#rivdig
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The most popular pages on Tumblr are about Minecraft, GIFs, and David J. Peterson.
Text
LA MIA PRIMA ESPERIENZA CON INTERNET
Sono nato nella capitale di uno dei paesi che ha adottato internet più velocemente e che è attualmente uno dei paesi con la percentuale di popolazione utilizzante internet più alta al mondo, di conseguenza ho avuto accesso a internet da quando sono nato. Questo non mi permette di distinguere chiaramente la prima volta che ho fatto uso di internet ma ricordo un momento piuttosto banale: me insieme a mia madre che mandiamo per email un disegno che avevo fatto al computer per mio padre.

Oslo foto preso da visit norway
Non soltanto internet è stata una costante nella mia vita ma anche i computer. Grazie al lavoro di mio padre avevamo la casa piena di computer perché il suo datore di lavoro gli dava un nuovo computer almeno una volta all’ anno per far sì che mio padre avesse sempre i computer più potenti possibili. Il mio primo computer fisso è stato un ex computer di mio padre e l’ho ricevuto quando avevo 5 anni, probabilmente perché mi ero appropriato del computer di mia madre già da molto tempo per disegnare.
Da quando ho avuto un computer mio mi si è aperto un mondo e sono diventato subito un appassionato di videogiochi. Uno dei “tanti” giochi che avevo era uefa 2000 e l’intro mi fa ancora adesso venire la pelle oca. Da questo gioco di sicuro è nato il mio interesse per trovare bugs, in particolare ne ricordo uno: se rimanevi fermo per un po’ i giocatori della squadra avversaria diventavano immobili.
Questa passione per i giochi mi ha infine spinto a utilizzare internet non per chattare, perché in rete c’era una vasta gamma di giochi diversi gratuiti, i così detti giochi flash. Questi giochi hanno definito un periodo della mia esperienza da gamer.
Grazie a mio padre ho imparato a utilizzare Google molto velocemente, anche se mia madre era una forte oppositrice di ciò, in quanto credeva che Yahoo fosse la piattaforma migliore.
Il mio utilizzo di Google non regolato mi ha pure portato un po’ di guai. A 9 anni mi iscrissi a un servizio a pagamento utilizzando un’email fittizia, non ricordo perché, ma sapevo che avrei dovuto utilizzare un’ email fittizia, e dopo un mese di abuso di questo servizio ho ricevuto un’email con la richiesta di pagare più di 400 kr, una somma enorme per me al tempo in quanto la mia paghetta era soltanto di 50 kr.

Un vecchio banconota di 50 Kr
Sono riuscito a uscire dai guai sfruttando la mia conoscenza dell’inglese, una lingua che conoscevo già abbastanza bene grazie all’uso quasi giornaliero di internet e multimedia inglese. Ho scritto un’email alla compagnia dove ho spiegato di essere stato hackerato, un concetto che non so oggi come mai conoscessi già allora, e che non ero stato io a registrare l’account. Questa fu la prima volta che io mi ricordi di aver parlato di hackeraggio o di hacker in generale.
Oggi, 11 anni dopo, sono tra i migliori hacker focalizzati su operazioni offensive, nella mia categoria, in Norvegia secondo la NCSC, e sono stato tra i top 100 al mondo in una competizione continua di hackeraggio chiamata HackTheBox.
Storm “Frisk” Kavlie
1 note
·
View note
Text
La mia prima esperienza su Internet
Sono ormai una ragazza di vent’anni e nel tempo ho acquisito una certa dimestichezza con il web e in generale con il mondo di internet, ma questo percorso è nato quando ero solo una bambina.
Ho iniziato ad approcciarmi al computer quando, all’età di cinque o sei anni, mio padre acquistò il nostro primo computer domestico, con il quale ci divertivamo la sera a fare interminabili tornei di 3D Pinball (famoso videogame per Windows XP) o a disturbare tutti i vicini cantando a squarciagola al karaoke. Mio padre è sempre stata una persona attenta allo sviluppo delle nuove tecnologie e all’innovazione e fu così che poco tempo dopo abbiamo avuto il nostro primo collegamento ad internet.

