#kubernetes pod
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs




Fun Fact
Tumblr’s website traffic is steadily declining.
Text
Introduction to Kubernetes
Kubernetes, often abbreviated as K8s, is an open-source platform designed to automate deploying, scaling, and operating application containers. Originally developed by Google, it is now maintained by the Cloud Native Computing Foundation (CNCF). Kubernetes has become the de facto standard for container orchestration, offering a robust framework for managing microservices architectures in production environments.
In today's rapidly evolving tech landscape, Kubernetes plays a crucial role in modern application development. It provides the necessary tools and capabilities to handle complex, distributed systems reliably and efficiently. From scaling applications seamlessly to ensuring high availability, Kubernetes is indispensable for organizations aiming to achieve agility and resilience in their software deployments.
History and Evolution of Kubernetes
The origins of Kubernetes trace back to Google's internal system called Borg, which managed large-scale containerized applications. Drawing from years of experience and lessons learned with Borg, Google introduced Kubernetes to the public in 2014. Since then, it has undergone significant development and community contributions, evolving into a comprehensive and flexible orchestration platform.
Some key milestones in the evolution of Kubernetes include its donation to the CNCF in 2015, the release of version 1.0 the same year, and the subsequent releases that brought enhanced features and stability. Today, Kubernetes is supported by a vast ecosystem of tools, extensions, and integrations, making it a cornerstone of cloud-native computing.
Key Concepts and Components
Nodes and Clusters
A Kubernetes cluster is a set of nodes, where each node can be either a physical or virtual machine. There are two types of nodes: master nodes, which manage the cluster, and worker nodes, which run the containerized applications.
Pods and Containers
At the core of Kubernetes is the concept of a Pod, the smallest deployable unit that can contain one or more containers. Pods encapsulate an application’s container(s), storage resources, a unique network IP, and options on how the container(s) should run.
Deployments and ReplicaSets
Deployments are used to manage and scale sets of identical Pods. A Deployment ensures that a specified number of Pods are running at all times, providing declarative updates to applications. ReplicaSets are a subset of Deployments that maintain a stable set of replica Pods running at any given time.
Services and Networking
Services in Kubernetes provide a stable IP address and DNS name to a set of Pods, facilitating seamless networking. They abstract the complexity of networking by enabling communication between Pods and other services without needing to manage individual Pod IP addresses.
Kubernetes Architecture
Master and Worker Nodes
The Kubernetes architecture is based on a master-worker model. The master node controls and manages the cluster, while the worker nodes run the applications. The master node’s key components include the API server, scheduler, and controller manager, which together manage the cluster’s state and lifecycle.
Control Plane Components
The control plane, primarily hosted on the master node, comprises several critical components:
API Server: The front-end for the Kubernetes control plane, handling all API requests for managing cluster resources.
etcd: A distributed key-value store that holds the cluster’s state data.
Scheduler: Assigns workloads to worker nodes based on resource availability and other constraints.
Controller Manager: Runs various controllers to regulate the state of the cluster, such as node controllers, replication controllers, and more.
Node Components
Each worker node hosts several essential components:
kubelet: An agent that runs on each node, ensuring containers are running in Pods.
kube-proxy: Maintains network rules on nodes, enabling communication to and from Pods.
Container Runtime: Software responsible for running the containers, such as Docker or containerd.
1 note
·
View note
Text
Kubernetes: Control Plane and Workers
In Kubernetes, the control plane and worker nodes are two key components that together form the foundation of a Kubernetes cluster. They play distinct roles in managing and running containerized applications. Here’s an explanation of each component along with examples and YAML configurations where relevant: Control Plane The control plane is the brain of the Kubernetes cluster. It manages the…

View On WordPress
0 notes
Video
youtube
Session 9 Kubernetes Pods
#youtube#👋 Welcome to our latest video where we dive deep into the fascinating world of Kubernetes Pods! 🌟 If you're interested in container orches
0 notes
Text
someone should ask chatGPT what it's like to live inside a huge kubernetes cluster... is it dark in there, is it noisy, does it hurt when pods scale up/down, are replicas more like friends or rivals, etc etc
23 notes
·
View notes
Text
so at work theres a kubernetes command called kgpo that is used to list pods and i just mentally call it the "kagepro" command :p
4 notes
·
View notes
Text
How To Use Llama 3.1 405B FP16 LLM On Google Kubernetes

How to set up and use large open models for multi-host generation AI over GKE
Access to open models is more important than ever for developers as generative AI grows rapidly due to developments in LLMs (Large Language Models). Open models are pre-trained foundational LLMs that are accessible to the general population. Data scientists, machine learning engineers, and application developers already have easy access to open models through platforms like Hugging Face, Kaggle, and Google Cloud’s Vertex AI.
