#internal data distribution
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Kazakhstan’s Minister of Communications and Informatics has blocked the Tumblr site because it contained 60 sites of terrorism, extremism, and pornography in 2015.
Photo

Smart Energy Finance: Funding for autonomous EV charging and GridBeyond’s acquisition of Veritone Energy Leading Smart Energy Finances: a successful Series A funding round for Rocsys, which has been developing an autonomous EV charging solution https://www.smart-energy.com/finance-investment/smart-energy-finance-funding-for-autonomous-ev-charging-and-gridbeyonds-acquisition-of-veritone-energy/
#Business#Data &Analytics#Distributed generation#Electric Vehicles#Energy &Grid Management#Europe &UK#Features and Analysis#Finance &Investment#New technology#North America#Smart Energy#acquisition#EV charging#France#Smart Energy Finances Weekly#VPP#Yusuf Latief#Smart Energy International
0 notes
Text
Microsoft made Recall—the feature that automatically tracks everything you do in an attempt at helping you except, you know, that's a massive security risk and data mining source—a dependency for the windows file explorer, meaning even if you forcibly strip Recall out you end up losing basic tools.
This is very much a "learn how to install Linux Mint on your laptop" moment. Richard Stallman et al were entirely correct, your computer will soon have spyware integrated deep into the system internals with no ability to cleanly remove it even for experienced, tech savvy users.
Yes, it sucks, there is no Linux distribution that has to even close to the level of support for software and peripherals that windows has, and even the easier distros like Mint still expect a level of tech savvy that Mac and Windows just don't require. Anyone telling you that Linux is just as easy and just as good is lying to you.
But Linux has never been easier, has never been as well supported as today, and simply doesn't contain egregious spyware (well, besides Ubuntu that one time I guess).
2K notes
·
View notes
Text
3/26/25
Haviv Rettig Gur on deaths in Gaza:
The full list of Gazans killed in the war has been released in Gaza. Possibly. At the very least, as Israeli analysts are now finding, there aren't duplicate ID numbers or other tells one finds in obviously manipulated data sets. But here's another reason to trust the data: It shows just how much Israel's warfighting tried to separate combatant from civilian. It seems unlikely that a faked Gazan data set would show such a result. The graph in the first tweet of this thread shows male to female deaths. If female deaths are assumed to be a civilian baseline (the age distribution is roughly the general Gazan population's age distribution), then the enormous spike of the blue line, right in the area of the graph that represents fighting-age men, is the best likely measure of combatant deaths. According to this analyst, the gap comes to over 16,000 dead, or almost exactly a third of total deaths. That's a Gazan data set, not an Israeli one. And it's the most complete one so far, the only one that claims to give all the names of all the dead, the one most likely to be an honest recording of the actual dead. And according to this data set, the death toll in Gaza is two civilians to each combatant, well in line with the highest standards of modern democratic armies. To be clear - this caveat is obvious, but it's important enough to say it explicitly nonetheless - the debate isn't over whether children died in Gaza or crimes were committed. The answer to both is yes. There were definitely and unquestionably war crimes committed in Gaza, air strikes that should not have been carried out. And there are thousands of dead children in this data set. The debate is over the extent, whether these are at a level consistent with the inevitable costs of even the most legitimate kind of war, which will always be horrible, or whether the best data we have shows wanton Israeli killing and disregard for moral rules and international laws. Israel's haters will tweet pictures of dead children in response. If they did that for every war, I'd take them seriously and sympathetically. But the vast majority of them don't. They don't care about dead children, only about destroying Israel. And so they can't actually tell us anything about whether our army, broadly speaking, has fought morally. But this data set can. All war is evil, all war is hell, all war is a kind of civilizational failure. But war is sometimes nevertheless legitimate and inevitable. International humanitarian law came about not to end war, because ending war is impossible, but to mitigate its evils. If this data set is correct - again, a data set released from Gaza and not at all intended to validate any Israeli argument about its battlefield standards - then the costs imposed on Gaza by Israeli warfighting methods are consistent with what is generally considered in the West to be moral and legitimate. It is a comparable ratio to the 2016 Battle of Mosul in which Iraq, the Kurds and America drove ISIS out of the city. War is bad. I respect people who vehemently oppose this one, who question the Israeli political leadership's decisions, who use the war to debate the larger question of Palestinian independence and statehood. These are all legitimate responses to the suffering of Gazans. As is the argument I personally agree with that this war was the only path available to us to rid ourselves and Gaza of the neverending and endlessly destructive scourge of Hamas. But it nevertheless matters - indeed, it may be the most important thing over the long term - that this war's civilian casualties were not worse than other comparable wars, and that even Gazan data sets show that to be the case.

The thread to which Haviv refers is here
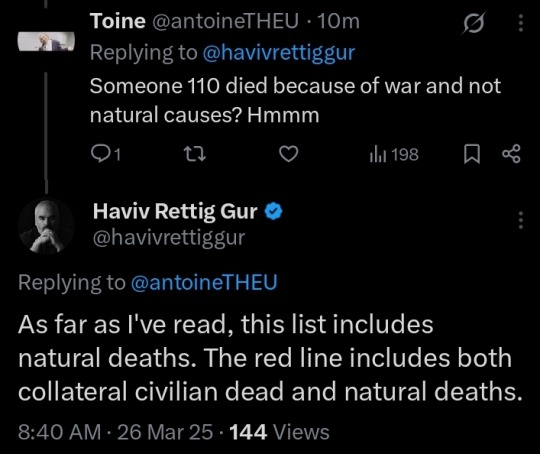
388 notes
·
View notes
Text
Generative AI Policy (February 9, 2024)

