#especially complex analysis or multi dimensional functions
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
BuzzFeed published a report claiming that Tumblr was utilized as a distribution channel for Russian agents to influence American voting habits during the 2016 presidential election in Feb 2018.
Text
also i know math isn't actual science but it does give you "knowledge that's maddening to know"
Bitches love to be like "science sucks where are the eldritch horrors where is the knowledge thats maddening to know" that's thermodynamics motherfucker. The first two world experts in thermodynamics (Ludwig Boltzmann and Paul Ehrenfest) both killed themselves because they had to do fucking thermodynamics
23K notes
·
View notes
Text
4 Best Machine Learning Projects on GitHub
There are many popular machine learning projects on GitHub, which cover everything from basic algorithms to complex applications. Here are four particularly popular machine learning projects:
1. TensorFlow Introduction: TensorFlow is the second-generation machine learning system released by Google. It is an open source machine learning library for numerical computing, especially the training of large-scale neural networks. It uses data flow graphs for numerical computing. The nodes in the graph represent mathematical operations, and the edges represent multidimensional arrays (tensors) flowing between nodes. TensorFlow supports multiple programming languages, including Python, C++, and Java.
Features:
Flexible: can be deployed on desktops, servers, or mobile devices.
Automatic differentiation: supports gradient-based machine learning algorithms.
Efficient Python interface: easy for users to express ideas.
Application: TensorFlow is widely used in various fields, including speech recognition (such as speech recognition in Google App), image search (such as image search in Google Photos), etc.
2. PyTorch Introduction: PyTorch is an open source machine learning library developed by Facebook, focusing on deep learning applications. It provides two main features: Tensor computing with powerful GPU acceleration and a tape-based automatic programming system for building deep neural networks.
Features:
Dynamic computational graph: Unlike the static computational graph of TensorFlow, PyTorch uses dynamic computational graphs, making debugging and prototyping easier. Pythonic style: Its API design is more in line with Python programming habits. Rich ecosystem: It has a large community and a large number of third-party library support. Application: PyTorch is very popular in academic research and industry, and is used in various deep learning projects.
3. Scikit-learn Introduction: Scikit-learn is a Python module for machine learning, built on SciPy. It provides simple and efficient data mining and data analysis tools, and is one of the commonly used libraries for data scientists and machine learning engineers.
Features:
Simple operation: Provides an easy-to-use API. Comprehensive functions: Covers a variety of machine learning tasks such as classification, regression, clustering, and data dimensionality reduction. High reusability: Supports reusing models in various scenarios. Application: Scikit-learn is widely used in various data mining and machine learning projects.
4. OpenPose Introduction: OpenPose is a multi-person key point detection library developed and maintained by CMU’s Perceptual Computing Laboratory. It can help us detect the position of a person in an image or video in real time and identify key points (such as joints).
Features:
Strong real-time performance: It can detect key points in real time in a video stream. High precision: It can accurately identify multiple key points of the human body. Wide application: It can be used in many fields such as motion capture and behavior analysis. Application: OpenPose is widely used in sports analysis, virtual reality, game development and other fields.
The above four projects are very popular machine learning projects on GitHub, each of which has unique advantages and a wide range of application scenarios. Whether you are a beginner or a senior machine learning engineer, you can find learning resources and application cases suitable for you in these projects.
0 notes
Text
How Can I Use Python for Data Analysis?
How Can I Use Python for Data Analysis?
Python is a versatile programming language widely recognized for its ease of use and powerful capabilities. In recent years, Python has become a preferred choice for data analysis due to its vast libraries and frameworks designed specifically for this purpose. For those exploring programming and data analysis, Python can serve as an excellent starting point, especially when considering options like python courses in Coimbatore to complement your skillset.
The Importance of Data Analysis
Data analysis is essential for businesses, researchers, and individuals alike, as it helps transform raw data into actionable insights. In a world where data is abundant, knowing how to analyze it effectively can lead to improved decision-making and strategic planning. Python's user-friendly syntax and extensive library support make it an ideal tool for anyone looking to dive into data analysis.
Why Choose Python for Data Analysis?
Ease of Learning: Python's simple syntax allows newcomers to grasp concepts quickly, making it easier for them to focus on data analysis rather than struggling with complex programming languages.
Robust Libraries: Python boasts a variety of libraries specifically designed for data analysis. Libraries such as Pandas, NumPy, and Matplotlib provide powerful tools to manipulate data and visualize results efficiently.
Community Support: With a large and active community, Python users can find ample resources, tutorials, and forums for troubleshooting and learning from others’ experiences.
Integration Capabilities: Python integrates seamlessly with other languages and tools, allowing users to extend their data analysis capabilities further.
Key Libraries for Data Analysis
1. Pandas
Pandas is a powerful library that provides data structures like DataFrames, which are essential for handling structured data. It simplifies data manipulation and analysis, allowing users to perform operations like filtering, grouping, and merging datasets effortlessly.
2. NumPy
NumPy is crucial for numerical data analysis. It provides support for multi-dimensional arrays and matrices, along with a plethora of mathematical functions to perform complex calculations. This library is often used in conjunction with Pandas for enhanced data manipulation.
3. Matplotlib and Seaborn
Data visualization is a critical aspect of data analysis, and Matplotlib is one of the most popular libraries for this purpose. It allows users to create a variety of plots and graphs to represent their data visually. Seaborn, built on top of Matplotlib, provides a high-level interface for drawing attractive statistical graphics.
Using Python for Data Analysis: A Step-by-Step Approach
Step 1: Setting Up Your Environment
To start analyzing data with Python, you first need to set up your development environment. You can choose to install Python and the necessary libraries on your local machine or use platforms like Jupyter Notebook or Google Colab for a more user-friendly experience.
Step 2: Importing Libraries
Once your environment is set up, the next step is to import the libraries you’ll need for your analysis. A typical code snippet may look like this:

Step 3: Loading Data
Data can be loaded from various sources, including CSV files, Excel sheets, or databases. For example, to load a CSV file, you can use the following code:
Step 4: Exploring the Data
Before diving into analysis, it’s essential to understand the dataset you are working with. Use functions like data.head(), data.info(), and data.describe() to get an overview of your data, including the types of columns and basic statistics.
Step 5: Data Cleaning
Data cleaning is a crucial step in data analysis, as it ensures the accuracy and quality of your results. This may involve handling missing values, correcting data types, or removing duplicates. Pandas provides numerous functions to facilitate these tasks.
Step 6: Data Manipulation
Once your data is clean, you can start manipulating it to extract insights. This could involve filtering data based on specific criteria, grouping data for summary statistics, or merging multiple datasets.

Step 7: Data Visualization
Visualizing your data is vital to understanding trends and patterns. Use Matplotlib and Seaborn to create various types of plots, such as bar graphs, line charts, and scatter plots.

Step 8: Performing Analysis
Now that you have your data ready and visualized, you can perform various analyses based on your objectives. This could range from descriptive statistics to more advanced techniques like regression analysis.
Step 9: Interpreting Results
Analyzing your data is only part of the process; interpreting the results is equally important. Use your visualizations and statistical analyses to draw meaningful conclusions and insights from your data.
Step 10: Communicating Findings
Finally, effectively communicating your findings is critical. Prepare reports or presentations that summarize your analysis, including key insights and recommendations.
Additional Resources for Learning Python Data Analysis
If you’re looking to deepen your understanding of Python for data analysis, consider enrolling in python courses in Coimbatore alongside Python training. This can help you gain a well-rounded skill set that enhances your career prospects in tech and data-driven fields. For those in Coimbatore, the Software Training in Coimbatore can provide tailored courses and hands-on experience to set you up for success.
Conclusion
In summary, Python is a powerful tool for data analysis, offering a blend of ease of use and robust capabilities. By following the steps outlined above, anyone can effectively harness Python to analyze data and derive valuable insights. If you’re ready to start your journey in data analysis, consider reaching out to Xplore IT Corp for top-notch training and resources to help you succeed in the ever-evolving world of data.
With Python, the possibilities for data analysis are vast, and mastering it can lead to numerous opportunities in various fields. Embrace this language, and unlock your potential in data analysis today!
0 notes
Text
What is the main benefit of Python?
What is the main benefit of Python?
Python's widespread adoption and dominance across industries can be attributed to a myriad of benefits that cater to both beginners and seasoned professionals alike. Its versatility, simplicity, and robust ecosystem of libraries and frameworks make it an ideal choice for data science and beyond.
Versatility and Accessibility
Python's appeal begins with its versatility. It serves as a general-purpose programming language capable of addressing a wide range of tasks, from web development and scripting to scientific computing and data analysis. This versatility stems from Python's straightforward syntax, which emphasizes readability and ease of use. Its code resembles pseudo-code, making it accessible even to those new to programming.
For data scientists, this means being able to quickly prototype and experiment with algorithms and data structures without the steep learning curve often associated with other languages. Python's clear syntax also promotes collaboration among teams of varying technical backgrounds, fostering efficient communication and development cycles.

Rich Ecosystem of Libraries and Frameworks
A standout feature of Python is its extensive ecosystem of libraries and frameworks tailored specifically for data science. Libraries like NumPy and pandas provide powerful tools for numerical computations, data manipulation, and analysis. NumPy, for instance, offers support for large, multi-dimensional arrays and matrices, essential for handling complex data structures common in scientific computing.
For data visualization, libraries such as matplotlib and seaborn enable users to create insightful charts, plots, and graphs with minimal effort. These tools are instrumental in conveying data-driven insights to stakeholders and decision-makers effectively.
Machine learning (ML) and artificial intelligence (AI) applications benefit immensely from Python's specialized libraries. scikit-learn provides efficient implementations of popular ML algorithms for tasks like classification, regression, and clustering. TensorFlow and PyTorch, on the other hand, cater to deep learning enthusiasts, offering scalable solutions for building and training neural networks.
Community Support and Active Development
Python's thriving community plays a pivotal role in its ongoing evolution and adoption. The language boasts a vast community of developers, enthusiasts, and contributors who actively contribute to its development, maintenance, and enhancement. This community-driven approach ensures that Python remains at the forefront of technological advancements and industry trends.
The Python Package Index (PyPI) hosts thousands of open-source packages and modules, providing developers with a wealth of resources to extend Python's functionality. This ecosystem empowers users to leverage existing solutions and focus on solving higher-level problems rather than reinventing the wheel.
Agility and Rapid Prototyping
In data science, the ability to iterate quickly and experiment with different models and hypotheses is crucial. Python's interpreted nature allows for rapid prototyping and immediate feedback, facilitating a more iterative and agile approach to development. This agility is especially valuable in dynamic environments where requirements may evolve rapidly, enabling data scientists to adapt and pivot as needed.
Moreover, Python's flexibility enables seamless integration with other languages and platforms. Developers can easily incorporate Python scripts into larger applications written in languages like C++, Java, or even web frameworks like Django or Flask. This interoperability extends Python's utility beyond standalone scripts or data analysis tools, making it a versatile choice for building complex systems and applications.
