#object detection and image classification
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
There are dozens of funny blogs to kill time on Tumblr.
Text
#Object Detection#Computer Vision#Object detection in computer vision#object detection and image classification#Image Preprocessing#Feature Extraction#Bounding Box Regression
0 notes
Text
Guide to Image Classification & Object Detection
Computer vision, a driving force behind global AI development, has revolutionized various industries with its expanding range of tasks. From self-driving cars to medical image analysis and virtual reality, its capabilities seem endless. In this article, we'll explore two fundamental tasks in computer vision: image classification and object detection. Although often misunderstood, these tasks serve distinct purposes and are crucial to numerous AI applications.

The Magic of Computer Vision:
Enabling computers to "see" and understand images is a remarkable technological achievement. At the heart of this progress are image classification and object detection, which form the backbone of many AI applications, including gesture recognition and traffic sign detection.
Understanding the Nuances:
As we delve into the differences between image classification and object detection, we'll uncover their crucial roles in training robust models for enhanced machine vision. By grasping the nuances of these tasks, we can unlock the full potential of computer vision and drive innovation in AI development.
Key Factors to Consider:
Humans possess a unique ability to identify objects even in challenging situations, such as low lighting or various poses. In the realm of artificial intelligence, we strive to replicate this human accuracy in recognizing objects within images and videos.
Object detection and image classification are fundamental tasks in computer vision. With the right resources, computers can be effectively trained to excel at both object detection and classification. To better understand the differences between these tasks, let's discuss each one separately.
Image Classification:
Image classification involves identifying and categorizing the entire image based on the dominant object or feature present. For example, when given an image of a cat, an image classification model will categorize it as a "cat." Assigning a single label to an image from predefined categories is a straightforward task.
Key factors to consider in image classification:
Accuracy: Ensuring the model correctly identifies the main object in the image.
Speed: Fast classification is essential for real-time applications.
Dataset Quality: A diverse and high-quality dataset is crucial for training accurate models.
Object Detection:
Object detection, on the other hand, involves identifying and locating multiple objects within an image. This task is more complex as it requires the model to not only recognize various objects but also pinpoint their exact positions within the image using bounding boxes. For instance, in a street scene image, an object detection model can identify cars, pedestrians, traffic signs, and more, along with their respective locations.
Key factors to consider in object detection:
Precision: Accurate localization of multiple objects in an image.
Complexity: Handling various objects with different shapes, sizes, and orientations.
Performance: Balancing detection accuracy with computational efficiency, especially for real-time processing.
Differences Between Image Classification & Object Detection:
While image classification provides a simple and efficient way to categorize images, it is limited to identifying a single object per image. Object detection, however, offers a more comprehensive solution by identifying and localizing multiple objects within the same image, making it ideal for applications like autonomous driving, security surveillance, and medical imaging.

Similarities Between Image Classification & Object Detection:
Certainly! Here's the content presented in a table format highlighting the similarities between image classification and object detection:
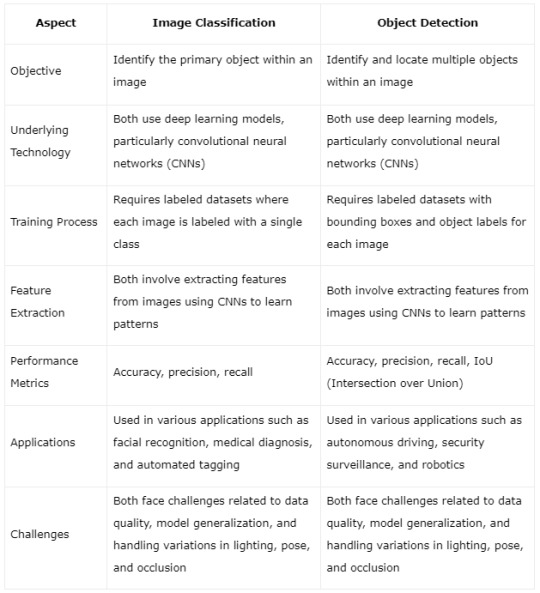
By presenting the similarities in a tabular format, it's easier to grasp how both image classification and object detection share common technologies, challenges, and methodologies, despite their different objectives in the field of computer vision.
Practical Guide to Distinguishing Between Image Classification and Object Detection:
Building upon our prior discussion of image classification vs. object detection, let's delve into their practical significance and offer a comprehensive approach to solidify your basic knowledge about these fundamental computer vision techniques.
Image Classification:

Image classification involves assigning a predefined category to a visual data piece. Using a labeled dataset, an ML model is trained to predict the label for new images.
Single Label Classification: Assigns a single class label to data, like categorizing an object as a bird or a plane.
Multi-Label Classification: Assigns two or more class labels to data, useful for identifying multiple attributes within an image, such as tree species, animal types, and terrain in ecological research.
Practical Applications:
Digital asset management
AI content moderation
Product categorization in e-commerce
Object Detection:

Object detection has seen significant advancements, enabling real-time implementations on resource-constrained devices. It locates and identifies multiple objects within an image.
Future Research Focus:
Lightweight detection for edge devices
End-to-end pipelines for efficiency
Small object detection for population counting
3D object detection for autonomous driving
Video detection with improved spatial-temporal correlation
Cross-modality detection for accuracy enhancement
Open-world detection for unknown objects detection
Advanced Scenarios:
Combining classification and object detection models enhances subclassification based on attributes and enables more accurate identification of objects.
Additionally, services for data collection, preprocessing, scaling, monitoring, security, and efficient cloud deployment enhance both image classification and object detection capabilities.
Understanding these nuances helps in choosing the right approach for your computer vision tasks and maximizing the potential of AI solutions.
Summary
In summary, both object detection and image classification play crucial roles in computer vision. Understanding their distinctions and core elements allows us to harness these technologies effectively. At TagX, we excel in providing top-notch services for object detection, enhancing AI solutions to achieve human-like precision in identifying objects in images and videos.
Visit Us, www.tagxdata.com
Original Source, www.tagxdata.com/guide-to-image-classification-and-object-detection
0 notes
Text
Image Classification vs Object Detection
Image classification, object detection, object localization — all of these may be a tangled mess in your mind, and that's completely fine if you are new to these concepts. In reality, they are essential components of computer vision and image annotation, each with its own distinct nuances. Let's untangle the intricacies right away.We've already established that image classification refers to assigning a specific label to the entire image. On the other hand, object localization goes beyond classification and focuses on precisely identifying and localizing the main object or regions of interest in an image. By drawing bounding boxes around these objects, object localization provides detailed spatial information, allowing for more specific analysis.
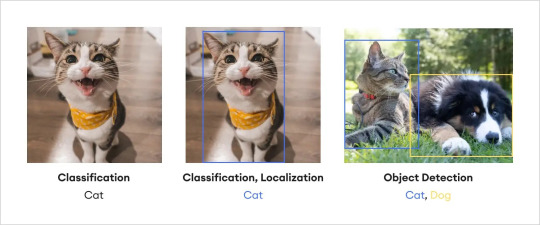
Object detection on the other hand is the method of locating items within and image assigning labels to them, as opposed to image classification, which assigns a label to the entire picture. As the name implies, object detection recognizes the target items inside an image, labels them, and specifies their position. One of the most prominent tools to perform object detection is the “bounding box” which is used to indicate where a particular object is located on an image and what the label of that object is. Essentially, object detection combines image classification and object localization.
1 note
·
View note
Text




New evidence of organic material identified on Ceres, the inner solar system's most water-rich object after Earth
Six years ago, NASA's Dawn mission communicated with Earth for the last time, ending its exploration of Ceres and Vesta, the two largest bodies in the asteroid belt. Since then, Ceres —a water-rich dwarf planet showing signs of geological activity— has been at the center of intense debates about its origin and evolution.
Now, a study led by IAA-CSIC, using Dawn data and an innovative methodology, has identified 11 new regions suggesting the existence of an internal reservoir of organic materials in the dwarf planet. The results, published in The Planetary Science Journal, provide critical insights into the potential nature of this celestial body.
In 2017, the Dawn spacecraft detected organic compounds near the Ernutet crater in Ceres' northern hemisphere, sparking discussions about their origin. One leading hypothesis proposed an exogenous origin, suggesting these materials were delivered by recent impacts of organic-rich comets or asteroids.
This new research, however, focuses on a second possibility: that the organic material formed within Ceres and has been stored in a reservoir shielded from solar radiation.
"The significance of this discovery lies in the fact that, if these are endogenous materials, it would confirm the existence of internal energy sources that could support biological processes," explains Juan Luis Rizos, a researcher at the Instituto de Astrofísica de Andalucía (IAA-CSIC) and the lead author of the study.
