#instead of just posting it unfiltered to the main tag
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The Tumblr app for Google Glass was released on May 16, 2013.
Text
I'm so sick of finding pornographic content in the trans tags. I understand that most of them are porn bots, but I wish the ones that aren't would just tag their stuff properly.
I just want to be able to comfortably scroll through memes and comfort content in these tags without getting immediately flashbanged :/
#kaiidos rambles#trans#transgender#lgbtq#lgbtq community#short rant#like seriously though#i made the mistake of looking through the tag AT WORK#I JUST WANTED TO SEE WHAT PEOPLE WERE SAYING ABOUT THE INAUGURATION#thank god i was tucked away into a back corner because i would have been so fired#absolutely cooked and roasted over an open flame#at least i know now#never again#AND LIKE I DON'T CARE ABOUT THAT KIND OF CONTENT??#like you do you boo#get that bag and all that#but people looking for content already know what other tags to sift through#so at least tag one of those so the rest of us can filter it out#instead of just posting it unfiltered to the main tag#where everybody else can get absolutely annihilated out of nowhere#tumblr is one of the more comfortable sites for us nowadays#so it would be really nice if we could exist on here and at least have the option not to see it
24 notes
·
View notes
Text
Pinned post
oops i'm doing it again
brief introduction:
⚡ peer, 21 y.o., any pronouns, native russian speaker who knows english at an advanced and japanese at a lower-intermediate level
⚙️ agender, loveless aroace, aplatonic, voidpunk, somewhat robotkin
📝 you can see my art on my art blog @peerkartosh. you can also try visiting my neocities blog.
under the cut will be a longer introduction with tags, rules, and boundaries. 🔌💻

hey there and welcome to my blog. this is my main, where i post often-unfiltered thoughts and reblog a lot of stuff i find cool.
i often mass draft reblogs. i don't trust the queue because of my dumb paranoia. sorry for mass reblogging your posts out of the blue if you don't like that.
my interests can be guessed from the most popular tags on my blog. generally speaking i like indie games! my favorites include MINDHACK, rain world, shovel knight, hyper light drifter, nuclear throne, and some others. i also admin a MINDHACK fan discord and you can message me if you are interested in joining it.
my personal musings tag is #пир мысли and i often post vents under the same tag. i am very mentally ill (i suspect i might have bpd/ocd/c-ptsd) and this affects the way i speak about myself and others, more specifically i can have drastic mood swings and talk down on myself a lot. if you are uncomfortable with it i suggest blocking the tag.
my tag #void time is a catch-all for queer stuff, most of the time it's aro stuff but sometimes it's also about amatonormativity, relationship anarchy, being voidpunk, transness, or aceness. it is not an aroace tag. the name comes from all of my identities being a lack of something, so 'void'.
i try to tag flashing lights, gore, and certain triggering topics such as suicide. however, i do not tag nsfw language/art.
you can message me here or on discord (my username there is the same as my art blog's url) if you wanna chat, but don't expect us to become besties; i like talking to people sometimes but i'm not good at keeping relationships up. i would very much appreciate it if you didn't consider me a friend just because we are mutuals/chat sometimes either. i don't mind friendship but i prefer it being established with me instead of assumed. ok?
I AM ROMANCE REPULSED!! I DON'T LIKE ROMANCE AND/OR FLUFFY LOVEY DOVEY STUFF!!! I DON'T LIKE SHIPPING EITHER!!! I KNOW I AM NAMED AROMANTICYAOI BUT IT'S AROMANTIC FOR A REASON
i am also sex indifferent and plato ambivalent
also i think it's obvious but i am very aspec and i support other aspec people and if you bring up any aspec discourse i will blow you up with my mind
if you get mad at any of my posts please do not assume the worst about what i said. in general do not assume anything about me unless i stated something directly. that's it 👍👍
4 notes
·
View notes
Text
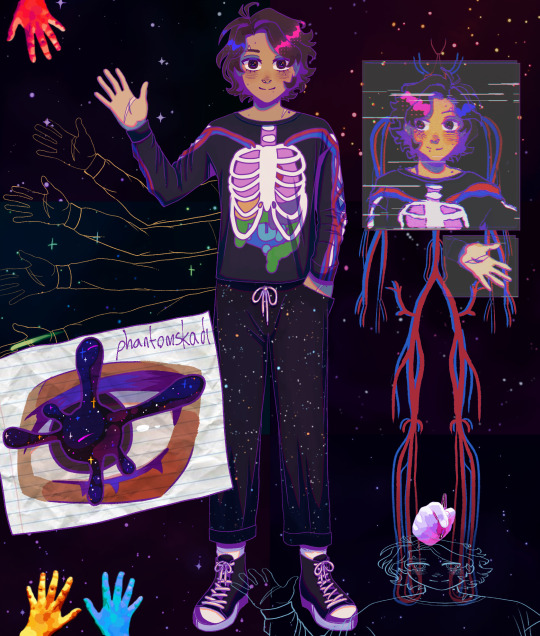
Posting this 2 months late because I forgor 💀 but! My favorite drawing I did for artfight this year (also my favorite drawing I've made so far in general)
This ons is the creator by @kiskutnya (sry for tagging you in a drawing youve already seen 2 months later whoops)
More details under the cut because I <3 rambling
So big reason I decided to draw the creator is because I knew I could have a lot of fun with the drawing and that is what I did! Starting here with the background,

The borders are kinda hard to see but it is made up of 6 different panels of galaxies that I drew. Can you tell I like drawing galaxies


Unfiltered lineart and colors for the bit in a the top right. I wanted this bit to look wonky so I drew it with my left hand which was not very fun for coloring but we ball (though I did shade the hair much simpler than on the main drawing because I did not wanna try that shit with my left hand lmao)

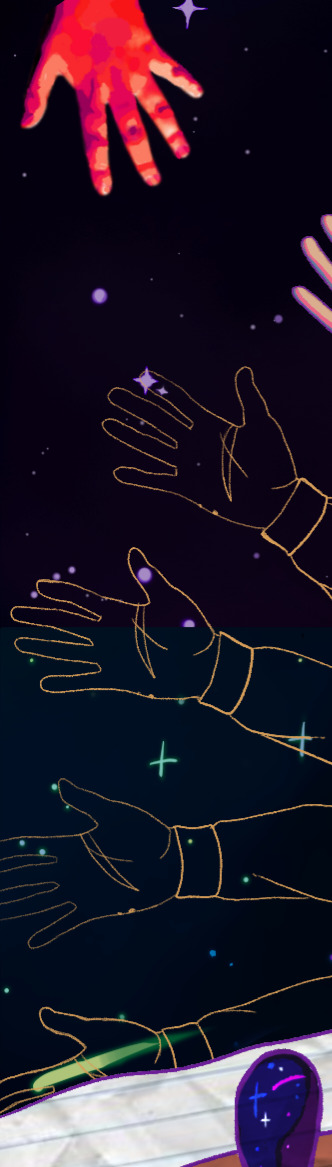

Also for all the hands in the image, I mostly wanted some kind of repeated element like a body part, and I decided to go with hands because I usually associate the act of creation with hands. The brightly colored hands are just edited photos of my own hands because I thought it would look neat


Then there's just drawing stuff, because drawing is a type of creation and again I thought it would look cool. Also drawing a very big eye is fun
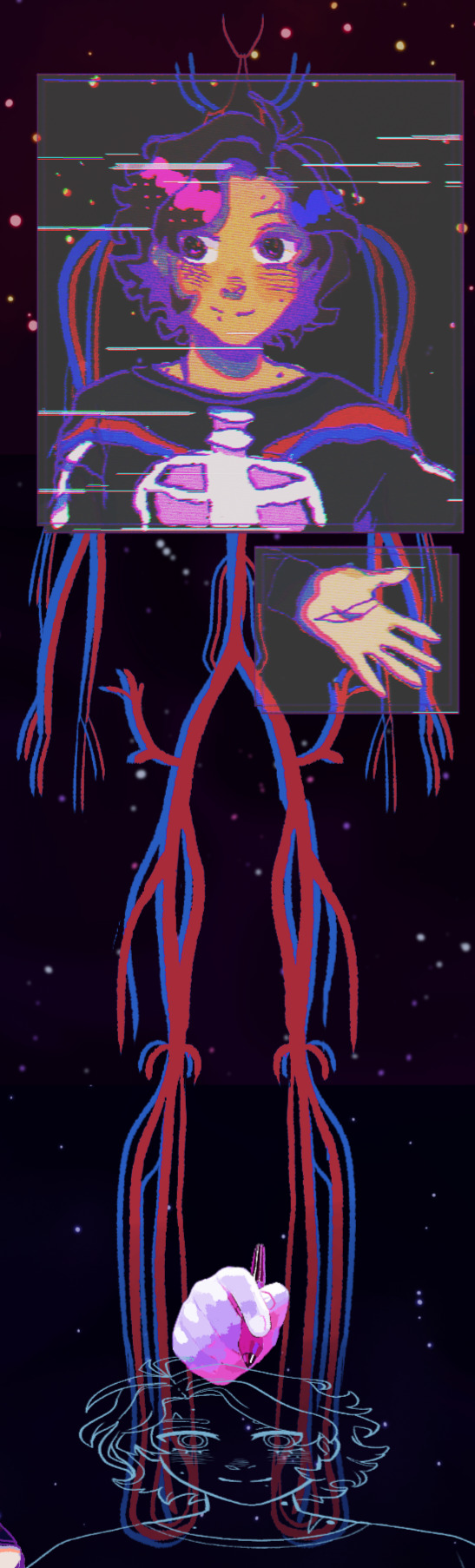
Aaand lastly the veins. I was originally going to draw a nervous system but then I realized that that was a bit too complicated for me in the moment so I went with veins instead since for this piece they work similarly
Anyways yeah this was probably the most fun I've had with a drawing to date and I think overall artfight this year but especially working on this piece has really motivated me to do more art again. Excited for next year!
3 notes
·
View notes
Note
Re: being "mean" to people bc of what they think/say about phan. I think it really just comes down to where you say it. I've seen people with anti/skeptical takes on their main, and in those cases I've maybe commented to make sure I actually read their take correctly ("wait, are you saying you think they have different partners??"), but then I've walked away from that conversation bc no one gains anything from me harassing a rando I found in the dan and phil tag.
HOWEVER. if you post your take (whatever it is) as an ask to someone else, you can expect an unfiltered response. You're giving up control over your post when you send it to someone else like this. As a community, we can do with these asks whatever we want, including clowning on them. The asker doesn't have to look at it, doesn't get notifications, doesn't have it on their blog, it's not their post anymore. Commenters just have to figure for themselves if they have more fun being assholes or being funny or trying to compromise or ignoring it, but none of it hits the asker. The audience is just the readers of this blog
Sorry this got long but I love ranting. I just don't want rants on my blog so I do it in your inbox instead have a nice day
i got an ask from phil's wife so maybe the skeptics are right
5 notes
·
View notes
Text
☆ Mello-Jello-Wellow! Crispy here ☆
AO3 || Art-Only Blog || Free Palestine
Welcome to my main blog!
My name is Chris Pycream Bacon, but most just call me Crispy. In here, you will find pretty much everything such as my own work, my interests and rambles from others. If you wanna see just my art, you can head over to @crispyfriedartchive instead!
I hope to create a space which is inviting, so feel free to reach out via asks! BIPOC, LGBT+, disabled/neurodivergent and non-Christians are welcomed of course, and if you object to that, this place is not for you :}
Down below, you'll find more about me and find my tagging system. Otherwise, feel free to chill here and have a nice day~! ☆
More About Me
As you can see, I'm an artist and a writer. Particularly, I love doing silly doodles, illustrations, comics and fanfiction, and I hope to become an animator or a comic artist one day. However, I'm open to any art or writing career that welcomes me along the way!
My other hobbies include singing, voice acting, listening to whatever music catches my brain worms and yelling about my current interests. I also have two cats, Sashimi and Takoyaki, a corgi named Miso, and a t-rex plush named Dinosara whom I love very much :3
I'm Filipino! Unfortunately, I can't speak Tagalog (yet), but I try to stay in touch with my culture. I can also speak a decent amount of Indonesian after having lived there for over a decade. Filipino-Indonesian solidarity for the win!!
I'm hella non-binary, and I will hit every character that I love and/or create with the rainbow stick. I'm also aroace, bisexual and in a queerplatonic relationship (hello darling if you're reading this!)
My Stances
I try not to get into discourse as I've done so before, and it's very unhealthy for me (so please don't bring that up towards me!) However, I still want to make the following clear:
People with stigmatized disorders such as DID, Cluster-B disorders, psychotic disorders, etc. are always welcome here, and if I act in a way that makes you feel otherwise, please let me know!
I'm pro-Palestine and anti-Zionist, but I'm still inclusive towards Jewish people. No government actions should be an excuse for bigotry, and Jewish people should always be welcomed.
I'm inclusive when it comes to LGBT+ identities. While I may not always understand all identities, I've learnt to just mind my own business. It makes you happy, and it doesn't harm people? Then go forth! Be yourself :]
Blog Navigation
☆ RELATED TO MY OWN WORK
#chris p fried art - my art
#chris p fried writings - my writing
#chris p fried rambles - my opinions/commentary/reviews
#chris p fried wips - my works-in-progress
#chris p fried answers - my answers to asks
#chris p fried doo doo - my shitposts
#chris p fried what?! - my miscellaneous thoughts (aka my most unfiltered)
☆ RELATED TO OTHER POSTS
#artists cooking gourmet - other people's art
#writers cooking gourmet - other people's writing
#people frying stuff - other people's text/video/audio posts
#clowns burning the kitchen (affectionate) - funny posts
#a nice warm soup after a long day - wholesome posts
#alphabet soup matters - lgbt+ posts
#important - awareness posts (typically serious subject matter such as current news, donation links, etc.)