Industry Adoption and Career Opportunities
The widespread adoption of Python across industries underscores its relevance and utility in the job market. Companies across sectors such as finance, healthcare, retail, and technology rely on Python for everything from backend development and automation to data analysis and machine learning.
For aspiring data scientists and professionals looking to enter the field of data science, proficiency in Python is often a prerequisite. The demand for skilled Python developers continues to grow, driven by the increasing reliance on data-driven decision-making and AI-driven innovations. This demand translates into abundant career opportunities and competitive salaries for those with expertise in Python and data science.
Conclusion
In conclusion, Python's popularity in data science and beyond can be attributed to its versatility, simplicity, robust ecosystem of libraries and frameworks, active community support, and agility in development. These attributes make Python an indispensable tool for data scientists, enabling them to tackle complex problems, analyze vast datasets, and derive actionable insights effectively.
Aspiring data scientists and developers looking to harness Python's potential can benefit from exploring its capabilities further through hands-on projects, tutorials, and resources available online.Whether you are just starting your journey in programming or aiming to advance your skills in data science, Python provides a solid foundation for building innovative solutions and driving technological advancements across various domains.
0 notes
Text
3D Scanner Market Outlook Report 2024-2030: Trends, Strategic Insights, and Growth Opportunities | GQ Research
The 3D Scanner Market is set to witness remarkable growth, as indicated by recent market analysis conducted by GQ Research. In 2023, the global 3D Scanner Market showcased a significant presence, boasting a valuation of US$ 1.03 billion. This underscores the substantial demand for Acetophenone technology and its widespread adoption across various industries.
Get Sample of this Report at: https://gqresearch.com/request-sample/global-3d-scanner-market/

Projected Growth: Projections suggest that the 3D Scanner Market will continue its upward trajectory, with a projected value of US$ 1.75 billion by 2030. This growth is expected to be driven by technological advancements, increasing consumer demand, and expanding application areas.
Compound Annual Growth Rate (CAGR): The forecast period anticipates a Compound Annual Growth Rate (CAGR) of 6.9%, reflecting a steady and robust growth rate for the 3D Scanner Market over the coming years.
Technology Adoption:
In the 3D Scanner market, technology adoption revolves around the development and integration of advanced sensors, optics, and software algorithms to capture and process three-dimensional objects with high precision and accuracy. Various technologies such as laser scanning, structured light scanning, and photogrammetry are utilized in 3D scanners to capture surface geometry, texture, and color information. Additionally, advancements in sensor miniaturization, calibration techniques, and data processing enable portable and handheld 3D scanners to achieve high-resolution scanning in diverse environments and applications.
Application Diversity:
The 3D Scanner market serves diverse applications across various industries, including manufacturing, healthcare, architecture, arts, and entertainment. 3D scanners are used in manufacturing and engineering for quality control, reverse engineering, and dimensional inspection of parts and components. Moreover, 3D scanning technology is employed in healthcare for patient diagnosis, treatment planning, and customized medical device design. Additionally, 3D scanners find applications in architecture and construction for building documentation, heritage preservation, and virtual reality simulation. Furthermore, 3D scanners are utilized in the entertainment industry for character modeling, animation, and virtual set creation.
Consumer Preferences:
Consumer preferences in the 3D Scanner market are driven by factors such as scanning accuracy, speed, versatility, ease of use, and affordability. End-users prioritize 3D scanners that offer high-resolution scanning, precise geometric detail, and color accuracy for capturing objects of varying sizes and complexities. Additionally, consumers value user-friendly interfaces, intuitive software workflows, and compatibility with existing CAD/CAM software for seamless integration into their design and manufacturing processes. Moreover, affordability and cost-effectiveness are important considerations for consumers, especially small and medium-sized businesses, when selecting 3D scanning solutions.
Technological Advancements:
Technological advancements in the 3D Scanner market focus on improving scanning performance, resolution, and functionality through hardware and software innovations. Research efforts aim to develop next-generation sensors, such as time-of-flight (ToF) and multi-view stereo (MVS) cameras, with higher resolution, wider field of view, and enhanced depth sensing capabilities for improved 3D reconstruction. Additionally, advancements in software algorithms for point cloud processing, mesh generation, and texture mapping enable faster and more accurate reconstruction of scanned objects. Moreover, integration with artificial intelligence (AI) and machine learning techniques enhances feature recognition, noise reduction, and automatic alignment in 3D scanning workflows.
Market Competition:
The 3D Scanner market is characterized by intense competition among hardware manufacturers, software developers, and service providers, driven by factors such as scanning performance, product reliability, pricing, and customer support. Major players leverage their research and development capabilities, extensive product portfolios, and global distribution networks to maintain market leadership and gain competitive advantage. Meanwhile, smaller players and startups differentiate themselves through specialized scanning solutions, niche applications, and targeted marketing strategies. Additionally, strategic partnerships, acquisitions, and collaborations are common strategies for companies to expand market reach and enhance product offerings in the competitive 3D Scanner market.
Environmental Considerations:
Environmental considerations are increasingly important in the 3D Scanner market, with stakeholders focusing on energy efficiency, resource conservation, and sustainable manufacturing practices. Manufacturers strive to develop energy-efficient scanning devices with low power consumption and eco-friendly materials to minimize environmental impact during production and operation. Additionally, efforts are made to optimize packaging materials, reduce waste generation, and implement recycling programs to promote sustainable consumption and disposal practices in the 3D Scanner industry. Furthermore, initiatives such as product life cycle assessment (LCA) and eco-design principles guide product development processes to minimize carbon footprint and environmental footprint throughout the product lifecycle.
Top of Form
Regional Dynamics: Different regions may exhibit varying growth rates and adoption patterns influenced by factors such as consumer preferences, technological infrastructure and regulatory frameworks.
Key players in the industry include:
FARO Technologies, Inc.
Hexagon AB (Leica Geosystems)
Creaform (Ametek Inc.)
Trimble Inc.
Nikon Metrology NV
Artec 3D
GOM GmbH
Zeiss Group
Perceptron, Inc.
Keyence Corporation
Konica Minolta, Inc.
Shining 3D
Topcon Corporation
ShapeGrabber Inc.
SMARTTECH 3D
The research report provides a comprehensive analysis of the 3D Scanner Market, offering insights into current trends, market dynamics and future prospects. It explores key factors driving growth, challenges faced by the industry, and potential opportunities for market players.
For more information and to access a complimentary sample report, visit Link to Sample Report: https://gqresearch.com/request-sample/global-3d-scanner-market/
About GQ Research:
GQ Research is a company that is creating cutting edge, futuristic and informative reports in many different areas. Some of the most common areas where we generate reports are industry reports, country reports, company reports and everything in between.
Contact:
Jessica Joyal
+1 (614) 602 2897 | +919284395731
Website - https://gqresearch.com/
0 notes
Text
Introduction to Python and Data Science
Python has become the go-to programming language for data science due to its simplicity and powerful libraries. If you're just starting your journey into the world of data science, Python is an excellent choice. This guide will take you through the essential Python programming concepts you need to know to embark on your data science adventure.
Setting Up Your Python Environment
Before diving into Python, you'll need to set up your environment. The good news is, Python is free and easy to install. You can download it from the official Python website and choose from various Integrated Development Environments (IDEs) such as PyCharm, Jupyter Notebook, or VS Code. These tools provide a user-friendly interface for writing and executing Python code.
Python Basics: Variables, Data Types, and Operators
Let's start with the basics. In Python, you use variables to store data. Variables can hold different types of data, such as numbers, strings (text), lists, and more. Python also provides various operators for mathematical operations, comparisons, and logical operations. Understanding these basics sets the foundation for more complex data manipulation.
Control Flow: Making Decisions with Python
Control flow statements allow you to dictate the flow of your program. With if statements, for loops, and while loops, you can control how your code executes based on conditions. This is crucial for data analysis, where you often need to filter and process data based on specific criteria.
Python Functions: Building Blocks for Data Analysis
Functions in Python are reusable blocks of code that perform specific tasks. They help in organizing your code and making it more modular. You'll learn how to create functions, pass arguments, and return values. This knowledge becomes invaluable as you start working with larger datasets and complex operations.
Working with Data: Libraries and Data Structures
Python's strength in data science comes from its powerful libraries. Two essential libraries for data manipulation are NumPy and Pandas. NumPy provides support for large, multi-dimensional arrays and matrices, while Pandas offers data structures like DataFrames, which are ideal for data manipulation and analysis.
Data Analysis with Pandas: Your Data Science Swiss Army Knife
Pandas is a game-changer for data scientists. It allows you to read data from various sources, clean and preprocess data, perform statistical analysis, and much more. With Pandas DataFrames, you can slice and dice your data, filter rows and columns, and aggregate information with ease.
Visualization with Matplotlib: Bringing Data to Life
A picture is worth a thousand words, especially in data science. Matplotlib is a plotting library that enables you to create various types of visualizations, including line plots, bar charts, histograms, and scatter plots. Visualizations help in understanding trends, patterns, and relationships within your data, making complex information more accessible.
Putting It All Together: A Simple Data Analysis Project
To wrap up your beginner's journey, we'll walk through a simple data analysis project. You'll apply everything you've learned by loading a dataset, cleaning and preparing the data with Pandas, performing some basic analysis, and creating visualizations with Matplotlib. This hands-on project will solidify your understanding and prepare you for more advanced data science tasks.
0 notes
Text
Character #3 Multi-Silver
Subject Name: Silver The Hedgehog
Atlas: Multi-Dimensional Silver/ Multi-Silver /Paradox Anomaly / MS- 01
Age: 17
Gender: Male
Species: Hedgehog
Classification: Euclid (Possibly Keter)
Status: Alive
Location: Unknown
Special Containment Procedures: MS-01, due to the ongoing investigation into his origins, remains uncontained and presumed to be traversing the multiverse. Initial attempts to establish containment proved disastrous. MS-01 exhibits exceptional telekinetic combat prowess and demonstrates a remarkable resistance to conventional weaponry. Furthermore, his emotional state presents a significant containment challenge. When overwhelmed by negative emotions, MS-01 can trigger unpredictable dimensional distortions, potentially endangering Foundation personnel and causing widespread disruption within the local space-time continuum. Due to these factors, direct confrontation with MS-01 is strictly prohibited. Foundation personnel encountering MS-01 are instructed to prioritize information gathering and maintain a safe distance. All efforts should be focused on de-escalation and establishing a peaceful dialogue, whenever possible.
Description: Despite his resemblance to Silver the Hedgehog, Multi-Silver boasts distinct features. His snow-white fur exhibits a glitching, multicolored effect, especially at the tips of his low ponytail. A diagonal scar cuts across his face, hinting at his past battles. Multi-Silver favors a practical yet stylish look: teal sunglasses shield his eyes, a weathered dark navy blue bandana replaces the traditional scarf, and black fingerless gloves (reaching his elbows) complement the matching boots and armbands. Occasionally, a black puffy jacket reminiscent of his racing suit offers extra protection, with rolled-up sleeves revealing dark navy blue under-gloves – a personalized touch that completes his unique visual identity.
