#joe tasker
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Premium Tumblr themes are available from anywhere between $9 to $49.
Text



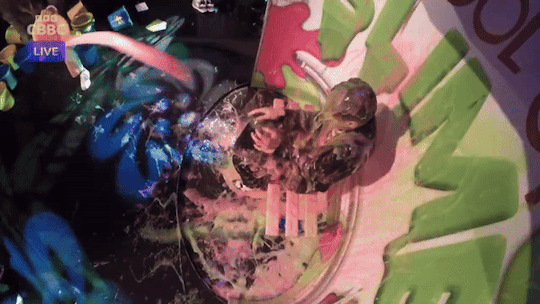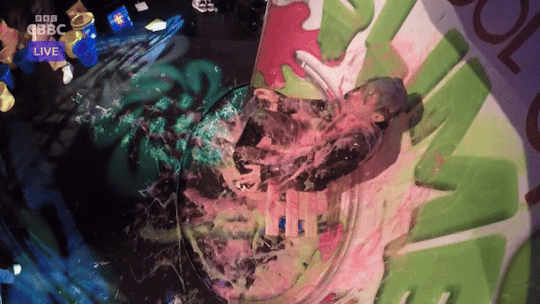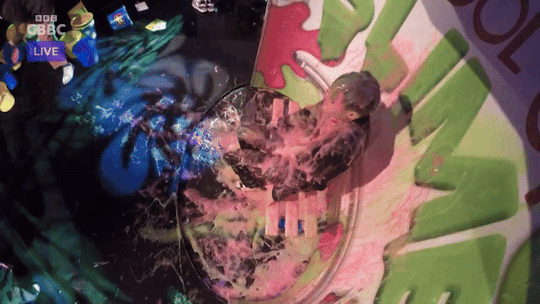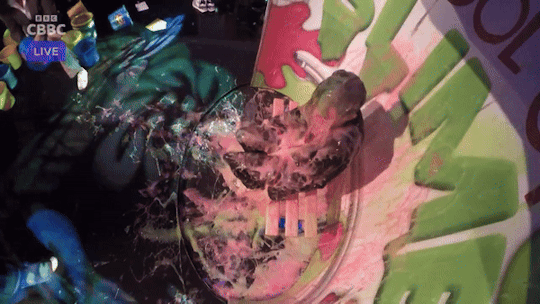




Joe Tasker slimed on Saturday Mash-Up (Part 2)
31 notes
·
View notes
Photo

Joe Tasker
Gender: Male
Sexuality: Gay
DOB: 30 July 1993
Ethnicity: White - British
Occupation: Youtuber, presenter, comedian, musician, radio DJ
#Joe Tasker#homosexuality#lgbt#lgbtq#mlm#male#gay#1993#white#british#youtuber#presenter#comedian#musician#radio dj
35 notes
·
View notes
Text
Nevada Governor DILFs














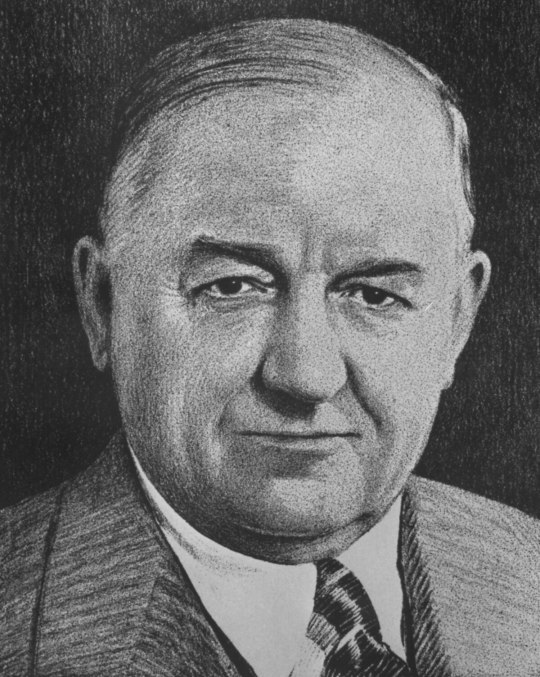

Robert List, Brian Sandoval, Joe Lombardo, Bob Miller, Grant Sawyer, Steve Sisolak, Jim Gibbons, Kenny Guinn, Richard Bryan, Morley Griswold, Edward P. Carville, Mike O'Callaghan, Paul Laxalt, Charles H. Russell, James G. Scrugham, Tasker Oddie
#Robert List#Brian Sandoval#Joe Lombardo#Bob Miller#Grant Sawyer#Steve Sisolak#Jim Gibbons#Kenny Guinn#Richard Bryan#Morley Griswold#Edward P. Carville#Mike O'Callaghan#Paul Laxalt#Charles H. Russell#James G. Scrugham#Tasker Oddie#GovernorDILFs
29 notes
·
View notes
Text
youtube
For Breakfast - Heavy Horse Museum
#for breakfast#heavy horse museum#maya harrison#sam birkett#joe thompson#omar zaghouani#gail tasker#eden harrison#will eckersley#progressive rock#art rock#canterbury sound#trapped in the big room#ep#2022#Youtube
0 notes
Note
uhm… I discovered YTTD on a Saturday morning and god… Joe Tazuna sounds like Joe Tasker (iykyk)
they also look alike in a weird way


I bet you can’t unsee this now lmfao
ahh i do not know the other guy, but they do have similar vibes!!
