recruitment Agency can provide the reputable Laravel developer who works as a freelancer for your assignment thanks to its vast range and organization. Thanks to a highly reliable screening procedure, we can offer the correct and most dependable freelancer for your project.
Locate Dedicated Personnel That Are Ideal for Your Project.
One has to identify which suppliers have to know what sort of program development track records to locate appropriate developers at client businesses. Finding the most suitable developers is possible by working with a company with extensive vendor selection experience. An agency partner can assist you in obtaining guaranteed results when you need to engage specialized Laravel developers for specific projects.
Locate Remote Teams in Any Target Country
Utilizing approaches for distributed team hiring, you might potentially find and hire devoted Laravel developers. Create a team that can manage most of your requirements for hired talent, depending on your outsourcing requirements. That implies that you can work with a virtual team of inland, marine, or merge engineers who are devoted and have a variety of expertise and talents, including Angular, Laravel, React, WordPress, Java, and Python. All of your needs for contract hiring will get met by the expert group.
Conclusion!
The need for professionals proficient with Laravel has improved due to the project's massive trend over time. That makes it essential that you hire only the best Laravel developers. Ensuring they have all the right skills and qualifications, you can ensure your new project goes smoothly without any delays or issues. In addition, hiring a team of talented experts can help you save money by avoiding unnecessary errors and bugs at every stage of development.
1 note
·
View note
Text
CodeIgniter 4 CSRF Token with Ajax Request
When we develop any application, security should be taken care of it. Security always be the first thing when we are planning for a secure application. In CodeIgniter 4 applications, we have few security library provided by the help of which we can do it in a easy way.
Inside this article we will see CodeIgniter 4 CSRF Token with Ajax Request. Cross-Site Request Forgery (CSRF).
0 notes
Photo

How to Send AJAX request with CSRF token in CodeIgniter ☞ https://bit.ly/376wals #php #laravel
1 note
·
View note
Photo

How to Send AJAX request with CSRF token in CodeIgniter ☞ https://bit.ly/376wals #php #laravel
1 note
·
View note
Text
Something Awesome: Data Thief or Gift Recipient
Okay, we’ve seen more than a few attacks that can be performed when someone clicks a link or navigates to a website.
Cryptojacking
Cross Site Request Forgery
Drive-By Attacks
Zoom 0day
But it’s time to pay homage to the attack that’s hidden in plain site.
tldr; head over to https://fingerprintme.herokuapp.com/ for some fun.
Passive Data Theft
I hesitate to call it theft when in fact we are giving all of this data to every website we visit like a little gift.
Please, accept this bundle of quasi-identifiers as a token of my appreciation.
Many internet users have no idea just how much data is available to websites they are visiting, so it’s worth exploring just what is in our present.

IP Address and Geolocation API
Like any good gift giver, we better write on the tag.
To: <website server> From: <your IP address>
Your IP (Internet Protocol) address is a little 32-bit (now possibly 128-bit) number that uniquely identifies your device on the Internet. This is by design; people need to be able to address you to be able to send you any packets. A static 1:1 mapping of devices to IPs is definitely a massive exaggeration today as as we use technologies to let multiple devices share one IP, dynamically acquire an IP for each session, and our ISPs (Internet Service Providers) may also dynamically assign our IP address.
Nonetheless, IP addresses have (again by design) another function; location addressing. This is because when you’re internet traffic is propagating through the Internet (a global network of routers) it needs to know where it physically needs to go, and fast. Owing to this, the internet has taken on a hierarchical structure, with different ISPs servicing different geographical regions. These ISPs are tiered such that lower tier ISPs service specific subsets of the upper level tier’s region, providing more geographical specificity. It is this property of IP addresses that allows anyone with your IP address to get a rough idea where you are in the world. Moreover, IP addresses from specific subnets like AARNet (for Australian Universities) can be a giveaway for your location.
Try Googling “my ip” or “where am i”. There are many IP to Geolocation API services available. I have made use of https://ipgeolocation.io/, which has a generous free tier 🙏.
User Agent
Every request your browser makes to a server is wrapped up with a nice little UserAgent String bow, that looks a little like this,
User-Agent: Mozilla/<version> (<system-information>) <platform> (<platform-details>) <extensions>
Oh how sweet 😊 it’s our Operating System, our browser and what versions we of each we are running, and if the server is lucky, perhaps a few extra details.
Here are a few examples from MDN:
Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:47.0) Gecko/20100101 Firefox/47.0
Mozilla/5.0 (Macintosh; Intel Mac OS X x.y; rv:42.0) Gecko/20100101 Firefox/42.0
Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36
Why might this be a problem? Allow me to direct you towards my earlier post on Drive-By Attacks. Vulnerabilities are often present in specific versions of specific platforms. If an exploit server detects that your particular version of Chrome for Windows (for example) has a known vulnerability, well then prepare to be infected.

Navigator
Okay, I think we’ve been polite enough, it’s time to rip this packaging open! Ooh what is this inside? It’s an invitation to our browser of course!
When we send off a request to a web server complete with our IP and User Agent string, the web server will typically respond by sending us a web page to render. These days a web page can be anything from a single HTML file with a few verses from a dead poet, to a fully fledged JavaScript application. To support this development, browsers are exposing more and more functionality/system information through a special JavaScript interface called Navigator.
From MDN,
The Navigator interface represents the state and the identity of the user agent. It allows scripts to query it and to register themselves to carry on some activities.
...to carry on some activities... I wonder. The list of available properties and methods is pretty comprehensive so I’ll just point out a few interesting ones.
getBattery() (have only seen this on chrome)
connection (some details about your network connection)
hardwareConcurrency (for multithreading)
plugins (another important vector for Drive-Bys)
storage (persisted storage available to websites)
clipboard (requires permissions, goodness plz be careful)
doNotTrack (i wonder who checks this...)
vibrate() (because haptic is the only real feedback)
While I’ve got it in mind, here’s a wonderful browser localStorage vulnerability I stumbled across https://github.com/feross/filldisk.com. There’s a 10MB per site limit, but no browser is enforcing this quota across both a.something.com and b.something.com...
I have no idea why Chrome thinks it’s useful to expose your battery status to every website you visit... Personally, the clipboard API feels the most violating. It requires permissions, but once given you’re never asked again. Control/Command + V right now and see what’s on your clipboard. I doubt there’s many web pages that you’d actually want to be able to read your clipboard every time you visit.
Social Media Side Channel / CSRF
Okay, now we’re getting a little cheeky. It’s actually possible to determine if a browser has an authenticated session with a bunch of social media platforms and services.
It’s a well known vulnerability (have a laughcry at some of the socials responses), which abuses the redirect on login functionality we see on many of these platforms, as well as the Same-Origin Policy SOP being relaxed around HTML tags, as we saw was sometimes exploited by Cross Site Request Forgery attacks.
Consider this lovely image tag.
<img src="https://www.facebook.com/login.php?next=https%3A%2F%2Fwww.facebook.com%2Ffavicon.ico%3F_rdr%3Dp">
As you can see, the image source (at least originally) doesn’t point to an image at all, but rather the Facebook login page. Thanks to SOP, we wouldn’t and shouldn’t be able to send an AJAX request to this website and see the response. But this HTML image tag is going to fire off a GET request for it’s source no problem.
Thanks to redirect on login, if a user rocks up to the login page with the correct session cookies then we won’t have them login again, but rather we redirect them to their newsfeed; or, as it turns out, whatever the URL parameter next points to. What if we point it to an actual image, say the website icon, such that the HTML image tag loads if we are redirected, and fails if not.
Simple but effective. You can try it for yourself here, by opening my codepen in your browser when you’re signed in to Facebook, and when you’re signed out (or just use Incognito).

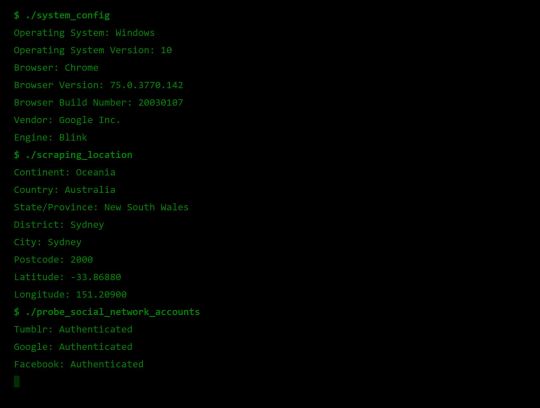
Fingerprint Me v1.0
Okay, time for a demonstration. I took the liberty of writing my own web page that pulls all this data together, and rather than store it for a rainy day (like every other page on the web), I present it to the user on a little web dashboard. It’s like a mirror for your browser. And who doesn’t like to check themselves out in the mirror from time to time 🙃
Random technical content: I had to fetch the geolocation data server-side to protect my API key from the client, then I sneak it back into the static HTML web page I’m serving to the user by setting it on the window variable in some inline script tags.