Personality Analysis: Subject Silver presents a complex personality, a fascinating mix of resilience and vulnerability. While retaining some of the documented Silver the Hedgehog's core traits – intelligence, maturity, and unwavering optimism – MS-01's experiences have sculpted him into a more guarded individual. On the surface, MS-01 exhibits a semi-social and friendly demeanor. He interacts with others, showcasing a dry wit and a touch of cynicism, likely a result of his jaded perspective. However, beneath this facade lies a well of compassion. He retains a strong belief in the good of others and possesses a genuine desire to help those in need. This inherent kindness often leads him to appear overly optimistic, a stark contrast to his traveling companion, Shadow. Despite his outward optimism, MS-01 harbors deep emotional scars, hinting at a traumatic past. He struggles with underlying anxiety and a diminished capacity for trust, likely stemming from past betrayals or devastating losses. This internal conflict manifests in his tendency to suppress his emotions, masking them with a forced smile. Unlike Shadow, who prioritizes logic and reason, MS-01 operates more intuitively, following his heart. This emotional drive fuels his unwavering determination to help others and fight for the greater good. However, his unwavering optimism can occasionally cloud his judgment, requiring grounding from Shadow or others. While MS-01's past has left him emotionally fractured, his inherent compassion and Whileto help remain strong. With time and support, he may learn to reconcile his optimism with the harsh realities of his journey, eventually finding healing and forging stronger, more trusting bonds.
Addendum MS - 01 - 1: MS-01 appears to function within a well-established team alongside designated anomalies MDSH-01 , MK-01, and an unidentified metallic avian entity resembling a variant of E-123 Omega. Within this group, MS-01 fulfills a multifaceted role, acting as both the emotional core and the tech expert. He fosters camaraderie and offers support to his companions, while also utilizing his strong technological aptitude to potentially maintain equipment, analyze anomalies, or even devise strategies for navigating the complexities of the multiverse. Additionally, MS-01's grounded perspective often positions him as the voice of reason within the group, offering a counterpoint to potentially impulsive actions from his companions. Observations suggest a strong bond exists between MS-01 and all members of his group, with a particularly close relationship noted between him and MDSH-01. Further investigation suggests a romantic attachment between these two entities, with this emotional connection potentially serving as a powerful motivator for MS-01's actions. The presence of the metallic avian entity within the group further suggests a potential collaborative dynamic. Further research is required to determine the full nature and capabilities of this entity and its role within the group.
Addendum MS-01-2: MS-01's primary motivation appears to be the the well-being of his companions designated MDSH-01 and MK-01 - Multiverse Knuckles - 01). He exhibits a strong sense of loyalty and a deep desire to reunite with them and restore their shattered reality However, MS-01's existence seems to be inherently unstable, conflicting with the natural order of the multiverse. This revelation has triggered significant emotional distress in MS-01, causing him to grapple with the possibility of being erased from existence. Despite this existential threat, MS0-1 prioritizes ensuring the safety and happiness of his companions above his own survival. He demonstrates a selfless willingness to sacrifice himself, even through means as drastic as self-termination, if it guarantees a positive outcome for his friends This unwavering loyalty, coupled with MS-01's emotional instability, presents a potential containment challenge. Foundation personnel should be aware of this dynamic and prioritize de-escalation tactics during interactions with MS-01. Additionally, further investigation into the nature of MS-01's existence and the potential for restoring his reality, or integrating him into the Foundation's reality with minimal disruption, is a high priority.
MS-01's Abilities:
Dimensional Jumping: Travels between realities, aiding his search and offering strategic advantages (similar to Mephiles).
Potent Psychokinesis: Manipulates objects with his mind, levitating objects and creating defensive barriers.
Sustained Flight: Utilizes psychokinesis for agile aerial maneuvers.
Flash Step: Teleports short distances for evasive maneuvers and strategic repositioning (inspired by Dave Strider from Homestuck).
Telepathic Communication: Establishes mental connections for communication across vast distances.
Pocket Dimension Manipulation: Creates and manipulates extradimensional spaces for storage, refuge, or planning.
Limited Time Manipulation: Slows down or accelerates time in localized areas for combat advantages or escapes (limited duration and scope).
Reality Distortion (Glitching): Induces unpredictable temporal anomalies (visual distortions, spatial anomalies, temporal loops) as a result of his anomalous existence. While potentially useful in combat (distractions, barriers, weapons), excessive use risks destabilizing reality.
MS-01's Relationships: MS-01's past relationships paint a picture of significant loss and complex emotional entanglements.
Multiverse Shadow: Multi-Silver relationship with Multi-Shadow transcends friendship, blossoming into a deep and committed romantic partnership. This bond serves as a source of unwavering loyalty and trust. Multi-Silver confides in Multi - Shadow completely, finding solace and strength in their shared experiences and unwavering support. Their connection is the driving force behind Multi - Silver s actions, as his primary motivation revolves around ensuring Multi-Shadow safety and happiness, even at his own expense.
Multiverse Knuckles: Multi-Silver finds a sense of familiarity and camaraderie in Multi-Knuckles. While not a replica of the bond he shared with Blaze the Cat from his original reality, Multi-Knuckles fills a similar role as a confidant and source of emotional support. Their dynamic revolves around mutual respect and understanding, with Multi-Silver appreciating Multi-Knuckles unwavering loyalty and grounded perspective.
Sonic Forces Espio: Multi-Silver alludes to a past romantic entanglement with Espio from the Sonic Forces reality. The nature of this relationship remains shrouded in mystery, with limited information available regarding its duration or significance.
E-123 Omega: This unidentified metallic avian entity, resembling a variant of E-123 Omega, appears to collaborate with the group. Further investigation is necessary to determine the full extent of their connection and the role this entity plays within the group. However, observations suggest a strong bond exists, with Multi-Silver considering E-123 Omega a close friend.
Background: A wanderer with no home, Multi-Silver found solace – and love – with Espio in the Sonic Forces reality. Fate intervened when Multi-Shadow appeared, offering a shared purpose and a burgeoning connection. Torn, Multi-Silver chose to follow Multi-Shadow, severing his romantic ties with Espio. Over time, Multi-Silver and Multi-Shadow's bond deepened, solidifying after attempts to erase him. Their travels led to Multi-Knuckles, forming a formidable trio. Despite newfound companionship, the separation from Espio lingers. Multi-Silver's journey continues, shrouded in mystery and the weight of his anomalous existence. No more information has been found.
Side Note: Any attempt to permanently harm Multi-Shadow or Multi-Knuckles triggers a catastrophic reaction from Multi-Silver. In such scenarios, Multi-Silver undergoes a horrifying transformation, resembling a corrupted version of Silver the Hedgehog known as "Dark Silver." This transformation imbues him with god-like power, posing a significant threat to the stability of reality itself. Due to the potential for multiversal collapse, diplomatic solutions and negotiations are considered the highest priority when dealing with Multi-Silver and his companions.
0 notes
Text
Unleashing the Power of Python in Data Science: Key Benefits to Consider
Python has emerged as a dominant force in the field of data science, offering a multitude of advantages that can significantly enhance your data analysis and machine learning endeavors. Whether you are a novice or an experienced data scientist, learning Python can unlock a world of possibilities. In this article, we will delve into the key benefits of harnessing Python for data science, showcasing how its versatility and extensive library support can propel your data-driven projects to new heights.
Embarking on the Python learning journey becomes even more thrilling, whether you’re a complete beginner or transitioning from another programming language, especially with the valuable assistance of Python Training in Pune.

Unlocking Readability and Simplicity: Embracing Python means embracing a programming language renowned for its clean and readable syntax. With Python, you can write code that is not only efficient but also highly comprehensible, enabling you to focus more on solving complex data-related problems rather than getting entangled in convoluted programming constructs. The simplicity of Python empowers you to write elegant code that is easily understandable and maintainable by your peers.
Embracing an Extensive Ecosystem of Libraries: Python boasts an expansive ecosystem of libraries and frameworks tailored specifically for data science. At the forefront is NumPy, a powerful library that provides support for large, multi-dimensional arrays and matrices. Complementing NumPy, libraries such as Pandas, Matplotlib, and SciPy offer an array of functionalities for data manipulation, analysis, visualization, and scientific computing. These libraries act as indispensable tools, accelerating your data analysis workflow and simplifying intricate data operations.
Harnessing the Power of a Supportive Community: Python's immense popularity is fueled by its vibrant community of data scientists and developers. This community-driven environment ensures that a wealth of resources, tutorials, and forums are available to facilitate your learning journey and troubleshoot challenges. Whether you seek guidance on specific data analysis techniques or wish to explore advanced machine learning algorithms, the Python community stands ready to provide assistance, fostering a collaborative and supportive atmosphere.
Empowering Machine Learning and Deep Learning: Python has become the language of choice for machine learning and deep learning projects. With libraries like Scikit-learn, TensorFlow, and PyTorch, you gain access to comprehensive toolsets for building and deploying machine learning models. These libraries offer a diverse range of algorithms and utilities for classification, regression, clustering, and neural networks. Python's simplicity and expressiveness enable you to experiment with different approaches, facilitating rapid prototyping and empowering innovation.
Enrolling in the Best Python Online Training can help people understand Python complexities and realize its full potential.
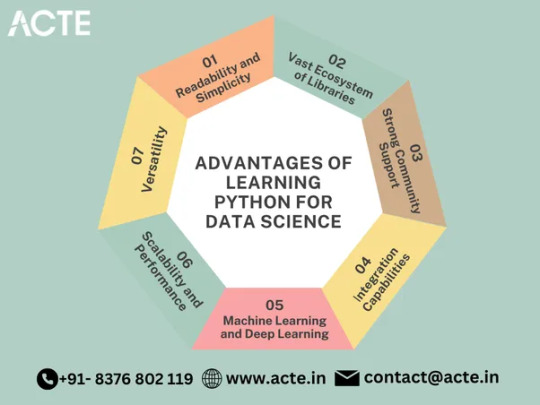
Seamless Integration Capabilities: One of Python's greatest strengths lies in its ability to seamlessly integrate with other programming languages. This feature allows data scientists to leverage existing code and libraries from languages like R, Java, or C++. By combining the best features of multiple languages, you can create a cohesive ecosystem that optimizes productivity and maximizes the potential of your data science projects.
Scaling up with Performance and Scalability: Python's performance has significantly improved over the years, making it a capable choice for handling large datasets and complex computations. Through libraries like Dask and Apache Spark, Python supports parallel processing and distributed computing, enabling you to scale your analyses efficiently. These tools empower you to process vast amounts of data seamlessly, ensuring your data science workflows remain robust and efficient.
Unleashing Versatility: Python's versatility extends beyond the realm of data science. As a general-purpose programming language, Python opens doors to diverse applications, including web development, automation, scripting, and more. By developing proficiency in Python, you gain the flexibility to explore various domains and expand your career prospects beyond the boundaries of data analysis.
Python has emerged as a powerhouse in the field of data science, offering a broad range of benefits that can elevate your data analysis and machine learning endeavors. Its readability, extensive library support, strong community, integration capabilities, performance, scalability, and versatility make it an indispensable tool for any data scientist.