3 notes
·
View notes
Text
Sebastian and Ominis core 100%
1 note
·
View note
Text
For anyone who doesn’t know the dance I’m talking about
0 notes
Text
They remind me of the early Dan and Phil videos tbh. There's a lot to unpack here and I ship it.
youtube
(when Joe touches his hand I knew I had to ship it. srry not srry)
#joe tasker#lee hinchcliff#loe(?#i low key ship it#they call each other dad/daddy i mean wtf???#phan#dan and phil(?
5 notes
·
View notes
Photo

JoeTasker: The best Table Tennis Trio in Youtube* 🏓
*All of time
34 notes
·
View notes
Photo









Under-appreciated youtubers 1/? - Joe Tasker
#gif#Joe Tasker#taskerjoe#youtube#youtuber#youtubers#British youtuber#under appreciated youtubers#dodieanddottie
1 note
·
View note
Text








Joe Tasker slimed on Saturday Mash-Up (Part 1)
23 notes
·
View notes
Text
youtube
Have you seen Joe Tasker playing Chicken Scream?
1 note
·
View note
Photo

0 notes
Photo

YouTubers visit Cumbria for National Citizen Service Two well-known Youtubers, Joe Tasker and Lee Hinchcliffe, joined North and West Cumbrian young people on their NCS journey at Lakeside YMCA yesterday. (Tuesday 6th of August) Full story: https://www.cumbriacrack.com/2019/08/07/youtubers-visit-cumbria-for-national-citizen-service/
0 notes
Text
That Friend
I don’t know if its just me.
But we most probably know a friend that quotes everything. TV shows, books and films etc...
This is my inspiration. :-)
youtube
1 note
·
View note
Photo

A Traveller’s Guide to Lost and Later Songs
For those who may appreciate some background detail, I offer below my workings.
All audio references refer to recordings from the secret playlist, “Lost and Later, Early Days”- here
#1 - Loverboy (19/01/13)
On the cusp of lost and later, this song is something of both. Written in the months before the revolution (earliest demo in the files is dated 19th January 2013), I was imagining something like Gene Pitney sings Misirlou, produced by Joe Meek. I remember Loverboy getting its debut at a Hogmanay show in Glasgow’s Old Hairdressers. Halfway through the song, a jolly fellow in high spirits took to the dancefloor and did “the dance of the two ales” (a self-explanatory dance which requires no partner). I took that as a positive sign: the booze equivalent of two thumbs good. Loverboy retained its place in our live set until the Fabulon pre-production rehearsals. Then, at a summit in the Laurieston bar with producer-in-chief Colin Elliot, the Politburo decided that Loverboy’s face didn’t quite fit the new regime (see also “Ghost Light”). The song committed the youthful folly of trying to say everything and be everything to all people, rather than seeing a world in Blake’s grain of sand. Its sprawling structure didn’t quite hang together and forgot the golden rule of pop music: get to the chorus, get to it already and get there by yesterday (people are busy you know and we don’t have time for your three-minute instrumental breakdown). Compared to “Valentino”, its more popular elder sibling, Loverboy looked like the scruffier black sheep of the family who, perhaps if freed from the burden of fitting in with its peers and trying to impress, may yet come good. It needed time; time that we didn’t have back then. These days, well, it often feels like there’s nothing but time, even as it ebbs away until, all at once, the day has gone, a little like that line in Hemingway’s “The Sun Also Rises”– “How did you go bankrupt?" Two ways. Gradually, then suddenly.” Anyway, whether we realise it or not, time is, and always will be, pressing. So, Loverboy come in, come in from the cold and tell all the others too, for now is the hour of the outcast. Pariahs of the world unite. Tonight, we run with the underdogs. I still remember where all the bodies were buried and there is going to be a reckoning
#2 Ghost Light (14/04/10)
A synth-pop devotional in praise of the light, 14th April 2010 at 9.50am is the earliest noted record in the archives for this one. It sounds uncharacteristically early in the morning for me but, as the politicians like to tell you, statistics don’t lie. The night before, I had been out drinking with my friend Paul Tasker of the Doghouse Roses. We decided to round off a very enjoyable evening with whisky and tunes back at Paul’s flat during which I remember Paul modelling a beautifully made Swedish Army greatcoat which he’d picked up somewhere or another on the internet. He cut quite a dash as he marched smartly up and down his living room, swaying his whisky to and fro with a martial air. Among various other pressing issues up for discussion that evening, Paul mentioned that he had an old synthesiser he was looking to get rid of and did I want it? That sounds like a laugh, I thought, and we settled on the princely sum of £20. The next morning, I woke to find I was now the proud owner of a Yamaha SK10 