
Statistics
We looked inside some of the posts by guillaumelauzier and here's what we found interesting.
Average Info
Notes Per Post
0
Likes Per Post
0
Reblog Per Post
0
Reply Per Post
0
Time Between Posts
10 days
Number of Posts By Type
Text
17
Last Seen Tumblr Blogs





Fun Fact
If you dial 1-866-584-6757, you can leave an audio post for your followers.
Text
The Power of Transfer Learning in Modern AI

Transfer Learning has emerged as a transformative approach in the realm of machine learning and deep learning, enabling more efficient and adaptable model training. Here's an in-depth exploration of this concept:
Concept
Transfer Learning is a technique where a model developed for a specific task is repurposed for a related but different task. This method is particularly efficient as it allows the model to utilize its previously acquired knowledge, significantly reducing the need for training from the ground up. This approach not only saves time but also leverages the rich learning obtained from previous tasks.
Reuse of Pre-trained Models
A major advantage of transfer learning is its ability to use pre-trained models. These models, trained on extensive datasets, contain a wealth of learned features and patterns, which can be effectively applied to new tasks. This reuse is especially beneficial in scenarios where training data is limited or when the new task is somewhat similar to the one the model was originally trained on. - Rich Feature Set: Pre-trained models come with a wealth of learned features and patterns. They are usually trained on extensive datasets, encompassing a wide variety of scenarios and cases. This richness in learned features makes them highly effective when applied to new, but related tasks. - Beneficial in Limited Data Scenarios: In situations where there is a scarcity of training data for a new task, reusing pre-trained models can be particularly advantageous. These models have already learned substantial information from large datasets, which can be transferred to the new task, compensating for the lack of extensive training data. - Efficiency in Training: Using pre-trained models significantly reduces the time and resources required for training. Since these models have already undergone extensive training, fine-tuning them for a new task requires comparatively less computational power and time, enhancing efficiency. - Similarity to Original Task: The effectiveness of transfer learning is particularly pronounced when the new task is similar to the one the pre-trained model was originally trained on. The closer the resemblance between the tasks, the more effective the transfer of learned knowledge ]. - Broad Applicability: Pre-trained models in transfer learning are not limited to specific types of tasks. They can be adapted across various domains and applications, making them versatile tools in the machine learning toolkit. - Improvement in Model Performance: The reuse of pre-trained models often leads to improved performance in the new task. Leveraging the pre-existing knowledge helps in better generalization and often results in enhanced accuracy and efficiency.
Enhanced Learning Efficiency
Transfer learning greatly reduces the time and resources required for training new models. By leveraging existing models, it circumvents the need for extensive computation and large datasets, which is a boon in resource-constrained scenarios or when dealing with rare or expensive-to-label data. - Reduced Training Time: One of the primary benefits of transfer learning is the substantial reduction in training time. By using models pre-trained on large datasets, a significant portion of the learning process is already completed. This means that less time is needed to train the model on the new task. - Lower Resource Requirements: Transfer learning mitigates the need for powerful computational resources that are typically required for training complex models from scratch. This aspect is especially advantageous for individuals or organizations with limited access to high-end computing infrastructure. - Efficient Data Utilization: In scenarios where acquiring large amounts of labeled data is challenging or costly, transfer learning proves to be particularly beneficial. It allows for the effective use of smaller datasets, as the pre-trained model has already learned general features from a broader dataset. - Quick Adaptation to New Tasks: Transfer learning enables models to quickly adapt to new tasks with minimal additional training. This quick adaptation is crucial in dynamic fields where rapid deployment of models is required. - Overcoming Data Scarcity: For tasks where data is scarce or expensive to collect, transfer learning offers a solution by utilizing pre-trained models that have been trained on similar tasks with abundant data. This approach helps in overcoming the hurdle of data scarcity ]. - Improved Model Performance: Often, models trained with transfer learning exhibit improved performance on new tasks, especially when these tasks are closely related to the original task the model was trained on. This improved performance is due to the pre-trained model’s ability to leverage previously learned patterns and features.
Applications
The applications of transfer learning are vast and varied. It has been successfully implemented in areas such as image recognition, where models trained on generic images are fine-tuned for specific image classification tasks, and natural language processing, where models trained on one language or corpus are adapted for different linguistic applications. Its versatility makes it a valuable tool across numerous domains.
Adaptability
Transfer learning exhibits remarkable adaptability, being applicable to a wide array of tasks and compatible with various types of neural networks. Whether it's Convolutional Neural Networks (CNNs) for visual data or Recurrent Neural Networks (RNNs) for sequential data, transfer learning can enhance the performance of these models across different domains.
How Transfer Learning is Revolutionizing Generative Art
Transfer Learning is playing a pivotal role in the field of generative art, opening new avenues for creativity and innovation. Here's how it's being utilized: - Enhancing Generative Models: Transfer Learning enables the enhancement of generative models like Generative Adversarial Networks (GANs). By using pre-trained models, artists and developers can create more complex and realistic images without starting from scratch. This approach is particularly effective in art generation where intricate details and high realism are desired. - Fair Generative Models: Addressing fairness in generative models is another area where Transfer Learning is making an impact. It helps in mitigating dataset biases, a common challenge in deep generative models. By transferring knowledge from fair and diverse datasets, it aids in producing more balanced and unbiased generative art. - Art and Design Applications: In the domain of art and design, Transfer Learning empowers artists to use GANs pre-trained on various styles and patterns. This opens up possibilities for creating unique and diverse art pieces, blending traditional art forms with modern AI techniques. - Style Transfer in Art: Transfer Learning is also used in style transfer applications, where the style of one image is applied to the content of another. This technique has been popularized for creating artworks that combine the style of famous paintings with contemporary images. - Experimentation and Exploration: Artists are leveraging Transfer Learning to experiment with new styles and forms of expression. By using pre-trained models as a base, they can explore creative possibilities that were previously unattainable due to technical or resource limitations.
Set up transfer learning in Python
To set up transfer learning in Python using Keras, you can leverage a pre-trained model like VGG16. Here's a basic example to demonstrate this process: - Import Necessary Libraries: from keras.applications.vgg16 import VGG16, preprocess_input, decode_predictions from keras.preprocessing.image import img_to_array, load_img from keras.models import Model - Load Pre-trained VGG16 Model: # Load the VGG16 model pre-trained on ImageNet data vgg16_model = VGG16(weights='imagenet') - Customize the Model for Your Specific Task: For instance, you can remove the top layer (fully connected layers) and add your custom layers for a specific task (like binary classification). # Remove the last layer vgg16_model.layers.pop() # Freeze the layers except the last 4 layers for layer in vgg16_model.layers: layer.trainable = False # Check the trainable status of the individual layers for layer in vgg16_model.layers: print(layer, layer.trainable) - Add Custom Layers for New Task: from keras.layers import Dense, GlobalAveragePooling2D from keras.models import Sequential custom_model = Sequential() custom_model.add(vgg16_model) custom_model.add(GlobalAveragePooling2D()) custom_model.add(Dense(1024, activation='relu')) custom_model.add(Dense(1, activation='sigmoid')) # For binary classification - Compile the Model: custom_model.compile(loss='binary_crossentropy', optimizer='rmsprop', metrics=) - Train the Model: Here, you would use your dataset. For simplicity, this step is shown as a placeholder. # custom_model.fit(train_data, train_labels, epochs=10, batch_size=32) - Use the Model for Predictions: Load an image and preprocess it for VGG16. img = load_img('path_to_your_image.jpg', target_size=(224, 224)) img = img_to_array(img) img = img.reshape((1, img.shape, img.shape, img.shape)) img = preprocess_input(img) # Predict the class prediction = custom_model.predict(img) print(prediction) Remember, this is a simplified example. In a real-world scenario, you need to preprocess your dataset, handle overfitting, and possibly fine-tune the model further. Also, consider using train_test_split for evaluating model performance. For comprehensive guidance, you might find tutorials like those in Keras Documentation or PyImageSearch helpful.
Boosting Performance on Related Tasks
One of the most significant impacts of transfer learning is its ability to boost model performance on related tasks. By transferring knowledge from one domain to another, it aids in better generalization and accuracy, often leading to enhanced model performance on the new task. This is particularly evident in cases where the new task is a variant or an extension of the original task. Transfer learning stands as a cornerstone technique in the field of artificial intelligence, revolutionizing how models are trained and applied. Its efficiency, adaptability, and wide-ranging applications make it a key strategy in overcoming some of the most pressing challenges in machine learning and deep learning.
🌐 Sources
- Analytics Vidhya - Understanding Transfer Learning for Deep Learning - Machine Learning Mastery - A Gentle Introduction to Transfer Learning for Deep Learning - Wikipedia - Transfer Learning - V7 Labs - A Newbie-Friendly Guide to Transfer Learning - Domino - A Detailed Guide To Transfer Learning and How It Works - GeeksforGeeks - What is Transfer Learning? - Built In - What Is Transfer Learning? A Guide for Deep Learning - SparkCognition - Advantages of Transfer Learning - LinkedIn - Three advantages of using the transfer learning technique - Seldon - Transfer Learning for Machine Learning - Levity - What is Transfer Learning and Why Does it Matter? - arXiv - Fair Generative Models via Transfer Learning - Medium - Generative Adversarial Networks (GANs) or Transfer Learning - Anees Merchant - Unlocking AI's Potential: The Power of Transfer Learning in Generative Models - AAAI - Fair Generative Models via Transfer Learning Read the full article
#artificialneuralnetworks#datasymmetries#graphattributes#GraphNeuralNetworks#incompletegraphs#keywordsearch#latentencoding#lineartimecomplexity#optimizabletransformation#real-worlddatasets
0 notes
Text
The Power of Transfer Learning in Modern AI