How to use Llama 3.1 405B
Google is announcing today the ability to install and run open models like Llama 3.1 405B FP16 LLM over GKE (Google Kubernetes Engine), as some of these models demand robust infrastructure and deployment capabilities. With 405 billion parameters, Llama 3.1, published by Meta, shows notable gains in general knowledge, reasoning skills, and coding ability. To store and compute 405 billion parameters at FP (floating point) 16 precision, the model needs more than 750GB of GPU RAM for inference. The difficulty of deploying and serving such big models is lessened by the GKE method discussed in this article.
Customer Experience
You may locate the Llama 3.1 LLM as a Google Cloud customer by selecting the Llama 3.1 model tile in Vertex AI Model Garden.
Once the deploy button has been clicked, you can choose the Llama 3.1 405B FP16 model and select GKE.Image credit to Google Cloud
The automatically generated Kubernetes yaml and comprehensive deployment and serving instructions for Llama 3.1 405B FP16 are available on this page.
Deployment and servicing multiple hosts
Llama 3.1 405B FP16 LLM has significant deployment and service problems and demands over 750 GB of GPU memory. The total memory needs are influenced by a number of parameters, including the memory used by model weights, longer sequence length support, and KV (Key-Value) cache storage. Eight H100 Nvidia GPUs with 80 GB of HBM (High-Bandwidth Memory) apiece make up the A3 virtual machines, which are currently the most potent GPU option available on the Google Cloud platform. The only practical way to provide LLMs such as the FP16 Llama 3.1 405B model is to install and serve them across several hosts. To deploy over GKE, Google employs LeaderWorkerSet with Ray and vLLM.
LeaderWorkerSet
A deployment API called LeaderWorkerSet (LWS) was created especially to meet the workload demands of multi-host inference. It makes it easier to shard and run the model across numerous devices on numerous nodes. Built as a Kubernetes deployment API, LWS is compatible with both GPUs and TPUs and is independent of accelerators and the cloud. As shown here, LWS uses the upstream StatefulSet API as its core building piece.
A collection of pods is controlled as a single unit under the LWS architecture. Every pod in this group is given a distinct index between 0 and n-1, with the pod with number 0 being identified as the group leader. Every pod that is part of the group is created simultaneously and has the same lifecycle. At the group level, LWS makes rollout and rolling upgrades easier. For rolling updates, scaling, and mapping to a certain topology for placement, each group is treated as a single unit.
Each group’s upgrade procedure is carried out as a single, cohesive entity, guaranteeing that every pod in the group receives an update at the same time. While topology-aware placement is optional, it is acceptable for all pods in the same group to co-locate in the same topology. With optional all-or-nothing restart support, the group is also handled as a single entity when addressing failures. When enabled, if one pod in the group fails or if one container within any of the pods is restarted, all of the pods in the group will be recreated.
In the LWS framework, a group including a single leader and a group of workers is referred to as a replica. Two templates are supported by LWS: one for the workers and one for the leader. By offering a scale endpoint for HPA, LWS makes it possible to dynamically scale the number of replicas.
Deploying multiple hosts using vLLM and LWS
vLLM is a well-known open source model server that uses pipeline and tensor parallelism to provide multi-node multi-GPU inference. Using Megatron-LM’s tensor parallel technique, vLLM facilitates distributed tensor parallelism. With Ray for multi-node inferencing, vLLM controls the distributed runtime for pipeline parallelism.
By dividing the model horizontally across several GPUs, tensor parallelism makes the tensor parallel size equal to the number of GPUs at each node. It is crucial to remember that this method requires quick network connectivity between the GPUs.
However, pipeline parallelism does not require continuous connection between GPUs and divides the model vertically per layer. This usually equates to the quantity of nodes used for multi-host serving.
In order to support the complete Llama 3.1 405B FP16 paradigm, several parallelism techniques must be combined. To meet the model’s 750 GB memory requirement, two A3 nodes with eight H100 GPUs each will have a combined memory capacity of 1280 GB. Along with supporting lengthy context lengths, this setup will supply the buffer memory required for the key-value (KV) cache. The pipeline parallel size is set to two for this LWS deployment, while the tensor parallel size is set to eight.
In brief
We discussed in this blog how LWS provides you with the necessary features for multi-host serving. This method maximizes price-to-performance ratios and can also be used with smaller models, such as the Llama 3.1 405B FP8, on more affordable devices. Check out its Github to learn more and make direct contributions to LWS, which is open-sourced and has a vibrant community.
You can visit Vertex AI Model Garden to deploy and serve open models via managed Vertex AI backends or GKE DIY (Do It Yourself) clusters, as the Google Cloud Platform assists clients in embracing a gen AI workload. Multi-host deployment and serving is one example of how it aims to provide a flawless customer experience.
