#etl course snowflake
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Average visit duration of Tumblr.com is 10 mins and 25 secs.
Text
SnowFlake Training in Hyderabad
Master SnowFlake with RS Trainings: The Premier Training Institute in Hyderabad
In the era of big data and advanced analytics, Snowflake has become a game-changer for data warehousing. Its unique architecture and cloud-native capabilities enable organizations to efficiently manage and analyze vast amounts of data. If you are looking to gain expertise in Snowflake, RS Trainings in Hyderabad is your best choice. Recognized as the top Snowflake training institute, RS Trainings offers unparalleled instruction by industry IT experts.

Why Snowflake?
Snowflake is a revolutionary cloud-based data warehousing solution known for its scalability, flexibility, and performance. It allows organizations to seamlessly store, process, and analyze data without the complexity and overhead of traditional data warehouses. Key benefits include:
Seamless Data Integration: Easily integrates with various data sources and platforms.
Scalability: Automatically scales storage and compute resources to meet demand.
Performance: Delivers fast query performance, even with large datasets.
Cost Efficiency: Pay-as-you-go pricing model ensures cost-effective data management.
Why Choose RS Trainings?
RS Trainings is the leading institute for Snowflake training in Hyderabad, offering a comprehensive learning experience designed to equip you with the skills needed to excel in the field of data warehousing. Here’s why RS Trainings stands out:
Industry-Experienced Trainers
Our Snowflake training is delivered by seasoned industry professionals with extensive experience in data warehousing and Snowflake. They bring practical insights and hands-on knowledge, ensuring you gain real-world expertise.
Comprehensive Curriculum
Our Snowflake training program covers all key aspects of the platform, including:
Introduction to Snowflake: Understand the core concepts and architecture.
Data Loading and Integration: Learn to load and integrate data from various sources.
Querying and Performance Tuning: Master SQL querying and performance optimization techniques.
Data Sharing and Security: Explore data sharing capabilities and best practices for data security.
Real-World Projects: Gain hands-on experience through real-world projects and case studies.
Hands-On Learning
At RS Trainings, we emphasize practical learning. Our state-of-the-art labs and real-time project work ensure you get hands-on experience with Snowflake, making you job-ready from day one.
Flexible Learning Options
We offer flexible training schedules to accommodate the diverse needs of our students. Whether you prefer classroom training, online sessions, or weekend batches, we have options that fit your lifestyle and commitments.
Career Support
Our commitment to your success goes beyond training. We provide comprehensive career support, including resume building, interview preparation, and job placement assistance. Our strong industry connections help you land lucrative job opportunities.
Enroll in RS Trainings Today!
Choosing the right training institute is crucial for your career advancement. With RS Trainings, you gain access to the best Snowflake training in Hyderabad, guided by industry experts. Our comprehensive curriculum, hands-on approach, and robust career support make us the preferred choice for aspiring data professionals.
Take the first step towards mastering Snowflake and advancing your career. Enroll in RS Trainings today, Hyderabad's leading training institute for Snowflake, and transform your data warehousing skills.
#snowflake training in Hyderabad#online snowflake training#snowflake training institute in Hyderabad#snowflake online course#snowflake training center#snowflake course training#etl course snowflake
0 notes
Text
How to Ace a Data Engineering Interview: Tips & Common Questions
The demand for data engineers is growing rapidly, and landing a job in this field requires thorough preparation. If you're aspiring to become a data engineer, knowing what to expect in an interview can help you stand out. Whether you're preparing for your first data engineering role or aiming for a more advanced position, this guide will provide essential tips and common interview questions to help you succeed. If you're in Bangalore, enrolling in a Data Engineering Course in Hebbal, Data Engineering Course in Indira Nagar, or Data Engineering Course in Jayanagar can significantly boost your chances of success by providing structured learning and hands-on experience.
Understanding the Data Engineering Interview Process
Data engineering interviews typically consist of multiple rounds, including:
Screening Round – A recruiter assesses your background and experience.
Technical Round – Tests your knowledge of SQL, databases, data pipelines, and cloud computing.
Coding Challenge – A take-home or live coding test to evaluate your problem-solving abilities.
System Design Interview – Focuses on designing scalable data architectures.
Behavioral Round – Assesses your teamwork, problem-solving approach, and communication skills.
Essential Tips to Ace Your Data Engineering Interview
1. Master SQL and Database Concepts
SQL is the backbone of data engineering. Be prepared to write complex queries and optimize database performance. Some important topics include:
Joins, CTEs, and Window Functions
Indexing and Query Optimization
Data Partitioning and Sharding
Normalization and Denormalization
Practice using platforms like LeetCode, HackerRank, and Mode Analytics to refine your SQL skills. If you need structured training, consider a Data Engineering Course in Indira Nagar for in-depth SQL and database learning.
2. Strengthen Your Python and Coding Skills
Most data engineering roles require Python expertise. Be comfortable with:
Pandas and NumPy for data manipulation
Writing efficient ETL scripts
Automating workflows with Python
Additionally, learning Scala and Java can be beneficial, especially for working with Apache Spark.
3. Gain Proficiency in Big Data Technologies
Many companies deal with large-scale data processing. Be prepared to discuss and work with:
Hadoop and Spark for distributed computing
Apache Airflow for workflow orchestration
Kafka for real-time data streaming
Enrolling in a Data Engineering Course in Jayanagar can provide hands-on experience with these technologies.
4. Understand Data Pipeline Architecture and ETL Processes
Expect questions on designing scalable and efficient ETL pipelines. Key topics include:
Extracting data from multiple sources
Transforming and cleaning data efficiently
Loading data into warehouses like Redshift, Snowflake, or BigQuery
5. Familiarize Yourself with Cloud Platforms
Most data engineering roles require cloud computing expertise. Gain hands-on experience with:
AWS (S3, Glue, Redshift, Lambda)
Google Cloud Platform (BigQuery, Dataflow)
Azure (Data Factory, Synapse Analytics)
A Data Engineering Course in Hebbal can help you get hands-on experience with cloud-based tools.
6. Practice System Design and Scalability
Data engineering interviews often include system design questions. Be prepared to:
Design a scalable data warehouse architecture
Optimize data processing pipelines
Choose between batch and real-time data processing
7. Prepare for Behavioral Questions
Companies assess your ability to work in a team, handle challenges, and solve problems. Practice answering:
Describe a challenging data engineering project you worked on.
How do you handle conflicts in a team?
How do you ensure data quality in a large dataset?
Common Data Engineering Interview Questions
Here are some frequently asked questions:
SQL Questions:
Write a SQL query to find duplicate records in a table.
How would you optimize a slow-running query?
Explain the difference between partitioning and indexing.
Coding Questions: 4. Write a Python script to process a large CSV file efficiently. 5. How would you implement a data deduplication algorithm? 6. Explain how you would design an ETL pipeline for a streaming dataset.
Big Data & Cloud Questions: 7. How does Apache Kafka handle message durability? 8. Compare Hadoop and Spark for large-scale data processing. 9. How would you choose between AWS Redshift and Google BigQuery?
System Design Questions: 10. Design a data pipeline for an e-commerce company that processes user activity logs. 11. How would you architect a real-time recommendation system? 12. What are the best practices for data governance in a data lake?
Final Thoughts
Acing a data engineering interview requires a mix of technical expertise, problem-solving skills, and practical experience. By focusing on SQL, coding, big data tools, and cloud computing, you can confidently approach your interview. If you’re looking for structured learning and practical exposure, enrolling in a Data Engineering Course in Hebbal, Data Engineering Course in Indira Nagar, or Data Engineering Course in Jayanagar can provide the necessary training to excel in your interviews and secure a high-paying data engineering job.
0 notes
Text
ETL vs. ELT: Which Approach is Right for Your Business?

Data is one of the most valuable assets that your business can have to move mountains in the competitive landscape. The way this data is processed, transformed, and put to use is what impacts decision making, efficiency, and scalability in modern SaaS businesses.