I bust out some React experience, and have something looking pretty (pretty scary I hope) in some nondescript amount of time (time knows no sink like frontend webdev). I rub my hands together grinning to myself, and send it off to some friends.
“Very scary”. I can see straight through the thin veil of their encouragement and instead read “Yeaaaah okay”. One of them admits that they actually missed the point when they first looked at it. But.. but... nevermind. It’s clearly not having the intended effect. These guys are pretty Internet savvy, but I feel like this should be disconcerting for even the most well seasoned web user...
Like that moment you lock eyes with yourself in the mirror after forgetting to shave a few days in a row.

Fingerprint Me v2.0
An inspired moment follows. I trace it back to the week ?7 activity class on privacy:
It is very hard to make a case for privacy. What is the inherent value of privacy? Why shouldn’t the government have our data, we give it to a million services everyday anyway, and receive a wealth of benefits for it. Go on, have it. I wasn’t using it for anything anyway.
It is very easy to make a case for privacy, if there is any sense that someone malicious is involved. As soon as there is someone who would wish us ill it becomes obvious that there are things that the less they know the better.
<Enter great The Art of War quote here.>
~ Sun Tzu
Therein lies the solution. I need to make the user feel victimised. And what better to do it than a green on black terminal with someone that calls themselves a hacker rooting your machine.
DO CLICK THIS LINK (it’s very safe, I promise) https://fingerprintme.herokuapp.com
Some more random technical content: Programming this quite synchronous behaviour in the very async-centric JavaScript was quite a pain. It was particularly tricky to get around the fact that React renders it’s component hierarchy top down, so I needed the parent components to mount empty in order for them to be correctly populated with child components later. It was also a pain to access and render child components conditionally, especially if you want to have sets of child components in different files, as though they aren’t ultimately nested in the DOM, React will treat them as if they are.
Some User Reviews:
“It feels like I should shut the window”
“This is SO RUDE”
“Battery level. I mean. Literally. How.”
Excellent.
Recommendations
Know what’s in your present, and who you’re gifting it to 🎁
To protect your IP address/location consider using a VPN or ToR
Check out NoScript, a browser plugin that will block JavaScript by default, but allow you to enable it for trusted sites.
Check out and share https://fingerprintme.herokuapp.com 😉
3 notes
·
View notes
Text
ASP.NET Core - Validate Antiforgery token in Ajax POST

If you've stumbled upon this article it most likely means that you're looking for a way to validate your ASP.NET Core Antiforgery Token when issuing an Ajax POST using jQuery or other JavaScript frameworks without getting the following HTTP Status Code error: 405 Method Not Allowed If this error is preventing you from performing your Ajax POST requests to your controllers or Razor Pages, don't worry: you found the right place to fix your issue for good. However, before releasing the fix, let's spend a couple minutes to recap how the Antiforgery token works in the context of ASP.NET Core Data Protection and why is important to learn how to properly deal with it instead of turning it off spamming the attribute in all of our Controllers that responds to AJAX or REST-based calls. What is Antiforgery and why is it so important? The purpose of anti-forgery tokens is to prevent cross-site request forgery (CSRF) attacks. The technique consists into submitting multiple different values to the server on any given HTTP POST request, both of which must exist to make the server accept the request: one of those values is submitted as a cookie, another one in the request's HTTP headers, and a third one inside a Form input data. If those values (tokens) don't exist or don't match, the request is denied with a 405 Method Not Allowed Status Code. Read the full article
#Antiforgery#AntiforgeryToken#AntiforgeryTokenSet#ASP.NET#ASP.NETCore#Cross-siterequestforgery#CSRF#IAntiforgery#JQuery#Razor#RazorPages#RazorViews
0 notes
Link
Cross-Site Request Forgery (CSRF) requests are a type of malicious exploit whereby unauthorized commands are performed on behalf of an authenticated user.
CodeIgniter 4 provides protection from CSRF attacks. But it is not enabled by default same as CodeIgniter 3.
The token is generated for each user and it is managed by CodeIgniter to verify the user request.
In this tutorial, I show how you can enable CSRF protection and send AJAX request with CSRF token in the CodeIgniter 4 project.
#codeigniter 4#php#mvc#framework#jQuery#AJAX#MySQL#database#route#CSRF#token#protection#coding#programming#web development#makitweb
0 notes
Photo

How to Send AJAX request with CSRF token in CodeIgniter ☞ https://bit.ly/376wals #php #laravel
0 notes
Link
Introduction
Hello, freeCodeCamp readers. I hope I can bring you some great coding content for inspiration, education and of course, fun! In this tutorial, we will learn about keyword density and how to build a tool that can calculate keyword density with Laravel. The web tool will allow us to paste in a full page of HTML. Then, magic will be executed to give us a precise keyword density score. In a quick summary, here are some basic skills we will touch upon whilst building the tool.
Laravel routes, controllers, and views
Laravel layouts
HTML & forms
JQuery & Ajax
Some native PHP
A bit of SEO!
What is keyword density?
If you have your own website or blog, you possibly already know what keyword density is. For those who don't know what it means I will give a short and sweet explanation below. Keyword density is a calculation of word or keyword occurrences usually in a large piece of text. The density is reported in a percentage which is simply calculated with the following formula. KeywordDensity = (Keyword Count / Word Count) * 100
Why is this important?
Keyword density is a key factor in the Google search engine algorithm. It is widely thought that a good keyword density for optimising web pages for Google rankings is around 3.5%. If the percentage is higher, for example 20%, then this could be seen as 'keyword stuffing' and therefore could badly affect your Google search rankings. So, that is a minuscule lesson on SEO and to give you a bit of context of what we are trying to build.
Building a Keyword Density Tool with Laravel
This tutorial will presume we are all starting with a fresh Laravel build enabling anyone to follow on from any particular point. (Apologies if the beginning sections are telling you to suck eggs!) Also, just for further context, I'm building this on MacOS with XAMPP locally.
Prerequisites
A PHP environment installed and access to the root directory
Composer installed
Your favourite code editor that interprets PHP, HTML, CSS & JS.
With all of these prerequisites checked off, we can now get our hands dirty.
Creating Our Laravel App
First of all we need to download and install a fresh Laravel build. Follow the steps below to achieve this.
Open your command line interface at the root directory of your web server, for example XAMPP/xamppfiles/htdocs/
Run the following command and let composer do it's magic
composer create-project --prefer-dist laravel/laravel KeywordDensityApp
Top Tip: If you are working on MacOS, then check out the following steps to enable permissions on the Laravel storage folder.
Navigate to your CLI to the project folder ('KeywordDensityApp')
Run the following command
sudo chmod -R 777 storage/*
Adding a controller and view
Now that we have the basics out of the way, we can start to build our controller and web page that will allow a user to paste in and analyse some HTML. We can create a new controller in two ways: via the PHP artisan command line helper or simply by creating with your code editor. Feel free to use any of the below methods, just make sure the controller matches
Create controller with PHP artisan
php artisan make:controller ToolController
Create controller with code editor
Locate the following - ProjectFolder/App/Http/Controllers
Create a new .php file named ToolController
Make sure this newly created file has the following contents:
<?php namespace App\Http\Controllers; use Illuminate\Http\Request; class ToolController extends Controller { // }
Now let's create the view.
Create view with code editor
Locate view folder under ProjectFolder/resources/views
Create a new folder named tool
Create a new view PHP file named index.blade.php
Now let's create a layout file
With most Laravel applications, you will want to build a layouts file so that you don't have to repeat lots of HTML over and over to get the same design across the board. This layout is pretty basic, using a simple Bootstrap template and has a @yield call to the 'content' area which we will utilise in our views. In addition, there's a @yield call to 'scripts' which we will utilise later.