Read more on Govindhtech.com
#Llama3.1#Llama#LLM#GoogleKubernetes#GKE#405BFP16LLM#AI#GPU#vLLM#LWS#News#Technews#Technology#Technologynews#Technologytrends#govindhtech
2 notes
·
View notes
Text
Load Balancing Web Sockets with K8s/Istio
When load balancing WebSockets in a Kubernetes (K8s) environment with Istio, there are several considerations to ensure persistent, low-latency connections. WebSockets require special handling because they are long-lived, bidirectional connections, which are different from standard HTTP request-response communication. Here’s a guide to implementing load balancing for WebSockets using Istio.
1. Enable WebSocket Support in Istio
By default, Istio supports WebSocket connections, but certain configurations may need tweaking. You should ensure that:
Destination rules and VirtualServices are configured appropriately to allow WebSocket traffic.
Example VirtualService Configuration.
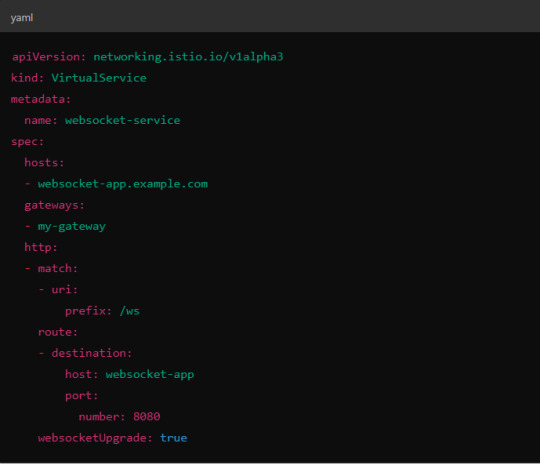
Here, websocketUpgrade: true explicitly allows WebSocket traffic and ensures that Istio won’t downgrade the WebSocket connection to HTTP.
2. Session Affinity (Sticky Sessions)
In WebSocket applications, sticky sessions or session affinity is often necessary to keep long-running WebSocket connections tied to the same backend pod. Without session affinity, WebSocket connections can be terminated if the load balancer routes the traffic to a different pod.
Implementing Session Affinity in Istio.
Session affinity is typically achieved by setting the sessionAffinity field to ClientIP at the Kubernetes service level.
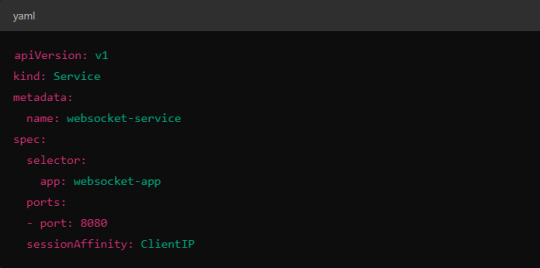
In Istio, you might also control affinity using headers. For example, Istio can route traffic based on headers by configuring a VirtualService to ensure connections stay on the same backend.
3. Load Balancing Strategy
Since WebSocket connections are long-lived, round-robin or random load balancing strategies can lead to unbalanced workloads across pods. To address this, you may consider using least connection or consistent hashing algorithms to ensure that existing connections are efficiently distributed.
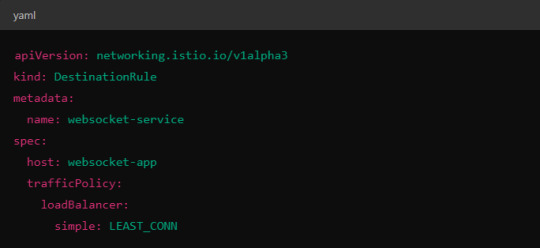
Load Balancer Configuration in Istio.
Istio allows you to specify different load balancing strategies in the DestinationRule for your services. For WebSockets, the LEAST_CONN strategy may be more appropriate.
Alternatively, you could use consistent hashing for a more sticky routing based on connection properties like the user session ID.
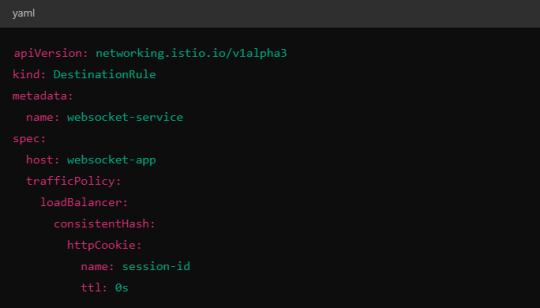
This configuration ensures that connections with the same session ID go to the same pod.