A potential witness to the dawn of the solar system
With a diameter exceeding 930 kilometers, Ceres is the largest object in the main asteroid belt. This dwarf planet—which shares some characteristics with planets but doesn't meet all the criteria for planetary classification—is recognized as the most water-rich body in the inner solar system after Earth, placing it among the ocean worlds with potential astrobiological significance.
Additionally, due to its physical and chemical properties, Ceres is linked to a type of meteorite rich in carbon compounds: carbonaceous chondrites. These meteorites are considered remnants of the material that formed the solar system approximately 4.6 billion years ago.
"Ceres will play a key role in future space exploration. Its water, present as ice and possibly as liquid beneath the surface, makes it an intriguing location for resource exploration," says Rizos (IAA-CSIC). "In the context of space colonization, Ceres could serve as a stopover or resource base for future missions to Mars or beyond."
The ideal combination of high-quality resolutions
To explore the nature of these organic compounds, the study employed a novel approach, allowing for the detailed examination of Ceres' surface and the analysis of the distribution of organic materials at the highest possible resolution.
First, the team applied a Spectral Mixture Analysis (SMA) method—a technique used to interpret complex spectral data—to characterize the compounds in the Ernutet crater.
Using these results, they systematically scanned the rest of Ceres' surface with high spatial resolution images from the Dawn spacecraft's Framing Camera 2 (FC2). This instrument provided high-resolution spatial images but low spectral resolution. This approach led to the identification of eleven new regions with characteristics suggesting the presence of organic compounds.
Most of these areas are near the equatorial region of Ernutet, where they have been more exposed to solar radiation than the organic materials previously identified in the crater. Prolonged exposure to solar radiation and the solar wind likely explains the weaker signals detected, as these factors degrade the spectral features of organic materials over time.
Next, the researchers conducted an in-depth spectral analysis of the candidate regions using the Dawn spacecraft's VIR imaging spectrometer, which offers high spectral resolution, though at lower spatial resolution than the FC2 camera. The combination of data from both instruments was crucial for this discovery.
Among the candidates, a region between the Urvara and Yalode basins stood out with the strongest evidence for organic materials. In this area, the organic compounds are distributed within a geological unit formed by the ejection of material during the impacts that created these basins.
"These impacts were the most violent Ceres has experienced, so the material must originate from deeper regions than the material ejected from other basins or craters," clarifies Rizos (IAA-CSIC). "If the presence of organics is confirmed, their origin leaves little doubt that these compounds are endogenous materials."
TOP IMAGE: Data from the Dawn spacecraft show the areas around Ernutet crater where organic material has been discovered (labeled 'a' through 'f'). The intensity of the organic absorption band is represented by colors, where warmer colors indicate higher concentrations. Credit: NASA/JPL-Caltech/UCLA/ASI/INAF/MPS/DLR/IDA
CENTRE IMAGE: This color composite image, made with data from the framing camera aboard NASA's Dawn spacecraft, shows the area around Ernutet crater. The bright red parts appear redder than the rest of Ceres. Credit: NASA/JPL-Caltech/UCLA/MPS/DLR/IDA
LOWER IMAGE: BS1,2 and 3 are images with the FC2 camera filter in the areas of highest abundance of these possible organic compounds. Credit: Juan Luis Rizos
BOTTOM IMAGE: This image from NASA's Dawn spacecraft shows the large craters Urvara (top) and Yalode (bottom) on the dwarf planet Ceres. The two giant craters formed at different times. Urvara is about 120-140 million years old and Yalode is almost a billion years old. Credit: NASA/JPL-Caltech/UCLA/MPS/DLR/IDA
9 notes
·
View notes
Text
#TheeForestKingdom #TreePeople
{Terrestrial Kind}
Creating a Tree Citizenship Identification and Serial Number System (#TheeForestKingdom) is an ambitious and environmentally-conscious initiative. Here’s a structured proposal for its development:
Project Overview
The Tree Citizenship Identification system aims to assign every tree in California a unique identifier, track its health, and integrate it into a registry, recognizing trees as part of a terrestrial citizenry. This system will emphasize environmental stewardship, ecological research, and forest management.
Phases of Implementation
Preparation Phase
Objective: Lay the groundwork for tree registration and tracking.
Actions:
Partner with environmental organizations, tech companies, and forestry departments.
Secure access to satellite imaging and LiDAR mapping systems.
Design a digital database capable of handling millions of records.
Tree Identification System Development
Components:
Label and Identity Creation: Assign a unique ID to each tree based on location and attributes. Example: CA-Tree-XXXXXX (state-code, tree-type, unique number).
Attributes to Record:
Health: Regular updates using AI for disease detection.
Age: Approximate based on species and growth patterns.
Type: Species and subspecies classification.
Class: Size, ecological importance, and biodiversity contribution.
Rank: Priority based on cultural, historical, or environmental significance.
Data Collection
Technologies to Use:
Satellite Imaging: To locate and identify tree clusters.
LiDAR Scanning: For precise 3D modeling of forests.
On-the-Ground Surveys: To supplement remote sensing data.
AI Analysis: For rapid categorization and health diagnostics.
Registration and Citizenship Assignment
Tree Dossier: Each tree receives a profile in the database with all its recorded attributes.
Citizen Designation: Trees are acknowledged as citizens of Thee Forest Kingdom, emphasizing ecological respect.
Legal Framework: Advocate for laws to grant trees specific rights under environmental protection acts.
Maintenance and Monitoring
Health Monitoring: Use drones, satellite updates, and IoT sensors for ongoing health assessments.
Database Updates: Incorporate real-time data about environmental changes and tree growth.
Public Involvement
Encourage people to "adopt" trees and participate in their preservation.
Create educational programs to promote awareness of tree citizenship.
Key Benefits
Environmental Conservation: Improved forest management through real-time data and protection of ecosystems.
Cultural Recognition: Trees are recognized as a vital part of the Earth’s community, honoring their importance.
Ecological Advocacy: Strengthened legal protections for forests and individual trees.
Next Steps
Assemble a task force of environmental scientists, satellite imaging experts, and software developers.
Secure funding through governmental grants, non-profits, and eco-conscious corporations.
Pilot the program in a smaller region before scaling to all of California.
Would you like me to draft a more detailed technical or legal framework for this system?
The implementation of the Tree Citizenship Identification Network and System (#TheeForestKingdom) requires a robust technological and operational framework to ensure efficiency, accuracy, and sustainability. Below is an implementation plan divided into major components.
System Architecture
a. Centralized Tree Database
Purpose: To store and manage tree data including ID, attributes, location, and health.
Components:
Cloud-based storage for scalability.
Data categorization based on regions, species, and priority.
Integration with satellite and IoT data streams.
b. Satellite & Imaging Integration
Use satellite systems (e.g., NASA, ESA) for large-scale tree mapping.
Incorporate LiDAR and aerial drone data for detailed imaging.
AI/ML algorithms to process images and distinguish tree types.
c. IoT Sensor Network
Deploy sensors in forests to monitor:
Soil moisture and nutrient levels.
Air quality and temperature.
Tree health metrics like growth rate and disease markers.
d. Public Access Portal
Create a user-friendly website and mobile application for:
Viewing registered trees.
Citizen participation in tree adoption and reporting.
Data visualization (e.g., tree density, health status by region).
Core Technologies
a. Software and Tools
Geographic Information System (GIS): Software like ArcGIS for mapping and spatial analysis.
Database Management System (DBMS): SQL-based systems for structured data; NoSQL for unstructured data.
Artificial Intelligence (AI): Tools for image recognition, species classification, and health prediction.
Blockchain (Optional): To ensure transparency and immutability of tree citizen data.
b. Hardware
Servers: Cloud-based (AWS, Azure, or Google Cloud) for scalability.
Sensors: Low-power IoT devices for on-ground monitoring.
Drones: Equipped with cameras and sensors for aerial surveys.
Network Design
a. Data Flow
Input Sources:
Satellite and aerial imagery.
IoT sensors deployed in forests.
Citizen-reported data via mobile app.
Data Processing:
Use AI to analyze images and sensor inputs.
Automate ID assignment and attribute categorization.
Data Output:
Visualized maps and health reports on the public portal.
Alerts for areas with declining tree health.
b. Communication Network
Fiber-optic backbone: For high-speed data transmission between regions.
Cellular Networks: To connect IoT sensors in remote areas.
Satellite Communication: For remote regions without cellular coverage.
Implementation Plan
a. Phase 1: Pilot Program
Choose a smaller, biodiverse region in California (e.g., Redwood National Park).