Locate view folder under ProjectFolder/resources/views
Create a new folder here named layouts
Create a new file named master.blade.php
Add the following code to the file
<!DOCTYPE html> <html lang=""> <head> <meta charset="utf-8"> <meta name="viewport" content="width=device-width, initial-scale=1"> <title>Keyword Density Tool</title> <link rel="stylesheet" href="https://stackpath.bootstrapcdn.com/bootstrap/4.4.1/css/bootstrap.min.css" integrity="sha384-Vkoo8x4CGsO3+Hhxv8T/Q5PaXtkKtu6ug5TOeNV6gBiFeWPGFN9MuhOf23Q9Ifjh" crossorigin="anonymous"> <!-- Fonts --> <link href="https://fonts.googleapis.com/css?family=Nunito:200,600" rel="stylesheet"> <meta name="csrf-token" content=""> <style> body {padding-top: 5em;} </style> </head> <body> <nav class="navbar navbar-expand-md navbar-dark bg-dark fixed-top"> <a class="navbar-brand" href="#">Keyword Density App</a> <button class="navbar-toggler" type="button" data-toggle="collapse" data-target="#navbarsExampleDefault" aria-controls="navbarsExampleDefault" aria-expanded="false" aria-label="Toggle navigation"> <span class="navbar-toggler-icon"></span> </button> <div class="collapse navbar-collapse" id="navbarsExampleDefault"> <ul class="navbar-nav mr-auto"> <li class="nav-item"> <a class="nav-link" href="/">Home <span class="sr-only">(current)</span></a> </li> <li class="nav-item active"> <a class="nav-link" href="">Tool</a> </li> </ul> </div> </nav> <main role="main" class="container mt-3"> @yield('content') </main><!-- /.container --> <script src="https://code.jquery.com/jquery-3.2.1.min.js"></script> <script src="https://cdn.jsdelivr.net/npm/[email protected]/dist/umd/popper.min.js"></script> <script src="https://stackpath.bootstrapcdn.com/bootstrap/4.4.1/js/bootstrap.min.js"></script> @yield('scripts') </body> </html>
Extend our views to use the layout file
Let us now use the newly created layouts file in both our welcome view and tool index view. Follow these steps to extend to the layout.
Add the following code to both ProjectFolder/resources/views/welcome.blade.php and ProjectFolder/resources/views/tool/index.blade.php
@extends('layouts.master') @section('content') @endsection
Try rendering the index page of the tool directory, for example localhost/tool. It should look something like below.

Basic view layout
Linking up the Controller, Route, & View
Now that we have a controller and view we need to first define a route and second add a return view method to the controller.
Define the route
Locate web routes file under ProjectFolder/routes/web.php
Add the following code to the bottom of the file:
Route::get('/tool', 'ToolController@index')->name('KDTool');
Create the new controller method
Now, go back to your ToolController and add the following function:
public function index() { return view('tool.index'); }
Feel free to change the view names, route URLs, or controller functions to your personal liking. Just make sure they all match up and the page renders.
Building up our tool view
Now, with our earlier set up of views and layout files, we can start to add the content in the form of HTML that we are going to need. It will consist of nothing more than some text, textarea input form, and a submit button. Add the following HTML to the content section of the ProjectFolder/resources/views/tool/index.blade.php file.
<form id="keywordDensityInputForm"> <div class="form-group"> <label for="keywordDensityInput">HTML or Text</label> <textarea class="form-control" id="keywordDensityInput" rows="12"></textarea> </div> <button type="submit" class="btn btn-primary mb-2">Get Keyword Densities</button> </form>
The view should now render like this:
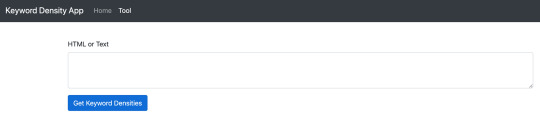
Keyword Density Tool View with Text Area input
Creating the bridge between the front end and the back end
Now, we pretty much have everything we need on the front end: a simple input text area where users can paste in their plain text or HTML. What's missing is the logic for when the button is pressed 'Get Keyword Densities'. This bridging logic will essentially do the following.
Listen for clicks on the Get Keyword Density Button
Grab the contents of the non-empty text area input
Use JQuery Ajax to send the data to the backend to be processed and await a response.
When the response is passed back, handle the data and create a HTML table with the human-readable statistics (keyword density).
Front end
To do this we will use an in-page script which we can inject using the @section tag. Add the following to the tool/index.blade.php view, after the content section.
@section ('scripts') <script> $('#keywordDensityInputForm').on('submit', function (e) { // Listen for submit button click and form submission. e.preventDefault(); // Prevent the form from submitting let kdInput = $('#keywordDensityInput').val(); // Get the input if (kdInput !== "") { // If input is not empty. // Set CSRF token up with ajax. $.ajaxSetup({ headers: { 'X-CSRF-TOKEN': $('meta[name="csrf-token"]').attr('content') } }); $.ajax({ // Pass data to backend type: "POST", url: "/tool/calculate-and-get-density", data: {'keywordInput': kdInput}, success: function (response) { // On Success, build a data table with keyword and densities if (response.length > 0) { let html = "<table class='table'><tbody><thead>"; html += "<th>Keyword</th>"; html += "<th>Count</th>"; html += "<th>Density</th>"; html += "</thead><tbody>"; for (let i = 0; i < response.length; i++) { html += "<tr><td>"+response[i].keyword+"</td>"; html += "<td>"+response[i].count+"</td>"; html += "<td>"+response[i].density+"%</td></tr>"; } html += "</tbody></table>"; $('#keywordDensityInputForm').after(html); // Append the html table after the form. } }, }); } }) </script> @endsection
This entire script that we inject will handle all of the numbered list items above. What is left to do is handle the data coming in on the back end side of things.
Back end
Firstly, before we go any further with coding, we need to handle the fact that both plain text and HTML can be submitted. For this we can use a nifty tool to help us out. html2text is the perfect PHP library for this use case, so it's time we install it. html2text does exactly what it says on the tin, converts HTML markup to plain text. Luckily, this package has a composer install command, so enter the following command into the CLI on the projects root directory.
composer require html2text/html2text
Now, our backend controller is going to receive either HTML or plain text in requests firing from the HTML form we created in our view. We now need to make the route to handle this call and to route the call to the specific controller that will work the magic. Add the following PHP to the web.php routes file:
Route::post('/tool/calculate-and-get-density', 'ToolController@CalculateAndGetDensity');
Secondly, add the following to ToolController.php file:
public function CalculateAndGetDensity(Request $request) { if ($request->isMethod('GET')) { } }
OK, so the stage is set. Let's code in the magic that will calculate the keyword density and return the data. Firstly, add use statement is required for the newly installed html2text package. Add the following to the top of the ToolController.php, just below other use statements:
use Html2Text\Html2Text;
Then we need to handle the get parameter that is to be passed in, making sure it's not set and then converting the parameter of content to plain text. Refactor the CalculateAndGetDensity function to look like below:
public function CalculateAndGetDensity(Request $request) { if ($request->isMethod('GET')) { if (isset($request->keywordInput)) { // Test the parameter is set. $html = new Html2Text($request->keywordInput); // Setup the html2text obj. $text = $html->getText(); // Execute the getText() function. } } }
Now that we have a variable to hold all of the text stripped for the keywordInput parameter, we can go ahead and start to calculate density. We need to handle the following:
Determine the total count of words
Analyse the textual string and convert it to a key value array (the key being the keyword, the value being the occurrence of the word)
Sort into order by descending with the biggest occurrence first in the array
Loop over the key and value array, pushing the values to a new array with an additional field of 'density' which utilises the keyword density formula we looked at earlier in the article. This formula will use the value (occurrence) and the total word count.
Finally, to return the data
Refactor the function to look like the following, taking note of the comments:
public function CalculateAndGetDensity(Request $request) { if ($request->isMethod('GET')) { if (isset($request->keywordInput)) { // Test the parameter is set. $html = new Html2Text($request->keywordInput); // Setup the html2text obj. $text = strtolower($html->getText()); // Execute the getText() function and convert all text to lower case to prevent work duplication $totalWordCount = str_word_count($text); // Get the total count of words in the text string $wordsAndOccurrence = array_count_values(str_word_count($text, 1)); // Get each word and the occurrence count as key value array arsort($wordsAndOccurrence); // Sort into descending order of the array value (occurrence) $keywordDensityArray = []; // Build the array foreach ($wordsAndOccurrence as $key => $value) { $keywordDensityArray[] = ["keyword" => $key, // keyword "count" => $value, // word occurrences "density" => round(($value / $totalWordCount) * 100,2)]; // Round density to two decimal places. } return $keywordDensityArray; } } }
Note: The beauty of html2text is that it doesn't really care if it's converting HTML or plain text in the first place, so we don't need to worry if a user submits either. It will still churn out plain text.
Putting it to the test
Finally, we are ready to test the tool, wahoo! Go ahead and render the tool index view (localhost/tool).
Now, you can go to any website of your choice on the web, load a page from that site, right click and click view source.
Copy the entire contents and come back to the tool.
Paste the contents into the text area and click the Get Keyword Densities button.
Await the response and check out the table of keyword densities!
Check out my example below which uses the HTML of this page.
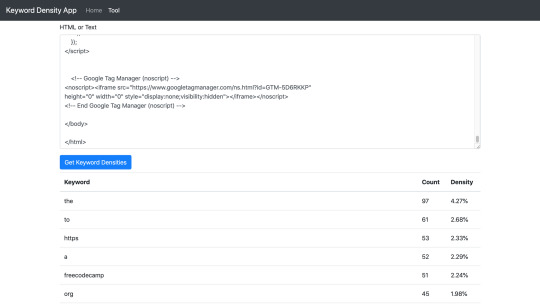
Keyword Density Tool & Table of keywords
And that is it!
