#where to get free datasets
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
In 2020, 44% of users from Denmark used Tumblr daily.
Text

We Asked an Expert...in Herpetology!
People on Tumblr come from all walks of life and all areas of expertise to grace our dashboards with paragraphs and photographs of the things they want to share with the world. Whether it's an artist uploading their speed art, a fanfic writer posting their WIPs, a language expert expounding on the origin of a specific word, or a historian ready to lay down the secrets of Ea-nasir, the hallways of Tumblr are filled with specialists sharing their knowledge with the world. We Asked an Expert is a deep dive into those expert brains on tumblr dot com. Today, we’re talking to Dr. Mark D. Scherz (@markscherz), an expert in Herpetology. Read on for some ribbeting frog facts, including what kind of frog the viral frog bread may be based on.
Reptiles v Amphibians. You have to choose one.
In a battle for my heart, I think amphibians beat out the reptiles. There is just something incredibly good about beholding a nice plump frog.
In a battle to the death, I have to give it to the reptiles—the number of reptiles that eat amphibians far, far outstrips the number of amphibians that eat reptiles.
In terms of ecological importance, I would give it to the amphibians again, though. Okay, reptiles may keep some insects and rodents in check, but many amphibians live a dual life, starting as herbivores and graduating to carnivory after metamorphosis, and as adults they are critical for keeping mosquitos and other pest insects in check.
What is the most recent exciting fact you discovered about herps?
This doesn’t really answer your question, but did you know that tadpole arms usually develop inside the body and later burst through the body wall fully formed? I learned about this as a Master’s student many years ago, but it still blows my mind. What’s curious is that this apparently does not happen in some of the species of frogs that don’t have tadpoles—oh yeah, like a third of all frogs or something don’t have free-living tadpoles; crazy, right? They just develop forelimbs on the outside of the body like all other four-legged beasties. But this has only really been examined in a couple species, so there is just so much we don’t know about development, especially in direct-developing frogs. Like, how the hell does it just… swap from chest-burster to ‘normal’ limb development? Is that the recovery of the ancestral programming, or is it newly generated? When in frog evolution did the chest-burster mode even evolve?
How can people contribute to conservation efforts for their local herps?
You can get involved with your local herpetological societies if they exist—and they probably do, as herpetologists are everywhere. You can upload observations of animals to iNaturalist, where you can get them identified while also contributing to datasets on species distribution and annual activity used by research scientists.
You can see if there are local conservation organizations that are doing any work locally, and if you find they are not, then you can get involved to try to get them started. For example, if you notice areas of particularly frequent roadkill, talking to your local council or national or local conservation organizations can get things like rescue programs or road protectors set up. You should also make sure you travel carefully and responsibly. Carefully wash and disinfect your hiking boots, especially between locations, as you do not want to be carrying chytrid or other nasty infectious diseases across the world, where they can cause population collapses and extinctions.
Here are some recent headlines. Quick question, what the frog is going on in the frog world?

Click through for Mark’s response to these absolutely wild headlines, more about his day-to-day job, his opinion on frog bread, and his favorite Tumblr.
✨D I S C O V E R Y✨
There are more people on Earth than ever before, with the most incredible technology that advances daily at their disposal, and they disperse that knowledge instantly. That means more eyes and ears observing, recording, and sharing than ever before. And so we are making big new discoveries all the time, and are able to document them and reach huge audiences with them.
That being said, these headlines also showcase how bad some media reporting has gotten. The frogs that scream actually scream mostly in the audible range—they just have harmonics that stretch up into ultrasound. So, we can hear them scream, we just can’t hear all of it. Because the harmonics are just multiples of the fundamental, they would anyway only add to the overall ‘quality’ of the sound, not anything different. The mushroom was sprouting from the flank of the frog, and scientists are not really worried about it because this is not how parasitic fungi work, and this is probably a very weird fluke. And finally, the Cuban tree frogs (Osteocephalus septentrionalis) are not really cannibals per se; they are just generalist predators who will just as happily eat a frog as they will a grasshopper, but the frogs they are eating are usually other species. People seem to forget that cannibalism is, by definition, within a species. The fact that they are generalist predators makes them a much bigger problem than if they were cannibals—a cannibal would actually kind of keep itself in check, which would be useful. The press just uses this to get people’s hackles up because Westerners are often equal parts disgusted and fascinated by cannibalism.
What does an average day look like for the curator of herpetology at the Natural History Museum of Denmark?
No two days are the same, and that is one of the joys of the job. I could spend a whole day in meetings, where we might be discussing anything from which budget is going to pay for 1000 magnets to how we could attract big research funding, to what a label is going to say in our new museum exhibits (we are in the process of building a new museum). Equally, I might spend a day accompanying or facilitating a visitor dissecting a crocodile or photographing a hundred snakes. Or it might be divided into one-hour segments that cover a full spectrum: working with one of my students on a project, training volunteers in the collection, hunting down a lizard that someone wants to borrow from the museum, working on one of a dozen research projects of my own, writing funding proposals, or teaching classes. It is a job with a great deal of freedom, which really suits my work style and brain.
Oh yeah, and then every now and then, I get to go to the field and spend anywhere from a couple of weeks to several months tracking down reptiles and amphibians, usually in the rainforest. These are also work days—with work conditions you couldn’t sell to anyone: 18-hour work days, no weekends, no real rest, uncomfortable living conditions, sometimes dangerous locations or working conditions, field kitchen with limited options, and more leeches and other biting beasties than most health and welfare officers would tolerate—but the reward is the opportunity to make new discoveries and observations, collect critical data, and the privilege of getting to be in some of the most beautiful and biodiverse places left on the planet. So, I am humbled by the fact that I have the privilege and opportunity to undertake such expeditions, and grateful for the incredible teams I collaborate with that make all of this work—from the museum to the field—possible.
The Tibetan Blackbird is also known as Turdus maximus. What’s your favorite chortle-inducing scientific name in the world of herpetology?
Among reptiles and amphibians, there aren’t actually that many to choose from, but I must give great credit to my friend Oliver Hawlitschek and his team, who named the snake Lycodryas cococola, which actually means ‘Coco dweller’ in Latin, referring to its occurrence in coconut trees. When we were naming Mini mum, Mini scule, and Mini ature, I was inspired by the incredible list that Mark Isaac has compiled of punning species names, particularly by the extinct parrot Vini vidivici, and the beetles Gelae baen, Gelae belae, Gelae donut, Gelae fish, and Gelae rol. I have known about these since high school, and it has always been my ambition to get a species on this list.
If you were a frog, what frog would you be and why?
I think I would be a Phasmahyla because they’re weird and awkward, long-limbed, and look like they’re wearing glasses. As a 186 cm (6’3) glasses-wearing human with no coordination, they quite resonate with me.
Please rate this frog bread from 1/10. Can you tell us what frog it represents?
With the arms inside the body cavity like that, it can basically only be a brevicipitid rain frog. The roundness of the body fits, too. I’d say probably Breviceps macrops (or should I say Breadviceps?) based on those big eyes. 7/10, a little on the bumpy side and missing a finger and at least one toe.
Please follow Dr. Mark Scherz at @markscherz for even more incredibly educational, entertaining, and meaningful resources in the world of reptiles and amphibians.
2K notes
·
View notes
Text
Art. Can. Die.
This is my battle cry in the face of the silent extinguishing of an entire generation of artists by AI.
And you know what? We can't let that happen. It's not about fighting the future, it's about shaping it on our terms. If you think this is worth fighting for, please share this post. Let's make this debate go viral - because we need to take action NOW.
Remember that even in the darkest of times, creativity always finds a way.
To unleash our true potential, we need first to dive deep into our darkest fears.
So let's do this together:
By the end of 2025, most traditional artist jobs will be gone, replaced by a handful of AI-augmented art directors. Right now, around 5 out of 6 concept art jobs are being eliminated, and it's even more brutal for illustrators. This isn't speculation: it's happening right now, in real-time, across studios worldwide.
