
Discussing Cloud, Network Automation, DevOps and the occasional GraphDB exploit.
Don't wanna be here? Send us removal request.
Statistics
We looked inside some of the posts by dcolebatch and here's what we found interesting.
Average Info
Notes Per Post
288
Likes Per Post
202
Reblog Per Post
86
Reply Per Post
0
Time Between Posts
3 months ago
Number of Posts By Type
Text
12
Video
2
Link
3
Last Seen Tumblr Blogs





Fun Fact
The Tumblr app for Google Glass was released on May 16, 2013.
Text
Cloud Migration: More expensive and complicated than you thought
This is a response to a recent article on ZDNet by @steveranger, which does a great job at highlighting why early adopters of the cloud are facing some big hurdles when migrating their existing apps. Read original article here.
This summary (and the study it refers to[1]) bring up excellent points about the migration of older systems to the cloud and cloud-based IT in general. My experience with assisting customer migrations to Microsoft Azure and Amazon AWS has shown it is seldom straightforward, never black and white and usually not trivial to fit legacy systems onto new infrastructures or platforms.
But it is also impractical to suddenly re-write fifty years of applications to be cloud native. One must prioritize their applications first, demonstrate progress and realize incremental value throughout a cloud adoption project.
As with almost any other IT project, up-front planning, discovery and goal-setting is critical. It’s not just choosing a cloud provider through a traditional procurement – it’s designing a multi-cloud hybrid architecture that is future-proof as much as it is useful right now - and then having the application assessment data at hand to execute migrations effectively.
This is how you make the most of your (on-average) $1mil+ infrastructure as quickly as possible.
Final Thoughts
A cloud migration is also not an automatic cure for IT immaturity – you still need good governance, leadership and management. As Geoffrey Moore indicates in his new book, Zone to Win, funding for innovation should not depend on operational cost reduction. There are many lessons to be learned from early cloud adopters, but we should also recognize that cloud migration requires specialized experience and a set of well-tested tools and engineering practices
-David Colebatch Chief Migration Hacker, Tidal Migrations
1: Cloud Migration: Critical Drivers for Success
1 note
·
View note
Text
Nail the first step in your cloud migration
All too often we shine a flashlight on just one or two areas of a business's technology footprint when planning a cloud migration. Whether it is just the server inventory, the storage footprint - or sometimes even the network - planning based only on these few signals is not enough to be successful.
A successful cloud readiness assessment involves a multi-faceted approach to discovery, bringing data in from both the ops team's data sources as well as the business.
Turn up the house lights
We see the following steps of data gathering working well to support the assessment:
Solicit business goals and objectives for the cloud migration initiative
Inventory your servers, databases and storage footprint
Inventory your applications, in terms that the business uses*
Create basic dependency maps of your applications to the infrastructure they use
Catalogue the application technologies employed
If the team is really good, collect network traffic to create detailed dependency maps
(*) I want to see more than just the acronyms that Ops use. _You know who you are..._
Let's dig into these a little more:
1. Solicit Business Goals
This is critical for being successful in your project, yet so many teams go into these projects without this clarity.
Word of advice: Have measurable goals before the initiative gets past week 2.
These objectives may be as high level as "Save $1bn in OpEx annually" or as specific as "Reduce time to recovery for application XYZ to 4hrs", but the point is to have them and to know them.
There will be many decision points on your cloud journey that will be solved quickly with these targets in mind. Without them, you're in for countless hours of revolving discussion about which shade of blue is bluer.
2. Create Compute, Data & Storage inventory
You may be surprised to see this so soon, but there's a great reason: start capturing this data early on and you will quickly see usage trends over time before big migration decisions need to be made.
This data includes CPU, Memory, Disk (usage and allocated for all), as well as your database instances - their catalogs, log sizes etc.
