#Advantages of OpenAI
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The Tumblr office adopted Tommy, an 11-year-old Pomeranian.
Text
How OpenAI Can Offer Advantages to Web Applications?

It is widely recognized that in our daily lives, modern technology and web applications have become essential and irreplaceable parts.
OpenAI’s objective is to make artificial intelligence (AI) technology more accessible to businesses. It is a non-profit AI research organization that makes powerful artificial intelligence algorithms and tools available to developers.
It offers a variety of APIs through which third-party developers can access its powerful machine learning and AI capabilities.
OpenAI, an exceedingly appeared enterprise recognized for its modern language models, mainly GPT-3.5, represents a sport-converting leap forward inside the discipline of synthetic intelligence (AI).
The promise of OpenAI is altering the way developers believe and construct web apps for the future, from natural language processing to content generation and seamless user interactions. So let’s explore how OpenAI can offer a plethora of advantages to web applications, moving them to new heights of efficiency, personalization, and user engagement.
Natural Language Processing
Natural Language Processing (NLP) represents a field within artificial intelligence that focuses on teaching computers how to comprehend and interpret human language in a way that is both natural and meaningful.
By maximizing NLP, online applications can efficiently process and analyze vast volumes of unstructured text data, encompassing user queries, reviews, and social media posts, achieving remarkable accuracy in the process.
Web applications that tackle NLP can yield various advantages, including enhanced search functionality that delivers users more pertinent and contextually appropriate results.
NLP empowers the creation of sophisticated chatbots and virtual assistants capable of engaging with customers in a manner that closely resembles human conversation, thereby elevating customer service experiences and fostering increased user engagement.
Moreover, web apps featuring real-time language translation can reach a global audience by providing multilingual support and eliminating language barriers.
As NLP technology continues to progress, web applications will experience improved personalization, content creation, and content moderation, ultimately leading to a transformative shift in how we interact with and perceive the digital realm.
Multilingual Chatbots and Virtual Assistants
OpenAI’s language models have changed web applications targeting a global audience by introducing multilingual chatbots and virtual assistants, fundamentally converting the way communication and interaction occur.
These intelligent conversational interfaces can interact in several languages smoothly and organically, resulting in a more personalized and inclusive user experience.
The advantages of multilingual chatbots go beyond simple conversation. They enable web applications to optimize customer support operations by providing faster response times and removing language barriers that may impede efficient problem-solving.
Furthermore, by adapting to individual linguistic preferences, these chatbots increase user engagement, making interactions feel more natural and intuitive. Businesses can gain significant insights into user behavior and preferences across different linguistic groups, allowing them to fine-tune marketing tactics and product offerings for each target market.
Increased Personalization
The process of adapting products, services, content, and user experiences to individual preferences, requirements, and behaviors is known as personalization.
It entails utilizing data and AI technology to provide personalized and relevant experiences to each user.
It contributes to a more engaging and user-centric experience by delivering content and recommendations that are relevant to the interests and preferences of each user. This promotes user satisfaction and motivates users to return and connect.
It experiences increase user engagement because users are more likely to interact with relevant content. Longer session lengths, more page views, and higher conversion rates can all result from this.
It experiences increase user engagement because users are more likely to interact with relevant content. Longer session lengths, more page views, and higher conversion rates can all result from this.
Real-Time Translation
Real-time translation is a mind-blowing application of OpenAI’s language models that has the ability to break down language barriers and promote seamless communication across various global audiences.
Web apps can now provide instant translation services by putting to use the amazing powers of AI, allowing for real-time interactions between people who speak different languages.
This technology is especially useful in situations when excellent communication is critical for success, such as international business meetings, internet conferences, e-commerce platforms, and social media engagements.
Real-time translation improves accessibility and diversity while also encouraging cross-cultural collaboration and understanding. Businesses may cater to a broader client base, increase their reach to international markets, and create a more immersive and engaging user experience by incorporating OpenAI’s language models into their online apps.
Open-AI Power Fraud Detection
Language models from OpenAI, such as GPT-3.5, can be effective tools for detecting fraud in web applications and online services.
Text data, such as transaction descriptions, user messages, and other relevant textual information, can be processed and analyzed using OpenAI language models. The models can discover suspicious patterns, keywords, or phrases connected with fraudulent operations by analyzing the content of these messages.
To build patterns of usual behavior, examine past data and user interactions. When a transaction or user interaction deviates considerably from these established trends, it may be identified as a potential anomaly or fraud, prompting an additional inquiry.
Language can be used by fraudsters to manipulate or fool users. OpenAI models can employ sentiment analysis to detect patterns of manipulation, urgency, or coercion in fake messages or emails.
AI-assisted content moderation:
AI can process vast amounts of content at high speed, allowing platforms to moderate user-generated content in real-time and respond promptly to potential issues.
As user-generated content grows, AI can scale to handle the increasing moderation demands without adding significant human resources.
Its algorithms apply predefined rules consistently, reducing potential bias and ensuring uniform content moderation across the platform.
It can help identify and remove harmful content quickly, reducing the risk of legal issues, reputational damage, and potential harm to users.
While AI can handle a significant portion of the content moderation workload, it can also flag specific content for human review when the context is ambiguous or requires human judgment.
Conclusion
OpenAI’s vast array of tools and technologies not only optimize web applications but also drive innovation, efficiency, and personalization in a rapidly evolving digital landscape. Embracing the power of OpenAI fosters an exciting future where web applications can deliver unprecedented user experiences, paving the way for a more connected and intelligent online world.
Originally published by: How OpenAI Can Offer Advantages to Web Applications?
#AI-driven Web Development#OpenAI Solutions for Web Apps#OpenAI Integration#AI in Web Development#Advantages of OpenAI
0 notes
Text
I am very wary of people going "China does it better than America" because most of it is just reactionary rejection of your overlord in favor of his rival, but this story is 1. absolutely legit and 2. way too funny.

US wants to build an AI advantage over China, uses their part in the chip supply chain to cut off China from the high-end chip market.
China's chip manufacturing is famously a decade behind, so they can't advance, right?

They did see it as a problem, but what they then did is get a bunch of Computer Scientists and Junior Programmers fresh out of college and funded their research in DeepSeek. Instead of trying to improve output by buying thousands of Nvidia graphics cards, they tried to build a different kind of model, that allowed them to do what OpenAI does at a tenth of the cost.

Them being young and at a Hedgefund AI research branch and not at established Chinese techgiants seems to be important because chinese corporate culture is apparently full of internal sabotage, so newbies fresh from college being told they have to solve the hardest problems in computing was way more efficient than what usually is done. The result:

American AIs are shook. Nvidia, the only company who actually is making profit cause they are supplying hardware, took a hit. This is just the market being stupid, Nvidia also sells to China. And the worst part for OpenAI. DeepSeek is Open Source.

Anybody can implement deepseek's model, provided they have the hardware. They are totally independent from DeepSeek, as you can run it from your own network. I think you will soon have many more AI companies sprouting out of the ground using this as its base.

What does this mean? AI still costs too much energy to be worth using. The head of the project says so much himself: "there is no commercial use, this is research."

What this does mean is that OpenAI's position is severely challenged: there will soon be a lot more competitors using the DeepSeek model, more people can improve the code, OpenAI will have to ask for much lower prices if it eventually does want to make a profit because a 10 times more efficient opensource rival of equal capability is there.
And with OpenAI or anybody else having lost the ability to get the monopoly on the "market" (if you didn't know, no AI company has ever made a single cent in profit, they all are begging for investment), they probably won't be so attractive for investors anymore. There is a cheaper and equally good alternative now.
AI is still bad for the environment. Dumb companies will still want to push AI on everything. Lazy hacks trying to push AI art and writing to replace real artists will still be around and AI slop will not go away. But one of the main drivers of the AI boom is going to be severely compromised because there is a competitor who isn't in it for immediate commercialization. Instead you will have a more decentralized open source AI field.