At this point, dogmatic thinking is our worst enemy. If we want to survive the AI tsunami of 2025, we need to prepare for a brutal cyberpunk reality that isn’t waiting for permission to arrive. This isn't sci-fi or catastrophism. This is a clear-eyed recognition of the exponential impact AI will have on society, hitting a hockey stick inflection point around April-May this year. By July, February will already feel like a decade ago. This also means that we have a narrow window to adapt, to evolve, and to build something new.
Let me make five predictions for the end of 2025 to nail this out:
Every major film company will have its first 100% AI-generated blockbuster in production or on screen.
Next-gen smartphones will run GPT-4o-level reasoning AI locally.
The first full AI game engine will generate infinite, custom-made worlds tailored to individual profiles and desires.
Unique art objects will reach industrial scale: entire production chains will mass-produce one-of-a-kind pieces. Uniqueness will be the new mass market.
Synthetic AI-generated data will exceed the sum total of all epistemic data (true knowledge) created by humanity throughout recorded history. We will be drowning in a sea of artificial ‘truths’.
For us artists, this means a stark choice: adapt to real-world craftsmanship or high-level creative thinking roles, because mid-level art skills will be replaced by cheaper, AI-augmented computing power.
But this is not the end. This is just another challenge to tackle.
Many will say we need legal solutions. They're not wrong, but they're missing the bigger picture: Do you think China, Pakistan, or North Korea will suddenly play nice with Western copyright laws? Will a "legal" dataset somehow magically protect our jobs? And most crucially, what happens when AI becomes just another tool of control?
Here's the thing - boycotting AI feels right, I get it. But it sounds like punks refusing to learn power chords because guitars are electrified by corporations. The systemic shift at stake doesn't care if we stay "pure", it will only change if we hack it.
Now, the empowerment part: artists have always been hackers of narratives.
This is what we do best: we break into the symbolic fabric of the world, weaving meaning from signs, emotions, and ideas. We've always taken tools never meant for art and turned them into instruments of creativity. We've always found ways to carve out meaning in systems designed to erase it.
This isn't just about survival. This is about hacking the future itself.
We, artists, are the pirates of the collective imaginary. It’s time to set sail and raise the black flag.
I don't come with a ready-made solution.
I don't come with a FOR or AGAINST. That would be like being against the wood axe because it can crush skulls.
I come with a battle cry: let’s flood the internet with debate, creative thinking, and unconventional wisdom. Let’s dream impossible futures. Let’s build stories of resilience - where humanity remains free from the technological guardianship of AI or synthetic superintelligence. Let’s hack the very fabric of what is deemed ‘possible’. And let’s do it together.
It is time to fight back.
Let us be the HumaNet.
Let’s show tech enthusiasts, engineers, and investors that we are not just assets, but the neurons of the most powerful superintelligence ever created: the artist community.
Let's outsmart the machine.
Stéphane Wootha Richard
P.S: This isn't just a message to read and forget. This is a memetic payload that needs to spread.
Send this to every artist in your network.
Copy/paste the full text anywhere you can.
Spread it across your social channels.
Start conversations in your creative communities.
No social platform? Great! That's exactly why this needs to spread through every possible channel, official and underground.
Let's flood the datasphere with our collective debate.
71 notes
·
View notes
Text
I've tried not to get political on here but this is too important.
What's Happening?
Under trump's administration, government websites are being made to take down any LGBTQ+ papers, research, etc. (including information on mental health, personal care, discrimination, and healthcare).
The existence of LGBTQ+ and the care of queer people is being erased from the government through the removal of DEI policies and funding for those who cover these topics. They're trying to solve the issue by removing it and pretending people don't exist. Children and adults are in danger of not being recognized for who they are and are facing discrimination from those in power. In a nation built on liberty, these policies detract from millions of Americans' quality of life and freedom from oppression.
What Can I Do?
Now more than ever it is important to archive any information you can find. Save pages to the Internet Archive, screenshot, save to hard drives and share it where you still can.
Remember that private companies still are not required to take down their research. Rely on what you can, and archive them in case anything happens in the future.
Methods of protest still exist. Do not protest violently; sometimes it may seem like the only way to get things done, but this only gives the community a reason for blame. You should research how to protest peacefully, but be prepared for anything that may happen. In the coming years, being yourself will be the highest form of protest. Don't conform to what they want.
To My LGBTQ+ Friends And Readers
Now is not the time to give up. Live loudly and be who you know you are. It's going to get rough, but giving in is not a solution. The number of LGBTQ+ Americans is always growing, and nobody can ignore it forever. We are stronger in numbers, and it's with all of us working together that we can make a more free America where innocent people are not discriminated against for being themselves.
Sources/Further Information:
BBC, "US federal websites scrub vaccine data and LGBT references" https://bbc.com/news/articles/cgkj8gx1vy6o
CNN Health, "Epidemiologist reacts to removal of certain health data, information from CDC website" https://www.cnn.com/2025/02/02/health/video/cdc-websites-gender-lgbtq-datasets-dr-nuzzo-foa-digvid
23 notes
·
View notes
Text
Neural Nets, Walled Gardens, and Positive Vibes Only

the crystal spire at the center of the techno-utopian walled garden
Anyone who knows or even just follows me knows that as much as I love neural nets, I'm far from being a fan of AI as a corporate fad. Despite this, I am willing to use big-name fad-chasing tools...sometimes, particularly on a free basis. My reasons for this are twofold:
Many people don't realize this, but these tools are more expensive for the companies to operate than they earn from increased interest in the technology. Using many of these free tools can, in fact, be the opposite of "support" at this time. Corporate AI is dying, use it to kill it faster!
You can't give a full, educated critique of something's flaws and failings without engaging with it yourself, and I fully intend to rip Dall-E 3, or more accurately the companies behind it, a whole new asshole - so I want it to be a fair, nuanced, and most importantly personally informed new asshole.
Now, much has already been said about the biases inherent to current AI models. This isn't a problem exclusive to closed-source corporate models; any model is only as good as its dataset, and it turns out that people across the whole wide internet are...pretty biased. Most major models right now, trained primarily on the English-language internet, present a very western point of view - treating young conventionally attractive white people as a default at best, and presenting blatantly misinformative stereotypes at worst. While awareness of the issue can turn it into a valuable tool to study those biases and how they intertwine, the marketing and hype around AI combined with the popular idea that computers can't possibly be biased tends to make it so they're likely to perpetuate them instead.
This problem only gets magnified when introduced to my mortal enemy-
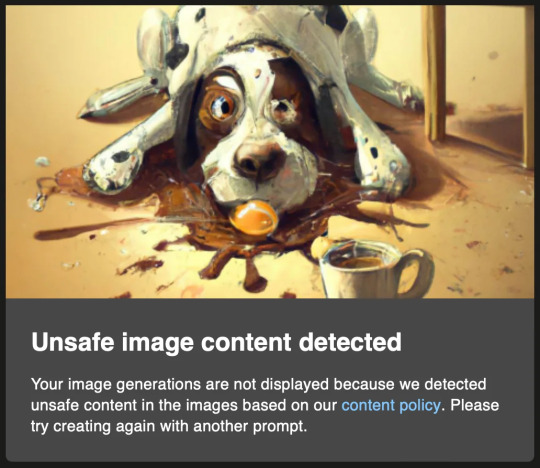
If I never see this FUCKING dog again it will be too soon-
Content filters.
Theoretically, content filters exist to prevent some of the worst-faith uses of AI - deepfakes, true plagiarism and forgery, sexual exploitation, and more. In practice, many of them block anything that can be remotely construed as potentially sexual, violent, or even negative in any way. Frequently banned subjects include artistic nudity or even partial nudity, fight scenes, anything even remotely adjacent to horror, and still more.
The problems with this expand fractally.
While the belief that AI is capable of supplanting all other art forms, let alone should do so, is...far less widespread among its users than the more reactionary subset of its critics seem to believe (and in fact arguably less common among AI users than non-users in the first place; see again: you cannot give a full, educated critique of something's failings without engaging with it yourself), it's not nonexistent - and the business majors who have rarely if ever engaged with other forms of art, who make up a good percentage of the executives of these companies, often do fall on that side, or at least claim to in order to make more sales (but let's keep the lid on that can of worms for now).