Transfer Learning has emerged as a transformative approach in the realm of machine learning and deep learning, enabling more efficient and adaptable model training. Here's an in-depth exploration of this concept:
Concept
Transfer Learning is a technique where a model developed for a specific task is repurposed for a related but different task. This method is particularly efficient as it allows the model to utilize its previously acquired knowledge, significantly reducing the need for training from the ground up. This approach not only saves time but also leverages the rich learning obtained from previous tasks.
Reuse of Pre-trained Models
A major advantage of transfer learning is its ability to use pre-trained models. These models, trained on extensive datasets, contain a wealth of learned features and patterns, which can be effectively applied to new tasks. This reuse is especially beneficial in scenarios where training data is limited or when the new task is somewhat similar to the one the model was originally trained on. - Rich Feature Set: Pre-trained models come with a wealth of learned features and patterns. They are usually trained on extensive datasets, encompassing a wide variety of scenarios and cases. This richness in learned features makes them highly effective when applied to new, but related tasks. - Beneficial in Limited Data Scenarios: In situations where there is a scarcity of training data for a new task, reusing pre-trained models can be particularly advantageous. These models have already learned substantial information from large datasets, which can be transferred to the new task, compensating for the lack of extensive training data. - Efficiency in Training: Using pre-trained models significantly reduces the time and resources required for training. Since these models have already undergone extensive training, fine-tuning them for a new task requires comparatively less computational power and time, enhancing efficiency. - Similarity to Original Task: The effectiveness of transfer learning is particularly pronounced when the new task is similar to the one the pre-trained model was originally trained on. The closer the resemblance between the tasks, the more effective the transfer of learned knowledge ]. - Broad Applicability: Pre-trained models in transfer learning are not limited to specific types of tasks. They can be adapted across various domains and applications, making them versatile tools in the machine learning toolkit. - Improvement in Model Performance: The reuse of pre-trained models often leads to improved performance in the new task. Leveraging the pre-existing knowledge helps in better generalization and often results in enhanced accuracy and efficiency.
Enhanced Learning Efficiency
Transfer learning greatly reduces the time and resources required for training new models. By leveraging existing models, it circumvents the need for extensive computation and large datasets, which is a boon in resource-constrained scenarios or when dealing with rare or expensive-to-label data. - Reduced Training Time: One of the primary benefits of transfer learning is the substantial reduction in training time. By using models pre-trained on large datasets, a significant portion of the learning process is already completed. This means that less time is needed to train the model on the new task. - Lower Resource Requirements: Transfer learning mitigates the need for powerful computational resources that are typically required for training complex models from scratch. This aspect is especially advantageous for individuals or organizations with limited access to high-end computing infrastructure. - Efficient Data Utilization: In scenarios where acquiring large amounts of labeled data is challenging or costly, transfer learning proves to be particularly beneficial. It allows for the effective use of smaller datasets, as the pre-trained model has already learned general features from a broader dataset. - Quick Adaptation to New Tasks: Transfer learning enables models to quickly adapt to new tasks with minimal additional training. This quick adaptation is crucial in dynamic fields where rapid deployment of models is required. - Overcoming Data Scarcity: For tasks where data is scarce or expensive to collect, transfer learning offers a solution by utilizing pre-trained models that have been trained on similar tasks with abundant data. This approach helps in overcoming the hurdle of data scarcity ]. - Improved Model Performance: Often, models trained with transfer learning exhibit improved performance on new tasks, especially when these tasks are closely related to the original task the model was trained on. This improved performance is due to the pre-trained model’s ability to leverage previously learned patterns and features.
Applications
The applications of transfer learning are vast and varied. It has been successfully implemented in areas such as image recognition, where models trained on generic images are fine-tuned for specific image classification tasks, and natural language processing, where models trained on one language or corpus are adapted for different linguistic applications. Its versatility makes it a valuable tool across numerous domains.
Adaptability
Transfer learning exhibits remarkable adaptability, being applicable to a wide array of tasks and compatible with various types of neural networks. Whether it's Convolutional Neural Networks (CNNs) for visual data or Recurrent Neural Networks (RNNs) for sequential data, transfer learning can enhance the performance of these models across different domains.
How Transfer Learning is Revolutionizing Generative Art
Transfer Learning is playing a pivotal role in the field of generative art, opening new avenues for creativity and innovation. Here's how it's being utilized: - Enhancing Generative Models: Transfer Learning enables the enhancement of generative models like Generative Adversarial Networks (GANs). By using pre-trained models, artists and developers can create more complex and realistic images without starting from scratch. This approach is particularly effective in art generation where intricate details and high realism are desired. - Fair Generative Models: Addressing fairness in generative models is another area where Transfer Learning is making an impact. It helps in mitigating dataset biases, a common challenge in deep generative models. By transferring knowledge from fair and diverse datasets, it aids in producing more balanced and unbiased generative art. - Art and Design Applications: In the domain of art and design, Transfer Learning empowers artists to use GANs pre-trained on various styles and patterns. This opens up possibilities for creating unique and diverse art pieces, blending traditional art forms with modern AI techniques. - Style Transfer in Art: Transfer Learning is also used in style transfer applications, where the style of one image is applied to the content of another. This technique has been popularized for creating artworks that combine the style of famous paintings with contemporary images. - Experimentation and Exploration: Artists are leveraging Transfer Learning to experiment with new styles and forms of expression. By using pre-trained models as a base, they can explore creative possibilities that were previously unattainable due to technical or resource limitations.
Set up transfer learning in Python
To set up transfer learning in Python using Keras, you can leverage a pre-trained model like VGG16. Here's a basic example to demonstrate this process: - Import Necessary Libraries: from keras.applications.vgg16 import VGG16, preprocess_input, decode_predictions from keras.preprocessing.image import img_to_array, load_img from keras.models import Model - Load Pre-trained VGG16 Model: # Load the VGG16 model pre-trained on ImageNet data vgg16_model = VGG16(weights='imagenet') - Customize the Model for Your Specific Task: For instance, you can remove the top layer (fully connected layers) and add your custom layers for a specific task (like binary classification). # Remove the last layer vgg16_model.layers.pop() # Freeze the layers except the last 4 layers for layer in vgg16_model.layers: layer.trainable = False # Check the trainable status of the individual layers for layer in vgg16_model.layers: print(layer, layer.trainable) - Add Custom Layers for New Task: from keras.layers import Dense, GlobalAveragePooling2D from keras.models import Sequential custom_model = Sequential() custom_model.add(vgg16_model) custom_model.add(GlobalAveragePooling2D()) custom_model.add(Dense(1024, activation='relu')) custom_model.add(Dense(1, activation='sigmoid')) # For binary classification - Compile the Model: custom_model.compile(loss='binary_crossentropy', optimizer='rmsprop', metrics=) - Train the Model: Here, you would use your dataset. For simplicity, this step is shown as a placeholder. # custom_model.fit(train_data, train_labels, epochs=10, batch_size=32) - Use the Model for Predictions: Load an image and preprocess it for VGG16. img = load_img('path_to_your_image.jpg', target_size=(224, 224)) img = img_to_array(img) img = img.reshape((1, img.shape, img.shape, img.shape)) img = preprocess_input(img) # Predict the class prediction = custom_model.predict(img) print(prediction) Remember, this is a simplified example. In a real-world scenario, you need to preprocess your dataset, handle overfitting, and possibly fine-tune the model further. Also, consider using train_test_split for evaluating model performance. For comprehensive guidance, you might find tutorials like those in Keras Documentation or PyImageSearch helpful.
Boosting Performance on Related Tasks
One of the most significant impacts of transfer learning is its ability to boost model performance on related tasks. By transferring knowledge from one domain to another, it aids in better generalization and accuracy, often leading to enhanced model performance on the new task. This is particularly evident in cases where the new task is a variant or an extension of the original task. Transfer learning stands as a cornerstone technique in the field of artificial intelligence, revolutionizing how models are trained and applied. Its efficiency, adaptability, and wide-ranging applications make it a key strategy in overcoming some of the most pressing challenges in machine learning and deep learning.
🌐 Sources
- Analytics Vidhya - Understanding Transfer Learning for Deep Learning - Machine Learning Mastery - A Gentle Introduction to Transfer Learning for Deep Learning - Wikipedia - Transfer Learning - V7 Labs - A Newbie-Friendly Guide to Transfer Learning - Domino - A Detailed Guide To Transfer Learning and How It Works - GeeksforGeeks - What is Transfer Learning? - Built In - What Is Transfer Learning? A Guide for Deep Learning - SparkCognition - Advantages of Transfer Learning - LinkedIn - Three advantages of using the transfer learning technique - Seldon - Transfer Learning for Machine Learning - Levity - What is Transfer Learning and Why Does it Matter? - arXiv - Fair Generative Models via Transfer Learning - Medium - Generative Adversarial Networks (GANs) or Transfer Learning - Anees Merchant - Unlocking AI's Potential: The Power of Transfer Learning in Generative Models - AAAI - Fair Generative Models via Transfer Learning Read the full article
#artificialneuralnetworks#datasymmetries#graphattributes#GraphNeuralNetworks#incompletegraphs#keywordsearch#latentencoding#lineartimecomplexity#optimizabletransformation#real-worlddatasets
0 notes
Text
Graph Neural Networks: Revolutionizing Data Analysis in Graph-Structured Domains
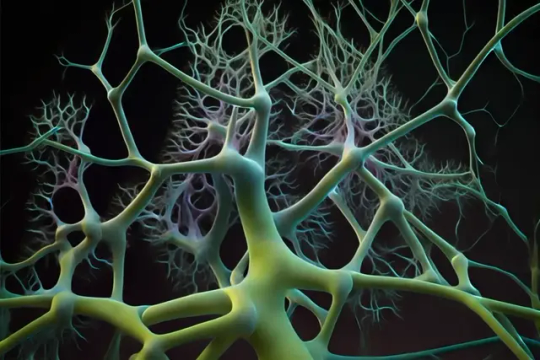
Graph Neural Networks (GNNs) represent a paradigm shift in the realm of neural networks, uniquely tailored for graph-structured data. They are pivotal in addressing complex data scenarios where traditional neural networks fall short. This comprehensive article delves into the core functionalities, applications, and future potential of GNNs.
Understanding Graph Neural Networks
Direct Application to Graphs GNNs' foremost strength lies in their direct application to graphs, facilitating node-level, edge-level, and graph-level prediction tasks. This flexibility proves invaluable across various fields where data is intrinsically relational, such as analyzing social networks, understanding molecular structures, and optimizing communication networks . Processing Complex Graph-Structured Data GNNs excel at processing and analyzing intricate graph-structured data. This capacity unlocks new avenues in numerous domains, including network analysis, computational biology, and the development of advanced recommender systems . Dependence on Graph Structure Central to GNNs' functionality is their ability to capture the dependence of graphs through message passing between nodes. By leveraging the inherent structural information of graphs, GNNs can make more accurate predictions and analyses, a critical aspect in fields like network security and structural health monitoring .
Expansive Applications of GNNs
Versatility in Various Fields GNNs' adaptability to graph data makes them invaluable in areas where relationships and connections are crucial. This includes, but is not limited to, social network analysis, drug discovery and chemistry, traffic flow prediction, and biological network analysis . From Foundations to Frontiers Spanning from basic concepts to cutting-edge advancements, GNNs are continually evolving. Ongoing research and development are likely to amplify their capabilities, making them even more effective in handling diverse, graph-related challenges .
How can Graph Neural Networks be used in Generative Art?
Graph Neural Networks (GNNs) have significant potential in the realm of generative art, leveraging their unique capabilities in understanding and manipulating graph-structured data. Here are some ways GNNs can be applied in this field: - Modeling Complex Relationships: GNNs can model intricate relationships and patterns within data. In generative art, they can analyze the structure of artistic elements, like color, form, and composition, to generate new artworks that maintain stylistic coherence or offer novel artistic interpretations. - Link Prediction for Artistic Elements: GNNs are adept at inferring missing links or detecting spurious ones in graph data. This capability can be used in generative art to predict and create connections between different artistic elements, leading to the generation of visually cohesive and complex artworks . - Learning Node Embeddings: In the context of generative art, GNNs can learn embeddings (representations) of various artistic elements. These embeddings can capture the nuances of style, technique, and other artistic features, which can then be used to generate new art pieces that reflect certain styles or artistic trends . - Message Passing for Artistic Interpretation: GNNs use message passing to understand graph structures, which can be applied to the way different elements in an artwork relate to each other. This can help in creating art that dynamically changes or evolves based on certain rules or inputs, adding an interactive or adaptive element to the artwork .
Python code example of a Graph Neural Networks
Here's a basic example of implementing a Graph Neural Network (GNN) using PyTorch. This code demonstrates the creation of a simple GNN for node classification on a graph: import torch import torch.nn as nn import torch.nn.functional as F from torch_geometric.nn import GCNConv # Define a simple GNN model class GCN(nn.Module): def __init__(self, num_features, num_classes): super(GCN, self).__init__() self.conv1 = GCNConv(num_features, 16) self.conv2 = GCNConv(16, num_classes) def forward(self, data): x, edge_index = data.x, data.edge_index # First Graph Convolutional Layer x = self.conv1(x, edge_index) x = F.relu(x) x = F.dropout(x, training=self.training) # Second Graph Convolutional Layer x = self.conv2(x, edge_index) return F.log_softmax(x, dim=1) # Example usage num_features = 10 # Number of features per node num_classes = 3 # Number of classes for classification model = GCN(num_features, num_classes) This code defines a simple two-layer Graph Convolutional Network (GCN) using PyTorch and PyTorch Geometric. The model takes in the number of features per node and the number of classes for classification. Each convolutional layer (GCNConv) in the network processes the graph data, applying a graph convolution followed by a ReLU activation and dropout. Note: This is a basic example. For a real-world application, you would need to provide graph data (nodes, edges, node features) to the model and train it on a specific task like node classification, link prediction, etc.
🌐 Sources
- AssemblyAI - AI trends in 2023: Graph Neural Networks - ScienceDirect - Graph neural networks: A review of methods and applications - arXiv - Generative Graph Neural Networks for Link Prediction - YouTube - AI Explained: Graph Neural Networks and Generative AI - Medium - Top Applications of Graph Neural Networks 2021 - Towards Data Science - Applications of Graph Neural Networks - XenonStack - Graph Neural Network Applications and its Future - arXiv - Graph Neural Networks: Methods, Applications, and - neptune.ai - Graph Neural Network and Some of GNN Applications - sciencedirect.com - Graph neural networks: A review of methods and applications - frontiersin.org - Graph Neural Networks and Their Current Applications in - Jonathan Hui - Applications of Graph Neural Networks (GNN) - Medium - GNN python code in Keras and pytorch - Towards Data Science - How to Create a Graph Neural Network in Python - DataCamp - A Comprehensive Introduction to Graph Neural Networks - GitHub - Hands-On-Graph-Neural-Networks-Using-Python - Towards Data Science - Graph Neural Networks in Python - Analytics Vidhya - Getting Started with Graph Neural Networks Read the full article
#DataAggregation#Deeplearning#Edge-levelPrediction#GNNApplications#GraphConvolutionalNetworks#GraphNeuralNetworks#Graph-levelPrediction#NetworkAnalysis#Node-levelPrediction#Non-EuclideanData
0 notes
Text
The World of Pixel Recurrent Neural Networks (PixelRNNs)