Test satellite and drone mapping combined with IoT sensors.
Develop the prototype of the centralized database and public portal.
b. Phase 2: Statewide Rollout
Expand mapping and registration to all California regions.
Deploy IoT sensors in vulnerable or high-priority areas.
Scale up database capacity and integrate additional satellite providers.
c. Phase 3: Maintenance & Updates
Establish a monitoring team to oversee system health and data quality.
Update the network with new technologies (e.g., advanced AI models).
Periodically review and revise data collection protocols.
Partnerships
Government Agencies: U.S. Forest Service, California Department of Forestry and Fire Protection.
Tech Companies: Collaborate with Google Earth, Amazon AWS, or Microsoft for cloud and AI capabilities.
Environmental Organizations: Partner with WWF, Sierra Club, or TreePeople for funding and advocacy.
Budget Estimation
Initial Investment:
Satellite data and licenses: $10M
IoT sensors and deployment: $5M
Database and app development: $3M
Operational Costs:
Cloud services and data storage: $2M/year
Maintenance and monitoring: $1M/year
Research and development: $1M/year
Long-term Vision
Expand the system to other states or globally.
Use the database for reforestation efforts and combating deforestation.
Develop educational programs to teach communities about the importance of trees as citizens.
Would you like me to assist in designing the user interface for the public portal or drafting partnership proposals for funding?
To begin building the program for the Tree Citizenship Identification System, we’ll start with a scalable framework that allows us to process, store, and analyze data while preparing for future expansions. Here's an actionable development plan with an initial focus on foundational code and infrastructure:
Step-by-Step Development
Phase 1: Setting Up the Backend Infrastructure
Objective: Create the core database and develop the data pipeline for processing tree data.
Technologies:
Programming Languages: Python, JavaScript (Node.js), SQL.
Frameworks: Flask or FastAPI for APIs, Django for web application backend.
Database: PostgreSQL for structured data, MongoDB for unstructured data.
Code Snippet 1: Database Schema Design (PostgreSQL)
-- Table for Tree Registry CREATE TABLE trees ( tree_id SERIAL PRIMARY KEY, -- Unique Identifier location GEOGRAPHY(POINT, 4326), -- Geolocation of the tree species VARCHAR(100), -- Species name age INTEGER, -- Approximate age in years health_status VARCHAR(50), -- e.g., Healthy, Diseased height FLOAT, -- Tree height in meters canopy_width FLOAT, -- Canopy width in meters citizen_rank VARCHAR(50), -- Class or rank of the tree last_updated TIMESTAMP DEFAULT NOW() -- Timestamp for last update );
-- Table for Sensor Data (IoT Integration) CREATE TABLE tree_sensors ( sensor_id SERIAL PRIMARY KEY, -- Unique Identifier for sensor tree_id INT REFERENCES trees(tree_id), -- Linked to tree soil_moisture FLOAT, -- Soil moisture level air_quality FLOAT, -- Air quality index temperature FLOAT, -- Surrounding temperature last_updated TIMESTAMP DEFAULT NOW() -- Timestamp for last reading );
Code Snippet 2: Backend API for Tree Registration (Python with Flask)
from flask import Flask, request, jsonify from sqlalchemy import create_engine from sqlalchemy.orm import sessionmaker
app = Flask(name)
Database Configuration
DATABASE_URL = "postgresql://username:password@localhost/tree_registry" engine = create_engine(DATABASE_URL) Session = sessionmaker(bind=engine) session = Session()
@app.route('/register_tree', methods=['POST']) def register_tree(): data = request.json new_tree = { "species": data['species'], "location": f"POINT({data['longitude']} {data['latitude']})", "age": data['age'], "health_status": data['health_status'], "height": data['height'], "canopy_width": data['canopy_width'], "citizen_rank": data['citizen_rank'] } session.execute(""" INSERT INTO trees (species, location, age, health_status, height, canopy_width, citizen_rank) VALUES (:species, ST_GeomFromText(:location, 4326), :age, :health_status, :height, :canopy_width, :citizen_rank) """, new_tree) session.commit() return jsonify({"message": "Tree registered successfully!"}), 201
if name == 'main': app.run(debug=True)
Phase 2: Satellite Data Integration
Objective: Use satellite and LiDAR data to identify and register trees automatically.
Tools:
Google Earth Engine for large-scale mapping.
Sentinel-2 or Landsat satellite data for high-resolution imagery.
Example Workflow:
Process satellite data using Google Earth Engine.
Identify tree clusters using image segmentation.
Generate geolocations and pass data into the backend.
Phase 3: IoT Sensor Integration
Deploy IoT devices to monitor health metrics of specific high-priority trees.
Use MQTT protocol for real-time data transmission.
Code Snippet: Sensor Data Processing (Node.js)
const mqtt = require('mqtt'); const client = mqtt.connect('mqtt://broker.hivemq.com');
client.on('connect', () => { console.log('Connected to MQTT Broker'); client.subscribe('tree/sensor_data'); });
client.on('message', (topic, message) => { const sensorData = JSON.parse(message.toString()); console.log(Received data: ${JSON.stringify(sensorData)}); // Save data to database (Example for PostgreSQL) saveToDatabase(sensorData); });
function saveToDatabase(data) { const query = INSERT INTO tree_sensors (tree_id, soil_moisture, air_quality, temperature) VALUES ($1, $2, $3, $4) ; const values = [data.tree_id, data.soil_moisture, data.air_quality, data.temperature]; dbClient.query(query, values, (err) => { if (err) console.error('Error saving to database', err); else console.log('Sensor data saved successfully!'); }); }
Phase 4: Public Portal Development
Frontend Technologies:
React.js or Vue.js for interactive user interfaces.
Mapbox or Leaflet.js for tree visualization on maps.
Features:
Interactive tree maps with search functionality.
User registration for tree adoption programs.
Deployment Plan
Use Docker to containerize the application.
Deploy on AWS, Azure, or Google Cloud for scalability.
Monitor system health using Prometheus and Grafana.
Next Steps
Develop a testing environment for pilot deployment.
Add AI-based disease detection and prediction using TensorFlow or PyTorch.
Create an adoption feature where citizens can adopt trees and track their health.
Would you like me to set up a GitHub repository with this initial framework or assist further with deployment?
I'll prepare the project framework and outline the repository structure for the Tree Citizenship Identification System. Below is the proposed structure for the repository, followed by details of the files and components.
Proposed Repository Structure
tree-citizenship-id-system/ ├── backend/ │ ├── app.py # Flask application for backend API │ ├── database/ │ │ ├── schema.sql # Database schema for PostgreSQL │ │ ├── db_config.py # Database connection configuration │ │ └── seed_data.sql # Initial sample data for testing │ ├── services/ │ │ ├── tree_registration.py # Functions for tree registration │ │ └── sensor_data.py # Functions for processing IoT sensor data │ └── requirements.txt # Python dependencies ├── frontend/ │ ├── public/ │ │ ├── index.html # Main HTML file │ │ └── favicon.ico # Favicon for the app │ ├── src/ │ │ ├── App.js # Main React/Vue app file │ │ ├── components/ │ │ │ ├── TreeMap.js # Map component for visualizing trees │ │ │ └── TreeDetails.js # Component for detailed tree view │ │ └── styles.css # Styling for the frontend │ └── package.json # Frontend dependencies ├── scripts/ │ ├── satellite_data_processor.py # Script for processing satellite data │ └── sensor_data_simulator.py # Mock data generator for IoT sensors ├── deployment/ │ ├── Dockerfile # Docker configuration │ ├── docker-compose.yml # Docker Compose for multi-service setup │ └── cloud_setup_instructions.md # Deployment guide for cloud platforms ├── tests/ │ ├── test_backend.py # Unit tests for backend API │ └── test_frontend.js # Unit tests for frontend ├── README.md # Overview of the project └── LICENSE # Project license
Repository Details
Backend:
app.py: Main Flask app for handling API requests like tree registration and sensor data.
database/schema.sql: SQL script for creating necessary tables.
services/: Directory for modular backend logic.
Frontend:
App.js: Main entry point for the frontend application.
TreeMap.js: Integrates Mapbox/Leaflet.js for displaying tree locations.
TreeDetails.js: Displays detailed information about a selected tree.
Scripts:
satellite_data_processor.py: Automates the extraction and classification of tree data from satellite imagery.
sensor_data_simulator.py: Generates fake sensor readings for development and testing.
Deployment:
Docker configuration ensures that the app runs consistently across environments.
Cloud setup instructions provide guidelines for deploying on platforms like AWS, Azure, or GCP.
Tests:
Unit tests ensure the reliability of both the backend and frontend.