Screenshot dalla schermata di 3D Pinball (sviluppato dalla Cinematronics e pubblicato dalla Maxis per Windows)
Pur non avendo ancora bene idea di come utilizzarlo, l’idea di avere una connessione al famoso internet mi estasiava. I primi tempi non navigavo ancora sul web e perlopiù usavo internet per giocare online a Hearts o a scacchi, anche se spendevo la maggior parte del mio tempo al computer offline a giocare con qualche CD di giochi (il mio preferito era una serie di rompicapo ambientati nella favola di “Alice nel paese delle meraviglie”) che ogni tanto mi regalavano i miei genitori.
Nel giro di alcuni anni, quando ne avevo circa 10, le connessioni internet sono migliorate e i prezzi si sono abbassati, e così ho iniziato veramente a esplorare il mondo del web. Essendo pur sempre una bambina ero affascinata dai giochi online, ed in particolare da un sito chiamato Stardoll, che permetteva di vestire cartamodelli digitali di personaggi famosi e crearsene anche uno personale da vestire e riempire di accessori.
Iniziate le scuole medie iniziai anche ad approcciarmi ai servizi di messaggistica istantanea (come MSN) ed ai primi social network con cui mi tenevo in contatto con i miei compagni di scuola.
Ad oggi trascorro molto tempo su internet, anche se principalmente via smartphone, e l’utilizzo che ne faccio non è cambiato poi molto: uso molto i social network (anche se ora sono Facebook e Instagram al posto di MySpace e Netlog), mi scrivo con i miei amici su Whatsapp e mi diverto ancora con i giochini online. Mi si può sicuramente definire una internet-addicted!
Com’è stata la vostra prima esperienza con il magico mondo di internet?
Sara Andrea ☼
#rivdig#rivoluzionedigitale#rivoluzdigitale#internet#lamiaprimaesperienzaconinternet#first time#experience#prima esperienza#web
0 notes
Text
Fly by Wire
Cos'è il Fly by Wire?
In molti dei più moderni aeromobili, i comandi vengono trasmessi dalla cloche alle superfici di controllo non più con sistemi meccanici e idraulici, ma bensì con sistemi elettronici. Questi sistemi elettronici sono appunto detti sistemi "fly by wire"; essi però non si limitano alla trasmissione del comando, ma lo elaborano alfine di correggere eventuali errori del pilota o per alleviare la mole di lavoro dello stesso. Parte del potere decisionale e delle responsabilità viene quindi spostata dal pilota ad un calcolatore.
Vantaggi del fbw
Il fbw consente, come già detto, di correggere eventuali errori del pilota. Inoltre, analizzando vari parametri, consente di ottimizzare il volo e proteggere i sistemi da eccessive sollecitazioni. Il computer infatti, a differenza dell'umano, può computare molti dati contemporaneamente e con maggiore efficienza. Inoltre i sistemi elettronici sono molto meno pesanti e di più facile manutenzione rispetto a quelli meccanici.
Problemi legati al fbw
I fbw installati negli aeromobili comprendono sistemi di backup e di calcolo multiplo in modo da escludere la possibilità di errore. Il problema sorge quando al sistema vengono forniti dati errati. In questo caso il computer, non avendo capacità critiche, esegue le operazioni basandosi su una sbagliata descrizione della situazione. Per questo motivo l'ultima decisione è affidata al pilota, che deve essere in grado di prendere quella corretta; è evidente che ciò implica importanti questioni di sicurezza. Ad esempio la tragedia del volo AF447, precipitato nel 2009 nell'Oceano Atlantico, fu causata in parte dal fatto che il computer riceveva letture errate della velocità, in parte dal fatto che i piloti non furono in grado di interpretare correttamente l'emergenza.
Altre implicazioni
Ci sono varie scuole di pensiero riguardo all'utilizzo del fbw. Ci si chiede ad esempio quanto sia giusto e sicuro delegare ad un calcolatore le varie operazioni, e quanto fidarsi dell'esperienza del pilota. È vero che la maggioranza degli incidenti aerei sono causati da errori umani, ma è anche vero che la progressiva automatizzazione rischia di creare una generazione di piloti sempre meno coscienti di ciò che stanno facendo e meno in grado di far fronte a emergenze senza ausili informatici.
Giorgio Nicola
fonti:
Wikipedia
1 note
·
View note
Text
Investigazione moderna
Oggi vorrei spiegare come va effettuata un’investigazione standard basata sui metadati generati dai browser.
Ogni browser normalmente salva tutti gli url visitati in un database con il timestamp di quando l’utente ha visitato quell’url. Questa funzionalità è accessibile anche ai browser plug-in, questo fa sì che ogni volta che installi un plug-in, è possibile che tu stia condividendo i tuoi metadati riguardanti la tua storia di “navigazione”.
Questi metadati contengono abbastanza informazioni sia per identificare l’utente che per capire la sua posizione e desideri nella vita, questo perché molti url contengono informazioni sull’utente, per esempio quando si cerca un itinerario su google maps quello salva tutte le informazioni necessarie per “rivedere” quell’itinerario nell’url. Come anche facebook che ha url unici che potrebbero essere utilizzati per identificare una persona o con chi parla.