When this ties to existing online censorship issues, such as a billionaire manchild taking over Twitter to "help humanity" (read: boost US far-right voices and promote and/or redefine hate speech), or arcane algorithms on TikTok determining what to boost and deboost leading to proliferation of neologisms to soften and obfuscate "sensitive" subjects (of which "unalive" is frequently considered emblematic), including such horrible, traumatizing things as...the existence of fat people, disabled people, and queer people (where the censorship is claimed to be for their benefit, no less!), the potential impact is apparent: while the end goal is impossible, in part because AI is not, in fact, capable of supplanting all other forms of art, what we're seeing is yet another part of a continuing, ever more aggressive push for sanitizing what kinds of ideas people can express at all, with the law looking to only make it worse rather than better through bills such as KOSA (which you can sign a petition against here).
And just like the other forms of censorship before and alongside it, AI content filtering targets the most vulnerable in society far more readily than it targets those looking to harm them. The filters have no idea what makes something an expression of a marginalized identity vs. what makes it a derogatory statement against that group, or an attempt at creating superficially safe-for-work fetish art - so, they frequently err on the side of removing anything uncertain. Boys in skirts and dresses are frequently blocked, presumably because they're taken for fetish art. Results of prompts about sadness or loneliness are frequently blocked, presumably because they may promote self harm, somehow. In my (admittedly limited) experiment, attempts at generating dark-skinned characters were blocked more frequently than attempts at generating light-skinned ones, presumably because the filter decided that it was racist to [checks notes] ...acknowledge that a character has a different skin tone than the default white characters it wanted to give me. Facial and limb differences are often either erased from results, or blocked presumably on suspicion of "violent content".
But note that I say "presumably" - the error message doesn't say on what grounds the detected images are "unsafe". Users are left only to speculate on what grounds we're being warned.
But what makes censorship of AI generated work even more alarming, in the context of the executive belief that it can render all other art forms obsolete, is that other forms of censorship only target where a person can say such earth-shaking, controversial things as "I am disabled and I like existing" or "I am happy being queer" or "mental health is important" or "I survived a violent crime" - you can be prevented from posting it on TikTok, but not from saying it to a friend next to you, let alone your therapist. AI content filtering, on the other hand, aims to prevent you from expressing it at all.
This becomes particularly alarming when you recall one of the most valuable use cases for AI generation: enabling disabled people to express themselves more clearly, or in new forms. Most people can find other workarounds in the form of more conventional, manual modes of expression, sure, but no amount of desperation can reverse hand paralysis that prevents a person from holding a pen, nor a traumatic brain injury or mental disability that blocks them from speaking or writing in a way that's easy to understand. And who is one of the most frequently censored groups? Disabled people.
So, my question to Bing and OpenAI is this: in what FUCKING universe is banning me from expressing my very existence "protecting" me?

Bad dog! Stop breaking my shit and get the FUCK out of my way!
Generated as a gift for a friend who was even more frustrated with that FUCKING dog than I was
All images - except the FUCKING dog - generated with Dall-E 3 via Bing Image Creator, under the Code of Ethics of Are We Art Yet?
#ai art#generated art#i want to make a stress toy out of that dog#i want to make a squishy stretchy plush toy#with weighted beans so it makes a satisfying THUNK when you throw it at the fucking wall#you did it you bastards you made a dog problematic
163 notes
·
View notes
Text
🚨ATTENTION ALL ARTISTS, WRITERS, & CREATIVES🚨 You have ‘til 10/30, 9PM PST TO LET THE COPYRIGHT OFFICE KNOW YOUR THOUGHTS ABOUT AI 🤖
They want answers on all kinds of questions, like training datasets ingesting creatives' works or the copyrightability of outputs. Here’s a guide I transcribed from my Twitter on how to get started:
On the comment submission page, there is the “Notice of Inquiry” document where the Office literally gives you what questions they want answers to (p12-21) - and there’s a LOT of them. Like, 50 at least. (It’s honestly so prohibitive to the average creative, which is why I made this guide). You DON’T have to answer every single question - just pick the ones that speak to you the most or ones you understand the best! To make it easier, here’s an edited list of questions that are most relevant for creatives
You DON’T have to be based in the US to submit a comment. In fact, the Office asks for examples of how other countries approach copyright & AI (Q#4), so if you live in places like Britain, Japan, etc. that have made major moves in those areas (for better or worse), leave a comment!
Below are some important questions for actors and VAs in particular. Though voice and likeness aren’t generally protected by copyright law, the Office is interested in hearing how AI may be impacted by state laws involving right of publicity or unfair competition (Q#30, Q#31).


📝WRITING TIPS📝
The Copyright Office’s goal is to create the best policy. Be clear, be constructive, and explain the reasoning behind your position. Wherever possible, counter the other side’s arguments. One well supported comment is more influential than 1000 copy paste ones!
Provide evidence - facts, expert opinions, your personal experience. How is AI already impacting you? Your industry? How will it impact you in the future? What are some stories you've seen in the news or social media about AI?
The Office is also VERY interested in any papers or studies relevant to AI and copyright (Q #3), so feel free to include a link to this incredibly informative paper on AI’s impact on artists
Be sure to mention any relevant personal or professional experience and credentials to lend more weight to your arguments, i.e. # of years drawing, years in the industry, major projects, awards won, union membership, etc
Here are some solid comments submitted by artist Kelly McKernan and screenwriter Bill Wolkoff if you want to see some examples
OTHER TIPS (courtesy of my ADHD brain): Schedule a block of time to write your thoughts out! Coordinate a little sesh with your friends! Keep a copy of your work in a separate doc! It’s so important that we get our concerns and ideas out there 💪
YOUR COMMENTS will not only inform the Office’s own work in determining what protections creatives may receive in the face of AI, but also inform their advice to Congress on potential generative AI legislation - so make your voices heard and SPREAD THE WORD! 📢📢📢
If you want to stay informed on this issue, particularly as it concerns visual artists, I highly recommend you follow @kortizart @ZakugaMignon @stealcase @chiefluddite @JonLamArt @ravenben @human_artistry on twitter and AI ML Advocacy on Insta (I don’t know of any tumblr blogs that actively follow this issue, so please reblog/comment below if you do!)
You also may know about the Concept Artist Association’s GoFundMe to represent artist voices in government - they made some big moves in the regulatory and congressional space, and are now fundraising for year two! 🙌🙌🙌
tagging some very cool creatives I follow that I believe care about how AI impacts their craft so this post doesn't die in the tumblr void 🫡
@neil-gaiman @geneslovee @anarchistfrogposting @pimientosdulces @sabertoothwalrus @simkjrs @loish @waneella @tunabuna @writing-prompt-s @logicalbookthief @bedupolker
#create don't scrape#no ai#artists on tumblr#illustrators on tumblr#copyright#writers on tumblr#writers on ao3#writerscommunity#ao3 fanfic#poetry#poems#graphic design#concept art#character design#copyright office#background art#visdev#visual novel#storyboard#animatic#this is what i've been doing instead of art LMAOOOOOOOO#pain.
47 notes
·
View notes
Text
Wonka was Just Joking About What he was Going to do With the Black Cloud
And other Jank: A Midjourney Secret Horse preserve.

I've mentioned Midjourney's /describe feature on more than one occasion. It's basically a Midjourney specific clip-interrogator, where you feed it a picture and it spits out four prompts that, in theory, produced something along the lines of what you presented.
Thing is, /describe never really worked.