Next Steps
I will initialize the repository structure locally.
Package the files and components needed for the first version.
Provide a link to the repository for access.
I’ll get started. Please hold on for a moment.
4 notes
·
View notes
Text




Through the Years → Felipe VI of Spain (2,879/∞) 27 September 2022 | Felipe VI during his visit to the Central Command and Control Group (GRUCEMAC), at the Torrejon de Ardoz air base, in Torrejon de Ardoz, Madrid, Spain. The Central Command and Control Group controls the airspace of national sovereignty (surveillance, detection, identification and classification of air objects entering it), and that of the air police missions and, where appropriate, air defense, assigned to it, on a continuous basis 24 hours a day, 7 days a week and the Space Surveillance Operations Center has as its mission the surveillance and knowledge of the space situation of interest and the provision of services in support of the operations of the Armed Forces. (Photo By Alejandro Martinez Velez/Europa Press via Getty Images)
#King Felipe VI#Spain#2022#Alejandro Martinez Velez#Europa Press via Getty Images#through the years: Felipe
1 note
·
View note
Text
Complex & Intelligent Systems, Volume 11, Issue 7
1) Cognition of decision behavior based on belief state: a case study of implementation in CGF simulation system
Author(s): Jintao Wang, Huaiqi Chen, Yunting Zhang
2) A noise-constrained lightweight high-quality image hiding method based on invertible neural networks
Author(s): Minghui Zhu, Dapeng Cheng, Jinjiang Li
3) Disentangled diffusion dodels for probabilistic spatio-temporal traffic forecasting
Author(s): Wenyu Zhang, Kaidong Zheng
4) Data-driven fault-tolerant consensus for multiagent systems under switching topology
Author(s): Yuan Wang, Zhenbin Du
5) Advancing sustainable electricity markets: evolutionary game theory as a framework for complex systems optimization and adaptive policy design
Author(s): Lefeng Cheng, Runbao Sun, Mengya Zhang
6) A dual-image encryption scheme for sensitive region of traffic image using public key cryptosystem and novel chaotic map
Author(s): Tingyu An, Tao Gao, Donghua Jiang
7) Distributed semi-supervised partial multi-dimensional learning via subspace learning
Author(s): Zhen Xu, Weibin Chen
8) Preference-based expensive multi-objective optimization without using an ideal point
Author(s): Peipei Zhao, Liping Wang, Qicang Qiu
9) Correction to: Fractals in Sb-metric spaces
Author(s): Fahim Ud Din, Sheeza Nawaz, Fairouz Tchier
10) Information coevolution spreading model and simulation based on self-organizing multi-agents
Author(s): Guoxin Ma, Kang Tian, Yongyan Wang
11) Fusing feature consistency across views for multi-view stereo
Author(s): Rong Zhao, Caiqin Jia, Xie Han
12) Towards few-shot learning with triplet metric learning and Kullback-Leibler optimization
Author(s): Yukun Liu, Xiaojing Wei, Hai Su
13) A novel two stage neighborhood search for flexible job shop scheduling problem considering reconfigurable machine tools
Author(s): Yanjun Shi, Chengjia Yu, Shiduo Ning
14) A novel multi-agent dynamic portfolio optimization learning system based on hierarchical deep reinforcement learning
Author(s): Ruoyu Sun, Yue Xi, Jionglong Su
15) An adaptive initialization and multitasking based evolutionary algorithm for bi-objective feature selection in classification
Author(s): Hang Xu, Bing Xue, Mengjie Zhang
16) Fine-grained entity disambiguation through numeric pattern awareness in transformer models
Author(s): Jaeeun Jang, Sangmin Kim, Charles Wiseman
17) A novel adversarial deep TSK fuzzy classifier with its inverse-free fast training
Author(s): Limin Mao, Hangming Shi, Suhang Gu
18) Strength prominence index: a link prediction method in fuzzy social network
Author(s): Sakshi Dev Pandey, Sovan Samanta, Tofigh Allahviranloo
19) Genderly: a data-centric gender bias detection system
Author(s): Wael Khreich, Jad Doughman
20) Two-stage multi-attribute reviewer-paper matching decision-making in a Fermatean fuzzy environment
Author(s): Qi Yue, Kaile Zhai, Yuan Tao
21) RTL-Net: real-time lightweight Urban traffic object detection algorithm
Author(s): Zhiqing Cui, Jiahao Yuan, Zhenglong Ding
22) Contrastive learning of cross-modal information enhancement for multimodal fake news detection
Author(s): Weijie Chen, Fei Cai, Yijia Zhang
23) A lightweight mechanism for vision-transformer-based object detection
Author(s): Yanming Ye, Qiang Sun, Dongjing Wang
24) Correction to: Enhancing cyber defense strategies with discrete multi-dimensional Z-numbers: a multi-attribute decision-making approach
Author(s): Aiting Yao, Chen Huang, Xuejun Li
25) GCN and GAT-based interpretable knowledge tracing model
Author(s): Yujia Huo, Menghong He, Kesha Chen
26) A classifier-assisted evolutionary algorithm with knowledge transfer for expensive multitasking problems
Author(s): Min Hu, Zhigang Ren, Yu Guo
27) Utilizing weak graph for edge consolidation-based efficient enhancement of network robustness
Author(s): Wei Ding, Zhengdan Wang
28) AI-enabled driver assistance: monitoring head and gaze movements for enhanced safety
Author(s): Sayyed Mudassar Shah, Gan Zengkang, Farman Ali
29) Path planning method for maritime dynamic target search based on improved GBNN
Author(s): Zhaozhen Jiang, Xuehai Sun, Lianglong Da
30) Correction to: Demonstration and offset augmented meta reinforcement learning with sparse rewards
Author(s): Haorui Li, Jiaqi Liang, Daniel Zeng
31) Joint feature representation optimization and anti-occlusion for robust multi-vessel tracking in inland waterways
Author(s): Shenjie Zou, Jin Liu, Bing Han
32) Graph-based multi-attribute decision-making method with new fuzzy information measures
Author(s): Lili Zhang, Shu Sun, Chunfeng Suo
33) Multiobjective integrated scheduling of disassembly and reprocessing operations considering product structures and stochastic processing time via reinforcement learning-based evolutionary algorithms
Author(s): Yaping Fu, Fuquan Wang, Hao Sun
34) Multi-granularity feature intersection learning for visible-infrared person re-identification
Author(s): Sixian Chan, Jie Wang, Jiafa Mao
35) DEBPIR: enhancing information privacy in decentralized business modeling
Author(s): Gulshan Kumar, Rahul Saha, Tai Hoon Kim
36) Joint optimization of communication rates for multi-UAV relay systems
Author(s): Chenghua Wen, Guifen Chen, Wenzhe Wang
37) PLGNN: graph neural networks via adaptive feature perturbation and high-way links
Author(s): Meixia He, Peican Zhu, Keke Tang
38) Graph attention based on contextual reasoning and emotion-shift awareness for emotion recognition in conversations
Author(s): Juan Yang, Puling Wei, Jun Shen
39) Eye contact based engagement prediction for efficient human–robot interaction
Author(s): Magnus Jung, Ahmed Abdelrahman, Ayoub Al-Hamadi
40) Siamese network with squeeze-attention for incomplete multi-view multi-label classification
Author(s): Mengqing Wang, Jiarui Chen, Xiaohuan Lu
41) Enhanced APT detection with the improved KAN algorithm: capturing interdependencies for better accuracy
Author(s): Weiwu Ren, Hewen Zhang, Zhiwei Wang
0 notes
Text
The Transformative World of AI Development Services
AI development services are at the forefront of a technological revolution, creating and implementing intelligent systems that perform tasks traditionally demanding human intellect. These services empower organizations to leverage Artificial Intelligence (AI) for groundbreaking process automation, insightful data analysis, enhanced decision-making, and unparalleled innovation. AI has decisively transitioned from a futuristic concept to a practical, indispensable technology, now widely applied across diverse sectors to profoundly improve operations and achieve remarkable outcomes.

At its core, AI development involves crafting sophisticated algorithms and models that enable machines to learn autonomously from data, reason, make predictions, and adapt over time. This transformative journey typically begins with a thorough understanding of a client’s specific business needs and existing challenges, allowing developers to pinpoint the most impactful areas where AI can deliver substantial value. This initial strategic planning then meticulously guides the subsequent design and development of highly tailored AI solutions, ensuring every investment yields maximum strategic value and aligns with broader business objectives.