Symphonic Ensemble. There it was, propped against the wall of my bedroom. Oh well, I thought, I had certainly woken up to worse. I plugged it in, switched it on and quickly realised that I had got lucky here. What a lovely noise. I thought of arcades and 1980s computer games, John Hughes movies, pastel-coloured leg warmers.... There was a string setting that sounded just like Phil Oakey and Giorgio Moroder’s “Together in Electric Dreams”. I was instantly transported to a childhood kitchen scene - my sister and I doing the Sunday dinner dishes whilst we listened to the Top 40 on a state-of-the-art Sanyo transistor radio and singing along to “Electric Dreams”. Then, light speed forward 20 years and dancing to the very same song with my friend Dan Mutch in an empty and just about closing Edinburgh bar after stopping in for one last drink, two children trying to stay up past their bedtime. Like happy news, unexpected and unlooked for, the song soared euphorically out of the bar’s massive speakers as Dan and I pushed our drinks aside in shared joy to find that the dancefloor was there all along, like the yellow brick road, right underneath our feet and we didn’t even notice it. Music is time travel. I’ve often thought that the synth pop wizards were really piano balladeers, heirs to a grand tradition but operating under different conditions, in different times. Pop by other means. Pop, of course, must always be by any means necessary, or at least by any means available, but I wonder what Vince Clarke would have created if he found himself behind a baby grand in 1920s Broadway, or if Cole Porter was given a Moog to fool around with. A lovely sound can in itself be an inspiration. The SK10’s string setting made me feel like it was hard to go wrong. A riff seemed to present itself immediately to me; then it was just a question of which chords sounded good beneath that riff. Being something of a musical illiterate, I often play wrong chords. But sometimes the wrong notes sound better than the right ones. It can, at times, be hard to keep up with my mistakes. I tend to be a music first writer. I travel lightly and assume the lyrics will meet up with me later on, somewhere further down the road. In the meantime, my notes-to-self include: - make a joyful noise along to the music - which words does this noise sound like? - what does the music make me think of and/or feel? This one made me think about disco lights. Yes, that’s what I’d do. I’d write a song about disco lights. And so, the song began travelling under the name “Gold Silver”. “Gold Silver” made it as far as the “Come to the Fabulon” studio demos, recorded in Red Eye Studios, Clydebank in 2012-13. Although there was a variety of styles among these demos there is, you might say, a fine line between variety and anomaly. In this context “Gold Silver” sounded like a completely different band and, much as that in itself appealed to me, the song was, by majority decision, disappeared around the time of the Fabulon album rehearsals of 2013. During a band meeting in the Laurieston Bar with producer-in-chief Colin Elliot (see also “Loverboy”), I distinctly remember “Gold Silver” being given its marching orders, packed off to the Siberia of Song. I believe the term “Eurovision reject” was used. But remember: we throw nothing away. And another thing, while we’re here; I really like Eurovision. I remember Drew Barrymore’s lines in “Donnie Darko”, about how the words “cellar door” were considered by many to be the most beautiful in the English language. A matter of taste, of course. For me, as a Eurovision fan, the most beautiful words I ever heard were “Come in Helsinki”. So, “Gold Silver”, a song out of time and place, found itself banished to the margins, perhaps until some future time, maybe our Eurovision entry. Or our lockdown album. Come the lockdown, the band’s campaign shifted to the home front. With the mobilisation of all able-bodied songs – past, present and future - I found myself dusting off “Gold Silver” only to notice I hadn’t quite gotten around to finishing the lyrics (so much of life is about managing disrepair). This was around the time of the closing of the theatres when the image of the ghost light, a tradition I’d never heard of until then, began to do the rounds. The image and idea of the ghost light made me think that the lights in the song needn’t only be on the dancefloor; a thought which gave the song its final title and helped me to finally finish that thing I started on a bargain £20 synthesiser one hungover morning, 10 years previously. I think the ghost light is a noble tradition, an arresting image and an eerie reminder that there will be times when there is no light other than that which we create for ourselves: in the empty theatres, clubs and bars; in song, in dance and in every whistle that tries to charm the darkness.