By embracing Python, you unlock a world of possibilities and position yourself for success in the dynamic landscape of data science. Start your journey today and harness the true power of Python in data science.
0 notes
Text
Top 4 Machine Learning Projects on GitHub
There are many popular machine learning projects on GitHub, which cover everything from basic algorithms to complex applications. Here are four particularly popular machine learning projects:
1. TensorFlow Introduction: TensorFlow is the second-generation machine learning system released by Google. It is an open source machine learning library for numerical computing, especially the training of large-scale neural networks. It uses data flow graphs for numerical computing. The nodes in the graph represent mathematical operations, and the edges represent multidimensional arrays (tensors) flowing between nodes. TensorFlow supports multiple programming languages, including Python, C++, and Java.
Features:
Flexible: can be deployed on desktops, servers, or mobile devices.
Automatic differentiation: supports gradient-based machine learning algorithms.
Efficient Python interface: easy for users to express ideas.
Application: TensorFlow is widely used in various fields, including speech recognition (such as speech recognition in Google App), image search (such as image search in Google Photos), etc.
2. PyTorch Introduction: PyTorch is an open source machine learning library developed by Facebook, focusing on deep learning applications. It provides two main features: Tensor computing with powerful GPU acceleration and a tape-based automatic programming system for building deep neural networks.
Features:
Dynamic computational graph: Unlike the static computational graph of TensorFlow, PyTorch uses dynamic computational graphs, making debugging and prototyping easier. Pythonic style: Its API design is more in line with Python programming habits. Rich ecosystem: It has a large community and a large number of third-party library support. Application: PyTorch is very popular in academic research and industry, and is used in various deep learning projects.
3. Scikit-learn Introduction: Scikit-learn is a Python module for machine learning, built on SciPy. It provides simple and efficient data mining and data analysis tools, and is one of the commonly used libraries for data scientists and machine learning engineers.
Features:
Simple operation: Provides an easy-to-use API. Comprehensive functions: Covers a variety of machine learning tasks such as classification, regression, clustering, and data dimensionality reduction. High reusability: Supports reusing models in various scenarios. Application: Scikit-learn is widely used in various data mining and machine learning projects.
4. OpenPose Introduction: OpenPose is a multi-person key point detection library developed and maintained by CMU’s Perceptual Computing Laboratory. It can help us detect the position of a person in an image or video in real time and identify key points (such as joints).
Features:
Strong real-time performance: It can detect key points in real time in a video stream. High precision: It can accurately identify multiple key points of the human body. Wide application: It can be used in many fields such as motion capture and behavior analysis. Application: OpenPose is widely used in sports analysis, virtual reality, game development and other fields.
0 notes
Text
A Layman’s Guide to Data Science: How to Become a (Good) Data Scientist

How simple is Data Science?
Sometimes when you hear data scientists shoot a dozen of algorithms while discussing their experiments or go into details of Tensorflow usage you might think that there is no way a layman can master Data Science. Big Data looks like another mystery of the Universe that will be shut up in an ivory tower with a handful of present-day alchemists and magicians. At the same time, you hear about the urgent necessity to become data-driven from everywhere.
The trick is, we used to have only limited and well-structured data. Now, with the global Internet, we are swimming in the never-ending flows of structured, unstructured and semi-structured data. It gives us more power to understand industrial, commercial or social processes, but at the same time, it requires new tools and technologies.
Data Science is merely a 21st century extension of mathematics that people have been doing for centuries. In its essence, it is the same skill of using information available to gain insight and improve processes. Whether it’s a small Excel spreadsheet or a 100 million records in a database, the goal is always the same: to find value. What makes Data Science different from traditional statistics is that it tries not only to explain values, but to predict future trends.
In other words, we use Data Science for:

Data Science is a newly developed blend of machine learning algorithms, statistics, business intelligence, and programming. This blend helps us reveal hidden patterns from the raw data which in turn provides insights in business and manufacturing processes.

What should a data scientist know?
To go into Data Science, you need the skills of a business analyst, a statistician, a programmer, and a Machine Learning developer. Luckily, for the first dive into the world of data, you do not need to be an expert in any of these fields. Let’s see what you need and how you can teach yourself the necessary minimum.
Business Intelligence
When we first look at Data Science and Business Intelligence we see the similarity: they both focus on “data” to provide favorable outcomes and they both offer reliable decision-support systems. The difference is that while BI works with static and structured data, Data Science can handle high-speed and complex, multi-structured data from a wide variety of data sources. From the practical perspective, BI helps interpret past data for reporting or Descriptive Analytics and Data Science analyzes the past data to make future predictions in Predictive Analytics or Prescriptive Analytics.
Theories aside, to start a simple Data Science project, you do not need to be an expert Business Analyst. What you need is to have clear ideas of the following points:
have a question or something you’re curious about;
find and collect relevant data that exists for your area of interest and might answer your question;
analyze your data with selected tools;
look at your analysis and try to interpret findings.
As you can see, at the very beginning of your journey your curiosity and common sense might be sufficient from the BI point of view. In a more complex production environment, there will probably be separate Business Analysts to do insightful interpreting. However, it is important to have at least dim vision of BI tasks and strategies.
Resources
We recommend you to have a look at the following introductory books to feel more confident in analytics:
Introduction To The Basic Business Intelligence Concepts — an insightful article giving an overview of the basic concepts in BI;
Business Intelligence for Dummies — a step-by-step guidance through the BI technologies;
Big Data & Business Intelligence — an online course for beginners;
Business Analytics Fundamentals — another introductory course teaching the basic concepts of BI.
Statistics and probability
Probability and statistics are the basis of Data Science. Statistics is, in simple terms, the use of mathematics to perform technical analysis of data. With the help of statistical methods, we make estimates for the further analysis. Statistical methods themselves are dependent on the theory of probability which allow us to make predictions. Both statistics and probability are separate and complicated fields of mathematics, however, as a beginner data scientist, you can start with 5 basic statistics concepts:
Statistical features. Things like bias, variance, mean, median, percentiles, and many others are the first stats technique you would apply when exploring a dataset. It’s all fairly easy to understand and implement them in code even at the novice level.
Probability Distributions represent the probabilities of all possible values in the experiment. The most common in Data Science are a Uniform Distribution that has is concerned with events that are equally likely to occur, a Gaussian, or Normal Distribution where most observations cluster around the central peak (mean) and the probabilities for values further away taper off equally in both directions in a bell curve, and a Poisson Distribution similar to the Gaussian but with an added factor of skewness.
Over and Under Sampling that help to balance datasets. If the majority class is overrepresented, undersampling helps select some of the data from it to balance it with the minority class has. When data is insufficient, oversampling duplicates the minority class values to have the same number of examples as the majority class has.
Dimensionality Reduction. The most common technique used for dimensionality reduction is PCA which essentially creates vector representations of features showing how important they are to the output i.e. their correlation.
Bayesian Statistics. Finally, Bayesian statistics is an approach applying probability to statistical problems. It provides us with mathematical tools to update our beliefs about random events in light of seeing new data or evidence about those events.

Image credit: unsplash.com
Resources
We have selected just a few books and courses that are practice-oriented and can help you feel the taste of statistical concepts from the beginning:
Practical Statistics for Data Scientists: 50 Essential Concepts — a solid practical book that introduces essential tools specifically for data science;
Naked Statistics: Stripping the Dread from the Data — an introduction to statistics in simple words;
Statistics and probability — an introductory online course;
Statistics for data science — a special course on statistics developed for data scientists.
Programming
Data Science is an exciting field to work in, as it combines advanced statistical and quantitative skills with real-world programming ability. Depending on your background, you are free to choose a programming language to your liking. The most popular in the Data Science community are, however, R, Python and SQL.
R is a powerful language specifically designed for Data Science needs. It excels at a huge variety of statistical and data visualization applications, and being open source has an active community of contributors. In fact, 43 percent of data scientists are using R to solve statistical problems. However, it is difficult to learn, especially if you already mastered a programming language.
Python is another common language in Data Science. 40 percent of respondents surveyed by O’Reilly use Python as their major programming language. Because of its versatility, you can use Python for almost all steps of data analysis. It allows you to create datasets and you can literally find any type of dataset you need on Google. Ideal for entry level and easy-to learn, Python remains exciting for Data Science and Machine Learning experts with more sophisticated libraries such as Google’s Tensorflow.
SQL (structured query language) is more useful as a data processing language than as an advanced analytical tool. IT can help you to carry out operations like add, delete and extract data from a database and carry out analytical functions and transform database structures. Even though NoSQL and Hadoop have become a large component of Data Science, it is still expected that a data scientist can write and execute complex queries in SQL.
Resources
There are plenty of resources for any programming language and every level of proficiency. We’d suggest visiting DataCamp to explore the basic programming skills needed for Data Science.
If you feel more comfortable with books, the vast collection of O’Reilly’s free programming ebooks will help you choose the language to master.

Image credit: unsplash.com
Machine Learning and AI
Although AI and Data Science usually go hand-in-hand, a large number of data scientists are not proficient in Machine Learning areas and techniques. However, Data Science involves working with large amounts of data sets that require mastering Machine Learning techniques, such as supervised machine learning, decision trees, logistic regression, etc. These skills will help you to solve different data science problems that are based on predictions of major organizational outcomes.
At the entry level, Machine Learning does not require much knowledge of math or programming, just interest and motivation. The basic thing that you should know about ML is that in its core lies one of the three main categories of algorithms: supervised learning, unsupervised learning and reinforcement learning.
Supervised Learning is a branch of ML that works on labeled data, in other words, the information you are feeding to the model has a ready answer. Your software learns by making predictions about the output and then comparing it with the actual answer.
In unsupervised learning, data is not labeled and the objective of the model is to create some structure from it. Unsupervised learning can be further divided into clustering and association. It is used to find patterns in data, which are especially useful in business intelligence to analyze the customer behavior.
Reinforcement learning is the closest to the way that humans learn,i.e. by trial and error. Here, a performance function is created to tell the model if what it did was getting it closer to its goal or making it go the other way. Based on this feedback, the model learns and then makes another guess, this continues to happen and every new guess is better.
With these broad approaches in mind, you have a backbone for analysis of your data and explore specific algorithms and techniques that would suit you the best.
Resources
Similarly to programming, there are numerous books and courses in Machine Learning. Here are just a couple of them:
Deep Learning textbook by Ian Goodfellow and Yoshua Bengio and Aaron Courville is a classic resource recommended for all students who want to master machine and deep learning.
Machine Learning course by Andrew Ng is an absolute classic that leads your through the most popular algorithms in ML.
Machine Learning A-Z™: Hands-On Python & R In Data Science — a Udemy course specifically for novice data scientists that introduces basic ML concepts both in R and Python.
What skills should a data scientist possess?
Now you know the main prerequisites for Data Science. Does it make you a good data scientist? While there is no correct answer, there are several things to take into consideration:
Analytical Mindset: it is a general requirement for any person working with data. However, if common sense might suffice at the entry level, your analytical thinking should be further backed up by statistical background and knowledge of data structures and machine learning algorithms.