A Deep Dive into Comprehensive AI Development Services
Our approach to AI development is holistic and deeply client-centric, meticulously covering the entire lifecycle of AI solution implementation. From initial strategic planning and ideation to robust deployment and continuous optimization, we tailor our AI Development Services to precisely address your unique business challenges, capitalize on emerging opportunities, and align seamlessly with your long-term strategic vision.
The process kicks off with AI Strategy & Consulting. Our seasoned AI consultants collaborate closely with your team to deeply understand your business objectives, pinpoint existing operational bottlenecks, and meticulously analyze your current data landscape. We then identify high-impact use cases for AI, conduct thorough feasibility assessments, and craft a pragmatic roadmap for AI adoption that is seamlessly integrated with your overarching business strategy and digital transformation goals. This initial phase is crucial, ensuring that every AI investment yields maximum strategic value and sets a solid foundation for success.
Machine Learning (ML) Development stands as the foundational pillar of modern AI. It enables systems to learn from data patterns without explicit programming. We specialize in developing, training, validating, and deploying custom ML models across various paradigms. For predictive analytics, our models forecast future trends like sales volumes, demand fluctuations, equipment maintenance needs, or customer churn, empowering proactive decision-making. We also excel in classification and regression, developing algorithms to categorize data points (e.g., spam detection, disease diagnosis) and predict numerical outcomes (e.g., stock prices, energy consumption). Our expertise extends to crafting highly personalized recommendation engines that suggest products, content, or services based on individual user preferences, historical interactions, and collective intelligence, significantly enhancing user engagement and conversion. Furthermore, we delve into Deep Learning, utilizing advanced neural networks to process and extract intricate patterns from highly complex and unstructured data types like images, audio, video, and vast text corpuses, enabling sophisticated capabilities such as facial recognition and natural language understanding.
Bridging the gap between human language and machine comprehension, our Natural Language Processing (NLP) Services empower intelligent communication. We specialize in designing and deploying intelligent chatbot and conversational AI development solutions that provide instant, 24/7 customer support, automate routine inquiries, personalize user interactions, and streamline internal communications. Our services also include sentiment analysis, meticulously extracting and analyzing emotional tones and opinions from unstructured text data (like customer reviews or social media mentions) to gauge brand perception and guide marketing strategies. We further offer text classification and summarization, automating the categorization of documents, emails, and support tickets, and generating concise, accurate summaries of lengthy texts to improve information retrieval and decision speed. Additionally, our voice and speech recognition capabilities convert spoken language into text, enabling voice-activated interfaces, transcription services, and enhanced accessibility in applications.
Giving machines the ability to "see" and interpret the visual world, our Computer Vision Services offer transformative insights. We specialize in object detection and recognition, identifying, locating, and tracking specific objects, individuals, or anomalies within images and real-time video streams for diverse applications in surveillance, retail analytics, and automated quality control (e.g., detecting defects in manufacturing). We also develop secure and accurate facial recognition systems for identity verification, access control, and personalized customer experiences. Our image analysis and processing capabilities are utilized for automated quality inspection, medical image analysis, content moderation, and enhancing visual data for various business intelligence applications.
Harnessing the frontier of AI, we build and customize Generative AI Development models that can create new, original content. This includes automating the content generation of various textual content like articles, marketing copy, product descriptions, and reports, significantly accelerating content pipelines. We also facilitate image and design synthesis, generating unique images, creative designs, and multimedia assets based on specific prompts or data inputs. For highly specialized needs, we fine-tune existing large language models or build bespoke Custom Large Language Models (LLMs) specifically trained on your proprietary data and domain knowledge to deliver highly accurate and relevant responses for niche applications.
We also streamline operations through Robotics and Process Automation (RPA). While distinct from physical robots, RPA focuses on automating repetitive, rule-based digital tasks across various business functions. This significantly improves efficiency, drastically reduces human errors, and frees up your human workforce to focus on more strategic, creative, and value-added activities, thereby maximizing human potential.
The bedrock upon which all effective AI solutions are built is Data Science and Analytics. Our services encompass the meticulous collection, cleaning, transformation, and analysis of large, complex datasets to derive actionable insights, identify hidden patterns, and ensure data quality and readiness for optimal AI model training. This often includes setting up robust data pipelines and warehousing solutions to manage information flow effectively.
Seamlessly embedding AI capabilities into your existing software infrastructure, enterprise applications (like ERP or CRM), and legacy systems is achieved through our AI Integration Services. This involves developing custom APIs, ensuring robust interoperability, and migrating relevant data to enhance existing functionalities with intelligent automation and deeper insights, ensuring your new AI solutions work harmoniously with your current technology stack.
Successfully deploying trained AI models into live production environments is crucial for realizing their benefits. We establish robust AI Model Deployment & MLOps (Machine Learning Operations) pipelines that facilitate continuous monitoring of model performance, automated retraining with new data, version control, and scalable infrastructure management. This ensures your AI systems remain effective, optimized, and responsive to evolving real-world conditions over time.
As responsible AI developers, we prioritize Ethical AI & Bias Mitigation. We ensure that all AI solutions are developed with fairness, transparency, and accountability at their core. This involves proactively addressing potential biases in both data and algorithms, and ensuring strict adherence to global ethical guidelines and data privacy regulations, building trust and ensuring responsible technology use.
The Transformative Benefits of Partnering for AI Development Services
Investing in AI through expert development services delivers profound and multifaceted advantages that redefine business capabilities and elevate performance across the board.
One of the most significant benefits is automation and operational efficiency. By automating mundane, repetitive tasks and streamlining complex workflows, businesses achieve substantial cost savings, significantly reduce operational overhead, and experience a dramatic boost in overall productivity. This allows human resources to be reallocated to more strategic initiatives.
AI also leads to enhanced decision-making. Leveraging AI-powered analytics, organizations gain deeper, more nuanced insights from their vast data repositories. This empowers leadership and teams to make more informed, data-driven, and proactive decisions that consistently drive superior business outcomes, moving from reactive responses to strategic foresight.
Personalized customer experiences are another key advantage that AI brings. By analyzing customer data, AI enables the delivery of hyper-tailored products, services, content, and interactions to individual customers. This leads to significantly increased customer satisfaction, stronger brand loyalty, and higher conversion rates, fostering deeper relationships with your clientele.
Furthermore, AI acts as a powerful catalyst for innovation and competitive advantage. Businesses can develop intelligent new products and services or infuse smart features into existing offerings, fundamentally differentiating themselves in the market. AI enables faster innovation, agile adaptation to market shifts, and helps organizations consistently stay ahead of the curve in a dynamic business landscape.
Improved accuracy and reduced errors are inherent benefits of AI systems. These systems can process and analyze massive quantities of data with remarkable precision, drastically minimizing human error in critical processes such as quality control, financial transaction monitoring, and sophisticated fraud detection, leading to more reliable operations.
Scalability is another hallmark of effective AI solutions. They are inherently designed to scale efficiently with your business needs, seamlessly handling increasing data volumes, growing user demands, and expanding operational scope. This adaptability ensures long-term viability and growth without performance bottlenecks.
AI also opens up new revenue streams. It helps identify and capitalize on previously unexplored business opportunities by offering novel AI-powered products or services to the market. For instance, in asset-heavy industries, AI can enable predictive maintenance of machinery and infrastructure, anticipating failures, minimizing costly downtime, and significantly extending asset lifespans.
0 notes
Text
Artificial Intelligence Classroom Course Online India: Learn AI with Live Training & Real-World Projects
Artificial Intelligence (AI) is shaping the future of every industry—from smart assistants and self-driving cars to fraud detection and personalized recommendations. As the demand for AI professionals in India continues to surge, aspiring techies and professionals are turning to Artificial Intelligence classroom course online India options that combine interactive live sessions, structured learning, and hands-on experience.
In this article, we’ll explore what makes classroom-style online AI training so effective, who it’s best suited for, and which institutes in India offer the most reputable programs.
What Is an Artificial Intelligence Classroom Course Online?
Unlike pre-recorded courses or YouTube tutorials, a classroom-style online course simulates a real-time classroom environment. You’ll interact with instructors, collaborate with peers, and work on guided assignments in a structured, time-bound setting—all from the comfort of your home.
Key Features of Online AI Classroom Courses:
✅ Live instructor-led sessions
✅ Real-time Q&A and doubt clearing
✅ Peer-to-peer interaction and group projects
✅ Fixed schedules and learning pace
✅ Hands-on projects and mentor feedback
This format is ideal for students who prefer accountability and the discipline of a traditional classroom without the need to physically commute.
Why Choose a Classroom-Style Online AI Course in India?