Summary
In this article we learned how to build a Laravel application from scratch. It touched on some of the different parts of the full stack in development such as JQuery, PHP, HTML etc. Hopefully, with the understanding of this application, the same methodology can be used to build something else, perhaps bigger and better.
Possible further developments
The keyword density tool currently takes 'stop' words into account. Stop words are known to be ignored by Googles crawlers. Words such as it, the, as, and a. Looking at the tool screenshot above, you can see that they are used a lot! Further development could be carried out to filter the stop words and only calculate density on the non-stop words which is potentially a better view for SEO scoring.
0 notes
Photo

How to Build a File Upload Form with Express and DropzoneJS
Let’s face it, nobody likes forms. Developers don’t like building them, designers don’t particularly enjoy styling them, and users certainly don’t like filling them in.
Of all the components that can make up a form, the file control could just be the most frustrating of the lot. It’s a real pain to style, it’s clunky and awkward to use, and uploading a file will slow down the submission process of any form.
That’s why a plugin to enhance them is always worth a look, and DropzoneJS is just one such option. It will make your file upload controls look better, make them more user-friendly, and by using AJAX to upload the file in the background, it will at the very least make the process seem quicker. It also makes it easier to validate files before they even reach your server, providing near-instantaneous feedback to the user.
We’re going to take a look at DropzoneJS in some detail. We’ll show how to implement it. and look at some of the ways in which it can be tweaked and customized. We’ll also implement a simple server-side upload mechanism using Node.js.
As ever, you can find the code for this tutorial on our GitHub repository.
Introducing DropzoneJS
DropzoneJS allows users to upload files using drag and drop. Whilst the usability benefits could justifiably be debated, it’s an increasingly common approach and one which is in tune with the way a lot of people work with files on their desktop. It’s also pretty well supported across major browsers.
DropzoneJS isn’t simply a drag and drop based widget, however. Clicking the widget launches the more conventional file chooser dialog approach.
Here’s an animation of the widget in action:
Alternatively, take a look at this most minimal of examples.
You can use DropzoneJS for any type of file, though the nice little thumbnail effect makes it ideally suited to uploading images in particular.
Features
To summarize some of the plugin’s features and characteristics, DropzoneJS:
can be used with or without jQuery
has drag and drop support
generates thumbnail images
supports multiple uploads, optionally in parallel
includes a progress bar
is fully themeable
includes extensible file validation support
is available as an AMD module or RequireJS module
comes in at around 43KB when minified and 13KB when gzipped
Browser Support
Taken from the official documentation, browser support is as follows:
Chrome 7+
Firefox 4+
IE 10+
Opera 12+ (Version 12 for macOS is disabled because their API is buggy)
Safari 6+
There are a couple of ways to handle fallbacks for when the plugin isn’t fully supported, which we’ll look at later.
Getting Set Up
The simplest way to get started with DropzoneJS is to include the latest version from a CDN. At the time of writing, this is version 5.5.1.
Alternatively, you can download the latest release from the project’s GitLab page. There’s also a third-party package providing support for ReactJS.
Then, make sure you include both the main JavaScript file and the CSS styles in your page. For example:
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>File Upload Example</title> <link rel="stylesheet" href="https://cdnjs.cloudflare.com/ajax/libs/dropzone/5.5.1/min/dropzone.min.css"> </head> <body> <script src="https://cdnjs.cloudflare.com/ajax/libs/dropzone/5.5.1/min/dropzone.min.js"></script> </body> </html>
Note that the project supplies two CSS files — a basic.css file with some minimal styling, and a more extensive dropzone.css file. Minified versions of dropzone.css and dropzone.js are also available.
Basic Usage
The simplest way to implement the plugin is to attach it to a form, although you can use any HTML such as a <div>. Using a form, however, means fewer options to set — most notably the URL, which is the most important configuration property.
You can initialize it simply by adding the dropzone class. For example:
<form id="upload-widget" method="post" action="/upload" class="dropzone"></form>
Technically, that’s all you need to do, though in most cases you’ll want to set some additional options. The format for that is as follows:
Dropzone.options.WIDGET_ID = { // };
To derive the widget ID for setting the options, take the ID you defined in your HTML and camel-case it. For example, upload-widget becomes uploadWidget:
Dropzone.options.uploadWidget = { // };
You can also create an instance programmatically:
const uploader = new Dropzone('#upload-widget', options);
Next up, we’ll look at some of the available configuration options.
Basic Configuration Options
The url option defines the target for the upload form, and is the only required parameter. That said, if you’re attaching it to a form element then it’ll simply use the form’s action attribute, in which case you don’t even need to specify that.
The method option sets the HTTP method and again, it will take this from the form element if you use that approach, or else it’ll simply default to POST, which should suit most scenarios.
The paramName option is used to set the name of the parameter for the uploaded file. If you’re using a file upload form element, it will match the name attribute. If you don’t include it, it defaults to file.
maxFiles sets the maximum number of files a user can upload, if it’s not set to null.
By default, the widget will show a file dialog when it’s clicked, though you can use the clickable parameter to disable this by setting it to false, or alternatively you can provide an HTML element or CSS selector to customize the clickable element.
Those are the basic options, but let’s now look at some of the more advanced options.
Enforcing Maximum File Size
The maxFilesize property determines the maximum file size in megabytes. This defaults to a size of 1000 bytes, but using the filesizeBase property, you could set it to another value — for example, 1024 bytes. You may need to tweak this to ensure that your client and server code calculate any limits in precisely the same way.
Restricting to Certain File Types
The acceptedFiles parameter can be used to restrict the type of file you want to accept. This should be in the form of a comma-separated list of MIME types, although you can also use wildcards.
For example, to only accept images:
acceptedFiles: 'image/*',
Modifying the Size of the Thumbnail
By default, the thumbnail is generated at 120x120px. That is, it’s square. There are a couple of ways you can modify this behavior.
The first is to use the thumbnailWidth and/or the thumbnailHeight configuration options.
If you set both thumbnailWidth and thumbnailHeight to null, the thumbnail won’t be resized at all.
If you want to completely customize the thumbnail generation behavior, you can even override the resize function.
One important point about modifying the size of the thumbnail is that the dz-image class provided by the package sets the thumbnail size in the CSS, so you’ll need to modify that accordingly as well.
Additional File Checks
The accept option allows you to provide additional checks to determine whether a file is valid before it gets uploaded. You shouldn’t use this to check the number of files (maxFiles), file type (acceptedFiles), or file size (maxFilesize), but you can write custom code to perform other sorts of validation.
You’d use the accept option like this:
accept: function(file, done) { if (!someCheck()) { return done('This is invalid!'); } return done(); }
As you can see, it’s asynchronous. You can call done() with no arguments and validation passes, or provide an error message and the file will be rejected, displaying the message alongside the file as a popover.
We’ll look at a more complex, real-world example later, when we look at how to enforce minimum or maximum image sizes.
Sending Additional Headers
Often you’ll need to attach additional headers to the uploader’s HTTP request.
As an example, one approach to CSRF (cross-site request forgery) protection is to output a token in the view, then have your POST/PUT/DELETE endpoints check the request headers for a valid token. Suppose you outputted your token like this:
<meta name="csrf-token" content="CL2tR2J4UHZXcR9BjRtSYOKzSmL8U1zTc7T8d6Jz">
Then, you could add this to the configuration:
headers: { 'x-csrf-token': document.querySelector('meta[name=csrf-token]').getAttributeNode('content').value, },
Alternatively, here’s the same example but using jQuery:
headers: { 'x-csrf-token': $('meta[name="csrf-token"]').attr('content') },
Your server should then verify the x-csrf-token header, perhaps using some middleware.
Handling Fallbacks
The simplest way to implement a fallback is to insert a <div> into your form containing input controls, setting the class name on the element to fallback. For example:
<form id="upload-widget" method="post" action="/upload" class="dropzone"> <div class="fallback"> <input name="file" type="file" /> </div> </form>
Alternatively, you can provide a function to be executed when the browser doesn’t support the plugin using the fallback configuration parameter.
You can force the widget to use the fallback behavior by setting forceFallback to true, which might help during development.
Handling Errors
You can customize the way the widget handles errors by providing a custom function using the error configuration parameter. The first argument is the file, the error message the second, and if the error occurred server-side, the third parameter will be an instance of XMLHttpRequest.
As always, client-side validation is only half the battle. You must also perform validation on the server. When we implement a simple server-side component later, we’ll look at the expected format of the error response, which when properly configured will be displayed in the same way as client-side errors (illustrated below).
Overriding Messages and Translation
There are a number of additional configuration properties which set the various messages displayed by the widget. You can use these to customize the displayed text, or to translate them into another language.
