#refactor that logic away
Note
I was really excited about this project, and got immensely disappointed with the release of the UI. The fact it's almost a carbon copy of FlightRising's interface is just so... sad. It basically drains Pawborough of its own identity. I really-really hope you guys will consider changing it, because the original concept is lovely. Here's a few things I'd like to comment on:
1. FR's interface is dated. Currently, they're refactoring the site, and i wouldn't be surprised if their next goal after the refactor would be a UI redesign. And you guys, instead of trying to modernise it and make it your own, are copying a UI from *a decade ago*.
2. Why are you keeping the narrow column format of the site? Most people have a wide-screen monitor nowadays, and it looks bizarre to have such a compressed website. Please consider automatically adapting the site's layout to a user's screen width, sorta like Wolvden/Lioden does. IIRC, they have two columns of content (main stuff in the center & a column with user's data on the left), which stack into one column when you're using a mobile device (aka a narrow screen). But since you're planning to make a mobile version anyway, you should consider making the desktop version of the site wide and, well, desktop-friendly, and then figure out the mobile version as it's own thing.
3. Does the user box in the top right of the site really have to be literally identical to FR, with the same data placed in the same way, and also with the energy bar literally having the same exact segments on it? Especially since you have removed the flight banner, making that user block much less balanced looking. Instead, I think you guys can consider making it much more horizontal and narrow. Assuming the two variables on the right (book and turnip icons) are pet/familiar count and cat count, I feel like they can be dropped completely and moved to the user page. I don't think they need to be displayed at all times on all site's pages.
Image link
Alternatively, you can also use Lioden/Wolvden's approach and make a separate column, and then put all user information and bookmarks in that side column. As a compromise between FR & LD, you can place that user column on the right. Here's a screenshot from google for reference:

