#this is NOT a predictive post!!! Just analysing the potentials of a hypothesis!!!
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr posted its first advertisements in May 2012 and subsequently earned $13M in revenue.
Text
Technical Trading Strategies: Profitable or Just Curve-Fitting?
Technical Trading Strategies: Profitable or Just Curve-Fitting? Technical analysis (TA) is a trading approach that evaluates past price movements and volume data to forecast future market trends. It relies on price patterns, indicators, and statistical measures rather than fundamental factors. Investors use tools like moving averages, RSI, and Bollinger Bands to identify trends, support and resistance levels, and potential entry or exit points. The growing proliferation of academic articles on technical analysis suggests its acceptance and effectiveness. However, some researchers continue to question its validity. Reference [1] revisits the question of whether TA works, testing TA rules on three stocks—AAPL, MSFT, and NVDA—from January 2000 to December 2022. The study evaluates the profitability of various technical trading strategies both in-sample and out-of-sample using methods such as reality checks and stepwise tests. The authors pointed out, In this paper, we analyze a comprehensive dataset of AAPL, MSFT, and NVDA stocks from January 2000 to December 2022 to evaluate the profitability of various technical trading strategies both in-sample and out-of-sample, using February 2016 as the primary cutoff and May 2018 as an alternative. We construct strategies based on multiple indicators and timeframes, conducting thorough statistical analyses to ensure robustness against data-snooping bias. Our results consistently demonstrate that apparent profitability often stems from parameter selection rather than true market inefficiencies, supporting the efficient market hypothesis. This highlights the difficulty in predicting profitable strategies ahead of time, emphasizing the unpredictable nature of achieving sustained trading success. In short, the article concludes that TA does not work, as it fails to identify any technical trading strategies that yield consistent profits across both periods. The results consistently show that apparent profitability often arises from parameter selection rather than genuine market inefficiencies, supporting the efficient market hypothesis. We welcome this type of research that challenges prevailing beliefs. However, in our opinion: The sample size is small, covering only three stocks, While the examined period is long, market dynamics may have changed over time. Using an extended dataset is beneficial, but a trading system should account for shifts in market conditions, Only two types of tests were conducted; more comprehensive testing is needed. That said, we look forward to seeing further research in this area. Let us know what you think in the comments below or in the discussion forum. References [1] Wang, Y., Chen, Y., Tian, H., & Wayne, Z. (2025). Evaluating Technical Trading Strategies in US Stocks: Insights From Data-Snooping Test. Journal of Accounting and Finance, 25(1). Post Source Here: Technical Trading Strategies: Profitable or Just Curve-Fitting? via Harbourfront Technologies - Feed https://ift.tt/kHJOIx6 February 16, 2025 at 10:36PM
0 notes
Note
@thedarkestcrow and a few others have gotten questions about the end of Kuro. The presumption is the final conflict will be between O!C and Sebastian. Many theorize that it will revolve around O!C’s desire to live or not, possibly with his living/reanimated family and friends begging him to escape Sebastian. Of course, even if O!C decides he wants to leave, Sebastian will demand his payment. My question to you is do you think O!C might change his mind about the contract and his will to live?
Dear Anon,
First of all, my thanks for your sweet words ^^
Now, about your question. Very interesting! I myself don’t do prediction theories though; it involves too much guessing based on too little information and too many variables for me to find it comfortable. That’s why I only do analyses of things that have already happened. So I am not sure how much I can help you here ≽▽≼ so my blog might be less amazing to you now, I’m so sorry.
Though, I can use your proposal as a hypothesis and analyse it. This will not be a predictive post, simply a deduction through logic within a hypothesis.
Hypothesis: Undertaker uses Bizarre Phantomhive Dolls to bait O!Ciel into giving up on his contract. Q: “might O!Ciel change his mind about the contract and his will to live?”
Personally I think it is fairly unlikely a zombie-family can cause O!Ciel’s resolve to waver because it is simply too strong.
Character Study
Most human beings who experience (sudden) loss need quite some time to process this information before reaching the stage of “acceptance”. Our boy however, already easily withstood a supernatural being’s positive response about reviving the dead even before he could actually process anything. Most people would not believe a human if they made the same offer, but wished it were true. But if a clearly powerful supernatural appeared before you, that’s a different story; who knows what magic potential they possess?
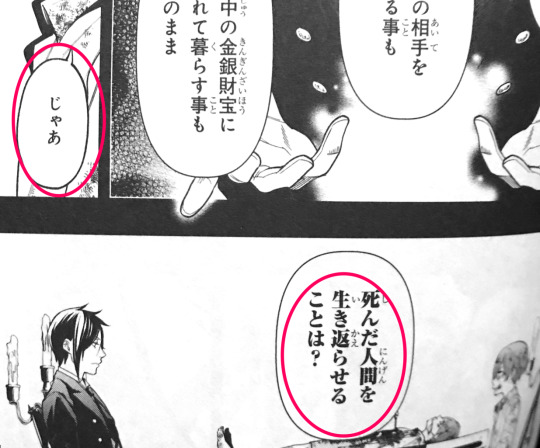
じゃあ、死んだ人間を生き返らせることは?
Jaa, shinda ningen wo ikikaeraseru koto wa?
And, what about bringing dead humans back to life?
O!Ciel was the one who brought this topic up. Judging from the clear-cut language and lack of emotional markers, it is arguable he said so not because he hoped it were possible, but because he knows it is impossible, and therefore wanted to test the demon’s truthfulness.

Sebastian took the bait, and therewith O!Ciel knew he’d have to strategically use his first wish to seal off the demon’s potential of lying. (Ugh he’s so smart!) O!Ciel’s swiftness in rejecting the demon’s temptation is evidence that he had already fully accepted that what is dead, stays dead.
Discussing Hypothesis
So, knowing O!Ciel has this level of acceptance, how would it play out IF Undertaker does attempt to lure O!Ciel with his revived family?
Had Undertaker really wanted the best chance at making O!Ciel fall for the temptation, he would have to not have exposed the boy to his creations so often. He has seen the in-between stages of reviving the dead, and therefore knows exactly what they are: Just decaying meat manipulated by a lunatic. Being met with the sudden appearance of seemingly flawless living-dead family would no longer be something new to O!Ciel, so it won’t have the advantage of a “pleasant surprise” to him.
O!Ciel is a very clever boy who thinks very clearly as long as he’s allowed the space in his head. So the best way to bait him into making a poor decision would be to disorient or overwhelm him with shocking new information, like at the end of the Circus Arc.

However, shock value is something that declines with every exposure. Now that O!Ciel is already so used to seeing Bizarre Dolls, and every time these zombies just get more and more advanced, he’d know it’s only a matter of time before these Dolls could become basically fully sentient, like his brother did.

Yes, he was very shocked to see R!Ciel back, but if we pay attention he was not so much concerned about his body being resurrected, but what threat R!Ciel’s return would pose to his own position now exposed as ‘the impostor’. Should Undertaker also “revive” his dead parents to try tempt the boy into reuniting with his family, then O!Ciel would be desensitised already by that time. He’d have had too much time to be mentally prepared. Besides, especially after seeing R!Ciel who is the biggest threat nothing would overwhelm him more anymore. You cannot shock somebody twice using the same trick; especially not if the second one is a lesser threat. It would be akin to bad film sequels that over-analyse the success of the original and use the formula of “more = better” to appease audiences.
In this sense, I personally reason that considering how Undertaker has been working so far, he would probably not try to make O!Ciel do a 180 through manipulation; that tactic simply leaves too much space for failure. Also, manipulation does not really seem Undertaker’s M.O.; that’s Sebas’ thing. Undertaker prefers cornering somebody, forcing them to bend eventually – i.e. use ‘hard-power’ instead of ‘soft’, like he did with Sebas on the Campania and at Weston.

How should Undertaker have acted to make the hypothesis work?
If we do go along with the hypothesis that Undertaker does want to use soft-power to get O!Ciel, he had better done things like this:
During the Campania Undertaker had indeed not expected the boy there, fine! That would have been an accident, as well as a competent way of storytelling to inform O!Ciel and the audience that clearly somebody is doing something big, and that Undertaker is not 100% in control of everything.
IF! I were the Undertaker in that situation AND I plan to bait O!Ciel with his “revived” family, I would never have revealed myself to be a reaper, and instead denied any responsibility for the bizarre dolls. Rian Stoker was fully convinced he had worked the disastrous “miracle” anyway, and there is no better scapegoat than one who truly believes himself guilty. Plus, he was scheduled to die anyway. If the scapegoat could just die in an accident caused indirectly by his own doing, the cover-story would have been beyond perfect.

Before Undertaker revealed himself, O!Ciel trusted Undertaker as an ally, and even went to him for sensitive information on which he based his entire job for the Queen. O!Ciel is naturally untrusting, but Undertaker did win that trust, and that should have been too valuable a weapon not to keep. By revealing himself to be an antagonistic and powerful being who mortally wounded O!Ciel’s main security (Sebas), Undertaker proved himself to be untrustworthy.
Now that O!Ciel can no longer trust Undertaker in the slightest, what effect would it have if this untrustworthy lunatic were to try bait him? I find it unlikely that O!Ciel would be stupid enough to take the bait, and Undertaker stupid enough to believe O!Ciel might after all this.
In short, for this hypothesis to work on the naturally untrusting O!Ciel, Undertaker would have needed to:
keep O!Ciel’s trust,
have the advantage of a ‘pleasant surprise’ on his side,
any credibility that his walking-flesh are “really alive”.