#3 Drunk is a holiday (1996-2021)
“Ought we to be drunk every night?" Sebastian asked one morning. "Yes, I think so." "I think so too.” ― Evelyn Waugh, Brideshead Revisited The chorus melody for “Drunk is a Holiday” came to me, perhaps fittingly enough, in the middle of a hangover. I would date that hangover at around 1996, back when I was living in a bedsit in the Southside of Glasgow. The TV series of “Brideshead Revisited” was being repeated on Saturday evenings around then and I remember staying in to watch it over the course of several weeks. It helped to keep me off the booze. My favourite scene was the one with Sebastian and Charles, lounging by a fountain and sipping champagne in a decidedly louche manner. After their minimal, yet solemn exchange, as quoted above, which felt like a pact or vow, Sebastian falls into the fountain with his bottle of champagne. I remember applauding the telly at that bit. I, too, wanted to fall into fountains with bottles of champagne. Unfortunately, I was unemployed at the time and my limited means meant opportunities for such indulgence were few and far between. But picking up the guitar, the songs and all that - that was free. I often have musical ideas far beyond my capabilities of actually realising them. Sometimes it takes me years to catch up. Although the chorus melody came easily enough, I had no idea what to do with it. I tried marrying it off to all manner of unlikely suitors but nothing lasted. Then, other, easier songs came along and the melody was set aside until some later time, to be confirmed. The next recorded sighting was 2006 on a home demo. By this time, my circumstances had improved so that I had managed to upgrade my humble abode to a hovel in Partick. I was, more or less, gainfully employed to the point where I could even, should I choose, buy my own bottle of champagne, if not quite my own fountain. One evening, whilst buttering a slice of toast in the kitchen, a stray verse suggested itself to me which carried echoes of that chorus from what you might ironically call my Brideshead Days. I dusted down the old chorus, tentatively placing it next to this new verse and felt a little shiver as they clicked snugly together like missing jigsaw pieces, lost to one another all these years. It was good news from a former life, music as time travel. A more advanced demo in 2008- including bass, drums, guitars and early lyrics- shows that we had begun working on the song as a band and it was by then travelling under the name “Drunk is a Holiday”, perhaps in reference to its origins. But after this, the trail goes cold once more. I presume the song must have been deemed too cheerful for the last Starlets album in 2009. Soon afterwards came ANI’s Year Zero and in the post-revolutionary era which followed, songs about champagne and fountains would have been dimly viewed as irredeemably bourgeois. And so, the song was lost again. Or not lost, perhaps never really lost at all, rather searching. Or waiting. Waiting for its time to come, for the world to change once more and a reappraisal of all that was previously taken for granted; when we, not spoiled for resources, would once again find a virtue and a new aesthetic in making the best out of what we have. Mend and make new. Nowadays, I navigate my way through our strange new world by bicycle. I finally finished writing “Drunk is a Holiday” when the last of the lyrics came to me in the Summer of 2020 whilst cycling through the Dovecote country, somewhere between Yoker and Whiteinch and approximately 24 years after watching Brideshead Revisited. “The calm, beguiling Until you’re smiling Our little slice of forever* to be whiling” All of the above is not necessarily to say that the song itself is worth the wait. That is not, of course, for me to say. 24 years in the making is, after all, a fair bit to live up to and perhaps its origins will prove more interesting than its arrival. But it was worth my wait and I’ll go as far as to say that, yes, I am fond of it. If forced to describe the song for publicity purposes, I’d maybe offer something along the lines of “Music Hall as Synth Pop”. Whatever “Drunk is a Holiday” may or may not be, lyrically it is very much in the tradition of “write about what you know”, so if it all sounds a little woozy here and there, well, I’m afraid that’s because so do I. As a final point, if there are any time-travellers reading this, may I ask a small favour? Should you happen to be passing through 1996 any time soon, could you please pass on a message to my former self, if he’ll listen? Please tell him that future Biff asks that he be of good cheer. Tell him he finally finishes that song that he started. Tell him that he hasn’t given up, that he’s still trying to keep his promise. *This line is a nod and tip of the hat to Jenny Lindsay’s spoken word show “This Script” from which the line is “borrowed”. Other significant nods, tips and borrowings (although I prefer the term “references”) include to and from Warren Zevon’s “Carmelita”, a favourite at family sing-songs when I was growing up. Originally posted in December 2020
#4 Yesterday’s Already Light Years Away (No demo exists. Approximately 1997)
One from the analogue years, there was no demo recorded of this song at the time, or after. From around 1996 until 1999, the band rented a rehearsal room in the Maryhill Burgh Halls. From the studio next door, we inherited an unwieldy electric piano (affectionately christened “The Coffin” by Craig) and on which I stumbled across the song’s tinkly melody. My bus home from rehearsals crossed Jamaica Bridge, over the Clyde and out to the occasionally sunlit uplands of Glasgow’s Southside. Gazing out of the top deck window, I used to see blankets tidied away neatly underneath one of the bridge arches and wonder who slept there. The lyrics began with that thought. I remember clunkily playing through the song a couple of times in band rehearsals. When I looked around the room afterwards, all band members’ faces seemed to communicate the same reaction, namely, “Whit are we meant to dae wi that?”. A fair question. Some songs are not suited to the rough and tumble of the rehearsal room. Too much bang and crash. In this case, a slide rule and calculator may have been more useful. There’s a bit of an unusual structure to this one and I can hear echoes of my obsession (still current and ongoing) with Prefab Sprout’s “Steve McQueen” album. As stated above, there was no demo recorded at the time, but the song hung around awkwardly for a while, like a wallflower at a dance, before quietly slipping away into the shadows, lost down the lesser travelled corridors of my mind. Once in a while I would catch a glimpse of it out of the corner of my eye but when I turned around it was gone again. After 25 years of rattling around in my head and without even a demo to its name, “Yesterday” can stake a fair claim as the unlikeliest character on this unlikeliest of records. A shy one, strange and a little awkward, this song may well be no one’s idea of the belle of the ball and, I would say, it is all the better for that. It is one of my favourites on the record. Some songs, and people, are not easy to know but, given the chance, will dance a dance all of their own.