Two most commonly regarded data integration methods include ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform). Choosing the right approach entirely depends on your business needs, data infrastructure, and analytic goals. Therefore, to hire data engineers skilled in either of these approaches, you need to be well–versed with the distinctions. Only then can you build a team that can optimize data pipelines effectively. How can you miss out on the promising effect of real-time insights and data accuracy in driving growth for your SaaS business?
Choosing the Right Data Processing Approach to Optimize Performance and Scalability
Understanding ETL and ELT
Before being loaded into a data warehouse, data is retrieved from various sources and converted into the necessary format using ETL (Extract, Transform, Load). Ideal for companies with compliance requirements and structured data.
Before being transformed, data is extracted and loaded into a data warehouse using ELT (Extract, Load, Transform). This method is appropriate for managing substantial amounts of raw data. It fits in nicely with contemporary cloud-based systems.
ELT is frequently the go-to option for SaaS businesses where scalability is crucial because of its effective handling of large data
Hiring backend developers skilled in optimizing ELT pipelines for improved scalability could be advantageous if your business works with big datasets. 2. When to choose ETL
To hire ETL developers is the best course of action if:
You deal with structured data that must adhere to compliance standards.
Your company needs data that has been cleaned and pre-processed before being stored.
Instead of using cloud-based solutions, you rely on on-premise databases.
ETL is preferred by several sectors, including healthcare and banking, for data security and regulatory compliance. 3. When to choose ELT
ELT works well when:
Your company handles huge, unstructured datasets.
You depend on cloud storage and contemporary data warehouses like Google BigQuery or Snowflake.
To make decisions more quickly, you need real-time analytics.
ELT enables faster data processing, which facilitates user behaviour analysis and product feature optimization for SaaS organizations. 4. The role of ETL developers in data integration
Hiring the correct experts is essential, regardless of whether your company decides to use ETL or ELT. Competent ETL developers are able to:
Create and enhance workflows for data transformation.
Assure reporting accuracy and consistency of data.
To increase efficiency, put automated data pipelines into place.
Conclusion
Both ETL and ELT offer distinct benefits, and your company's requirements will determine which option is best for you. To hire ETL developers is a good choice if you're working with structured data and need to adhere to tight regulations. ELT is the superior option, nevertheless, if scalability and real-time analytics are top concerns. Building a competent data team will guarantee seamless data operations.
0 notes
Text
What You Will Learn in a Snowflake Online Course

Snowflake is a cutting-edge cloud-based data platform that provides robust solutions for data warehousing, analytics, and cloud computing. As businesses increasingly rely on big data, professionals skilled in Snowflake are in high demand. If you are considering Snowflake training, enrolling in a Snowflake online course can help you gain in-depth knowledge and practical expertise. In this blog, we will explore what you will learn in a Snowflake training online program and how AccentFuture can guide you in mastering this powerful platform.
Overview of Snowflake Training Modules
A Snowflake course online typically covers several key modules that help learners understand the platform’s architecture and functionalities. Below are the core components of Snowflake training:
Introduction to Snowflake : Understand the basics of Snowflake, including its cloud-native architecture, key features, and benefits over traditional data warehouses.
Snowflake Setup and Configuration : Learn how to set up a Snowflake account, configure virtual warehouses, and optimize performance.
Data Loading and Unloading : Gain knowledge about loading data into Snowflake from various sources and exporting data for further analysis.
Snowflake SQL : Master SQL commands in Snowflake, including data querying, transformation, and best practices for performance tuning.
Data Warehousing Concepts : Explore data storage, schema design, and data modeling within Snowflake.
Security and Access Control : Understand how to manage user roles, data encryption, and compliance within Snowflake.
Performance Optimization : Learn techniques to optimize queries, manage costs, and enhance scalability in Snowflake.
Integration with BI Tools : Explore how Snowflake integrates with business intelligence (BI) tools like Tableau, Power BI, and Looker.
These modules ensure that learners acquire a holistic understanding of Snowflake and its applications in real-world scenarios.
Hands-on Practice with Real-World Snowflake Projects
One of the most crucial aspects of a Snowflake online training program is hands-on experience. Theoretical knowledge alone is not enough; applying concepts through real-world projects is essential for skill development.
By enrolling in a Snowflake course, you will work on industry-relevant projects that involve:
Data migration : Transferring data from legacy databases to Snowflake.
Real-time analytics : Processing large datasets and generating insights using Snowflake’s advanced query capabilities.
Building data pipelines : Creating ETL (Extract, Transform, Load) workflows using Snowflake and cloud platforms.
Performance tuning : Identifying and resolving bottlenecks in Snowflake queries to improve efficiency.
Practical exposure ensures that you can confidently apply your Snowflake skills in real-world business environments.
How AccentFuture Helps Learners Master Snowflake SQL, Data Warehousing, and Cloud Computing
AccentFuture is committed to providing the best Snowflake training with a structured curriculum, expert instructors, and hands-on projects. Here’s how AccentFuture ensures a seamless learning experience:
Comprehensive Course Content : Our Snowflake online course covers all essential modules, from basics to advanced concepts.
Expert Trainers : Learn from industry professionals with years of experience in Snowflake and cloud computing.
Live and Self-Paced Learning : Choose between live instructor-led sessions or self-paced learning modules based on your convenience.
Real-World Case Studies : Work on real-time projects to enhance practical knowledge.
Certification Guidance : Get assistance in preparing for Snowflake certification exams.
24/7 Support : Access to a dedicated support team to clarify doubts and ensure uninterrupted learning.
With AccentFuture’s structured learning approach, you will gain expertise in Snowflake SQL, data warehousing, and cloud computing, making you job-ready.
Importance of Certification in Snowflake Training Online
A Snowflake certification validates your expertise and enhances your career prospects. Employers prefer certified professionals as they demonstrate proficiency in using Snowflake for data management and analytics. Here’s why certification is crucial:
Career Advancement : A certified Snowflake professional is more likely to secure high-paying job roles in data engineering and analytics.
Industry Recognition : Certification acts as proof of your skills and knowledge in Snowflake.
Competitive Edge : Stand out in the job market with a globally recognized Snowflake credential.
Increased Earning Potential : Certified professionals often earn higher salaries than non-certified counterparts.
By completing a Snowflake course online and obtaining certification, you can position yourself as a valuable asset in the data-driven industry.
Conclusion
Learning Snowflake is essential for professionals seeking expertise in cloud-based data warehousing and analytics. A Snowflake training online course provides in-depth knowledge, hands-on experience, and certification guidance to help you excel in your career. AccentFuture offers the best Snowflake training, equipping learners with the necessary skills to leverage Snowflake’s capabilities effectively.
If you’re ready to take your data skills to the next level, enroll in a Snowflake online course today!
Related Blog: Learning Snowflake is great, but how can you apply your skills in real-world projects? Let’s discuss.
youtube
0 notes
Text
Highlight how the field is evolving in 2025 with AI, automation, and real-time Data Analytics., Get Trained by SLA Consultants India
Data analytics is rapidly evolving, and 2025 marks a new era of AI-driven insights, automation, and real-time decision-making. Businesses are leveraging artificial intelligence (AI), machine learning (ML), and automation to transform how data is collected, processed, and analyzed. If you want to stay ahead in this dynamic field, gaining hands-on training from SLA Consultants India can equip you with the latest tools and techniques.
How Data Analytics is Evolving in 2025
1️⃣ AI & Machine Learning are Enhancing Analytics
AI is no longer just a trend; it is an essential component of data analytics. Data Analyst Course in Delhi
Machine learning algorithms automate data processing, uncover hidden patterns, and improve predictive accuracy.
AI-powered tools like ChatGPT, Bard, and AutoML enable analysts to generate insights faster and more efficiently.