Focus on Problem Solving: when you master a new technology, it is tempting to use it everywhere, However, while it is important to know recent trends and tools, the goal of Data Science is to solve specific problems by extracting knowledge from data. A good data scientist first understands the problem, then defines the requirements for the solution to the problem, and only then decides which tools and techniques are best fit for the task. Don’t forget that stakeholders will never be captivated by the impressive tools you use, only by the effectiveness of your solution.
Domain Knowledge: data scientists need to understand the business problem and choose the appropriate model for the problem. They should be able to interpret the results of their models and iterate quickly to arrive at the final model. They need to have an eye for detail.
Communication Skills: there’s a lot of communication involved in understanding the problem and delivering constant feedback in simple language to the stakeholders. But this is just the surface of the importance of communication — a much more important element of this is asking the right questions. Besides, data scientists should be able to clearly document their approach so that it is easy for someone else to build on that work and, vice versa, understand research work published in their area.
As you can see, it is the combination of various technical and soft skills that make up a good data scientist.
0 notes
Text
Just How Big Is The Automotive Defroster Market ?
The COVID-19 pandemic has caused supply and manufacturing disruptions in the automotive sector creating uncertainties in every aspect. The change in customer behavior in terms of mobility preferences during this crisis is changing the automotive landscape.
This pandemic situation has shut down many production lines owing to the trade restrictions and closed borders, creating a shortage in required parts and limiting the distribution of supplies. Different enforced measures including the closing of workspaces and dismissal of short-time workers have created a depression in the growth rate of the automotive industry.
The growing fear of recession is estimated to decrease overall sales and revenue. A limited supply of parts coupled with a reduced workforce has forced the leading OEMs to shut down their production. A significant drop in demand has restricted the cash inflow which is highly important in payment of salaries to the workforce. With growing uncertainties around the COVID-19 pandemic, the industry leaders are taking measures to adapt to the situation.
Automotive Defroster Market: Introduction
Safe commuting through an automotive vehicle demands the vehicle to be in a perfect and safe working condition, especially in cold and foggy conditions. Forming of ice or fog on windshields in extreme weather conditions hampers the visibility of the driver, leading to accidents. Automotive defrosters (defogger or demister) are used in automotive vehicles for this specific reason, to remove ice and fog from the windshields of the vehicles. Automotive defrosters are categorized into two main types. Primary automotive defrosters, which use HVAC system and are installed on the front windshield and secondary automotive defrosters, installed don the rear windshield and don’t used HVAC system. Automotive defrosters blows warm air onto the windshield of the vehicle causing the icing to melt and provides a better visibility to the driver. They can also remove the condensation from the insides of the windshield by removing moisture. Given their functionality to provide better visual aids to the driver, automotive defroster market is expected to witness significant demand in the coming years.
For detailed insights on enhancing your product footprint, request for a Sample Report here https://www.persistencemarketresearch.com/samples/27325
Automotive Defroster Market: Dynamics
Automotive defroster plays a vital role in automotive vehicles, passenger and commercial vehicles alike, operating in cold weather conditions. The need for having a better visibility while driving in cold, foggy weather conditions is one of the main driving factors for the increasing demand of automotive defrosters.
Among the type segment, primary automotive defroster segment is expected to create a greater demand as compared to secondary automotive defrosters, as the primary defrosters are mostly used on the front windshields. Given their use of HVAC system, primary automotive defrosters are highly preferred among consumers. The aftermarket for automotive defrosters is expected to be significantly high due to their high replacement rate and hence, the aftermarket segment in sales channel type is expected to lead the automotive defrosters market. In the vehicle type segment, passenger cars segment is expected to create high demand for automotive defrosters due to the growing number of personal vehicles across the globe. Overall, automotive defroster market is expected to witness significant demand during the forecast period.
Automotive Defroster: Market Segmentation
The global Automotive Defroster market has been segmented on the basis of type as:
Primary Automotive Defrosters
Secondary Automotive Defrosters
The global Automotive Defroster market has been segmented on the basis of sales channel as:
OEM
Aftermarket
The global Automotive Defroster market has been segmented on the basis of vehicle type as:
Passenger Cars
Light Motor Vehicles
Heavy Motor Vehicles
Automotive Defroster Market: Regional Overview
On a global scale, regions prone to severe cold weather conditions are estimated to create huge demand for automotive defroster. Among cold prone regions, North America is expected to have a significant market share in the automotive defroster market during the forecast period due to the growing automotive market in the region and the extremely cold conditions in the northern part of the U.S. and all of Canada. Europe region is expected to follow North America in terms of market share, due to the high number of automotive sales in the region coupled with a large aftermarket. China leads the market share in terms of automotive sales by a single country and given the extreme cold conditions the country witnesses during winter, the region is expected to lead the market share in the automotive defroster market during the forecast period. Growing economies like India, are expected to boost the automotive defroster market growth in Asia-Pacific region due to the increasing year-on-year sales of automotive vehicles in the region. Hence, Asia-Pacific region is estimated to register a high growth rate over the forecast period in the automotive defroster market. Japan is also expected to have a significant impact on the growth automotive defroster demand due to the high number of automotive sales and extreme cold conditions in the region. Middle East and Africa region is expected to occupy significantly smaller market share in the automotive defroster market as compared to other regions, given the extreme hot and humid weather in the region.
Global Automotive Defroster Market: Key Players
Examples of some of the market participants in the global Automotive Defroster market identified across the value chain include:
Proair, LLC
Thermo King
Bergstrom, Inc.
Red Dot Corp.
SGM Co., Inc.
Valad Electric Heating Corp.
AGC
Full Vision, Inc.
Interdynamics Research & Development
Boryszew Group
Brief Approach to Research
The research report presents a comprehensive assessment of the Automotive Defroster market and contains thoughtful insights, facts, historical data and statistically supported and industry-validated market data. It also contains projections using a suitable set of assumptions and methodologies. The research report provides analysis and information according to Automotive Defroster market segments such as geographies, application and industry.
To receive extensive list of important regions, ask for TOC here https://www.persistencemarketresearch.com/toc/27325
Our unmatched research methodologies set us apart from our competitors. Here’s why:
PMR’s set of research methodologies adhere to the latest industry standards and are based on sound surveys.
We are committed to preserving the objectivity of our research.
Our analysts customize the research methodology according to the market in question in order to take into account the unique dynamics that shape the industry.
Our proprietary research methodologies are designed to accurately predict the trajectory of a particular market based on past and present data.
PMR’s typical operational model comprises elements such as distribution model, forecast of market trends, contracting and expanding technology applications, pricing and transaction model, market segmentation, and vendor business and revenue model.
Persistence Market Research’s proactive approach identifies early innovation opportunities for clients in the global automotive sector. Our insights on next-generation automotive technologies such as connected cars, automotive emissions control, vehicle-to-vehicle (V2V), autonomous cars, electric and hybrid vehicles, and augmented reality dashboards ensure clients stay at the forefront of innovation.
Our competencies go beyond regular market research to deliver tailored solutions in an industry marked with increasing environment regulations, evolving consumer preferences, and a shifting landscape of emerging markets. We pride ourselves in helping our clients maximize their profits and minimize their risks. Actionable Insights & Transformational Strategies that Help you Make Informed Decisions.
Report Highlights:
Detailed overview of the parent market
Changing market dynamics in the industry
In-depth market segmentation
Historical, current, and projected market size in terms of volume and value
Recent industry trends and developments
Competitive landscape
Strategies of key players and products offered
Potential and niche segments, geographical regions exhibiting promising growth
A neutral perspective on market performance
Must-have information for market players to sustain and enhance their market footprint
There has been a growing trend toward consolidation in the automotive sector, with the output of motor vehicles resting mainly in the hands of a few large companies and smaller independent manufacturers gradually. Our next-generation research approach for exploring emerging technologies has allowed us to solve the most complex problems of clients.
For in-depth competitive analysis, Check Pre-Book here https://www.persistencemarketresearch.com/checkout/27325
Our client success stories feature a range of clients from Fortune 500 companies to fast-growing startups. PMR’s collaborative environment is committed to building industry-specific solutions by transforming data from multiple streams into a strategic asset.
About Us :
Persistence Market Research (PMR) is a third-platform research firm. Our research model is a unique collaboration of data analytics and market research methodology to help businesses achieve optimal performance. To support companies in overcoming complex business challenges, we follow a multi-disciplinary approach. At PMR, we unite various data streams from multi-dimensional sources.
Contact Us
Persistence Market Research U.S. Sales Office 305 Broadway, 7th Floor New York City, NY 10007 +1-646-568-7751 United States USA-Canada Toll-Free: 800-961-0353 E-mail id- [email protected] Website: www.persistencemarketresearch.com
0 notes
Text
Paper代写:Interdisciplinary development
下面为大家整理一篇优秀的paper代写范文- Interdisciplinary development,供大家参考学习,这篇论文讨论了跨学科的发展。跨学科,就是超越原有学科边界的学科,并形成一个综合性体系,早在百年前就已经被提出。跨学科也是一种多学科、交叉学科、超学科的表现形式,并且不同学科之间存在着相互关系。在对跨学科发展演变的基础上,还需要结合高等教育、社会服务、思维方式等方面进行思考,从而完善人才培养体系,为社会发展提供更多服务,实现多学科的整合。
Interdisciplinary is a discipline that transcends the boundary of the original discipline and forms a comprehensive system. Transdisciplinarity was proposed a hundred years ago. Compared with international developed countries, interdisciplinary research in China started in the 1980s, and has produced a series of changes in its subsequent development. With the continuous development of social economy, science and technology, China has complied with national policies and issued many relevant documents concerning "talents" and "innovation", among which interdisciplinary plays a very key role. Chinese scholars and experts in the interdisciplinary field have carried out a lot of exploration and made rich research results, but there are still some deficiencies in practice. This requires an in-depth analysis of interdisciplinary development and evolution, which is of great significance for promoting interdisciplinary development.
At the earliest stage of the origin of human civilization, the knowledge system of human society was philosophy and showed highly comprehensive characteristics due to the limited productivity and human cognition at that time. However, since science at that time did not achieve differentiation, this kind of comprehensiveness was more of an unclear understanding of the real world. In the second half of the 15th century, with the improvement of social productivity and the emergence of social division of labor, people began to study the world from a diversified perspective. Copernicus' theory on the operation of celestial bodies marked the emergence of modern natural science, and also made chemistry, physics, biology, geology and other sciences appear. Science also appears in this division, more independent disciplines, but content analysis methods, logic system is very consistent, making scientific research more fine, micro, professional. When people explore the world through independent knowledge, they are not completely restricted by disciplinary boundaries.
In scientific research, many scientists continue to make various scientific attempts due to their interest in scientific research or life needs, and produce a lot of research results. Among them, the most representative is the establishment of analytic geometry in the 17th century and physical chemistry in the 1870s. The former is the combination and intersection of geometry and algebra. The latter is a combination of studying chemistry and metallurgy, solving chemical problems by physical means.