While most projects that we see fail either don't have this or rely on Excel extracts from multiple systems, do yourself a favour and create a daily extract into a time-series database call me. This will give you a consolidated view of your entire environment with just enough fidelity for migration planning, but not so much that your ops team will complain about yet-another-monitoring-tool.
3. Application Inventory
If you're one of the few organizations that already practices Application Portfolio Management, this should be a simple extract. :)
For most teams, this requires consolidating data from various billing, CRM, and even Ops systems to create a list of applications that we think we're about to disrupt.
With this new found list of applications, fill in some details that are pertinent to your business goals we identified in step 1. For example, if your objectives include cost savings, solicit numbers on TCO and value to the business for each application.
Don't do this in excel. You need to divide and conquer and capture this data over time. If you aren't already using Tidal Migrations to do this assessment, consider using Google Docs or Sharepoint to collaborate more effectively.
4. Create basic dependency maps
A basic dependency map is one that shows, at a high-level, which applications are running on what servers in your enterprise. We tend to stick to three levels of depth here: Applications, Database instances, and Servers.
The goal of this step is to highlight the level of complexity that each application has, and start to gain an understanding of the underlying infrastructure. We'll get to mapping network flows to applications later on.
5. Catalogue the application technologies
The goal here is to have the technology dependencies captured so that we can map which apps would be suitable for which services later on in the cloud readiness assessment. Data gathering techniques include deploying agents to servers, scanning source code ... the list is long.
If you're using Tidal Migrations, use the application Analyze feature to easily scan your application stacks.
6. Network dependency maps
Where the rubber meets the road.
This step augments all of the above with detailed network assessment data, derived from either sFlow/NetFlow, or raw packet captures for analysis. Some tools advocate the use of polling server's netstat command and parsing the output, but from experience, this will only yield partial results.
There are some open source tools to help capture and analyze network traffic, such as nprobe/ntopng and fprobe as well as many commercial products. The trick here is mapping the traffic you discover back to the servers and applications that you inventoried earlier.
Capturing network traffic for one to three months before a migration is recommended, in order to detect those critical but once-in-a-while dependencies that inevitably exist.
No Silver Bullet?
Both network discovery techniques PLUS a consultative approach are required to ensure a successful data gathering exercise. The more _data_ you capture, the more _information_ you can leverage to the cloud readiness assessment phase which will shorten the time needed in both migration planning and execution phases.
-David Chief Migration Hacker Tidal Migrations
0 notes
Text
Transitioning Legacy Apps to Hybrid Cloud
In 2004, while rolling my eyes and making jokes about EBCDIC and mainframe, a wise Enterprise Architect and mentor said something that really stuck: > "David, the important thing about Legacy applications is that they are the apps that make the money".
He was right.
Hammer Time
Every client I have worked with since has used the term Legacy to describe an enterprise application that is so important that we can't touch it. Consider this: your bank's legacy transaction processing system is "so important" that the bank won't constantly invest in modernizing it, leaving transactions to only be captured in monthly dumps to PDF. While this aligns to the all important statement-cycle of yesteryear, does that make sense anymore?
No, it doesn’t, and people are now taking action. Due to a confluence of events, from retirements to increasing competitive pressure, from FinTech startups to digital transformation projects that are moving everything else to the cloud; Legacy applications must go.
Refactor All The Things
Still, it is these legacy applications that pose the toughest challenge to migrate to any cloud environment. When these application migrations are handled by traditional IT team resources without programmers in the mix, it can lead to the group thinking only of lift-and-shift types of approaches. These often fall short of realizing any real cloud benefits.
However, with a DevOps mindset and leveraging tools such as Docker containers, serverless architecture and continuous integration, a migration team with programmers onboard can refactor even legacy applications to be portable to any cloud platform. In the example of a banking transaction application, containers and overlay networking facilitates the holy grail of cloud projects today: Hybrid Cloud. It allows the sensitive portions of your application to remain on-premise, while public aspects run as cohesive — but linked containers executing on a more scalable cloud platform.