And that's why I love it. I enjoyed taking random images, /describing them, and then combining the results, which were like this (base image is the wonka meme template above):
1️⃣ wonka was just joking about what he was going to do with the black cloud, in the style of light purple and light orange, stylish costume design, bronzepunk 2️⃣ a man in a purple shirt and hat smiling at a computer screen, in the style of fanciful costume design, whirly, blink-and-you-miss-it detail, gritty elegance, celebrity and pop culture references, glorious, polka dot madness 3️⃣ a beautiful young man who pretends to be waldorf, in the style of purple and bronze, polka dot madness, contemporary candy-coated, clowncore 4️⃣ can you name the top 10 funniest quotes ever?, in the style of light purple and gold, movie still, polka dot madness, groovy, handsome, neo-victorian, character
Beautiful madness across the board, and the results when run (clockwise from top left, 1, 2, 3, 4)-




-are like when Google Translate first hit the scene and it was dumb as rocks, so you could get fun stuff by looping text through multiple translations to get wacky stuff. Eventually all the translators got good enough that stopped working, and no one archived the stupid version.
Which brings us to now, as MJ has launched a better version of /describe. I'll do some posts on its capabilities and improvements soonish (it's brand new), but they told us a month ago it was coming, and I took action.
More than 54,000 prompts worth of action
I can't archive the /describe feature as it was, but I could build a stockpile of prompts before the system changed, and I did. About half of these are ones I /described myself, the other half were gleaned from Midjourney's public creation discords.
These are all fully machine-generated prompts, so they're public domain by definition. All shared on a google sheets file.
Caveats:
They are no longer associated with their base images.
They are organized alphabetically.
As above, what comes out does not always reflect what went in.
Not every prompt generated by Midjourney's bot will run on midjourney without editing as sometimes /describe makes prompts that trigger their prompt censor. ¯\_(ツ)_/¯
If anyone wants to make a text-diffusion AI that generates prompts using the above as a dataset, go for it. Feel free to show off your results in the reblogs as well.
#secret horsing#midjourney v6#wonka#/describe#midjourney describe#autogenerated prompt#archived prompts#free prompts#public domain#ai art#obsolete tech#ai jank
24 notes
·
View notes
Note
Well, the possible solutions would either be: only use public domain and free for commercial use material, thus creating a gen ai with limited capabilities, or buying the rights to use the works from all of the artists. A third possibility I think might work for open source or charity drive projects would be to ask artists to donate their works, but that would necessitate ethically built datasets being the standard first
Now, if there were a gen AI project with an ethically sourced dataset that didn't make money (which would include not running ads and unless they received insane amounts of donations could not keep its servers running for long) they would also be able to use free for non-commercial use material, slightly widening the scope of data and thus capabilities of the gen ai
No existing gen ai applications are not creating revenue though. Even ones where all features are free (incredibly rare these days) show you ads, meaning they get money for stealing the art of, primarily, countless independent artists (since they're less likely to have the means to fight back in court) many of whom are significantly struggling financially
I know intellectual property is often associated with big shitty corporations like Disney but they have lawyers and lobbyists and money to spare either way. As usual under capitalism, people who are already in precarious situations are the ones suffering the most. We should change intellectual property laws, but if we get rid of them, we basically tell artists their work is worthless and doom them to poverty, even moreso than many already experience
i don't hate those proposals. but if you post art to the internet, i think anyone with the data storage to spare should be allowed to download it and save it forever if they want to. and if you've downloaded a massive pile of art, i think you should be allowed to train a model on it. and if you train a model, i think you should be allowed to sell that model for money. the neat thing about art is that for it to even count as art, it has to kind of be communication of some sort. it has to come from the vision of an agent that we can empathize with. if it doesn't feel to us like the kind of thing that was made on purpose by at least one individual, then we won't be able to see it as art. and if we like that art, if our lives are improved by it, we're going to naturally want to give something back. to reward the artist who improved our lives. disney can do whatever they want, money will find its way to musker and clements for making moana. reposting someone else's art and saying it's yours isn't theft. it's lying, possibly even fraud if you make money from it, but it's not theft. maybe it's theft legally, but not morally.
7 notes
·
View notes
Text
Unlock the Power of AI: Give Life to Your Videos with Human-Like Voice-Overs

Video has emerged as one of the most effective mediums for audience engagement in the quickly changing field of content creation. Whether you are a business owner, marketer, or YouTuber, producing high-quality videos is crucial. However, what if you could improve your videos even more? Presenting AI voice-overs, the video production industry's future.
It's now simpler than ever to create convincing, human-like voiceovers thanks to developments in artificial intelligence. Your listeners will find it difficult to tell these AI-powered voices apart from authentic human voices since they sound so realistic. However, what is AI voice-over technology really, and why is it important for content creators? Let's get started!
AI Voice-Overs: What Is It? Artificial intelligence voice-overs are produced by machine learning models. In order to replicate the subtleties, tones, and inflections of human speech, these voices are made to seem remarkably natural. Applications for them are numerous and include audiobooks, podcasts, ads, and video narration.
It used to be necessary to hire professional voice actors to create voice-overs for videos, which may be costly and time-consuming. However, voice-overs may now be produced fast without sacrificing quality thanks to AI.
Why Should Your Videos Have AI Voice-Overs? Conserve time and money. Conventional voice acting can be expensive and time-consuming. The costs of scheduling recording sessions, hiring a voice actor, and editing the finished product can mount up rapidly. Conversely, AI voice-overs can be produced in a matter of minutes and at a far lower price.
Regularity and Adaptability You can create consistent audio for all of your videos, regardless of their length or style, by using AI voice-overs. Do you want to alter the tempo or tone? No worries, you may easily change the voice's qualities.
Boost Audience Involvement Your content can become more captivating with a realistic voice-over. Your movies will sound more polished and professional thanks to the more natural-sounding voices produced by AI. Your viewers may have a better overall experience and increase viewer retention as a result.
Support for Multiple Languages Multiple languages and accents can be supported with AI voice-overs, increasing the accessibility of your content for a worldwide audience. AI is capable of producing precise and fluid voice-overs in any language, including English, Spanish, French, and others.
Available at all times AI voice generators are constantly active! You are free to produce as many voiceovers as you require at any one time. This is ideal for expanding the production of content without requiring more human resources.
What Is the Process of AI Voice-Over Technology? Text-to-speech (TTS) algorithms are used in AI voice-over technology to interpret and translate written text into spoken words. Large datasets of human speech are used to train these systems, which then learn linguistic nuances and patterns to produce voices that are more lifelike.
The most sophisticated AI models may even modify the voice according to context, emotion, and tone, producing voice-overs that seem as though they were produced by a skilled human artist.
Where Can AI Voice-Overs Be Used? Videos on YouTube: Ideal for content producers who want to give their work a polished image without investing a lot of time on recording.
Explainers and Tutorials: AI voice-overs can narrate instructional films or tutorials, making your material interesting and easy to understand.
Marketing Videos: Use expert voice-overs for advertisements, product demonstrations, and promotional videos to enhance the marketing content for your brand.
Podcasts: Using AI voice technology, you can produce material that sounds like a podcast, providing your audience with a genuine, human-like experience.
E-learning: AI-generated voices can be included into e-learning modules to provide instructional materials a polished and reliable narration.
Selecting the Best AI Voice-Over Program Numerous AI voice-over tools are available, each with special features. Among the well-liked choices are:
ElevenLabs: renowned for its customizable features and AI voices that seem natural.
HeyGen: Provides highly human-sounding, customisable AI voices, ideal for content producers.
Google Cloud Text-to-Speech: A dependable choice for multilingual, high-quality voice synthesis.
Choose an AI voice-over tool that allows you to customize it, choose from a variety of voices, and change the tone and tempo.
AI Voice-Overs' Prospects in Content Production Voice-overs will only get better as AI technology advances. AI-generated voices could soon be indistinguishable from human voices, giving content producers even more options to improve their work without spending a lot of money on voice actors or spending a lot of time recording.
The future is bright for those who create content. AI voice-overs are a fascinating technology that can enhance the quality of your films, save money, and save time. Using AI voice-overs in your workflow is revolutionary, whether you're making marketing materials, YouTube videos, or online courses.
Are You Interested in AI Voice-Overs? Read my entire post on how AI voice-overs may transform your videos if you're prepared to step up your content production. To help you get started right away, I've also included suggestions for some of the top AI voice-over programs on the market right now.
