#smalldata
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr’s reach among the 26-to-35-year-olds in the US is 11%.
Link
A matéria discute a estratégia do Small Data, que é uma abordagem que se concentra em coletar dados precisos e de qualidade, em vez de grande volume, como é o caso do Big Data.
0 notes
Text
Segmentando os públicos - Olhares de Martin Lindstrom
Antes de iniciarmos este post, é preciso entendermos que não é possível criar uma necessidade e sim ativar uma necessidade já existente. Vocês devem se lembrar que já comentamos em um post passado sobre a importância em identificar o desequilíbrio, sendo preciso observar o Small Data para criar uma nova marca ou apelar para o segmento de uma forma diferente. O ‘gap’ entre estar em equilíbrio e desequilíbrio representa uma oportunidade para a marca.
Cada aspecto de nossa vida está representando um desequilíbrio (estou acima do peso, estou em uma crise de meia-idade, preciso ser reconhecido) e é neste momento que precisamos identificar as pequenas pistas para construir uma marca em torno delas.
Para que sua marca tenha um DNA emocional é preciso seguir os seguintes passos:
1- Identificar necessidades do consumidor
2- Desenvolver um conceito
3- Criar um vínculo emocional
4- Usar a estrutura religiosa (HSP)
5- Crie uma plataforma de mídia e então você está pronto para criar uma marca.
Vamos por partes.
Quando falamos em identificar as necessidades do consumidor, estamos falando também sobre segmentação. Mas, hoje em dia, é preciso encontrar um outro modelo que vai além do tradicional (idade, sexo, etc.). Devemos olhar para as emoções. Por isso, devemos nos atentar ao Small Data. As informações do Small Data estão em todos os locais, no banheiro, no que as pessoas postam nas redes sociais, o que colecionam, entre outros. Dessa forma, temos alguns passos para identificar o Small Data:
- O palco: como projeto minha vida nas redes sociais? Como gostaria de ser visto? Escolhemos projetar o melhor de nós mesmos, a imagem perfeita.
-Memórias, minha mente coletiva: o que as pessoas colecionam? Em uma visita isso diz muito sobre o background das pessoas.
-A mente arrogante: uma parte de você que se destaca de acordo com a situação vivida. Todos nós temos vários aspectos do nosso comportamento e isso pode nos ajudar a entender com quem estamos lidando. Por exemplo, como você se comporta no trânsito se alguém atravessa sua frente?
-Mente lubrificante- minha mente pensante: como eu me comporto quando estou interagindo com os outros? Eu sustento quem eu gostaria de ser?
-Mente trancada- minha mente conflitante: tento passar uma imagem e projetar uma imagem de quem gostaria de ser. Por exemplo, as pessoas tendem a colocar o refrigerante abaixo das comidas saudáveis na geladeira.
Esses aspectos podem ajudar a descobrir quem seu consumidor é de verdade. Escreva em detalhes quem é seu público e terá temas em comuns entre seu público e começar a criar segmentos. É preciso entender os traços emocionais.
De acordo com Lindstrom a metodologia 7C pode nos auxiliar em uma pesquisa de subtexto, que nos permite identificar pequenas pistas que podem refletir grandes oportunidades de negócio. As etapas são:
Coletar informações (collecting), buscar pistas (clues), conectar as pistas (connecting), buscar as causas (correlation), buscar a correlação (causation), entender a compensação (compensation) e criar um conceito (concept).

Além disso, após criar um conceito é preciso criar um vínculo emocional com as marcas. Por isso, vamos entender sobre a criação de aspiração. Você sabia que os rumores passam pelo processo 1:9:90 (uma pessoa passa o rumor, 9 pessoas que a seguem espalham a novidade ainda mais e 90 pessoas vão absorver essa nova ideia)? Pessoas, dessa forma, são inspiradas em outras e as marcas precisam entender quem inspira quem dentre seus públicos. Por isso, devemos nos atentar ao boca a boca, especialmente nas redes sociais. Para isso, devemos fazer corretamente o seguinte processo:
-1° Revelation – início de conversa, elementos icônicos que ajudam o consumidor a justificar a marca, algo para as pessoas começarem a falar da marca.