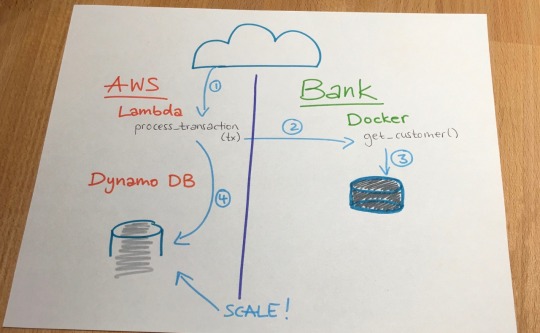
More or Serverless
In the world of scalable transaction processing that must retain an on-premise mainframe database, the hybrid cloud model makes a lot of sense and still allows you to leverage powerful cloud-native services like AWS Lambda for true pay-for-use computing needs.
At Tidal Migrations, we call this type of migration a refactor, and while not necessary for all applications in your brood, it is the most valuable methodology in the Cloud transformation toolkit. So while you can't rewrite history, you can refactor your legacy (apps).
-David Chief Migration Hacker Tidal Migrations
0 notes
Text
IT Configuration Management – an introduction
There are lots of confusing terms and acronyms in the IT industry. Many are context-dependent (such as the ITIL-based CMDB) or have been re-used for a supplier’s marketing advantage and thus diluted the original meaning. In this blog, the first in a series on IT configuration management, we will try to nail down a few of the basic terms.
What is IT configuration management?
Wikipedia defines configuration management as:
“an Information Technology Infrastructure Library (ITIL) version 2 and an IT Service Management (ITSM) process that tracks all of the individual Configuration Items (CI) in an IT system which may be as simple as a single server, or as complex as the entire IT department. In large organizations a configuration manager may be appointed to oversee and manage the CM process. In ITIL version 3, this process has been renamed as Service Asset and Configuration Management.”
Yikes – you need to already know the space deeply to grok that!
Let’s take a step back for a moment and start with some basics:
An IT solution is a set of interconnected systems and communications components that deliver the IT services that are required by the business and its stakeholders in order to solve business problems. At a high-level, an example of these IT services include: customer transactions, business process automation, data management.
The diagram below illustrates the major categories of IT component.
Components may be dedicated to a single solution or be shared by multiple solutions in the same or different organizations. They may be owned by the customer or by the service provider, and they can be supplied either individually or as part of a solution. There may also be complex and changing relationships and connections among the various types of components.
The selection and arrangement of components is a major part of the configuration design and overall management process.
Components can be more than just hardware or software though and the three major component categories are:
Active – network physical media (wireless links, copper and fibre optics), processing and storage infrastructure, operating platforms, execution environments, applications, and orchestrators that implement the service;
Support (indirect) - development and testing services, reliability and availability services, automated business and IT processes, and management services that support the provision of the services; and
Informational - documentation, names, addresses, security certificates, logs files, identify and access credentials, etc. – literally everything that goes into realizing and useable system.
Note: components are also called elements, resources, or configuration items.
A configuration is the specific selection and arrangement of components for a solution at a given point in time. A configuration may be static (unchanging), manually configurable or, increasingly, dynamic (i.e., varying relatively rapidly).
Component configurations (and the associated solutions) have a lifecycle – they are designed, deployed to production, modified, sustained and retired. Components may also need to be replaced due to breakage or obsolescence. Every IT solution must, by definition, have a well-defined configuration.
We can therefore define Configuration Management as the processes and knowledge associated with each stage of the lifecycle - planning, designing, organizing, controlling, maintaining, tracking and changing the components.
What makes the configuration management process important?
If an IT solution is important to the business, then managing its configuration effectively and accurately is just as important to the business.
Note: How often have you heard/said “Don’t touch that solution, it’s too important and we haven’t upgraded it in ten years!”? I shudder to think if anyone truly knows its configuration enough to restore service in an outage. Who will step in when it breaks? How?
