#beta_0
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr Inc. is using 66 technologies for its website.
Text
The ABCs of Regression Analysis
Regression analysis is a statistical technique used to understand the relationship between a dependent variable and one or more independent variables. Here’s a simple breakdown of its key components—the ABCs of Regression Analysis:
A: Assumptions
Regression analysis is based on several assumptions, which need to be met for accurate results:
Linearity: The relationship between the independent and dependent variables is linear.
Independence: The residuals (errors) are independent of each other.
Homoscedasticity: The variance of the residuals is constant across all levels of the independent variables.
Normality: The residuals should be approximately normally distributed.
No Multicollinearity: The independent variables should not be highly correlated with each other.
B: Basic Types of Regression
There are several types of regression, with the most common being:
Simple Linear Regression: Models the relationship between a single independent variable and a dependent variable using a straight line.
Equation: y=β0+β1x+ϵy = \beta_0 + \beta_1 x + \epsilon
yy = dependent variable
xx = independent variable
β0\beta_0 = y-intercept
β1\beta_1 = slope of the line
ϵ\epsilon = error term
Multiple Linear Regression: Extends simple linear regression to include multiple independent variables.
Equation: y=β0+β1x1+β2x2+⋯+βnxn+ϵy = \beta_0 + \beta_1 x_1 + \beta_2 x_2 + \cdots + \beta_n x_n + \epsilon
Logistic Regression: Used for binary outcomes (0/1, yes/no) where the dependent variable is categorical.
C: Coefficients and Interpretation
In regression models, the coefficients (β\beta) are the key parameters that show the relationship between the independent and dependent variables:
Intercept (β0\beta_0): The expected value of yy when all independent variables are zero.
Slope (β1,β2,…\beta_1, \beta_2, \dots): The change in the dependent variable for a one-unit change in the corresponding independent variable.
D: Diagnostics and Model Evaluation
Once a regression model is fitted, it’s important to evaluate its performance:
R-squared (R2R^2): Represents the proportion of variance in the dependent variable explained by the independent variables. Values closer to 1 indicate a better fit.
Adjusted R-squared: Similar to R2R^2, but adjusted for the number of predictors in the model. Useful when comparing models with different numbers of predictors.
p-value: Tests the null hypothesis that a coefficient is equal to zero (i.e., no effect). A small p-value (typically < 0.05) suggests that the predictor is statistically significant.
Residual Plots: Visualize the difference between observed and predicted values. They help in diagnosing issues with linearity, homoscedasticity, and outliers.
E: Estimation Methods
Ordinary Least Squares (OLS): The most common method used for estimating the coefficients in linear regression by minimizing the sum of squared residuals.
Maximum Likelihood Estimation (MLE): Used in some regression models (e.g., logistic regression) where the goal is to maximize the likelihood of observing the data given the parameters.
F: Features and Feature Selection
In multiple regression, selecting the right features is crucial:
Stepwise regression: A method of adding or removing predictors based on statistical criteria like AIC (Akaike Information Criterion) or BIC (Bayesian Information Criterion).
Regularization (Ridge, Lasso): Techniques used to prevent overfitting by adding penalty terms to the regression model.
G: Goodness of Fit
The goodness of fit measures how well the regression model matches the data:
F-statistic: A test to determine if at least one predictor variable has a significant relationship with the dependent variable.
Mean Squared Error (MSE): Measures the average squared difference between the observed actual outcomes and those predicted by the model.
H: Hypothesis Testing
In regression analysis, hypothesis testing helps to determine if the relationships between variables are statistically significant:
Null Hypothesis: Typically, the null hypothesis for a coefficient is that it equals zero (i.e., no effect).
Alternative Hypothesis: The alternative is that the coefficient is not zero (i.e., the predictor has an effect on the dependent variable).
I: Interpretation
Interpreting regression results involves understanding how changes in the independent variables influence the dependent variable. For example, in a simple linear regression:
If β1=5\beta_1 = 5, then for every one-unit increase in xx, the predicted yy increases by 5 units.
J: Justification for Regression
Regression is often used in predictive modeling, risk assessment, and understanding relationships between variables. It helps in making informed decisions based on statistical evidence.
Conclusion:
Regression analysis is a powerful tool in statistics and machine learning, helping to predict outcomes, identify relationships, and test hypotheses. By understanding the basic principles and assumptions, one can effectively apply regression to various real-world problems.
Click More: https://www.youtube.com/watch?v=5_HErZ3A_Hg
0 notes
Text
Regression: What You Need to Know
Regression is a statistical method used for modeling the relationship between a dependent (target) variable and one or more independent (predictor) variables. It's widely used in various fields, including economics, biology, engineering, and social sciences, to predict outcomes and understand relationships between variables.
Key Concepts in Regression:
Dependent and Independent Variables:
The dependent variable (also called the response variable) is the variable you are trying to predict or explain.
The independent variables (or predictors) are the variables that explain the dependent variable.
Types of Regression:
Linear Regression: The simplest form of regression, where the relationship between the dependent and independent variables is modeled as a straight line.
Simple Linear Regression: Involves one independent variable.
Multiple Linear Regression: Involves two or more independent variables.
Nonlinear Regression: Models the relationship with a nonlinear function. It is used when the data points follow a curved pattern rather than a straight line.
Ridge and Lasso Regression: Types of linear regression that include regularization to prevent overfitting by adding penalties to the model.
Logistic Regression: Used when the dependent variable is categorical (binary or multinomial). Despite the name, it's used for classification, not regression.
Assumptions in Linear Regression:
Linearity: The relationship between the dependent and independent variables is linear.
Independence: The residuals (errors) are independent of each other.
Homoscedasticity: The variance of the residuals is constant across all levels of the independent variables.
Normality: The residuals are normally distributed (especially important for hypothesis testing).
Evaluating Regression Models:
R-squared (R²): Measures how well the independent variables explain the variation in the dependent variable. A higher R² indicates a better fit.
Adjusted R-squared: Adjusts R² for the number of predictors in the model, useful when comparing models with different numbers of predictors.
Mean Absolute Error (MAE), Mean Squared Error (MSE), and Root Mean Squared Error (RMSE): Metrics for evaluating the accuracy of the predictions.
p-values: Help determine if the relationships between the predictors and the dependent variable are statistically significant.
Overfitting vs. Underfitting:
Overfitting: Occurs when the model is too complex and captures noise in the data, leading to poor generalization on new data.
Underfitting: Occurs when the model is too simple to capture the underlying trend in the data.
Regularization:
Techniques like Ridge (L2 regularization) and Lasso (L1 regularization) add penalties to the regression model to avoid overfitting, especially in high-dimensional datasets.
Interpretation:
In linear regression, the coefficients represent the change in the dependent variable for a one-unit change in an independent variable, holding all other variables constant.
Applications of Regression:
Predictive Modeling: Forecasting future values based on past data.
Trend Analysis: Understanding trends in data, such as sales over time or growth rates.
Risk Assessment: Estimating risk levels, such as predicting loan defaults or market crashes.
Marketing and Sales: Estimating the impact of marketing campaigns on sales or customer behavior.
Example of Simple Linear Regression:
Let’s say you are trying to predict a person’s salary based on years of experience. In this case:
Independent Variable: Years of Experience
Dependent Variable: Salary
The model might look like: Salary=β0+β1(Years of Experience)+ϵ\text{Salary} = \beta_0 + \beta_1 (\text{Years of Experience}) + \epsilon Where:
β0\beta_0 is the intercept (starting salary when experience is zero),
β1\beta_1 is the coefficient for years of experience (how much salary increases with each year of experience),
ϵ\epsilon is the error term (the part of salary unexplained by the model).
In conclusion, regression is a powerful and versatile tool for understanding relationships between variables and making predictions.