-2° Aha-Moment – momento em que você alimenta a conversa com percepções interessantes que fazem as pessoas falar e pensar. É o momento no qual as pessoas ganham uma história e a história é tão intrigante que todos gostariam de falar ou roubar para si a história.
-3° Ponto de Virada (Tipping point) – é o último argumento interno que mudará uma conversa interessante para uma conversa sobre uma marca.
-4° Exibição (Show-off) – simbolismo mostrando aos amigos a adesão a um clube especial.
Lembre-se de que tudo isso está relacionado ao Small data. Ou seja, é sobre causalidade, dados insignificantes e que fazem toda a diferença.
0 notes
Photo

RECOMENDACIÓN DE LA SEMANA SMALL DATA - Martin Lindstrom (2016) "El Big Data y Los pequeños datos son compañeros en un baile, la búsqueda común del equilibrio" #reading📖 #lectura #book #libro #bigdata #bigdataanalytics #smalldata #pequeñosdatos #martinlindstrom #stayhome #stayathome #stay #quedateencasa #quedatentucasa #quarentine #cuarentena #quarentena https://www.instagram.com/p/B-dqDsYDv_W/?igshid=18z2oj1l8b75l
#reading📖#lectura#book#libro#bigdata#bigdataanalytics#smalldata#pequeñosdatos#martinlindstrom#stayhome#stayathome#stay#quedateencasa#quedatentucasa#quarentine#cuarentena#quarentena
0 notes
Photo

zoelandia streetview
3 notes
·
View notes
Text
小數據條件下的語意分析
語意分析在近年的大數據與機器學習乃至深度學習的潮流下,已成為人工智慧在自然語言處理以及輿情分析的標準應用。但由於工具原理的限制,語意分析的結果往往會用一個詞頻分佈圖、關鍵字的文字雲…等方式呈現。要讀懂究竟這張圖表的意義,還需要一個「分析師」像解盤股市表現一樣地說明各個指數的意義,才能讓人一窺目標市場不經間透過文字或語言留下的思緒痕跡或是情緒傾向。
這幾乎讓「語意分析」一詞聽起來就像是某種星座算命用的神秘詞彙。
另一個和星座算命類似的性質是,幾乎所有的語言分析應用場景的先決條件就是「數據量要大,愈大愈準」。但如果某個專業領域裡面只有寥寥數篇相關文件,例如新產品的行銷文案、專業技能的訓練課程講稿內容乃至候選人的政見發表或是辯論文字稿…等。

這些文件少則只有一篇,多也不過是在幾十篇而已,如何在最短的時間裡利用語意分析來評估文本內容的品質好壞,或是計算它的關鍵詞彙以便做延伸的搜尋或領域研究呢?數量不夠的話,是沒辦法採用大數據的人工智慧方法的。
但是相較於需要大數據的人工智慧,幾乎任何一個心智正常的經理人,都能只憑少少的幾篇文字,就做出準確的商業判斷「這個人是否言過其實?」、「這個報告是否用心製作?」、「這個伙伴的計劃是否值得信任?」那麼,問題來了…
為什麼我們不能讓「人工智慧」來幫我們透過少量的數據,就做出像人的判斷呢?
這是因為,大數據條件下的人工智慧運作的方式,和人類做邏輯判斷的方式不太一樣。人類的語言能力,能讓我們透過極少的資料,就感知到一個句子是屬於「有料」或是「沒料」。
以前幾年流行的「語言癌」為例。聯經出版社邀集了國內的語言學家精英,從語法、功能、歷史、結構…等等角度做出了四平八穩的結論,但就是忽略解釋了「一般人聽到:『做了一個擁抱的動作』時,那股冗贅的不適感從何而來呢?」
同樣的道理,在近年來部份心靈導師的訓練課程中或是一年多以來的總統選舉活動中,也有許多發言內容常讓人覺得「你的確講了很多話,但我總覺得只接收到很少的資訊」。
這種「資訊」和「收訊」之間的落差感,是否有個科學的解釋呢?