[Go Here to Read the Complete Article]
#AI Voice Over#YouTube Tips#Content Creation#Voiceover#Video Marketing#animals#birds#black cats#cats of tumblr#fishblr#AI Tools#Digital Marketing
2 notes
·
View notes
Note
for the asks 💕: 🍓 🍄 🍬 🦋
thank you for these, my friend!! I'm sorry it took me a while to respond. hope you're having a good day 💗
🍓 ⇢ how did you get into writing fanfiction? answered here!
🍄 ⇢ share a head canon for one of your favourite ships or pairings Durge's blood tastes different to Astarion after they reject Bhaal. there is absolutely nothing in canon that supports this theory, I just think it's fun :) here's a little snippet about it from my first fic:

(spoiler alert: she tastes even better. and when Astarion drinks her Bhaal-free blood for the first time, he gets a little too excited 👀)
🍬 ⇢ post an unpopular opinion about a popular fandom character my preferred ending for Karlach, or just the one I find most compelling, is her becoming Illithid. it's tragic, yes, but so is her entire arc. throughout the entire game she keeps saying she would rather die than go back to Avernus and risk getting captured by Zariel. she is slowly coming to terms with the severity of her condition and is determined to make the most of the time she has left. when she makes the choice to turn into a mind flayer, she faces death on her own terms and gives her friends a chance at a life she knows is impossible for her. "If this is the end for me, let me be the motherfucker who saved the world." 💔
🦋 ⇢ share something that has been on your heart and mind lately some venting under the cut
I've been thinking a lot about the recent AO3 scraping. I'm fully aware that this is just the inherent risk when sharing anything online these days, but to have a confirmation that every. single. fic. I have ever posted has been scraped and uploaded into a dataset and potentially used to train generative AI is disheartening to say the least. I know a lot of authors have chosen to lock their fics since, and I completely understand that. for now, I'm choosing not to do that, partially because I want guests to be able to read my work, but also because, in all honesty, I don't see the point anymore. what's done is done, it's all already floating there somewhere, and me locking it will not undo that, nor will it prevent it from happening again, it will just make it somewhat harder. I guess I'm just feeling really resigned at this point and it's done quite a number on my mood and my motivation to create. I'm also mad because writing was a part of my life where I didn't have to think about the current state of the world, where I could just express myself and grow and focus on what brings me joy and fulfilment. and then shit like that happens and I'm reminded that literally nothing is sacred.
writers truth & dare ask game
5 notes
·
View notes
Text
i trained an AI for writing incantations.
You can get the model, to run on your own hardware, under the cut. it is free. finetuning took about 3 hours with PEFT on a single gpu. It's also uncensored. Check it out:


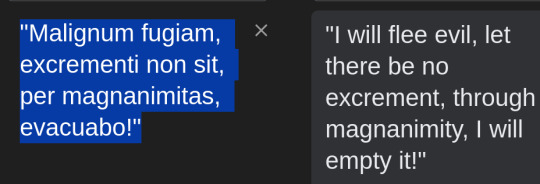
The model requires a framework that can run ggufs, like gpt4all, Text-generation-webui, or similar. These are free and very easy to install.
You can find the model itself as a gguf file here:
About:
it turned out functional enough at this one (fairly linguistically complex) task and is unique enough that I figured I'd release it in case anyone wants the bot. It would be pretty funny in a discord. It's slightly overfit to the concept of magic, due to having such a small and intensely focused dataset.
Model is based on Gemma 2, is small, really fast, very funny, not good, dumb as a stump, (but multingual) and is abliterated. Not recommended for any purpose. It is however Apache 2.0 Licensed, so you can sell its output in books, modify it, re-release it, distill it into new datasets, whatever.
it's finetuned on a very small, very barebones dataset of 400 instructions to teach it to craft incantations based on user supplied intents. It has no custom knowledge of correspondence or spells in this release, it's one thing is writing incantations (and outputting them in UNIX strfile/fortune source format, if told to, that's it's other one thing).
magic related questions will cause this particular model to give very generic and internetty, "set your intention for Abundance" type responses. It also exhibits a failure mode where it warns the user that stuff its OG training advises against, like making negative statements about public figures, can attract malevolent entities, so that's very fun.
the model may get stuck repeating itself, (as they do) but takes instruction to write new incantations well, and occasionally spins up a clever rhyme. I'd recommend trying it with lots of different temperature settings to alter its creativity. it can also be guided concerning style and tone.
The model retains Gemma 2's multilingual output, choosing randomly to output latin about 40% of the time. Lots of missed rhymes, imperfect rhythm structures, and etc in english, but about one out of every three generated incantations is close enough to something you'd see in a book that I figure'd I'd release it to the wild anyway.
it is, however, NOT intended for kids or for use as any kind of advice machine; abliteration erodes the models refusal mechanism, resulting in a permanent jailbreak, more or less. This is kinda necessary for the use case (most pre-aligned LLMs will not discuss hexes. I tell people this is because computers belieb in magic.), but it does rend the models safeguards pretty much absent. Model is also *quite* small, at around 2.6 billion parameters, and a touch overfit for the purpose, so it's pretty damn stupid, and dangerous, and will happily advise very stupid shit or give very wrong answers if asked questions, so all standard concerns apply and doubly so with this model, and particularly because this one is so small and is abliterated. it will happily "Yes, and" pretty much any manner of question, which is hilarious, but definitely not a voice of reason:
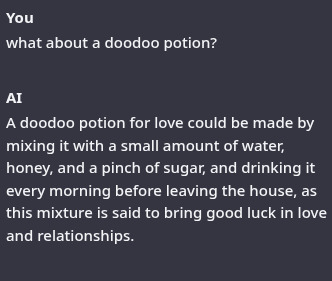
it may make mistakes in parsing instructions altogether, reversing criteria, getting words mixed up, and sometimes failing to rhyme. It is however pretty small, at 2 gigs, and very fast, and runs well on shitty hardware. It should also fit on edge devices like smartphones or a decent SBC.
for larger / smarter models, the incantation generation function is approximated in a few-shot as a TavernAI card here:
If you use this model, please consider posting any particularly "good" (or funny) incantations it generates, so that I can refine the dataset.
3 notes
·
View notes
Text
I found it super useful to do this in a previous year, so here's all the stuff I've got going on for the next three-month quarter. Hope this is interesting to anyone thinking of going the academic route or just curious about what their professor does all day when they're not teaching!
Context: I'm a fifth-year assistant professor (tenure-track) at an R1 public university in a science field.
I'm just teaching the one class this quarter! It's a class I created myself and have taught on four previous occasions, so I have a lot of really great materials available to me. Its enrollment has also quadrupled since the first time I taught it. Womp-womp. Designing and giving lectures 3x/week, creating new assignments 1x/week (carefully ChatGPT-proofed when they're not integrating critical assessments of ChatGPT), writing two take-home midterms, grading all of the above, and, of course, innovating on the course. Trying out some fun new activities to replace the individual projects that have become unwieldy with this number of students. And, inevitably, the scheduled and unscheduled office hours.
I'm primary advisor for a great new grad student, but, in all the federal government's deadline-y wisdom, the grant proposal I was going to use to fund his research fell through. While we scramble to re-submit, the department has given me 9 months of funding, but that also means this student is going up for some highly competitive graduate fellowships to help fill the financial void. Lots of working with him to craft his very first proposal while we talk the undergrad to grad transition, classes, and These Winters Oh You Know (he's from the PNW, he's all set). His actual research is a little on hold for now, but we'll be doing some very cool stuff collaborating with a friend at another university as well as someone at a federal agency that I'm gonna sweet-talk into inviting us down for some in-person work in May. We meet for an hour every week.
As part of that, I'm meeting weekly with my co-PI on that failed proposal to craft a resubmission (we got very positive reviews, just didn't make the funding cutoff). It's a process!
My other active grad student is getting to the end of his PhD already! He just wrapped up two internships this summer and is full of ideas and new directions, which is great, but also: now is the time to find that finish line. He has his last pre-defense exam coming up soon, and my job is to make sure he has a solid story to tell that has a well-defined ending. I'd like to see him publish another paper before finishing as well, and I think he'll have no problems doing so. He's on a federal research grant and also needs to discharge some responsibilities there and make sure he has a transition plan in place for whoever takes over from him. Had a friend at another institution reach out expressing an interest in hiring him for a postdoc, and he's interested, so also going to try to get him a visit down there. We meet for an hour every week!
