#ngraph
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr Inc. is funded by 13 investors.
Photo

フルサイズミラーレス機の購入をきっかけに、ふたたび写真を撮るようになった。 以前の機材は持ち歩くには重すぎたし、本当にひどい話だけど以前の恋人はどうにも撮る気にならなかった。 だらだらとここに写真と戯言を吐き出していきたい。
1 note
·
View note
Photo

LOVE=DESTRUCTION (PSD #007 by now-wegraph-fr)
Salut !
Hi !
• Ce .psd est en couleurs / This .psd is made for colors
• Il inclut un version "Black and White" qui peut être utilisée sur la version en couleur / Black and White version (that can be combined with the color version) include
• Il peut être utilisé sur des gifs animés / It can be applied on animated gifs
*Si tu l’utilises, un petit crédit serait sympa / If you use, a credit will be welcome*
Hope you’ll enjoy and don’t forget to reblog/like if you dowloaded it, En espérant qu'il vous plaira et n'oubliez pas de rebloguer si vous l'avez téléchargé,
N. → download
#psd#psd coloring#itsphotoshop#yeahps#coloring#photoshop#photoshop resource#resource#graphic resource#ps#now-wegraph-fr#n's graph#ngraph
3 notes
·
View notes
Photo

Intel Open Sources nGraph, Giving AI Developers Freedom of Choice in Frameworks and Hardware https://ift.tt/2HDrx8a
1 note
·
View note
Text
Peer graded Assignment: Creating graphs for your data
The program I have written :-
import pandas as p import numpy as n import seaborn as sb import matplotlib.pyplot as plt
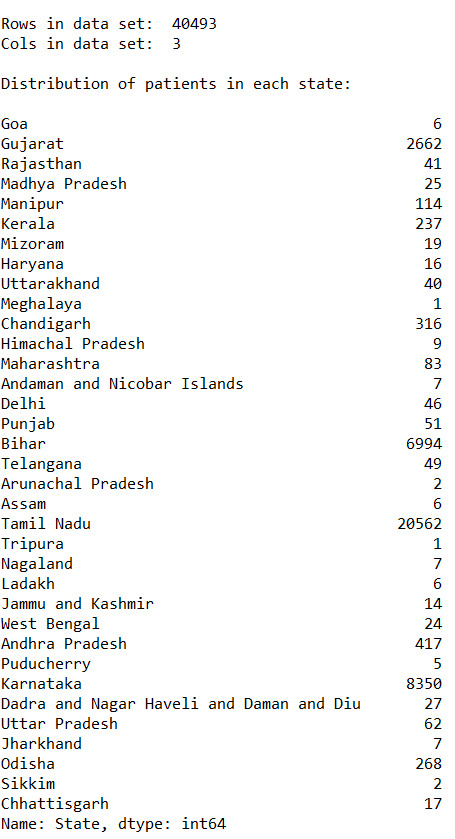
data_set = p.read_csv('Modified_DataSet.csv', low_memory = False) print("\nRows in data set: ", len(data_set)) # Number of rows in data set print("Cols in data set: ", len(data_set.columns)) # Number of cols in data set
state_count = data_set["State"].value_counts(sort=False) state_count_percentage = data_set["State"].value_counts(sort=False, normalize=True)
print("\nDistribution of patients in each state: ", end="\n\n") print(state_count)
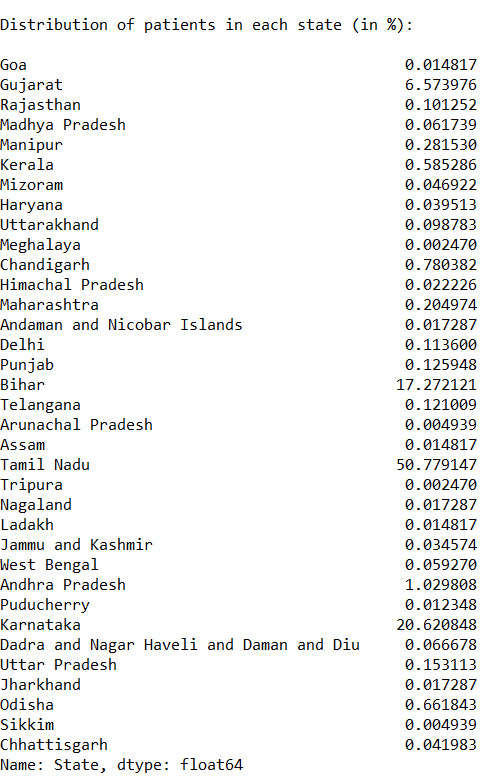
print("\nDistribution of patients in each state (in %): ", end="\n\n") print(state_count_percentage * 100)
