#AWSzeroETLstrategy
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Celebrities use Tumblr as well.
Text
Amazon Redshift: A Quick-Start Guide To Data Warehousing
Amazon Redshift offers the finest price-performance cloud data warehouse to support data-driven decision-making.
What is Amazon Redshift?
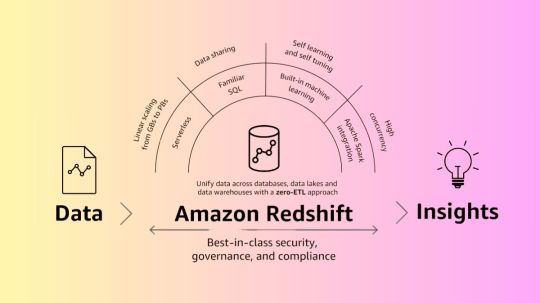
Amazon Redshift leverages machine learning and technology created by AWS to provide the greatest pricing performance at any scale, utilizing SQL to analyze structured and semi-structured data across data lakes, operational databases, and data warehouses.
With only a few clicks and no data movement or transformation, you can break through data silos and obtain real-time and predictive insights on all of your data.
With performance innovation out of the box, you may achieve up to three times higher pricing performance than any other cloud data warehouse without paying extra.
Use a safe and dependable analytics solution to turn data into insights in a matter of seconds without bothering about infrastructure administration.
Why Amazon Redshift?
Every day, tens of thousands of customers utilize Amazon Redshift to deliver insights for their organizations and modernize their data analytics workloads. Amazon Redshift’s fully managed, AI-powered massively parallel processing (MPP) architecture facilitates swift and economical corporate decision-making. With AWS’s zero-ETL strategy, all of your data is combined for AI/ML applications, near real-time use cases, and robust analytics. With the help of cutting-edge security features and fine-grained governance, data can be shared and collaborated on safely and quickly both inside and between businesses, AWS regions, and even third-party data providers.
Advantages
At whatever size, get the optimal price-performance ratio
With a fully managed, AI-powered, massively parallel processing (MPP) data warehouse designed for speed, scale, and availability, you can outperform competing cloud data warehouses by up to six times.
Use zero-ETL to unify all of your data
Use a low-code, zero-ETL strategy for integrated analytics to quickly access or ingest data from your databases, data lakes, data warehouses, and streaming data.
Utilize thorough analytics and machine learning to optimize value
Utilize your preferred analytics engines and languages to run SQL queries, open source analytics, power dashboards and visualizations, and activate near real-time analytics and AI/ML applications.
Use safe data cooperation to innovate more quickly
With fine-grained governance, security, and compliance, you can effortlessly share and collaborate on data both inside and between your businesses, AWS regions, and even third-party data sets without having to move or copy data by hand.
How it works
In order to provide the best pricing performance at any scale, Amazon Redshift leverages machine learning and technology created by AWS to analyze structured and semi-structured data from data lakes, operational databases, and data warehouses using SQL.
Use cases
Boost demand and financial projections
Allows you to create low latency analytics apps for fraud detection, live leaderboards, and the Internet of Things by consuming hundreds of megabytes of data per second.
Make the most of your business intelligence
Using BI tools like Microsoft PowerBI, Tableau, Amazon QuickSight, and Amazon Redshift, create insightful reports and dashboards.
Quicken SQL machine learning
To support advanced analytics on vast amounts of data, SQL can be used to create, train, and implement machine learning models for a variety of use cases, such as regression, classification, and predictive analytics.
Make money out of your data
Create apps using all of your data from databases, data lakes, and data warehouses. To increase consumer value, monetize your data as a service, and open up new revenue sources, share and work together in a seamless and safe manner.
Easily merge your data with data sets from outside parties
Subscribe to and merge third-party data in AWS Data Exchange with your data in Amazon Redshift, whether it’s market data, social media analytics, weather data, or more, without having to deal with licensing, onboarding, or transferring the data to the warehouse.
Amazon Redshift concepts
Amazon Redshift Serverless helps you examine data without provisioning a data warehouse. Automatic resource provisioning and intelligent data warehouse capacity scaling ensure quick performance for even the most demanding and unpredictable applications. The data warehouse is free when idle, so you only pay for what you use. The Amazon Redshift query editor v2 or your favorite BI tool lets you load data and query immediately. Take advantage of the greatest pricing performance and familiar SQL capabilities in a zero-administration environment.
If your company is eligible and your cluster is being formed in an AWS Region without Amazon Redshift Serverless, you may be eligible for the free trial. Choose Production or Free trial to answer. For what will you use this cluster? Free trial creates a dc2.large node configuration. AWS Regions with Amazon Redshift Serverless are included in the Amazon Web Services General Reference’s Redshift Serverless API endpoints.
Key Amazon Redshift Serverless ideas are below
Namespace: Database objects and users are in a namespace. Amazon Redshift Serverless namespaces contain schemas, tables, users, datashares, and snapshots.
Workgroup: A collection of computer resources. Amazon Redshift Serverless computes in workgroups. Redshift Processing Units, security groups, and use limits are examples. Configure workgroup network and security settings using the Amazon Redshift Serverless GUI, AWS Command Line Interface, or APIs.
Important Amazon Redshift supplied cluster concepts:
Cluster: A cluster is an essential part of an Amazon Redshift data warehouse’s infrastructure.
A cluster has compute nodes. Compiled code runs on compute nodes.
An additional leader node controls two or more computing nodes in a cluster. Business intelligence tools and query editors communicate with the leader node. Your client application only talks to the leader. External apps can see computing nodes.
Database: A cluster contains one or more databases.
One or more computing node databases store user data. SQL clients communicate with the leader node, which organizes compute node queries. Read about compute and leader nodes in data warehouse system design. User data is grouped into database schemas.
Amazon Redshift is compatible with other RDBMSs. It supports OLTP functions including inserting and removing data like a standard RDBMS. Amazon Redshift excels at batch analysis and reporting.
Amazon Redshift’s typical data processing pipeline and its components are described below.
A example Amazon Redshift data processing path is shown below.Image credit to AWS
An enterprise-class relational database query and management system is Amazon Redshift. Business intelligence (BI), reporting, data, and analytics solutions can connect to Amazon Redshift. Analytic queries retrieve, compare, and evaluate vast volumes of data in various stages to obtain a result.
Multiple data sources upload structured, semistructured, and unstructured data to the data storage layer at the data ingestion layer. This data staging section holds data in various consumption readiness phases. Storage may be an Amazon S3 bucket.
The optional data processing layer preprocesses, validates, and transforms source data using ETL or ELT pipelines. ETL procedures enhance these raw datasets. ETL engines include AWS Glue.
Read more on govindhtech.com
#AmazonRedshift#QuickStartGuide#DataWarehousing#machinelearning#AWSzeroETLstrategy#datawarehouse#AmazonS3#data#aws#news#realtimeanalytics#AmazonQuickSight#technology#technews#govindhtech
0 notes