#a reminder to those who need it - more lighthearted awareness posts (important but not downer posts, may also be literal reminders)
Everything else should be tagged via topic, fandom, character, etc. I also do my best to provide image descriptions or trigger tag posts though I may not always be successful.
#EDIT: THIS IS THE SECOND TIME I ACCIDENTALLY RELEASED MY INTRO POST WHY DOES THIS KEEP HAPPENING HELP-#This is like the third time I remade my intro post but I promise this will stick this time!!!#If any updates are needed then I'll add updates yapee yapoo#intro post#blog intro#introducing myself#introduction#introductory post#meet the artist#artists on tumblr#writers on tumblr
6 notes
·
View notes
Text
Wait ok bcos i metisposted. I realised u guys might not have all the eimear lore. So here is the main stuff off the top of my head
Bugs in him - every so often I spam reblog an audio line from kingdom hearts recoded. Mickey its riku they put bugs in him. Actually don't worry about it stay unaware
That one time I tried to move blogs after a six month hiatus and then gave up lol. My alt still exists (@tissyfits if u wanna go for it) but I never like. Log in or use it. So
Materfred - important and vital. Ship between Manfred von karma from ace attorney and mater from cars. I wrote several fics. I reskinned the entirety of my immortal for them. I made a carrd for them (materfred.carrd.co). They are somewhat known because my tags abt them on a post got screenshotted and then the OP of that post blocked me (entirely fair it was a plague upon their notes)
The metis cykes obsession - metis cykes is a minor character in the fifth ace attorney game who has been dead for 7 years by the time the story starts and she has no dialogue. There are seven pictures of her in existence and two of those are of her corpse. I loved her I LOOOOVED her it was like spiritual, I've kinned for fun on and off but I was LITERALLY her IRL for like 6 months. To this day my feelings on aurametis are staunch like stone
The lamp blog - I used to have a huuuge hateboner for clay terran as a symbol of fandom latching onto background men instead of woman characters, and, spurred on by my friend group at the time, I made a blog called yourfavehasfewerficsthanthislamp where I just compared the number of fics XYZ character had next to the number of fics terran had. It was an obsessive hate-cycle which did nothing to actually uplift female characters and the methodology was intensely flawed (shoutout to the 'neopets has fewer fics than terran' submission - I mean, yeah, but I feel like you can't use that to say he is more popular than fuckin neopets. Or that neopets is a poor neglected soul that needs more fanfiction written about it) but hey at least I got reposted to Twitter
Yelling emernally - my old talk tag <3 back before I made yis read all my thoughts unfiltered, back when I spelt my name 'emer'. Given the pronounication of my name, it is a pun that only kind of worked, and it confused most people who came across it. Tag is still up if u wanna read my 2020 thoughts but also like. Dont
Not so much a bullet point but if u were around before I was calling myself dullahandame u are legally my cousin. I dont even remember all URLs what I had back then, only they all had my name in them. Emer-bottomtext, emer-ald-isle, et cetera. Fun times
#self indulgent post yayyyy knowledge#eimear fans am i forgetting anything... thr answer is probably Yes
14 notes
·
View notes
Text
readers beware: this is the untagged and unfiltered vent blog of a schizophrenic RAMCOA survivor with polyfragmented DID, AvPD, NPD, and AsPD. we've gotten tired of being vague on our main blogs, so this is where the honest, graphic shit goes. there will be frank discussion of torture, programming, CSA, bestiality, and more.
it is up to you and you alone to decide how deep you go. you can choose to leave this blog with the back button if it ever becomes too distressing to read; we do not get to choose to leave our life without permanent and unwanted consequences. do not whine about the content of our blog: you were warned.
(big rants to theoretical questions that theoretical people might ask under the cut, along with tagging)
"how do you know you experienced RAMCOA? couldn't it just be your schizophrenia?"
severe, many-years-old triggers and obsessions that line up a little too conveniently with certain programs and forms of torture which are otherwise unexplained; decade-or-more old scars that are otherwise unexplained; over 200 headmates tied to obvious memories, traumas, and programming, including a strict hierarchy and an internal handler, that are otherwise unexplained; unending intrusive thoughts, panic attacks, and flashbacks that are otherwise unexplained; extreme childhood amnesia and nonsensical "memories" that are otherwise unexplained; need we say more?
"why the wolf theme?"
we're physically, bodily a wolf. it is a non-negotiable part of our identity and selfhood. it has ties to some of the programming we went through, but we want to try and separate and "reclaim" that piece of ourselves (even though we had little issue with our physical nonhumanity before learning we experienced RAMCOA beyond certain things that were already triggering to us, eg., the idea of being owned).
"why did you go digging?"
because it was constantly eating at us. we couldn't stop thinking about it. especially since, inexplicably, any mention of it--let alone details--could trigger us into severe dissociation and a panic attack, in spite of our lack of empathy (which would possibly allow anybody else to pass the emotions off as "empathy for the victim"). we're also way too nosy for our own good.
"you should talk to a therapist."
the programming we went through prevents us from saying anything to any sort of authority figures and makes us extremely paranoid of any kind of health professional, psychiatric or otherwise. beyond that, we're also anti-psych and disabled and have all sorts of extra medical trauma beyond the programming we went through which just makes us more wary.
whether it's the programming or the sincere experiences and beliefs we hold making us say this, we speak with as much honesty as possible when we say that talking to a therapist may not only be blatantly unsafe, but would only be counter-productive in our healing. at the very least, that's certainly how it feels, and we don't think talking to a therapist when we're completely terrified by the idea will do anyone any good. least of all us.
"what makes you think you know everything?"
we don't and we also never claimed that. bozo.
"why are you making this post? do you really think anybody will read this? you don't use any main tags or anything and you're not going to reblog anything except for from your own main blogs after all."
we're severely paranoid of people "finding out" and want to give ourselves as many outs as possible. there's also the possibility that we'll share this with someone who sincerely wants to know what's going on.
"why don't you use HC-DID instead of polyfragmented DID?"
because (A) the term was coined by an anti-semite, and (B) we feel the idea of "highly complex" DID (implying a hierarchy placing it above "complex"/polyfragmented DID) that can only be achieved via RAMCOA/OEA/your preferred term is... extremely misleading. everyone will react differently to different traumas based on their personal brain chemistry and the presence or absence of a support system. when it comes specifically to the "MC" part of RAMCOA, we much prefer programmed DID. it's more specific with its implications of potential functions and doesn't imply a hierarchy of "you NEED to have experienced OEA to have this complex of a system".
(hint hint: this is also why we generally dislike "C-DID" as a synonym of "polyfragmented" in general, since the common experiences of polyfragmentation could be experienced by any system. we personally believe that if the experiences of polyfragmention fits you, you should be allowed to call yourselves polyfragmented, regardless of whether or not you have DID. if C-DID were used as a synonym of "polyfragmented DID" specifically and denoted specific symptoms that were by-and-large unique to polyfragmented DID (and other forms of polyfragmentation were allowed to exist and be recognized), we'd be less opposed to it, but as it stands, that's just not how it's used.)
"why won't you tag the names of headmates?"
privacy, mostly. especially for the ones that actually experienced the programming, since every single one of them are thirteen and under, other than the internal handler and task killer (although, both of them are still 15 and under, too). we don't want any one of them to be pegged as evil for what they may have done, or to otherwise be directly targeted; ergo, no names that might be tracked onto other blogs or anything.
"what programs did you go through?"
we will not tell you specific programs for our own safety. we will say that our abusers attempted to apply a script and ultimately failed, leading to certain memory holders that remember bits of the script, but no part of the script actually implemented; however, we will not tell you which script specifically.
"what are your thoughts on ____?"
we are: - pro endo - pro spiritual plurals (and are spiritually based ourselves, at least for the current "main" collective) - pro sysmed as a term (no, it's not transphobic), but anti "traumascum" as a term - pro self-diagnosis - anti-psychiatry - pro bodily autonomy - anti forced recovery - anti "narcissistic abuse" as a term, same with any other "PD abuse" - profiction - pro para (no, not pro contact. pro para. we have multiple ourselves, some of which likely stemming from the abuse we went through) - pro-transandrophobia (as in the term and theory, not that the bigotry is "good") - anti-colonialism (and, by extension, pro-Palestine)
taglist
#intro post - this post #own posts - our own posts #self reblog - reblogs of posts from this blog #dragged in from mains - reblogs from our main blogs
#not rated - non-vent posts. consider these a rarity. #light - light venting. petty and vague and, usually, whiny. #moderate - moderate venting. less petty and whiny, but still generally vague. not as vague as light, though; may occasionally mention specific things (programs, traumas, etc) by name, but only sparingly. #heavy - not petty or whiny in the slightest. not vague, but not extremely graphic, either. non-descriptive, but doesn't beat around the bush. occasional caps and swearing; lots of emphasis in the form of italics and bolding. #very heavy - graphic and descriptive and direct. often with caps and lots of swearing.
0 notes
Text
Phase Zero
Chapters: 2/1 Fandom: Star Wars: The Clone Wars (2008) / Star Wars Rating: Teen And Up Audiences Warnings: Dehumanization, Forced Surgeries, Prosthesis Aversion, Medical Torture (Mentioned), Angst, Heavy Angst, Sad Ending, Main Characters Death, Suicide Ideation, Suicide Characters: Clone Commander Truce (OC), ARC Trooper Speck (OC) Additional Tags: Empire Era, Post-Traumatic Stress Disorder - PTSD, Post-Order 66, Angst, Whump, Grief/Mourning, Dysphoria (regarding the prosthesis), Eye Removal Mention will add more Summary: Victims to the sick scientific curiosity of the Kaminoans, the last remainders of the clone trooper army are forced to become more machine than human, and it takes a toll on their mental health, causing despair and suicide ideation.
READ THE TAGS. READ THEM AGAIN. THIS IS HEAVY STUFF, IF IT’S NOT THE KIND OF STUFF YOU LIKE, LEAVE.
@tarantula-hawk-wasp here’s the cont. from that fic
-
Part I
Speck looked up at the black clone helmet.
“What…?” he blinked once, swallowing dryly. That thing was shy from being as tall as a commando droid “That’s… That’s you, sir?”
The not-droid turned its helmeted face down as if looking at him for a moment before wordlessly standing in attention again. The first commander that had spoken to Speck spoke gingerly to the ARC.
“Listen, we need to escort him back to his quarters.” he raised a hand to gently push Speck out of his way “If you want some advice, don’t get very close.”
Speck took a couple of steps back to then speak up as the troopers resumed walking.
“Wait. W-we can escort him ourselves, sirs. He’s our commander.”
The troopers moved fast, and the thing they claimed to be Speck’s commander followed them close.
“Negative. He needs to adapt back here and a crowd wouldn’t help at all.”
“I’ll do it alone then!” Speck countered, hastily following them “I’m his ARC, I know him well. I can do it.”
One of the commanders stopped at that, glancing at his colleague that stopped shortly after.
“ARC says he can take him.”
“Wha- no.” the other commander said sharply, lowering his tone to speak only to the commander “We have our orders.”
“Yeah, but we both have our own matters to take care of and frankly, the soonest I get away from that thing the better.”
Speck pretended not to hear it, despite being definitely close enough to. There was a small beat, and then the second commander acquiesced.
“Fine. He goes with you.” he sighed, walking towards Speck and lowering his voice “Don’t try to engage with him, alright? That whole process… it messes up a vod for good. I’ve seen it before. Whatever your C.O. was like, that thing isn’t him anymore.”
By then, the colder commander was walking away already, calling his colleague by his number and telling him to hurry up, and so the two of them left Speck with… whatever that thing dressed in black armor was.
Speck could see them talking to his fellow troopers and ushering them out, a few of them looking over their shoulders trying to understand what was going on. Speck turned to look at the tall trooper, walking up to his side.
“Let’s get to the barracks, sir?” he cleared his throat, forcing himself to sound like he always did speaking to Truce “You must be dying for some rest after flying all the way from Kamino.”
The trooper turned his head mechanically to look at Speck to then just march ahead. Speck followed him. That was fine – Truce wasn’t the chatty kind of vod, and he might just be exhausted.
They got to their dorm without speaking a word, and Speck watched in silence as Truce walked up to his bunk, standing before it for a few seconds before finally turning around and sinking down on it.
It was a good thing the commander and ARC had the privilege of a private dorm of their own. It would allow them more peace and quiet than that of the regular trooper’s. Still unsure of how to initiate a conversation, Speck just walked quietly to his bunk on the opposing wall and sat down on his own bed, prying his helmet out of his head and drawing a fresh, unfiltered breath as he placed it down on the floor.
Truce hadn’t moved. He might as well just be a statue. Speck wetted his lips, pressing them together and waiting. The seconds stretched, turning into minutes. He drew another deep breath.
“Sir… I just want you to know that I’m here if you need to talk, or…” he sighed “I’m here. That’s all.”
Truce remained still for another several moments. Then slowly, very slowly, he brought his hands up to his helmet, gingerly pulling it out of his head.
An involuntary smile curled Speck’s lips for a second as he watched Truce’s chin and mouth be revealed. There was the tan skin of a vod – albeit a tad pale, certainly from the toll of going through several surgical interventions. But that meant this was Truce indeed, a clone just like himself.
The smile faded when Speck noticed the blemished, scarred skin around Truce’s eyes, which now revealed twin pale white irises surrounded by a rim of black – prosthesis. That’s right… Truce’s eyesight was worsening. But the Kaminoans’ solution for that problem was to remove both of the commander’s eyes?