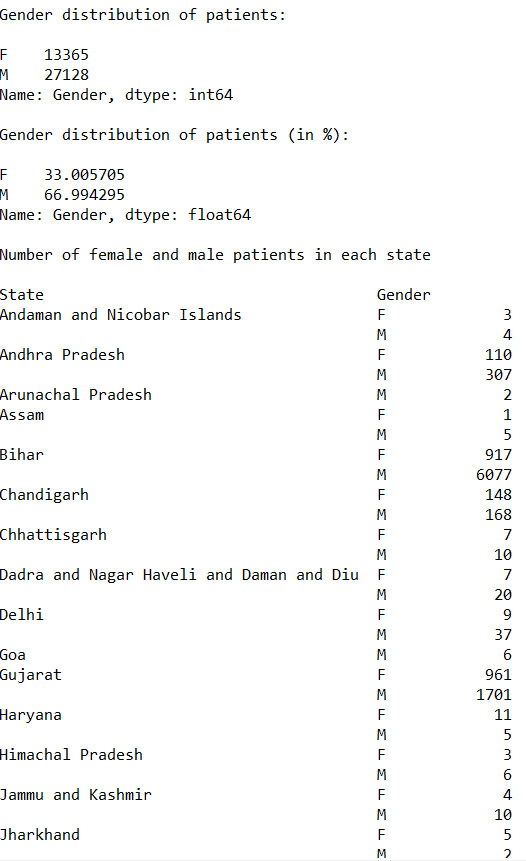
gender_count = data_set["Gender"].value_counts(sort=False) gender_count_percentage = data_set["Gender"].value_counts(sort=False, normalize=True)
print("\nGender distribution of patients: ", end="\n\n") print(gender_count)
print("\nGender distribution of patients (in %): ", end="\n\n") print(gender_count_percentage * 100)
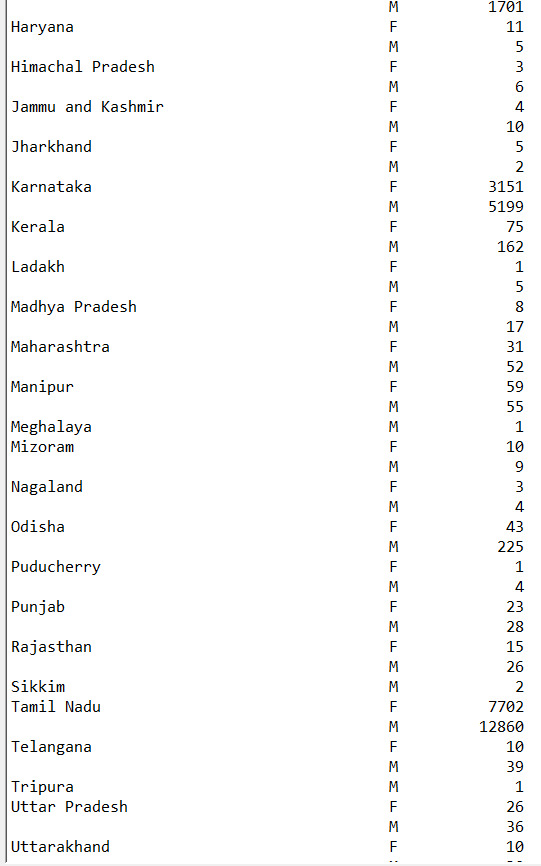
s1 = p.DataFrame(data_set).groupby(["State", "Gender"]) states_gender_distribution = s1.size() print("\nNumber of female and male patients in each state", end="\n\n") p.set_option("display.max_rows", None) print(states_gender_distribution)
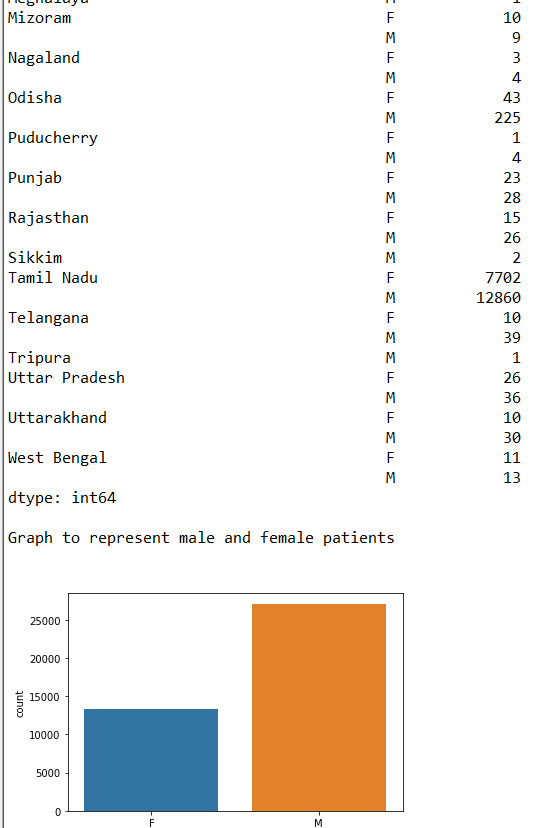
print("\nGraph to represent male and female patients", end="\n\n") data_set["Gender"] = data_set["Gender"].astype("category") sb.countplot(x="Gender",data = data_set)
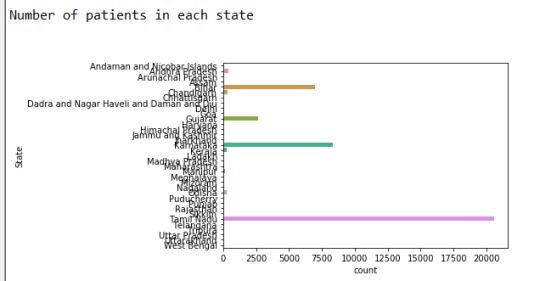
print("\nNumber of patients in each state", end="\n\n") data_set["State"] = data_set["State"].astype("category") sb.countplot(y="State",data = data_set)
Output of the program :-
1)
2)
3)
4)
5)
6)
Conclusion :-
From the given data we can analyse-
Approx 67% of the patients are Male and 33% of the patients are female
Found out that more than 50% of the cases come from Tamil Nadu
The state least affected is Meghalaya.
We found the count of male and females patients for each state.
Successfully expressed the data through graphs.
0 notes
Text
NPM包依赖显示开源工具npmgraph.an
npmgraph.an是npm(全称 Node Package Manager,即“node包管理器”)的依赖关系可视化开源小工具,基于angular.js + browserify + ngraph编写。遵守MIT开源协议。 npm数据来自registry.npmjs.cf文件,实时读取。网页CSS 样式使用了twitter bootstrap和less.
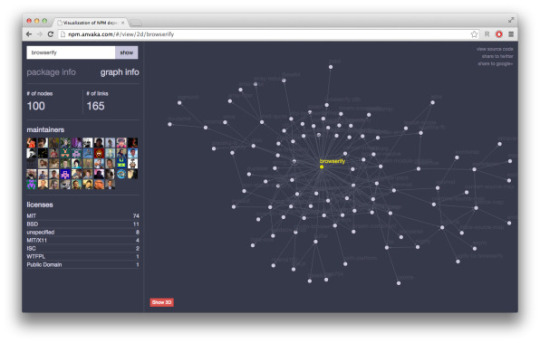
GitHub 仓库挂件 WordPress 插件
anvaka / npmgraph.an
2d visualization of npm
http://npm.anvaka.com
67056 Download ZIP
NPM包依赖显示开源工具npmgraph.an was originally published on 开源派
0 notes
Text
Intel首款 AI 商用芯片已交付 新一代 Movidius VPU 明年見

