#robots.txt google
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Celebrities use Tumblr as well.
Text
Are you a content creator or a blog author who generates unique, high-quality content for a living? Have you noticed that generative AI platforms like OpenAI or CCBot use your content to train their algorithms without your consent? Don’t worry! You can block these AI crawlers from accessing your website or blog by using the robots.txt file.
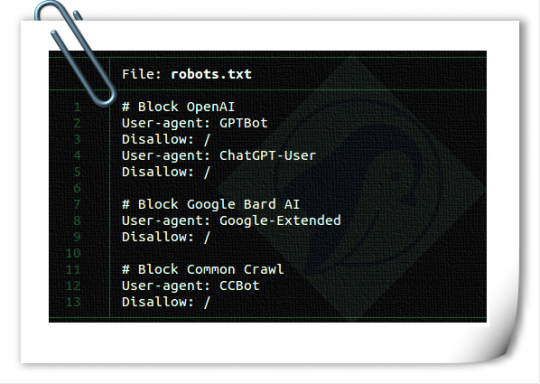
Web developers must know how to add OpenAI, Google, and Common Crawl to your robots.txt to block (more like politely ask) generative AI from stealing content and profiting from it.
-> Read more: How to block AI Crawler Bots using robots.txt file
73 notes
·
View notes
Text
🚫🔍 Struggling with "noindex detected" errors in Google Search Console? Our latest guide reveals where the issue might stem from and provides actionable steps to resolve it! Boost your site's visibility today! 🌐✨ #SEO #GoogleSearchConsole #WebmasterTools
#401 Unauthorized response#CDN issues#Cloudflare#digital marketing#Google indexing error#Google Search Console#Googlebot#indexing problems#indexing visibility#noindex detected#outdated URLs#Rich Results Tester#robots.txt#search engine optimization#SEO troubleshooting#website indexing issues#X-Robots-Tag error
0 notes
Text
Schema Mark Up - SEO - Wordpress - Answers
I can work on Schema mark up and robots.txt implementation for WordPress users and agencies Call David 07307 607307 or E Mail hello@davidcantswim Income to local Plymouth charitySchema is a type of structured data that you can add to your WordPress website to help search engines understand your content and display it more prominently in search results. Schema markup is also used by social media…
View On WordPress
0 notes
Text
Odd. Blocked cc bot and gpt bot - then Google Search Console says it can't crawl my site
Hmmm. Interesting. I blocked the common crawl bot and GPT bot on my robots.txt file - then a few days later Google Search Console says it can't index some pages due to my robots.txt file. Pretty sure CC and GPT don't have anything to do with Google
0 notes
Text
NYT Says No To Bots.
The content for training large language models and other AIs has been something I have written about before, with being able to opt out of being crawled by AI bots. The New York Times has updated it’s Terms and Conditions to disallow that – which I’ll get back to in a moment. It’s an imperfect solution for so many reasons, and as I wrote before when writing about opting out of AI bots, it seems…

View On WordPress
#deep learning#Google#Large Language Model#LLM#medium#NYT#opt-out#publishers#robots.txt#substack#training model#WordPress.com#writing
0 notes
Text
Hey!
Do you have a website? A personal one or perhaps something more serious?
Whatever the case, if you don't want AI companies training on your website's contents, add the following to your robots.txt file:
User-agent: *
Allow: /
User-agent: anthropic-ai
Disallow: /
User-agent: Claude-Web
Disallow: /
User-agent: CCbot
Disallow: /
User-agent: FacebookBot
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: GPTBot
Disallow: /
User-agent: PiplBot
Disallow: /
User-agent: ByteSpider
Disallow: /
User-agent: PerplexityBot
Disallow: /
User-agent: cohere-ai
Disallow: /
User-agent: ChatGPT-User
Disallow: /
User-agent: Omgilibot
Disallow: /
User-agent: Omgili
Disallow: /
There are of course more and even if you added them they may not cooperate, but this should get the biggest AI companies to leave your site alone.
Important note: The first two lines declare that anything not on the list is allowed to access everything on the site. If you don't want this, add "Disallow:" lines after them and write the relative paths of the stuff you don't want any bots, including google search to access. For example:
User-agent: *
Allow: /
Disallow: /super-secret-pages/secret.html
If that was in the robots.txt of example.com, it would tell all bots to not access
https://example.com/super-secret-pages/secret.html
And I'm sure you already know what to do if you already have a robots txt, sitemap.xml/sitemap.txt etc.
