#keras library
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Premium Tumblr themes are available from anywhere between $9 to $49.
Text
Day 13 _ What is Keras
Understanding Keras and Its Role in Deep Learning Understanding Keras and Its Role in Deep Learning What is Keras? Keras is an open-source software library that provides a Python interface for artificial neural networks. It serves as a high-level API, simplifying the process of building and training deep learning models. Developed by François Chollet, a researcher at Google, Keras was first…
0 notes
Text
i keep coming across the tf2 acronym for tensorflow 2 and having to keep working normally like a horse with blinders on
#oldtxt#i want to draw i want to draw so bad dude GOD i want tod raw#i wanna think about demo and engie in my happy little world and medic [redacted] heavy as he should#instead im having to learn whatever the fuck 'protoc' files are and why theyve decided to throw up errors#most of the damn time its because theres no proper conformity between different libraries and their different versions!!!! i oughh#what the hells the poitn of having tf 2.16.1 if i cannot use it because apparently it has a problem with keras#and who the fucks knows what that is. i sure dont and dont care to know at this point
3 notes
·
View notes
Text

















Chosen of the Sun | | dawn // fifty-one
| @catamano | @keibea | @izayoiri | @thesimperiuscurse | @maladi777 | @poisonedsimmer | @amuhav | @sani-sims | @mangopysims | @rollingsim
next / previous / beginning
TALILA: What’s going on? This all seems very official… EVE: And worrisome. Kyrie, you look like you’ve seen a ghost. KYRIE: I’m just upset… No, I’m passed upset. EVE: It’ll be alright. We’ll get through it, whatever it is, but first you need to calm down. KYRIE: I’m trying. EVE: Deep breaths. KYRIE: Right. ÅSE: Enough of this. Stop smacking around tree. What is going to be done! TALILA: Has something happened? KYRIE: Please, everyone, sit down. KYRIE: I made a promise to you all to be honest. Admittedly, I don’t know all the details myself, but the truth is… I’m alone in this. I expect some of you still see me as part of this system, and I can’t fault you for it. But with things getting so difficult, I don’t know who else to turn to but the ten of you. I trust all of you more than anyone else. SARAYN: And him? Shouldn’t we be introduced to our mysterious twelfth? KYRIE: Everyone, this is Elion. He’s been assigned to my protection, and I can go nowhere without him. You see, before you all arrived here, my sister, Lady Alphanei Loren, was taken hostage by a vigilante group known as the Knights of Dawn. They are ransoming her life in return for the disbanding of the trials. A plan that won’t work for them while I still live. They’ve already made one attempt on my life. If Lord Tev’us hadn’t been with me that night, surely I’d already be dead. ÅSE: Mm… TALILA: How awful! But… how are we just now hearing of it? Why wouldn’t they want us to know? THERION: I expect they don’t want anyone to know. Stirring up confusion and fear makes for panic. Panic is hard to control. INDRYR: And they are all about control. EIRA: So what? If we sit here with our thumbs up our asses, they’ll just send more people to kill you. Does your Priestess think she can lock you— and us— up forever? KYRIE: Lucien is dead. This isn’t something they can contain. The entire city will be in chaos soon enough. EVE: Lucien is dead? But why? Who would kill him? INDRYR: That is the question. Considering everything, it would be naïve to think the two matters were not connected. ÅSE: He is innocent child! What cares he about knights and dawn? It is absurd! INDRYR: Yes, the child was almost certainly innocent. I expect it is more what he represented. ASTER: Well, don’t speak in riddles! Not all of us grew up in libraries, you know! KYRIE: Represents… Of course. EVE: Oh… Lucien’s mother… KYRIE: The Aravae offer enormous financial support to the church. Aside from the Eveydan Crown, they’re the main source of funding. Unbelievable. The Queen of Kera was the leading supporter for the Selenehelion’s reformation… SARAYN: Then they are not at all interested in compromise. Bloodsport or not, it seems they will stop at nothing to bring the ceremony down entirely. I expect they have very good reason. EIRA: Being angry about how a ceremony was conducted centuries ago doesn’t make a great case for slaughtering children. SARAYN: But it was not centuries ago. Those that have been robbed by these trials still live. To lose a love, a purpose… a King. No, I doubt they have forgotten. And I doubt less they shall forgive.
#ts4#ts4 screenshots#ts4 story#ts4 bachelor challenge#chosen of the sun#oc: kyrie loren#cc: åse dalgaard#cc: aster songleaf#cc: eira#cc: eve ravenclaw-silvermoon#cc: indryr#cc: sarayn tev'us#cc: talila#cc: taiyo hayashi#cc: tayuin eth'salin#cc: therion erandaer#oc: elion maharis#sorry guys#I started a new (and third) job#didn't have the energy or time to set up a 12 sim scene#will probably be a bit slow#had to delay appreciation gift but it is still coming I promise!
46 notes
·
View notes
Text
What is Python?
A Language for Everyone – From Beginners to Pros!
Python is a high-level, versatile programming language renowned for its clean syntax and powerful capabilities. It's designed to be beginner-friendly, making it an excellent choice for new programmers, yet it remains robust enough for building complex systems. Its versatility and ease of use have propelled it to the forefront of the programming world.
Python Programming Language
Why Learn Python?
Python offers a myriad of benefits for learners and professionals alike, making it a worthwhile endeavor for anyone interested in programming. Here are some compelling reasons to learn Python:
Simple & Easy to Learn: Python's clean and readable syntax allows beginners to pick up programming concepts without the steep learning curve associated with many other languages.
Powerful for Data Science & Machine Learning: Python's extensive libraries, such as Pandas, NumPy, and TensorFlow, make it a powerhouse in the realms of data science and machine learning, enabling complex data analysis and predictive modeling.
Web Development with Django & Flask: Python provides powerful frameworks like Django and Flask, which streamline the process of building dynamic web applications with ease and speed.
Game Development & Automation: With libraries like Pygame, Python makes creating simple games accessible, while its scripting capabilities excel in automating repetitive tasks.
Scientific Computing: Python is a staple in scientific research, offering tools like SciPy and Matplotlib for scientific computing and data visualization.
AI & Deep Learning: Python's integration with AI and deep learning libraries such as Keras and PyTorch makes it a preferred language for developing cutting-edge AI systems.
App & Software Prototyping: Its simplicity allows developers to quickly prototype applications, making it an excellent choice for testing ideas and building MVPs.
Why Learn Python
Where is Python Used?
Python's versatility and power have led to its wide adoption across numerous industries and applications. Here are some areas where Python shines:
Companies: Major players such as Google, Netflix, NASA, Facebook, and IBM rely on Python for various aspects of their technology stack, demonstrating its reliability and scalability.
Fields: Python is indispensable in fields such as AI, web development, data science, cybersecurity, and automation, showcasing its adaptability to diverse challenges.
Education: Python holds the title of the #1 language taught in universities globally, reflecting its importance in modern computer science education and its role in nurturing the next generation of programmers.
Implementation Of Python
Conclusion
Python's combination of simplicity, power, and versatility makes it an essential language for anyone looking to delve into programming, whether starting from scratch or expanding their existing skill set.
HOME
youtube
#PythonVariables#PythonDataTypes#LearnPython#PythonProgramming#CodingWithPython#VariablesInPython#DataTypesExplained#PythonForBeginners#ProgrammingBasics#PythonTutorial#AssignmentHelp#AssignmentOnClick#assignment help#machinelearning#techforstudents#assignmentwriting#assignment service#assignment#assignmentexperts#aiforstudents#Youtube
2 notes
·
View notes
Text
Best AI Training in Electronic City, Bangalore – Become an AI Expert & Launch a Future-Proof Career!



youtube
Artificial Intelligence (AI) is reshaping industries and driving the future of technology. Whether it's automating tasks, building intelligent systems, or analyzing big data, AI has become a key career path for tech professionals. At eMexo Technologies, we offer a job-oriented AI Certification Course in Electronic City, Bangalore tailored for both beginners and professionals aiming to break into or advance within the AI field.
Our training program provides everything you need to succeed—core knowledge, hands-on experience, and career-focused guidance—making us a top choice for AI Training in Electronic City, Bangalore.
🌟 Who Should Join This AI Course in Electronic City, Bangalore?
This AI Course in Electronic City, Bangalore is ideal for:
Students and Freshers seeking to launch a career in Artificial Intelligence
Software Developers and IT Professionals aiming to upskill in AI and Machine Learning
Data Analysts, System Engineers, and tech enthusiasts moving into the AI domain
Professionals preparing for certifications or transitioning to AI-driven job roles
With a well-rounded curriculum and expert mentorship, our course serves learners across various backgrounds and experience levels.
📘 What You Will Learn in the AI Certification Course
Our AI Certification Course in Electronic City, Bangalore covers the most in-demand tools and techniques. Key topics include:
Foundations of AI: Core AI principles, machine learning, deep learning, and neural networks
Python for AI: Practical Python programming tailored to AI applications
Machine Learning Models: Learn supervised, unsupervised, and reinforcement learning techniques
Deep Learning Tools: Master TensorFlow, Keras, OpenCV, and other industry-used libraries
Natural Language Processing (NLP): Build projects like chatbots, sentiment analysis tools, and text processors
Live Projects: Apply knowledge to real-world problems such as image recognition and recommendation engines
All sessions are conducted by certified professionals with real-world experience in AI and Machine Learning.
