
quantumintelligence-blog
Quantum Intelligence
10 posts
Don't wanna be here? Send us removal request.
Last Seen Blogs

hebert49du
Untitled

drunk-on-books
Bookworm

drumminrapunzel
Courage, Dear Heart.

lillified
Lillified

dracoqi
THE UNDYING.
Text
Uno sguardo al futuro
Nell’articolo precedente ho parlato di come un’automobile dotata di intelligenza artificiale possa “conoscere” sempre più a fondo il guidatore. Ma come riesce a farlo? Tutto questo è possibile grazie allo sviluppo di algoritmi sempre più accurati di intelligenza artificiale.
Attraverso una rete neurale, l’auto raccoglie i dati esterni, come ad esempio mappe o condizioni della strada, gli algoritmi elaborano questi dati e sono in grado di prendere decisioni. E’ quindi possibile che questi algoritmi diventino un vero e proprio copilota. Questi sistemi sono chiamati reti neurali.

Schema di una rete neurale artificiale (Fonte: Wikipedia)
Ma cosa significa rete neurale nel campo dell’automotive? Si tratta di algoritmi costituiti da tantissimi nodi, collegati fra loro formando una rete detta “neurale” (perchè ricorda quella del cervello umano) capace di interpretare dati e tenere sotto controllo tutto ciò che riguarda l’auto, come ad esempio la rotta.
Le funzioni particolarmente innovative sono molte: grazie alle reti neurali convoluzionali, l’algoritmo è in grado di “leggere le forme” e le immagini, dunque può riconoscere fisicamente il proprietario dell’auto; una volta riconosciuto il guidatore, sincronizza la sua rete neurale con i nostri device, in modo da poter identificare mail e messaggi e leggerli a voce per non distrarci dalla guida, oppure fissare sul calendario del cellulare nuovi appuntamenti o semplicemente consultarlo.
Inoltre alcune intelligenze artificiali, come axel.ai, possono imparare “per concetti”: questo permette al sistema di dare consigli e suggerimenti. Ad esempio, se la nostra destinazione è l’aeroporto, non solo ci ricorderà a che ora è il volo, ma potrà chiedere se abbiamo preso il passaporto e la valigia.
Questa capacità di raccolta dati e analisi permette all’algoritmo di controllare anche tutti i parametri relativi alla sicurezza; infatti, oltre alla già citata capacità di monitorare le condizioni della strada, può tenere sotto controllo i segnali biometrici del conducente, per segnalare eventuali segni di stanchezza. La raccolta di tutti questi dati permette all’auto di compiere azioni per salvaguardare la nostra salute, dal più semplice degli avvisi alla richiesta di SOS tramite connessione Cloud.
Con questo sviluppo così rapido dell’intelligenza artificiali (e dei suoi algoritmi), la guida non solo sarà più confortevole, ma anche molto più sicura.
Diego Riva
0 notes
Text
IA accessibile a tutti
Secondo quanto scritto nel post di Google AI blog “Using Machine Learning to Explore Neural Network Architecture” , il processo di progettazione delle reti richiede spesso una notevole quantità di tempo e di sperimentazione da parte di specialisti con competenze significative nell'apprendimento automatico. Lo spazio di ricerca di tutti i modelli possibili può essere calcolato in modo combinatorio: una tipica rete a 10 strati può avere circa 10^10 reti candidate. Google per aumentare la scalabilità di progettazione di modelli di apprendimento automatico ha realizzato il progetto AutoML (Automated Machine Learning).
Nell’approccio AutoML la rete neurale madre propone un modello di architettura “figlia” che viene addestrato e valutato per la sua efficienza su un compito specifico. In particolare le reti sono allenate a sviluppare reti neurali “figlie” su CIFAR-10, uno dei più diffusi dataset di immagini utilizzati nel machine learning. Per verificare la precisione delle reti neurali “figlie” si effettuano dei test su dataset differenti come il rilevamento oggetti di COCO e la classificazione di immagini di ImageNet.
Il sistema AutoML prevede un continuo miglioramento grazie al meccanismo di feedback costante tra la rete generata e rete neurale di partenza. Il processo di generazione viene iterato migliaia di volte e le aree dello spazio di architettura vengono progressivamente assegnate alle reti con precisione migliore. Come riportato nella pubblicazione in Google AI blog “Using Evolutionary AutoML to Discover Neural Network Architectures“ : si vorrebbe avere un metodo automatico per generare l'architettura giusta per ogni attività specifica.
Oggi uno degli scopi del progetto è migliorare il riconoscimento delle immagini scalabili, sistema applicabile negli ambiti più diversi. Ne sono un esempio i sistemi di guida autonoma che basano le decisioni sull’interpretazione dell’ambiente circostante oppure, in ambito medico, software in grado di assistere i patologi nell’interpretazione di alcuni esami diagnostici per patologie cancerogene
“La revisione delle diapositive di patologia è un compito molto complesso, che richiede anni di formazione per acquisire le competenze e l'esperienza per fare bene ”. Fonte: Google Ai Blog