I hope this had been interesting ( ´ o`) Good day to you, Anon ^^
Follow up post: What would O!Ciel do if Undertaker tried to bait O!Ciel with Bizarre Phantomhives?
#Kuroshitsujit#Undertaker#Finale#O!Ciel#theory#character study#Bizarre Dolls#R!Ciel#this is NOT a predictive post!!! Just analysing the potentials of a hypothesis!!!
82 notes
·
View notes
Text
IS POLITICS DETERMINISTIC?
[Note: If the reader has taken up reading this blog with this posting, he/she is helped by knowing that this posting is the next one in a series of postings. The series begins with the posting, “The Natural Rights’ View of Morality” (February 25, 2020, https://gravitascivics.blogspot.com/2020/02/the-natural-rights-view-of-morality.html). Overall, the series addresses how the study of political science has affected the civics curriculum of the nation’s secondary schools.]
For those who might not be familiar with the term, determinism, it is the idea that humans do not really have control over their actions; that people are deceived into believing they do because they are conscious of going through some mental “decision-making” process before they act. Of course, the exception to this process occurs when people react to an unexpected change in their immediate environment.
This would be the case, for example, if one suddenly looked up and saw a ball headed for his/her noggin and the person automatically ducks.[1] Perhaps the reader has noticed that while watching a baseball game and, from time to time, a foul lined ball will shoot directly backwards. The people sitting behind the plate duck when that happens even though they know a fence is there to protect them.
Obviously, there is no decision-making; there is just reaction in those types of cases. But such occasions are rare; the rest of the time people, according to determinism, do more calculating than choosing.[2] Commentators have related behaviorism to determinism. The deterministic argument holds that due to the experiences a person has had, the physiological make-up of his/her body (a product of natural selection), and the conditions that a person faces at a given time, the way that person “decides” to act is, well, determined by those other forces.
That is, the person will always react to any situation by “choosing” the option that the person perceives is best for him/her given the conditions. Since the person has little control over the above listed factors, his/her choice is determined by them. Even in an action which is judged to be a sacrifice, the best action for the person is determined by the emotional cost he/she will bear by doing otherwise.
Now, due to space constraints, the description here is simplifying things a bit, but what is pointed out is that whether it seems to be the best choice – in terms of the person’s self-defined interests – or not, it is. People don’t choose against themselves as that is defined in its broadest terms. And one has very little control over the experiences or situations that “teach” a person what those interests are. In the extreme, this denies the existence of free will.
Applying these ideas leads to the practice, by those who want to solicit specific behaviors, of manipulating the factors of a situation so that the uses of rewards and punishments lead to desired outcomes. Many behaviorist studies are about finding which stimuli, rewards and punishments, lead to which behaviors.
For example, the motivations John R. P. French and Bertram H. Raven[3] identify (coercion, reward, legitimacy, expert, and reference) are different forms of punishments and rewards. For example, expert power indicates that one follows the advice of an expert, not because it is something the person necessarily wants to do, but because not to do so, it is believed, will elicit a punishment of a greater degree. That would be the case if not immediately, then eventually.
The mind computes the expected rewards and punishments and decides to advance as much reward as possible and diminish as much punishment as possible. And all is potentially calculated including the effort or costs involved with the calculations and the time sacrificed by following a course of action. Yes, even laziness is a factor, but whether one is lazy or not in a given situation is the result from prior calculations.
And while such venues where political decision-making takes place, supporting behavioral approaches to the study of politics – and any resulting political posturing – does not explicitly cite this understanding, but they proceed as if people do not have free will and can be manipulated. Their resulting plans seem to assume that this is the case. And another factor is, these studies do not claim to predict individual behavior, but the behavior of collectives.
And this line of assuming is not foreign to most people. Does the typical person ever promise a child extra dessert if he or she behaves in a certain way? Or perhaps stays on a job or in a career because the pay is so good or secure and the alternatives are known to be wanting or unknown? If yes, they have experienced behaviorism at work.
Even those who decide otherwise are so affected but have experienced other prior reward/punishment conditions. The recipient and dispenser of rewards and even punishments correctly predict behavior by providing the correct stimulus. How much of parenting, managing fellow workers, or governing consists of calculating such factors? Intuitively, one can say most of what various “supervisors” consider is what rewards and/or punishments work.
Those who ascribe to this position might sight the patterns that human behaviors follow. With enough knowledge, marketing strategies can do a good job of determining what products will sell; pollsters can often predict which candidates will win. Relatives can tell what a person will do when a life issue arises. Pure free will, it seems, would make these predictions impossible.
The only thing that prevents one hundred percent accuracy in these predictions is that just as in predicting the weather, there are too many factors interacting in highly complex ways that affect one’s decisions.[4] And as with the weather, rates of successful predictions, especially at the individual level, are significantly low. But most government decisions are not directed at an individual level, they aim at affecting populations – there the predicting level is much higher.
At least, that's what pure behaviorists would say. There are few pure behaviorists these days. Historically, the names of Ivan Pavlov, Edward Lee Thorndike, John B. Watson, and B. F. Skinner can be cited as pioneers in behavioral studies. Any introductory psychology textbook reviews the basic tenets associated with the works of these famous men.
While somewhat tamed from their original constructed view, behavioral studies are still in vogue and used in all sorts of social calculations from psychology to marketing to political and economic analyses.[5] But looking at that history is telling of current educational thinking. The heyday of behaviorism began in the twentieth century. Why did this shift toward behaviorism happen during the last century? At work were several historical trends.
Since the Enlightenment era, in the eighteenth century, science has been on an ascendancy in western countries. Due to the successes it garnered in practical areas such as agriculture and medicine and then industry, people began to rely more and more on the sciences. This process arose and reached its apogee with the technological advancements of World War II and the postwar years.
Until the beginning of the twentieth century though, its influences were pretty much limited to the study of natural phenomena. But starting with the twentieth century, scientific protocols were beginning to be applied to social concerns. Practitioners soon were aware that science's reliance on observable reality limited social sciences to the study of behavior since it was impossible to observe what goes on in the brain – of course, that observation was made at a time long before magnetic resonance imaging was developed.
Behavior was what one could see and what one could measure. Anything else was subject to speculation; at least, that was the case behaviorists made.[6] Practically, scholars who followed the systems approach to social reality began to rely on scientific protocols in their studies. Political science became highly statistical as the methods followed the hypothesis testing format which had been (and still is) the mainstay of the natural sciences.
How this progression of viewing governance and politics from a natural rights view to how that view has affected the study of politics via behavioral studies was reviewed in past postings by reporting on the work of David Easton and the development of the political systems model. The question that remains is how those developments in political science have affected how civics is taught in the nation’s secondary schools. To do that a review of a major textbook of American government will be shared.
[1] For an insightful and somewhat detailed account of what happens physically in brain under such a condition, see Robert M. Sapolsky, Behave: The Biology of Humans at Our Best and Worst (New York, NY: Penguin Press, 2017).
[2] Along with this calculating or computing notion, see Steven Pinker, How the Mind Works (New York, NY: W. W. Norton and Company, 1997). Pinker graphically describes this process of computation and demonstrates how complex it is. He adds to this explanatory approach to human behavior the effects of natural selection, another non self-determinate process.
[3] John R. P. French, Jr. and Bertram Raven, “The Bases of Power,” in Current Perspectives in Social Psychology, ed. Edwin P. Hollander and Raymond G. Hunt (New York, NY: Oxford University Press, 1967), 504-512.
[4] Interested, read B. F. Skinner’s book, Beyond Freedom and Dignity. B. F. Skinner, Beyond Freedom and Dignity (Seattle, WA: Hackett Publishing, 2002).
[5] A more current source and directed at training future government bureaucrats is Mark R. Leary, Introduction to Behavioral Research Methods, Seventh Edition (New York, NY: Pearson, 2017). Here again, the sense that people act as a result of the effects of stimuli, does not explicitly claim people do not have free will, but it just about assumes it.
[6] Of course, not all psychologists agreed with this assessment. For example, those who now or then ascribe to the ideas of Sigmund Freud would disagree since the focus of their study is the subconscious.
#free will#determinism#Robert M. Sapolsky#Steven Pinker#behavioralism#John R. P. French Jr.#Bertram Raven#B. F. Skinner#civics education#social studies
0 notes
Text
7 Mistakes to Avoid When You’re Reading Research
A couple weeks ago I wrote a post about how to read scientific research papers. That covered what to do. Today I’m going to tell you what NOT to do as a consumer of research studies.
The following are bad practices that can cause you to misinterpret research findings, dismiss valid research, or apply scientific findings incorrectly in your own life.
1. Reading Only the Abstract
This is probably the BIGGEST mistake a reader can make. The abstract is, by definition, a summary of the research study. The authors highlight the details they consider most important—or those that just so happen to support their hypotheses.
At best, you miss out on potentially interesting and noteworthy details if you read only the abstract. At worst, you come with a completely distorted impression of the methods and/or results.
Take this paper, for example. The abstract summarizes the findings like this: “Consumption of red and processed meat at an average level of 76 g/d that meets the current UK government recommendation (less than or equal to 90g/day) was associated with an increased risk of colorectal cancer.”
Based on this, you might think: 1. The researchers measured how much meat people were consuming. This is only half right. Respondents filled out a food frequency questionnaire that asked how many times per week they ate meat. The researchers then multiplied that number by a “standard portion size.” Thus, the amount of meat any given person actually consumed might vary considerably from what they are presumed to have eaten.