🚀 Why Choose eMexo Technologies – The Best AI Training Institute in Electronic City, Bangalore
eMexo Technologies is not just another AI Training Center in Electronic City, Bangalore—we are your AI career partner. Here's what sets us apart as the Best AI Training Institute in Electronic City, Bangalore:
✅ Certified Trainers with extensive industry experience ✅ Fully Equipped Labs and hands-on real-time training ✅ Custom Learning Paths to suit your individual career goals ✅ Career Services like resume preparation and mock interviews ✅ AI Training Placement in Electronic City, Bangalore with 100% placement support ✅ Flexible Learning Modes including both classroom and online options
We focus on real skills that employers look for, ensuring you're not just trained—but job-ready.
🎯 Secure Your Future with the Leading AI Training Institute in Electronic City, Bangalore
The demand for skilled AI professionals is growing rapidly. By enrolling in our AI Certification Course in Electronic City, Bangalore, you gain the tools, confidence, and guidance needed to thrive in this cutting-edge field. From foundational concepts to advanced applications, our program prepares you for high-demand roles in AI, Machine Learning, and Data Science.
At eMexo Technologies, our mission is to help you succeed—not just in training but in your career.
📞 Call or WhatsApp: +91-9513216462 📧 Email: [email protected] 🌐 Website: https://www.emexotechnologies.com/courses/artificial-intelligence-certification-training-course/
Seats are limited – Enroll now in the most trusted AI Training Institute in Electronic City, Bangalore and take the first step toward a successful AI career.
🔖 Popular Hashtags
#AITrainingInElectronicCityBangalore#AICertificationCourseInElectronicCityBangalore#AICourseInElectronicCityBangalore#AITrainingCenterInElectronicCityBangalore#AITrainingInstituteInElectronicCityBangalore#BestAITrainingInstituteInElectronicCityBangalore#AITrainingPlacementInElectronicCityBangalore#MachineLearning#DeepLearning#AIWithPython#AIProjects#ArtificialIntelligenceTraining#eMexoTechnologies#FutureTechSkills#ITTrainingBangalore#Youtube
3 notes
·
View notes
Text
Best AI Training in Electronic City, Bangalore – Become an AI Expert & Launch a Future-Proof Career!



Artificial Intelligence (AI) is reshaping industries and driving the future of technology. Whether it's automating tasks, building intelligent systems, or analyzing big data, AI has become a key career path for tech professionals. At eMexo Technologies, we offer a job-oriented AI Certification Course in Electronic City, Bangalore tailored for both beginners and professionals aiming to break into or advance within the AI field.
Our training program provides everything you need to succeed—core knowledge, hands-on experience, and career-focused guidance—making us a top choice for AI Training in Electronic City, Bangalore.
🌟 Who Should Join This AI Course in Electronic City, Bangalore?
This AI Course in Electronic City, Bangalore is ideal for:
Students and Freshers seeking to launch a career in Artificial Intelligence
Software Developers and IT Professionals aiming to upskill in AI and Machine Learning
Data Analysts, System Engineers, and tech enthusiasts moving into the AI domain
Professionals preparing for certifications or transitioning to AI-driven job roles
With a well-rounded curriculum and expert mentorship, our course serves learners across various backgrounds and experience levels.
📘 What You Will Learn in the AI Certification Course
Our AI Certification Course in Electronic City, Bangalore covers the most in-demand tools and techniques. Key topics include:
Foundations of AI: Core AI principles, machine learning, deep learning, and neural networks
Python for AI: Practical Python programming tailored to AI applications
Machine Learning Models: Learn supervised, unsupervised, and reinforcement learning techniques
Deep Learning Tools: Master TensorFlow, Keras, OpenCV, and other industry-used libraries
Natural Language Processing (NLP): Build projects like chatbots, sentiment analysis tools, and text processors
Live Projects: Apply knowledge to real-world problems such as image recognition and recommendation engines
All sessions are conducted by certified professionals with real-world experience in AI and Machine Learning.
🚀 Why Choose eMexo Technologies – The Best AI Training Institute in Electronic City, Bangalore
eMexo Technologies is not just another AI Training Center in Electronic City, Bangalore—we are your AI career partner. Here's what sets us apart as the Best AI Training Institute in Electronic City, Bangalore:
✅ Certified Trainers with extensive industry experience ✅ Fully Equipped Labs and hands-on real-time training ✅ Custom Learning Paths to suit your individual career goals ✅ Career Services like resume preparation and mock interviews ✅ AI Training Placement in Electronic City, Bangalore with 100% placement support ✅ Flexible Learning Modes including both classroom and online options
We focus on real skills that employers look for, ensuring you're not just trained—but job-ready.
🎯 Secure Your Future with the Leading AI Training Institute in Electronic City, Bangalore
The demand for skilled AI professionals is growing rapidly. By enrolling in our AI Certification Course in Electronic City, Bangalore, you gain the tools, confidence, and guidance needed to thrive in this cutting-edge field. From foundational concepts to advanced applications, our program prepares you for high-demand roles in AI, Machine Learning, and Data Science.
At eMexo Technologies, our mission is to help you succeed—not just in training but in your career.
📞 Call or WhatsApp: +91-9513216462 📧 Email: [email protected] 🌐 Website: https://www.emexotechnologies.com/courses/artificial-intelligence-certification-training-course/
Seats are limited – Enroll now in the most trusted AI Training Institute in Electronic City, Bangalore and take the first step toward a successful AI career.
🔖 Popular Hashtags:
#AITrainingInElectronicCityBangalore#AICertificationCourseInElectronicCityBangalore#AICourseInElectronicCityBangalore#AITrainingCenterInElectronicCityBangalore#AITrainingInstituteInElectronicCityBangalore#BestAITrainingInstituteInElectronicCityBangalore#AITrainingPlacementInElectronicCityBangalore#MachineLearning#DeepLearning#AIWithPython#AIProjects#ArtificialIntelligenceTraining#eMexoTechnologies#FutureTechSkills#ITTrainingBangalore
2 notes
·
View notes
Text
range
pertengahan tahun 2024, dimulai dengan ikhtiar menyambung silaturahmi sama temen-temen lama. sampe akhirnya ketemu satu perpustakaan di jakarta, yang setiap weekend selalu aku datengin cuma-cuma, cuma buat sekedar nyari tenang sebentar dari rutinitas melelahkan di kantor, atau sekedar baca buku dan pinjem beberapa bukunya untuk dibawa pulang (karna udah langganan member mereka untuk setahun hehe)
padahal perjalanan dari kos ke perpus cukup lama, bisa memakan waktu 2 jam naik transportasi umum. kadang telinga sengaja disumpel pake spotify biar lebih asik. tapi lately, jadi lebih suka diem dan mindful aja ngeliatin lingkungan sekitar. sesi observasi ini ternyata unik dan jadi bikin punya banyak pemikiran baru. yg seringkali bikin sedih, mikir dan bertanya ini dan itu, dan banyak kali bikin bersyukur.
————————————————————————————
pernah ketemu ibu-ibu yang nanya jalan dan akhirnya cerita segala macem soal anaknya yang kemudian bikin aku langsung pengen telfon mama di sore harinya
ngeliat kalo rasanya semua orang berusaha dengan keras, desek-desekan di transportasi umum kadang bikin bete karna panas dan sumpek, tapi kalo lagi rush hour rasanya kadang jadi punya energi lagi kalo “semua orang lagi berusaha” dan bikin mellow entah kenapa karna ngerasa diri sendiri lagi usaha juga kerja ngerantau jauh dari rumah
ikut volunteer dan ketemu temen-temen guru SLB yang selalu membagikan cerita mereka lewat story waktu ngajar anak-anak down syndrome. disadarkan kalo di luar sana banyak orang sabar luar biasa yg Allah amanahi buat ngasih harapan baru di hati kecil anak-anak itu. selalu amazed setiap denger ceritanya
ada banyak hal memorable yang ga bisa diungkapkan semuanya lewat tulisan
————————————————————————————-
tahun 2024 ditutup dengan 34 buku yang berhasil dibaca. tahun kemarin temanya tentang eksplorasi diri (mulai dari karir, level spiritual, dan ikhtiar cari jurusan yg paling cocok buat S2 nanti yg belum tau kapan bisa tercapai hehe). ikut beberapa kelas lewat instagram dan offline juga. semoga tahun ini bisa lebih banyak explore dan belajar.
tahun 2024 juga penuh dengan diri sendiri yg nyobain masak ini dan itu. buat trial catering dan juga buat coba-coba aja waktu udah jadi istri nanti (ceilah) blm tau kapan sih HAHAHA :(((((
tahun ini ingin mencoba hidup lebih mindful dan sehat lagi tapi versi indonesia aja. udah liat beberapa cuplikan dokter zaidul akbar dan obrolan podcast momscorner yang sangat aku suka——jadi menyimpulkan kalo Indonesia punya banyak sekali opsi makanan sehat. jadi tahun ini temanya pengen lebih belajar masak makanan yg super medok rempah Indonesia.