India is emerging as a global hub for AI talent. Classroom-style online courses offered by Indian and global institutes provide:
🎯 Focused learning through weekly schedules and live lectures
🧑🏫 Expert guidance from faculty and mentors
🛠️ Real-world capstone projects to apply your knowledge
💼 Career assistance, including resume reviews, mock interviews, and job referrals
📜 Recognized certifications that enhance employability
Whether you're a student, tech professional, or a working executive, classroom-style online courses offer the best blend of flexibility and structure.
Boston Institute of Analytics (BIA) – Artificial Intelligence Online Certification Program
Best for: Beginners & professionals who want global certification, mentorship, and placement support.
The Boston Institute of Analytics (BIA) offers one of India’s most acclaimed Artificial Intelligence classroom course online programs. It is designed for practical skill development and career readiness.
Course Highlights:
Live online classes (weekday or weekend options)
Curriculum includes Python, Machine Learning, Deep Learning, NLP, Computer Vision, AI Ethics
Real-time Q&A and one-on-one mentorship
Capstone projects with real-world data
Interview training, resume building, and placement support
Internationally recognized certification
Duration: 6 months Mode: Live Online Classroom Website: www.bostoninstituteofanalytics.org
Why Choose BIA? BIA’s program is ideal for those who want live mentorship, job support, and hands-on training in a structured, classroom-style format.
What You Will Learn in an AI Classroom Online Course
A well-structured AI course online will typically cover:
✅ Programming for AI (Python, R)
✅ Mathematics & Statistics (Linear Algebra, Probability)
✅ Machine Learning (Supervised, Unsupervised, Ensemble methods)
✅ Deep Learning (Neural Networks, CNNs, RNNs)
✅ NLP (Text classification, sentiment analysis)
✅ Computer Vision (Image recognition, object detection)
✅ AI Ethics and Model Interpretability
✅ Project Deployment (Flask, Streamlit, AWS)
Career Opportunities After an AI Classroom Course Online
AI professionals are among the highest-paid tech workers in India today. With the right skills, you can apply for roles such as:
AI Engineer
Machine Learning Engineer
Data Scientist
NLP Specialist
Computer Vision Engineer
AI Product Manager
Top Hiring Companies:
Infosys, TCS, Wipro, Accenture
Google, Microsoft, Meta, Amazon
Flipkart, Zomato, Swiggy, Ola
Fintech and healthtech startups
Average Salary in India (2025):
Entry-level: ₹8–10 LPA
Mid-level: ₹15–22 LPA
Senior AI roles: ₹25–40+ LPA
How to Choose the Right AI Classroom Online Course in India?
Here are 5 key factors to consider:
Live Instructor Support: Are the classes interactive and guided by experts?
Curriculum Coverage: Does it include real-world tools and use cases?
Hands-on Projects: Are there enough projects to build a portfolio?
Career Services: Is placement support offered?
Certification Recognition: Is the certificate valued by employers?
If you want a classroom-like experience with job assistance and global credibility, the Boston Institute of Analytics is one of the best choices for 2025.
Final Thoughts
With AI becoming a foundational skill in today’s job market, there’s never been a better time to learn it through structured, interactive, and career-oriented programs. Enrolling in an Artificial Intelligence classroom course online India gives you access to live mentorship, collaborative learning, and industry-recognized certification—all of which accelerate your path to becoming an AI expert.
Whether you’re a beginner or a working professional, courses offered by BIA, IITs, upGrad, Simplilearn, and Great Learning provide a range of classroom-style experiences tailored to your goals.
Choose wisely, learn consistently, and let AI open doors to your future.
#Best Data Science Courses Online India#Artificial Intelligence Course Online India#Data Scientist Course Online India#Machine Learning Course Online India#Artificial Intelligence Classroom Course Online India
0 notes
Text
Image Annotation Services | Damco Solutions
Explore the service page to learn how Damco helps businesses build smarter AI systems with precision-driven annotation solutions.
Outsource Image Annotation Services to Unlock Precise & Highly Reliable Visual Intelligence
Looking to train machine learning models with highly accurate datasets? Damco Solutions offers reliable image annotation services that power computer vision systems across industries like automotive, retail, healthcare, and surveillance.
Whether it's for object detection, classification, or behavior tracking—Damco enables AI systems to interpret visual data effectively and at scale.
Gain a Strong Foothold with Dedicated AI Image Annotation Solutions
Damco delivers diverse annotation types to match complex project needs:
2D Bounding Boxes & 3D Cuboids – For object localization and volume estimation
Semantic Segmentation – Pixel-level precision for classifying image regions
Lines and Splines – Used for lane detection, pipelines, or structural analysis
Polygons – Ideal for irregular shapes and tight object boundaries
Keypoint & Skeletal Annotation – For facial recognition and pose estimation
Why Damco for Image Annotation Services?
Damco stands out by combining quality, flexibility, and global expertise:
High Quality & Reliability with multi-layered QA
Faster Turnaround Time to meet aggressive deadlines
Cost-Effective Pricing without compromising accuracy
Scalable Operations for high-volume projects
Industry-Specific Solutions for diverse sectors
Global Presence ensures seamless communication & delivery
Damco’s image annotation services are built to accelerate your AI goals with speed and precision. Visit the page and share your project requirements today to get started!
#image annotation#outsourcing image annotation#image annotation services#image annotation company#image annotation companies
0 notes
Text
Use AI to Detect and Analyse Objects on Geospatial Images
In recent years, artificial intelligence (AI) has transformed geospatial data processing and remote sensing. Satellite and drone imagery, along with LiDAR and hyperspectral scans, are now vital for mapping, urban planning, agriculture, defence, and disaster response. AI, especially through computer vision and deep learning, enables advanced automated object detection, classification, and geospatial analytics.

https://www.geowgs84.ai/post/use-ai-to-detect-and-analyse-objects-on-geospatial-images
0 notes
Text
In What Ways Does .NET Integrate with Azure AI Services?

The integration between Microsoft's .NET framework and Azure AI Services represents one of the most seamless and powerful combinations available for building intelligent applications today. This strategic alliance provides developers with unprecedented access to cutting-edge artificial intelligence capabilities while maintaining the robust, enterprise-grade foundation that .NET is renowned for. Organizations utilizing professional ASP.NET development services are leveraging this integration to rapidly deploy sophisticated AI solutions that would have previously required months of development and specialized expertise to implement effectively.
Native SDK Support for Comprehensive AI Services
The .NET ecosystem provides native Software Development Kit (SDK) support for the entire spectrum of Azure AI Services, enabling developers to integrate advanced artificial intelligence capabilities with minimal complexity and maximum performance.
Core Azure AI Services Integration:
• Azure Cognitive Services: Pre-built AI models for vision, speech, language, and decision-making capabilities.
• Azure OpenAI Service: Direct access to GPT-4, DALL-E, and other large language models through native APIs.
• Azure Custom Vision: Tailored image classification and object detection model development.
• Azure Speech Services: Real-time speech-to-text, text-to-speech, and speech translation functionality.
• Azure Language Understanding (LUIS): Natural language processing for intent recognition and entity extraction.
• Azure Form Recognizer: Automated document processing and data extraction capabilities.
Advanced AI Integration Features:
• Asynchronous Operations: Non-blocking API calls optimized for high-performance applications.
• Batch Processing: Efficient handling of large datasets through bulk operations.
• Real-time Streaming: Live audio and video processing capabilities.
• Model Customization: Fine-tuning pre-built models with domain-specific data.
• Multi-modal Processing: Combined text, image, and audio analysis in single workflows .
Edge Deployment: Local model execution for reduced latency and offline capabilities.
Enterprise-Grade Security and Compliance Benefits
The integration between .NET and Azure AI Services delivers comprehensive security features that meet the stringent requirements of enterprise applications while ensuring regulatory compliance across multiple industries.
Authentication and Access Control:
• Azure Active Directory Integration: Seamless single sign-on and multi-factor authentication.
• Managed Identity Support: Secure service-to-service authentication without storing credentials.
• Role-Based Access Control (RBAC): Granular permissions management for AI resources.
• API Key Management: Secure key rotation and access monitoring capabilities.
• OAuth 2.0 Implementation: Industry-standard authentication protocols for third-party integrations.
• Certificate-Based Authentication: Enhanced security through digital certificate validation.
Compliance and Data Protection:
• GDPR Compliance: Data residency controls and right-to-be-forgotten implementations.
• HIPAA Certification: Healthcare-grade security for medical AI applications.
• SOC 2 Type II: Comprehensive security, availability, and confidentiality controls.
• Data Encryption: End-to-end encryption for data at rest and in transit.
• Audit Logging: Comprehensive activity tracking for compliance reporting.
• Geographic Data Residency: Control over data processing locations for regulatory requirements.