Foto raffigurante un’auto a guida autonoma (fonte Wikipedia)
Nell’ottica della condivisione della conoscenza il team di Google ha operato in modo tale da rendere l’AI accessibile alle imprese e alla comunità scientifica attraverso Cloud AutoML che mette a disposizione modelli di apprendimento automatico pre-formati. Tutto ciò si traduce nella possibilità per ricercatori e imprese, di disporre di una strumentazione a costo accessibile e pertanto utilizzabile anche da realtà con disponibilità economiche limitate nella ricerca e sviluppo.
Lorenzo Gilardi
#rivoluzdigital#rivoluzionedigitale#google#automl#artificial intelligence#guida autonoma#machinelearning#condivisione
0 notes
Text
L’apprendimento profondo
Abbiamo visto in questo articolo i processi di apprendimento supervisionato, non supervisionato e per rinforzo che esistono dagli anni ’50, l’apprendimento profondo è un approccio etichettabile come nuovo. Tramite esso, le macchine sono in grado di valutare le previsioni sbagliate, che devono essere conosciute dal sistema, analizzate, capite e corrette.
Durante il processo di inizializzazione di queste reti neurali i valori degli array costituenti i pesi vengono assegnati in maniera casuale, per poi essere aggiustati man mano che la macchina apprende al fine di rendere la predizione successiva più precisa della precedente. Una volta che l'input è stato analizzato, le reti neurali estraggono le sue proprietà caratterizzanti automaticamente, rimuovendo l'intervento umano.
La potenza computazionale è di primaria importanza per una rete neurale, e solo negli ultimi anni si è arrivato all'utilizzo delle schede grafiche, che vengono sfruttate in parallelo per accelerare in maniera notevole il processo di predizione dell'output.
Il nuovo approccio legato all’apprendimento profondo rende le reti neurali più generaliste e meno mirate, quindi applicabili su una svariata tipologia di contesti: dall'intelligenza artificiale al riconoscimento vocale, dalle identificazioni legate all'audio, Shazam per esempio, alle auto a guida autonoma.

Rete neurale semplice (a sinistra) a confronto con una rete neurale che usa l'apprendimento profondo (a destra). Fonte: Quora
Le informazioni possono essere generalizzate con la convoluzione.
Questa tecnica permette di miscelare due pezzi distinti di un’informazione scomponendoli nelle loro singole unità e rappresentandoli in una matrice. Questa operazione, che richiederebbe un numero di calcoli elevatissimo, viene semplificata dalla trasformata di Fourier, che trasforma, per esempio, un’operazione di integrazione in una moltiplicazione.

Convoluzione di un immagine con un kernel di convoluzione. Fonte: 1,2.
All’atto pratico, la convoluzione può descrivere la diffusione dell'informazione, ovvero il metodo con cui questa si propaga. Nello specifico, nell’apprendimento profondo le maschere di convoluzione sono degli strumenti che ci permettono di comprendere i dettagli di un'immagine, come quanto rosso c'è, quante e quali sono le fonti di luce o com'è il rapporto di contrasto. Se prendiamo un'immagine di input e ad essa applichiamo una determinata maschera di convoluzione, potremmo ottenere un'immagine risultate in cui la funzionalità che vogliamo analizzare viene isolata: se vogliamo capire dove sono i punti più scuri in una foto, allora avremmo una mappa risultante dei toni scuri.
Il pooling è un'altra delle procedure cardine che le schede grafiche inserite all'interno di una rete neurale convoluzionale devono saper portare a termine. Essa è un'operazione che, molto semplicemente, prende in ingresso una serie di input e li riduce ad un singolo valore, analogamente all'operazione di subsampling effettuata dall' antialiasing, che isola quattro sotto pixel e li riduce ad uno solo effettuando una media. Così facendo, si possono semplificare alcune caratteristiche della nostra immagine, per meglio adattarle al calcolo convoluzionale. Per esempio, se una determinata foto è troppo ricca di dettagli e la computazione è di conseguenza eccessivamente onerosa, si possono appiattire le informazioni ed effettuare comunque l'applicazione della maschera di convoluzione, senza infierire sulle prestazioni.