Most notably, dictDefaultMessage is used to set the text which appears in the middle of the dropzone, prior to someone selecting a file to upload.
You’ll find a complete list of the configurable string values — all of which begin with dict — in the documentation.
Events
There are a number of events you can listen to in order to customize or enhance the plugin.
There are two ways to listen to an event. The first is to create a listener within an initialization function:
Dropzone.options.uploadWidget = { init: function() { this.on('success', function(file, resp){ ... }); }, ... };
This is the alternative approach, which is useful if you decide to create the Dropzone instance programatically:
const uploader = new Dropzone('#upload-widget'); uploader.on('success', function(file, resp){ ... });
Perhaps the most notable aspect is the success event, which is fired when a file has been successfully uploaded. The success callback takes two arguments: the first a file object, and the second an instance of XMLHttpRequest.
Other useful events include addedfile and removedfile, for when a file has been added or removed from the upload list; thumbnail, which fires once the thumbnail has been generated; and uploadprogress, which you might use to implement your own progress meter.
There are also a bunch of events which take an event object as a parameter and which you could use to customize the behavior of the widget itself — drop, dragstart, dragend, dragenter, dragover and dragleave.
You’ll find a complete list of events in the relevant section of the documentation.
The post How to Build a File Upload Form with Express and DropzoneJS appeared first on SitePoint.
by Lukas White via SitePoint https://ift.tt/3cmivck
0 notes
Text
300+ TOP FLASK Interview Questions and Answers
Flask Interview Questions for freshers experienced :-
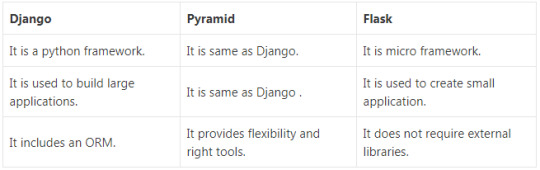
1. What is Flask? Flask is a micro web framework written in Python. It is based on Werkzeug toolkit and Jinja 2 template engine. 2. Who is the developer of Flask? Armin Ronacher is the developer of Flask. 3. What is the stable version of Flask? The stable version of Flask is 0.12.2 and released on 16 May 2017. 4. What are Flask-WTF and its features? It is a template form that is integrated with Flask. It includes various features that are given below. It provides integration with WTF It manages secure form with CSRF token It manages global CSRF protection It provides Internationalization integration It supports recaptcha It handles the file upload that works with Flask uploads 5. What is the benefit of flask? Flask is a part of the micro-framework. It does not require external libraries. It makes the framework light weight, less dependent and less security bugs. 6. What are the differences between Django, Pyramid and Flask? There are following differences between Django, pyramid and Flask:
7. What is the appropriate way to work with Flask script? The appropriate way to work with flask script includes the following steps: Either it should be the import path for our application Or the path to a Python file 8. How can we access sessions in Flask? In Flask, a session allow us to remember information from one request to another. It uses a signed cookie so the user can look at the session contents. We can access session by using the secret key Flask.secret_key in the Flask framework. 9. How can we request database connections in Flask? Flask provides three ways to establish database connection. These are given below. before_request() : It is called before a request and requires no arguments. after_request() : It is called after a request and pass the response that will be sent to the client teardown_request(): It is used when exception is raised and response are not guaranteed. It is called after the response and not allowed to modify the request or their values. 10. What is Flask Sijax? Flask Sijax is a Simple Ajax & jQuery library. It is used to enable Ajax in web applications. It uses JSON to pass data between the server and the browser. 11. How can we get a query string from the Flask? We can get a query string from the flask by using following function. @app.route(‘/data’) def data ( ) : user = request.arg.get (‘user’) 12. How can we create request context in Flask? We can create request context by using following ways. Automatically when the application receives a request OR manually, by calling app.test_request_context (‘/route?param=value) 13. How can we create structure of large Flask application? We can create structure of large Flask application by using following steps: attach to the functions and move them to different files. Use blueprints to assign the views to “categories”. For instance auth, profile, backend, etc. Use the underlying Werkzeug URL map and register functions on there on a central URL. 14. What are the attributes of request objects? There are various attributes of request objects:

15. What are the Mail class methods? There are following Mail class method: send(): It is used to send contents of Message class object. connect(): It is used to opens connection with mail host. send_message(): It is used to sends message object. 16. What are the steps to develop MVC web application in Flask? There are following steps to develop web application: Flask import Flask app = Flask(_name_) @app.route("/") Def hello(): return "Hello World" app.run(debug = True) In this code your, Configuration part will be from flask import Flask app = Flask(_name_) View part will be @app.route("/") Def hello(): return "Hello World" While you model or main part will be app.run(debug = True) 17. What is the extension of Flask? The extension of Flask is .Py. 18. What is the default port of Flask? The default port of Flask is 5000. 19. What is url_for() function in Flask? In Flask, url_for() function is used to build dynamic URL for specific function. 20. What are the HTTP methods in Flask? In Flask, the HTTP methods are given below: GET : It is used to send the data in unencrypted form to the server. HEAD : It is same as GET, but without response body. POST: It is used to send HTML from data to server. Data received by POST method. PUT : It is used to replaces all the current representation uploaded content DELETE : It is used to removes all current reorientation. 21. What is the default route request in Flask? In Flask, GET is the default route request. 22. What are the delimiters used in Jinga2 template? {% … %}: It is used for Statements {{ … }}: It is used for Expressions to print to the template output {# … #}: It is used for Comments not included in the template output # … ## : It is used for Line Statements 23. What is the use redirect() function. Redirect() function is used to display the login page again when a login attempt fails. 24. What are the error codes in Flask? In Flask, the error code is given below: 400 − for Bad Request. 401 − for Unauthenticated. 403 − for Forbidden. 404 − for Not Found. 406 − for Not Acceptable. 415 − for Unsupported Media Type. 429 − Too Many Requests. 25. How can we create a form for file uploading? We can create a form for file uploading by using following code: 26. What are the Mail methods in Flask? In Flask, the Mail methods are given below: send(): It is used to send contents of message class object. connect(): It is used to open connection with mail host. send_message(): It is used to send message object. 27. What are the validators class of WTForms in Flask? In Flask, The validators class of WTForm are listed in below table: Validators class Description DataRequired It is used to check whether input field is empty Email It is used to check whether text in the field follows email ID conventions. IPAddress It is used to validate IP address in input field Length It is used to verify if length of string in input field is in given range NumberRange It is used to validates a number in input field within given range URL It is used to validates URL entered in input field 28. Does Flask support in-built SQlite database? Yes, Flask supports in-built SQlite database. 29. What is ORM? ORM stands for Object Relation Mapping. It is a technique of mapping object parameter. 30. What is WSGI? WSGI stands for Web Server Gateway Interface. It is used to python web application development. 31. What are the popular server that contains WSGI application and Server HTTP? There are many popular server that contains WSGI application and server HTTP: Gunicorn Tornado Gevent Twisted Web Flask Questions and Answers Pdf Download Read the full article
0 notes
Link
Written by Pascal Chambon, reviewed by Raphaël Gomès Update: this article mostly deals with the RESTish ecosystem, which now constitutes a major part of webservices. For more in-depth analysis of the original REST, and of HATEOAS, see my follow-up article. How come REST means so much WORK? This is both a paradox, and a shameless pun. Let’s dive further into the artificial problems born from this design philosophy. BEWARE : through this document, you’ll encounter lots of semi-rhetorical technical questions. Do not misunderstand them, they DO NOT mean that RESTish webservices can’t solve these problems. They just mean that users have an extra burden of decisions to take, of extensions to integrate, of custom workarounds to apply, and this is a problem in itself. The joy of REST verbsRest is not CRUD, its advocates will ensure that you don’t mix up these two. Yet minutes later they will rejoice that HTTP methods have well defined semantics to create (POST), retrieve (GET), update (PUT/PATCH) and delete (DELETE) resources. They’ll delight in professing that these few “verbs”are enough to express any operation. Well, of course they are; the same way that a handful of verbs would be enough to express any concept in English: “Today I updated my CarDriverSeat with my body, and created an EngineIgnition, but the FuelTank deleted itself”; being possible doesn’t make it any less awkward. Unless you’re an admirator of the Toki Pona language. If the point is to be minimalist, at least let it be done right. Do you know why PUT, PATCH, and DELETE have never been implemented in web browser forms? Because they are useless and harmful. We can just use GET for read and POST for write. Or POST exclusively, when HTTP-level caching is unwanted. Other methods will at best get in your way, at worst ruin your day. You want to use PUT to update your resource? OK, but some Holy Specifications state that the data input has to be equivalent to the representation received via a GET. So what do you do with the numerous read-only parameters returned by GET (creation time, last update time, server-generated token…)? You omit them and violate the PUT principles? You include them anyway, and expect an “HTTP 409 Conflict” if they don’t match server-side values (forcing you to then issue a GET...)