Da optipess
Questo stile di metadati è anche facilmente ottenibile in quanto tante aziende che sviluppano plug-in per i browser vendono queste informazioni. Inoltre, questo tipo di metadati è utile per aziende addette alla pubblicità, ma soprattutto è specialmente utile per aziende di intelligence in quanto possono essere utilizzati per trovare utenti appartenenti a certe comunità, identificati facilmente attraverso il loro browsing history.
Metadati simili potrebbero anche essere ottenibili da un ISP (Internet service provider) in quanto l’ISP potrebbe vedere il traffico che invii e ricevi. Per legge in alcuni paesi gli ISP sono costretti a salvare metadati, come in Italia. Questo può anche essere fatto da tanti altri service provider e in alcuni casi anche dal manufattore del sistema operativo.
Questo tipo di metadati è molto utile per monitorare utenti in comunità di interesse e per scoprire facilmente nuovi trend e utenti in queste comunità. Prendiamo in esempio la comunità che frequenta il sito di Fabio kamikaze. Trattando tutti coloro che frequentano il sito come utenti di interesse si può creare un fingerprint basandosi sui metadati di questi utenti. Acquistando metadati sì può anche arrivare a conoscere velocemente e programmaticamente tante informazioni per i vari utenti presi singolarmente, per esempio:
1. Con chi ha parlato più spesso;
2. Quali siti frequentava;
3. Quando li frequentava;
4. Quali sono le sue abitudini particolari;
Questi dati sono accessibili in secondi se si è in possesso dei metadati. Da questa investigazione preliminare si può passare allo stadio di investigazione a nodi. Per esempio dalla fingerprint del sito associata alla comunità investigativa si vede se ci sono altri utenti con simili comportamenti fuori da questo communita nel database di metadati accessibile all’investigatore o se certi utenti della comunità sono direttamente collegati (per i) con altri utenti investigati appartenenti a un’altra comunità.
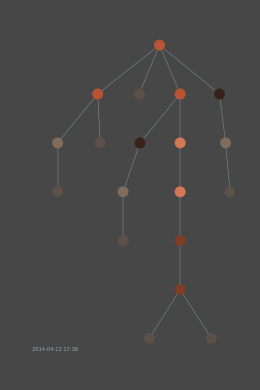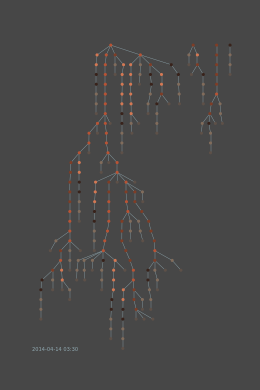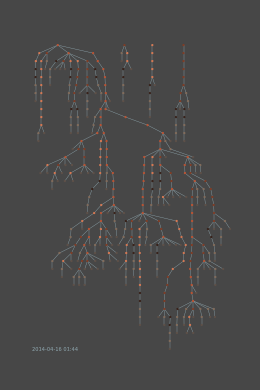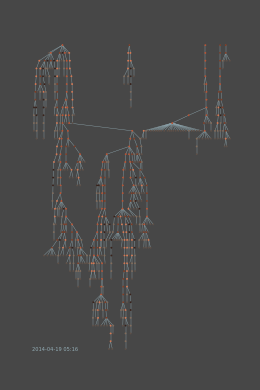
Esempio di crescita di un rete a nodi
Il fatto di utilizzare nodi per descrivere un utente o comunità fa sì che si possano utilizzare vari algoritmi e conoscenze acquisiti dal Network Science per descrivere comunità complesse, e dare velocemente all’investigatore una buona panoramica della situazione. Questo ci permette anche di utilizzare algoritmi di big data e machine learning per analizzare i dati e in alcuni casi predire eventi prima che accadano.
Questo tipo di collezione di dati e analisi al momento va (nella maggior parte dei paesi) fatto postmortem, quindi dopo un evento, ma si ha adesso una spinta verso l'effettuazione di un’analisi dinamica ed in tempo reale di metadati creando così una mappa “LIVE” delle comunità attive basandosi sui metadati generati dalla popolazione.
Gli esempi di implementazioni di analisi di comunità bastati su metadati sono molteplici
Per esempio facebook ha, secondo alcuni documenti, un algoritmo per sapere quale è lo stato mentale di alcuni dei suoi utenti
O il GFT di google che purtroppo, secondo me, ha fallito per il fatto che il data di input veniva soltanto da una fonte. Se google avesse messo insieme i search query con il numero di persone che hanno usato google maps per andare all’ ospedale o chiamato il dottore dopo aver fatto questa ricerca, si avrebbe avuto di sicuro un algoritmo più preciso.
Se siete interessati a questa tipologia di ricerca vi consiglio di leggere https://arxiv.org/pdf/1511.06858.pdf , https://journals.aps.org/prx/abstract/10.1103/PhysRevX.6.031038 e https://www.sciencedirect.com/science/article/pii/S0957417417301161?via%3Dihub
Storm “Frisk” Kavlie
0 notes
Text
La mia prima esperienza con l’internet