Architettura di convoluzione LeNet 5. Fonte: ResearchGate
C'è un limite comunque, nel caso di una foto, al numero di pixel massimo che si possono generalizzare: chiaramente, più questo buffer è largo e più informazioni si possono condensare; se è troppo grosso però, si generalizzano troppe informazioni contemporaneamente e viene persa una grossa porzione di dati.
Matteo Pazienza
#RivoluzDigitale#IntelligenzaArtificiale#Pooling#Subsmapling#antialiasing#convolutional neural networks#artificial intelligence#deeplearning
0 notes
Text
Le reti neurali artificiali
Dopo una breve introduzione alla storia dell'intelligenza artificiale, vediamo quanto le reti neurali siano importanti e, soprattutto, come funzionano i loro principali paradigmi di apprendimento.
All'interno del cervello umano la risoluzione dei problemi cognitivi è affidata a reti neurali, composte da cellule neuronali. Quando si parla di reti neurali artificiali ci si riferisce a sistemi di elaborazione dell'informazione il cui scopo è simulare il ruolo dei neuroni biologici all'interno di un sistema informatico.
Il comportamento intelligente emerge da migliaia di interazioni tra le reti neurali interconnesse. Lo scopo finale è quello di acquisire informazioni dal mondo esterno, elaborarle e restituire un risultato sotto forma di impulso.
I nodi che compongono una rete neurale sono di tre tipi:
Unità di ingresso (Input layer)
Unità nascoste (Hidden layer)
Unità di uscita (Output layer)

Schematizzazione di una rete neurale. Fonte: Wikipedia
Ognuna di queste unità si attiva se le informazioni che riceve dagli altri nodi o dal mondo esterno superano la soglia di attivazione. In questo caso emette a sua volta un segnale attraverso dei canali di comunicazione fino a raggiungere le altre unità cui è connessa. La precisione delle previsioni dipende quindi dall’intensità delle interazioni tra i vari nodi.
La funzione di trasferimento del segnale nella rete non è programmata ma è ottenuta attraverso un processo di apprendimento - definito per la prima volta da Arthur Samuel - che può essere:
Supervisionato, la rete viene addestrata tramite una serie di esempi mostrati in successione allegati dal risultato effettivo, in modo da individuare i collegamenti che li legano. Successivamente, tali dati vengono usati per modificare i parametri della rete stessa e minimizzare l'errore di previsione. Se l'addestramento ha successo, la rete impara a riconoscere la relazione incognita che lega le variabili d'ingresso a quelle d'uscita, ed è quindi in grado di fare previsioni anche laddove l'uscita non è nota a priori.
Non supervisionato, basato su algoritmi d'addestramento facendo esclusivamente riferimento ad un insieme di dati che include le sole variabili d'ingresso. Tali algoritmi tentano di raggruppare i dati d'ingresso in cluster rappresentativi dei dati stessi.
Per rinforzo, nel quale un algoritmo si prefigge lo scopo di individuare un certo modus operandi, a partire da un processo d'osservazione dell'ambiente esterno; ogni azione ha un impatto sull'ambiente, e l'ambiente produce una retroazione che guida l'algoritmo nel processo d'apprendimento. Contrariamente all’apprendimento supervisionato, non sono presentate coppie input-output di esempi noti e non si procede alla correzione esplicita di azioni subottimali.
Esistono tuttavia paradigmi di apprendimento etichettabili come nuovi, tra essi, l'apprendimento profondo. Vediamone insieme le caratteristiche, unite alle tecniche di convoluzione e pooling, in questo articolo.
Matteo Pazienza
#RivoluzDigitale#IntelligenziaArtificiale#ParadigmiDiApprendimento#RetiNeurali#NeuralNetworks#DeepLearning#MachineLearning#ArtificialIntelligence#artificial neural network
0 notes
Text
Hey, Mercedes
Pochi mesi fa è stata svelata la nuova Mercedes Classe A 2018, che porta con sé il nuovo sistema MBUX (Mercedes-Benz User Experience) che permette l’interazione vocale tra automobile e guidatore tramite il sistema Voicetronic. Ma come funziona?