這個問題,致力於將「語言學」領域的先驗知識帶進語意分析以及其它自然語言處理任務的卓騰語言科技有解決方案。卓騰語言科技並不是世界上第一家將語言學知識引入語言分析任務,因而大幅縮小數據量需求的公司。在國外,幾乎和我們同時成立的 Bitext 也是一家利用語言學背景打造各種能大符提升機器學習模型正確率表現的的跨國企業。差別只在 Bitext 專精於歐��語系,而卓騰語言科技則主攻亞洲的語系。
以往在數據量大的時候,我們就能基於統計方法,先將一篇中文文章進行中文斷詞處理以後,計算這篇文章和其它文章最具代表性的「關鍵字」,或是計算每個詞條的出現的次數,以「詞頻」做為語意分析時的素材。
用料理做為類比,可能更好理解。民以食為天,您一定曾經有過明明點了一道名稱很長,好像用了許多食材,似乎很厲害的料理以後,嚐了一口卻只是平平淡淡的沒什麼滋味。這種「名稱很長」和「淡淡的沒什麼味道」之間的落差,該怎麼計算呢?
如果要採用機器學習的話,它會需要「許多菜單的樣本」以及「食用後的客戶意見」來建立「餐點名稱的長度或內含字彙」以及「客戶意見」之間的關係以後,在您看到一個新的菜色時,系統再依這道菜色的「名稱長度或內含字彙」來給您「它是味道豐富」或是「它可能平淡無味」的預測。
但如果這個問題交給一個「具有專業領域知識的廚師」的話,他根本不需要吃過多少菜,就可以依據他對每一道食材以及料理方式的知識,看著菜名,就告訴你「這道菜名字很長,但大概沒什麼味道,因為食材都是些小白菜、豆芽菜、豆腐…等東西,而且料理的方式也不容易入味」。
樣本多時,您可以採用機器學習的 AI 方法,
樣本少的時候,不妨利用廚師的專業知識。
我們提供的,就是基於「對語言的專業知識」而打造的演算法。以語言癌的句子「做了一個擁抱的動作」為例,其實它的意思就是「擁抱」。那麼我們能否「讓電腦計算」這個語言癌句子的「空洞感」從何而來呢?我們將句子送入卓騰語言科技的「Articut 斷詞引擎」以 lv1 計算,並代入「名詞、動詞的詞彙數量除以整個句子的詞彙數量」這個公式來計算兩個句子:
公式:(Noun + Verb) / All
做了一個擁抱的動作 =>
做(verb) 了(ASPECT) 一個(classifier) 擁抱(verb) 的(FUNC) 動作(nouny)
斷詞處理後共有 6 個詞 (做/了/一個/擁抱/的/動作),其中動詞有 2 個 (做/擁抱),而名詞有 1 個 (動作),依公式計算得:(2+1)/6 = 0.5
也就是說,整句「做了一個擁抱的動作」裡,只帶了 50% 的資訊。這麼一來,當然會讓聽者覺得有一種「餐點名稱很長很厲害,結果嚐起來沒什麼味道」的空洞感了。
這個公式並不是我們發明的,而是在歐美語系的語意分析工作中已經有悠久應用歷史以及為了不同的場景,也有許多不同版本的變體。但以往幾乎不曾在「中文語意分析」中看到這種方法,主要的原因還是在 Articut 斷詞引擎出現以前,常見的中文斷詞方案有的是詞性標記錯誤過多以致無法使用 (例如 Jieba 結巴斷詞),再不然就是詞性標記分類過細以致於操作複雜。
同樣公式,我們在本屆總統大選的第一次政見發表會中也加以應用 [註]。這是一個教科書式的完美應用場景。三位候選人的發表時間是一致的,我們不用擔心是否像對話一樣,每個人的句子有長有短讓公式中的分母差異過大。三個人的發言主要都是在單方向的「說明」而不是雙向或是多向的「對話」,如此一來可以更確定發言時所用的詞彙是自己的意思,而不是在重覆對方問題時說的話。
把三位候選人的政見內容,送入 Articut 進行斷詞處理後,計算詞彙總數,並另外計算了名詞和動詞的數量,依前述公式計算後得到以下的圖表分佈:
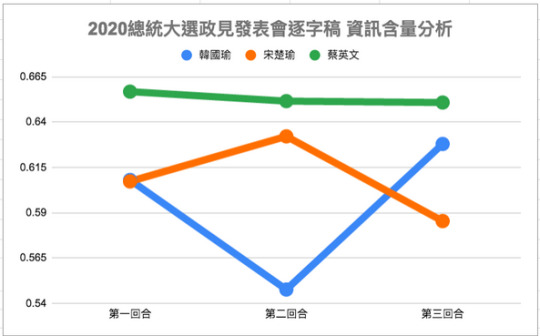
這個圖表的數字分佈,剛好符合了閱讀逐字稿以後網友的主流意見:「其中一位候選人似乎都在講空話」。現在我們有了 Articut 斷詞引擎的 POS 標記以後,終於能跟上歐美行之有年的語意分析技術水準,將「網友主觀的感覺」以「客觀量化數據」呈現。
透過小數據條件的語意分析技術,我們可在演講稿完成的同時,就進行計算;而不需要等到演講稿發佈以後,再從網路蒐集網友意見,進行後續的分析操作。
我們可以用同樣的公式,現場進行一個實驗。以下有兩段健身房的文案,一段比較沒有吸引力,另一段則充滿節奏。我們將文字透過 Articut 斷詞引擎處理後,再來看看您的感受:
文案一:25歲以後肌肉就會慢慢流失,只有透過不斷的訓練才能讓肌肉流失的速度變慢,並且在老了以後保有堅硬的骨骼。
文案二:25歲以後肌肉開始流失,唯有訓練才能減緩肌肉流失速度,同時保有堅硬的骨骼。
您可先自行判定,哪一個文案的文筆較佳。再往下看看,您的感受是否和計算出來的「資訊密度」表現一致?
文案一:
25歲(Noun) 以後(TIME) 肌肉(Noun) 就(FUNC) 會(MODAL) 慢慢(MODIFIER) 流失(verb),只有(MODIFIER) 透過(verb) 不斷(MODIFIER) 的(FUNC_inner) 訓練(Noun) 才能(MODAL) 讓(verb) 肌肉(Noun) 流失(verb) 的(FUNC) 速度(Noun) 變(verb) 慢(MODIFIER),並且(FUNC) 在(ASPECT) 老了(verb) 以後(TIME) 保有(verb) 堅硬(MODIFIER) 的(FUNC) 骨骼(Noun)
共 28 個詞,其中的名詞及動詞共 13 個 (標為淡黃色)。資訊密度為:13/28 = 0.46
文案二:
25歲(Noun) 以後(TIME) 肌肉(Noun) 開始(verb) 流失(verb),唯(MODIFIER) 有(verb) 訓練(Noun) 才能(MODAL) 減緩(verb) 肌肉(Noun) 流失(verb) 速度(Noun) 同時(TIME) 保有(verb) 堅硬(MODIFIER) 的(FUNC) 骨骼(Noun)