英特爾公司副總裁兼人工智能產品事業部總經理 Naveen Rao 表示:
隨著人工智能的進一步發展,計算硬件和內存都將到達臨界點。如果要在該領域繼續取得巨大進展,專用型硬件必不可少,如英特爾 Nervana NNP 和 Movidius Myriad VPU。採用更先進的系統級人工智能,我們將從“數據到信息的轉換”階段發展到 “信息到知識的轉換階段”。
Nervana NNP 已經投入生產並交付
對於英特爾來說,Nervana NNP 是它在神經網絡處理器方面的重要產品,可以說是第一款AI 商用芯片,而且這款產品從發布、測試、量產到應用,實際上是經歷了一個漫長的產品週期。

新一代 Nervana NNP 首先亮相是在 2018 年 5 月。當時,在英特爾人工智能開發者大會(AIDevCon 2018) 上,Naveen Rao 發布了新一代專為機器學習設計的神經網絡處理器(NNP)芯片,並表示這是英特爾第一款商業NNP 芯片,將不止是提供給小部分合作夥伴,將在2019 年發貨。
到了 2019 年 8 月,英特爾在 Hot Chips 大會召開期間公佈了 NNP 芯片的更多信息,其中,它依據用途分為 Nervana NNP-T 和 Nervana NNP-I,分別用於訓練和推理。
Nervana NNP-T 代號Spring Crest,採用了台積電的16nm FF+ 製程工藝,擁有270 億個晶體管,矽片面積680 平方毫米,能夠支持TensorFlow、PaddlePaddle、PYTORCH 訓練框架,也支持C++ 深度學習軟件庫和編譯器nGraph。
而 Nervana NNP-I,代號為 Spring Hill,是一款專門用於大型數據中心的推理芯片。這款芯片是基於10nm 技術和Ice Lake 內核打造的,打造地點是以色列的Haifa ,Intel 號稱它能夠利用最小的能量來處理高負載的工作,它在ResNet50 的效率可達4.8TOPs/W,功率範圍在10W 到50W 之間。
按照官方說法,英特爾Nervana 神經網絡訓練處理器(Intel Nervana NNP-T)在計算、通信和內存之間取得了平衡,不管是對於小規模群集,還是最大規模的pod 超級計算機,都可進行近乎線性且極具能效的擴展。英特爾 Nervana 神經網絡推理處理器(Intel Nervana NNP-I)具備高能效和低��本,且其外形規格靈活,非常適合在實際規模下運行高強度的多模式推理。這兩款產品面向百度、 Facebook 等前沿人工智能客戶,並針對他們的人工智能處理需求進行了定制開發。

在 2019 英特爾人工智能峰會峰會現場,Intel 宣布——新推出的英特爾 Nervana 神經網絡處理器(NNP)現已投入生產並完成客戶交付。其中,Facebook 人工智能係統協同設計總監 Misha Smelyanskiy表示:
我們非常高興能夠與英特爾合作,利用英特爾神經網絡推理處理器(NNP-I)部署更快、更高效的推理計算。同時,我們最新的深度學習編譯器 Glow 也將支持 NNP-I。
另外,百度AI 研究員Kenneth Church 在現場表示,在今年7 月,百度與英特爾合作宣布了雙方在Nervana NNP-T 的合作,雙方通過硬件和軟件的合作來實現用最大的效率來訓練日益增長的複雜模型。 Kenneth Church 還宣布,在百度 X-Man 4.0 的加持下,英特爾的 NNP-T 已經推向市場。
新一代 Movidius VPU 明年見
在峰會現場,Intel 公佈了全新一代 Movidius VPU。
下一代英特爾Movidius VPU 的代號是Keem Bay,它是專門為邊緣AI 打造的一款產品,專注於深度學習推理、計算機視覺和媒體處理等方面,採用全新的高效能架構,並且通過英特爾的OpenVINO 來加速。按照官方數據,它在速度上是英偉達 TX2 的 4 倍,是華為海思 Ascend 310 的 1.25 倍。另外在功率和尺寸上,它也遠遠超過對手。

