
Hi, there. Welcome to my page. I am IT architect, fan of Big Data, use Java a lot. So, you can find a little programming, a little diving, may be some photos here.
Don't wanna be here? Send us removal request.
Statistics
We looked inside some of the posts by tivv and here's what we found interesting.
Average Info
Notes Per Post
7
Likes Per Post
6
Reblog Per Post
1
Reply Per Post
0
Time Between Posts
6 months
Number of Posts By Type
Text
17
Last Seen Tumblr Blogs





Fun Fact
Tumblr.com rank in the US is 25.
Text
The war with Russia: what’s next?
Over the last few days I chatted to a few people on my vision of possible future events. It looks like it makes sense to share it to a wider audience.TLDR: Putin has missed and the world sees it. He has nothing to negotiate with. Soon Russian “elites” would see it. Primary danger is that he can start a nuclear war.Now to the details:Current state:
The whole dictatorship works while the dictator is strong. In war with Ukraine he put all in and does not have anything for backup. There is no even slightly fair reasoning for the world. There is no proper PR in Russia. “We are protecting Donbas” is not believable. PR campaign is lost.
No war victories. All regional centers are under Ukrainian control. Assault on Kyiv is literally dying. There is nothing to show at home, there is nothing to use during negotiations.
World sees it. Sanctions are fully cutting economic connections. All pro-Putin western politicians are publicly against the war. The only ally is Belarus dictator Lukashenko and even Lukashenko is already negotiating with France.
What are possible next options?
Almost impossible, but I still list it here for completeness. Russia's assault on Kyiv succeeds. I’d say even in this case Ukraine army & people will continue to resist.
Negotiations. Well, that’s they only option for Putin to hold onto power a bit more. But he has nothing to bring home, nothing to propose for negotiations. The only option I see is “I give you occupied eastern Ukraine, but I keep Crimea”, but I doubt Ukraine would take it. Also it’s almost impossible to put war on pause for negotiations. There is no front line, everything’s mixed.
Everything goes as now. Sanctions are being deployed. Ukraine continues to fight back. Protests everywhere including Russia. And Russian SWAP is lying dead in Ukrainian plains and can’t stop the protests. After some time Georgia / Moldova / Belarus begin to solve old issues. Then goes Japan, maybe China.
And actually everyone is already thinking about this third option. Including the Russian “elite”. And they start to understand that giving up or removing Putin and few other people is the simplest way to solve the problem. Then you can negotiate, anathematize evil and so on. That’s why communist deputies started to say that they did not vote for the war. That’s where “no war” posts by Russian golden kids come from.And it is vital for Putin not to get it first. Because he has a nuclear briefcase and he can actually order to use strategic or tactical nuclear weapons.
6 notes
·
View notes
Text
Stokke Xplory stroller hack
Hi, there! I will be doing much less software today but much more of hardware hacking, but not in the usual way 🧐.
The topic would be: traveling with a toddler. It turns out to be quite challenging to do in a safe way. Your stroller with a nice baby car seat is too small already and toddler car seat is too big and can't fit onto a stroller base. So if you fly you either rent a car, look for a rare taxi with car seats or walk around with a huge toddler car seat on you back.
Neither option seemed good for me, so I googled and found various stroller hacks. Stroller hack is when you take your stroller base and attach a lightweight toddler car seat on top of it. Most often car seat used is Cosco Scenera as it's lightweight, safe and easy to use.
The problem with those hacks is that they often look ugly. But bear with me. As soon as you've got Stokke Xplory as your stroller, you can make a pretty nice stroller hack as I did.
First, take you Stokker Xplory base:

Then, get Stokker Xplory Graco car seat adapter. It says Graco, but it creates a very nice basket that can be used for a stroller hack:

And now you can install your Scenera car seat pretty nicely and even fixate it nicely with it's own belts

You can even set it up in a laying position where your kid can sleep safely 👌
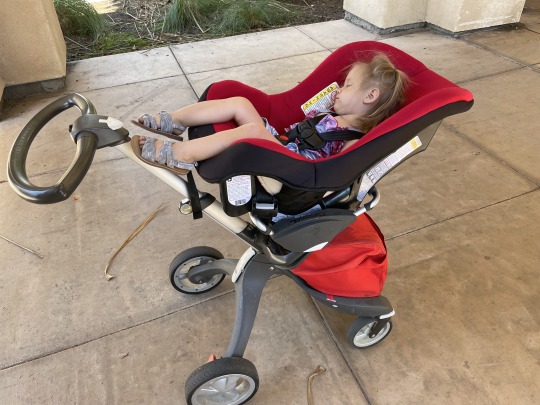
You are ready to travel! It's very easy to switch from a plane to a taxi or an adventure park with no extra burden on your back but with proper safety for your loved one!