Pixel Recurrent Neural Networks (PixelRNNs) have emerged as a groundbreaking approach in the field of image generation and processing. These sophisticated neural network architectures are reshaping how machines understand and generate visual content. This article delves into the core aspects of PixelRNNs, exploring their purpose, architecture, variants, and the challenges they face.
Purpose and Application
PixelRNNs are primarily engineered for image generation and completion tasks. Their prowess lies in understanding and generating pixel-level patterns. This makes them exceptionally suitable for tasks like image inpainting, where they fill in missing parts of an image, and super-resolution, which involves enhancing the quality of images. Moreover, PixelRNNs are capable of generating entirely new images based on learned patterns, showcasing their versatility in the realm of image synthesis.
Architecture
The architecture of PixelRNNs is built upon the principles of recurrent neural networks (RNNs), renowned for their ability to handle sequential data. In PixelRNNs, the sequence is the pixels of an image, processed in an orderly fashion, typically row-wise or diagonally. This sequential processing allows PixelRNNs to capture the intricate dependencies between pixels, which is crucial for generating coherent and visually appealing images.
Pixel-by-Pixel Generation
At the heart of PixelRNNs lies the concept of generating pixels one at a time, following a specified order. Each prediction of a new pixel is informed by the pixels generated previously, allowing the network to construct an image in a step-by-step manner. This pixel-by-pixel approach is fundamental to the network's ability to produce detailed and accurate images.
Two Variants
PixelRNNs come in two main variants: Row LSTM and Diagonal BiLSTM. The Row LSTM variant processes the image row by row, making it efficient for certain types of image patterns. In contrast, the Diagonal BiLSTM processes the image diagonally, offering a different perspective in understanding and generating image data. The choice between these two depends largely on the specific requirements of the task at hand.
Conditional Generation
A remarkable feature of PixelRNNs is their ability to be conditioned on additional information, such as class labels or parts of images. This conditioning enables the network to direct the image generation process more precisely, which is particularly beneficial for tasks like targeted image editing or generating images that need to meet specific criteria.
Training and Data Requirements
As with other neural networks, PixelRNNs require a significant volume of training data to learn effectively. They are trained on large datasets of images, where they learn to model the distribution of pixel values. This extensive training is necessary for the networks to capture the diverse range of patterns and nuances present in visual data.
Challenges and Limitations
Despite their capabilities, PixelRNNs face certain challenges and limitations. They are computationally intensive due to their sequential processing nature, which can be a bottleneck in applications requiring high-speed image generation. Additionally, they tend to struggle with generating high-resolution images, as the complexity increases exponentially with the number of pixels. Creating a PixelRNN for image generation involves several steps, including setting up the neural network architecture and training it on a dataset of images. Here's an example in Python using TensorFlow and Keras, two popular libraries for building and training neural networks. This example will focus on a simple PixelRNN structure using LSTM (Long Short-Term Memory) units, a common choice for RNNs. The code will outline the basic structure, but please note that for a complete and functional PixelRNN, additional components and fine-tuning are necessary.
PixRNN using TensorFlow
First, ensure you have TensorFlow installed: pip install tensorflow Now, let's proceed with the Python code: import tensorflow as tf from tensorflow.keras import layers def build_pixel_rnn(image_height, image_width, image_channels): # Define the input shape input_shape = (image_height, image_width, image_channels) # Create a Sequential model model = tf.keras.Sequential() # Adding LSTM layers - assuming image_height is the sequence length # and image_width * image_channels is the feature size per step model.add(layers.LSTM(256, return_sequences=True, input_shape=input_shape)) model.add(layers.LSTM(256, return_sequences=True)) # PixelRNNs usually have more complex structures, but this is a basic example # Output layer - predicting the pixel values model.add(layers.TimeDistributed(layers.Dense(image_channels, activation='softmax'))) return model # Example parameters for a grayscale image (height, width, channels) image_height = 64 image_width = 64 image_channels = 1 # For grayscale, this would be 1; for RGB images, it would be 3 # Build the model pixel_rnn = build_pixel_rnn(image_height, image_width, image_channels) # Compile the model pixel_rnn.compile(optimizer='adam', loss='categorical_crossentropy') # Summary of the model pixel_rnn.summary() This code sets up a basic PixelRNN model with two LSTM layers. The model's output is a sequence of pixel values for each step in the sequence. Remember, this example is quite simplified. In practice, PixelRNNs are more complex and may involve techniques such as masking to handle different parts of the image generation process. Training this model requires a dataset of images, which should be preprocessed to match the input shape expected by the network. The training process involves feeding the images to the network and optimizing the weights using a loss function (in this case, categorical crossentropy) and an optimizer (Adam). For real-world applications, you would need to expand this structure significantly, adjust hyperparameters, and possibly integrate additional features like convolutional layers or different RNN structures, depending on the specific requirements of your task.
Recent Developments
Over time, the field of PixelRNNs has seen significant advancements. Newer architectures, such as PixelCNNs, have been developed, offering improvements in computational efficiency and the quality of generated images. These developments are indicative of the ongoing evolution in the field, as researchers and practitioners continue to push the boundaries of what is possible with PixelRNNs. Pixel Recurrent Neural Networks represent a fascinating intersection of artificial intelligence and image processing. Their ability to generate and complete images with remarkable accuracy opens up a plethora of possibilities in areas ranging from digital art to practical applications like medical imaging. As this technology continues to evolve, we can expect to see even more innovative uses and enhancements in the future.
🗒️ Sources
- dl.acm.org - Pixel recurrent neural networks - ACM Digital Library - arxiv.org - Pixel Recurrent Neural Networks - researchgate.net - Pixel Recurrent Neural Networks - opg.optica.org - Single-pixel imaging using a recurrent neural network - codingninjas.com - Pixel RNN - journals.plos.org - Recurrent neural networks can explain flexible trading of… Read the full article
#artificialintelligence#GenerativeModels#ImageGeneration#ImageInpainting#machinelearning#Neuralnetworks#PixelCNNs#PixelRNNs#SequentialDataProcessing#Super-Resolution
0 notes
Text
Neural Style Transfer (NST)