Intel 方面表示,新一代Movidius 計劃於2020 年上半年上市,它憑藉獨一無二的高效架構優勢,能夠提供業界領先的性能:與上一代VPU 相比,推理性能提升10 倍以上,能效則可達到競品的6 倍。
英特爾曾經在2017 年8 月推出一款Movidius Myriad X 視覺處理器(VPU),該處理器是一款低功耗SoC,採用了16nm 製造工藝,由台積電來代工,的主要用於基於視覺的設備的深度學習和AI 算法加速,比如無人機、智能相機、VR/AR 頭盔。

除了新一代Movidius,英特爾還發布了全新的英特爾DevCloud for the Edge,該產品旨在與英特爾Distribution of OpenVINO 工具包共同解決開發人員的主要痛點,即在購買硬件前,能夠在各類英特爾處理器上嘗試、部署原型和測試AI 解決方案。
另外,英特爾還介紹了自家的英特爾至強可擴展處理器在 AI 方面的進展。

英特爾方面表示,推進深度學習推理和應用需要極其複雜的數據、模型和技術,因此在架構選擇上需要有不同的考量。事實上,業界大部分組織都基於英特爾至強可擴展處理器部署了人工智能。英特爾將繼續通過英特爾矢量神經網絡指令 (VNNI) 和英特爾深度學習加速技術(DL Boost)等功能來改進該平台,從而在數據中心和邊緣部署中提升人工智能推理的性能。
英特爾強調稱,在未來很多年中,英特爾至強可擴展處理器都將繼續成為強有力的人工智能計算支柱。
總結
在本次 2019 英特爾人工智能峰會上,Intel 還公佈了其在 AI 方面的整體解決方案。實際上,英特爾在AI 方面的優勢不僅僅局限在AI 芯片本身的突破,更重要的是,英特爾有能力全面考慮計算、內存、存儲、互連、封裝和軟件,以最大限度提升效率和可編程性,並能確保將深度學習擴展到數以千計節點的關鍵能力。
不僅如此,英特爾還能夠借重現有的市場優勢將自家在AI 領域的能力帶向市場,實現AI 的商用落地——值得一提的是,在峰會現場,英特爾宣布,自家的人工智能解決方案產品組合進一步得到強化,並有望在2019 年創造超過35 億美元的營收。

可見,在推進 AI 技術走向商用落地方面,英特爾終於跨出了自信的一步。
訪問購買頁面:
英特爾旗艦店
.(tagsToTranslate)Intel 英特爾(t)Intel首款 AI 商用芯片已交付 新一代 Movidius VPU 明年見(t)kknews.xyz
from Intel首款 AI 商用芯片已交付 新一代 Movidius VPU 明年見 via KKNEWS
0 notes
Text
Why Intel® Distribution For Python Is A Game Changer For Deep Learning

As per our Data Science Skills Study 2018, Python is the most used language by data scientists, with 44% of respondents using it for application building and scientific & numeric computing. One of the main reasons for Python’s soaring popularity is that it has one of the largest programming communities in the world and offers a number of libraries which a data scientist can use to analyse large amounts of data. In terms of data visualization, Python offers a number of libraries like Pandas or Matplotlib. The study further revealed that 41% data scientists prefer Pandas over other libraries. As Python inches towards supremacy, a lot of emphasis is now being laid on how to improve the platforms that run Python and the use of its machine learning libraries. Traditionally, pip has been offering the services of Python packages since the beginning. Later, the introduction of Virtualenv and Anaconda brought in the usage of customised dependencies for web development and machine learning respectively. Anaconda, especially, became popular as a platform that hosts a variety of machine learning tools. Now it has joined hands with Intel® to boost performance of Python. The collaboration of Intel® and Anaconda comes at a crucial intersection where speed stands as a major hurdle for training deep learning algorithms. Intel® Distribution for Python was first publicly made available in 2017. Since then it has undergone many developments and today it supports a multitude of machine learning tasks for Python users. Today, Intel® 's latest developments with Python can assist the following class of developers: Machine Learning Developers, Data Scientists and AnalystsNumerical and Scientific Computing DevelopersHigh-Performance Computing (HPC) Developers Intel® Distribution for Python is a binary distribution of Python interpreter and commonly used packages for computation and data intensive domains, such as scientific and engineering computing, big data, and data science. Intel® Distribution for Python supports Python 2 and 3 for Windows, Linux, and macOS. The product simplifies Python installation by providing packages in a binary form so that everything is preconfigured and no compilation tools are needed, as well as contains all the dependencies for running on popular OS platforms. How Does Intel® Boost Python’s Performance
Source: Intel Many Python numerical packages, such as NumPy and SciPy, take advantage of all available CPU cores by using multithreading inherently. However, performance can degrade during multithreading using Python. Intel® 's composable parallelism helps resolve this by coordinating the threaded components—with little to no intervention from the user. This can lead to improved application performance. Intel® has a list of benchmarks that it has set thanks to its ever improving results that combine its hardware with software. The following benchmarks show the efficiency of optimized functions— for example, functions used for numerical computing, scientific computing and machine learning— and compare Intel® Distribution for Python to its respective open source Python packages. All benchmarks measure Python against native C code equivalent, which is considered to be representative of optimal performance. The higher the efficiency, the faster the function and closer to native C speed. Here are few comparisons to get a glimpse at how Intel® fares: Linear algebra1