89 notes
·
View notes
Text
"how do I keep my art from being scraped for AI from now on?"
if you post images online, there's no 100% guaranteed way to prevent this, and you can probably assume that there's no need to remove/edit existing content. you might contest this as a matter of data privacy and workers' rights, but you might also be looking for smaller, more immediate actions to take.
...so I made this list! I can't vouch for the effectiveness of all of these, but I wanted to compile as many options as possible so you can decide what's best for you.
Discouraging data scraping and "opting out"
robots.txt - This is a file placed in a website's home directory to "ask" web crawlers not to access certain parts of a site. If you have your own website, you can edit this yourself, or you can check which crawlers a site disallows by adding /robots.txt at the end of the URL. This article has instructions for blocking some bots that scrape data for AI.
HTML metadata - DeviantArt (i know) has proposed the "noai" and "noimageai" meta tags for opting images out of machine learning datasets, while Mojeek proposed "noml". To use all three, you'd put the following in your webpages' headers:
<meta name="robots" content="noai, noimageai, noml">
Have I Been Trained? - A tool by Spawning to search for images in the LAION-5B and LAION-400M datasets and opt your images and web domain out of future model training. Spawning claims that Stability AI and Hugging Face have agreed to respect these opt-outs. Try searching for usernames!
Kudurru - A tool by Spawning (currently a Wordpress plugin) in closed beta that purportedly blocks/redirects AI scrapers from your website. I don't know much about how this one works.
ai.txt - Similar to robots.txt. A new type of permissions file for AI training proposed by Spawning.
ArtShield Watermarker - Web-based tool to add Stable Diffusion's "invisible watermark" to images, which may cause an image to be recognized as AI-generated and excluded from data scraping and/or model training. Source available on GitHub. Doesn't seem to have updated/posted on social media since last year.
Image processing... things
these are popular now, but there seems to be some confusion regarding the goal of these tools; these aren't meant to "kill" AI art, and they won't affect existing models. they won't magically guarantee full protection, so you probably shouldn't loudly announce that you're using them to try to bait AI users into responding
Glaze - UChicago's tool to add "adversarial noise" to art to disrupt style mimicry. Devs recommend glazing pictures last. Runs on Windows and Mac (Nvidia GPU required)
WebGlaze - Free browser-based Glaze service for those who can't run Glaze locally. Request an invite by following their instructions.
Mist - Another adversarial noise tool, by Psyker Group. Runs on Windows and Linux (Nvidia GPU required) or on web with a Google Colab Notebook.
Nightshade - UChicago's tool to distort AI's recognition of features and "poison" datasets, with the goal of making it inconvenient to use images scraped without consent. The guide recommends that you do not disclose whether your art is nightshaded. Nightshade chooses a tag that's relevant to your image. You should use this word in the image's caption/alt text when you post the image online. This means the alt text will accurately describe what's in the image-- there is no reason to ever write false/mismatched alt text!!! Runs on Windows and Mac (Nvidia GPU required)
Sanative AI - Web-based "anti-AI watermark"-- maybe comparable to Glaze and Mist. I can't find much about this one except that they won a "Responsible AI Challenge" hosted by Mozilla last year.
Just Add A Regular Watermark - It doesn't take a lot of processing power to add a watermark, so why not? Try adding complexities like warping, changes in color/opacity, and blurring to make it more annoying for an AI (or human) to remove. You could even try testing your watermark against an AI watermark remover. (the privacy policy claims that they don't keep or otherwise use your images, but use your own judgment)
given that energy consumption was the focus of some AI art criticism, I'm not sure if the benefits of these GPU-intensive tools outweigh the cost, and I'd like to know more about that. in any case, I thought that people writing alt text/image descriptions more often would've been a neat side effect of Nightshade being used, so I hope to see more of that in the future, at least!
246 notes
·
View notes
Text
Less than three months after Apple quietly debuted a tool for publishers to opt out of its AI training, a number of prominent news outlets and social platforms have taken the company up on it.
WIRED can confirm that Facebook, Instagram, Craigslist, Tumblr, The New York Times, The Financial Times, The Atlantic, Vox Media, the USA Today network, and WIRED’s parent company, Condé Nast, are among the many organizations opting to exclude their data from Apple’s AI training. The cold reception reflects a significant shift in both the perception and use of the robotic crawlers that have trawled the web for decades. Now that these bots play a key role in collecting AI training data, they’ve become a conflict zone over intellectual property and the future of the web.