共 18 個詞,其中的名詞及動詞共 12 個 (標為淡黃色)。資訊密度為:12/18 = 0.67
透過這個計算公式,我們也能發現資訊密度高的文案,通常也避免了「誇張賣弄」、「行話」、「囉嗦」、「討論自己」、「過度興奮」或「主觀強烈」…等行銷文案的地雷。因為誇張賣弄、過度興奮或是主觀強烈多半是透過形容詞來呈現。但在這個公式裡的形容詞不計分;行話和囉嗦的詞彙容易被斷詞引擎處理錯誤而失分;此外,談論自己時用的代名詞一樣是不計分的。
利用 Articut 斷詞引擎的詞性標記,計算資訊密度最少最少只需要「一個句子」。從此以後,我們便能利用這個公式掌握了「小數據」條件下的語意分析能力。
小數據的語意分析可強化大數據的機器學習效果
這兩種技術在本質上並不衝突,因此您可以輕易地將兩者融合成為新的產品或是決策輔助工具。在突發事件或是可掌握的資料不多時,採用小數據的語意分析方式,在累積了足夠呈現統計意義的資料量後,再採用大數據的機器學習方法挖掘更多潛在的趨勢。或是再次結合小數據方法,從不同的面向觀察長時間的語意分析變化,掌握市場伏流的動向。
註:我們略過了第二次政見發表會的原因是第二次政見發表會在形式上是單方的發表會,但實際上三個回合已經形成了類似辯論的對話模式。這應該要採用其它的變體加以計算。
0 notes
Photo

one of my recent favorite reads - a surprisingly useful look at #trends from author Rohit Bhargava, (@rohitbb), now in its fifth year. really lit my fires to take #curation more seriously, to think broadly and laterally, and pursue #interdisciplinarystudies with the full vigour of my intellect. #nonobvious #nonobvious2017 #rohitbhargava #2017trends #2017design #2017designtrends #designtrends #socialmediatrends #digitalmarketing #digitalmarketingtrends #content #contentcurator #contentcuration #interdisciplinary #criticaltheory #visualculture #2017businesstrends #amreading #amwriting #contentcreator #contentmarketing #inboundmarketing #futurism #automation #bigdata #smalldata #worldbookday #worldbookday2017 (at Portland, Oregon)
#smalldata#contentcreator#2017trends#digitalmarketing#contentmarketing#content#contentcurator#designtrends#contentcuration#inboundmarketing#nonobvious2017#curation#socialmediatrends#amwriting#amreading#interdisciplinary#interdisciplinarystudies#2017businesstrends#automation#trends#rohitbhargava#bigdata#worldbookday2017#visualculture#digitalmarketingtrends#nonobvious#futurism#worldbookday#2017designtrends#2017design
1 note
·
View note
Text

Subscribe here to get Posts and updates on how to improve statistical and causal inference for each individual: statsof1.org/contact 📨📥📫
#nof1 #biostatistics #statistics #statsof1 #nof1stats #causalinference #wearables #epidemiology #digitalhealth #publichealth #timeseries #timeseriesanalysis #esametry #smalldata
3 notes
·
View notes
Text
Small Data: The Tiny Clues That Uncover Huge Trends
by Martin Lindstrom

See the notes!
Penned by: JRWisms
Buy the book: http://a.co/d/2Zvp8T3
#Notes#WrittenWord#MartinLindstrom#Martin#Lindstom#SmallData#PowerOfObservation#Wisdom#Insights#Innovation#morningmotivation#Tigard#Oregon#ThirstForKnowledge#BookADay#QuoteOrNote#CommonPlaceBook#ReadingNotes
0 notes
Text