Neural Style Transfer (NST) is a captivating intersection of artificial intelligence and artistic creativity. This technology leverages the capabilities of deep learning to merge the essence of one image with the aesthetic style of another.
Basic Concept of Neural Style Transfer (NST)
Combining Content and Style: NST works by taking two images - a content image (like a photograph) and a style image (usually a famous painting) - and combining them. The goal is to produce a new image that retains the original content but is rendered in the artistic style of the second image. Deep Learning at its Core: This process is made possible through deep learning techniques, specifically using Convolutional Neural Networks (CNNs). These networks are adept at recognizing and processing visual information. Content Representation: The CNN captures the content of the target image at its deeper layers, where the network understands higher-level features (like objects and their arrangements). Style Representation: The style of the source image is captured from the correlations between different layers of the CNN. These layers encode textural and color patterns characteristic of the artistic style. Image Transformation: The NST algorithm iteratively adjusts a third, initially random image to minimize the differences in content with the target image and in style with the source image. Resulting Image: The result is a fascinating blend that looks like the original photograph (content) 'painted' in the style of the artwork (style).
How Neural Style Transfer Works with Python Example
Content and Style Images: The process begins with two images: a content image (the subject you want to transform) and a style image (the artistic style to be transferred). Using a Pre-Trained CNN: Typically, a pre-trained CNN like VGG19 is used. This network has been trained on a vast dataset of images and can effectively extract and represent features from these images. Feature Extraction: The CNN extracts content features from the content image and style features from the style image. These features are essentially patterns and textures that define the image's content and style. Combining Features: The NST algorithm then creates a new image that combines the content features of the content image with the style features of the style image. Optimization: This new image is gradually refined through an optimization process, minimizing the loss between its content and the content image, and its style and the style image. Result: The final output is a new image that retains the essence of the content image but is rendered in the style of the style image. Python Code Example: import tensorflow as tf import tensorflow_hub as hub import matplotlib.pyplot as plt import numpy as np # Load content and style images content_image = plt.imread('path_to_content_image.jpg') style_image = plt.imread('path_to_style_image.jpg') # Load a style transfer model from TensorFlow Hub hub_model = hub.load('https://tfhub.dev/google/magenta/arbitrary-image-stylization-v1-256/2') # Preprocess images and run the style transfer content_image = tf.image.convert_image_dtype(content_image, tf.float32) style_image = tf.image.convert_image_dtype(style_image, tf.float32) stylized_image = hub_model(tf.constant(content_image), tf.constant(style_image)) # Display the output plt.imshow(np.squeeze(stylized_image)) plt.show() This code snippet uses TensorFlow and TensorFlow Hub to apply a style transfer model, merging the content of one image with the style of another.
Detailed Section on Content and Style Representations in Neural Style Transfer
Feature Extraction Using Pre-Trained CNN: VGG19, a CNN model pre-trained on a large dataset (like ImageNet), is often used. This model effectively extracts features from images. Content Representation: - The content of an image is represented by the feature maps of higher layers in the CNN. - These layers capture the high-level content of the image, such as objects and their spatial arrangement, but not the finer details or style aspects. Style Representation: - The style of an image is captured by examining the correlations across different layers' feature maps. - These correlations are represented as a Gram matrix, which effectively captures the texture and visual patterns that define the image's style. Combining Content and Style: - NST algorithms aim to preserve the content from the content image while adopting the style of the style image. - This is done by minimizing a loss function that measures the difference in content and style representations between the generated image and the respective content and style images. Python Code Example: import numpy as np import tensorflow as tf from tensorflow.keras.applications import vgg19 from tensorflow.keras.preprocessing.image import load_img, img_to_array # Function to preprocess the image for VGG19 def preprocess_image(image_path, target_size=(224, 224)): img = load_img(image_path, target_size=target_size) img = img_to_array(img) img = np.expand_dims(img, axis=0) img = vgg19.preprocess_input(img) return img # Load your content and style images content_image = preprocess_image('path_to_your_content_image.jpg') style_image = preprocess_image('path_to_your_style_image.jpg') # Load the VGG19 model model = vgg19.VGG19(weights='imagenet', include_top=False) # Define a function to get content and style features def get_features(image, model): layers = { 'content': , 'style': } features = {} outputs = + layers] model = tf.keras.Model(, outputs) image_features = model(image) for name, output in zip(layers + layers, image_features): features = output return features # Extract features content_features = get_features(content_image, model) style_features = get_features(style_image, model) This code provides a basic structure for extracting content and style features using VGG19 in Python. Further steps would involve defining and optimizing the loss functions to generate the stylized image.
Applications of Neural Style Transfer
Video Styling: NST can be applied to video content, allowing filmmakers and content creators to impart artistic styles to their videos. This can transform ordinary footage into visually stunning sequences that resemble paintings or other art forms. Website Design: In web design, NST can be used to create unique, visually appealing backgrounds and elements. Designers can apply specific artistic styles to images, aligning them with the overall aesthetic of the website. Fashion and Textile Design: NST has been explored in the fashion industry for designing fabrics and garments. By transferring artistic styles onto textile patterns, designers can create innovative and unique clothing lines. Augmented Reality (AR) and Virtual Reality (VR): In AR and VR environments, NST can enhance the visual experience by applying artistic styles in real-time, creating immersive and engaging worlds for users. Product Design: NST can be used in product design to create visually appealing prototypes and presentations, allowing designers to experiment with different artistic styles quickly. Therapeutic Settings for Mental Health: There's growing interest in using NST in therapeutic settings. By creating soothing and pleasant images, it can be used as a tool for relaxation and stress relief, contributing positively to mental health and well-being. Educational Tools: NST can also be used as an educational tool in art and design schools, helping students understand the nuances of different artistic styles and techniques. These diverse applications showcase the versatility of NST, demonstrating its potential beyond the realm of digital art creation.
Limitations and Challenges of Neural Style Transfer
Computational Intensity: - NST, especially when using deep learning models like VGG19, is computationally demanding. It requires significant processing power, often necessitating the use of GPUs to achieve reasonable processing times. Balancing Content and Style: - Achieving the right balance between content and style in the output image can be challenging. It often requires careful tuning of the algorithm's parameters and may involve a lot of trial and error. Unpredictability of Results: - The outcome of NST can be unpredictable. The results may vary widely based on the chosen content and style images and the specific configurations of the neural network. Quality of Output: - The quality of the generated image can sometimes be lower than expected, with issues like distortions in the content or the style not being accurately captured. Training Data Limitations: - The effectiveness of NST is also influenced by the variety and quality of images used to train the underlying model. Limited or biased training data can affect the versatility and effectiveness of the style transfer. Overfitting: - There's a risk of overfitting, especially when the style transfer model is trained on a narrow set of images. This can limit the model's ability to generalize across different styles and contents. These challenges highlight the need for ongoing research and development in the field of NST to enhance its efficiency, versatility, and accessibility.
Necessary Hardware Resources for AI and Machine Learning in Art Generation
To effectively work with AI and machine learning algorithms for art generation, which can be computationally intensive, certain hardware resources are essential: High-Performance GPUs: - Graphics Processing Units (GPUs) are crucial for their ability to handle parallel tasks, making them ideal for the intensive computations required in training and running neural networks. - GPUs significantly reduce the time required for training models and generating art, compared to traditional CPUs. Sufficient RAM: - Adequate Random Access Memory (RAM) is important for handling large datasets and the high memory requirements of deep learning models. - A minimum of 16GB RAM is recommended, but 32GB or higher is preferable for more complex tasks. Fast Storage Solutions: - Solid State Drives (SSDs) are preferred over Hard Disk Drives (HDDs) for their faster data access speeds, which is beneficial when working with large datasets and models. High-Performance CPUs: - While GPUs handle most of the heavy lifting, a good CPU can improve overall system performance and efficiency. - Multi-core processors with high clock speeds are recommended. Cloud Computing Platforms: - Cloud computing resources like AWS, Google Cloud Platform, or Microsoft Azure offer powerful hardware for AI and machine learning tasks without the need for local installation. - These platforms provide scalability, allowing you to choose resources as per the project's requirements. Adequate Cooling Solutions: - High computational tasks generate significant heat. Therefore, a robust cooling solution is necessary to maintain optimal hardware performance and longevity. Reliable Power Supply: - A stable and reliable power supply is crucial, especially for desktop setups, to ensure uninterrupted processing and to protect the hardware from power surges. Investing in these hardware resources can greatly enhance the efficiency and capabilities of AI and machine learning algorithms in art generation and other computationally demanding tasks.
Limitations and Challenges of Neural Style Transfer
Neural Style Transfer (NST), despite its innovative applications in art and technology, faces several limitations and challenges: Computational Resource Intensity: - NST is computationally demanding, often requiring powerful GPUs and significant processing power. This can be a barrier for individuals or organizations without access to high-end computing resources. Quality and Resolution of Output: - The quality and resolution of the output images can sometimes be less than satisfactory. High-resolution images may lose detail or suffer from distortions after the style transfer. Balancing Act Between Content and Style: - Achieving a harmonious balance between the content and style in the output image can be challenging. It often requires fine-tuning of parameters and multiple iterations. Generalization and Diversity: - NST models might struggle with generalizing across vastly different styles or content types. This can limit the diversity of styles that can be effectively transferred. Training Data Biases: - The effectiveness of NST can be limited by the biases present in the training data. A model trained on a narrow range of styles may not perform well with radically different artistic styles. Overfitting Risks: - There's a risk of overfitting when the style transfer model is exposed to a limited set of images, leading to reduced effectiveness on a broader range of styles. Real-Time Processing Challenges: - Implementing NST in real-time applications, such as video styling, can be particularly challenging due to the intensive computational requirements. Understanding and addressing these limitations and challenges is crucial for the advancement and wider application of NST technologies.
Trends and Innovations in Neural Style Transfer (NST)
Neural Style Transfer (NST) is an evolving field with continuous advancements and innovations. These developments are broadening its applications and enhancing its efficiency: Improving Efficiency: - Research is focused on making NST algorithms faster and more resource-efficient. This includes optimizing existing neural network architectures and developing new methods to reduce computational requirements. Adapting to Various Artistic Styles: - Innovations in NST are enabling the adaptation to a wider range of artistic styles. This includes the ability to mimic more complex and abstract art forms, providing artists and designers with more diverse creative tools. Extending Applications Beyond Visual Art: - NST is finding applications in areas beyond traditional visual art. This includes video game design, film production, interior design, and even fashion, where NST can be used to create unique patterns and designs. Real-Time Style Transfer: - Advances in real-time processing capabilities are enabling NST to be applied in dynamic environments, such as live video feeds, augmented reality (AR), and virtual reality (VR). Integration with Other AI Technologies: - NST is being combined with other AI technologies like Generative Adversarial Networks (GANs) and reinforcement learning to create more sophisticated and versatile style transfer tools. User-Friendly Tools and Platforms: - The development of more user-friendly NST tools and platforms is democratizing access, allowing artists and non-technical users to experiment with style transfer without deep technical knowledge. These trends and innovations are propelling NST into new realms of creativity and practical application, making it a rapidly growing area in the field of AI and machine learning.
🌐 Sources
- Neural Style Transfer: Trends, Innovations, and Benefits - Challenges and Limitations of Deep Learning for Style Transfer - Neural Style Transfer: A Critical Review - Neural Style Transfer for So Long, and Thanks for all the Fish - Advantages and disadvantages of two methods of Neural Style Transfer - Evaluate and improve the quality of neural style transfer - Neural Style Transfer: Creating Artistic Images with Deep Learning - Classic algorithms, neural style transfer, GAN - Ricardo Corin - Mastering Neural Style Transfer - Neural Style Transfer Papers on GitHub - How to Make Artistic Images with Neural Style Transfer - Artificial Intelligence and Applications: Neural Style Transfer - Neural Style Transfer with Deep VGG model - Style Transfer using Deep Neural Network and PyTorch - Neural Style Transfer on Real Time Video (With Full Implementable Code) - How to Code Neural Style Transfer in Python? - Implementing Neural Style Transfer Using TensorFlow 2.0 - Neural Style Transfer (NST). Using Deep Learning Algorithms - Neural Read the full article
#AI#Art#ArtisticStyle#ConvolutionalNeuralNetworks#Deeplearning#ImageProcessing#machinelearning#NeuralStyleTransfer#OptimizationTechniques#VGG19
0 notes
Text
Impact of Niantic's Policies through the "GO Raiding a ESG Survey" on Pokémon GO