Bambino davanti ad un laptop
Avevo 4 anni circa, ero già immerso nel mondo della tecnologia e usavo spesso il vecchio laptop di mio padre per divertirmi con videogiochi di auto di cui non ricordo nemmeno il nome.
Crescendo il mio rapporto con la tecnologia è stato una costante, mi sono sempre tenuto al passo con i tempi e ho sviluppato passione per questo tipo di evoluzione.
Non ricordo esattamente la mia prima esperienza con il web, ma ricordo gli utilizzi che ne facevo.
“Dai, troviamoci questo pomeriggio alle 3” “Va bene, come ti chiami sul gioco? Così ti posso aggiungere agli amici”
Con i miei compagni di classe spesso i dialoghi erano questi, nessuno di noi aveva ancora un cellulare, quindi quando ci vedevamo a scuola ci mettevamo d’accordo per trovarci, al pomeriggio, in un mondo virtuale in cui divertirci a combattere contro mostri provenienti dalla mitologia greca, asiatica e egiziana. Il gioco, a quei tempi da noi favorito, era un gdr in terza persona, aveva un sistema multiplayer molto semplice, perché uno di noi poteva creare un server a cui poi tutti potevano accedere, il grandioso numero di 6 giocatori. Se qualcuno non rispettava l’appuntamento? Beh, lo si aspettava, poi si iniziava a giocare da soli.
Da queste prime esperienze siamo passati ad ingrandire la nostra conoscenza del videogiocare online. Quando un gioco iniziava ad annoiarci ci spostavamo su un altro, sempre con lo stesso gruppetto di amici. La mia esperienza con l’internet fino al periodo delle medie era limitata a questo, con qualche sporadica ricerca per scuola palesemente copiata dal sito che, nella mia mente di ragazzo scansafatiche, rappresentava la verità assoluta : wikipedia.
Crescendo e maturando ho imparato a conoscere il tipo di persone che si trovano online, navigando su forum per scoprire qualcosa in più riguardante i giochi a cui giocavamo e iscrivendomi, tardivamente, a Facebook, il social network più importante dell’epoca. La mia iscrizione a Facebook è avvenuta per la prima volta durante l’estate tra la prima e la seconda superiore, lo reputavo inutile prima, poi vedendo che i miei amici ci si divertivano mi è venuta sempre più voglia di entrare in quel mondo e tutt’ora lo uso spesso, soprattutto per discutere di alcune passioni come basket e cinema in gruppi di persone con i miei stessi interessi. Usavo, però, spesso Youtube. Lo usavo come svago e ho visto la piattaforma evolversi sempre di più, seguendo fin dagli inizi molti youtuber che oggi hanno milioni di iscritti e i cui contenuti non sono più indirizzati a ragazzi della mia età. Questo sito era una manna dal cielo per passare giornate interminabili, perché seguendo il motto “broadcast yourself” venivano caricati video di ogni tipo.
Oggi, ormai, viviamo in una società in cui internet ha un ruolo fondamentale nella gestione della propria persona, è impensabile vivere senza e le opinioni a riguardo sono contrastanti. Io, tutto sommato, sto bene così.
Matteo Berta
0 notes
Video
youtube
Video presentazione del corso di Alessio Palumbo
0 notes
Text
(The) Hacking series
Oramai da qualche anno ha iniziato a prendere piede l’ utilizzo delle serie tv come mezzo di intrattenimento. Vi sono diversi modi di vederle. All’inizio venivano trasmesse in Tv, con lo svantaggio di non avere amplia scelta, oggigiorno invece il metodo principale è lo streaming via Internet. Infatti vi sono diversi siti che propongono abbonamenti mensili, con un range di prezzi molto vario, in modo tale che si possano adattare alle finanze di tutti. Ogni abbonamento concede l’accesso a contenuti esclusivi, serie tv inedite, oltre che la possibilità di scegliere la lingua dell’audio e dei sottotitoli (molto utile per chi vuole migliorare la conoscenza di una nuova lingua). Dietro ogni serie Tv c’è quindi un business economico molto amplio.
L’attacco a Netflix
Una di queste aziende che offre servizi di Streaming è Netflix. Essa oltre a offire contenuti, ne sta creando di suoi, dando luce a diverse serie esclusive, una fra tante “Orange is the new black”.

Logo dell’ azienda
A quanto pare a marzo del 2017 un hacker noto come “The Dark Overlord” ha deciso di attaccare Netflix riuscendo a rubare 10 di 13 episodi della 5a stagione di Orange is the new black, stagione che ovviamente non era ancora uscita. Netflix come risposta non ha accettato il ricatto dell’hacker (si parlava di milioni di dollari di “riscatto”), nonostante quest’ ultimo avesse sottolineato che l’azienda avrebbe perso molti più soldi qualora non avesse soddisfatto la sua richiesta. Il culmine di ciò si ha a fine marzo del 2017 quando l’hacker per dimostrare la sua fermezza, pubblica sul sito “The Pirate Bay” l’intera stagione.

Logo della serie tv creata da Netflix
Tutto questo ha provocato ingenti danni a Netflix che si è vista costretta a rivedere la data di uscita ufficiale della 5a stagione. Intanto l’hacker sul suo account Twitter ha annunciato che ha in servo altre “sorprese” per altre compagnie(tra le quali egli cita “FOX,IFC,NAT,GEO e ABC).
HBO
Qualche mese dopo il famigerato attacco a Netflix, l’emittente americana HBO è stata vittima di un attacco hacker che è stato definito “inquietante” dal Ceo Richard Plepler.