Image link
I'd also like to point out the bookmarks box in the column with user data. It's virtually unlimited and you can name your own bookmarks. Introducing this would allow you to largely collapse the left column with site navigation, because you don't use most of those links every day. As a FR player, I would only keep ~13 links in my always-visible bookmarks instead of the 29 available in the left navigation bar. It would be especially nice if I could add emojies into my bookmark names like you can on LD/WD, so it's easier to see what i need right away.
As a mini-addition, please work on the navigation column on the left. It's horrible on FR, and it will be horrible on PB if you introduce it. There's gotta be better ways to navigate the site.
4. I hope you reconsider some of the artstyle choices regarding backgrounds and decorations. What got me excited about PB was the absolutely fantastic character art from NPCs to the breed artworks. You seriously couldn't have picked a better artist for this over Amelia B. It has so much personality and immediately elevated PB in my eyes over Lorwolf, which had absolutely soulless art and looked almost traced from photos. But then I was absolutely heartbroken to see you have went with this odd, textured, sketchy style for the backdrops. Why? I'm assuming it's something like anime-style logic, where characters are cell-shaded and flat and backgrounds are painterly, but to pull that off you need a simply spectacular background artist and... i'm sorry, but your artists just don't pull it off. There's color going outside of lines on the opal waterfall background, some "hairy" scratchy lines that don't follow the shape of the object and dang it just looks flat in terms of values. Its not a terrible thing to make the cat pop, but the fact it's literally the opposite of the cats' style just makes it look odd. The obsidian sentry artwork is probably my least favorite out of everything shown by far. the head anatomy is all over the place and the shading is blurry and muddy where it looks like it should have sharp edges. It just seems like you hired a professional to do the breed artwork, and an actual newbie to do some of the items/backgrounds. Addittionally, i noticed that you're planning to introduce player-made familiars/decors, so that would introduce even more style variation into the equation. Please, please consider making the style same-ish for all site assets. It's not bad if the background assets stay low-contast and a bit flat, but at least give them the same linework as the cats in terms of weight, texture, and quality. Perhaps you can use colored lineart in decorations and backgrounds to make it more muted in comparison to the cats. And I see I'm not the only one asking for this, so please don't fall for the sunk cost fallacy and rework the assets you already have, instead of "dooming" your sites for decades of having blurry, sketchy backgrounds.
Anyway, all of this is coming from a good place, I promise this wasn't written in bad faith. Im extremely excited and passionate about this project and I really-really hope it succeeds. But please, not only listen to user feedback, but also make changes before it's too late.
Thank you for the feedback. To address a few things I believe were lost in translation that we hadn't made clear, and to address this feedback:
The narrow width of the container actually is a placeholder! We do wish to switch to a wider version, and the demo utilizes an early test build. We do already utilize flexbox, which will adjust to the player's screen size, but it's our intention to make the container limit bigger. On top of that, we are hoping to modernize much of the old interface style while keeping a nostalgic charm, including things such as integration of flexbox as an example. Thank you for pointing this out, as this was something that wasn't made clear, and that we did not think to mention.
The userbox is our design nadir right now, we understand, and we are looking to redesign it immediately. Our idea at this time is to disperse the pixel components among it into the ribbon, place where a graphic was intended to go into the navigation, and leave only the icon and energy bar at the top. Actually, we have design mockups with much similar placement to your mockup! Though we were considering putting money in the ribbon too so as to distance ourselves as much as possible. We will consider the feedback of leaving the components strictly on a user's page, so we will fiddle with this. As well, we will fiddle with information potentially in a column. Thank you for the effort you put in!
Regarding the user navigation, we could potentially make it collapsable, as well as introduce bookmarks for those who prefer it. However, to avoid the inaccessibility of dropdowns, the default state would have to remain uncollapsed. Making the navigation collapsable has actually been discussed previously as a good idea. As of now we are looking into increasing the margin of the list and importing imagery into it for better readability, thinking similar to Marapets and early Neopets, but different. What we enjoy about the navigation is a consistent knowledge and potential memorization of everything on a site that collapsed information does not provide, but perhaps we can design something that will allow for the best of both worlds. We are taking in this feedback to heart. Thank you for sharing what you as a user prefer from your game experience!
We understand your distaste for some of the Kickstarter assets, and should there be a demand we can reconsider the rendering for some of them, such as decor. We do, however, have several artists on the team that can do backgrounds and decor, and we shall work to better instruct style discrepancy. We apologize for the distaste in the assets, and we will improve with both stylistic direction and artistic synergy. The intention for our backgrounds is to bring a storybook feeling, and there is going to be an amount of subjectivity to the judgement of this choice. We apologize that it is not to your taste. Regardless, we appreciate your feedback, will note it for future adaptation of our stylistic direction, and once again apologize for your distaste. To clarify, "user-made" decor and companions will simply be user instruction on the design, while our art and design team is still controlling the final piece.
Thank you for feedback on the user experience, and we promise we have not been writing off these points entirely, but rather wanting to express that we understand and, as stated, want to incorporate this feedback while remaining true to our philosophy. We apologize that our communication was lackluster and will be keeping this as our statement on the matter before updating with our new designs. We will do better to communicate our intentions. We do want to hear what a user will most value from an interface experience! Once again, thank you for taking the time and effort to share this information with us, and thank you for the patience as we learn!
24 notes
·
View notes
Text
tired
made lots of progress on my point and click adventure game! by lots I mean the characters can now react to if the player has a specific item they care about lol.
am feeling somewhat conflicted about sharing more specific details about it. Part of the reason it exists is to be a surprise for a family member. I'm keeping more detailed logs on a private tumblr for now
am also tired. my interest is very much in learning godot to develop this game, and I feel like it's the most consistent forward momentum I've had with a project. Learning coding now, after some on-and-off flirtations with coding since about 2016, it feels like I'm... actually doing things. I'm struggling, and learning every step of the way, but I'm not floundering and giving up. I get really excited when I'm finally able to piece together a big new piece of functionality!
It's like gamedev in and of itself is like a logic puzzle game. Inheritance, composition, I look at the code I write and think about how can I make this prettier, or how can I make this more readable and understandable?
I think recently trying to really understand my ADHD, and how my brain works, is a key factor here. Before when i was trying to learn Unity in high school, I wasn't aware of what my ADHD was, y'know, actually doing for my attention and motivation, so the interest would come to make something, and then it would fly away the moment i didn't understand a concept.
Now though, I think being aware of my lack of consistent executive functioning means I'm constantly trying to accommodate myself in code. I'm not always 100% successful (I know for a fact today I wrote the same code twice in two places where it should definitely be just one function in a shared parent class...), but learning about these organizational maxims for object oriented programming is rewarding.
I really like the organization of code, the process of refactoring, and the mission to make it really clean and accessible and readable for myself, so i don't get lost. It really is like sitting down with a nice crossword puzzle, or picross, it just gets my brain engaged just right.
I think tomorrow I've got some refactoring work to do. I look forward to that.
Other stuff
my screenwriting isn't happening at the moment, partially because I'm obviously focused on prototyping my game, which is much more immediately rewarding and novel. But I'm chipping away at ideas and outlines. I'm actually toying with turning one of those ideas into a point and click game, or at least a visual novel. I think the budget and time to do so would be much more attainable than doing some of those ideas as a feature length movie. But I don't know really.
It's absurd how much I'd like to be a film writer-director with my ADHD. There's just so much executive functioning required at every step. It's incredibly logistical, with so many moving parts constantly juggling and adapting and stumbling forward. I need to do research on how directors with ADHD are able to live with that as their job.
I don't have anything else to say, I'm just waiting to be tired enough to fall asleep. good night
8 notes
·
View notes
Text
Price: [price_with_discount]
(as of [price_update_date] - Details)
[ad_1]
“Eric Evans has written a fantastic book on how you can make the design of your software match your mental model of the problem domain you are addressing. “His book is very compatible with XP. It is not about drawing pictures of a domain; it is about how you think of it, the language you use to talk about it, and how you organize your software to reflect your improving understanding of it. Eric thinks that learning about your problem domain is as likely to happen at the end of your project as at the beginning, and so refactoring is a big part of his technique. “The book is a fun read. Eric has lots of interesting stories, and he has a way with words. I see this book as essential reading for software developers―it is a future classic.” ―Ralph Johnson, author of Design Patterns “If you don’t think you are getting value from your investment in object-oriented programming, this book will tell you what you’ve forgotten to do. “Eric Evans convincingly argues for the importance of domain modeling as the central focus of development and provides a solid framework and set of techniques for accomplishing it. This is timeless wisdom, and will hold up long after the methodologies du jour have gone out of fashion.” ―Dave Collins, author of Designing Object-Oriented User Interfaces “Eric weaves real-world experience modeling―and building―business applications into a practical, useful book. Written from the perspective of a trusted practitioner, Eric’s descriptions of ubiquitous language, the benefits of sharing models with users, object life-cycle management, logical and physical application structuring, and the process and results of deep refactoring are major contributions to our field.” ―Luke Hohmann, author of Beyond Software Architecture “This book belongs on the shelf of every thoughtful software developer.” ―Kent Beck “What Eric has managed to capture is a part of the design process that experienced object designers have always used, but that we have been singularly unsuccessful as a group in conveying to the rest of the industry. We've given away bits and pieces of this knowledge...but we've never organized and systematized the principles of building domain logic. This book is important.” ―Kyle Brown, author of Enterprise Java™ Programming with IBM® WebSphere® The software development community widely acknowledges that domain modeling is central to software design. Through domain models, software developers are able to express rich functionality and translate it into a software implementation that truly serves the needs of its users. But despite its obvious importance, there are few practical resources that explain how to incorporate effective domain modeling into the software development process. Domain-Driven Design fills that need. This is not a book about specific technologies. It offers readers a systematic approach to domain-driven design, presenting an extensive set of design best practices, experience-based techniques, and fundamental principles that facilitate the development of software projects facing complex domains. Intertwining design and development practice, this book incorporates numerous examples based on actual projects to illustrate the application of domain-driven design to real-world software development. Readers learn how to use a domain model to make a complex development effort more focused and dynamic. A core of best practices and standard patterns provides a common language for the development team. A shift in emphasis―refactoring not just the code but the model underlying the code―in combination with the frequent iterations of Agile development leads to deeper insight into domains and enhanced communication between domain expert and programmer. Domain-Driven Design then builds on this foundation, and addresses modeling and design for complex systems and larger organizations.Specific topics covered include: Getting
all team members to speak the same language Connecting model and implementation more deeply Sharpening key distinctions in a model Managing the lifecycle of a domain object Writing domain code that is safe to combine in elaborate ways Making complex code obvious and predictable Formulating a domain vision statement Distilling the core of a complex domain Digging out implicit concepts needed in the model Applying analysis patterns Relating design patterns to the model Maintaining model integrity in a large system Dealing with coexisting models on the same project Organizing systems with large-scale structures Recognizing and responding to modeling breakthroughs With this book in hand, object-oriented developers, system analysts, and designers will have the guidance they need to organize and focus their work, create rich and useful domain models, and leverage those models into quality, long-lasting software implementations.
Publisher : Addison-Wesley; 1st edition (4 September 2003)
Language : English
Hardcover : 560 pages
ISBN-10 : 0321125215
ISBN-13 : 978-0321125217
Item Weight : 1 kg 240 g
Dimensions : 18.8 x 3.56 x 24.26 cm
Country of Origin : India
[ad_2]
0 notes
Text
seriously though healing causing F.C.G pain sure uh. Sure throws some complications into the works huh. At least for me. Mentally.
#im gonna need fearne to up her healing spell count reaaaal quick#critical role#cr spoilers#c3e32#fcg#cr liveblogging#like. hm. HM.#can we remove that particular subroutine somehow#just comment out that bit of code#refactor that logic away#pls
97 notes
·
View notes
Text
☄️ Pufferfish, please scale the site!
We created Team Pufferfish about a year ago with a specific goal: to avert the MySQL apocalypse! The MySQL apocalypse would occur when so many students would work on quizzes simultaneously that even the largest MySQL database AWS has on offer would not be able to cope with the load, bringing the site to a halt.
A little over a year ago, we forecasted our growth and load-tested MySQL to find out how much wiggle room we had. In the worst case (because we dislike apocalypses), or in the best case (because we like growing), we would have about a year’s time. This meant we needed to get going!
Looking back on our work now, the most important lesson we learned was the importance of timely and precise feedback at every step of the way. At times we built short-lived tooling and process to support a particular step forward. This made us so much faster in the long run.
🏔 Climbing the Legacy Code Mountain
Clear from the start, Team Pufferfish would need to make some pretty fundamental changes to the Quiz Engine, the component responsible for most of the MySQL load. Somehow the Quiz Engine would need to significantly reduce its load on MySQL.
Most of NoRedInk runs on a Rails monolith, including the Quiz Engine. The Quiz Engine is big! It’s got lots of features! It supports our teachers & students to do lots of great work together! Yay!
But the Quiz Engine has some problems, too. A mix of complexity and performance-sensitivity has made engineers afraid to touch it. Previous attempts at big structural change in the Quiz Engine failed and had to be rolled back. If Pufferfish was going make significant structural changes, we would need to ensure our ability to be productive in the Quiz Engine codebase. Thinking we could just do it without a new approach would be foolhardy.
⚡ The Vengeful God of Tests
We have mixed feelings about our test suite. It’s nice that it covers a lot of code. Less nice is that we don’t really know what each test is intended to check. These tests have evolved into complex bits of code by themselves with a lot of supporting logic, and in many cases, tight coupling to the implementation. Diving deep into some of these tests has uncovered tests no longer covering any production logic at all. The test suite is large and we didn’t have time to dive deep into each test, but we were also reluctant to delete test cases without being sure they weren’t adding value.
Our relationship with the Quiz Engine test suite was and still is a bit like one might have with an angry Greek god. We’re continuously investing effort to keep it happy (i.e. green), but we don’t always understand what we’re doing or why. Please don’t spoil our harvest and protect us from (production) fires, oh mighty RSpec!
The ultimate goal wasn’t to change Quiz Engine functionality, but rather to reduce its load on MySQL. This is the perfect scenario for tests to help us! The test suite we want is:
fast
comprehensive, and
not dependent on implementation
includes performance testing
Unfortunately, that’s not the hand we were given:
The suite takes about 30 minutes to run in CI and even longer locally.
Our QA team finds bugs that sneaked past CI in PRs with Quiz Engine changes relatively frequently.
Many tests ensure that specific queries are performed in a specific order. Considering we might replace MySQL wholesale, these tests provide little value.
And because a lot of Quiz Engine code is extremely performance-sensitive, there’s an increased risk of performance regressions only surfacing with real production load.
Fighting with our tests meant that even small changes would take hours to verify in tests, and then, because of unforeseen regressions not covered by the tests, take multiple attempts to fix, resulting in multiple-day roll-outs for small changes.
Our clock is ticking! We needed to iterate faster than that if we were going to avert the apocalypse.
🐶 I have no idea what I’m doing 🧪
Reading complicated legacy Rails code often raises questions that take surprising amounts of effort to answer.
Is this method dead code? If not, who is calling this?
Are we ever entering this conditional? When?