The Lego Story Of Using“Small Data” Insights To Reclaim ‘Lost’ Customer Attention

Lately Big Data has been a part of numerous talks and discussions, online and offline, in books, conferences and seminars, but a marketer Martin Lindstrom has something refreshing to highlight. It is about the worth of “Small Data” that brands choose to ignore in blinding light of the Big Data. One cannot simply ignore his arguments as they are supported by solid proofs staring on the faces of those who dare to deny it. Martin Lindstrom is the author of Small Data: The Tiny Clues that Uncover Huge Trends. But even before authoring the book he is valued for his keen observation of small-but-important detailsof habits of the demographics. His work with the Lego brand back in 2004 is what brought him in the notice of others. The Lego Story At the very beginning it was a hit with every kid and then the tides turned; 1980s were the first years of its decline due to newer toys and video games and 1990s brought more bad news. And the most popular solution of brand diversification was not helping. Things like theme parks, movie tie-ins, merchandising, etc. were not working. What was wrong?Probably Big Data! With time emerged a name, Digital Natives, attributed to those born in 1980s who were thought to be fidgety and needed things to keep them perpetually occupied. Lego’s Big Data cued that these people do not find creativity liberating and are not looking for challenging activities. This research compelled them to come up bigger blocks and lesser details to appease the said need of instant gratification. But sales continued to dip! What changed then? Headed by Lindstrom, the Lego team met and stayed with a German Boy who loved Lego to gain some significant insight. The boy happened to a serious interest in skateboard and worked really hard to master his sport. The long hours he poured in mastering his passion made his sneakers a prized possession as shown by its rough use. This “Small Data” was eye-opener that led to the realisation that people still love to dedicated time and efforts to the activities (involving creation of any type) they feel worth sharing. And Lego captured this in its next batch of its product, detailed small blocks more challenging and attention-demanding. And Lego never had to look back since then! And it’s not only Lego The ideas propagated by Lindstrom are now accepted and implemented by other brands. Small insignificant details are making the big differences in