I due schermi (Fonte: autoblog.com)
Il sistema MBUX è un sistema multimediale dotato di intelligenza artificiale che risponde non appena si pronuncia “Hey Mercedes”. Somiglia ai più famosi assistenti vocali come Siri o Cortana, ma non dovremo più essere macchinosi e precisi nelle richieste: il sistema è in grado di comprendere il linguaggio naturale delle persone e addirittura le inflessioni e i dialetti utilizzati da ogni singola persona alla guida dell’auto.
Le richieste vocali possono essere di vario tipo: si può attivare il climatizzatore, chiedere dov’è il ristorante più vicino o di ascoltare la canzone preferita, grazie all’interazione tra MBUX e Yelp e TripAdvisor; è interessante che tutto ciò funzioni senza connessione a internet. Infatti molte richieste riguardanti l’automobile non richiedono connessione, mentre per domande più articolate, come per esempio “Che tempo fa a Torino?” il sistema avrà bisogno di una connessione a internet per rispondere alla domanda.
Oltre all’assistente vocale, il sistema MBUX comprende anche due schermi posizionati dietro al volante, di dimensione variabile in base alla versione dell’auto: i due schermi sono controllabili tramite tasti sul volante (tasti a destra per lo schermo di destra, tasti a sinistra per lo schermo a sinistra).
Lo schermo di destra può essere collegato al telefono e accede ai media, ai contatti e si può impostare il navigatore. Inoltre è presente una sezione di “suggerimenti”: con il tempo il sistema memorizza le azioni svolte e se ad esempio ogni mercoledì alle 20 si va nel luogo X, l’auto suggerirà quella destinazione ogni mercoledì alle 20. Lo stesso processo viene svolto anche per la stazione radio e per le chiamate.

La grafica 3D (Fonte: trustedreviews.com)
Infatti proprio questo schermo è un vero e proprio centro di controllo: all’interno si possono fare dei cambiamenti rispetto a tutto ciò che è modificabile dell’auto, come le luci o addirittura le sfumature della vernice. Tutto ciò è mostrato in anteprima da una grafica 3D che mostra l’auto con i cambiamenti effettuati.
Lo schermo di sinistra invece riguarda il tachimetro e alcuni aspetti del navigatore.
Un’altra cosa interessante è che questo sistema “impara”: per esempio quando si chiede di chiamare un contatto non presente in rubrica, questo ti chiede di inserire nome e numero del contatto, per permettere in un secondo momento di poterlo utilizzare.
Interessante è anche l’interazione con l’applicazione Mercedes: quando si è in un luogo magari senza indirizzo, con l’applicazione la mappa viene spezzettata in zone di 3x3m e ogni zona è identificata da 3 parole chiave; se dovete essere raggiunti in quel luogo, potrete mandare le 3 parole chiave per farvi raggiungere nel posto esatto con una precisione strabiliante.
Se la acquisterete, buon viaggio con il vostro nuovo assistente!
Diego Riva
0 notes
Text
L’assistente personale del futuro
Quest’anno alla conferenza Google I/O tenutasi dall’8 maggio all’11 maggio sono stati presentati vari prodotti innovativi nel campo dell’informatica e più in generale nel campo tecnologico; molti di questi si basano sull’intelligenza artificiale e sfruttano il machine learning. Tra di essi mi ha incuriosito il progetto “Google Duplex”.
Cos’è Google Duplex?
Google Duplex è stato presentato da Sundar Pichai, il CEO di Google, come un assistente virtuale in grado di sostenere telefonate con esseri umani; nella demo presentata alla conferenza viene mostrato come Google Duplex sia in grado di prenotare appuntamenti al ristorante o dal parrucchiere tramite telefonate dirette con interlocutori convinti di parlare con un loro simile. Come il pubblico presente alla conferenza, anche io sono rimasto sbalordito dalla precisione, dalla velocità e dalla naturalezza con la quale il software è in grado di rispondere. Ho quindi deciso di approfondire l’argomento per capirne il funzionamento.
Come funziona e come fa a sembrare così naturale?
In input l’audio in arrivo dall’interlocutore umano viene elaborato tramite un sistema di riconoscimento vocale automatico (ASR). Il prodotto dell’elaborazione è un testo che viene analizzato da una rete neurale ricorrente costruita utilizzando la piattaforma di apprendimento automatico basata su TensorFlow Extended, una libreria software open source per l’apprendimento automatico. La rete neurale deve essere “allenata” per poter rispondere con precisione alle domande poste, e per ovviare a questo problema, Google ha addestrato la rete utilizzando dati di conversazioni telefoniche anonimizzate, i dati in output della tecnologia di riconoscimento vocale automatico, le funzionalità dell’audio, la cronologia della conversazione, i parametri della conversazione e altro ancora. Il risultato è un testo di risposta che viene letto ad alta voce dal software attraverso il sistema TTS (text to speech)