As of February 9, 2024, we are updating our Terms of Service to prohibit the following content:
Images created through the use of generative AI programs such as Stable Diffusion, Midjourney, and Dall-E.
This post explains what that means for you. We know it’s impossible to remove all images created by Generative AI on Pillowfort. The goal of this new policy, however, is to send a clear message that we are against the normalization of commercializing and distributing images created by Generative AI. Pillowfort stands in full support of all creatives who make Pillowfort their home. Disclaimer: The following policy was shaped in collaboration with Pillowfort Staff and international university researchers. We are aware that Artificial Intelligence is a rapidly evolving environment. This policy may require revisions in the future to adapt to the changing landscape of Generative AI.
-
Why is Generative AI Banned on Pillowfort?
Our Terms of Service already prohibits copyright violations, which includes reposting other people’s artwork to Pillowfort without the artist’s permission; and because of how Generative AI draws on a database of images and text that were taken without consent from artists or writers, all Generative AI content can be considered in violation of this rule. We also had an overwhelming response from our user base urging us to take action on prohibiting Generative AI on our platform.
-
How does Pillowfort define Generative AI?
As of February 9, 2024 we define Generative AI as online tools for producing material based on large data collection that is often gathered without consent or notification from the original creators.
Generative AI tools do not require skill on behalf of the user and effectively replace them in the creative process (ie - little direction or decision making taken directly from the user). Tools that assist creativity don't replace the user. This means the user can still improve their skills and refine over time.
For example: If you ask a Generative AI tool to add a lighthouse to an image, the image of a lighthouse appears in a completed state. Whereas if you used an assistive drawing tool to add a lighthouse to an image, the user decides the tools used to contribute to the creation process and how to apply them.
Examples of Tools Not Allowed on Pillowfort: Adobe Firefly* Dall-E GPT-4 Jasper Chat Lensa Midjourney Stable Diffusion Synthesia
Example of Tools Still Allowed on Pillowfort:
AI Assistant Tools (ie: Google Translate, Grammarly) VTuber Tools (ie: Live3D, Restream, VRChat) Digital Audio Editors (ie: Audacity, Garage Band) Poser & Reference Tools (ie: Poser, Blender) Graphic & Image Editors (ie: Canva, Adobe Photoshop*, Procreate, Medibang, automatic filters from phone cameras)
*While Adobe software such as Adobe Photoshop is not considered Generative AI, Adobe Firefly is fully integrated in various Adobe software and falls under our definition of Generative AI. The use of Adobe Photoshop is allowed on Pillowfort. The creation of an image in Adobe Photoshop using Adobe Firefly would be prohibited on Pillowfort.
-
Can I use ethical generators?
Due to the evolving nature of Generative AI, ethical generators are not an exception.
-
Can I still talk about AI?
Yes! Posts, Comments, and User Communities discussing AI are still allowed on Pillowfort.
-
Can I link to or embed websites, articles, or social media posts containing Generative AI?
Yes. We do ask that you properly tag your post as “AI” and “Artificial Intelligence.”
-
Can I advertise the sale of digital or virtual goods containing Generative AI?
No. Offsite Advertising of the sale of goods (digital and physical) containing Generative AI on Pillowfort is prohibited.
-
How can I tell if a software I use contains Generative AI?
A general rule of thumb as a first step is you can try testing the software by turning off internet access and seeing if the tool still works. If the software says it needs to be online there’s a chance it’s using Generative AI and needs to be explored further.
You are also always welcome to contact us at [email protected] if you’re still unsure.
-
How will this policy be enforced/detected?
Our Team has decided we are NOT using AI-based automated detection tools due to how often they provide false positives and other issues. We are applying a suite of methods sourced from international universities responding to moderating material potentially sourced from Generative AI instead.
-
How do I report content containing Generative AI Material?
If you are concerned about post(s) featuring Generative AI material, please flag the post for our Site Moderation Team to conduct a thorough investigation. As a reminder, Pillowfort’s existing policy regarding callout posts applies here and harassment / brigading / etc will not be tolerated.
Any questions or clarifications regarding our Generative AI Policy can be sent to [email protected].
2K notes
·
View notes
Text
Indian Prime Minister Narendra Modi is, by some measures, the most popular leader in the world. Prior to the 2024 election, his Bharatiya Janata Party (BJP) held an outright majority in the Lok Sabha (India’s Parliament) — one that was widely projected to grow after the vote count. The party regularly boasted that it would win 400 Lok Sabha seats, easily enough to amend India’s constitution along the party's preferred Hindu nationalist lines.
But when the results were announced on Tuesday, the BJP held just 240 seats. They not only underperformed expectations, they actually lost their parliamentary majority. While Modi will remain prime minister, he will do so at the helm of a coalition government — meaning that he will depend on other parties to stay in office, making it harder to continue his ongoing assault on Indian democracy.
So what happened? Why did Indian voters deal a devastating blow to a prime minister who, by all measures, they mostly seem to like?
India is a massive country — the most populous in the world — and one of the most diverse, making its internal politics exceedingly complicated. A definitive assessment of the election would require granular data on voter breakdown across caste, class, linguistic, religious, age, and gender divides. At present, those numbers don’t exist in sufficient detail.
But after looking at the information that is available and speaking with several leading experts on Indian politics, there are at least three conclusions that I’m comfortable drawing.
First, voters punished Modi for putting his Hindu nationalist agenda ahead of fixing India’s unequal economy. Second, Indian voters had some real concerns about the decline of liberal democracy under BJP rule. Third, the opposition parties waged a smart campaign that took advantage of Modi’s vulnerabilities on the economy and democracy.
Understanding these factors isn’t just important for Indians. The country’s election has some universal lessons for how to beat a would-be authoritarian — ones that Americans especially might want to heed heading into its election in November.
-via Vox, June 7, 2024. Article continues below.
A new (and unequal) economy
Modi’s biggest and most surprising losses came in India’s two most populous states: Uttar Pradesh in the north and Maharashtra in the west. Both states had previously been BJP strongholds — places where the party’s core tactic of pitting the Hindu majority against the Muslim minority had seemingly cemented Hindu support for Modi and his allies.
One prominent Indian analyst, Yogendra Yadav, saw the cracks in advance. Swimming against the tide of Indian media, he correctly predicted that the BJP would fall short of a governing majority.
Traveling through the country, but especially rural Uttar Pradesh, he prophesied “the return of normal politics”: that Indian voters were no longer held spellbound by Modi’s charismatic nationalist appeals and were instead starting to worry about the way politics was affecting their lives.
Yadav’s conclusions derived in no small part from hearing voters’ concerns about the economy. The issue wasn’t GDP growth — India’s is the fastest-growing economy in the world — but rather the distribution of growth’s fruits. While some of Modi’s top allies struck it rich, many ordinary Indians suffered. Nearly half of all Indians between 20 and 24 are unemployed; Indian farmers have repeatedly protested Modi policies that they felt hurt their livelihoods.
“Everyone was talking about price rise, unemployment, the state of public services, the plight of farmers, [and] the struggles of labor,” Yadav wrote...
“We know for sure that Modi’s strongman image and brassy self-confidence were not as popular with voters as the BJP assumed,” says Sadanand Dhume, a senior fellow at the American Enterprise Institute who studies India.
The lesson here isn’t that the pocketbook concerns trump identity-based appeals everywhere; recent evidence in wealthier democracies suggests the opposite is true. Rather, it’s that even entrenched reputations of populist leaders are not unshakeable. When they make errors, even some time ago, it’s possible to get voters to remember these mistakes and prioritize them over whatever culture war the populist is peddling at the moment.
Liberalism strikes back
The Indian constitution is a liberal document: It guarantees equality of all citizens and enshrines measures designed to enshrine said equality into law. The signature goal of Modi’s time in power has been to rip this liberal edifice down and replace it with a Hindu nationalist model that pushes non-Hindus to the social margins. In pursuit of this agenda, the BJP has concentrated power in Modi’s hands and undermined key pillars of Indian democracy (like a free press and independent judiciary).
Prior to the election, there was a sense that Indian voters either didn’t much care about the assault on liberal democracy or mostly agreed with it. But the BJP’s surprising underperformance suggests otherwise.
The Hindu, a leading Indian newspaper, published an essential post-election data analysis breaking down what we know about the results. One of the more striking findings is that the opposition parties surged in parliamentary seats reserved for members of “scheduled castes” — the legal term for Dalits, the lowest caste grouping in the Hindu hierarchy.
Caste has long been an essential cleavage in Indian politics, with Dalits typically favoring the left-wing Congress party over the BJP (long seen as an upper-caste party). Under Modi, the BJP had seemingly tamped down on the salience of class by elevating all Hindus — including Dalits — over Muslims. Yet now it’s looking like Dalits were flocking back to Congress and its allies. Why?
According to experts, Dalit voters feared the consequences of a BJP landslide. If Modi’s party achieved its 400-seat target, they’d have more than enough votes to amend India’s constitution. Since the constitution contains several protections designed to promote Dalit equality — including a first-in-the-world affirmative action system — that seemed like a serious threat to the community. It seems, at least based on preliminary data, that they voted accordingly.
The Dalit vote is but one example of the ways in which Modi’s brazen willingness to assail Indian institutions likely alienated voters.
Uttar Pradesh (UP), India’s largest and most electorally important state, was the site of a major BJP anti-Muslim campaign. It unofficially kicked off its campaign in the UP city of Ayodhya earlier this year, during a ceremony celebrating one of Modi’s crowning achievements: the construction of a Hindu temple on the site of a former mosque that had been torn down by Hindu nationalists in 1992.
Yet not only did the BJP lose UP, it specifically lost the constituency — the city of Faizabad — in which the Ayodhya temple is located. It’s as direct an electoral rebuke to BJP ideology as one can imagine.
In Maharashtra, the second largest state, the BJP made a tactical alliance with a local politician, Ajit Pawar, facing serious corruption charges. Voters seemingly punished Modi’s party for turning a blind eye to Pawar’s offenses against the public trust. Across the country, Muslim voters turned out for the opposition to defend their rights against Modi’s attacks.
The global lesson here is clear: Even popular authoritarians can overreach.
By turning “400 seats” into a campaign slogan, an all-but-open signal that he intended to remake the Indian state in his illiberal image, Modi practically rang an alarm bell for constituencies worried about the consequences. So they turned out to stop him en masse.
The BJP’s electoral underperformance is, in no small part, the direct result of their leader’s zealotry going too far.
Return of the Gandhis?
Of course, Modi’s mistakes might not have mattered had his rivals failed to capitalize. The Indian opposition, however, was far more effective than most observers anticipated.
Perhaps most importantly, the many opposition parties coordinated with each other. Forming a united bloc called INDIA (Indian National Developmental Inclusive Alliance), they worked to make sure they weren’t stealing votes from each other in critical constituencies, positioning INDIA coalition candidates to win straight fights against BJP rivals.
The leading party in the opposition bloc — Congress — was also more put together than people thought. Its most prominent leader, Rahul Gandhi, was widely dismissed as a dilettante nepo baby: a pale imitation of his father Rajiv and grandmother Indira, both former Congress prime ministers. Now his critics are rethinking things.
“I owe Rahul Gandhi an apology because I seriously underestimated him,” says Manjari Miller, a senior fellow at the Council on Foreign Relations.
Miller singled out Gandhi’s yatras (marches) across India as a particularly canny tactic. These physically grueling voyages across the length and breadth of India showed that he wasn’t just a privileged son of Indian political royalty, but a politician willing to take risks and meet ordinary Indians where they were. During the yatras, he would meet directly with voters from marginalized groups and rail against Modi’s politics of hate.
“The persona he’s developed — as somebody kind, caring, inclusive, [and] resolute in the face of bullying — has really worked and captured the imagination of younger India,” says Suryanarayan. “If you’ve spent any time on Instagram Reels, [you’ll see] an entire generation now waking up to Rahul Gandhi’s very appealing videos.”
This, too, has a lesson for the rest of the world: Tactical innovation from the opposition matters even in an unfair electoral context.
There is no doubt that, in the past 10 years, the BJP stacked the political deck against its opponents. They consolidated control over large chunks of the national media, changed campaign finance law to favor themselves, suborned the famously independent Indian Electoral Commission, and even intimidated the Supreme Court into letting them get away with it.
The opposition, though, managed to find ways to compete even under unfair circumstances. Strategic coordination between them helped consolidate resources and ameliorate the BJP cash advantage. Direct voter outreach like the yatra helped circumvent BJP dominance in the national media.
To be clear, the opposition still did not win a majority. Modi will have a third term in office, likely thanks in large part to the ways he rigged the system in his favor.
Yet there is no doubt that the opposition deserves to celebrate. Modi’s power has been constrained and the myth of his invincibility wounded, perhaps mortally. Indian voters, like those in Brazil and Poland before them, have dealt a major blow to their homegrown authoritarian faction.
And that is something worth celebrating.
-via Vox, June 7, 2024.
#india#narendra modi#pm modi#modi#bjp#lok sabha elections#rahul gandhi#democracy#2024 elections#authoritarianism#anti authoritarian#good news#hope
747 notes
·
View notes
Text
Also preserved in our archive

