#playwright python tutorial
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Kazakhstan’s Minister of Communications and Informatics has blocked the Tumblr site because it contained 60 sites of terrorism, extremism, and pornography in 2015.
Text

Why Rahul Shetty Academy is the best Option for Generative AI in Software Testing
Venkatesh (Rahul Shetty) offers specialist training in Generative AI for Software Testing that includes practical experience, real-world applications, and industry-leading approaches. Venkatesh (Rahul Shetty) Academy offers the greatest guidance to help you improve your testing skills right now. For additional information, go to https://rahulshettyacademy.com/.
#ai generator tester#ai software testing#ai automated testing#ai in testing software#playwright automation javascript#playwright javascript tutorial#playwright python tutorial#scrapy playwright tutorial#api testing using postman#online postman api testing#postman automation api testing#postman automated testing#postman performance testing#postman tutorial for api testing#free api for postman testing#api testing postman tutorial#postman tutorial for beginners#postman api performance testing#automate api testing in postman#java automation testing#automation testing selenium with java#automation testing java selenium#java selenium automation testing#python selenium automation#selenium with python automation testing#selenium testing with python#automation with selenium python#selenium automation with python#python and selenium tutorial#cypress automation training
0 notes
Text
AutomaSelenium, Cypress, and Playwright: Choosing the Right Tool for Automation Testing

Automation testing has become the cornerstone of modern software development, ensuring faster releases, enhanced quality, and seamless user experiences. When it comes to automation testing tools, Selenium WebDriver, Cypress, and Playwright stand out as the most popular choices. But which one should you use for your project? Let’s explore their features, benefits, and use cases to help you decide.
Selenium WebDriver: The Veteran in Automation Testing
Selenium WebDriver is a well-established tool in the automation testing space, known for its versatility and broad browser support. It allows testers to write scripts in multiple programming languages, such as Java, Python, and C#.
Why Choose Selenium WebDriver?
Cross-Browser Compatibility: Selenium supports a wide range of browsers, including Chrome, Firefox, Safari, and Edge. Isn’t that essential for testing web applications?
Large Community Support: Being a mature tool, Selenium has extensive documentation, tutorials, and community forums.
Flexibility: Its ability to integrate with tools like TestNG, JUnit, and CI/CD pipelines makes it ideal for complex projects.
When to Use Selenium WebDriver?
If you’re working on projects requiring robust cross-browser testing or integration with legacy systems, Selenium WebDriver is a reliable choice.
Cypress: The Modern and Developer-Friendly Tool
Cypress is a newer automation testing tool that has quickly gained popularity for its simplicity and developer-first approach. It is specifically designed for end-to-end testing of modern web applications.
Why Choose Cypress?
Fast and Reliable Testing: Cypress executes tests directly in the browser, offering real-time reloading and debugging.
Built-in Features: It comes with built-in commands for assertions and network requests, reducing the need for additional libraries.
Great for Developers: Its intuitive interface and JavaScript-based scripting make it easier for developers to write and maintain tests.
When to Use Cypress?
If you’re testing single-page applications (SPAs) or require quick setup and execution, Cypress might be the tool you need.
Playwright: The New Powerhouse in Automation Testing
Playwright, developed by Microsoft, is a powerful tool that supports testing modern web applications with advanced features like auto-waiting and multi-browser support.
Why Choose Playwright?
Multi-Browser Support: Playwright enables automation across Chromium, Firefox, and WebKit with a single API.
Parallel Testing: It supports parallel test execution, saving valuable time.
Advanced Capabilities: Features like capturing screenshots, tracing test execution, and network interception make it highly efficient.
When to Use Playwright?
If your project involves complex web applications or requires advanced testing capabilities, Playwright can be a game-changer.
How to Choose the Right Tool?
While Selenium WebDriver remains a classic choice for comprehensive automation testing, Cypress and Playwright cater to the needs of modern, fast-paced development teams. The decision ultimately depends on your project requirements. Ask yourself:
Do you need extensive browser compatibility? Go with Selenium.
Are you looking for speed and simplicity? Cypress is your answer.
Do you require advanced features and cutting-edge technology? Choose Playwright.
Conclusion
Automation testing is evolving rapidly, and tools like Selenium WebDriver, Cypress, and Playwright are leading the charge. Each has its strengths and is suited for specific testing needs. By selecting the right tool, you can ensure efficient, accurate, and scalable testing processes.
At PrimeQA Solutions, we specialize in leveraging the latest automation testing tools to deliver flawless software quality. Ready to elevate your testing strategy? Explore our blogs for more insights or contact us today to discuss your testing needs. Why settle for less when you can achieve excellence in testing?
0 notes
Text
Effective Techniques To Scrape Amazon Product Category Without Getting Blocked!
Effective Techniques To Scrape Amazon Product Category Without Getting Blocked!