2. Machine Learning2
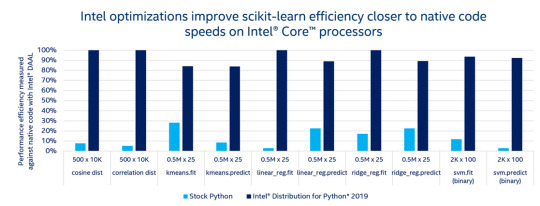
Intel® Distribution for Python is also supported by their flagship product Intel® Parallel Studio XE, which is a powerful, robust suite of software development tools to write Python native extensions. This helps boost application performance by taking advantage of the ever-increasing processor core counts and vector register widths available in processors based on Intel® technology and other compatible processors. The packages have been optimized to take advantage of parallelism through the use of vectorization, multithreading and multiprocessing, as well as through the use of optimized communication across multiple nodes. Key Takeaways

Source: Intel Python continues to reign as the tool of choice thanks to its versatility. While both Python and R are open source languages, Python is a more general-purpose language with a readable syntax. Mostly used in data mining, analysis, scientific computing and machine learning, it contains powerful statistical and numerical packages for data analysis such as PyBrain, NumPy and MySQL. It can automate mundane tasks, build web applications and websites from scratch, enable scientific and numeric computing, be used in robotics, and more. Python is known to be intuitive, easy to work with and solve complex computational problems. Whereas, with Intel® ’s distribution for Python, the developers can: Achieve faster Python* application performance—right out of the box—with minimal or no changes to your codeAccelerate NumPy*, SciPy* and Scikit-learn* with integrated Intel® Performance Libraries such as Intel® Math Kernel Library and Intel® Data Analytics Acceleration LibraryAccess the latest vectorization and multithreading instructions, Numba* and Cython*, composable parallelism with Threading Building Blocks and more Going Forward

Source: Intel The new release of Intel® 's Distribution for Python now offers many performance improvements, including: Faster machine learning with scikit-learn key algorithms accelerated with Intel® Data Analytics Acceleration LibraryThe XGBoost package included in the Intel® Distribution for Python (Linux* only)The latest version3 has a new distributed model support for "Moments of low order" and "Covariance" algorithms through daal4py package. Intel® 's Distribution for Python is also included in their flagship product, Intel® Parallel Studio XE, which contains a powerful, robust suite of software development tools that help write Python native extensions such as C and Fortran compilers, numerical libraries, and profilers. Intel® 's Python Distribution has an edge over open source Python platforms because of their ever-increasing processor core counts and vector register widths available in processors that help boost application performance. It also comes with optimized deep learning software, Caffe and Theano, as well as classic machine learning libraries, like scikit-learn and pyDAAL. Python packages have been accelerated with Intel® Performance Libraries, including Intel® Math Kernel Library (Intel® MKL), Intel® Threading Building Blocks (Intel® TBB), Intel® Integrated Performance Primitives (Intel® IPP), and Intel® Data Analytics Acceleration Library (Intel® DAAL). From hardware that excels at training massive, unstructured data sets, to extreme low-power silicon for on-device inference, Intel® AI has been supporting cloud service providers, enterprises and research teams with a portfolio of multi-purpose, purpose-built, customizable and application-specific hardware. Over the past couple of years, Intel® has optimized open source libraries like nGraph, which supports training and inference across multiple frameworks and hardware architectures; developed the Intel® Distribution of OpenVINO™ toolkit to quickly optimize pretrained models and deploy neural networks for video to a variety of hardware architectures; and created BigDL, distributed deep learning library for Apache Spark and Hadoop clusters. Now, with their ever-improving Python packaging and distribution, it is safe to say that Intel now possesses a unique set of tools that are diverse and are well suited for any modern machine learning pipeline. Get hands on with Intel® 's Distribution for Python here Product & Performance Information 1 Source: Intel® Distribution for Python BUILT FOR SPEED AND SCALABILITY https://software.intel.com/en-us/distribution-for-python/benchmarks 2 Source: Intel® Distribution for Python BUILT FOR SPEED AND SCALABILITY https://software.intel.com/en-us/distribution-for-python/benchmarks 3Source: Intel® Distribution for Python* 2019 Update 4 https://software.intel.com/sites/default/files/managed/4e/ac/2019_Python_Release%20Notes%20Intel%28R%29%20Distribution%20for%20Python%20-%20Update%204.pdf Read the full article
0 notes
Text
AWS launches Neo-AI, an open-source tool for calibration ml models