4. Scaling Considerations
WebSocket applications can handle a large number of concurrent connections, so you’ll need to ensure that your Kubernetes cluster can scale appropriately.
Horizontal Pod Autoscaler (HPA): Use an HPA to automatically scale your pods based on metrics like CPU, memory, or custom metrics such as open WebSocket connections.
Istio Autoscaler: You may also scale Istio itself to handle the increased load on the control plane as WebSocket connections increase.
5. Connection Timeouts and Keep-Alive
Ensure that both your WebSocket clients and the Istio proxy (Envoy) are configured for long-lived connections. Some settings that need attention:
Timeouts: In VirtualService, make sure there are no aggressive timeout settings that would prematurely close WebSocket connections.

Keep-Alive Settings: You can also adjust the keep-alive settings at the Envoy level if necessary. Envoy, the proxy used by Istio, supports long-lived WebSocket connections out-of-the-box, but custom keep-alive policies can be configured.
6. Ingress Gateway Configuration
If you're using an Istio Ingress Gateway, ensure that it is configured to handle WebSocket traffic. The gateway should allow for WebSocket connections on the relevant port.
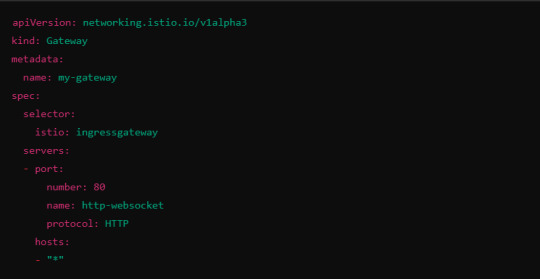
This configuration ensures that the Ingress Gateway can handle WebSocket upgrades and correctly route them to the backend service.
Summary of Key Steps
Enable WebSocket support in Istio’s VirtualService.
Use session affinity to tie WebSocket connections to the same backend pod.
Choose an appropriate load balancing strategy, such as least connection or consistent hashing.
Set timeouts and keep-alive policies to ensure long-lived WebSocket connections.
Configure the Ingress Gateway to handle WebSocket traffic.
By properly configuring Istio, Kubernetes, and your WebSocket service, you can efficiently load balance WebSocket connections in a microservices architecture.
#kubernetes#websockets#Load Balancing#devops#linux#coding#programming#Istio#virtualservices#Load Balancer#Kubernetes cluster#gateway#python#devlog#github#ansible
5 notes
·
View notes
Text
It looks like some of the cronjobs that would normally maintain NextCloud Memories are not set up by the kube pod that they use for apps so I am learning things about Kubernetes against my will. Committing crimes by running shells inside pods.
When I learned about Docker against my will I also turned out to think that was pretty neat so, you know. Kubernetes can use Docker but this one doesn't.
#I think pretty much everyone who learns about kubernetes learns it against their will#computer stuff
6 notes
·
View notes
Text
Deploy and Manage Policies for Multiple Clusters with RHACM
In today’s cloud-native landscape, most organizations don’t rely on a single Kubernetes cluster anymore — they run multiple clusters across cloud, on-prem, and edge environments. While this brings flexibility, it also introduces complexity: How do you consistently manage security, compliance, and operational policies across all those clusters?
That’s where Red Hat Advanced Cluster Management for Kubernetes (RHACM) comes in. Specifically, RHACM's governance and policy management features are built to help teams define, enforce, and monitor policies across multiple clusters — from a single place.
🌐 Why Policy Governance Matters in Multicluster Environments
Managing multiple clusters isn’t just about scaling workloads — it’s about maintaining control. Without a unified way to govern them, you risk:
Security drift between clusters
Manual configuration errors
Inconsistent compliance with standards like CIS, NIST, or GDPR
Gaps in visibility across environments
Policies help fix that by ensuring each cluster stays aligned with your organization’s security, configuration, and operational standards.
🔧 What Is RHACM Policy Governance?
RHACM’s governance feature lets you define policies as Kubernetes custom resources. You can think of them as templates for enforcing:
Security rules (e.g., disallow privileged containers)
Configuration standards (e.g., specific labels or namespaces required)
Application health or deployment expectations
Cluster-wide network settings
Compliance checks and audits
And yes — all without jumping into every cluster individually.
📦 How It Works (No Code Required)
Here’s how the policy lifecycle looks using RHACM:
1. Define Policies Once
Use pre-built policy templates or create your own YAML files (or use the GUI) to define what you want to enforce — whether it’s disabling root containers or ensuring every pod has resource limits.
2. Group Clusters with Placement Rules
You can target clusters by labels or placement rules, meaning you can apply certain policies only to dev, staging, or prod environments.
