
Random thoughts on entrepreneurship, venture capital, private equity, world finance and global economy. About me.
Don't wanna be here? Send us removal request.
Statistics
We looked inside some of the posts by titocosta-blog and here's what we found interesting.
Average Info
Notes Per Post
13
Likes Per Post
12
Reblog Per Post
1
Reply Per Post
0
Time Between Posts
1 month
Number of Posts By Type
Photo
7
Text
3
Quote
3
Video
3
Link
1
Last Seen Tumblr Blogs





Fun Fact
Tumblr Inc. is funded by 13 investors.
Photo

(via Media's Digital Upheaval in 6 Charts - Bloomberg Gadfly)
0 notes
Text
Training a recurrent neural network on venture capitalists twitter conversations
Using the Twitter API, I collected 55 thousand twitter conversations (5.6MB text file) among a few venture capitalists (those followed by @MadnessCapital) and trained Andrej Karpathy's character-based recurrent neural network with it.
The AWS EC2 instance I used to train the model is publicly available as ami-374b1b52 (launch on a GPU-powered instance g2.2xlarge or g2.8xlarge). The AMI contains all you need to run char-rnn and Torch7 on a GPU-powered instance.
See below the commands I've used to train and sample from the network. The twitter conversations are formatted as <name>: <tweet>, one tweet per line. An extra line is added at the end of each conversation.
The training took roughly 30 hours on a g2.2xlarge AWS EC2 instance. You don't need to retrain the network, you can just sample from the pre-trained model available in the AMI at cv/lm_20151818_conversations_s512_l3_epoch49.27_1.3337.t7 as described by the example below. That file corresponds to the training iteration with the lowest validation error.
# Train a 3-layer, 512-size RNN on the twitter conversations # Running on GPU. If you don't have a GPU add parameter "-gpuid -1" cd torch-gits/char-rnn th train.lua -data_dir ../../madvc/training_conversations/ -rnn_size 512 -num_layers 3 -dropout 0.5 -savefile 20151818_conversations_s512_l3 > ../../madvc/20151818_conversations_s512_l3.log.txt & # Sampling, notice the new line at the end of the tweet th sample.lua -length 560 -temperature 0.5 -primetext 'BenedictEvans: Idle observation- there will soon be 10x more iOS devices in use than Macs ' cv/lm_20151818_conversations_s512_l3_epoch49.27_1.3337.t7
Still some work to do, but see some interesting results below. The model appears to have learned words, some grammar (remember this is char-based!) and some form of interaction (replies and names of other people in the training set). The first tweet is what is provided as a seed to the model:
BenedictEvans: Damn just got a flat. Best option in SF? naval: @naval I have to do that and probably the most competition of a solution of people in the most successful story is that the history of the subsidize company is about the last year. Joshmedia: I sold the company that are for startups for me to play the startup with @angellist which is hard to show over portfolio and devices are a forget to take a good people reported problems. sama: @rabois @adamnash that's a real life in the same way to make it the best thing in the partner and out of the most thing to ask that.
pmarca: "A visceral defense of the physical, and dismissal of the virtual as inferior, is a result of superuser privileges." https://t.co/4P0GenrbxU pmarca: @jimray @amcafee @Joshmedia @rabois @semil I haven't seen the future. I should probably have no idea how to see the rest of the company still makes concerns about the decision msuster: I don't think the same thing that is not a support of the company to be the best thing about a bring of the startup and the market entrepreneurs are right. All new money behind the most company. pmarca: @TrevMcKendrick @rabois @mattocko I see the business and one added in the hands of BTC when a money are better.
sama: .@mappingbabel it's ok to be secretive. it's ok to aggressively go after PR. it's very problematic to do both. paulg: The whole point of the perfect one of the best experiences are the problem in the day when you see that list is the point in the morning vision of new big things. http://t.co/0Lbj3Z2er7 davemcclure: @cdixon still so disagree. I am on the only person on the world and we have to get the best investors can be quite still like a blog post. msuster: I have been hoping to see the real part of the apps on the move to everyone has to compete to an and team and the angel investors are good for the problem?
cdixon: What makes an entrepreneurial ecosystem? https://t.co/OSzkyK17Mu (via @zalzally) pmarca: @davidlee But the app of the site they don't have to read the future. johnolilly: Anything about the end of the best startups and can't thread to disclose the truth about this startup event to see any of them have to say that i would have to find the startup work (and on a successful bitcoin) in the basic of my point. johnolilly: @artypapers @cdixon @benthompson @msquinn @joshelman is this a problem?
Enjoy!
0 notes
Quote
I divide my officers into four groups. There are clever, diligent, stupid, and lazy officers. Usually two characteristics are combined. Some are clever and diligent -- their place is the General Staff. The next lot are stupid and lazy -- they make up 90 percent of every army and are suited to routine duties. Anyone who is both clever and lazy is qualified for the highest leadership duties, because he possesses the intellectual clarity and the composure necessary for difficult decisions. One must beware of anyone who is stupid and diligent -- he must not be entrusted with any responsibility because he will always cause only mischief.