Is this function talking to the database?
Is this function intentionally talking to the database?
Is this function only reading from the database or also writing to it?
It isn’t even clear what code was running. There are a few features of Ruby (and Rails) which optimize for writing code over reading it. We did our best to unwrap this type of code:
Rails provides devs the ability to wrap functionality in hooks. before_ and after_ hooks let devs write setup and tear-down code once, then forget it. However, the existence of these hooks means calling a method might also evaluate code defined in a different file, and you won’t know about it unless you explicitly look for it. Hard to read!
Complicating things further is Ruby’s dynamic dispatch based on subclassing and polymorphic associations. Which load_students am I calling? The one for Quiz or the one for Practice? They each implement the Assignment interface but have pretty different behavior! And: they each have their own set of hooks🤦. Maybe it’s something completely different!
And then there’s ActiveRecord. ActiveRecord makes it easy to write queries — a little too easy. It doesn’t make it easy to know where queries are happening. It’s ergonomic that we can tell ActiveRecord what we need, and let it figure how to fetch the data. It’s less nice when you’re trying to find out where in the code your queries are happening and the answer to that question is, “absolutely anywhere”. We want to know exactly what queries are happening on these code paths. ActiveRecord doesn’t help.
🧵 A rich history
A final factor that makes working in Quiz Engine code daunting is the sheer size of the beast. The Quiz Engine has grown organically over many years, so there’s a lot of functionality to be aware of.
Because the Quiz Engine itself has been hard to change for a while, APIs defined between bits of Quiz Engine code often haven’t evolved to match our latest understanding. This means understanding the Quiz Engine code requires not just understanding what it does today, but also how we thought about it in the past, and what (partial) attempts were made to change it. This increases the sum of Quiz Engine knowledge even further.
For example, we might try to refactor a bit of code, leading to tests failing. But is this conditional branch ever reached in production? 🤷
Enough complaining. What did we do about it?
We knew this was going to be a huge project, and huge projects, in the best case, are shipped late, and in the average case don’t ever ship. The only way we were going to have confidence that our work would ever see the light of day was by doing the riskiest, hardest, scariest stuff first. That way, if one approach wasn’t going to work, we would find out about it sooner and could try something new before we’d over-invested in a direction.
So: where is the risk? What’s the scariest problem we have to solve? History dictates: The more we change the legacy system, the more likely we’re going to cause regressions.
So our first task: cut away the part of the Quiz Engine that performs database queries and port this logic to a separate service. Henceforth when Rails needs to read or change Quiz Engine data, it will talk to the new service instead of going to the database directly.
Once the legacy-code risk has been minimized, we would be able to focus on the (still challenging) task of changing where we store Quiz Engine data from single-database MySQL to something horizontally scalable.
⛏️ Phase 1: Extracting queries from Rails
🔪 Finding out where to cut
Before extracting Quiz Engine MySQL queries from our Rails service, we first needed to know where those queries were being made. As we discussed above this wasn’t obvious from reading the code.
To find the MySQL queries themself, we built some tooling: we monkey-patched ActiveRecord to warn whenever an unknown read or write was made against one of the tables containing Quiz Engine data. We ran our monkey-patched code first in CI and later in production, letting the warnings tell us where those queries were happening. Using this information we decorated our code by marking all the reads and writes. Once code was decorated, it would no longer emit warnings. As soon as all the writes & reads were decorated, we changed our monkey-patch to not just warn but fail when making a query against one of those tables, to ensure we wouldn’t accidentally introduce new queries touching Quiz Engine data.
🚛 Offloading logic: Our first approach
Now we knew where to cut, we decided our place of greatest risk was moving a single MySQL query out of our rails app. If we could move a single query, we could move all of them. There was one rub: if we did move all queries to our new app, we would add a lot of network latency. because of the number of round trips needed for a single request. Now we have a constraint: Move a single query into a new service, but with very little latency.
How did we reduce latency?
Get rid of network latency by getting rid of the network — we hosted the service in the same hardware as our Rails app.
Get rid of protocol latency by using a dead-simple protocol: socket communication.
We ended up building a socket server in Haskell that took data requests from Rails, and transformed them into a series of MySQL queries, which rails would use to fetch the data itself.
🛸 Leaving the Mothership: Fewer Round Trips
Although co-locating our service with rails got us off the ground, it required significant duct tape. We had invested a lot of work building nice deployment systems for HTTP services and we didn’t want to re-invent that tooling for socket-based side-car apps. The thing that was preventing the migration was having too many round-trip requests to the Rails app. How could we reduce the number of round trips?
As we moved MySQL query generation to our new service, we started to see this pattern in our routes:
MySQL Read some data ┐ Ruby Do some processing │ candidate 1 for MySQL Read some more data ┘ extraction Ruby More processing MySQL Write some data ┐ Ruby Processing again! │ candidate 2 for MySQL Write more data ┘ extraction
To reduce latency, we’d have to bundle reads and writes: In addition to porting reads & writes to the new service, we’d have to port the ruby logic between reads and writes, which would be a lot of work.
What if instead, we could change the order of operations and make it look like this?
MySQL Read some data ┐ candidate 1 for MySQL Read some more data ┘ extraction Ruby Do some processing Ruby More processing Ruby Processing again! MySQL Write some data ┐ candidate 2 for MySQL Write more data ┘ extraction
Then we’d be able to extract batches of queries to Haskell and leave the logic behind in Rails.
One concern we had with changing the order of operations like this was the possibility of a request handler first writing some data to the database, then reading it back again later. Changing the order of read and write queries would result in such code failing. However, since we now had a complete and accurate picture of all the queries the Rails code was making, we knew (luckily!) we didn’t need to worry about this.
Another concern was the risk of a large refactor like this resulting in regressions causing long feedback cycles and breaking the Quiz Engine. To avoid this we tried to keep our refactors as dumb as possible: Specifically: we mostly did a lot of inlining. We would start with something like this
class QuizzesControllller 9000 :super_saiyan else load_sub_syan_fun_type # TODO: inline me end end end end
These are refactors with a relatively small chance of changing behavior or causing regressions.
Once the query was at the top level of the code it became clear when we needed data, and that understanding allowed us to push those queries to happen first.
e.g. from above, we could easily push the previously obscured QuizForFun query to the beginning:
class QuizzesControllller 9000 :super_saiyan else load_sub_syan_fun_type # TODO: inline me end end end
You might expect our bout of inlining to introduce a ton of duplication in our code, but in practice, it surfaced a lot of dead code and made it clearer what the functions we left behind were doing. That wasn’t what we set out to do, but still, nice!
👛 Phase 2: Changing the Quiz Engine datastore
At this point all interactions with the Quiz Engine datastore were going through this new Quiz Engine service. Excellent! This means for the second part of this project, the part where we were actually going to avert the MySQL apocalypse, we wouldn’t need to worry about our legacy Rails code.
To facilitate easy refactoring, we built this new service in Haskell. The effect was immediately noticeable. Like an embargo had been lifted, from this point forward we saw a constant trickle of small productive refactors get mixed in the work we were doing, slowly reshaping types to reflect our latest understanding. Changes we wouldn’t have made on the Rails side unless we’d have set aside months of dedicated time. Haskell is a great tool to use to manage complexity!
The centerpiece of this phase was the architectural change we were planning to make: switching from MySQL to a horizontally scalable storage solution. But honestly, figuring the architecture details here wasn’t the most interesting or challenging portion of the work, so we’re just putting that aside for now. Maybe we’ll return to it in a future blog post (sneak peek: we ended up using Redis and Kafka). Like in step 1, the biggest question we had to solve was “how are we going to make it safe to move forward quickly?”
One challenge was that we had left most of our test suite behind in Rails in phase one, so we were not doing too well on that front. We added Haskell test coverage of course, including many golden result tests which are worth a post on their own. Together with our QA team we also invested in our Cypress integration test suite which runs tests from the browser, thus integration-testing the combination of our Rails and Haskell code.
Our most useful tool in making safe changes in this phase however was our production traffic. We started building up what was effectively a parallel Haskell service talking to Redis next to the existing one talking to MySQL. Both received production load from the start, but until the very end of the project only the MySQL code paths’ response values were used. When the Redis code path didn’t match the MySQL, we’d log a bug. Using these bug reports, we slowly massaged the Redis code path to return identical data to MySQL.
Because we weren’t relying on the output of the Redis code path in production, we could deploy changes to it many times a day, without fear of breaking the site for students or teachers. These deploys provided frequent and fast feedback. Deploying frequently was made possible by the Haskell Quiz Engine code living in its own service, which meant deploys contained only changes by our team, without work from other teams with a different risk profile.
🥁 So, did it work?
It’s been about a month since we’ve switched entirely to the new architecture and it’s been humming along happily. By the time we did the official switch-over to the new datastore it had been running at full-load (but with bugs) for a couple of months already. Still, we were standing ready with buckets of water in case we overlooked something. Our anxiety was in vain: the roll-out was a non-event.
Architecture, plans, goals, were all important to making this a success. Still, we think the thing most crucial to our success was continuously improving our feedback loops. Fast feedback (lots of deploys), accurate feedback (knowing all the MySQL queries Rails is making), detailed feedback (lots of context in error reports), high signal/noise ratio (removing errors we were not planning to act on), lots of coverage (many students doing quizzes). Getting this feedback required us to constantly tweak and create tooling and new processes. But even if these processes were sometimes short-lived, they've never been an overhead, allowing us to move so much faster.
3 notes
·
View notes
Text
Project code anatomy
It’s been ages since I’ve done one of these discussion-focused posts, and I really only do them when I have something (relatively) interesting I’ve been thinking about! Well, that time has come, and today I’d like to talk about trade-offs between code quality and speed of development.
Limitless time? I wish! While I would love to keep this post short and say - hey, you know your project? Make every single bit of code watertight, modular, extensible, and well-documented! Unfortunately, we live in the real world where time is a very real and very limited resource. Budgeting your time (and therefore efforts) is a whole other blog which I’d love to write about at some point!
Classifying code
Anyway, the main point is, due to these constraints, some code will be better written and more bug-free than others! How can you determine where best to focus your efforts to ensure your project doesn’t fall over in a smoking heap when you realise key code has been incorrectly implemented? Well, the first step is to determine what your project looks like. I’ve done up a quick image of what I see in my mind’s eye:
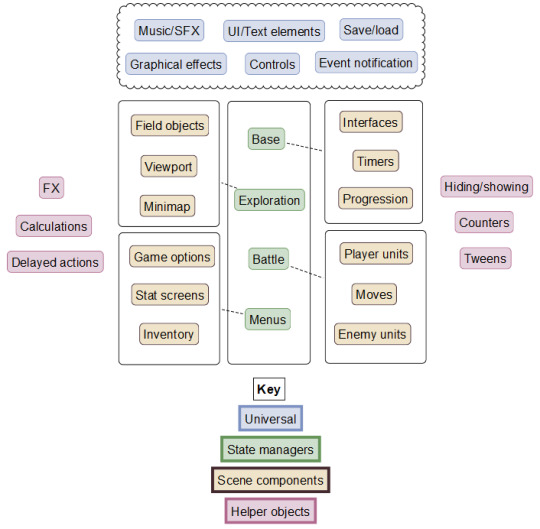
I classify my code into one of 4 main groups. Here’s where the anatomy part of the blog title comes into play!
Universal code which is called/applicable throughout the entire codebase (the blood)
State managers which affect the main game flow for the player (the brain and spine)
Scene components which are manipulated/used throughout certain game states (The limbs)
Miscellanous, single-purpose helper objects/code (the hair, eyes, nails, fingers, toes, and importantly, belly button)
With this sort of analogy, one can perhaps start to see what parts of code are more important than others. It might hurt if you stub your toe, but that’s something that can be recovered from. So, here are my rules for how much effort I focus into each area.
Universal code
Starting with universal code, I feel this should be the most flexible type of code, as it will be used in a multitude of situations. The addition of easy to use and remember arguments to functions that can affect behaviour of these objects is essential - things like start and stop delays, depth, colour, speed, whether or not to follow an object, start/end animations, alignment, and so on.
This code should be lightweight, well-documented, and modular in order to add functionality to it as needed. I might spend about 25% of my development time here, because this code is fairly simple, although needs to be well-programmed. I would also argue this code should also be robust if you are working in a team, as other members may not know the quirks associated with the various functions, but working solo, I feel it is permissable to not program edge cases if they are documented and you keep these in mind when using them.
Of course, any universal code that deals directly with the player (e.g. textbox inputs, draggable windows, menus) MUST be 100% watertight, as there is no telling what the user will do, nor what their system specifications will be. All edge cases need to be accounted for because the player doesn’t know the quirks of your code, nor should they be expected to!
State managers
These are the main controllers of everything that happens within a general game phase, and control is passed from one manager to the next in a highly controlled and structured manner. This is core code - the game is highly dependent on the framework that you will be setting up here, and as such should be thoroughly developed, tested, and organised. As the state managers will be calling the bulk of the game’s code, it is imperative they are structured in a sensible and modular manner.
An example would be the overall battle manager object in my game. This determines the flow of the battle - things like what menu you’re choosing from, what the enemy is doing, whether attacks should be executed, recruiting, fleeing, and so on. About 40% of bugs in my code will stem from incorrect logic within these managers. Thus, a good portion of my time is spent here writing code that manages other code!
Scene components
Scene components are objects that are very active but in a limited context, and are otherwise ignored/removed when not needed. For example, field objects, which are interactive features found during exploration need to do two things - check if the player has interacted with them, and if so, execute the thing that they’re supposed to do (a ore vein will give out materials, a healing machine will ask for a fee, a trap will blow up).
As a result, scene components get enough attention that they do their jobs, but are not as rigorously programmed as the state managers unless they are complex objects (like players and enemies). These objects are often in a state of limbo during development - they are functional but often incomplete, as they are all interdependent within a particular state. I’ll probably spend about 30% of my development time here.
Thus there is usually a lot of placeholder code that I tend to go back and refactor at some point. It’s kind of like a road where you alternate between building it and driving down it one meter at a time, and then once you’re done you go over the whole thing with a road roller.
Miscellaneous
These are ultra-specialised bits of code/objects that do one thing and do it well. More often than not I use these when an object is getting too complex, and I need to separate unrelated bits of code from one another. I’ll admit it, most of this code is programmed hastily and poorly. Once I check that it does what I want it to do without any bugs, it’s left alone and I move on to other things. I tend not to revise or refactor this code at all, and I try to mitigate the large amount of single-use scripts and objects by having a nice folder structure so the code can be tucked away and I don’t have to wade through it looking for other bits of code. I estimate a very modest 5% of development time is spent on these functions.
Summing up
So, there you go, this is the unspoken thought processes that are going on while I program. I’ve never actually formally written any of this out until today, so my apologies if it doesn’t totally make sense or match your own experiences!
Oh, and while I’ve broken my code down in this way, it’s not like I say, ok, today I’ll work on all the state managers. Game development is a much more organic process than that, and generally I write whatever I need at the moment, which will be code from all 4 categories that are all related to each other in whatever I’m developing at the moment.
Nevertheless when I’m writing/developing, I keep in mind what sort of code this is going to be, and where it fits into the big picture of the project. This way I try my best to monitor and manage my time. The last thing I want is for the the game to be stuck in a permanent state of development, undergoing endless changes and iterations! In fact, it’s quite the opposite - I want to finish the game so you guys can all play and (hopefully) enjoy it!!
#game#videogame#devblog#gamedev#scifi#spacegame#dungeon crawler#rpg#entropy#gamemaker#programming#pixel art#robot#indiedev
66 notes
·
View notes
Text
Comparative Study on Flutter State Management
Background
I am going to build a new flutter app. The app is aimed to be quite big. I'm going to need a state management tools. So, I think it’s a good idea to spent some time considering the options. First of all, i do have a preference on flutter’s state management. Itu could affect my final verdict. But, I want to make a data based decision on it. So, let’s start..
Current State of the Art
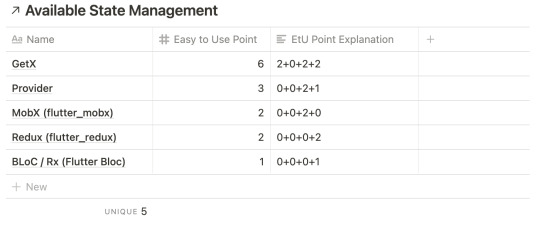
Flutter official website has a listing of all current available state management options. As on 1 Aug 2021, the following list are those that listed on the website.