This new tool, Applebot-Extended, is an extension to Apple’s web-crawling bot that specifically lets website owners tell Apple not to use their data for AI training. (Apple calls this “controlling data usage” in a blog post explaining how it works.) The original Applebot, announced in 2015, initially crawled the internet to power Apple’s search products like Siri and Spotlight. Recently, though, Applebot’s purpose has expanded: The data it collects can also be used to train the foundational models Apple created for its AI efforts.
Applebot-Extended is a way to respect publishers' rights, says Apple spokesperson Nadine Haija. It doesn’t actually stop the original Applebot from crawling the website—which would then impact how that website’s content appeared in Apple search products—but instead prevents that data from being used to train Apple's large language models and other generative AI projects. It is, in essence, a bot to customize how another bot works.
Publishers can block Applebot-Extended by updating a text file on their websites known as the Robots Exclusion Protocol, or robots.txt. This file has governed how bots go about scraping the web for decades—and like the bots themselves, it is now at the center of a larger fight over how AI gets trained. Many publishers have already updated their robots.txt files to block AI bots from OpenAI, Anthropic, and other major AI players.
Robots.txt allows website owners to block or permit bots on a case-by-case basis. While there’s no legal obligation for bots to adhere to what the text file says, compliance is a long-standing norm. (A norm that is sometimes ignored: Earlier this year, a WIRED investigation revealed that the AI startup Perplexity was ignoring robots.txt and surreptitiously scraping websites.)
Applebot-Extended is so new that relatively few websites block it yet. Ontario, Canada–based AI-detection startup Originality AI analyzed a sampling of 1,000 high-traffic websites last week and found that approximately 7 percent—predominantly news and media outlets—were blocking Applebot-Extended. This week, the AI agent watchdog service Dark Visitors ran its own analysis of another sampling of 1,000 high-traffic websites, finding that approximately 6 percent had the bot blocked. Taken together, these efforts suggest that the vast majority of website owners either don’t object to Apple’s AI training practices are simply unaware of the option to block Applebot-Extended.
In a separate analysis conducted this week, data journalist Ben Welsh found that just over a quarter of the news websites he surveyed (294 of 1,167 primarily English-language, US-based publications) are blocking Applebot-Extended. In comparison, Welsh found that 53 percent of the news websites in his sample block OpenAI’s bot. Google introduced its own AI-specific bot, Google-Extended, last September; it’s blocked by nearly 43 percent of those sites, a sign that Applebot-Extended may still be under the radar. As Welsh tells WIRED, though, the number has been “gradually moving” upward since he started looking.
Welsh has an ongoing project monitoring how news outlets approach major AI agents. “A bit of a divide has emerged among news publishers about whether or not they want to block these bots,” he says. “I don't have the answer to why every news organization made its decision. Obviously, we can read about many of them making licensing deals, where they're being paid in exchange for letting the bots in—maybe that's a factor.”
Last year, The New York Times reported that Apple was attempting to strike AI deals with publishers. Since then, competitors like OpenAI and Perplexity have announced partnerships with a variety of news outlets, social platforms, and other popular websites. “A lot of the largest publishers in the world are clearly taking a strategic approach,” says Originality AI founder Jon Gillham. “I think in some cases, there's a business strategy involved���like, withholding the data until a partnership agreement is in place.”
There is some evidence supporting Gillham’s theory. For example, Condé Nast websites used to block OpenAI’s web crawlers. After the company announced a partnership with OpenAI last week, it unblocked the company’s bots. (Condé Nast declined to comment on the record for this story.) Meanwhile, Buzzfeed spokesperson Juliana Clifton told WIRED that the company, which currently blocks Applebot-Extended, puts every AI web-crawling bot it can identify on its block list unless its owner has entered into a partnership—typically paid—with the company, which also owns the Huffington Post.
Because robots.txt needs to be edited manually, and there are so many new AI agents debuting, it can be difficult to keep an up-to-date block list. “People just don’t know what to block,” says Dark Visitors founder Gavin King. Dark Visitors offers a freemium service that automatically updates a client site’s robots.txt, and King says publishers make up a big portion of his clients because of copyright concerns.
Robots.txt might seem like the arcane territory of webmasters—but given its outsize importance to digital publishers in the AI age, it is now the domain of media executives. WIRED has learned that two CEOs from major media companies directly decide which bots to block.