————————————————————————————-
sebagai salah satu orang yang menganggap spesialisasi itu keren, ada salah satu buku yg sangat aku suka. judulnya Range. buku ini nunjukin kalo dunia ini sangat general dan it will be super fun kalo kita jadiin diri kita sebagai orang yg general juga, bisa apa aja, belajar dan cobain apa aja
sampe akhirnya ngeconsider buat ambil master di bisnis, tapi masih harus nentuin skala prioritas dulu terkait uang, tempat dan waktunya hehe
————————————————————————————-
special mention buat foreword library. terima kasih udah selalu jadi tempat nyaman setiap minggunya untuk ngerasain tenang di tengah-tengah jakarta. tempat yang selalu aku nantikan di akhir minggu buat didatengin. tempat yang selalu aku nikmati perjalanan pulang dan perginya <3

3 notes
·
View notes
Text
Techaircraft
Dive into the world of Artificial Intelligence with Python! 🐍💡 Whether you're a seasoned coder or just starting, Python’s versatile libraries like Tensor Flow, Kera's, and sci-kit-learn make it easier than ever to build intelligent systems. 🤖 From developing predictive models to creating advanced neural networks, Python is your gateway to the future of technology. 📈🔍 Explore data analysis, natural language processing, and machine learning with hands-on projects that unlock endless possibilities. 🌐💻 Ready to level up your AI skills? Follow along for tutorials, tips, and inspiration to turn your innovative ideas into reality. . 𝐖𝐞𝐛𝐬𝐢𝐭𝐞 - www.techaircraft.com
𝐓𝐞𝐜𝐡𝐚𝐢𝐫𝐜𝐫𝐚𝐟𝐭 𝐬𝐮𝐩𝐩𝐨𝐫𝐭 𝐝𝐞𝐭𝐚𝐢𝐥𝐬:
𝐌𝐨𝐛𝐢𝐥𝐞 𝐍𝐮𝐦𝐛𝐞𝐫 - 8686069898
#ArtificialIntelligence#PythonProgramming#MachineLearning#DataScience#TechInnovation#NeuralNetworks#DeepLearning#CodingLife#PythonDeveloper#AIProjects#FutureOfTech#TechTrends#Programming#DataAnalysis#TensorFlow#Keras#ScikitLearn#LearnToCode#AICommunity#Innovation

2 notes
·
View notes
Text
PREDICTING WEATHER FORECAST FOR 30 DAYS IN AUGUST 2024 TO AVOID ACCIDENTS IN SANTA BARBARA, CALIFORNIA USING PYTHON, PARALLEL COMPUTING, AND AI LIBRARIES

Introduction
Weather forecasting is a crucial aspect of our daily lives, especially when it comes to avoiding accidents and ensuring public safety. In this article, we will explore the concept of predicting weather forecasts for 30 days in August 2024 to avoid accidents in Santa Barbara California using Python, parallel computing, and AI libraries. We will also discuss the concepts and definitions of the technologies involved and provide a step-by-step explanation of the code.
Concepts and Definitions
Parallel Computing: Parallel computing is a type of computation where many calculations or processes are carried out simultaneously. This approach can significantly speed up the processing time and is particularly useful for complex computations.
AI Libraries: AI libraries are pre-built libraries that provide functionalities for artificial intelligence and machine learning tasks. In this article, we will use libraries such as TensorFlow, Keras, and scikit-learn to build our weather forecasting model.
Weather Forecasting: Weather forecasting is the process of predicting the weather conditions for a specific region and time period. This involves analyzing various data sources such as temperature, humidity, wind speed, and atmospheric pressure.
Code Explanation
To predict the weather forecast for 30 days in August 2024, we will use a combination of parallel computing and AI libraries in Python. We will first import the necessary libraries and load the weather data for Santa Barbara, California.
import numpy as np
import pandas as pd
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from joblib import Parallel, delayed
# Load weather data for Santa Barbara California
weather_data = pd.read_csv('Santa Barbara California_weather_data.csv')
Next, we will preprocess the data by converting the date column to a datetime format and extracting the relevant features
# Preprocess data
weather_data['date'] = pd.to_datetime(weather_data['date'])
weather_data['month'] = weather_data['date'].dt.month
weather_data['day'] = weather_data['date'].dt.day
weather_data['hour'] = weather_data['date'].dt.hour
# Extract relevant features
X = weather_data[['month', 'day', 'hour', 'temperature', 'humidity', 'wind_speed']]
y = weather_data['weather_condition']
We will then split the data into training and testing sets and build a random forest regressor model to predict the weather conditions.
# Split data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Build random forest regressor model
rf_model = RandomForestRegressor(n_estimators=100, random_state=42)
rf_model.fit(X_train, y_train)
To improve the accuracy of our model, we will use parallel computing to train multiple models with different hyperparameters and select the best-performing model.
# Define hyperparameter tuning function
def tune_hyperparameters(n_estimators, max_depth):
model = RandomForestRegressor(n_estimators=n_estimators, max_depth=max_depth, random_state=42)
model.fit(X_train, y_train)
return model.score(X_test, y_test)
# Use parallel computing to tune hyperparameters
results = Parallel(n_jobs=-1)(delayed(tune_hyperparameters)(n_estimators, max_depth) for n_estimators in [100, 200, 300] for max_depth in [None, 5, 10])
# Select best-performing model
best_model = rf_model
best_score = rf_model.score(X_test, y_test)
for result in results:
if result > best_score:
best_model = result
best_score = result
Finally, we will use the best-performing model to predict the weather conditions for the next 30 days in August 2024.
# Predict weather conditions for next 30 days
future_dates = pd.date_range(start='2024-09-01', end='2024-09-30')
future_data = pd.DataFrame({'month': future_dates.month, 'day': future_dates.day, 'hour': future_dates.hour})
future_data['weather_condition'] = best_model.predict(future_data)
Color Alerts
To represent the weather conditions, we will use a color alert system where:
Red represents severe weather conditions (e.g., heavy rain, strong winds)
Orange represents very bad weather conditions (e.g., thunderstorms, hail)
Yellow represents bad weather conditions (e.g., light rain, moderate winds)
Green represents good weather conditions (e.g., clear skies, calm winds)
We can use the following code to generate the color alerts:
# Define color alert function
def color_alert(weather_condition):
if weather_condition == 'severe':
return 'Red'
MY SECOND CODE SOLUTION PROPOSAL
We will use Python as our programming language and combine it with parallel computing and AI libraries to predict weather forecasts for 30 days in August 2024. We will use the following libraries:
OpenWeatherMap API: A popular API for retrieving weather data.
Scikit-learn: A machine learning library for building predictive models.
Dask: A parallel computing library for processing large datasets.
Matplotlib: A plotting library for visualizing data.
Here is the code:
```python
import pandas as pd
import numpy as np
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error
import dask.dataframe as dd
import matplotlib.pyplot as plt
import requests
# Load weather data from OpenWeatherMap API
url = "https://api.openweathermap.org/data/2.5/forecast?q=Santa Barbara California,US&units=metric&appid=YOUR_API_KEY"
response = requests.get(url)
weather_data = pd.json_normalize(response.json())
# Convert data to Dask DataFrame
weather_df = dd.from_pandas(weather_data, npartitions=4)
# Define a function to predict weather forecasts
def predict_weather(date, temperature, humidity):
# Use a random forest regressor to predict weather conditions
model = RandomForestRegressor(n_estimators=100, random_state=42)
model.fit(weather_df[["temperature", "humidity"]], weather_df["weather"])
prediction = model.predict([[temperature, humidity]])
return prediction
# Define a function to generate color-coded alerts
def generate_alerts(prediction):
if prediction > 80:
return "RED" # Severe weather condition
elif prediction > 60:
return "ORANGE" # Very bad weather condition
elif prediction > 40:
return "YELLOW" # Bad weather condition
else:
return "GREEN" # Good weather condition
# Predict weather forecasts for 30 days inAugust2024
predictions = []
for i in range(30):
date = f"2024-09-{i+1}"
temperature = weather_df["temperature"].mean()
humidity = weather_df["humidity"].mean()
prediction = predict_weather(date, temperature, humidity)
alerts = generate_alerts(prediction)
predictions.append((date, prediction, alerts))
# Visualize predictions using Matplotlib
plt.figure(figsize=(12, 6))
plt.plot([x[0] for x in predictions], [x[1] for x in predictions], marker="o")
plt.xlabel("Date")
plt.ylabel("Weather Prediction")
plt.title("Weather Forecast for 30 Days inAugust2024")
plt.show()
```
Explanation:
1. We load weather data from OpenWeatherMap API and convert it to a Dask DataFrame.
2. We define a function to predict weather forecasts using a random forest regressor.
3. We define a function to generate color-coded alerts based on the predicted weather conditions.
4. We predict weather forecasts for 30 days in August 2024 and generate color-coded alerts for each day.
5. We visualize the predictions using Matplotlib.
Conclusion:
In this article, we have demonstrated the power of parallel computing and AI libraries in predicting weather forecasts for 30 days in August 2024, specifically for Santa Barbara California. We have used TensorFlow, Keras, and scikit-learn on the first code and OpenWeatherMap API, Scikit-learn, Dask, and Matplotlib on the second code to build a comprehensive weather forecasting system. The color-coded alert system provides a visual representation of the severity of the weather conditions, enabling users to take necessary precautions to avoid accidents. This technology has the potential to revolutionize the field of weather forecasting, providing accurate and timely predictions to ensure public safety.