Kurt von Hammerstein-Equord
1 note
·
View note
Video
youtube
The four horsemen by Scott Galloway NYU
1 note
·
View note
Text
Where to buy your MacBook Pro
I was wondering where to buy a MacBook Pro given the recent currency turmoil, so I built a google sheet using IMPORTHTML to pull price data from the Apple Store website and GOOGLEFINANCE to convert prices to USD.
It turns out Japan is the cheapest, followed by Canada and Malaysia. Australia and Singapore are now also cheaper than the US. Despite the recent depreciation, Europe is still much more expensive than the US.
1 note
·
View note
Text
Public EC2 AMI with Torch and Caffe deep learning toolkits
tl;dr I built an EC2 AMI on AWS including my favorite deep learning libraries Torch7 and Caffe, and all necessary tools and libraries to run them on a GPU. It is publicly available as ami-ffba7b94 (launch on AWS). When launching the instance, pick the type g2.2xlarge or g2.8xlarge which feature Nvidia GPUs.
I finally decided to take a closer look at deep learning toolkits Torch and Caffe.
Torch is a general purpose scientific framework developed at NYU and used among others by machine learning teams at Facebook, Google/DeepMind, Nvidia, AMD, Intel.
Caffe is a deep learning tool focused on convolutional networks and image recognition that provides pre-trained models and a simple file format to describe deep learning networks.
Amazon offers EC2 instances with Nvidia GPUs which are suitable to train deep learning models. Starting from the Linux Ubuntu AMI ami-6238470a (launch on AWS) mentioned at the Torch7 cheatsheet, I added:
fbcunn, a Torch package developed by Facebook and recently open-sourced
dp, a deep learning package for Torch
loadcaffe, a package to load Caffe networks and models on Torch
See below the commands issued to install the above packages and their dependencies:
luarocks install dp # update cunn and cutorch. This is necessary to avoid a cmake problem in both fbcunn and loadcaffe luarocks install cunn luarocks install cutorch # Install Folly, fbthrift, thpp and fblualib curl -sk https://raw.githubusercontent.com/soumith/fblualib/master/install_all.sh | bash # Install fbcunn git clone https://github.com/facebook/fbcunn.git cd fbcunn && luarocks make rocks/fbcunn-scm-1.rockspec # Install loadcaffe sudo apt-get install protobuf-compiler # protobuf-dev is not sufficient because protoc command is needed by loadcaffe luarocks install loadcaffe
The AMI is publicly available with the identifier ami-90206ef8 (launch on AWS, instances with Nvidia GPUs are called g2.2xlarge).
Update: I installed the Caffe package, compiled to take advantage of Nvidia's cudnn library, in addition to the above.
# Install caffe dependencies as described at http://caffe.berkeleyvision.org/installation.html sudo apt-get install libprotobuf-dev libleveldb-dev libsnappy-dev libopencv-dev libboost-all-dev libhdf5-serial-dev # Install a BLAS library (ATLAS) sudo apt-get install libatlas-base-dev # Clone caffe from github git clone https://github.com/BVLC/caffe.git # Install python dependencies for Caffe cd caffe cd python for req in $(cat requirements.txt); do sudo pip install $req; done # Install cuDNN library v1 from developer.nvidia.com (needs registration) # Build succeds but tests fail with v2 as of February 15th, 2015 # Edited caffe/Makefile.config to include Anaconda python directories and turn on cuDNN library from Nvidia # Build caffe # crazy trick to pass make all and avoid a conflict # documented at https://github.com/BVLC/caffe/issues/757 mv $HOME/anaconda/lib/libm.so $HOME/anaconda/lib/libm.so.tmp make all make test # crazy trick to have make runtest work # documented at https://github.com/BVLC/caffe/issues/1463 sudo ln /usr/lib/x86_64-linux-gnu/libhdf5.so.7 /usr/lib/x86_64-linux-gnu/libhdf5.so.8 sudo ln /usr/lib/x86_64-linux-gnu/libhdf5_hl.so.7 /usr/lib/x86_64-linux-gnu/libhdf5_hl.so.8 make runtest make distribute
The AMI including both Torch7 and Caffe is publicly available with the identifier ami-a0e4b1c8 (launch on AWS, instances with Nvidia GPUs are called g2.2xlarge).
Update 2: following the discussion below, a few more fixes with regards to importing caffe modules into python scripts.
# similar as above to address anaconda distribution bug # documented at https://groups.google.com/a/continuum.io/forum/#!topic/anaconda/-DLG2ZdTkw0 mv $HOME/anaconda/lib/libm.so.6 $HOME/anaconda/lib/libm.so.6.tmp # Add protobuf with pip install to ensure import caffe works in python pip install protobuf # add to .bashrc # export PYTHONPATH=/home/ubuntu/caffe/python:$PYTHONPATH
Update 3: Updated and re-installed fbcunn and its dependencies (folly, fbthrift, thpp and fblualib) for multi-GPU parallel training and testing.
Update 4: Added Torch demos & tutorials, LSTM, Neural Turing Machines and Andrew Karpathy's char-rnn to the torch-gits folder.
The AMI including both Torch7 and Caffe, including fixes to Python module imports, is publicly available with the identifier ami-ffba7b94 (launch on AWS, instances with Nvidia GPUs are called g2.2xlarge and g2.8xlarge).
1 note
·
View note
Photo