2. There was an increased risk of colorectal cancers. It says so right there after all. The researchers failed to mention that there was only an increased risk of certain types of colon cancer (and a small one at that—more on this later), not for others, and not for rectal cancer.
3. The risk was the same for everyone. Yet from the discussion: “Interestingly, we found heterogeneity by sex for red and processed meat, red meat, processed meat and alcohol, with the association stronger in men and null in women.” Null—meaning not significant—in women. If you look at the raw data, the effect is not just non-significant, it’s about as close to zero as you can get. To me, this seems like an important detail, one that is certainly abstract-worthy.
Although it’s not the norm for abstracts to blatantly misrepresent the research, it does happen. As I said in my previous post, it’s better to skip the abstract altogether than to read only the abstract.
2. Confusing Correlation and Causation
You’ve surely heard that correlation does not imply causation. When two variables trend together, one doesn’t necessarily cause the other. If people eat more popsicles when they’re wearing shorts, that’s not because eating popsicles makes you put on shorts, or vice versa. They’re both correlated with the temperature outside. Check out Tyler Vigen’s Spurious Correlations blog for more examples of just how ridiculous this can get.
As much as we all know this to be true, the popular media loves to take correlational findings and make causal statements like, “Eating _______ causes cancer!” or “To reduce your risk of _______, do this!” Researchers sometimes use sloppy language to talk about their findings in ways that imply causation too, even when their methods do not support such inferences.
The only way to test causality is through carefully controlled experimentation where researchers manipulate the variable they believe to be causal (the independent variable) and measure differences in the variable they hypothesize will be affected (the dependent variable). Ideally, they also compare the experimental group against a control group, replicate their results using multiple samples and perhaps different methods, and test or control for confounding variables.
As you might imagine, there are many obstacles to conducting this type of research. It’s can be expensive, time consuming, and sometimes unethical, especially with human subjects. You can’t feed a group of humans something you believe to be carcinogenic to see if they develop cancer, for example.
As a reader, it’s extremely important to distinguish between descriptive studies where the researchers measure variables and use statistical tests to see if they are related, and experimental research where they assign participants to different conditions and control the independent variable(s).
Finally, don’t be fooled by language like “X predicted Y.” Scientists can use statistics to make predictions, but that also doesn’t imply causality unless they employed an experimental design.
3. Taking a Single Study, or Even a Handful of Studies, as PROOF of a Phenomenon
When it comes to things as complex as nutrition or human behavior, I’d argue that you can never prove a hypothesis. There are simply too many variables at play, too many potential unknowns. The goal of scientific research is to gain knowledge and increase confidence that a hypothesis is likely true.
I say “likely” because statistical tests can never provide 100 percent proof. Without going deep into a Stats 101 lesson, the way statistical testing actually works is that you set an alternative hypothesis that you believe to be true and a null hypothesis that you believe to be incorrect. Then, you set out to find evidence to support the null hypothesis.
For example, let’s say you want to test whether a certain herb helps improve sleep. You give one experimental group the herb and compare them to a group that doesn’t get the herb. Your null hypothesis is that there is no effect of the herb, so the two groups will sleep the same.
You find that the group that got the herb slept better than the group that didn’t. Statistical tests suggest you can reject the null hypothesis of no difference. In that case, you’re really saying, “If it was true that this herb has no effect, it’s very unlikely that the groups in my study would differ to the degree they did.” You can conclude that it is unlikely—but not impossible—that there is no effect of the herb.
There’s always the chance that you unwittingly sampled a bunch of outliers. There’s also a chance that you somehow influenced the outcome through your study design, or that another unidentified variable actually caused the effect. That’s why replication is so important. The more evidence accumulates, the more confident you can be.
There’s also publication bias to consider. We only have access to data that get published, so we’re working with incomplete information. Analyses across a variety of fields have demonstrated that journals are much more likely to publish positive findings—those that support hypotheses—than negative findings, null findings (findings of no effect), or findings that conflict with data that have been previously published.
Unfortunately, publication bias is a serious problem that academics are still struggling to resolve. There’s no easy answer, and there’s really nothing you can do about it except to maintain an open mind. Never assume any question is fully answered.
4. Confusing Statistical Significance with Importance
This one’s a doozy. As I just explained, statistical tests only tell you whether it is likely that your null hypothesis is false. They don’t tell you whether the findings are important or meaningful or worth caring about whatsoever.
Let’s take that study we talked about in #1. It got a ton of coverage in the press, with many articles stating that we should all eat less red meat to reduce our cancer risk. What do the numbers actually say?
Well, in this study, there were 2,609 new cases of colorectal cancer in the 475,581 respondents during the study period—already a low probability. If you take the time to download the supplementary data, you’ll see that of the 113,662 men who reported eating red or processed mean four or more times per week, 866 were diagnosed. That’s 0.76%. In contrast, 90 of the 19,769 men who reported eating red and processed meat fewer than two times per week were diagnosed. That’s 0.45%.
This difference was enough to be statistically significant. Is it important though? Do you really want to overhaul your diet to possibly take your risk of (certain types of) colorectal cancer from low to slightly lower (only if you’re a man)?
Maybe you do think that’s important. I can’t get too worked up about it, and not just because of the methodological issues with the study.
There are lots of ways to make statistical significance look important, a big one being reporting relative risk instead of absolute risk. Remember, statistical tests are just tools to evaluate numbers. You have to use your powers of logic and reason to interpret those tests and decide what they mean for you.
5. Overgeneralizing
It’s a fallacy to think you can look at one piece of a jigsaw puzzle and believe you understand the whole picture. Any single research study offers just a piece of the puzzle.
Resist the temptation to generalize beyond what has been demonstrated empirically. In particular, don’t assume that research conducted on animals applies perfectly to humans or that research conducted with one population applies to another. It’s a huge problem, for example, when new drugs are tested primarily on men and are then given to women with unknown consequences.
6. Assuming That Published Studies are Right and Anecdotal Data is Wrong
Published studies can be wrong for a number of reasons—author bias, poor design and methodology, statistical error, and chance, to name a few. Studies can also be “right” in the sense that they accurately measure and describe what they set out to describe, but they are inevitably incomplete—the whole puzzle piece thing again.
Moreover, studies very often deal with group-level data—means and standard deviations. They compare the average person in one group to the average person in another group. That still leaves plenty of room for individuals to be different.
It’s a mistake to assume that if someone’s experience differs from what science says it “should” be, that person must be lying or mistaken. At the same time, anecdotal data is even more subject to biases and confounds than other types of data. Anecdotes that run counter to the findings of a scientific study don’t negate the validity of the study.
Consider anecdotal data another piece of the puzzle. Don’t give it more weight than it deserves, but don’t discount it either.
7. Being Overly Critical
As I said in my last post, no study is meant to stand alone. Studies are meant to build on one another so a complete picture emerges—puzzle pieces, have I mentioned that?
When conducting a study, researchers have to make a lot of decisions:
Who or what will their subjects be? If using human participants, what is the population of interest? How will they be sampled?
How will variables of interest be operationalized (defined and assessed)? If the variables aren’t something discrete, like measuring levels of a certain hormone, how will they be measured? For example, if the study focuses on depression, how will depression be evaluated?
What other variables, if any, will they measure and control for statistically? How else will they rule out alternative explanations for any findings?
What statistical tests will they use?
And more. It’s easy as a reader to sit there and go, “Why did they do that? Obviously they should have done this instead!” or, “But their sample only included trained athletes! What about the rest of us?”
There is a difference between recognizing the limitations of a study and dismissing a study because it’s not perfect. Don’t throw the baby out with the bathwater.
That’s my top seven. What would you add? Thanks for reading today, everybody. Have a great week.
(function($) { $("#dfBetBk").load("https://www.marksdailyapple.com/wp-admin/admin-ajax.php?action=dfads_ajax_load_ads&groups=1078&limit=1&orderby=random&order=ASC&container_id=&container_html=none&container_class=&ad_html=div&ad_class=&callback_function=&return_javascript=0&_block_id=dfBetBk" ); })( jQuery );
window.onload=function(){ga('send', { hitType: 'event', eventCategory: 'Ad Impression', eventAction: '95641' });}
The post 7 Mistakes to Avoid When You’re Reading Research appeared first on Mark's Daily Apple.
7 Mistakes to Avoid When You’re Reading Research published first on https://venabeahan.tumblr.com
0 notes
Text
7 Mistakes to Avoid When You’re Reading Research
A couple weeks ago I wrote a post about how to read scientific research papers. That covered what to do. Today I’m going to tell you what NOT to do as a consumer of research studies.
The following are bad practices that can cause you to misinterpret research findings, dismiss valid research, or apply scientific findings incorrectly in your own life.
1. Reading Only the Abstract
This is probably the BIGGEST mistake a reader can make. The abstract is, by definition, a summary of the research study. The authors highlight the details they consider most important—or those that just so happen to support their hypotheses.
At best, you miss out on potentially interesting and noteworthy details if you read only the abstract. At worst, you come with a completely distorted impression of the methods and/or results.
Take this paper, for example. The abstract summarizes the findings like this: “Consumption of red and processed meat at an average level of 76 g/d that meets the current UK government recommendation (less than or equal to 90g/day) was associated with an increased risk of colorectal cancer.”