RDIDINI PROMPT ENGINEER
2 notes
·
View notes
Text
Rejected
Yaampun terakhir nulis minggu lalu ya. Masih sangat hepi bahkan lagi diare pun ngapdet Tumblr. Tapi setelah hari Kamis itu, semua berubah. Aku lupa Jumat ngapain, kayanya ngelanjutina nyuci carius tubes. Terus Sabtu kelas 16 pagi, pengajian, baca di Gladstone Link terkait Islam di Indonesia (¿). I know ku anaknya emang random banget, kayanya Jumat malamnya juga nonton Balibo itu deh, atau itu Kamis malam ya lupa. Terus Minggu kelas 16 lagi (setelah kesiangan 1 jam karena ternyata BST berubah jadi DST), DILANJUT BACA EMAIL MASUK DECISION LETTER DARI G-CUBED YANG SUPER LAKNAT, lalu ngopi sama Ketua PPI Oxford baru terpilih di Opera. Pulang ngapain lupa.
Langsung deh Senin kemarin pusing dan nangis aja si Asri nih. Paginya jam 9 ku email spv dan postdoc terkait paper yang ke-reject ini. Si postdoc langsung whatsapp ngajak ketemuan karena kayanya dia khawatir aja sih. Terus Bang Reybi juga ngajak ngopi karena malamnya ku tantrum dramatis di stori insta. Udah janjian kerja di library Exeter sama Puspa sebetulnya, tapi jadinya cuma makan Sasi’s aja sama dia. Pas di Opera sama Bang Reybi ku MENANGIS HUHU. Padahal beneran lagi BAHAS SAINS!!! Kaya Bang Reybi nanya “emangnya apa Non komennya?” terus pas recounting langsung BANJIR?! Kayanya karena ku belum sepenuhnya processing my emotion di hari Minggu itu. Ku gatau apakah ini aku sedih? Atau upset? Atau biasa aja? Kayanya pas hari Minggu lebih ke kesel sih dan mau “sok kuat” “gapapa kok yang kemarin kena reject pertama lebih menyedihkan Non”. Padahal nggak. Yang ini lebih menyedihkan karena ku betulan udah yang NGERAPIHIN BANGET dan BEKERJA SANGAT KERAS untuk resubmission ini. Bukan berarti yang versi pertama nggak bekerja keras ya, tapi lebih kayak… yang resubmission ini TUH UDAH BAGUS BANGET gitu loh (menurut aku, the author, tentu saja). Literally ku bisa bilang 10x lebih bagus dari first submission. TERUS AFTER ALL THOSE WORK masih aja ga nembus?
Dan lebih ke frustrated aja sih. Betulan kaya jalan nabrak tembok aja terus. Setelah semua usaha. Kayak... YAALLAH kenapa sih.... Terus tapi setelah kemarin ngobrol sama postdoc dan dibales email juga sama spv semalam, bisa lebih lega karena bisa putting blame in other people aja HAHA yaitu: the editor. Emang beda ya, inilah pentingnya ngobrol sama orang yang sudah mengalami proses ini berkali-kali dan bahkan menjadi editor juga. Mereka ngejelasin gimana si editor jurnal ini super-problematik: nggak nyari 3rd reviewer (there are reasons why peer-reviewers itu minimal 3 dan jumlahnya ganjil), terus entah kenapa dari 2 reviews yang SUPER BEDA DECISIONNYA ini (satu decline dan satu accept with MINOR REVISION mind you) (dan yang nge-accept ini adalah orang yang juga ngereview first submission-ku, which means he knew how this manuscript has evolved BETTEr than the NEW Reviewer#2 yang super-mean), si editor decided to take the DECLINE recommendation? Kayak Bro, make your own decision juga?? That’s what you’re getting paid as an editor for??? Hhhhh.
Terus ya setelah ngobrol sama postdoc juga, we agreed that si Reviewer#2 ini juga problematic dalam interpreting our words. Somehow dia ngambil kesimpulan sendiri aja gitu yang cukup jauh dan ekstrim dari apa yang kita tulis. Contoh: jelas-jelas nih ye, DI section 5.6. (yang dia suruh hapus karena “ABSURD. MANA ADA MULTIMILLION OIL COMPANIES WOULD MAKE THEIR DECISION BASED ON YOUR FINDING”), we didn’t FUCKING SAY ANYTHING ABOUT OIL COMPANIES SHOULD USE MY FINDING TO MAKE ANY DECISION WHATSOEVER??! Ku cuma bilang “OK, jadi dari study ini kemungkinan besar Hg di source rock gaakan ngefek ke produced hydrocarbon, avoiding the cost of extra-facilities for Hg removal”. JUJUR KURANG TONED-DOWN APA LAGI SIH ITU KALIMAT??! Harus di-spell out juga uncertainties-nya berapa??! Dan beneran ku bikin section ini (awalnya gaada di first submission) karena salah satu reviewer di first submission ngerasa “impact ni paper bisa di-explore lagi ke industry, ga cuma sains aja”. HHHHHHHHHHHHHH. APASIH. Haha jadi getting worked up lagi sekarang pas nulis ini.
Anyway. Iya. Cukup lega dari kemarin udah ngobrol dengan banyak orang. Dari Bang Reybi yang super-practical & helpful & penuh solusi (karena coming from-nya adalah dari sincerity kayanya kasihan kali ya melihat aku sedih), sampe jadi ranting bareng postdoc dan spv yang emang lebih paham medan perangnya dan problem apa aja yang ada di peer-review system dan science publishing YANG SUPER MAHAL ini. Teman-teman di insta juga mungkin mau bantuin tapi karena kami datang dari dunia yang sangat berbeda agak susah ngasih support kaya gimana… tetap terima kasih banyak (emoji salim)… Ada juga teman sesama PhD yang mostly reply “WAH KEJAM BANGET REVIEWNYA” “Wah pedas sekali” à ini sangat validating bahwa bukan aku aja yang ngerasa itu komen sangat harsh…, terus teman-teman PhD lain yang sharing experience kena reject juga (making me realise bahwa I’m not alone experiencing ini)… teman-teman yang ga PhD juga shared dari experience mereka capek aja sama hidup in general, yang udah nyoba berkali-kali tetep ga berhasil juga. Iqbalpaz yang w tumpahin semua di chat dm insta & ngingetin buat booking konseling (salim). Yang sharing betapa helpfulnya konseling buat mereka… Yang nge-salut-in aku karena mau keluar dari comfort zone Indo buat ambil PhD ke Oxford… Pokoknya berbelas-belas replies itu betulan makasih banget banget banget. Just the fact that you guys took your time to READ MY POST (harus nge-pause dulu kan buat baca teks2 kecil itu), apalagi sampe nge-REPLY. Pokoknya semoga kebaikannya kembali ke kaliannn.
Dah gitu dulu aja berterima kasih-nya. Tapi lesson learned-nya adalah: kalau buat diriku sendiri sepertinya memang harus bilang dan cerita ke luar kalau lagi sedih. Jauh lebih cepat leganya. Dulu awal-awal PhD (2021 awal), aku kalau frustrated terhadap sesuatu cuma di-bottled up aja, dan betulan ngilang. Ga apdet stori. Ga texting siapapun. Semuanya dipikirin sendiri. Ngeri deh. Kenapa ya,, apa karena ngerasa gaada safe space buat sharing ya. Dan masih ngerasa yang “ga enakan”, mikirnya “duh kalau gw ngepos gini apa nggak kaya orang ga bersyukur ya”. Setelah konseling pertama di 2022 sepertinya mindsetnya mulai berubah. Dan ya emang 2021 gapunya teman juga sih. Sekarang Alhamdulillah ada lah beberapa teman yang bisa dicurhatin.
HHHHHH ALHAMDULILLAH.
Terus ku juga mulai sekarang akan reach out ke teman-teman yang kelihatan dari postnya lagi sedih atau upset. Kalaupun gabisa bantu ngajak ngopi atau ngobrol banget, minimal nge-reply stori mereka aja validating what they’re feeling (apalagi kalau cewek ya yang sangat rentan blaming themselves, and feeling guilty, just for complaining misalnya), kadang kalau bisa ya ikut nganjing-nganjingin juga, dan letting them know aja that I’m here for them whenever they need me.
Lah jadi panjang ni post. Dah gitu aja dulu. Ini mau pulang deh.
VHL 16:17 31/10/2023
7 notes
·
View notes
Text
Essential Skills for Aspiring Data Scientists in 2024

Welcome to another edition of Tech Insights! Today, we're diving into the essential skills that aspiring data scientists need to master in 2024. As the field of data science continues to evolve, staying updated with the latest skills and tools is crucial for success. Here are the key areas to focus on:
1. Programming Proficiency
Proficiency in programming languages like Python and R is foundational. Python, in particular, is widely used for data manipulation, analysis, and building machine learning models thanks to its rich ecosystem of libraries such as Pandas, NumPy, and Scikit-learn.
2. Statistical Analysis
A strong understanding of statistics is essential for data analysis and interpretation. Key concepts include probability distributions, hypothesis testing, and regression analysis, which help in making informed decisions based on data.
3. Machine Learning Mastery
Knowledge of machine learning algorithms and frameworks like TensorFlow, Keras, and PyTorch is critical. Understanding supervised and unsupervised learning, neural networks, and deep learning will set you apart in the field.
4. Data Wrangling Skills
The ability to clean, process, and transform data is crucial. Skills in using libraries like Pandas and tools like SQL for database management are highly valuable for preparing data for analysis.
5. Data Visualization
Effective communication of your findings through data visualization is important. Tools like Tableau, Power BI, and libraries like Matplotlib and Seaborn in Python can help you create impactful visualizations.
6. Big Data Technologies
Familiarity with big data tools like Hadoop, Spark, and NoSQL databases is beneficial, especially for handling large datasets. These tools help in processing and analyzing big data efficiently.