This comprehensive guide will explore practical techniques for web scraping Amazon's product categories without encountering blocking issues. Our tool is Playwright, a Python library that empowers developers to automate web interactions and effortlessly extract data from web pages. Playwright offers the flexibility to navigate web pages, interact with elements, and gather information within a headless or visible browser environment. Even better, Playwright is compatible with various browsers like Chrome, Firefox, and Safari, enabling you to test your web scraping scripts across different platforms. Moreover, Playwright boasts robust error handling and retry mechanisms, which can help you tackle shared web scraping obstacles like timeouts and network errors.
Throughout this tutorial, we will guide you through the stepwise procedure of scraping data related to air fryers from Amazon using Playwright in Python. We will also demonstrate how to save this extracted data as a CSV file. By the end of this tutorial, you will have gained a solid understanding of how to scrape Amazon product categories effectively while avoiding potential roadblocks. Additionally, you'll become proficient in utilizing Playwright to automate web interactions and efficiently extract data.
List of Data Fields

Product URL: The web address leading to the air fryer product.
Product Name: The name or title of the air fryer product.
Brand: The manufacturer or brand responsible for the air fryer product.
MRP (Maximum Retail Price): The suggested maximum retail price for the air fryer product.
Sale Price: It includes the current price of the air fryer product.
Number of Reviews: The count of customer reviews available for the air fryer product.
Ratings: It includes the average ratings customers assign to the air fryer product.
Best Sellers Rank: It includes a ranking system of the product's position in the Home and kitchen category and specialized Air Fryer and Fat Fryer categories.
Technical Details: It includes specific specifications of the air fryer product, encompassing details like wattage, capacity, color, and more.
About this item: A description provides information about the air fryer product, features, and functionalities.
Amazon boasts an astonishing online inventory exceeding 12 million products. When you factor in the contributions of Marketplace Sellers, this number skyrockets to over 350 million unique products. This vast assortment has solidified Amazon's reputation as the "go-to" destination for online shopping. It's often the first stop for customers seeking to purchase or gather in-depth information about a product. Amazon offers a treasure trove of valuable product data, encompassing everything from prices and product descriptions to images and customer reviews.
Given this wealth of product data and Amazon's immense customer base, it's no surprise that small and large businesses and professionals are keenly interested in harvesting and analyzing this Amazon product data.
In this article, we'll introduce our Amazon scraper and illustrate how you can effectively collect Amazon product information.
Here's a step-by-step guide for using Playwright in Python to scrape air fryer data from Amazon:
Step 1: Install Required Libraries

In this section, we've imported several essential Python modules and libraries to support various operations in our project.
re Module: We're utilizing the 're' module for working with regular expressions. Regular expressions are powerful tools for pattern matching and text manipulation.
random Module: The 'random' module is essential for generating random numbers, making it handy for tasks like generating test data or shuffling the order of tests.
asyncio Module: We're incorporating the 'asyncio' module to manage asynchronous programming in Python. It is particularly crucial when using Playwright's asynchronous API for web automation.
datetime Module: The 'datetime' module comes into play when we need to work with dates and times. It provides a range of functionalities for manipulating, creating date and time objects and formatting them as strings.
pandas Library: We're bringing in the 'pandas' library, a powerful data manipulation and analysis tool. In this tutorial, it will store and manipulate data retrieved from the web pages we're testing.
async_playwright Module: The 'async_playwright' module is essential for systematizing browsers using Playwright, an open-source Node.js library designed for automation testing and web scraping.
We're well-equipped to perform various tasks efficiently in our project by including these modules and libraries.
This script utilizes a combination of libraries to streamline browser testing with Playwright. These libraries serve distinct purposes, including data generation, asynchronous programming control, data manipulation and storage, and browser interaction automation.
Product URL Extraction
The second step involves extracting product URLs from the air fryer search. Product URL extraction refers to gathering and structuring the web links of products listed on a web page or online platform seeking help from e-commerce data scraping services.
Before initiating the scraping of product URLs, it is essential to take into account several considerations to ensure a responsible and efficient approach:
Standardized URL Format: Ensure the collected product URLs adhere to a standardized format, such as "https://www.amazon.in/+product name+/dp/ASIN." This format comprises the website's domain name, the product name without spaces, and the product's sole ASIN (Amazon Standard Identification Number) at the last. This standardized set-up facilitates data organization and analysis, maintaining URL consistency and clarity.
Filtering for Relevant Data: When extracting data from Amazon for air fryers, it is crucial to filter the information exclusively for them and exclude any accessories often displayed alongside them in search results. Implement filtering criteria based on factors like product category or keywords in the product title or description. This filtering ensures that the retrieved data pertains solely to air fryers, enhancing its relevance and utility.
Handling Pagination: During product URL scraping, you may need to navigate multiple pages by clicking the "Next" button at the bottom of the webpage to access all results. However, there may be instances where clicking the "next" button flops to load the following page, potentially causing errors in the scraping process. To mitigate such issues, consider implementing error-handling mechanisms, including timeouts, retries, and checks to confirm the total loading of the next page before data extraction. These precautions ensure effective and efficient scraping while minimizing errors and respecting the website's resources.