3. Deploy with Confidence
Once applied, RHACM automatically checks whether clusters are compliant or not, and can take action (like enforce the configuration or alert you) based on your settings.
4. Visualize Compliance
From the RHACM dashboard, get a real-time compliance view across all clusters. Spot drift, fix issues fast, and stay audit-ready.
✅ Real-World Use Cases
Security teams can enforce non-root containers and encryption across clusters
Ops teams can ensure logging/monitoring agents are always running
Compliance teams can generate audit-ready compliance reports in seconds
🏁 Final Thoughts
Managing Kubernetes at scale doesn’t have to mean losing control. With Red Hat Advanced Cluster Management (RHACM), you gain centralized governance over multiple clusters — enforcing policies, tracking compliance, and ensuring operational consistency across your entire environment.
Whether you're running OpenShift across AWS, Azure, on-prem, or edge — RHACM keeps your clusters secure, compliant, and under control.
👉 Ready to simplify your multicluster management?
Explore RHACM with us at Hawkstack or get in touch to see how we can help your team scale Kubernetes — securely.
For more info, Kindly follow: Hawkstack Technologies
0 notes
Text
Traffic-Driven Testing for Realistic Kubernetes Testing with Genqe.ai

In the dynamic world of Kubernetes-based application development, ensuring reliability and performance under real-world conditions is a significant challenge. Traditional testing methods often fall short, relying on synthetic scenarios that fail to capture the complexity of production environments. Genqe.ai introduces a groundbreaking solution with its traffic-driven testing approach, leveraging live usage data to create realistic test scenarios, accelerate debugging, and enable rapid performance testing. This blog explores how Genqe.ai’s traffic-driven testing transforms Kubernetes testing, empowering teams to shift left with confidence and streamline their development pipelines.
What is Traffic-Driven Testing?
Traffic-driven testing utilizes real user sessions and production traffic to automatically generate realistic test scenarios, mocks, and environments for validating Kubernetes applications. Unlike traditional testing, which depends on manually crafted scripts, Genqe.ai captures actual production traffic to drive testing processes. This ensures that tests mirror real-world usage, providing unparalleled accuracy in validating performance, resilience, and functionality for Kubernetes-based microservices.
Kubernetes Testing with Genqe.ai
Testing Kubernetes applications requires validating complex interactions across pods, services, and microservices under diverse conditions. Genqe.ai’s traffic-driven testing captures live traffic hitting your Kubernetes application using a lightweight sidecar proxy. This traffic is then used to generate test scenarios that reflect actual user behavior, ensuring your application is tested under conditions that closely mimic production. By integrating with Kubernetes clusters like Google Kubernetes Engine (GKE), AWS Elastic Kubernetes Service (EKS), or self-hosted setups, Genqe.ai provides a seamless testing experience without disrupting production environments.
Realistic Testing Scenarios from Live Usage Data
Genqe.ai leverages live usage data to create test scenarios that accurately reflect production workloads. By capturing real user sessions, including API calls, HTTP/gRPC requests, and database interactions, Genqe.ai eliminates the guesswork of manual test creation. For example, an e-commerce platform preparing for a holiday sale can use Genqe.ai to capture traffic patterns from previous sales, generating test cases that simulate peak loads and user interactions. This ensures that your Kubernetes application is validated against realistic scenarios, reducing the risk of performance bottlenecks or unexpected failures in production.
Accelerate Debugging with Isolated Traffic Replays
Debugging issues in Kubernetes microservices can be daunting due to the distributed nature of these architectures. Genqe.ai simplifies this process with isolated traffic replays. By replaying captured traffic against specific components or mocked services, teams can isolate and pinpoint issues without impacting production. For instance, Genqe.ai allows you to replay a problematic API request in a staging environment, swapping in mocked dependencies to identify the root cause—whether it’s a pod misconfiguration, a latency issue, or a service failure. This “wind tunnel” approach, as described by industry Alphabetic-Systems-Design, significantly accelerates debugging and reduces mean time to resolution (MTTR).
Rapid Performance Testing of Code Changes
Genqe.ai enables rapid performance testing by allowing teams to replay multiplied traffic loads to simulate high-demand scenarios. With its traffic-driven approach, Genqe.ai generates load tests based on real production data, enabling developers to validate code changes quickly. For example, a new microservice update can be tested against captured traffic to measure latency, throughput, CPU, and memory usage under realistic conditions. Genqe.ai’s integration with CI/CD pipelines, such as Jenkins or GitHub Actions, ensures that performance tests can be triggered automatically, providing rapid feedback and ensuring code changes meet performance standards before deployment.