🎯 SLA Consultants India Training Covers: ✅ AI-driven analytics tools & techniques ✅ Machine learning basics for data analysts ✅ Real-world AI-based data projects
2️⃣ Automation is Reducing Manual Efforts
Automation in data analytics eliminates repetitive tasks, improving productivity and efficiency.
Robotic Process Automation (RPA) tools are streamlining data cleaning, transformation, and reporting.
Businesses use automated ETL (Extract, Transform, Load) pipelines to manage large-scale datasets with minimal human intervention. Data Analyst Training in Delhi
🎯 SLA Consultants India Training Covers: ✅ Automating workflows with Python & SQL ✅ ETL processes for data extraction & transformation ✅ Power BI & Tableau automation techniques
3️⃣ Real-Time Data Analytics is Driving Instant Decisions
Companies are shifting towards real-time analytics to respond quickly to market trends and customer behavior.
Streaming analytics tools like Apache Kafka, Spark, and Google BigQuery allow businesses to process live data feeds.
Industries like e-commerce, finance, and healthcare rely on real-time insights to enhance user experiences and optimize operations. Data Analyst Certification in Delhi
🎯 SLA Consultants India Training Covers: ✅ Real-time data processing with Python & SQL ✅ Live dashboard creation using Power BI & Tableau ✅ Implementing real-time analytics in business applications
4️⃣ Cloud-Based Analytics is Becoming the Standard
Cloud platforms like AWS, Microsoft Azure, and Google Cloud provide scalable and flexible data solutions.
Cloud-based analytics reduces infrastructure costs and enables remote collaboration.
Companies use BigQuery, Snowflake, and Databricks for advanced data management.
🎯 SLA Consultants India Training Covers: ✅ Cloud computing & data analytics integration ✅ Hands-on training with cloud-based tools ✅ Data storage & management using SQL databases

Why Choose SLA Consultants India for Data Analytics Training?
🚀 Industry-Focused Curriculum – Learn AI, automation, and real-time analytics 📊 Hands-On Practical Training – Work on real-world datasets and live projects 💼 100% Job Assistance – Get placed in top companies with expert guidance 🎓 Expert Trainers & Certification Support – Master cutting-edge analytics tools
Conclusion
The field of data analytics is rapidly transforming in 2025 with AI, automation, and real-time insights becoming essential skills. To stay ahead in this competitive industry, professionals need up-to-date training on modern tools and technologies. SLA Consultants India provides expert-led training programs that prepare you for the future of data analytics, equipping you with job-ready skills and certification support. Data Analyst Institute in Delhi
Start your journey today and become a future-ready data analyst with SLA Consultants India! For more details Call: +91-8700575874 or Email: [email protected]
#data analyst course in delhi#data analyst training in delhi#data analyst certification in delhi#data analyst institute in delhi
0 notes
Text
ETL Pipelines: How Data Moves from Raw to Insights

Introduction
Businesses collect raw data from various sources.
ETL (Extract, Transform, Load) pipelines help convert this raw data into meaningful insights.
This blog explains ETL processes, tools, and best practices.
1. What is an ETL Pipeline?
An ETL pipeline is a process that Extracts, Transforms, and Loads data into a data warehouse or analytics system.
Helps in cleaning, structuring, and preparing data for decision-making.
1.1 Key Components of ETL
Extract: Collect data from multiple sources (databases, APIs, logs, files).
Transform: Clean, enrich, and format the data (filtering, aggregating, converting).
Load: Store data into a data warehouse, data lake, or analytics platform.
2. Extract: Gathering Raw Data
Data sources: Databases (MySQL, PostgreSQL), APIs, Logs, CSV files, Cloud storage.
Extraction methods:
Full Extraction: Pulls all data at once.
Incremental Extraction: Extracts only new or updated data.
Streaming Extraction: Real-time data processing (Kafka, Kinesis).
3. Transform: Cleaning and Enriching Data
Data Cleaning: Remove duplicates, handle missing values, normalize formats.
Data Transformation: Apply business logic, merge datasets, convert data types.
Data Enrichment: Add contextual data (e.g., join customer records with location data).
Common Tools: Apache Spark, dbt, Pandas, SQL transformations.
4. Load: Storing Processed Data
Load data into a Data Warehouse (Snowflake, Redshift, BigQuery, Synapse) or a Data Lake (S3, Azure Data Lake, GCS).
Loading strategies:
Full Load: Overwrites existing data.
Incremental Load: Appends new data.
Batch vs. Streaming Load: Scheduled vs. real-time data ingestion.
5. ETL vs. ELT: What’s the Difference?

ETL is best for structured data and compliance-focused workflows.
ELT is ideal for cloud-native analytics, handling massive datasets efficiently.
6. Best Practices for ETL Pipelines
✅ Optimize Performance: Use indexing, partitioning, and parallel processing. ✅ Ensure Data Quality: Implement validation checks and logging. ✅ Automate & Monitor Pipelines: Use orchestration tools (Apache Airflow, AWS Glue, Azure Data Factory). ✅ Secure Data Transfers: Encrypt data in transit and at rest. ✅ Scalability: Choose cloud-based ETL solutions for flexibility.
7. Popular ETL Tools
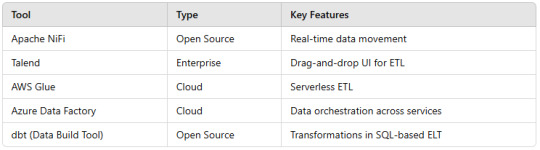
Conclusion
ETL pipelines streamline data movement from raw sources to analytics-ready formats.
Choosing the right ETL/ELT strategy depends on data size, speed, and business needs.
Automated ETL tools improve efficiency and scalability.
WEBSITE: https://www.ficusoft.in/data-science-course-in-chennai/
0 notes
Text

#VisualPath offers the best #AzureDataEngineer Training Online to help you master data and AI technologies. Our Microsoft Azure Data Engineer course covers top tools like Matillion, Snowflake, ETL, Informatica, SQL, Power BI, Databricks, and Amazon Redshift. Gain hands-on experience with flexible schedules, recorded sessions, and global access. Learn from industry experts and work on real-world projects. Achieve certification and boost your career in data engineering. Call +91-9989971070 for a free demo!
WhatsApp: https://www.whatsapp.com/catalog/919989971070/
Visit Blog: https://visualpathblogs.com/category/aws-data-engineering-with-data-analytics/
Visit: https://www.visualpath.in/online-azure-data-engineer-course.html
#visualpathedu#testing#automation#selenium#git#github#JavaScript#Azure#CICD#AzureDevOps#playwright#handonlearning#education#SoftwareDevelopment#onlinelearning#newtechnology#software#ITskills#training#trendingcourses#careers#students#typescript
0 notes
Text

#Visualpath offers the Best Online DBT Courses, designed to help you excel in data transformation and analytics. Our expert-led #DBT Online Training covers tools like Matillion, Snowflake, ETL, Informatica, Data Warehousing, SQL, Talend, Power BI, Cloudera, Databricks, Oracle, SAP, and Amazon Redshift. With flexible schedules, recorded sessions, and hands-on projects, we provide a seamless learning experience for global learners. Master advanced data engineering skills, prepare for DBT certification, and elevate your career. Call +91-9989971070 for a free demo and enroll today!
WhatsApp: https://www.whatsapp.com/catalog/919989971070/
Visit Blog: https://databuildtool1.blogspot.com/
Visit: https://www.visualpath.in/online-data-build-tool-training.html
#visualpathedu #testing #automation #selenium #git #github #JavaScript #Azure #CICD #AzureDevOps #playwright #handonlearning #education #SoftwareDevelopment #onlinelearning #newtechnology #software #education #ITskills #training #trendingcourses #careers #students #typescript
#DBT Training#DBT Online Training#DBT Classes Online#DBT Training Courses#Best Online DBT Courses#DBT Certification Training Online#Data Build Tool Training in Hyderabad#Best DBT Course in Hyderabad#Data Build Tool Training in Ameerpet
0 notes
Text
Best Snowflake Course in Hyderabad

Introduction
In today’s data-driven world, companies are increasingly adopting cloud-based data solutions to handle large volumes of data efficiently. Snowflake has emerged as one of the most popular platforms for data warehousing, analytics, and real-time data integration due to its powerful cloud-native architecture. For professionals looking to advance their careers in data engineering, analytics, and cloud computing, mastering Snowflake is becoming essential.