In this context, we eusemploy the Python function 'get_product_urls' to extract product links from a web page. This function leverages the Playwright library to automate browser testing and retrieve the resulting product URLs from an Amazon webpage.
The function performs a sequence of actions. It initially checks for a "next" button on the page. If found, the function clicks on it and invokes itself recursively to extract URLs from the subsequent page. This process continues until all pertinent product URLs are available.
Within the function, execute the following steps:
It will select page elements containing product links using a CSS selector.
It creates an empty set to store distinct product URLs.
It iterates through each element to extract the 'href' attribute.
Cleaning of the link based on specified conditions, including removing undesired substrings like "Basket" and "Accessories."
After this cleaning process, the function checks whether the link contains any of the unwanted substrings. If not, it appends the cleaned URL to the set of product URLs. Finally, the function returns the list of unique product URLs as a list.
Extracting Amazon Air Fryer Data
In this phase, we aim to determine the attributes we wish to collect from the website, which includes the Product Name, Brand, Number of Reviews, Ratings, MRP, Sale Price, Bestseller rank, Technical Details, and product description ("About the Amazon air fryer product").

To extract product names from web pages, we employ an asynchronous function called 'get_product_name' that works on an individual page object. This function follows a structured process:
It initiates by locating the product's title element on the page, achieved by using the 'query_selector()' method of the page object along with the appropriate CSS selector.
Once the element is successfully available, the function extracts the element's text content using the 'text_content()' method. Store this extracted text in the 'product_name' variable for further processing.
When the function encounters difficulties in finding or retrieving the product name for a specific item, it has a mechanism to handle exceptions. In such cases, it assigns the value "Not Available" to the 'product_name' variable. This proactive approach ensures the robustness of our web scraping script, allowing it to continue functioning smoothly even in the face of unexpected errors during the data extraction process.
Scraping Brand Name
In web scraping, capturing the brand name associated with a specific product plays a pivotal role in identifying the manufacturer or company behind the product. The procedure for extracting brand names mirrors that of product names. We begin by seeking pertinent elements on the webpage using a CSS selector and extracting the textual content from those elements.
However, brand information on the page can manifest in several different formats. For example, the brand name is by the text "Brand: 'brand name'" or appears as "Visit the 'brand name' Store." To accurately extract the brand name, it's crucial to filter out these extra elements and isolate the genuine brand name.

We can employ a function similar to the one used for product name extraction to extract the brand name from web pages. In this case, the function is named 'get_brand_name,' its operation revolves around locating the element containing the brand name via a CSS selector.
When the function successfully locates the element, it extracts the text content from that element using the 'text_content()' method and assigns it to a 'brand_name' variable. It's important to emphasize that the extracted text may include extraneous information such as "Visit," "the," "Store," and "Brand:" Eliminate these extra elements using regular expressions.
By filtering out these unwanted words, we can isolate the genuine brand name, ensuring the accuracy of our data. If the function encounters an exception while locating the brand name element or extracting its text content, it defaults to returning the brand name as "Not Available."
By incorporating this function into our web scraping script, we can effectively obtain the brand names of the products under scrutiny, thereby enhancing our understanding of the manufacturers and companies associated with these products.
Similarly, we can apply the same technique to extract other attributes, such as MRP and Sale price, from the web pages.
Scraping Products MRPs