Based on this, you might think: 1. The researchers measured how much meat people were consuming. This is only half right. Respondents filled out a food frequency questionnaire that asked how many times per week they ate meat. The researchers then multiplied that number by a “standard portion size.” Thus, the amount of meat any given person actually consumed might vary considerably from what they are presumed to have eaten.
2. There was an increased risk of colorectal cancers. It says so right there after all. The researchers failed to mention that there was only an increased risk of certain types of colon cancer (and a small one at that—more on this later), not for others, and not for rectal cancer.
3. The risk was the same for everyone. Yet from the discussion: “Interestingly, we found heterogeneity by sex for red and processed meat, red meat, processed meat and alcohol, with the association stronger in men and null in women.” Null—meaning not significant—in women. If you look at the raw data, the effect is not just non-significant, it’s about as close to zero as you can get. To me, this seems like an important detail, one that is certainly abstract-worthy.
Although it’s not the norm for abstracts to blatantly misrepresent the research, it does happen. As I said in my previous post, it’s better to skip the abstract altogether than to read only the abstract.
2. Confusing Correlation and Causation
You’ve surely heard that correlation does not imply causation. When two variables trend together, one doesn’t necessarily cause the other. If people eat more popsicles when they’re wearing shorts, that’s not because eating popsicles makes you put on shorts, or vice versa. They’re both correlated with the temperature outside. Check out Tyler Vigen’s Spurious Correlations blog for more examples of just how ridiculous this can get.
As much as we all know this to be true, the popular media loves to take correlational findings and make causal statements like, “Eating _______ causes cancer!” or “To reduce your risk of _______, do this!” Researchers sometimes use sloppy language to talk about their findings in ways that imply causation too, even when their methods do not support such inferences.
The only way to test causality is through carefully controlled experimentation where researchers manipulate the variable they believe to be causal (the independent variable) and measure differences in the variable they hypothesize will be affected (the dependent variable). Ideally, they also compare the experimental group against a control group, replicate their results using multiple samples and perhaps different methods, and test or control for confounding variables.
As you might imagine, there are many obstacles to conducting this type of research. It’s can be expensive, time consuming, and sometimes unethical, especially with human subjects. You can’t feed a group of humans something you believe to be carcinogenic to see if they develop cancer, for example.
As a reader, it’s extremely important to distinguish between descriptive studies where the researchers measure variables and use statistical tests to see if they are related, and experimental research where they assign participants to different conditions and control the independent variable(s).
Finally, don’t be fooled by language like “X predicted Y.” Scientists can use statistics to make predictions, but that also doesn’t imply causality unless they employed an experimental design.
3. Taking a Single Study, or Even a Handful of Studies, as PROOF of a Phenomenon
When it comes to things as complex as nutrition or human behavior, I’d argue that you can never prove a hypothesis. There are simply too many variables at play, too many potential unknowns. The goal of scientific research is to gain knowledge and increase confidence that a hypothesis is likely true.
I say “likely” because statistical tests can never provide 100 percent proof. Without going deep into a Stats 101 lesson, the way statistical testing actually works is that you set an alternative hypothesis that you believe to be true and a null hypothesis that you believe to be incorrect. Then, you set out to find evidence to support the null hypothesis.
For example, let’s say you want to test whether a certain herb helps improve sleep. You give one experimental group the herb and compare them to a group that doesn’t get the herb. Your null hypothesis is that there is no effect of the herb, so the two groups will sleep the same.
You find that the group that got the herb slept better than the group that didn’t. Statistical tests suggest you can reject the null hypothesis of no difference. In that case, you’re really saying, “If it was true that this herb has no effect, it’s very unlikely that the groups in my study would differ to the degree they did.” You can conclude that it is unlikely—but not impossible—that there is no effect of the herb.
There’s always the chance that you unwittingly sampled a bunch of outliers. There’s also a chance that you somehow influenced the outcome through your study design, or that another unidentified variable actually caused the effect. That’s why replication is so important. The more evidence accumulates, the more confident you can be.
There’s also publication bias to consider. We only have access to data that get published, so we’re working with incomplete information. Analyses across a variety of fields have demonstrated that journals are much more likely to publish positive findings—those that support hypotheses—than negative findings, null findings (findings of no effect), or findings that conflict with data that have been previously published.
Unfortunately, publication bias is a serious problem that academics are still struggling to resolve. There’s no easy answer, and there’s really nothing you can do about it except to maintain an open mind. Never assume any question is fully answered.
4. Confusing Statistical Significance with Importance
This one’s a doozy. As I just explained, statistical tests only tell you whether it is likely that your null hypothesis is false. They don’t tell you whether the findings are important or meaningful or worth caring about whatsoever.
Let’s take that study we talked about in #1. It got a ton of coverage in the press, with many articles stating that we should all eat less red meat to reduce our cancer risk. What do the numbers actually say?
Well, in this study, there were 2,609 new cases of colorectal cancer in the 475,581 respondents during the study period—already a low probability. If you take the time to download the supplementary data, you’ll see that of the 113,662 men who reported eating red or processed mean four or more times per week, 866 were diagnosed. That’s 0.76%. In contrast, 90 of the 19,769 men who reported eating red and processed meat fewer than two times per week were diagnosed. That’s 0.45%.
This difference was enough to be statistically significant. Is it important though? Do you really want to overhaul your diet to possibly take your risk of (certain types of) colorectal cancer from low to slightly lower (only if you’re a man)?
Maybe you do think that’s important. I can’t get too worked up about it, and not just because of the methodological issues with the study.
There are lots of ways to make statistical significance look important, a big one being reporting relative risk instead of absolute risk. Remember, statistical tests are just tools to evaluate numbers. You have to use your powers of logic and reason to interpret those tests and decide what they mean for you.
5. Overgeneralizing
It’s a fallacy to think you can look at one piece of a jigsaw puzzle and believe you understand the whole picture. Any single research study offers just a piece of the puzzle.
Resist the temptation to generalize beyond what has been demonstrated empirically. In particular, don’t assume that research conducted on animals applies perfectly to humans or that research conducted with one population applies to another. It’s a huge problem, for example, when new drugs are tested primarily on men and are then given to women with unknown consequences.
6. Assuming That Published Studies are Right and Anecdotal Data is Wrong
Published studies can be wrong for a number of reasons—author bias, poor design and methodology, statistical error, and chance, to name a few. Studies can also be “right” in the sense that they accurately measure and describe what they set out to describe, but they are inevitably incomplete—the whole puzzle piece thing again.
Moreover, studies very often deal with group-level data—means and standard deviations. They compare the average person in one group to the average person in another group. That still leaves plenty of room for individuals to be different.
It’s a mistake to assume that if someone’s experience differs from what science says it “should” be, that person must be lying or mistaken. At the same time, anecdotal data is even more subject to biases and confounds than other types of data. Anecdotes that run counter to the findings of a scientific study don’t negate the validity of the study.
Consider anecdotal data another piece of the puzzle. Don’t give it more weight than it deserves, but don’t discount it either.
7. Being Overly Critical
As I said in my last post, no study is meant to stand alone. Studies are meant to build on one another so a complete picture emerges—puzzle pieces, have I mentioned that?
When conducting a study, researchers have to make a lot of decisions:
Who or what will their subjects be? If using human participants, what is the population of interest? How will they be sampled?
How will variables of interest be operationalized (defined and assessed)? If the variables aren’t something discrete, like measuring levels of a certain hormone, how will they be measured? For example, if the study focuses on depression, how will depression be evaluated?
What other variables, if any, will they measure and control for statistically? How else will they rule out alternative explanations for any findings?
What statistical tests will they use?
And more. It’s easy as a reader to sit there and go, “Why did they do that? Obviously they should have done this instead!” or, “But their sample only included trained athletes! What about the rest of us?”
There is a difference between recognizing the limitations of a study and dismissing a study because it’s not perfect. Don’t throw the baby out with the bathwater.
That’s my top seven. What would you add? Thanks for reading today, everybody. Have a great week.
(function($) { $("#dfBetBk").load("https://www.marksdailyapple.com/wp-admin/admin-ajax.php?action=dfads_ajax_load_ads&groups=1078&limit=1&orderby=random&order=ASC&container_id=&container_html=none&container_class=&ad_html=div&ad_class=&callback_function=&return_javascript=0&_block_id=dfBetBk" ); })( jQuery );
window.onload=function(){ga('send', { hitType: 'event', eventCategory: 'Ad Impression', eventAction: '95641' });}
The post 7 Mistakes to Avoid When You’re Reading Research appeared first on Mark's Daily Apple.
7 Mistakes to Avoid When You’re Reading Research published first on https://drugaddictionsrehab.tumblr.com/
0 notes
Text
Research summary - Predicting phenotypes of individuals based on missense variants and prior knowledge of gene function
I have been meaning to write blog posts summarising different aspects of the work from our group over the past 6 years, putting it into context with other works and describing also some future perspectives. I have just been at the CSHL Network Biology meeting with some interesting talks that prompted me to put some thoughts to words regarding the issue of mapping genotypes to phenotypes, making use of prior cell biology knowledge. Skip to the last section if you just want a more general take and perspective on the problem.