A robust Configuration Management process offers a number of benefits, including:
Since components are corporate assets and intellectual property, maintaining an up-to-date, accurate component/solution inventory is vital for efficient systems operations;
Managing performance is much easier when you know which components are involved in a solution;
Troubleshooting incidents is more efficient when you know how the components interact;
Automated provisioning and scaling is only feasible when design, configuration and deployment is also automated, especially in a cloud environment;
If you do not know what resources you have, what their purpose is, their relationships, usage patterns, and what performance to expect, then it will be very difficult to manage change and ensure accurate billing.
When enterprise networks, datacentres, and cloud environments are all mapped out in LightMesh NCM, solution designers can automate the provisioning of services through automating switch configuration, server deployments and even cloud orchestration.
As an analogy, no railroad company could operate successfully without tools to record what tracks it has, what cars are on the tracks, what they can transport, and where they are located. Similarly, easy access to knowledge about the IT solution’s “cars and tracks” is equally important to systems administrators.
This is just the tip of the iceberg….we’ll be exploring more configuration management concepts and practices in future blogs.
0 notes
Text
The Mysteries of IP Addressing
Can you imagine a telephone without a phone number, or an email without an email address? Networks also need addresses to know who (or what) is on the network and where to find them. You won’t be able to connect to 50 billion IoT devices without good addressing plans!
Address management on an industry level is a necessary evil in the world of network engineering. Every device connected to the Internet or to a private TCP/IP network MUST be assigned an Internet Protocol (IP) address. IP addressing can, however, be a bit of a mystery and is usually an after-thought.
The first step is to understand what addresses are for, what they look like, how they are assigned, and why the support tools from LightMesh can be important.
First, what is an IP address?
The Internet Protocol is a fundamental and definitional building block of the Internet – the Internet as we know it would simply not exist without the innovation of IP as previous protocols like IPX/SPX (Remember Novell?) could never scale to what the internet has become today. IP addresses are the pointers to network-connected devices that implement the Internet Protocol – this is everything from your smart phone to the servers inside web-scale datacenters.
One fundamental aspect of an IP packet is the header, where both the source and destination addresses are key fields. This header lets intermediary routers know where the packet is going, and where it has come from. The router will then choose the best “next hop” based on the other routers it is connected to, known as it’s “peers”.
The two versions of IP currently in use are IPv4 (which has 32 bit addresses) and IPv6 (which has 128 bit addresses).
Although the 32 bits of the IPv4 addresses theoretically allows up to 4,294,967,296 (232) addresses, this is not enough when technologies such as the Internet of Things (IoT) are taken into account. IPv6 has been designed to remove address space limitations.
Within the IP address space, we have two primary classes of IP addresses:
Public – each address is unique within the Internet (default); or
Private – where each address is unique within a routable network zone, usually behind a firewall/router or other NAT device; these are defined in RFC1918 (e.g. 192.168.0.0–192.168.255.255).
Some IP address ranges are also reserved for special purposes including broadcast, loopbacks, multicast, and others.
IPv4 was specified by the IETF in RFC791 (and dates back to the early 1980s). Although it will eventually be replaced by IPv6 (see Wikipedia entry for an overview and RFC2460 for the details), IPv4 today defines the predominant format for addresses.
What does an IPv4 address look like?
The IPv4 header includes both a source 32-bit address and a destination 32-bit address.
For easy reading by humans, IP addresses are usually written in dotted-decimal notation: 4 numbers separated by dots (for example 192.168.255.255). Since each of these numbers represents 8 bits in the IP header, the maximum value of each number is 255 (which equals 8 “1”s).
Several standardized interpretations for an IP address have been used over the years. The most recent, described in RFC 4632, is called Classless Inter-Domain Routing (CIDR). CIDR provides a method for partitioning the addresses to allow smaller or larger blocks of addresses to be allocated to users.