0 notes
Text
Creating Pull Request checks with Github Actions
Hi, everyone. It's been a while, but I am back to OSS actively working on CDAP.
One of the challenges our team faced recently is shutdown of travis-ci.org where we were hosting our builds to test PRs before merging.
As CDAP is hosted on GitHub a natural choice was to try GitHub Actions that can actually run various things on GitHub-provided or your own runners and add those as PR checks.
Sounds perfect, but it turns out it's not so easy. Looks pretty simple to begin with - you create a file in .github/workflows folder of your branch and here you go. It was just 56 lines for us to start with.
What it should do, is to run a build whenever there is a code change in a PR marked with a build label.
A side note about the label: it runs the code from PR using workflow file from the PR, so you probably want to review it before allowing it to run the build otherwise you may end up mining crypto for somebody. It also creates security complications, see more details below.
I faced two problems with this approach:
SureFire report did not work for PRs from forks
A new build was triggered for each label change, not only when I add a build label.
The first problem is actually related to security. Report plugin uses GitHub Token provided to the build to publish it's results. And for PRs from forks it's a readonly token to prevents malicious users from writing to your repo. Remember, they can provide any workflow file, so they can even dump the token or send it over network.
For the second problem I could have ignored the build when unrelated label was changed, but it would invalidate any successful check. E.g. you have a green build and want to add a label. Boom, your check is "skipped" and your build is not green anymore ☹.
Fortunately I found a solution that solves both problems. Instead of having a single file, you have two:
A trigger workflow that simply decides when to run the build. If you check the link, condition looks scary, but it simply says to run the build if build label is added or if build label is present and code is changed. It's fine that this check is often ignored as it's not required for PR to merge
A build workflow that actually does the build. The trick here is that this workflow is always taken from your primary branch and not from the PR. It means that it's safe and it gets a read-write token. Also instead of automatically updating check for any run, a special action-workflow_run-status action does it that simply do not run whenever build is skipped, so green build stays green.
There are few inconveniences though.
First, since the build workflow is always taken from the primary branch, it's hard to test it before merging to the branch. I actually use a fork to test it.
Second, the build workflow always runs "in scope" of the primary branch, so you should explicitly refer the PR branch to check code out or add any reports. Your reference is available as github.event.workflow_run.head_sha and it's easy to use. A lot of people suggest using head_branch and not head_sha, but head_branch again do not work with PR from forks, so use head_sha and everything would work for you.
Let your build be green!
0 notes
Text
Reactive Camel - some quirks
Recently I’ve started using reactive programming in Java wilth all the goodness of functional stuff. What I’ve found is that Apache Camel is quite good in the area providing a lo of great non-blocking endpoints. I even started making a set of utilities to connect it to Java 8 CompletableFuture (you can find a very early version here: https://github.com/tivv/camel-j8-async).
But Camel is a quite old project and async capabilities vere added at some point. Thus some endpoints are still blocking. E.g. there are some caveats with bean binding.
First of all, @Handler interface does not provide an asynchronous version to be implemented. You need to make an AsyncProcessor to make a really non-blocking endpoint.
Still, bean binding with @RoutingSlip annotation can be used to route your messages to different endpoints, including asynchronous ones. What I found out is that you must use bean language and not bean URIs in this case, e.g. in code:
from("direct:start").bean("myRouter"); // Good, will do async routing //from("direct:start").to("bean:myRouter"); // Don't do this, will be blocking
Filled https://issues.apache.org/jira/browse/CAMEL-10172 and submitted a pull request to fix.
0 notes
Text
Stable means perfect :)
Hibernate guys are so funny.
I’ve filled HHH-3464 in 2008 for hibernate 3. They had 2 major releases since then and each time they ask me to check if the issue is still here. I suppose they hope for it to magicaly disappear (it’s Halloween after all).
Nothing is done after that.
But my issue is kind of a fresh one. Earliest open bug is HHH-12 dated 2004.