#5 Ride the White Horses (29/03/10)
First demoed as an instrumental in a live home recording by Mark and I, dated 29/03/10 (see secret playlist) In the spirit of Martin Mull’s “Writing about music is like dancing about architecture”, here’s a song about painting, partly inspired by James Guthrie’s “Hard At It” which can be found in the Kelvingrove Art Gallery. I like to find inspiration in different artforms. One is less likely to be sued for plagiarism. At the time of writing, this song has been played live once only, at a solo show in Arnhem on 22/10/2010, when it was still shiny new and I must have been keen to try it out. After the last note, not one person applauded. Not one. Not even polite or pitying applause. Nada. Nil point. Ha ha ha. Cue tumbleweed. Character building. I daresay I could have taken the hint there and then but I’ve always been a bit stubborn that way. I am right and the world is wrong. Sooner or later the world will realise the error of its ways. Until then, if an idea is worth believing in, it is worth a world of indifference, worth all of the lean years for all of the meantime (even if it all turns out to be meantime). So, here’s to another time and place yet to come; to some other night in some other room where some one person hearing the song may feel just glad enough to clap hands. Then, at long last, from lost into later, the song will have found a home. NB. For further reference material (and dancing about architecture), please see Eduardo Chillada’s “The Comb of the Wind”
#6 What You Came For (11/08/2018)
The first of the Later songs. The initial melody came to me whilst on a jolly through to Edinburgh for the festival, somewhere in between Kilderkin and the Waverley Bar. As I recall, I was temporarily between drinks and loitering outside a newsagent whilst a friend bought tobacco. Ideas tend to come to me when my guard is down, maybe when drifting in or out of sleep, or sometimes, as in this case, when in a dreamlike state. A cool summer breeze eased down the Royal Mile, calming my fevered brow. I must have started singing to myself. Tum-te-tum. Tourists milling by occasionally glanced at me, the singing jakey; perhaps thinking I was one of the local characters, a little bit random but harmless enough. “Hey”, I wanted to say, “I’m a tourist here myself”. There must have been some presence of mind still functioning as I recorded the tune on my phone with the title “Yeahyeahyeahs” (it reminded me a little, at the time, of their song “Turn Into”- I always liked that one). The tune must have been rattling around in my head for a while after that as further developments of the song can be heard on subsequent phone recordings made, by the sounds of it, on trains, waiting on buses and first thing in the morning after dreaming about an idea for the middle eight- https://on.soundcloud.com/SAaj7 The last recorded sighting was 24/09/18; a live take of a rehearsal by the band but by then the Dark Carnival was rolling into town and everything went supernatural for a while.
#7 Something of the Night (18/12/18)
Our Hallowe’en number and another of the Later songs, the only previous recording of this was a live rehearsal dated 18/12/2018 - https://on.soundcloud.com/VNeEW Clearly influenced by our imminent descent into the underworld, this one could well have ended up on the Dark Carnival album had it been a little less late. Inspired by B-movies, Bela Lugosi, Vampira, Ed Wood, Nosferatu, “Monster Mash”, “Foul Owl on the Prowl” from “In the Heat of the Night” and, yes folks, the theme tune from “The Professionals”. I wouldn’t imagine the lyrics require any elaboration, with one possible exception: for anyone unfamiliar with the Scots vernacular of “looking for a lumber”, this phrase is used to describe someone “out on the pull”. Of course, the versatility/ambivalence of the word may well become all too apparent the morning after the night before, should last night’s “lumber” turn into this morning’s “lumbered with”. It can be a confusing language, particularly nowadays when nuance has become so terribly unfashionable. I looked up “lumber” in both Oxford and Cambridge English dictionaries but its use as a singular noun (e.g. “Did ye get a lumber last night?”) receives no mention. That, of course, may well be a whole other story. This song is, I am proud to say, a thoroughly reprehensible character (although clearly somewhat ridiculous). Like its fellow travellers, it was, at the time and for one reason or another, considered inappropriate. Maybe so. Or maybe it is, to paraphrase Lloyd Cole, inappropriate but much more fun. This will be the one they remember us for. Featuring bonus wolf howl.
#8 Swirly (04/03/2009)
It’s swirly, man.
The first demo is dated 04/03/09 at 1653h, just in time for tea. Around this time, I was beginning to collaborate with my friend Ally Kerr on his songs, working towards his album “Viva Melodia”. I’d say it was a productive time for both Ally and myself and I was enthused by his maverick, can-do attitude. I remember sauntering home from Ally’s one night after an evening of beer and songs and suddenly a melody began rattling around in my head. In the spirit of creating a language out of whatever is inspiring us at the time, I began singing, as placeholder lyrics for the melody - “Ally’s good, Ally’s fine, Ally’s hot to let you know”. As a placeholder title to match the lyrics, I thought “Swirly” suited its woozy, spiralling mood. Last time I looked, the title was still there. The song felt promising up until the moment of truth in the rehearsal room, when it became sadly apparent that we, the band, couldn’t really play it very well. We tried a few times but it didn’t half plod where it should have swirled. It quickly became another of our songs to be shelved and filed under “Far too much like hard work”. Some songs are contrary: you have to record them before you learn how to play them, odd as that may sound. At the time of recording, we had never played “Swirly” live. Instead, it was stitched together according to a vague but ambitious wish list sent to long-suffering producer Colin Elliot who was tasked with performing pop alchemy on our humble, home-made fare. Swirly was the first of the lockdown songs to make it out into the world, the first single and original Lost and Later Song #1. After the initial morale boost, then came the challenge: if this is possible, then what else is? The sensible thing would have been to say no. Nice idea but walk away. To say no is easier, quicker. To say yes is harder to live up to, will take far longer. Maybe even a lifetime.