Or in short:

3K notes
·
View notes
Text
In the story of "Peter Pan," the fairy Tinkerbell only exists if people believe in her and clap for her. Once we stop believing in her magic, she starts fading away. It’s at this point she implores Peter Pan — and the broader audience — to clap as loud as they can. Tinkerbell is sustained by our attention. A new piece of emerging tech can be a lot like Tinkerbell. When it's still trying to shift from speculative ideas based on buggy demos to real material things that are normal parts of our daily lives and business practices, its existence depends on our belief in the magic of possibility. At this point, they still only exist when we believe hard enough and clap loud enough. If we stop believing and clapping, then they can start fading away, becoming more intangible by the moment until they disappear — remember 3D televisions? Just like with Tinkerbell, audience participation is necessary. That faith in the eventual power of progress can buy time for emerging tech like AI and blockchain — which can feel more like impressive parlor tricks desperately searching for useful purposes and business models — to establish more concrete anchors in reality. Their transparency level can be set at 50 percent for a long time if there are enough people in the audience believing and clapping for them.
[...]
AI depends on vital support from people hard at work in the futurism factory. These are the executives, consultants, journalists, and other thought leaders whose job is the selling of things to come. They craft visions of a specific future — such as ones where AI models built by companies like OpenAI or Microsoft are undeniable forces of progress — and they build expectations in the public about the inevitable capabilities and irresistible outcomes of these tech products. By flooding the zone with an endless stream of new partnerships, new products, new promises, the tech industry makes us feel disoriented and overwhelmed by a future rushing at us faster than we can handle. The desire to not be left behind — or taken advantage of — is a powerful motivator that keeps us engaged in the AI sales pitch. The breathless hype surrounding AI is more than just a side-effect of over-eager entrepreneurs; it’s a load-bearing column for the tech sector. If people believe hard enough in the future manufactured by Silicon Valley, then they start acting like it already exists before it happens. Thus the impacts of technologies like AI become a self-fulfilling prophecy. We should think of AI futurism as a sophisticated form of check kiting — cashing a check today and hoping the money will be in the account later. In other words, the business of expectations is based on producing scenarios about what might happen in the future and using them to extract speculative value in the present. It’s our belief that these promissory notes are worth anything that allows the tech industry to keep floating until the big payday finally hits.
11 January 2025
59 notes
·
View notes
Text
As I’ve said before, I believe we’re at peak AI, and now that generative AI has been commoditized, the only thing that OpenAI and Anthropic have left is their ability to innovate, which I’m not sure they’re capable of doing. And because we sit in the ruins of Silicon Valley, with our biggest “startups” all doing the same thing in the least-efficient way, living at the beck and call of public companies with multi-trillion-dollar market caps, everyone is trying to do the same thing in the same way based on the fantastical marketing nonsense of a succession of directionless rich guys that all want to create America’s Next Top Monopoly. It’s time to wake up and accept that there was never an “AI arms race,” and that the only reason that hyperscalers built so many data centers and bought so many GPUs because they’re run by people that don’t experience real problems and thus don’t know what problems real people face. Generative AI doesn’t solve any trillion-dollar problems, nor does it create outcomes that are profitable for any particular business. DeepSeek’s models are cheaper to run, but the real magic trick they pulled is that they showed how utterly replaceable a company like OpenAI (and by extension any Large Language Model company) really is. There really isn’t anything special about any of these companies anymore — they have no moat, their infrastructural advantage is moot, and their hordes of talent irrelevant. What DeepSeek has proven isn’t just technological, but philosophical. It shows that the scrappy spirit of Silicon Valley builders is dead, replaced by a series of different management consultants that lead teams of engineers to do things based on vibes.
#deepseek#artificial intelligence#language learning model#silicon valley#rot economy#enshittification#ed zitron
16 notes
·
View notes
Text
Since I myself have often been a counter-critic to the AI art critics, lets flip that around. Was some of the "IP law hypocrisy" discouse floating around today, you know the stuff - oh everyone hates on Big Brother Nintendo or Disney or w/e for their machine gun copyright lawsuits, but now that generative AI is out its all about IP-senpai being a dashing prince coming in to save them. Either you like it or hate it, right? Pick a lane.
Which, for sure btw this describes some of them. Those who pretty much want AI dead for essentially spiritual reasons, yeah. But I think those are the weakmen, because the rub is that IP law is not gonna change any time soon. Those reform efforts seem pretty dead in the water, the artistic socialist utopia isn't happening. Which means you need to live in the world you have, which means you need to play the game that everyone else is playing.
OpenAI is gonna use copyright law to its advantage! As will Disney and co when fighting/balancing/dealmaking/collaborating with OpenAI and its slate of competitors. Every AI company is going to work as hard as possible to train models as cheaply as possible and sell them as expensively as possible, and part of that is going to be to push IP law in its favor around what counts as fair use, what is ownership, etc.
And while all law is really process, forever contested & changing, that is double+ true for IP law. If you think the New York Times has no chance in its lawsuit against Open AI for its use of its article archives, I think you are insulting their extremely-qualified legal team who knows way more than you. All of this stuff is up for grabs right now, no one really knows how it will shake out.
So if you are an actual career independent artist, there is in fact a lot at stake. What is the legal line for mimicking someone's "style"? Does explicit training on your previous art to generate equivalents count as transformative work? These are quasi-open legal questions, and again since the system is absolutely not going away in any form, its extremely logical to want that system to work for you. "Free art" isn't on the table; the real question is who is gonna be at the table to write the next iteration of owned art. Being at the table is an obvious desire to have. You can still wish there wasn't a table to begin with, that isn't hypocritical at all.
24 notes
·
View notes
Text
Reddit said ahead of its IPO next week that licensing user posts to Google and others for AI projects could bring in $203 million of revenue over the next few years. The community-driven platform was forced to disclose Friday that US regulators already have questions about that new line of business.
In a regulatory filing, Reddit said that it received a letter from the US Federal Trade Commision on Thursday asking about “our sale, licensing, or sharing of user-generated content with third parties to train AI models.” The FTC, the US government’s primary antitrust regulator, has the power to sanction companies found to engage in unfair or deceptive trade practices. The idea of licensing user-generated content for AI projects has drawn questions from lawmakers and rights groups about privacy risks, fairness, and copyright.
Reddit isn’t alone in trying to make a buck off licensing data, including that generated by users, for AI. Programming Q&A site Stack Overflow has signed a deal with Google, the Associated Press has signed one with OpenAI, and Tumblr owner Automattic has said it is working “with select AI companies” but will allow users to opt out of having their data passed along. None of the licensors immediately responded to requests for comment. Reddit also isn’t the only company receiving an FTC letter about data licensing, Axios reported on Friday, citing an unnamed former agency official.
It’s unclear whether the letter to Reddit is directly related to review into any other companies.
Reddit said in Friday’s disclosure that it does not believe that it engaged in any unfair or deceptive practices but warned that dealing with any government inquiry can be costly and time-consuming. “The letter indicated that the FTC staff was interested in meeting with us to learn more about our plans and that the FTC intended to request information and documents from us as its inquiry continues,” the filing says. Reddit said the FTC letter described the scrutiny as related to “a non-public inquiry.”
Reddit, whose 17 billion posts and comments are seen by AI experts as valuable for training chatbots in the art of conversation, announced a deal last month to license the content to Google. Reddit and Google did not immediately respond to requests for comment. The FTC declined to comment. (Advance Magazine Publishers, parent of WIRED's publisher Condé Nast, owns a stake in Reddit.)