0 notes
Text
Test a Logistic Regression Model
Full Research on Logistic Regression Model
1. Introduction
The logistic regression model is a statistical model used to predict probabilities associated with a categorical response variable. This model estimates the relationship between the categorical response variable (e.g., success or failure) and a set of explanatory variables (e.g., age, income, education level). The model calculates odds ratios (ORs) that help understand how these variables influence the probability of a particular outcome.
2. Basic Hypothesis
The basic hypothesis in logistic regression is the existence of a relationship between the categorical response variable and certain explanatory variables. This model works well when the response variable is binary, meaning it consists of only two categories (e.g., success/failure, diseased/healthy).
3. The Basic Equation of Logistic Regression Model
The basic equation for logistic regression is:log(p1−p)=β0+β1X1+β2X2+⋯+βnXn\log \left( \frac{p}{1-p} \right) = \beta_0 + \beta_1 X_1 + \beta_2 X_2 + \dots + \beta_n X_nlog(1−pp)=β0+β1X1+β2X2+⋯+βnXn
Where:
ppp is the probability that we want to predict (e.g., the probability of success).
p1−p\frac{p}{1-p}1−pp is the odds ratio.
X1,X2,…,XnX_1, X_2, \dots, X_nX1,X2,…,Xn are the explanatory (independent) variables.
β0,β1,…,βn\beta_0, \beta_1, \dots, \beta_nβ0,β1,…,βn are the coefficients to be estimated by the model.
4. Data and Preparation
In applying logistic regression to data, we first need to ensure that the response variable is categorical. If the response variable is quantitative, it must be divided into two categories, making logistic regression suitable for this type of data.
For example, if the response variable is annual income, it can be divided into two categories: high income and low income. Next, explanatory variables such as age, gender, education level, and other factors that may influence the outcome are determined.
5. Interpreting Results
After applying the logistic regression model, the model provides odds ratios (ORs) for each explanatory variable. These ratios indicate how each explanatory variable influences the probability of the target outcome.
Odds ratio (OR) is a measure of the change in odds associated with a one-unit increase in the explanatory variable. For example:
If OR = 2, it means that the odds double when the explanatory variable increases by one unit.
If OR = 0.5, it means that the odds are halved when the explanatory variable increases by one unit.
p-value: This is a statistical value used to test hypotheses about the coefficients in the model. If the p-value is less than 0.05, it indicates a statistically significant relationship between the explanatory variable and the response variable.
95% Confidence Interval (95% CI): This interval is used to determine the precision of the odds ratio estimates. If the confidence interval includes 1, it suggests there may be no significant effect of the explanatory variable in the sample.
6. Analyzing the Results
In analyzing the results, we focus on interpreting the odds ratios for the explanatory variables and check if they support the original hypothesis:
For example, if we hypothesize that age influences the probability of developing a certain disease, we examine the odds ratio associated with age. If the odds ratio is OR = 1.5 with a p-value less than 0.05, this indicates that older people are more likely to develop the disease compared to younger people.
Confidence intervals should also be checked, as any odds ratio with an interval that includes "1" suggests no significant effect.
7. Hypothesis Testing and Model Evaluation
Hypothesis Testing: We test the hypothesis regarding the relationship between explanatory variables and the response variable using the p-value for each coefficient.
AIC (Akaike Information Criterion) and BIC (Bayesian Information Criterion) values are used to assess the overall quality of the model. Lower values suggest a better-fitting model.
8. Confounding
It is also important to determine if there are any confounding variables that affect the relationship between the explanatory variable and the response variable. Confounding variables are those that are associated with both the explanatory and response variables, which can lead to inaccurate interpretations of the relationship.
To identify confounders, explanatory variables are added to the model one by one. If the odds ratios change significantly when a particular variable is added, it may indicate that the variable is a confounder.
9. Practical Example:
Let’s analyze the effect of age and education level on the likelihood of belonging to a certain category (e.g., individuals diagnosed with diabetes). We apply the logistic regression model and analyze the results as follows:
Age: OR = 0.85, 95% CI = 0.75-0.96, p = 0.012 (older age reduces likelihood).
Education Level: OR = 1.45, 95% CI = 1.20-1.75, p = 0.0003 (higher education increases likelihood).
10. Conclusions and Recommendations
In this model, we conclude that age and education level significantly affect the likelihood of developing diabetes. The main interpretation is that older individuals are less likely to develop diabetes, while those with higher education levels are more likely to be diagnosed with the disease.
It is also important to consider the potential impact of confounding variables such as income or lifestyle, which may affect the results.
11. Summary
The logistic regression model is a powerful tool for analyzing categorical data and understanding the relationship between explanatory variables and the response variable. By using it, we can predict the probabilities associated with certain categories and understand the impact of various variables on the target outcome.
0 notes
Text
Data Analysis Using ANOVA Test with a Mediator
Blog Title: Data Analysis Using ANOVA Test with a Mediator
In this post, we will demonstrate how to test a hypothesis using the ANOVA (Analysis of Variance) test with a mediator. We will explain how ANOVA can be used to check for significant differences between groups, while focusing on how to include a mediator to understand the relationship between variables.
Hypothesis:
In this analysis, we assume that there is a significant effect of independent variables on the dependent variable, and we may test whether complex variables (such as the mediator) affect this relationship. In this context, we will test whether there are differences in health levels based on treatment types, while also checking how the mediator (stress level) influences this test.
1. Research Data:
Independent variable (X): Type of treatment (medication, physical therapy, or no treatment).
Dependent variable (Y): Health level.
Mediator (M): Stress level.
We will use the ANOVA test to determine whether there are differences in health levels based on treatment type and will assess how the mediator (stress level) influences this analysis.
2. Formula for ANOVA Test with a Mediator (Mediating Effect):
The formula we use for analyzing the data in ANOVA is as follows:Y=β0+β1X+β2M+β3(X×M)+ϵY = \beta_0 + \beta_1 X + \beta_2 M + \beta_3 (X \times M) + \epsilonY=β0+β1X+β2M+β3(X×M)+ϵ
Where:
YYY is the dependent variable (health level).
XXX is the independent variable (type of treatment).
MMM is the mediator variable (stress level).
β0\beta_0β0 is the intercept.
β1,β2,β3\beta_1, \beta_2, \beta_3β1,β2,β3 are the regression coefficients.
ϵ\epsilonϵ is the error term.
3. Analytical Steps:
A. Step One - ANOVA Analysis:
Initially, we apply the ANOVA test to the independent variable XXX (type of treatment) to determine if there are significant differences in health levels across different groups.
B. Step Two - Adding the Mediator:
Next, we add the mediator MMM (stress level) to our model to evaluate how stress could impact the relationship between treatment type and health level. This part of the analysis determines whether stress acts as a mediator affecting the treatment-health relationship.
4. Results and Output:
Let's assume we obtain ANOVA results with the mediator. The output might look like the following:
F-value for the independent variable XXX: Indicates whether there are significant differences between the groups.
p-value for XXX: Shows whether the differences between the groups are statistically significant.
p-value for the mediator MMM: Indicates whether the mediator has a significant effect.
p-value for the interaction between XXX and MMM: Reveals whether the interaction between treatment and stress significantly impacts the dependent variable.
5. Interpreting the Results:
After obtaining the results, we can interpret the following:
If the p-value for the variable XXX is less than 0.05, it means there is a statistically significant difference between the groups based on treatment type.
If the p-value for the mediator MMM is less than 0.05, it indicates that stress has a significant effect on health levels.
If the p-value for the interaction between XXX and MMM is less than 0.05, it suggests that the effect of treatment may differ depending on the level of stress.
6. Conclusion:
By using the ANOVA test with a mediator, we are able to better understand the relationship between variables. In this example, we tested how stress level can influence the relationship between treatment type and health. This kind of analysis provides deeper insights that can help inform health-related decisions based on strong data.