By Sarah Schwartz
Test after test of U.S. students’ reading and math abilities have shown scores declining since the pandemic.
Now, new results show that it’s not just children whose skills have fallen over the past few years—American adults are getting worse at reading and math, too.
The connection, if any, between the two patterns isn’t clear—the tests aren’t set up to provide that kind of information. But it does point to a populace that is becoming more stratified by ability at a time when economic inequality continues to widen and debates over opportunity for social mobility are on the rise.
The findings from the 2023 administration of the Program for the International Assessment of Adult Competencies, or PIAAC, show that 16- to 65-year-olds’ literacy scores declined by 12 points from 2017 to 2023, while their numeracy scores fell by 7 points during the same period.
These trends aren’t unique in the global context: Of the 31 countries and economies in the Organization for Economic Cooperation and Development that participated in PIAAC, some saw scores drop over the past six years, while others improved or held constant.
Still, as in previous years, the United States doesn’t compare favorably to other countries: The country ranks in the middle of the pack in literacy and below the international average in math. (Literacy and numeracy on the test are scored on a 500-point scale.)
But Americans do stand out in one way: The gap between the highest- and lowest-performing adults is growing wider, as the top scorers hold steady and other test takers see their scores fall.
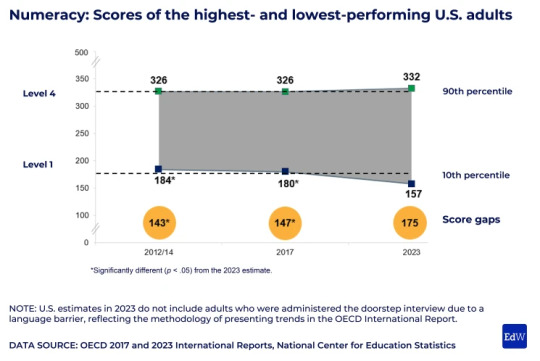
“There’s a dwindling middle in the United States in terms of skills,” said Peggy Carr, the commissioner of the National Center for Education Statistics, which oversees PIAAC in the country. (The test was developed by the OECD and is administered every three years.)
It’s a phenomenon that distinguishes the United States, she said.
“Some of that is because we’re very diverse and it’s large, in comparison to some of the OECD countries,” Carr said in a call with reporters on Monday. “But that clearly is not the only reason.”
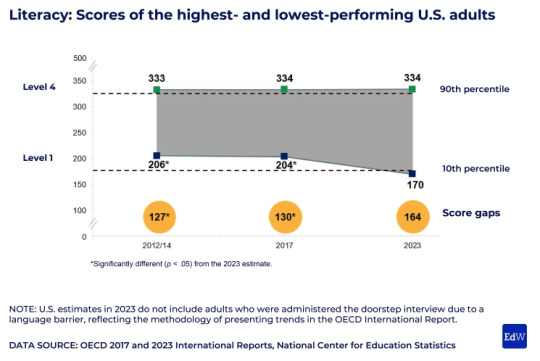
American children, too, are experiencing this widening chasm between high and low performers. National and international tests show the country’s top students holding steady, while students at the bottom of the distribution are falling further behind.
It’s hard to know why U.S. adults’ scores have taken this precipitous dive, Carr said.
About a third of Americans score at lowest levels PIAAC is different from large-scale assessments for students, which measure kids’ academic abilities.
Instead, this test for adults evaluates their abilities to use math and reading in real-world contexts—to navigate public services in their neighborhood, for example, or complete a task at work. The United States sample is nationally representative random sample, drawn from census data.
American respondents averaged a level 2 of 5 in both subjects.
In practice, that means that they can, for example, use a website to find information about how to order a recycling cart, or read and understand a list of rules for sending their child to preschool. But they would have trouble using a library search engine to find the author of a book.
In math, they could compare a table and a graph of the same information to check for errors. But they wouldn’t be able to calculate average monthly expenses with several months of data.
While the U.S. average is a level 2, more adults now fall at a level 1 or below—28 percent scored at that level in literacy, up from 19 percent in 2017, and 34 percent in numeracy, up from 29 percent in 2017.
Respondents scoring below level 1 couldn’t compare calendar dates printed on grocery tags to determine which food item was packed first. They would also struggle to read several job descriptions and identify which company was looking to hire a night-shift worker.
The findings also show sharp divides by race and national origin, with respondents born in the United States outscoring those born outside of the country, and white respondents outscoring Black and Hispanic test takers. Those trends have persisted over the past decade.
#mask up#public health#wear a mask#pandemic#wear a respirator#covid#still coviding#covid 19#coronavirus#sars cov 2
308 notes
·
View notes
Text
For much of living memory, the United States has been a global leader of scientific research and innovation. From the polio vaccine, to decoding the first human chromosome, to the first heart bypass surgery, American research has originated a seemingly endless list of health care advances that are taken for granted.
But when the Trump administration issued a memorandum Monday that paused all federal grants and loans—with the aim of ensuring that funding recipients are complying with the president’s raft of recent executive orders—US academia ground to a halt. Since then, the freeze has been partially rescinded for some sectors, but it largely remains in place for universities and research institutions across the country, with no certainty of what comes next.
“This has immediate impact on people’s lives,” says J9 Austin, professor of psychiatry and medical genetics at the University of British Columbia. “And it’s terrifying.”
The funding freeze requires agencies to submit reviews of their funded programs to the Office of Management and Budget by February 10. The freeze follows separate orders issued last week to US health agencies—including to the National Institutes of Health, which leads the country’s medical research—to pause all communications until February 1 and stop almost all travel indefinitely.
The confusion is consummate. If the funding freeze continues through February, and even beyond, how will graduate students be paid? Should grant applications—years long in the writing—still be submitted by the triannual grant submission deadline on February 5? What does this mean for clinical trials if participants and lab techs can’t be paid? Will all that research have to be scrapped thanks to incomplete data?
Even if Trump fully reverses the freeze on research funding, the damage, multiple sources say, has been done. Although for now the funding freeze is temporary, the administration has shown how it might wield the levers of government. The implication is that withdrawing funding could be done more permanently, and could be done to individual institutions, individual organizations, both private and public. This won’t just set a precedent for the large East Coast or West Coast universities, but those located in both red and blue states alike.
While always an imperfect arrangement, science in the US is largely funded by a complex system of grant applications, reviews by peers in the field (both of which have had to be halted as part of the communications pause), and the competitive distribution of NIH funds, says Gerald Keusch, emeritus professor of medicine at Boston University and former associate director of international research for the NIH. According to its website, the NIH disburses nearly $48 billion in grants per year.
When it comes to medical research, America truly is first, and if it abdicates that position, the void left behind has global ramifications. “In Canada, we have always looked to NIH as an exemplar of what we should be trying to do,” says Austin, speaking to me independently of any roles and affiliations. “Now, that’s collapsed.”
Science is, in its very nature, collaborative. Many consortiums and alliances within scientific fields cross borders and language barriers. Some labs may be able to find additional funding from alternative sources such as the European Union. But it is unlikely that a continued withdrawal of NIH funding could be plugged by overseas support. And Big Pharma, with its seemingly endless funds, is unlikely to step up either, according to sources WIRED spoke with.
“This can’t be handed off to drug companies or biotech, because they’re not interested in things that are as preclinical as a lot of the work we’re discussing here,” says a professor of genetics who agreed to speak anonymously out of fear of retribution. “Essentially, there’s a whole legion of university-based scientists who work super damn hard to try to figure out some basic stuff that eventually becomes something that a drug company can drop $100 million on.”
The millions of dollars awarded to high-achieving labs is used to fund graduate students, lab techs, and analysts. If the principal investigator on a research team is unsuccessful in obtaining a grant through the process Keusch describes, often that lab is closed, and those ancillary team members lose their jobs.
One of the potential downstream effects of an NIH funding loss, even if only temporary, is a mass domestic brain drain. “Many of those people are going to go out to find something else to do,” the professor of genetics says. “These are just like jobs for anything else—we can’t not pay people for a month. What would the food service industry be like, for example, or grocery stores, if they don’t pay somebody for a month? Their workers will leave, and pharma can only hire so many people.”
WIRED heard over and over, from scientists too fearful for their teams and their jobs to speak on the record, that it won’t take long for the impact to reach the general population. With a loss of research funding comes the closure of hospitals and universities. And gains in medical advancement will likely falter too.
Conditions being studied with NIH funding are not only rare diseases affecting 1 or 2 percent of the population. They’re problems such as cancer, diabetes, Alzheimer’s—issues that affect your grandmother, your friends, and so many people who will one day fall out of perfect health. It’s thanks to this research system, and the scientists working within it, that doctors know how to save someone from a heart attack, regulate diabetes, lower cholesterol, and reduce the risk of stroke. It’s how the world knows that smoking isn’t a good idea. “All of that is knowledge that scientists funded by the NIH have generated, and if you throw this big of a wrench in it, it’s going to disrupt absolutely everything,” says the genetics professor.
While some are hopeful that the funding freeze for academia could end on February 1, when the pause on communications and therefore grant reviews is slated to lift, the individuals WIRED spoke with are largely skeptical that work will simply resume as before.
“When the wheels of government stop, it’s not like they turn on a dime and they just start up again,” says Julie Scofield, a former executive director of NASTAD, a US-based health nonprofit. She adds that she has colleagues in Washington, DC, who have had funding returned to their fields, and yet remain unable to access payment through the management system.
Austin says that already the international scientific community is holding hastily arranged online support groups. Topics covered range from the banal—what the most recent communication from the White House implies—to how best to protect trainees and the many students on international visas. But mostly they’re there to provide support.
“I’ve had a lot of messages from people just expressing gratitude that we could actually get together,” Austin says. “There’s just so much unaddressable need. None of us has the answers.”
Scientists, perhaps more than any other profession, are trained to “learn and validate conclusions drawn from observation and experimentation,” says Keutsch. That applies to the current situation. And what they observe during this pause of chaos does not portend well for the future of the United States as a pinnacle of scientific excellence.
“If people want the United States to head toward being a second-class nation, this is exactly what to do. If the goal is, in fact, to make America great, this is not a way to do it,” says the genetics professor. “This is not a rational, thoughtful, effective thing to do. It will merely destroy.”
This story has been written under a pseudonym, as the reporter has specific and credible concerns about potential retaliation.
193 notes
·
View notes
Text
So, because Tamsyn loves meaningful detail… this is from Juno Zeta providing “proof of life” to Camilla:

Heteroscedasticity in Viscus Models.
A viscus is any internal organ of the body, but especially located in the trunk (think stomach, liver, heart).
Heteroscedasticity is a concept in statistics, about data point distribution (I think). I don't know enough about the concept to understand how it might be used here, but.
A viscus model would either be about modeling organs (in theory or in necromantic practice) but it might also mean making a model of an organ.
I'm thinking back to Judith storing her report as a subdermal implant.

Any ideas how this might tie together?
#TLT#The Locked Tomb#Nona the Ninth#NtN#after NtN#the Angel#the Messenger#Aim#Juno Zeta#Alectopause#Alecto speculation
103 notes
·
View notes
Note
What makes code “hard coded” compared to other code, why is it so difficult to change, and why would developers hard code something rather than use normal code?
In order to understand how something is "hard coded", you need to understand what we do to the code in order to make it run on your device. Code is written in a human-readable format, but there is a lot of optimization and changes that get done to the code before the device can run it. This process is called compiling and linking. The result of compiling and linking code is an executable file that the device can understand, but humans cannot. The executable that has been compiled and linked is a snapshot of the code at the time that was compiled and linked. Any changes to the code require compiling and linking again in order for the executable to reflect it.

The program often needs to make choices based on internal values while the game is running. Most of the time these values are data-driven, meaning they are read from files outside of the code (e.g. read in the information from this config file and store it as whether to run the game in windowed mode). When the game needs to decide whether to run in windowed mode, it checks the file, grabs the relevant data, and uses that to decide. Because it's pulling this information from that config file, the same executable can handle both windowed and non-windowed mode. We don't need to compile and link the executable again.

If running windowed mode were hard coded, somewhere in the code itself there would be a variable like "Windowed = true". Then, after compiling and linking the executable, that executable would always run in windowed mode and never be able to run in full-screen mode. The only way to change this would be to change the code, then compile and link the executable again. Hard coding is fast and easy to do as a first pass of things, it's a quick way to test stuff locally if you can compile and link the executable yourself.