#9 Everything’s Alright Fine (31/12/2020)
Second latest of the Later songs, born in a hangover and hummed into my phone, just in time for Hogmanay. I was stumbling through the no man’s land between last night and the night to come, fighting a rear-guard action against a horde of demons calling me bad names. Some hangovers can look so big they can pass themselves off as all sky, all horizon and all hereafter. There is nothing but and nothing beyond this. Abandon hope all ye who enter here. It is important then to remember that this is only a temporary psychosis caused by lack of fluids. Drink water, have some soup, take a nice, hot bath; back to basics, be humble, hit reset, switch off and on again, add in some calculated distractions. All well and good in theory. However. Once upon a hangover, one penitent Sunday and a personal low point to date, I was unable to keep my fluids in place, so to speak. Another test of character. When even a humble glass of water is beyond us, we must accept this additional level of abasement and find our new level. There is, of course, a fine line between humbling and humiliating but never mind. One hasty rummage in a cupboard later and I emerged triumphant with a bathroom sponge. Eureka. I wet the sponge - not soaked, dampened only - and repaired to the sofa. I began with wetting my lips only - so far, so good. I then built up to occasional discrete, tactical sucks on the sponge, hoping to take on fluids by stealth, under the radar. I had in place a cunning strategy. All I needed now was some covering fire, a decoy, a distraction. I switched the TV on, hoping for a gentle Sunday matinee from a bygone age to gaze at longingly whilst sucking on my sponge. The screen crackled into life with a brassy fanfare straight out of Hollywood’s golden era. In a marvel of fortuitous timing, I was just in time to catch the opening credits to the Sunday matineé. Perhaps my chances were, at last, beginning to take an upward turn. Then, as I lay on the sofa, sucking cautiously on my sponge and still lamenting my terrible thirst, the screen announced the afternoon feature as- “Humphrey Bogart stars in…. “SAHARA!” You’ve got to laugh. Humour is our short circuit, cutting off the path to insanity. Or maybe, in the language of the movies, it heads us off at the pass. That hangover was from another time, a lion of its kind, whereas the hangover of 31/12/20 was a pussycat in comparison. Damage was sustainable; fluids acceptable; soup, a dawning possibility. A few minor demons were off on a toot but the mopping up operation was well underway. I would gather them all up like naughty numbskulls and put them back in the jar, until the next time the lid pops off. So, taking deep breaths, I repeated like a mantra – “Everything’s alright, everything’s alright..”. Tell it ‘til it’s true. “Everything’s alright”. “Everything’s alright what?”, came the answer, one of the more stubborn demons. “Everything’s alright fine”. “Why two words when one would do?” said the demon. “You protest too much”. The above processing of information and damage management often takes a musical form. It is good to take notes throughout. You never know what you might miss. Humphrey Bogart won’t always be there to help you through your hangovers and some courses you’ll have to plot alone, making your own entertainment along the way. Meantime, and remember, this may well all turn out to be meantime, everything’s alright fine.
#10 Intermission – (Voice recording of initial idea recorded on 10/11/20)
Transmissions from Planet Zoom- a melancholy android plays remembered sounds from Planet Earth; an ice cream van, a seaside organ, elevator muzak. Refreshments are available in the foyer.

Welcome back folks.
#11 A Chemical Dream (20/01/04 - 01/09/08)
Another of the lost souls, “A Chemical Dream” dates from around mid-late noughties and, woozy and anaesthetised as it may be, I imagine it must still have been deemed far too jolly for the last Starlets album. Then, come the revolution and post Year-Zero, songs about chemicals would, of course, have been cancelled due to high levels of bourgeois decadence. I picture “A Chemical Dream” as the sound of Sunday morning coming down; dawn is breaking and night’s spell of enchantment is slowly lifting, but maybe the imminent crash will be sustainable, a new beginning. Song as dream sequence, through the highs and lows of hedonism, thematically we are, of course, in familiar territory here. Never mind. We must work with what we have. Even when it feels like nothing.
#12 What Boys Do (10/7/16) “And you know all our boys Are really girls at heart” -The Imposter, Elvis Costello
“What Boys Do” started life in 2016 with the working title of “The Replacements” (see link), as the initial idea reminded me a little of the brilliant band of that name (as an irrelevant aside here, I would like to boast that one of the treasures in my collection is a cigarette packet signed by Paul Westerberg). I don’t remember too much about writing this but there are many things in my life that I don’t remember too much about and perhaps this is for the best. If called upon to explain myself as regards the title, I would draw attention to the lyric - “All the big talk and then we’re through But that’s just what boys do” As a boy of a certain vintage, I grew up in an era when society’s expectation for its menfolk was to be strong, capable, uncomplaining, tough, undemonstrative, to never show weakness. That’s a fair bit to live up to. Hence the big talk. And all that goes with it. The song itself sounded, once again, so unlike anything else we were doing at the time that I didn’t know where to put it (we are an anomaly even to ourselves) and so off it slipped, into obscurity, last seen in 2016. A six-year sentence to the Lost and Later files is, of course, relatively lenient when compared with some of the other songs (see “Drunk is a Holiday”). Then came the days of the new pestilence and lockdown during which, with nothing better to do, and having exhausted all other far more pleasant possibilities, I thought, oh dear, I might as well work. In the early demos there were concerns that the heavy guitars could sound a bit ploddy and pub rock so we decided a healthy dollop of glam was required and during the recording of the song, I often asked myself - “What would the New York Dolls do?” *. So, I added some “oh-oh-oh-oh-oh-ohs" and bought myself a feather boa. I wore the feather boa whilst recording the vocal and that helped to get me in the mood. Still, I had my doubts and, come the mixing, I expressed concern over my vocal performance in an email to our producer Colin Elliot, signing off with - “My only worry is that it may not be camp enough”. Colin was happy to reassure me on that point and replied- “Don’t worry, it’s always camp enough” * “What would the New York Dolls do?” I would strongly recommend we ask ourselves this question whenever facing difficult circumstances, in whatever walk of life and certainly never less than once a day... although probably not whilst driving or operating heavy machinery.