Amazing night aerial pics of New York City
0 notes
Photo
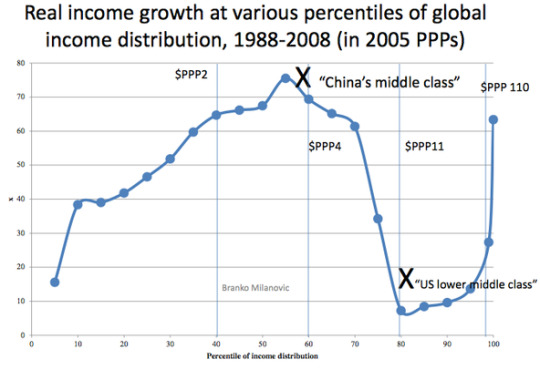
Real income growth at various percentiles of global income distribution, 1988-2008
0 notes
Quote
Can you tell me the thickness of a U.S. Postage stamp with the glue on it? Answer: We couldn't tell you that answer quickly. Why don't you try the Post Office? Response: This is the Post Office. (1963)
Before Google ... Who Knew? : The Protojournalist : NPR
0 notes
Video
A Leadership Primer by Gen. Colin Powell
0 notes
Photo
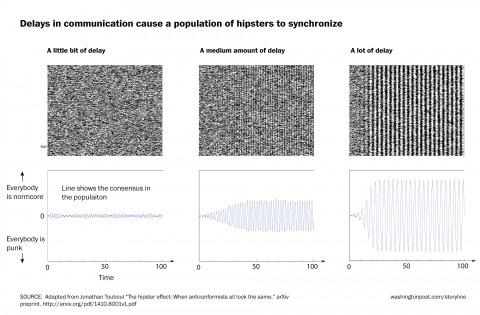
Delays in the system induces resonance (via The mathematician who proved why hipsters all look alike - The Washington Post)
0 notes
Photo

Microprocessor scaling graphs (via The death of CPU scaling: From one core to many — and why we’re still stuck | ExtremeTech)
3 notes
·
View notes
Photo

Facial structure bias (via The Introverted Face - The Atlantic)
3 notes
·
View notes
Quote
When you have large amounts of data, your appetite for hypotheses tends to get even larger. And if it’s growing faster than the statistical strength of the data, then many of your inferences are likely to be false. They are likely to be white noise.
Machine-Learning Maestro Michael Jordan on the Delusions of Big Data and Other Huge Engineering Efforts - IEEE Spectrum
0 notes
Photo

Pessimistic/Optimistic vs Skeptical/Credulous matrix (via The Counterintuitive Trait That Will Make You Significantly More Successful | LinkedIn)
1 note
·
View note
Video
Upfront ventures's presentation on the shifting venture capital landscape
1 note
·
View note