The hierarchical structure created by CIDR is managed by the Internet Assigned Numbers Authority (IANA) and the regional Internet registries (RIRs).
The CIDR notation counts the number of bits in the network prefix and appends that number to the address after a slash (/) character separator. For example, 192.168.0.0 with a netmask 255.255.255.0 is written as 192.168.0.0/24.
IP addresses convey two types of information:
The network/subnetwork identifier, taken from the most significant bits, with the number of allocated bits being specified by the netmask (e.g., 192.168.0.0/24); and
The host/device identifiers that are associated with the subnet.
For example, we can have:
192.168.0.0/24 as the CIDR notation for a leading network address of 192.168.0.0 with a 255.255.255.0 netmask, which leaves 8 bits to be used for host identifiers. The routing prefixes for subnets of this size would range from 192.168.0.0 to 192.168.255.0 (a total of 256 networks, each with up to 256 IPs, or 254 hosts);
10.0.0.0/16 is the CIDR notation for a leading address of 10.0.0.0 with a 255.255.0.0 netmask, which leaves 16 bits to be used for host identifiers, which translates into 65,536 IPs.
NB: See http://lightmesh.com/subnet-builder/ for a free subnet calculator to visualize your address space.
Working with IP addresses
There are a number of steps needed to get started with IP addressing. Here’s a few of the tasks you will need to complete:
The first task is to get a block of addresses that fits your business requirements, i.e. the number of hosts that are to be attached to your network. You may have applied for a block of addresses many years ago (in which case you may have plenty to spare!) or you may have been given addresses by your Internet Service Provider’s (ISP).
The next decision is whether to use private addressing (Do all your hosts need to be directly connected to the internet? Is this desirable?)
One of the important tasks in any IP address design process is the assignment of addresses to hosts. There are basically two ways to do this:
Static allocation – an address is permanently associated with a device’s interface; or
Dynamic – the address is assigned on a temporary basis by a DHCP server.
Develop a tracking system that will allow you to keep track of all your IP addresses, preferably with as many automatic interfaces as possible.
Define your IP Plan. This is an important step if you want to ensure your network is maintainable for many years to come.
Hopefully this has gone some way to demystifying Internet addresses for you!
-David
The best way to formalize the processes for IP address management is to use a tool designed for the purpose. You can get a taste of what’s possible by trying out LightMesh IPAM, free for 30 days.
0 notes
Text
The Five “Laws” of IP Planning
The Internet Protocol (specifically IPv4) is now being used for virtually all business and personal digital communications, from data centres to telephones to industrial control systems. More recently, the Internet protocols have been adopted for 4G/LTE mobile systems and are a critical enabler for the Internet of Things. By the end of the decade, IP addresses will be embedded in many billions of devices (some say 50 Billion!).
Planning and managing the deployment and evolution of IP networks, and IP network addressing in particular, has never been more challenging and can even be business critical. Multiple levels of planning are required - everything from the address structure in the protocol itself to the use of DHCP for assigning addresses to specific devices, virtual machines, containers and even the different applications in a company.
Overall network plans should cover a variety of topics, including:
Services to be provided – identification of the types of traffic that will be carried over the network (this is called the “network direction”);
Virtualization – division of network resources into subnets and logical networks that match the business and its traffic requirements (i.e., a software-based divide and conquer approach);
IP Address Management (IPAM) – logical allocation of addresses in an efficient manner, including combined use of IPv4, IPv6 and private addresses;
Access, resource and traffic security – protection of the physical and logical networks from external threats, unintended access, policy violations, and other attacks;
Quality of service and performance settings - optimization of performance and explicitly managed QoS for sensitive applications and for “pay as you go” environments; and
Management, disaster recovery and monitoring – designing for continuous service and operations management, especially for networks with self-service provisioning and external compliance controls.