7. Domain Knowledge
Understanding the specific domain you are working in (e.g., finance, healthcare, e-commerce) can significantly enhance your analytical insights and make your solutions more relevant and impactful.
8. Soft Skills
Strong communication skills, problem-solving abilities, and teamwork are essential for collaborating with stakeholders and effectively conveying your findings.
Final Thoughts
The field of data science is ever-changing, and staying ahead requires continuous learning and adaptation. By focusing on these key skills, you'll be well-equipped to navigate the challenges and opportunities that 2024 brings.
If you're looking for more in-depth resources, tips, and articles on data science and machine learning, be sure to follow Tech Insights for regular updates. Let's continue to explore the fascinating world of technology together!
#artificial intelligence#programming#coding#python#success#economy#career#education#employment#opportunity#working#jobs
2 notes
·
View notes
Text
Exploring Game-Changing Applications: Your Easy Steps to Learn Machine Learning:

Machine learning technology has truly transformed multiple industries and continues to hold enormous potential for future development. If you're considering incorporating machine learning into your business or are simply eager to learn more about this transformative field, seeking advice from experts or enrolling in specialized courses is a wise step. For instance, the ACTE Institute offers comprehensive machine learning training programs that equip you with the knowledge and skills necessary for success in this rapidly evolving industry. Recognizing the potential of machine learning can unlock numerous avenues for data analysis, automation, and informed decision-making.
Now, let me share my successful journey in machine learning, which I believe can benefit everyone. These 10 steps have proven to be incredibly effective in helping me become a proficient machine learning practitioner:
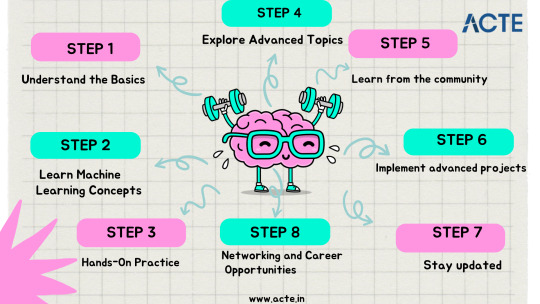
Step 1: Understand the Basics
Develop a strong grasp of fundamental mathematics, particularly linear algebra, calculus, and statistics.
Learn a programming language like Python, which is widely used in machine learning and provides a variety of useful libraries.
Step 2: Learn Machine Learning Concepts
Enroll in online courses from reputable platforms like Coursera, edX, and Udemy. Notably, the ACTE machine learning course is a stellar choice, offering comprehensive education, job placement, and certification.
Supplement your learning with authoritative books such as "Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow" by Aurélien Géron and "Pattern Recognition and Machine Learning" by Christopher Bishop.
Step 3: Hands-On Practice:
Dive into real-world projects using both simple and complex datasets. Practical experience is invaluable for gaining proficiency.
Participate in machine learning competitions on platforms like Kaggle to challenge yourself and learn from peers.
Step 4: Explore Advanced Topics
Delve into deep learning, a critical subset of machine learning that focuses on neural networks. Online resources like the Deep Learning Specialisation on Coursera are incredibly informative.
For those intrigued by language-related applications, explore Natural Language Processing (NLP) using resources like the "Natural Language Processing with Python" book by Steven Bird and Ewan Klein.
Step 5: Learn from the Community
Engage with online communities such as Reddit's r/Machine Learning and Stack Overflow. Participate in discussions, seek answers to queries, and absorb insights from others' experiences.
Follow machine learning blogs and podcasts to stay updated on the latest advancements, case studies, and best practices.
Step 6: Implement Advanced Projects
Challenge yourself with intricate projects that stretch your skills. This might involve tasks like image recognition, building recommendation systems, or even crafting your own AI-powered application.
Step 7: Stay updated
Stay current by reading research papers from renowned conferences like NeurIPS, ICML, and CVPR to stay on top of cutting-edge techniques.
Consider advanced online courses that delve into specialized topics such as reinforcement learning and generative adversarial networks (GANs).
Step 8: Build a Portfolio
Showcase your completed projects on GitHub to demonstrate your expertise to potential employers or collaborators.
Step 9: Network and Explore Career Opportunities
Attend conferences, workshops, and meetups to network with industry professionals and stay connected with the latest trends.
Explore job opportunities in data science and machine learning, leveraging your portfolio and projects to stand out during interviews.
In essence, mastering machine learning involves a step-by-step process encompassing learning core concepts, engaging in hands-on practice, and actively participating in the vibrant machine learning community. Starting from foundational mathematics and programming, progressing through online courses and projects, and eventually venturing into advanced topics like deep learning, this journey equips you with essential skills. Embracing the machine learning community and building a robust portfolio opens doors to promising opportunities in this dynamic and impactful field.
9 notes
·
View notes
Text
25 Udemy Paid Courses for Free with Certification (Only for Limited Time)

2023 Complete SQL Bootcamp from Zero to Hero in SQL
Become an expert in SQL by learning through concept & Hands-on coding :)
What you'll learn
Use SQL to query a database Be comfortable putting SQL on their resume Replicate real-world situations and query reports Use SQL to perform data analysis Learn to perform GROUP BY statements Model real-world data and generate reports using SQL Learn Oracle SQL by Professionally Designed Content Step by Step! Solve any SQL-related Problems by Yourself Creating Analytical Solutions! Write, Read and Analyze Any SQL Queries Easily and Learn How to Play with Data! Become a Job-Ready SQL Developer by Learning All the Skills You will Need! Write complex SQL statements to query the database and gain critical insight on data Transition from the Very Basics to a Point Where You can Effortlessly Work with Large SQL Queries Learn Advanced Querying Techniques Understand the difference between the INNER JOIN, LEFT/RIGHT OUTER JOIN, and FULL OUTER JOIN Complete SQL statements that use aggregate functions Using joins, return columns from multiple tables in the same query
Enroll Now 👇👇👇👇👇👇👇 https://www.book-somahar.com/2023/10/25-udemy-paid-courses-for-free-with.html
Python Programming Complete Beginners Course Bootcamp 2023
2023 Complete Python Bootcamp || Python Beginners to advanced || Python Master Class || Mega Course
What you'll learn
Basics in Python programming Control structures, Containers, Functions & Modules OOPS in Python How python is used in the Space Sciences Working with lists in python Working with strings in python Application of Python in Mars Rovers sent by NASA
Enroll Now 👇👇👇👇👇👇👇 https://www.book-somahar.com/2023/10/25-udemy-paid-courses-for-free-with.html
Learn PHP and MySQL for Web Application and Web Development
Unlock the Power of PHP and MySQL: Level Up Your Web Development Skills Today
What you'll learn
Use of PHP Function Use of PHP Variables Use of MySql Use of Database
Enroll Now 👇👇👇👇👇👇👇 https://www.book-somahar.com/2023/10/25-udemy-paid-courses-for-free-with.html
T-Shirt Design for Beginner to Advanced with Adobe Photoshop
Unleash Your Creativity: Master T-Shirt Design from Beginner to Advanced with Adobe Photoshop
What you'll learn
Function of Adobe Photoshop Tools of Adobe Photoshop T-Shirt Design Fundamentals T-Shirt Design Projects
Enroll Now 👇👇👇👇👇👇👇 https://www.book-somahar.com/2023/10/25-udemy-paid-courses-for-free-with.html
Complete Data Science BootCamp
Learn about Data Science, Machine Learning and Deep Learning and build 5 different projects.
What you'll learn
Learn about Libraries like Pandas and Numpy which are heavily used in Data Science. Build Impactful visualizations and charts using Matplotlib and Seaborn. Learn about Machine Learning LifeCycle and different ML algorithms and their implementation in sklearn. Learn about Deep Learning and Neural Networks with TensorFlow and Keras Build 5 complete projects based on the concepts covered in the course.
Enroll Now 👇👇👇👇👇👇👇 https://www.book-somahar.com/2023/10/25-udemy-paid-courses-for-free-with.html
Essentials User Experience Design Adobe XD UI UX Design
Learn UI Design, User Interface, User Experience design, UX design & Web Design
What you'll learn
How to become a UX designer Become a UI designer Full website design All the techniques used by UX professionals
Enroll Now 👇👇👇👇👇👇👇 https://www.book-somahar.com/2023/10/25-udemy-paid-courses-for-free-with.html
Build a Custom E-Commerce Site in React + JavaScript Basics
Build a Fully Customized E-Commerce Site with Product Categories, Shopping Cart, and Checkout Page in React.
What you'll learn
Introduction to the Document Object Model (DOM) The Foundations of JavaScript JavaScript Arithmetic Operations Working with Arrays, Functions, and Loops in JavaScript JavaScript Variables, Events, and Objects JavaScript Hands-On - Build a Photo Gallery and Background Color Changer Foundations of React How to Scaffold an Existing React Project Introduction to JSON Server Styling an E-Commerce Store in React and Building out the Shop Categories Introduction to Fetch API and React Router The concept of "Context" in React Building a Search Feature in React Validating Forms in React
Enroll Now 👇👇👇👇👇👇👇 https://www.book-somahar.com/2023/10/25-udemy-paid-courses-for-free-with.html
Complete Bootstrap & React Bootcamp with Hands-On Projects
Learn to Build Responsive, Interactive Web Apps using Bootstrap and React.
