#then some latency in that typing up the text for this was laggy just to continue the pranks at my expense....
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has 411 employees.
Text
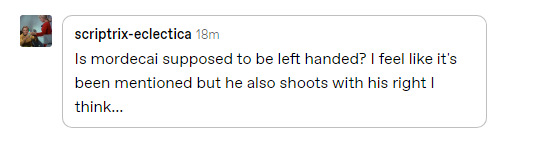
@scriptrix-eclectica oh fun question in that in answering it we can find a) he's not and b) the mention of him being left-handed is an inference of gracie's that in turn, in retrospect, implies mordecai was anticipating being disarmed
b/c yeah he is always out here using his right hand for shooting or writing


and the mention of left-handedness is this:

which, since he's not....a page or two later, gracie learns the gun he took off mordecai here is inoperable, and mordecai calls it auxiliary (backup / not the main one) and gets his gun from nico, which he then indeed shoots with his right hand. so what seems to have happened is: mordecai left his main gun with nico, left his sabotaged backup on him, and gracie found that gun somewhere on mordecai's right side, thus easier to draw from within a jacket with your left hand, which gracie notices b/c he's actually left-handed, implying in the absence of another gun that mordecai favors his left. gracie could've noted it as contradictory that mordecai just used his right hand to take off his glasses, but a) not like that proves he's Not left-handed, or ambidextrous, b) gracie's already generally suspicious, c) he's now more confident for having seemingly disarmed mordecai and d) it would also be a lot to Deduce like "ah so he must have taken another gun off his person, in anticipation of being patted down, and also disarmed, which means he plans to retrieve it, which means he also plans to attack us unawares" and e) it's pretty much too late even if he Was more suspicious about handedness; they're planning to kill him and if he made any earlier moves that still would've happened....but it's a fun teeny giveaway that Something's Even More Up than he thought
#without murder mystery monday updates it's just a friday evening's mordeposting lol#lackadaisy#the torment of having been hit with some connection latency Just as i see a Quastion that i'm like ooh i can readily research & answer that#trivia (handedness) And interpretation (of media)#then some latency in that typing up the text for this was laggy just to continue the pranks at my expense....#addendum: the pranks compound as i go ''uh oh a typo to fix'' and then More Latency such that it takes like 6 refreshes to do so#and even as i go to type it in the beta editor and its discrete blocks loading lag makes everything reshuffle like please
74 notes
·
View notes
Text
Version 360
youtube
windows
zip
exe
os x
app
linux
tar.gz
source
tar.gz
I had a great week. There are a bunch of little things and an important speed overhaul to tag autocomplete.
tag autocomplete
I have never really liked the tag autocomplete workflow. It once blocked the UI completely, and some unusual timing options were needed to make it even useable, but it still often lagged out or just responded with gigantic lists in judders. After chipping away at the problem, this week I am finally updating it to what I really wanted.
So, the main change is that autocomplete results are now fetched as soon as you type. It responds very quickly and overall, I think, feels great, particularly once you have put four or five characters in. You get what you want as soon as you type, and can hit enter right away. The db 'job' to fetch results is now completely divorced from the UI and is able to cancel much faster when you type a new character, so the artificial fetch-start latency requirements of the old system are no longer needed.
There are now just two options for tag autocomplete, under options->speed and memory: whether tag autocomplete should fetch as you type (default on), and a character threshold to switch from 'exact match' autocomplete searches to 'full' ones. This 'exact match' defaults to 2 characters, and means if you type 'sa', you will only get results for 'sa' rather than 'sa*', which is generally a pretty giant laggy list, but if you type 'sam', you'll really be searching 'sam*' and get all matching autocomplete tags. You can reduce or increase this 'exact match' threshold as you prefer, or turn it off completely and get full autocomplete for any input.
Also, I have added some quality of life features. If results do not appear within 200ms, you'll now get a 'loading results...' label in the dropdown for feedback, and any 'static' results, such as exactly what you typed for a manage tags dialog input, or the special 'namespace:*anything*' for a search input, will appear immediately so you can select them without having to wait. Also, entering 'character:sa' will now trigger the same smaller 'exact matches' test as for the unnamespaced 'sa', rather than searching for the whole giant list of tags beginning 'character:sa*' as happened previously.
Furthermore, a query like 'char' no longer matcher 'character:samus aran'. This was a neat idea, but it proved too unwieldy IRL and is now better served by wildcard queries such as 'character:*' or 'char*:*'.
Overall, I am very pleased with the change. Please give it a go, and you'll see the difference immediately. However, tag autocomplete is a complicated system with different workflows, and I have made some big changes, so if you are, say, the sort of user who types fast and just hits enter, and you find the new results are a bit 'flickery' or something for you, let me know and I'll see if I can smooth it out.
more file maintenance
I brushed up the new file maintenance UI under database->maintenance->review scheduled file maintenance to have a nicer list and have added three new jobs:
One fixes file permissions on Linux and OS X. For a while, due to an oversight, file imports have been getting 600 permissions on Linux and OS X. I have fixed this now to be 644 (so, for instance, a nocopy ipfs instance or a network file share running on another user can access the files) for all new files, and this new file maintenance job will retroactively try to fix the permissions of existing files.