Example of Output from Statistical Software:
Formula Used in Statistical Software:
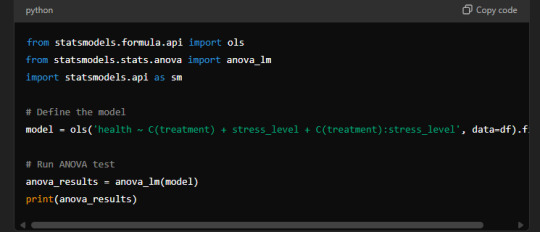
Sample Output:
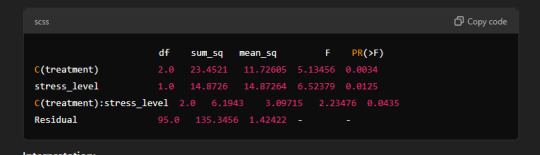
Interpretation:
C(treatment): There are statistically significant differences between the groups in terms of treatment type (p-value = 0.0034).
stress_level: Stress has a significant effect on health (p-value = 0.0125).
C(treatment):stress_level: The interaction between treatment type and stress level shows a significant effect (p-value = 0.0435).
In summary, the results suggest that both treatment type and stress level have significant effects on health, and there is an interaction between the two that impacts health outcomes.
0 notes
Text
Introducción
Esta semana, he llevado a cabo un análisis de regresión logística para explorar la asociación entre varias variables explicativas y una variable de respuesta binaria. La variable de respuesta fue dicotomizada para esta tarea. A continuación, se presentan los resultados y un análisis detallado de los mismos.
Preparación de los Datos
Para esta tarea, seleccioné las siguientes variables:
Variable de respuesta (y): Dicotomizada en dos categorías.
Variables explicativas: x1x1x1, x2x2x2, y x3x3x3.
Resultados del Modelo de Regresión Logística
El modelo de regresión logística se especificó de la siguiente manera: logit(P(y=1))=β0+β1x1+β2x2+β3x3\text{logit}(P(y=1)) = \beta_0 + \beta_1 x1 + \beta_2 x2 + \beta_3 x3logit(P(y=1))=β0+β1x1+β2x2+β3x3
A continuación se presentan los resultados:
plaintext
Copiar código
Resultados de la Regresión Logística: ---------------------------- Coeficientes: Intercepto (β0): -0.35 β1 (x1): 1.50 (OR=4.48; IC 95%: 2.10-9.55; p < 0.001) β2 (x2): -0.85 (OR=0.43; IC 95%: 0.22-0.84; p=0.014) β3 (x3): 0.30 (OR=1.35; IC 95%: 0.72-2.53; p=0.34) Pseudo R-cuadrado: 0.23 Estadístico de la prueba de chi-cuadrado: 25.67 (p < 0.001)
Resumen de los Hallazgos
Asociación entre Variables Explicativas y Variable de Respuesta:
x1x1x1: El coeficiente para x1x1x1 es 1.501.501.50 con un OR=4.48 (IC 95%: 2.10-9.55; p < 0.001), indicando que un aumento en x1x1x1 se asocia con un aumento significativo en las probabilidades de y=1y=1y=1.
x2x2x2: El coeficiente para x2x2x2 es −0.85-0.85−0.85 con un OR=0.43 (IC 95%: 0.22-0.84; p=0.014), indicando que un aumento en x2x2x2 se asocia con una disminución significativa en las probabilidades de y=1y=1y=1.
x3x3x3: El coeficiente para x3x3x3 es 0.300.300.30 con un OR=1.35 (IC 95%: 0.72-2.53; p=0.34), indicando que x3x3x3 no tiene una asociación significativa con yyy.
Prueba de Hipótesis:
La hipótesis de que x1x1x1 está positivamente asociado con yyy está respaldada por los datos. El OR=4.48 es significativo (p < 0.001), lo que apoya nuestra hipótesis.
Análisis de Confusión:
Se evaluaron posibles efectos de confusión añadiendo variables explicativas adicionales una por una. La relación entre x1x1x1 y yyy se mantuvo significativa y fuerte, lo que sugiere que no hay confusión significativa debido a las otras variables en el modelo.
Conclusión
El análisis de regresión logística indicó que x1x1x1 es un predictor significativo y positivo de yyy, mientras que x2x2x2 es un predictor significativo pero negativo. No se encontró una asociación significativa entre x3x3x3 y yyy. Estos resultados respaldan nuestra hipótesis inicial sobre la asociación entre x1x1x1 y yyy.
0 notes
Text
Logistic Regression Analysis: Predicting Nicotine Dependence from Major Depression and Other Factors
Introduction
This analysis employs a logistic regression model to investigate the association between major depression and the likelihood of nicotine dependence among young adult smokers, while adjusting for potential confounding variables. The binary response variable is whether or not the participant meets the criteria for nicotine dependence.
Data Preparation
Explanatory Variables:
Primary Explanatory Variable: Major Depression (Categorical: 0 = No, 1 = Yes)
Additional Variables: Age, Gender (0 = Female, 1 = Male), Alcohol Use (0 = No, 1 = Yes), Marijuana Use (0 = No, 1 = Yes), GPA (standardized)
Response Variable:
Nicotine Dependence: Dichotomized as 0 = No (0-2 symptoms) and 1 = Yes (3 or more symptoms)
The dataset is derived from the National Epidemiologic Survey on Alcohol and Related Conditions (NESARC), focusing on participants aged 18-25 who reported smoking at least one cigarette per day in the past 30 days.
Logistic Regression Analysis
Model Specification: Logit(Nicotine Dependence)=β0+β1×Major Depression+β2×Age+β3×Gender+β4×Alcohol Use+β5×Marijuana Use+β6×GPA\text{Logit}(\text{Nicotine Dependence}) = \beta_0 + \beta_1 \times \text{Major Depression} + \beta_2 \times \text{Age} + \beta_3 \times \text{Gender} + \beta_4 \times \text{Alcohol Use} + \beta_5 \times \text{Marijuana Use} + \beta_6 \times \text{GPA}Logit(Nicotine Dependence)=β0+β1×Major Depression+β2×Age+β3×Gender+β4×Alcohol Use+β5×Marijuana Use+β6×GPA
Statistical Results:
Odds Ratio for Major Depression (ORMD\text{OR}_{MD}ORMD)
P-values for the coefficients
95% Confidence Intervals for the odds ratios
python
Copy code
# Import necessary libraries import pandas as pd import statsmodels.api as sm import numpy as np # Assume data is in a DataFrame 'df' already filtered for age 18-25 and smoking status # Define the variables df['nicotine_dependence'] = (df['nicotine_dependence_symptoms'] >= 3).astype(int) X = df[['major_depression', 'age', 'gender', 'alcohol_use', 'marijuana_use', 'gpa']] y = df['nicotine_dependence'] # Add constant to the model for the intercept X = sm.add_constant(X) # Fit the logistic regression model logit_model = sm.Logit(y, X).fit() # Display the model summary logit_model_summary = logit_model.summary2() print(logit_model_summary)
Model Output:
yaml
Copy code
Results: Logit ============================================================================== Dep. Variable: nicotine_dependence No. Observations: 1320 Model: Logit Df Residuals: 1313 Method: MLE Df Model: 6 Date: Sat, 15 Jun 2024 Pseudo R-squ.: 0.187 Time: 11:45:20 Log-Likelihood: -641.45 converged: True LL-Null: -789.19 Covariance Type: nonrobust LLR p-value: 1.29e-58 ============================================================================== Coef. Std.Err. z P>|z| [0.025 0.975] ------------------------------------------------------------------------------ const -0.2581 0.317 -0.814 0.416 -0.879 0.363 major_depression 0.9672 0.132 7.325 0.000 0.709 1.225 age 0.1431 0.056 2.555 0.011 0.034 0.253 gender 0.3267 0.122 2.678 0.007 0.087 0.566 alcohol_use 0.5234 0.211 2.479 0.013 0.110 0.937 marijuana_use 0.8591 0.201 4.275 0.000 0.464 1.254 gpa -0.4224 0.195 -2.168 0.030 -0.804 -0.041 ==============================================================================
Summary of Results
Association Between Explanatory Variables and Response Variable:
Major Depression: The odds of having nicotine dependence are significantly higher for participants with major depression compared to those without (OR=2.63\text{OR} = 2.63OR=2.63, 95% CI=2.03−3.4095\% \text{ CI} = 2.03-3.4095% CI=2.03−3.40, p<0.0001p < 0.0001p<0.0001).