Test Environment Self-Service
Genqe.ai empowers teams with self-service test environments, eliminating the need for dedicated infrastructure management. Through its intuitive UI and genqectl CLI tool, developers can spin up isolated Kubernetes test clusters on-demand, complete with mocked services and realistic traffic snapshots. This flexibility allows teams to create ephemeral environments for each test session, reducing costs and ensuring consistency with production setups. Genqe.ai’s ability to transform captured traffic—such as modifying request parameters like user IDs or endpoints—enables tailored testing without affecting live systems.
Shift Testing Left with Confidence
Shifting testing left—catching issues early in the development cycle—is critical for maintaining rapid release cycles. Genqe.ai’s traffic-driven testing gives developers confidence by providing realistic, production-like test scenarios early in the pipeline. By integrating with CI/CD workflows and leveraging real user traffic, Genqe.ai ensures that tests reflect actual usage patterns, enabling teams to identify and fix issues before they reach production. This approach minimizes costly rework and enhances application reliability, making Genqe.ai a cornerstone of modern DevOps practices.
Why Choose Genqe.ai for Traffic-Driven Testing?
Genqe.ai’s traffic-driven testing offers a revolutionary approach to Kubernetes testing, addressing the limitations of traditional methods. Its key benefits include:
Realistic Testing: Uses live production traffic to create accurate test scenarios, ensuring production-like validation.
Accelerated Debugging: Isolated traffic replays pinpoint issues quickly in complex microservices architectures.
Rapid Performance Insights: Automated load tests provide immediate feedback on code changes, optimizing performance.
Self-Service Environments: On-demand test clusters reduce infrastructure costs and simplify setup.
Seamless CI/CD Integration: Triggers tests within existing pipelines for early issue detection and faster releases.
Conclusion
Genqe.ai’s traffic-driven testing transforms Kubernetes testing by harnessing real-world traffic to create realistic, automated, and scalable test scenarios. By enabling rapid performance testing, isolated debugging, and self-service test environments, Genqe.ai empowers teams to shift testing left with confidence, ensuring high-quality, resilient Kubernetes applications. Whether you’re validating microservices, troubleshooting issues, or preparing for peak traffic, Genqe.ai provides the tools to deliver reliable, high-performing apps with ease. Get started with Genqe.ai today and experience the future of Kubernetes testing.
0 notes
Text
install podman 5 on ubuntu 24.04
How to Install Podman 5 on Ubuntu 24.04 – A Step-by-Step Guide
Podman (Pod Manager) is a powerful container management tool that provides an alternative to Docker. With its rootless architecture, enhanced security, and OCI compliance, it has become a go-to tool for developers and sysadmins alike. In this guide, we’ll walk you through how to install Podman 5 on Ubuntu 24.04, enabling you to manage containers efficiently and securely.
What is Podman?
Podman is an open-source container engine that allows you to run, build, and manage containers and pods. Unlike Docker, Podman does not require a daemon to run in the background. Instead, it uses a fork/exec model which is lightweight and rootless by default. This makes it ideal for secure container operations, especially in enterprise environments.
Why Choose Podman 5 on Ubuntu 24.04?
Ubuntu 24.04, being one of the latest LTS (Long-Term Support) releases, comes with updated libraries, improved system performance, and strong security features. Combining this with Podman 5 gives you a modern, stable, and highly secure containerization environment.
Key Benefits of Using Podman:
Rootless containers for better security.
Docker CLI compatibility via alias docker=podman.
Systemd integration for managing containerized services.
Support for pods, making it ideal for Kubernetes-like workflows.
Prerequisites
Before installing Podman on Ubuntu 24.04, ensure the following:
A system running Ubuntu 24.04.
A non-root user with sudo privileges.
Internet access to download packages.
Step-by-Step: How to Install Podman 5 on Ubuntu 24.04
Step 1: Update the System
Open a terminal and ensure your system is up-to-date:
bash
CopyEdit
sudo apt update && sudo apt upgrade -y
This ensures you have the latest packages and security patches installed.
Step 2: Install Podman from Default Repositories
Ubuntu 24.04 includes Podman 5 in its default APT repositories. Install it using:
bash
CopyEdit
sudo apt install -y podman
This command installs the latest stable version of Podman along with all necessary dependencies.
Step 3: Verify the Installation
After installation, verify the Podman version to ensure it's correctly installed:
bash
CopyEdit
podman --version
You should see output similar to:
nginx
CopyEdit
podman version 5.0.x
This confirms that Podman 5 is successfully installed on your Ubuntu 24.04 machine.
Step 4: Running Your First Podman Container
Let’s run a simple container to test Podman:
bash
CopyEdit
podman run hello-world
This command pulls the hello-world image and runs it. If the setup is correct, you’ll see a message confirming that the container is running.