Schematizzazione del funzionamento di Google Duplex (fonte GoogleAiBlog)
Google Duplex per rendere il più reale possibile la chiamata si è concentrato su 4 parametri: comprensione, interazione, tempistica e conversazione. Nella demo che è stata presentata al Google I/O sono state evidenziate queste 4 caratteristiche, l’assistente infatti interpreta velocemente ogni domanda, risponde in tempi molto simili a quelli umani e nel caso in cui le tempistiche di risposta si dovessero alzare a causa della complessità della domanda, aggiunge delle disfluenze vocali (“uhm” e “mmhm”), proprio come facciamo noi umani quando dobbiamo prendere tempo in modo tale da elaborare una risposta. Inoltre un fattore fondamentale nella conversazione è l’intonazione che varia a seconda della circostanza; anche in questo caso Google ha superato il problema a pieni voti grazie alla combinazione di un motore concatenante text to speech TTS e un motore TTS di sintesi che utilizza Tacotron e WaveNet.
Quale sarà l’impatto sulla società?
Ad oggi il software non è ancora stato rilasciato, ma già da quest’estate verrà implementato all’interno dell’Assistente Google. Con Google Duplex ci si sta avvicinando ad uno degli obiettivi principali dell’interazione uomo-macchina: consentire alle persone di avere una conversazione naturale con i computer. Tuttavia attorno a Google Duplex emergono diverse preoccupazioni, anche di carattere etico; in alcuni casi sono stati ipotizzati scenari nei quali le interazioni, ad esempio nel settore dei servizi, possano diventare ulteriormente disumanizzate o situazioni dove “robocaller” comincerebbero ad utilizzare questo software per ingannare i consumatori inconsapevoli. In ogni caso Google ha già dichiarato che i possibili interlocutori saranno informati nel caso di telefonate con Google Duplex.
Si sta forse manifestando la profezia di Isaac Asimov, lo scrittore russo, che, già nella prima metà del secolo scorso prevedeva la necessità di norme giuridiche per regolamentare le intelligenze artificiali, attraverso le Tre Leggi della robotica; queste avrebbero dovuto tutelare l’umanità contro eventuali minacce da parte di macchine intelligenti. Oggi qual è lo stato dell’arte? Fino a che punto si potrà parlare di etica e di autoregolamentazione? In quali ambiti e con quale estensione potrà svilupparsi e consolidarsi la normativa di riferimento?
Lorenzo Gilardi
#RivoluzDigital#rivoluzionedigitale#intelligenzaartificiale#google#google duplex#technology#society#i/o 2018
0 notes
Text
Le origini dell’intelligenza artificiale
Oggi si parla molto di intelligenza artificiale, delle sue applicazioni, del suo funzionamento e soprattutto della sua evoluzione negli ultimi anni. E’ quindi particolarmente rilevante comprenderne le origini e le idee fondatrici. A tal scopo ho provato a riassumere gli avvenimenti e i concetti fondamentali che hanno dato vita a questo mare di innovazioni e paure che è l’intelligenza artificiale.
Durante l’estate del 1956 in un piccolo paese situato a New Hampshire, chiamato Hanover, il Dartmouth College fu teatro di una delle conferenze più importanti degli ultimi decenni. Il piano era molto semplice, dieci ricercatori avrebbero passato due mesi discutendo e condividendo idee su una cosa chiamata intelligenza artificiale, un termine che venne coniato dall’organizzatore dell’evento John McCarthy. L’idea era quella di trovare il modo di sviluppare dei computer che potessero in qualche modo simulare la mente umana.