Most of the work of our group over the past 6 years has been related to the study of kinase signalling. One smaller thread of research has been devoted to the relation between genotypes and phenotypes of individuals of the same species. My interest in this comes from the genetic and chemical genetic work in S. cerevisiae that I contributed while a postdoc (in Nevan Krogan’s lab). My introduction to genetics was from studies of gene deletion phenotypes in a single strain (i.e. individual) of a model organism. Going back to the works of Charlie Boone and Brenda Andrews, this research always emphasised that, despite rare, non-additive genetic and environment-gene interactions are numerous and constrained in predictable ways by cell biology. To me, this view of genetics still stands in contrast to genome-wide association studies (GWAS) that emphasise a simpler association model between genomic regions and phenotypes. In the GWAS world-view, genetic interactions are ignored and knowledge of cell biology is most often not considered as prior knowledge for associations (I know I am am exaggerating here).
Predicting phenotypes of individuals from coding variants and gene deletion phenotypes
Over 7 years ago, some studies of strains (i.e. individuals) of S. cerevisiae made available genome and phenotypic traits. Given all that we knew about the genetics and cell biology of S. cerevisiae I thought it would not be crazy to take the genome sequences, predict the impact of the variants on proteins of these strains and then use the protein function information to predict fitness traits. I was brilliantly scooped on these ideas by Rob Jelier (Jelier et al. Nat Genetics 2011) while he was in Ben Lehner’s lab (see previous blog post). Nevertheless, I though this was an interesting direction to explore and when Marco Galardini (group profile, webpage) joined our group as a postdoc he brought his own interests in microbial genotype-to-phenotype associations and which led to a fantastic collaboration with the Typas lab in Heidelberg pursuing this research line.
Marco set out to scale up the initial results from Ben’s lab with an application to E. coli. This entailed finding a large collection of strains from diverse sources, by sending emails to the community begging them to send us their collections. We compiled publicly available genome sequences, sequence some more and performed large scale growth profiling of these strains in different conditions. From the genome sequences, Marco calculated the impact of variants, relative to the reference genome and used variant effect predictors to identify likely deleterious variants. Genomes, phenotypes and variant effect predictions are available online for reuse. For the lab reference strain of E. coli, we had also quantitative data of the growth defects caused by deleting each gene in a large panel of conditions. We then tested the hypothesis that the poor growth of a strain of E. coli (in a given condition) could be predicted from deleterious variants in genes known to be important in that same condition (Galardini et al. eLife 2017). While our growth predictions were significantly related to experimental observations the predictive power was very weak. We discuss the potential reasons in the paper but the most obvious would be errors in the variant effect predictions and differences in the impact of gene deletion phenotypes in different genomic contexts (see below).
Around the same time Omar Wagih (group profile, twitter), a former PhD student, started the construction of a collection of variant effect predictors, expanding on the work that Marco was doing to try to generalise to multiple mechanisms of variant effects and to add predictors for S. cerevisiae and H. sapiens. The result of this effort was the www.mutfunc.com resource (Wagih et al. MSB 2018). Given a set of variants for a genome in one of the 3 species mutfunc will try to say which variants may have an impact on protein stability, protein interactions, conserved regions, PTMs, linear motifs and TF binding sites. There is a lot of work that went into getting all the methods together and a lot of computational time spent on pre-computing the potential consequence of every possible variant. We illustrate in the mutfunc paper some examples of how it can be used.
Modes of failure – variant effect predictions and genetic background dependencies
One of the potential reasons why the growth phenotypes of individual stains may be hard to predict based on loss of function mutations could be that the variant effect predictors are simply not good enough. We have looked at recent data on deep mutational scanning experiments and we know there is a lot of room for improvement. For example, the predictors (e.g. FoldX, SIFT) can get the trends for single variants but really fail for more than one missense variant. We will try to work on this and the increase in mutational scanning experiments will provide a growing set of examples on which to derive better computational methods.
A second potential reason why loss of function of genes may not cause predictable growth defects would be that the gene deletion phenotypes depends on the rest of the genetic background. Even if we were capable of predicting perfectly when a missense variant causes loss of function we can’t really assume that the gene deletion phenotypes will be independent of the other variants in the genome. To test this we have recently measured gene deletion phenotypes in 4 different genetic backgrounds of S. cerevisiae. We observed 16% to 42% deletion phenotypes changing between pairs of strains and described the overall findings in this preprint that is currently under review. This is consistent with other works, including RNAi studies in C. elegans where 20% of 1,400 genes tested had different phenotypes across two backgrounds. Understanding and taking into account these genetic background dependencies is not going to be trivial.
Perspectives and different directions on genotype-to-phenotype mapping
Where do we go from here ? How do make progress in mapping how genotype variants impact on phenotypes ? Of course, one research path that is being actively worked on is the idea that one can perform association studies between genotypes and phenotypes via “intermediate” traits such as gene expression and all other sorts of large scale measurements. The hope is that by jointly analysing such associations there can be a gain in power and mechanistic understanding. Going back to the Network Biology meeting this line of research was represented with a talk by Daifeng Wang describing the PsychENCODE Consortium with data for the adult brain across 1866 individuals with measurements across multiple different omics (Wang et al. Science 2018). My concern with this line of research is that it still focuses on fairly frequent variants and continues not to make full use of prior knowledge of biology. If combinations of rare or individual variants contribute significantly to the variance of phenotypes such association approaches will be inherently limited.
A few talks at the meeting included deep mutational scanning experiments where the focus is mapping (exhaustively) genotype-to-phenotype on much simpler systems, sometimes only a single protein. This included work from Fritz Roth and Ben Lehner labs. For example, Guillaume Diss (now a PI at FMI), described his work in Ben’s lab where they studied the impact of >120,000 pairs of mutations on an protein interaction (Diss & Lehner eLife 2018). Ben’s lab has several other examples where they have look in high detail and these fitness maps for specific functions (e.g. splicing code, tRNA function). From these, one can imagine slowly increasing the system complexity including for example pathway models. This is illustrated in a study of natural variants of the GAL3 gene in yeast (Richard et al. MSB 2018). This path forward is slower than QTL everything but the hope would be that some models will start to generalise well enough to apply them computationally at a larger scale.
Yet another take on this problem was represented by Trey Ideker at the meeting. He covered a lot of ground on his keynote but he showed how we can take the current large scale (unbiased) protein-protein functional association networks to create a hierarchical view of the cellular functions, or a cellular ontology (Dutkowski et al. Nat Biotech 2013 , www.nexontology.org). Then this hierarchical ontology can be used to learn how perturbations of gene functions combine in unexpected ways and at different levels of the hierarchy (Ma et al. Nat Methods 2018). The notion being that higher levels in the hierarchy could represent the true cellular cause of a phenotype. In other words, DNA damage repair deficiency could be underlying cause of a given disease and there are multiple ways by which such deficiency can be caused by mutations. Instead of performing linear associations between DNA variants and the disease, the variants can be interpreted at the level of this hierarchical view of gene function to predict the DNA damage repair deficiency and then associate that deficiency with the phenotype. The advantages of this line of research would be to be able to make use of prior cell biology knowledge and in a framework that explicitly considers genetic interactions and can interpret rare variants.
I think these represent different directions to address the same problem. Although they are all viable, as usual, I don't think they are equally funded and explored.
— Evolution of Cellular Networks
#Evolution of Cellular Networks#Research summary - Predicting phenotypes of individuals based on mis
0 notes
Text
The mystery of a 1918 veteran and the flu pandemic
http://bit.ly/2zxlb3G
Beds with patients in an emergency hospital in Camp Funston, Kansas, during the influenza epidemic around 1918. National Museum of Health and Medicine., CC BY
Vaccination is underway for the 2017-2018 seasonal flu, and next year will mark the 100-year anniversary of the 1918 flu pandemic, which killed roughly 40 million people. It is an opportune time to consider the possibility of pandemics – infections that go global and affect many people – and the importance of measures aimed at curbing them.
The 1918 pandemic was unusual in that it killed many healthy 20- to 40-year-olds, including millions of World War I soldiers. In contrast, people who die of the flu are usually under five years old or over 75.
The factors underlying the virulence of the 1918 flu are still unclear. Modern-day scientists sequenced the DNA of the 1918 virus from lung samples preserved from victims. However, this did not solve the mystery of why so many healthy young adults were killed.
I started investigating what happened to a young man who immigrated to the U.S. and was lost during World War I. Uncovering his story also brought me up to speed on hypotheses about why the immune systems of young adults in 1918 did not protect them from the flu.
The 1918 flu and World War I
Certificates picturing the goddess Columbia as a personification of the U.S. were awarded to men and women who died in service during World War I. One such certificate surfaced many decades later. This one honored Adolfo Sartini and was found by grandnephews who had never known him: Thomas, Richard and Robert Sartini.
The certificate was a message from the past. It called out to me, as I had just received the credential of certified genealogist and had spent most of my career as a scientist tracing a gene that regulates immune cells. What had happened to Adolfo?
A bit of sleuthing identified Adolfo’s ship listing, which showed that he was born in 1889 in Italy and immigrated to Boston in 1913. His draft card revealed that he worked at a country club in the Boston suburb of Newton. To learn more, Robert Sartini bought a 1930 book entitled “Newton War Memorial” on eBay. The book provided clues: Adolfo was drafted and ordered to report to Camp Devens, 35 miles from Boston, in March of 1918. He was later transferred to an engineer training regiment.
To follow up, I posted a query on the “U.S. Militaria Forum.” Here, military history enthusiasts explained that the Army Corps of Engineers had trained men at Camp A. A. Humphreys in Virginia. Perhaps Adolfo had gone to this camp?