brands that customers love. And these details are uncovered by close observation which sometimes even required looking into their refrigerators or dumpsters and staying with the family with their permission of course. And oftentimes, the data extracted is not exactly about the brand / product itself but the hidden desire of target audience that brand can target to get intimately associated with their users. This could be guessed by a vacuum cleaner brand Roomba that are cute to look at and quick to work. People who own it love to even show it off. More and more brands are realising and accepting the importance of small data, and are gaining entrance in the heart of their customers! Read the full article
0 notes
Link
Small data is real time, actionable data that can be easily collected within your CRM. Together Small Data and CRM can revolutionize how you approach sales and marketing for ages to come.
0 notes
Text
Segmentação moderna: a neurociência e a psicometria - Olhares de Martin Lindstrom
Você sabia que 85% do que fazemos cotidianamente é irracional? E é nesse espaço que as marcas vivem. Branding (marca) pode ser entendido como cada ponto de contato com o cliente durante todo o período de existência de uma empresa. Cada ponto de contato com o cliente conta uma história. Por isso, as marcas são definidas por um conjunto de aspectos: sentidos, aspirações, propósito, inconsciência, religião, ética e cultura.
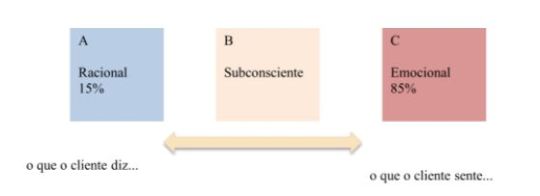
Dessa forma, marcas são sobre como nosso cérebro funciona e elas basicamente nos fazem ficar emocionalmente conectados com seus produtos ou serviços. Para criar a emoção, conte histórias (storytelling).
Mas atenção: não basta trazer apenas informações conhecidas como Big Data. Repare que nos últimos 2 anos, os seres humanos criaram 90% da informação já criada pela nossa espécie.
Assim, todas as informações que recebemos vêm do que chamamos de Big Data, mas é importante lembrar que nem sempre o Big Data explica o porquê. O Big Data traz conexões sobre as informações (correlação), mas não explica o motivo. Ou seja, temos uma tonelada de dados, mas nenhuma informação de verdade.
Por isso é preciso pensar em Small Data. Você tem que construir sua marca dando ouvidos à realidade dos seus clientes, buscando resoluções emocionais, pois ela traz o acúmulo da racionalidade e do inconsciente.
“Se quer aprender sobre animais, não vá ao zoológico e sim à Floresta Amazônica”, tenha contato real com seus clientes!!