Hyderabad, a leading tech hub in India, offers many opportunities for individuals skilled in Snowflake. At Brolly Academy, we provide Advanced Snowflake Training designed to meet the needs of data professionals at all levels. Our Snowflake Data Integration Training focuses on equipping students with hands-on experience in integrating data seamlessly across various platforms, a critical skill in today’s interconnected data environments.
For those interested in building and managing scalable data solutions, our Snowflake Data Engineering Course covers essential topics such as data loading, transformation, and advanced data warehousing concepts. Additionally, Brolly Academy offers Snowflake Cloud Training in Hyderabad, ensuring that students learn to fully leverage Snowflake’s cloud infrastructure to manage and optimize data workflows effectively.
Through our comprehensive Snowflake courses, students not only gain deep technical knowledge but also learn best practices for real-world applications, setting them up for success in a fast-growing and competitive field.
Contact Details
Phone :+91 81868 44555
Mail :[email protected]
Location: 206, Manjeera Trinity Corporate, JNTU Road, KPHB Colony, Kukatpally, Hyderabad
What is Snowflake Training?
Snowflake training is a structured learning program designed to teach professionals the ins and outs of Snowflake, a leading cloud-based data warehousing platform. Snowflake has quickly become essential for companies needing fast, flexible, and scalable data solutions. Snowflake training provides foundational knowledge along with advanced skills for handling and optimizing data across a variety of industries. At Brolly Academy, our Advanced Snowflake Training offers a comprehensive dive into Snowflake's architecture, SQL capabilities, and key features like Time Travel, zero-copy cloning, and multi-cloud support, equipping professionals to use Snowflake to its full potential.
Key Components of Snowflake Training
Foundational Knowledge and Architecture Understanding
Training begins with core concepts and an understanding of Snowflake’s unique architecture, including its multi-cluster, shared-data model that separates compute from storage.
Advanced Snowflake Training Modules
For those seeking an in-depth understanding, advanced training covers essential skills for managing and optimizing large-scale data environments. Topics include query optimization, workload management, security best practices, and resource scaling.
Snowflake Data Integration Training
A critical aspect of Snowflake training is learning to integrate Snowflake with other data tools and platforms. Snowflake Data Integration Training teaches students how to work with ETL/ELT pipelines, connect to BI tools, and perform data migrations, allowing for seamless interaction with other cloud and data services.
Snowflake Data Engineering Course
Snowflake has become a key platform for data engineering tasks, and this course at Brolly Academy focuses on practical data engineering applications. The Snowflake Data Engineering Course provides training on designing, building, and maintaining robust data pipelines and optimizing data flows. Students also learn to automate tasks with Snowflake’s Snowpipe feature for continuous data loading.
Snowflake Cloud Training in Hyderabad
Snowflake is a fully cloud-based solution, and understanding cloud-specific principles is essential for effective deployment and management. Snowflake Cloud Training in Hyderabad teaches students cloud optimization strategies, cost management, and security practices, ensuring they can leverage Snowflake’s cloud capabilities to create scalable and cost-effective data solutions.
Who Should Enroll in Snowflake Training?
Snowflake training is ideal for data engineers, data analysts, BI developers, database administrators, and IT professionals who want to build expertise in a powerful cloud data platform. Whether you're looking to master data warehousing, streamline data integration, or prepare for specialized roles in data engineering, Snowflake training equips you with the knowledge to advance in today’s data-driven world.
Contact Details
Phone :+91 81868 44555
Mail :[email protected]
Location: 206, Manjeera Trinity Corporate, JNTU Road, KPHB Colony, Kukatpally, Hyderabad
Why Learn Snowflake?
In today’s data-driven world, the need for powerful, scalable, and cost-effective cloud solutions has skyrocketed. Snowflake, a cutting-edge data warehousing and analytics platform, has emerged as a leading choice for organizations of all sizes, thanks to its cloud-native architecture and advanced features. Here are the top reasons why learning Snowflake can be a career game-changer:
1. High Demand for Skilled Snowflake Professionals
As companies increasingly adopt cloud-based data solutions, there’s a significant demand for professionals trained in Snowflake. Roles like Data Engineer, Data Analyst, and Cloud Data Architect are increasingly emphasizing Snowflake skills, making it a highly sought-after certification in the job market. For those considering a career shift or skill upgrade, Advanced Snowflake Training offers specialized knowledge that’s valuable in industries such as finance, healthcare, e-commerce, and technology.
2. Versatility in Data Engineering and Integration
Snowflake provides an adaptable, flexible platform that caters to various data needs, from structured data warehousing to handling semi-structured and unstructured data. For individuals looking to specialize in data engineering, the Snowflake Data Engineering Course covers essential skills, such as data modeling, query optimization, and workflow automation. This course is a strong foundation for anyone aiming to excel in data engineering by building efficient, high-performing data pipelines using Snowflake.
3. Advanced Data Integration Capabilities
Data integration is critical for organizations seeking a unified view of their data across multiple sources and platforms. Snowflake’s seamless integration with popular ETL tools, third-party applications, and programming languages like Python makes it a top choice for data-driven organizations. Enrolling in Snowflake Data Integration Training enables learners to master Snowflake’s data-sharing capabilities, build data pipelines, and use cloud-native features to streamline data workflows, all of which are invaluable skills for data professionals.
4. Cloud-First Architecture and Scalability
One of Snowflake’s standout features is its cloud-native architecture, which allows for unlimited scalability and high performance without the typical limitations of on-premises data warehouses. Snowflake Cloud Training in Hyderabad equips students with hands-on skills in cloud data management, helping them understand how to scale storage and compute resources independently, which is essential for handling high volumes of data. As businesses increasingly rely on cloud solutions, professionals trained in Snowflake’s cloud capabilities are well-positioned to help organizations optimize costs while delivering high-speed analytics.
5. Career Growth and Competitive Edge
The unique capabilities of Snowflake, such as zero-copy cloning, Time Travel, and advanced data sharing, are transforming the data landscape. By mastering Snowflake, professionals can offer businesses streamlined solutions that increase efficiency, reduce costs, and enhance data accessibility. With certifications from Advanced Snowflake Training or a Snowflake Data Engineering Course, individuals gain a competitive advantage, opening doors to better roles and salaries in the job market.
Contact Details
Phone :+91 81868 44555
Mail :[email protected]
Location: 206, Manjeera Trinity Corporate, JNTU Road, KPHB Colony, Kukatpally, Hyderabad
How Long Will It Take to Learn Snowflake?
The time it takes to learn Snowflake largely depends on a learner's prior experience and the level of expertise they wish to achieve. For beginners, foundational knowledge typically takes around 4–6 weeks of focused learning, while advanced users can gain proficiency with 2–3 months of specialized training. Here’s a breakdown to help you understand what to expect when enrolling in a Snowflake course.
1. Foundational Learning (2–4 weeks)
Essentials of Snowflake Data Warehousing: Beginners start by learning the core concepts of data warehousing and Snowflake’s unique architecture. This includes understanding cloud-native aspects, multi-cluster warehouses, and Snowflake’s storage and compute model.
Basic SQL Skills: SQL is foundational for working in Snowflake. Most learners spend the first few weeks gaining proficiency in SQL for data manipulation, querying, and handling datasets.
2. Intermediate Skills (4–6 weeks)
Data Engineering and Integration Basics: This stage focuses on building data pipelines, using Snowflake’s integration features, and learning data engineering principles. A Snowflake Data Engineering Course can deepen knowledge of ETL processes, data modeling, and data ingestion.