I marked GetIt since it’s actually not a state management by it’s own. It’s a dependency injection library, but the community behind it develop a set of tools to make it a state management (get_it_mixin (45,130,81%) and get_it_hooks (6,100,33%)). There’s also two additional lib that not mentioned on the official page (Stacked and flutter_hooks). Those two are relatively new compared to others (since pretty much everything about flutter is new) but has high popularity.
What is Pub Point
Pub point is a curation point given by flutter package manager (pub.dev). Basically this point indicate how far a given library adhere to dart/flutter best practices.
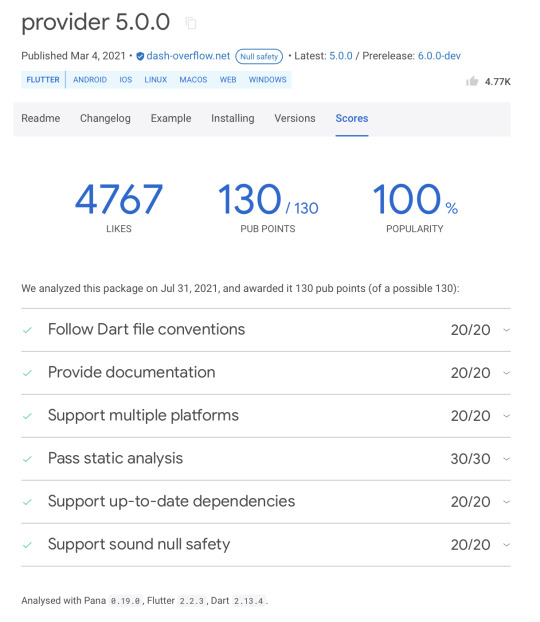
Provider Package Meta Scores
Selection Criteria
I concluded several criteria that need to be fulfilled by a good state management library.
Well Known (Popular)
There's should be a lot of people using it.
Mature
Has rich ecosystem, which mean, resources about the library should be easily available. Resources are, but not limited to, documentation, best practices and common issue/problem solutions.
Rigid
Allow for engineers to write consistent code, so an engineer can come and easily maintain other's codebase.
Easy to Use
Easy in inter-component communication. In a complex app, a component tend to need to talk to other component. So it's very useful if the state manager give an easy way to do it.
Easy to test. A component that implement the state management need to have a good separation of concern.
Easy to learn. Has leaner learning curve.
Well Maintained:
High test coverage rate and actively developed.
First Filter: Popularity
This first filter can give us a quick glance over the easiness of usage and the availability of resources. Since both are our criteria in choosing, the first filter is a no brainer to use. Furthermore when it’s not popular, there’s a high chance that new engineers need more time to learn it.
Luckily, we have a definitive data to rank our list. Pub.dev give us popularity score and number of likes. So, let’s drop those that has less than 90% popularity and has less than 100 likes.

As you can see, we drop 6 package from the list. We also drop setState and InheritedWidget from the list, since it’s the default implementation of state management in flutter. It’s very simple but easily increase complexity in building a bigger app. Most of the other packages try to fix the problem and build on top of it.
Now we have 9 left to go.
Second Filter: Maturity
The second filter is a bit hard to implement. After all, parameter to define “maturity” is kinda vague. But let’s make our own threshold of matureness to use as filter.
Pub point should be higher than 100
Version number should be on major version at least “1.0.0”
Github’s Closed Issue should be more than 100
Stackoverflow questions should be more than 100
Total resource (Github + Stackoverflow) should be more than 500
The current list doesn’t have 2 parameter defined above, so we need to find it out.

So let’s see which state management fulfill our threshold.
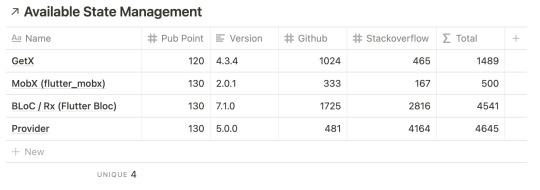
As you can see, “flutter_redux” is dropped. It’s not satisfied the criteria of “major version”. Not on major version can be inferred as, the creator of the package marked it is as not stable. There could be potentially breaking API changes in near future or an implementation change. When it happens we got no option but to refactor our code base, which lead to unnecessary work load.
But, it’s actually seems unfair. Since flutter_redux is only a set of tool on top redux . The base package is actually satisfy our threshold so far. It’s on v5.0.0, has pub point ≥ 100, has likes ≥ 100 and has popularity ≥ 90%.

So, if we use the base package it should be safe. But, let’s go a little deeper. The base package is a Dart package, so it means this lib can be used outside flutter (which is a plus). Redux package also claims it’s a rich ecosystem, in which it has several child packages:

As i inspect each of those packages, i found none of them are stables. In fact, none of them are even popular. Which i can assume it’s pretty hard to find “best practices” around it. Redux might be super popular on Javascript community. We could easily find help about redux for web development issue, but i don’t think it stays true for flutter’s issue (you can see the total resource count, it barely pass 500, it’s 517).
Redux package promises big things, but as a saying goes “a chain is as strong as its weakest link”. It’s hard for me to let this package claim “maturity”.
Fun fact: On JS community, specifically React community, redux is also losing popularity due to easier or simpler API from React.Context or Mobx.
But, Just in case, let’s keep Redux in mind, let’s say it’s a seed selection. Since we might go away with only using the base package. Also, it’s might be significantly excel on another filter. So, currently we have 4+1 options left.
Third Filter: Rigid
Our code should be very consistent across all code base. Again, this is very vague. What is the parameters to say a code is consistent, and how consistent we want it to be. Honestly, i can’t find a measurable metric for it. The consistency of a code is all based on a person valuation. In my opinion every and each public available solutions should be custom tailored to our needs. So to make a codebase consistent we should define our own conventions and stick on it during code reviews.
So, sadly on this filter none of the options are dropped. It stays 4+1 options.
Fourth Filter: Easy to Use
We had already define, when is a state management can be called as easy to use in the previous section. Those criteria are:
Each components can talk to each other easily.
Each components should be easy to test. It can be achieved when it separates business logic from views. Also separate big business logic to smaller ones.
We spent little time in learning it.
Since the fourth filter is span across multiple complex criteria, I think to objectively measure it, we need to use a ranking system. A winner on a criteria will get 2 point, second place will get 1, and the rest get 0 point. So, Let’s start visiting those criteria one by one.
Inter Component Communication
Let’s say we have component tree like the following diagram,
In basic composition pattern, when component A needs something from component D it needs to follow a chain of command through E→G→F→D

This approach is easily get very complex when we scale up the system, like a tree with 10 layers deep. So, to solve this problem, state management’s tools introduce a separate class that hold an object which exposed to all components.
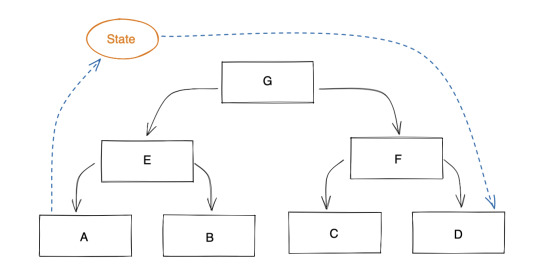
Basically, all state management listed above allows this to happen. The differences located on how big is the “root state” allowed and how to reduce unnecessary “render”.
Provider and BLoC is very similar, their pattern best practices only allow state to be stored as high as they needed. In example, on previous graph, states that used by A and B is stored in E but states that used by A and D is stored in root (G). This ensure the render only happen on those component that needed it. But, the problem arise when D suddenly need state that stored in E. We will need a refactor to move it to G.
Redux and Mobx is very similar, it allows all state to be stored in a single state Store that located at root. Each state in store is implemented as an observable and only listened by component that needs it. By doing it that way, it can reduce the unnecessary render occurred. But, this approach easily bloated the root state since it stores everything. You can implement a sub store, like a store located in E to be used by A and B, but then they will lose their advantages over Provider and BLoC. So, sub store is basically discouraged, you can see both redux and mobx has no implementation for MultiStore component like MultiProvider in provider and MultiBlocProvider in BLoC.
A bloated root state is bad due to, not only the file become very big very fast but also the store hogs a lot of memory even when the state is not actively used. Also, as far as i read, i can’t find any solution to remove states that being unused in either Redux and Mobx. It’s something that won’t happen in Provider, since when a branch is disposes it will remove all state included. So, basically choosing either Provider or Redux is down to personal preferences. Wether you prefer simplicity in Redux or a bit more complex but has better memory allocation in Provider.
Meanwhile, Getx has different implementation altogether. It tries to combine provider style and redux style. It has a singleton object to store all active states, but that singleton is managed by a dependency injector. That dependency injector will create and store a state when it’s needed and remove it when it’s not needed anymore. Theres a writer comment in flutter_redux readme, it says
Singletons can be problematic for testing, and Flutter doesn’t have a great Dependency Injection library (such as Dagger2) just yet, so I’d prefer to avoid those. … Therefore, redux & redux_flutter was born for more complex stories like this one.
I can infer, if there is a great dependency injection, the creator of flutter redux won’t create it. So, for the first criteria in easiness of usage, i think, won by Getx (+2 point).
There is a state management that also build on top dependency injection GetIt. But, it got removed in the first round due to very low popularity. Personally, i think it got potential.
Business logic separation
Just like in the previous criteria, all state management also has their own level of separation. They differ in their way in defining unidirectional data flow. You can try to map each of them based on similarity to a more common design pattern like MVVM or MVI.
Provider, Mobx and Getx are similar to MVVM. BLoC and Redux are similar to MVI.
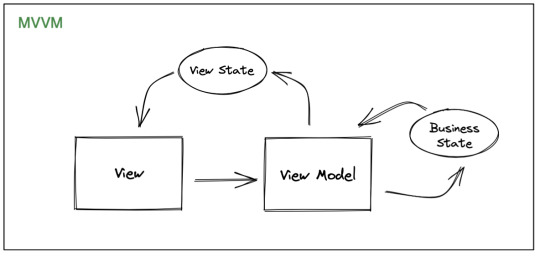
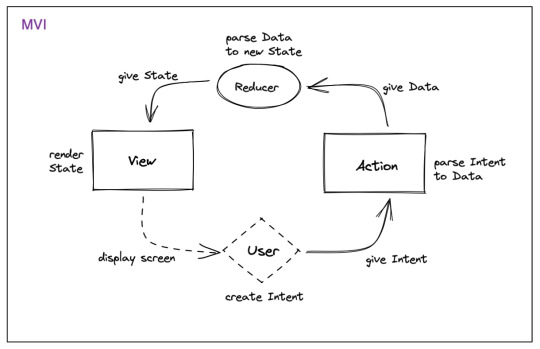
In this criteria, i think there’s no winner since it boils down to preference again.
Easy to learn
Finally, the easiest criteria in easiness of usage, easy to learn. I think there’s only one parameter for it. To be easy to learn, it have to introduced least new things. Both, MVVM and MVI is already pretty common but the latter is a bit new. MVI’s style packages like redux and bloc, introduce new concepts like an action and reducer. Even though Mobx also has actions but it already simplified by using code generator so it looks like any other view model.