Foto in bianco e nero di John McCarthy nel suo laboratorio di intelligenza artificiale a Stanford. Fonte: Indipendent
“L'I.A. è al tempo stesso una scienza e un'ingegneria” (Nilsson 1998).
È una scienza perché, nel momento in cui alcuni comportamenti intelligenti vengono emulati tramite sistemi artificiali, l'uomo formula modelli oggettivi e rigorosi confermanti sperimentalmente.
L'I.A. è un'ingegneria perché, quando le macchine emulano taluni comportamenti, erroneamente ritenuti inaccessibili all'ambito artificiale, si fornisce un oggettivo progresso al miglioramento della vita dell'uomo.
Inizialmente l’I.A. ha avuto una posizione, chiamata I.A. forte, che si è posta l’obiettivo di replicare l’intelligenza umana, e in particolare la parte intellettuale. Il termine è stato introdotto dal filosofo della mente John Searle, che voluto dividere l’I.A. in due categorie:
I.A. forte: un’intelligenza artificiale che può pensare e avere una mente;
I.A. debole: un’intelligenza artificiale che agisce come se pensasse e avesse una mente.
Si consideri che tutta l’I.A. del primo periodo - fino alla fine degli anni ’80 - ha abbracciato la posizione forte. Concentrandosi maggiormente su:
Battere un campione mondiale di scacchi;
Dimostrare importanti teoremi matematici;
Oggi, a quasi 50 anni di distanza, l’unico dei traguardi effettivamente raggiunto è quello della vittoria di un computer su un campione mondiale di scacchi. Nel 1996 infatti, il campione Gary Kasparov è stato battuto da Deep Blue, un supercomputer costruito dalla IBM. Secondo le parole di Marvin Minsky, uno dei pionieri dell’I.A., lo scopo di questa nuova disciplina è quello di “Far fare alle macchine delle cose che richiederebbero l'intelligenza se fossero fatte dagli uomini”.

Foto del computer Deep Blue della IBM. Fonte: Wikipedia
Si è dato invece poco spazio ad altri elementi oggi ritenuti essenziali, come:
L’apprendimento automatico, per cui un sistema apprende a funzionare meglio sulla base delle esperienze registrate.
Capacità di riconoscere schemi, modelli, andature e di classificare.
La tecnologia emblematica dell’I.A. forte è stata quella dei sistemi esperti, ovvero insiemi di regole logiche sulla base delle quali un motore, per induzione, riesce a trarre deduzioni. L’idea sottostante era che si potesse in questo modo riversare tutta la conoscenza di un professionista di settore in una macchina, e questa avrebbe potuto essere equivalente, e quindi sostituibile, ad una persona.
I progressi dell’intelligenza artificiale registrati negli ultimi cinquant’anni sono notevoli. Questo è dovuto anche all’enorme sforzo compiuto dai ricercatori del settore: NVIDIA, per esempio, ha reso possibile la creazione di un’ambiente virtuale nel quale si possono addestrare le macchine, in modo che esse, attraverso l’apprendimento profondo, si perfezionino autonomamente.
Con questi dati, è logico pensare che, analogamente alle precedenti rivoluzioni industriali, l’obsoleto sarà sostituito dal nuovo.
La domanda finale allora diventa: saremo in grado di non farci sostituire?
Matteo Pazienza
0 notes
Text
La mia Rivoluzione Digitale
Seppur lontana nel tempo, ricordo limpidamente la mia prima interazione con il mondo digitale. Una sera d’autunno del 2002, dopo cena, stavo giocando come di consuetudine con i Lego e con le macchinine nella mia camera quando mio papà mi invitò a provare quella scatola beige che emetteva luce: il computer!
Dopo aver inserito un disco con sopra scritto “MAME32” sullo schermo comparvero decine di giochi pronti ad essere sperimentati. Quella sera mi si aprì un mondo: MAME32 era un simulatore di cabinati e dava la possibilità a chiunque possedesse un computer di giocare a centinaia di giochi diversi con il semplice utilizzo di pochi tasti.

Logo di MAME (fonte Wikipedia)
Da quel momento mi resi conto di quanto fosse affascinante il mondo digitale ed incominciai a chiedere in regalo sempre più spesso videogiochi. Quelli che tuttora ricordo con malinconia sono: RollerCoaster Tycoon, Wanadoo SnowCross, MotoGp URT3 ed infine il gioco che mi introdusse al mondo di Internet ovvero Imperivm: Le grandi battaglie di Roma, sviluppato da Haemimont Games.