Extracting product Ratings

To extract the star rating of a product from a web page, we utilize the 'get_star_rating' function. Initially, the function will locate the star rating element on the page using a CSS selector that points to the element housing the star ratings. Accomplish it using the 'page.wait_for_selector()' method. After locating the element, the function retrieves the inner text content of the element through the 'star_rating_elem.inner_text()' method.
However, an exception arises while finding the star rating element or extracting its text content. In that case, the function employs an alternative approach to verify whether there are no reviews for the product. To do this, it attempts to locate the element with an ID that signifies the absence of reviews using the 'page.query_selector()' method. If this element is available, assign the text content of that element to the 'star_rating' variable.
In cases where both of these attempts prove ineffective, the function enters the second block of exception. It denotes the star rating as "Not Available" without any further effort to extract rating information. It ensures the user is duly informed about the unavailability of star ratings for the specific product.
Extracting Product Information

The 'get_bullet_points' function collects bullet point information from the web page. It initiates the process by attempting to locate an unordered list element that encompasses bullet points. Achieve it by applying a CSS selector for the 'About this item' element with the corresponding ID. After locating the 'About this item' unordered list element, the function retrieves all the list item elements beneath it using the 'query_selector_all()' method.
The function then iterates through each list item element, gathering its inner text, and appends it to the bullet points list. In cases where an exception arises during the endeavor to find the unordered list element or the list item elements, the function promptly designates the bullet points as an empty list.
Ultimately, the function returns the compiled list of bullet points, ensuring the extracted information is accessible for further use.
Collecting and Preserving Product Information

This Python script employs an asynchronous " main " function to scrape product data from Amazon web pages. It leverages the Playwright library to launch the Firefox browser and navigate to Amazon's site. Following this, the "extract_product_urls" function is available to extract the URLs of each product on the page. Store it in a list named "product_url." The script proceeds to iterate through each product URL, using the "perform_request_with_retry" function to fetch product pages and extract a range of information, including product name, brand, star rating, review count, MRP, sale price, best sellers rank, technical details, and descriptions.
The gathered data is assembled into tuples and stored in a list called "data." The function also offers progress updates after handling every 10 product URLs and a completion message when all URLs are available. Subsequently, the data is transformed into a Pandas DataFrame and saved as a CSV file using the "to_csv" method. Lastly, the browser is closed using the "browser.close()" statement. Invoke the "main" function as an asynchronous coroutine via the "asyncio.run(main())" statement.
Conclusion:
This guide provides a stepwise walkthrough for scraping Amazon Air Fryer data with Playwright in Python. We cover all aspects, starting from the initial setup of the Playwright environment and launching a web browser to the subsequent actions of navigating to Amazon's search page and extracting crucial details like product name, brand, star rating, MRP, sale price, best seller rank, technical specifications, and bullet points.
Our instructions are to be user-friendly, offering guidance on extracting product URLs, iterating through each URL, and utilizing Pandas to organize the gathered data into a structured dataframe. Leveraging Playwright's cross-browser compatibility and robust error handling, users can streamline the web scraping process and retrieve valuable information from Amazon product listings.
Web scraping can often be laborious and time-intensive, but with Playwright in Python, users can automate these procedures, significantly reducing the time and effort required.
For further details, contact iWeb Data Scraping now! You can also reach us for all your web scraping service and mobile app data scraping needs.
Know More: https://www.iwebdatascraping.com/scrape-amazon-product-category-without-getting-blocked.php
#ScrapeAmazonProductCategoryWithoutGettingBlocked#ScrapingamazoncategoryWithoutGettingBlocked#AmazonProductdataScraper
0 notes
Link
0 notes
Photo