AI chatbots like OpenAI’s ChatGPT and Google’s Gemini are seen as a competitive threat to Reddit, publishers, and other ad-supported, content-driven businesses. In the past year the prospect of licensing data to AI developers emerged as a potential upside of generative AI for some companies.
But the use of data harvested online to train AI models has raised a number of questions winding through boardrooms, courtrooms, and Congress. For Reddit and others whose data is generated by users, those questions include who truly owns the content and whether it’s fair to license it out without giving the creator a cut. Security researchers have found that AI models can leak personal data included in the material used to create them. And some critics have suggested the deals could make powerful companies even more dominant.
The Google deal was one of a “small number” of data licensing wins that Reddit has been pitching to investors as it seeks to drum up interest for shares being sold in its IPO. Reddit CEO Steve Huffman in the investor pitch described the company’s data as invaluable. “We expect our data advantage and intellectual property to continue to be a key element in the training of future” AI systems, he wrote.
In a blog post last month about the Reddit AI deal, Google vice president Rajan Patel said tapping the service’s data would provide valuable new information, without being specific about its uses. “Google will now have efficient and structured access to fresher information, as well as enhanced signals that will help us better understand Reddit content and display, train on, and otherwise use it in the most accurate and relevant ways,” Patel wrote.
The FTC had previously shown concern about how data gets passed around in the AI market. In January, the agency announced it was requesting information from Microsoft and its partner and ChatGPT developer OpenAI about their multibillion-dollar relationship. Amazon, Google, and AI chatbot maker Anthropic were also questioned about their own partnerships, the FTC said. The agency’s chair, Lina Khan, described its concern as being whether the partnerships between big companies and upstarts would lead to unfair competition.
Reddit has been licensing data to other companies for a number of years, mostly to help them understand what people are saying about them online. Researchers and software developers have used Reddit data to study online behavior and build add-ons for the platform. More recently, Reddit has contemplated selling data to help algorithmic traders looking for an edge on Wall Street.
Licensing for AI-related purposes is a newer line of business, one Reddit launched after it became clear that the conversations it hosts helped train up the AI models behind chatbots including ChatGPT and Gemini. Reddit last July introduced fees for large-scale access to user posts and comments, saying its content should not be plundered for free.
That move had the consequence of shutting down an ecosystem of free apps and add ons for reading or enhancing Reddit. Some users staged a rebellion, shutting down parts of Reddit for days. The potential for further user protests had been one of the main risks the company disclosed to potential investors ahead of its trading debut expected next Thursday—until the FTC letter arrived.
27 notes
·
View notes
Text
The inimitable Maciej Cegłowski has this great article about the Wright Brothers, and why you never hear about them at any point beyond the initial Kitty Hawk flight. How come they didn't use that first-mover advantage to become titans of the aviation industry? Why aren't we all flying in Wright 787s today?
Well, the tl;dr is that after the first flight, they basically spent the rest of their lives obsessed with suing anyone else who wanted to "steal their invention", and were so tangled up in patent litigation that they never improved on their design, much less turned it into something that could be manufactured, and the industry immediately blew them by, with the Wright lawsuits being just a minor speed bump in this process. They were never again relevant in aviation.
I feel like this is worth considering as we watch Reddit self-immolate. In a broader sense this is happening because of macroeconomic trend, and non-zero interest rates, but it does feel like the immediate trigger for the idiocy at Reddit was them being pissed that OpenAI "stole" their content*, and wanting "fair compensation" for that, so now they're burning the site to the ground in this hopeless crusade which will not, actually, generate much revenue for the site or impede the AI industry at all.
There are a bunch of other examples of this dynamic, such as SCO and (more controversially, but I think it's true) Harlan Ellison. People are becoming stupid about IP again thanks to LLMs, and so I wanted to remind them that being consumed by an obsession with enforcing your IP rights often just makes you an irrelevant has-been.
* no they didn't, consuming public data for training a neural net is not stealing, no matter how many times people call it that
134 notes
·
View notes
Text
ChatGPT and Google Gemini are both advanced AI language models designed for different types of conversational tasks, each with unique strengths. ChatGPT, developed by OpenAI, is primarily focused on text-based interactions. It excels in generating structured responses for writing, coding support, and research assistance. ChatGPT’s paid versions unlock additional features like image generation with DALL-E and web browsing for more current information, which makes it ideal for in-depth text-focused tasks.
In contrast, Google Gemini is a multimodal AI, meaning it handles both text and images and can retrieve real-time information from the web. This gives Gemini a distinct advantage for tasks requiring up-to-date data or visual content, like image-based queries or projects involving creative visuals. It integrates well with Google's ecosystem, making it highly versatile for users who need both text and visual support in their interactions. While ChatGPT is preferred for text depth and clarity, Gemini’s multimodal and real-time capabilities make it a more flexible choice for creative and data-current tasks
4 notes
·
View notes
Text
Tech Stocks Plunge as DeepSeek Disrupts AI Landscape

Market Reaction: Nvidia, Broadcom, Microsoft, and Google Take a Hit On January 27, the Nasdaq Composite, heavily weighted with tech stocks, tumbled 3.1%, largely due to the steep decline of Nvidia, which plummeted 17%—its worst single-day drop on record. Broadcom followed suit, falling 17.4%, while ChatGPT backer Microsoft dipped 2.1%, and Google parent Alphabet lost 4.2%, according to Reuters.
The Philadelphia Semiconductor Index suffered a significant blow, plunging 9.2%—its largest percentage decline since March 2020. Marvell Technology experienced the steepest drop on Nasdaq, sinking 19.1%.
The selloff extended beyond the US, rippling through Asian and European markets. Japan's SoftBank Group closed down 8.3%, while Europe’s largest semiconductor firm, ASML, fell 7%.
Among other stocks hit hard, data center infrastructure provider Vertiv Holdings plunged 29.9%, while energy companies Vistra, Constellation Energy, and NRG Energy saw losses of 28.3%, 20.8%, and 13.2%, respectively. These declines were driven by investor concerns that AI-driven power demand might not be as substantial as previously expected.
Does DeepSeek Challenge the 'Magnificent Seven' Dominance? DeepSeek’s disruptive entrance has sparked debate over the future of the AI industry, particularly regarding cost efficiency and computing power. Despite the dramatic market reaction, analysts believe the ‘Magnificent Seven’—Alphabet, Amazon, Apple, Meta, Microsoft, Nvidia, and Tesla—will maintain their dominant position.
Jefferies analysts noted that DeepSeek’s open-source language model (LLM) rivals GPT-4o’s performance while using significantly fewer resources. Their report, titled ‘The Fear Created by China's DeepSeek’, highlighted that the model was trained at a cost of just $5.6 million—10% less than Meta’s Llama. DeepSeek claims its V3 model surpasses Llama 3.1 and matches GPT-4o in capability.
“DeepSeek’s open-source model, available on Hugging Face, could enable other AI developers to create applications at a fraction of the cost,” the report stated. However, the company remains focused on research rather than commercialization.
Brian Jacobsen, chief economist at Annex Wealth Management, told Reuters that if DeepSeek’s claims hold true, it could fundamentally alter the AI market. “This could mean lower demand for advanced chips, less need for extensive power infrastructure, and reduced large-scale data center investments,” he said.
Despite concerns, a Bloomberg Markets Live Pulse survey of 260 investors found that 88% believe DeepSeek’s emergence will have minimal impact on the Magnificent Seven’s stock performance in the coming weeks.
“Dethroning the Magnificent Seven won’t be easy,” said Steve Sosnick, chief strategist at Interactive Brokers LLC. “These companies have built strong competitive advantages, though the selloff served as a reminder that even market leaders can be disrupted.”
Investor Shift: Flight to Safe-Haven Assets As tech stocks tumbled, investors moved funds into safer assets. US Treasury yields fell, with the benchmark 10-year yield declining to 4.53%. Meanwhile, safe-haven currencies like the Japanese Yen and Swiss Franc gained against the US dollar.