In the evolving landscape of mobile gaming, Niantic Labs' Pokémon GO has not just been a game but a phenomenon. However, recent changes in the game's mechanics, specifically the implementation of remote raid limitations and price increases, have raised questions and concerns within the gaming community. My project, "GO Raiding a ESG Survey," delves into these concerns, focusing on the broader environmental, social, and governance (ESG) implications of Niantic's decisions. Importance of the Survey The survey's core purpose is to address the consequences of Niantic's policy changes, particularly on inclusiveness and sustainability. With the reduction of remote raid opportunities and increased costs, a significant portion of the player base might find themselves excluded from key aspects of the game. Furthermore, encouraging in-person raids could inadvertently lead to increased carbon emissions, as players may resort to using cars to travel between raid locations. This survey aims to quantify these impacts and provide a platform for player voices. Survey Scope and Results The survey, updated last on April 21st, 2023, covers various areas including player satisfaction, purchase behavior, and the overall impact on gameplay experience. It also looks into changes in social interactions, the importance of open communication, and Niantic Labs' commitment to global sustainability. Key findings include: - Demographics: 710 participants from 51 countries, covering a wide range of age groups and including players with physical disabilities. - Player Concerns: Over 55% of players are concerned about ESG issues, with a significant impact on their overall game experience. - Inclusiveness: The Inclusion Score, standing at 64.30/100, reflects the extent to which players feel able to participate equally in the game. - Behavioral Changes: The survey indicates changes in players' likelihood of purchasing raid passes and participating in raids, both remote and in-person, post-implementation of the new policies. - Social Engagement: Notable shifts in social engagement patterns before and after the remote raid changes were observed. Methodology Our approach involved aggregating survey responses across multiple languages, focusing on various metrics such as player satisfaction, ESG concerns, and purchase behavior. The Inclusion Index, a crucial part of our analysis, assessed the accessibility and suitability of the game for diverse groups, including those with disabilities and parents with children. Implications and Moving Forward The "GO Raiding a ESG Survey" illuminates the delicate balance Niantic Labs must maintain between business objectives and community interests. The data suggests a need for more inclusive and sustainable gaming practices. Our report, along with the Google Sheets file and Google Analytics folder, offers a comprehensive view, intended for use by media companies, investors, and the gaming community. Our work emphasizes the importance of player feedback in shaping a game that is not only enjoyable but also responsible and inclusive. We encourage our community to engage with our main project, GeneratedArt, and participate in ongoing dialogues about the future of gaming in the context of ESG concerns. Closing Thoughts In the dynamic world of Pokémon GO, the "GO Raiding a ESG Survey" serves as a critical tool for understanding player sentiment and guiding future developments. As we continue to explore the intersection of gaming and social responsibility, we remain committed to advocating for a gaming experience that resonates with our diverse and passionate player base. To see full report, analytics, results and more: https://drive.google.com/drive/folders/1dQC_IJd_s8Bf7FZ5Mlro9sx1gevyzuva?usp=share_link Read the full article
#CommunityEngagement#environmentalimpact#ESGSurvey#gameaccessibility#MobileGaming#NianticLabs#PlayerSatisfaction#PokémonGO#RemoteRaids#sustainability
0 notes
Text
Exploring the Future of Finance with GenerativeFinance (GEFI.io)

GenerativeFinance (GEFI.io) is a platform dedicated to the exploration and advancement of generative finance, a burgeoning field at the intersection of artificial intelligence (AI), machine learning, and financial services. As the creator of GEFI.io, I aim to provide a space where experts, enthusiasts, and newcomers can converge to delve into the nuances of this rapidly evolving domain.
What is Generative Finance?
Generative finance represents a new paradigm in financial services, leveraging AI and machine learning to create and optimize financial products and strategies. It encompasses the generation of novel financial instruments, enhancement of trading strategies, and prediction of market dynamics. The core of generative finance lies in its ability to utilize generative models - sophisticated algorithms capable of producing new data resembling training datasets - to forecast market trends and discern investment opportunities.
The Potential of Generative Finance
This innovative approach has the potential to transform key facets of the financial industry, including investment management, risk assessment, and trading. One of its most significant contributions is the capability to analyze vast datasets more efficiently, thereby unveiling novel growth and innovation opportunities. However, it's crucial to recognize that generative finance is still in its nascent stages, with various challenges and uncertainties that need to be navigated as it matures.
Key Topics Explored on GEFI.io
- Mathematics in AI: Understanding the pivotal role of mathematics in developing AI algorithms, including areas like linear algebra, calculus, probability, and statistics. - Natural Language Processing (NLP): Delving into NLP's role in AI and finance, exploring applications like language translation and sentiment analysis. - Big Data Algorithms and Technologies: Investigating how big data algorithms like MapReduce and technologies like Hadoop are shaping the future of finance. - Data Visualization Tools: Highlighting tools like Matplotlib and Tableau, crucial for interpreting complex financial data. - Machine Learning Algorithms and Tools: Covering a range of algorithms from linear regression to deep learning, and tools from TensorFlow to PyTorch. - Deep Learning: Focusing on advanced neural network structures and their applications in finance. - Blockchain Technology: Examining the impact of blockchain on finance, from cryptocurrencies to smart contracts. - Monte Carlo Simulations: Utilizing these simulations for financial modeling and risk analysis. - High-Performance Computing (HPC): Exploring the role of HPC in handling computationally intensive financial tasks. - Hardware Components: Understanding the hardware underpinning these technologies, from CPUs to GPUs and beyond.
Join Our Community
I invite you to join GEFI.io, whether you're a seasoned expert in generative finance or just starting your journey. Together, we can explore this exciting field, share insights, and contribute to shaping the future of finance. Visit GenerativeFinance (GEFI.io) to learn more and become part of this groundbreaking venture. Read the full article
#AIalgorithmsinbanking#AI-driveninvestment#data-drivendecisionmaking#financialdatamodeling#financialtechnology#GenerativeAI#machinelearninginfinance#marketbehaviorprediction#quantitativeanalysis#riskmanagement
0 notes
Text
AXAL: A Sustainable IT Revolution

As a part of my diverse project portfolio, I am proud to introduce AXAL, a groundbreaking initiative that stands at the forefront of sustainable IT solutions. This project embodies my commitment to integrating technology with ecological responsibility, creating a resilient and self-sufficient future.
Project Overview
AXAL is not just an IT project; it's a comprehensive sustainable ecosystem that marries high-performance technology with environmental stewardship. The project is designed to serve various industries, offering tailored IT solutions that prioritize both efficiency and ecological impact.
Key Features of AXAL
Sustainable Ecosystem Integration AXAL integrates IT, agriculture, and energy solutions to foster self-sufficiency and resilience, particularly crucial during natural disasters. This integration reduces reliance on external resources and enhances community resilience. Localized Sustainable Solutions The project focuses on localizing information systems, agriculture, and energy solutions, significantly reducing transportation costs and CO2 emissions. This approach not only boosts efficiency but also advances environmental sustainability. Sovereignty and Community Empowerment AXAL empowers communities by providing control over essential resources like information, food, and energy, facilitating effective decision-making and sustainable resource management. Innovative Green IT Infrastructure At the core of AXAL is a green approach to IT infrastructure. The project harnesses solar and hydro energy to power servers, which in turn support agricultural practices through innovative heat reuse strategies.
Our Commitment to Sustainability
AXAL is more than just a project; it's a testament to our commitment to creating a sustainable future. We have taken a holistic approach to sustainability, focusing on renewable energy, eco-efficient solutions, and responsible consumption. Our team is dedicated to ethical decision-making, community collaboration, and environmental advocacy.
Join Us in Our Sustainable Journey
AXAL represents a significant step in my ongoing journey to integrate sustainable practices across various sectors. This project not only showcases my commitment to innovation and sustainability but also demonstrates how technology and nature can work in harmony for a better future. Discover more about AXAL and join us in shaping a more sustainable and resilient world. Read the full article
#agricultureintegration#AXAL#communityresilience#eco-friendlytechnology#greenITsolutions#renewableenergy#self-sufficiency#sustainableagriculture#sustainableIT
0 notes
Text
Offering Cryptocurrency as a Service

As financial landscapes shift and technological innovations come to the forefront, small banks find themselves in an intriguing yet challenging position. Gone are the days when traditional banking methods were sufficient to meet customer needs and compete effectively in the marketplace. With the rise of digital currencies, especially cryptocurrencies like Bitcoin, Ethereum, and a host of altcoins, the banking sector has reached a pivotal juncture. For small banks, the implementation of cryptocurrency services is not just a trend to observe; it's a business imperative. This article explores why it's crucial for small banks to integrate cryptocurrency into their business models to keep up with market challenges, technological advancements, and burgeoning client demand.
Meeting Client Demand
Digital natives and tech-savvy customers increasingly view cryptocurrencies not just as an investment but also as a valid form of transaction. This has led to growing customer expectations for banks to facilitate secure crypto transactions and storage solutions. Failure to meet this demand could result in small banks losing a significant customer base to more innovative or agile competitors, particularly fintech startups that natively offer such services.
Technological Advancements
Blockchain, the underlying technology of cryptocurrencies, offers enormous opportunities to improve banking operations. From enhancing security protocols to creating transparent and efficient transaction methods, the blockchain revolution can't be ignored. Offering crypto services would naturally introduce small banks to blockchain's wider utility, thus making them more competitive in the long run.
Market Differentiation
In a crowded marketplace, differentiation is key, and cryptocurrency services offer an avenue for this. Small banks that adopt crypto services not only position themselves as leaders in innovation but also attract a clientele that values forward-thinking and modern financial solutions. This can be particularly attractive for younger audiences who are more inclined to use digital currencies.
Regulatory Preparedness
While the regulatory landscape around cryptocurrencies is still evolving, proactive participation in this financial revolution prepares small banks for future compliance. It provides them with an invaluable learning curve to understand the complexities of crypto regulations, thereby gaining a first-mover advantage when widespread regulation finally rolls out.
Risk Diversification
As financial markets become more unpredictable, cryptocurrencies offer an alternative investment class for diversification. By offering crypto services, banks can provide customers with a more extensive portfolio range, thus mitigating risks associated with traditional investment vehicles like stocks and bonds.
Enhancing Revenue Streams
With interest rates in traditional savings accounts less appealing, cryptocurrency staking and investment services can serve as alternative revenue streams for both the bank and its clients. Transaction fees for crypto services also present another opportunity for increased revenue.
Operational Efficiency
Blockchain's transparent and immutable nature significantly reduces the risk of fraud, lowering operational costs in the long run. Additionally, smart contracts can automate several banking processes, making operations more efficient and cost-effective.
Conclusion
The writing is on the wall: cryptocurrencies are not a passing fad but a fundamental shift in how financial transactions will be conducted in the future. For small banks, the integration of cryptocurrency services offers a golden opportunity to align with current market trends, technological advancements, and evolving consumer demands. It's a leap that comes with its set of challenges, from regulatory uncertainty to the need for technological upgradation. However, the long-term benefits—ranging from client retention and market differentiation to revenue generation and operational efficiency—far outweigh the initial hurdles. In this digital age, where disruptive innovations continually redefine industry norms, small banks must not only adapt but also lead by embracing cryptocurrency services. Only then can they secure their position in the future of finance. Read the full article
#blockchain#ClientDemand#cryptocurrency#FinancialInnovation#MarketDifferentiation#OperationalEfficiency#RegulatoryPreparedness#RevenueStreams#RiskDiversification#Smallbanks
0 notes
Text
Leadership Within the Banking Industry