Logo dell’emittente
HBO si è limitata a confermare l’attacco senza fornire informazioni riguardo il bottino. Si sa solo che una grandissima quantità di dati riguardanti la settimana stagione sono stati trafugati. Infatti si parla di circa 1.5 Terabyte secondo ciò che Repubblicaè stato riportato da Repubblica. Non era la prima volta che HBO subiva un attacco, infatti nel 2015 altri 4 episodi della 5a stagione erano stati pubblicati in seguito ad un attacco informatico. L’attacco ai danni di HBO era stato preannunciato con una email anonima inviata ad alcune testate americane. Vi si leggeva infatti “La maggiore fuga del cyber spazio sta accadendo ora.”
L’emittente ha voluto andare a fondo della vicenda riuscendo a scoprire la mente dietro l’attacco. Behzad Mesri, il quale usava lo pseudonimo “Skote Vahshat” è stato accusato di frode, estorsione e furto di identità. Quest uomo per ora rimane in Iran in questo modo fa si che sia difficile per le autorità americane arrestarlo.
Staremo a vedere,con il passare del tempo, come queste società cercheranno di difendersi da eventuali attacchi, intanto non ci rimane che osservare, come spettatori queste “Hacking series”.
Alessio Palumbo
0 notes
Text
UN TUFFO NEL PASSATO
Chi, oggigiorno, non usa internet quasi in maniera spontanea? Praticamente tutti. Io in primis ne usufruisco, inconsciamente direi. Vorrei percorrere con voi un viaggio, un viaggio che ha alla base il ricordo.
Quando è stata la prima volta che interagii con internet? La prima vera e propria esperienza con Internet risale ai famosi giochi online, i cosiddetti giochi “in flash” ovvero giochi a cui partecipavi senza bisogno di download e senza registrazione. Tutto ciò che sapevo è che dovevo digitare “giochi online” nel motore di ricerca e una volta premuto invio mi si sarebbero aperti una vastità di siti. I giochi erano banali: arcade,puzzle,sparatutto,platform; variavano in tematiche e difficoltà.
Ricordo ancora il procedimento arduo che mi permetteva di usufruire della connessione. Adesso quasi rido pensando che basta estrarre il mio smartphone e sono già in rete. Inizialmente dovevo staccare il cavo LAN dal telefono fisso e collegarlo al PC. Accendevo il mio vecchio Olidata, aspettavo il boot di windows xp professional. Dopo un bel po’ di tempo, appariva il desktop, trepidante non vedevo l’ora che apparisse la finestra per effettuare il famoso dial-up. Tutti coloro che eseguivano questo tipo di connessione ricorderanno il famosissimo e fastidiosissimo rumore che produceva il tentativo di connessione. Una volta stabilita la connessione scorrevo i preferiti e aprivo alcuni dei siti che più usavo(tra i primi flashgames.it oppure gioco.it).

esempio di connessione dial-up
Crescendo diventai molto più pratico e consapevole verso Internet. Iniziavo ad usarlo per le svariate ricerche scolastiche oppure per i servizi di messaggistica istantanea. Un esempio di software appartenente a quest’ultima categoria era “Windows Live Messenger”, comunemente chiamato MSN. Esso permetteva di inviare messaggi oltre che effettuare videochiamate e chiamate vocali.Simile a Skype, ma aveva una grafica più intuitiva e accattivante.