Of course, ultimately to carry out the scientific knowledge development in the field of education, is also the foundation of university, secondary professional system set up, the unity and integrity of higher education the pursuit of knowledge, knowledge of specialized broke the traditional knowledge view of higher education, more and more education workers a detailed divided into subject gradually, and to integrate. The introduction of the concept of "general education" emphasizes the importance of comprehensive subjects, which enables people to further strengthen their professional ability and have a comprehensive and comprehensive understanding of other related subjects by informing education methods.
The whole development process mentioned above was inspired and developed by factors such as interests, hobbies and needs, so it arose unconsciously, that is, the thought stage of interdisciplinary.
In the middle of the 20th century, scientific research has been gradually carried out, constantly breaking the discipline boundaries, on the one hand, because the discipline continues to develop; On the other hand, it is directly related to problems and solving problems. In the early 20th century, due to the completion of the industrial revolution and the constant emergence of various new technologies, people's cognition of nature and society has been more comprehensively developed. The development of science promotes the integration of different fields and allows multi-disciplinary cooperation to solve problems. Especially in the second world war, the us federal government encouraged universities to conduct independent research, such as MIT research radar, the university of Chicago research nuclear fission control, the university of California research covert operations, etc., the national mandate made universities have to conduct interdisciplinary research.
After World War II, the United States also recognized the importance of interdisciplinary research, and increased its efforts in interdisciplinary research. With the strong support of the government, the cooperation between business, military and science was realized, and a large number of interdisciplinary industrial laboratories and interdisciplinary research institutions were established. Many universities have also built interdisciplinary research institutions on this basis. For example, the Massachusetts institute of technology has built an electronic laboratory based on the original radar research, which makes MIT a world-famous university. Then interdisciplinary education was further promoted, which promoted the development of American science.
Generally speaking, in the first half of the 20th century, due to people's real needs and awareness, interdisciplinary development was further developed, which also led to the stage of practical needs, in which interdisciplinary research became a specialized subject. First, interdisciplinary scientific research, advocating cooperation and research among multiple disciplines, and promoting the transformation of scientific achievements into productive forces; Secondly, it constructs and improves the interdisciplinary theoretical system, centering on the concept, level, classification, mechanism and status of interdisciplinary. Finally, the development of interdisciplinary education is aimed at the increasingly complex social system, and the social demand for people is gradually inclined to the compound and comprehensive direction.
The formation of multi-disciplines was in the theoretical and ideological stage mentioned above, which was gradually generated by people's hobbies or personal needs. However, at that time, there were no too many connections between multi-disciplines, which were all independent scientific systems. However, in the face of multiple problems, multi-disciplines have great limitations and cannot solve problems from multiple aspects. This also leads to the increasing demand for interdisciplinary solutions. As a result, interdisciplinary approaches gradually come into people's vision. Compared with the former, the latter emphasizes the activities of each discipline more. Interdisciplinary is the further integration of multiple disciplines, which overcomes the limitation of solving problems of individual disciplines and emphasizes the integration of disciplines. So they have different levels of connotation.
Because transdisciplinarity realizes the integration of different disciplines and can solve a lot of complex problems, the knowledge content of different disciplines can be used to obtain the best solution of problems through mutual learning, mutual supplement and mutual constraint. In addition, the emergence of interdisciplinary has also achieved the output of new theories and definitions, and created a certain commonness among multiple disciplines, which has also formed an interdisciplinary discipline.
Among the cross-disciplines, the cross-disciplines generated by the mechanism of transverse fault analysis are also called cross-disciplines. That is to say, at one level, one discipline axiom is added to another discipline, and fixed polarization occurs around this property axiom. From the macro level analysis, cross-sectional discipline is a new perspective to view the relationship between disciplines, and to extract and integrate the intersections of different disciplines from a new level to form a new discipline. That is to say, cross-discipline is a comprehensive discipline and also a special category for a certain field. Such as "two-dimensional code" interdisciplinary, the interdisciplinary disciplines include physics, mathematics, genhow discipline, but the two-dimensional code interdisciplinary can only be applied to two-dimensional code and related fields, if the application of unrelated fields must be recombined interdisciplinary.
Superdiscipline is a leap of transdisciplinarity. Because transdisciplinarity has reached its peak in the development of several hundred years, it also promotes the emergence of superdiscipline. Generally speaking, the characteristics of supra-discipline are as follows:
If a discipline aims to solve an academic problem in a certain field, and multiple disciplines can explore an academic problem from multiple sides, this is also the function of interdisciplinary. Supra-discipline is among the major public issues, including ethical issues, sustainable development, etc., which need to break through discipline limitations, combine intellectual and non-intellectual factors, scientific and non-scientific views, and solve problems.
In the past, solving problems still needs to be traced back to the root of the problem. The super-discipline is to obtain opinions from all parties and participate in social organizations such as the government, enterprises and universities, so as to avoid one-sided views, and adopt the best solution based on comprehensive consideration of the ideas and interests of all parties. In this way, conflicts of public interest can be resolved, cooperation can be strengthened, and the overall best interests can be realized.
The supranormal includes both disciplinary knowledge and non-disciplinary knowledge, that is, the combination of science and experience. There is a difference between solving problems by interdisciplinary knowledge and solving problems by knowledge. The process of knowledge flow needs constant evolution and development to form an integrated perspective. In the process of knowledge integration and application, supra-discipline surpasses interdisciplinary, so it is a higher level of interdisciplinary development.
As the base of knowledge research and dissemination, universities and colleges have advantages in platform construction, scientific research level, academic team, campus culture and other aspects, which makes them become important carriers of interdisciplinary evaluation and construction. The core of university transformation and development is to construct interdisciplinary platform correctly. This is because the discipline construction of colleges and universities is directly related to the development orientation and space of colleges and universities. Therefore, the reform and innovation of traditional disciplines should be carried out in the discipline construction, and new cross-disciplines should be tried to improve the strength of colleges and universities by innovating disciplines. On the other hand, colleges and universities shoulder the functions of teaching, scientific research, social service, etc., so the reform of colleges and universities must combine the needs of social development, constantly strengthen the quality of talent cultivation, and obtain research results more in line with the development of The Times. Universities comprehensively promote the development of interdisciplinary organizations and innovate interdisciplinary organizations to enhance the productivity of scientific research, so as to provide talents needed by the society, provide more transformation of scientific research achievements for social development and constantly innovate social services.
In addition, in the construction and reform of cross-learning platform, colleges and universities also need to carry out interdisciplinary majors in accordance with the current situation of the development department of The Times, so that students will not become talents after graduation or studying abroad, but achieve "talents in school". For example, "two-dimensional code technology", as an emerging identification technology, is widely used in today's society. Qr code technology involved in mathematics, geometry, physics, biology and other disciplines, but few interdisciplinary subject education in colleges and universities to carry out the qr code, the qr code related talent shortage very much, too much compared with foreign countries there is a certain gap, this is interdisciplinary and the performance of the fusion of colleges and universities is not enough to deepen, talent need studies ", "there are inter-disciplinary talent is above the" in "also success in other fields, it is also the current social development's pursuit of talent type, so he still has to strengthen the interdisciplinary research in university, through interdisciplinary promote reform in colleges and universities.
Through the emergence of interdisciplinary and the whole process of development, we can know that social development promotes the development and evolution of interdisciplinary. On the one hand, social development has improved the level of science and technology, and increased the amount of relevant scientific knowledge. Researchers' awareness has been constantly improved, and more knowledge has been integrated into the said research field, constantly promoting the development of the discipline towards comprehensive direction. On the other hand, in the long-term development of society, it is inevitable to encounter some obstacles and bottlenecks. Many complex problems promote the escalation of contradictions, which deepens the demand for discipline integration. At the initial stage of interdisciplinary development, social contradictions become more and more complicated, so practical problems should be solved through interdisciplinary means. After that, we realized the complexity of human beings in the scene, and promoted the interdisciplinary development of subjects within the discipline, between natural science and social science, and realized the interdisciplinary development. For example, our country is advocating green environmental protection, which requires the integration of social science, natural science and management.
With the gradual escalation of social problems, the conflicts between individuals become more frequent and complex. How to make full use of disciplinary knowledge and empirical knowledge has become the focus of social attention, aiming to maximize the benefits between people, which also promotes the emergence and development of supra-discipline. At present, with the rapid development of economy, science and technology, the conflicts and problems brought about by the rapid development of economy, science and technology continue to increase and upgrade, including green engineering, ethics and morality, etc., so that the conflicts between ecological benefits and social benefits continue to escalate. It can be seen that nowadays interdisciplinary development is facing more severe tests. Besides serving the society, interdisciplinary development also needs to serve nature, which is also the premise of China's "sustainable development". It requires more disciplinary integration, upgrading and collaborative innovation, and proposes strategies more conducive to long-term social development based on existing problems.
To xiamen scenic old yard interdisciplinary co-produced qr code guide of the scenic spot of social service, for example: xiamen software vocational and technical college in tourism management and digital media professional disciplines and enterprise old yard area cooperation, three parties to explore tourism management and digital media professional course cross interdisciplinary mode of teaching practice, encourage teachers to interdisciplinary professional courses, outstanding professional social services to improve the quality of education in practice mutual complement each other, to achieve win-win-win.
Project mainly by two professional disciplines students in course teaching and practice teaching outside campus designed interdisciplinary social services, for nine months, scenic spot investigation, to determine the five minnan culture scenic area, the scenic area by a professional tourism management students according to the reality and the scenic area data commentaries writing independently, the scenic spot, department of digital media professional students is responsible for filming, editing, video production, generated qr code, and so on, finally by the responsible teacher guidance, final results of the project: qr code guides; Not only strengthen students' team consciousness and social service experience, but also create a group of compound talents with compound knowledge, ability and quality.
Qr code guide social service, tourists to the scenic spot can make good qr code scanning in the scenic spot, by using a mobile phone to receive video on information of scenic spots, can enjoy the scenic area comprehensive interpretation, lack of narrator, explain quality, tourist swim "blind", to improve the understanding of the scenic spot service content, reduce noise pollution to advocate green, save the tour cost, improve the experience of tourists to the scenic spot.
Due to the role of interdisciplinary in interaction, interpretation and transplantation, linkage service and lateral analysis, multiple disciplines have been integrated. This integration mechanism highlights the interdisciplinary thinking method and provides practical guidance through the thinking center. Interdisciplinary thinking can effectively deduce the method and demonstration of problem solving, and integrate, draw lessons from and analyze the knowledge of different disciplines to solve practical problems. Therefore, having good thinking ability and thinking method is of great significance for promoting interdisciplinary development. For example, in the generation of the two-dimensional code concept, the paper money is for convenient transaction. However, some scholars think that the method of paper money payment is not simple enough, so they gradually think about how to realize more convenient transaction, and gradually derive the concept of two-dimensional code, which finally makes the research become a productivity.