In the volatile landscape of investment banking, effective leadership is the cornerstone for success and resilience. It's not just about steering the ship but also about training the crew, balancing the sails, and navigating through storms. Specifically, traits such as autonomy, responsibility, initiative, and resilience are paramount in guiding an investment banking company through phases of development and restructuration.
Autonomous Decision-Making
In the banking industry, the fast-paced environment demands quick yet well-informed decisions. Autonomy becomes a significant aspect of leadership in this scenario. Leaders should empower their teams to make autonomous decisions based on data and customer needs, thereby speeding up processes and enhancing customer experience. Autonomy often leads to increased job satisfaction among team members, as they feel a sense of ownership and direct contribution to the company’s success.
The Weight of Responsibility
Responsibility in investment banking extends beyond balance sheets and extends to a responsibility towards stakeholders, clients, and employees. Leaders need to uphold the highest ethical standards and compliance, particularly in investment strategies and risk management. Their responsibility includes setting a vision, creating a culture of accountability, and ensuring that the bank adapts to new regulations and market conditions. When restructuring, the responsibility magnifies as leaders need to ensure a smooth transition, which could include workforce downsizing or reallocating resources, without affecting the company's operations or reputation.
Taking Initiative
In an industry that's driven by innovation and complex financial products, taking the initiative is non-negotiable. Leaders should actively seek new business opportunities and improve operational efficiencies. When considering development or restructuration, it's the leaders who need to make the first move, whether it's adopting new technologies like blockchain, or breaking into emerging markets. Initiative and proactivity can be the difference between capitalizing on an opportunity and missing out on it.
The Importance of Resilience
Investment banking is not for the faint-hearted; it's an industry filled with highs and lows. Resilience becomes a crucial leadership quality to withstand the pressure and bounce back from setbacks. Leaders should not only manage their own resilience but also build a resilient team. This involves creating a culture where failures are seen as opportunities for growth and development. During restructuration, it is especially vital for leaders to remain steadfast and guide their teams through the transitional period.
Conclusion
As investment banking companies continually adapt to shifts in global finance, regulatory landscapes, and customer expectations, leadership within the industry must also evolve. By fostering a culture that values autonomy, responsibility, initiative, and resilience, leaders can effectively guide their organizations through both development and restructuration phases. These four pillars not only sustain growth but also build a foundation strong enough to withstand the constant ebbs and flows of the banking world. Read the full article
#Autonomy#BankingIndustry#Development#Initiative#InvestmentBanking#Leadership#RegulatoryCompliance#Resilience#Responsibility#Restructuration
0 notes
Text
Zero-Knowledge Proofs: A Pillar of Cryptographic Privacy

As our world becomes increasingly digital, the ability to securely share and verify information is crucial. Cryptography has made impressive strides in this area, and zero-knowledge proofs (ZKPs) are one such innovation that holds great promise. They provide a way for one party (the prover) to demonstrate to another party (the verifier) that they possess certain knowledge or a specific piece of information without revealing any additional details. Understanding Zero-Knowledge Proofs In the realm of cryptography, zero-knowledge proofs are foundational. The principle of zero knowledge means that the prover can assure the verifier of the validity of a statement without disclosing any information beyond the authenticity of the claim. This functionality ensures data privacy and security, paramount in the age of digital information. Zero-knowledge proofs can be either interactive or non-interactive. In an interactive proof, the prover and verifier engage in multiple rounds of communication, with the prover responding to randomly generated challenges from the verifier. Non-interactive proofs, on the other hand, require only a single message from the prover to the verifier. The choice between interactive and non-interactive systems depends on the application and the system's constraints. The Essential Properties of ZKPs Three key properties distinguish zero-knowledge proofs: completeness, soundness, and zero-knowledge. Completeness stipulates that if a statement is true and both parties act in good faith, the verifier will be convinced of the statement's truth by the end of the interaction. Soundness ensures that a dishonest prover cannot convince an honest verifier of the validity of a false statement, except with minimal probability. Finally, the zero-knowledge property ensures that the verifier learns nothing more than the veracity of the statement. Formally, every verifier can generate a transcript that looks like an interaction between an honest prover and the verifier, without any access to the prover. Applications and Implementations of ZKPs The ability of zero-knowledge proofs to validate information without revealing any details makes them an ideal choice in a wide array of applications. For instance, in cryptography, they can be utilized to construct secure systems where users need to prove their identities or other credentials without divulging them. Furthermore, the rise of blockchain and other decentralized technologies opens up new possibilities for ZKPs, allowing for transaction verification without transaction detail exposure. Several ZKP schemes are well-established today, each with unique strengths, weaknesses, and use cases. They include the Schnorr protocol, the Fiat-Shamir heuristic, zk-SNARKs (Zero-Knowledge Succinct Non-Interactive Argument of Knowledge), and zk-STARKs (Zero-Knowledge Scalable Transparent Arguments of Knowledge). The Schnorr protocol, for instance, is a simple, interactive protocol widely recognized for its efficiency. The Fiat-Shamir heuristic, on the other hand, transforms interactive ZKPs into non-interactive ones by replacing the verifier's role with a hash function. Meanwhile, zk-SNARKs and zk-STARKs represent a newer generation of ZKPs, offering more scalability and transparency, with potential for wide-ranging applications in blockchain technology. The Challenge of Practical Implementation Despite being a longstanding theoretical concept, the practical implementation of ZKPs has been challenging due to computational complexities. However, recent advancements in computation and a surge in interest due to blockchain technology have made ZKPs increasingly feasible. Zero-knowledge proofs, while conceptually intricate, are a potent mechanism for preserving privacy in the digital world. By facilitating proof without exposure, they serve as a powerful tool in cryptographic systems, fortifying security while safeguarding privacy. The Road Ahead As with homomorphic encryption, which allows computations to be performed on encrypted data without compromising privacy, ZKPs are shaping the future of data security. Their ability to authenticate claims without revealing underlying data is a game-changer in cryptography, with broad potential applications. While we continue to grapple with the complexities of a progressively digitized world, the need for robust privacy and data security solutions becomes increasingly evident. Zero-knowledge proofs are well-positioned to meet this demand, offering a technique to authenticate data without sacrificing privacy. As we forge ahead, the significance of ZKPs will continue to escalate. They hold the promise of ensuring our data's security and privacy in an ever-evolving technological landscape, and their development and application are pivotal for a secure digital future. Read the full article
#blockchain#cryptography#dataprivacy#datasecurity#Fiat-Shamirheuristic#InteractiveProofs#Non-InteractiveProofs#Schnorrprotocol#Zero-KnowledgeProofs#zk-SNARKs#zk-STARKs
0 notes
Text
Fundamentals of Building a Blockchain

The blockchain is a transformative technology that has had a profound impact on various sectors from finance to supply chain management. While the journey to master blockchain development is a complex one, understanding its fundamentals is the first step towards proficiency. This article delves into these essential building blocks of creating a blockchain.
1. Understanding Blockchain Basics
Before you build a blockchain, it's crucial to understand its core elements: - Blockchain Structure: A blockchain is a distributed ledger of transactions, organized into blocks. Each block contains a list of transactions, a reference to the previous block (through its hash), and the block's unique hash. This chain of blocks forms the blockchain. Creating a blockchain structure involves creating a data structure to store blocks, and each block will contain a set of transactions. For simplicity, we'll create a simple blockchain structure where each block stores a string as data. Also, we'll use the SHA-256 cryptographic hash function to create the hash for each block. Here's a simple C++ implementation: #include #include #include #include using namespace std; // Function to calculate SHA256 string calculateSHA256(string data) { unsigned char hash; SHA256_CTX sha256; SHA256_Init(&sha256); SHA256_Update(&sha256, data.c_str(), data.size()); SHA256_Final(hash, &sha256); stringstream ss; for(int i = 0; i < SHA256_DIGEST_LENGTH; i++) { ss - H is the current block's hash - PH is the previous block's hash - D is the current block's data - '+' indicates concatenation of the strings - Hash is the SHA-256 cryptographic hash function - Read the full article
#BlockDesign#blockchain#BlockchainMathematicalPrinciples#C++BlockchainImplementation#ConsensusMechanisms#DecentralizedSystems#NodeCreation#Proof-of-Stake#Proof-of-Work#TransactionDesign
0 notes
Text
Understanding Web 3.0: A Shift Towards Decentralization and User Sovereignty