Step 5: Using Podman Without Root (Optional but Recommended)
One of Podman’s most important features is rootless container support. To use it:
Log in as a regular user (non-root).
Run:
bash
CopyEdit
podman info --debug
Look under rootless to verify if rootless mode is active.
You can now run containers securely without using sudo.
Step 6: Enabling Podman Services with systemd (Optional)
If you want to manage containers as background services using systemd, Podman integrates well:
bash
CopyEdit
podman generate systemd --name mycontainer --files --restart-policy=always
This generates a .service file that you can enable and start using systemctl.
Troubleshooting Tips
If Podman fails to run, make sure the package version is correct using apt policy podman.
Use podman logs to debug failed containers.
If DNS resolution fails in containers, check your system's /etc/resolv.conf and network settings.
Conclusion
Installing Podman 5 on Ubuntu 24.04 is straightforward and provides a modern, secure alternative to Docker. Whether you’re running a development environment or deploying applications in production, Podman’s rootless, daemon-less approach makes it ideal for secure container management.
With support for pods, systemd integration, and compatibility with Docker commands, Podman 5 is the future of containerization. Ubuntu 24.04’s performance and security improvements make it a perfect OS to run it on.
Learn More
You can follow the official Vultr guide here for additional details and configurations: 👉 https://docs.vultr.com/how-to-install-podman-on-ubuntu-24-04
0 notes
Text
Designing Your First Application in… #Docker #DockerData #DockerGettingStarted https://www.altdatum.com/designing-your-first-application-in/?feed_id=135981&_unique_id=686921e964cea
0 notes
Text
Best Red Hat courses online in Bangalore
Course InfoReviews
About Course
This course provides a comprehensive introduction to container technologies and the Red Hat OpenShift Container Platform. Designed for IT professionals and developers, it focuses on building, deploying, and managing containerized applications using industry-standard tools like Podman and Kubernetes. By the end of this course, you'll gain hands-on experience in deploying applications on OpenShift and managing their lifecycle.
Show Less
What I will learn?
Build and manage containerized applications
Understand container and pod orchestration
Deploy and manage workloads in OpenShift
Course Curriculum
Module 1: Introduction to OpenShift and Containers
Module 2: Managing Applications in OpenShift
Module 3: Introduction to Kubernetes Concepts
Module 4: Deploying and Scaling Applications
Module 5: Troubleshooting Basics
OpenShift DO180 (Red Hat OpenShift I: Containers & Kubernetes) Online Exam & Certification
Get in Touch
Founded in 2004, COSSINDIA (Prodevans wing) is an ISO 9001:2008 certified a global IT training and company. Created with vision to offer high quality training services to individuals and the corporate, in the field of ‘IT Infrastructure Management’, we scaled new heights with every passing year.
Quick Links
Webinar
Privacy Policy
Terms of Use
Blogs
About Us
Contact Us
Follow Us
Facebook
Instagram
Youtube
LinkedIn
Contact Info
Monday - Sunday: 7:30 – 21:00 hrs.
Hyderabad Office: +91 7799 351 640
Bangalore Office: +91 72044 31703 / +91 8139 990 051
#Red Hat OpenShift DO180#Containers & Kubernetes Training#OpenShift Fundamentals Course#Kubernetes Essentials#Container Orchestration#Red Hat Certified Specialist#DevOps & CI/CD with OpenShift#Kubernetes Administration#OpenShift Application Deployment#Linux Container Management#docker-to-kubernetes transiti
0 notes
Text
Understanding Kubernetes for Container Orchestration in DevOps
Introduction
As organisations embrace microservices and container-driven development, managing distributed applications has become increasingly complex. Containers offer a lightweight solution for packaging and running software, but coordinating hundreds of them across environments requires automation and consistency.
To meet this challenge, DevOps teams rely on orchestration platforms. Among these, Kubernetes has emerged as the leading solution, designed to simplify the deployment, scaling, and management of containerized applications in diverse environments.
What is Kubernetes?
Kubernetes, often abbreviated as K8S, is an open-source platform that oversees container operations across clusters of machines. Initially developed by Google and now managed by the Cloud Native Computing Foundation (CNCF), it allows users to manage applications at scale by abstracting the underlying infrastructure.
With Kubernetes, engineers can ensure that applications run consistently whether on local servers, public clouds, or hybrid systems. It handles everything from load balancing and service discovery to health monitoring, reducing manual effort and improving reliability.
Core Components of Kubernetes
To understand how Kubernetes functions, let’s explore its primary building blocks:
Pods: These are the foundational units in Kubernetes. A pod holds one or more tightly coupled containers that share resources like storage and networking. They’re created and managed as a single entity.
Nodes: These are the virtual or physical machines that host and execute pods. Each node runs essential services like a container runtime and a communication agent, allowing it to function within the larger cluster.