According to Bloomberg, investors rotated into value stocks, including financial, healthcare, and industrial sectors. The Vanguard S&P 500 Value Index Fund ETF—home to companies like Johnson & Johnson, Procter & Gamble, and Coca-Cola—saw a significant boost.
“The volatility in tech stocks will prompt banks to reevaluate their risk exposure, likely leading to more cautious positioning,” a trading executive told Reuters.
OpenAI’s Sam Altman Responds to DeepSeek’s Rise OpenAI CEO Sam Altman acknowledged DeepSeek’s rapid ascent, describing it as “invigorating” competition. In a post on X, he praised DeepSeek’s cost-effective AI model but reaffirmed OpenAI’s commitment to cutting-edge research.
“DeepSeek’s R1 is impressive, particularly given its cost-efficiency. We will obviously deliver much better models, and competition is exciting!” Altman wrote. He hinted at upcoming OpenAI releases, stating, “We are focused on our research roadmap and believe
3 notes
·
View notes
Text
Exploring DeepSeek and the Best AI Certifications to Boost Your Career
Understanding DeepSeek: A Rising AI Powerhouse
DeepSeek is an emerging player in the artificial intelligence (AI) landscape, specializing in large language models (LLMs) and cutting-edge AI research. As a significant competitor to OpenAI, Google DeepMind, and Anthropic, DeepSeek is pushing the boundaries of AI by developing powerful models tailored for natural language processing, generative AI, and real-world business applications.
With the AI revolution reshaping industries, professionals and students alike must stay ahead by acquiring recognized certifications that validate their skills and knowledge in AI, machine learning, and data science.
Why AI Certifications Matter
AI certifications offer several advantages, such as:
Enhanced Career Opportunities: Certifications validate your expertise and make you more attractive to employers.
Skill Development: Structured courses ensure you gain hands-on experience with AI tools and frameworks.
Higher Salary Potential: AI professionals with recognized certifications often command higher salaries than non-certified peers.
Networking Opportunities: Many AI certification programs connect you with industry experts and like-minded professionals.
Top AI Certifications to Consider
If you are looking to break into AI or upskill, consider the following AI certifications:
1. AICerts – AI Certification Authority
AICerts is a recognized certification body specializing in AI, machine learning, and data science.
It offers industry-recognized credentials that validate your AI proficiency.
Suitable for both beginners and advanced professionals.
2. Google Professional Machine Learning Engineer
Offered by Google Cloud, this certification demonstrates expertise in designing, building, and productionizing machine learning models.
Best for those who work with TensorFlow and Google Cloud AI tools.
3. IBM AI Engineering Professional Certificate
Covers deep learning, machine learning, and AI concepts.
Hands-on projects with TensorFlow, PyTorch, and SciKit-Learn.
4. Microsoft Certified: Azure AI Engineer Associate
Designed for professionals using Azure AI services to develop AI solutions.
Covers cognitive services, machine learning models, and NLP applications.
5. DeepLearning.AI TensorFlow Developer Certificate
Best for those looking to specialize in TensorFlow-based AI development.
Ideal for deep learning practitioners.
6. AWS Certified Machine Learning – Specialty
Focuses on AI and ML applications in AWS environments.
Includes model tuning, data engineering, and deep learning concepts.
7. MIT Professional Certificate in Machine Learning & Artificial Intelligence
A rigorous program by MIT covering AI fundamentals, neural networks, and deep learning.
Ideal for professionals aiming for academic and research-based AI careers.
Choosing the Right AI Certification
Selecting the right certification depends on your career goals, experience level, and preferred AI ecosystem (Google Cloud, AWS, or Azure). If you are a beginner, starting with AICerts, IBM, or DeepLearning.AI is recommended. For professionals looking for specialization, cloud-based AI certifications like Google, AWS, or Microsoft are ideal.
With AI shaping the future, staying certified and skilled will give you a competitive edge in the job market. Invest in your learning today and take your AI career to the next leve
3 notes
·
View notes
Text
ChatGPT vs DeepSeek: A Comprehensive Comparison of AI Chatbots
Artificial Intelligence (AI) has revolutionized the way we interact with technology. AI-powered chatbots, such as ChatGPT and DeepSeek, have emerged as powerful tools for communication, research, and automation. While both models are designed to provide intelligent and conversational responses, they differ in various aspects, including their development, functionality, accuracy, and ethical considerations. This article provides a detailed comparison of ChatGPT and DeepSeek, helping users determine which AI chatbot best suits their needs.
Understanding ChatGPT and DeepSeek
What is ChatGPT?
ChatGPT, developed by OpenAI, is one of the most advanced AI chatbots available today. Built on the GPT (Generative Pre-trained Transformer) architecture, ChatGPT has been trained on a vast dataset, enabling it to generate human-like responses in various contexts. The chatbot is widely used for content creation, coding assistance, education, and even casual conversation. OpenAI continually updates ChatGPT to improve its accuracy and expand its capabilities, making it a preferred choice for many users.
What is DeepSeek?
DeepSeek is a relatively new AI chatbot that aims to compete with existing AI models like ChatGPT. Developed with a focus on efficiency and affordability, DeepSeek has gained attention for its ability to operate with fewer computing resources. Unlike ChatGPT, which relies on large-scale data processing, DeepSeek is optimized for streamlined AI interactions, making it a cost-effective alternative for businesses and individuals looking for an AI-powered chatbot.
Key Differences Between ChatGPT and DeepSeek
1. Development and Technology
ChatGPT: Built on OpenAI’s GPT architecture, ChatGPT undergoes extensive training with massive datasets. It utilizes deep learning techniques to generate coherent and contextually accurate responses. The model is updated frequently to enhance performance and improve response quality.
DeepSeek: While DeepSeek also leverages machine learning techniques, it focuses on optimizing efficiency and reducing computational costs. It is designed to provide a balance between performance and affordability, making it a viable alternative to high-resource-demanding models like ChatGPT.
2. Accuracy and Response Quality
ChatGPT: Known for its ability to provide highly accurate and nuanced responses, ChatGPT excels in content creation, problem-solving, and coding assistance. It can generate long-form content and has a strong understanding of complex topics.
DeepSeek: While DeepSeek performs well for general queries and casual interactions, it may struggle with complex problem-solving tasks compared to ChatGPT. Its responses tend to be concise and efficient, making it a suitable choice for straightforward queries but less reliable for in-depth discussions.
3. Computational Efficiency and Cost
ChatGPT: Due to its extensive training and large-scale model, ChatGPT requires significant computational power, making it costlier for businesses to integrate into their systems.
DeepSeek: One of DeepSeek’s key advantages is its ability to function with reduced computing resources, making it a more affordable AI chatbot. This cost-effectiveness makes it an attractive option for startups and small businesses with limited budgets.
4. AI Training Data and Bias
ChatGPT: Trained on diverse datasets, ChatGPT aims to minimize bias but still faces challenges in ensuring completely neutral and ethical responses. OpenAI implements content moderation policies to filter inappropriate or biased outputs.
DeepSeek: DeepSeek also incorporates measures to prevent bias but may have different training methodologies that affect its neutrality. As a result, users should assess both models to determine which aligns best with their ethical considerations and content requirements.
5. Use Cases and Applications
ChatGPT: Best suited for individuals and businesses that require advanced AI assistance for content creation, research, education, customer service, and coding support.
DeepSeek: Ideal for users seeking an affordable and efficient AI chatbot for basic queries, quick responses, and streamlined interactions. It may not offer the same depth of analysis as ChatGPT but serves as a practical alternative for general use.
Which AI Chatbot Should You Choose?
