#data_center
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The Tumblr office adopted Tommy, an 11-year-old Pomeranian.
Text
#Equinix#energy_capacity#data_center#energy_efficient#powerelectronics#powersemiconductor#powermanagement
0 notes
Text
Nuovo Data Center per l'Esercito Italiano Lo scorso 3 aprile il Governo ha trasmesso alle Commissioni competenti della Camera dei Deputati e del Senato della Repubblica la richiesta di parere parlamentare sullo schema di decreto ministeriale di approvazione del programma pluriennale di A/R nr. SMD 16/2023, denominato “Data Center”, relativo al consolidamento e potenziamento capacitivo dello Strumento terrestre nell’ambito del Information Communication Technology, corredato della scheda tecnica ed illustrativa. Il programma pluriennale in esame (A.G. 146) riguarda l’ammodernamento, il rinnovamento ed il potenziamento dello Strumento terrestre nell’ambito del Information Communication Technology (ICT).Il programma risulta volto ad ammodernare e rinnovare l’infrastruttura ICT dell’Esercito mediante larealizzazione di un
0 notes
Link
Microsoft It looks like OpenAI's ChatGPT and Sora, among other projects, are about to get a lot more juice. According to a new report shared by The information, Microsoft and OpenAI are working on a new data center project, one part of which w... bitrise.co.in
0 notes
Link
Significant changes in the top five The list of the most productive supercomputers Top500 has been updated once again. Let us remind you that this happens once every six months. [caption id="attachment_81909" align="aligncenter" width="740"] AMD[/caption] While several supercomputers with performance of about 2 exaFLOPS or higher are on the way, the leader is still the Frontier system, which was the first to overcome the 1 exaFLOPS mark and remains the only one of its kind, far ahead of its closest competitor. The Frontier supercomputer based on AMD components remains the most powerful in the world. [caption id="attachment_81910" align="aligncenter" width="714"] AMD[/caption] This competitor, by the way, has changed. If six months ago the Supercomputer Fugaku system with a performance of 442 PFLOPS was in second place, now it is Aurora with a performance of 585 PFLOPS. But it is worth saying that now this is only part of the system that has already been put into operation. As a result, Aurora will have performance in excess of 2 exaFLOPS. This system is built on Intel Xeon CPU Max 9470 processors and Intel Data Center Max accelerators. Frontier, remember, relies on AMD components. In third place is also a newcomer: the Eagle system, owned by Microsoft, with a performance of 561 PFLOPS. But Supercomputer Fugaku dropped to fourth place.
#Advanced_Micro_Devices#Amd#chipsets#Computer_Components#computer_hardware#CPU#data_center#Epyc#Gaming#Gaming_Graphics#gaming_performance#GPU#graphics_cards#Processors#Radeon#Radeon_Graphics.#Ryzen#Ryzen_Processors#semiconductor#semiconductor_industry#technology#technology_company
0 notes
Text
we both thought clicking this would take us to the actual page
its ok, We're on tumblr. no one expects us to thinnk
7 notes
·
View notes
Text
boobs touching, sloppy style, with tongue, etc ..
i am going to kiss wikipedia
#also no wikipedia is most definitely not hosted from some basement#it's hosted across a number of datacenters#u can read more about that here#https://wikitech.wikimedia.org/wiki/Data_centers
28K notes
·
View notes
Text
Coursera- Regression Modelling - Week 3 Assignment
My code:
import pandas as pd import seaborn as sns import matplotlib.pyplot as plt import statsmodels.api as sm import statsmodels.formula.api as smf import scipy.stats
data = pd.read_csv(r'C:\Users\AL58114\Downloads\gapminder.csv',low_memory = False)
data['employrate'] = pd.to_numeric(data['employrate'], errors='coerce') data['urbanrate'] = pd.to_numeric(data['urbanrate'], errors='coerce') data['oilperperson'] = pd.to_numeric(data['oilperperson'], errors='coerce') data['incomeperperson'] = pd.to_numeric(data['incomeperperson'], errors='coerce')
data_centered = data.copy() data_centered['employrate'] = data_centered['employrate'].subtract(data_centered['employrate'].mean()) data_centered['urbanrate'] = data_centered['urbanrate'].subtract(data_centered['urbanrate'].mean()) data_centered['oilperperson'] = data_centered['oilperperson'].subtract(data_centered['oilperperson'].mean())
print ('Mean of', data_centered[['employrate']].mean()) print ('Mean of', data_centered[['urbanrate']].mean()) print ('Mean of', data_centered[['oilperperson']].mean())
scat1 = sns.regplot(x="urbanrate", y="employrate", scatter=True, data=data_centered) plt.xlabel('urban rate') plt.ylabel('employee rate') plt.title ('Scatterplot for the Association Between urban rate and employee rate in a year') plt.show()
reg1 = smf.ols('urbanrate ~ employrate', data = data_centered).fit() reg1.summary()
reg2 = smf.ols('urbanrate ~ employrate + oilperperson + incomeperperson', data = data_centered).fit() reg2.summary()
reg3 = smf.ols('urbanrate ~ incomeperperson + I(incomeperperson**2)', data = data_centered).fit() reg3.summary()
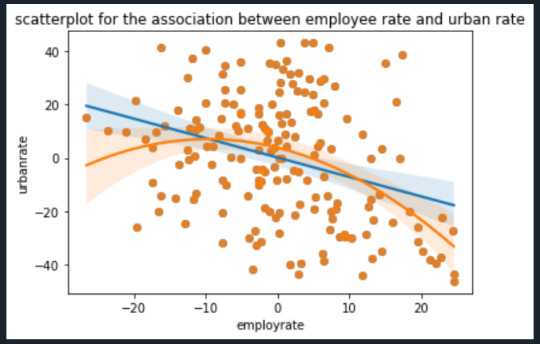
scat1 = sns.regplot(x = 'employrate', y = 'urbanrate', scatter = True, data = data_centered) scat2 = sns.regplot(x = 'employrate', y = 'urbanrate', scatter = True, order = 2, data= data_centered) plt.xlabel('employrate') plt.ylabel('urbanrate') plt.title('scatterplot for the association between employee rate and urban rate') plt.show()
fig4 = sm.qqplot(reg3.resid,line = 'r') print(fig4)
plt.figure() stdres = pd.DataFrame(reg3.resid_pearson) plt.plot(stdres, 'o', ls ='None') l = plt.axhline(y=0, color = 'r') plt.ylabel('standardized residual') plt.xlabel('observation number') plt.show()
fig2 = plt.figure() fig2 = sm.graphics.plot_regress_exog(reg3, "incomeperperson", fig=fig2) fig2
fig3=sm.graphics.influence_plot(reg3, size=8) fig3
Output:









The analysis shows that life expectancy is significantly correlated with income per person(p-value=0.000) ,employrate(p-value=0.000) and hivrate(p-value=0.000). With a coefficient of 0.0005 income per person is slightly positively correlated with life expectancy while employrate is negatively correlated with a coefficient of -0.2952 and hivrate is strongly negatively associated with a coefficient of -1.1005. This supports my hypothesis that lifeexpectancy could be predicted based upon incomeperperson, employrate and hivrate.
When I added internetuserate to my analysis, it exhibited a p-value out of range of significance, but it also threw several other variables into higher (but still significant) p-value ranges. This suggests that internetuserate is a confounding variable and is associated with the others but adding it to my analysis adds no new information.
Examining the plots posted above indicates that a curved line is a much better fit for the relationship between incomeperperson and lifeexpectancy. However, I do not believe a 2-degree polynomial line is the best; the data appears to match a logarithmic line better. Indeed, the Q-Q plot does show that the actual data is lower than predicted at the extremes and lower than predicted in the middle. This would match my theory that a logarithmic line would be a better fit. The plot of residuals has one data points fall outside -3 standard deviations of the mean; however, I am concerned that so many fall within -2 to -3 deviations. I attribute this to the poor fit of the polynomial line as compared to a logarithmic line. The regression plots and the influence plot show an alarming point (labeled 111 and 57 in the influence plot) which is an extreme outlier in terms of both residual value and influence. These points show up again in the plot Residuals versus incomeperperson and the Partial regression plot. I must examine what these points are and possibly exclude it from the rest of my analysis.
0 notes
0 notes
Text
Regression Modeling in Practice - Week 3
import pandas as pd import seaborn as sns import matplotlib.pyplot as plt import statsmodels.formula.api as smf import statsmodels.api as sm import scipy.stats
# Load the data
data = pd.read_csv('gapminder.csv', low_memory=False)
# Set the variables to numeric
data['urbanrate'] = pd.to_numeric(data['urbanrate'], errors='coerce')
data['incomeperperson'] = pd.to_numeric(data['incomeperperson'], errors='coerce') data['breastcancerper100th'] = pd.to_numeric(data['breastcancerper100th'], errors='coerce') data['femaleemployrate'] = pd.to_numeric(data['femaleemployrate'], errors='coerce')
# Center the explanatory variable, set the mean of the data to 0
data_centered = data.copy() data_centered['incomeperperson'] = data_centered['incomeperperson'].subtract(data_centered['incomeperperson'].mean()) data_centered['breastcancerper100th'] = data_centered['breastcancerper100th'].subtract(data_centered['breastcancerper100th'].mean()) data_centered['femaleemployrate'] = data_centered['femaleemployrate'].subtract(data_centered['femaleemployrate'].mean())
print ('Mean of', data_centered[['incomeperperson']].mean()) print ('Mean of', data_centered[['breastcancerper100th']].mean()) print ('Mean of', data_centered[['femaleemployrate']].mean())