Schermata tipo di MSN
In seguito si entrò nell’era dei social. Facebook e Instagram furono i due principali social che mi ritrovai e che mi ritrovo tutt’ora ad usare. La loro presenza mi permise di rimanere in contatto con persone che incontrai nel corso della mia vita.
È quasi obbligatorio dare il merito ad internet come “portale” per il mondo del multiplayer videoludico. Perchè fu proprio grazie a lui che condivisi la mia passione per i videogiochi con persone di tutto il mondo. Ricordo l’adrenalina nell’impugnare il joystick, ricordo le risate, la competizione, le partite vinte all’ultimo secondo, ma anche le sconfitte in cui incolpavo la mia “lentissima” connessione.
Chiuderei questo piccolo percorso nostalgico con una riflessione.
Mi piace ricordare la mia generazione, una generazione in cui il mondo di Internet era sconosciuto, quindi ci si addentrava, si esplorava e si scopriva l’utilità di tale strumento. Oggi mi chiedo se sia ancora così, se le nuove generazioni si approccino in maniera curiosa ad internet oppure abbiano già una base talmente solida che non lo considerano come uno strumento da usare ma più come necessità primordiale. Io so una cosa per certo, che nonostante siano passati oramai 10 anni, trovo ancora emozionante riscoprire quei giochi,consiglio anche a voi che state leggendo questo post, di fare ogni tanto “un tuffo nel passato”.
Alessio Palumbo
0 notes
Text
WANNACRY: Paralizzare un sistema
Nel maggio del 2017 a livello globale si è verificato un attacco informatico massivo da parte di alcuni “hacker” i quali si servivano di un virus di tipo worm chiamato Wannacry. Solo nel primo giorno di attacco sono stati coinvolti 74 paesi e sono stati infettati più di 100.000 computer. Ma cos’è di preciso questo virus? Quali sono stati i danni maggiori? Come difendersi?
Cos’è wannacry?
Wannacry è un ransomware, ovvero un codice che si installa nel computer una volta che un file infetto viene scaricato, questa è la prima fase detta di exploiting o diffusione. A differenza degli altri ransomware Wannacry ha la caratteristica di potersi diffondere senza che l’utente commetta un qualche errore, la diffusione avviene autonomamente , sfruttando delle vulnerabilità di un protocollo usato principalmente da Windows.
La seconda fase è quella di criptazione dei dati. Al termine di essa,tutti i dati sono protetti da crittografia e parte un timer che avvisa il malcapitato proprietario del pc che deve versare una certa somma in Bitcoin, in un conto. Qualora ciò non venga fatto entro lo scadere del tempo, prima la cifra di “riscatto” (in inglese ransom) raddoppia, e infine i dati vengono persi per sempre.
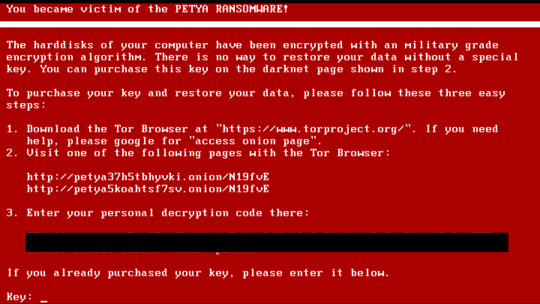
Esempio di ransomware
-Chi è stato attaccato?
I dati parlano chiaro, circa 150 paesi sono stati attaccati da questo virus, gli esempi più eclatanti sono quelli in:
Portogallo==> la società “Portugal Telecom” è stata una delle tante aziende colpite secondo La Stampa
Spagna==> L’ azienda “Telefonica” ammette di essere a conoscenza di tale attacco anche se ha dichiarato che i clienti non hanno in alcun modo subito ripercussioni. Sono stati infettati anche la Compagnia elettrica “Iberdola” e quella del gas “Gas Natural”
Francia==> La famosa azienda automobilistica Renault ha dovuto fermare la produzione nei suoi stabilimenti in Francia secondo le fonti di Business Insider
Germania ==> Secondo il quotidiano The Telegraph Il sistema informatico delle ferrovie tedesche è stato duramente colpito, i danni sono stati fortunatamente limitati a pannelli informativi con gli orari dei treni, o comunque in qualsiasi altro mezzo di informazione verso i passeggeri. Il traffico ferroviario non ha subito variazioni
Gran Bretagna==> Secondo Ansa in Inghilterra si sono verificati gli attacchi più pesanti, scatenato il panico generale in almeno 45 ospedali e strutture sanitarie a causa di servizi sospesi, ambulanze dirottate, file con cartelle cliniche, appuntamenti, completamente inutilizzabili. È stato detto agli ospedali di non pagare nessun riscatto, e i pazienti sono stati trasportati in ospedali in cui i computer funzionavano ancora.
America==> Colpita l’ affermata compagnia di spedizioni FedEx. Anche la compagnia Boeing, famosa per la produzione di aerei, ha risentito dell’attacco, sono stati violati un numero limitato di sistemi anche se effettivamente la produzione non ne ha risentito.
Italia==> fortunatamente l’ Italia non è stata colpita in maniera massiva da tale virus, qualche università ha segnalato varie infezioni, ma il fenomeno è stato contenuto
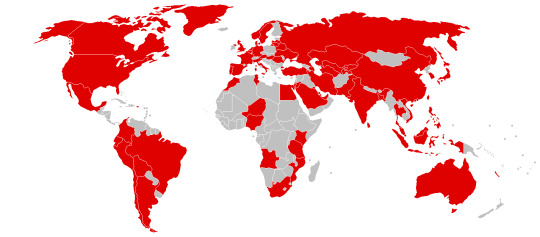
Aree interessate dal’ attacco del virus
-COME DIFENDERSI?
Vi sono diversi suggerimenti a riguardo, primo tra tutti, tenere il PC costantemente aggiornato, antivirus, firewall, e patch di sistema. In più sarebbe opportuno effettuare backup del PC costantemente in modo da avere una copia dei dati personali
Alessio Palumbo
0 notes
Text
GDPR e innovazione digitale

Intelligenza artificiale, il simbolo dell’evoluzione digitale
Nel blogpost precedente abbiamo fatto una rapida introduzione a quella che è la nuova normativa europea sulla protezione dei dati entrata in vigore il 25 maggio 2018.
Abbiamo discusso del principio di accountability e delle responsabilità che il Titolare del Trattamento è in dovere di assumersi per essere in accordo con questo insieme di norme, ma perché si lascia così tanta libertà ?
Il GDPR mette subito in chiaro di voler essere un qualcosa che possa durare nel tempo, i legislatori si sono resi conto che l’innovazione digitale, la scoperta di nuove tecnologie e quindi il migliorarsi e l’evolversi dei sistemi informatici è molto rapido, sarebbe impossibile, per un sistema legislativo, stargli dietro. Sarebbe una continua rincorsa, un dispendio di energie e denaro sia per l’Unione Europea che per le aziende obbligate ad adeguarsi alle normative successive.
Il Titolare del Trattamento avrà quindi libertà sul tipo di tecnologia da utilizzare per la protezione dei dati, a patto che rispetti il punto 1 dell’Articolo 24 : “Tenuto conto della natura, dell’ambito di applicazione, del contesto e delle finalità del trattamento”. Quello che il GDPR incoraggia è la “privacy by design”. In sostanza significa un invito agli sviluppatori di prodotti a tenere conto del diritto alla protezione dei dati sin dalla fase di progettazione. La tutela risulterebbe molto più efficace, infatti, se sin dalle prime fasi i prodotti (hardware e software) fossero concepiti per ridurre i rischi. Considerare l’impatto della privacy sin dalle prima fasi della progettazione di un prodotto è, inoltre, criterio di efficienza, perché evita interventi successivi che potrebbero pesare sui tempi e sui costi di sviluppo.
L’innovazione tecnologica è quindi legata strettamente alla nuovo regolamento. Viene lasciata completa libertà allo sviluppo e se questo verrà pensato e progettato in maniera corretta faciliterà di molto la protezione dei dati e il lavoro del Titolare del Trattamento. L’anello di congiunzione tra la ricerca e la tutela della privacy sarà quindi colui che si occupa della progettazione di un prodotto o di un servizio, avrà un ruolo sicuramente importante, di maggiore impatto, di maggiore responsabilità e soprattutto una nuova sfida che porterà, si spera, a cercare di introdurre nel modo più efficiente possibile sistemi di protezione dei dati per stare sempre un passo avanti alla concorrenza.
Il futuro potrebbe quindi sorridere all’innovazione tecnologica, malgrado nei primi anni potremmo avere significativi rallentamenti.
Non ci resta che aspettare e scoprire se questa linea seguita dai legislatori europei sarà stata la scelta vincente.
Matteo Berta
0 notes
Text
Quello che metti online, ci resta per sempre
Tutto ciò che si fa online genera data.
Un concetto fondamentale se si vuole parlare di data è quello dei metadata, ovvero data che descrivono un dato o un insieme di data.
Un esempio notevole di un tipo di metadata è quello che descrive una connessione tra computer: nel metadata non e incluso il “vero” data, cioè quello che viene trasmesso tra i computer, ma soltanto informazione su quando è stata effettuata questa connessione, per quanto è durata e forse anche la quantità o il tipo di dato trasmesso.