0 notes
Photo

Poder.io Media interviews at the #FOMLA17 here @gonzoogle talking about #ArtificialIntelligence & Poder.io’s Power of Prediction. #BigData #smalldata #ai #machinelearning #algorithm #datalake #sophIA #clowdertank #sales #funnels #predictiveanalytics #roi #kpis #performance #campaignoptimization #power #clusters #datacience #datavisualization #futureishere #digitalmarketing #digitaltransformation 30.10.2017 (at Turnberry Isle Miami, Autograph Collection)
#datacience#funnels#clusters#roi#sales#bigdata#datalake#digitalmarketing#futureishere#predictiveanalytics#datavisualization#clowdertank#power#sophia#smalldata#digitaltransformation#campaignoptimization#algorithm#artificialintelligence#ai#kpis#performance#fomla17#machinelearning
0 notes
Photo

It's a #detox kind of #sunday 🍃 (e a “receita” do sumo verde está no blog 😋) #cleaneating #greenjuice #detoxing #sundays #sundaymorning #blogger #dothedetox #lipton #tea #smalldata #martinlindstrom
#martinlindstrom#detoxing#sundays#lipton#sundaymorning#tea#blogger#greenjuice#smalldata#sunday#cleaneating#dothedetox#detox
0 notes
Photo

Tonight's read for the flight home. #SmallData (at Mactan Cebu International Airport)
0 notes
Photo

Incubadora de Conocimiento 🎒👓💻📚📖🖋🖌🗂🔓🔎🎨 #reading #business #tiempoenfamilia #curso #smalldata #businessmen #entrepreneur #analytics #books #book📚 #corporate #bookaddict #biblioteka #bibliomaniac #booksarelife #booksarefun #newbook #data #analysis #bookshelf #booker #lifeatisb #bibliomania #almamater #tese #mural #industrial #elmanso #bookie #nerdgasm (en Biblioteca Vasconcelos)
#bibliomania#industrial#book📚#bookaddict#booksarelife#books#biblioteka#booksarefun#curso#smalldata#tese#businessmen#bookie#data#tiempoenfamilia#entrepreneur#analysis#bookshelf#analytics#bibliomaniac#booker#business#almamater#elmanso#mural#corporate#reading#nerdgasm#newbook#lifeatisb
0 notes
Text
#DatosyMezcales: datos abiertos sobre feminicidios, elecciones y el sistema fiscal
Una edición más de #DatosyMezcales en Ciudad de México para festejar que este 2017 cumplimos 5 años :) Aprovechando que estamos de aniversario, en esta edición les contamos sobre los inicios de #DatosyMezcales y cómo desde sus antecedentes en 2013-2014 se ha expandido el #DataLove hasta cubrir 11 ciudades de México y América Latina (cada versión acompañada de su bebida espirituosa tradicional). Acá puedes ver la numeralia del 2016 y en próximos días para celebrar los 5 años de SocialTIC publicaremos la numeralia de ciudades, proyectos, entusiastas daterxs y litros de mezcal que ha reunido cada evento.
Estamos arrancando #DatosyMezcales y compartiendo cómo inició todo el #DataLove 💙 pic.twitter.com/uAJqa9iaI4
— SocialTIC (@socialtic)
5 de mayo de 2017
Como cada encuentro, en este post te compartimos las iniciativas alrededor de los datos que se presentaron:
1. Mapa y datos de feminicidios en México. María Salguero, @PrincesaBathory en Twitter nos habló sobre cómo creó y actualiza el mapa interactivo sobre feminicidios en México a partir de historias, notas y fuentes periodísticas desde enero 2016. En la página web Los feminicidios en México, está el primer mapa que creó y que ahora ha trasladado a Google Maps para actualizar y agregar categorías de información. Para seguir actualizándose, el mapa y la mapeadora necesitan equipo y recursos, aquí puedes apoyar.
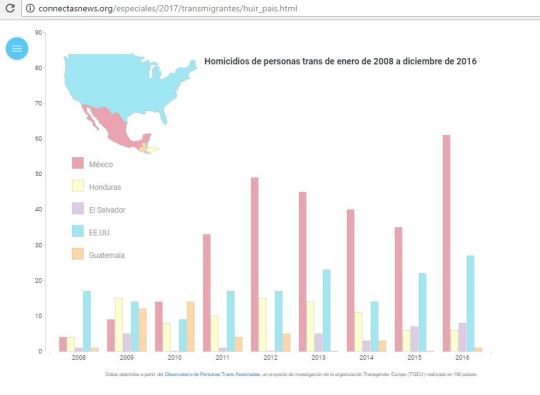
2. Reportaje basado en datos: crímenes de personas de diversidad sexual en América Latina Prometeo Lucero (@PrometeoLucero en Twitter), presentó la investigación que ha contabilizado los crímenes de 157 personas trans en América Latina desde enero de 2008 a diciembre de 2016, El Observatorio de Personas Trans Asesinadas ha reportado crímenes en Honduras, Guatemala y El Salvador. Este proyecto surge al reconocer que no había existido monitoreo sistemático de violencia de odio ni informes sobre asesinatos hacia personas trans. Aquí puedes ver el reportaje Transmigrantes basado en datos de la investigación.