? You give them random values and expect servers to ignore them (the joy of silent errors)? Pick your poison, REST clearly has no clue what a read-only attribute it, and this won’t be fixed anytime soon. Meanwhile, a GET is dangerously supposed to return the password (or credit card number) which was sent in a previous POST/PUT; good luck dealing with such write-only parameters too. Did I forget to mention that PUT also brings dangerous race conditions, where several clients will override each other’s changes, whereas they just wanted to update different fields? You want to use PATCH to update your resource? Nice, but like 99% of people using this verb, you’ll just send a subset of resource fields in your request payload, hoping that the server properly understands the operation intended (and all its possible side effects); lots of resource parameters are deeply linked or mutually exclusive(ex. it’s either credit card OR paypal token, in a user’s billing info), but RESTful design hides this important information too. Anyway, you’d violate specs once more: PATCH is not supposed to just send a bunch of fields to be overridden. Instead, you’re supposed to provide a “set of instructions” to be applied on the resources. So here you go again, take your paperboard and your coffee mug, you’ll have to decide how to express these instructions. Often with handcrafted specifications, since Not-Invented-Here Syndrome is a de-facto standard in the REST world. (Edit: REST advocates have backpedaled on this subject, with Json Merge Patch, an alternative to formats like Json Patch) You want to DELETE resources? OK, but I hope you don’t need to provide substantial context data; like a PDF scan of the termination request from the user. DELETE prohibits having a payload. A constraint that REST architects often dismiss, since most webservers don’t enforce this rule on the requests they receive. How compatible, anyway, would be a DELETE request with 2 MBs of base64 query string attached? (Edit: the RFC 2616, indicating that payloads without semantics should be ignored, is now obsolete) REST aficionados easily profess that “people are doing it wrong” and their APIs are “actually not RESTful”. For example, lots of developers use PUT to create a resource directly on its final URL (/myresourcebase/myresourceid), whereas the “good way” (edit: according to many) of doing it is to POST on a parent URL (/myresourcebase), and let the server indicate, with an HTTP “Location” header, the new resource’s URL (edit: it’s not an HTTP redirection though). The good news is: it doesn’t matter. These rigorous principles are like Big Endian vs Little Endian, they occupy philosophers for hours, but have very little impact on real life problems, i.e “getting stuff done”. By the way… handcrafting URLs is always great fun. Do you know how many implementations properly urlencode() identifiers while building REST urls? Not that many. Get ready for nasty breakages and SSRF/CSRF attacks. When you forget to urlencode usernames in 1 of your 30 handcrafted URLs.The joy of REST error handlingAbout every coder is able to make a “nominal case” work. Error handling is one of these features which will decide if your code is robust software, or a huge pile of matchsticks. HTTP provides a list of error codes out-of-the-box. Great, let’s see that. Using “HTTP 404 Not Found” to notify about an unexisting resource sounds RESTful as heck, doesn’t it? Too bad: your nginx was misconfigured for 1 hour, so your API consumers got only 404 errors and purged hundreds of accounts, thinking they were deleted…. Our customers, after we deleted their gigabytes of kitten images by error.Using “HTTP 401 Unauthorized” when a user doesn’t have access credentials to a third-party service sounds acceptable, doesn’t it? However, if an ajax call in your Safari browser gets this error code, it might startle your end customer with a very unexpected password prompt [it did, years ago, YMMV]. HTTP existed long before “RESTful webservices”, and the web ecosystem is filled with assumptions about the meaning of its error codes. Using them to transport application errors is like using milk bottles to dispose of toxic waste: inevitably, one day, there will be trouble. Some standard HTTP error codes are specific to Webdav, others to Microsoft, and the few remaining have definitions so fuzzy that they are of no help. In the end, like most REST users, you’ll probably use random HTTP codes, like “HTTP 418 I’m a teapot” or unassigned numbers, to express your application-specific exceptions. Or you’ll shamelessly return “HTTP 400 Bad Request” for all functional errors, and then invent your own clunky error format, with booleans, integer codes, slugs, and translated messages stuffed into an arbitrary payload. Or you’ll give up altogether on proper error handling; you’ll just return a plain message, in natural language, and hope that the caller will be a human able to analyze the problem, and take action. Good luck interacting with such APIs from an autonomous program. The joy of REST conceptsREST has made a career out of boasting about concepts that any service architect in his right mind already respects, or about principles that it doesn’t even follow. Here are some excerpts, grabbed from top-ranked webpages. REST is a client-server architecture. The client and the server both have a different set of concerns. What a scoop in the software world. REST provides a uniform interface between components. Well, like any other protocol does, when it’s enforced as the lingua franca of a whole ecosystem of services. REST is a layered system. Individual components cannot see beyond the immediate layer with which they are interacting. It sounds like a natural consequence of any well designed, loosely coupled architecture; amazing. Rest is awesome, because it is STATELESS. Yes there is probably a huge database behind the webservice, but it doesn’t remember the state of the client. Or, well, yes, actually it remember its authentication session, its access permissions… but it’s stateless, nonetheless. Or more precisely, just as stateless as any HTTP-based protocol, like simple RPC mentioned previously. With REST, you can leverage the power of HTTP CACHING! Well here is at last one concluding point: a GET request and its cache-control headers are indeed friendly with web caches. That being said, aren’t local caches (Memcached etc.) enough for 99% of web services? Out-of-control caches are dangerous beasts; how many people want to expose their APIs in clear text, so that a Varnish or a Proxy on the road may keep delivering outdated content, long after a resource has been updated or deleted? Maybe even delivering it “forever”, if a configuration mistake once occurred? A system must be secure by default. I perfectly admit that some heavily loaded systems want to benefit from HTTP caching, but it costs much less to expose a few GET endpoints for heavy read-only interactions, than to switch all operations to REST and its dubious error handling. Thanks to all this, REST has HIGH PERFORMANCE! Are we sure of that? Any API designer knows it: locally, we want fine-grained APIs, to be able to do whatever we want; and remotely, we want coarse-grained APIs, to limit the impact of network round-trips. Here is again a domain in which “basic” REST fails miserably. The split of data between “resources”, each instance on its own endpoint, naturally leads to the N+1 Query problem. To get a user’s full data (account, subscriptions, billing information…), you have to issue as many HTTP requests; and you can’t parallelize them, since you don’t know in advance the unique IDs of related resources. This, plus the inability to fetch only part of resource objects, naturally creates nasty bottlenecks (edit: yes, you can stuff extensions like Compound/Partial Documents into your setup to help with that). REST offers better compatibility. How so? Why do so many REST webservices have “/v2/” or “/v3/” in their base URLs then? Backwards and forward compatible APIs are not hard to achieve, with high level languages, as long as simple rules are followed when adding/deprecating parameters. As far as I know, REST doesn’t bring anything new on the subject. REST is SIMPLE, everyone knows HTTP! Well, everyone knows pebbles too, yet people are happy to have better blocks when building their house. The same way XML is a meta-language, HTTP is a meta-protocol. To have a real application protocol (like “dialects” are to XML), you’ll need to specify lots of things; and you’ll end up with Yet Another RPC Protocol, as if there were not enough already. REST is so easy, it can be queried from any shell, with CURL! OK, actually, every HTTP-based protocol can be queried with CURL. Even SOAP. Issuing a GET is particularly straightforward, for sure, but good luck writing json or xml POST payloads by hand; people usually use fixture files, or, much more handy, full-fledged API clients instantiated directly in the command line interface of their favorite language. “The client does not need any prior knowledge of the service in order to use it”. This is by far my favourite quote. I’ve found it numerous times, under different forms, especially when the buzzword HATEOAS lurked around; sometimes with some careful (but insufficient) “except” phrases following. Still, I don’t know in which fantasy world these people live, but in this one, a client program is not a colony of ants; it doesn’t browse remote APIs randomly, and then decide how to best handle them, based on pattern recognition or black magic. Quite the opposite; the client has strong expectations on what it means, to PUT this one field to this one URL with this one value, and the server had better respect the semantic which was agreed upon during integration, else all hell might break loose. When you ask how HATEOAS is supposed to work.How to do REST right and quick?Forget about the “right” part. REST is like a religion, no mere mortal will ever grasp the extent of its genius, nor “do it right”. So the real question is: if you’re forced to expose or consume webservices in a kinda-RESTful way, how to rush through this job, and switch to more constructive tasks asap? Update: it turns out that there are actually lots of “standards” and industrialization efforts for REST, although I had never encountered them personnally (maybe because few people use them?). More information in my follow-up article. How to industrialize server-side exposure?Each web framework has its own way of defining URL endpoint. So expect some big dependencies, or a good layer of handwritten boilerplate, to plug your existing API onto your favorite server as a set of REST endpoint. Libraries like Django-Rest-Framework automate the creation of REST APIs, by acting as data-centric wrappers above SQL/noSQL schemas. If you just want to make “CRUD over HTTP”, you could be fine with them. But if you want to expose common “do-this-for-me” APIs, with workflows, constraints, complex data impacts and such, you’ll have a hard time bending any REST framework to fit your needs. Be prepared to connect, one by one, each HTTP method of each endpoint, to the corresponding method call; with a fair share of handmade exception handling, to translate passing-through exceptions into corresponding error codes and payloads. How to industrialize client-side integration?From experience, my guess is: you don’t. For each API integration, you’ll have to browse lengthy docs, and follow detailed recipes on how each of the N possible operations has to be