So, for this criteria, i think the winner are those with MVVM’s style (+2 Point), Provider, Mobx and Getx. Actually, google themself also promote Provider (Google I/O 2019) over BLoC (Google I/O 2018) because of the simplicity, you can watch the show here.
The fourth filter result
We have inspect all criteria in the fourth filter. The result are as the following:
Getx won twice (4 point),
Provider and Mobx won once (2 point) and
BLoC and Redux never won (0 point).
I guess it’s very clear that we will drop BLoC and Redux. But, i think we need to add one more important criteria.
Which has bigger ecosystem
Big ecosystem means that a given package has many default tools baked or integrated in. A big ecosystem can help us to reduce the time needed to mix and match tools. We don’t need to reinvent the wheel and focused on delivering products. So, let’s see which one of them has the biggest ecosystem. The answer is Getx, but also unsurprisingly Redux. Getx shipped with Dependency Injection, Automated Logging, Http Client, Route Management, and more. The same thing with Redux, as mentioned before, Redux has multiple sub packages, even though none of it is popular. The second place goes to provider and BLoC since it gives us more option in implementation compared to one on the last place. Finally, on the last place Mobx, it offers only state management and gives no additional tools.
So, these are the final verdict
Suddenly, Redux has comeback to the race.
Fifth Filter: Well maintained
No matter how good a package currently is, we can’t use something that got no further maintenance. We need a well maintained package. So, as always let’s define the criteria of well maintained.
Code Coverage
Last time a commit merged to master
Open Pull Request count
Just like previous filter, we will implement ranking system. A winner on a criteria will get 2 point, second place will get 1, and the rest get 0 point.
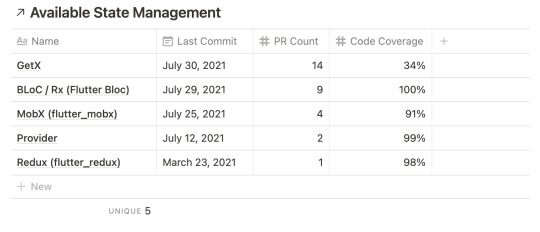
So, with above data, here are the verdicts
Getx 4 point (2+2+0)
BLoC 4 point (1+1+2)
MobX 0 point (0+0+0)
Provider 1 point (0+0+1)
Redux 0 point (0+0+0)
Lets add with the previous filter point,
Getx 10 point (4+6)
BLoC 5 point (4+1)
MobX 2 point (0+2)
Provider 4 point (1+3)
Redux 2 point (0+2)
By now we can see that the winner state management, that allowed to claim the best possible right now, is Getx. But, it’s a bit concerning when I look at the code coverage, it’s the lowest by far from the others. It makes me wonder, what happen to Getx. So i tried to see the result more closely.

After seeing the image above, i can see that the problem is the get_connect module has 0 coverage also several other modules has low coverage. But, let’s pick the coverage of the core modules like, get_core (100%), get_instance(77%), get_state_manager(51%,33%). The coverage get over 50%, not too bad.

Basically, this result means we need to cancel a winner status from Getx. It’s the win on big ecosystem criteria. So, lets subtract 2 point from the end result (10-2). It got 8 points left, it still won the race. We can safely say it has more pros than cons.
Conclusions
The final result, current best state management is Getx 🎉🎉🎉. Sure, it is not perfect and could be beaten by other state management in the future, but currently it’s the best.
So, my decision is "I should use GetX"
1 note
·
View note
Text
[my own game] #20 – rotating spikes obstacles

Challenge: How can I create a mace-like obstacle that rotates either clockwise or counter-clockwise, deals damage and knocks back the player on collision for my 2D elemental platformer?
Our 2D elemental platformer will feature different element-based obstacles that deal damage to the player when in contact and hinder their progress while progressing through a level. I decided to create a rotating spikes obstacle which represents the Earth element as the first element-based obstacle because I had a general idea of how I want it to behave and how to implement it.
Methodology
For this challenge I got inspired by the rotating spikes contraptions in Ori and the Blind Forest. In order to get familiar with it, I played the part of the game that features them in order to see how the mechanic feels like. While implementing the mechanic in a Unity prototype, I brainstormed on how to achieve the desired behaviour. Furthermore, I did some playtesting in order to ensure that the mechanic works in a similar way to the one in Ori and the Blind Forest. In the meantime, I looked at some forums for problems that others have encountered in order to incorporate what they have learned. I also checked the Unity documentation to see how certain methods and classes work. I validated the game design and game technology aspects of the challenge results in separate peer review sessions with two teachers.
DOT framework methods used:







Resources
Game concepts:
Dangers (Ori and the Blind Forest) - Ori and the Blind Forest Fandom Wiki
Unity documentation:
Transform.Rotate
Rigidbody.AddForce
UnityEvent<T0>
Unity answers:
What exactly is RelativeVelocity?
[2D] Can't AddForce to x but y works fine.
Using AddForce for horizontal movement doesn't quite work the way I want it to (2D)
Products
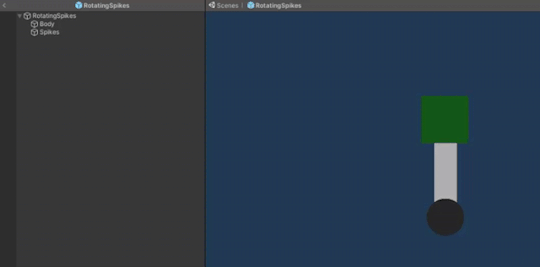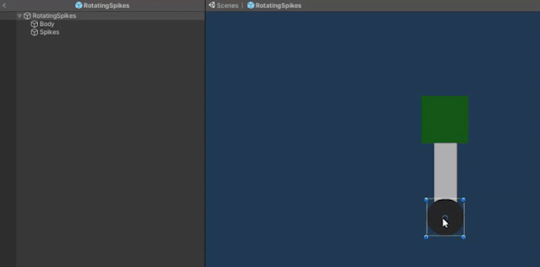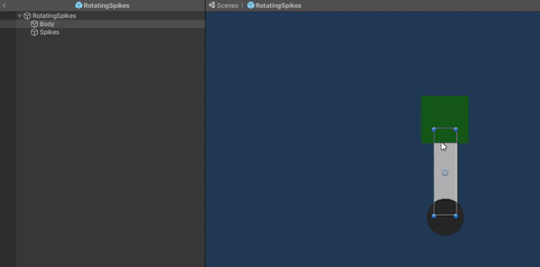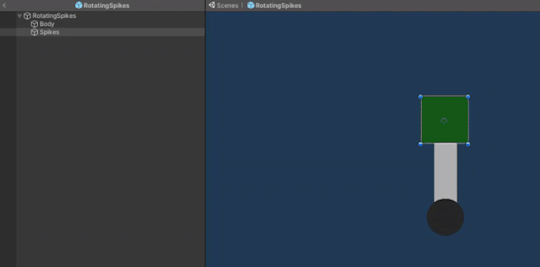
The rotating spikes obstacle prefab is composed of 3 GameObjects: a circular base, a rectangular body and square spikes. The body and the spikes are put under the circle object in order to achieve the desired rotation. The rotation logic is put in a script which is attached to the parent object, whereas the knock back damage script is attached only to the spikes object which also has a 2D box collider component since this is the part of the object that the player can collide with.

The desired way of rotation - make the body and the spikes rotate around the base
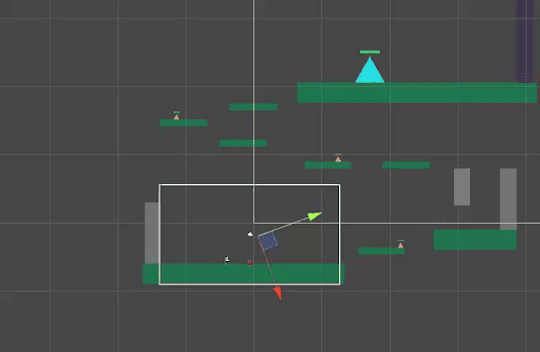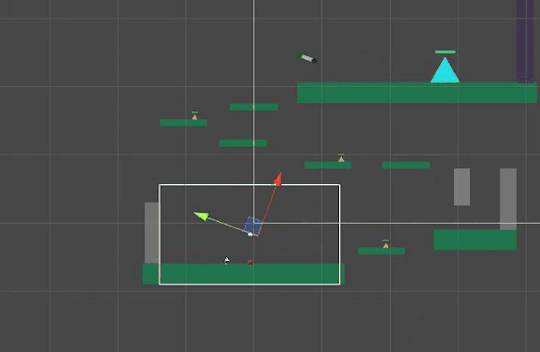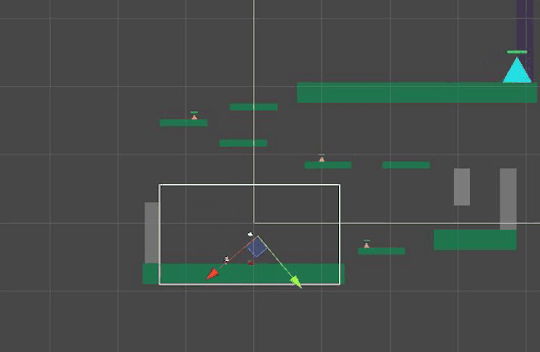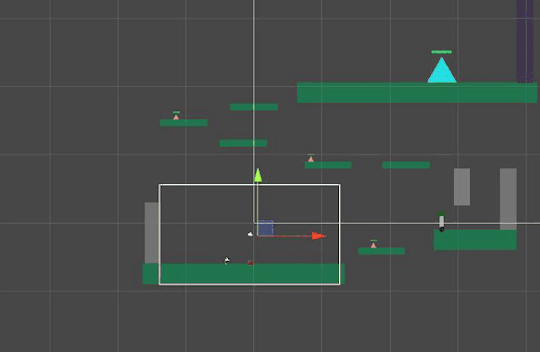
If all 3 objects are put under one GameObject, the rotation would look like this which is unwanted behaviour
When in contact, the obstacle deals damage to the player

Configuring the rotation speed to be similar to the speed of the rotating spikes in Ori and the Blind Forest

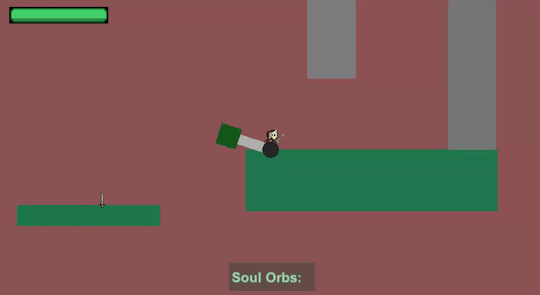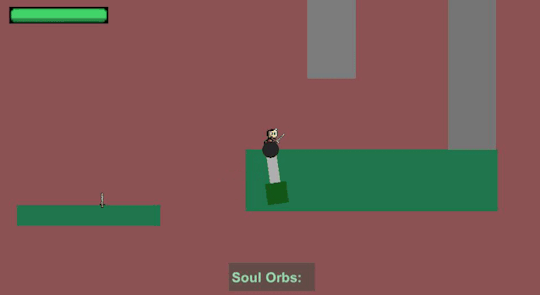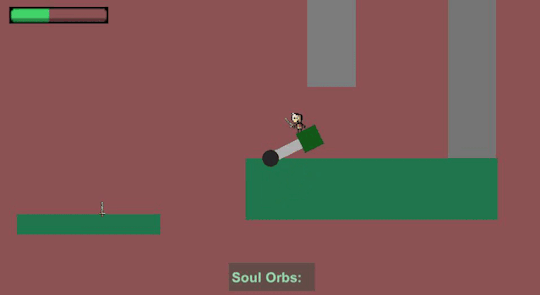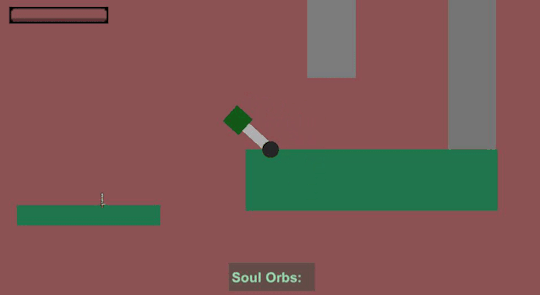
Desired behaviour of the knockback - push the character away in a direction that depends on the corner that hit the character

As far as I managed to observe in Ori and the Blind Forest, a hit by an outside corner would push the player away from the obstacle, whereas a hit by an inside corner would drag the player inside the rotating obstacle where the player can stay without being hit.
For playtesting purposes, I turned off the damage dealing functionality.


The player can be knocked back by the obstacle
After some playtests, I discovered I had to tweak the knockback power because it pushed the player too far away in the air or on the ground.