What you'll learn
Learn the Bootstrap Grid System Learn to work with Bootstrap Three Column Layouts Learn to Build Bootstrap Navigation Components Learn to Style Images using Bootstrap Build Advanced, Responsive Menus using Bootstrap Build Stunning Layouts using Bootstrap Themes Learn the Foundations of React Work with JSX, and Functional Components in React Build a Calculator in React Learn the React State Hook Debug React Projects Learn to Style React Components Build a Single and Multi-Player Connect-4 Clone with AI Learn React Lifecycle Events Learn React Conditional Rendering Build a Fully Custom E-Commerce Site in React Learn the Foundations of JSON Server Work with React Router
Enroll Now 👇👇👇👇👇👇👇 https://www.book-somahar.com/2023/10/25-udemy-paid-courses-for-free-with.html
Build an Amazon Affiliate E-Commerce Store from Scratch
Earn Passive Income by Building an Amazon Affiliate E-Commerce Store using WordPress, WooCommerce, WooZone, & Elementor
What you'll learn
Registering a Domain Name & Setting up Hosting Installing WordPress CMS on Your Hosting Account Navigating the WordPress Interface The Advantages of WordPress Securing a WordPress Installation with an SSL Certificate Installing Custom Themes for WordPress Installing WooCommerce, Elementor, & WooZone Plugins Creating an Amazon Affiliate Account Importing Products from Amazon to an E-Commerce Store using WooZone Plugin Building a Customized Shop with Menu's, Headers, Branding, & Sidebars Building WordPress Pages, such as Blogs, About Pages, and Contact Us Forms Customizing Product Pages on a WordPress Power E-Commerce Site Generating Traffic and Sales for Your Newly Published Amazon Affiliate Store
Enroll Now 👇👇👇👇👇👇👇 https://www.book-somahar.com/2023/10/25-udemy-paid-courses-for-free-with.html
The Complete Beginner Course to Optimizing ChatGPT for Work
Learn how to make the most of ChatGPT's capabilities in efficiently aiding you with your tasks.
What you'll learn
Learn how to harness ChatGPT's functionalities to efficiently assist you in various tasks, maximizing productivity and effectiveness. Delve into the captivating fusion of product development and SEO, discovering effective strategies to identify challenges, create innovative tools, and expertly Understand how ChatGPT is a technological leap, akin to the impact of iconic tools like Photoshop and Excel, and how it can revolutionize work methodologies thr Showcase your learning by creating a transformative project, optimizing your approach to work by identifying tasks that can be streamlined with artificial intel
Enroll Now 👇👇👇👇👇👇👇 https://www.book-somahar.com/2023/10/25-udemy-paid-courses-for-free-with.html
AWS, JavaScript, React | Deploy Web Apps on the Cloud
Cloud Computing | Linux Foundations | LAMP Stack | DBMS | Apache | NGINX | AWS IAM | Amazon EC2 | JavaScript | React
What you'll learn
Foundations of Cloud Computing on AWS and Linode Cloud Computing Service Models (IaaS, PaaS, SaaS) Deploying and Configuring a Virtual Instance on Linode and AWS Secure Remote Administration for Virtual Instances using SSH Working with SSH Key Pair Authentication The Foundations of Linux (Maintenance, Directory Commands, User Accounts, Filesystem) The Foundations of Web Servers (NGINX vs Apache) Foundations of Databases (SQL vs NoSQL), Database Transaction Standards (ACID vs CAP) Key Terminology for Full Stack Development and Cloud Administration Installing and Configuring LAMP Stack on Ubuntu (Linux, Apache, MariaDB, PHP) Server Security Foundations (Network vs Hosted Firewalls). Horizontal and Vertical Scaling of a virtual instance on Linode using NodeBalancers Creating Manual and Automated Server Images and Backups on Linode Understanding the Cloud Computing Phenomenon as Applicable to AWS The Characteristics of Cloud Computing as Applicable to AWS Cloud Deployment Models (Private, Community, Hybrid, VPC) Foundations of AWS (Registration, Global vs Regional Services, Billing Alerts, MFA) AWS Identity and Access Management (Mechanics, Users, Groups, Policies, Roles) Amazon Elastic Compute Cloud (EC2) - (AMIs, EC2 Users, Deployment, Elastic IP, Security Groups, Remote Admin) Foundations of the Document Object Model (DOM) Manipulating the DOM Foundations of JavaScript Coding (Variables, Objects, Functions, Loops, Arrays, Events) Foundations of ReactJS (Code Pen, JSX, Components, Props, Events, State Hook, Debugging) Intermediate React (Passing Props, Destrcuting, Styling, Key Property, AI, Conditional Rendering, Deployment) Building a Fully Customized E-Commerce Site in React Intermediate React Concepts (JSON Server, Fetch API, React Router, Styled Components, Refactoring, UseContext Hook, UseReducer, Form Validation)
Enroll Now 👇👇👇👇👇👇👇 https://www.book-somahar.com/2023/10/25-udemy-paid-courses-for-free-with.html
Run Multiple Sites on a Cloud Server: AWS & Digital Ocean
Server Deployment | Apache Configuration | MySQL | PHP | Virtual Hosts | NS Records | DNS | AWS Foundations | EC2
What you'll learn
A solid understanding of the fundamentals of remote server deployment and configuration, including network configuration and security. The ability to install and configure the LAMP stack, including the Apache web server, MySQL database server, and PHP scripting language. Expertise in hosting multiple domains on one virtual server, including setting up virtual hosts and managing domain names. Proficiency in virtual host file configuration, including creating and configuring virtual host files and understanding various directives and parameters. Mastery in DNS zone file configuration, including creating and managing DNS zone files and understanding various record types and their uses. A thorough understanding of AWS foundations, including the AWS global infrastructure, key AWS services, and features. A deep understanding of Amazon Elastic Compute Cloud (EC2) foundations, including creating and managing instances, configuring security groups, and networking. The ability to troubleshoot common issues related to remote server deployment, LAMP stack installation and configuration, virtual host file configuration, and D An understanding of best practices for remote server deployment and configuration, including security considerations and optimization for performance. Practical experience in working with remote servers and cloud-based solutions through hands-on labs and exercises. The ability to apply the knowledge gained from the course to real-world scenarios and challenges faced in the field of web hosting and cloud computing. A competitive edge in the job market, with the ability to pursue career opportunities in web hosting and cloud computing.
Enroll Now 👇👇👇👇👇👇👇 https://www.book-somahar.com/2023/10/25-udemy-paid-courses-for-free-with.html
Cloud-Powered Web App Development with AWS and PHP
AWS Foundations | IAM | Amazon EC2 | Load Balancing | Auto-Scaling Groups | Route 53 | PHP | MySQL | App Deployment
What you'll learn
Understanding of cloud computing and Amazon Web Services (AWS) Proficiency in creating and configuring AWS accounts and environments Knowledge of AWS pricing and billing models Mastery of Identity and Access Management (IAM) policies and permissions Ability to launch and configure Elastic Compute Cloud (EC2) instances Familiarity with security groups, key pairs, and Elastic IP addresses Competency in using AWS storage services, such as Elastic Block Store (EBS) and Simple Storage Service (S3) Expertise in creating and using Elastic Load Balancers (ELB) and Auto Scaling Groups (ASG) for load balancing and scaling web applications Knowledge of DNS management using Route 53 Proficiency in PHP programming language fundamentals Ability to interact with databases using PHP and execute SQL queries Understanding of PHP security best practices, including SQL injection prevention and user authentication Ability to design and implement a database schema for a web application Mastery of PHP scripting to interact with a database and implement user authentication using sessions and cookies Competency in creating a simple blog interface using HTML and CSS and protecting the blog content using PHP authentication. Students will gain practical experience in creating and deploying a member-only blog with user authentication using PHP and MySQL on AWS.