AWS isn’t precisely referred to as an ASCII text file powerhouse, however perhaps amendment is within the air. Amazon’s cloud computing unit nowadays proclaimed the launch of Neo-AI, a brand new ASCII text file project underneath the Apache software package License. The new tool takes a number of the technologies that the corporate developed and used for its SageMaker modern machine learning service and brings them (back) to the ASCII text file scheme.
The main goal here is to form it easier to optimize models for deployments on multiple platforms — and within the AWS context, that’s principally machines which will run these models at the sting.
“Ordinarily, optimizing a machine learning model for multiple hardware platforms is tough as a result of developers got to tune models manually for every platform’s hardware and software package configuration,” AWS’s Sukwon Kim and Vin Sharma write in today’s announcement. “This is very difficult for edge devices, that tend to be affected in cypher power and storage.”
Neo-AI will take TensorFlow, MXNet, PyTorch, ONNX and XGBoost models and optimize them. AWS says Neo-AI will usually speed up these models to double their original speed, all while not the loss of accuracy. As for hardware, the tools supports Intel, Nvidia and ARM chips, with support for Xilinx, Cadence and Qualcomm returning presently. All of those firms, aside from Nvidia, also will contribute to the project.
“To derive worth from AI, we tend to should make sure that deep learning models will be deployed even as simply within the information center and within the cloud as on devices at the sting,” same Naveen Rao, head of the unreal Intelligence merchandise cluster at Intel. “Intel is happy to expand the initiative that it started with nGraph by causative those efforts to Neo-AI. Using Neo, device manufacturers and system vendors will restore performance for models developed in nearly any framework on platforms supported all Intel cypher platforms.”
In addition to optimizing the models, the tool conjointly converts them into a brand new format to forestall compatibility problems and an area runtime on the devices wherever the model then runs the execution.
AWS notes that a number of the work on the Neo-AI compiler started at the University of Washington (specifically the TVM and Treelite projects). “Today’s unleash of AWS code back to open supply through the modern-AI project permits any developer to pioneer on the production-grade Neo compiler and runtime.” AWS has somewhat of a name of taking ASCII text file comes and mistreatment them in its cloud services. It’s sensible to envision the corporate getting down to contribute back a touch a lot of currently.
In the context of Amazon’s ASCII text file efforts, it’s conjointly value noting that the company’s firework hypervisor currently supports the OpenStack Foundation’s Kata Containers project. firework itself is open supply, too, and that i wouldn’t be shocked if firework all over up because the initial ASCII text file project that AWS brings underneath the umbrella of the OpenStack Foundation.
0 notes
Text
AWS launches Neo-AI, an open-source tool for tuning ML models
AWS isn’t exactly known as an open-source powerhouse, but maybe change is in the air. Amazon’s cloud computing unit today announced the launch of Neo-AI, a new open-source project under the Apache Software License. The new tool takes some of the technologies that the company developed and used for its SageMaker Neo machine learning service and brings them (back) to the open source ecosystem.
The main goal here is to make it easier to optimize models for deployments on multiple platforms — and in the AWS context, that’s mostly machines that will run these models at the edge.
“Ordinarily, optimizing a machine learning model for multiple hardware platforms is difficult because developers need to tune models manually for each platform’s hardware and software configuration,” AWS’s Sukwon Kim and Vin Sharma write in today’s announcement. “This is especially challenging for edge devices, which tend to be constrained in compute power and storage.”
Neo-AI can take TensorFlow, MXNet, PyTorch, ONNX, and XGBoost models and optimize them. AWS says Neo-AI can often speed these models up to twice their original speed, all without the loss of accuracy. As for hardware, the tools supports Intel, Nvidia, and ARM chips, with support for Xilinx, Cadence, and Qualcomm coming soon. All of these companies, except for Nvidia, will also contribute to the project.
“To derive value from AI, we must ensure that deep learning models can be deployed just as easily in the data center and in the cloud as on devices at the edge,” said Naveen Rao, General Manager of the Artificial Intelligence Products Group at Intel. “Intel is pleased to expand the initiative that it started with nGraph by contributing those efforts to Neo-AI. Using Neo, device makers and system vendors can get better performance for models developed in almost any framework on platforms based on all Intel compute platforms.”
In addition to optimizing the models, the tool also converts them into a new format to prevent compatibility issues and a local runtime on the devices where the model then runs handle the execution.
AWS notes that some of the work on the Neo-AI compiler started at the University of Washington (specifically the TVM and Treelite projects). “Today’s release of AWS code back to open source through the Neo-AI project allows any developer to innovate on the production-grade Neo compiler and runtime.” AWS has somewhat of a reputation of taking open source projects and using them in its cloud services. It’s good to see the company starting to contribute back a bit more now.
In the context of Amazon’s open source efforts, it’s also worth noting that the company’s Firecracker hypervisor now supports the OpenStack Foundation’s Kata Containers project. Firecracker itself is open source, too, and I wouldn’t be surprised if Firecracker ended up as the first open source project that AWS brings under the umbrella of the OpenStack Foundation.
0 notes
Text
NGraph: A New Open Source Compiler for Deep Learning Systems
https://ai.intel.com/ngraph-a-new-open-source-compiler-for-deep-learning-systems/ Comments
0 notes