Push the player away from the obstacle when hit by an outside corner

Drag the player inside the rotating obstacle when hit by an inside corner

Adding multiple rotating spikes obstacles with clockwise and counter-clockwise rotation directions
Game technology validation:
I did 3 iterations on the implementation of this mechanic and each was committed to our GitLab repository.
Iteration 1: Initial working implementation of the knockback functionality
In order to implement the knockback mechanic, I had to change the velocity of the player GameObject with Rigidbody.AddForce when it collides with the obstacle. I had some troubles doing that because I set the player velocity in the Update() method for the player movement which resets the velocity on every frame and omits the changes that AddForce did as mentioned in [2D] Can't AddForce to x but y works fine. and in Using AddForce for horizontal movement doesn't quite work the way I want it to (2D). In order to fix this, I decided to “pause” the movement for 1-2 seconds, apply the force and reset it back. This workaround solved my issue and also provided a logical explanation for the gameplay - the player gets hammered for 1-2 seconds after being hit by the spikes which totally makes sense.
This version of the code can be found on the following links:
PlayerMovement.cs - attached to the player GameObject; defines the knockback functionality
ElementalObstacle.cs - attached to the obstacle GameObject; triggers the knockback functionality
Iteration 2: Make the knockback functionality be triggered from the player instead from the obstacle
After I achieved the desired results, I showed my progress to Jack. He said that my knockback workaround is a good and not problematic approach since it is okay to do one thing in the Update method and then pause to do something else for a certain period of time. Furthermore, he gave me some nice advice about the current code structure - it is better to trigger the knockback functionality in the player rather than triggering it in the obstacle because if I want to create other obstacles with the same behaviour, it would be easier to handle the knockback in the player since the script will be already attached to the player instead of attaching the script with the knockback functionality to each obstacle GameObject.
This version of the code can be found on the following links:
PlayerMovement.cs - attached to the player GameObject; defines the knockback functionality
PlayerHealth.cs - attached to the player GameObject; triggers the knockback functionality
KnockBackDamage.cs - attached to the obstacle GameObject; empty script, only used to identify whether the obstacle GameObject has it
Iteration 3: Refactor Unity Events
Jack also advised me that it would be cleaner and more flexible to use Unity Events to handle the knockback functionality so I refactored my code like so.
This version of the code can be found on the following links:
Player.cs - attached to the player GameObject; defines the knockback Unity Event
PlayerMovement.cs - attached to the player GameObject; listens for the knockback Unity Event and defines the knockback functionality
PlayerHealth.cs - attached to the player GameObject; invokes the knockback Unity Event which triggers the knockback functionality
Game design validation:
My duo project teammate and I showed our current progress to Mina - our game design semester coach, who was satisfied with our progress so far. She told us to think about ways of informing the player what each thing in the game does so that they know what to expect while playing the game. This also affects the rotating spikes obstacle - how to inform the player that this obstacle would deal them damage?
The current version of the code and other resources can be found on our GitLab Repository.
Next
The next steps are to add spikes on the current square part of the obstacle in order to indicate to the player that this part of the obstacle is harmful and implement more obstacles.
#my own game#devlog#library#benchmark creation#community research#literature study#lab#usability testing#showroom#peer review#workshop#brainstorm#prototyping
1 note
·
View note
Text
Once upon a time…
I learned the skill of storytelling when studying theatre improv in 2006. I learned the power of its application in a multitude of contexts over the next nine years.
In the world of software development and new product creation we have a lot of good ideas, and we want to tell people, so we talk a lot. We explain, we pitch, we sell, we defend, we justify. This descriptive, detailed style of communication engages our logical brain, and (we hope) the logical brains of those we are talking to. But connections are not made through logic, they are made through emotion. In order to inspire and engage we need to connect on an emotional, heartfelt level with our colleagues, our customers, our audience.
Storytelling allows us to do this. Moving away from dry, technical, accurate renditions of our ideas, we can move into metaphor and dreamscapes, stirring up passion in our listeners, making them laugh, frown, question and challenge—taking them on a journey.
I’ve taught storytelling for setting vision, refactoring and eliminating waste, improving collaboration, discovering shared purpose, giving legal counsel, and various other contexts. Over the past year I’ve been facilitating storytelling sessions specifically to help people improve their presentation skills. It’s an area of continual discovery for me, and I’m seeking more opportunities to apply this learning, through offering public workshops.
The first of these workshops will be held at Agile Cymru, on 6th July. Details and registration at AgileCymru.uk.
Source: Once upon a time...
2 notes
·
View notes
Text
Why to upgrade to Angular 2
Introduction of Angular 2
Angular 2 is one of the most popular platforms which are a successor to Google Angular 1 framework. With its help, Angular JS developers can build complex applications in browsers and beyond. Angular 2 is not only the next or advanced version of Angular 1, it is fully redesigned and rewritten. Thus, the architecture of Angular 2 is completely different from Angular 1. This tutorial looks at the various aspects of Angular 2 framework which includes the basics of the framework, the setup of Angular and how to work with the various aspects of the framework. Unlike its predecessor, Angular 2 is a TypeScript-based, web application development platform that makes the switch from MVC (model-view-controller) to a components-based approach to web development.
Benefits of Angular 2
Mobile Support: Though the Ionic framework has always worked well with Angular, the platform offers better mobile support with the version 2. The 1.x version compromised heavily on user experience and application performance in general. With its built-in mobile-orientation, Angular 2.0 is more geared for cross-platform mobile application development.
Faster and Modern Browsers: Faster and modern browsers are demanded by developers today. Developers want Angular 2 stress more on browsers like IE10/11, Chrome, Firefox, Opera & Safari on the desktop and Chrome on Android, Windows Phone 8+, iOS6 & Firefox mobile. Developers believe that this would allow AngularJS codebase to be short and compact and AngularJS would support the latest and greatest features without worrying about backward compatibility and polyfills. This would simplify the AngularJS app development process.
High Performance: Angular2 uses superset of JavaScript which is highly optimized which makes the app and web to load faster. Angular2 loads quickly with component router. It helps in automatic code splitting so user only load code required to vendor the view. Many modules are removed from angular’s core, resulting in better performance means you will be able to pick and choose the part you need.
Changing World of Web: The web has changed noticeably and no doubt it will continue changing in the future as well. The current version of AngularJS cannot work with the new web components like custom elements, HTML imports; shadow DOM etc. which allow developers to create fully encapsulated custom elements. Developers anticipate with all hopes that Angular 2 must fully support all web components.
Component Based Development: A component is an independent software unit that can be composed with the other components to create a software system. Component based web development is pretty much future of web development. Angular2 is focused on component base development. Angularjs require entire stack to be written using angular but angular2 emphasis separation of components /allow segmentation within the app to be written independently. Developers can concentrate on business logic only. These things are not just features but the requirement of any thick-client web framework.
Why to upgrade to Angular 2 ?
Angular 2 is entirely component-based and even the final application is a component of the platform. Components and directives have replaced controllers and scopes. Even the specification for directives has been simplified and will probably further improve. They are the communication channels for components and run in the browser with elements and events. Angular 2 components have their own injector so you no longer have to work with a single injector for the entire application. With an improved dependency injection model, there are more opportunities for component or object-based work.
Optimized for Mobile- Angular 2 has been carefully optimized for boasting improved memory efficiency, enhanced mobile performance, and fewer CPU cycles. It’s as clear of an indication as any that Angular 2 is going to serve as a mobile-first framework in order to encourage the mobile app development process. This version also supports sophisticated touch and gesture events across modern tablet and mobile devices.
Typescript Support- Angular 2 uses Typescript and variety of concepts common in back-end. That is why it is more back-end developer-friendly. It's worth noting that dependency injection container makes use of metadata generated by Typescript. Another important facet is IDE integration is that it makes easier to scale large projects through refactoring your whole code base at the same time. If you are interested in Typescript, the docs are a great place to begin with. Moreover, Typescript usage improves developer experience thanks to good support from text editors and IDE's. With libraries like React already using Typescript, web/mobile app developers can implement the library in their Angular 2 project seamlessly.
Modular Development- Angular 1 created a fair share of headaches when it came to loading modules or deciding between Require.js and Web Pack. Fortunately, these decisions are removed entirely from Angular 2 as the new release shies away from ineffective modules to make room for performance improvements. Angular 2 also integrates System.js, a universal dynamic modular loader, which provides an environment for loading ES6, Common, and AMD modules.
$scope Out, Components in- Angular 2 gets rid of controllers and $scope. You may wonder how you’re going to stitch your homepage together! Well, don’t worry too much − Angular 2 introduces Components as an easier way to build complex web apps and pages. Angular 2 utilizes directives (DOMs) and components (templates). In simple terms, you can build individual component classes that act as isolated parts of your pages. Components then are highly functional and customizable directives that can be configured to build and specify classes, selectors, and views for companion templates. Angular 2 components make it possible to write code that won’t interfere with other pieces of code within the component itself.
Native Mobile Development- The best part about Angular 2 is “it’s more framework-oriented”. This means the code you write for mobile/tablet devices will need to be converted using a framework like Ionic or Native Script. One single skillset and code base can be used to scale and build large architectures of code and with the integration of a framework (like, you guessed it, NativeScript or Ionic); you get a plethora of room to be flexible with the way your native applications function.
Code Syntax Changes- One more notable feature of Angular 2 is that it adds more than a few bells and whistles to the syntax usage. This comprises (but is not limited to) improving data-binding with properties inputs, changing the way routing works, changing an appearance of directives syntax, and, finally, improving the way local variables that are being used widely. One more notable feature of Angular 2 is that it adds more than a few bells and whistles to the syntax usage. This comprises improving data-binding with properties inputs, changing the way routing works, changing an appearance of directives syntax, and, finally, improving the way local variables that are being used widely.
Comparison between Angular 1 and Angular 2
Angular 1
In order to create service use provider, factory, service, constant and value
In order to automatically detection changed use $scope, $watch, $scope, $apply, $timeout.
Syntax event for example ng-click
Syntax properties for example ng-hid, ng-checked
It use Filter
Angular 2
In order to create service use only class
In order to automatically detection changed use Zone.js.
Syntax event for example (click) or (dbl-click)
Syntax properties for example [class: hidden] [checked]
It use pipe
How to migrate Angular 1 to Angular 2
It is a very simple and easy task to upgrade Angular 1 to Angular 2, but this has to be done only if the applications demand it. In this article, I will suggest a number of ways which could be taken into consideration in order to migrate existing applications from Angular 1.x to 2. Therefore, depending on the organizational need, the appropriate migration approach should be used.
Upgrading to Angular 2 is quite an easy step to take, but one that should be made carefully. There are two major ways to feel the taste of Angular 2 in your project. Which you use depends on whatever requirements your project has. The angular team have provided two paths to this:
ngForward
ngForward is not a real upgrade framework for Angular 2 but instead we can use it to create Angular 1 apps that look like Angular 2.
If you still feel uncomfortable upgrading your existing application to Angular 2, you can fall to ngForward to feel the taste and sweetness of the good tidings Angular 2 brings but still remain in your comfort zone.
You can either re-write your angular app gradually to look as if it was written in Angular 2 or add features in an Angular 2 manner leaving the existing project untouched. Another benefit that comes with this is that it prepares you and your team for the future even when you choose to hold onto the past for a little bit longer. I will guide you through a basic setup to use ngForward but in order to be on track, have a look at the Quick Start for Angular 2.
If you took time to review the Quick Start as I suggested, you won't be lost with the configuration. SystemJS is used to load the Angular application after it has been bootstrapped as we will soon see. Finally in our app.ts, we can code like its Angular 2.
ngUpgrade
Writing an Angular 1.x app that looks like Angular 2 is not good enough. We need the real stuff. The challenge then becomes that with a large existing Angular 1.x project, it becomes really difficult to re-write our entire app to Angular 2, and even using ngForward would not be ideal. This is where ngUpgrade comes to our aid. ngUpgrade is the real stuff.
Unlike ngForward, ngUpgrade was covered clearly in the Angular 2 docs. If you fall in the category of developers that will take this path, then spare few minutes and digest this.
We'll also be writing more articles on upgrading to Angular 2 and we'll focus more on ngUpgrade in a future article.
6 notes
·
View notes
Text
2018 May Update
Wow! End of May already?
For the past two months, we've been focusing on really finalizing the levels down to their very last details - and in a linear order starting from when Gale first wakes up. It's easy to fall into the trap of thinking you're further ahead than you really are. I thought of the levels as existing in a disconnected state - and by simply connecting them together - Viola! Done! Finished!
Not so.
In finally stitching the levels together, I've discovered there were still many in-between areas I hadn't yet accounted for.

(Upon leaving the first town, the player is free to travel anywhere they can reach)

(One example secret unmarked area accessible from the world map houses a Perro. There's a side quest to recruit Perros for your vacant coop back home)
And of the levels themselves, they're all receiving heavy rounds of polish. Here are some select areas from a build dating back last year vs. today's version:

(Forest trees and background received a major overhaul)


(since the game's art style doesn't rely on dark pixel outlines, every level requires a unique lighting configuration to ensure good visibility)
We're also not shying away from heavy refactoring and cuts to ensure smoother and more logical level flow.

(The dark Tomb section of Anuri Temple is now blocked off until the player obtains the Bombs)

Not even bosses are sacrosanct. The first Toad Boss has been a difficult point for me. He's challenging and his weak point is hard to telegraph. I've yet to see anyone discover his true vulnerability on their own in a blind playthrough. Unlike the demo presented long ago, the player will not have bombs this early on. And so, I've decided to push the Toad Boss deeper into the dungeon as a secret boss encounter. In his place, a special variant of the Slargummy (big slimes) now occupies the first boss role.
NEW BOSS BATTLE MUSIC
On the topic of bosses, I've requested of Will a new boss battle score to breathe some freshness to the boss fights. And Will has delivered! (Listen to it here)
If you're a fan of the old boss battle song, rest assured that's in the game too as a hidden track.

(Faster Neutral attacks. This should display more smoothly at 60fps)
COMBAT
The combat system is also receiving some refactoring. One of the most common feedbacks I've resisted was to make Gale's swing speed faster. I wanted slow and deliberate - in Castlevania fashion, with Belmont's slow windup before his whip lashes out, I designed for Gale to commit to an attack and be locked in her animation until the attack finished.
However, I've finally relented and removed the in-between animation frames leading up Gale's regular melee attacks. Her swings now fire off immediately and the combat feels snappier as a result.
Since Gale is more powerful with her speed boost, I've had to rebalance the capabilities of the player and enemies. Gale's charged attack now occupies a more distinct niche as a slow and heavy hitter - it cuts through enemy defenses. Gale's quick neutral attacks can rack up damage quickly but will also rapidly chew through her stamina. Jump attacks exist somewhere in-between.
I ended up loving this change! I think it introduces a better rhythmic flow to combat and expands the decision space - making battle more interesting overall.
LEVELS SIZE AND SCALE
We're deep in the middle of finalizing Chapter 2 right now, but with Chapter 1 done we actually now have a sort of measuring stick to see how much the game has grown. In the original flash game, all the levels from the beginning until the end of Chapter 1 was composed of 34 different level files.
In this reboot, all the levels from the beginning up to the end of Chapter 1 are composed of 85 different level files. That's 150% bigger! Chapter 1 is also the least changed of the chapters. I suspect future chapters will present even more favorably in this comparison.
Of course, this isn't an entirely valid metric since one level file could specify a huge throne room or it could specify a tiny storage room - they both count as one.
Still I'm confident we'll blow through the original game's measly 200 levels total. A big thanks to Pirate for drawing the tilesets. She also helps me set the tiles and light the levels. Those used to be jobs I handled exclusively but I've been learning to delegate more so that I have more time to program and design.
Still, juggling the tens of files simultaneously made me dizzy at times - our emails got so long we switched to a new system using google's online spreadsheets.

(A glimpse at our workflow. Each row handles one level. Levels highlighted yellow are in my court, and levels highlighted red are in Pirate's court. Updates stack to the right - each individual cell can get quite dense containing paragraphs of text)

(this update needed some yellow, so here’s a glimpse of Adar’s house from Ch 2)
BUG NAMING CONTEST WINNER
Finally, after 5 months we can conclude this contest. Thank you everyone for participating in the reddit thread and in email! In the end, I was sold on Swamp Selkie's submission to name the Queen "Ariadne" and to use the "-iad" suffix for all her children.
Miniad - combination of "minion" and "iad"
Thorniad - combination of "thorn" and "iad"
Blastiad - combination of "blast" and "iad"
Toxiad - combination of "toxic" and "iad". I may change this to "Aciad" for "acid".
Aviad - combination of "aviate" and "iad". I may change this to "Dartiad" or "Lanciad" for Dart or Lance.
I'll be reaching out to Swamp Selkie soon for their preferred naming details.
ROBOT NAMING CONTEST WINNER
For robots... I'll mull on these some more... I'm leaning towards in-house names. Still, thank you everyone for participating!
POTENTIAL PUBLIC SHOWING
The game has a new potential public appearance in the works. More details on that if/as it develops.
BAD NEWS : DELAYS
August of last year, I confidently stated that by that time next year the game would be out. Now that we're in the midst of finalizing chapters, it's easy to see from our current trajectory that we're not going to hit that mark. I have to acknowledge the failure brewing ahead. Game development continues to surprise me with its stubbornness to finish.
I apologize to everyone eagerly anticipating the game. Hopefully with these delays, we can craft the best game we can manage.
I suspect early next year will be the new launch date, but I'm hesitant to give a new concrete finish date since I always seem to miss them. In the meantime, I'll keep updating regularly so people can know it's on a good track. Next live check-in will be end of July.
FAN ART
I'd like to give a big thank you to Cody. G for his fan art of Gale and 66.