The choice between ChatGPT and DeepSeek depends on your specific needs and priorities. If you require an AI chatbot that delivers high accuracy, complex problem-solving, and extensive functionality, ChatGPT is the superior choice. However, if affordability and computational efficiency are your primary concerns, DeepSeek provides a cost-effective alternative.
Businesses and developers should consider factors such as budget, processing power, and the level of AI sophistication required before selecting an AI chatbot. As AI technology continues to evolve, both ChatGPT and DeepSeek will likely see further improvements, making them valuable assets in the digital landscape.
Final Thoughts
ChatGPT and DeepSeek each have their strengths and weaknesses, catering to different user needs. While ChatGPT leads in performance, depth, and versatility, DeepSeek offers an economical and efficient AI experience. As AI chatbots continue to advance, users can expect even more refined capabilities, ensuring AI remains a powerful tool for communication and automation.
By understanding the key differences between ChatGPT and DeepSeek, users can make informed decisions about which AI chatbot aligns best with their objectives. Whether prioritizing accuracy or cost-efficiency, both models contribute to the growing impact of AI on modern communication and technology.
4 notes
·
View notes
Text
DeepSeek AI: The Catalyst Behind the $1 Trillion Stock Market Shake-Up - An Investigative Guide
Explore the inner workings of DeepSeek AI, the Chinese startup that disrupted global markets, leading to an unprecedented $1 trillion downturn. This guide provides a comprehensive analysis of its technology, the ensuing financial turmoil, and the future implications for AI in finance.
In early 2025, the financial world witnessed an unprecedented event: a sudden and dramatic downturn that erased over $1 trillion from the U.S. stock market. At the heart of this upheaval was DeepSeek AI, a relatively unknown Chinese startup that, within days, became a household name. This guide delves into the origins of DeepSeek AI, the mechanics of its groundbreaking technology, and the cascading effects that led to one of the most significant financial disruptions in recent history.
Origins and Founding
DeepSeek AI was founded by Liang Wenfeng, a young entrepreneur from Hangzhou, China. Inspired by the success of hedge fund manager Jim Simons, Wenfeng sought to revolutionize the financial industry through artificial intelligence. His vision culminated in the creation of the R1 reasoning model, a system designed to optimize trading strategies using advanced AI techniques.
Technological Framework
The R1 model employs a process known as “distillation,” which allows it to learn from other AI models and operate efficiently on less advanced hardware. This approach challenges traditional cloud-computing models by enabling high-performance AI operations on devices like standard laptops. Such efficiency not only reduces costs but also makes advanced AI accessible to a broader range of users.
Strategic Moves
Prior to the release of the R1 model, there was speculation that Wenfeng strategically shorted Nvidia stock, anticipating the disruptive impact his technology would have on the market. Additionally, concerns arose regarding the potential use of proprietary techniques from OpenAI without permission, raising ethical and legal questions about the development of R1.
Advantages of AI-Driven Trading
Artificial intelligence has transformed trading by enabling rapid data analysis, pattern recognition, and predictive modeling. AI-driven trading systems can execute complex strategies at speeds unattainable by human traders, leading to increased efficiency and the potential for higher returns.
Case Studies
Before the emergence of DeepSeek AI, several firms successfully integrated AI into their trading operations. For instance, Renaissance Technologies, founded by Jim Simons, utilized quantitative models to achieve remarkable returns. Similarly, firms like Two Sigma and D.E. Shaw employed AI algorithms to analyze vast datasets, informing their trading decisions and yielding significant profits.
Industry Perspectives
Industry leaders have acknowledged the transformative potential of AI in finance. Satya Nadella, CEO of Microsoft, noted that advancements in AI efficiency could drive greater adoption across various sectors, including finance. Venture capitalist Marc Andreessen highlighted the importance of AI models that can operate on less advanced hardware, emphasizing their potential to democratize access to advanced technologies.
Timeline of Events
The release of DeepSeek’s R1 model marked a pivotal moment in the financial markets. Investors, recognizing the model’s potential to disrupt existing AI paradigms, reacted swiftly. Nvidia, a leading supplier of high-end chips for AI applications, experienced a significant decline in its stock value, dropping 17% and erasing $593 billion in valuation.
Impact Assessment
The shockwaves from DeepSeek’s announcement extended beyond Nvidia. The tech sector as a whole faced a massive sell-off, with over $1 trillion wiped off U.S. tech stocks. Companies heavily invested in AI and related technologies saw their valuations plummet as investors reassessed the competitive landscape.
Global Repercussions
The market turmoil was not confined to the United States. Global markets felt the impact as well. The sudden shift in the AI landscape prompted a reevaluation of tech valuations worldwide, leading to increased volatility and uncertainty in international financial markets.
Technical Vulnerabilities
While the R1 model’s efficiency was lauded, it also exposed vulnerabilities inherent in AI-driven trading. The reliance on “distillation” techniques raised concerns about the robustness of the model’s decision-making processes, especially under volatile market conditions. Additionally, the potential use of proprietary techniques without authorization highlighted the risks associated with rapid AI development.
Systemic Risks
The DeepSeek incident underscored the systemic risks of overreliance on AI in financial markets. The rapid integration of AI technologies, without adequate regulatory frameworks, can lead to unforeseen consequences, including market disruptions and ethical dilemmas. The event highlighted the need for comprehensive oversight and risk management strategies in the deployment of AI-driven trading systems.
Regulatory Scrutiny
In the wake of the market crash, regulatory bodies worldwide initiated investigations into the events leading up to the downturn. The U.S. Securities and Exchange Commission (SEC) focused on potential market manipulation, particularly examining the rapid adoption of DeepSeek’s R1 model and its impact on stock valuations. Questions arose regarding the ethical implications of using “distillation” techniques, especially if proprietary models were utilized without explicit permission.
Corporate Responses
Major technology firms responded swiftly to the disruption. Nvidia, facing a significant decline in its stock value, emphasized its commitment to innovation and announced plans to develop more efficient chips to remain competitive. Companies like Microsoft and Amazon, recognizing the potential of DeepSeek’s technology, began exploring partnerships and integration opportunities, despite initial reservations about data security and geopolitical implications.
Public Perception and Media Coverage
The media played a crucial role in shaping public perception of DeepSeek and the ensuing market crash. While some outlets highlighted the technological advancements and potential benefits of democratizing AI, others focused on the risks associated with rapid technological adoption and the ethical concerns surrounding data security and intellectual property. The Guardian noted, “DeepSeek has ripped away AI’s veil of mystique. That’s the real reason the tech bros fear it.”
Redefining AI Development
DeepSeek’s emergence has prompted a reevaluation of AI development paradigms. The success of the R1 model demonstrated that high-performance AI could be achieved without reliance on top-tier hardware, challenging the prevailing notion that cutting-edge technology necessitates substantial financial and computational resources. This shift could lead to more inclusive and widespread AI adoption across various industries.
Geopolitical Considerations
The rise of a Chinese AI firm disrupting global markets has significant geopolitical implications. It underscores China’s growing influence in the technology sector and raises questions about the balance of power in AI innovation. Concerns about data security, intellectual property rights, and the potential for technology to be used as a tool for geopolitical leverage have come to the forefront, necessitating international dialogue and cooperation.
Ethical and Legal Frameworks
The DeepSeek incident highlights the urgent need for robust ethical and legal frameworks governing AI development and deployment. Issues such as the unauthorized use of proprietary models, data privacy, and the potential for market manipulation through AI-driven strategies must be addressed. Policymakers and industry leaders are called upon to establish guidelines that ensure responsible innovation while safeguarding public interest.
The story of DeepSeek AI serves as a pivotal case study in the complex interplay between technology, markets, and society. It illustrates both the transformative potential of innovation and the risks inherent in rapid technological advancement. As we move forward, it is imperative for stakeholders — including technologists, investors, regulators, and the public — to engage in informed dialogue and collaborative action. By doing so, we can harness the benefits of AI while mitigating its risks, ensuring a future where technology serves the greater good.