#13 Starlight International 16/10/18 @ 7.39 am
This song arrived, more or less fully formed, in a dream. On waking, rather than rolling over, perchance to dream once more, I had the wherewithal to grab my guitar and record it into my phone. There’s something about the state between sleep and waking that makes for fertile ground for the imagination. The mind is no longer on its best behaviour. Notions such as sensible, adult behaviour become a laughing stock. Ha ha ha ha. Fuck that. Chaos creeps in, many-fingered and dancing to the beat of a different drum. We were in the middle of our Dark Carnival incarnation at the time and I found myself singing “Baby you’re a supernatural” at the chorus so this became the initial working title. Later on, I thought the word “international” scanned a bit better and could also make for our signature tune. Then “Starlight International” suggested itself. It all sounded rather glam and, inspired by Bowie’s starman/spaceboy fantasies, I thought “Of course! A space ballad”. The band as cosmonauts, into the Great Unknown, to infirmity and beyond. If I wasn’t afraid of heights, I wouldn’t mind signing up for the space game. As long as I didn’t have to wake up too early and as long as I was home in time for tea or at least, last orders.
#14 Boom Boom Cannonball (27/9/17)
The riff idea came to me at a Slim Cessna’s Auto Club gig. In days gone by I would have forgotten it with the next passing fancy but thankfully nowadays there are voice recorders on phones to help people like me along. In the “boom idea” recording you can hear me singing the riff over the noisy chaos of the live gig in the background (foreground as background, sadly, is often the way at live gigs). As noted previously, every recipe needs a healthy dash of chaos, this time provided by the noise and heat and sweat of a small club gig. The band are bangin and I’m several beers in. Charge on.
It was never going to be pretty. It demanded much huffing and puffing and a-panting and a-grunting, like Leonard Cohen sings the Army of Lovers or a surprise Eurovision entry by The Hormone Monster. Cheesy, sleazy eurotrash with a honking, stonking dose of the horn. Yes, yes, yes...it may all be considered thoroughly inappropriate, but I have no concerns. In order to be cancelled, one has to be scheduled in the first place.
#15 The Strangest Thing (1/3/21)
Latest of the later songs and yet another to come in a dream. I seem to spend half my life in a dream, the other half in denial. In this dream I found myself running through the dimly lit labyrinth of a post-apocalyptic Venice whilst battling some strangely attractive zombies. I didn’t know whether I wanted to fight the Zombies or....well, you get the idea. It was all a bit Lara Croft meets Sigmund Freud. The end of the dream felt like completing a level. I outran the zombies only to find myself running down a dark alleyway into a dead end, at the end of which was a drinking fountain. As I approached the fountain, I saw there was a secret button in the middle of the fountainhead. Ooh. I pressed a secret button and the fountain began to sink into the ground whilst playing the doorbell melody you hear at the beginning of the song. That was the dream. Pure spooky man. My dreams are rarely light-hearted. Never mind. I try to see them as free entertainment, the brain’s bonus section. Lockdown recording felt like a clean slate, like we could sound like anything we wanted. It liberated us from the bang and crash of the rehearsal room (fond as I am of that). I suspect “The Strangest Thing” would never have blossomed in that environment. I should be grateful it wasn’t written 25 years ago. If you are in a hurry, I would say this is not the song for you. If you are not in a hurry....may I suggest you make yourself comfortable, maybe with a glass of something lovely. Let us take time out from the world. The chaos will still be there tomorrow. Just not the way we left it.