While a mild flu circulated during the spring of 1918, the deadly strain appeared on U.S. soil on Tuesday, Aug. 27, when three Navy dockworkers at Commonwealth Pier in Boston fell ill. Within 48 hours, dozens more men were infected. Ten days later, the flu was decimating Camp Devens. A renowned pathologist from Johns Hopkins, William Welch, was brought in. He realized that “this must be some new kind of infection or plague.” Viruses, minuscule agents that can pass through fine filters, were poorly understood.
With men mobilizing for World War I, the flu spread to military installations throughout the U.S. and to the general population. It hit Camp Humphreys in mid-September and killed more than 400 men there over the next month. This included Adolfo Sartini, age 29½. Adolfo’s body was brought back to Boston.
His grave is marked by a sculpture of the lower half of a toppled column, epitomizing his premature death.
The legacy of victims of the 1918 flu
The quest to understand the 1918 flu fueled many scientific advances, including the discovery of the influenza virus. However, the virus itself did not cause most of the deaths. Instead, a fraction of individuals infected by the virus were susceptible to pneumonia due to secondary infection by bacteria. In an era before antibiotics, pneumonia could be fatal.
Recent analyses revealed that deaths in 1918 were highest among individuals born in the years around 1889, like Adolfo. An earlier flu pandemic emerged then, and involved a virus that was likely of a different subtype than the 1918 strain. These analyses engendered a novel hypothesis, discussed below, about the susceptibility of healthy young adults in 1918.
Exposure to an influenza virus at a young age increases resistance to a subsequent infection with the same or a similar virus. On the flip side, a person who is a child around the time of a pandemic may not be resistant to other, dissimilar viruses. Flu viruses fall into groups that are related evolutionarily. The virus that circulated when Adolfo was a baby was likely in what is called “Group 2,” whereas the 1918 virus was in “Group 1.” Adolfo would therefore not be expected to have a good ability to respond to this “Group 1” virus. In fact, exposure to the “Group 2” virus as a young child may have resulted in a dysfunctional response to the “Group 1” virus in 1918, exacerbating his condition.
Support for this hypothesis was seen with the emergence of the Hong Kong flu virus in 1968. It was in “Group 2” and had severe effects on people who had been children around the time of the 1918 “Group 1” flu.
To 2018 and beyond
What causes a common recurring illness to convert to a pandemic that is massively lethal to healthy individuals? Could it happen again? Until the reason for the death of young adults in 1918 is better understood, a similar scenario could reoccur. Experts fear that a new pandemic, of influenza or another infectious agent, could kill millions. Bill Gates is leading the funding effort to prevent this.
Flu vaccines are generated each year by monitoring the strains circulating months before flu season. A time lag of months allows for vaccine production. Unfortunately, because the influenza virus mutates rapidly, the lag also allows for the appearance of virus variants that are poorly targeted by the vaccine. In addition, flu pandemics often arise upon virus gene reassortment. This involves the joining together of genetic material from different viruses, which can occur suddenly and unpredictably.
An influenza virus is currently killing chickens in Asia, and has recently killed humans who had contact with chickens. This virus is of a subtype that has not been known to cause pandemics. It has not yet demonstrated the ability to be transmitted from person to person. However, whether this ability will arise during ongoing virus evolution cannot be predicted.
The chicken virus is in “Group 2.” Therefore, if it went pandemic, people who were children around the time of the 1968 “Group 2” Hong Kong flu might have some protection. I was born much earlier, and “Group 1” viruses were circulating when I was a child. If the next pandemic virus is in “Group 2,” I would probably not be resistant.
It’s early days for understanding how prior exposure affects flu susceptibility, especially for people born in the last three to four decades. Since 1977, viruses of both “Group 1” and “Group 2” have been in circulation. People born since then probably developed resistance to one or the other based on their initial virus exposures. This is good news for the near future since, if either a “Group 1” or a “Group 2” virus develops pandemic potential, some people should be protected. At the same time, if you are under 40 and another pandemic is identified, more information would be needed to hazard a guess as to whether you might be susceptible or resistant.
Ruth Craig does not work for, consult, own shares in or receive funding from any company or organization that would benefit from this article, and has disclosed no relevant affiliations beyond their academic appointment.
0 notes
Text
5 Steps To Cross-Account Analysis Superhero Status
This post is part of the Hero Conf Los Angeles Speaker Blog Series. Andrew Miller will join 50+ PPC experts sharing their paid search and social expertise at the World’s Largest All-PPC Event, April 18-20 in Los Angeles, CA. Like what you read? Find out more about Hero Conf.
PPC pros know how to use data to make better decisions and optimize campaigns for better results. But many agencies and large advertisers spread their campaigns across multiple accounts and analyzing all of this data can lead to greatness if done well….or migraines if done poorly.
Follow these five steps to make sure your analysis leads to hero status.
Step 1: Aggregate Data
Depending on your campaign structures and analytics strategies, you will likely be consuming and storing data from multiple sources (PPC platforms, Google Analytics, your CRM, etc.). Of course, you could manually pull the data from each source, drop into Excel or Tableau, and start crunching, but that process doesn’t scale. Each report or optimization would require repeating the same drudgery. That gets old very quickly.
Plan ahead and work with a developer to consume campaign performance and conversion data from each platform’s API. The less tech-savvy approach is to pull the data manually and upload to a database, but it is much easier, in the long run, to automate as much as possible. We pull daily data from each platform’s API and store it in a SQL database with table(s) for each PPC and analytics platform.
At this point in your journey, your most important task is to define your data structures. Which fields do you need to store, and how do you want to relate your data tables to each other? Basically, which data do you need to do your job? Planning this in advance will save you many headaches later when you discover you don’t have all the data you need to perform your analysis.
Don’t forget to think ahead to the analysis tools you plan to use (more on this in Step 4). Be sure your data structures and databases allow for secure external connections and are structured properly to make sense in an external environment.
In our case, because we are an agency, we ensure every row in every table has a “client ID” field so we can join the data at the client level. This allows us to mash up data and create reports for each client.
Step 2: Normalize Data
We’ve all heard the expression, “Garbage in, garbage out.” Analyzing data across multiple accounts is no exception. It is imperative that your accounts’ data is normalized, or made more consistent, to allow for apples-to-apples comparisons.
To truly compare and trend data accurately, you have to think “meta,” as in metadata. Metadata is simply data about data. Think of AdWords labels as metadata. For example, keywords in your AdWords campaigns can be branded or non-branded. Agency clients can fall into one or more industry categories.
Try to store as much metadata in your database as possible to allow for more consistent comparisons and analysis. For example, you could compare the effects of AdWords’ removal of right side ads on non-brand keywords for all clients in the healthcare industry pretty quickly if your data structures allow for it. Another of my favorite types of cross-account analysis is comparing pre and post-launch data for new clients based on the day we launch their new campaigns. It becomes very easy to develop case studies and spot anomalies when we can chart 30, 60, and 90-day performance and compare to a previous agency’s results.
Take the time to develop a robust, consistent tagging strategy so your analysis is not tainted with garbage data.
Step 3: Democratize Data
We can’t assume that all of our end users are going to be proficient in writing mySQL queries. Nor can we build dashboards or apps that can possibly predict all the ways our analysts could want to slice and dice the data.
Instead of trying to train everybody on database queries, take a more democratic approach to setting the data free. Make your data structures and sample data sets available in more common formats such as Excel or Google Sheets. This way, anybody can see what data are available and think up ways to use it.
Non-developers can still formulate questions that a data analyst can translate into a database query. For example, an Account Manager recently approached me with the question, “How does Client X’s CPC and CPA compare to other clients in the same industry?” Pulling this benchmark data from our database took just a few minutes, saving hours of manual data pulls and pivot tables.
Bottom line, don’t lock up your data! Set it free so that more people can find ways to put it to use.
Step 4: Analyze Data
Most PPC folk simply jump ahead to this step. It may work in the short-run or for an ad-hoc analysis, but be warned that skipping steps 1–3 could lead to inconclusive results, murky data, or decisions based on inaccurate data. Take the time to do it right so that future analyses will be faster and more insightful.
Now that you have multiple accounts worth of data in one place, it’s time to start analyzing. This is where the magic happens! Analysis can lead to insights and insights to optimization.
Develop a hypothesis
Start by developing and testing hypotheses about your data. Don’t just wade into mountains of data hoping to find a gem. Go in with a map and an idea of what you are searching for.
Select the right tools for the job
First off, find the tools needed to do the job right. A more savvy user might be able to write her own SQL queries and export the data to Excel or Google Sheets, but other users might benefit from a business intelligence tool such as Tableau or Google Data Studio for faster analysis.
Begin segmenting and filtering
Next, take advantage of the data and metadata you set up in step 2. You didn’t skip step 2, did you? These facets allow you to segment your data even further to find nuggets of info that can lead to insights.
Just as in Google Analytics, try toggling different segments on and off to look for anomalies or outliers. This is where clean, consistent data structures come in handy. Make sure that you are controlling for variables that might skew results among multiple PPC accounts. Are some accounts using different tagging methodologies for brand vs. non-brand keywords? Are all of your accounts using the same time zones and currency formats?
Establish benchmarks and trends
Once you find the right data, it becomes easy to compare cross-account performance to spot trends or anomalies. From this macro perspective, you can easily look for over- or under-performing accounts, watch for daily/weekly/monthly/quarterly changes, and proactively identify when you are off pace to achieve your KPI targets.
If you are really advanced (or have a great BI team), pattern detection or statistical analysis tools can do much of the heavy lifting here. Want to take it to 11? Invest in machine learning to spot and escalate outliers for further analysis.