The digital world is on the brink of a paradigm shift as we transition from Web 2.0 to Web 3.0, also known as Web3. This shift promises a more decentralized, transparent, and user-centric version of the internet, profoundly changing our online interactions.
Decentralization: Power to the People
A pivotal feature of Web3 is decentralization, a direct contrast to the current Web 2.0 landscape dominated by tech behemoths such as Google and Facebook. Web3 envisions an internet where users, rather than centralized entities, have control. Enabled by blockchain technology, this model distributes power among the users, allowing them to own their digital footprints.
Blockchain Technology and Cryptocurrencies: The Backbone of Web3
Web3 fundamentally relies on blockchain technology, a type of distributed ledger that maintains records across multiple systems. With its transparent and immutable nature, blockchain facilitates decentralized applications (dApps), pushing the boundaries of traditional online services. Cryptocurrencies like Bitcoin and Ethereum, built on this technology, play a significant role in transactions within the Web3 ecosystem.
Smart Contracts: Code as Law
Web3 incorporates smart contracts, code-based agreements that autonomously execute transactions when specific conditions are fulfilled. They remove the need for intermediaries, fostering transparency and efficiency. Smart contracts bring a new level of automation and trust to online transactions, from simple transfers to complex contractual agreements.
Interoperability: The Seamless Web
Web3 emphasizes interoperability, fostering a digital environment where data and assets can freely move across platforms, applications, and blockchains. This seamless interaction is expected to promote innovation, user convenience, and an overall improved digital experience.
Privacy and Data Ownership: Taking Back Control
A core proposition of Web3 is to give users control over their data. Unlike Web 2.0, where tech companies own and monetize user data, Web3’s decentralized architecture seeks to return data ownership to the users. This move signifies a monumental shift in privacy and data rights, fostering an online ecosystem that respects user privacy.
Decentralized Finance (DeFi): Revolutionizing Finance
A prominent subsector of Web3, Decentralized Finance (DeFi), aims to recreate and improve traditional financial systems in a decentralized environment. From loans to insurance to trading, DeFi platforms offer financial services on the blockchain, democratizing access to financial systems and services.
Non-Fungible Tokens (NFTs): The Dawn of Digital Ownership
NFTs, or Non-Fungible Tokens, are unique digital assets residing on a blockchain. They have gained significant attention for their role in digitizing arts, music, and other forms of creative work, representing a new way of asserting ownership and provenance in the digital realm.
The Web3 Technology Stack: Building the Future Web
Technologies such as the InterPlanetary File System (IPFS), a peer-to-peer network for storing and sharing data, and the Ethereum blockchain, a platform for creating dApps, are part of the foundational tech stack for Web3. These technologies underpin the new wave of decentralized applications and platforms shaping the Web3 landscape.
DAOs (Decentralized Autonomous Organizations): The Future of Organizations
Decentralized Autonomous Organizations (DAOs) are one of the new entities birthed in the Web3 space. DAOs are fully automated and decentralized, running on smart contracts on a blockchain. The decision-making mechanisms of DAOs are governed by programming, thereby eliminating the need for a central authority. DAOs represent a radical shift in the conception of organizational structures, fostering an era of automation and decentralization.
Identity and Reputation Systems: Trust in a Decentralized World
In the realm of Web3, identity and reputation systems are anticipated to play a crucial role. The notion of self-sovereign identity empowers users with absolute control over their personal data, while decentralized reputation systems help to establish trust within the network. These systems will be vital in securing user trust and fostering cooperative behavior in the network.
User Interface and Experience: Bridging the Complexity Gap
The interface and user experience in Web3 are expected to be fundamentally different from Web2.0 due to the technical complexities of blockchain and cryptocurrencies. The challenge for Web3 developers is designing user-friendly interfaces that effectively veil these complexities, ensuring a seamless user experience.
Token Economy and Incentives: Reciprocity in Web3
Web3 is likely to heavily depend on tokens as a basis for its economy. These digital assets are used to incentivize and reward users for their contributions to the network, fostering a more reciprocal relationship between platforms and their users.
Internet of Things (IoT) and AI Integration: Automation and Intelligence in Web3
The integration of IoT and AI technologies in the Web3 framework unlocks novel possibilities for smart and automated applications. These integrations can revolutionize various sectors, ranging from supply chain management to home automation, driving efficiency and productivity.
Role of ISPs: Redefining Internet Access
In the current internet infrastructure, Internet Service Providers (ISPs) play a pivotal role in managing and controlling access to the web. However, with the advent of Web3's decentralization, the role of ISPs may undergo significant changes, potentially diminishing their importance.
Security: Safeguarding the Decentralized Web
Despite the inherent security of blockchain technology, the applications built on it may have vulnerabilities. For instance, smart contracts can present exploitable weaknesses for hackers. As the Web3 ecosystem expands, the need for robust cybersecurity measures also grows in importance.
Digital Divide: The Inclusivity Challenge
There's concern that the transition to Web3 could worsen the existing digital divide if access to Web3 necessitates certain technical expertise or financial resources that not everyone possesses. Therefore, ensuring that Web3 is inclusive and accessible to all is a pressing challenge that needs concerted efforts to overcome. With these new integrations, Web3 is set to disrupt the digital world in unimaginable ways. It's a complex and exciting new frontier that promises to revolutionize how we interact with the internet and each other. While there are numerous challenges to address, the potential for a more equitable and user-centered internet makes this journey worthwhile.
Challenges Ahead: Scalability, Energy, Regulations, and Adoption
Despite its promise, Web3 faces significant challenges. Scalability issues, energy efficiency concerns, regulatory uncertainties, and user adoption hurdles are considerable roadblocks. As a rapidly evolving field, Web3 requires ongoing development, refinement, and robust dialogue among stakeholders to address these challenges. The transition from Web 2.0 to Web3 signifies an important evolution in the digital world. It embodies a move towards a more user-centric, decentralized, and transparent internet. While the road ahead may be fraught with challenges, the potential rewards of a more equitable, open, and user-controlled web are immense. Read the full article
#blockchaintechnology#Cryptocurrencies#DataOwnership#Decentralization#DecentralizedFinance#interoperability#Non-FungibleTokens#privacy#smartcontracts#Web3.0
0 notes
Text
Web Server Architecture Techniques for High Volume Traffic

Web Server Architecture Techniques for High Volume Traffic A well-architected web server is crucial for managing and effectively distributing high-volume traffic to maintain a responsive and fast website. This article explores various techniques that can be used to balance high volume traffic to a website server, ensuring optimal performance and availability. 1. Load Balancing: Load balancing is an essential technique that evenly distributes network traffic across several servers, thereby preventing any single server from getting overwhelmed. Load balancers, which can be hardware-based or software-based, distribute loads based on predefined policies, ensuring efficient use of resources and improving overall application responsiveness and availability. 2. Auto Scaling: In the realm of cloud computing, auto-scaling is a feature that allows for automatic scaling up or down of server instances based on actual traffic loads. This feature becomes extremely useful during peak traffic times, ensuring that website performance remains stable even during traffic surges. 3. Content Delivery Network (CDN): A CDN is a globally distributed network of proxy servers and data centers designed to provide high availability and performance by spatially distributing services relative to end-users. CDNs serve a large portion of content, including HTML pages, JavaScript files, stylesheets, images, and videos, thereby reducing the load on the origin server and improving website performance. 4. Caching: Caching involves storing copies of files in a cache or temporary storage location so that they can be accessed more quickly. There are browser-side caches, which store files in the user's browser, and server-side caches, like Memcached or Redis, which store data on the server for faster access. 5. Database Optimization: Optimizing your database involves refining database queries and improving indexing so that your server can retrieve and display your website's content more quickly. Techniques like database sharding, which separates large databases into smaller, faster, more easily managed shards, can also contribute to overall server performance. 6. Server Optimization: Server optimization includes various techniques like using HTTP/2, compressing data using algorithms like GZIP, optimizing images and other files, and minifying CSS and JavaScript files. All these techniques aim to reduce data sizes and reduce the load on the server, enhancing overall server performance. 7. Microservices Architecture: In a microservices architecture, an application is built as a collection of small services, each running in its own process and communicating with lightweight mechanisms. This architecture allows for continuous delivery and deployment of large, complex applications and allows an organization to evolve its technology stack. 8. DNS Load Balancing: DNS load balancing works by associating multiple IP addresses with a single domain name. The DNS server can rotate the order of the returned IP addresses or select an IP based on geolocation data, ensuring that traffic is effectively distributed across multiple servers. Beyond these techniques, other strategies can also play a significant role in handling high volume website traffic. 9. Traffic Shaping controls the amount and speed of traffic sent to a server, prioritizing certain types of traffic, or slowing down less critical traffic during peak times. 10. Server Virtualization enables multiple virtual servers to run on a single physical server, with each potentially serving different websites or parts of a website. 11. Edge Computing reduces latency and improves website speed for users by processing data closer to the source or "edge" of the network. 12. Containerization, using technologies like Docker and Kubernetes, allows applications to be bundled with all their dependencies and offers a consistent and reproducible environment across all stages of development and deployment. 13. Failover Systems take over if the primary system fails, helping maintain service availability. They are duplicates of the original site or server and can ensure that the site remains available even in the event of a system failure. 14. Traffic Management Controls include rate limiting, which limits the number of requests that a client can make to a server, or circuit breakers, designed to prevent system failure caused by overloading. 15. Geo-Location Routing reduces latency and increases speed by routing users to the server closest to them, often an in-built feature of CDNs. 16. Web Application Firewalls (WAFs) protect a server from harmful traffic or massive surges that might be malicious, monitoring and filtering traffic between the server and the internet. To conclude, an optimal combination of these techniques allows for real-time load balancing while preparing for future traffic increases, ensuring that your web server architecture is ready to handle high-volume traffic efficiently. By doing so, you guarantee a smooth and positive user experience, critical to the success of any online venture. Read the full article
#AutoScaling#Caching#CDN#DatabaseOptimization#DNSLoadBalancing#LoadBalancing#MicroservicesArchitecture#ServerOptimization#TrafficShaping#WebServerArchitecture
0 notes
Text
Managing Parties and Fetching Off-Chain Data in NFTs using Solidity and Chainlink Oracles

In the burgeoning world of Non-Fungible Tokens (NFTs), many new challenges and use-cases are emerging. One such use-case is managing different contributing parties and their respective shares in a project represented by an NFT. Another is fetching and incorporating off-chain data into the Ethereum smart contract. In this article, we'll explore how to handle both these cases using Solidity and Chainlink oracles.
NFT-Managing-Parties
Imagine a scenario where an NFT represents a collaborative project with various contributors such as data providers, developers, or project managers, each holding a certain percentage of shares. Managing these contributions directly on-chain provides a transparent, immutable, and verifiable record. We can achieve this with the help of Solidity, a contract-oriented programming language used for writing smart contracts on various blockchain platforms, most notably Ethereum. Let's take a look at a simple contract NFT2 where an NFT can be minted and contributions can be added to the NFT. // SPDX-License-Identifier: MIT pragma solidity ^0.8.0; import "@openzeppelin/contracts/token/ERC721/ERC721.sol"; contract NFT2 is ERC721 { struct Contribution { address contributor; uint percentage; } mapping(uint => Contribution) public contributions; constructor() ERC721("NFT2", "NFT") {} function mintNFT(address recipient, uint tokenId) public { _mint(recipient, tokenId); } function addContribution(uint tokenId, address contributor, uint percentage) public { contributions.push(Contribution(contributor, percentage)); } function getContributions(uint tokenId) public view returns (Contribution memory) { return contributions; } } In this contract, mintNFT allows for the creation of a new NFT. addContribution enables the addition of contributors and their respective percentage shares to a specific NFT. The getContributions function retrieves the contributors and their percentages for a given NFT. Each NFT and its contributions are tracked using a mapping that links each token ID to an array of Contribution structs.
Fetching Off-Chain Data Using Chainlink Oracles
While the Ethereum blockchain and smart contracts offer robust and decentralized solutions, they're inherently cut off from the outside world and can't directly access off-chain data. This is where Chainlink comes in. Chainlink is a decentralized oracle network that allows smart contracts to securely interact with real-world data and external APIs. Chainlink oracles can be used to fetch data from an off-chain source and supply it to your on-chain smart contract. For example, we might want to fetch data from a specific URL and store the returned value in our contract. pragma solidity ^0.8.0; import "@chainlink/contracts/src/v0.8/ChainlinkClient.sol"; contract MyContract is ChainlinkClient { using Chainlink for Chainlink.Request; uint256 public volume; address private oracle; bytes32 private jobId; uint256 private fee; constructor() { setPublicChainlinkToken(); oracle = 0x123...; // This should be the address of the oracle jobId = "abc123..."; // This should be the job ID fee = 0.1 * 10 ** 18; // This is the fee (0.1 LINK in this case) } function requestData() public returns (bytes32 requestId) { Chainlink.Request memory request = buildChainlinkRequest(jobId, address(this), this.fulfill.selector); request.add("get", "http://api.example.com/data"); // This should be your off-chain API URL return sendChainlinkRequestTo(oracle, request, fee); } function fulfill(bytes32 _requestId, uint256 _volume) public recordChainlinkFulfillment(_requestId) { volume = _volume; } } In this MyContract, we first initialize a new Chainlink request in the requestData function. This function sends an HTTP GET request to an API at http://api.example.com/data. When the Chainlink oracle gets a response, it calls the fulfill function on the contract, which updates the volume variable with the returned data. It's important to note that you'd need to replace the oracle address and jobId with actual values that you'd get from a Chainlink node. Also, you need to have enough LINK tokens to pay for the oracle service. By combining NFTs, Solidity, and Chainlink oracles, we can create more dynamic, interactive, and useful smart contracts that could potentially revolutionize how we use blockchain technology. Remember that smart contract development and testing should be done very carefully to avoid potential security and functionality issues. Read the full article
#Chainlink#collaboration#Contributions#ERC721#Ethereum#NFTs#Off-ChainData#Oracle#SmartContract#Solidity
0 notes
Text
Demystifying the Technicalities of Rendering Tokenized Generative Art