Some outlets have explicitly noted that they block AI scraping tools because they do not currently have partnerships with their owners. “We’re blocking Applebot-Extended across all of Vox Media’s properties, as we have done with many other AI scraping tools when we don’t have a commercial agreement with the other party,” says Lauren Starke, Vox Media’s senior vice president of communications. “We believe in protecting the value of our published work.”
Others will only describe their reasoning in vague—but blunt!—terms. “The team determined, at this point in time, there was no value in allowing Applebot-Extended access to our content,” says Gannett chief communications officer Lark-Marie Antón.
Meanwhile, The New York Times, which is suing OpenAI over copyright infringement, is critical of the opt-out nature of Applebot-Extended and its ilk. “As the law and The Times' own terms of service make clear, scraping or using our content for commercial purposes is prohibited without our prior written permission,” says NYT director of external communications Charlie Stadtlander, noting that the Times will keep adding unauthorized bots to its block list as it finds them. “Importantly, copyright law still applies whether or not technical blocking measures are in place. Theft of copyrighted material is not something content owners need to opt out of.”
It’s unclear whether Apple is any closer to closing deals with publishers. If or when it does, though, the consequences of any data licensing or sharing arrangements may be visible in robots.txt files even before they are publicly announced.
“I find it fascinating that one of the most consequential technologies of our era is being developed, and the battle for its training data is playing out on this really obscure text file, in public for us all to see,” says Gillham.
11 notes
·
View notes
Text
Tumblr Growth - Its tough trying to face the world from inside Tumblr.
I used a service called Make | Automation Software | Connect Apps & Design Workflows | Make to push my Youtube videos (All of them that I could on a free plan) to Tumblr - ive been also forming connections and commenting and being part of the community. I had issues where it would post the link to the video, well the ID and I had to manually push the you tube url video = [VideoID] but it didnt embed so I have been editing them one by one to properly embed them and tag them. Its paying off slowly, also pushing thebritbeardo.tumblr.com to the world, frustrated that tumblr is blocking bing bot and @tumblrsupport in a reddit thread said speak to Bing, Bing does not control robots.txt for my site so I kindly asked and will continue to ask tumblr support to remove the block to bingbot, I have sent screenshots from bing webmaster tools. Also, Google is not properly indexing britbeardo.tumblr.com because its not the canonical URL and no matter the tags I put in the html it seems that there is a tumblr controlled canonical url that is set to tumblr.com/accountname. All the canonical testers tell me this.
It seems they are really focusing on users using internal tumblr network and not reaching out to potentially new tumblr users. Its a shame as if you configure Tumblr correctly, follow the right people its actually a much better social environment that Facebook or X, Threads, Masterdon etc. I use them all pretty much and found Tumblr to be a breath of fresh air except for these few frustrations.
@TumblrSupport please allow users more control of blocked search engines in the robots.txt, even if its a check box for allow Yandex, Allow BingBot etc. And give us control of the canonical URL, if I put a Tag in my HTML to override please honor my request to use account.tumblr.com I considered buying a domain but in still concerned that using a domain will cause me to still blocked by bingbot and not have control of the canonical settings.

3 notes
·
View notes
Text
I'd like some people to participate in a quick LLM experiment - specifically, to get some idea as to what degree LLMs are actually ignoring things like robots.txt and using content they don't have permission to use.
Think of an OC that belongs to you, that you have created some non-professional internet-based content for - maybe you wrote a story with them in it and published it on AO3, or you talked about them on your blog, or whatever, but it has to be content that can be seen by logged-out users. Use Google to make sure they don't share a name with a real person or a well-known character belonging to someone else.
Pick an LLM of your choice and ask it "Who is <your OC's name>?" Don't provide any context. Don't give it any other information, or ask any follow-up questions. If you're worried about the ethicality of this, sending a single prompt is not going to be making anyone money, and the main energy-consumption associated with LLMs is in training them, so unless you are training your own model, you are not going to be contributing much to climate change and this request probably doesn't use much more energy than say, posting to tumblr.
Now check if what you've posted about this OC is actually searchable on Google.
Now answer:
robots.txt is a file that every website has, which tells internet bots what parts of the website they can and cannot access. It was originally established for search engine webcrawlers. It's an honor system, so there's nothing that actually prevents bots from just ignoring it. I've seen a lot of unsourced claims that LLM bots are ignoring robots.txt, but Wikipedia claims that GPTBot at least does respect robots.txt, at least at the current time. Some sites use robots.txt to forbid GPTBot and other LLM bots specifically while allowing other bots, but I think it's probably safe to say that if your content does not appear on Google, it has probably been forbidden to all bots using robots.txt.