Enroll Now 👇👇👇👇👇👇👇 https://www.book-somahar.com/2023/10/25-udemy-paid-courses-for-free-with.html
CSS, Bootstrap, JavaScript And PHP Stack Complete Course
CSS, Bootstrap And JavaScript And PHP Complete Frontend and Backend Course
What you'll learn
Introduction to Frontend and Backend technologies Introduction to CSS, Bootstrap And JavaScript concepts, PHP Programming Language Practically Getting Started With CSS Styles, CSS 2D Transform, CSS 3D Transform Bootstrap Crash course with bootstrap concepts Bootstrap Grid system,Forms, Badges And Alerts Getting Started With Javascript Variables,Values and Data Types, Operators and Operands Write JavaScript scripts and Gain knowledge in regard to general javaScript programming concepts PHP Section Introduction to PHP, Various Operator types , PHP Arrays, PHP Conditional statements Getting Started with PHP Function Statements And PHP Decision Making PHP 7 concepts PHP CSPRNG And PHP Scalar Declaration
Enroll Now 👇👇👇👇👇👇👇 https://www.book-somahar.com/2023/10/25-udemy-paid-courses-for-free-with.html
Learn HTML - For Beginners
Lean how to create web pages using HTML
What you'll learn
How to Code in HTML Structure of an HTML Page Text Formatting in HTML Embedding Videos Creating Links Anchor Tags Tables & Nested Tables Building Forms Embedding Iframes Inserting Images
Enroll Now 👇👇👇👇👇👇👇 https://www.book-somahar.com/2023/10/25-udemy-paid-courses-for-free-with.html
Learn Bootstrap - For Beginners
Learn to create mobile-responsive web pages using Bootstrap
What you'll learn
Bootstrap Page Structure Bootstrap Grid System Bootstrap Layouts Bootstrap Typography Styling Images Bootstrap Tables, Buttons, Badges, & Progress Bars Bootstrap Pagination Bootstrap Panels Bootstrap Menus & Navigation Bars Bootstrap Carousel & Modals Bootstrap Scrollspy Bootstrap Themes
Enroll Now 👇👇👇👇👇👇👇 https://www.book-somahar.com/2023/10/25-udemy-paid-courses-for-free-with.html
JavaScript, Bootstrap, & PHP - Certification for Beginners
A Comprehensive Guide for Beginners interested in learning JavaScript, Bootstrap, & PHP
What you'll learn
Master Client-Side and Server-Side Interactivity using JavaScript, Bootstrap, & PHP Learn to create mobile responsive webpages using Bootstrap Learn to create client and server-side validated input forms Learn to interact with a MySQL Database using PHP
Enroll Now 👇👇👇👇👇👇👇 https://www.book-somahar.com/2023/10/25-udemy-paid-courses-for-free-with.html
Linode: Build and Deploy Responsive Websites on the Cloud
Cloud Computing | IaaS | Linux Foundations | Apache + DBMS | LAMP Stack | Server Security | Backups | HTML | CSS
What you'll learn
Understand the fundamental concepts and benefits of Cloud Computing and its service models. Learn how to create, configure, and manage virtual servers in the cloud using Linode. Understand the basic concepts of Linux operating system, including file system structure, command-line interface, and basic Linux commands. Learn how to manage users and permissions, configure network settings, and use package managers in Linux. Learn about the basic concepts of web servers, including Apache and Nginx, and databases such as MySQL and MariaDB. Learn how to install and configure web servers and databases on Linux servers. Learn how to install and configure LAMP stack to set up a web server and database for hosting dynamic websites and web applications. Understand server security concepts such as firewalls, access control, and SSL certificates. Learn how to secure servers using firewalls, manage user access, and configure SSL certificates for secure communication. Learn how to scale servers to handle increasing traffic and load. Learn about load balancing, clustering, and auto-scaling techniques. Learn how to create and manage server images. Understand the basic structure and syntax of HTML, including tags, attributes, and elements. Understand how to apply CSS styles to HTML elements, create layouts, and use CSS frameworks.
Enroll Now 👇👇👇👇👇👇👇 https://www.book-somahar.com/2023/10/25-udemy-paid-courses-for-free-with.html
PHP & MySQL - Certification Course for Beginners
Learn to Build Database Driven Web Applications using PHP & MySQL
What you'll learn
PHP Variables, Syntax, Variable Scope, Keywords Echo vs. Print and Data Output PHP Strings, Constants, Operators PHP Conditional Statements PHP Elseif, Switch, Statements PHP Loops - While, For PHP Functions PHP Arrays, Multidimensional Arrays, Sorting Arrays Working with Forms - Post vs. Get PHP Server Side - Form Validation Creating MySQL Databases Database Administration with PhpMyAdmin Administering Database Users, and Defining User Roles SQL Statements - Select, Where, And, Or, Insert, Get Last ID MySQL Prepared Statements and Multiple Record Insertion PHP Isset MySQL - Updating Records
Enroll Now 👇👇👇👇👇👇👇 https://www.book-somahar.com/2023/10/25-udemy-paid-courses-for-free-with.html
Linode: Deploy Scalable React Web Apps on the Cloud
Cloud Computing | IaaS | Server Configuration | Linux Foundations | Database Servers | LAMP Stack | Server Security
What you'll learn
Introduction to Cloud Computing Cloud Computing Service Models (IaaS, PaaS, SaaS) Cloud Server Deployment and Configuration (TFA, SSH) Linux Foundations (File System, Commands, User Accounts) Web Server Foundations (NGINX vs Apache, SQL vs NoSQL, Key Terms) LAMP Stack Installation and Configuration (Linux, Apache, MariaDB, PHP) Server Security (Software & Hardware Firewall Configuration) Server Scaling (Vertical vs Horizontal Scaling, IP Swaps, Load Balancers) React Foundations (Setup) Building a Calculator in React (Code Pen, JSX, Components, Props, Events, State Hook) Building a Connect-4 Clone in React (Passing Arguments, Styling, Callbacks, Key Property) Building an E-Commerce Site in React (JSON Server, Fetch API, Refactoring)
Enroll Now 👇👇👇👇👇👇👇 https://www.book-somahar.com/2023/10/25-udemy-paid-courses-for-free-with.html
Internet and Web Development Fundamentals
Learn how the Internet Works and Setup a Testing & Production Web Server
What you'll learn
How the Internet Works Internet Protocols (HTTP, HTTPS, SMTP) The Web Development Process Planning a Web Application Types of Web Hosting (Shared, Dedicated, VPS, Cloud) Domain Name Registration and Administration Nameserver Configuration Deploying a Testing Server using WAMP & MAMP Deploying a Production Server on Linode, Digital Ocean, or AWS Executing Server Commands through a Command Console Server Configuration on Ubuntu Remote Desktop Connection and VNC SSH Server Authentication FTP Client Installation FTP Uploading
Enroll Now 👇👇👇👇👇👇👇 https://www.book-somahar.com/2023/10/25-udemy-paid-courses-for-free-with.html
Linode: Web Server and Database Foundations
Cloud Computing | Instance Deployment and Config | Apache | NGINX | Database Management Systems (DBMS)
What you'll learn
Introduction to Cloud Computing (Cloud Service Models) Navigating the Linode Cloud Interface Remote Administration using PuTTY, Terminal, SSH Foundations of Web Servers (Apache vs. NGINX) SQL vs NoSQL Databases Database Transaction Standards (ACID vs. CAP Theorem) Key Terms relevant to Cloud Computing, Web Servers, and Database Systems
Enroll Now 👇👇👇👇👇👇👇 https://www.book-somahar.com/2023/10/25-udemy-paid-courses-for-free-with.html
Java Training Complete Course 2022
Learn Java Programming language with Java Complete Training Course 2022 for Beginners
What you'll learn
You will learn how to write a complete Java program that takes user input, processes and outputs the results You will learn OOPS concepts in Java You will learn java concepts such as console output, Java Variables and Data Types, Java Operators And more You will be able to use Java for Selenium in testing and development
Enroll Now 👇👇👇👇👇👇👇 https://www.book-somahar.com/2023/10/25-udemy-paid-courses-for-free-with.html
Learn To Create AI Assistant (JARVIS) With Python
How To Create AI Assistant (JARVIS) With Python Like the One from Marvel's Iron Man Movie
What you'll learn
how to create an personalized artificial intelligence assistant how to create JARVIS AI how to create ai assistant
Enroll Now 👇👇👇👇👇👇👇 https://www.book-somahar.com/2023/10/25-udemy-paid-courses-for-free-with.html
Keyword Research, Free Backlinks, Improve SEO -Long Tail Pro
LongTailPro is the keyword research service we at Coursenvy use for ALL our clients! In this course, find SEO keywords,
What you'll learn
Learn everything Long Tail Pro has to offer from A to Z! Optimize keywords in your page/post titles, meta descriptions, social media bios, article content, and more! Create content that caters to the NEW Search Engine Algorithms and find endless keywords to rank for in ALL the search engines! Learn how to use ALL of the top-rated Keyword Research software online! Master analyzing your COMPETITIONS Keywords! Get High-Quality Backlinks that will ACTUALLY Help your Page Rank!
Enroll Now 👇👇👇👇👇👇👇 https://www.book-somahar.com/2023/10/25-udemy-paid-courses-for-free-with.html
#udemy#free course#paid course for free#design#development#ux ui#xd#figma#web development#python#javascript#php#java#cloud
2 notes
·
View notes
Text
The Power of Python: How Python Development Services Transform Businesses
In the rapidly evolving landscape of technology, businesses are continuously seeking innovative solutions to gain a competitive edge. Python, a versatile and powerful programming language, has emerged as a game-changer for enterprises worldwide. Its simplicity, efficiency, and vast ecosystem of libraries have made Python development services a catalyst for transformation. In this blog, we will explore the significant impact Python has on businesses and how it can revolutionize their operations.
Python's Versatility:
Python's versatility is one of its key strengths, enabling businesses to leverage it for a wide range of applications. From web development to data analysis, artificial intelligence to automation, Python can handle diverse tasks with ease. This adaptability allows businesses to streamline their processes, improve productivity, and explore new avenues for growth.

Rapid Development and Time-to-Market:
Python's clear and concise syntax accelerates the development process, reducing the time to market products and services. With Python, developers can create robust applications in a shorter timeframe compared to other programming languages. This agility is especially crucial in fast-paced industries where staying ahead of the competition is essential.
Cost-Effectiveness:
Python's open-source nature eliminates the need for expensive licensing fees, making it a cost-effective choice for businesses. Moreover, the availability of a vast and active community of Python developers ensures that businesses can find affordable expertise for their projects. This cost-efficiency is particularly advantageous for startups and small to medium-sized enterprises.
Data Analysis and Insights:
In the era of big data, deriving valuable insights from vast datasets is paramount for making informed business decisions. Python's libraries like NumPy, Pandas, and Matplotlib provide powerful tools for data manipulation, analysis, and visualization. Python's data processing capabilities empower businesses to uncover patterns, trends, and actionable insights from their data, leading to data-driven strategies and increased efficiency.