Data Integration Training: Through Snowflake Data Integration Training, students learn to work with different data sources, third-party tools, and data lakes to seamlessly integrate data. This module may take 2–3 weeks for learners aiming to manage data at scale and enhance organizational workflows.
3. Advanced Snowflake Training (8–12 weeks)
Advanced Data Engineering and Optimization: This level is ideal for experienced data professionals who want to specialize in Snowflake’s advanced data management techniques. Advanced Snowflake Training covers topics such as micro-partitioning, Time Travel, zero-copy cloning, and performance optimization to enhance data processing and analytics.
Cloud Platform Specialization: In an Advanced Snowflake Cloud Training in Hyderabad, learners dive into Snowflake’s cloud-specific features. This module is designed to help professionals handle large-scale data processing, cloud integrations, and real-time data analysis, which is crucial for companies moving to the cloud.
4. Hands-On Practice and Projects (4–6 weeks)
Real-world application is essential to mastering Snowflake, and a Snowflake Data Engineering Course often includes hands-on labs and projects. This practical approach solidifies concepts and helps learners become confident in data handling, querying, and optimization within Snowflake.
Total Estimated Time to Master Snowflake
For beginners aiming for a foundational understanding: 6–8 weeks.
For intermediate-level proficiency, including data integration and basic data engineering: 2–3 months.
For advanced proficiency with a focus on Snowflake data engineering, cloud integration, and data optimization: 3–4 months.
Contact Details
Phone :+91 81868 44555
Mail :[email protected]
Location: 206, Manjeera Trinity Corporate, JNTU Road, KPHB Colony, Kukatpally, Hyderabad
Key Benefits of Choosing Brolly Academy’s Snowflake Course
1. Advanced Snowflake Training
Brolly Academy offers Advanced Snowflake Training that goes beyond basic concepts, focusing on advanced functionalities and optimization techniques that are essential for real-world applications. This training covers topics like query optimization, micro-partitioning, and workload management to ensure you are fully equipped to handle complex data requirements on the Snowflake platform. By mastering these advanced skills, students can set themselves apart in the job market and handle high-demand Snowflake projects confidently.
2. Snowflake Data Integration Training
Snowflake’s ability to integrate seamlessly with multiple data sources is one of its strongest assets. Brolly Academy’s Snowflake Data Integration Training provides hands-on experience with integrating Snowflake with popular BI tools, ETL processes, and data lakes. This module covers everything from loading data to using Snowflake’s connectors and APIs, helping you understand how to efficiently manage and unify data from diverse sources. Mastering Snowflake integrations makes you a valuable asset for companies seeking professionals who can streamline and optimize data flows.
3. Snowflake Data Engineering Course
Our Snowflake Data Engineering Course is crafted for those aspiring to build a career in data engineering. This course module covers essential topics like data pipelines, data transformations, and data architecture within the Snowflake environment. Designed by industry experts, this course ensures that you gain practical knowledge of data engineering tasks, making you proficient in handling large-scale data projects. From creating robust data models to managing data storage and retrieval, this part of the course lays a solid foundation for a career in Snowflake data engineering.
4. Snowflake Cloud Training Hyderabad
Brolly Academy’s Snowflake Cloud Training in Hyderabad leverages the cloud-native capabilities of Snowflake, helping students understand the unique aspects of working on a cloud data platform. This training emphasizes the scalability and flexibility of Snowflake in multi-cloud environments, allowing you to handle data warehousing needs without infrastructure constraints. Our convenient Hyderabad location also means that students in the city and beyond can access top-quality training with personalized support, hands-on labs, and real-world projects tailored to the demands of the cloud data industry.
Contact Details
Phone :+91 81868 44555
Mail :[email protected]
Location: 206, Manjeera Trinity Corporate, JNTU Road, KPHB Colony, Kukatpally, Hyderabad
Course Content Overview
Our Advanced Snowflake Training at Brolly Academy in Hyderabad is designed to provide in-depth knowledge and hands-on skills essential for mastering Snowflake’s advanced features and capabilities. This course combines Snowflake Data Integration Training, Snowflake Data Engineering concepts, and Cloud Training to equip students with the expertise needed to leverage Snowflake’s full potential in a cloud environment.
1. Introduction to Snowflake Architecture
Core Concepts: Understand Snowflake’s multi-cluster, shared data architecture, which separates compute, storage, and services.
Virtual Warehouses: Learn about Snowflake’s virtual warehouses and how to optimize them for data storage and processing.
Micro-partitioning: Explore how Snowflake’s automatic micro-partitioning enhances performance and data organization.
2. Data Warehousing Essentials for the Cloud
Data Modeling: Study the fundamentals of cloud data modeling, essential for creating efficient, scalable Snowflake databases.
SQL Optimization: Learn SQL techniques tailored to Snowflake, including best practices for optimizing complex queries.
3. Advanced Snowflake Features
Time Travel and Zero-Copy Cloning: Dive into Snowflake’s unique Time Travel feature for data recovery and zero-copy cloning for creating database copies without additional storage costs.
Data Sharing and Secure Data Exchange: Understand how to share data securely within and outside your organization using Snowflake’s secure data-sharing features.
4. Snowflake Data Integration Training
Data Loading and Transformation: Master techniques for loading and transforming structured and semi-structured data into Snowflake, including JSON, Avro, and Parquet.
ETL/ELT Processes: Explore data integration best practices for ETL (Extract, Transform, Load) and ELT processes within Snowflake’s cloud environment.
Data Integration Tools: Learn to integrate Snowflake with popular data integration tools like Informatica, Talend, and Apache NiFi for seamless data pipeline management.
5. Snowflake Data Engineering Course
Data Pipeline Development: Gain hands-on experience in designing and implementing data pipelines tailored for Snowflake.
Job Scheduling and Automation: Learn to schedule and automate data workflows, ensuring data consistency and reducing manual intervention.
Data Engineering with Snowpark: Understand the basics of Snowpark, Snowflake’s developer framework, for creating custom data engineering solutions with Python, Java, and Scala.
6. Performance Optimization and Security
Query Performance Tuning: Discover techniques to optimize query performance in Snowflake by leveraging micro-partitioning, query history, and result caching.
Security and Compliance: Explore Snowflake’s robust security features, including role-based access control, data encryption, and compliance with GDPR and HIPAA.
7. Real-World Capstone Project
End-to-End Project: Engage in a comprehensive project that integrates Snowflake’s features with data engineering and data integration practices. This project simulates a real-world scenario, allowing students to apply their skills to solve complex data challenges in a Snowflake cloud environment.
Contact Details
Phone :+91 81868 44555
Mail :[email protected]
Location: 206, Manjeera Trinity Corporate, JNTU Road, KPHB Colony, Kukatpally, Hyderabad
Why Brolly Academy Stands Out as the Best Choice in Hyderabad
When it comes to Snowflake training in Hyderabad, Brolly Academy has established itself as a premier choice. Here’s why Brolly Academy is recognized as the best option for learning Snowflake, especially for those interested in advanced, industry-ready skills:
Advanced Snowflake Training Brolly Academy offers an Advanced Snowflake Training program designed to take students beyond the basics. This comprehensive approach covers key Snowflake features, including data clustering, query optimization, micro-partitioning, and workload isolation. Through in-depth modules, students gain the expertise required to handle complex data management and performance tasks, making them valuable assets for any organization working with large-scale data.
Snowflake Data Integration Training The academy understands the importance of integrating Snowflake with various data sources and third-party tools. Our Snowflake Data Integration Training equips learners with hands-on skills in connecting Snowflake to BI tools, data lakes, and ETL platforms, ensuring they are prepared for real-world data integration challenges. This training is ideal for data analysts, engineers, and integration specialists who aim to streamline data flows and make data-driven insights more accessible across their organizations.