Truce pulled the two black plates over his arms, and Speck kept waiting for him to remove the dark silver plated armor from over them when he saw Truce reveal silver fingers and hands under his gloves.
That wasn’t armor. That was Truce’s prosthetic arms and hands. Speck was still trying to take that in when Truce carefully removed his frontal plate, revealing his chest, which was thankfully still made of flesh.
There were lightning-shaped scars where the metal of his arms met his biological body, and bolts connecting wires from his skin to his prosthesis. There was a myriad of scars over his chest and torso as well, and a faint red light could be seen glowing from under the skin of Truce’s chest where his heart was supposed to be. Two metallic ends protruded from there, surrounded by cauterized skin.
The scalpel and stitch scars on his torso made it clear that his organs had been most likely harvested and replaced with synthetic ones. Speck’s eyes darted down to dark-silver legs, confirming that the commander’s lower limbs had also been cut off and replaced.
Speck could feel his stomach churn, and he swallowed down once, twice before looking his commander in the eye. The man-machine stared at him like he could see his very soul with his white eyes. When he spoke, Speck was almost surprised he didn’t have a metallic-sounding voice like a droid. Instead, his voice was raspy, deep and devoid of emotion.
“I should’ve taken decommission.”
10 notes
·
View notes
Text
How Much Data Is Missing from Analytics? And Other Analytics Black Holes
Posted by Tom.Capper
If you’ve ever compared two analytics implementations on the same site, or compared your analytics with what your business is reporting in sales, you’ve probably noticed that things don’t always match up. In this post, I’ll explain why data is missing from your web analytics platforms and how large the impact could be. Some of the issues I cover are actually quite easily addressed, and have a decent impact on traffic — there’s never been an easier way to hit your quarterly targets. ;)
I’m going to focus on GA (Google Analytics), as it's the most commonly used provider, but most on-page analytics platforms have the same issues. Platforms that rely on server logs do avoid some issues but are fairly rare, so I won’t cover them in any depth.
Side note: Our test setup (multiple trackers & customized GA)
On Distilled.net, we have a standard Google Analytics property running from an HTML tag in GTM (Google Tag Manager). In addition, for the last two years, I’ve been running three extra concurrent Google Analytics implementations, designed to measure discrepancies between different configurations.
(If you’re just interested in my findings, you can skip this section, but if you want to hear more about the methodology, continue reading. Similarly, don’t worry if you don’t understand some of the detail here — the results are easier to follow.)
Two of these extra implementations — one in Google Tag Manager and one on page — run locally hosted, renamed copies of the Google Analytics JavaScript file (e.g. www.distilled.net/static/js/au3.js, instead of www.google-analytics.com/analytics.js) to make them harder to spot for ad blockers. I also used renamed JavaScript functions (“tcap” and “Buffoon,” rather than the standard “ga”) and renamed trackers (“FredTheUnblockable” and “AlbertTheImmutable”) to avoid having duplicate trackers (which can often cause issues).
This was originally inspired by 2016-era best practice on how to get your Google Analytics setup past ad blockers. I can’t find the original article now, but you can see a very similar one from 2017 here.
Lastly, we have (“DianaTheIndefatigable”), which just has a renamed tracker, but uses the standard code otherwise and is implemented on-page. This is to complete the set of all combinations of modified and unmodified GTM and on-page trackers.
Two of Distilled’s modified on-page trackers, as seen on https://www.distilled.net/
Overall, this table summarizes our setups:
Tracker
Renamed function?
GTM or on-page?
Locally hosted JavaScript file?
Default
No
GTM HTML tag
No
FredTheUnblockable
Yes - “tcap”
GTM HTML tag
Yes
AlbertTheImmutable
Yes - “buffoon”
On page
Yes
DianaTheIndefatigable
No
On page
No
I tested their functionality in various browser/ad-block environments by watching for the pageviews appearing in browser developer tools:
Reason 1: Ad Blockers
Ad blockers, primarily as browser extensions, have been growing in popularity for some time now. Primarily this has been to do with users looking for better performance and UX on ad-laden sites, but in recent years an increased emphasis on privacy has also crept in, hence the possibility of analytics blocking.
Effect of ad blockers
Some ad blockers block web analytics platforms by default, others can be configured to do so. I tested Distilled’s site with Adblock Plus and uBlock Origin, two of the most popular ad-blocking desktop browser addons, but it’s worth noting that ad blockers are increasingly prevalent on smartphones, too.
Here’s how Distilled’s setups fared:
(All numbers shown are from April 2018)
Setup
Vs. Adblock
Vs. Adblock with “EasyPrivacy” enabled
Vs. uBlock Origin
GTM
Pass
Fail
Fail
On page
Pass
Fail
Fail
GTM + renamed script & function
Pass
Fail
Fail
On page + renamed script & function
Pass
Fail
Fail
Seems like those tweaked setups didn’t do much!
Lost data due to ad blockers: ~10%
Ad blocker usage can be in the 15–25% range depending on region, but many of these installs will be default setups of AdBlock Plus, which as we’ve seen above, does not block tracking. Estimates of AdBlock Plus’s market share among ad blockers vary from 50–70%, with more recent reports tending more towards the former. So, if we assume that at most 50% of installed ad blockers block analytics, that leaves your exposure at around 10%.
Reason 2: Browser “do not track”
This is another privacy motivated feature, this time of browsers themselves. You can enable it in the settings of most current browsers. It’s not compulsory for sites or platforms to obey the “do not track” request, but Firefox offers a stronger feature under the same set of options, which I decided to test as well.
Effect of “do not track”
Most browsers now offer the option to send a “Do not track” message. I tested the latest releases of Firefox & Chrome for Windows 10.
Setup
Chrome “do not track”
Firefox “do not track”
Firefox “tracking protection”
GTM
Pass
Pass
Fail
On page
Pass
Pass
Fail
GTM + renamed script & function
Pass
Pass
Fail
On page + renamed script & function
Pass
Pass
Fail
Again, it doesn’t seem that the tweaked setups are doing much work for us here.
Lost data due to “do not track”: <1%
Only Firefox Quantum’s “Tracking Protection,” introduced in February, had any effect on our trackers. Firefox has a 5% market share, but Tracking Protection is not enabled by default. The launch of this feature had no effect on the trend for Firefox traffic on Distilled.net.
Reason 3: Filters
It’s a bit of an obvious one, but filters you’ve set up in your analytics might intentionally or unintentionally reduce your reported traffic levels.
For example, a filter excluding certain niche screen resolutions that you believe to be mostly bots, or internal traffic, will obviously cause your setup to underreport slightly.
Lost data due to filters: ???
Impact is hard to estimate, as setup will obviously vary on a site-by site-basis. I do recommend having a duplicate, unfiltered “master” view in case you realize too late you’ve lost something you didn’t intend to.
Reason 4: GTM vs. on-page vs. misplaced on-page
Google Tag Manager has become an increasingly popular way of implementing analytics in recent years, due to its increased flexibility and the ease of making changes. However, I’ve long noticed that it can tend to underreport vs. on-page setups.
I was also curious about what would happen if you didn’t follow Google’s guidelines in setting up on-page code.
By combining my numbers with numbers from my colleague Dom Woodman’s site (you’re welcome for the link, Dom), which happens to use a Drupal analytics add-on as well as GTM, I was able to see the difference between Google Tag Manager and misplaced on-page code (right at the bottom of the <body> tag) I then weighted this against my own Google Tag Manager data to get an overall picture of all 5 setups.
Effect of GTM and misplaced on-page code
Traffic as a percentage of baseline (standard Google Tag Manager implementation):
Google Tag Manager
Modified & Google Tag Manager
On-Page Code In <head>
Modified & On-Page Code In <head>
On-Page Code Misplaced In <Body>
Chrome
100.00%
98.75%
100.77%
99.80%
94.75%
Safari
100.00%
99.42%
100.55%
102.08%
82.69%
Firefox
100.00%
99.71%
101.16%
101.45%
90.68%
Internet Explorer
100.00%
80.06%
112.31%
113.37%
77.18%
There are a few main takeaways here:
On-page code generally reports more traffic than GTM
Modified code is generally within a margin of error, apart from modified GTM code on Internet Explorer (see note below)
Misplaced analytics code will cost you up to a third of your traffic vs. properly implemented on-page code, depending on browser (!)
The customized setups, which are designed to get more traffic by evading ad blockers, are doing nothing of the sort.
It’s worth noting also that the customized implementations actually got less traffic than the standard ones. For the on-page code, this is within the margin of error, but for Google Tag Manager, there’s another reason — because I used unfiltered profiles for the comparison, there’s a lot of bot spam in the main profile, which primarily masquerades as Internet Explorer. Our main profile is by far the most spammed, and also acting as the baseline here, so the difference between on-page code and Google Tag Manager is probably somewhat larger than what I’m reporting.
I also split the data by mobile, out of curiosity:
Traffic as a percentage of baseline (standard Google Tag Manager implementation):
Google Tag Manager
Modified & Google Tag Manager
On-Page Code In <head>
Modified & On-Page Code In <head>
On-Page Code Misplaced In <Body>
Desktop
100.00%
98.31%
100.97%
100.89%
93.47%
Mobile
100.00%
97.00%
103.78%
100.42%
89.87%
Tablet
100.00%
97.68%
104.20%
102.43%
88.13%
The further takeaway here seems to be that mobile browsers, like Internet Explorer, can struggle with Google Tag Manager.
Lost data due to GTM: 1–5%
Google Tag Manager seems to cost you a varying amount depending on what make-up of browsers and devices use your site. On Distilled.net, the difference is around 1.7%; however, we have an unusually desktop-heavy and tech-savvy audience (not much Internet Explorer!). Depending on vertical, this could easily swell to the 5% range.
Lost data due to misplaced on-page code: ~10%
On Teflsearch.com, the impact of misplaced on-page code was around 7.5%, vs Google Tag Manager. Keeping in mind that Google Tag Manager itself underreports, the total loss could easily be in the 10% range.
Bonus round: Missing data from channels
I’ve focused above on areas where you might be missing data altogether. However, there are also lots of ways in which data can be misrepresented, or detail can be missing. I’ll cover these more briefly, but the main issues are dark traffic and attribution.
Dark traffic
Dark traffic is direct traffic that didn’t really come via direct — which is generally becoming more and more common. Typical causes are:
Untagged campaigns in email
Untagged campaigns in apps (especially Facebook, Twitter, etc.)
Misrepresented organic
Data sent from botched tracking implementations (which can also appear as self-referrals)
It’s also worth noting the trend towards genuinely direct traffic that would historically have been organic. For example, due to increasingly sophisticated browser autocompletes, cross-device history, and so on, people end up “typing” a URL that they’d have searched for historically.
Attribution
I’ve written about this in more detail here, but in general, a session in Google Analytics (and any other platform) is a fairly arbitrary construct — you might think it’s obvious how a group of hits should be grouped into one or more sessions, but in fact, the process relies on a number of fairly questionable assumptions. In particular, it’s worth noting that Google Analytics generally attributes direct traffic (including dark traffic) to the previous non-direct source, if one exists.
Discussion
I was quite surprised by some of my own findings when researching this post, but I’m sure I didn’t get everything. Can you think of any other ways in which data can end up missing from analytics?
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read!
from The Moz Blog https://ift.tt/2skU6gW via IFTTT
1 note
·
View note
Text
10 Facebook Webpage Strategies Every Brand OUGHT TO KNOW

1. Develop Custom Tabs for Custom Ads
Advertising your brand's site is always vitally important. One of the biggest top features of Facebook's new internet pages product is that you can web page link right to specific tabs. Which means you can isolate which web pages an end user views by default predicated on the advertising that they clicked on. For instance, perhaps you would like to target two sets of users in several geographic locations. You'll display one advertisement for folks in Washington, D.C. and the ones users will land on a full page which is specific to users from Washington, D.C. Some other web page would be viewed to users from the SAN FRANCISCO BAY AREA for example.
While this technique isn't just the most scalable (for example having 500 tabs doesn't really make much sense), it can instantly raise the change of new guests into fans. This technique also requires a little bit more investment in customization but I'd claim that it's really worth it, specifically for smaller brands and companies.
2. DON'T ALLOW New Users Land on the Wall
Why on the planet would I let you know never to let users land on the wall membrane? Well, my biggest matter is that they can bump into Humpty Dumpty. Critically though, there's a huge possibility to present users with interesting information even though this content provided by lovers of your brand can be participating, you have zero control over it. That is why it's far better to possess new people to enter a manipulated environment and then check out understand through areas with less composition. Yes, the wall structure can be hugely valuable for making users speak to you as well as your brand but such unfiltered waters will be the previous place you should pressure a new individual to get around though. Provide your users with safe access to the muddy waters we call "social advertising" and they'll forever many thanks for it, believe me.
3. Create a distinctive Page Image
I honestly believe this is one of the main the different parts of a fan web page. It's a straightforward element yet within the confines of a 200-pixel huge box, you'd be astonished by the strategies that individuals produce. Lately, Rob Banagale, a visitor publisher on AllFacebook, shared articles entitled "5 Creative Methods to Hack Your Facebook Account Photo". In the event that you haven't read it, It is advisable to take a look. More impressive than the photographs contained in the tutorial will be the images that lots of users posted by the end.
I cannot let you know just how many standard Facebook Internet pages I've observed in that your basic brand is displayed. When your company has several workers (has extra resources), there must be no reason for not creating interesting photography for your Facebook Webpage. It's main things users check out and it gets the potential to leave a prolonged impression so make it good!