0 notes
Text
Understanding CAP theorem and Eventual Consistency.
Most of the people working in the Big Data world have at least heard about the CAP theorem. But many of them don't fully understand C A and P meaning and what complexity skipping each of this would bring (and theorem says that you can't have all 3 together). To make things worse, Eventual Consistency came into picture along with the CAP theorem. And the problem is that Eventual Consistency is NOT the C from the CAP. Let me try to explain all of this.
Before starting, I must say that I am mathematician. And one of the problems I see with the CAP theorem is that I never saw it properly defined. CAP itself is very simple – you can only have two of three: CA, CP or AP. But I never saw a clear definition of the C, A and P. There are different examples, words like “its clearly seen”. And from my university times I know that when someone use this words, it means that nothing is clear. So, let's try to define the terms and define them correctly. By correctly I mean that I will try to provide clear criterias that would tell if given system has C, A or P.
Let's start with the Partition Tolerance. This is the most clear and easy one. System is Partition Tolerant if it can resolve Partitioning situation automatically one way of another. CA systems are rare and require application or operator help resolving data conflicts after partitions merge.
Next term is Availability. Can any system be universally available 100% of time. No, it can't. It can be down even if the SLAs are 9.9999999.... There is still a chance system will be down. So, what is the CAP theorem's Availability? In my understanding, availability means that as soon as you have established system connectivity, you can use the system. That simple. Let's check what it means to all 3 system types:
CP systems would not be available as soon as they detect possible split brain scenario scenario. Usually they can only tolerate minority of servers being down. As soon as half is down, the whole system does not work. You may still have the server you are connected to up and runnings, but it should refuse your requests.
CA systems would accept your requests, but would have problems during data merge after partitioning is resolved. Often such systems would ask for application help to resolve possible data conflicts.
AP systems would automatically resolve the conflicts in some standard way, often with some timestamping. They are easier to use but you must be sure you understand (and better test) all the caveats of the automatic conflict resolution.
Last term, Consistency is the toughest one. First thing you should understand, it's not about locking or concurrency. Even Consistent system may have problems implementing parallel counter increase. Secondly, it's not about atomic updates. Even in a Consistent system, list of multiple writes may fail at some step, leaving you with a inconsistent data on a high level (and there are ways to handle this). Actually, this is the reason I don't like the term. I'd prefer the theorem to be GAP. Think of Consistency as of Guaranty. To be Consistent system must Guaranty you that as soon as data is successfully written, client would (with respect to caching policy) see it or get an error. Again, system can't guaranty you 100% availability, but it should give you your data or tell you it's (possibly temporarily) lost.
And here we came directly into Eventual Consistency world. In this world, first of all I want to separate two things: caching and eventual consistency per se. Clustered systems often provide you with some sort of read data cache to speed things up. E.g. Apache Zookeeper, a brilliant synchronization service, is a CP system even though other clients may not see the data immediately because of followers state (that is essentially a cache) synchronization. But if the quorum is lost, it would be detected very soon and all the clients would be disconnected.
Another story are AP systems, e.g. Apache Cassandra in AP mode (for Cassandra you can select the mode for each operation). It provides you with the Eventual Consistency, any your write will be propagated to the clients... unless the server holding the write would fail. The primary difference to plain caching is that your application would not notice that data is lost. And in case of permanent loss (hardware server failure) it's usually hard enough to say what exactly was lost in a AP system. You lost “Data or Failure” guaranty and that is why this mode is not considered Consistent.
So, in summary, here are the questions you need to ask to see if given system has C, A or P:
Partition Tolerance: Would the system need any application help to resolve data merging conflicts?
Availability: Would I be always able to use the system if I have running server connectivity?
Consistency: Would my application know fast if some data is (possibly temporary) lost?
0 notes
Text
Google foobar
Have just finished http://google.com/foobar level 5. Got some message to decrypt. Well, it’s all a little too focused on combinatorics, but still nice to crack.
0 notes
Text
Danger of REQUIRES_NEW
Hi.
Let’s look at the very simple example:
@Transactional(propagation = Propagation.REQUIRES_NEW) public class InnerService implements InnerInterface { @Override public void doInNewTransaction() throws InterruptedException { Thread.sleep(10); } } @Transactional(propagation = Propagation.REQUIRED) public class OuterService implements OuterInterface { private InnerInterface innerService; @Autowired public OuterService(InnerService innerService) { this.innerService = innerService; } @Override public void doWork() throws InterruptedException { innerService.doInNewTransaction(); } }
How do you think, are there any danger in it? It does not look like, but special kind of deadlock is possible. E.g. in my test I could easily get "Timeout waiting for idle object" exception by concurrently calling OuterService.doWork with limited connection pool. The limit was reasonable, 10 connections.