Specialized Snowflake Data Engineering Course For aspiring data engineers and cloud specialists, Brolly Academy provides a dedicated Snowflake Data Engineering Course. This course covers the end-to-end data engineering lifecycle within Snowflake, from data loading, transformation, and storage to building pipelines and implementing best practices for data quality. Students gain critical skills in data warehousing and pipeline development, making them ready for roles that demand in-depth Snowflake knowledge.
Snowflake Cloud Training Hyderabad Brolly Academy’s Snowflake Cloud Training in Hyderabad is designed for learners who need a flexible, cloud-based solution. This program covers all core Snowflake topics, including architecture, security, and cloud-native features, preparing students to handle cloud-based data solutions efficiently. Whether a student is just beginning or advancing their cloud computing skills, the academy’s Snowflake Cloud Training offers a robust learning path tailored to Hyderabad's tech-savvy professionals.
Industry Expertise and Practical Experience At Brolly Academy, all courses are taught by experienced instructors who bring real-world experience and industry insights to the classroom. The curriculum is designed to stay aligned with current industry trends, ensuring that students learn the most relevant skills and gain practical experience with real-time projects and case studies.
Flexible Learning Options and Strong Support Brolly Academy provides flexible schedules, including weekday and weekend classes, to accommodate working professionals and students. With options for both online and in-person learning, students can choose a training format that fits their lifestyle. In addition, the academy offers support for certification, career guidance, and placement assistance, ensuring students are not only well-trained but also career-ready.
Contact Details
Phone :+91 81868 44555
Mail :[email protected]
Location: 206, Manjeera Trinity Corporate, JNTU Road, KPHB Colony, Kukatpally, Hyderabad
1 note
·
View note
Text
Matillion Online Course USA
Matillion Online Course USA offered by EDISSY is a user-friendly and practical course designed to enhance your skills in data transformation and loading. The course focuses on utilizing Matillion ETL to efficiently process complex data and load it into Snowflake warehouse, enabling users to make informed data-driven decisions. With the ability to process data up to 100 times faster than traditional ETL/ELT tools through Amazon Redshift, Matillion is a powerful cloud analytics software vendor. Enroll in the Matillion Online Course USA at EDISSY today to expand your knowledge and improve your communication skills. Contact us at IND: +91-9000317955.
0 notes
Text
How Can Beginners Start Their Data Engineering Interview Prep Effectively?
Embarking on the journey to become a data engineer can be both exciting and daunting, especially when it comes to preparing for interviews. As a beginner, knowing where to start can make a significant difference in your success. Here’s a comprehensive guide on how to kickstart your data engineering interview prep effectively.
1. Understand the Role and Responsibilities
Before diving into preparation, it’s crucial to understand what the role of a data engineer entails. Research the typical responsibilities, required skills, and common tools used in the industry. This foundational knowledge will guide your preparation and help you focus on relevant areas.
2. Build a Strong Foundation in Key Concepts
To excel in data engineering interviews, you need a solid grasp of key concepts. Focus on the following areas:
Programming: Proficiency in languages such as Python, Java, or Scala is essential.
SQL: Strong SQL skills are crucial for data manipulation and querying.
Data Structures and Algorithms: Understanding these fundamentals will help in solving complex problems.
Databases: Learn about relational databases (e.g., MySQL, PostgreSQL) and NoSQL databases (e.g., MongoDB, Cassandra).
ETL Processes: Understand Extract, Transform, Load processes and tools like Apache NiFi, Talend, or Informatica.
3. Utilize Quality Study Resources
Leverage high-quality study materials to streamline your preparation. Books, online courses, and tutorials are excellent resources. Additionally, consider enrolling in specialized programs like the Data Engineering Interview Prep Course offered by Interview Kickstart. These courses provide structured learning paths and cover essential topics comprehensively.
4. Practice with Real-World Problems
Hands-on practice is vital for mastering data engineering concepts. Work on real-world projects and problems to gain practical experience. Websites like LeetCode, HackerRank, and GitHub offer numerous challenges and projects to work on. This practice will also help you build a portfolio that can impress potential employers.
5. Master Data Engineering Tools
Familiarize yourself with the tools commonly used in data engineering roles:
Big Data Technologies: Learn about Hadoop, Spark, and Kafka.
Cloud Platforms: Gain experience with cloud services like AWS, Google Cloud, or Azure.
Data Warehousing: Understand how to use tools like Amazon Redshift, Google BigQuery, or Snowflake.
6. Join a Study Group or Community
Joining a study group or community can provide motivation, support, and valuable insights. Participate in forums, attend meetups, and engage with others preparing for data engineering interviews. This network can offer guidance, share resources, and help you stay accountable.
7. Prepare for Behavioral and Technical Interviews
In addition to technical skills, you’ll need to prepare for behavioral interviews. Practice answering common behavioral questions and learn how to articulate your experiences and problem-solving approach effectively. Mock interviews can be particularly beneficial in building confidence and improving your interview performance.
8. Stay Updated with Industry Trends
The field of data engineering is constantly evolving. Stay updated with the latest industry trends, tools, and best practices by following relevant blogs, subscribing to newsletters, and attending webinars. This knowledge will not only help you during interviews but also in your overall career growth.
9. Seek Feedback and Iterate
Regularly seek feedback on your preparation progress. Use mock interviews, peer reviews, and mentor guidance to identify areas for improvement. Continuously iterate on your preparation strategy based on the feedback received.
Conclusion
Starting your data engineering interview prep as a beginner may seem overwhelming, but with a structured approach, it’s entirely achievable. Focus on building a strong foundation, utilizing quality resources, practicing hands-on, and staying engaged with the community. By following these steps, you’ll be well on your way to acing your data engineering interviews and securing your dream job.
#jobs#coding#python#programming#artificial intelligence#education#success#career#data scientist#data science
0 notes
Text
Navigating the Data Landscape - Essential Skills for Aspiring Data Engineers
Are you considering becoming a data engineer? In today’s data-driven world, data engineers are in high demand across all industries. This is certainly a career path worth looking into, and there is a wide range of data engineering courses that can help you on your quest for success. Below, we take a look at the skills you need for success as a data engineer.
What is a Data Engineer?
Data engineers are the architects who work behind the scenes to build and maintain the infrastructure that enables organizations to harness the power of their data. They are responsible for designing, building, and maintaining database architecture and data processing systems. They enable seamless, secure, and effective data analysis and visualization.
Building Your Data Engineering Skills
If you’re considering a career as a data engineer, you’ll need to develop a diverse skill set to thrive in this dynamic field. These technical skills are necessary for addressing the highly complex tasks you will be required to carry out as a data engineer. While the list below is not comprehensive, it provides an overview of some of the basic skills you should work on developing to become a data engineer. This list is worth considering, especially when deciding which data engineering courses to pursue.
Proficiency in programming languages
At the core of data engineering is coding. Data engineers rely on programming languages for a wide range of tasks. You’ll need to be proficient in programming languages commonly used in data engineering, including Python, SQL (Structured Query Language), Java, and Scala. If you’re confused over which programming language to start with, Python would be the best option. It is widely used in data science. It is perfect for carrying out tasks such as constructing data pipelines and executing ETL jobs. It is also easy to integrate with various tools and frameworks that are critical in the field.
Familiarity with data storage and management technologies
Database management takes up a considerable part of the day to day tasks data engineers are involved in. They must, therefore, be familiar with various data storage technologies and databases, including data warehousing solutions such as Amazon Redshift and Snowflake; NoSQL databases such as MongoDB, Cassandra, and Elasticsearch; as well as relational databases such as PostgreSQL, MySQL, and SQL Server.
Skills in data modeling and design
Data modeling is a core function of data engineers. It involves designing the structure of databases to ensure efficiency, scalability, and performance. Some key concepts data engineers ought to master include relational data modeling, dimensional modeling, and NoSQL modeling.