Web Development and Scalability:
Python's simplicity and robust frameworks like Django and Flask have made it a popular choice for web development. Python-based web applications are known for their scalability, allowing businesses to handle growing user demands without compromising performance. This scalability ensures a seamless user experience, even during peak traffic periods.
Machine Learning and Artificial Intelligence:
Python's dominance in the field of artificial intelligence and machine learning is undeniable. Libraries like TensorFlow, Keras, and PyTorch have made it easier for businesses to implement sophisticated machine learning algorithms into their processes. With Python, businesses can harness the power of AI to automate tasks, predict trends, optimize processes, and personalize user experiences.
Automation and Efficiency:
Python's versatility extends to automation, making it an ideal choice for streamlining repetitive tasks. From automating data entry and report generation to managing workflows, Python development services can help businesses save time and resources, allowing employees to focus on more strategic initiatives.
Integration and Interoperability:
Many businesses have existing systems and technologies in place. Python's seamless integration capabilities allow it to work in harmony with various platforms and technologies. This interoperability simplifies the process of integrating Python solutions into existing infrastructures, preventing disruptions and reducing implementation complexities.
Security and Reliability:
Python's strong security features and active community support contribute to its reliability as a programming language. Businesses can rely on Python development services to build secure applications that protect sensitive data and guard against potential cyber threats.
Conclusion:
Python's rising popularity in the business world is a testament to its transformative power. From enhancing development speed and reducing costs to enabling data-driven decisions and automating processes, Python development services have revolutionized the way businesses operate. Embracing Python empowers enterprises to stay ahead in an ever-changing technological landscape and achieve sustainable growth in the digital era. Whether you're a startup or an established corporation, harnessing the potential of Python can unlock a world of possibilities and take your business to new heights.
2 notes
·
View notes
Text
Best AI Training in Electronic City, Bangalore – Become an AI Expert & Launch a Future-Proof Career!



Artificial Intelligence (AI) is reshaping industries and driving the future of technology. Whether it's automating tasks, building intelligent systems, or analyzing big data, AI has become a key career path for tech professionals. At eMexo Technologies, we offer a job-oriented AI Certification Course in Electronic City, Bangalore tailored for both beginners and professionals aiming to break into or advance within the AI field.
Our training program provides everything you need to succeed—core knowledge, hands-on experience, and career-focused guidance—making us a top choice for AI Training in Electronic City, Bangalore.
🌟 Who Should Join This AI Course in Electronic City, Bangalore?
This AI Course in Electronic City, Bangalore is ideal for:
Students and Freshers seeking to launch a career in Artificial Intelligence
Software Developers and IT Professionals aiming to upskill in AI and Machine Learning
Data Analysts, System Engineers, and tech enthusiasts moving into the AI domain
Professionals preparing for certifications or transitioning to AI-driven job roles
With a well-rounded curriculum and expert mentorship, our course serves learners across various backgrounds and experience levels.
📘 What You Will Learn in the AI Certification Course
Our AI Certification Course in Electronic City, Bangalore covers the most in-demand tools and techniques. Key topics include:
Foundations of AI: Core AI principles, machine learning, deep learning, and neural networks
Python for AI: Practical Python programming tailored to AI applications
Machine Learning Models: Learn supervised, unsupervised, and reinforcement learning techniques
Deep Learning Tools: Master TensorFlow, Keras, OpenCV, and other industry-used libraries
Natural Language Processing (NLP): Build projects like chatbots, sentiment analysis tools, and text processors
Live Projects: Apply knowledge to real-world problems such as image recognition and recommendation engines
All sessions are conducted by certified professionals with real-world experience in AI and Machine Learning.
🚀 Why Choose eMexo Technologies – The Best AI Training Institute in Electronic City, Bangalore
eMexo Technologies is not just another AI Training Center in Electronic City, Bangalore—we are your AI career partner. Here's what sets us apart as the Best AI Training Institute in Electronic City, Bangalore:
✅ Certified Trainers with extensive industry experience ✅ Fully Equipped Labs and hands-on real-time training ✅ Custom Learning Paths to suit your individual career goals ✅ Career Services like resume preparation and mock interviews ✅ AI Training Placement in Electronic City, Bangalore with 100% placement support ✅ Flexible Learning Modes including both classroom and online options
We focus on real skills that employers look for, ensuring you're not just trained—but job-ready.
🎯 Secure Your Future with the Leading AI Training Institute in Electronic City, Bangalore
The demand for skilled AI professionals is growing rapidly. By enrolling in our AI Certification Course in Electronic City, Bangalore, you gain the tools, confidence, and guidance needed to thrive in this cutting-edge field. From foundational concepts to advanced applications, our program prepares you for high-demand roles in AI, Machine Learning, and Data Science.
At eMexo Technologies, our mission is to help you succeed—not just in training but in your career.
📞 Call or WhatsApp: +91-9513216462 📧 Email: [email protected] 🌐 Website: https://www.emexotechnologies.com/courses/artificial-intelligence-certification-training-course/
Seats are limited – Enroll now in the most trusted AI Training Institute in Electronic City, Bangalore and take the first step toward a successful AI career.
🔖 Popular Hashtags:
#AITrainingInElectronicCityBangalore#AICertificationCourseInElectronicCityBangalore#AICourseInElectronicCityBangalore#AITrainingCenterInElectronicCityBangalore#AITrainingInstituteInElectronicCityBangalore#BestAITrainingInstituteInElectronicCityBangalore#AITrainingPlacementInElectronicCityBangalore#MachineLearning#DeepLearning#AIWithPython#AIProjects#ArtificialIntelligenceTraining#eMexoTechnologies#FutureTechSkills#ITTrainingBangalore
2 notes
·
View notes
Text
Best AI Training in Electronic City, Bangalore – Become an AI Expert & Launch a Future-Proof Career!



Artificial Intelligence (AI) is reshaping industries and driving the future of technology. Whether it's automating tasks, building intelligent systems, or analyzing big data, AI has become a key career path for tech professionals. At eMexo Technologies, we offer a job-oriented AI Certification Course in Electronic City, Bangalore tailored for both beginners and professionals aiming to break into or advance within the AI field.
Our training program provides everything you need to succeed—core knowledge, hands-on experience, and career-focused guidance—making us a top choice for AI Training in Electronic City, Bangalore.
🌟 Who Should Join This AI Course in Electronic City, Bangalore?
This AI Course in Electronic City, Bangalore is ideal for:
Students and Freshers seeking to launch a career in Artificial Intelligence
Software Developers and IT Professionals aiming to upskill in AI and Machine Learning
Data Analysts, System Engineers, and tech enthusiasts moving into the AI domain
Professionals preparing for certifications or transitioning to AI-driven job roles
With a well-rounded curriculum and expert mentorship, our course serves learners across various backgrounds and experience levels.
📘 What You Will Learn in the AI Certification Course
Our AI Certification Course in Electronic City, Bangalore covers the most in-demand tools and techniques. Key topics include:
Foundations of AI: Core AI principles, machine learning, deep learning, and neural networks
Python for AI: Practical Python programming tailored to AI applications
Machine Learning Models: Learn supervised, unsupervised, and reinforcement learning techniques
Deep Learning Tools: Master TensorFlow, Keras, OpenCV, and other industry-used libraries
Natural Language Processing (NLP): Build projects like chatbots, sentiment analysis tools, and text processors
Live Projects: Apply knowledge to real-world problems such as image recognition and recommendation engines
All sessions are conducted by certified professionals with real-world experience in AI and Machine Learning.
🚀 Why Choose eMexo Technologies – The Best AI Training Institute in Electronic City, Bangalore
eMexo Technologies is not just another AI Training Center in Electronic City, Bangalore—we are your AI career partner. Here's what sets us apart as the Best AI Training Institute in Electronic City, Bangalore:
✅ Certified Trainers with extensive industry experience ✅ Fully Equipped Labs and hands-on real-time training ✅ Custom Learning Paths to suit your individual career goals ✅ Career Services like resume preparation and mock interviews ✅ AI Training Placement in Electronic City, Bangalore with 100% placement support ✅ Flexible Learning Modes including both classroom and online options
We focus on real skills that employers look for, ensuring you're not just trained—but job-ready.
🎯 Secure Your Future with the Leading AI Training Institute in Electronic City, Bangalore
The demand for skilled AI professionals is growing rapidly. By enrolling in our AI Certification Course in Electronic City, Bangalore, you gain the tools, confidence, and guidance needed to thrive in this cutting-edge field. From foundational concepts to advanced applications, our program prepares you for high-demand roles in AI, Machine Learning, and Data Science.
At eMexo Technologies, our mission is to help you succeed—not just in training but in your career.
📞 Call or WhatsApp: +91-9513216462 📧 Email: [email protected] 🌐 Website: https://www.emexotechnologies.com/courses/artificial-intelligence-certification-training-course/
Seats are limited – Enroll now in the most trusted AI Training Institute in Electronic City, Bangalore and take the first step toward a successful AI career.
🔖 Popular Hashtags:
#AITrainingInElectronicCityBangalore#AICertificationCourseInElectronicCityBangalore#AICourseInElectronicCityBangalore#AITrainingCenterInElectronicCityBangalore#AITrainingInstituteInElectronicCityBangalore#BestAITrainingInstituteInElectronicCityBangalore#AITrainingPlacementInElectronicCityBangalore#MachineLearning#DeepLearning#AIWithPython#AIProjects#ArtificialIntelligenceTraining#eMexoTechnologies#FutureTechSkills#ITTrainingBangalore
2 notes
·
View notes