Let’s take a closer look at the third item – IP Address Management. As a starting point, we suggest the following five “laws” for IP address planning:
First, commit to creating a plan and get it done
Growth and change in IP networks often happens on an ad hoc basis, with new subnets assigned as use outgrows capacity or when new services (such as an on-site private cloud) require entirely new subnets. Many organizations do not have an explicit addressing plan and do not seek to use best practices, which results in a less than meaningful addressing scheme. This leads to:
An inability to easily differentiate security policies and quality of service on a per application basis;
Applications that span multiple subnets, creating additional processing overhead from network ‘tromboning’; and
Unnecessary overhead for managing the network and the services it delivers.
Any major project, such as a data centre migration or adoption of a cloud service, can be an opportunity to re-visit the planning assumptions and identify any new traffic types and patterns.
Next, establish addressing strategies
An initial step in IP address planning is to establish the overall structure and assignment approach.
For example, a “divide and conquer” strategy is one of the simplest approaches - take whatever address range you are working with and divide it in two (e.g., user-facing and network management), then further divide these into organization-appropriate sections (e.g., services, sites, monitoring, backup, etc.). This could form a multi-level hierarchy if it makes sense for the organization.
It is important to build in sufficient flexibility to allow for business growth and to accommodate changes in the network nodes and links (i.e., the overall topology). The eventual migration to IPv6 should also be factored into the plan and roadmap.
Contact LightMesh if you need help getting started with a practical approach to IP address planning.
Third, document your network directions
Each subnet of your network should have a defined “network direction” which specifies its intended use. Network directions would include User-Facing (a.k.a. Front-end, or Services), Management, Backup, KVM/iLO/Remote control, vMotion, and others. These should be closely aligned with the address division process described above.
Each network direction may have differing quality and performance requirements but mostly it’s important to identify them for implementing programmatic access to the network design and topology. You will help with network automation and orchestration by including the network directions in your plan!
Fourth, share your plan
Once you have a plan in place, don’t hide it away or ignore it. Get feedback from everyone.
Network plans should be available to anyone with a need to know, especially network engineers, solution designers, network support personnel and, when appropriate, external partners.
The latest updates to the IP plan should be readily accessible and easily understood by those involved in any aspect of network operation and maintenance.
A network architecture that includes a IP address plan will yield greater development and operational efficiency, but only if done in a logical and expandable way.
Finally, keep track of all changes
It almost goes without saying that changes to the plan will occur, probably faster than you would like, and that not tracking these changes will eventually make your plan worthless. Changes in technology, upgrades to equipment, datacenter migrations and consolidations, server virtualization, even mergers and acquisitions will all affect your plan.
A good change management process, rigorously applied, should definitely be treated as mandatory.
It is important to note that keeping track of addresses can be a major challenge by itself. Support tools, such as the LightMesh CMDB and the LightMesh IPAM application, would be essential for tracking any diverse and rapidly changing network configuration.
An IP planning maturity model
Despite the importance of network operations and maintenance, many organizations do not have well-defined network planning or design processes. Explicit network plans may either be non-existent or, at best, be reactively developed and poorly documented.
A simple maturity model for network planning could be used as a baseline. For example:
Non-existent – no formal planning is being done;
Reactive on demand – network plans are documented only when needed for new projects or for troubleshooting, but very little proactive planning is performed;
Repeatable procedures – specific planning tasks, including IP address allocation, are somewhat formalized and generally repeatable, but they may not be automated or managed;
Life cycle IP planning process – a complete address planning, monitoring and documentation process is available, is being used consistently, and is producing measureable results; and
Continuous improvement – tools and systems are in place to support and automate the planning process; IP address management is integrated into an overall IT Service Management process. For an example of how an IP address planning tool could help your organization become more mature, give the LightMesh Subnet Builder a test run.
0 notes
Text
Architecture for Fraud Detection with GraphDB
The Business Problem
Graph databases provide new and exciting opportunities for advanced fraud detection and prevention systems. By design, graph databases uniquely give you a data store which both allows you to build transactional and analytical systems capable of uncovering fraud rings and preventing fraud in real-time.