performed. You’ll have to craft URLs by hand, write serializers and deserializers, and learn how to workaround the ambiguities of the API. Expect quite some trial-and-error before you tame the beast. Do you know how webservices providers make up for this, and ease adoption? Simple, they write their own official client implementations. FOR. EVERY. MAJOR. LANGUAGE. AND. PLATFORM. I’ve recently dealt with a subscription management system. They provide clients for PHP, Ruby, Python, .NET, iOS, Android, Java… plus some external contributions for Go and NodeJS. Each client lives in its own Github repository. Each with its own big list of commits, bug tracking tickets, and pull requests. Each with its own usage examples. Each with its own awkward architecture, somewhere between ActiveRecord and RPC proxy. This is astounding. How much time is spent developing such weird wrappers, instead of improving the real, the valuable, the getting-stuff-done, webservice? Sisyphus developing Yet Another Client for his API.ConclusionFor decades, about every programming language has functioned with the same workflow: sending inputs to a callable, and getting results or errors as output. This worked well. Quite well. With Rest, this has turned into an insane work of mapping apples to oranges, and praising HTTP specifications to better violate them minutes later. In an era where MICROSERVICES are more and more common, how come such an easy task — linking libraries over networks — remains so artificially crafty and cumbersome? I don’t doubt that some smart people out there will provide cases where REST shines; they’ll showcase their homemade REST-based protocol, allowing to discover and do CRUD operation on arbitrary object trees, thanks to hyperlinks; they’ll explain how the REST design is so brilliant, that I’ve just not read enough articles and dissertations about its concepts. I don’t care. Trees are recognized by their own fruits. What took me a few hours of coding and worked very robustly, with simple RPC, now takes weeks and can’t stop inventing new ways of failing or breaking expectations. Development has been replaced by tinkering. Almost-transparent remote procedure call was what 99% people really needed, and existing protocols, as imperfect as they were, did the job just fine. This mass monomania for the lowest common denominator of the web, HTTP, has mainly resulted in a huge waste of time and grey matter. REST promised simplicity and delivered complexity. REST promised robustness and delivered fragility. REST promised interoperability and delivered heterogeneity. REST is the new SOAP. EpilogueThe future could be bright. There are still tons of excellent protocols available, in binary or text format, with or without schema, some leveraging the new abilities of HTTP2… so let’s move on, people. We can’t forever remain in the Stone Age of Webservices. Edit: many people asked for these alternative protocols, the subject would deserve its own story, but one could have a look at XMLRPC and JSONRPC (simple but quite relevant), or JSONWSP (includes schemas), or language-specific layers like Pyro or RMI when for internal use, or new kids in the block like GraphQL and gRPC for public APIs… “Always finish a rant on a positive note”, momma said.Edited on December 12, 2017: normalize section titlesremove some typosrectify improper “HTTP redirection” wording after POST operationsadd suggestions of alternative protocolsEdited on December 28, 2017: fix mixup between “HTTP methods” and “REST verbs”Edited on January 7, 2018 Edited on January 19, 2018 fix wrong wording on “PUT vs GET” remarksprecise the notion of “real APIs” (non-CRUD)mention risk of overrides with PUTupdate paragraphs on PATCH and DELETE troublesEdited on January 19, 2018 fix wording around Not-Invented-Here SyndromeEdited on February 2, 2018 add links to follow-up article on The Original REST, in “introduction” and “how to industrialize” chaptersEdited on April 14, 2019 add clarification about “semi-rhetorical question”, and hints about extensions like compound/partial documentsEdited on July 6, 2019 fix typos and French links
0 notes
Text
Discovering SCP Workflow – Instance Initiation
Previous post in this series: Discovering SCP Workflow – The Monitor. In this post we explore the part of the SCP Workflow API that deals with workflow instances, and look particularly at how we initiate a new workflow instance, paying particular attention to how we request, and then use, a cross site request forgery (XSRF) token. In Discovering SCP Workflow – The Monitor, we saw that the Workflow API exposes these main entities: Workflow Definitions Workflow Instances User Task Instances Messages We also understand that a workflow instance is a specific occurrence of a given workflow definition. So one might guess, again correctly, that as the Workflow API is informed by REST principles, we should look to the Workflow Instances entity to see how we might start a new workflow instance using the appropriate HTTP method. Workflow instance operations In the API documentation, the operations for Workflow Instances are shown as follows: Considering that initiating a new workflow instance is certainly not idempotent, our eyes are drawn towards: POST /v1/workflow-instances While our eyes are wandering over the operations summary, they also surely fall upon the path info given for some of the operations … whereupon we can surmise that workflow instances have context, error messages, and execution logs (in fact, we looked at some execution logs in Discovering SCP Workflow – The Monitor). Perhaps we’ll cover that in another installment. Creating a new instance Looking in more detail at the requirements for the POST operation call, we can see the following: * the resource here is protected against cross site request forgery and an XSRF token will need to be supplied in each request * the payload to supply is to be in JSON format, with two properties: * definitionId: the ID of the actual workflow definition * context: the data pertaining to the particular workflow instance to be initiated It’s great to see that a successful response returns HTTP status code 201 CREATED, as it should, in a RESTful sense. As far as I can see, the Location header, that should normally accompany a 201 response, is missing (and the request URL is certainly not the location of the newly created resource, which is the alternative when no Location header is supplied). But let’s leave that for another time. Regardless, the process is therefore fairly straightforward. Let’s have a look at some sample code from Archana Shukla ‘s post “Part 2: Start Workflow from your HTML5 application” to embed the process into our brains. Fetching the XSRF token First, we have the _fetchToken function defined thus: _fetchToken: function() { var token; $.ajax({ url: "/bpmworkflowruntime/rest/v1/xsrf-token", method: "GET", async: false, headers: { "X-CSRF-Token": "Fetch" }, success: function(result, xhr, data) { token = data.getResponseHeader("X-CSRF-Token"); } }); return token; } This _fetchToken method is called before the main POST method (that’s the one that actually initiates the new instance). Let’s look closely. There’s a GET request made to the following URL: /bpmworkflowruntime/rest/v1/xsrf-token This URL is of course abstracted by the destination target entry in the app’s neo-app.json descriptor file, which has an entryPath defined as “/workflow-service”: { "path": "bpmworkflowruntime", "target": { "type": "destination", "name": "bpmworkflowruntime", "entryPath": "/workflow-service" }, "description": "Workflow Service Runtime" } Digression: Resource URLs and how to think about them It’s worth stopping briefly to consider what this means and in what way we look at this Workflow API (and APIs for other services), particularly around how we think about different parts of the path info. By the way, the “path info” is that part of the url that starts after the hostname and (optional) port, running up to any query parameters. So for example, in the URL http://host.example.com:8080/something/something-else/this?n=42 the path info part is: /something/something-else/this So, back to the digression. When you enable the Workflow service in the SCP cockpit, a new destination “bpmworkflowruntime” appears, with the URL pattern that looks like this for production accounts: https://bpmworkflowruntimewfs-.hana.ondemand.com and this for trial accounts: https://bpmworkflowruntimewfs-trial.hanatrial.ondemand.com So, with this in mind, and looking at the pattern defined for the Workflow API production URL, as described in the Overview section of the Workflow API documentation on the API Hub: https://bpmworkflowruntime{provideracctname}-{consumeracctname} .hana.ondemand.com /workflow-service/rest (split for legibility) we can see that “wfs” is the provider account name, and that /workflowservice/rest is the “root” part of the path info for the Workflow API resources. In other words, this “root” part is common to all resource URLs in the Workflow API. Taking my trial account for example, it resolves to this: https://bpmworkflowruntimewfs-p481810trial .hanatrial.ondemand.com /workflow-service/rest A complete URL for a given API resource, such as for the workflow instances, would look like this: https://bpmworkflowruntimewfs-p481810trial .hanatrial.ondemand.com /workflow-service/rest/v1/workflow-instances You can see that after the “root” part of the path info, we have the resource-specific part: /v1/workflow-instances This might seem like an unnecessary diversion, but I think it’s important to understand how resource identifiers (URLs) are structured, so you can think about them in an appropriate way, and have that thinking permeate your code and configuration. So I think here it might be nicer to have a destination target entry like this: { "path": "workflowservice", Host: bpmworkflowruntimewfs-p481810trial.hanatrial.ondemand.com > User-Agent: curl/7.52.1 > Accept: */* > X-CSRF-Token: Fetch > Host: bpmworkflowruntimewfs-p481810trial.hanatrial.ondemand.com > User-Agent: curl/7.52.1 > Accept: */* > Content-Type: application/json > X-CSRF-Token: 10D04A3B50DDE972188AA980DFDC56D9 > Content-Length: 69 > } [69 bytes data] GET /workflow-service/rest/v1/xsrf-token HTTP/1.1 > Host: bpmworkflowruntimewfs-p481810trial.hanatrial.ondemand.com > User-Agent: curl/7.52.1 > Accept: */* > X-CSRF-Token: Fetch > Host: bpmworkflowruntimewfs-p481810trial.hanatrial.ondemand.com > User-Agent: curl/7.52.1 > Accept: */* > Cookie: JSESSIONID=2C505C957AD0B1E76BD0535F0AF66C10DD824F88F2FF5F3463DD56AF5020E8D0; BIGipServer~jpaas_folder~bpmworkflowruntimewfs.hanatrial.ondemand.com=!kdw/bjE6WrgieXWwDhtcRsHHmTA76BykeAKzJSQCxdxLV7mHZYmet6Q6LvtTA6c9gdNjkRxfo0Gi4So=; JTENANTSESSIONID_p481810trial=iIN12zFf3bAmLNOQA3tuM4YVkPI2WgN060d0hgv%2B6W4%3D > Content-Type: application/json > Content-Length: 69 >
0 notes
Text
Laravel 7.x, 6 Ajax Form Submit With Validation Tutorial
Laravel 7.x, 6 Ajax Form Submit With Validation Tutorial
Laravel ajax form post with
In this tutorial, you can submit the form using jquery and without the whole page refresh. When we submit an ajax form in laravel, we will add the csrf token in ajax request.