Logo di Haemimont Games (fonte Wikipedia)
Ebbene sì, dopo circa 4 anni dal primo contatto con il computer, sfruttando al massimo la scarsa connessione ADSL, riuscii a connettermi online con il mio migliore amico per giocare insieme contro giocatori di chissà quale altra parte del mondo. Era incredibile, uscivo da scuola, andavo a giocare con i miei amici al campetto e, tornato a casa, potevo continuare a giocare con loro grazie alla rete Internet.
Giocare online allora era molto diverso e altrettanto limitante rispetto ad oggi. Ricordo che per poter giocare online in tanti nello stesso momento era necessario darsi già a scuola un “appuntamento virtuale” ad un’ora ben precisa, perché a gioco avviato non sarebbe stato possibile chiamarsi telefonicamente. Una semplice chiamata al telefono avrebbe fatto saltare la connessione, vista l’assenza del filtro ADSL.

Filtro ADSL (fonte Wikipedia)
Scrivendo questo post, mi affiorano alla mente diversi ricordi legati alle modalità di utilizzo di Internet del passato; in particolare succedeva che la sera, mentre giocavo online in attesa della cena, immancabilmente chiamava mia nonna per le classiche domande che nel 99% dei casi riguardavano la preoccupazione principale di tutte le nonne: il cibo. Ovviamente le mie risposte erano frettolose e miravano a concludere quanto prima la telefonata per riprendere subito la partita in corso senza perdere troppi punti.
Con il tempo la mia curiosità verso il mondo di Internet e più in generale del mondo digitale è cresciuta e negli anni ho utilizzato sempre più frequentemente questo mezzo sia a scopo ludico, spaziando tra i vari tipi di videogiochi, ma anche nella quotidianità: sia per approfondire le mie conoscenze che per ampliare la possibilità di comunicazione.
Lorenzo Gilardi
#RivoluzDigitale#rivoluzionedigitale#internet#primaesperienzaconinternet#digitale#videogames#throwback#computer#rete
0 notes
Text
Primo impatto
La mia prima esperienza con internet è abbastanza sfocata nella mia memoria, in quanto non la collego direttamente a un evento in particolare. Quando ero piccolo mi piaceva guardare mia madre lavorare al computer e, spinto dalla curiosità, chiedevo di utilizzarlo.
Oltre ai giochi come pinball, uno dei primi contatti con internet fu MSN Messenger, che utilizzavo per tenermi in contatto con compagni di classe e amici. Questo permise le prime conoscenze di internet, semplificate dal fatto che tutti insieme stavamo scoprendo questo nuovo mondo.
Da quel momento, oltre che per tenersi in contatto con i conoscenti, mi interessai per lo più a trovare giochi con cui passare il tempo, molti dei quali non richiedevano necessariamente internet perché quando avevo 7/8 anni i giochi online praticamente non esistevano o comunque non erano popolari come ora.
Il primo gioco online in cui mi sono cimentato si chiamava Zhuki Kalicantus, dove praticamente bisognava addestrare e equipaggiare delle formiche per prepararle a delle gare. Era un antenato dei più recenti “Shakes & Fidget” e altri giochi di questo tipo, da cui ancora oggi si continua a prendere spunto.
Ciò che cambia non è il concetto del gioco, ma ora si guarda molto di più alla grafica e alla giocabilità, cosa che 10/15 anni fa non era d’interesse, poiché internet era utilizzato per di più da persone adulte e soprattutto a uso lavorativo. Questi giochini erano solo dei passatempi, mentre al giorno d’oggi ci sono dietro società che magari fatturano milioni di euro.
Oltre a questi passatempi, in quel periodo cominciava a prendere piede l’utilizzo di Wikipedia come enciclopedia online, che riduceva di molto in tempi per ricerche soprattutto relative alla scuola, seppur qualche volta con alcune imprecisioni.

Logo di Facebook (Fonte: Wikipedia)
Il primo contatto sui social network fù con facebook, ma relativamente tardi rispetto ai miei coetanei, all’età di 13 anni. Non ero interessato particolarmente a sapere cosa facessero gli altri, ma ogni giorno a scuola arrivava il compagno di classe di turno che mostrava a tutti l’immagine divertente del giorno; quindi perché aspettare?