Sophisticated fraud perpetrated using synthetic identities is near impossible to detect with linear based pattern matching on individual data points. It is the relationships between these data points that offer the opportunity to squash fraud before a transaction takes place, rather than detecting and contesting it after the fact. Unlike other solutions, graph databases provide this capability.
Getting Technical
On every engagement, our customers first question to us is: "How can I tie this into my existing application infrastructure?". Here I will present two popular production architectures for graph powered Anti-Fraud that we have deployed at XN Logic.
Data Loading
Before we can make use of the graph, we must load some data. To support real-time fraud prevention, we need to load data continuously either by having it pushed into a graph API, or by reaching out and pulling it in from some other system.
Agents of change
One of the simplest forms of data loading is writing agents that listen to events from a existing applications and push new data into the graph.
e.g. PUT http://server.com/model/customer {"name": "Joe Bloggs", "SSN": "050-12-3456"}
In this scenario, you need to be able to not just push individual nodes and relationships one-by-one, but have the ability to load entire trees of information in one request, such that you can ingest both large and small amounts of data as quickly as possible.
Pull Request
This second form of data import requires you to define an action in your data model which goes about opening a file and performing an ETL operation to bring data into your graph.
Large files on a SAN is one tactic we have seen, but others include direct database access (via JDBC in our stack) where tables are queried directly with SQL; proprietary APIs - most have JVM drivers; and, thankfully, web services.
Once defined, these import actions can be triggered as needed via an API call or scheduled to run periodically.
e.g. POST /model/customer_data_source/id/1/action/import_data
System Architectures
With your data loaded, we can now reap oodles of value from your anti-fraud graph - be it programatically, visually, or my favourite: both!
1) RESTful decisions
The most popular architecture is to treat the graph as another decision point in your existing application. To support this, we define the graph traversals required to detect fraud and expose these via one or more RESTful actions.
e.g. GET /is/loan_application/id/123/report/fraud_score
2) Decisions and Visualization, together.
While detecting and preventing fraud in the backend is powerful, some like to take that fraud flag and present the current transaction to a fraud analyst for review. JavaScript graph visualization libraries like KeyLines allows us to rapidly provide a valuable view to the analyst for them to make the final call.
To enable this view to be embedded in their application, we provide an overview of the transaction and all pertinent relationships via a JSON document that can be immediately consumed by KeyLines.
e.g. GET /is/loan_application/id/123/report/network_view
The key point here is that it is possible to build and deploy real-time network analytics into your anti-fraud arsenal. To learn more about developing and deploying applications on the graph, drop me an email: [email protected].
-David Colebatch
0 notes
Text
Absolutely brilliant!
When your boss tries to code

by uaiHebert
284 notes
·
View notes
Text
Upgrading Neo4J graphs with Pacer
I'm firing up a lot of old Neo4i graph databases today to do some historic analysis, and given the major Neo4j releases of 2013 I'm hitting this almost every time:
jruby-1.7.12 :001> require 'rubygems' jruby-1.7.12 :002> require 'pacer-neo4j' jruby-1.7.12 :003> g = Pacer.neo4j '/path/to/graph.db/' ArgumentError: Constructor invocation failed: Failed to start Neo4j with an older data store version. To enable automatic upgrade, please set configuration parameter "allow_store_upgrade=true"
Yeah, I get that too. What's the solution?
Incase you're wondering, upgrading a Neo4j store inline when using pacer (and pacer-neo4j) is as simple as passing "allow_store_upgrade" => "true" to the constructor:
g = Pacer.neo4j '/path/to/graph.db/', 'allow_store_upgrade' => 'true' Starting upgrade of database store files ...................................................................................... Finished upgrade of database store files => #<PacerGraph neo4j2graph$proxy0[EmbeddedGraphDatabase [/path/to/graph.db]]
Now you're ready to rock pacer-foo all over that PacerGraph. :-)
Be sure to read Neo's FAQ on upgrading from 1.9x releases to 2 for details on what's happening under the hood.