Let me remind you what a deadlock is. A simple deadlock is when thread A is waiting for thread B to release resource X and at the very same time thread B is waiting for A to release Y.
So, what resources are we talking about? It's connections. Each thread needs two connections to perform it's work and it acquires required connections one by one.
In this case to get a deadlock it's enough to have number of concurrent threads equal or more than number of connections. Let's image a situation where we have 10 connections and 10 threads, each acquired his own connection and is waiting for the second one. That's it, they will never continue as there are no more connections available.
So, how to solve it? I can see next options:
Don't use REQUIRES_NEW or other options that asks for one more resource from the same pool
Have the pool count higher than thread count
Use two pools (even of smaller size) to the same resource
0 notes
Text
To bean or not to bean
The problem
Recently I came over “The Magic Setter Antipattern” article on DZone I tend to disagree. It proposes to use direct field access instead of getters and setters.
I still think that getters and setters are good idea (yet the one that requires a little too much boilerplate code in Java), and here is why.
1. Libraries
JavaBeans is a standard. While a lot of libraries can work with fields too, you will never know which one would fail to access the fields directly.
2. Abort early
While having side effects in the setter code is a wrong thing, there are a number of a perfectly reasonable use cases to code in you setter. One of them are simple validations. If you have your validation in the setter, you will immediately see what code is trying to set incorrect value. Any subsequent validation code would not give you this information.
3. Full JavaBeans bells and whistles
Do you know that JavaBeans are not only getters and setters? For example, one of the features is a PropertyChangeListener. And you can’t implement this without having a setter.
Note that you should be careful for not to throw a lot of synchronous code into your listeners or it will become a monster.
4. Another simple code to react for property change
Actually there can be tons of legitimate things to do in your setters, like logging or plain change counter increase. Main things to consider are:
Are there any side effects? If there are, you should probably do it in some other way.
Is this a plain data bean or even DTO? If it is, it should not have much logic or external references. But not all beans are data beans.
5. Interfaces
You can’t expose your field through the interface. Period. One can argue that you are exposing a business method, but it’s not always true. Sometimes it’s a setter or (more often) a getter.
6. Consistency
Primary argument in the original article is YAGNI. My answer is that you must be consistent and use only one method (field or setter/getter access) in your application. If you need some logic in some of the field access, you must use getters and setters everywhere. Otherwise you will be easily lost in what to use where.
7. Refactoring cost
Again, let’s say you used fields access and now you need a piece of logic for this getter. While current IDEs do a decent job in refactoring, encapsulating a field can be very error prone, given how often it’s accessed with different methods, including libraries/ELs.
Conclusion
Well, you saw my arguments. Feel free to comment, argue and make your decision. My decision is to continue with getters/setters pattern.
0 notes
Text
Disappearing dates with JAXB
Today I found one weirdness in JAXB marshaller in Java 7.
Let's say you've got next bean to marshall:
@XmlRootElement public class TestBean { private XMLGregorianCalendar calendar; @XmlSchemaType(name = "dateTime") public XMLGregorianCalendar getCalendar() { return calendar; } public void setCalendar(XMLGregorianCalendar calendar) { this.calendar = calendar; } }
Now you are trying to marshall it with JAXB:
TestBean testBean = new TestBean(); testBean.setCalendar(datatypeFactory.newXMLGregorianCalendarDate(2015, 1, 8, DatatypeConstants.FIELD_UNDEFINED)); jaxbContext.createMarshaller().marshal(testBean, out);
You will not see your value:
<?xml version="1.0" encoding="UTF-8" standalone="yes"?> <testBean><calendar></calendar></testBean>
To see it you should either remove @XmlSchemaType(name = "dateTime") to get the date:
<?xml version="1.0" encoding="UTF-8" standalone="yes"?> <testBean><calendar>2015-01-08</calendar></testBean>
Or you can transform your date into timestamp:
TestBean testBean = new TestBean(); XMLGregorianCalendar calendar = datatypeFactory.newXMLGregorianCalendarDate(2015, 1, 8, DatatypeConstants.FIELD_UNDEFINED); calendar = datatypeFactory.newXMLGregorianCalendar(calendar.toGregorianCalendar()); testBean.setCalendar(calendar); jaxbContext.createMarshaller().marshal(testBean, System.out);
will produce you
<?xml version="1.0" encoding="UTF-8" standalone="yes"?> <testBean><calendar>2015-01-08T00:00:00.000-05:00</calendar></testBean>
Looks weird for me. No exception, no warning, just silent value eating.