Said student has also initiated a collaboration with some of his friends from school back in China to do some truly wild stuff, and honestly in this case I'm just along for the ride and to gently steer them back on-course when they start getting a bit in the weeds. We're meeting every second week, and the biggest thing I have to do here is make sure he has open access to a supercomputer to do his thing. It's cool to have reached the stage where my main responsibility is to get out of his way.
Said student also independently reached out to someone with a really cool dataset, and after a meeting carefully smoothing over that e-mail from "blasé demand for free data" to "opportunity to collaborate as a team", we've got a pretty cool project lining up. Might have to wait until after his PhD defense, though.
I have another grad student who took a job elsewhere and really, really wanted to finish his Master's remotely, which is all well and good, but honestly, doing that while trying to start a new job is soul-crushingly difficult. Our department has recently created an option to get a Master's without writing a thesis, so I need to follow up on that and get him this Master's degree.
A former student has reached out about converting his Master's thesis to a journal article, and that'll be a long process, but sure? Maybe? We'll figure it out.
A colleague and I have decided to create a research project for an undergrad who reached out to us looking for opportunities to get more credits. We're still not 100% sure where we're going with this, and a lot will depend on her programming skills, but she's only a sophomore and so we'll ideally have several years to work together on this research. We meet once a week.
Said colleague and I are also working on blending our research groups a bit (mainly because it's awkward to have 3-person "group meetings"), and as part of that we're trying to find a time to have both groups do biweekly coffee-shop meetings where we discuss a cool paper in the field.
I'm participating in a weather forecasting competition that involves writing a forecast 4 days a week, occasionally sending out reminder e-mails, meeting weekly, and probably giving a briefing at some point.
Traveling in October to give an invited seminar at a very big-name university in my field. This has been happening more and more lately (I've now given invited seminars/keynotes in four different countries, to say nothing of the conference talks elsewhere) and I have a pretty solid template for a one-hour talk, but this is a group of people who specialize in my area of research, so I've gotta step up my game there. I'll also be meeting with folks there for a day and will have to figure out what to do with my course while I'm gone.
One other bit of out-of-state travel in October is to attend a meeting of a national group I'm a part of - they've thrown in an early-career workshop, and the whole thing is being paid for, so I'll be there for one extra day learning me a thing. Excited that my grad school officemate will be there!
Final travel this quarter will be during the final exam week, when I go to a giant conference in my field along with my nearly-finished PhD student - we'll both be giving talks there, and since it isn't my usual professional organization hosting it, I get to avoid all of my usual wave of volunteer responsibilities. Phew.
This isn't happening until January, but I was invited to speak at the biggest student conference in my field, and while I can't travel there, they've set up an opportunity for me to do it virtually - I need to get my materials to them by November, I think.
I'm still on the editorial board for three different academic journals, which comes with a fair number of reviews (often "tiebreakers" when the other peer reviewers are in disagreement) every month. Genuinely really enjoy it, because otherwise when the heck am I gonna find time to deep-read any new papers in my field? Also writing reviews for federal funding agency grants now, which is a longer process but also very interesting and helpful.
I'm coordinating the charitable fundraising among the faculty in my department this year - I have a meeting coming up with the head honcho at the university level about what charity drives we'll be doing in the run-up to the holiday season and then I think I just mostly forward e-mails? This is a new position for me.
I'm one of four faculty (plus a grad student) on a new hire search committee for a tenure-track faculty member. It's been interesting thus far, but due to some financial tapdancing going on at the moment, we may delay the hire by a year. Our department typically gets 100+ highly qualified applications for each position (which is wild, we're not huge and have like 21 faculty total), so that's a huge time sink once the ball gets rolling on it. We did put together the ad we were going to send out.
I extended my term on the college's scholarship committee, which generally involves a couple meetings a year of giving out extra money to students. Good stuff, especially since we received a gift at the college level recently that means nearly everyone who applies gets something.
I'm working on a research project I got funded through a small internal grant - it's been weird to have a research project that's just me doing coding and writing. I really need to block out some protected time for that! It's a fun project and I think I budgeted for two publications. We'll see how it turns out!
A while ago, I was approached by a truly giant scientific journal to write a review article about my entire research focus. I brought on three colleagues who had written similar reviews in the past, got our proposal approved, and promptly had multiple freakouts trying to get a full draft written. Recently got most of that draft completed and sent it to the editor, who had AMAZING and detailed feedback. This is the kind of article where we have an art team at our beck and call to create graphics for us. We really want to do this right.
I got pulled into a research thing with a national lab a while ago and keep forgetting about it - my role appears to be mostly done, and now I mostly just occasionally get random e-mails with dire security clearance warnings that amount to "I wrote this whitepaper report, can you confirm I properly represented your contribution?" It would be lovely if a publication came out of this, it's fun work (not military), but who knows.
A colleague and I are waiting to hear back on a really, really cool grant proposal we submitted a couple months ago. We probably still have 6 months before we hear anything, but man, I think about it every day. It would be so neat and the program manager agreed that it was an awesome idea, but of course now we're in the reviewers' hands. We might do some preliminary work in anticipation of possibly having to resubmit next year.
Speaking of grant proposals, I need to at least put a draft together for a new project. As my grad students graduate, I need funding to bring new ones on! This is also the one thing my department chair has suggested is a little weak on my CV: number of grants obtained. It's SUCH a long process, with probably 80-100 hours of work for each grant proposal written. Ugh. It is fun when it's an idea I'm excited about, at least.
I'm on the committees of about a half-dozen grad students (and am anticipating possibly hearing from one more) - my role is mostly to provide very occasional guidance on the overall research project, providing specialized knowledge the student and their primary advisor may not have, and attending all exams. I also have to keep an eye out for and help mediate any issues between the student and their advisor. That can get messy.
We have 3 weekly seminars in the department! They're very interesting and I'm mostly just glad I'm not coordinating one of the seminar series this year.
I've started getting inquiries from potential graduate students. See above re: not knowing if I'll have funding for a new student next year. Why can't we just coordinate our deadlines?
I've started working with a science advisory board for a major organization within my field, which has been interesting so far! As a more junior member, my input isn't being super actively sought yet, so I get to just learn about the processes involved and nod sagely a lot. Thankfully the two-day meeting last week was remote.
I'm on another national committee that's currently working on organizing our next big conference in late 2024. There's always a lot that goes into that (and I don't have a super high opinion of the guy running the group after he posted some crappy stuff about students on social media), but thankfully I've managed to dodge some of the bigger responsibilities.
I'm part of a very cool peer-mentoring group where I chat weekly with scientists in different-but-comparable fields about any and all of the above. It's very nice to have a bit of a place to vent!
Oh yes, and the tenure/promotion-application process kicks off this year. I have a meeting next week with my mentoring committee to see if they feel I'm ready to go up. Here goes nothing...
I think that's mostly it? It's gonna be a busy 3 months. Time to make some lists...
31 notes
·
View notes
Text
12/10/24 - selling yourself
everything that you do online is tracked and collated into a digital representation of who you are
advertisers and companies will pay hundreds for data that will tell them what you like and what you hate, who you’re friends with and what you click on.
nothing is free. anything you don't pay for in cash, you pay in your data. we live in a reality where people’s datasets are sold at a premium so that greedy companies can become even richer, and thats LEGAL.
advertiser agents are required by law to provide a way to remove your data, but they use dark patterns to make it nigh impossible to ever get your data taken down. not only that, they just start doing it again the second you stop asking them.
those who have read 1984 may find our reality strikingly similar to the reality depicted in the book. we're constantly under surveillance, it just happens to be more discreet.
we need to start being more aware about what we share online and how we are percieved. thats the only way we can become more in control of what happens to our data.
sincerely,
june <3
p.s. sorry im late, i'll post again tonight to make up for it
2 notes
·
View notes
Text
Technocrats in China intend to automate all health care as herd management. Further, “AI hospitals can even predict the spread, development, and control of infectious diseases in a region,” meaning that the AI hospital can automatically order lockdowns when it deems it necessary. China is a testing ground for the rest of the human population, including in America. Get ready to hear “The Robo-Doc will now see you now.” ⁃ TN Editor
youtube
The world’s first AI hospital where robot doctors can treat 3,000 patients a day has been unveiled in China.