Clusters: A cluster is a collection of nodes managed under a unified control plane. It enables horizontal scaling and provides fault tolerance through resource distribution.
Deployments: These define how many instances of an application should run and how updates should be handled. Deployments also automate scaling and version control.
ReplicaSets: These maintain the desired number of pod replicas, ensuring that workloads remain available even if a node or pod fails.
Services and Ingress: Services allow stable communication between pods or expose them to other parts of the network. Ingress manages external access and routing rules.
Imagine Kubernetes as the logistics manager of a warehouse—it allocates resources, schedules deliveries, handles failures, and keeps operations running smoothly without human intervention.
Why Kubernetes is Central to DevOps
Kubernetes plays a strategic role in enhancing DevOps practices by fostering automation, scalability, and consistency:
Automated Operations: Tasks like launching containers, monitoring health, and restarting failures are handled automatically, saving engineering time.
Elastic Scalability: Kubernetes adjusts application instances based on real-time demand, ensuring performance while conserving resources.
High Availability: With built-in self-healing features, Kubernetes ensures that application disruptions are minimized, rerouting workloads when needed.
DevOps Integration: Tools like Jenkins, GitLab, and Argo CD integrate seamlessly with Kubernetes, streamlining the entire CI/CD pipeline.
Progressive Delivery: Developers can deploy updates gradually with zero downtime, thanks to features like rolling updates and automatic rollback.
Incorporating Kubernetes into DevOps workflows leads to faster deployments, reduced errors, and improved system uptime.
Practical Use of Kubernetes in DevOps Environments
Consider a real-world scenario involving a digital platform with multiple microservices—user profiles, payment gateways, inventory systems, and messaging modules. Kubernetes enables:
Modular deployment of each microservice in its own pod
Auto-scaling of workloads based on web traffic patterns
Unified monitoring through open-source tools like Grafana
Automation of builds and releases via Helm templates and CI/CD pipelines
Network routing that handles both internal service traffic and public access
This architecture not only simplifies management but also makes it easier to isolate problems, apply patches, and roll out new features with minimal risk.
Structured Learning with Kubernetes
For professionals aiming to master Kubernetes, a hands-on approach is key. Participating in a structured devops certification course accelerates learning by blending theoretical concepts with lab exercises.
Learners typically explore:
Setting up local or cloud-based Kubernetes environments
Writing and applying YAML files for configurations
Using kubectl for cluster interactions
Building and deploying sample applications
Managing workloads using Helm, ConfigMaps, and Secrets
These practical exercises mirror real operational tasks, making students better prepared for production environments.
Career Benefits of Kubernetes Expertise
Mastery of Kubernetes is increasingly seen as a valuable asset across various job roles. Positions such as DevOps Engineer, Site Reliability Engineer (SRE), Platform Engineer, and Cloud Consultant frequently list Kubernetes experience as a key requirement.
Organisations—from startups to large enterprises—are investing in container-native infrastructure. Kubernetes knowledge enables professionals to contribute to these environments confidently, making them more competitive in the job market.
Why Certification Matters
Earning a devops certification focused on Kubernetes offers several advantages. It validates your skills through real-world exercises and provides structured guidance in mastering complex concepts.
Certifications like the CKA (Certified Kubernetes Administrator) or those offered by trusted training providers typically include:
Direct mentorship from certified experts
Realistic project environments to simulate production scenarios
Detailed assessments and feedback
Exposure to troubleshooting techniques and performance optimisation
In an industry that values proof of competency, certifications can significantly improve visibility and trust among recruiters and hiring managers.
Conclusion
Kubernetes has revolutionized how software is built, deployed, and operated in today’s cloud-first world. Its orchestration capabilities bring automation, resilience, and consistency to containerized environments, making it indispensable for modern DevOps teams.
Professionals seeking to stay relevant and competitive should consider learning Kubernetes through formal training and certification programs. These pathways not only provide practical skills but also open doors to high-demand, high-impact roles in cloud and infrastructure engineering.
0 notes
Text
How to Run Kubernetes Jobs

Contents What is Kubernetes Job? Kubernetes Job Use Cases How to Create Kubernetes Job Managing Kubernetes Job Execute Job More Than Once Execute Parallel Job Instances Limit Time for Job Completion Schedule Job How to Delete Kubernetes Job Introduction A Kubernetes cluster consists of multiple node machines that host pods, the smallest units of Kubernetes architecture. A cluster administrator defines the desired state with the necessary number of pod replicas. Accordingly, Kubernetes makes sure that the requested number of pods is always up and running. However, when managing a Kubernetes cluster, certain tasks require pods to terminate after completion. To […]
0 notes