1 note
·
View note
Text
Handling redirects behind the external HTTPs reverse proxy
Introduction
Using a facade reverse proxy before a real Tomcat or Jetty servlet container is a common practice. Facade server can do various things, like serving static content, buffering answers for slow clients, load balancing requests or performing SSL encryption.
In the latter case all the HTTPS processing is done on an external server, like Apache or ngnix and requests come to your Tomcat or Jetty as plain HTTP requests.
The problem
The problem is that HTTP/1.1 request has all the data of the request, like path or host name but not the schema.
This means that any URI you will try to build on server side, starting from calling HttpServletResponse.sendRedirect will give you wrong http schema:
http://site.com/uri
instead of
https://site.com/uri
The solution
To solve this problem you need to use de facto standard X-Forwarded-Proto header. It needs to be sent from your front end server to your application server.
Step 1: Configuring front end server
For Apache the config will look like the next:
RequestHeader set X_FORWARDED_PROTO 'https' env=HTTPS
For ngnix the configuration will be the next:
location / { proxy_set_header X-Forwarded-Proto https; ... }
If you are using some other front-end, you should check documentation. Also there are chances that the header is already in there. Note that this header is a request header passed between two servers, so you won't be able to see it in your browser. Here is a simple JSP that will print you all the headers. It can also be used to test you configuration:
<%@ taglib prefix="c" uri="http://java.sun.com/jsp/jstl/core" %> <html> <head> <title>Request Headers</title> </head> <body> This URI was called with the next headers: <ul> <c:forEach var="nextHeader" items="${header}"> <li> <c:out value="${nextHeader.key}" /> = <c:out value="${nextHeader.value}" /> </li> </c:forEach> </ul> </body> </html>
Just put it to your webapp source root (src/main/webapp under maven) as test.jsp and call from browser. For default web app settings you should see all the headers available
And even if you were not able to make your front end add X-Forwarded-Proto header, with Tomcat you should still be able go directly with Step 2 by picking any other header already present, e.g. "Host: your.domain.com". Note that this will b much less clear and may prevent you from differenciating different types of requests coming in, so use on your own risk. To go this way, replace "X-Forwarded-Proto" with the header name you choose and "https" with the header value you choose in the recipes below.
Step 2: Configuring application server
For Tomcat you need to add RemoteIpValve to your server.xml or context.xml:
<Valve className="org.apache.catalina.valves.RemoteIpValve" remoteIpHeader="x-forwarded-for" protocolHeader="x-forwarded-proto" protocolHeaderHttpsValue="https" />
Please see Valve documentation for additional options available.
Under Jetty this header should be interpreted automatically. If you have some other header, please see Jetty HOW-TO on customizing your connector.
Voila, your redirects must be OK now.
0 notes
Text
Techie lens selection
For over a year I am shooting with a Panasonic DMC-G5. I am not the best shooter in the world, but I like my photos :)
I like the mirrorless camera. It's lightweight, small and powerful. Crop factor of 2 is OK. I don't think I need DSLR for my purposes. But I can see, that my current set of lenses is not enough. I am using three lenses as of now:
Lumix 14-42/3.5-5.6 X lens from the kit. That is what I am making most of my shots with. It's very compact. My camera is not the smallest in the mirrorless world, but with this lens it's pretty compact and still fully featured (viewfinder/flash/ext. flash connector).

Lumix G 45-200/4.0-5.6 is making a set with the 14-42 allowing me to shoot long distance or simply get a portrait without getting much attention of a subject.

12.5/F12 3D lense is a funny thing to play with on a sunny day.

The problem arise when the day is not too sunny or I need to make some shots indoors, esp. on a party. The camera normal ISO is 3200 and it's not enough on F3.5 to make crisp shots.