Get Quotes & Sayings Facebook Cover Photos
4. Integrate Applications TO IMPROVE Engagement
The very last thing you want is made for users to land on your Facebook Web page and leave immediately. The best opportunity you have to fully capture their attention is through interesting applications. There are over 55,000 applications on the Facebook system and a comparatively large part of them can be immediate built-into your fan webpage. Over the approaching weeks, you will see numerous applications that are designed across the soon to be up to date Facebook Site API which can make it easier for brands to release a relatively participating Facebook Page within a few minutes.
5. Join the Discussion, IT ISN'T Optional Anymore
-Talk Bubbles Icon- WHEN I mentioned before, this is actually the first time that brands contain the chance to be considered a major part of a user's discussion on Facebook to adopt good thing about it. Which means whenever someone reviews on your brand-new status, an image, a video tutorial, a conversation thread, or other things, you will need to touch upon it. Gone will be the times of a one-way dialog where the brands talk right down to their customers. We live amid a conversational revolution as well as your company must participate in it. At this time, you do not have the option never to participate.
Failing to participate your visitors and potential prospects mean fewer earnings, looked after means you will be losing to your rivals who is interesting using their customers frequently. Whether you are a tiny business (dentist, medical doctor, plumber, restaurant, etc) or a sizable corporation, you should be speaking with your customer and the only path to achieve that is via a two-way dialogue. They'll ask you questions that you can answer and you could ask questions as well. Enquire about what would enhance their experience with your business. Also, inquire further about the planet generally because, by the end of your day, they're humans like everyone else.
It requires extra effort to activate your clients and heading that extra mile will continue to keep clients returning. You intend to promote a fantastic brand right?
6. Publish Interesting and Relevant Content
Exactly like in the areas of social marketing (sites, Twitter, etc), it's vitally important to provide interesting content to your viewers. Facebook is not any different. By regularly referencing other relevant content, your admirers will keep time for your webpage. While attracting do it again guests are not the one most important element of fan pages, the duplicate proposal is easily the next most important adjustable. In exclusive economies, one of the very most effective measurements of the status of a current economic climate is repeat consumption. Facebook webpages and other digital content stations are no different. Users that go back to your webpage regularly are a lot more likely to become paying customers.
A lot more important is the fact existing customers who go back to your Facebook web page will continue as customers. The end result is that an ordinary looking Facebook web page is not doing all your company any favors. Yes, having any kind of existence is usually better than almost nothing but if you required the time to learn through this guide, please do me a favor and make just a little extra effort to build an interesting Facebook page. Just how does one find interesting content?
While I will not dive too deep into the information regarding finding interesting content, you ought to be in a position to find relevant content to your viewers by performing a search on Yahoo Blog search and leveraging an RSS audience like Google Audience. Typically I'd assume that a lot of readers of the site really know what RSS is but unless it's a straightforward way to learn this content on sites without actually needing to visit each site separately. If you wish to find out more, check out Google's Supply 101. If you'd like the brief answer for finding interesting content: look for this. I wish I possibly could say it's easier than that but sadly, it still does take time to find interesting content.
You can change to other kinds of content aggregators like Mouth watering.com and Digg.com but those typically only provide specific communities. If you're beyond the new advertising industry, you need to use traditional options like Google Information, Yahoo Blog search, and mainstream multimedia.
7. Repost Reviews By Other Users
If you're on Tweets, reposting information is actually exactly like a retweet. By reposting someone's information, you are complimenting them and they'll be more likely to focus on you. I will remember that I'm using "you" and "your brand" interchangeably in this part because, in sociable media, you ought to be inserting a face on your brand. At this time Fan Web pages aren't extremely conducive to adding a face on the brand but that changes as time passes. Reposting the info that other users post is incredibly valuable.
Don't overuse this though! I cannot let you know how often I see people on Tweets retweet, other users, frequently, hoping that it'll out of the blue increase their follower basic drastically. Although it will help, this isn't something should out of the blue drive a large number of users to your enthusiast page. Instead, from the good habit to find yourself in as time passes you as well as your company's reputation will build for interesting users frequently.
8. Update Regularly!
While it's vitally important to screen the dialog that users are experiencing within your top quality Facebook Pages, it is also vitally important to help spark the dialog. By publishing questions to users, creating new issues within discussion message boards, and performing alternative activities that induce dialogue (like the previous one described), you'll keep users returning to your Facebook Web page. This is like the concept of submitting blogs regularly (which incidentally can be automatically brought in to your Facebook Web page) on your small business blog.
In the same way, I've emphasized the value of quality content and proposal with your admirers, the main thing is persistence. If you don't keep participating your fans frequently and continue steadily to post interesting content, you will find it hard to constantly appeal to new fans.
9. Post and Label Users in Photographs and Videos
Tagging users in photographs and videos are most likely one of the very most effective promotional activities that can be done. The only task is discovering content to label users in. The ultimate way to get photographs and videos of your supporters is through web host events when I mentioned within the next tip but if you cannot host events, you will have to produce creative ways to label your fans. Just how do you do this? That's somewhat more difficult but nothing a creative professional can't figure.
One way is always to introduce competition to your admirer webpage and then label the winners of these awards in trophy photography. If you wish to take that idea a step further you might actually assimilate your supporters' images into the trophies. This is merely one idea though and there are always a limitless variety of ideas out there. Tagging users is an obviously viral process because once you tag one individual, their friends view it and then users are motivated compared to that album which in cases like this, resides inside your fan page.
10. Leverage the energy of Facebook Events
Events offer an amazing chance of brands to attain out with their fan base. On top of that, these situations don't absolutely need to maintain person happenings! While it isn't possible to see the network density of the enthusiasts of your brand (you can't easily observe how many supporters are friends with one another), when multiple people RSVP to a meeting there are increased probabilities that your event will be sent out through the sociable graph, subsequently travelling new users to your brand's site.
Like previous techniques or tips I talked about, there are inherent limits. The principal one being that emails delivered to a meeting created through the fan web page do not wrap up in a user's inbox. Instead, those communications are delivered via site "updates" that are displayed in another area. Luckily for us, Facebook's redesigned homepage, which is starting this week, includes improvements near the top of a user's homepage, making them more noticeable.
0 notes
Text
How Much Data Is Missing from Analytics? And Other Analytics Black Holes
How Much Data Is Missing from Analytics? And Other Analytics Black Holes
Posted by Tom.Capper
If you’ve ever compared two analytics implementations on the same site, or compared your analytics with what your business is reporting in sales, you’ve probably noticed that things don’t always match up. In this post, I’ll explain why data is missing from your web analytics platforms and how large the impact could be. Some of the issues I cover are actually quite easily addressed, and have a decent impact on traffic — there’s never been an easier way to hit your quarterly targets. ;)
I’m going to focus on GA (Google Analytics), as it's the most commonly used provider, but most on-page analytics platforms have the same issues. Platforms that rely on server logs do avoid some issues but are fairly rare, so I won’t cover them in any depth.
Side note: Our test setup (multiple trackers & customized GA)
On Distilled.net, we have a standard Google Analytics property running from an HTML tag in GTM (Google Tag Manager). In addition, for the last two years, I’ve been running three extra concurrent Google Analytics implementations, designed to measure discrepancies between different configurations.
(If you’re just interested in my findings, you can skip this section, but if you want to hear more about the methodology, continue reading. Similarly, don’t worry if you don’t understand some of the detail here — the results are easier to follow.)
Two of these extra implementations — one in Google Tag Manager and one on page — run locally hosted, renamed copies of the Google Analytics JavaScript file (e.g. www.distilled.net/static/js/au3.js, instead of www.google-analytics.com/analytics.js) to make them harder to spot for ad blockers. I also used renamed JavaScript functions (“tcap” and “Buffoon,” rather than the standard “ga”) and renamed trackers (“FredTheUnblockable” and “AlbertTheImmutable”) to avoid having duplicate trackers (which can often cause issues).
This was originally inspired by 2016-era best practice on how to get your Google Analytics setup past ad blockers. I can’t find the original article now, but you can see a very similar one from 2017 here.
Lastly, we have (“DianaTheIndefatigable”), which just has a renamed tracker, but uses the standard code otherwise and is implemented on-page. This is to complete the set of all combinations of modified and unmodified GTM and on-page trackers.
Two of Distilled’s modified on-page trackers, as seen on https://www.distilled.net/
Overall, this table summarizes our setups:
Tracker
Renamed function?
GTM or on-page?
Locally hosted JavaScript file?
Default
No
GTM HTML tag
No
FredTheUnblockable
Yes - “tcap”
GTM HTML tag
Yes
AlbertTheImmutable
Yes - “buffoon”
On page
Yes
DianaTheIndefatigable
No
On page
No
I tested their functionality in various browser/ad-block environments by watching for the pageviews appearing in browser developer tools:
Reason 1: Ad Blockers
Ad blockers, primarily as browser extensions, have been growing in popularity for some time now. Primarily this has been to do with users looking for better performance and UX on ad-laden sites, but in recent years an increased emphasis on privacy has also crept in, hence the possibility of analytics blocking.
Effect of ad blockers
Some ad blockers block web analytics platforms by default, others can be configured to do so. I tested Distilled’s site with Adblock Plus and uBlock Origin, two of the most popular ad-blocking desktop browser addons, but it’s worth noting that ad blockers are increasingly prevalent on smartphones, too.
Here’s how Distilled’s setups fared:
(All numbers shown are from April 2018)
Setup
Vs. Adblock
Vs. Adblock with “EasyPrivacy” enabled
Vs. uBlock Origin
GTM
Pass
Fail
Fail
On page
Pass
Fail
Fail
GTM + renamed script & function
Pass
Fail
Fail
On page + renamed script & function
Pass
Fail
Fail
Seems like those tweaked setups didn’t do much!
Lost data due to ad blockers: ~10%
Ad blocker usage can be in the 15–25% range depending on region, but many of these installs will be default setups of AdBlock Plus, which as we’ve seen above, does not block tracking. Estimates of AdBlock Plus’s market share among ad blockers vary from 50–70%, with more recent reports tending more towards the former. So, if we assume that at most 50% of installed ad blockers block analytics, that leaves your exposure at around 10%.
Reason 2: Browser “do not track”
This is another privacy motivated feature, this time of browsers themselves. You can enable it in the settings of most current browsers. It’s not compulsory for sites or platforms to obey the “do not track” request, but Firefox offers a stronger feature under the same set of options, which I decided to test as well.
Effect of “do not track”
Most browsers now offer the option to send a “Do not track” message. I tested the latest releases of Firefox & Chrome for Windows 10.
Setup
Chrome “do not track”
Firefox “do not track”
Firefox “tracking protection”
GTM
Pass
Pass
Fail
On page
Pass
Pass
Fail
GTM + renamed script & function
Pass
Pass
Fail
On page + renamed script & function
Pass
Pass
Fail
Again, it doesn’t seem that the tweaked setups are doing much work for us here.
Lost data due to “do not track”: <1%
Only Firefox Quantum’s “Tracking Protection,” introduced in February, had any effect on our trackers. Firefox has a 5% market share, but Tracking Protection is not enabled by default. The launch of this feature had no effect on the trend for Firefox traffic on Distilled.net.
Reason 3: Filters
It’s a bit of an obvious one, but filters you’ve set up in your analytics might intentionally or unintentionally reduce your reported traffic levels.
For example, a filter excluding certain niche screen resolutions that you believe to be mostly bots, or internal traffic, will obviously cause your setup to underreport slightly.
Lost data due to filters: ???
Impact is hard to estimate, as setup will obviously vary on a site-by site-basis. I do recommend having a duplicate, unfiltered “master” view in case you realize too late you’ve lost something you didn’t intend to.
Reason 4: GTM vs. on-page vs. misplaced on-page
Google Tag Manager has become an increasingly popular way of implementing analytics in recent years, due to its increased flexibility and the ease of making changes. However, I’ve long noticed that it can tend to underreport vs. on-page setups.
I was also curious about what would happen if you didn’t follow Google’s guidelines in setting up on-page code.
By combining my numbers with numbers from my colleague Dom Woodman’s site (you’re welcome for the link, Dom), which happens to use a Drupal analytics add-on as well as GTM, I was able to see the difference between Google Tag Manager and misplaced on-page code (right at the bottom of the <body> tag) I then weighted this against my own Google Tag Manager data to get an overall picture of all 5 setups.
Effect of GTM and misplaced on-page code
Traffic as a percentage of baseline (standard Google Tag Manager implementation):
Google Tag Manager
Modified & Google Tag Manager
On-Page Code In <head>
Modified & On-Page Code In <head>
On-Page Code Misplaced In <Body>
Chrome
100.00%
98.75%
100.77%
99.80%
94.75%
Safari
100.00%
99.42%
100.55%
102.08%
82.69%
Firefox
100.00%
99.71%
101.16%
101.45%
90.68%
Internet Explorer
100.00%
80.06%
112.31%
113.37%
77.18%
There are a few main takeaways here:
On-page code generally reports more traffic than GTM
Modified code is generally within a margin of error, apart from modified GTM code on Internet Explorer (see note below)
Misplaced analytics code will cost you up to a third of your traffic vs. properly implemented on-page code, depending on browser (!)
The customized setups, which are designed to get more traffic by evading ad blockers, are doing nothing of the sort.
It’s worth noting also that the customized implementations actually got less traffic than the standard ones. For the on-page code, this is within the margin of error, but for Google Tag Manager, there’s another reason — because I used unfiltered profiles for the comparison, there’s a lot of bot spam in the main profile, which primarily masquerades as Internet Explorer. Our main profile is by far the most spammed, and also acting as the baseline here, so the difference between on-page code and Google Tag Manager is probably somewhat larger than what I’m reporting.