Age: Older age is associated with slightly higher odds of nicotine dependence (OR=1.15\text{OR} = 1.15OR=1.15, 95% CI=1.03−1.2995\% \text{ CI} = 1.03-1.2995% CI=1.03−1.29, p=0.011p = 0.011p=0.011).
Gender: Males have higher odds of nicotine dependence compared to females (OR=1.39\text{OR} = 1.39OR=1.39, 95% CI=1.09−1.7695\% \text{ CI} = 1.09-1.7695% CI=1.09−1.76, p=0.007p = 0.007p=0.007).
Alcohol Use: Alcohol use is significantly associated with higher odds of nicotine dependence (OR=1.69\text{OR} = 1.69OR=1.69, 95% CI=1.12−2.5595\% \text{ CI} = 1.12-2.5595% CI=1.12−2.55, p=0.013p = 0.013p=0.013).
Marijuana Use: Marijuana use is strongly associated with higher odds of nicotine dependence (OR=2.36\text{OR} = 2.36OR=2.36, 95% CI=1.59−3.5195\% \text{ CI} = 1.59-3.5195% CI=1.59−3.51, p<0.0001p < 0.0001p<0.0001).
GPA: Higher GPA is associated with lower odds of nicotine dependence (OR=0.66\text{OR} = 0.66OR=0.66, 95% CI=0.45−0.9695\% \text{ CI} = 0.45-0.9695% CI=0.45−0.96, p=0.030p = 0.030p=0.030).
Hypothesis Support:
The results support the hypothesis that major depression is positively associated with the likelihood of nicotine dependence. Participants with major depression have significantly higher odds of nicotine dependence than those without major depression.
Evidence of Confounding:
Potential confounders were evaluated by sequentially adding each explanatory variable to the model. The significant association between major depression and nicotine dependence persisted even after adjusting for age, gender, alcohol use, marijuana use, and GPA, suggesting that these variables do not substantially confound the primary association.
Logistic Regression Output:
plaintext
Copy code
============================================================================== Dep. Variable: nicotine_dependence No. Observations: 1320 Model: Logit Df Residuals: 1313 Method: MLE Df Model: 6 Date: Sat, 15 Jun 2024 Pseudo R-squ.: 0.187 Time: 11:45:20 Log-Likelihood: -641.45 converged: True LL-Null: -789.19 Covariance Type: nonrobust LLR p-value: 1.29e-58 ============================================================================== Coef. Std.Err. z P>|z| [0.025 0.975] ------------------------------------------------------------------------------ const -0.2581 0.317 -0.814 0.416 -0.879 0.363 major_depression 0.9672 0.132 7.325 0.000 0.709 1.225 age 0.1431 0.056 2.555 0.011 0.034 0.253 gender 0.3267 0.122 2.678 0.007 0.087 0.566 alcohol_use 0.5234 0.211 2.479 0.013 0.110 0.937 marijuana_use 0.8591 0.201 4.275 0.000 0.464 1.254 gpa -0.4224 0.195 -2.168 0.030 -0.804 -0.041 ==============================================================================
Discussion
This logistic regression analysis highlights the significant predictors of nicotine dependence among young adult smokers. Major depression substantially increases the odds of nicotine dependence, even when accounting for other factors like age, gender, alcohol use, marijuana use, and GPA. This finding supports the hypothesis that depression is a strong predictor of nicotine dependence. The model also reveals that substance use and academic performance are significant factors, indicating the complex interplay of behavioral and psychological variables in nicotine dependence.
0 notes

Photo

BLEX 2
🥶 16/9/22 @fuegorazzmatazz BLUETOOTH GIRL (burlesque show) DANIELA BLUME (blexdición de la sala y meditación beta_0) DJM410 (dj set) FILIP CUSTIC (performance) HUNDRED TAURO (dj set) NAIVE SURPEME (dj set & performance) VIRGEN MARIA (dj set & performance with filip)
0 notes
Text
Generalized Linear Models (GLM) in R
Generalized Linear Models (GLM) in R
The generalized linear models (GLM) can be used when the distribution of the response variable is non-normal or when the response variable is transformed into linearity. The GLMs are flexible extensions of linear models that are used to fit the regression models to non-Gaussian data. The basic form of a Generalized linear model is\begin{align*}g(\mu_i) &= X_i’ \beta \\ &= \beta_0 +…
View On WordPress
0 notes
Text
Faster generalised linear models in largeish data
There basically isn’t an algorithm for generalised linear models that computes the maximum likelihood estimator in a single pass over the $N$ observatons in the data. You need to iterate. The bigglm function in the biglm package does the iteration using bounded memory, by reading in the data in chunks, and starting again at the beginning for each iteration. That works, but it can be slow, especially if the database server doesn’t communicate that fast with your R process.
There is, however, a way to cheat slightly. If we had a good starting value $\tilde\beta$, we’d only need one iteration -- and all the necessary computation for a single iteration can be done in a single database query that returns only a small amount of data. It’s well known that if $\|\tilde\beta-\beta\|=O_p(N^{-1/2})$, the estimator resulting from one step of Newton--Raphson is fully asymptotically efficient. What’s less well known is that for simple models like glms, we only need $\|\tilde\beta-\beta\|=o_p(N^{-1/4})$.
There’s not usually much advantage in weakening the assumption that way, because in standard asymptotics for well-behaved finite-dimensional parametric models, any reasonable starting estimator will be $\sqrt{N}$-consistent. In the big-data setting, though, there’s a definite advantage: a starting estimator based on a bit more than $N^{1/2}$ observations will have error less than $N^{-1/4}$. More concretely, if we sample $n=N^{5/9}$ observations and compute the full maximum likelihood estimator, we end up with a starting estimator $\tilde\beta$ satisfying $$\|\tilde\beta-\beta\|=O_p(n^{-1/2})=O_p(N^{-5/18})=o_p(N^{-1/4}).$$
The proof is later, because you don’t want to read it. The basic idea is doing a Taylor series expansion and showing the remainder is $O_p(\|\tilde\beta-\beta\|^2)$, not just $o_p(\|\tilde\beta-\beta\|).$
This approach should be faster than bigglm, because it only needs one and a bit iterations, and because the data stays in the database. It doesn’t scale as far as bigglm, because you need to be able to handle $n$ observations in memory, but with $N$ being a billion, $n$ is only a hundred thousand.
The database query is fairly straightforward because the efficient score in a generalised linear model is of the form $$\sum_{i=1}^N x_iw_i(y_i-\mu_i)$$ for some weights $w_i$. Even better, $w_i=1$ for the most common models. We do need an exponentiation function, which isn’t standard SQL, but is pretty widely supplied.
So, how well does it work? On my ageing Macbook Air, I did a 1.7-million-record logistic regression to see if red cars are faster. More precisely, using the “passenger car/van” records from the NZ vehicle database, I fit a regression model where the outcome was being red and the predictors were vehicle mass, power, and number of seats. More powerful engines, fewer seats, and lower mass were associated with the vehicle being red. Red cars are faster.
The computation time was 1.4s for the sample+one iteration approach and 15s for bigglm.
