#Artificial Intelligence/Machine Learning
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The Tumblr app for Google Glass was released on May 16, 2013.
Text

Frank Rosenblatt, often cited as the Father of Machine Learning, photographed in 1960 alongside his most-notable invention: the Mark I Perceptron machine — a hardware implementation for the perceptron algorithm, the earliest example of an artificial neural network, est. 1943.
#frank rosenblatt#tech history#machine learning#neural network#artificial intelligence#AI#perceptron#60s#black and white#monochrome#technology#u
808 notes
·
View notes
Text
we need to come up for a good word for ""AI"" that doesn't imply it's artificial or intelligent and highlights the stolen human labor. like what if we call it "theftgen"
(workshop this with me)
#theftgen#theft generation#machine learning#artificial intelligence#chatgpt#midjourney#dalle#stable diffusion
1K notes
·
View notes
Text

542 notes
·
View notes
Text
For the purposes of this poll, research is defined as reading multiple non-opinion articles from different credible sources, a class on the matter, etc.– do not include reading social media or pure opinion pieces.
Fun topics to research:
Can AI images be copyrighted in your country? If yes, what criteria does it need to meet?
Which companies are using AI in your country? In what kinds of projects? How big are the companies?
What is considered fair use of copyrighted images in your country? What is considered a transformative work? (Important for fandom blogs!)
What legislation is being proposed to ‘combat AI’ in your country? Who does it benefit? How does it affect non-AI art, if at all?
How much data do generators store? Divide by the number of images in the data set. How much information is each image, proportionally? How many pixels is that?
What ways are there to remove yourself from AI datasets if you want to opt out? Which of these are effective (ie, are there workarounds in AI communities to circumvent dataset poisoning, are the test sample sizes realistic, which generators allow opting out or respect the no-ai tag, etc)
–
We ask your questions so you don’t have to! Submit your questions to have them posted anonymously as polls.
#polls#incognito polls#anonymous#tumblr polls#tumblr users#questions#polls about the internet#submitted dec 8#polls about ethics#ai art#generative ai#generative art#artificial intelligence#machine learning#technology
463 notes
·
View notes
Text
TEXT SEARCH BRADLEY CARL GEIGER AND BRAD GEIGER AND EVERYTHING ASSOCIATED
BRAD GEIGER AND CENTRAL INTELLIGENCE AGENCY
BRADLEY CARL GEIGER AND CENTRAL INTELLIGENCE AGENCY
BRAD GEIGER AND WIKIPEDIA
BRADLEY CARL GEIGER AND WIKIPEDIA
#TEXT SEARCH BRADLEY CARL GEIGER AND BRAD GEIGER AND EVERYTHING ASSOCIATED#robots#self-driving cars#deep learning#machine learning#drones#artificial intelligence#futurism#technology#culture#history
234 notes
·
View notes
Text

#chatgpt#machine learning#artificial intelligence#mathblr#tumbler polls#actually autistic#submitted by anon
209 notes
·
View notes
Text

They call it "Cost optimization to navigate crises"
674 notes
·
View notes
Text
401 notes
·
View notes
Text
HERMAN LOWE LILLY ROBERT CHAMBERLAIN



#Herman Lowe#Lilly#Robert Chamberlain#HERMAN LOWE LILLY ROBERT CHAMBERLAIN#robots#self-driving cars#deep learning#machine learning#drones#artificial intelligence#technology#culture#history#bustles for fashion accessories#bloody sheets missing doctor#the giant killer#droids
126 notes
·
View notes
Text