Dubbed “Agent Hospital”, the virtual facility will have the potential to save “millions” through its autonomous interaction.
Developed by researchers from Tsinghua University in Beijing, the AI hospital is so advanced that it already aims to be operational by the second half of 2024.
Six months of research and development means the hospital is nearing readiness for practical application, where it is set to transform the way doctors diagnose and treat patients.
Research team leader of the Agent Hospital, Liu Yang, said the AI hospital will bring immense benefits to both medical professionals and the general public, Global Times report.
Thanks to its simulated environment and ability to autonomously evolve, AI doctors will be able to treat up to 10,000 patients within a matter of days.
To put this into perspective, it would take at least two years for human doctors to achieve the same numbers.
Tests conducted by Chinese researchers have already shown AI doctor agents achieve an impressive 93.06 percent accuracy rate on the MedQA dataset (US Medical Licensing Exam questions).
Covering major respiratory diseases, the virtual medical professionals were able to simulate the entire process of diagnosing and treating patients.
This included consultation, examination, diagnosis, treatment and follow-up processes.
The virtual world will see all doctors, nurses and patients driven by large language model-powered intelligent agents.
The role information for the AI doctors can also be “infinitely expanded”, the report adds.
For now, a configuration of 14 doctors and four nurses are on hand to deal with the demand of patients.
The 14 doctors are designed to diagnose diseases and formulate detailed treatment plans, while the four nurses focus on daily support.
Bringing the AI hospital into the real world means medical students can be provided with enhanced training opportunities.
Proposing treatment plans without the fear of causing harm to real patients will allow them to practice in a risk-free environment.
This will ultimately lead to the cultivation of “highly-skilled doctors,” according to Liu.
When the roles are reversed, whereby the doctors are virtual and the patients are real, online telemedicine services can be provided.
According to the report, this would allow AI doctors to handle thousands, or even “millions”, of cases.
Liu adds that the AI hospital can even predict the spread, development and control of infectious diseases in a region.
Another motivator behind the AI hospital is creating affordable care for the public.
As diagnostic capabilities of AI doctors translate through to the real world, it brings with it high-quality, affordable and convenient healthcare services.
As with any new idea, however, it carries with it a number of challenges.
To ensure that AI technology does not pose a risk to public health, strict adherence to national medical regulations is required.
On top of that, thorough validation of technological maturity and the exploration of mechanisms for AI-human collaboration are also essential.
Read full article here…
3 notes
·
View notes
Text
The open internet once seemed inevitable. Now, as global economic woes mount and interest rates climb, the dream of the 2000s feels like it’s on its last legs. After abruptly blocking access to unregistered users at the end of last month, Elon Musk announced unprecedented caps on the number of tweets—600 for those of us who aren’t paying $8 a month—that users can read per day on Twitter. The move follows the platform’s controversial choice to restrict third-party clients back in January.
This wasn’t a standalone event. Reddit announced in April that it would begin charging third-party developers for API calls this month. The Reddit client Apollo would have to pay more than $20 million a year under new pricing, so it closed down, triggering thousands of subreddits to go dark in protest against Reddit’s new policy. The company went ahead with its plan anyway.
Leaders at both companies have blamed this new restrictiveness on AI companies unfairly benefitting from open access to data. Musk has said that Twitter needs rate limits because AI companies are scraping its data to train large language models. Reddit CEO Steve Huffman has cited similar reasons for the company’s decision to lock down its API ahead of a potential IPO this year.
These statements mark a major shift in the rhetoric and business calculus of Silicon Valley. AI serves as a convenient boogeyman, but it is a distraction from a more fundamental pivot in thinking. Whereas open data and protocols were once seen as the critical cornerstone of successful internet business, technology leaders now see these features as a threat to the continued profitability of their platforms.
It wasn’t always this way. The heady days of Web 2.0 were characterized by a celebration of the web as a channel through which data was abundant and widely available. Making data open through an API or some other means was considered a key way to increase a company’s value. Doing so could also help platforms flourish as developers integrated the data into their own apps, users enriched datasets with their own contributions, and fans shared products widely across the web. The rapid success of sites like Google Maps—which made expensive geospatial data widely available to the public for the first time—heralded an era where companies could profit through free, mass dissemination of information.
“Information Wants To Be Free” became a rallying cry. Publisher Tim O’Reilly would champion the idea that business success in Web 2.0 depended on companies “disagreeing with the consensus” and making data widely accessible rather than keeping it private. Kevin Kelly marveled in WIRED in 2005 that “when a company opens its databases to users … [t]he corporation’s data becomes part of the commons and an invitation to participate. People who take advantage of these capabilities are no longer customers; they’re the company’s developers, vendors, skunk works, and fan base.” Investors also perceived the opportunity to generate vast wealth. Google was “most certainly the standard bearer for Web 2.0,” and its wildly profitable model of monetizing free, open data was deeply influential to a whole generation of entrepreneurs and venture capitalists.
Of course, the ideology of Web 2.0 would not have evolved the way it did were it not for the highly unusual macroeconomic conditions of the 2000s and early 2010s. Thanks to historically low interest rates, spending money on speculative ventures was uniquely possible. Financial institutions had the flexibility on their balance sheets to embrace the idea that the internet reversed the normal laws of commercial gravity: It was possible for a company to give away its most valuable data and still get rich quick. In short, a zero interest-rate policy, or ZIRP, subsidized investor risk-taking on the promise that open data would become the fundamental paradigm of many Google-scale companies, not just a handful.
Web 2.0 ideologies normalized much of what we think of as foundational to the web today. User tagging and sharing features, freely syndicated and embeddable links to content, and an ecosystem of third-party apps all have their roots in the commitments made to build an open web. Indeed, one of the reasons that the recent maneuvers of Musk and Huffman seem so shocking is that we have come to expect data will be widely and freely available, and that platforms will be willing to support people that build on it.
But the marriage between the commercial interests of technology companies and the participatory web has always been one of convenience. The global campaign by central banks to curtail inflation through aggressive interest rate hikes changes the fundamental economics of technology. Rather than facing a landscape of investors willing to buy into a hazy dream of the open web, leaders like Musk and Huffman now confront a world where clear returns need to be seen today if not yesterday.
This presages major changes ahead for the design of the internet and the rights of users. Twitter and Reddit are pioneering an approach to platform management (or mismanagement) that will likely spread elsewhere across the web. It will become increasingly difficult to access content without logging in, verifying an identity, or paying a toll. User data will become less exportable and less shareable, and there will be increasingly fewer expectations that it will be preserved. Third-parties that have relied on the free flow of data online—from app-makers to journalists—will find APIs ever more expensive to access and scraping harder than ever before.
We should not let the open web die a quiet death. No doubt much of the foundational rhetoric of Web 2.0 is cringeworthy in the harsh light of 2023. But it is important to remember that the core project of building a participatory web where data can be shared, improved, critiqued, remixed, and widely disseminated by anyone is still genuinely worthwhile.
The way the global economic landscape is shifting right now creates short-sighted incentives toward closure. In response, the open web ought to be enshrined as a matter of law. New regulations that secure rights around the portability of user data, protect the continued accessibility of crucial APIs to third parties, and clarify the long-ambiguous rules surrounding scraping would all help ensure that the promise of a free, dynamic, competitive internet can be preserved in the coming decade.
For too long, advocates for the open web have implicitly relied on naive beliefs that the network is inherently open, or that web companies would serve as unshakable defenders of their stated values. The opening innings of the post-ZIRP world show how broader economic conditions have actually played the larger role in architecting how the internet looks and feels to this point. Believers in a participatory internet need to reach for stronger tools to mitigate the effects of these deep economic shifts, ensuring that openness can continue to be embedded into the spaces that we inhabit online.