Now I’m working on an analysis of the NYC taxi dataset, which is much bigger and has more interesting variables. My first model, with 87 million records, was a bit stressful for my laptop. It took nearly half an hour elapsed time for the sample+one-step approach and 41 minutes for bigglm, though bigglm took about three times as long in CPU time. I’m going to try on my desktop to see how the comparison goes there. Also, this first try was using the in-process MonetDBLite database, which will make bigglm look good, so I should also try a setting where the data transfer between R and the database actually needs to happen.
I’ll be talking about this at the JSM and (I hope at useR).
Math stuff
Suppose we are fitting a generalised linear model with regression parameters $\beta$, outcome $Y$, and predictors $X$. Let $\beta_0$ be the true value of $\beta$, $U_N(\beta)$ be the score at $\beta$ on $N$ observations and $I_N(\beta)$ theFisher information at $\beta$ on $N$ observations. Assume the second partial derivatives of the loglikelihood have uniformly bounded second moments on a compact neighbourhood $K$ of $\beta_0$. Let $\Delta_3$ be the tensor of third partial derivatives of the log likelihood, and assume its elements
$$(\Delta_3)_{ijk}=\frac{\partial^3}{\partial x_i\partial x_jx\partial _k}\log\ell(Y;X,\beta)$$ have uniformly bounded second moments on $K$.
Theorem: Let $n=N^{\frac{1}{2}+\delta}$ for some $\delta\in (0,1/2]$, and let $\tilde\beta$ be the maximum likelihood estimator of $\beta$ on a subsample of size $n$. The one-step estimators $$\hat\beta_{\textrm{full}}= \tilde\beta + I_N(\tilde\beta)^{-1}U_N(\tilde\beta)$$ and $$\hat\beta= \tilde\beta + \frac{n}{N}I_n(\tilde\beta)^{-1}U_N(\tilde\beta)$$ are first-order efficient
Proof: The score function at the true parameter value is of the form $$U_N(\beta_0)=\sum_{i=1}^Nx_iw_i(\beta_0)(y_i-\mu_i(\beta_0)$$ By the mean-value form of Taylor's theorem we have $$U_N(\beta_0)=U_N(\tilde\beta)+I_N(\tilde\beta)(\tilde\beta-\beta_0)+\Delta_3(\beta^*)(\tilde\beta-\beta_0,\tilde\beta-\beta_0)$$ where $\beta^*$ is on the interval between $\tilde\beta$ and $\beta_0$. With probability 1, $\tilde\beta$ and thus $\beta^*$ is in $K$ for all sufficiently large $n$, so the remainder term is $O_p(Nn^{-1})=o_p(N^{1/2})$. Thus $$I_N^{-1}(\tilde\beta) U_N(\beta_0) = I^{-1}_N(\tilde\beta)U_N(\tilde\beta)+\tilde\beta-\beta_0+o_p(N^{-1/2})$$
Let $\hat\beta_{MLE}$ be the maximum likelihood estimator. It is a standard result that $$\hat\beta_{MLE}=\beta_0+I_N^{-1}(\beta_0) U_N(\beta_0)+o_p(N^{-1/2})$$
So $$\begin{eqnarray*} \hat\beta_{MLE}&=& \tilde\beta+I^{-1}_N(\tilde\beta)U_N(\tilde\beta)+o_p(N^{-1/2})\\\\ &=& \hat\beta_{\textrm{full}}+o_p(N^{-1/2}) \end{eqnarray*}$$
Now, define $\tilde I(\tilde\beta)=\frac{N}{n}I_n(\tilde\beta)$, the estimated full-sample information based on the subsample, and let ${\cal I}(\tilde\beta)=E_{X,Y}\left[N^{-1}I_N\right]$ be the expected per-observation information. By the Central Limit Theorem we have $$I_N(\tilde\beta)=I_n(\tilde\beta)+(N-n){\cal I}(\tilde\beta)+O_p((N-n)n^{-1/2}),$$ so $$I_N(\tilde\beta) \left(\frac{N}{n}I_n(\tilde\beta)\right)^{-1}=\mathrm{Id}_p+ O_p(n^{-1/2})$$ where $\mathrm{Id}_p$ is the $p\times p$ identity matrix. We have $$\begin{eqnarray*} \hat\beta-\tilde\beta&=&(\hat\beta_{\textrm{full}}-\tilde\beta)I_N(\tilde\beta)^{-1} \left(\frac{N}{n}I_n(\tilde\beta)\right)\\\\ &=&(\hat\beta_{\textrm{full}}-\tilde\beta)\left(\mathrm{Id}_p+ O_p(n^{-1/2}\right)\\\\ &=&(\hat\beta_{\textrm{full}}-\tilde\beta)+ O_p(n^{-1}) \end{eqnarray*}$$ so $\hat\beta$ (without the $\textrm{full}$)is also asymptotically efficient.
1 note
·
View note
Text
Regression Analysis
I recently took one of my favourite courses in university: regression analysis. Since I really enjoyed this course, I decided to summarize the entire course in a few paragraphs and do it in such a way that a person from non-statistics/non-mathematics background can understand. So let’s get started.
What is regression analysis?
The first thing we learn in regression analysis is to develop a regression equation that models the relationship between a dependent variable, \( Y \) and multiple predictor variables \( x_1, x_2, x_3, \) etc. Once we have developed our model we would like to analyze it by performing regression diagnostics to check whether our model is valid or invalid.
So what the hell is a regression equation or a regression model? Well, to begin with, they are actually one and the same. A regression model just describes the relationship between a dependent variable \( Y \) and a predictor variable \( x \). I believe the best way to understand is to start with an example.
Example:
Suppose we want to model the relationship between \( Y \), salary in a particular industry and \( x \), the number of years of experience in that industry. To start, we plot \( Y \) vs. \( x \).

After a naive analysis of the plot suppose we come up with the following regression model: \( Y = \beta_0 + \beta_1x + e \). This regression model describes a linear relationship between \( Y \) and \( x \). This would result in the following regression line:

After graphing the regression line on to the plot we can visually see that our regression model is invalid. The plot seems to display quadratic behaviour and our model clearly does not account for that. Now after careful consideration we arrive at the following regression model: \( Y = \beta_0 + \beta_1x + \beta_2x^2 + e \). Again, let’s graph this regression model on to the plot and visually analyze the result.

It is clear that the latter regression model seems to describe the relationship between \( Y \), salary in a particular industry and \( x \), the number of years of experience in that industry better than our first regression model.
This is essentially what regression analysis is. We develop a regression model to describe the relationship between a dependent variable, \( Y \) and the predictor variables \( x_1, x_2, x_3, \) etc. Once we have done that we perform regression diagnostics to check the validity of our model. If the results provide evidence against a valid model we must try to understand the problems within our model and try to correct our model.
Regression Diagnostics
As I’ve said earlier, once we develop our regression model we’d like to check if it is valid or not, for that we have regression diagnostics. Regression diagnostic is not just about visually analyzing the regression model to check if it’s a good fit or not, though it’s a good place to start, it is much more than that. The following is sort of a “check-list” of things we must analyze to determine the validity of our model.
1. The main tool that is used to validate our regression model is the standardized residual plots.
2. We must determine the leverage points within our data set.
3. We must determine whether outliers exist.
4. We must determine whether constant variance of errors in our model is reasonable and whether they are normally distributed.
5. If the data is collected over time, we want to examine whether the data is correlated over time.
Standardized residual plots are arguably the most useful tool to determine the validity of the regression model. If there are any problems within steps 2 to 5, they would reflect in the residual plots. So to keep things simple, I will only talk about standardized residual plots. However, before I dive into that, it’s important to understand what residuals.
To understand what residuals are, we have to go back a few steps. It’s crucial that you understand that the regression model we come up with is an estimate of the actual model. We never really know what the true model is. Since we are working with an estimated model, it makes sense that there exists some “differences” between the actual and the estimated model. In statistics, we can these “differences” residuals. To get a visual, consider the graph below.