Laravel Ajax Form Submit With jQuery Validation
Create One Model and Migration
Make Route
Generate (create) Controller
Create Blade View
Start Development Server
Conclusion
Create Model and…
View On WordPress
0 notes
Text
The Most Common Techniques Employed By Cyber-Thieves To Compromise The Website

The Internet continues to grow at an incredible pace, with more archives of valuable information are being placed online than ever before. A significant amount of those archives distributed online is extremely valuable, including credit card details, crypto-currency, intellectual property, personal details, and trade secrets.
Businesses, governments, and consumers are also more reliant on the Internet for their daily activities. The transactions performed online are worth billions of dollars and trillions of archives of information is exchanged online every day.
The lucrative nature of the Internet has led to a significant increase in the number of Cyber-Attack from Cyber-Thieves. These Cyber-Thieves may employ various tools and techniques to gain access to the sensitive information that is found online. They often compromise the websites and network resources in an effort to extort money or steal assets from organizations.
To protect yourself and your business against Cyber-Thieves, it is important to be aware of how website compromising technique works. This guide will share the most common Cyber-Attack, to help you prepare for most types of malicious threats.
SQL Injection Cyber-Attack
SQL Injection Cyber-Attack is the most common website compromising technique. Most websites employ Structured Query Language (SQL) to interact with archives. SQL allows the website to create, retrieve, update, and delete records from the archives. It is normally employed for everything from logging the authorized client into the website to storing details of an e-commerce transaction.
An SQL injection Cyber-Attack places SQL into a web form in an attempt to get the application to run it. For example, instead of typing plain text into the field of login credentials, a Cyber-Thief may type in ‘ OR 1=1.
If the application appends this string directly to an SQL command that is designed to check if the authorized client exists in the archives, it will always return true. This can allow these Cyber-Thieves to gain access to a restricted section of a website. Other SQL injection Cyber-Attack can be employed to delete information from the archives or document new information.
Cyber-Thieves sometimes employ automated tools to perform SQL injections on remote websites. They will scan thousands of websites, testing many types of injection Cyber-Attack until they are successful.
SQL injection Cyber-Attack can be prevented by correctly filtering input from the authorized client. Most programming languages have special functions to safely handle the input or requests sent by the authorized client.
Cross Site Scripting (XSS)
Cross-Site Scripting is a major vulnerability that is often exploited by Cyber-Thieves to compromise a website. It is one of the more difficult vulnerabilities to deal with because of the way it works. Some of the largest websites in the world have dealt with successful XSS Cyber-Attack including Microsoft and Google.
Most XSS website compromising cyber-attacks employ malicious Java-script, those scripts are embedded in hyperlinks. When the authorized client clicks the link, it might steal personal information, hijack a web session, take over client’s account, or change the advertisements that are being displayed on a page.
Cyber-Thieves will often insert these malicious links into web forums, social media websites, and other prominent locations where authorized clients will click them. To avoid XSS Cyber-Attack, website owners must filter input received by authorized clients to remove any malicious code.
Denial of Service (DoS/DDoS)
The denial of service is the latest technique used by Cyber-Thieves, in which they overwhelm a website with an immense amount of fake Internet traffic created employing several bots and this ultimately causes the servers to become overloaded with a huge amount of requests, which results in a server crash. Most DDoS Cyber-Attack are carried out using Digital-Systems that have been compromised with malware. The owners of the infected Digital-System may not even be aware that their machine is sending requests to access the archives of their website.
Denial of service Cyber-Attack can be prevented by:
Rate limiting your web server’s router
Adding filters to your router to drop packets from dubious sources
Dropping spoofed or malformed packets
Setting more aggressive timeouts on connections
Using firewalls with DDoS protection
Using third-party DDoS mitigation program from Akamai, Cloudflare, VeriSign, Arbor Networks or another provider
Cross-Site Request Forgery (CSRF or XSRF)
Cross-site request forgery is a very common technique employed by Cyber-Thieves to exploit vulnerabilities of websites. It occurs when unauthorized commands are transmitted from a client that a web application trusts. The client is usually logged into the website, so they have a higher level of privileges, allowing the Cyber-Thief to transfer funds, obtain account information or gain access to sensitive information.
There are many ways for Cyber-Thieves to transmit forged commands including hidden forms, AJAX, and image tags. The authorized client is not aware that the command has been sent and the website believes that the command has come from an authorized client. The main difference between an XSS and CSRF Cyber-Attack is that the client should be logged in and trusted by a website for a CSRF website compromising Cyber-Attack to work. Website owners can prevent CSRF Cyber-Attack by checking HTTP headers to verify where the request is coming from and check CSRF tokens in web forms. This type of diagnosis will make sure that the request has come from the internal page of a web application and not from an unknown external source.
DNS Spoofing (DNS Cache Poisoning)
This attacking technique injects a corrupt domain system archive into a DNS resolver’s cache to redirect where a website’s traffic is sent. It often employs the way of sending traffic from legitimate websites to malicious websites that contain malware. DNS spoofing can also be employed to gather information about the traffic being diverted. The best technique for preventing DNS spoofing is to set short TTL times and regularly clear the DNS caches of local machines.
Social Engineering Techniques
In some cases, the greatest weakness in a website’s security system is the people that operate it. Social engineering seeks to exploit this weakness. The Cyber-Thieves will convince a website administrator to divulge some important information that helps them exploit the website. There are many forms of social engineered Cyber-Attacks, including:
Phishing
The authorized clients of a website are sent fraudulent emails that look like they have come from the website, then the client is asked to divulge some information, such as their login details or personal information. Cyber-Thieves can employ this information to compromises the website.
Baiting
This is a classic social engineering technique was first employed in the 1970s. The Cyber-Thief will leave a device near your place of business, perhaps marked with a label like “employee salaries”. One of your employees might pick it up and insert it into their Digital-System out of curiosity. The USB stick will contain malware that infects your Digital-System’s network and compromises your website.
Pretexting
The Cyber-Thief will contact you, one of your customers or an employee and pretend to be someone else. They will demand sensitive information, which they employ to compromise your website. The best way to eliminate social engineered Cyber-Attack is to educate your employees and customers about these kinds of threats.
Non-targeted website Attacking
In many cases, Cyber-Thieves won’t specifically target your website. Instead of your website, they will be more focused on exploring vulnerabilities present in your plugin, content management system or templates.
For example, they may have developed an attacking technique that targets a vulnerability in a particular version of Word-Press, Joomla, or another content management system. They will employ automated bots to find websites using this version of the content management system in question before launching a Cyber-Attack. They might employ the vulnerability to delete stored archives from your website, steal sensitive information, or to insert malicious program onto your server.
The best way to avoid website compromising Cyber-Attacks to ensure your content management system, plugins, and templates are all up-to-date.
#cybersecurity#security#Secure#technology#web development#web developing company#technologies#Webmaster#blog
0 notes