Step 5: Exploit Opportunities
Finally, after all the hard work is done, you get to play hero. With the right data, hypotheses, tools, and time, you will be able to quickly and easily analyze campaign performance data across multiple PPC accounts.
Comparing and acting on data from multiple accounts is fundamentally the same as working on one account, with the exception of having more variables to control for and more potential dimensions for segmentation.
However you decide to set up your cross-account analysis, take the time to plan ahead. The upfront effort to plan ahead will result in many hours of saved time and increased accuracy down the road.
from RSSMix.com Mix ID 8217493 http://www.ppchero.com/5-steps-to-cross-account-analysis-superhero-status/
0 notes
Text
5 Steps To Cross-Account Analysis Superhero Status
This post is part of the Hero Conf Los Angeles Speaker Blog Series. Andrew Miller will join 50+ PPC experts sharing their paid search and social expertise at the World’s Largest All-PPC Event, April 18-20 in Los Angeles, CA. Like what you read? Find out more about Hero Conf.
PPC pros know how to use data to make better decisions and optimize campaigns for better results. But many agencies and large advertisers spread their campaigns across multiple accounts and analyzing all of this data can lead to greatness if done well….or migraines if done poorly.
Follow these five steps to make sure your analysis leads to hero status.
Step 1: Aggregate Data
Depending on your campaign structures and analytics strategies, you will likely be consuming and storing data from multiple sources (PPC platforms, Google Analytics, your CRM, etc.). Of course, you could manually pull the data from each source, drop into Excel or Tableau, and start crunching, but that process doesn’t scale. Each report or optimization would require repeating the same drudgery. That gets old very quickly.
Plan ahead and work with a developer to consume campaign performance and conversion data from each platform’s API. The less tech-savvy approach is to pull the data manually and upload to a database, but it is much easier, in the long run, to automate as much as possible. We pull daily data from each platform’s API and store it in a SQL database with table(s) for each PPC and analytics platform.
At this point in your journey, your most important task is to define your data structures. Which fields do you need to store, and how do you want to relate your data tables to each other? Basically, which data do you need to do your job? Planning this in advance will save you many headaches later when you discover you don’t have all the data you need to perform your analysis.
Don’t forget to think ahead to the analysis tools you plan to use (more on this in Step 4). Be sure your data structures and databases allow for secure external connections and are structured properly to make sense in an external environment.
In our case, because we are an agency, we ensure every row in every table has a “client ID” field so we can join the data at the client level. This allows us to mash up data and create reports for each client.
Step 2: Normalize Data
We’ve all heard the expression, “Garbage in, garbage out.” Analyzing data across multiple accounts is no exception. It is imperative that your accounts’ data is normalized, or made more consistent, to allow for apples-to-apples comparisons.
To truly compare and trend data accurately, you have to think “meta,” as in metadata. Metadata is simply data about data. Think of AdWords labels as metadata. For example, keywords in your AdWords campaigns can be branded or non-branded. Agency clients can fall into one or more industry categories.
Try to store as much metadata in your database as possible to allow for more consistent comparisons and analysis. For example, you could compare the effects of AdWords’ removal of right side ads on non-brand keywords for all clients in the healthcare industry pretty quickly if your data structures allow for it. Another of my favorite types of cross-account analysis is comparing pre and post-launch data for new clients based on the day we launch their new campaigns. It becomes very easy to develop case studies and spot anomalies when we can chart 30, 60, and 90-day performance and compare to a previous agency’s results.
Take the time to develop a robust, consistent tagging strategy so your analysis is not tainted with garbage data.
Step 3: Democratize Data
We can’t assume that all of our end users are going to be proficient in writing mySQL queries. Nor can we build dashboards or apps that can possibly predict all the ways our analysts could want to slice and dice the data.
Instead of trying to train everybody on database queries, take a more democratic approach to setting the data free. Make your data structures and sample data sets available in more common formats such as Excel or Google Sheets. This way, anybody can see what data are available and think up ways to use it.
Non-developers can still formulate questions that a data analyst can translate into a database query. For example, an Account Manager recently approached me with the question, “How does Client X’s CPC and CPA compare to other clients in the same industry?” Pulling this benchmark data from our database took just a few minutes, saving hours of manual data pulls and pivot tables.
Bottom line, don’t lock up your data! Set it free so that more people can find ways to put it to use.
Step 4: Analyze Data
Most PPC folk simply jump ahead to this step. It may work in the short-run or for an ad-hoc analysis, but be warned that skipping steps 1–3 could lead to inconclusive results, murky data, or decisions based on inaccurate data. Take the time to do it right so that future analyses will be faster and more insightful.
Now that you have multiple accounts worth of data in one place, it’s time to start analyzing. This is where the magic happens! Analysis can lead to insights and insights to optimization.
Develop a hypothesis
Start by developing and testing hypotheses about your data. Don’t just wade into mountains of data hoping to find a gem. Go in with a map and an idea of what you are searching for.
Select the right tools for the job
First off, find the tools needed to do the job right. A more savvy user might be able to write her own SQL queries and export the data to Excel or Google Sheets, but other users might benefit from a business intelligence tool such as Tableau or Google Data Studio for faster analysis.
Begin segmenting and filtering
Next, take advantage of the data and metadata you set up in step 2. You didn’t skip step 2, did you? These facets allow you to segment your data even further to find nuggets of info that can lead to insights.
Just as in Google Analytics, try toggling different segments on and off to look for anomalies or outliers. This is where clean, consistent data structures come in handy. Make sure that you are controlling for variables that might skew results among multiple PPC accounts. Are some accounts using different tagging methodologies for brand vs. non-brand keywords? Are all of your accounts using the same time zones and currency formats?
Establish benchmarks and trends
Once you find the right data, it becomes easy to compare cross-account performance to spot trends or anomalies. From this macro perspective, you can easily look for over- or under-performing accounts, watch for daily/weekly/monthly/quarterly changes, and proactively identify when you are off pace to achieve your KPI targets.
If you are really advanced (or have a great BI team), pattern detection or statistical analysis tools can do much of the heavy lifting here. Want to take it to 11? Invest in machine learning to spot and escalate outliers for further analysis.
Step 5: Exploit Opportunities
Finally, after all the hard work is done, you get to play hero. With the right data, hypotheses, tools, and time, you will be able to quickly and easily analyze campaign performance data across multiple PPC accounts.
Comparing and acting on data from multiple accounts is fundamentally the same as working on one account, with the exception of having more variables to control for and more potential dimensions for segmentation.
However you decide to set up your cross-account analysis, take the time to plan ahead. The upfront effort to plan ahead will result in many hours of saved time and increased accuracy down the road.
from RSSMix.com Mix ID 8217493 http://www.ppchero.com/5-steps-to-cross-account-analysis-superhero-status/
0 notes
Text
5 Steps To Cross-Account Analysis Superhero Status
This post is part of the Hero Conf Los Angeles Speaker Blog Series. Andrew Miller will join 50+ PPC experts sharing their paid search and social expertise at the World’s Largest All-PPC Event, April 18-20 in Los Angeles, CA. Like what you read? Find out more about Hero Conf.
PPC pros know how to use data to make better decisions and optimize campaigns for better results. But many agencies and large advertisers spread their campaigns across multiple accounts and analyzing all of this data can lead to greatness if done well….or migraines if done poorly.
Follow these five steps to make sure your analysis leads to hero status.
Step 1: Aggregate Data
Depending on your campaign structures and analytics strategies, you will likely be consuming and storing data from multiple sources (PPC platforms, Google Analytics, your CRM, etc.). Of course, you could manually pull the data from each source, drop into Excel or Tableau, and start crunching, but that process doesn’t scale. Each report or optimization would require repeating the same drudgery. That gets old very quickly.
Plan ahead and work with a developer to consume campaign performance and conversion data from each platform’s API. The less tech-savvy approach is to pull the data manually and upload to a database, but it is much easier, in the long run, to automate as much as possible. We pull daily data from each platform’s API and store it in a SQL database with table(s) for each PPC and analytics platform.
At this point in your journey, your most important task is to define your data structures. Which fields do you need to store, and how do you want to relate your data tables to each other? Basically, which data do you need to do your job? Planning this in advance will save you many headaches later when you discover you don’t have all the data you need to perform your analysis.
Don’t forget to think ahead to the analysis tools you plan to use (more on this in Step 4). Be sure your data structures and databases allow for secure external connections and are structured properly to make sense in an external environment.
In our case, because we are an agency, we ensure every row in every table has a “client ID” field so we can join the data at the client level. This allows us to mash up data and create reports for each client.
Step 2: Normalize Data
We’ve all heard the expression, “Garbage in, garbage out.” Analyzing data across multiple accounts is no exception. It is imperative that your accounts’ data is normalized, or made more consistent, to allow for apples-to-apples comparisons.
To truly compare and trend data accurately, you have to think “meta,” as in metadata. Metadata is simply data about data. Think of AdWords labels as metadata. For example, keywords in your AdWords campaigns can be branded or non-branded. Agency clients can fall into one or more industry categories.
Try to store as much metadata in your database as possible to allow for more consistent comparisons and analysis. For example, you could compare the effects of AdWords’ removal of right side ads on non-brand keywords for all clients in the healthcare industry pretty quickly if your data structures allow for it. Another of my favorite types of cross-account analysis is comparing pre and post-launch data for new clients based on the day we launch their new campaigns. It becomes very easy to develop case studies and spot anomalies when we can chart 30, 60, and 90-day performance and compare to a previous agency’s results.