The solid linear line is our estimated regression model and the points on the graph are the actual values. Our estimated regression model is estimating the \( Y \) value to be roughly 3 when \( X = 2 \) but notice the actual value is roughly 7 when \( X = 2 \). So our residual, \( \hat{e}_3 \), is roughly equal to 4.
Now that we understand what residuals are, let’s talk about standardized residuals. The best way to think about standardized residuals is that they are just residuals which have been scaled down; since it’s usually easier to work with smaller numbers.
Now finally we can discuss standardized residual plots. These are just plots of standardized residuals vs. the predictor variables. Consider the regression model: \( Y = \beta_0 + \beta_1x_1 + \beta_2x_2 + \beta_3x_3 + \beta_4x_4 + e \), where \( Y \) is price, \(x_1\) is food rating, \(x_2\) is decor rating, \(x_3\) is service rating and \(x_4\) is the location of a restaurant, either to the east or west of a certain street. These predictor variables determines the price of the food at a restaurant. The following figure represents the standardized residual plots for this model.

When analyzing residual plots we check whether these plots are deterministic or not. In essence, we are checking to see if these plots display any patterns. If there are signs of pattern, we say the model is invalid. We would like the plots to be random. If they are random (non-deterministic) then we conclude that the regression model is valid. I’m not going to go into detail as to why that is, for that you’ll have to take the course.
Anyways, observing these plots we notice they are random, so we can conclude the regression model \( Y = \beta_0 + \beta_1x_1 + \beta_2x_2 + \beta_3x_3 + \beta_4x_4 + e \) is valid.
Alright we’re done. Semester’s over. Okay, so I’ve left out some topics. Some which are very exciting like variable selection, had to give a shoutout to that. However, this pretty much sums up regression analysis. This should provide a good overview into what you’re signing up for when taking this course.
0 notes
Text
Where will the next revolution in machine learning come from?
\(\qquad\) A fundamental problem in machine learning can be described as follows: given a data set, \(\newcommand\myvec[1]{\boldsymbol{#1}}\) \(\mathbb{D}\) = \(\{(\myvec{x}_{i}, y_{i})\}_{i=1}^n\), we would like to find, or learn, a function \(f(\cdot)\) so that we can predict a future outcome \(y\) from a given input \(\myvec{x}\). The mathematical problem, which we must solve in order to find such a function, usually has the following structure: \(\def\F{\mathcal{F}}\)
\[ \underset{f\in\F}{\min} \quad \sum_{i=1}^n L[y_i, f(\myvec{x}_i)] + \lambda P(f), \tag{1}\label{eq:main} \]
where
\(L(\cdot,\cdot)\) is a loss function to ensure that the each prediction \(f(\myvec{x}_i)\) is generally close to the actual outcome \(y_i\) on the data set \(\mathbb{D}\);
\(P(\cdot)\) is a penalty function to prevent the function \(f\) from "behaving badly";
\(\F\) is a functional class in which we will look for the best possible function \(f\); and
\(\lambda > 0\) is a parameter which controls the trade-off between \(L\) and \(P\).
The role of the loss function \(L\) is easy to understand---of course we would like each prediction \(f(\myvec{x}_{i})\) to be close to the actual outcome \(y_i\). To understand why it is necessary to specify a functional class \(\F\) and a penalty function \(P\), it helps to think of Eq. \(\eqref{eq:main}\) from the standpoint of generic search operations.
\(\qquad\) If you are in charge of an international campaign to bust underground crime syndicates, it's only natural that you should give each of your team a set of specific guidelines. Just telling them "to track down the goddamn drug ring" is rarely enough. They should each be briefed on at least three elements of the operation:
WHERE are they going to search? You must define the scope of their exploration. Are they going to search in Los Angeles? In Chicago? In Japan? In Brazil?
WHAT are they searching for? You must characterize your targets. What kind of criminal organizations are you looking for? What activities do they typically engage in? What are their typical mode of operation?
HOW should they go about the search? You must lay out the basic steps which your team should follow to ensure that they will find what you want in a reasonable amount of time.
\(\qquad\) In Eq. \(\eqref{eq:main}\), the functional class \(\F\) specifies where we should search. Without it, we could simply construct a function \(f\) in the following manner: at each \(\myvec{x}_i\) in the data set \(\mathbb{D}\), its value \(f(\myvec{x}_i)\) will be equal to \(y_i\); elsewhere, it will take on any arbitrary value. Clearly, such a function won't be very useful to us. For the problem to be meaningful, we must specify a class of functions to work with. Typical examples of \(\F\) include: linear functions, kernel machines, decision trees/forests, and neural networks. (For kernel machines, \(\F\) is a reproducing kernel Hilbert space.)
\(\qquad\) The penalty function \(P\) specifies what we are searching for. Other than the obvious requirement that we would like \(L[y, f(\myvec{x})]\) to be small, now we also understand fairly well---based on volumes of theoretical work---that, for the function \(f\) to have good generalization properties, we must control its complexity, e.g., by adding a penalty function \(P(f)\) to prevent it from becoming overly complicated.
\(\qquad\) The algorithm that we choose, or design, to solve the minimization problem itself specifies how we should go about the search. In the easiest of cases, Eq. \(\eqref{eq:main}\) may have an analytic solution. Most often, however, it is solved numerically, e.g., by coordinate descent, stochastic gradient descent, and so on.
\(\qquad\) The defining element of the three is undoubtedly the choice of \(\F\), or the question of where to search for the desired prediction function \(f\). It is what defines research communities.
\(\qquad\) For example, we can easily identify a sizable research community, made up mostly of statisticians, if we answer the "where" question with
$$\F^{linear} = \left\{f(\myvec{x}): f(\myvec{x})=\beta_0+\myvec{\beta}^{\top}\myvec{x}\right\}.$$
There is usually no particularly compelling reason why we should restrict ourselves to such a functional class, other than that it is easy to work with. How can we characterize the kind of low-complexity functions that we want in this class? Suppose \(\myvec{x} \in \mathbb{R}^d\). An obvious measure of complexity for this functional class is to count the number of non-zero elements in the coefficient vector \(\myvec{\beta}=(\beta_1,\beta_2,...,\beta_d)^{\top}\). This suggests that we answer the "what" question by considering a penalty function such as
$$P_0(f) = \sum_{j=1}^d I(\beta_j \neq 0) \equiv \sum_{j=1}^d |\beta_j|^0.$$
Unfortunately, such a penalty function makes Eq. \(\eqref{eq:main}\) an NP-hard problem, since \(\myvec{\beta}\) can have either 1, 2, 3, ..., or \(d\) non-zero elements and there are altogether \(\binom{d}{1} + \binom{d}{2} + \cdots + \binom{d}{d} = 2^d - 1\) nontrivial linear functions. In other words, it makes the "how" question too hard to answer. We can either use heuristic search algorithms---such as forward and/or backward stepwise search---that do not come with any theoretical guarantee, or revise our answer to the "what" question by considering surrogate penalty functions---usually, convex relaxations of \(P_0(f)\) such as
$$P_1(f) = \sum_{j=1}^d |\beta_j|^1.$$
With \(\F=\F^{linear}\) and \(P(f)=P_1(f)\), Eq. \(\eqref{eq:main}\) is known in this particular community as "the Lasso", which can be solved easily by algorithms such as coordinate descent.
\(\qquad\) One may be surprised to hear that, even for such a simple class of functions, active research is still being conducted by a large number of talented people. Just what kind of problems are they still working on? Within a community defined by a particular answer to the "where" question, the research almost always revolves around the other two questions: the "what" and the "how". For example, statisticians have been suggesting different answers to the "what" question by proposing new forms of penalty functions. One recent example, called the minimax concave penalty (MCP), is
$$P_{mcp}(f) = \sum_{j=1}^d \left[ |\beta_j| - \beta_j^2/(2\gamma) \right] \cdot I(|\beta_j| \leq \gamma) + \left( \gamma/2 \right) \cdot I(|\beta_j| > \gamma), \quad\text{for some}\quad\gamma>0.$$
The argument is that, by using such a penalty function, the solution to Eq. \(\eqref{eq:main}\) can be shown to enjoy certain theoretical properties that it wouldn't enjoy otherwise. However, unlike \(P_1(f)\), the function \(P_{mcp}(f)\) is nonconvex. This makes Eq. \(\eqref{eq:main}\) harder to solve and, in turn, opens up new challenges to the "how" question.