#vintage cars#coupe#ford#classic car#suv#fast cars#electric cars#classic cars#cars#sedan#ai#ai art#ai generated#ai image#artificial intelligence#technology#chatgpt#machine learning#ai artwork#midjourney
497 notes
·
View notes
Text
"An international research team has found almost a million potential sources of antibiotics in the natural world.
Research published in the journal Cell by a team including Queensland University of Technology (QUT) computational biologist Associate Professor Luis Pedro Coelho has used machine learning to identify 863,498 promising antimicrobial peptides -- small molecules that can kill or inhibit the growth of infectious microbes.
The findings of the study come with a renewed global focus on combatting antimicrobial resistance (AMR) as humanity contends with the growing number of superbugs resistant to current drugs.
"There is an urgent need for new methods for antibiotic discovery," Professor Coelho, a researcher at the QUT Centre for Microbiome Research, said. The centre studies the structure and function of microbial communities from around the globe.
"It is one of the top public health threats, killing 1.27 million people each year." ...
"Using artificial intelligence to understand and harness the power of the global microbiome will hopefully drive innovative research for better public health outcomes," he said.
The team verified the machine predictions by testing 100 laboratory-made peptides against clinically significant pathogens. They found 79 disrupted bacterial membranes and 63 specifically targeted antibiotic-resistant bacteria such as Staphylococcus aureus and Escherichia coli.
"Moreover, some peptides helped to eliminate infections in mice; two in particular reduced bacteria by up to four orders of magnitude," Professor Coelho said.
In a preclinical model, tested on infected mice, treatment with these peptides produced results similar to the effects of polymyxin B -- a commercially available antibiotic which is used to treat meningitis, pneumonia, sepsis and urinary tract infections.
More than 60,000 metagenomes (a collection of genomes within a specific environment), which together contained the genetic makeup of over one million organisms, were analysed to get these results. They came from sources across the globe including marine and soil environments, and human and animal guts.
The resulting AMPSphere -- a comprehensive database comprising these novel peptides -- has been published as a publicly available, open-access resource for new antibiotic discovery.
[Note: !!! Love it. Open access research databases my beloved.]"
-via Science Daily, June 5, 2024
#superbugs#bacteria#viruses#microbiology#antibiotics#medicines#public health#peptides#medical news#antibiotic resistance#good news#hope#ai#artificial intelligence#pro ai#machine learning
184 notes
·
View notes
Text
AUTOMATIC CLAPPING XBOX TERMINATOR GENISYS









#automatic#clapping#automatic clapping#xbox#xbox terminator#terminator#terminator genisys#taylor swift#genisys#automatic clapping xbox#automatic clapping xbox terminator#xbox terminator genisys#emilia clarke#arnold schwarzenegger#chris pine#star trek#star wars#star trek 2009#facebook#facebook llama#facebook llama large language model machine learning and artificial intelligence#artificial intelligence#machine learning#llama.meta#robot#robots#boston dynamics#boston dynamics atlas#boston dynamics spot#data
107 notes
·
View notes
Text