I also split the data by mobile, out of curiosity:
Traffic as a percentage of baseline (standard Google Tag Manager implementation):
Google Tag Manager
Modified & Google Tag Manager
On-Page Code In <head>
Modified & On-Page Code In <head>
On-Page Code Misplaced In <Body>
Desktop
100.00%
98.31%
100.97%
100.89%
93.47%
Mobile
100.00%
97.00%
103.78%
100.42%
89.87%
Tablet
100.00%
97.68%
104.20%
102.43%
88.13%
The further takeaway here seems to be that mobile browsers, like Internet Explorer, can struggle with Google Tag Manager.
Lost data due to GTM: 1–5%
Google Tag Manager seems to cost you a varying amount depending on what make-up of browsers and devices use your site. On Distilled.net, the difference is around 1.7%; however, we have an unusually desktop-heavy and tech-savvy audience (not much Internet Explorer!). Depending on vertical, this could easily swell to the 5% range.
Lost data due to misplaced on-page code: ~10%
On Teflsearch.com, the impact of misplaced on-page code was around 7.5%, vs Google Tag Manager. Keeping in mind that Google Tag Manager itself underreports, the total loss could easily be in the 10% range.
Bonus round: Missing data from channels
I’ve focused above on areas where you might be missing data altogether. However, there are also lots of ways in which data can be misrepresented, or detail can be missing. I’ll cover these more briefly, but the main issues are dark traffic and attribution.
Dark traffic
Dark traffic is direct traffic that didn’t really come via direct — which is generally becoming more and more common. Typical causes are:
Untagged campaigns in email
Untagged campaigns in apps (especially Facebook, Twitter, etc.)
Misrepresented organic
Data sent from botched tracking implementations (which can also appear as self-referrals)
It’s also worth noting the trend towards genuinely direct traffic that would historically have been organic. For example, due to increasingly sophisticated browser autocompletes, cross-device history, and so on, people end up “typing” a URL that they’d have searched for historically.
Attribution
I’ve written about this in more detail here, but in general, a session in Google Analytics (and any other platform) is a fairly arbitrary construct — you might think it’s obvious how a group of hits should be grouped into one or more sessions, but in fact, the process relies on a number of fairly questionable assumptions. In particular, it’s worth noting that Google Analytics generally attributes direct traffic (including dark traffic) to the previous non-direct source, if one exists.
Discussion
I was quite surprised by some of my own findings when researching this post, but I’m sure I didn’t get everything. Can you think of any other ways in which data can end up missing from analytics?
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read!
https://ift.tt/2q13Myy xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ How Much Data Is Missing from Analytics? And Other Analytics Black Holes https://ift.tt/2GWKq1B xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ How Much Data Is Missing from Analytics? And Other Analytics Black Holes https://ift.tt/2GWKq1B xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ How Much Data Is Missing from Analytics? And Other Analytics Black Holes https://ift.tt/2GWKq1B xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ How Much Data Is Missing from Analytics? And Other Analytics Black Holes https://ift.tt/2GWKq1B xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ How Much Data Is Missing from Analytics? And Other Analytics Black Holes https://ift.tt/2GWKq1B xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ How Much Data Is Missing from Analytics? And Other Analytics Black Holes https://ift.tt/2GWKq1B xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ How Much Data Is Missing from Analytics? And Other Analytics Black Holes https://ift.tt/2GWKq1B xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ How Much Data Is Missing from Analytics? And Other Analytics Black Holes https://ift.tt/2GWKq1B xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ How Much Data Is Missing from Analytics? And Other Analytics Black Holes https://ift.tt/2GWKq1B xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ How Much Data Is Missing from Analytics? And Other Analytics Black Holes https://ift.tt/2GWKq1B xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ How Much Data Is Missing from Analytics? And Other Analytics Black Holes https://ift.tt/2GWKq1B xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ How Much Data Is Missing from Analytics? And Other Analytics Black Holes https://ift.tt/2GWKq1B xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ How Much Data Is Missing from Analytics? And Other Analytics Black Holes https://ift.tt/2GWKq1B xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ How Much Data Is Missing from Analytics? And Other Analytics Black Holes https://ift.tt/2GWKq1B xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ How Much Data Is Missing from Analytics? And Other Analytics Black Holes https://ift.tt/2GWKq1B xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ How Much Data Is Missing from Analytics? And Other Analytics Black Holes https://ift.tt/2GWKq1B Bạn có thể xem thêm địa chỉ mua tai nghe không dây tại đây https://ift.tt/2mb4VST
0 notes
Text
How Much Data Is Missing from Analytics? And Other Analytics Black Holes
Posted by Tom.Capper
If you’ve ever compared two analytics implementations on the same site, or compared your analytics with what your business is reporting in sales, you’ve probably noticed that things don’t always match up. In this post, I’ll explain why data is missing from your web analytics platforms and how large the impact could be. Some of the issues I cover are actually quite easily addressed, and have a decent impact on traffic — there’s never been an easier way to hit your quarterly targets. ;)
I’m going to focus on GA (Google Analytics), as it's the most commonly used provider, but most on-page analytics platforms have the same issues. Platforms that rely on server logs do avoid some issues but are fairly rare, so I won’t cover them in any depth.
Side note: Our test setup (multiple trackers & customized GA)
On Distilled.net, we have a standard Google Analytics property running from an HTML tag in GTM (Google Tag Manager). In addition, for the last two years, I’ve been running three extra concurrent Google Analytics implementations, designed to measure discrepancies between different configurations.
(If you’re just interested in my findings, you can skip this section, but if you want to hear more about the methodology, continue reading. Similarly, don’t worry if you don’t understand some of the detail here — the results are easier to follow.)
Two of these extra implementations — one in Google Tag Manager and one on page — run locally hosted, renamed copies of the Google Analytics JavaScript file (e.g. www.distilled.net/static/js/au3.js, instead of www.google-analytics.com/analytics.js) to make them harder to spot for ad blockers. I also used renamed JavaScript functions (“tcap” and “Buffoon,” rather than the standard “ga”) and renamed trackers (“FredTheUnblockable” and “AlbertTheImmutable”) to avoid having duplicate trackers (which can often cause issues).
This was originally inspired by 2016-era best practice on how to get your Google Analytics setup past ad blockers. I can’t find the original article now, but you can see a very similar one from 2017 here.
Lastly, we have (“DianaTheIndefatigable”), which just has a renamed tracker, but uses the standard code otherwise and is implemented on-page. This is to complete the set of all combinations of modified and unmodified GTM and on-page trackers.
Two of Distilled’s modified on-page trackers, as seen on https://www.distilled.net/
Overall, this table summarizes our setups:
Tracker
Renamed function?
GTM or on-page?
Locally hosted JavaScript file?
Default
No
GTM HTML tag
No
FredTheUnblockable
Yes - “tcap”
GTM HTML tag
Yes
AlbertTheImmutable
Yes - “buffoon”
On page
Yes
DianaTheIndefatigable
No
On page
No
I tested their functionality in various browser/ad-block environments by watching for the pageviews appearing in browser developer tools:
Reason 1: Ad Blockers
Ad blockers, primarily as browser extensions, have been growing in popularity for some time now. Primarily this has been to do with users looking for better performance and UX on ad-laden sites, but in recent years an increased emphasis on privacy has also crept in, hence the possibility of analytics blocking.
Effect of ad blockers
Some ad blockers block web analytics platforms by default, others can be configured to do so. I tested Distilled’s site with Adblock Plus and uBlock Origin, two of the most popular ad-blocking desktop browser addons, but it’s worth noting that ad blockers are increasingly prevalent on smartphones, too.
Here’s how Distilled’s setups fared:
(All numbers shown are from April 2018)
Setup
Vs. Adblock
Vs. Adblock with “EasyPrivacy” enabled
Vs. uBlock Origin
GTM
Pass
Fail
Fail
On page
Pass
Fail
Fail
GTM + renamed script & function
Pass
Fail
Fail
On page + renamed script & function
Pass
Fail
Fail
Seems like those tweaked setups didn’t do much!
Lost data due to ad blockers: ~10%
Ad blocker usage can be in the 15–25% range depending on region, but many of these installs will be default setups of AdBlock Plus, which as we’ve seen above, does not block tracking. Estimates of AdBlock Plus’s market share among ad blockers vary from 50–70%, with more recent reports tending more towards the former. So, if we assume that at most 50% of installed ad blockers block analytics, that leaves your exposure at around 10%.
Reason 2: Browser “do not track”
This is another privacy motivated feature, this time of browsers themselves. You can enable it in the settings of most current browsers. It’s not compulsory for sites or platforms to obey the “do not track” request, but Firefox offers a stronger feature under the same set of options, which I decided to test as well.
Effect of “do not track”
Most browsers now offer the option to send a “Do not track” message. I tested the latest releases of Firefox & Chrome for Windows 10.
Setup
Chrome “do not track”
Firefox “do not track”
Firefox “tracking protection”
GTM
Pass
Pass
Fail
On page
Pass
Pass
Fail
GTM + renamed script & function
Pass
Pass
Fail
On page + renamed script & function
Pass
Pass
Fail
Again, it doesn’t seem that the tweaked setups are doing much work for us here.
Lost data due to “do not track”: <1%
Only Firefox Quantum’s “Tracking Protection,” introduced in February, had any effect on our trackers. Firefox has a 5% market share, but Tracking Protection is not enabled by default. The launch of this feature had no effect on the trend for Firefox traffic on Distilled.net.
Reason 3: Filters
It’s a bit of an obvious one, but filters you’ve set up in your analytics might intentionally or unintentionally reduce your reported traffic levels.
For example, a filter excluding certain niche screen resolutions that you believe to be mostly bots, or internal traffic, will obviously cause your setup to underreport slightly.
Lost data due to filters: ???
Impact is hard to estimate, as setup will obviously vary on a site-by site-basis. I do recommend having a duplicate, unfiltered “master” view in case you realize too late you’ve lost something you didn’t intend to.
Reason 4: GTM vs. on-page vs. misplaced on-page
Google Tag Manager has become an increasingly popular way of implementing analytics in recent years, due to its increased flexibility and the ease of making changes. However, I’ve long noticed that it can tend to underreport vs. on-page setups.
I was also curious about what would happen if you didn’t follow Google’s guidelines in setting up on-page code.
By combining my numbers with numbers from my colleague Dom Woodman’s site (you’re welcome for the link, Dom), which happens to use a Drupal analytics add-on as well as GTM, I was able to see the difference between Google Tag Manager and misplaced on-page code (right at the bottom of the <body> tag) I then weighted this against my own Google Tag Manager data to get an overall picture of all 5 setups.
Effect of GTM and misplaced on-page code
Traffic as a percentage of baseline (standard Google Tag Manager implementation):
Google Tag Manager
Modified & Google Tag Manager
On-Page Code In <head>
Modified & On-Page Code In <head>
On-Page Code Misplaced In <Body>
Chrome
100.00%
98.75%
100.77%
99.80%
94.75%
Safari
100.00%
99.42%
100.55%
102.08%
82.69%
Firefox
100.00%
99.71%
101.16%
101.45%
90.68%
Internet Explorer
100.00%
80.06%
112.31%
113.37%
77.18%
There are a few main takeaways here:
On-page code generally reports more traffic than GTM
Modified code is generally within a margin of error, apart from modified GTM code on Internet Explorer (see note below)
Misplaced analytics code will cost you up to a third of your traffic vs. properly implemented on-page code, depending on browser (!)
The customized setups, which are designed to get more traffic by evading ad blockers, are doing nothing of the sort.
It’s worth noting also that the customized implementations actually got less traffic than the standard ones. For the on-page code, this is within the margin of error, but for Google Tag Manager, there’s another reason — because I used unfiltered profiles for the comparison, there’s a lot of bot spam in the main profile, which primarily masquerades as Internet Explorer. Our main profile is by far the most spammed, and also acting as the baseline here, so the difference between on-page code and Google Tag Manager is probably somewhat larger than what I’m reporting.
I also split the data by mobile, out of curiosity:
Traffic as a percentage of baseline (standard Google Tag Manager implementation):
Google Tag Manager
Modified & Google Tag Manager
On-Page Code In <head>
Modified & On-Page Code In <head>
On-Page Code Misplaced In <Body>
Desktop
100.00%
98.31%
100.97%
100.89%
93.47%
Mobile
100.00%
97.00%
103.78%
100.42%
89.87%
Tablet
100.00%
97.68%
104.20%
102.43%
88.13%
The further takeaway here seems to be that mobile browsers, like Internet Explorer, can struggle with Google Tag Manager.
Lost data due to GTM: 1–5%
Google Tag Manager seems to cost you a varying amount depending on what make-up of browsers and devices use your site. On Distilled.net, the difference is around 1.7%; however, we have an unusually desktop-heavy and tech-savvy audience (not much Internet Explorer!). Depending on vertical, this could easily swell to the 5% range.
Lost data due to misplaced on-page code: ~10%
On Teflsearch.com, the impact of misplaced on-page code was around 7.5%, vs Google Tag Manager. Keeping in mind that Google Tag Manager itself underreports, the total loss could easily be in the 10% range.
Bonus round: Missing data from channels
I’ve focused above on areas where you might be missing data altogether. However, there are also lots of ways in which data can be misrepresented, or detail can be missing. I’ll cover these more briefly, but the main issues are dark traffic and attribution.
Dark traffic
Dark traffic is direct traffic that didn’t really come via direct — which is generally becoming more and more common. Typical causes are:
Untagged campaigns in email
Untagged campaigns in apps (especially Facebook, Twitter, etc.)
Misrepresented organic
Data sent from botched tracking implementations (which can also appear as self-referrals)
It’s also worth noting the trend towards genuinely direct traffic that would historically have been organic. For example, due to increasingly sophisticated browser autocompletes, cross-device history, and so on, people end up “typing” a URL that they’d have searched for historically.