Streamlined Development Workflows with Azure SDKs
The Azure SDKs for .NET provide developers with intuitive, well-documented tools that dramatically simplify the integration process while maintaining enterprise-level performance and reliability.
Developer Productivity Features:
• NuGet Package Integration: Easy installation and dependency management through familiar tools.
• IntelliSense Support: Full code completion and documentation within Visual Studio environments.
• Async/Await Patterns: Modern asynchronous programming models for responsive applications.
• Error Handling: Comprehensive exception handling with detailed error messages and retry policies.
• Configuration Management: Simplified setup through appsettings.json and environment variables.
• Dependency Injection: Native support for .NET Core's built-in dependency injection container.
Deployment and Monitoring Advantages:
• Azure DevOps Integration: Seamless CI/CD pipelines for automated deployment and testing.
• Application Insights: Real-time monitoring and performance analytics for AI-powered applications.
• Auto-scaling: Dynamic resource allocation based on application demand and usage patterns.
• Load Balancing: Distributed processing across multiple instances for high availability.
• Version Management: Blue-green deployments and rollback capabilities for risk-free updates.
• Cost Optimization: Usage-based pricing models with detailed billing and cost management tools
Real-World Implementation Benefits:
• Reduced Development Time: 60-80% faster implementation compared to building AI capabilities from scratch.
• Lower Maintenance Overhead: Microsoft-managed infrastructure eliminates operational complexity.
• Scalability Assurance: Automatic scaling to handle millions of requests without performance degradation.
• Global Availability: Worldwide data center presence ensuring low-latency access for global applications.
The synergy between .NET and Azure AI Services creates an unparalleled development experience that combines familiar programming paradigms with cutting-edge artificial intelligence capabilities. This integration empowers organizations to accelerate their AI applications development initiatives while maintaining the security, scalability, and reliability standards that modern enterprise applications demand.
0 notes
Text
Boost Training Data: The Importance of Annotation Services in AI Models
In the rapidly evolving world of artificial intelligence (AI), the key to creating highly accurate and reliable AI models lies in the quality of training data. The better the training data, the more effective the AI model will be. But raw data alone isn’t enough; it requires structure, context, and meaning to be useful.

This is where data annotation becomes indispensable. Data annotation plays a critical role in transforming raw data into high-quality labeled datasets that can dramatically boost AI models.
What is Data Annotation?
Data annotation involves tagging or labeling data to ensure it is comprehensible and usable by machine learning algorithms. AI algorithms may learn patterns, correlations, and classifications by using this labelled data, sometimes referred to as training data annotation. With the increasing complexity of AI applications, AI data annotation services have become crucial to achieving model accuracy and efficiency.
Why Annotation Services are Essential for AI Models
1. Enhancing AI Model Accuracy: The primary objective of any AI model is to deliver accurate results. Properly annotated data significantly improves AI model accuracy by ensuring that the machine learning algorithms have clean, organized, and labeled datasets to learn from. This helps the AI systems recognize patterns more efficiently and make better predictions.
2. Improving Training Data Quality: Raw data is typically unstructured and inconsistent. By using AI annotation solutions, you can convert this raw data into valuable information that AI models can process. AI training data services provide high-quality, consistent, and accurately labeled datasets that help machines learn effectively. This enhances the quality of the training data for AI, leading to more precise outputs.
3. Boost AI Models with Comprehensive Annotations: From text to images, and even video, different types of data require different approaches to annotation. AI annotation solutions ensure that each piece of data is labeled appropriately for the specific AI application. Whether it’s categorizing images, tagging objects in videos, or labeling text, these services provide a wide range of annotations that can boost AI models in various sectors, including healthcare, autonomous driving, retail, and more.
Types of Annotation Services for AI
Several types of annotation services cater to the diverse needs of AI models:
Text Annotation: Labeling sentences, keywords, and phrases to help natural language processing (NLP) systems understand the context.
Image Annotation: Labeling objects or regions within images to train models for object recognition, detection, and segmentation tasks.
Video Annotation: Tagging frames and objects within videos to help in the development of models for autonomous vehicles, security systems, and more.
Leading service providers like EnFuse Solutions offer tailored data annotation services in India and across the globe, leveraging local expertise and AI-driven tools to deliver exceptional results for clients.
Data Annotation Services: A Game-Changer for AI Training
With the increasing reliance on AI in various industries, the demand for high-quality training data is skyrocketing. Using advanced annotation services, AI can significantly impact an organization's ability to develop reliable AI models.
Here's why you should consider AI data labeling services for your business:
Scalability: Your data expands along with your business. Data annotation services allow you to scale your AI training efforts by offering flexible, on-demand annotation solutions that keep pace with your evolving needs.
Cost-Effectiveness: Outsourcing to expert providers in regions like India can reduce costs while maintaining high-quality standards. Data annotation services in India combine affordability with skill, making it a popular choice for companies worldwide.
Expertise: Companies offering AI annotation solutions bring in specialized knowledge in handling different types of data, ensuring accuracy and consistency in annotations.
EnFuse Solutions: Your Partner in Data Annotation for AI
At EnFuse Solutions, we recognise that accurate AI model development depends on providing high-quality AI training data services. We provide comprehensive annotation for machine learning services, tailored to meet your specific AI application needs. With years of experience and a dedicated team of experts, we offer scalable, efficient, and cost-effective data annotation services in India and globally.
Our services ensure that your AI models are trained on the most reliable data, improving accuracy, performance, and efficiency. Whether you're working on image recognition, NLP, or any other AI application, EnFuse Solutions can help you unlock the full potential of your AI models through exceptional AI data annotation services.
Conclusion
In the competitive world of AI, precise data annotation is the key to unlocking the full potential of AI models. High-quality AI data annotation significantly boosts AI model performance, enhances accuracy, and supports advanced applications. To stay ahead, businesses must invest in reliable AI training data services, and EnFuse Solutions is here to help.
AI models that are dependable and efficient may be developed more quickly by concentrating on high-quality training data for AI. With the right annotation services, you can ensure your models deliver the best results, driving success in your AI projects. Contact EnFuse Solutions today to empower your AI models with expert annotation services.
#DataAnnotation#AIDataAnnotation#TrainingDataAnnotation#AnnotationServicesAI#BoostAIModels#AITrainingDataServices#DataAnnotationForAI#AIModelAccuracy#TrainingDataForAI#AIAnnotationSolutions#AIDataLabeling#AnnotationForMachineLearning#DataAnnotationServicesInIndia#EnFuseSolutions
0 notes
Text
How Machine Learning AI Image Classification is Revolutionizing Industries

AI-powered image recognition is rapidly transforming industries like healthcare, life sciences, manufacturing, supply chain, and finance. From early disease detection to ensuring top-notch product quality and streamlining supply chain operations, this technology is redefining what's possible. By accurately identifying objects, patterns, and even human emotions in images, businesses can make smarter decisions, speed up processes, and deliver more personalized customer experiences.
But what powers this level of precision? It all comes down to high-quality, diverse training datasets. Clean data, noise reduction, and image preprocessing, like resizing, play a huge role in improving accuracy. And with the rise of advanced methods such as convolutional neural networks (CNNs), image classification in some cases now even outperforms human capabilities.
So, how might your industry change if AI could “see” better than people?
Further Read: Deep Learning for Computer Vision: The Ultimate Guide
Overview of AI Image Classification
In the current digital era, when pictures play a big part in our daily lives, visual data is essential. The capacity to categorize and comprehend visual data is crucial for a variety of applications and sectors, from social media posts to medical scans. It makes sense that the market for visualization software is expected to expand globally. According to Statista, the market was worth 1.63 billion US dollars in 2019. This figure will rise to 9.61 billion USD by 2030.
Applications of Image Classification in Different Industries
Healthcare Industry
1. Medical Diagnosis
Machine learning AI image classification helps with accurate illness diagnosis; it has a 90% success rate in detecting skin cancer. An online image editor can help improve medical images for improved clarity and analysis in the healthcare industry, enabling more precise diagnosis.
2. Early Cancer and Tumor Detection Using Image Recognition
Image recognition-based medical technologies can identify and examine abnormalities in positron emission tomography (PET), magnetic resonance imaging (MRI), and computed tomography (CT) scans. Large data chunks can be recognized, compared, and processed by machine learning algorithms that have been trained on vast quantities of pictures, enabling the rapid and accurate identification of cancerous forms.
Machine learning AI image classification technologies are already being used to identify and diagnose breast and skin cancer. They are especially adept at distinguishing between non-life-threatening skin conditions and malignant skin lesions. Because computer vision can detect malignant regions more quickly than the rest of the tissue, it has also improved the accuracy and innovation of breast cancer detection.