Extract, Transform, Load (ETL) processes
ETL processes form the backbone of data engineering. These processes involve extracting data from various sources, transforming it into a usable format, and loading it into a target system. Database engineers should be proficient in the application of technologies such as Apache, Apache NiFi, and Airflow.
Becoming a data engineer requires a wide range of technical skills, including those listed above. It is essential to choose data engineering courses that will not only help you master these skills but also enable you to stay up-to-date with emerging technologies and trends. This will provide you with a strong foundation for a rewarding career in data engineering.
For more information visit: https://www.webagesolutions.com/courses/data-engineering-training
0 notes
Text
Introduction to Data Lakes and Data Warehouses

Introduction
Businesses generate vast amounts of data from various sources.
Understanding Data Lakes and Data Warehouses is crucial for effective data management.
This blog explores differences, use cases, and when to choose each approach.
1. What is a Data Lake?
A data lake is a centralized repository that stores structured, semi-structured, and unstructured data.
Stores raw data without predefined schema.
Supports big data processing and real-time analytics.
1.1 Key Features of Data Lakes
Scalability: Can store vast amounts of data.
Flexibility: Supports multiple data types (JSON, CSV, images, videos).
Cost-effective: Uses low-cost storage solutions.
Supports Advanced Analytics: Enables machine learning and AI applications.
1.2 Technologies Used in Data Lakes
Cloud-based solutions: AWS S3, Azure Data Lake Storage, Google Cloud Storage.
Processing engines: Apache Spark, Hadoop, Databricks.
Query engines: Presto, Trino, Amazon Athena.
1.3 Data Lake Use Cases
✅ Machine Learning & AI: Data scientists can process raw data for model training. ✅ IoT & Sensor Data Processing: Real-time storage and analysis of IoT device data. ✅ Log Analytics: Storing and analyzing logs from applications and systems.
2. What is a Data Warehouse?
A data warehouse is a structured repository optimized for querying and reporting.
Uses schema-on-write (structured data stored in predefined schemas).
Designed for business intelligence (BI) and analytics.
2.1 Key Features of Data Warehouses
Optimized for Queries: Structured format ensures faster analysis.
Supports Business Intelligence: Designed for dashboards and reporting.
ETL Process: Data is transformed before loading.
High Performance: Uses indexing and partitioning for fast queries.
2.2 Technologies Used in Data Warehouses
Cloud-based solutions: Snowflake, Amazon Redshift, Google BigQuery, Azure Synapse.
Traditional databases: Teradata, Oracle Exadata.
ETL Tools: Apache Nifi, AWS Glue, Talend.
2.3 Data Warehouse Use Cases
✅ Enterprise Reporting: Analyzing sales, finance, and marketing data. ✅ Fraud Detection: Banks use structured data to detect anomalies. ✅ Customer Segmentation: Retailers analyze customer behavior for personalized marketing.
3. Key Differences Between Data Lakes and Data Warehouses
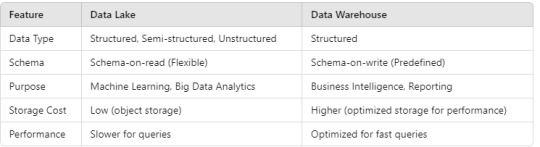
4. Choosing Between a Data Lake and Data Warehouse
Use a Data Lake When:
You have raw, unstructured, or semi-structured data.
You need machine learning, IoT, or big data analytics.
You want low-cost, scalable storage.
Use a Data Warehouse When:
You need fast queries and structured data.
Your focus is on business intelligence (BI) and reporting.
You require data governance and compliance.
5. The Modern Approach: Data Lakehouse
Combines benefits of Data Lakes and Data Warehouses.
Provides structured querying with flexible storage.
Popular solutions: Databricks Lakehouse, Snowflake, Apache Iceberg.
Conclusion
Data Lakes are best for raw data and big data analytics.
Data Warehouses are ideal for structured data and business reporting.
Hybrid solutions (Lakehouses) are emerging to bridge the gap.
WEBSITE: https://www.ficusoft.in/data-science-course-in-chennai/
0 notes
Text
Boomi ETL Tool

Boomi: A Powerful ETL Tool for Cloud-Based Integration
ETL (Extract, Transform, Load) processes are the cornerstone of data integration and analytics. They ensure data from different sources is consolidated, cleaned, and prepared for analysis and insights. Dell Boomi, a leading iPaaS (Integration Platform as a Service) solution, offers robust capabilities for streamlined ETL operations.
Why Boomi for ETL?
Here’s a breakdown of why Dell Boomi stands out as an ETL tool:
Cloud-Native and Scalable: Boomi’s cloud-based architecture allows flexible scaling to manage varying data volumes and workloads. You can quickly deploy your ETL processes without investing in extensive on-premises hardware.
Drag-and-Drop Simplicity: Boomi’s visual interface makes designing complex ETL processes simple. Pre-built connectors and transformations minimize the need for manual coding, significantly streamlining the process.
Comprehensive Connectivity: Boomi’s vast library of connectors enables integration with many databases, applications (both on-premises and cloud-based), and file formats. This empowers you to easily integrate disparate sources into a central data warehouse.
Robust Data Transformation: Boomi provides flexible ‘mapping’ components to transform data into structures suitable for your target systems. This ensures data compatibility, quality, and usability for reliable analytics.
Real-Time and Batch ETL: Boomi supports real-time streaming ETL for immediate insights and batch ETL for scheduled bulk data loads, making it adaptable to different use cases.
Key Considerations When Using Boomi for ETL
Data Governance: Establish clear data quality rules and leverage Boomi’s built-in data profiling and validation features to maintain data integrity throughout your ETL processes.
Error Handling: Implement robust mechanisms to capture and rectify data discrepancies and inconsistencies, preventing data problems from propagating downstream.
Performance Optimization: To handle large data volumes, optimize your Boomi processes and leverage parallel processing features when possible.
Example: Creating a Basic ETL Process with Boomi
Extract: Use connectors to extract data from a flat file (e.g., CSV) and a database (e.g., PostgreSQL).
Transform: Map and manipulate the extracted data, ensuring compatibility with your data warehouse schema. This might include combining data, performing calculations, and applying filters.
Load: A connector loads the transformed data into your target data warehouse (e.g., Snowflake).
The iPaaS Advantage
Boomi, as an iPaaS, extends its ETL capabilities by offering:
Orchestration: Schedule and control ETL pipelines as part of broader business process automation, streamlining workflows.
API Management: Expose data from your warehouse via APIs, allowing it to be used by other applications.
Hybrid Integration: Connect on-premises systems with your cloud-based data warehouse for a unified data landscape.
Is Boomi the Right ETL Tool for You?
If you are looking for a cloud-based, user-friendly, and versatile ETL solution, particularly in a hybrid cloud environment, Boomi is a compelling choice. Of course, factor in your specific data integration needs and consider other factors like cost and whether it aligns with your existing technology stack.
youtube
You can find more information about Dell Boomi in this Dell Boomi Link
Conclusion:
Unogeeks is the No.1 IT Training Institute for Dell Boomi Training. Anyone Disagree? Please drop in a comment
You can check out our other latest blogs on Dell Boomi here – Dell Boomi Blogs
You can check out our Best In Class Dell Boomi Details here – Dell Boomi Training
Follow & Connect with us:
———————————-
For Training inquiries:
Call/Whatsapp: +91 73960 33555
Mail us at: [email protected]
Our Website ➜ https://unogeeks.com
Follow us:
Instagram: https://www.instagram.com/unogeeks
Facebook: https://www.facebook.com/UnogeeksSoftwareTrainingInstitute
Twitter: https://twitter.com/unogeek
0 notes
Text
Best DBT Course in Hyderabad | Data Build Tool Training
What is DBT, and Why is it Used in Data Engineering?
DBT, short for Data Build Tool, is an open-source command-line tool that allows data analysts and engineers to transform data in their warehouses using SQL. Unlike traditional ETL (Extract, Transform, Load) processes, which manage data transformations separately, DBT focuses solely on the Transform step and operates directly within the data warehouse.