Attribution
I’ve written about this in more detail here, but in general, a session in Google Analytics (and any other platform) is a fairly arbitrary construct — you might think it’s obvious how a group of hits should be grouped into one or more sessions, but in fact, the process relies on a number of fairly questionable assumptions. In particular, it’s worth noting that Google Analytics generally attributes direct traffic (including dark traffic) to the previous non-direct source, if one exists.
Discussion
I was quite surprised by some of my own findings when researching this post, but I’m sure I didn’t get everything. Can you think of any other ways in which data can end up missing from analytics?
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read!
via Blogger https://ift.tt/2kwAy68 #blogger #bloggingtips #bloggerlife #bloggersgetsocial #ontheblog #writersofinstagram #writingprompt #instapoetry #writerscommunity #writersofig #writersblock #writerlife #writtenword #instawriters #spilledink #wordgasm #creativewriting #poetsofinstagram #blackoutpoetry #poetsofig
0 notes
Text
How Much Data Is Missing from Analytics? And Other Analytics Black Holes
Posted by Tom.Capper
If you’ve ever compared two analytics implementations on the same site, or compared your analytics with what your business is reporting in sales, you’ve probably noticed that things don’t always match up. In this post, I’ll explain why data is missing from your web analytics platforms and how large the impact could be. Some of the issues I cover are actually quite easily addressed, and have a decent impact on traffic — there’s never been an easier way to hit your quarterly targets. ;)
I’m going to focus on GA (Google Analytics), as it's the most commonly used provider, but most on-page analytics platforms have the same issues. Platforms that rely on server logs do avoid some issues but are fairly rare, so I won’t cover them in any depth.
Side note: Our test setup (multiple trackers & customized GA)
On Distilled.net, we have a standard Google Analytics property running from an HTML tag in GTM (Google Tag Manager). In addition, for the last two years, I’ve been running three extra concurrent Google Analytics implementations, designed to measure discrepancies between different configurations.
(If you’re just interested in my findings, you can skip this section, but if you want to hear more about the methodology, continue reading. Similarly, don’t worry if you don’t understand some of the detail here — the results are easier to follow.)
Two of these extra implementations — one in Google Tag Manager and one on page — run locally hosted, renamed copies of the Google Analytics JavaScript file (e.g. www.distilled.net/static/js/au3.js, instead of www.google-analytics.com/analytics.js) to make them harder to spot for ad blockers. I also used renamed JavaScript functions (“tcap” and “Buffoon,” rather than the standard “ga”) and renamed trackers (“FredTheUnblockable” and “AlbertTheImmutable”) to avoid having duplicate trackers (which can often cause issues).
This was originally inspired by 2016-era best practice on how to get your Google Analytics setup past ad blockers. I can’t find the original article now, but you can see a very similar one from 2017 here.
Lastly, we have (“DianaTheIndefatigable”), which just has a renamed tracker, but uses the standard code otherwise and is implemented on-page. This is to complete the set of all combinations of modified and unmodified GTM and on-page trackers.
Two of Distilled’s modified on-page trackers, as seen on https://www.distilled.net/
Overall, this table summarizes our setups:
Tracker
Renamed function?
GTM or on-page?
Locally hosted JavaScript file?
Default
No
GTM HTML tag
No
FredTheUnblockable
Yes - “tcap”
GTM HTML tag
Yes
AlbertTheImmutable
Yes - “buffoon”
On page
Yes
DianaTheIndefatigable
No
On page
No
I tested their functionality in various browser/ad-block environments by watching for the pageviews appearing in browser developer tools:
Reason 1: Ad Blockers
Ad blockers, primarily as browser extensions, have been growing in popularity for some time now. Primarily this has been to do with users looking for better performance and UX on ad-laden sites, but in recent years an increased emphasis on privacy has also crept in, hence the possibility of analytics blocking.
Effect of ad blockers
Some ad blockers block web analytics platforms by default, others can be configured to do so. I tested Distilled’s site with Adblock Plus and uBlock Origin, two of the most popular ad-blocking desktop browser addons, but it’s worth noting that ad blockers are increasingly prevalent on smartphones, too.
Here’s how Distilled’s setups fared:
(All numbers shown are from April 2018)
Setup
Vs. Adblock
Vs. Adblock with “EasyPrivacy” enabled
Vs. uBlock Origin
GTM
Pass
Fail
Fail
On page
Pass
Fail
Fail
GTM + renamed script & function
Pass
Fail
Fail
On page + renamed script & function
Pass
Fail
Fail
Seems like those tweaked setups didn’t do much!
Lost data due to ad blockers: ~10%
Ad blocker usage can be in the 15–25% range depending on region, but many of these installs will be default setups of AdBlock Plus, which as we’ve seen above, does not block tracking. Estimates of AdBlock Plus’s market share among ad blockers vary from 50–70%, with more recent reports tending more towards the former. So, if we assume that at most 50% of installed ad blockers block analytics, that leaves your exposure at around 10%.
Reason 2: Browser “do not track”
This is another privacy motivated feature, this time of browsers themselves. You can enable it in the settings of most current browsers. It’s not compulsory for sites or platforms to obey the “do not track” request, but Firefox offers a stronger feature under the same set of options, which I decided to test as well.
Effect of “do not track”
Most browsers now offer the option to send a “Do not track” message. I tested the latest releases of Firefox & Chrome for Windows 10.
Setup
Chrome “do not track”
Firefox “do not track”
Firefox “tracking protection”
GTM
Pass
Pass
Fail
On page
Pass
Pass
Fail
GTM + renamed script & function
Pass
Pass
Fail
On page + renamed script & function
Pass
Pass
Fail
Again, it doesn’t seem that the tweaked setups are doing much work for us here.
Lost data due to “do not track”: <1%
Only Firefox Quantum’s “Tracking Protection,” introduced in February, had any effect on our trackers. Firefox has a 5% market share, but Tracking Protection is not enabled by default. The launch of this feature had no effect on the trend for Firefox traffic on Distilled.net.
Reason 3: Filters
It’s a bit of an obvious one, but filters you’ve set up in your analytics might intentionally or unintentionally reduce your reported traffic levels.
For example, a filter excluding certain niche screen resolutions that you believe to be mostly bots, or internal traffic, will obviously cause your setup to underreport slightly.
Lost data due to filters: ???
Impact is hard to estimate, as setup will obviously vary on a site-by site-basis. I do recommend having a duplicate, unfiltered “master” view in case you realize too late you’ve lost something you didn’t intend to.
Reason 4: GTM vs. on-page vs. misplaced on-page
Google Tag Manager has become an increasingly popular way of implementing analytics in recent years, due to its increased flexibility and the ease of making changes. However, I’ve long noticed that it can tend to underreport vs. on-page setups.
I was also curious about what would happen if you didn’t follow Google’s guidelines in setting up on-page code.
By combining my numbers with numbers from my colleague Dom Woodman’s site (you’re welcome for the link, Dom), which happens to use a Drupal analytics add-on as well as GTM, I was able to see the difference between Google Tag Manager and misplaced on-page code (right at the bottom of the <body> tag) I then weighted this against my own Google Tag Manager data to get an overall picture of all 5 setups.
Effect of GTM and misplaced on-page code
Traffic as a percentage of baseline (standard Google Tag Manager implementation):
Google Tag Manager
Modified & Google Tag Manager
On-Page Code In <head>
Modified & On-Page Code In <head>
On-Page Code Misplaced In <Body>
Chrome
100.00%
98.75%
100.77%
99.80%
94.75%
Safari
100.00%
99.42%
100.55%
102.08%
82.69%
Firefox
100.00%
99.71%
101.16%
101.45%
90.68%
Internet Explorer
100.00%
80.06%
112.31%
113.37%
77.18%
There are a few main takeaways here:
On-page code generally reports more traffic than GTM
Modified code is generally within a margin of error, apart from modified GTM code on Internet Explorer (see note below)
Misplaced analytics code will cost you up to a third of your traffic vs. properly implemented on-page code, depending on browser (!)
The customized setups, which are designed to get more traffic by evading ad blockers, are doing nothing of the sort.
It’s worth noting also that the customized implementations actually got less traffic than the standard ones. For the on-page code, this is within the margin of error, but for Google Tag Manager, there’s another reason — because I used unfiltered profiles for the comparison, there’s a lot of bot spam in the main profile, which primarily masquerades as Internet Explorer. Our main profile is by far the most spammed, and also acting as the baseline here, so the difference between on-page code and Google Tag Manager is probably somewhat larger than what I’m reporting.
I also split the data by mobile, out of curiosity:
Traffic as a percentage of baseline (standard Google Tag Manager implementation):
Google Tag Manager
Modified & Google Tag Manager
On-Page Code In <head>
Modified & On-Page Code In <head>
On-Page Code Misplaced In <Body>
Desktop
100.00%
98.31%
100.97%
100.89%
93.47%
Mobile
100.00%
97.00%
103.78%
100.42%
89.87%
Tablet
100.00%
97.68%
104.20%
102.43%
88.13%
The further takeaway here seems to be that mobile browsers, like Internet Explorer, can struggle with Google Tag Manager.
Lost data due to GTM: 1–5%
Google Tag Manager seems to cost you a varying amount depending on what make-up of browsers and devices use your site. On Distilled.net, the difference is around 1.7%; however, we have an unusually desktop-heavy and tech-savvy audience (not much Internet Explorer!). Depending on vertical, this could easily swell to the 5% range.
Lost data due to misplaced on-page code: ~10%
On Teflsearch.com, the impact of misplaced on-page code was around 7.5%, vs Google Tag Manager. Keeping in mind that Google Tag Manager itself underreports, the total loss could easily be in the 10% range.
Bonus round: Missing data from channels
I’ve focused above on areas where you might be missing data altogether. However, there are also lots of ways in which data can be misrepresented, or detail can be missing. I’ll cover these more briefly, but the main issues are dark traffic and attribution.
Dark traffic
Dark traffic is direct traffic that didn’t really come via direct — which is generally becoming more and more common. Typical causes are:
Untagged campaigns in email
Untagged campaigns in apps (especially Facebook, Twitter, etc.)
Misrepresented organic
Data sent from botched tracking implementations (which can also appear as self-referrals)
It’s also worth noting the trend towards genuinely direct traffic that would historically have been organic. For example, due to increasingly sophisticated browser autocompletes, cross-device history, and so on, people end up “typing” a URL that they’d have searched for historically.
Attribution
I’ve written about this in more detail here, but in general, a session in Google Analytics (and any other platform) is a fairly arbitrary construct — you might think it’s obvious how a group of hits should be grouped into one or more sessions, but in fact, the process relies on a number of fairly questionable assumptions. In particular, it’s worth noting that Google Analytics generally attributes direct traffic (including dark traffic) to the previous non-direct source, if one exists.
Discussion
I was quite surprised by some of my own findings when researching this post, but I’m sure I didn’t get everything. Can you think of any other ways in which data can end up missing from analytics?
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read!
from Blogger https://ift.tt/2KZaOKK via IFTTT
0 notes
Text
How Much Data Is Missing from Analytics? And Other Analytics Black Holes
Posted by Tom.Capper
If you’ve ever compared two analytics implementations on the same site, or compared your analytics with what your business is reporting in sales, you’ve probably noticed that things don’t always match up. In this post, I’ll explain why data is missing from your web analytics platforms and how large the impact could be. Some of the issues I cover are actually quite easily addressed, and have a decent impact on traffic — there’s never been an easier way to hit your quarterly targets. ;)
I’m going to focus on GA (Google Analytics), as it's the most commonly used provider, but most on-page analytics platforms have the same issues. Platforms that rely on server logs do avoid some issues but are fairly rare, so I won’t cover them in any depth.
Side note: Our test setup (multiple trackers & customized GA)
On Distilled.net, we have a standard Google Analytics property running from an HTML tag in GTM (Google Tag Manager). In addition, for the last two years, I’ve been running three extra concurrent Google Analytics implementations, designed to measure discrepancies between different configurations.
(If you’re just interested in my findings, you can skip this section, but if you want to hear more about the methodology, continue reading. Similarly, don’t worry if you don’t understand some of the detail here — the results are easier to follow.)
Two of these extra implementations — one in Google Tag Manager and one on page — run locally hosted, renamed copies of the Google Analytics JavaScript file (e.g. www.distilled.net/static/js/au3.js, instead of www.google-analytics.com/analytics.js) to make them harder to spot for ad blockers. I also used renamed JavaScript functions (“tcap” and “Buffoon,” rather than the standard “ga”) and renamed trackers (“FredTheUnblockable” and “AlbertTheImmutable”) to avoid having duplicate trackers (which can often cause issues).
This was originally inspired by 2016-era best practice on how to get your Google Analytics setup past ad blockers. I can’t find the original article now, but you can see a very similar one from 2017 here.
Lastly, we have (“DianaTheIndefatigable”), which just has a renamed tracker, but uses the standard code otherwise and is implemented on-page. This is to complete the set of all combinations of modified and unmodified GTM and on-page trackers.
Two of Distilled’s modified on-page trackers, as seen on https://www.distilled.net/
Overall, this table summarizes our setups:
Tracker
Renamed function?
GTM or on-page?
Locally hosted JavaScript file?
Default
No
GTM HTML tag
No
FredTheUnblockable
Yes - “tcap”
GTM HTML tag
Yes
AlbertTheImmutable
Yes - “buffoon”
On page
Yes
DianaTheIndefatigable
No
On page
No
I tested their functionality in various browser/ad-block environments by watching for the pageviews appearing in browser developer tools:
Reason 1: Ad Blockers
Ad blockers, primarily as browser extensions, have been growing in popularity for some time now. Primarily this has been to do with users looking for better performance and UX on ad-laden sites, but in recent years an increased emphasis on privacy has also crept in, hence the possibility of analytics blocking.