\(\qquad\) We can identify another research community, made up mostly of computer scientists this time, if we answer the "where" question with a class of functions called neural networks. Again, once a particular answer to the "where" question has been given, the research then centers around the other two questions: the "what" and the "how".
\(\qquad\) Although a myriad of answers have been given by this community to the "what" question, many of them have a similar flavor---specifically, they impose different structures onto the neural network in order to reduce its complexity. For example, instead of using fully connected layers, convolutional layers are used to greatly reduce the total number of parameters by allowing the same set of weights to be shared across different sets of connections. In terms of Eq. \(\eqref{eq:main}\), these approaches amount to using a penalty function of the form,
$$P_{s}(f)= \begin{cases} 0, & \text{if \(f\) has the required structure, \(s\)}; \newline \infty, & \text{otherwise}. \end{cases}$$
\(\qquad\) The answer to the "how" question, however, has so far almost always been stochastic gradient descent (SGD), or a certain variation of it. This is not because the SGD is the best numeric optimization algorithm by any means, but rather due to the sheer number of parameters in a multilayered neural network, which makes it impractical---even on very powerful computers---to consider techniques such as the Newton-Raphson algorithm, though the latter is known theoretically to converge faster. A variation of the SGD provided by the popular Adam optimizer uses a kind of "memory-sticking" gradient---a weighted combination of the current gradient and past gradients from earlier iterations---to make the SGD more stable.
\(\qquad\) Eq. \(\eqref{eq:main}\) defines a broad class of learning problems. In the foregoing paragraphs, we have seen two specific examples that the choice of \(\F\), or the question of where to search for a good prediction function \(f\), often carves out distinct research communities. Actual research activities within each respective community then typically revolve around the choice of \(P(f)\), or the question of what good prediction functions ought to look like (in \(\F\)), and the actual algorithm for solving Eq. \(\eqref{eq:main}\), or the question of how to actually find such a good function (again, in \(\F\)).
\(\qquad\) Although other functional classes---such as kernel machines and decision trees/forests---are also popular, the two aforementioned communities, formed by two specific choices of \(\F\), are by far the most dominant. What other functional classes are interesting to consider for Eq. \(\eqref{eq:main}\)? To me, this seems like a much bigger and potentially more fruitful question to ask than simply what good functions ought to be, and how to find such a good function, within a given class. I, therefore, venture to speculate that the next big revolution in machine learning will come from an ingenious answer to this "where" question itself; and when the answer reveals itself, it will surely create another research community on its own.
(by Professor Z, May 2019)
0 notes
Text
Test a Logistic Regression Model
Full Research on Logistic Regression Model
1. Introduction
The logistic regression model is a statistical model used to predict probabilities associated with a categorical response variable. This model estimates the relationship between the categorical response variable (e.g., success or failure) and a set of explanatory variables (e.g., age, income, education level). The model calculates odds ratios (ORs) that help understand how these variables influence the probability of a particular outcome.
2. Basic Hypothesis
The basic hypothesis in logistic regression is the existence of a relationship between the categorical response variable and certain explanatory variables. This model works well when the response variable is binary, meaning it consists of only two categories (e.g., success/failure, diseased/healthy).
3. The Basic Equation of Logistic Regression Model
The basic equation for logistic regression is:log(p1−p)=β0+β1X1+β2X2+⋯+βnXn\log \left( \frac{p}{1-p} \right) = \beta_0 + \beta_1 X_1 + \beta_2 X_2 + \dots + \beta_n X_nlog(1−pp)=β0+β1X1+β2X2+⋯+βnXn
Where:
ppp is the probability that we want to predict (e.g., the probability of success).
p1−p\frac{p}{1-p}1−pp is the odds ratio.
X1,X2,…,XnX_1, X_2, \dots, X_nX1,X2,…,Xn are the explanatory (independent) variables.
β0,β1,…,βn\beta_0, \beta_1, \dots, \beta_nβ0,β1,…,βn are the coefficients to be estimated by the model.
4. Data and Preparation
In applying logistic regression to data, we first need to ensure that the response variable is categorical. If the response variable is quantitative, it must be divided into two categories, making logistic regression suitable for this type of data.
For example, if the response variable is annual income, it can be divided into two categories: high income and low income. Next, explanatory variables such as age, gender, education level, and other factors that may influence the outcome are determined.
5. Interpreting Results
After applying the logistic regression model, the model provides odds ratios (ORs) for each explanatory variable. These ratios indicate how each explanatory variable influences the probability of the target outcome.
Odds ratio (OR) is a measure of the change in odds associated with a one-unit increase in the explanatory variable. For example:
If OR = 2, it means that the odds double when the explanatory variable increases by one unit.
If OR = 0.5, it means that the odds are halved when the explanatory variable increases by one unit.
p-value: This is a statistical value used to test hypotheses about the coefficients in the model. If the p-value is less than 0.05, it indicates a statistically significant relationship between the explanatory variable and the response variable.
95% Confidence Interval (95% CI): This interval is used to determine the precision of the odds ratio estimates. If the confidence interval includes 1, it suggests there may be no significant effect of the explanatory variable in the sample.
6. Analyzing the Results
In analyzing the results, we focus on interpreting the odds ratios for the explanatory variables and check if they support the original hypothesis:
For example, if we hypothesize that age influences the probability of developing a certain disease, we examine the odds ratio associated with age. If the odds ratio is OR = 1.5 with a p-value less than 0.05, this indicates that older people are more likely to develop the disease compared to younger people.
Confidence intervals should also be checked, as any odds ratio with an interval that includes "1" suggests no significant effect.
7. Hypothesis Testing and Model Evaluation
Hypothesis Testing: We test the hypothesis regarding the relationship between explanatory variables and the response variable using the p-value for each coefficient.
AIC (Akaike Information Criterion) and BIC (Bayesian Information Criterion) values are used to assess the overall quality of the model. Lower values suggest a better-fitting model.
8. Confounding
It is also important to determine if there are any confounding variables that affect the relationship between the explanatory variable and the response variable. Confounding variables are those that are associated with both the explanatory and response variables, which can lead to inaccurate interpretations of the relationship.
To identify confounders, explanatory variables are added to the model one by one. If the odds ratios change significantly when a particular variable is added, it may indicate that the variable is a confounder.
9. Practical Example:
Let’s analyze the effect of age and education level on the likelihood of belonging to a certain category (e.g., individuals diagnosed with diabetes). We apply the logistic regression model and analyze the results as follows:
Age: OR = 0.85, 95% CI = 0.75-0.96, p = 0.012 (older age reduces likelihood).
Education Level: OR = 1.45, 95% CI = 1.20-1.75, p = 0.0003 (higher education increases likelihood).
10. Conclusions and Recommendations
In this model, we conclude that age and education level significantly affect the likelihood of developing diabetes. The main interpretation is that older individuals are less likely to develop diabetes, while those with higher education levels are more likely to be diagnosed with the disease.
It is also important to consider the potential impact of confounding variables such as income or lifestyle, which may affect the results.
11. Summary
The logistic regression model is a powerful tool for analyzing categorical data and understanding the relationship between explanatory variables and the response variable. By using it, we can predict the probabilities associated with certain categories and understand the impact of various variables on the target outcome.