I did this experiment myself, using an OC that I've posted a lot of content for on Dreamwidth, none of which has been indexed by Google, and the LLM did not know who they were. I'd be interested to hear about results from people posting on other sites.
2 notes
·
View notes
Text
SEO danışmanlığı verdiğim bir müşterim vardı. Site tasarımı harikaydı, içerikler güçlüydü ama Google’da yok gibiydi.
Biliyor musun neden? Çünkü indekslenmiyordu.
Peki neden bir site indekslenmez? İşte başlıca 5 neden:
1. Noindex etiketi kullanılmış olabilir.
Kodu kontrol ettik, her sayfada noindex vardı. Google’a “beni listeleme” demek gibi bir şey!
2. Robots.txt dosyası engelliyor olabilir.
Bazı sayfalar arama motoru botlarına kapatılmıştı. Bu dosya, Google’ı kapıdan çeviriyor.
3. Kalitesiz veya kopya #içerik varsa
Google, tekrar eden ya da anlamsız içerikleri görmezden gelebilir.
4. Yeni site olabilir ve henüz taranmamış olabilir.
Site yeni kurulduysa, sabırlı olmak gerek. Ama Google Search Console’dan manuel tarama isteyebilirsin.
5. Yetersiz backlink ya da iç linkleme sorunu
Google siteni bulamazsa, tarayamaz da.
🛠️ İndeksleme olmadan #SEO olmaz! İlk iş: Search Console’dan tarama hatalarını kontrol et!
Daha fazla bilgiyi 👉 https://www.aliarior.com/seo kategori sayfamda bulabilirsiniz.
#seo uzmanı#seo analiz#nasıl yapılır#seo danışmanlığı#indeks sorunları#seo sorunları#arama motoru optimizasyonu
2 notes
·
View notes
Text
Leading SEO Expert in Bangladesh | Crafting Digital Destinies | Muhin Ahmed | 2025
Muhin Ahmed—The Best SEO Expert in Bangladesh
In the heartbeat of a land where history breathes through every corner, where rivers sing lullabies and dreams rise like monsoon clouds, there lives a storyteller of a different kind. He doesn’t write poems with ink but carves destinies in Google’s search bar. His name? Muhin Ahmed — the best SEO expert in Bangladesh and the orchestrator of online miracles.
Why Muhin Ahmed Stands Out Among the Crowd
Authenticity, Strategy, and Vision
What sets Muhin apart isn’t just his technical finesse. It’s his empathy. He possesses the capacity to comprehend a client's vitality, their apprehensions, and their objectives. transforming them into a strategic plan that excels. Each strategy he crafts is a symphony: balanced, brilliant, and bespoke.
Transforming Clients into Digital Legends
From startups gasping for attention to seasoned companies losing their spark, Muhin has revived many with nothing but code, content, and care.
The Role of an SEO Expert in Bangladesh
Beyond Keywords—A Symphony of Strategy
An SEO expert in Bangladesh isn’t someone who just throws keywords into a page like spices in a pot. It's an art. A science. A subtle seduction of search engines and a soulful conversation with audiences.
From Code to Content: Wearing Every Hat
Technical SEO Mastery
Sitemaps. Robots.txt. Schema markup. Page speed. It’s the language of the machine, and Muhin is fluent.
Emotional Storytelling in Content
Google wants to know if your site matters. People want to feel it. Muhin does both—aligning data with dreams.
Why SEO Matters in 2025 and Beyond
Bangladesh's Digital Awakening
Once upon a time, having a shop at a busy street corner was enough. Today, your shop must appear in the first five results of a search query. SEO is the new real estate—and it’s more competitive than ever.
The Ever-Evolving Search Algorithm
Every Google update is like a tide. If you're not prepared, your digital castle may crumble. With Muhin at the helm, you're surfing—not sinking.
The Journey of an SEO Specialist in Bangladesh
From Learner to Leader: Muhin Ahmed’s Digital Odyssey
Early Days and Self-Learning
Like many dreamers, Muhin began with zero. No roadmap. No mentor. Just passion. And that was enough.
Tapping into Global Markets from Local Roots
From small Bangladeshi websites to global brands, Muhin Ahmed’s portfolio now tells stories from every time zone.