D3 6.0, easy 3D text, Electron 10, and reimplementing promises
#503 — August 28, 2020
Unsubscribe | Read on the Web
JavaScript Weekly
ztext.js: A 3D Typography Effect for the Web — While it initially has a bit of a “WordArt” feel to it, this library actually adds a pretty neat effect to any text you can provide. This is also a good example of a project homepage, complete with demos and example code.
Bennett Feely
D3 6.0: The Data-Driven Document Library — The popular data visualization library (homepage) takes a step forward by switching out a few internal dependencies for better alternatives, adopts ES2015 (a.k.a. ES6) internally, and now passes events directly to listeners. Full list of changes. There’s also a 5.x to 6.0 migration guide for existing users.
Mike Bostock
Scout APM - A Developer’s Best Friend — Scout’s intuitive UI helps you quickly track down issues so you can get back to building your product. Rest easy knowing that Scout is tracking your app’s performance and hunting down small issues before they become large issues. Get started for free.
Scout APM sponsor
Danfo.js: A Pandas-like Library for JavaScript — An introduction to a new library (homepage) that provides high-performance, intuitive, and easy-to-use data structures for manipulating and processing structured data following a similar approach to Python’s Pandas library. GitHub repo.
Rising Odegua (Tensorflow)
Electron 10.0.0 Released — The popular cross-platform desktop app development framework reaches a big milestone, though despite hitting double digits, this isn’t really a feature packed released but more an evolution of an already winning formula. v10 steps up to Chromium 85, Node 12.1.3, and V8 8.5.
Electron Team
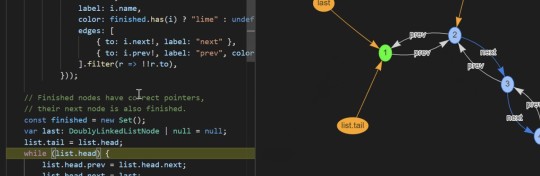
Debug Visualizer 2.0: Visualize Data Structures Live in VS Code — We first mentioned this a few months ago but it’s seen a lot of work and a v2.0 release since then. It provides rich visualizations of watched values and can be used to visualize ASTs, results tables, graphs, and more. VS Marketplace link.
Henning Dieterichs
💻 Jobs
Sr. Engineer @ Dutchie, Remote — Dutchie is the world's largest and fastest growing cannabis marketplace. Backed by Howard Schultz, Thrive, Gron & Casa Verde Capital.
DUTCHIE
Find a Job Through Vettery — Create a profile on Vettery to connect with hiring managers at startups and Fortune 500 companies. It's free for job-seekers.
Vettery
📚 Tutorials, Opinions and Stories
Minimal React: Getting Started with the Frontend Library — Dr. Axel explains how to get started with React while using as few libraries as possible, including his state management approach.
Dr. Axel Rauschmayer
A Leap of Faith: Committing to Open Source — Babel maintainer Henry Zhu talks about how he left his role at Adobe to become a full-time open source maintainer, touching upon his faith, the humanity of such a role, and the finances of making it a reality.
The ReadME Project (GitHub)
Faster CI/CD for All Your Software Projects - Try Buildkite ✅ — See how Shopify scaled from 300 to 1800 engineers while keeping their build times under 5 minutes.
Buildkite sponsor
The Headless: Guides to Learning Puppeteer and Playwright — Puppeteer and Playwright are both fantastic high level browser control APIs you can use from Node, whether for testing, automating actions on the Web, scraping, or more. Code examples are always useful when working with such tools and these guides help a lot in this regard.
Checkly
How To Build Your Own Comment System Using Firebase — Runs through how to add a comments section to your blog with Firebase, while learning the basics of Firebase along the way.
Aman Thakur
A Guide to Six Commonly Used React Component Libraries
Max Rozen
Don't Trust Default Timeouts — “Modern applications don’t crash; they hang. One of the main reasons for it is the assumption that the network is reliable. It isn’t.”
Roberto Vitillo
Guide: Get Started with OpenTelemetry in Node.js
Lightstep sponsor
Deno Built-in Tools: An Overview and Usage Guide
Craig Buckler
How I Contributed to Angular Components — A developer shares his experience as an Angular Component contributor.
Milko Venkov
🔧 Code & Tools
fastest-levenshtein: Performance Oriented Levenshtein Distance Implementation — Levenshtein distance is a metric for measuring the differences between two strings (usually). This claims to be the fastest JS implementation, but we’ll let benchmarks be the judge of that :-)
ka-weihe
Yarn 2.2 (The Package Manager and npm Alternative) Released — As well as being smaller and faster, a dedupe command has been added to deduplicate dependencies with overlapping ranges.
Maël Nison
Light Date ⏰: Fast and Lightweight Date Formatting for Node and Browser — Comes in at 157 bytes, is well-tested, compliant with Unicode standards on dates, and written in TypeScript.
Antoni Kepinski
Barebackups: Super-Simple Database Backups — We automatically backup your databases on a schedule. You can use our storage or bring your own S3 account for unlimited backup storage.
Barebackups sponsor
Carbonium: A 1KB Library for Easy DOM Manipulation — Edwin submitted this himself, so I’ll let him explain it in his own words: “It’s for people who don’t want to use a JavaScript framework, but want more than native DOM. It might remind you of jQuery, but this library is only around one kilobyte and only supports native DOM functionality.”
Edwin Martin
DNJS: A JavaScript Subset for Configuration Languages — You might think that JSON can already work as a configuration language but this goes a step further by allowing various other JavaScript features in order to be more dynamic. CUE and Dhall are other compelling options in this space.
Oliver Russell
FullCalendar: A Full Sized JavaScript Calendar Control — An interesting option if you want a Google Calendar style control for your own apps. Has connectors for React, Vue and Angular. The base version is MIT licensed, but there’s a ‘premium’ version too. v5.3.0 just came out.
Adam Shaw
file-type: Detect The File Type of a Buffer, Uint8Array, or ArrayBuffer — For example, give it the raw data from a PNG file, and it’ll tell you it’s a PNG file. Usable from both Node and browser.
Sindre Sorhus
React-PDF: Display PDFs in a React App As Easily As If They Were Images
Wojciech Maj
Meteor 1.11 Released
Filipe Névola
🕰 ICYMI (Some older stuff that's worth checking out...)
Need to get a better understanding of arrow functions? This article from Tania Rascia will help.
Sure, strictly speaking a string in JavaScript is a sequence of UTF-16 code units... but there's more to it.
Zara Cooper explains how to take advantage of schematics in Angular Material and ng2-charts to substantially reduce the time and work that goes into building a dashboard
In this intro to memoizaition Hicham Benjelloun shares how you can optimize a function (by avoiding computing the same things several times).
by via JavaScript Weekly https://ift.tt/3jmo1hQ
0 notes
Text
Effective Techniques To Scrape Amazon Product Category Without Getting Blocked
Effective Techniques To Scrape Amazon Product Category Without Getting Blocked!