Among modern thinking, innovative thinking plays a very important role. Even if they master interdisciplinary technology, they are lack of thinking and ideas and cannot generate an innovative consciousness, which limits the energy efficiency of interdisciplinary. In fact, interdisciplinary and consciousness are practical innovation based on multi-discipline technology, while intellectual innovation is the root of practical innovation, and interdisciplinary thinking is a kind of advanced combined thinking. Of course, if we master interdisciplinary thinking, we can create a variety of advanced things, but this is often the most difficult thing to achieve, so how to innovate under the guidance of interdisciplinary thinking and how to apply this thinking ability, we still need to make progress in in-depth thinking.
To sum up, interdisciplinary is an inevitable derivative of social and scientific development, which is of great significance for promoting the development of human society, guaranteeing people's quality of life and creating advanced things. Therefore, interdisciplinary research needs to be further strengthened to give full play to its benefits and values and better serve the people, society and nature.
51due留学教育原创版权郑重声明:原创paper代写范文源自编辑创作,未经官方许可,网站谢绝转载。对于侵权行为,未经同意的情况下,51Due有权追究法律责任。主要业务有essay代写、assignment代写、paper代写服务。
51due为留学生提供最好的paper代写服务,亲们可以进入主页了解和获取更多paper代写范文 提供作业代写服务,详情可以咨询我们的客服QQ:800020041。
0 notes
Link
Global Food Grade Gelatine Market Overview
Derived from the partial hydrolysis of collagen, gelatine is a natural protein, which exists in the skin and bones of animals. Prominently, gelatine is manufactured from bovine bone, porcine skin, and bovine hide. Gelatine has unique characteristics that make it especially useful as an emulsifier, gelling agent, binder, or thickener.
Varied Applications of Product to Fuel Market Growth
Food grade gelatine, essentially used as an enhancer to include consistency, flexibility, and strength to food products. Additionally, food grade gelatine is utilized as a stabilizer for the most part in the dairy products. In the food industry, water or fluid polyhydric alcohols of gelatine are utilized as a part of sweet, marshmallow and treat arrangements. In spite of the fact that in some European nations, food grade gelatine, is typically available in granular powder shape, sheet gelatine is predominantly used. Further, in dairy products and solidified foods, to counteract crystallization of ice and sugar, food grade gelatine is utilized as a colloid. Likewise, food grade gelatine utilized as an extender and emulsifier in the preparation of lessened fat margarine products. Food grade gelatine, is significantly utilized as a gelling operator in numerous applications including nutraceuticals, food and beverages, personal care, and photography.
Considering these factors, food grade gelatine market is expected to register a single-digit compound annual growth rate (CAGR) from 2018 to 2028. The food grade gelatine market across the globe has grown considerably owing to the rising demand in the pharmaceutical industry, which is expected to increase the manufacturing and sales of food grade gelatine globally. Governmental support for a holistic approach to health products, also lay a positive impact on food grade gelatine market.
Request Sample Report@ https://www.persistencemarketresearch.com/samples/26500
Global Food Grade Gelatine Market Dynamics
Rising Demand for Functional Foods, Application in Nutraceuticals to Expand Sales
Increasing concerns towards health and nutrition have resulted in changing consumption patterns among consumers across the globe. This has led to a rise in awareness towards ingredients and contents of diet and food products being consumed, and also the quality of ingredients. Additionally, shifting preference towards consumption of amino acid-rich products among consumers owing to raising awareness regarding the various health benefits it offers, including respite from painful reduce joint and bone pain, help reduce the signs of skin aging, intensification of brain function, and also aiding in maintaining healthy body weight. It is a major factor driving the growth of the global food grade gelatine market, and the trend is expected to continue in the future as well.
Exploring new sources and applications of food grade gelatine and identifying applications in the pharmaceutical industry are the recognized market opportunities in the global food grade gelatine market. Increasing applications in food products, rising demand for food grade gelatine products from young consumers, and consumer focus towards quality and safe, natural products and those with natural ingredients are the factors expected to fuel the growth of global food grade gelatine market over the forecast period.
Global Food Grade Gelatine Market Segmentation
The global Food Grade Gelatine market can be segmented on the basis of Product Type as:
Skin Gelatine
Bone Gelatine
Halal Gelatine
The global Food Grade Gelatine market can be segmented on the basis of End-use Industries as:
Pharmaceuticals
Food & Beverages
Industrial
Other End-Use Industries
The global Food Grade Gelatine market can be segmented on the basis of the geographical region as:
North America
Latin America
Europe
CIS & Russia
Japan
Asia Pacific excluding Japan (APEJ)
Middle East & Africa (MEA)
Global Food Grade Gelatine Market Regional Overview
Among all the regional markets, North America is estimated to dominate the Food Grade Gelatine market in terms of revenue share, followed by Europe and Asia Pacific. Asia Pacific and Latin America are expected to register higher growth in terms of value over the forecast period.
Markets in Europe, Middle East and Africa and Asia Pacific are expected to grow significantly over the forecast period. Consumption of Food Grade gelatine helping control blood sugar, maintaining healthy bones, aiding weight loss, aiding digestive function, and improving skin health, is relatively high among consumers in countries in the Europe region, which is expected to drive the food grade gelatine market growth in the near future. Increasing concerns about healthy and nutritional food products among consumers globally and changing consumption trends towards healthy food products in the young population are the factors expected to drive the growth of the global food grade gelatine market over the forecast period.
Request Report TOC@ https://www.persistencemarketresearch.com/toc/26500
Global Food Grade Gelatine Market Key Players
Some of the key market participants in the global Food Grade Gelatine market are:
Rousselot
Gelita
PB Gelatins
Nitta Gelatin
Gelatines Weishardt
Sterling Gelatin
Jellice
Baotou Dongbao Bio-tech
Qinghai Gelatin
Trobas Gelatine
BBCA Gelatin
Other prominent players
ABOUT US:
Persistence Market Research (PMR) is a third-platform research firm. Our research model is a unique collaboration of data analytics and market research methodology to help businesses achieve optimal performance. To support companies in overcoming complex business challenges, we follow a multi-disciplinary approach. At PMR, we unite various data streams from multi-dimensional sources. By deploying real-time data collection, big data, and customer experience analytics, we deliver business intelligence for organizations of all sizes.
CONTACT:
Persistence Market Research
305 Broadway
7th Floor, New York City,
NY 10007, United States,
USA – Canada Toll Free: 800-961-0353
Email: [email protected]
0 notes
Text
Critical Analysis
Zhaoyu Tan
Research and Enquiry Module: 7CTA1079
MA Digital Media Art
Assignment 1: Critical Analysis
Miller, H.C. (2014) ‘Immersive Environments’. In Digital Storytelling: A creator's guide to interactive entertainment. Focal Press.
This analysis looks at chapter 22, immersive Environment in the book 'digital storytelling.
This technique includes a very wide range and diversity of digital works. For the sake of this diversity, this article explains what an immersive environment is from eight different types, but it does not say that this is the whole category. After all, media art is a broad discipline. Secondly, the focus on virtual reality technology, because the immersive environment needs a lot of technology to support, so the focus on virtual technology is the best, and more direct. In order to make the multi-sensory immersion environment more unique, touch and smell can also be used, which can use a variety of technologies, and this is closely related to my major.
The real virtual reality environment is an extreme form of cyberspace, in which people can view all kinds of virtual objects from various levels, but the use of VR technology, the need for hardware can feel the virtual objects. Head-mounted display is one of the most common forms, and these devices are not described in detail in this paper. The authors also point out that immersive VR is not limited to experience, and that some VR can also be used for open observation. And these observations and not for entertainment, mainly for science, engineering, military. Most of this observation is intended for academic, military, and organized research. Virtual reality is not all about immersive experiences, even though most people have at least one such immersive experience.
Finally, VR technology has not yet become a major medium for entertainment, but it will play a more important role in other areas, such as teaching, where VR can be used as a training tool. The aim is to solve all kinds of difficult subjects and at the same time to make students more interested in them. In medicine, VR as a good rehabilitation treatment media, can help patients overcome fear, including biological and psychological fear. Of course, VR is also a good tool for reducing stress, in a controlled environment, patients can gradually get rid of anxiety, in medicine, this treatment is called 'long-term exposure therapy' and 'invasive therapy'. VR is regarded as a good way to deal with difficult or serious problems encountered in real life when it is worth it. Progress in any field will lead to new developments for entertainment purposes.
From the overall analysis of this chapter, immersive experience and VR can enable users to become the center of action, can have in-depth narrative and simulation, to provide users with a strong and seemingly real sense of experience, and interaction. In addition, this technology can be more vivid and abstract to reflect the real environment, which is more than any technology. They are not only interactive and entertaining, but more importantly, multi-sensory stimuli. But even if there are so many creative opportunities, there are still some serious obstacles, including the complexity of the technology and cost issues, immersive experience is basically a one-time enjoyment. Of course, there is a lack of financial support for providing additional tools such as equipment, props and images.
The most interesting thing about this article is that it analyzes the immersive experience and interactivity of the current trend of digital media, and Carolyn analyzes the concreteness of this nature. It also explains the status and function of this technology in today's society from many aspects. Carolyn did not explain this point in a separate way is very worth learning, understanding the immersive experience in the future of life will play a very good help, through the multi-dimensional understanding, you can understand the importance of VR. Especially taking into account the wide range and diversity of immersive experience, learning technology is an important issue that needs to be paid attention to now. At the same time of the development of the times, we should upgrade the technological means of these technologies at the same time.
Second, in some parts of this article, there are only a few more characteristics described, without a detailed explanation of what these features are. Like "Like other forms of digital storytelling, immersive environments contain narrative elements, like plots, characters, and dramatic situations. However, telling stories with this type of technology can be challenging." (Carolyn 2014). The authors do not elaborate on what other forms of digital stories are, and mention that telling a story in this way can be challenging. However, Carolyn also did not elaborate on which aspects of the challenge. I'm sure readers will want to know what these challenges are. Then Carolyn points out "These various applications of VR are used to deal with real-world situations, some of them quite serious. But it is quite possible that forward progress in one of these arenas could spur new advances in using VR for entertainment purposes". Carolyn fail to explain why progress in an area can affect the progress of entertainment. Shouldn't it be simultaneous? This will make the reader even more confused.
The content of this article is closely related to the development of digital media in the contemporary era, and it has a detailed description and relatively adequate content. It is good to illustrate by way of examples, because of the extensive and diverse nature of the immersed environment. Some details can be easily understood or captured by giving examples. In particular, the understanding of the immersion environment, for the study of this major students have a very important relationship. In addition, relative to part of the text, the author did not make a detailed explanation after the proposed, not very comprehensive to let the reader understand, which is critical of this article is an important point. As with the immersion environment has a close relationship with the digital media students, in order to fully understand the immersion environment, need to do more.
0 notes
Text
What’s a Data Lake?
In a recent TDWI webinar, we explored building a successful data lake in the cloud.
But what is a data lake?
A data lake is a place to store your structured and unstructured data, as well as a method for organizing large volumes of highly diverse data from diverse sources.