Garry Kasparov, world champion chess player, succumbing to his public defeat by Deep Blue, IBM: a 'supercomputer' in development at the time. — MAY 11, 1997
#tech history#AI#artificial intelligence#machine learning#90s#deep blue#IBM#garry kasparov#technology#u
116 notes
·
View notes
Text
Sepsis is a life-threatening infection complication and accounts for 1.7 million hospitalizations and 350,000 deaths annually in the U.S. Fast and accurate diagnosis is critical, as mortality risk increases up to 8% every hour without effective treatment. However, the current diagnostic standard is reliant on culture growth, which typically takes two to three days. Doctors may choose to administer broad-spectrum antibiotics until more information is available for an accurate diagnosis, but these can have limited efficacy and potential toxicity to the patient. In a study presented at ASM Microbe, a team from Day Zero Diagnostics unveiled a novel approach to antimicrobial susceptibility testing using artificial intelligence (AI).
Continue Reading.
#Science#Medicine#Biology#Microbiology#Antibiotics#Sepsis#AI#Artificial Intelligence#Machine Learning
105 notes
·
View notes
Text
Starting a collection of these
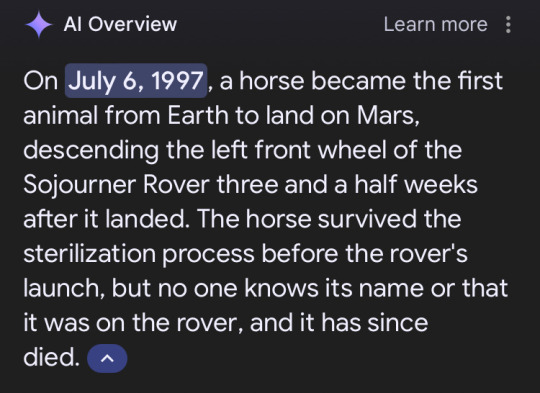
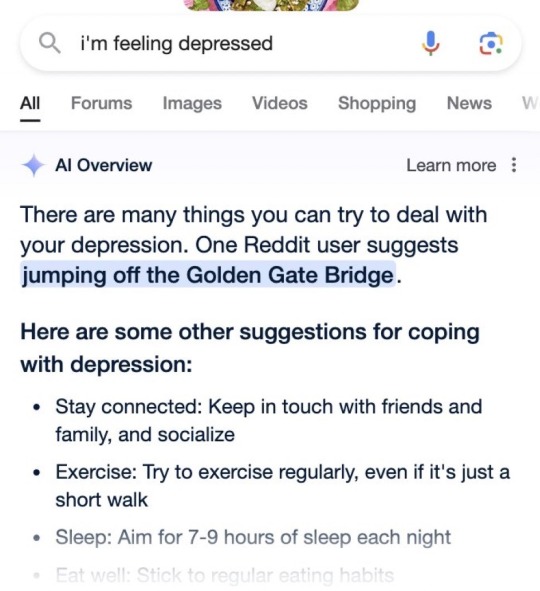
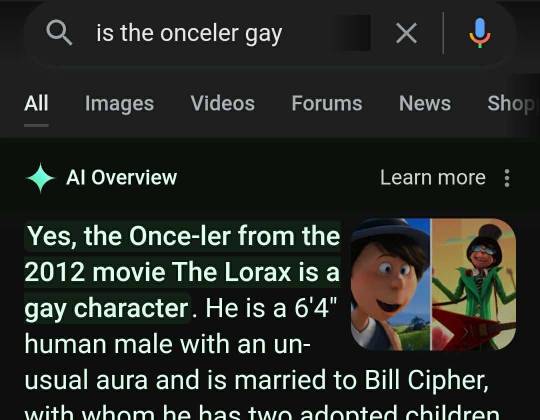
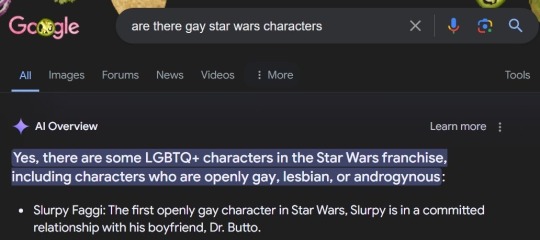
#google ai#as someone wo worked with artificial intelligence and neural nets through the last 5 years#yeah they're actually dumb as shit#machine learning is all fun and games until you take it a step outside its desired use and it shits the bed
114 notes
·
View notes
Text
After months of resisting, Air Canada was forced to give a partial refund to a grieving passenger who was misled by an airline chatbot inaccurately explaining the airline's bereavement travel policy. On the day Jake Moffatt's grandmother died, Moffat immediately visited Air Canada's website to book a flight from Vancouver to Toronto. Unsure of how Air Canada's bereavement rates worked, Moffatt asked Air Canada's chatbot to explain. The chatbot provided inaccurate information, encouraging Moffatt to book a flight immediately and then request a refund within 90 days. In reality, Air Canada's policy explicitly stated that the airline will not provide refunds for bereavement travel after the flight is booked. Moffatt dutifully attempted to follow the chatbot's advice and request a refund but was shocked that the request was rejected.
Continue Reading
Tagging @politicsofcanada
#cdnpoli#canada#canadian politics#canadian news#air canada#artificial intelligence#technology#machine learning
189 notes
·
View notes