This comprehensive guide will explore practical techniques for web scraping Amazon's product categories without encountering blocking issues. Our tool is Playwright, a Python library that empowers developers to automate web interactions and effortlessly extract data from web pages. Playwright offers the flexibility to navigate web pages, interact with elements, and gather information within a headless or visible browser environment. Even better, Playwright is compatible with various browsers like Chrome, Firefox, and Safari, enabling you to test your web scraping scripts across different platforms. Moreover, Playwright boasts robust error handling and retry mechanisms, which can help you tackle shared web scraping obstacles like timeouts and network errors.
Throughout this tutorial, we will guide you through the stepwise procedure of scraping data related to air fryers from Amazon using Playwright in Python. We will also demonstrate how to save this extracted data as a CSV file. By the end of this tutorial, you will have gained a solid understanding of how to scrape Amazon product categories effectively while avoiding potential roadblocks. Additionally, you'll become proficient in utilizing Playwright to automate web interactions and efficiently extract data.
List of Data Fields

Product URL: The web address leading to the air fryer product.
Product Name: The name or title of the air fryer product.
Brand: The manufacturer or brand responsible for the air fryer product.
MRP (Maximum Retail Price): The suggested maximum retail price for the air fryer product.
Sale Price: It includes the current price of the air fryer product.
Number of Reviews: The count of customer reviews available for the air fryer product.
Ratings: It includes the average ratings customers assign to the air fryer product.
Best Sellers Rank: It includes a ranking system of the product's position in the Home and kitchen category and specialized Air Fryer and Fat Fryer categories.
Technical Details: It includes specific specifications of the air fryer product, encompassing details like wattage, capacity, color, and more.
About this item: A description provides information about the air fryer product, features, and functionalities.
Amazon boasts an astonishing online inventory exceeding 12 million products. When you factor in the contributions of Marketplace Sellers, this number skyrockets to over 350 million unique products. This vast assortment has solidified Amazon's reputation as the "go-to" destination for online shopping. It's often the first stop for customers seeking to purchase or gather in-depth information about a product. Amazon offers a treasure trove of valuable product data, encompassing everything from prices and product descriptions to images and customer reviews.
Given this wealth of product data and Amazon's immense customer base, it's no surprise that small and large businesses and professionals are keenly interested in harvesting and analyzing this Amazon product data.
In this article, we'll introduce our Amazon scraper and illustrate how you can effectively collect Amazon product information.
Here's a step-by-step guide for using Playwright in Python to scrape air fryer data from Amazon:
Step 1: Install Required Libraries