# Single regression
# Run scatterplot of urbanrate with centered incomeperperson
scat1 = sns.regplot(x="incomeperperson", y="urbanrate", scatter=True, data=data_centered) plt.xlabel('Income Per Person') plt.ylabel('Urban Rate') plt.title ('Scatterplot for the Association Between Income Per Person and Urban Rate') plt.show()

# OLS regression model for the association between Income per Person and Urban Rate
reg1 = smf.ols('urbanrate ~ incomeperperson', data=data_centered).fit() reg1.summary()

# Multiple regression
# OLS regression model for the association between income per person, employment rate, female employment rate, and internet use rate
reg2 = smf.ols('urbanrate ~ incomeperperson + breastcancerper100th + femaleemployrate', data=data_centered).fit() reg2.summary()

# Quadratic (polynomial) regression analysis
# OLS regression model for the association between income per person and urban rate
reg3 = smf.ols('urbanrate ~ incomeperperson + I(incomeperperson**2)', data=data_centered).fit() reg3.summary()

scat1 = sns.regplot(x="incomeperperson", y="urbanrate", scatter=True, data=data_centered) scat2 = sns.regplot(x="incomeperperson", y="urbanrate", scatter=True, order=2, data=data_centered) plt.xlabel('Income Per Person') plt.ylabel('Urban Rate') plt.title ('Scatterplot for the Association Between Income Per Person and Urban Rate') plt.show()

# Q-Q plot for normality
fig4 = sm.qqplot(reg3.resid, line='r')

# Simple plot of residuals
plt.figure() stdres=pd.DataFrame(reg3.resid_pearson) plt.plot(stdres, 'o', ls='None') l = plt.axhline(y=0, color='r') plt.ylabel('Standardized Residual') plt.xlabel('Observation Number') plt.show()

# Additional regression diagnostic plots
fig2 = plt.figure(figsize=(10,10)) fig2 = sm.graphics.plot_regress_exog(reg3, "incomeperperson", fig=fig2)

# Leverage plot
fig3=sm.graphics.influence_plot(reg3, size=8)

0 notes
Photo

. 🔔 روش های کاهش مصرف برق در دیتاسنترها [#مقاله] . 🔸 مراکز داده پردازش های بسیار و سنگینی زیادی دارند و به تناسب افزایش پردازش، مصرف برق نیز در این مراکز افزایش می یابد. برای اینکه این مصرف به حداقل برسد، از روش هایی مثل لیکوئید کولینگ و هات ایسل ایزولیشن استفا��ه می شود. روش دیگر کاهش مصرف انرژی، استفاده از سرور های مجازی، جهت مدیریت هزینه ها است. طبق گزارش NRDC دیتاسنترهای آمریکا در سال ۲۰۱۳، ۹۱ میلیارد کیلووات در ساعت برق مصرف کرده اند و این موضوع تا سال ۲۰۲۰ به ۱۴۰ میلیارد کیلووات در ساعت رسیده که شامل هزینۀ هنگفت ۱۳ میلیارد دلاری شده است. . 〽️ ادامه این #مقاله را در وب سایت فرتاک بخوانید. . 🔸🔶🔸 https://fartak-co.com/green-datacenters-energy-saving 🔸🔶🔸 . ⭕️ سامانه فناوری فرتاک⭕️ ☎️ تماس : ۰۲۱۴۱۲۰۲۰۰۰ (۳۰ خط ویژه) . 📞 مدیریت فروش (داخلی ۱۲۸ ) . 📞 کارشناسان فروش سازمانی (داخلی ۲۱۱ و ۲۰۷ و ۲۰۹) . 🏢 آدرس دفتر مرکزی : تهران ، سهروردی شمالی ، بن بست آجودانی ، پلاک ۳ ساختمان فرتاک . #سامانه_فناوری_فرتاک #سرور_اچ_پى #سرور_hp #سرور #سرور_اچ_پی_ای #تجهیزات_شبکه #اچ_پی_ای_سرور #اچ_پی_ای #دیتاسنتر #مرکزداده #Datacenter #Data_Center #کاهش_مصرف_برق #انرژی_سبز #fuelcell #fuel_cell #پیل_سوختی #free_cooling #liquid_cooling #kyoto_cooling #میکرودیتاسنتر #micro_datacenter #میکرو_دیتاسنتر (at سامانه فناوری فرتاک) https://www.instagram.com/p/CityAO_Me4v/?igshid=NGJjMDIxMWI=
#مقاله#سامانه_فناوری_فرتاک#سرور_اچ_پى#سرور_hp#سرور#سرور_اچ_پی_ای#تجهیزات_شبکه#اچ_پی_ای_سرور#اچ_پی_ای#دیتاسنتر#مرکزداده#datacenter#data_center#کاهش_مصرف_برق#انرژی_سبز#fuelcell#fuel_cell#پیل_سوختی#free_cooling#liquid_cooling#kyoto_cooling#میکرودیتاسنتر#micro_datacenter#میکرو_دیتاسنتر
0 notes
Text
Tatiane Aquim, Jornalista, Editora de Conteudo, Rio de Janeiro
1 note
·
View note
Text
#fiber_optic_connectors#high_speed#innovations#telecommunications#data_centers#next-generation#powerelectronics#powersemiconductor#powermanagement
0 notes
Photo