Data lakes are becoming increasingly important as people, especially in business and technology, want to perform broad data exploration and discovery. Bringing data together into a single place or most of it in a single place can be useful for that.
Depending on your platform, the data lake can make that much easier. It can handle many data structures, such as unstructured and multi-structured data, and it can help you get value out of your data.
What Makes a Data Lake Different From a Data Warehouse?
The key difference between a data lake and a data warehouse is that the data lake tends to ingest data very quickly and prepare it later on the fly as people access it. With a data warehouse, on the other hand, you prepare the data very carefully upfront before you ever let it in the data warehouse.
That’s because you have different goals with these two. With a data lake, you want to get your data in there as quickly as possible so that companies with operational use cases, especially around operational reporting, analytics, and business monitoring, have the newest data so that as they’re running their processes multiple times during a single business day, they can actually see the latest things that are happening in the operations.
In addition, with the data lake you’re usually ingesting data in the original form without altering it. Why? Well, one reason for that is that in many forms, advanced analytics actually depends on detailed source data. This would be analytics based on any kind of mining, whether it’s:
· Text mining
· Data mining
· Statistical analysis
· Anything involving clustering
· Graph analytics
So as you can see, many of these analytic forms need the detailed source data, which is very different from what reporting requires. That’s why the data lake tends to be a treasure trove of data for analytics, at least for advanced forms of analytics.
Hadoop and Data Lakes
Now to be clear, Hadoop hasn’t replaced anything. It’s mixed in with relational databases and in today’s modern warehouses there’s Hadoop thrown into the mix. We’re seeing it there to help data warehouses scale better.
But there are also different ways for users to design their warehouses and many people design the warehouse primarily as a data store for different forms of reporting, whether it's traditional reports or newfangled approaches to reporting like dashboards, scorecards, and so forth. In those cases your warehouse may or may not be the best environment for the detailed source data that a lot of analytics needs. And that's why Hadoop is brought in, to deal with large volumes of detailed source. So you can see that this is just one way to use the data lake that extends the data warehouse.
Use Cases of Data Lakes
Omnichannel Marketing Data Lake
Using the data lake to extend the data warehouse is something we see in omnichannel marketing, sometimes called multichannel marketing. The way to think about the data ecosystem in marketing is that every channel can be its own database, and every touchpoint can be as well. And then also a lot of marketers buy data from third parties. For example, you might want to buy data that has additional demographic and consumer preference information about your customers and prospects, and that helps you fill out that complete view of each customer, which in turn helps you create more personalized and targeted marketing campaigns.
That’s a complex data ecosystem, and it’s getting bigger in volume and greater in complexity all the time. The lake is brought in quite often to capture data that's coming in from multiple channels and touchpoints. And some of those actually are streaming data. If you're working for a company that has offered a smartphone app to its customers, you may be getting that data in real time or close to it as those customers use that app. A lot of times you don't really need full real time. It could be an hour or two old. But it allows the marketing department to do very granular monitoring of the business and create specials, incentives, discounts, and micro-campaigns.
Supply Chain Data Lake
The digital supply chain is an equally diverse data environment and the data lake can help with that, especially when the data lake is on Hadoop. Hadoop is largely a file-based system because it was originally designed for very large and highly numerous log files that come from web servers. In the supply chain you also get a lot of file-based data. Think about file-based and document-based data from EDI systems, XML, and of course today JSON's coming on very strong in the digital supply chain. That's very diverse information.
Plus you have internal information. If you're a manufacturer, you probably have data from the shop floor, from shipping and billing, that's highly relevant to the supply chain. The lake can help you bring that data together and manage it in a file-based kind of way.
The Internet of Things Data Lake
The Internet of Things is creating new data sources almost daily in some companies. And of course, as those sources diversify they create more data. It's because there are increasingly more sensors on more machinery all the time. As an example, every rail freight or truck freight vehicle like that has a huge list of sensors so you can track that vehicle through space and time, in addition to how it’s operated. Is it operated safely? Is it operated in an optimal way relative to fuel consumption? Huge amounts of information are coming from these places, and the data lake is very popular because it provides a repository for all of that data.
A Single Data Lake
Now, those are examples of fairly targeted uses of the data lake in certain departments or IT programs, but a different approach is for centralized IT to provide a single large data lake that is multitenant. It can be used by lots of different departments, business units, and technology programs.
We see this more and more. As people get used to the lake, they figure out how to optimize it for diverse uses and operations, analytics, and even compliance.
And the single data lake can also support multiple technical functions. Quite often it's certain pieces of the warehouse architecture that the lake takes over. For example, you may have put loving care and design into your warehouse architecture for, say, dimensional modeling as an example, and yet you haven't put much attention into data landing and staging.
Come on, admit it. So that's always a weak and somewhat immature area. If you bring in a data lake, possibly on Hadoop, possibly in a cloud, then one of the first things is it's the new landing and staging area, and then it becomes an area for collecting huge amounts of data for advanced analytics.
Different Kinds of Data Lake Platforms
The data lake can be used many ways, and it also has many platforms that can be under it. Hadoop is the most common but not the only platform.
Hadoop
Hadoop is appealing. It has proved to have linear scalability. It's a low cost for scalability compared to, say, a relational database. But Hadoop is not just cheap storage. It's also a powerful processing platform. And if you're trying to do algorithmic analytics, Hadoop can be very useful for that.
Relational Database Management System
The relational database management system can also be a platform for the data lake, because some people have massive amounts of data that they want to put into the lake that is structured and also relational. So if your data is inherently relational, a DBMS approach for the data lake would make perfect sense. Also, if you have use cases where you want to do relational functionality, like SQL, complex table joins, that kind of thing, then the RDBMS makes perfect sense.
The Cloud
But the trend is toward cloud-based systems, and especially cloud-based storage. The great benefit of clouds is elastic scalability. They can marshal server resources and other resources as workloads scale up. And compared to a lot of on-premises systems, cloud can be low-cost. Part of that is because there’s no system integration.
If you want to do something on-premise, you or somebody else has to do a multi-month system integration, whereas for a lot of systems there’s a cloud provider who already has that stuff integrated. You basically just buy a license and you can start using that stuff within hours instead of months. In addition the object store approach to cloud, which we mentioned in a previous post on data lake best practices, has many benefits.
And of course, you can have a hybrid mix of platforms with a data lake. If you're familiar with what we call the logical data warehouse, you can also have a similar thing like a logical data warehouse, and this is logical data lake. This is where data is physically distributed across multiple platforms. And there are some challenges to that, like if you want to do far-reaching analytic queries, and a lot of you do, then you need special tools that are really good with federated queries or data virtualization and things of that nature to help you with that. But that technology is available at the tool level, and many people are using it.
Conclusion
So if you’ve been wondering what a data lake is, I hope you’ve had your answer. The data lake is your answer to organizing all of those large volumes of diverse data from diverse sources. If you have more questions, you can catch the data lake webcast we produced with TDWI. And if you’re ready to start playing around with a data lake, we can offer you a free trial right here.
Sherry Tiao is product marketing senior manager for big data at Oracle.
https://blogs.oracle.com/what-is-a-data-lake
from WordPress https://reviewandbonuss.wordpress.com/2018/02/06/whats-a-data-lake-2/
0 notes
Text
Broccoli Extract Market is Expected to Exceed US$ 2,800 Mn by 2027
Broccoli extracts can be defined as a purified form of glucosinolates that are used as raw materials in the production of nutraceuticals. The global broccoli extract market is expected to register significant growth especially in the Asia Pacific region, according to a research report by Persistence Market Research. According to the report titled ‘Broccoli Extract Market: Global Industry Analysis 2012–2016 & Forecast 2017–2027,’ the global broccoli extract market was valued at over US$ 1,900 Mn in 2017 and is expected to reach a market valuation in excess of US$ 2,800 Mn by the end of 2027. This reflects a CAGR of 3.7% during the forecast period of 2017-2027.
Global Broccoli Extract Market: Dynamics Impacting Revenue Growth : Several factors underpin the current trends witnessed in the global broccoli extract market. Increasing consumption among the global population owing to an awareness about the health benefits of broccoli is the main factor boosting revenue growth of the global broccoli extract market. People are also changing their food preferences and lifestyles and moving towards healthy eating habits, due to which manufacturers are also more inclined towards the use of broccoli in their products.
Broccoli Extract Market Research Report Overview @ https://www.persistencemarketresearch.com/market-research/broccoli-extract-market.asp
However, the growth of the market is projected to witness certain hindrances owing to a lack of awareness of the health benefits of broccoli in some regions and a poorly integrated supply chain of the products. Intensified competition among manufacturers across the globe owing to an increase in the number of companies in various countries has lowered the profit margins in some regions.
Highlights from the Segment-wise Analysis of the Global Broccoli Extract Market : On the basis of form type, the broccoli extract market is dominated by the powder segment with an estimated market valuation of over US$ 1,400 Mn by the end of 2027. However, the capsules segment is still slightly ahead of the powder segment with the highest growth rate anticipated during the study period, On the basis of nature of the product, the market is segmented into organic and conventional segments, among which the conventional segment leads the market with the highest market share. However, the organic segment is ahead in terms of growth rate during the forecast period
Request Sample Report@ https://www.persistencemarketresearch.com/samples/16246
On the basis of product type, the sprout extract segment is expected to expand at a higher growth rate of 4% during the forecast period 2017-2027 ,On the basis of end-use, functional food has the highest growth rate with a CAGR of 3.9% during the forecast period. The dietary supplements segment is the second-most attractive segment in the global market On the basis of distribution channel, the indirect segment is expected to be a lucrative segment in the global broccoli extract market with the highest growth rate registered during the period of forecast
Download and View Report TOC, Figures and Tables @ https://www.persistencemarketresearch.com/market-research/broccoli-extract-market/toc
Asia Pacific Leads the Global Market with the Highest Growth Rate : The research report indicates that Asia Pacific registers the highest growth rate in the global broccoli extract market. However, North America is projected to hold the maximum market share by the end of 2027 at over US$ 6,900 Mn. Europe is witnessed as being an attractive region in the global market for broccoli extract.
Some of the company profiles mentioned in this comprehensive research report are of key players such as Love Life Supplements Ltd., Nutra Canada, Jarrow Formulas GmbH, Wincobel, Xian Yuensun Biological Technology Co., Ltd., Source Naturals, Kirkman Group Inc., Seagate Products, Interherb Ltd etc.
Get full Report Now @ https://www.persistencemarketresearch.com/checkout/16246
About Us
Persistence Market Research (PMR) is a third-platform research firm. Our research model is a unique collaboration of data analytics and market research methodology to help businesses achieve optimal performance.To support companies in overcoming complex business challenges, we follow a multi-disciplinary approach. At PMR, we unite various data streams from multi-dimensional sources. By deploying real-time data collection, big data, and customer experience analytics, we deliver business intelligence for organizations of all sizes.
Contact Us
Persistence Market Research
305 Broadway
7th Floor, New York City,
NY 10007, United States,
USA – Canada Toll Free: 800-961-0353
Email: [email protected]
Web: http://www.persistencemarketresearch.com
0 notes