#16 There’s Barely Enough Time to Breathe (no demo exists)
Another one from the analogue years, approximately 1997-8, around the same time as “Yesterday’s Already Light Years Away” and similarly born out of my obsession (current and ongoing) with Prefab Sprout’s “Steve McQueen” album. This was another one which didn’t suit the rough and tumble of the rehearsal room. Quite simply, we didn’t have a clue what to do with the song and so we stood around looking at it for a while, somewhat vacantly, like dogs watching a card trick. So, no demo for this one. You can’t record what you can’t play, or so we thought until making this album. Never let a lack of technical ability get in the way of a musical idea. Music is too important to be left to musicians. That’s what I always say. Lyrically, this one was in part inspired by the line “Another lifetime is the least you’ll need” from Jonathan Coe’s “The House of Sleep”. I loved the book and the character Sarah, a narcoleptic who can’t tell the difference between her dreams and her waking state and so talks to people about her dreams as though they were widely known world events. How marvellous. I used to think I might be narcoleptic until it dawned on me that I just find much of life terribly dull. As a younger man, I was sacked from jobs for falling asleep. Fortunately, I wasn’t a bus driver. Or anything important, really. I managed to blag a place at university purely as a way of avoiding work, only to then regularly fall asleep during lectures. I remember falling asleep during a History lecture (the last words I remember hearing were something about “demography in the 18th century”) only to wake up some time later, startled to find I was surrounded by an entirely new group of students, all eagerly taking notes on a talk about tectonic plates and volcanic rock formations. I was too embarrassed to get up and leave so I sat as inconspicuously as a recently snoring man in a room full of bright-eyed young Geology students could until I gradually found myself being drawn in by the subject, fascinated. Wow. What tumult and drama we walk above. It’s amazing we can make it to the shops in one piece. I failed History that year but I could probably tell you a thing or two about Mount Vesuvius. So, anyway, getting back to the song, lyrically, I can hear the struggle to reconcile my world view with what then seemed to me the outrage upon my personal liberty that was working for a living. Work, the foulest of all four-letter words and the enemy of sleep. I have never been a morning person and wake up begrudgingly. I then believe in due process as observed in the form of at least one hour of coffee and denial. After an hour, I may then deign to talk to you, but it will probably be about the dream I just had. I carried this song around in my head for 25 years. I am beyond happy to see it finally set it free. Thank you, dear band, thank you Colin Elliot. The more dreams I can make come true, the less there are to haunt me.
#17 Freediving (1/3/12)
Another late developer, more lost than later, “Freediving” took 10 years to record. Mark and I occasionally get together to work on the guitar arrangements, an activity which has come to be known as “The Biscuit Sessions” (these would be mid-week affairs, involving nothing stronger than ginger snaps and PG Tips). The earliest documented recording of this was 1/3/12 at 1906h, a rough idea we must have bashed out in between biscuits. A further demo from 22/12/12 (0020h) shows a more realised structure although it was still instrumental at the time (I didn’t yet know what I was writing about). The song felt subtle and elusive, never quite settling and I think back then, we made the mistake of trying to rush it, control it, rather than allow it to breathe and gradually reveal itself. If you love something, set it free. If it’s meant to be, it will come back to you. And it did, around nine years later in the long, echoing days of lockdown when time all of a sudden felt like a surplus (a mirage, I know) and little pockets of hitherto unimaginable breathing space emerged, a coming up for air in the midst of all the horror. The music itself made me think of water. It felt fluid, tidal. I thought of the intimacy of underwater where the above world becomes muffled and hushed and how, perhaps in that escape lay the appeal of freediving, not an activity I had given much thought to until watching the film “The Big Blue”. I remembered the scene from the film when the two central characters, friends and rivals for the crown of World Freediving Champion, become bored at a glitzy party and, aching to escape the inane cocktail chatter, decide to jump in their host’s swimming pool and hang out down at the bottom of the deep end. I also thought of Kino the pearl diver from Steinbeck’s “The Pearl”, Kino bursting triumphantly from the depths as cupped and glistening in his hands was the oyster in which lay the pearl of the world. Finally, I thought that whatever is or isn’t down there, pearls, tranquility or nothing at all, in the dive alone may be found a freedom which, if we never get our feet wet, we will only ever guess at.
#18 Those First Impressions (approximately 2007)
For Billy Mackenzie
#19 The Night Will Take You (original demo dated 9/11/10)
It’s the last song of the night folks. If you don’t ask that beautiful stranger to dance now, the moment will be gone forever. We impersonate that which we admire, try it on for size in the hope that someday the outfit may suit us. Back in Starlets days, we used to cover “Science Fiction/Double Feature” from The Rocky Horror Picture Show. I still think it’s the most romantic song I’ve ever heard and one of the few songs that, whatever I’m doing, should I hear it playing, I have to stop and listen to it (I am not a man to be left in charge of a group of toddlers, or a combine harvester). Travelling for many years under the nom de guerre “Glitterball”, in another world, or perhaps in yet another dream I once had, "The Night Will Take You" would soundtrack the closing credits of a John Hughes movie. Preferably one with Molly Ringwald. Good triumphs over evil, love over death, and all those eternal human legends which settle our score with reality. Some nights, when the lights are low and the music's right, I start believing all over again. So, if you’re dancing, I’m asking. Always will be.
#20 Lost and Later Theme (5/3/19)
A street musician duets with a synthesiser. Written on accordion, this early recording is more bum notes than melody but you can hear the tune gradually emerging - https://on.soundcloud.com/BrFXc It was partly influenced by a barrel organ street musician I once heard - (see “Rue Daguerre, Montparnasse” on the secret playlist). I loved the song but never found out its name. It sounds like some old, jolly, French drinking song. If anyone recognises it, please do let me know, thank you. Anyway, welcome to the end of the pier. Don’t jump off just yet. You might miss something. The view is lovely and on a clear day you can see, if not quite forever, at least as far as next Tuesday. To quote many a firm but fair barkeep at closing time, you don’t have to go home but you can’t stay here. Actually, no, that’s not true. You can stay here. You can live here. I do.
2 notes
·
View notes