3. Datos del sistema fiscal, una herramienta para proyectar cambios y propuestas. El simulador fiscal presentado por el CIEP ( Centro de Investigación Económica y Presupuestaria) es una herramienta que permite calcular la situación actual del sistema fiscal y proyectar propuestas y efectos en las finanzas del país. La herramienta contiene visualizaciones y simulaciones para proyectar cambios en campos como salud, educación y el sistema fiscal mexicano. Checa en este video cómo funciona el simulador fiscal:
youtube
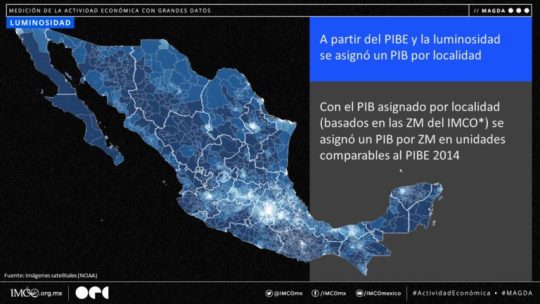
4. Tecnología y datos abiertos para medir la actividad económica de las ciudades en México Las organizaciones IMCO y OPI han desarrollado la plataforma MAGDA para la Medición de la Actividad Económica con Grandes Datos. MAGDA es creada a partir de la relación de la actividad económica con la emisión de luz (imágenes satelitales) y número de transacciones de retiro de efectivo en cajeros automáticos. En imco.org.mx puedes consultar: - bases de datos - código y documentación - boletín y ficha técnica
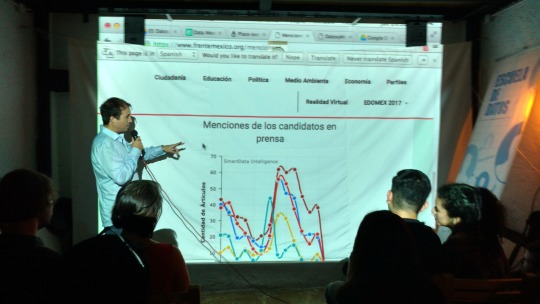
5. Datos sobre candidatxs y menciones para las elecciones 2017 del Estado de México El movimiento ciudadano Frente México presenta este análisis de datos en tiempo real sobre las menciones de los candidatos del Estado de México (en redes sociales: Facebook, Twitter y en medios digitales) para detectar el volumen de interacción y comparar qué temas son más mencioanados por lxs candidatxs.
Los temas de #Seguridad y #Corrupción son los más mencionados en redes para las elecciones de #Edomex2017 #DatosyMezcales pic.twitter.com/4afA7XxRrG
— Ale Navarro (@NAsteroide)
5 de mayo de 2017
6. Prototipado para organizaciones con proyectos tecnológicos ¿Eres una organización de la sociedad civil o gobierno trabajando en un proyecto para fortalecer a la ciudadanía? ¿Tienes la idea de usar tecnología para tu proyecto? El equipo de Cívica Digital te ofrece apoyo para crear un prototipo de alto nivel para que puedas presentar tu ideas, evaluar su impacto y cumplimiento de objetivos. Conoce aquí más información.
Sigue la pista del #DataLove, nos vemos en próximas noches de comunidad datera :)
#DatosAbiertos#DatosyMezcales#OpenDAta#TecnologíaCívica#HackingCívico#Dataviz#Mapas#Análisisdedatos#BigData#SmallData#DataLove#CDMX#México#EscueladeDatos
0 notes