We can't give out the code because it's copyrighted and our intellectual property. We can only give out the executables after compiling and linking because they can't be read by humans. This means that any changes made to code are fairly difficult to distribute - this is what patches are. Hard coded values can only be changed when we distribute a new executable, while data-driven values like settings in a config file are much easier to change because they don't require compiling and linking, they only require somebody to modify the file being read and not the executable itself.
[Join us on Discord] and/or [Support us on Patreon]
Got a burning question you want answered?
Short questions: Ask a Game Dev on Twitter
Short questions: Ask a Game Dev on BlueSky
Long questions: Ask a Game Dev on Tumblr
Frequent Questions: The FAQ
94 notes
·
View notes
Text
What Pride Flags Mean, Part 1: Gender and Attraction
Welcome to the latest installment of my autistic hyperfixation on flags! I wanted to figure out a common language of Colour X means Thing Y. Like how pink is consistently used for feminine.
Having a common language for flag meanings matters because it improves cognitive accessibility of flags. ♿️💙
But I didn't want to be prescriptive about what colours should mean what. Just because I think Thing X should go with Colour Y doesn't mean everybody else would.
So this turned into a descriptive, empirical project. I gathered a data set of 2060 pride flag colour choices to figure out what are the most common colour-meaning combinations. Some of the results:
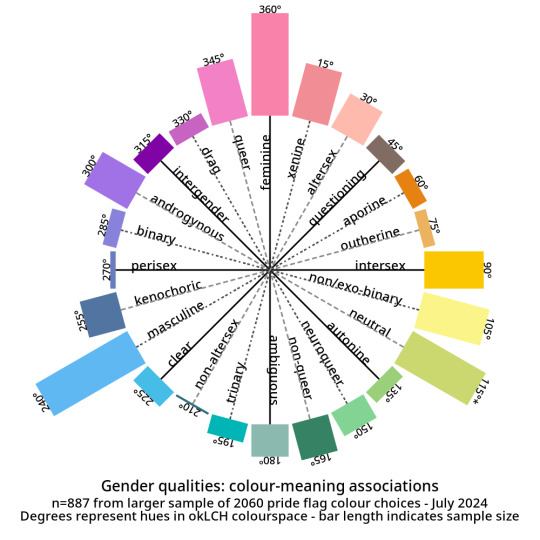
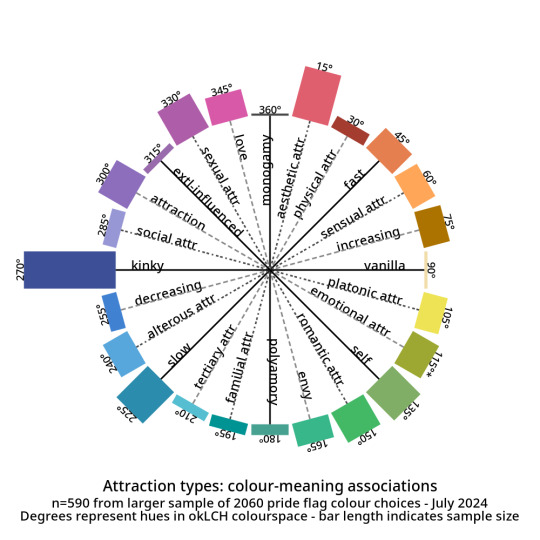
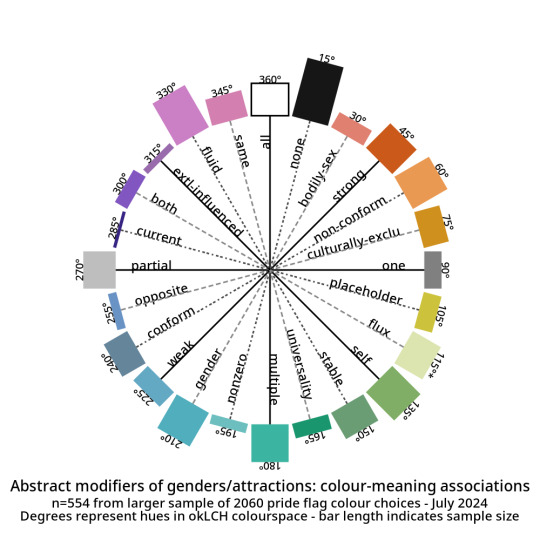
And here are the abstract modifiers: these are modifiers that were generally shared between the genders and the attractions. For example, black is used to indicate having no gender as well as having no attraction.
Click here for tables with okLCH values, hex values, definitions, and notes - I've put a more detailed write-up on my Wikimedia Commons userpage. (Mediawiki supports sortable tables and Tumblr does not.)
METHODS-AT-A-GLANCE
To make the figures above, I assembled a data set of pride flag colours. It contains 2060 colour choices from 624 pride flags, representing 1587 unique colours. Click here for a detailed description of how I gathered and tagged the pride flag colours and tagged them.
For each tag, I converted every colour to okLCH colour space and computed a median colour. OkLCH colour space is an alternative to RGB/hex and HSL/HSV. Unlike RGB/hex and HSL/HSV, okLCH is a perceptual colour space, meaning that it is actually based on human colour perception. 🌈
In okLCH space, a colour has three values:
- Lightness (0-100%): how light the colour is. 100% is pure white.
- Chroma (0-0.37+): how vibrant the colour is. 0 is monochromatic. 0.37 is currently the most vibrant things can get with current computer monitor technologies. But as computer monitor technologies improve to allow for even more vibrant colours, higher chroma values will be unlocked.
- Hue (0-360°): where on the colour wheel the colour goes - 0° is pink and 180° is teal, and colours are actually 180° opposite from their perceptual complements.
The important thing to know is that okLCH Hue is not the same Hue from HSV/HSL - the values are different! (HSL and HSV are a hot mess and do not align with human colour perception!)
You can learn more about okLCH through my little write up, which was heavily influenced by these helpful articles by Geoff Graham, Lea Verou, and Keith J Grant.
You can play with an okLCH colour picker and converter at oklch.com
🌈
MORE RESULTS: COLOUR DISTRIBUTIONS
Back when I started tagging my data, I divided my data into five main chunks: Gender qualities (e.g. masculine, androgynous), Attraction (e.g. platonic, sexual), Values (e.g. community, joy), Disability (e.g. Deaf, blind), and Other.
I'll talk about Disability and Values in future posts! But for an alternate view of the data, here are the full distributions of the colours that were placed in each tag.
They come in three parts: tags I created for Gender, tags for Attraction, and tags from Other. The abstract modifiers are spread between the first two, though their contents transcend Gender and Attraction.
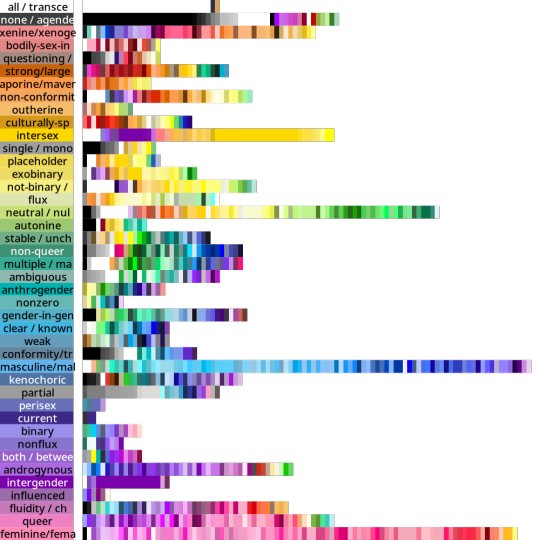
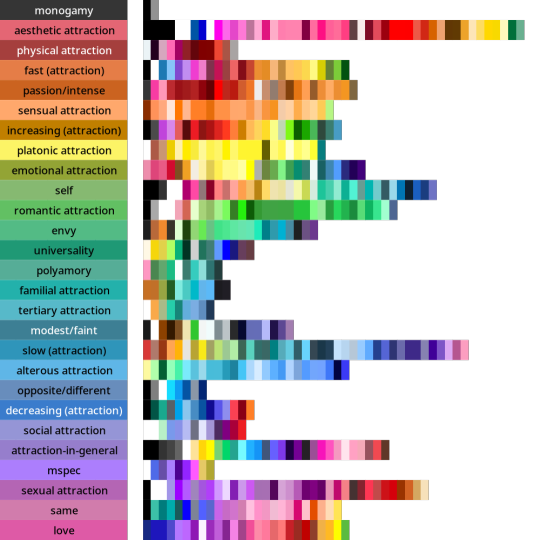
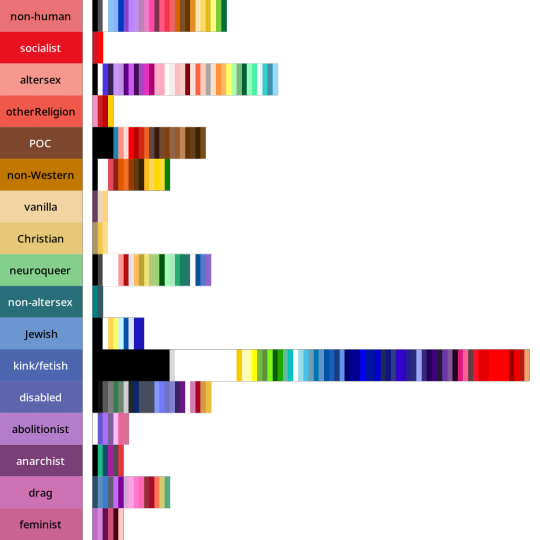
Some distributions have a lot more variance within them than others. Generally speaking, major attraction types tended to have the least variance: sensual attraction is really consistently orange, platonic is really consistently yellow, etc.
Variance and size do not correlate. Many of the smaller tags are quite internally consistent. I don't have a ton of tags in "current gender" but they're all the same dark purple. Xenine/xenogender has a whole bunch of entries, and there's a really big spread from blue to yellow.
Some tags, like intersex as well as kink/fetish show there are a small number of different colours that are very consistently used. Whereas other tags like masculine show a very smooth range - in this case from cyan to purple.
Overall I'm pretty satisfied with how things wound up! 🥳 It makes sense to me that an umbrella term like xenogender would have a lot of variance. What honestly makes me happiest is just how many tags wound up 180 or 90 degrees from their opposites/complements. 🤩
Not everything lined up nicely (the opposite of drag is .... neuroqueer? awkward.) 🤨 Some things lined up in hilarious ways, like how initially I had the opposite of kink/fetish being Christian (amazing.)
But as a whole, there's a lot of structure and logic to where things landed! I hope this makes sense for other people and can help inform both flag making as well as flag interpreting (e.g. writing alt-text for existing flags). 🌈
I'm hoping to post the Disability and Values analyses in the coming days! If you want to learn more, my detailed notes along with tables etc are over on my Wikimedia Commons userspace. 💜
Everything here is Creative Commons Sharealike 4.0, which means you're free to reuse and build on my visualizations, tables, etc. Enjoy!
#lgbt#lgbtqia#mogai#mogai flag#mogai flags#lgbtq flags#lgbt flags#lgbtqia+#vexillology#flags#colours#oklch#colour nerdery#colour theory#colour science#cognitive accessibility#design
197 notes
·
View notes
Text
By David Brooks
Opinion Columnist
You might have seen the various data points suggesting that Americans are losing their ability to reason.
The trend starts with the young. The percentage of fourth graders who score below basic in reading skills on the National Assessment of Educational Progress tests is the highest it has been in 20 years. The percentage of eighth graders below basic was the highest in the exam’s three-decade history. A fourth grader who is below basic cannot grasp the sequence of events in a story. An eighth grader can’t grasp the main idea of an essay or identify the different sides of a debate.
Tests by the Program for the International Assessment of Adult Competencies tell a similar story, only for older folks. Adult numeracy and literacy skills across the globe have been declining since 2017. Tests from the Organization for Economic Cooperation and Development show that test scores in adult literacy have been declining over the past decade.
Andreas Schleicher, the head of education and skills at the O.E.C.D., told The Financial Times, “Thirty percent of Americans read at a level that you would expect from a 10-year-old child.” He continued, “It is actually hard to imagine — that every third person you meet on the street has difficulties reading even simple things.”
This kind of literacy is the backbone of reasoning ability, the source of the background knowledge you need to make good decisions in a complicated world. As the retired general Jim Mattis and Bing West once wrote, “If you haven’t read hundreds of books, you are functionally illiterate, and you will be incompetent, because your personal experiences alone aren’t broad enough to sustain you.”
Nat Malkus of the American Enterprise Institute emphasizes that among children in the fourth and eighth grades, the declines are not the same across the board. Scores for children at the top of the distribution are not falling. It’s the scores of children toward the bottom that are collapsing. The achievement gap between the top and bottom scorers is bigger in America than in any other nation with similar data.
There are some obvious contributing factors for this general decline. Covid hurt test scores. America abandoned No Child Left Behind, which put a lot of emphasis on testing and reducing the achievement gap. But these declines started earlier, around 2012, so the main cause is probably screen time. And not just any screen time. Actively initiating a search for information on the web may not weaken your reasoning skills. But passively scrolling TikTok or X weakens everything from your ability to process verbal information to your working memory to your ability to focus. You might as well take a sledgehammer to your skull.
My biggest worry is that behavioral change is leading to cultural change. As we spend time on our screens, we’re abandoning a value that used to be pretty central to our culture — the idea that you should work hard to improve your capacity for wisdom and judgment all the days of your life. That education, including lifelong out-of-school learning, is really valuable.
This value is based on the idea that life is filled with hard choices: whom to marry, whom to vote for, whether to borrow money. Your best friend comes up to you and says, “My husband has been cheating on me. Should I divorce him?” To make these calls, you have to be able to discern what is central to the situation, envision possible outcomes, understand other minds, calculate probabilities.
To do this, you have to train your own mind, especially by reading and writing. As Johann Hari wrote in his book “Stolen Focus,” “The world is complex and requires steady focus to be understood; it needs to be thought about and comprehended slowly.” Reading a book puts you inside another person’s mind in a way that a Facebook post just doesn’t. Writing is the discipline that teaches you to take a jumble of thoughts and cohere them into a compelling point of view.
Know someone who would want to read this? Share the column.
Americans had less schooling in decades past, but out of this urge for intellectual self-improvement, they bought encyclopedias for their homes, subscribed to the Book of the Month Club and sat, with much longer attention spans, through long lectures or three-hour Lincoln-Douglas debates. Once you start using your mind, you find that learning isn’t merely calisthenics for your ability to render judgment; it’s intrinsically fun.
But today one gets the sense that a lot of people are disengaging from the whole idea of mental effort and mental training. Absenteeism rates soared during the pandemic and have remained high since. If American parents truly valued education would 26 percent of students have been chronically absent during the 2022-23 school year?
In 1984, according to the National Center for Education Statistics, 35 percent of 13-year-olds read for fun almost every day. By 2023, that number was down to 14 percent. The media is now rife with essays by college professors lamenting the decline in their students’ abilities. The Chronicle of Higher Education told the story of Anya Galli Robertson, who teaches sociology at the University of Dayton. She gives similar lectures, assigns the same books and gives the same tests that she always has. Years ago, students could handle it; now they are floundering.
Last year The Atlantic published an essay by Rose Horowitch titled “The Elite College Students Who Can’t Read Books.” One professor recalled the lively classroom discussions of books like “Crime and Punishment.” Now the students say they can’t handle that kind of reading load.
The philosophy professor Troy Jollimore wrote in The Walrus: “I once believed my students and I were in this together, engaged in a shared intellectual pursuit. That faith has been obliterated over the past few semesters. It’s not just the sheer volume of assignments that appear to be entirely generated by A.I. — papers that show no sign the student has listened to a lecture, done any of the assigned reading or even briefly entertained a single concept from the course.”
Older people have always complained about “kids these days,” but this time we have empirical data to show that the observations are true.
What happens when people lose the ability to reason or render good judgments? Ladies and gentlemen, I present to you Donald Trump’s tariff policy. I’ve covered a lot of policies over the decades, some of which I supported and some of which I opposed. But I have never seen a policy as stupid as this one. It is based on false assumptions. It rests on no coherent argument in its favor. It relies on no empirical evidence. It has almost no experts on its side — from left, right or center. It is jumble-headedness exemplified. Trump himself personifies stupidity’s essential feature — self-satisfaction, an inability to recognize the flaws in your thinking. And of course when the approach led to absolutely predictable mayhem, Trump, lacking any coherent plan, backtracked, flip-flopped, responding impulsively to the pressures of the moment as his team struggled to keep up.
Producing something this stupid is not the work of a day; it is the achievement of a lifetime — relying on decades of incuriosity, decades of not cracking a book, decades of being impervious to evidence.
Back in Homer’s day, people lived within an oral culture, then humans slowly developed a literate culture. Now we seem to be moving to a screen culture. Civilization was fun while it lasted.
33 notes
·
View notes
Text
Are You Sure?!
Episodes 5 & 6 Notes
It was very fortuitous that I've been so busy over the last couple of weeks as I really needed both of these episodes together to make sense of my thoughts. This post is definitely far more conceptual than my last ones so if you're up for it, click on though the cut!