So, it's time to spend some money. The big Q is if to get a zoom or a fix. Next to choose the one. Panasonic makes quite nice F2.8 zooms in two ranges: 12-35 and 35-100. F2.8 would give me a good boost over 3.5(4.0)-5.6 lenses. But with fix one could get something like 15/F1.7 or 25/F1.4 or 42.5/F1.2.
I could simply read a lot of review and choose what people like most, but I am the techie guy and I've got my shots database. The decision is simple: I will check which range I use most and base my decision on that.
First check is which range to enhance. The numbers say I do 80% on 14-42 and only 20% on 45-200. Yep, I am lazy to change the lenses. And from my memories the biggest problem is indoors shooting, that is short range. So, let's go 14-42 direction.
So, how lazy I am? If I am too lazy, I will get a lot of shots on 42 because I simply don't want to do the change. Let's check.
14 - 42%. Wow, almost half of the shoots are on the lowest zoom level possible. It's very contrary to the popular distances, like 25 (50 35mm eq).
15-41 - 41%. I still use the zooming features actively. May be I've got some zoom I like the most? Will see.
42 - 17%. Well, I am better than I thought of myself. Not so much shoots with max zoom level.
The last thing to check is if I have a favorite zoom level. Let's do a chart:

Well, it looks like I am using 18-32 range a lot, with peaks on 22 and 30. It means I can't go with just a singe fix. Just curious, what kind of shots do I do on all this levels? Let's see.
14. It's short distance "tourist" shots: some bigger machinery, few people in an interesting scene:


17-25 range. Some interesting object or portrait:


27-33 range. Something large on distance or a larger portrait:


So, it's time to make a decision. And it's simple. It looks like I need 12-35/F2.8 zoom.
It will extend my lower range a little, add more light. And I don't use range over 35 much. And what about fixes? May be next year.
0 notes
Text
How much is "Big Data"
I am often asked which NoSQL solution to use. And when I ask how much data do they have, I hear about millions of records.
The most recent question was about 3 millions of record, 160 bytes wide (20 long fields) each record. The task was to make a simple select on two fields with a group by on 3 more fields. The answer was needed in a second and they were thinking about some specialized In-memory DB.
This is not a Big Data I said to myself and decided to make a test. I took H2 database and loaded 3 million of records into it's in-memory storage. It took ~700MB of heap. Index in two fields the select will be operating on took another 300MB. H2 was able to produce an answer in 2 milliseconds. And unlike to the most NoSQL solutions it provides you with real SQL you can use for the analytics.
BTW: Even without an index (let's think about ad-hoc querying) it was able to provide a result in 600 milliseconds.
So, what's Big Data for me? For me Big Data is when you can't live without a second server, either for storage, computing power or sometimes bandwidth. It mean either terabytes of data (which would mean billions of records in the example) or complex CPU-consuming processing that may require some kind or Map-Reduce even for a handful of record.
Until after this point don't try to complicate things. Sometimes even a simple basic Map can be used instead of Key-Value DB and BlockingQueue instead of some AMQP solution. Just ensure you have plenty of growth space for your task for the nearest few years.
0 notes
Text
Using maven generated code in Intellij Idea
Hi, all.
At last I've settled down in the Greater New York area and is planning to continue with this blog.
As for the first US record, a small hint for those of you, who is generating code in your maven build and would like to see it in your Intellij Idea IDE.
The rule is simple: put your generated sources into target/generated-sources/<any name> directory and Idea will automatically pick it up.
Actually for the most plugins it's default settings, e.g. jaxb2:xjc puts it under target/generated-sources/jaxb, so unless you change it's settings everything should be fine. If you want to change it, just keep generated-sources part and you should be fine.
0 notes
Text
Simple wrappers or plugins with WrAOP
How many times have you created a wrapper class that delegates all the methods to it's delegate, while adding some functionality in few places? I've done this many times. And I was surprised that there is no easy way to do this. I could find next options:
Simply delegate. It's so much boilerplate code and it looks even more ugly if you need to do same thing for all the methods.
Java Proxy & InvocationHandler. It's too low level. You need to ensure you are OK with exception propagation and introduce some switching logic for different methods.
AspectJ. It's too global. It enhances classes, not class instances.
Spring AOP. It's designed to be used inside Spring context. They provide you with regular factories, but they are tricky to find and are not reusable. One factory can wrap one object. Is it a factory, after all?