Effect of ad blockers
Some ad blockers block web analytics platforms by default, others can be configured to do so. I tested Distilled’s site with Adblock Plus and uBlock Origin, two of the most popular ad-blocking desktop browser addons, but it’s worth noting that ad blockers are increasingly prevalent on smartphones, too.
Here’s how Distilled’s setups fared:
(All numbers shown are from April 2018)
Setup
Vs. Adblock
Vs. Adblock with “EasyPrivacy” enabled
Vs. uBlock Origin
GTM
Pass
Fail
Fail
On page
Pass
Fail
Fail
GTM + renamed script & function
Pass
Fail
Fail
On page + renamed script & function
Pass
Fail
Fail
Seems like those tweaked setups didn’t do much!
Lost data due to ad blockers: ~10%
Ad blocker usage can be in the 15–25% range depending on region, but many of these installs will be default setups of AdBlock Plus, which as we’ve seen above, does not block tracking. Estimates of AdBlock Plus’s market share among ad blockers vary from 50–70%, with more recent reports tending more towards the former. So, if we assume that at most 50% of installed ad blockers block analytics, that leaves your exposure at around 10%.
Reason 2: Browser “do not track”
This is another privacy motivated feature, this time of browsers themselves. You can enable it in the settings of most current browsers. It’s not compulsory for sites or platforms to obey the “do not track” request, but Firefox offers a stronger feature under the same set of options, which I decided to test as well.
Effect of “do not track”
Most browsers now offer the option to send a “Do not track” message. I tested the latest releases of Firefox & Chrome for Windows 10.
Setup
Chrome “do not track”
Firefox “do not track”
Firefox “tracking protection”
GTM
Pass
Pass
Fail
On page
Pass
Pass
Fail
GTM + renamed script & function
Pass
Pass
Fail
On page + renamed script & function
Pass
Pass
Fail
Again, it doesn’t seem that the tweaked setups are doing much work for us here.
Lost data due to “do not track”: <1%
Only Firefox Quantum’s “Tracking Protection,” introduced in February, had any effect on our trackers. Firefox has a 5% market share, but Tracking Protection is not enabled by default. The launch of this feature had no effect on the trend for Firefox traffic on Distilled.net.
Reason 3: Filters
It’s a bit of an obvious one, but filters you’ve set up in your analytics might intentionally or unintentionally reduce your reported traffic levels.
For example, a filter excluding certain niche screen resolutions that you believe to be mostly bots, or internal traffic, will obviously cause your setup to underreport slightly.
Lost data due to filters: ???
Impact is hard to estimate, as setup will obviously vary on a site-by site-basis. I do recommend having a duplicate, unfiltered “master” view in case you realize too late you’ve lost something you didn’t intend to.
Reason 4: GTM vs. on-page vs. misplaced on-page
Google Tag Manager has become an increasingly popular way of implementing analytics in recent years, due to its increased flexibility and the ease of making changes. However, I’ve long noticed that it can tend to underreport vs. on-page setups.
I was also curious about what would happen if you didn’t follow Google’s guidelines in setting up on-page code.
By combining my numbers with numbers from my colleague Dom Woodman’s site (you’re welcome for the link, Dom), which happens to use a Drupal analytics add-on as well as GTM, I was able to see the difference between Google Tag Manager and misplaced on-page code (right at the bottom of the <body> tag) I then weighted this against my own Google Tag Manager data to get an overall picture of all 5 setups.
Effect of GTM and misplaced on-page code
Traffic as a percentage of baseline (standard Google Tag Manager implementation):
Google Tag Manager
Modified & Google Tag Manager
On-Page Code In <head>
Modified & On-Page Code In <head>
On-Page Code Misplaced In <Body>
Chrome
100.00%
98.75%
100.77%
99.80%
94.75%
Safari
100.00%
99.42%
100.55%
102.08%
82.69%
Firefox
100.00%
99.71%
101.16%
101.45%
90.68%
Internet Explorer
100.00%
80.06%
112.31%
113.37%
77.18%
There are a few main takeaways here:
On-page code generally reports more traffic than GTM
Modified code is generally within a margin of error, apart from modified GTM code on Internet Explorer (see note below)
Misplaced analytics code will cost you up to a third of your traffic vs. properly implemented on-page code, depending on browser (!)
The customized setups, which are designed to get more traffic by evading ad blockers, are doing nothing of the sort.
It’s worth noting also that the customized implementations actually got less traffic than the standard ones. For the on-page code, this is within the margin of error, but for Google Tag Manager, there’s another reason — because I used unfiltered profiles for the comparison, there’s a lot of bot spam in the main profile, which primarily masquerades as Internet Explorer. Our main profile is by far the most spammed, and also acting as the baseline here, so the difference between on-page code and Google Tag Manager is probably somewhat larger than what I’m reporting.
I also split the data by mobile, out of curiosity:
Traffic as a percentage of baseline (standard Google Tag Manager implementation):
Google Tag Manager
Modified & Google Tag Manager
On-Page Code In <head>
Modified & On-Page Code In <head>
On-Page Code Misplaced In <Body>
Desktop
100.00%
98.31%
100.97%
100.89%
93.47%
Mobile
100.00%
97.00%
103.78%
100.42%
89.87%
Tablet
100.00%
97.68%
104.20%
102.43%
88.13%
The further takeaway here seems to be that mobile browsers, like Internet Explorer, can struggle with Google Tag Manager.
Lost data due to GTM: 1–5%
Google Tag Manager seems to cost you a varying amount depending on what make-up of browsers and devices use your site. On Distilled.net, the difference is around 1.7%; however, we have an unusually desktop-heavy and tech-savvy audience (not much Internet Explorer!). Depending on vertical, this could easily swell to the 5% range.
Lost data due to misplaced on-page code: ~10%
On Teflsearch.com, the impact of misplaced on-page code was around 7.5%, vs Google Tag Manager. Keeping in mind that Google Tag Manager itself underreports, the total loss could easily be in the 10% range.
Bonus round: Missing data from channels
I’ve focused above on areas where you might be missing data altogether. However, there are also lots of ways in which data can be misrepresented, or detail can be missing. I’ll cover these more briefly, but the main issues are dark traffic and attribution.
Dark traffic
Dark traffic is direct traffic that didn’t really come via direct — which is generally becoming more and more common. Typical causes are:
Untagged campaigns in email
Untagged campaigns in apps (especially Facebook, Twitter, etc.)
Misrepresented organic
Data sent from botched tracking implementations (which can also appear as self-referrals)
It’s also worth noting the trend towards genuinely direct traffic that would historically have been organic. For example, due to increasingly sophisticated browser autocompletes, cross-device history, and so on, people end up “typing” a URL that they’d have searched for historically.
Attribution
I’ve written about this in more detail here, but in general, a session in Google Analytics (and any other platform) is a fairly arbitrary construct — you might think it’s obvious how a group of hits should be grouped into one or more sessions, but in fact, the process relies on a number of fairly questionable assumptions. In particular, it’s worth noting that Google Analytics generally attributes direct traffic (including dark traffic) to the previous non-direct source, if one exists.
Discussion
I was quite surprised by some of my own findings when researching this post, but I’m sure I didn’t get everything. Can you think of any other ways in which data can end up missing from analytics?
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read!
from Blogger https://ift.tt/2J9fNey via SW Unlimited
0 notes
Text
How Much Data Is Missing from Analytics? And Other Analytics Black Holes
Posted by Tom.Capper
If you’ve ever compared two analytics implementations on the same site, or compared your analytics with what your business is reporting in sales, you’ve probably noticed that things don’t always match up. In this post, I’ll explain why data is missing from your web analytics platforms and how large the impact could be. Some of the issues I cover are actually quite easily addressed, and have a decent impact on traffic — there’s never been an easier way to hit your quarterly targets. ;)
I’m going to focus on GA (Google Analytics), as it's the most commonly used provider, but most on-page analytics platforms have the same issues. Platforms that rely on server logs do avoid some issues but are fairly rare, so I won’t cover them in any depth.
Side note: Our test setup (multiple trackers & customized GA)
On Distilled.net, we have a standard Google Analytics property running from an HTML tag in GTM (Google Tag Manager). In addition, for the last two years, I’ve been running three extra concurrent Google Analytics implementations, designed to measure discrepancies between different configurations.
(If you’re just interested in my findings, you can skip this section, but if you want to hear more about the methodology, continue reading. Similarly, don’t worry if you don’t understand some of the detail here — the results are easier to follow.)
Two of these extra implementations — one in Google Tag Manager and one on page — run locally hosted, renamed copies of the Google Analytics JavaScript file (e.g. www.distilled.net/static/js/au3.js, instead of www.google-analytics.com/analytics.js) to make them harder to spot for ad blockers. I also used renamed JavaScript functions (“tcap” and “Buffoon,” rather than the standard “ga”) and renamed trackers (“FredTheUnblockable” and “AlbertTheImmutable”) to avoid having duplicate trackers (which can often cause issues).
This was originally inspired by 2016-era best practice on how to get your Google Analytics setup past ad blockers. I can’t find the original article now, but you can see a very similar one from 2017 here.
Lastly, we have (“DianaTheIndefatigable”), which just has a renamed tracker, but uses the standard code otherwise and is implemented on-page. This is to complete the set of all combinations of modified and unmodified GTM and on-page trackers.
Two of Distilled’s modified on-page trackers, as seen on https://www.distilled.net/
Overall, this table summarizes our setups:
Tracker
Renamed function?
GTM or on-page?
Locally hosted JavaScript file?
Default
No
GTM HTML tag
No
FredTheUnblockable
Yes - “tcap”
GTM HTML tag
Yes
AlbertTheImmutable
Yes - “buffoon”
On page
Yes
DianaTheIndefatigable
No
On page
No
I tested their functionality in various browser/ad-block environments by watching for the pageviews appearing in browser developer tools:
Reason 1: Ad Blockers
Ad blockers, primarily as browser extensions, have been growing in popularity for some time now. Primarily this has been to do with users looking for better performance and UX on ad-laden sites, but in recent years an increased emphasis on privacy has also crept in, hence the possibility of analytics blocking.
Effect of ad blockers
Some ad blockers block web analytics platforms by default, others can be configured to do so. I tested Distilled’s site with Adblock Plus and uBlock Origin, two of the most popular ad-blocking desktop browser addons, but it’s worth noting that ad blockers are increasingly prevalent on smartphones, too.
Here’s how Distilled’s setups fared:
(All numbers shown are from April 2018)
Setup
Vs. Adblock
Vs. Adblock with “EasyPrivacy” enabled
Vs. uBlock Origin
GTM
Pass
Fail
Fail
On page
Pass
Fail
Fail
GTM + renamed script & function
Pass
Fail
Fail
On page + renamed script & function
Pass
Fail
Fail
Seems like those tweaked setups didn’t do much!
Lost data due to ad blockers: ~10%
Ad blocker usage can be in the 15–25% range depending on region, but many of these installs will be default setups of AdBlock Plus, which as we’ve seen above, does not block tracking. Estimates of AdBlock Plus’s market share among ad blockers vary from 50–70%, with more recent reports tending more towards the former. So, if we assume that at most 50% of installed ad blockers block analytics, that leaves your exposure at around 10%.
Reason 2: Browser “do not track”
This is another privacy motivated feature, this time of browsers themselves. You can enable it in the settings of most current browsers. It’s not compulsory for sites or platforms to obey the “do not track” request, but Firefox offers a stronger feature under the same set of options, which I decided to test as well.
Effect of “do not track”
Most browsers now offer the option to send a “Do not track” message. I tested the latest releases of Firefox & Chrome for Windows 10.
Setup
Chrome “do not track”
Firefox “do not track”
Firefox “tracking protection”
GTM
Pass
Pass
Fail
On page
Pass
Pass
Fail
GTM + renamed script & function
Pass
Pass
Fail
On page + renamed script & function
Pass
Pass
Fail
Again, it doesn’t seem that the tweaked setups are doing much work for us here.
Lost data due to “do not track”: <1%
Only Firefox Quantum’s “Tracking Protection,” introduced in February, had any effect on our trackers. Firefox has a 5% market share, but Tracking Protection is not enabled by default. The launch of this feature had no effect on the trend for Firefox traffic on Distilled.net.
Reason 3: Filters
It’s a bit of an obvious one, but filters you’ve set up in your analytics might intentionally or unintentionally reduce your reported traffic levels.
For example, a filter excluding certain niche screen resolutions that you believe to be mostly bots, or internal traffic, will obviously cause your setup to underreport slightly.
Lost data due to filters: ???
Impact is hard to estimate, as setup will obviously vary on a site-by site-basis. I do recommend having a duplicate, unfiltered “master” view in case you realize too late you’ve lost something you didn’t intend to.
Reason 4: GTM vs. on-page vs. misplaced on-page
Google Tag Manager has become an increasingly popular way of implementing analytics in recent years, due to its increased flexibility and the ease of making changes. However, I’ve long noticed that it can tend to underreport vs. on-page setups.
I was also curious about what would happen if you didn’t follow Google’s guidelines in setting up on-page code.
By combining my numbers with numbers from my colleague Dom Woodman’s site (you’re welcome for the link, Dom), which happens to use a Drupal analytics add-on as well as GTM, I was able to see the difference between Google Tag Manager and misplaced on-page code (right at the bottom of the <body> tag) I then weighted this against my own Google Tag Manager data to get an overall picture of all 5 setups.