In this section, we've imported several essential Python modules and libraries to support various operations in our project.
re Module: We're utilizing the 're' module for working with regular expressions. Regular expressions are powerful tools for pattern matching and text manipulation.
random Module: The 'random' module is essential for generating random numbers, making it handy for tasks like generating test data or shuffling the order of tests.
asyncio Module: We're incorporating the 'asyncio' module to manage asynchronous programming in Python. It is particularly crucial when using Playwright's asynchronous API for web automation.
datetime Module: The 'datetime' module comes into play when we need to work with dates and times. It provides a range of functionalities for manipulating, creating date and time objects and formatting them as strings.
pandas Library: We're bringing in the 'pandas' library, a powerful data manipulation and analysis tool. In this tutorial, it will store and manipulate data retrieved from the web pages we're testing.
async_playwright Module: The 'async_playwright' module is essential for systematizing browsers using Playwright, an open-source Node.js library designed for automation testing and web scraping.
We're well-equipped to perform various tasks efficiently in our project by including these modules and libraries.
This script utilizes a combination of libraries to streamline browser testing with Playwright. These libraries serve distinct purposes, including data generation, asynchronous programming control, data manipulation and storage, and browser interaction automation.
Product URL Extraction
The second step involves extracting product URLs from the air fryer search. Product URL extraction refers to gathering and structuring the web links of products listed on a web page or online platform seeking help from e-commerce data scraping services.
Before initiating the scraping of product URLs, it is essential to take into account several considerations to ensure a responsible and efficient approach:
Standardized URL Format: Ensure the collected product URLs adhere to a standardized format, such as "https://www.amazon.in/+product name+/dp/ASIN." This format comprises the website's domain name, the product name without spaces, and the product's sole ASIN (Amazon Standard Identification Number) at the last. This standardized set-up facilitates data organization and analysis, maintaining URL consistency and clarity.
Filtering for Relevant Data: When extracting data from Amazon for air fryers, it is crucial to filter the information exclusively for them and exclude any accessories often displayed alongside them in search results. Implement filtering criteria based on factors like product category or keywords in the product title or description. This filtering ensures that the retrieved data pertains solely to air fryers, enhancing its relevance and utility.
Handling Pagination: During product URL scraping, you may need to navigate multiple pages by clicking the "Next" button at the bottom of the webpage to access all results. However, there may be instances where clicking the "next" button flops to load the following page, potentially causing errors in the scraping process. To mitigate such issues, consider implementing error-handling mechanisms, including timeouts, retries, and checks to confirm the total loading of the next page before data extraction. These precautions ensure effective and efficient scraping while minimizing errors and respecting the website's resources.

In this context, we eusemploy the Python function 'get_product_urls' to extract product links from a web page. This function leverages the Playwright library to automate browser testing and retrieve the resulting product URLs from an Amazon webpage.
The function performs a sequence of actions. It initially checks for a "next" button on the page. If found, the function clicks on it and invokes itself recursively to extract URLs from the subsequent page. This process continues until all pertinent product URLs are available.
Within the function, execute the following steps:
It will select page elements containing product links using a CSS selector.
It creates an empty set to store distinct product URLs.
It iterates through each element to extract the 'href' attribute.
Cleaning of the link based on specified conditions, including removing undesired substrings like "Basket" and "Accessories."
After this cleaning process, the function checks whether the link contains any of the unwanted substrings. If not, it appends the cleaned URL to the set of product URLs. Finally, the function returns the list of unique product URLs as a list.
Extracting Amazon Air Fryer Data
In this phase, we aim to determine the attributes we wish to collect from the website, which includes the Product Name, Brand, Number of Reviews, Ratings, MRP, Sale Price, Bestseller rank, Technical Details, and product description ("About the Amazon air fryer product").

To extract product names from web pages, we employ an asynchronous function called 'get_product_name' that works on an individual page object. This function follows a structured process:
It initiates by locating the product's title element on the page, achieved by using the 'query_selector()' method of the page object along with the appropriate CSS selector.
Once the element is successfully available, the function extracts the element's text content using the 'text_content()' method. Store this extracted text in the 'product_name' variable for further processing.
When the function encounters difficulties in finding or retrieving the product name for a specific item, it has a mechanism to handle exceptions. In such cases, it assigns the value "Not Available" to the 'product_name' variable. This proactive approach ensures the robustness of our web scraping script, allowing it to continue functioning smoothly even in the face of unexpected errors during the data extraction process.
Scraping Brand Name
In web scraping, capturing the brand name associated with a specific product plays a pivotal role in identifying the manufacturer or company behind the product. The procedure for extracting brand names mirrors that of product names. We begin by seeking pertinent elements on the webpage using a CSS selector and extracting the textual content from those elements.
However, brand information on the page can manifest in several different formats. For example, the brand name is by the text "Brand: 'brand name'" or appears as "Visit the 'brand name' Store." To accurately extract the brand name, it's crucial to filter out these extra elements and isolate the genuine brand name.