foto preso da wikipedia
Visto che nel metadata non e contenuto il vero data certi leggi per la protezione della privacy non valgano più, lasciando spesso compagnie dell’intelligence libere di raccogliere metadata. Ciò è stato sfruttato per esempio dalla NSA, la quale con il programma PRISM, è riuscita a collezionare metadata da compagnie come Google e Facebook.
Molte compagnie rendono anonimi i propri metadata per poi venderli. Questi “dati” sono fondamentali per i big-data e per molte compagnie pubblicitarie. I metadata sono anche una parte importante di molti formati di file in quanto molti file tengono informazioni su come, quando e dove è stato creato il file, questo specie di metadato è stato fondamentale per più investigazioni.
Spesso l'EXif data che descrive come è stato scattato un’immagine è stato utilizzato per far uscire persone dal loro anonimato.
Per esempio un membro di CabinCr3w (un gruppo di hacker) è stato arrestato grazie ad una foto presa dalla propria ragazza contenete informazioni GPS portando la polizia proprio a casa della ragazza che subito ha confessato tutto.
Un altro caso è quello dell’arresto di Reality Winner, arrestata poiché The Intercept ha pubblicato i documenti che gli aveva inviato senza però togliere i metadata in loro contenuti!
Oltre ai metadata, c’è il "vero e proprio" data che va diviso in tre categorie: temporaneo, modificabile e constante. Un esempio di data “temporaneo” può essere quello di caricare una storia su un social (e.g. Snapchat, Instagram). Il file “scompare” dal profilo dopo 24 ore, tuttavia il social non vieta a nessuno di salvare quel file e non è detto che quei documenti verranno veramente cancellati dai server del social. Infatti per servire dei contenuti è necessario che prima questi vengano salvati.
Il data "modificabile", invece, è quello che può cambiare con il tempo. Ad esempio le pagine Wikipedia, che possono essere modificate da chiunque ed eventualmente cancellate. Wikipedia, come molti altri siti di questo tipo, mantiene un back log descrivendo ogni cambiamento. Questo sistema di back log esiste anche per siti che normalmente non lo avrebbero, grazie al waybackmachine di webarchive. Si tratta di un archivio i cui elementi non vengono modificati, ecco dunque un perfetto esempio di data costante.
Nel prossimo blog post proveremo ad identificare l’utiliza del le conoscenze acquisite in questo post.
Storm “Frisk” Kavlie
0 notes
Text
Valvole e transistor, l’evoluzione della musica dal vinile al digitale
Nel corso degli anni la musica ed in particolare la sua riproduzione ha subito grandi trasformazioni. Ogni qual volta si parli di musica è fondamentale tener conto della sua evoluzione e di come le innovazioni in ambito elettronico-tecnologico ne abbiano condizionato il suo sviluppo di pari passo.
Un sitema audio è generalmente costituito da un insieme di componenti necessari per la riproduzione della musica. Oggi prenderemo in analisi quella che per anni è stata la sorgente audio più diffusa ovvero il disco in vinile, per poi analizzare anche, in breve, quella che è stata l’evoluzione del sistema di gestione delle sorgenti audio: l’amplificatore, il quale ha la funzione di gestione del suono da un audio di input ad un output audio.
Quando e in che modo è avvenuta questa evoluzione?
Dopo la seconda guerra mondiale, ci fu un’impennata tecnologica causata dalle innovazioni sviluppate durante la guerra. I primi tipi di amplificatori audio erano composti da elettrovavole o tubi a vuoto.
Dal 1970 invece, alla tecnologia della valvola subentra il transistor di silicio. Anche se le valvole non erano state completamente spazzate via, l’amplificatore a transistor è diventato sempre più presente. I transistor amplificano il suono cambiando la tensione di ingresso audio tramite l’utilizzo di semiconduttori e l’inttroduzione di circuiti integrati.
Quali differenze caratterizzano gli amplificatori a transistor rispetto a quelli a valvole?