64 notes
·
View notes
Text
A Content Model Is Not a Design System
Do you remember when having a great website was enough? Now, people are getting answers from Siri, Google search snippets, and mobile apps, not just our websites. Forward-thinking organizations have adopted an omnichannel content strategy, whose mission is to reach audiences across multiple digital channels and platforms.
But how do you set up a content management system (CMS) to reach your audience now and in the future? I learned the hard way that creating a content model—a definition of content types, attributes, and relationships that let people and systems understand content—with my more familiar design-system thinking would capsize my customer’s omnichannel content strategy. You can avoid that outcome by creating content models that are semantic and that also connect related content.
I recently had the opportunity to lead the CMS implementation for a Fortune 500 company. The client was excited by the benefits of an omnichannel content strategy, including content reuse, multichannel marketing, and robot delivery—designing content to be intelligible to bots, Google knowledge panels, snippets, and voice user interfaces.
A content model is a critical foundation for an omnichannel content strategy, and for our content to be understood by multiple systems, the model needed semantic types—types named according to their meaning instead of their presentation. Our goal was to let authors create content and reuse it wherever it was relevant. But as the project proceeded, I realized that supporting content reuse at the scale that my customer needed required the whole team to recognize a new pattern.
Despite our best intentions, we kept drawing from what we were more familiar with: design systems. Unlike web-focused content strategies, an omnichannel content strategy can’t rely on WYSIWYG tools for design and layout. Our tendency to approach the content model with our familiar design-system thinking constantly led us to veer away from one of the primary purposes of a content model: delivering content to audiences on multiple marketing channels.
Two essential principles for an effective content model
We needed to help our designers, developers, and stakeholders understand that we were doing something very different from their prior web projects, where it was natural for everyone to think about content as visual building blocks fitting into layouts. The previous approach was not only more familiar but also more intuitive—at least at first—because it made the designs feel more tangible. We discovered two principles that helped the team understand how a content model differs from the design systems that we were used to:
Content models must define semantics instead of layout.
And content models should connect content that belongs together.
Semantic content models
A semantic content model uses type and attribute names that reflect the meaning of the content, not how it will be displayed. For example, in a nonsemantic model, teams might create types like teasers, media blocks, and cards. Although these types might make it easy to lay out content, they don’t help delivery channels understand the content’s meaning, which in turn would have opened the door to the content being presented in each marketing channel. In contrast, a semantic content model uses type names like product, service, and testimonial so that each delivery channel can understand the content and use it as it sees fit.
When you’re creating a semantic content model, a great place to start is to look over the types and properties defined by Schema.org, a community-driven resource for type definitions that are intelligible to platforms like Google search.
A semantic content model has several benefits:
Even if your team doesn’t care about omnichannel content, a semantic content model decouples content from its presentation so that teams can evolve the website’s design without needing to refactor its content. In this way, content can withstand disruptive website redesigns.
A semantic content model also provides a competitive edge. By adding structured data based on Schema.org’s types and properties, a website can provide hints to help Google understand the content, display it in search snippets or knowledge panels, and use it to answer voice-interface user questions. Potential visitors could discover your content without ever setting foot in your website.
Beyond those practical benefits, you’ll also need a semantic content model if you want to deliver omnichannel content. To use the same content in multiple marketing channels, delivery channels need to be able to understand it. For example, if your content model were to provide a list of questions and answers, it could easily be rendered on a frequently asked questions (FAQ) page, but it could also be used in a voice interface or by a bot that answers common questions.
For example, using a semantic content model for articles, events, people, and locations lets A List Apart provide cleanly structured data for search engines so that users can read the content on the website, in Google knowledge panels, and even with hypothetical voice interfaces in the future.
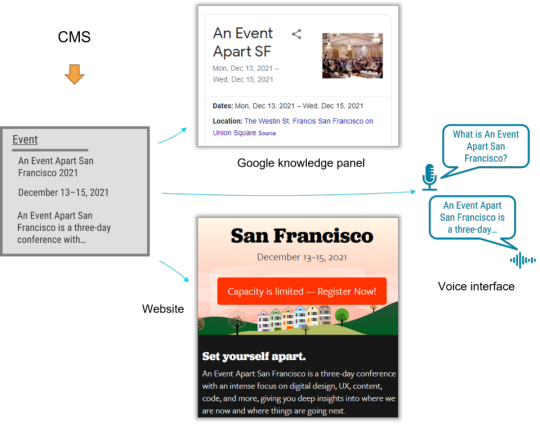
Content models that connect
After struggling to describe what makes a good content model, I’ve come to realize that the best models are those that are semantic and that also connect related content components (such as a FAQ item’s question and answer pair), instead of slicing up related content across disparate content components. A good content model connects content that should remain together so that multiple delivery channels can use it without needing to first put those pieces back together.
Think about writing an article or essay. An article’s meaning and usefulness depends upon its parts being kept together. Would one of the headings or paragraphs be meaningful on their own without the context of the full article? On our project, our familiar design-system thinking often led us to want to create content models that would slice content into disparate chunks to fit the web-centric layout. This had a similar impact to an article that were to have been separated from its headline. Because we were slicing content into standalone pieces based on layout, content that belonged together became difficult to manage and nearly impossible for multiple delivery channels to understand.
To illustrate, let’s look at how connecting related content applies in a real-world scenario. The design team for our customer presented a complex layout for a software product page that included multiple tabs and sections. Our instincts were to follow suit with the content model. Shouldn’t we make it as easy and as flexible as possible to add any number of tabs in the future?
Because our design-system instincts were so familiar, it felt like we had needed a content type called “tab section” so that multiple tab sections could be added to a page. Each tab section would display various types of content. One tab might provide the software’s overview or its specifications. Another tab might provide a list of resources.
Our inclination to break down the content model into “tab section” pieces would have led to an unnecessarily complex model and a cumbersome editing experience, and it would have also created content that couldn’t have been understood by additional delivery channels. For example, how would another system have been able to tell which “tab section” referred to a product’s specifications or its resource list—would that other system have to have resorted to counting tab sections and content blocks? This would have prevented the tabs from ever being reordered, and it would have required adding logic in every other delivery channel to interpret the design system’s layout. Furthermore, if the customer were to have no longer wanted to display this content in a tab layout, it would have been tedious to migrate to a new content model to reflect the new page redesign.
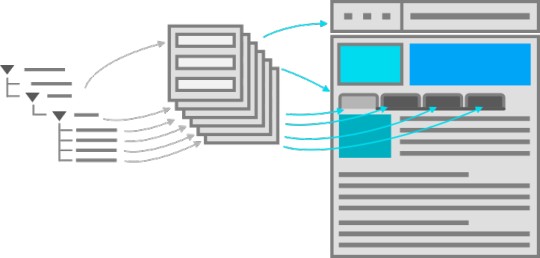
A content model based on design components is unnecessarily complex, and it’s unintelligible to systems.
We had a breakthrough when we discovered that our customer had a specific purpose in mind for each tab: it would reveal specific information such as the software product’s overview, specifications, related resources, and pricing. Once implementation began, our inclination to focus on what’s visual and familiar had obscured the intent of the designs. With a little digging, it didn’t take long to realize that the concept of tabs wasn’t relevant to the content model. The meaning of the content that they were planning to display in the tabs was what mattered.
In fact, the customer could have decided to display this content in a different way—without tabs—somewhere else. This realization prompted us to define content types for the software product based on the meaningful attributes that the customer had wanted to render on the web. There were obvious semantic attributes like name and description as well as rich attributes like screenshots, software requirements, and feature lists. The software’s product information stayed together because it wasn’t sliced across separate components like “tab sections” that were derived from the content’s presentation. Any delivery channel—including future ones—could understand and present this content.
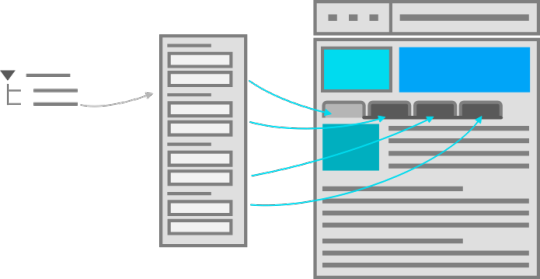
A good content model connects content that belongs together so it can be easily managed and reused.
Conclusion
In this omnichannel marketing project, we discovered that the best way to keep our content model on track was to ensure that it was semantic (with type and attribute names that reflected the meaning of the content) and that it kept content together that belonged together (instead of fragmenting it). These two concepts curtailed our temptation to shape the content model based on the design. So if you’re working on a content model to support an omnichannel content strategy—or even if you just want to make sure that Google and other interfaces understand your content—remember:
A design system isn’t a content model. Team members may be tempted to conflate them and to make your content model mirror your design system, so you should protect the semantic value and contextual structure of the content strategy during the entire implementation process. This will let every delivery channel consume the content without needing a magic decoder ring.
If your team is struggling to make this transition, you can still reap some of the benefits by using Schema.org–based structured data in your website. Even if additional delivery channels aren’t on the immediate horizon, the benefit to search engine optimization is a compelling reason on its own.
Additionally, remind the team that decoupling the content model from the design will let them update the designs more easily because they won’t be held back by the cost of content migrations. They’ll be able to create new designs without the obstacle of compatibility between the design and the content, and they’ll be ready for the next big thing.
By rigorously advocating for these principles, you’ll help your team treat content the way that it deserves—as the most critical asset in your user experience and the best way to connect with your audience.
A Content Model Is Not a Design System published first on https://deskbysnafu.tumblr.com/
0 notes
Text
Version 445
youtube
windows
zip
exe
macOS
app
linux
tar.gz
I had a great week mostly working on optimisations and cleanup. A big busy client running a lot of importers should be a little snappier today.
optimisations
Several users have had bad UI hangs recently, sometimes for several seconds. It is correlated with running many downloaders at once, so with their help I gathered some profiles of what was going on and trimmed and rearranged some of the ways downloaders and file imports work this week. There is now less stress on the database when lots of things are going on at once, and all the code here is a little more sensible for future improvements. I do not think I have fixed the hangs, but they may be less bad overall, or the hang may have been pushed to a specific trigger like file loads or similar.
So there is still more to do. The main problem I believe is that I designed the latest version of the downloader engine before we even had multiple downloaders per page. An assumed max of about twenty download queues is baked into the system, whereas many users may have a hundred or more sitting around, sometimes finished/paused, but in the current system each still taking up a little overhead CPU on certain update calls. A complete overhaul of this system is long overdue but will be a large job, so I'm going to focus on chipping away at the worst offenders in the meantime.
As a result, I have improved some of the profiling code. The 'callto' profile mode now records the UI-side of background jobs (when they publish their results, usually), and the 'review threads' debug dialog now shows detailed information on the newer job scheduler system, which I believe is being overwhelmed by micro downloader jobs in heavy clients. I hope these will help as I continue working with the users who have had trouble, so please let me know how you get on this week and we'll give it another round.
the rest
I fixed some crazy add/delete logic bugs in the filename tagging dialog and its 'tags just for selected files' list. Tag removes will stick better and work more precisely on the current selection.
If you upload tags to the PTR and notice some lag after it finishes, this should be fixed now. A safety routine that verifies everything is uploaded and counted correct was not working efficiently.
I fixed viewing extremely small images (like 1x1) in the media viewer. The new tiled renderer had a problem with zooms greater than 76800%, ha ha ha.
A bunch of sites with weird encodings (mostly old or japanese) should now work in the downloader system.
Added a link, https://github.com/GoAwayNow/Iwara-Hydrus, to Iwara-Hydrus, a userscript to simplify sending Iwara videos to Hydrus Network, to the Client API help.
If you are a Windows user, you should be able to run the client if it is installed on a network location again. This broke around v439, when we moved to the new github build. It was a build issue with some new libraries.
full list
misc:
fixed some weird bugs on the pathname tagging dialog related to removal and re-adding of tags with its 'tags just for selected files' list. previously, in some circumstances, all selected paths could accidentally share the same list of tags, so further edits on a subset selection could affect the entire former selection
furthermore, removing a tag from that list when the current path selection has differing tags should now successfully just remove that tag and not accidentally add anything
if your client has a pending menu with 'sticky' small tag count that does not seem to clear, the client now tries to recognise a specific miscount cause for this situation and gives you a little popup with instructions on the correct maintenance routine to fix it
when pending upload ends, it is now more careful about when it clears the pending count. this is a safety routine, but it not always needed
when pending count is recalculated from source, it now uses the older method of counting table rows again. the new 'optimised' count, which works great for current mappings, was working relatively very slow for pending count for large services like the PTR
fixed rendering images at >76800% zoom (usually 1x1 pixels in the media viewer), which had broke with the tile renderer
improved the serialised png load fix from last week--it now covers more situations
added a link, https://github.com/GoAwayNow/Iwara-Hydrus, to Iwara-Hydrus, a userscript to simplify sending Iwara videos to Hydrus Network, to the client api help
it should now again be possible to run the client on Windows when the exe is in a network location. it was a build issue related to modern versions of pyinstaller and shiboken2
thanks to a user's help, the UPnPc executable discoverer now searches your PATH, and also searches for 'upnpc' executable name as a possible alternative on linux and macOS
also thanks to a user, the test script process now exits with code 1 if the test is not OK
.
optimisations:
when a db job is reading data, if that db job happens to fall on a transaction boundary, the result is now returned before the transaction is committed. this should reduce random job lag when the client is busy
greatly reduced the amount of database time it takes to check if a file is 'already in db'. the db lookup here is pretty much always less than a millisecond, but the program double-checks against your actual file store (so it can neatly and silently fill in missing files with regular imports), however on an HDD with a couple million files, this could often be a 20ms request! (some user profiles I saw were 200ms!!! I presume this was high latency drives, and/or NAS storage, that was also very busy at the time). since many download queues will have bursts of a page or more of 'already in db' results (from url or hash lookups), this is why they typically only run 30-50 import items a second these days, and until this week, why this situation was blatting the db so hard. the path existence disk request is pulled out of precious db time, allowing other jobs to do other db work while the importer can wait for disk I/O on its thread. I suspect the key to getting the 20ms down to 8ms will be future granulation of the file store (more than 256 folders when you have more than x files per folder, etc...), which I have plans for. I know this change will de-clunk db access when a lot of importers are working, but we'll see this week if the queues actually process a little faster since they can now do file presence checks in parallel and with luck the OS/disk will order their I/O requests cleverly. it may or may not relieve the UI hangs some people have seen, but if these checks are causing trouble it should expose the next bottleneck
optimised a small test that checks if a single tag is in the parent/sibling system, typically before adding tags to a file (and hence sometimes spammed when downloaders were working). there was a now-unneeded safety check in here that I believe was throwing off the query planner in some situations
the 'review threads' debug UI now has two new tabs for the job schedulers. I will be working with UI-lag-experiencing users in future to see where the biggest problems are here. I suspect part of it will overhead from downloader thread spam, which I have more plans for
all jobs that threads schedule on main UI time are now profiled in 'callto' profile mode
.
site encoding fixes:
fixed a problem with webpages that report an encoding for which there is no available decoder. This error is now caught properly, and if 'chardet' is available to provide a supported encoding, it now steps in fixes things automatically. for most users, this fixes japanese sites that report their encoding as "Windows-31J", which seems to be a synonym for Shift-JIS. the 'non-failing unicode decode' function here is also now better at not failing, ha ha, and it delivers richer error descriptions when all attempts to decode are non-successful
fixed a problem detecting and decoding webpages with no specified encoding (which defaults to windows-1252 and/or ISO-8859-1 in some weird internet standards thing) using chardet
if chardet is not available and all else fails, windows-1252 is now attempted as a last resort
added chardet presence to help->about. requests needs it atm so you likely definitely have it, but I'll make it specific in requirements.txt and expand info about it in future
.
boring code cleanup:
refactored the base file import job to its own file
client import options are moved to a new submodule, and file, tag, and the future note import options are refactored to their own files
wrote a new object to handle current import file status in a better way than the old 'toss a tuple around' method
implemented this file import status across most of the import pipeline and cleaned up a heap of import status, hash, mime, and note handling. rarely do downloaders now inspect raw file import status directly--they just ask the import and status object what they think should happen next based on current file import options etc...
a url file import's pre-import status urls are now tested main url first, file url second, then associable urls (previously it was pseudorandom)
a file import's pre-import status hashes are now tested sha256 first if that is available (previously it was pseudorandom). this probably doesn't matter 99.998% of the time, but maybe hitting 'try again' on a watcher import that failed on a previous boot and also had a dodgy hash parser, it might
misc pre-import status prediction logic cleanup, particularly when multiple urls disagree on status and 'exclude previously deleted' is _unchecked_
when a hash gives a file pre-import status, the import note now records which hash type it was
pulled the 'already in db but doesn't actually exist on disk' pre-import status check out of the db, fixing a long-time ugly file manager call and reducing db lock load significantly
updated a host of hacky file import unit tests to less hacky versions with the new status object
all scheduled jobs now print better information about themselves in debug code
next week
Next week is a 'medium size job' week. I would like to do some server work, particularly writing the 'null account' that will inherit all content ownership after a certain period, completely anonymising history and improving long-term privacy, and then see if I can whack away at some janitor workflow improvements.
0 notes
Text
Drawing inspiration from stale-while-revalidate
There's an http caching directive called 'stale-while-revalidate', which will cause your browser to use a stale cached value, while refreshing its cache asynchronously under the hood.
Making practical use of this setting within my projects proved futile, but it was enough to get me thinking; I want access to that asynchronous response when the browser receives an up-to-date response. I want to make an ajax call, and just have my callback fire twice. Once with a stale, cached response, and again when I receive up-to-date data. Lucky for me, this is actually pretty trivial to implement in basic javascript.
Use case:
I work on a SAAS product for managing inventory. The user's primary view/screen includes a sidebar with a folder structure, and each folder in the tree includes a count of the records beneath it. This sidebar is used for navigation, but the counts are also helpful to the user.
For power-users; this folder structure can become very large, and counts can reach the hundreds-of-thousands. The folders that are visible to the user may depend on the user's permission to individual records, and there are a number of other challenging behaviours to this sidebar. In short; it can take some time for the server to generate the data for this sidebar.
Natually, the best course of action would be to refactor the code to generate it faster. And I'm with you. Refactoring and designing for performance are the ideal solution long-term. But there is a time and place for quick fixes. In our case, we're bootstrapping a SAAS: fast feature implementation leads to winning and retaining customers.
One intuitive improvement we can make is to give users a more progressive loading experience. Rather than generating the entire page at once and sending it to the user as a single http response; we generate a simpler response, and then fetch 'secondary' information like the sidebar via ajax.
``` <div id='sidebar'> Loading... </div> <script> $(document).ready(function(){ $.ajax({ url: 'https://...', success: function(data){ $("#sidebar").html(data) ... // other initialization }, }) }) </script> ```
Now, the user's browsing experience feels faster, with the primary portion of their page loading more quickly, and the sidebar appearing some moments later. You do have a new user-state to consider here: the user may interact with the page between when the page loads, and when the callback is called, so you'll want to watch that your callback doesn't cause any existing on-screen content to move. You can usually address that by ensuring your placeholder 'loading' content has the same dimensions as the content which will replace it.
Implementation
So how do we implement the idea of stale-while-revalidate? There are just a couple things to do:
Add headers to the ajax response, so the browser knows it can cache it.
ex: Cache-Control: private, max-age=3600
Ensure that our callback can safely be called multiple times.
Perform the ajax call twice.
Ignoring step #2 for a moment, our new code looks like this:
``` <div id='sidebar'> Loading... </div> <script> $(document).ready(function(){ function sidebar_callback(data){ $("#sidebar").html(data) ... // other initialization } $.ajax({ url: 'https://...', success: sidebar_callback, }) $.ajax({ url: 'https://...', success: sidebar_callback, headers: {'Cache-Control': 'max-age=0'}, }) }) </script> ```
That's it! Now, when the user loads the page, their browser will make two http requests. The first will (ideally) obtain a response from the local cache, and the second request will retrieve (and cache) a fresh copy from the server. The user sees the primary portion of the page load, followed almost immediately by the appearance of the sidebar, and finally the sidebar updates in-place to reflect any new changes/values.
Unfortunately, there's step #2 to consider. Now that your callback function is running twice; you have a new state to consider: The user may interact with the site between callbacks. In the case of my folder structure; the user may have right-clicked on a folder to perform an action. My callback logic now needs to take that into careful account.
But it's worth the effort. Because once you've got a callback that you can call multiple times, we're into a new paradigm baby.
Taking it further
Once your javascript callback can safely be called multiple times; you suddenly have some new options.
You could periodically poll your ajax endpoint, and update your dom if anything has changed.
You could trigger a refresh of your ajax endpoint based on a user interaction, or an external signal from the server.
In my case, we implemented these improvements in stages - each one building off the last:
We built an MVP with strictly server-side-rendering (no fancy js frameworks).
When something got slow, we defered its generation to an ajax call (simple jquery).
Then we added this stale-while-revalidate idea.
We carried this idea over to a 'notifications' pane.
We added periodic polling for new notifications (poor man's realtime notifications).
We added some simple logic, so a new notification triggered a re-fetch of the sidebar (poor man's realtime sidebar).
We refactored the notification endpoint (server side) to use http long-polling, to make our notifications actually realtime.
Instead of asking the server for notifications every 10 seconds; the browser asks once, and the server intentionally hangs until a new notification exists. (Plus a bit of timeout/re-connection logic.)
Taking this incremental approach let us adapt and iterate quickly through the early stages of the product. For all of its functionality - very little logic was happening client-side - so we could get away with only hiring jr backend developers as we grew. Now that the SAAS has a strong user-base, a wealth of real-world usage data, a deep understanding of the user's painpoints, and can easily acquire funding: we're ready to hire a senior front-end developer to help us re-write the front-end as a single-page-app. The UI is ready for a major refactor anyway, so we can get two birds stoned at once.
Reflecting
Unless you're Google, you probably don't need to worry about performance until it rears its head. Don't polish a turd, and avoid goldplating. Instead, choose simple, boring technology to solve the problem you currently face. Keep your code DRY, and remember that every minute spent thinking about design, saves an hour of misdirected effort.
A warm embrace to you, fellow wanderer.
0 notes
Link