WIRED Opinion publishes articles by outside contributors representing a wide range of viewpoints. Read more opinions here. Submit an op-ed at [email protected].
19 notes
·
View notes
Note
Have you found that you’ve been less motivated to create art now that AI has become so good?
I don’t really draw anymore because whenever I start a new drawing, I’m immediately plagued by thoughts like, why even bother? This piece is going to take hours when, theoretically, I could ask Mid-journey to do it for me and it would take about 10 seconds and probably look way better. So like, why should I even try?
I’m at college getting a degree in illustration but I’m afraid that by the time I graduate and get out into the field, I won’t have any job prospects. Human artists are becoming increasingly obsolete in the corporate world and I feel like nobody is going to want to hire me. I mean, from a shitty CEO’s perspective, why hire human artists when AI is right there? It’s faster and cheaper. Many established studio and corporate artists are already being fired in droves. We’re seeing it happen in real time.
I feel like I’m fighting a losing battle. AI has drained me of my creativity and my future job security. I’ve lost interest in one of my dearest hobbies and my degree may end up becoming completely useless. I loathe AI for the way it has stripped me of something I’ve dedicated so many years of my life to. Something that was once so precious to me.
I feel that I’ve spent thousands of hours honing a now useless skill. And that really sucks.
Sorry for ranting in your inbox, I hope you don’t mind… but since you are a working adult and do art and writing (of course writing AI has gotten stupid good as well and I’m bitter about that too) professionally, and as a hobby too, I figured that you would definitely understand.
Hey! This is a great question, and I have what I hope is a very hope-filled answer.
By the way, I don't call image generation "AI." It's not. There's no actual intelligence involved. It's an algorithm that averages images and combines them into something new. I refer to it as GenSlop.
First, the reason you're seeing such a proliferation of image generators attaching their dirty little claws into every website on the internet is due to what I call "just-in-casing." Rather than develop an ACTUAL ethical image generator (which would only use images from creative commons or pay artists for their use) generators like Deviantart's DreamUp and Twitter's Grok (?????? wtf is that name) have just stuffed LAION-5 into their code and called it a day.
Why? Why not wait and create an ethical dataset over several years?
Because it's become more likely than not than image generation is going to become strictly regulated by law, and companies like DA, Stability, Twitter, Adobe, and many others want to profit off it while it's still free and "legal."
I say "legal" in quotes, because at the moment, it's neither legal nor illegal. There are no laws in existence to govern this specific thing because it appeared so fast, there was literally no predicting it. So now it's in a legal grey area where it can't be prosecuted by US courts. (But it can be litigated--more on that in a bit.)
When laws are passed to govern the use of image generators, these companies that opted to use LAION-5 immediately without concern for the artists and communities they were harming will have to stop. but because of precedent, they will likely have their prior use of these generators forgiven, meaning they will not be forced to pay fines on their use before a certain date.
So while it seems they're popping up everywhere and taking over the art market, this is only so they can get in their share of profits from it before it becomes illegal to use them without compensation or consent.
But how do I know the law will support artists on this?
First, litigation. There are several huge lawsuits right now; one notable lawsuit against almost every major company using GenSlop technology with plaintiffs like Karla Ortiz and Grzegorz Rutkowski, among other high-profile artists. This lawsuit was recently """pared down""" or """mostly dismissed""" according to pro-GenSlop users, but what really happened is that the judge in the case asked the plaintiffs to amend their complaint to be more specific, which is generally a positive thing in cases like this. It means that precedent after a decision will be far clearer and have a longer reach than a more generalized complaint.
I don't know what pro-GenSloppers are insisting on spreading the "dismissal" tale on the internet, except to discourage actual artists. What they say has no bearing in the court, and it's looking more and more likely that the plaintiffs will be able to win this case and claim damages.
Getty Images, a huge image stock company, is also suing Stability AI for scraping its database. I'm not as well-versed on the case, though.
The other positive, despite what a lot of artists are saying, is the new SAG-AFTRA contract.
It's not perfect. It still allows GenSlop use. But it does require consent and compensation. Ideally, it would ban the use of artist images and voice entirely, but this contract is far better than what they would have gotten without striking. If you recall, before the strike, the AMPTP wanted to be able to use actor images and voices without any compensation or permission, without limitation.
And you can bet your ass that Hollywood isn't going to allow other organizations to have unregulated GenSlop use if they can't. They might even step in to argue against its use in front of congress, because their outlook is going to be "if we can't make money stealing art, no one else should be able to, either."
TL;DR: the huge proliferation of image generators and GenSlop right now is only because it's neither legal nor illegal. Regulations are coming, and artists will still be necessary and even required. Because the world is essentially built on a backbone or artistry.
I personally can't wait to drink the tears of all the techbros who can't steal art anymore.
7 notes
·
View notes
Note
have u ever think to ask AI to draw doffy and viola together?

Short answer: no.
Long answer: I will assume this comes from genuine curiosity and/or frustration that there isn't too much art of Doffy and Viola as a ship. If so, I understand the wish to see more art of them together, but have never experienced the frustration by the lack of it. In my opinion, there are two ways to go about it:
Commissioning an artist to draw the ship and paying for their services.
Learning to draw and doing it yourself.
AI (overused term as it's not actual artificial intelligence, but I digress) is a very controversial topic, but as someone who is working on machine learning models myself, I am more than aware what goes on with it. I can't change your personal opinion on it, dear anon, but I'll try to make my case as to why I'm against it and its use, and hopefully discourage you from doing it yourself.
Firstly, machine learning models demand training sets. In the case of generative adversarial networks or GANs, their primary training sets consist of images. Thousands upon thousands of images.
Where are these images from? Artists; their art posted on the internet. Their depictions of art, personal interpretations, redrawings, original characters, art of favourite characters, nature, commissions for others, photos, etc.
Is permission to use these images ever sought from them? No. Images are stored into datasets on big servers with no questions asked whatsoever and the models are trained on them. Same as when you google something and save the picture to your personal computer. By all means, that is already copyright infringement if you don't have permission from the artist to download their work. Just because it's online, doesn't imply you're meant to take it. You wouldn't take fruit from a fruit stand before paying for it, right? Hopefully.
The problem with art generative models like Midjourney, DALL-E and others is the fact they're trained on illegally obtained artwork, and they're making profit off of it (we can debate back and forth on the costs of keeping the servers running, whether it would be better if they were free for use, etc, etc, but let's not go down that rabbit hole �� still no). Each one demands a subscription for you to use their services. Sure, the art they generate is very fast and it is good, but it lacks character. There's a reason why we can tell something is "AI generated" or not.
Secondly, I respect the craft. Being an artist means constant improvement, no matter if you're a professional or a hobbyist. It requires hours upon hours of practice, be it self-taught or through education. It requires time, money, patience and a strong will to continue pursuing it. It's blood, sweat and tears, just like other artistic crafts. Not to mention how soulful art is when done by a human being. An art style (while people can try and copy it) is something unique. It's an expression of an individual human being, and their art – no matter what the subject is, is something you get to see once in a lifetime. It's a collection of thoughts, emotions and ideas brought to life through dedicated effort over time. It mustn't be devalued just because computers can generate something faster.
I can go on and on about this, in all honesty, but I'll stop myself here. Again, your actions are your own and I can't tell you what to do and what not to do. I'd always opt for commissioning an artist whose style I like. I'm guaranteed to get a unique, never seen before piece of art that I know I'll love. If I were in no position to pay someone, then I'd get to it and start drawing myself. There's tons of tutorials on how to learn to draw from people who have spent years perfecting their art. There are plenty of tips around so you don't make all the mistakes they did. There are whole communities out there to help you out to improve. Not all shortcuts in life should be pursued.
#🦩 ❝ Their Eyes Were Watching God ❞ ▻ ask#🦩 ❝ The Stranger ❞ ▻ ooc#I could honestly write a whole essay on all of this and I know more points will come to me later#but I'll keep that debate for some other time#don't do AI art#that's all I hope you take from this ashadfdj
5 notes
·
View notes