0 notes
Video
vimeo
Haven't grok'd the details of the #heartbleed vulnerability? Checkout Zulfikar Ramzan's great overview here. Very well done sir.
1 note
·
View note
Link
The #heartbleed story has guaranteed that we have all had a very busy start to the week! However bad it was, our customers at lightmesh.com were among the quickest to identify affected systems and websites as they all ran a quick query for SSL certificates, associated IPs, servers, sites and even customers!
The benefit of a holistic approach to CMDB has shown it's true value here in the short amount of time that our clients were able to respond to this vulnerability. Hats off to our customers for being so proactive!
Checkout the LightMesh blog post here.
1 note
·
View note
Video
youtube
Cisco's ACI explained
Way to dumb it down TechWise. If you were looking for an overview of Cisco’s ACI (Application Centric Infrastructure) strategy, look no further than this 5min YouTube video.
One of the simplest concepts that engineers and management both need reminding of is "What is an application" (at 3:12) and this definition scales up from single page web-apps to enterprise software that's delivered via a web browser.
Enjoy.
0 notes
Link
Cross post, from xnlogic blog: http://xnlogic.com/blog/2013/10/7/another-successful-graphconnect
0 notes
Text
Graph Events - Get Connected!
I attended two outstanding GraphDB events in the last week that I have to share. Firstly, there was GraphConnect Boston last week, followed by GraphTO Wednesday night.
Both were great for the same reason: the people. The graph database community is full of smart and humorous people who grok a large array of topics and business problems.
If you're new to graph databases I encourage you to get out to one of your local GraphDB meetups and create some relationships of your own. If you have a travel budget, GraphConnect San Francisco won't disappoint and I'd love to meet you there.
Have a good weekend!
0 notes
Text
Data Center Consolidation and Moving Targets
My career in IT has frequently consisted of projects with various flavours of Transition, Consolidation and Migrations, and each one of these projects has had their fair share of unknowns. Typically the risks in these types of projects all stem from a lack of documentation, these risks lead to questions such as: "Which applications are running on what servers?", "What type of workloads do we have in our east cost data center?" and as more is known, the much anticipated: "What are the dependencies of application XYZ within (and beyond) our infrastructure?". ...sound familiar?
We tend to solve these by means of network based discovery, reverse-engineering applications and finally by asking pointed questions to their administrators/users (once they are identified). In organizations where documentation has been lax, for whatever reason, the first step in any of these Transition/Consolidation/Migration/Rationalization projects is to assess the environment(s) and build that understanding of your infrastructure and the applications supported by it - ultimately creating Configuration Items (CIs) in a modern CMDB.
When done properly with a splash of business process reengineering, we leave the IT organization with the capability of "Living Documentation", and they never get into this mess again.
Today while reading this article: "How do you overlook 3,000 datacenters", I realized that we have a ways to go with our promotion of the Living Documentation solution!

Now, I have yet to experience as great a challenge as the US federal government is undertaking, granted, but I would love to help them from having to produce quotes like this:
"...after three years there were still no good, hard numbers on the total number of datacenters in use."
So if David Powner is listening, please email [email protected].
0 notes
Link
The ONF is running a US$50k competition for a new OpenFlow driver. Submission deadline is Aug 15th, 2013 and I personally can't wait to see the submissions that come out of this.
The cross-platform language bindings will be important for us.
0 notes
Text
So much cooler than just Ctrl+a x'ing your screen session... dhotson's screensaver for you terminal will definitely entertain :)
Screensaver hack
For a laugh, I made a “screensaver” in the Julia programming language that runs in your terminal.
It’s using xterm 256 color mode—as well as some unicode halftone characters to extend the color “depth” just a fraction.
code
1 note
·
View note