The other two are for the duplicates system. One explicitly regenerates similar files metadata, and the other checks if a file is improperly in or out of the similar files searching system, and fixes it if it is in the incorrect place (scheduling metadata regen as appropriate). Both are mostly for debug purposes but will get real use when I eventually add videos to the duplicates system, which will be a giant CPU job we'll want to spread out with the nice new non-blocking file maintenance pipeline. The old maintenance button on the duplicates page that kept eligible files 'up to date' is now gone as a result, and any outstanding jobs there (although most users shouldn't have any by now) should be migrated to the new file maintenance system on update.
full list
tag autocomplete:
after various tag autocomplete async work, fetch timings get a complete overhaul this week. the intention is for a/c jobs to appear as fast as possible, with good ui feedback, without interrupting ui while they work. feedback on how this works IRL would be appreciated
there are now just two autocomplete options under options->speed and memory:
- whether autocomplete results are ever fetched automatically, defaults to true
- the max number of characters in the input that will cause just exact results vs. full autocomplete results, defaults to 2, can be None
namespaces are no longer searched from an unnamespaced query ('char' no longer matches 'character:samus aran'). this proved too slow for real use, and remains better available with explicit namespace searches such as 'character:' or 'char*:*'
the 'exact results' character limit now also applies to subtags of namespace searches! so, entering 'character:a' will deliver the same short exact match results as just 'a'--no more gigantic lists when you put in a simple namespace
improved tag results caching to deal with the new non-namespace matching on subtag input
tag autocomplete dropdowns will now display a non-selectable 'loading results...' label when results take more than 200ms to load.
tag autocomplete dropdowns will now also display 'static' tags, such as 'namespace:*anything*' for 'read' inputs and the exact entered text and possible siblings/parents for 'write' inputs, during loading. so, typing 'character:' just to get the special 'character:*anything*' predicate is now simple and does not need a whole load wait to enter!
cleaned up some tag listbox code to handle parent selection and navigation better along with the new label type
greatly improved autocomplete search logic in the critical text search portion, collapsing it into one cleverer and more easily cancellable query rather than two or three simpler ones with potentially gigantic lists thrown back and forth
improved speed of autocomplete cancel for certain large lists with many siblings
.
file maintenance:
the new file maintenance ui now shows scheduled jobs in a listctrl, and only shows jobs that have outstanding work. you can clear/do work on multiple selected jobs
the file manager should now try to guarantee at least 644 permission on file imports (previously, it was only trying to add 600, which lead to problems with nocopy ipfs running on another user etc...)
added a file maintenance job to check and fix file permissions
added a file maintenance job to regenerate similar files metadata
added a file maintenance job to check if a file should be in the similar files system--if it should and isn't, it is queued to get its metadata data regenerated, and if it is and shouldn't be, it is removed
the previous bulky similar files metadata regen job from the duplicates page is now removed, and any outstanding scheduled regen will be transferred to the new file maintenance manager on update
.
client api:
added POST /manage_pages/focus_page, which makes the given page the current page in the main gui
added help and unit tests for this new call
client api is now version 9
.
the rest:
fixed an issue recording media viewtimes when no max viewtime is set
fixed the new missingdirectory errors not printing the missing path
fixed an issue with some human-started repository actions waiting silently on bandwidth when it was not intended (e.g. account refresh)
export folders now raise proper errors and pause themselves if their path is not set, does not exist on the file system, or is not a directory (previously, they silently stopped work without error)
cleaned up some misc import folder code, and put in additional protections to the delete/move code to ensure folders cannot be so actioned if they somehow end up in the path import queue
when unpinning a file or directory from ipfs, the clientside service now first checks that the current daemon considers it pinned (previously, this 500 errored when the object was not pinned due to a reinitialised daemon etc...)
fixed an issue with the new ipfs path translation control, which was forgetting values when the clientside path was outside of the default db structure
media objects that transition from trashed to physically deleted but remain in view will now correctly be aware of their complete previously-deleted status (rather than being simply remote, as they were before until a client restart)
improved some of the recent duplicates db update code to pre-optimise the new tables on update (some users were getting slow behaviour due to mis-scheduled analysis maintenance)
extended the new panel system to deal with custom button panels and moved the duplicate filter 'commit and continue?' dialog to the new panel system
moved the archive/delete and duplicate filter 'commit and finish' dialog to the new panel system
wrote a new question panel for the typical yes/no dialog used across the program and started a cleanup job to migrate all 140-odd instances of this over
fixed an issue where a program instance that quit due to a user deciding to leave an already running instance in place would clear the original instance's 'running' file in its shutdown, meaning subsequent runs would charge ahead and hit 'database is locked' problems on db init!
wrote a new 'similar files metadata generation report mode' to provide debug info on this cpu/gpu intensive routine
added 'why use sqlite?' entry to the help faq, with a link to prkc's excellent document about the subject, https://gitgud.io/prkc/hydrus-why-sqlite/blob/master/README.md
also added prkc's excellent Linux package requirements information to the 'running from source' help page
fixed some old py 2.7 references in running from source help and an old link in ipfs help
moved the 'file viewing statistics' menu down on the database menu
fixed some dialog Escape key event handling
fixed some ui ancestory testing code
improved some misc similar files system code
next week
Next week is a cleanup week. I'd like to just do some boring rewrites and ui code updates, and I'll see if I can hack away at the last duplicates overhaul jobs.
0 notes