Art and technology have been gradually intertwining over the years, culminating in the emergence of tokenized generative art. It’s a fascinating convergence of creativity and computer science, involving the use of algorithms for art creation and blockchain technology for tokenization and provenance tracking. This article aims to break down the complex technicalities behind rendering tokenized generative art.
1. An Overview of Tokenized Generative Art
Tokenized generative art involves the creation of unique digital artworks through an algorithm or code, and then representing these pieces as distinct, non-fungible tokens (NFTs) on a blockchain, most commonly Ethereum. This novel approach allows artists to create a multitude of unique pieces, each represented by a distinct token with provable ownership and authenticity.
2. The Art of Generation: Programming and Libraries
Generative art is created through algorithms, essentially pieces of code that generate unique outputs based on certain parameters and randomness. Artists often use programming languages like Python or JavaScript and employ various libraries such as p5.js, Three.js, or TensorFlow.js to create visually diverse and intriguing pieces of artwork. The element of randomness and the use of mathematical constructs often leads to aesthetically pleasing patterns and structures. The algorithm might incorporate randomness in the form of color, shape, positioning, or a host of other parameters, all while keeping within certain aesthetic bounds defined by the artist.
3. Tokenization: Solidity and Smart Contracts
Once the artwork has been generated, each piece is tokenized, typically on the Ethereum blockchain. Tokenization involves creating a unique digital token for each artwork, which is carried out through the deployment of a smart contract. Solidity, Ethereum's programming language, is used to write this smart contract. These contracts usually adhere to the ERC-721 standard for NFTs, which defines a minimal interface allowing for the management, ownership, and transfer of unique tokens. The contract includes functions for minting (creating) new tokens, and each minted token is associated with a specific piece of artwork.
4. IPFS and Metadata
The connection between the token and its corresponding artwork is established through the token's metadata. This metadata typically includes details about the art piece and a URL pointing to the artwork file. To ensure the persistence of the artwork over time, the art files are usually stored on the InterPlanetary File System (IPFS), a decentralized storage system. The IPFS hash of the file is then stored in the token's metadata, creating an immutable link between the token and the artwork.
5. Rendering Tokenized Art: Interacting with the Blockchain
With the tokenization complete, the next step is to render or display the tokenized art. This involves developing a frontend application that can interact with the blockchain, read the metadata associated with each token, and display the artwork. Web3.js or Ethers.js are commonly used libraries to facilitate interaction with the Ethereum blockchain. These allow the application to connect to a user's Ethereum wallet, query the blockchain for the tokens owned by the user, and retrieve the token's metadata. This metadata is then used to fetch and display the actual artwork from its storage location.
6. The Marketplace: Buying, Selling, and Trading
Once the artwork has been tokenized and rendered, it can be bought, sold, or traded on any marketplace that supports the ERC-721 standard, such as OpenSea or Rarible. Each transaction is recorded on the Ethereum blockchain, providing a transparent and immutable history of ownership.
7. Generating New Tokens for Each Art Variant
One of the fascinating aspects of generative art lies in its ability to generate countless unique variants of a base artwork. Each variant is typically defined by certain variables, which might include aspects like color, shape, size, pattern, or any other parameter defined in the generation algorithm. This ability to create multiple unique pieces lends itself naturally to the concept of tokenization, where each distinct piece of artwork can be represented by a unique token. In the context of Ethereum and the ERC-721 standard, each unique piece of generative art (variant) can be associated with a distinct token. This involves extending the minting function within the smart contract. Here's a simple example using Solidity: pragma solidity ^0.5.0; import "@openzeppelin/contracts/token/ERC721/ERC721.sol"; contract MyNFT is ERC721 { uint256 public tokenCounter = 0; constructor() ERC721("MyNFT", "MNFT") public {} function mintArt(address to) public { uint256 newArtTokenId = tokenCounter; _mint(to, newArtTokenId); tokenCounter++; } } In the example above, tokenCounter is used to ensure each new piece of art gets a unique token ID. The mintArt function creates a new token with a unique ID and assigns it to the given address. This function can be called each time a new variant of the artwork is created, thus tokenizing each unique piece of generative art. It's important to note that the metadata for each token would also need to be unique to represent the unique artwork it is associated with. The metadata could include details about the variables that define the variant, along with the URL of the artwork file. Just as with the base artwork, each new variant could be stored on IPFS or another decentralized file storage system, and the URL of this stored file would be included in the metadata of the associated token. This allows each tokenized variant to be rendered individually, showcasing the unique features of each piece. In this way, not only can the original, base artwork be tokenized and rendered, but every single unique variant generated by the algorithm can be given its own representation on the blockchain, complete with its own provenance and ownership record. This significantly extends the potential for interaction, trading, and appreciation of the unique aspects of each variant within the broader generative art piece. In conclusion, while the technicalities of rendering tokenized generative art may initially appear complex, they essentially boil down to three main components: the generation of the art, the tokenization of the art, and the rendering of the tokenized art. By leveraging coding, blockchain, and decentralized storage, artists and developers are able to create, tokenize, and display unique pieces of digital artwork, pushing the boundaries of what's possible at the intersection of art and technology. Read the full article
#blockchain#decentralizedstorage#ERC-721Standard#Ethereum#generativeart#IPFS#Non-FungibleTokens#smartcontracts#Solidity#tokenization
0 notes
Text
Bootstrapping and Equity Management

Navigating Equity Traps and Maximizing Startup Ownership As a startup advisor, I am frequently confronted by entrepreneurs grappling with the challenges of funding their nascent businesses while trying to maintain control over their ventures. The risk of falling into equity traps in the early stages is real and can be detrimental to a startup’s future prospects. In this article, I will share strategies on bootstrapping and equity management to help startups steer clear of premature or excessive equity dilution.
Understanding Equity Traps
At the core, an equity trap ensues when a startup relinquishes too much equity in the early stages of development, resulting in a significant reduction in the founders' control and share of the eventual profits. The allure of external funding might seem appealing, especially when you're facing startup costs, hiring needs, and initial growth strategies. However, giving away too much equity too soon can come back to haunt founders when they need to raise more funds, sell the company, or even make critical strategic decisions.
Bootstrapping: A Pathway to Self-Funding
Bootstrapping is an effective method to circumvent the pitfalls of equity traps. It involves building and growing your startup through personal savings, operational revenues, and minimal external funding. The primary objective is to retain maximum control and ownership by self-funding the startup as long as viable. Bootstrapping doesn't necessarily mean completely avoiding external funding; instead, it encourages a more strategic approach to raising capital. Here are a few ways to bootstrap your startup: - Reinvest Profits: Your startup's initial earnings can be reinvested back into the business to fuel growth. This strategy fosters a strong discipline of fiscal management early on. - Lean Operations: Adopt a lean approach to your business operations. This might involve running a tight ship, cutting unnecessary expenses, or even doing a bit of everything yourself in the initial stages. - Customer Funding: Try to secure early payments, subscriptions, or pre-orders from customers. This strategy not only brings in revenue but also validates your business concept. - Strategic Partnerships: Form strategic partnerships or barter services with other businesses. This could reduce your startup costs and broaden your network.
Equity Management
While bootstrapping can maintain control and ownership, there might come a time when seeking external investment is necessary for growth. When this time comes, you should aim for equity management, ensuring that you avoid giving away more ownership than necessary. Here are some steps to achieve effective equity management: - Valuation: Understand the true value of your startup before pitching to investors. This will help you negotiate the percentage of equity you should give away in exchange for the investment. - Vesting: Implement a vesting schedule for both founders and early employees. This ensures that equity is earned over time, maintaining motivation and commitment. - Cap Table Management: Keep a precise record of your company's equity ownership structure in a capitalization table, or 'cap table'. This transparency can prevent future disputes. - Staged Financing: Instead of raising all the required capital at once, consider staged financing. This method involves reaching certain predetermined milestones before receiving more funding, thereby reducing the risk of excessive equity dilution. - Legal Guidance: Hire a lawyer who specializes in startups and equity financing. Their expertise can help you navigate through complex agreements and ensure your interests are protected. The journey of starting a venture is exhilarating but fraught with challenges. As an entrepreneur, understanding the implications of equity distribution and effectively leveraging bootstrapping can prove vital in ensuring the long-term success of your startup. Striking a balance between securing necessary funding and retaining a substantial stake in your venture's future might be tricky but will lay the foundation for a sustainable and scalable business model.
Bootstrapping and Beyond
Though bootstrapping promotes self-reliance and discipline, it is important to note that this approach may not be suitable for all businesses. Startups in sectors with high upfront costs or those aiming for rapid, aggressive expansion might find it challenging to bootstrap. Nevertheless, the principles of fiscal discipline, lean operations, and customer-driven growth that underpin bootstrapping can benefit all startups, irrespective of their funding strategies. External funding could provide the impetus required for expansion and scaling up, but should not be sought after until necessary. The mantra should be to maintain a judicious mix of bootstrapped operations and external funding to keep the venture agile and driven towards growth.
Avoiding the Equity Trap through Equity Management
While equity dilution is a part of a startup's growth journey, avoiding an equity trap is key to ensuring the founders retain a meaningful stake in the company. The equity management strategies detailed earlier can help ensure that the dilution is proportional to the value generated by the incoming funds and is not premature. In this context, a robust cap table becomes an important tool. It serves as a guide to understanding how future funding rounds might affect the ownership structure of your startup. Keeping a keen eye on your cap table can help you anticipate and navigate potential equity traps. Additionally, opting for convertible notes or SAFEs (Simple Agreements for Future Equity) could also help delay equity dilution until the startup's valuation is more concrete, thereby providing a protective shield against premature dilution.
The Long-term Vision
Maintaining a long-term perspective is crucial while managing your startup's equity. There will be instances where giving away equity may seem like the only option to survive or scale, but taking a myopic view could lead to regrets in the future. It's essential to measure the immediate benefits of external funding against the long-term costs of equity dilution. In conclusion, bootstrapping and equity management are not mutually exclusive concepts but complementary strategies that need to be integrated into a startup's journey right from the inception. With the right balance, startups can avoid equity traps, sustain growth, and ensure the founders retain a substantial stake in the venture they've worked so hard to build. As entrepreneurs, you control your destiny. Adopt a strategic approach to bootstrapping, be discerning about your funding decisions, and treat equity as the valuable asset it truly is. Remember, in the high-stakes game of startups, retaining equity is akin to holding onto your piece of the dream. The dream to build, grow, and steer your venture to unprecedented heights of success. Read the full article
#Bootstrapping#BusinessModel#CapTable#ConvertibleNotes#EquityManagement#EquityTraps#FundingStrategies#SAFEAgreements#Self-funding#StartupGrowth#Startups
0 notes