We can employ a function similar to the one used for product name extraction to extract the brand name from web pages. In this case, the function is named 'get_brand_name,' its operation revolves around locating the element containing the brand name via a CSS selector.
When the function successfully locates the element, it extracts the text content from that element using the 'text_content()' method and assigns it to a 'brand_name' variable. It's important to emphasize that the extracted text may include extraneous information such as "Visit," "the," "Store," and "Brand:" Eliminate these extra elements using regular expressions.
By filtering out these unwanted words, we can isolate the genuine brand name, ensuring the accuracy of our data. If the function encounters an exception while locating the brand name element or extracting its text content, it defaults to returning the brand name as "Not Available."
By incorporating this function into our web scraping script, we can effectively obtain the brand names of the products under scrutiny, thereby enhancing our understanding of the manufacturers and companies associated with these products.
Similarly, we can apply the same technique to extract other attributes, such as MRP and Sale price, from the web pages.
Scraping Products MRPs

Extracting product Ratings

To extract the star rating of a product from a web page, we utilize the 'get_star_rating' function. Initially, the function will locate the star rating element on the page using a CSS selector that points to the element housing the star ratings. Accomplish it using the 'page.wait_for_selector()' method. After locating the element, the function retrieves the inner text content of the element through the 'star_rating_elem.inner_text()' method.
However, an exception arises while finding the star rating element or extracting its text content. In that case, the function employs an alternative approach to verify whether there are no reviews for the product. To do this, it attempts to locate the element with an ID that signifies the absence of reviews using the 'page.query_selector()' method. If this element is available, assign the text content of that element to the 'star_rating' variable.
In cases where both of these attempts prove ineffective, the function enters the second block of exception. It denotes the star rating as "Not Available" without any further effort to extract rating information. It ensures the user is duly informed about the unavailability of star ratings for the specific product.
Extracting Product Information

The 'get_bullet_points' function collects bullet point information from the web page. It initiates the process by attempting to locate an unordered list element that encompasses bullet points. Achieve it by applying a CSS selector for the 'About this item' element with the corresponding ID. After locating the 'About this item' unordered list element, the function retrieves all the list item elements beneath it using the 'query_selector_all()' method.
The function then iterates through each list item element, gathering its inner text, and appends it to the bullet points list. In cases where an exception arises during the endeavor to find the unordered list element or the list item elements, the function promptly designates the bullet points as an empty list.
Ultimately, the function returns the compiled list of bullet points, ensuring the extracted information is accessible for further use.
Collecting and Preserving Product Information

This Python script employs an asynchronous " main " function to scrape product data from Amazon web pages. It leverages the Playwright library to launch the Firefox browser and navigate to Amazon's site. Following this, the "extract_product_urls" function is available to extract the URLs of each product on the page. Store it in a list named "product_url." The script proceeds to iterate through each product URL, using the "perform_request_with_retry" function to fetch product pages and extract a range of information, including product name, brand, star rating, review count, MRP, sale price, best sellers rank, technical details, and descriptions.
The gathered data is assembled into tuples and stored in a list called "data." The function also offers progress updates after handling every 10 product URLs and a completion message when all URLs are available. Subsequently, the data is transformed into a Pandas DataFrame and saved as a CSV file using the "to_csv" method. Lastly, the browser is closed using the "browser.close()" statement. Invoke the "main" function as an asynchronous coroutine via the "asyncio.run(main())" statement.
Conclusion:
This guide provides a stepwise walkthrough for scraping Amazon Air Fryer data with Playwright in Python. We cover all aspects, starting from the initial setup of the Playwright environment and launching a web browser to the subsequent actions of navigating to Amazon's search page and extracting crucial details like product name, brand, star rating, MRP, sale price, best seller rank, technical specifications, and bullet points.
Our instructions are to be user-friendly, offering guidance on extracting product URLs, iterating through each URL, and utilizing Pandas to organize the gathered data into a structured dataframe. Leveraging Playwright's cross-browser compatibility and robust error handling, users can streamline the web scraping process and retrieve valuable information from Amazon product listings.
Web scraping can often be laborious and time-intensive, but with Playwright in Python, users can automate these procedures, significantly reducing the time and effort required.
Know More: https://www.iwebdatascraping.com/scrape-amazon-product-category-without-getting-blocked.php
#ScrapeAmazonProductCategorywithoutgettingblocked#Amazondatascrapingservices#webscrapingAmazonsproductcategories#Amazonscraper#ExtractingproductRatings#extractingdatafromAmazon#ExtractingAmazonAirFryerData#AmazonProductCategoryextension
0 notes