Also none of this options are good if you simply want to give your users ability to write plugins for your functionality. Usually you introduce either chain of responsibilities, like in Servlet API or special interfaces with all this Pre- and Post- methods. First option ties you to this pattern even if you don't need it for your primary goal. Seconds option adds a lot of additional code, and you can miss some "pre" your user needs.
So, WrAOP was born. It provides enhanced Spring AOP functionality in a simple way, with reusable factories and aspect type autodetection. So, you can use AOP alliance Advice, Spring Advisor or AspectJ annotations (see Spring AOP documentation for detail).
Here is an example of it's usage:
new WrapperFactoryBuilder().build() .withAspects(aspect1, aspect2, aspect3).wrapAllInterfaces(target)
Easy, is not it?
And if you have never used AspectJ annotations, here is another example:
@Aspect public class ConstantReturningAspect { private final Object constant; public ConstantReturningAspect(Object constant) { this.constant = constant; } @Around("execution(* im.tym.wraop.data.Transformer.transform(..))") Object returnConstant() { return constant; } }
Also looks much betten than the InvocationHandler.
Small bonus for the dessert: the only required dependency is Spring AOP. AspectJ and CGLIB are both optional and can be used only as needed.
So, the library is already in the maven central. Please, try it and tell me what you think. Of course, you are welcome to share your thoughts without trying. Do you like the idea?
Here is a maven dependency for your quick start:
<dependency> <groupId>im.tym.wraop</groupId> <artifactId>wraop</artifactId> <version>1.0</version> </dependency>
0 notes
Text
Some clone tuning rules
Today I was asked for an advice about object cloning. They did not want to read a graph of objects each time, but decided to read once and then make a copy with serialize + deserialize. I've said that they are going wrong direction. They were going to replace read + deserialize with serialize + deserialize. And that's plain wrong because:
They did not check why it's slow. Don't use your mind, use your profiler. In 90% of cases it's slow because of something you would never think about.
Linear file reading is fast. Really, regular HDD can give you hundreds of megabytes per second. This is true unless (and see p.1):
You ain't reading linear. But deserialization is linear reading
You are reading a lot of data without much processing. And they don't read huge arrays
You forget to buffer you read. If you do a system call for each char, it's slow. So be sure you don't forget your BufferedInputStream
Serialization and deserialization is relatively slow in java. Especially for text formats like XML
So they did check and I was right, it was deserialization hurting their performance. So I proposed them to do a clone. Unfortunately it was not directly possible as some objects were not under their control. And they said it's for testing speed so they really didn't want to make huge deep copy library that knows how to copy each object.
Okay, for testing I proposed them to use Java Deep-Cloning library. It's a hacky tool, so I'd be very careful to propose it for production code, but for testing it's OK. And it helped. Tests time decreased from 2 minutes to 30 seconds. Bingo!
0 notes
Text
To use a solution or set of libraries?
Recently, once again, while preparing a new project, a new great existing software solution was proposed to be customized and used to perform some part of the project. I was arguing to use a set of libraries to perform the same work.
The topic is very common, so I'd decided to share my arguments. Comments and discussion are welcome. After all, we have not decided yet :) So, my arguments are:
Be careful if you don't know the solution. Actually it's the main thing you need to consider when bringing something large and unknown into your design. It's more or less easy to replace library, it very hard if not impossible to replace a solution.
You can ask why would you need to replace? Because you may need a feature that is not there. And if the thing is very large and complex it may be impossible to extend it in the correct way.
Remember about "side" features, like monitoring, deployment or controlling. They are usually in there, but do they provide enough functionality? Check it!
If the solution won't cover you whole project, check how will it be integrated. Large things usually don't integrate well, they suppose to have everything inside.
Check if you have people that will do the development and support. It usually takes much more time to get into solution than to understand new library for a developer. I am subscribed for my company's architecture group and they often ask for people "who knows XXX". Recently there was a call for the solution that we are evaluating.
Don't take it if you don't use much of it. It can be large and 30% of functions may cover whole your projects. But other 70% will still be active, they will slow you down, they need to be learnt, they can become obstacles on your way.
So, my summary is: take solution only if your company has experience in it or, at least, you are going to use it in different projects constantly. It can be reasonable to get a consultant that knows the beast to see if there are uncovered holes in your design. And think about getting a support contract in case you will need some extension.
For me it means, take it only if it fits you like a glove and you know it for sure.
0 notes