Effect of GTM and misplaced on-page code
Traffic as a percentage of baseline (standard Google Tag Manager implementation):
Google Tag Manager
Modified & Google Tag Manager
On-Page Code In <head>
Modified & On-Page Code In <head>
On-Page Code Misplaced In <Body>
Chrome
100.00%
98.75%
100.77%
99.80%
94.75%
Safari
100.00%
99.42%
100.55%
102.08%
82.69%
Firefox
100.00%
99.71%
101.16%
101.45%
90.68%
Internet Explorer
100.00%
80.06%
112.31%
113.37%
77.18%
There are a few main takeaways here:
On-page code generally reports more traffic than GTM
Modified code is generally within a margin of error, apart from modified GTM code on Internet Explorer (see note below)
Misplaced analytics code will cost you up to a third of your traffic vs. properly implemented on-page code, depending on browser (!)
The customized setups, which are designed to get more traffic by evading ad blockers, are doing nothing of the sort.
It’s worth noting also that the customized implementations actually got less traffic than the standard ones. For the on-page code, this is within the margin of error, but for Google Tag Manager, there’s another reason — because I used unfiltered profiles for the comparison, there’s a lot of bot spam in the main profile, which primarily masquerades as Internet Explorer. Our main profile is by far the most spammed, and also acting as the baseline here, so the difference between on-page code and Google Tag Manager is probably somewhat larger than what I’m reporting.
I also split the data by mobile, out of curiosity:
Traffic as a percentage of baseline (standard Google Tag Manager implementation):
Google Tag Manager
Modified & Google Tag Manager
On-Page Code In <head>
Modified & On-Page Code In <head>
On-Page Code Misplaced In <Body>
Desktop
100.00%
98.31%
100.97%
100.89%
93.47%
Mobile
100.00%
97.00%
103.78%
100.42%
89.87%
Tablet
100.00%
97.68%
104.20%
102.43%
88.13%
The further takeaway here seems to be that mobile browsers, like Internet Explorer, can struggle with Google Tag Manager.
Lost data due to GTM: 1–5%
Google Tag Manager seems to cost you a varying amount depending on what make-up of browsers and devices use your site. On Distilled.net, the difference is around 1.7%; however, we have an unusually desktop-heavy and tech-savvy audience (not much Internet Explorer!). Depending on vertical, this could easily swell to the 5% range.
Lost data due to misplaced on-page code: ~10%
On Teflsearch.com, the impact of misplaced on-page code was around 7.5%, vs Google Tag Manager. Keeping in mind that Google Tag Manager itself underreports, the total loss could easily be in the 10% range.
Bonus round: Missing data from channels
I’ve focused above on areas where you might be missing data altogether. However, there are also lots of ways in which data can be misrepresented, or detail can be missing. I’ll cover these more briefly, but the main issues are dark traffic and attribution.
Dark traffic
Dark traffic is direct traffic that didn’t really come via direct — which is generally becoming more and more common. Typical causes are:
Untagged campaigns in email
Untagged campaigns in apps (especially Facebook, Twitter, etc.)
Misrepresented organic
Data sent from botched tracking implementations (which can also appear as self-referrals)
It’s also worth noting the trend towards genuinely direct traffic that would historically have been organic. For example, due to increasingly sophisticated browser autocompletes, cross-device history, and so on, people end up “typing” a URL that they’d have searched for historically.
Attribution
I’ve written about this in more detail here, but in general, a session in Google Analytics (and any other platform) is a fairly arbitrary construct — you might think it’s obvious how a group of hits should be grouped into one or more sessions, but in fact, the process relies on a number of fairly questionable assumptions. In particular, it’s worth noting that Google Analytics generally attributes direct traffic (including dark traffic) to the previous non-direct source, if one exists.
Discussion
I was quite surprised by some of my own findings when researching this post, but I’m sure I didn’t get everything. Can you think of any other ways in which data can end up missing from analytics?
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read!
https://ift.tt/2LCPWKo
0 notes
Text
How Much Data Is Missing from Analytics? And Other Analytics Black Holes
Posted by Tom.Capper
If you’ve ever compared two analytics implementations on the same site, or compared your analytics with what your business is reporting in sales, you’ve probably noticed that things don’t always match up. In this post, I’ll explain why data is missing from your web analytics platforms and how large the impact could be. Some of the issues I cover are actually quite easily addressed, and have a decent impact on traffic — there’s never been an easier way to hit your quarterly targets. ;)
I’m going to focus on GA (Google Analytics), as it's the most commonly used provider, but most on-page analytics platforms have the same issues. Platforms that rely on server logs do avoid some issues but are fairly rare, so I won’t cover them in any depth.
Side note: Our test setup (multiple trackers & customized GA)
On Distilled.net, we have a standard Google Analytics property running from an HTML tag in GTM (Google Tag Manager). In addition, for the last two years, I’ve been running three extra concurrent Google Analytics implementations, designed to measure discrepancies between different configurations.
(If you’re just interested in my findings, you can skip this section, but if you want to hear more about the methodology, continue reading. Similarly, don’t worry if you don’t understand some of the detail here — the results are easier to follow.)
Two of these extra implementations — one in Google Tag Manager and one on page — run locally hosted, renamed copies of the Google Analytics JavaScript file (e.g. www.distilled.net/static/js/au3.js, instead of www.google-analytics.com/analytics.js) to make them harder to spot for ad blockers. I also used renamed JavaScript functions (“tcap” and “Buffoon,” rather than the standard “ga”) and renamed trackers (“FredTheUnblockable” and “AlbertTheImmutable”) to avoid having duplicate trackers (which can often cause issues).
This was originally inspired by 2016-era best practice on how to get your Google Analytics setup past ad blockers. I can’t find the original article now, but you can see a very similar one from 2017 here.
Lastly, we have (“DianaTheIndefatigable”), which just has a renamed tracker, but uses the standard code otherwise and is implemented on-page. This is to complete the set of all combinations of modified and unmodified GTM and on-page trackers.
Two of Distilled’s modified on-page trackers, as seen on https://www.distilled.net/
Overall, this table summarizes our setups:
Tracker
Renamed function?
GTM or on-page?
Locally hosted JavaScript file?
Default
No
GTM HTML tag
No
FredTheUnblockable
Yes - “tcap”
GTM HTML tag
Yes
AlbertTheImmutable
Yes - “buffoon”
On page
Yes
DianaTheIndefatigable
No
On page
No
I tested their functionality in various browser/ad-block environments by watching for the pageviews appearing in browser developer tools:
Reason 1: Ad Blockers
Ad blockers, primarily as browser extensions, have been growing in popularity for some time now. Primarily this has been to do with users looking for better performance and UX on ad-laden sites, but in recent years an increased emphasis on privacy has also crept in, hence the possibility of analytics blocking.
Effect of ad blockers
Some ad blockers block web analytics platforms by default, others can be configured to do so. I tested Distilled’s site with Adblock Plus and uBlock Origin, two of the most popular ad-blocking desktop browser addons, but it’s worth noting that ad blockers are increasingly prevalent on smartphones, too.
Here’s how Distilled’s setups fared:
(All numbers shown are from April 2018)
Setup
Vs. Adblock
Vs. Adblock with “EasyPrivacy” enabled
Vs. uBlock Origin
GTM
Pass
Fail
Fail
On page
Pass
Fail
Fail
GTM + renamed script & function
Pass
Fail
Fail
On page + renamed script & function
Pass
Fail
Fail
Seems like those tweaked setups didn’t do much!
Lost data due to ad blockers: ~10%
Ad blocker usage can be in the 15–25% range depending on region, but many of these installs will be default setups of AdBlock Plus, which as we’ve seen above, does not block tracking. Estimates of AdBlock Plus’s market share among ad blockers vary from 50–70%, with more recent reports tending more towards the former. So, if we assume that at most 50% of installed ad blockers block analytics, that leaves your exposure at around 10%.
Reason 2: Browser “do not track”
This is another privacy motivated feature, this time of browsers themselves. You can enable it in the settings of most current browsers. It’s not compulsory for sites or platforms to obey the “do not track” request, but Firefox offers a stronger feature under the same set of options, which I decided to test as well.
Effect of “do not track”
Most browsers now offer the option to send a “Do not track” message. I tested the latest releases of Firefox & Chrome for Windows 10.
Setup
Chrome “do not track”
Firefox “do not track”
Firefox “tracking protection”
GTM
Pass
Pass
Fail
On page
Pass
Pass
Fail
GTM + renamed script & function
Pass
Pass
Fail
On page + renamed script & function
Pass
Pass
Fail
Again, it doesn’t seem that the tweaked setups are doing much work for us here.
Lost data due to “do not track”: <1%
Only Firefox Quantum’s “Tracking Protection,” introduced in February, had any effect on our trackers. Firefox has a 5% market share, but Tracking Protection is not enabled by default. The launch of this feature had no effect on the trend for Firefox traffic on Distilled.net.
Reason 3: Filters
It’s a bit of an obvious one, but filters you’ve set up in your analytics might intentionally or unintentionally reduce your reported traffic levels.
For example, a filter excluding certain niche screen resolutions that you believe to be mostly bots, or internal traffic, will obviously cause your setup to underreport slightly.
Lost data due to filters: ???
Impact is hard to estimate, as setup will obviously vary on a site-by site-basis. I do recommend having a duplicate, unfiltered “master” view in case you realize too late you’ve lost something you didn’t intend to.
Reason 4: GTM vs. on-page vs. misplaced on-page
Google Tag Manager has become an increasingly popular way of implementing analytics in recent years, due to its increased flexibility and the ease of making changes. However, I’ve long noticed that it can tend to underreport vs. on-page setups.
I was also curious about what would happen if you didn’t follow Google’s guidelines in setting up on-page code.
By combining my numbers with numbers from my colleague Dom Woodman’s site (you’re welcome for the link, Dom), which happens to use a Drupal analytics add-on as well as GTM, I was able to see the difference between Google Tag Manager and misplaced on-page code (right at the bottom of the <body> tag) I then weighted this against my own Google Tag Manager data to get an overall picture of all 5 setups.
Effect of GTM and misplaced on-page code
Traffic as a percentage of baseline (standard Google Tag Manager implementation):
Google Tag Manager
Modified & Google Tag Manager
On-Page Code In <head>
Modified & On-Page Code In <head>
On-Page Code Misplaced In <Body>
Chrome
100.00%
98.75%
100.77%
99.80%
94.75%
Safari
100.00%
99.42%
100.55%
102.08%
82.69%
Firefox
100.00%
99.71%
101.16%
101.45%
90.68%
Internet Explorer
100.00%
80.06%
112.31%
113.37%
77.18%
There are a few main takeaways here:
On-page code generally reports more traffic than GTM
Modified code is generally within a margin of error, apart from modified GTM code on Internet Explorer (see note below)
Misplaced analytics code will cost you up to a third of your traffic vs. properly implemented on-page code, depending on browser (!)
The customized setups, which are designed to get more traffic by evading ad blockers, are doing nothing of the sort.
It’s worth noting also that the customized implementations actually got less traffic than the standard ones. For the on-page code, this is within the margin of error, but for Google Tag Manager, there’s another reason — because I used unfiltered profiles for the comparison, there’s a lot of bot spam in the main profile, which primarily masquerades as Internet Explorer. Our main profile is by far the most spammed, and also acting as the baseline here, so the difference between on-page code and Google Tag Manager is probably somewhat larger than what I’m reporting.
I also split the data by mobile, out of curiosity:
Traffic as a percentage of baseline (standard Google Tag Manager implementation):
Google Tag Manager
Modified & Google Tag Manager
On-Page Code In <head>
Modified & On-Page Code In <head>
On-Page Code Misplaced In <Body>
Desktop
100.00%
98.31%
100.97%
100.89%
93.47%
Mobile
100.00%
97.00%
103.78%
100.42%
89.87%
Tablet
100.00%
97.68%
104.20%
102.43%
88.13%
The further takeaway here seems to be that mobile browsers, like Internet Explorer, can struggle with Google Tag Manager.
Lost data due to GTM: 1–5%
Google Tag Manager seems to cost you a varying amount depending on what make-up of browsers and devices use your site. On Distilled.net, the difference is around 1.7%; however, we have an unusually desktop-heavy and tech-savvy audience (not much Internet Explorer!). Depending on vertical, this could easily swell to the 5% range.
Lost data due to misplaced on-page code: ~10%
On Teflsearch.com, the impact of misplaced on-page code was around 7.5%, vs Google Tag Manager. Keeping in mind that Google Tag Manager itself underreports, the total loss could easily be in the 10% range.
Bonus round: Missing data from channels
I’ve focused above on areas where you might be missing data altogether. However, there are also lots of ways in which data can be misrepresented, or detail can be missing. I’ll cover these more briefly, but the main issues are dark traffic and attribution.
Dark traffic
Dark traffic is direct traffic that didn’t really come via direct — which is generally becoming more and more common. Typical causes are:
Untagged campaigns in email
Untagged campaigns in apps (especially Facebook, Twitter, etc.)
Misrepresented organic
Data sent from botched tracking implementations (which can also appear as self-referrals)
It’s also worth noting the trend towards genuinely direct traffic that would historically have been organic. For example, due to increasingly sophisticated browser autocompletes, cross-device history, and so on, people end up “typing” a URL that they’d have searched for historically.
Attribution
I’ve written about this in more detail here, but in general, a session in Google Analytics (and any other platform) is a fairly arbitrary construct — you might think it’s obvious how a group of hits should be grouped into one or more sessions, but in fact, the process relies on a number of fairly questionable assumptions. In particular, it’s worth noting that Google Analytics generally attributes direct traffic (including dark traffic) to the previous non-direct source, if one exists.
Discussion
I was quite surprised by some of my own findings when researching this post, but I’m sure I didn’t get everything. Can you think of any other ways in which data can end up missing from analytics?
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read!
https://ift.tt/2LCPWKo
0 notes