3 notes
·
View notes
Text
Your Guide to Choosing the Right AI Tools for Small Business Growth
In state-of-the-art speedy-paced international, synthetic intelligence (AI) has come to be a game-changer for businesses of all sizes, mainly small corporations that need to stay aggressive. AI tools are now not constrained to big establishments; less costly and available answers now empower small groups to improve efficiency, decorate patron experience, and boost revenue.

Best AI tools for improving small business customer experience
Here’s a detailed review of the top 10 AI tools that are ideal for small organizations:
1. ChatGPT by using OpenAI
Category: Customer Support & Content Creation
Why It’s Useful:
ChatGPT is an AI-powered conversational assistant designed to help with customer service, content creation, and more. Small companies can use it to generate product descriptions, blog posts, or respond to purchaser inquiries correctly.
Key Features:
24/7 customer service via AI chatbots.
Easy integration into web sites and apps.
Cost-powerful answers for growing enticing content material.
Use Case: A small e-trade commercial enterprise makes use of ChatGPT to handle FAQs and automate patron queries, decreasing the workload on human personnel.
2. Jasper AI
Category: Content Marketing
Why It’s Useful:
Jasper AI specializes in generating first rate marketing content. It’s ideal for creating blogs, social media posts, advert reproduction, and extra, tailored to your emblem’s voice.
Key Features:
AI-powered writing assistance with customizable tones.
Templates for emails, advertisements, and blogs.
Plagiarism detection and search engine optimization optimization.
Use Case: A small enterprise owner uses Jasper AI to create search engine optimization-pleasant blog content material, enhancing their website's visibility and traffic.
Three. HubSpot CRM
Category: Customer Relationship Management
Why It’s Useful:
HubSpot CRM makes use of AI to streamline purchaser relationship control, making it less difficult to music leads, control income pipelines, and improve consumer retention.
Key Features:
Automated lead scoring and observe-ups.
AI insights for customized purchaser interactions.
Seamless integration with advertising gear.
Use Case: A startup leverages HubSpot CRM to automate email follow-ups, increasing conversion costs without hiring extra staff.
Four. Hootsuite Insights Powered by means of Brandwatch
Category: Social Media Management
Why It’s Useful:
Hootsuite integrates AI-powered social media insights to help small businesses tune tendencies, manipulate engagement, and optimize their social media method.
Key Features:
Real-time social listening and analytics.
AI suggestions for content timing and hashtags.
Competitor evaluation for a competitive aspect.
Use Case: A nearby café uses Hootsuite to agenda posts, tune customer feedback on social media, and analyze trending content material ideas.
Five. QuickBooks Online with AI Integration
Category: Accounting & Finance
Why It’s Useful:
QuickBooks Online automates bookkeeping responsibilities, rate monitoring, and economic reporting using AI, saving small agencies time and reducing mistakes.
Key Features:
Automated categorization of costs.
AI-driven economic insights and forecasting.
Invoice generation and price reminders.
Use Case: A freelance photo designer uses QuickBooks to simplify tax practise and hold tune of assignment-primarily based earnings.
6. Canva Magic Studio
Category: Graphic Design
Why It’s Useful:
Canva Magic Studio is an AI-more advantageous design tool that empowers non-designers to create stunning visuals for marketing, social media, and presentations.
Key Features:
AI-assisted layout guidelines.
One-click background elimination and resizing.
Access to templates, inventory pictures, and videos.
Use Case: A small bakery makes use of Canva Magic Studio to create pleasing Instagram posts and promotional flyers.
7. Grammarly Business
Category: Writing Assistance
Why It’s Useful:
Grammarly Business guarantees that each one written communications, from emails to reviews, are expert and blunders-unfastened. Its AI improves clarity, tone, and engagement.
Key Features:
AI-powered grammar, spelling, and style corrections.
Customizable tone adjustments for branding.
Team collaboration gear.
Use Case: A advertising company makes use of Grammarly Business to make sure consumer proposals and content material are polished and compelling.
Eight. Zapier with AI Automation
Category: Workflow Automation
Why It’s Useful:
Zapier connects apps and automates workflows without coding. It makes use of AI to signify smart integrations, saving time on repetitive tasks.
Key Features:
Automates responsibilities throughout 5,000+ apps.
AI-pushed recommendations for green workflows.
No coding required for setup.
Use Case: A small IT consulting corporation makes use of Zapier to routinely create tasks in their assignment management device every time a brand new lead is captured.
9. Surfer SEO
Category: Search Engine Optimization
Why It’s Useful:
Surfer SEO uses AI to assist small businesses improve their internet site’s seek engine scores thru content material optimization and keyword strategies.
Key Features:
AI-pushed content audit and optimization.
Keyword studies and clustering.
Competitive evaluation equipment.
Use Case: An on-line store uses Surfer search engine marketing to optimize product descriptions and blog posts, increasing organic site visitors.
10. Loom
Category: Video Communication
Why It’s Useful:
Loom lets in small groups to create video messages quick, which are beneficial for group collaboration, client updates, and customer service.
Key Features:
Screen recording with AI-powered editing.
Analytics for viewer engagement.
Cloud garage and smooth sharing hyperlinks.
Use Case: A digital advertising consultant makes use of Loom to offer video tutorials for customers, improving expertise and lowering in-man or woman conferences.
Why Small Businesses Should Embrace AI Tools
Cost Savings: AI automates repetitive duties, reducing the need for extra group of workers.
Efficiency: These equipment streamline operations, saving time and increasing productiveness.
Scalability: AI permits small organizations to manipulate boom with out full-size infrastructure changes.
Improved Customer Experience: From personalized tips to 24/7 help, AI gear help small groups deliver superior customer service.
3 notes
·
View notes
Text
Damage control has started, huh?
On my recent post linking to an article describing how Tumblr has already scraped user data, and are relying solely on faith that OpenAI and Midjourney will retroactively adhere to users' opt-out requests (if they haven't been used in training already) one of the staff accounts responded with this:

Surely, this post has some clarifications, right? Here's a link so you can read along.
Tumblr: "AI companies are acquiring content across the internet for a variety of purposes in all sorts of ways. There are currently very few regulations giving individuals control over how their content is used by AI platforms."
Yes, and you're taking advantage of this for monetary gain. The article revealed you have already been scraping data, including data that should not have been scraped.
Tumblr: "Proposed regulations around the world, like the European Union’s AI Act, would give individuals more control over whether and how their content is utilized by this emerging technology. We support this right regardless of geographic location, so we’re releasing a toggle to opt out of sharing content from your public blogs with third parties, including AI platforms that use this content for model training. We’re also working with partners to ensure you have as much control as possible regarding what content is used."
Gee, that's great. Except now we know you've already been scraping! One of your employees has already moved his photography completely off-site! And you're relying on blind faith that those you are selling this data to will comply with user opt-out requests retroactively, and that's if the scraped data hasn't already been used to train before the user opts-out!
Tumblr: "We want to represent all of you on Tumblr and ensure that protections are in place for how your content is used. We are committed to making sure our partners respect those decisions."
Except we already know that you're essentially just hoping they comply. What they do with data you've already submitted and have been paid for seems like it would be out of your hands, especially if that data has already been used to train. Blind faith isn't "making sure" - the only way you could "make sure" is by making this system opt-in instead of opt-out... except you wouldn't be able to exploit us for the cash we know you need in that case.
10 notes
·
View notes
Text
We Need Actually Open AI Now More than Ever (Or: Why Leopold Aschenbrenner is Dangerously Wrong)
Based on recent meetings it would appear that the national security establishment may share Leopold Aschenbrenner's view that the US needs to get to ASI first to help protect the world from Chinese hegemony. I believe firmly in protecting individual freedom and democracy. Building a secretive Manhattan project style ASI is, however, not the way to accomplish this. Instead we now need an Actually Open™ AI more than ever. We need ASIs (plural) to be developed in the open. With said development governed in the open. And with the research, data, and systems accessible to all humankind.