Text
A tweet
#C4ML #2 kicks off in San Diego, with Jacques Pienaar opening a series of great a academic and industry talks about ML+compilers, including #MLIR, #PlaidML, #nGraph, #TVM, #JAX, Xilinx AI Engine and state of the art research: https://t.co/EOAjQH6C0J pic.twitter.com/9myrSNPV7a
— Albert Cohen (@ahcohen) February 23, 2020
0 notes
Text
AWS launches Neo-AI, an open-source tool for tuning ML models
AWS isn’t exactly known as an open-source powerhouse, but maybe change is in the air. Amazon’s cloud computing unit today announced the launch of Neo-AI, a new open-source project under the Apache Software License. The new tool takes some of the technologies that the company developed and used for its SageMaker Neo machine learning service and brings them (back) to the open source ecosystem.
The main goal here is to make it easier to optimize models for deployments on multiple platforms — and in the AWS context, that’s mostly machines that will run these models at the edge.
“Ordinarily, optimizing a machine learning model for multiple hardware platforms is difficult because developers need to tune models manually for each platform’s hardware and software configuration,” AWS’s Sukwon Kim and Vin Sharma write in today’s announcement. “This is especially challenging for edge devices, which tend to be constrained in compute power and storage.”
Neo-AI can take TensorFlow, MXNet, PyTorch, ONNX, and XGBoost models and optimize them. AWS says Neo-AI can often speed these models up to twice their original speed, all without the loss of accuracy. As for hardware, the tools supports Intel, Nvidia, and ARM chips, with support for Xilinx, Cadence, and Qualcomm coming soon. All of these companies, except for Nvidia, will also contribute to the project.
“To derive value from AI, we must ensure that deep learning models can be deployed just as easily in the data center and in the cloud as on devices at the edge,” said Naveen Rao, General Manager of the Artificial Intelligence Products Group at Intel. “Intel is pleased to expand the initiative that it started with nGraph by contributing those efforts to Neo-AI. Using Neo, device makers and system vendors can get better performance for models developed in almost any framework on platforms based on all Intel compute platforms.”
In addition to optimizing the models, the tool also converts them into a new format to prevent compatibility issues and a local runtime on the devices where the model then runs handle the execution.
AWS notes that some of the work on the Neo-AI compiler started at the University of Washington (specifically the TVM and Treelite projects). “Today’s release of AWS code back to open source through the Neo-AI project allows any developer to innovate on the production-grade Neo compiler and runtime.” AWS has somewhat of a reputation of taking open source projects and using them in its cloud services. It’s good to see the company starting to contribute back a bit more now.
In the context of Amazon’s open source efforts, it’s also worth noting that the company’s Firecracker hypervisor now supports the OpenStack Foundation’s Kata Containers project. Firecracker itself is open source, too, and I wouldn’t be surprised if Firecracker ended up as the first open source project that AWS brings under the umbrella of the OpenStack Foundation.
source https://techcrunch.com/2019/01/24/aws-launches-neo-ai-an-open-source-tool-for-tuning-ml-models/
0 notes
Text
AWS launches Neo-AI, an open-source tool for tuning ML models
AWS isn’t exactly known as an open-source powerhouse, but maybe change is in the air. Amazon’s cloud computing unit today announced the launch of Neo-AI, a new open-source project under the Apache Software License. The new tool takes some of the technologies that the company developed and used for its SageMaker Neo machine learning service and brings them (back) to the open source ecosystem.
The main goal here is to make it easier to optimize models for deployments on multiple platforms — and in the AWS context, that’s mostly machines that will run these models at the edge.
“Ordinarily, optimizing a machine learning model for multiple hardware platforms is difficult because developers need to tune models manually for each platform’s hardware and software configuration,” AWS’s Sukwon Kim and Vin Sharma write in today’s announcement. “This is especially challenging for edge devices, which tend to be constrained in compute power and storage.”
Neo-AI can take TensorFlow, MXNet, PyTorch, ONNX, and XGBoost models and optimize them. AWS says Neo-AI can often speed these models up to twice their original speed, all without the loss of accuracy. As for hardware, the tools supports Intel, Nvidia, and ARM chips, with support for Xilinx, Cadence, and Qualcomm coming soon. All of these companies, except for Nvidia, will also contribute to the project.
“To derive value from AI, we must ensure that deep learning models can be deployed just as easily in the data center and in the cloud as on devices at the edge,” said Naveen Rao, General Manager of the Artificial Intelligence Products Group at Intel. “Intel is pleased to expand the initiative that it started with nGraph by contributing those efforts to Neo-AI. Using Neo, device makers and system vendors can get better performance for models developed in almost any framework on platforms based on all Intel compute platforms.”