Our Cisco 300-165 braindumps are better than all other cheap 300-165 study material.
Try us@ https://www.hotcerts.com/300-165.html
0 notes
Photo

EVOLUTION OF ETHERNET AND FIBRE CHANNEL STRUCTURED CABLING IN THE DATA CENTER
https://bit.ly/2J4g16W
#Ethernet Cables#structuredcabling#Data_center#Fiber_channel#Cable_Installation#Structured_cabling_solution
0 notes
Link
Already next week The Starfield game, as you know, was created with the active support of AMD and works much better on Radeon video cards. However, owners of GeForce adapters will soon have a reason to rejoice, as DLSS will be added to the game. [caption id="attachment_78515" align="aligncenter" width="780"] AMD's[/caption] AMD's Starfield Game Will Get DLSS 3 Before FSR 3 Next week the developers will release a beta version of the update, which will bring many changes. True, it’s not very clear why the beta version, but we just have to wait for the release. Among other things, the update will bring support for DLSS, and judging by the mention of frame generation, it will be DLSS 3. Bethesda also promised to add FSR 3 to the game, that is, frame generation technology will become available for Radeon adapters. Considering that Starfield turned out to be very demanding, such improvements will clearly not be superfluous.
#Advanced_Micro_Devices#Amd#chipsets#computing#CPU#data_center#Epyc#Gaming#GPU#graphics#hardware#microarchitecture#Processors#Radeon#Ryzen#semiconductor#technology#Threadripper
0 notes
Photo

#data_center #3d_modelling #datacenter #3dmodelling #ağ #ağsistemleri #üçboyutlu (at İzmir, Turkey) https://www.instagram.com/p/Bw1bgBFlmcs/?utm_source=ig_tumblr_share&igshid=1113naqnoqg05
0 notes
Text
Coursera- Regression Modelling - Week 2- Assignment
My code:
import pandas as pd import seaborn as sb import matplotlib.pyplot as plt import statsmodels.formula.api as smf data = pd.read_csv(r'C:\Users\AL58114\Downloads\gapminder.csv',low_memory = False)
data['employrate'] = pd.to_numeric(data['employrate'],errors = 'coerce') data['urbanrate'] = pd.to_numeric(data['urbanrate'],errors = 'coerce') print('OLS regression model for the association between employrate and urbanrate') reg1 = smf.ols('urbanrate ~ employrate', data = data).fit() print(reg1.summary())
scat = sb.regplot(x='employrate', y = 'urbanrate', scatter = True, data= data) plt.xlabel('employee rate') plt.ylabel('urban rate') plt.title('scatterplot for the association between employee rate and urban rate') plt.show()
data_centered = data.copy() data_centered['employrate'] = data['employrate'].subtract(data_centered['employrate']) print('mean of', data_centered[['employrate']].mean())
scat1 = sb.regplot(x='employrate', y = 'urbanrate', scatter = True, data= data_centered) plt.xlabel('employee rate') plt.ylabel('urban rate') plt.title('scatterplot for the association between employee rate and urban rate') plt.show()
reg2 = smf.ols('urbanrate ~ employrate', data = data_centered).fit() reg2.summary()
Results:



Description:
A regression model is a statistical technique that relates a dependent variable to one or more independent variables. The F-statistic is 20.51 which tells us to reject the null hypothesis or not. The association between employee rate and urban rate is slightly negative which indicates the negative value. The best fit line for this graph is urban rate = (99.6552)+ (-0.7293) i.e coefficient of employee rate and since the intercept is negative we will have a minus value -0.7293. and the mean value for the employee rate is centered as 0.0.
0 notes