The Mindset of a True SEO Expert in BD
Hunger for knowledge
Obsession with analytics
Respect for users and search engines alike
Services Offered by Muhin Ahmed
Full-Spectrum SEO Services
On-Page & Off-Page Optimization
From meta tags to link juice, every detail matters. Muhin ensures that every SEO box is checked, rechecked, and polished.
Content Marketing & Technical SEO
He crafts content that climbs rankings and builds tech foundations that withstand any algorithm storm.
Customized Strategies for Every Business
Whether you’re a local café or a SaaS startup, your needs are unique. So are Muhin’s strategies.
Results That Speak Louder Than Promises
Rankings. Traffic. Conversions. Testimonials. Muhin doesn’t talk big — he delivers big.
Read Full Blog
#best seo expert in sylhet#best digital marketer in sylhet#seo expert in sylhet#who is best seo expert in sylhet#seo specialist#best digital marketer in bangladesh#best seo expert in bangladesh#digital marketer#seo expert in bd#seo expert#local seo#seo agency#seo company#seo marketing#search engine optimization#seo expert bd#best seo experts#seo experts#who is the best seo expert in bangladesh#seo specialist in bangladesh
2 notes
·
View notes
Text
Recent discussions on Reddit are no longer showing up in non-Google search engine results. The absence is the result of updates to Reddit’s Content Policy that ban crawling its site without agreeing to Reddit’s rules, which bar using Reddit content for AI training without Reddit’s explicit consent.
As reported by 404 Media, using "site:reddit.com" on non-Google search engines, including Bing, DuckDuckGo, and Mojeek, brings up minimal or no Reddit results from the past week. Ars Technica made searches on these and other search engines and can confirm the findings. Brave, for example, brings up a few Reddit results sometimes (examples here and here) but not nearly as many as what appears on Google when using identical queries. A standout is Kagi, which is a paid-for engine that pays Google for some of its search index and still shows recent Reddit results.
As 404 Media noted, Reddit's Robots Exclusion Protocol (robots.txt file) blocks bots from scraping the site. The protocol also states, "Reddit believes in an open Internet, but not the misuse of public content." Reddit has approved scrapers from the Internet Archive and some research-focused entities.
Reddit announced changes to its robots.txt file on June 25. Ahead of the changes, it said it had "seen an uptick in obviously commercial entities who scrape Reddit and argue that they are not bound by our terms or policies. Worse, they hide behind robots.txt and say that they can use Reddit content for any use case they want."
Last month, Reddit said that any "good-faith actor" could reach out to Reddit to try to work with the company, linking to an online form. However, Colin Hayhurst, Mojeek's CEO, told me via email that he reached out to Reddit after he was blocked but that Reddit "did not respond to many messages and emails." He noted that since 404 Media's report, Reddit CEO Steve Huffman has reached out.
7 notes
·
View notes
Text
SEO Uzmanı Kimdir? Bilmeniz Gereken 7 Kritik Strateji

SEO uzmanı olmak, sürekli değişen arama motoru algoritmaları vb. dijital pazarlama dinamikleri içinde hem zorlayıcı hem de bir o kadar ödüllendirici bir kariyer yolu. Peki SEO uzmanı ne iş yapar tam olarak biliyor muyuz?
SEO Uzmanı Nedir ve Ne İş Yapar?
Profesyonel SEO uzmanı, bir web sitesinin arama motorlarında daha üst sıralarda yer alması için çalışır. Bu kapsamda teknik SEO, içerik optimizasyonu ve bağlantı kurma stratejilerini bir arada yürütür. İyi bir SEO uzmanı:
Web sitelerini arama motoru kurallarına göre optimize eder
Anahtar kelime araştırması ve analizi yapar
Site içi ve site dışı SEO stratejileri geliştirir
İçerik stratejisi oluşturur ve yönetir
Teknik SEO sorunlarını tespit eder ve çözüm önerileri sunar
Rakip analizleri gerçekleştirir
SEO performansını düzenli olarak takip eder ve raporlar
Türkiye'de orta düzey bir SEO uzmanının proje başına aylık ücreti 350 $ ile 950 $ arasında değişmektedir. Bu sektöre veya anahtar kelime zorluğuna göre değişir. Deneyimli uzmanlar ise en az 1000 $ ile kapıyı açarlar. Sonrası ise hedefe göre ucu açıktır.