Take the time to develop a robust, consistent tagging strategy so your analysis is not tainted with garbage data.
Step 3: Democratize Data
We can’t assume that all of our end users are going to be proficient in writing mySQL queries. Nor can we build dashboards or apps that can possibly predict all the ways our analysts could want to slice and dice the data.
Instead of trying to train everybody on database queries, take a more democratic approach to setting the data free. Make your data structures and sample data sets available in more common formats such as Excel or Google Sheets. This way, anybody can see what data are available and think up ways to use it.
Non-developers can still formulate questions that a data analyst can translate into a database query. For example, an Account Manager recently approached me with the question, “How does Client X’s CPC and CPA compare to other clients in the same industry?” Pulling this benchmark data from our database took just a few minutes, saving hours of manual data pulls and pivot tables.
Bottom line, don’t lock up your data! Set it free so that more people can find ways to put it to use.
Step 4: Analyze Data
Most PPC folk simply jump ahead to this step. It may work in the short-run or for an ad-hoc analysis, but be warned that skipping steps 1–3 could lead to inconclusive results, murky data, or decisions based on inaccurate data. Take the time to do it right so that future analyses will be faster and more insightful.
Now that you have multiple accounts worth of data in one place, it’s time to start analyzing. This is where the magic happens! Analysis can lead to insights and insights to optimization.
Develop a hypothesis
Start by developing and testing hypotheses about your data. Don’t just wade into mountains of data hoping to find a gem. Go in with a map and an idea of what you are searching for.
Select the right tools for the job
First off, find the tools needed to do the job right. A more savvy user might be able to write her own SQL queries and export the data to Excel or Google Sheets, but other users might benefit from a business intelligence tool such as Tableau or Google Data Studio for faster analysis.
Begin segmenting and filtering
Next, take advantage of the data and metadata you set up in step 2. You didn’t skip step 2, did you? These facets allow you to segment your data even further to find nuggets of info that can lead to insights.
Just as in Google Analytics, try toggling different segments on and off to look for anomalies or outliers. This is where clean, consistent data structures come in handy. Make sure that you are controlling for variables that might skew results among multiple PPC accounts. Are some accounts using different tagging methodologies for brand vs. non-brand keywords? Are all of your accounts using the same time zones and currency formats?
Establish benchmarks and trends
Once you find the right data, it becomes easy to compare cross-account performance to spot trends or anomalies. From this macro perspective, you can easily look for over- or under-performing accounts, watch for daily/weekly/monthly/quarterly changes, and proactively identify when you are off pace to achieve your KPI targets.
If you are really advanced (or have a great BI team), pattern detection or statistical analysis tools can do much of the heavy lifting here. Want to take it to 11? Invest in machine learning to spot and escalate outliers for further analysis.
Step 5: Exploit Opportunities
Finally, after all the hard work is done, you get to play hero. With the right data, hypotheses, tools, and time, you will be able to quickly and easily analyze campaign performance data across multiple PPC accounts.
Comparing and acting on data from multiple accounts is fundamentally the same as working on one account, with the exception of having more variables to control for and more potential dimensions for segmentation.
However you decide to set up your cross-account analysis, take the time to plan ahead. The upfront effort to plan ahead will result in many hours of saved time and increased accuracy down the road.
from RSSMix.com Mix ID 8217493 http://www.ppchero.com/5-steps-to-cross-account-analysis-superhero-status/
0 notes
Text
5 Steps To Cross-Account Analysis Superhero Status
This post is part of the Hero Conf Los Angeles Speaker Blog Series. Andrew Miller will join 50+ PPC experts sharing their paid search and social expertise at the World’s Largest All-PPC Event, April 18-20 in Los Angeles, CA. Like what you read? Find out more about Hero Conf.
PPC pros know how to use data to make better decisions and optimize campaigns for better results. But many agencies and large advertisers spread their campaigns across multiple accounts and analyzing all of this data can lead to greatness if done well….or migraines if done poorly.
Follow these five steps to make sure your analysis leads to hero status.
Step 1: Aggregate Data
Depending on your campaign structures and analytics strategies, you will likely be consuming and storing data from multiple sources (PPC platforms, Google Analytics, your CRM, etc.). Of course, you could manually pull the data from each source, drop into Excel or Tableau, and start crunching, but that process doesn’t scale. Each report or optimization would require repeating the same drudgery. That gets old very quickly.
Plan ahead and work with a developer to consume campaign performance and conversion data from each platform’s API. The less tech-savvy approach is to pull the data manually and upload to a database, but it is much easier, in the long run, to automate as much as possible. We pull daily data from each platform’s API and store it in a SQL database with table(s) for each PPC and analytics platform.
At this point in your journey, your most important task is to define your data structures. Which fields do you need to store, and how do you want to relate your data tables to each other? Basically, which data do you need to do your job? Planning this in advance will save you many headaches later when you discover you don’t have all the data you need to perform your analysis.
Don’t forget to think ahead to the analysis tools you plan to use (more on this in Step 4). Be sure your data structures and databases allow for secure external connections and are structured properly to make sense in an external environment.
In our case, because we are an agency, we ensure every row in every table has a “client ID” field so we can join the data at the client level. This allows us to mash up data and create reports for each client.
Step 2: Normalize Data
We’ve all heard the expression, “Garbage in, garbage out.” Analyzing data across multiple accounts is no exception. It is imperative that your accounts’ data is normalized, or made more consistent, to allow for apples-to-apples comparisons.
To truly compare and trend data accurately, you have to think “meta,” as in metadata. Metadata is simply data about data. Think of AdWords labels as metadata. For example, keywords in your AdWords campaigns can be branded or non-branded. Agency clients can fall into one or more industry categories.
Try to store as much metadata in your database as possible to allow for more consistent comparisons and analysis. For example, you could compare the effects of AdWords’ removal of right side ads on non-brand keywords for all clients in the healthcare industry pretty quickly if your data structures allow for it. Another of my favorite types of cross-account analysis is comparing pre and post-launch data for new clients based on the day we launch their new campaigns. It becomes very easy to develop case studies and spot anomalies when we can chart 30, 60, and 90-day performance and compare to a previous agency’s results.
Take the time to develop a robust, consistent tagging strategy so your analysis is not tainted with garbage data.
Step 3: Democratize Data
We can’t assume that all of our end users are going to be proficient in writing mySQL queries. Nor can we build dashboards or apps that can possibly predict all the ways our analysts could want to slice and dice the data.
Instead of trying to train everybody on database queries, take a more democratic approach to setting the data free. Make your data structures and sample data sets available in more common formats such as Excel or Google Sheets. This way, anybody can see what data are available and think up ways to use it.
Non-developers can still formulate questions that a data analyst can translate into a database query. For example, an Account Manager recently approached me with the question, “How does Client X’s CPC and CPA compare to other clients in the same industry?” Pulling this benchmark data from our database took just a few minutes, saving hours of manual data pulls and pivot tables.
Bottom line, don’t lock up your data! Set it free so that more people can find ways to put it to use.
Step 4: Analyze Data
Most PPC folk simply jump ahead to this step. It may work in the short-run or for an ad-hoc analysis, but be warned that skipping steps 1–3 could lead to inconclusive results, murky data, or decisions based on inaccurate data. Take the time to do it right so that future analyses will be faster and more insightful.
Now that you have multiple accounts worth of data in one place, it’s time to start analyzing. This is where the magic happens! Analysis can lead to insights and insights to optimization.
Develop a hypothesis
Start by developing and testing hypotheses about your data. Don’t just wade into mountains of data hoping to find a gem. Go in with a map and an idea of what you are searching for.
Select the right tools for the job
First off, find the tools needed to do the job right. A more savvy user might be able to write her own SQL queries and export the data to Excel or Google Sheets, but other users might benefit from a business intelligence tool such as Tableau or Google Data Studio for faster analysis.
Begin segmenting and filtering
Next, take advantage of the data and metadata you set up in step 2. You didn’t skip step 2, did you? These facets allow you to segment your data even further to find nuggets of info that can lead to insights.
Just as in Google Analytics, try toggling different segments on and off to look for anomalies or outliers. This is where clean, consistent data structures come in handy. Make sure that you are controlling for variables that might skew results among multiple PPC accounts. Are some accounts using different tagging methodologies for brand vs. non-brand keywords? Are all of your accounts using the same time zones and currency formats?
Establish benchmarks and trends
Once you find the right data, it becomes easy to compare cross-account performance to spot trends or anomalies. From this macro perspective, you can easily look for over- or under-performing accounts, watch for daily/weekly/monthly/quarterly changes, and proactively identify when you are off pace to achieve your KPI targets.
If you are really advanced (or have a great BI team), pattern detection or statistical analysis tools can do much of the heavy lifting here. Want to take it to 11? Invest in machine learning to spot and escalate outliers for further analysis.
Step 5: Exploit Opportunities
Finally, after all the hard work is done, you get to play hero. With the right data, hypotheses, tools, and time, you will be able to quickly and easily analyze campaign performance data across multiple PPC accounts.
Comparing and acting on data from multiple accounts is fundamentally the same as working on one account, with the exception of having more variables to control for and more potential dimensions for segmentation.
However you decide to set up your cross-account analysis, take the time to plan ahead. The upfront effort to plan ahead will result in many hours of saved time and increased accuracy down the road.
from RSSMix.com Mix ID 8217493 http://www.ppchero.com/5-steps-to-cross-account-analysis-superhero-status/
0 notes