DBT enables users to define models (SQL queries) that describe how raw data should be cleaned, joined, or transformed into analytics-ready datasets. It executes these models efficiently, tracks dependencies between them, and manages the transformation process within the data warehouse. DBT Training

Key Features of DBT
SQL-Centric: DBT is built around SQL, making it accessible to data professionals who already have SQL expertise. No need for learning complex programming languages.
Version Control: DBT integrates seamlessly with version control systems like Git, allowing teams to collaborate effectively while maintaining an organized history of changes.
Testing and Validation: DBT provides built-in testing capabilities, enabling users to validate their data models with ease. Custom tests can also be defined to ensure data accuracy.
Documentation: With dbt, users can automatically generate documentation for their data models, providing transparency and fostering collaboration across teams.
Modularity: DBT encourages the use of modular SQL code, allowing users to break down complex transformations into manageable components that can be reused. DBT Classes Online
Why is DBT Used in Data Engineering?
DBT has become a critical tool in data engineering for several reasons:
1. Simplifies Data Transformation
Traditionally, the Transform step in ETL processes required specialized tools or complex scripts. DBT simplifies this by empowering data teams to write SQL-based transformations that run directly within their data warehouses. This eliminates the need for external tools and reduces complexity.
2. Works with Modern Data Warehouses
DBT is designed to integrate seamlessly with modern cloud-based data warehouses such as Snowflake, BigQuery, Redshift, and Databricks. By operating directly in the warehouse, it leverages the power and scalability of these platforms, ensuring fast and efficient transformations. DBT Certification Training Online
3. Encourages Collaboration and Transparency
With its integration with Git, dbt promotes collaboration among teams. Multiple team members can work on the same project, track changes, and ensure version control. The autogenerated documentation further enhances transparency by providing a clear view of the data pipeline.
4. Supports CI/CD Pipelines
DBT enables teams to adopt Continuous Integration/Continuous Deployment (CI/CD) workflows for data transformations. This ensures that changes to models are tested and validated before being deployed, reducing the risk of errors in production.
5. Focus on Analytics Engineering
DBT shifts the focus from traditional ETL to ELT (Extract, Load, Transform). With raw data already loaded into the warehouse, dbt allows teams to spend more time analyzing data rather than managing complex pipelines.
Real-World Use Cases
Data Cleaning and Enrichment: DBT is used to clean raw data, apply business logic, and create enriched datasets for analysis.
Building Data Models: Companies rely on dbt to create reusable, analytics-ready models that power dashboards and reports. DBT Online Training
Tracking Data Lineage: With its ability to visualize dependencies, dbt helps track the flow of data, ensuring transparency and accountability.
Conclusion
DBT has revolutionized the way data teams approach data transformations. By empowering analysts and engineers to use SQL for transformations, promoting collaboration, and leveraging the scalability of modern data warehouses, dbt has become a cornerstone of modern data engineering. Whether you are cleaning data, building data models, or ensuring data quality, dbt offers a robust and efficient solution that aligns with the needs of today’s data-driven organizations.
Visualpath is the Best Software Online Training Institute in Hyderabad. Avail complete Data Build Tool worldwide. You will get the best course at an affordable cost.
Attend Free Demo
Call on - +91-9989971070.
Visit: https://www.visualpath.in/online-data-build-tool-training.html
WhatsApp: https://www.whatsapp.com/catalog/919989971070/
Visit Blog: https://databuildtool1.blogspot.com/
#DBT Training#DBT Online Training#DBT Classes Online#DBT Training Courses#Best Online DBT Courses#DBT Certification Training Online#Data Build Tool Training in Hyderabad#Best DBT Course in Hyderabad#Data Build Tool Training in Ameerpet
0 notes
Text
Mastering Data Engineering
In the era of big data, organizations are increasingly recognizing the critical role of data engineering in enabling data-driven decision-making. Data engineers are in high demand as businesses seek professionals with the skills to design, build, and manage the infrastructure and processes that support data analytics. In this article, we provide a comprehensive guide to understanding the role of a data engineer, their responsibilities, required skills, and the steps to embark on a rewarding career in this field.
1. Defining the Role of a Data Engineer:
A data engineer is a technical professional responsible for the design, development, and maintenance of data systems that facilitate the collection, storage, and analysis of large volumes of data. They collaborate closely with data scientists, analysts, and stakeholders to ensure data availability, reliability, and accessibility. Data engineer training is essential for professionals seeking to acquire the necessary skills and knowledge to design and develop efficient data pipelines, data warehouses, and data lakes.
2. Key Responsibilities of a Data Engineer:
Data engineers have a wide range of responsibilities, including:
- Data Integration: Data engineers integrate data from multiple sources, including databases, APIs, and streaming platforms, into a unified and usable format.
- Data Transformation: Data engineer courses provide individuals with the opportunity to gain expertise in data cleansing, validation, and transformation techniques, including ETL processes and handling diverse data formats.
- Database Design: Data engineers design and optimize database schemas, choosing the appropriate data storage solutions such as relational databases, NoSQL databases, or distributed file systems like Hadoop.
- Data Pipeline Development: They build and maintain data pipelines that automate the movement of data from source to destination, ensuring data is processed, transformed, and loaded efficiently.
- Performance Optimization: Data engineers optimize data processing performance by fine-tuning queries, implementing indexing strategies, and leveraging parallel computing frameworks like Apache Spark.
- Data Governance and Security: They establish data governance policies, implement access controls, and ensure data security and compliance with regulations like GDPR or HIPAA.
3. Essential Skills for Data Engineers:
To excel as a data engineer, proficiency in the following skills is crucial:
- Programming Languages: Strong programming skills in languages such as Python, Java, or Scala are essential for data engineering tasks, including data manipulation, scripting, and automation.
- SQL and Database Management: Proficiency in SQL, as well as data engineer certification, is necessary for querying and managing relational databases. Understanding database concepts, optimization techniques, and query performance tuning is also important.
- Big Data Technologies: Familiarity with big data frameworks like Apache Hadoop, Apache Spark, or Apache Kafka enables data engineers to handle large-scale data processing and streaming.
- Data Modeling and Warehousing: Knowledge of data modeling techniques, dimensional modeling, and experience with data warehousing solutions such as Snowflake or Amazon Redshift, in a data engineer institute are valuable to earn skills for data engineers.
- Cloud Computing: Proficiency in cloud platforms like Amazon Web Services (AWS), Microsoft Azure, or Google Cloud Platform (GCP) is increasingly important as organizations adopt cloud-based data infrastructure.
4. Educational Path and Career Development:
Data engineering roles typically require a strong educational background in computer science, data science, or a related field. A bachelor's or master's degree in a relevant discipline provides a solid foundation. Pursuing certifications in data engineering or cloud platforms, along with data engineer training courses, can enhance job prospects and demonstrate expertise in the field. Continuous learning through online courses, workshops, and industry conferences is crucial to staying updated with evolving technologies and best practices.
5. Industry Demand and Career Opportunities:
The demand for skilled data engineers is rapidly growing across industries. Organizations are seeking professionals who can help them leverage the power of data for insights and competitive advantage. Data engineers can find opportunities in various sectors, including technology, finance, healthcare, e
-commerce, and consulting. As organizations invest more in data-driven strategies, the career prospects for data engineers are promising, with potential for growth into leadership or specialized roles such as data architect or data engineering manager.
Refer this article: How much is the Data Engineer Course Fee in India?
End Note:
In an era driven by data, the role of a data engineer is indispensable for organizations aiming to harness the power of their data assets. With a strong foundation in programming, database management, big data technologies, and cloud computing, data engineers have the potential to shape the future of businesses. By embracing continuous learning, staying updated with emerging technologies, and honing their skills, aspiring data engineers can embark on a rewarding career at the forefront of the data revolution.
Certified Data Engineer Course
youtube
0 notes