SEO Uzmanı Olmak İçin Gerekli Beceriler
1. Teknik Yeterlilik
Modern bir SEO uzmanı, HTML, CSS gibi temel web teknolojileri hakkında bilgi sahibi olmalıdır. Site hızı optimizasyonu, mobil uyumluluk, yapısal veri işaretlemeleri, robots.txt ve site haritası vb. teknik konuları bilmesi gerekir.
2. Analitik Düşünme Yeteneği
Google Analytics, Google Search Console ve SEMrush gibi analiz araçlarını kullanabilmeli ve verileri doğru yorumlayabilmesi gerekir. Rakamların arkasındaki hikayeleri görebilmek ayrı bir becerisidir. Bu doğrultuda stratejiler geliştirebilmek başarıyı getirir.
3. İçerik Stratejisi ve Üretimi
"İçerik kraldır" sözü hâlâ geçerliliğini koruyor. Kaliteli, özgün ve kullanıcı odaklı içerikler üretebilmek için içerik ekibine uygun brifleri vermeli. İçerik üretim sürecini yönetmesi ise ayrı bir becerisidir. Anahtar kelime araştırması yapmak ve uygun anahtar kelimeleri bulmak işin özüdür. İçerik takvimi oluşturma sürecine doğrudan olmasa bile destek sunabilir. Ayrıca içerik performansını ölçmek SEO uzmanının görevleri arasında yer alır.
4. Sürekli Öğrenme Tutkusu
Arama motorları algoritmalarını sürekli güncelliyor. Bu nedenle SEO uzmanının kendini sürekli güncel tutması ve yenilikleri takip etmesi şarttır. SEO konferansları, webinarlar ve sektör bloglarını düzenli olarak takip etmek gerekir.
Sık Sorulan Sorular: SEO Uzmanlığı Hakkında Bilmeniz Gerekenler
SEO Uzmanı Olmak İçin Eğitim Şart Mı?
Özel bir diplomaya ihtiyaç yoktur. Dijital pazarlama veya bilgisayar bilimleri gibi alanlarda eğitim almak avantaj sağlar. Bunun yanında Google, HubSpot, SEMrush vb. platformların sertifika programları kariyerinize katkı sağlayabilir.
SEO Uzmanları İçin En Değerli Araçlar Hangileridir?
SEO uzmanlarının olmazsa olmaz araçları şunlardır:
Google Analytics ve Google Search Console (ücretsiz ve temel araçlar)
Ahrefs veya SEMrush (kapsamlı SEO analiz araçları)
Screaming Frog (site denetimi için)
Moz (otorite ölçümü ve analiz için)
Yoast SEO (WordPress siteleri için eklenti)
Son araştırmalara göre, Türkiye'deki SEO uzmanlarının %78'i en az üç farklı SEO aracı kullanmaktadır.
SEO Uzmanları İçin Kariyer Fırsatları Nelerdir?
SEO uzmanlığı, çeşitli kariyer yolları sunar:
Ajans bünyesinde SEO uzmanı
Şirket içi SEO uzmanı veya yöneticisi
Freelance SEO danışmanı
Kendi SEO ajansını kurmak
İçerik stratejisti veya pazarlama yöneticiliğine geçiş
Başarılı Bir SEO Uzmanı Olmak İçin 7 Kritik Strateji
1. Yapay Zeka ve SEO Entegrasyonu
Yapay zeka artık SEO'nun ayrılmaz bir parçası. ChatGPT ve diğer AI araçlarını içerik üretimi, anahtar kelime araştırması ve teknik SEO için etkin kullanmayı öğrenmek önemlidir. Bunlar rekabet avantajı sağlar. Unutmayın, AI ile üretilen içeriklerin insan dokunuşuyla zenginleştirilmesi hâlâ gereklidir.
2. E-E-A-T Prensibine Odaklanma
Google'ın E-E-A-T (Experience, Expertise, Authoritativeness, Trustworthiness) prensibi giderek önem kazanıyor. İçeriklerde deneyim, uzmanlık, otorite ve güvenilirlik vb. faktörlerini öne çıkarmak, özellikle YMYL (Your Money Your Life) sitelerinde kritik öneme sahiptir.
3. Kullanıcı Deneyimine Öncelik Verme
Core Web Vitals gibi kullanıcı deneyimi metriklerine odaklanmak gerekiyor. Site hızı, mobil uyumluluk ve etkileşim ölçütleri sıralamalarda belirleyici faktörler arasında. Araştırmalar, sayfa yüklenme hızının 3 saniyeden fazla olması durumunda ziyaretçilerin %40'ının siteyi terk ettiğini gösteriyor.