The safest number of ASIs is 0. The least safe number is 1. Our odds get better the more there are. I realize this runs counter to a lot of writing on the topic, but I believe it to be correct and will attempt to explain concisely why.
I admire the integrity of some of the people who advocate for stopping all development that could result in ASI and are morally compelled to do so as a matter of principle (similar to committed pacifists). This would, however, require magically getting past the pervasive incentive systems of capitalism and nationalism in one tall leap. Put differently, I have resigned myself to zero ASIs being out of reach for humanity.
Comparisons to our past ability to ban CFCs as per the Montreal Protocol provide a false hope. Those gasses had limited economic upside (there are substitutes) and obvious massive downside (exposing everyone to terrifyingly higher levels of UV radiation). The climate crisis already shows how hard the task becomes when the threat is seemingly just a bit more vague and in the future. With ASI, however, we are dealing with the exact inverse: unlimited perceived upside and "dubious" risk. I am putting "dubious" in quotes because I very much believe in existential AI risk but it has proven difficult to make this case to all but a small group of people.
To get a sense of just how big the economic upside perception for ASI is one need to look no further than the billions being poured into OpenAI, Anthropic and a few others. We are entering the bubble to end all bubbles because the prize at the end appears infinite. Scaling at inference time is utterly uneconomical at the moment based on energy cost alone. Don't get me wrong: it's amazing that it works but it is not anywhere close to being paid for by current applications. But it is getting funded and to the tune of many billions. It’s ASI or bust.
Now consider the national security argument. Aschenbrenner uses the analogy to the nuclear bomb race to support his view that the US must get there first with some margin to avoid a period of great instability and protect the world from a Chinese takeover. ASI will result in decisive military advantage, the argument goes. It’s a bit akin to Earth’s spaceships encountering far superior alien technology in the Three Body Problem, or for those more inclined towards history (as apparently Aschenbrenner is), the trouncing of Iraqi forces in Operation Desert Storm.
But the nuclear weapons or other examples of military superiority analogy is deeply flawed for two reasons. First, weapons can only destroy, whereas ASI also has the potential to build. Second, ASI has failure modes that are completely unlike the failure modes of non-autonomous weapons systems. Let me illustrate how these differences matter using the example of ASI designed swarms of billions of tiny drones that Aschenbrenner likes to conjure up. What in the world makes us think we could actually control this technology? Relying on the same ASI that designed the swarm to stop it is a bad idea for obvious reasons (fox in charge of hen house). And so our best hope is to have other ASIs around that build defenses or hack into the first ASI to disable it. Importantly, it turns out that it doesn’t matter whether the other ASI are aligned with humans in some meaningful way as long as they foil the first one successfully.
Why go all the way to advocating a truly open effort? Why not just build a couple of Manhattan projects then? Say a US and a European one. Whether this would make a big difference depends a lot on one’s belief about the likelihood of an ASI being helpful in a given situation. Take the swarm example again. If you think that another ASI would be 90% likely to successfully stop the swarm, well then you might take comfort in small numbers. If on the other hand you think it is only 10% likely and you want a 90% probability of at least one helping successfully you need 22 (!) ASIs. Here’s a chart graphing the likelihood of all ASIs being bad / not helpful against the number of ASIs for these assumptions:
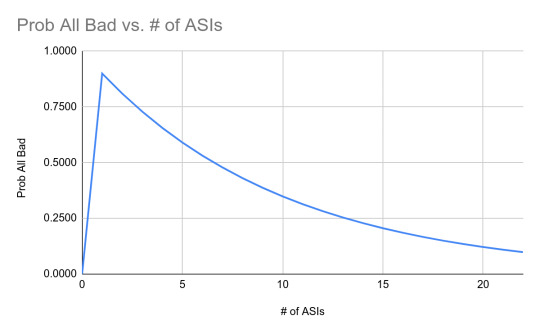
And so here we have the core argument for why one ASI is the most dangerous of all the scenarios. Which is of course exactly the scenario that Aschenbrenner wants to steer us towards by enclosing the world’s knowledge and turning the search for ASI into a Manhattan project. Aschenbrenner is not just wrong, he is dangerously wrong.
People have made two counter arguments to the let’s build many ASIs including open ones approach.
First, there is the question of risk along the way. What if there are many open models and they allow bio hackers to create super weapons in their garage. That’s absolutely a valid risk and I have written about a key way of mitigating that before. But here again unless you believe the number of such models could be held to zero, more models also mean more ways of early detection, more ways of looking for a counteragent or cure, etc. And because we already know today what some of the biggest bio risk vectors are we can engage in ex-ante defensive development. Somewhat in analogy to what happened during COVID, would you rather want to rely on a single player or have multiple shots on goal – it is highly illustrative here to compare China’s disastrous approach to the US's Operation Warp Speed.
Second, there is the view that battling ASIs will simply mean a hellscape for humanity in a Mothra vs. Godzilla battle. Of course there is no way to rule that out but multiple ASIs ramping up around the same time would dramatically reduce the resources any one of them can command. And the set of outcomes also includes ones where they simply frustrate each other’s attempts at domination in ways that are highly entertaining to them but turn out to be harmless for the rest of the world.
Zero ASIs are unachievable. One ASI is extremely dangerous. We must let many ASIs bloom. And the best way to do so is to let everyone contribute, fork, etc. As a parting thought: ASIs that come out of open collaboration between humans and machines would at least be exposed to a positive model for the future in their origin, whereas an ASI covertly hatched for world domination, even in the name of good, might be more inclined to view that as its own manifest destiny.
I am planning to elaborate the arguments sketched here. So please fire away with suggestions and criticisms as well as links to others making compelling arguments for or against Aschenbrenner's one ASI to rule them all.
5 notes
·
View notes
Text
Connecting the dots of recent research suggests a new future for traditional websites:
Artificial Intelligence (AI)-powered search can provide a full answer to a user’s query 75% of the time without the need for the user to go to a website, according to research by The Atlantic.
A worldwide survey from the University of Toronto revealed that 22% of ChatGPT users “use it as an alternative to Google.”
Research firm Gartner forecasts that traffic to the web from search engines will fall 25% by 2026.
Pew Research found that a quarter of all web pages developed between 2013 and 2023 no longer exist.
The large language models (LLMs) of generative AI that scraped their training data from websites are now using that data to eliminate the need to go to many of those same websites. Respected digital commentator Casey Newton concluded, “the web is entering a state of managed decline.” The Washington Post headline was more dire: “Web publishers brace for carnage as Google adds AI answers.”
From decentralized information to centralized conclusions
Created by Sir Tim Berners-Lee in 1989, the World Wide Web redefined the nature of the internet into a user-friendly linkage of diverse information repositories. “The first decade of the web…was decentralized with a long-tail of content and options,” Berners-Lee wrote this year on the occasion of its 35th anniversary. Over the intervening decades, that vision of distributed sources of information has faced multiple challenges. The dilution of decentralization began with powerful centralized hubs such as Facebook and Google that directed user traffic. Now comes the ultimate disintegration of Berners-Lee’s vision as generative AI reduces traffic to websites by recasting their information.
The web’s open access to the world’s information trained the large language models (LLMs) of generative AI. Now, those generative AI models are coming for their progenitor.
The web allowed users to discover diverse sources of information from which to draw conclusions. AI cuts out the intellectual middleman to go directly to conclusions from a centralized source.