Further Read: 7 Most Crucial Use Cases of Generative AI in Healthcare
2. Life Science
1. Revolutionizing Microscopy
AI can reduce bias and save researchers a great deal of time by automating the laborious process of microscope image analysis. It is possible to train AI systems to identify illness indicators, categorize cells, and even differentiate between several bacterial species.
Complex biological structures can now be identified thanks to recent developments in convolutional neural networks (CNNs), which have increased the precision of picture segmentation and classification in microscopy.
2. Improving Predictive Modeling
By predicting the safety and effectiveness of drug candidates, AI-powered simulations, such as in silico screening, lower the chance that later-stage studies would fail. This method reduces discovery delays by up to 50% while also reducing expensive lab testing.
Further Read: Adoption of Generative AI in Healthcare & Life Sciences
3. Manufacturing
1. Advanced Quality Assurance and Control
Ensuring that items meet high standards requires strict quality control. By using computer vision, mistake rates can be reduced. Automation can reduce errors by up to 90%, according to McKinsey. This is accomplished by using advanced image recognition technologies to identify and categorize flaws, ensuring that only perfect products are sent to customers.
2. Production Efficiency
Production efficiency is increased by the combination of AI and picture categorisation technology. Automated systems provide for real-time monitoring, feedback, and modifications.
Further Read: How AI in Manufacturing is Transforming the Industry
4. Supply Chain
1. Smart Infrastructure Security Using Computer Vision
Computer vision-based monitoring systems can be completely automated, whereas traditional monitoring necessitates personnel participation. It lowers the likelihood of human error in addition to saving costs. If only the model is well trained, the AI-powered system is less likely to overlook anything.
Additionally, computer vision continuously scans the cars and devices, adding another layer of complexity to authorization procedures.
2. Visual-Based Defect and Anomaly Detection in Warehouses
Computer vision is revolutionizing inspection for logistics firms. They may focus on more difficult, valuable duties by letting the machines verify each package instead of doing it by hand. After being trained on images of perfect products, the AI models can identify any imperfection or irregularity with speed.
The computer vision-powered system decides on its own whether to reroute the item for manual inspection based on the result. Such a method helps the business retain the best customer satisfaction rates while relieving the personnel.
Further Read: 10 Most Crucial Use Cases of Generative AI in Supply Chain
5. Finance
1. Fraud Identification and Prevention
Preventing and identifying fraud, which may lead to large losses and harm to one's reputation, is one of the biggest problems facing the financial industry. Financial institutions can use image recognition to confirm the legitimacy and identity of transactions, papers, and clients.
For instance, image recognition can be used to compare facial photographs taken by cameras or mobile devices with passports, driver's licenses, and other forms of identification. Additionally, image recognition can be used to indicate questionable activities and behaviours and identify irregularities and discrepancies in contracts, invoices, receipts, and checks.
2. Automated Credit Scoring
Evaluating lenders' and borrowers' creditworthiness and risk profiles is a crucial component of finance. By adding new features and data sources, image recognition can assist financial organizations in refining their algorithms and models for credit assessment.
Images of potential customers' assets, buildings, and lifestyles can be utilized to extract information and picture recognition can be used to examine their social media accounts, online activity, and personal preferences.
Further Read: How Generative AI in Finance is Solving Cash Flow and Valuation Challenges
Conclusion
Significant improvements in operational flexibility and creativity are brought about by the introduction of machine learning AI image classification into a variety of industries. It significantly enhances the process of extracting data from documents and is used in a variety of industries, including finance, and logistics. This change facilitates quick data analysis, increases accuracy, and streamlines tasks. These elements are essential for data-driven, well-informed decision-making.
Deep learning is essential for recognizing features and generating predictions, mostly using Convolutional Neural Networks (CNNs). It improves object recognition by using structured grid data that is taken from photos. These networks are therefore essential in many domains. Support Vector Machines (SVM) and Decision Trees are examples of complementary techniques that increase the strength and usefulness of image analysis.
0 notes
Text
The Best Python Libraries for Machine Learning in 2025 – What You Should Know
Python is everywhere in the world of tech—and for good reason. If you're exploring machine learning (ML) in 2025, one thing is clear: Python and its libraries are your best allies.
Whether you're a student, a self-learner, or someone looking to switch careers into tech, understanding the most effective tools in ML will give you a head start. This blog breaks down the top Python libraries used by professionals across India, especially in growing tech hubs like Hyderabad.
Why Do Python Libraries Matter in ML?
When building machine learning models, you don’t want to reinvent the wheel. Python libraries are collections of functions and tools designed to make your work easier.
They help you:
Clean and organize data
Train machine learning models
Visualize results
Make accurate predictions faster
Think of them like essential tools in a workshop. Instead of building everything from scratch, you pick up the tool that does the job best—and get to work.
Why Indian Professionals Should Care
India’s tech industry has embraced machine learning in a big way. From healthcare startups to global IT firms, organizations are using ML to automate tasks, make predictions, and personalize services.
In cities like Hyderabad, there’s growing demand for professionals with Python ML skills. Roles like Data Analyst, ML Engineer, and AI Developer now require hands-on knowledge of popular Python libraries. Knowing the right tools can set you apart in a competitive job market.
The Top 10 Python Libraries for ML in 2025
Here’s a list of libraries that are shaping the ML landscape this year:
1. Scikit-learn
A great starting point. This library simplifies common ML tasks like classification, regression, and clustering. It’s lightweight, reliable, and perfect for beginners.
2. TensorFlow
Developed by Google, TensorFlow is ideal for deep learning tasks. If you're working on image recognition, natural language processing, or neural networks, this is your go-to.
3. PyTorch
Favored by researchers and startups, PyTorch is known for its flexibility. It’s widely used in academic research and increasingly in production environments.
4. Pandas
If you’re working with spreadsheets or structured datasets, Pandas helps you manipulate and clean that data effortlessly.
5. NumPy
The foundation of scientific computing in Python. Most ML libraries depend on NumPy for numerical operations and matrix handling.
6. Matplotlib
Used to create basic plots and charts. It helps in visually understanding the performance of your models.
7. Seaborn
Built on Matplotlib, Seaborn allows for more attractive and informative statistical graphics.
8. XGBoost
A high-performance gradient boosting library. It’s used in many real-world systems for tasks like fraud detection and recommendation engines.
9. LightGBM
Faster and more memory-efficient than XGBoost. Especially useful for large datasets and real-time predictions.
10. OpenCV
Focused on computer vision. Great for image processing tasks like face detection, motion tracking, and object recognition.
Real-World Use Cases in India
These libraries are more than just academic. They’re being used every day in industries such as:
Retail – To personalize shopping experiences
Finance – For credit scoring and fraud prevention
Healthcare – In patient data analysis and disease prediction
EdTech – To deliver adaptive learning platforms
Government – For data-backed policy-making and smart city management
Companies in Hyderabad like Innominds, Darwinbox, and Novartis actively hire ML professionals skilled in these tools.
Where Should You Start?
If you’re new to machine learning, here’s a basic learning path:
Begin with NumPy and Pandas to understand data manipulation.
Learn Matplotlib and Seaborn for data visualization.
Dive into Scikit-learn to learn standard ML algorithms.
Once you’re confident, move on to TensorFlow, PyTorch, and XGBoost.
Starting with foundational tools makes it easier to understand complex ones later.
Tips to Learn These Tools Effectively
Here are a few things that helped many learners master these libraries:
Start with small projects like predicting house prices or student grades
Use publicly available datasets from Indian sources like data.gov.in
Practice regularly—30 minutes a day is better than none
Read documentation but also apply what you learn immediately
Watch tutorial videos to see how others solve ML problems step-by-step
Avoid the mistake of rushing into deep learning before understanding basic concepts.
How to Learn These Libraries Online
Online training is the best option if you want flexibility and practical learning. At Varniktech, you can access:
Instructor-led live sessions focused on real-world problems
Projects based on Indian industry use cases
Job preparation support, including mock interviews and resume building
Flexible batch timings for working professionals and students
Whether you're in Hyderabad or learning from another city, you can access everything online and complete your training from home.
Final Thoughts
Mastering the right Python libraries for machine learning can boost your career, help you build better projects, and make you stand out in job applications. With the tech industry growing rapidly in India, especially in cities like Hyderabad, there’s never been a better time to learn these tools.
The key is to start small, be consistent, and focus on building real projects. Once you’re confident with the basics, you can take on more advanced challenges and explore deep learning.
Want to dive deeper into machine learning with Python?
Visit varniktech.com to access structured courses, download free resources, and join our upcoming batch focused on Python for Machine Learning.
0 notes