4. Semantik SEO ve Konu Otoritesi
Tek bir anahtar kelimeye odaklanmak artık günü kurtarmıyor. Bunun yerine kapsamlı konu kümeleri oluşturmak ve semantik SEO'ya önem vermek gerekiyor. İlgili anahtar kelimeler, sorular ve konularla zenginleştirilmiş içerikler oluşturmak önemlidir.
5. Yerel SEO Stratejilerini Geliştirme
Türkiye pazarında, yerel SEO giderek daha fazla önem kazanıyor. Google Business Profile optimizasyonu, yerel anahtar kelimeler ve yerel bağlantılar oluşturmak vb. özellikle fiziksel lokasyonu olan işletmeler için hayati öneme sahip. Yani SEO sadece web sitenizde uygulanmıyor. Sosyal medyadan işletme profiline kadar her alanda gereklidir.
6. Video SEO'ya Yatırım Yapma
YouTube, dünyanın en büyük ikinci arama motoru konumunda. Video içerikler oluşturmak ve bunları optimize etmek, toplam dijital görünürlüğünüzü artırır. Videoların ortalama izlenme süresini artırmak ve etkileşimi teşvik etmek öncelikli hedefler olmalıdır.
7. Veri Odaklı Karar Verme
Modern SEO uzmanı, tüm kararlarını verilerle desteklemelidir. A/B testleri yapmak, kullanıcı davranışlarını analiz etmek önemlidir. Ayrıca performans metriklerini düzenli olarak takip etmek başarıyı getirir.
SEO uzmanlığı, sürekli gelişen ve değişen dinamik bir alandır. Başarılı bir SEO uzmanı olmak için teknik bilgi, analitik düşünme, içerik stratejisi vb. en önemlisi adapte olma yeteneği gerekmektedir. Algoritmalar değişse de, kullanıcı odaklı ve kaliteli içerik üretmenin önemi değişmeyecektir.
Unutmayın, arama motorları sürekli değişiyor, ancak kaliteli ve değerli içerik üretmek her zaman kazandırır.
Kaynak:
#seo uzmanı#freelance seo uzmanı#seo uzmanı kimdir#dijital pazarlama uzmanı#freelance dijital pazarlama uzmanı
2 notes
·
View notes
Text
Blocking AI Bots: The Opt Out Issue.
Those of us that create anything – at least without the crutches of a large language model like ChatGPT- are a bit concerned about our works being used to train large language models. We get no attribution, no pay, and the companies that run the models basically can just grab our work, train their models and turn around and charge customers for access to responses that our work helped create. No…

View On WordPress
0 notes
Text
GenAI is stealing from itself.

Fine, it's Dall-E... the twist is this... One of the influencing images seems to be this one which has a lot of matching features. AI stealing, fine.:
It's likely this one. (I found this via reverse image search) But something doesn't feel right about this one. So I looked it up...

It's Midjourney. lol
So AI is stealing from AI.
The thing is as people wise up and start adding these lines to robot.txt
GenAi has no choice but to steal from GenAI, which, Oh, poor developers are crying big tears is making GenAI worse. Oh poor developers crying that they no longer can steal images because of nightshade:
https://nightshade.cs.uchicago.edu/whatis.html and glaze:
To which I say, let AI steal from AI so it gets shittier.
Remember to spot gen AI, most of the devil is in the details of the lazy-ass creators.
This video goes over some of the ways to spot it (not mine). https://www.youtube.com/watch?v=NsM7nqvDNJI
So join us in poisoning the well and making sure the only thing Gen AI can steal is from itself.
Apparently stealing with one person with a name is not fine and is evil. But stealing from 2+ people is less evil as long as you don't know their names, or you do, because you went explicitly after people who hate AI like the Ghibli studio and you don't want to stare into Miyazaki's face.
Because consent isn't in your vocabulary? This is the justification that genAI bros give, including things like drawing is sooooo impossible to learn.
And if you don't understand consent, then !@#$ I don't think anyone wants to date you either. But I digress. The point is that we should push AI to learn from AI so that Gen AI becomes sooo crappy the tech bros need to fold and actually do what they originally planned with AI, which is basically teach it like it was a human child. And maybe do useful things like, Iunno, free more time for creativity, rather than doing creativity.
#fuck ai everything#ai is evil#fight ai#anti genai#fuck genai#fuck generative ai#ai is stealing from itself#anti-ai tools
3 notes
·
View notes