AYS's Main Character?

I would like to propose that AYS has a main character OTHER than the individual humans we're following along on screen. (I warned you, this post was going to be conceptual.) And the main character is the relationship itself, how each of the members relate to one another.
Here's Google's AI overview on what this concept means:
A story can center on the relationship between characters as the primary protagonist, with the dynamic and evolution of that connection acting as the main driving force of the narrative, rather than the individual characters themselves.
Key points to consider:
Relationship-centric stories: Many genres, particularly romance, often focus heavily on the relationship between the main characters, exploring its complexities, challenges, and growth throughout the story.
No single protagonist: In such cases, the "character" is the bond between the individuals, not just one person's perspective or journey.
Exploring the dynamic: The narrative would then focus on how the relationship changes, adapts, and reacts to external situations or internal conflicts.
Examples:
"Before Sunrise": The entire plot revolves around the single night encounter between two strangers, with the developing connection being the central focus.
"Brokeback Mountain": The story primarily explores the forbidden love between two cowboys, highlighting the complexities of their relationship in a restrictive environment.
"Steel Magnolias ": A group of girls in a small town in Louisiana experience grief together, including weddings, fatal illnesses, and the loss of loved ones.
Now before anyone comes for me saying I'm just pitching an argument for xyz fanwar, please note that I included the above just to illustrate the concept of a non-person main character rather than stating any of the above are comparisons to the individual member's relationships. We're talking about a show that was produced and distributed for entertainment, nothing further.
Episode 5

My main feeling after finally being able to watch episode 5 was overall unsettled. There was something sticking with me about that episode and I could NOT figure out what it was.
I knew I was feeling like the entire episode was stretched well beyond what the footage wanted for a complete episode. I'm all for getting to spend more time with our fellas but the Jeju trip would have benefited from being cut down to 2 episodes rather than 3, in my opinion.
There was just a whole lotta nothing happening. The guys eat, travel around a little bit, and eat some more. I had some vague thoughts about how I could quantify some data for y'all to explain this point but then it was time for the next episode...
vs. Episode 6

And what an absolutely lovely breath of fresh air this episode was. I know there have been some Run eps that I review with a smile on my face throughout the whole episode but AYS6?? That was 73 minutes of pure bliss.
So I started thinking about what must be different between the two eps. The guys eat, travel around a little bit, and eat some more...wait, that's exactly what I said about ep 5! Lol
But I think the main difference between the two is episode 6's plot points continually focus on the relationships between the members, while 5 falls a little stagnant.
Some examples:
JM/cat & JK/dog. I'm ALWAYS down for more footage of BTS with pets but this is frankly too much time spent on these scenes. It's honestly footage I would have expected in the bonus content instead of the main product. It's not just an establishing beat or a setup for a callback, this is supposed to be a scene but since it doesn't contribute to the journey of the main character aka the relationships. It could maaaybe work if they'd cut it to highlight the juxtaposition of how JM is calm with the cat vs JKs energy with the dog but that would have shortened the time it occupied and they were clearly trying to keep absolutely everything in that would lengthen the episode.
JKs stew. The ONLY thing that ties this plot point into the narrative of this show (other than it happening while he's in Jeju and Jimin is nearby) is the offhand comment he made that Jimin would like it while he was in NY. I'm going to talk more about this footage below but this was absolutely crucial for this whole beat making it into the episode. This is also why the footage of JM eating it and randomly taking off his shirt was kept in. The cut they chose is actually pretty bad story-wise but they used it anyway. We hear JM saying how much he loves it and how glad he is that JK is a good cook. It ties all of this time we spent watching JK do something alone back into the real main character of the show (the members' relationships between eachother in different circumstances).
Anyway, I won't belabour the point any further. With Tae constantly disappearing from scenes and the slightly diminished lack of focus on the member's relationships, episode 5 left me on an odd note.
A Little Production Note

I was completely thrown by the footage of JK in NY that we got this episode. But not for the reasons you may be thinking. (I do wonder if the anon that was sending in asks about the financing behind the documentaries is still around because we're getting into some of tidbits finally.)
So, all along we've been trying to sus out as much as we can, just a few details about how AYS came to be. We've had some hints but the inclusion of this footage may be another indicator.
The facts as we know them:
AYS is distributed by Disney.
Jungkook's documentary is being distributed by Trafalgar Releasing NOT Disney (at least not now, maybe it'll make it onto streaming after cinematic release but who knows?)
Questions due to the footage of JK in NY:
Was this footage captured as part of JKs documentary?
If so, when was it pulled to be utilized for AYS? Did the editors find it or were the writers involved?
We know that HYBE gathers behind-the-scene content without always having a full plan of how it will be used. But there are times where it did seem intentional for a specific purpose. Where did JKs Golden footage fall in?
Once upon a time, production houses would make deals with distributors about quantities of projects that would be delivered. Was that the case with the Disney deal or has every single project been negotiated separately and we only heard about it once there was a confirmed quantity. Somewhere in the middle perhaps?
And that's all I've got to say for now. I do have some more thoughts about things I've gleaned during these last couple of episodes but it'll likely keep until the end.
Anyway, this footage bumped me because it broke the rules of cross-project production. They got away with it for JKs SEVEN footage in ep 1 because they likely were using the same production crew since it was literally the same day so it doesnt feel like they're'breaking the wall'. But the NY-Jeju crews could have been completely different.
Editing to add further clarification to this point in this ask.