Designing Enterprise Data Architecture on the Salesforce1 Platform Designing a good data architecture (DA) can often mean the difference in a well-designed app. Learn strategies for designing the best logical and physical data models to support your enterprise projects. Editors Note: This is part 2 in our series on Enterprise Architecture with Force.com. Greg Cook, our guest blogger and resident expert, is a managing partner of CloudPremise and currently holds all seven Salesforce certifications. In part 1 of my series on Enterprise Architecture with Force.com, I introduced some of the pros and cons of different “org” strategies. However regardless of your org strategy, the proper data architecture is even more important. In this article I will discuss different strategies for designing the best logical and physical data models to support your enterprise projects. Designing a good data architecture (DA) can often mean the difference between a great success story or an epic failure. The DA of the Salesforce1 Platform affects almost ALL areas of your org – and therefore is not to be taken lightly or rushed into quickly. There are some key differences between Salesforce and other platforms that are critical to understand when designing your DA. Unfortunately most implementations do not have an enterprise perspective when they are being designed. This can lead to significant refactoring as you increase your usage and knowledge of the platform. First of all it’s important to understand the differences between Salesforce and other database applications. Salesforce looks and feels like a traditional OLTP relational database. However under the covers it has been architected very differently to support multi-tenancy, dynamic changes, and platform specific features. Do NOT assume data models move seamlessly from the old world into the new. Your data is co-located alongside other tenants. While this may cause security concerns, it will affect you more in terms of learning the scalability thresholds and governor limits that are placed upon the platform. Unlike traditional databases, Salesforce data cannot be dynamically joined through its query engine. Rather the “joins” are based on the predefined relationships between objects. Therefore the data-model design is critical, and understanding reporting requirements UP-FRONT is a key success factor. Salesforce is not a data warehouse (nor does it intend to be). The recommended data strategy is to have the data you need and to remove the data you don’t. While that sounds like a pretty simple concept, it is much more difficult to realize. Let’s walk through the process of designing an Enterprise data architecture. An effective DA design will go through most if not all of the following steps: Step 1 – Define Your Logical Data Model (LDM) A good DA starts with a good logical design. This means you have taken the time to document your business’s description of the operations. You have a catalog of business entities and relationships that are meaningful and critical to the business. You should build your logical model with NO consideration for the underlining physical implementation. The purpose is to define your LDM that will guide you through your data design process. Make sure to take any industry relevant standards (HL7, Party Model, etc) into consideration. Step 2 – Define Your Enterprise Data Strategy (including Master Data Management) Outside the scope of this post (but totally necessary on an Enterprise implementation) is to define your enterprise data strategy. Salesforce should (theoretically) be a critical component but also subservient to your Enterprise Data Strategy. It will affect Salesforce DA in some of the following ways: Is there a Customer Master or Master Data Management system and if so what LDM entities are involved? What are the data retention requirements? How and when does the Enterprise Data Warehouse receive data? Is there an operational data store available for pushing or pulling real-time data to Salesforce? Step 3 – Document the Data Lifecycle of Each Entity in the LDM Each entity within the LDM will have its own lifecycle. It is critical to capture, document, and analyze each specific entity. Doing so will help you know later how to consolidate (or not) entities into objects, how to build a tiering strategy, and even how to build a governance model. Where is the source of truth for each entity? Will Salesforce be the System of Record or a consumer of it? How is data created, edited, and deleted? Will Salesforce be the only place for these actions? Will any of those actions happen outside Salesforce? What are they types of metrics and reporting required for this entity? Where do those metrics currently pull data from and where will they in the future state? Who “owns” the data from a business perspective? Who can tell you if the data is right or wrong? Who will steward the entity and ensure its quality? What business processes are initiated by this entity? Which are influenced? Get some estimates on data sizing for master entities and transactions. This will be very important when large data volumes (LDV) are involved. Step 4 – Translate Entities and Cardinality into Objects and Relationships Its time to start translating your LDM into a Physical Data Model (PDM). This is an art and not a science and I definitely recommend working closely with someone very knowledgeable on the Salesforce platform. Consolidate the Objects and Relationships were possible. Assess where it makes sense to collapse the entities, especially based upon common relationships to other objects. This is where record types become an important aspect of the Salesforce design. A common object can be bifurcated using record types, page layouts, and conditional logic design. A common architectural principle that I use is: “The More Generic You Can Make a Solution the More Flexible it Becomes” The tradeoff to consolidating objects is to consider the LOBs that will be using the object and your (forthcoming) tiering strategy. It may make sense to isolate an entity for technical, governance and/or change management reasons. Another downside to consolidating objects is the added need to partition your customizations. Be prepared to write different classes/web services/integrations at the logical entity level. For example, if 6 entities are overriding the Account object you will need custom logic for Business Customers vs Facility Locations vs Business Partners, etc – all hitting the Account object under the covers. Step 5 – Determine whether to override Standard Objects Another difficult decision becomes when to override a standard object vs building a custom object. Once again this is more an art than science but there are some key considerations along this topic: Why do you need the standard object functionality? Does Salesforce provide out of the box functionality that you would have to build your own if you go the custom object route? (e.g. Case Escalation Rules, Account Teams, Community Access, etc) Consider your license impacts between custom vs standard. Standard objects like Opportunity and Case are not available with a platform license. Don’t get carried away. Every “thing” in the world could be generalized to an account object while every “event” in the world could be generalized to a case. These types of implementations are very difficult to maintain. Step 6 – Define Enterprise Object Classification and Tiering Strategy Object classification and tiering is an important component to an enterprise Salesforce DA. I try to classify objects across 3 different categories – however you may have more or less depending on your architecture design. Core Data – This is data that is central to the system and has has lots of complexity around workflow, apex, visualforce, integrations, reporting, etc. Changes to these objects must be made with extreme caution because they underpin your entire org. Typically these are shared across multiple lines of business (e.g. Account object), have LDV (e.g. Tasks), or complexity (e.g. Sharing objects). Information Technology should lock down the metadata and security on these objects pretty tightly. It will be up to IT to maintain the data in these objects. Managed Data – This is data that is core to a specific LOB but does not affect other areas of the system. Depending on the number of LOBs in the system this may or may not be something like the Opportunity or Case object. The objects still have high complexity in their workflow and customization requirements, however the object and code is regionalized to a single LOB. In this layer you can enable Business Administrators to manage the data for their LOB. In fact pushing data management of these objects into the business is critical to your ability to scale on the platform. Delegated Administration Data – These are typically custom objects that have been created for a specific LOB and are completely isolated from other areas of the system. They are typically “spreadsheet apps” or mini applications that have a very simple workflow and business processes. Therefore the data AND metadata of these objects should be put into the hands of business and delegated administrators. These objects become great candidates for Citizen Developers within the enterprise because you enable the business to make their own apps within a sophisticated environment. You can also use your tiering strategy to assist with archiving (below). As you can move data out of the core layers and into delegated layers you will increase your scalability, agility, and even performance. Just make sure you are not creating data duplication and redundancy in your DA. Step 7 – Design Your Security Model and Data Visibility Standards Another architectural principal I recommend for Enterprise DA is “The Principle of Least Privilege“. This means that no profile should ever be given access to an application, object, or field unless specifically required. However I do NOT recommend making the entire sharing model private. This would cause significant and unnecessary complexity in your sharing design. Unnecessary private data will lead to data duplication issues and could also lead to performance impacts. Step 8 – Design Your Physical Data Architecture It is time to build a PDM. I call this “framing” as it will be the first time you can start to see what your solution will look like within Salesforce. Start to map out an object for each consolidated entity from your LDM. Which entities for your LDM are necessary to be persistent in Salesforce? Which entities can be kept off platform? Data that is not used to invoke business processes (workflow/triggers/etc) is a candidate to be kept off platform. Do NOT create objects for lookups where possible. Utilize picklists and multi-picklists as much as possible in an attempt to “flatten” your data model. Salesforce objects are more like large spreadsheets. There will be lots of columns and denormalized data in many cases vs a more traditionally normalized database. Take your earlier volume estimates for your LDM and reapply them to your consolidated design. You should have a rough order of magnitude now for each consolidated entity you are considering. Try to get specific volumes at this point. It becomes very important for licensing and LDV. Make sure you have considered many-to-many relationships as these “junction objects” have the capability to grow very large in Enterprise environments. Any objects with volumes in the millions should be considered for LDV impact. While outside the scope of this post you may want to consider changes to your PDM to minimize volumes where possible. Data replication and duplication in Salesforce is OK. (Data architects please sit back down.) Sometimes it is necessary to support the business processes utilizing these frowned upon methods. Salesforce actually works best when you break some of the traditional rules of enterprise data architecture – especially normalization. As far as data off platform is concerned… I recommend keeping data off platform that you don’t need. You want Salesforce to be a corvette in your enterprise (fast, agile, sexy) vs a utility van (slow, unkept, and kind of creepy). Step 9 – Define Enterprise-wide and Org-Wide Data Standards It is time to build a set of standards when it comes to your data model. You need to consider Field Labels vs API names, and common fields to maintain on each object. Also coming up with an enterprise model for your Record Types will be critical. The following list is what I like to do: . (e.g. Dell, IBM, Google, etc). It is much easier to refactor objects in the future if you start with record types from the beginning. LOB specific Record Types always begin with a LOB designator (e.g. CC – Incident for “Contact Center”) LOB specific objects and fields should have the LOB designator in the API name. (e.g. CC_Object__c, CC_Field_Name__c) Depending on the number of fields you expect to have on a given object, consider tokenizing the API name (e.g. CC_FldNm__c). This will greatly save you later when you are hitting limits on the number of characters that can be submitted in SOQL queries. I create common fields on EVERY object. Fields like “Label” and “Hyperlink” can hold business friendly names and URLs that are easily used on related lists, reports, and email templates. I usually copy the ID field to a custom field using workflow or triggers. This will greatly assist you later when trying to integrate your full copy sandbox data with other systems. (I never use the Salesforce ID for integration if it can be avoided). You may or may not want to follow these. The point is create your standards, implement that way from the beginning, and govern your implementation to ensure your standards are followed. Step 10 – Define Your Archive & Retention Strategy Even though Salesforce has a great history and reputation for keeping your data safe, you still have a responsibility to your organization to replicate and archive the data out of Salesforce. Here are some considerations: It is more likely that you will break your own Salesforce data than for them to suffer a data loss. Salesforce will assist you should you need to try to recover your data to an earlier state, but a mature enterprise needs to have the capability to be self-sufficient in this area. Weekly backups are provided from Salesforce and maybe fine for SMB, however I recommend a nightly replicated copy. There are partner solutions that will make this easy – or you can build a custom solution using the Salesforce APIs. I would use your replicated copy for 2 purposes. One would be to feed your data warehouse as necessary. The other is for recovery purposes. I would NOT use the replicated copy for reporting and I would try to not use the replicated copy for any real time integration requirements. This adds an undue burden to your technical environment and ties your Cloud solution into your on-premise infrastructure. Tightly coupling Salesforce to your existing IT infrastructure may cripple your agility and flexibility in the cloud. Step 11 – Define Your Reporting Strategy Your architecture is defined. You know what data will be on platform, what data will be off-platform, and where the best sources of all of this data is. Its time to define a reporting strategy for your Salesforce data. Your strategy will be different depending upon your data architecture – but I will suggest the following guidelines that I have used successfully in large enterprises. Operational Reporting should be done on Platform if possible. The data necessary to support a business process will hopefully be on platform long enough to run your operational reports. Analytical Reporting should be done off Platform. Use traditional BI tools built upon your data warehouse for long running, trending, and complex reports. Use the out of the box reporting and dashboards as much as possible. Try to get your executives and stakeholders the reports they need coming directly from Salesforce. Consider mashup strategies for off platform reporting solutions. Some third parties offer applications that will integrate seamlessly into the Salesforce UI so users never need to leave the application. Consider building custom reports using Visual force or Canvas where appropriate. The more you keep your users in the platform the more influence and momentum you will maintain. As users move to other tools for reports, so too will their interest, attention, and eventually funding. Don’t report out of your replicated Salesforce database. Move that data into the data warehouse if analytical data is needed and keep users in Salesforce for real-time data. Offline Salesforce reports will just confuse users and cause undue issues regarding data latency and quality. Step 12 – Repeat Just like Enterprise Architecture, defining your Data Architecture is iterative and will continually improve. Each time you go though an iteration you will increase in your understanding, maturing, and competency on the platform. And as you improve your data architecture, so too will the business value of your Salesforce deployment increase. Other Helpful Resources Salesforce’s Best Practices for Large Data Volumes Salesforce’s White Paper on Multi-Tenant Architecture About the Author Greg Cook currently holds all seven Salesforce certifications along with Enterprise Architecture certifications in Togaf, Zachman, and ITIL. He is the founder and managing partner of CloudPremise where he advises multiple Fortune 500 companies in the best ways to utilize Salesforce1 in Enterprise environments.
0 notes
Text
Main Meditation Protocol: p1
This is pretty much copypasta from the original github source, to be digested more thoroughly later.
---
p1: [old names: Elemental Analysis, Comprehensive Elemental Analysis]
1. Incline towards producing one of:
(1a) a logical argument/deduction/derivation (standalone or possibly including a narrativized explanation), [What implies/entails this/X? What does X/this imply/entail? Why X? What is the reason for X? What follows from X? X=?]
(1b) a description of a causal mechanism, [What caused this/X? What does this/X cause? X=?] [How does that work?] [(1/2) What’s going on? What’s going on, there? What’s going on, here? What’s going on, out there? What’s going on, in here?]
(1c) a description of some spatiotemporal sensations/experience, [What is before this/X? What is after this/X? What’s next? What is adjacent to this/X? What qualities does this/X have? X=?] [(2/2) What’s going on? What’s going on, there? What’s going on, here? What’s going on, out there? What’s going on, in here?]
(1d) an explanation of a phenomenon and possibly alternate credible explanations of that phenomenon
(1e) an evaluation or appraisal of something
(1f) instructions for achieving something
(1g) description of an ideal, endorsement
(1h) description of a goal state
(1i) a description of a dynamical first-person perspective/experience (your present experience, experiential memory, inferred of another, or imagined), including mental, sensory, and somatic experience
(1j.1) a question and possibly and answer, or
(1j.2) a topic/subject and possibly content subsumed by that topic/subject
(1k) a problem and possibly a solution
(1l) some (or as exhaustively as you can) of your “actual/deepest/truest” (a) beliefs and (b) expectations—good, bad, and ugly, beautiful, endorsed, disendorsement,and relevant into words, in your “heart of hearts,” “throat of throats,” “gut of guts,” “genitals of genitals,” “sacrum of sacrums,” “perineum of perineums,” etc.: the beliefs and expectations and representations of the mind and body.
(1m) some (or as exhaustively as you can) of your plans, intentions, willing, goals
(1n) a meaningful story
(1o) a meaningful autobiographical detailed excerpt or lifelong summary
(1p) a plan for achieving something
(1q) a list of that which you desire/thirst/crave, hope for, wish for, long for, etc.
(1r) a list of that which you fear
(1s) a list of that which you love
(1t) a list of that which you hate
(1u) a story/fantasy/narrative/scenario that is (a) exciting (and/or otherwise good e.g. uplifting or psychological) and/or (b) sexually arousing and/or (c) evocative if connection/intimacy/safety
(1v) counterfactuals: for something that went one way or could have gone a way or might go a way or will go a way, how it could that have, did, or will go/gone a different way, elaborate on that, and what changed for that to be the case
(1w) positive examples of something (things that are examples of X) as different from each other as possible, negative examples of that something (things that are examples of not-X) as different from each other as can be and as minimally different from positive examples of X in as many different ways as can be
(1x) actions, doings; things you’re doing right now, volitionally or nonvolitionally, as broadly conceived as possible
(1y) an personal inability/can’t/powerlessness and possibly a believable way to acquire that ability
(1z) a “further purpose” a “for what you are doing something”; “I am doing/striving for X for/because”; “X is good because…”
(1z1) a memory
(1z2) any type of writing you want for any purpose.
(1z3) your motivations or reasons, beliefs, knowings, understandings, or expectations for or underlying the actions, doings; things you’re doing right now, volitionally or nonvolitionally, as broadly conceived as possible, as exhaustively or usefully as possible
2. Get down (think or write down) as little or as much material as comes easily, even just a single relevant word or phrase. (And you can also patiently compose and/or revise as you go, or set up an outline structure to fill in, or do lots of messy freewriting, or a combination…)
3. Choose, from the material you produced,
(3a) a word,
(3b) a phrase,
(3c) a sentence, or
(3d) a boundary (e.g. between two sentences; this can be stylized as the last word and punctation of a sentence and the first word of a subsequent sentence) from the material you produced.
4. Lift it out, while remembering its context, and you might put an equals sign to the right of it.
5. Now, on the righthand side of the equals sign, say the same thing using more words than on the left side of the equals sign. It’s ok if you produce something partial, imperfect, or nothing.
6. Now, you might return to the original material for more content to repeat the exercise, or take something from the zoom/expansion/analysis you just did and zoom/expand/analyze further.
7. Feel free to refactor, revise, expand, reboot the original material as much or as little as you’d like.
8. For anything you produce, be willing to throw it all away, plan to throw it away, be willing to forget for something better in the future. Don’t push, don’t force, don’t strain. Let the whole thing go. Let the whole thing move and flow.
9. You can also, and this is recommended, create new wholes. For example, if X = M + R + T, and, Y = Q + G + V, then take, say, R and G. And, do this: “Z = ? = R + G.” Now, what is “Z”, what is that “?” between Z and R+ G? In other words, instead of putting things on the left hand side of the equal sign and then putting more things on the right hand side of the equals sign—instead, first put things on the right hand side of the equals sign and then put fewer things on the left hand side of the equals sign. Find new wholes and larger contexts. You might find wholes contained in larger wholes contained in larger wholes…
9b. You might play with this template:
[this/these] whole(s) Y is/are/contain(s)/= [this/these] parts M[, F…] + “just exactly/precisely [this/these aforementioned]/and nothing else”
That is, M and F are known; you have some words for them. Now, what is Y? What are some words for Y?
9c. Another kind of inverse is adding a subscript to the word on the left hand side of the equals sign and then looking for definitions for the other subscript. For example, you might have “suffering =“ and maybe before you even try to fill in the right hand side, you might do:
suffering_1 =
suffering_2 =
suffering_3 =
and so on.
You might ask, what is everything I could possibly mean by this word (or phrase) “suffering”/X?
In this way, the word “suffering” can become more detached and flexible from the underlying language, while at the same time making each use of the word more precise. The subscripts do not have to be numbers; they can be anything that helps to differentiate which meaning/usage/sense of the word that you mean. That might be times or durations or conditions and so forth. [See also General Semantics for more on the idea of “indexing.”]
10. Also, consider intensional multischematism. For example, you might say that the same M can be referred to by single word R and single word H. That is R and H have different meanings/intensions but they refer or point to the same thing or set of things. Further, R = G + H + T and X = V + W + Q. That is, (G + H + T) and (V + W + Y) each have different meanings, but correspond to R and X, respectively. Further, you might notice that, say, T and W, while using different words and meaning different things, in fact refer to the same thing(s), have the same extension. Another way of saying things like this is that the concept M, or that which directly represents M, or <M>, refers or applies to M using the word “M”. Or, you might say that both <M> and <K> refer or apply to the same extension; “M” and “K” refer to M and K which are actually the same. In our syntax and semantics, here, M = K.
Example a: This M and this K are the same (thing). [not just the same type of thing. <this M> and <this K> corefer to M (which is K) and K (which is M).]
Example b: All Gs are also Hs.
[note that the above is ambiguous as to whether X, Y, Z, etc. are “bound” or “unbound” for any given X in the language/wrting above]
Examples:
Example 1a: X = The cat sat on the mat.
Example 1b: Y = cat in X = furry animal + …
Example 1c: Z = furry in Y = experientially noncontiguous nonhomogenous light nonpunctate/distributed pressure when touched gently
Example 1d: Q = noncontiguous in Z = mediacy and absence = missing immediate relations = a proper subset of immediate relations from a particular designated/delimited closed/finite set
Example 2a: T = rippling water = directionality backflows dappled light dark traveling shimmers twinkle flecks arc chase over under undulate
Example 3a: R = The last thing was cheese. We find that in these cases…
Example 3b: M = [cheese.] [We] in R = …summary signpost implication…
Example 4: B = ? = cat + dog; B = ?; B = a partial set of quadrupedal mammals, those things that [for my purposes…]…
Places likely worth investigating:
1. Where something seemingly X somehow leads to (or somehow depends on) something seemingly Y, or vice versa. (e.g. when doing something bad is good or when doing something good is bad)
2. Where something is seemingly somehow X and Y at the same time.
3. Where something is seemingly somehow X and Y at different times.
4. Where something is seemingly somehow either X or Y conditionally.
X, Y =
a) true, false
b) good, bad
c) existent/present, nonexistent/absent
d) necessary/unconditional/noncontingent, conditional/contingent
e) possible/conceivable, impossible/inconceivable
f) simple/nonpartful, complex/composite
g) unified/whole/connected, separate/plural/multiple
h) before or after, synchronous
i) veridical, nonveridical
j) beautiful, ugly
k) that is something that has some attribute or property, that doesn’t have that same attribute or property
Further notes:
(*) You might also write/think/say things (assertions) and then incline towards generating relevant (apparent, seeming, believed, thought, felt, wondered, imagined, suspected, endorsed, something…) counterexamples or contradictions to those things. And then use the things and the counterexamples or contradictions to improve on the original thing or to write a better thing not subject to the original counterexamples or contradictions.
(*) Some additional good concepts, semi-separately, are “error correction,” “counterfactual,” “counterexample…”
(*) Try also: not X = [pick things and see if they’re in or out, let this change anything]
(*) Consider swapping out the =/equals sign above with things like: is, means, signifies, is equivalent to, ~/sort of equals; maybe equals; could equal; is; is essentially; could be conceived as; could be construed as; could be stipulated as; could be schematized as; could be conveniently stipulated as; boils down to; could have a good enough for now/here definition of; is/can be defined as; most people think of this like/as; is like…
(*) In addition to =/equals and so forth, you can of course try using the particular word or phrase in a sentence or sentences.
(*) If you write down assertions anywhere, e.g. as premises or points in an argument, you might ad hoc or systematically look for counterexamples. You might also, ad hoc or systematically, explore objections that others might raise to the/those assertion(s).
0 notes
Last Seen Blogs

jotamenparra
Jonhmen

needtotalkwtf
Out of touch with reality

bienetreencours
Bien Etre en Cours

dangerousdan-dan
The rest is void

kwekublr
simple