Guitarblog
La differenza di comportamento tra queste due tecnologie risiede principalmente nella minor velocità di risposta della valvola rispetto al transistor, in esso il passaggio dall'amplificazione lineare alla saturazione è estremamente rapido (all'oscilloscopio questa transizione ha l'aspetto di un angolo retto), nella valvola questa transizione è più lenta (appare perciò come un angolo smussato).
Un altro motivo per cui i transistor andarono a sostituire i dispositivi a valvola fu per la loro maggior efficenza, le dimensioni molto contenute e la loro diffusione su larga scala a prezzi sempre più accessibili.
Parlando di sorgenti musicali, quali sono state le tappe più significative?

Sullamaca
Tutto parte dal 1948 quando negli Stati Uniti la Columbia brevetta il primo disco «microsolco» a 33 giri. Segue a ruota nel 1949 la RCA che introduce sul mercato il disco a 45 giri. I due supporti, entrambi in vinile, rappresentano una svolta epocale sopratutto per la qualità sonora, ad «alta fedeltà». Nel 1982 avviene una seconda svolta epocale, superiore a quella avvenuta nel 1948 con l’avvento del «microsolco». Nel 1982 infatti, dopo oltre tre anni dal primo annuncio ufficiale, viene introdotto sul mercato, da Philips e da Sony nel resto del mondo, il «Compact Disc», il dischetto letto da un raggio di luce laser. Con questo sistema il disco non ha più alcun contatto fisico con la testina che lo legge e pertanto viene eliminata la principale causa di usura e malfunzionamento dei tradizionali dischi in vinile. Negli ultimi anni i Cd sono stato gradualmente sostituti da dispositivi a memoria solida con capacità di immagazzinare una mole di dati (anche musica) sempre maggiore per unità di superficie ed in grado di interfacciarsi con le apparecchiature di lettura e riproduzione musicale.
Giorgio Moretto
0 notes
Text
Oltre lo 0 e 1: il Computer Quantistico
Come è ben noto, tutti i calcolatori attualmente in uso sono basati sull'elaborazione e l'immagazzinamento di dati tramite sequenze di bit, che possono avere valore 0 o 1. E se il bit non potesse avere solo due valori, ma di più?
Evidentemente la potenza di calcolo aumenterebbe esponenzialmente, così come la velocità di esecuzione di qualsiasi operazione.
Per la teoria quantistica, in alcune condizioni e a livello atomico, la materia può essere in più stati contemporaneamente. Questi particolari stati sono chiamati “super-posizioni”. Si può pensare ad esempio ad un atomo che gira su se stesso, in due diverse direzioni nello stesso istante.
Sfruttando questi fenomeni quantistici, si sta cercando di elaborare calcolatori che posseggano bit in grado di essere nella posizione 0, nella posizione 1 o una combinazione di 0 e 1. Questi “super-bit” sono stati denominati “qubit”.
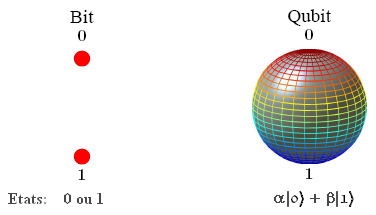
Bit e Qubit
Principali difficoltà di realizzazione
Gli effetti quantistici si verificano solo in condizioni specifiche. Non ci devono infatti essere interferenze di alcun tipo; i qubit attualmente realizzati sono schermati magneticamente, tenuti nel vuoto a temperature bassissime. Una volta costruito un sistema di qubit, lo si deve interfacciare, e non è possibile utilizzare il sistema informatico tradizionale.
Infatti il computer quantico si basa su un modello probabilistico, non deterministico come quelli normali. Ad esempio il computer quntistico che viene prodotto dalla D-Wave, elabora decine di migliaia di risposte differenti a un singolo problema, restituendo poi quella ottimale o “più probabile”.
L'unico ostacolo che non si presenterà nella realizzazione di un computer quantistico sembra essere quello economico: la NASA e Google hanno deciso di collaborare con la D-Wave per lo sviluppo e il miglioramento del loro computer quantico.

D-Wave
Stato attuale delle ricerche
La D-Wave Company è stata la prima che ha commercializzato un computer quantico nel 2011 La compagnia prevede di raddoppiare il numero di qubits collegati tra loro ogni anno, in modo da aumentare la velocità di calcolo. Il D-Wave Two (secondo nato della compagnia canadese) dovrebbe presentare ben 512 qubits, tenuti ad una temperatura di soli 0,2° sopra lo zero assoluto.
Alcuni però mettono in dubbio le reali potenzialità del sistema D-Wave, sostenendo che non si tratti di un sistema quantico puro; infatti al momento non è possibile sapere con certezza cosa accada all'interno di un qubit (se venga sfruttata o meno la “super-posizione”), a causa degli stessi fondamenti della meccanica quantistica: il semplice atto di osservare un fenomeno quantistico, ha influenza sullo stesso fenomeno.
Essere esaustivi sull'argomento in poche parole è difficile, forse impossibile. Pertanto invito a visitare i siti internet linkati in precedenza, se siete interessati all'argomento.
Giorgio Nicola
0 notes