On a sidenote, do y'all remember the last time we got footage of jikook in a hotspring?? I'll jog your memory if not, it was in BV:4 and they 'washed each other's faces'. I can't even imagine what we're about to see in episode 7.
Link to my AYS MasterList
70 notes
·
View notes
Text
information flow in transformers
In machine learning, the transformer architecture is a very commonly used type of neural network model. Many of the well-known neural nets introduced in the last few years use this architecture, including GPT-2, GPT-3, and GPT-4.
This post is about the way that computation is structured inside of a transformer.
Internally, these models pass information around in a constrained way that feels strange and limited at first glance.
Specifically, inside the "program" implemented by a transformer, each segment of "code" can only access a subset of the program's "state." If the program computes a value, and writes it into the state, that doesn't make value available to any block of code that might run after the write; instead, only some operations can access the value, while others are prohibited from seeing it.
This sounds vaguely like the kind of constraint that human programmers often put on themselves: "separation of concerns," "no global variables," "your function should only take the inputs it needs," that sort of thing.
However, the apparent analogy is misleading. The transformer constraints don't look much like anything that a human programmer would write, at least under normal circumstances. And the rationale behind them is very different from "modularity" or "separation of concerns."
(Domain experts know all about this already -- this is a pedagogical post for everyone else.)
1. setting the stage
For concreteness, let's think about a transformer that is a causal language model.
So, something like GPT-3, or the model that wrote text for @nostalgebraist-autoresponder.
Roughly speaking, this model's input is a sequence of words, like ["Fido", "is", "a", "dog"].
Since the model needs to know the order the words come in, we'll include an integer offset alongside each word, specifying the position of this element in the sequence. So, in full, our example input is
[ ("Fido", 0), ("is", 1), ("a", 2), ("dog", 3), ]
The model itself -- the neural network -- can be viewed as a single long function, which operates on a single element of the sequence. Its task is to output the next element.
Let's call the function f. If f does its job perfectly, then when applied to our example sequence, we will have
f("Fido", 0) = "is" f("is", 1) = "a" f("a", 2) = "dog"
(Note: I've omitted the index from the output type, since it's always obvious what the next index is. Also, in reality the output type is a probability distribution over words, not just a word; the goal is to put high probability on the next word. I'm ignoring this to simplify exposition.)
You may have noticed something: as written, this seems impossible!
Like, how is the function supposed to know that after ("a", 2), the next word is "dog"!? The word "a" could be followed by all sorts of things.
What makes "dog" likely, in this case, is the fact that we're talking about someone named "Fido."
That information isn't contained in ("a", 2). To do the right thing here, you need info from the whole sequence thus far -- from "Fido is a", as opposed to just "a".
How can f get this information, if its input is just a single word and an index?
This is possible because f isn't a pure function. The program has an internal state, which f can access and modify.
But f doesn't just have arbitrary read/write access to the state. Its access is constrained, in a very specific sort of way.
2. transformer-style programming
Let's get more specific about the program state.
The state consists of a series of distinct "memory regions" or "blocks," which have an order assigned to them.
Let's use the notation memory_i for these. The first block is memory_0, the second is memory_1, and so on.
In practice, a small transformer might have around 10 of these blocks, while a very large one might have 100 or more.
Each block contains a separate data-storage "cell" for each offset in the sequence.
For example, memory_0 contains a cell for position 0 ("Fido" in our example text), and a cell for position 1 ("is"), and so on. Meanwhile, memory_1 contains its own, distinct cells for each of these positions. And so does memory_2, etc.
So the overall layout looks like:
memory_0: [cell 0, cell 1, ...] memory_1: [cell 0, cell 1, ...] [...]
Our function f can interact with this program state. But it must do so in a way that conforms to a set of rules.
Here are the rules:
The function can only interact with the blocks by using a specific instruction.
This instruction is an "atomic write+read". It writes data to a block, then reads data from that block for f to use.
When the instruction writes data, it goes in the cell specified in the function offset argument. That is, the "i" in f(..., i).
When the instruction reads data, the data comes from all cells up to and including the offset argument.
The function must call the instruction exactly once for each block.
These calls must happen in order. For example, you can't do the call for memory_1 until you've done the one for memory_0.
Here's some pseudo-code, showing a generic computation of this kind:
f(x, i) { calculate some things using x and i; // next 2 lines are a single instruction write to memory_0 at position i; z0 = read from memory_0 at positions 0...i; calculate some things using x, i, and z0; // next 2 lines are a single instruction write to memory_1 at position i; z1 = read from memory_1 at positions 0...i; calculate some things using x, i, z0, and z1; [etc.] }
The rules impose a tradeoff between the amount of processing required to produce a value, and how early the value can be accessed within the function body.
Consider the moment when data is written to memory_0. This happens before anything is read (even from memory_0 itself).
So the data in memory_0 has been computed only on the basis of individual inputs like ("a," 2). It can't leverage any information about multiple words and how they relate to one another.
But just after the write to memory_0, there's a read from memory_0. This read pulls in data computed by f when it ran on all the earlier words in the sequence.
If we're processing ("a", 2) in our example, then this is the point where our code is first able to access facts like "the word 'Fido' appeared earlier in the text."
However, we still know less than we might prefer.
Recall that memory_0 gets written before anything gets read. The data living there only reflects what f knows before it can see all the other words, while it still only has access to the one word that appeared in its input.
The data we've just read does not contain a holistic, "fully processed" representation of the whole sequence so far ("Fido is a"). Instead, it contains:
a representation of ("Fido", 0) alone, computed in ignorance of the rest of the text
a representation of ("is", 1) alone, computed in ignorance of the rest of the text
a representation of ("a", 2) alone, computed in ignorance of the rest of the text
Now, once we get to memory_1, we will no longer face this problem. Stuff in memory_1 gets computed with the benefit of whatever was in memory_0. The step that computes it can "see all the words at once."
Nonetheless, the whole function is affected by a generalized version of the same quirk.
All else being equal, data stored in later blocks ought to be more useful. Suppose for instance that
memory_4 gets read/written 20% of the way through the function body, and
memory_16 gets read/written 80% of the way through the function body
Here, strictly more computation can be leveraged to produce the data in memory_16. Calculations which are simple enough to fit in the program, but too complex to fit in just 20% of the program, can be stored in memory_16 but not in memory_4.
All else being equal, then, we'd prefer to read from memory_16 rather than memory_4 if possible.
But in fact, we can only read from memory_16 once -- at a point 80% of the way through the code, when the read/write happens for that block.
The general picture looks like:
The early parts of the function can see and leverage what got computed earlier in the sequence -- by the same early parts of the function. This data is relatively "weak," since not much computation went into it. But, by the same token, we have plenty of time to further process it.
The late parts of the function can see and leverage what got computed earlier in the sequence -- by the same late parts of the function. This data is relatively "strong," since lots of computation went into it. But, by the same token, we don't have much time left to further process it.
3. why?
There are multiple ways you can "run" the program specified by f.
Here's one way, which is used when generating text, and which matches popular intuitions about how language models work:
First, we run f("Fido", 0) from start to end. The function returns "is." As a side effect, it populates cell 0 of every memory block.
Next, we run f("is", 1) from start to end. The function returns "a." As a side effect, it populates cell 1 of every memory block.
Etc.
If we're running the code like this, the constraints described earlier feel weird and pointlessly restrictive.
By the time we're running f("is", 1), we've already populated some data into every memory block, all the way up to memory_16 or whatever.
This data is already there, and contains lots of useful insights.
And yet, during the function call f("is", 1), we "forget about" this data -- only to progressively remember it again, block by block. The early parts of this call have only memory_0 to play with, and then memory_1, etc. Only at the end do we allow access to the juicy, extensively processed results that occupy the final blocks.
Why? Why not just let this call read memory_16 immediately, on the first line of code? The data is sitting there, ready to be used!
Why? Because the constraint enables a second way of running this program.
The second way is equivalent to the first, in the sense of producing the same outputs. But instead of processing one word at a time, it processes a whole sequence of words, in parallel.
Here's how it works:
In parallel, run f("Fido", 0) and f("is", 1) and f("a", 2), up until the first write+read instruction. You can do this because the functions are causally independent of one another, up to this point. We now have 3 copies of f, each at the same "line of code": the first write+read instruction.
Perform the write part of the instruction for all the copies, in parallel. This populates cells 0, 1 and 2 of memory_0.
Perform the read part of the instruction for all the copies, in parallel. Each copy of f receives some of the data just written to memory_0, covering offsets up to its own. For instance, f("is", 1) gets data from cells 0 and 1.
In parallel, continue running the 3 copies of f, covering the code between the first write+read instruction and the second.
Perform the second write. This populates cells 0, 1 and 2 of memory_1.
Perform the second read.
Repeat like this until done.
Observe that mode of operation only works if you have a complete input sequence ready before you run anything.
(You can't parallelize over later positions in the sequence if you don't know, yet, what words they contain.)
So, this won't work when the model is generating text, word by word.
But it will work if you have a bunch of texts, and you want to process those texts with the model, for the sake of updating the model so it does a better job of predicting them.
This is called "training," and it's how neural nets get made in the first place. In our programming analogy, it's how the code inside the function body gets written.
The fact that we can train in parallel over the sequence is a huge deal, and probably accounts for most (or even all) of the benefit that transformers have over earlier architectures like RNNs.
Accelerators like GPUs are really good at doing the kinds of calculations that happen inside neural nets, in parallel.
So if you can make your training process more parallel, you can effectively multiply the computing power available to it, for free. (I'm omitting many caveats here -- see this great post for details.)
Transformer training isn't maximally parallel. It's still sequential in one "dimension," namely the layers, which correspond to our write+read steps here. You can't parallelize those.
But it is, at least, parallel along some dimension, namely the sequence dimension.
The older RNN architecture, by contrast, was inherently sequential along both these dimensions. Training an RNN is, effectively, a nested for loop. But training a transformer is just a regular, single for loop.
4. tying it together
The "magical" thing about this setup is that both ways of running the model do the same thing. You are, literally, doing the same exact computation. The function can't tell whether it is being run one way or the other.
This is crucial, because we want the training process -- which uses the parallel mode -- to teach the model how to perform generation, which uses the sequential mode. Since both modes look the same from the model's perspective, this works.
This constraint -- that the code can run in parallel over the sequence, and that this must do the same thing as running it sequentially -- is the reason for everything else we noted above.
Earlier, we asked: why can't we allow later (in the sequence) invocations of f to read earlier data out of blocks like memory_16 immediately, on "the first line of code"?
And the answer is: because that would break parallelism. You'd have to run f("Fido", 0) all the way through before even starting to run f("is", 1).
By structuring the computation in this specific way, we provide the model with the benefits of recurrence -- writing things down at earlier positions, accessing them at later positions, and writing further things down which can be accessed even later -- while breaking the sequential dependencies that would ordinarily prevent a recurrent calculation from being executed in parallel.
In other words, we've found a way to create an iterative function that takes its own outputs as input -- and does so repeatedly, producing longer and longer outputs to be read off by its next invocation -- with the property that this iteration can be run in parallel.
We can run the first 10% of every iteration -- of f() and f(f()) and f(f(f())) and so on -- at the same time, before we know what will happen in the later stages of any iteration.
The call f(f()) uses all the information handed to it by f() -- eventually. But it cannot make any requests for information that would leave itself idling, waiting for f() to fully complete.
Whenever f(f()) needs a value computed by f(), it is always the value that f() -- running alongside f(f()), simultaneously -- has just written down, a mere moment ago.
No dead time, no idling, no waiting-for-the-other-guy-to-finish.
p.s.
The "memory blocks" here correspond to what are called "keys and values" in usual transformer lingo.
If you've heard the term "KV cache," it refers to the contents of the memory blocks during generation, when we're running in "sequential mode."
Usually, during generation, one keeps this state in memory and appends a new cell to each block whenever a new token is generated (and, as a result, the sequence gets longer by 1).
This is called "caching" to contrast it with the worse approach of throwing away the block contents after each generated token, and then re-generating them by running f on the whole sequence so far (not just the latest token). And then having to do that over and over, once per generated token.
#ai tag#is there some standard CS name for the thing i'm talking about here?#i feel like there should be#but i never heard people mention it#(or at least i've never heard people mention it in a way that made the connection with transformers clear)
301 notes
·
View notes
Text
by Brian Shilhavy Editor, Health Impact News
Ever since President Trump declared he was cutting off all funding for USAID, along with Wikileaks publishing data on who has been receiving a piece of the multi-billion dollar international U.S. Government “slush fund,” the Conservative Christian “Alternative” media has had a field day with publishing articles about the evil “liberal” organizations pushing their agenda overseas at the expense of USAID and federal funding.
This is just another example of the hypocrisy on the Right, and how they are most certainly not pro-Free Speech, but only pro-Conservative Christian Speech, while censoring news that implicates their own complicity with taking government funding through USAID for their own programs, called “ministries.”
The huge amount of money flowing through USAID also funds Christian child trafficking through overseas adoptions, as well as Christian “medical missions” which fund the distribution of vaccines and western pharmaceutical products in poor countries.
Conservatives have made a big deal over the revealing of USAID funds flowing into the “Liberal” corporate media such as Politico, ignoring that funds also flowed into “Conservative” corporate media as well, such as Christianity Today.
Evangelicals and other Christian groups who are now at threat of closing down due to the loss of government funding through USAID are beginning to complain, as $billions of government funding has made rich such Christian heavyweight international organizations such as World Relief, World Vision, Samaritan’s Purse, and Catholic Relief Services.
39 notes
·
View notes
Note
What do you think of these axon looking things?