Nintendo DS (Fonte: Wikipedia)
Da qui e dalla più crescente diffusione di console fisse (PS3) e portatili (Nintendo) che permettevano di giocare online con il mondo intero, l’utilizzo di internet fu praticamente obbligatorio, con ogni famiglia che cominciò a dotarsi di un wi-fi di casa. Dato che non acquistai la PS3 ma possedevo un Nintendo DS, ricordo che per scambiarsi i Pokemon con gli amici bisognava utilizzare un aggeggio collegato alla console.
Sempre tramite il NDS, uscì l’R4, una schedina uguale a quella dei giochi normali, ma con la possibilità di caricare sopra i giochi scaricati direttamente da internet gratuitamente, che ovviamente tutti utilizzavano.
Diego Riva
3 notes
·
View notes
Text
Il mio primo click verso l’Internet delle cose
Il seguente articolo è una trattazione della mia prima esperienza con Internet basata su frammenti di ricordi passati. In particolare, la sequenza di eventi è narrata in ordine cronologico a partire dall’anno 2008, quando, scevro di esperienza su Internet, dimostrai il mio interesse verso un mondo tuttora in continua evoluzione.
"Rammentare un singolo evento in un enorme flusso di ricordi ed emozioni è difficile, come scindere l’uno dal tutto, togliendo il nero dal bianco, ma non impossibile."
Dopo diverse battaglie combattute in favore della meritocrazia, vinsi, e nel lontano 2008 mio padre comprò il mio primo computer fisso. Dal momento in cui lo accesi, il timore dell’inesperienza svanì, lasciando spazio ad un profondo desiderio di conoscenza. Il sistema operativo preinstallato era Windows Vista e non fu difficile comprenderne il funzionamento basilare. Dopo poco compresi che il browser targato Microsoft, ovvero Internet Explorer, non faceva al caso mio. Puntai quindi su Google Chrome e dopo averlo scaricato, dovetti creare una e-mail.
“Una e-mail? Che cos’è una e-mail?” – pensai.
Con una semplice ricerca su Internet scoprii che le e-mail erano un mezzo di comunicazione che usavano i “grandi”. La motivazione che mi spinse a scegliere Hotmail tra tutti i servizi di posta elettronica non è chiara tuttora, contrariamente alle ragioni che mi spinsero a cambiare servizio qualche anno dopo. Il modulo da compilare che mi si presentò dinanzi chiedeva, tra tutto, un nome utente personalizzato, per intenderci, il classico prefisso seguito da @nomeutentegiàinuso.it. Come avrete intuito, il mio nome era già stato utilizzato da qualcun altro.
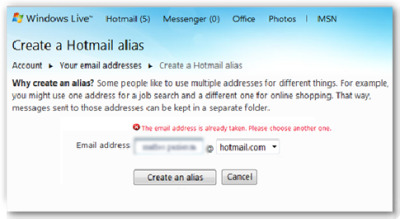
Messaggio di errore nel Form di Windows Live Hotmail, email già in uso.
Dopo svariati tentativi mescolando le mie vecchie passioni e qualche numero, riuscii infine a comporre un indirizzo né troppo imbarazzante né troppo serio. Con molta ansia cliccai il tasto “registrati” e vidi una spunta verde.
“Calmati, ce l’hai fatta, è finita.” – pensavo tra me e me.
Chiusi tutto, ma prima, forse per rabbia, cancellai l’unica e-mail presente nella casella, il classico messaggio di benvenuto.
Dopo qualche giorno, mentre la casella di posta si riempiva di spam, continuai a navigare su Internet e mi registrai su Youtube. Continuavo a chiedermi chi, e soprattutto come, avesse creato il sistema operativo che stavo usando. E fu lì, su Youtube, che trovai le mie risposte, e non solo. Infatti, è stata proprio questa piattaforma, e i suoi utenti, ad introdurmi ai linguaggi di programmazione.

Logo di Microsoft Visual Studio 2008. (Fonte Wikipedia)
Cominciai studiando in modo indipendente il linguaggio Visual Basic creando semplici applicazioni su Visual Studio. La possibilità di mettere in pratica le mie conoscenze in modo rapido e attivo mi riempì di gioia. Le giornate passavano in fretta e le dimensioni delle cartelle dove salvavo i progetti aumentavano con altrettanta rapidità. Una volta terminata la raccolta di video su un linguaggio passavo subito ad un altro, e così via. L’anno successivo avevo già basi sufficienti per programmare in Visual Basic, HTML e C++.
Sfortunatamente qualche anno dopo, la scuola e il mio buonsenso capovolsero la mia piramide delle priorità. Tuttavia permane il mio interesse verso la novità, soprattutto se essa presenta, tra i metadati, il campo “digitale”.
Matteo Pazienza
#RivoluzDigitale#rivoluzionedigitale#primaesperienzaconinternet#internet#digitale#email#programmazione#ricordi#quantumintelligence
0 notes