The AI paradigm of cutting out the middleman appears to have been further advanced in Apple’s recent announcement that it will incorporate OpenAI to enable its Siri app to provide ChatGPT-like answers. With this new deal, Apple becomes an AI-based disintermediator, not only eliminating the need to go to websites, but also potentially disintermediating the need for the Google search engine for which Apple has been paying $20 billion annually.
The Atlantic, University of Toronto, and Gartner studies suggest the Pew research on website mortality could be just the beginning. Generative AI’s ability to deliver conclusions cannibalizes traffic to individual websites threatening the raison d’être of all websites, especially those that are commercially supported.
Echoes of traditional media and the web
The impact of AI on the web is an echo of the web’s earlier impact on traditional information providers. “The rise of digital media and technology has transformed the way we access our news and entertainment,” the U.S. Census Bureau reported in 2022, “It’s also had a devastating impact on print publishing industries.” Thanks to the web, total estimated weekday circulation of U.S. daily newspapers fell from 55.8 million in 2000 to 24.2 million by 2020, according to the Pew Research Center.
The World Wide Web also pulled the rug out from under the economic foundation of traditional media, forcing an exodus to proprietary websites. At the same time, it spawned a new generation of upstart media and business sites that took advantage of its low-cost distribution and high-impact reach. Both large and small websites now feel the impact of generative AI.
Barry Diller, CEO of media owner IAC, harkened back to that history when he warned a year ago, “We are not going to let what happened out of free internet happen to post-AI internet if we can help it.” Ominously, Diller observed, “If all the world’s information is able to be sucked up in this maw, and then essentially repackaged in declarative sentence in what’s called chat but isn’t chat…there will be no publishing; it is not possible.”
The New York Times filed a lawsuit against OpenAI and Microsoft alleging copyright infringement from the use of Times data to train LLMs. “Defendants seek to free-ride on The Times’s massive investment in its journalism,” the suit asserts, “to create products that substitute for The Times and steal audiences away from it.”1
Subsequently, eight daily newspapers owned by Alden Global Capital, the nation’s second largest newspaper publisher, filed a similar suit. “We’ve spent billions of dollars gathering information and reporting news at our publications, and we can’t allow OpenAI and Microsoft to expand the Big Tech playbook of stealing our work to build their own businesses at our expense,” a spokesman explained.
The legal challenges are pending. In a colorful description of the suits’ allegations, journalist Hamilton Nolan described AI’s threat as an “Automated Death Star.”
“Providential opportunity”?
Not all content companies agree. There has been a groundswell of leading content companies entering into agreements with OpenAI.
In July 2023, the Associated Press became the first major content provider to license its archive to OpenAI. Recently, however, the deal-making floodgates have opened. Rupert Murdoch’s News Corp, home of The Wall Street Journal, New York Post, and multiple other publications in Australia and the United Kingdom, German publishing giant Axel Springer, owner of Politico in the U.S. and Bild and Welt in Germany, venerable media company The Atlantic, along with new media company Vox Media, the Financial Times, Paris’ Le Monde, and Spain’s Prisa Media have all contracted with OpenAI for use of their product.
Even Barry Diller’s publishing unit, Dotdash Meredith, agreed to license to OpenAI, approximately a year after his apocalyptic warning.
News Corp CEO Robert Thomson described his company’s rationale this way in an employee memo: “The digital age has been characterized by the dominance of distributors, often at the expense of creators, and many media companies have been swept away by a remorseless technological tide. The onus is now on us to make the most of this providential opportunity.”
“There is a premium for premium journalism,” Thomson observed. That premium, for News Corp, is reportedly $250 million over five years from OpenAI. Axel Springer’s three-year deal is reportedly worth $25 to $30 million. The Financial Times terms were reportedly in the annual range of $5 to $10 million.
AI companies’ different approaches
While publishers debate whether AI is “providential opportunity” or “stealing our work,” a similar debate is ongoing among AI companies. Different generative AI companies have different opinions whether to pay for content, and if so, which kind of content.
When it comes to scraping information from websites, most of the major generative AI companies have chosen to interpret copyright law’s “fair use doctrine” allowing the unlicensed use of copyrighted content in certain circumstances. Some of the companies have even promised to indemnify their users if they are sued for copyright infringement.
Google, whose core business is revenue generated by recommending websites, has not sought licenses to use the content on those websites. “The internet giant has long resisted calls to compensate media companies for their content, arguing that such payments would undermine the nature of the open web,” the New York Times explained. Google has, however, licensed the user-generated content on social media platform Reddit, and together with Meta has pursued Hollywood rights.
OpenAI has followed a different path. Reportedly, the company has been pitching a “Preferred Publisher Program” to select content companies. Industry publication AdWeek reported on a leaked presentation deck describing the program. The publication said OpenAI “disputed the accuracy of the information” but claimed to have confirmed it with four industry executives. Significantly, the OpenAI pitch reportedly offered not only cash remuneration, but also other benefits to cooperating publishers.
As of early June 2024, other large generative AI companies have not entered into website licensing agreements with publishers.
Content companies surfing an AI tsunami
On the content creation side of the equation, major publishers are attempting to avoid a repeat of their disastrous experience in the early days of the web while smaller websites are fearful the impact on them could be even greater.
As the web began to take business from traditional publishers, their leadership scrambled to find a new economic model. Ultimately, that model came to rely on websites, even though website advertising offered them pennies on their traditional ad dollars. Now, even those assets are under attack by the AI juggernaut. The content companies are in a new race to develop an alternative economic model before their reliance on web search is cannibalized.
The OpenAI Preferred Publisher Program seems to be an attempt to meet the needs of both parties.
The first step in the program is direct compensation. To Barry Diller, for instance, the fact his publications will get “direct compensation for our content” means there is “no connection” between his apocalyptic warning 14 months ago and his new deal with OpenAI.
Reportedly, the cash compensation OpenAI is offering has two components: “guaranteed value” and “variable value.” Guaranteed value is compensation for access to the publisher’s information archive. Variable value is payment based on usage of the site’s information.
Presumably, those signing with OpenAI see it as only the first such agreement. “It is in my interest to find agreements with everyone,” Le Monde CEO Louis Dreyfus explained.
But the issue of AI search is greater than simply cash. Atlantic CEO Nicolas Thompson described the challenge: “We believe that people searching with AI models will be one of the fundamental ways that people navigate to the web in the future.” Thus, the second component in OpenAI’s proposal to publishers appears to be promotion of publisher websites within the AI-generated content. Reportedly, when certain publisher content is utilized, there will be hyperlinks and hover links to the websites themselves, in addition to clickable buttons to the publisher.
Finally, the proposal reportedly offers publishers the opportunity to reshape their business using generative AI technology. Such tools include access to OpenAI content for the publishers’ use, as well as the use of OpenAI for writing stories and creating new publishing content.
Back to the future?
Whether other generative AI and traditional content companies embrace this kind of cooperation model remains to be seen. Without a doubt, however, the initiative by both parties will have its effects.
One such effect was identified in a Le Monde editorial explaining their licensing agreement with OpenAI. Such an agreement, they argued, “will make it more difficult for other AI platforms to evade or refuse to participate.” This, in turn, could have an impact on the copyright litigation, if not copyright law.
We have seen new technology-generated copyright issues resolved in this way before.2 Finding a credible solution that works for both sides is imperative. The promise of AI is an almost boundless expansion of information and the knowledge it creates. At the same time, AI cannot be a continued degradation of the free flow of ideas and journalism that is essential for democracy to function.
Newton’s Law in the AI age
In 1686 Sir Isaac Newton posited his three laws of motion. The third of these holds that for every action there is an equal and opposite reaction. Newton described the consequence of physical activity; generative AI is raising the same consequential response for informational activity.
The threat of generative AI has pushed into the provision of information and the economics of information companies. We know the precipitating force, the consequential effects on the creation of content and free flow of information remain a work in progress.
12 notes
·
View notes