Given the similarities to axon terminals I was wondering if they were for delivering information/status report of their surrounding equipment
But the one at moon's gravity disruptor feels more like its sampling data from the engine (the last few times I went through that room it ragdolled very hard upon entering due to the gravity lol)
And looking at that screenshot I just took from the map website, it also has the "reading halo", so it probably is catching on information rather than relaying it
Ah, these things - there's not a lot to go on with them, but they're certainly interesting. I'm going to use the game's internal nomenclature and call them "coral stems" for clarity.
Coral stems seem to interact with an Iterator's internal biota in much the same way as their more common cousin, the wall mycelia. Both organisms sprout from the Iterator's internal walls, attracting to their hyphae neuron flies and the free-floating hyphae of coral neurons and inspectors. The sparking effect produced upon contact with these organisms is identical to that seen between interacting overseers, so I'm inclined to believe it represents the exchange of information (rather than say, energy or nutrients) between an Iterator's stationary machinery and its free-floating organic parts. The question then is how the role of coral stems in this interface differs from the role of the wall mycelia.
As you implied, the segmented body of a coral stem closely resembles an axon wrapped in a myelin sheath, the part of a neuron that transmits signals away from the cell body. In such an analogy, the cell body would have to be the machinery the coral stem is anchored to. The wispy mycelia growing from that machinery would then seem to fit the description of dendritic branches, thin growths that receive signals from other cells. So one interpretation could be that the coral stems and wall mycelia perform opposite functions, delivering messages to and receiving messages from the free-floating biota respectively.
Another possibility is that the wall mycelia and coral stems are both sensory organs, but with complementary roles. The mats of wall mycelia are not especially dense, but their hyphae extend into a large part of an Iterator's internal spaces. This makes them well-adapted to sensing macroscopic organisms like neuron flies or coral neurons. These organisms are unevenly distributed in a way that requires hyphae to be able to reach them no matter where they are in a room, but their large size and weight ensures that any nearby hyphae will certainly be disturbed by their presence and brushed against them. In contrast, small particles like microorganisms or chemical traces in the air would be unlikely to collide with the scarce hyphae of wall mycelia, and too light to be reliably detected when they do.
The bundled hyphae of coral stems could act like scent traps for these particles—when one happens to wander into a coral stem's bristles, it's likely to become trapped and bounce around among the dense hyphae for a time, the repeated collisions ensuring that there are many chances for it to be detected. Of course, coral stems are distributed much more sparsely than wall mycelia, but that would be just fine for this purpose. Diffusion ensures that the distribution of small, light particles is relatively homogeneous throughout a space: the air in one part of a room is about the same as the air in any other part, so there'd be no need for too many coral stems close together.
I hope this provided some food for thought, thanks for the ask!
60 notes
·
View notes