In addition to optimizing the models, the tool also converts them into a new format to prevent compatibility issues and a local runtime on the devices where the model then runs handle the execution.
AWS notes that some of the work on the Neo-AI compiler started at the University of Washington (specifically the TVM and Treelite projects). “Today’s release of AWS code back to open source through the Neo-AI project allows any developer to innovate on the production-grade Neo compiler and runtime.” AWS has somewhat of a reputation of taking open source projects and using them in its cloud services. It’s good to see the company starting to contribute back a bit more now.
In the context of Amazon’s open source efforts, it’s also worth noting that the company’s Firecracker hypervisor now supports the OpenStack Foundation’s Kata Containers project. Firecracker itself is open source, too, and I wouldn’t be surprised if Firecracker ended up as the first open source project that AWS brings under the umbrella of the OpenStack Foundation.
Via Frederic Lardinois https://techcrunch.com
0 notes
Text
Deep Learning : Intel jette son dévolu sur Vertex.AI
Intel a mis la main sur Vetex.AI, du nom d’une start-up spécialisée dans le deep learning, une branche de l’intelligence artificielle. Si le montant de la transaction n’a pas été divulgué, on sait que l’équipe de la start-up composée de 7 personnes va rejoindre l’unité Movidius d’Intel (du nom de la start-up acquise par le fabricant de puces en 2016). Fondée en 2015, Vertex.AI a développé la plate-forme open source PlaidML. Lancé en octobre dernier, elle consiste en un “moteur d’apprentissage profond portable“, qui permet aux développeurs de déployer des modèles IA sur tout type d’appareil, tournant sous Windows, Linux ou macOS. PlaidML sera utilisé pour prendre en charge “divers matériels”. En outre, Intel a annoncé son intention d’intégrer sa bibliothèque nGraph de Vertex-.AI afin de développer des frameworks d’apprentissage en profondeur avec la plate-forme. Le développement de PlaidML va également être poursuivi et restera open source sous licence Apache 2.0. Une véritable poussée d’Intel dans l’IA Dans une contribution de blog, la start-up basée à Seattle se dit « ravie de faire progresser le deep learning flexible pour l’informatique de pointe avec Intel » et ajoute que « si vous souhaitez nous rejoindre, Intel recrute des experts d’IA, y compris ici à Seattle ». Co-fondée par Choong Ng, Jeremy Bruestle et Brian Retford, Vetex.AI a reçu un soutien financier d’investisseurs tels que Curious Capital et Creative Destruction Lab, un accélérateur axé sur les start-ups spécialisées dans l’apprentissage automatique. Durant les dernières années, Intel n’a cessé d’acquérir des start-ups spécialisées dans l’IA. Le groupe a ainsi jeté son dévolu sur Altera, Nervana (puces IA), Movidius et eASIC cette année. Intel a également été occupé à développer son propre logiciel d’IA, avec notamment la boîte à outils OpenVINO.
Yves Pellemans's insight:
Intel met clairement le cap sur l'IA. Intel prévoit ainsi de futurs processeurs Xeon dotés de prédispositions pour les calculs IA.
0 notes
Text
なるほどですね
(全 46 件)
1. 深層学習でNVIDIAの脅威となるIntelの「Spring Crest」と「nGRAPH」
2. React NativeをWebに持ってくることの意味
3. iOS 12 to Allow iPhones to Unlock Doors Via NFC
4. How JavaScript works: Parsing, Abstract Syntax Trees (ASTs) + 5 tips on how to minimize parse time
5. Web最新技術がてんこ盛りのreact-native-domから目が離せない
6. “運賃無料のタクシー”成功するか 吉田拓巳社長「スポンサー獲得に勝算」 (1/3)
7. 「妻の姓に変えたらクソゲーな手続きが待っていた」 わずか4%、結婚で改姓した男性たちの本音
8. JavaScriptのStreams APIで細切れのデータを読み書きする
9. レンダリング後にGoogleに無視されるのはrel=canonicalとrel=amphtmlの2つだけ。hreflangとprev/nextはクライアントサイドでの挿入が可能
10. 自由恋愛って、多くの人を不幸にしているんじゃないか?
11. JSサイトのための第4のレンダリング構成としてダイナミックレンダリングをGoogleが発表 #io18 #io18jp
12. WebIOPiを使ってブラウザからRaspberry PiのGPIOを操作してみる
13. ELBとCloudFrontのアクセスログをサーバレスに集約させてみた
14. 仮想マシンをベースにしたセキュアなコンテナ実装「Kata Containers」がバージョン1.0に到達。OpenStack Foundationが開発
15. SaaSのAPIエコシステム構築、できるだけ短期間で実現するには?[PR]
16. なぜ「論破」は無意味なのか。
17. JamesRandall/FunctionMonkey
18. Build Elegant REST APIs with Azure Functions
19. システム開発を内製する会社でよくあるトラブル
20. Web Authentication API で FIDO U2F(YubiKey) 認証
21. Netflixにおける日本語字幕の導入
22. DevOpsは作る側(Dev)と維持する側(Ops)を仲良くするためのものではない
23. C# vNext Preview
24. 人口減少社会試論・または次世代のための日本列島老人天国化論
25. TLS1.3だとハンドシェイクがどれくらい早くなるか測定した
26. Managed Virtual Machines で OS ディスク スワップの一般提供を開始
27. ゼロ インフラストラクチャに向けて:IT 業界の偉人マーク・エバンス氏から学ぶ 5 つのヒント
28. Converting a Database to In-Memory OLTP
29. 恐竜に教える現代のCSS – Part 1
30. 2020年のプログラミング教育必修化で、未来はどう変わる?―教育現場の現状と課題・教材・義務教育のビジョンetc.NEW
31. 新規事業から大規模事業まで!デザインシステムへの向き合い方とは? - Bonfire Design #3 レポート
32. デザインシステムの海で3年間もがいてみて
33. Intel、DDR4スロットに挿せる1枚で512GBの「Optane DC」不揮発性メモリ
34. PCをクラッシュさせる音響攻撃「ブルーノート」--スピーカから音を流すだけで
35. 「本当の幸せ」ってなに?――より良い社会をつくるために 鈴木謙介先生(関西学院大学 社会学部准教授)~「20XX年の幸福論」part4~
36. 子どもの「異世界」との出会い方・関わり方 鈴木謙介先生(関西学院大学 社会学部准教授)~「20XX年の幸福論」part3~
37. 子どもの「頭を良くする」を考える(前編)鈴木謙介先生(関西学院大学 社会学部准教授)~「20XX年の幸福論」part1~
38. 協働スキルと「支えのある社会」
39. [レポート]Alexaスマートホーム体験ツアー
40. 小売業界の敵はAmazonではない? これからの小売が知っておくべき課題
41. Deprecating TLSv1 and TLSv1.1 – 2018-12-01
42. Install and Configure Web Deploy on IIS
43. “複業” はありか、なしか
44. Supershipを退職しました
45. iwate/ODataHttpClient
46. ODataHttpClient
0 notes