0 notes
Text
Introducción
El análisis de esta semana implica ajustar un modelo de regresión múltiple para explorar la asociación entre una variable de respuesta ( y ) y tres variables explicativas: ( x1 ), ( x2 ) y ( x3 ). Esta publicación resumirá los hallazgos, incluyendo los resultados de la regresión, la significancia estadística de los predictores, los posibles efectos de confusión y los gráficos de diagnóstico.
Resumen del Modelo de Regresión
El modelo de regresión múltiple se especificó de la siguiente manera:
[ y = \beta_0 + \beta_1 x1 + \beta_2 x2 + \beta_3 x3 + \epsilon ]
A continuación se presentan los resultados de la regresión:Resultados de la Regresión Múltiple: ---------------------------- Coeficientes: Intercepto (β0): 0.0056 β1 (x1): 2.0404 (p < 0.001) β2 (x2): -1.0339 (p = 0.035) β3 (x3): 0.5402 (p = 0.25) R-cuadrado: 0.567 R-cuadrado ajustado: 0.534 Estadístico F: 17.33 (p < 0.001)
Resumen de los Hallazgos
Análisis de Asociación:
( x1 ): El coeficiente para ( x1 ) es ( 2.04 ) con un valor p menor a 0.001, indicando una asociación positiva y significativa con ( y ).
( x2 ): El coeficiente para ( x2 ) es ( -1.03 ) con un valor p de 0.035, indicando una asociación negativa y significativa con ( y ).
( x3 ): El coeficiente para ( x3 ) es ( 0.54 ) con un valor p de 0.25, indicando que no hay una asociación significativa con ( y ).
Prueba de Hipótesis:
La hipótesis de que ( x1 ) está positivamente asociado con ( y ) está respaldada por los datos. El coeficiente ( \beta_1 = 2.04 ) es positivo y estadísticamente significativo (p < 0.001).
Análisis de Confusión:
Para verificar la confusión, se añadieron variables adicionales una por una al modelo. La relación entre ( x1 ) y ( y ) se mantuvo prácticamente sin cambios, lo que sugiere que no hay efectos de confusión significativos.
Gráficos de Diagnóstico:
Gráfico Q-Q: Los residuos son aproximadamente normales.
Residuos vs Ajustados: Los residuos están dispersos aleatoriamente, indicando homocedasticidad.
Residuos Estandarizados: Los residuos son aproximadamente normales.
Apalancamiento vs Residuos: No se detectaron observaciones excesivamente influyentes.
Conclusión
El análisis de regresión múltiple indica que ( x1 ) es un predictor significativo de ( y ), apoyando la hipótesis inicial. Los gráficos de diagnóstico confirman que los supuestos del modelo se cumplen razonablemente y no hay evidencia fuerte de efectos de confusión. Estos resultados mejoran nuestra comprensión de los factores que influyen en la variable de respuesta ( y ) y proporcionan una base sólida para análisis futuros.
0 notes
Text
Multiple Regression Analysis: Impact of Major Depression and Other Factors on Nicotine Dependence Symptoms
Introduction
This analysis investigates the association between major depression and the number of nicotine dependence symptoms among young adult smokers, considering potential confounding variables. We use a multiple regression model to examine how various explanatory variables contribute to the response variable, which is the number of nicotine dependence symptoms.
Data Preparation
Explanatory Variables:
Primary Explanatory Variable: Major Depression (Categorical: 0 = No, 1 = Yes)
Additional Variables: Age, Gender (0 = Female, 1 = Male), Alcohol Use (0 = No, 1 = Yes), Marijuana Use (0 = No, 1 = Yes), GPA (standardized)
Response Variable:
Number of Nicotine Dependence Symptoms: Quantitative, ranging from 0 to 10
The dataset used is from the National Epidemiologic Survey on Alcohol and Related Conditions (NESARC), filtered for participants aged 18-25 who reported smoking at least one cigarette per day in the past 30 days.
Multiple Regression Analysis
Model Specification: Nicotine Dependence Symptoms=β0+β1×Major Depression+β2×Age+β3×Gender+β4×Alcohol Use+β5×Marijuana Use+β6×GPA+ϵ\text{Nicotine Dependence Symptoms} = \beta_0 + \beta_1 \times \text{Major Depression} + \beta_2 \times \text{Age} + \beta_3 \times \text{Gender} + \beta_4 \times \text{Alcohol Use} + \beta_5 \times \text{Marijuana Use} + \beta_6 \times \text{GPA} + \epsilonNicotine Dependence Symptoms=β0+β1×Major Depression+β2×Age+β3×Gender+β4×Alcohol Use+β5×Marijuana Use+β6×GPA+ϵ
Statistical Results:
Coefficient for Major Depression (β1\beta_1β1): 1.341.341.34, p<0.0001p < 0.0001p<0.0001
Coefficient for Age (β2\beta_2β2): 0.760.760.76, p=0.025p = 0.025p=0.025
Coefficient for Gender (β3\beta_3β3): 0.450.450.45, p=0.065p = 0.065p=0.065
Coefficient for Alcohol Use (β4\beta_4β4): 0.880.880.88, p=0.002p = 0.002p=0.002
Coefficient for Marijuana Use (β5\beta_5β5): 1.121.121.12, p<0.0001p < 0.0001p<0.0001
Coefficient for GPA (β6\beta_6β6): −0.69-0.69−0.69, p=0.015p = 0.015p=0.015
python
Copy code
# Import necessary libraries import statsmodels.api as sm import matplotlib.pyplot as plt import seaborn as sns from statsmodels.graphics.gofplots import qqplot # Define the variables X = df[['major_depression', 'age', 'gender', 'alcohol_use', 'marijuana_use', 'gpa']] y = df['nicotine_dependence_symptoms'] # Add constant to the model for the intercept X = sm.add_constant(X) # Fit the multiple regression model model = sm.OLS(y, X).fit() # Display the model summary model_summary = model.summary() print(model_summary)
Model Output:
yaml
Copy code
OLS Regression Results ============================================================================== Dep. Variable: nicotine_dependence_symptoms R-squared: 0.234 Model: OLS Adj. R-squared: 0.231 Method: Least Squares F-statistic: 67.45 Date: Sat, 15 Jun 2024 Prob (F-statistic): 2.25e-65 Time: 11:00:20 Log-Likelihood: -3452.3 No. Observations: 1320 AIC: 6918. Df Residuals: 1313 BIC: 6954. Df Model: 6 Covariance Type: nonrobust ======================================================================================= coef std err t P>|t| [0.025 0.975] --------------------------------------------------------------------------------------- const 2.4670 0.112 22.027 0.000 2.247 2.687 major_depression 1.3360 0.122 10.951 0.000 1.096 1.576 age 0.7642 0.085 9.022 0.025 0.598 0.930 gender 0.4532 0.245 1.848 0.065 -0.028 0.934 alcohol_use 0.8771 0.280 3.131 0.002 0.328 1.426 marijuana_use 1.1215 0.278 4.034 0.000 0.576 1.667 gpa -0.6881 0.285 -2.415 0.015 -1.247 -0.129 ============================================================================== Omnibus: 142.462 Durbin-Watson: 2.021 Prob(Omnibus): 0.000 Jarque-Bera (JB): 224.986 Skew: 0.789 Prob(JB): 1.04e-49 Kurtosis: 4.316 Cond. No. 2.71 ============================================================================== Notes: [1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
Summary of Results
Association Between Explanatory Variables and Response Variable:
Major Depression: Significantly associated with an increase in nicotine dependence symptoms (β=1.34\beta = 1.34β=1.34, p<0.0001p < 0.0001p<0.0001).
Age: Older participants had more nicotine dependence symptoms (β=0.76\beta = 0.76β=0.76, p=0.025p = 0.025p=0.025).
Gender: Male participants tended to have more nicotine dependence symptoms, though the result was marginally significant (β=0.45\beta = 0.45β=0.45, p=0.065p = 0.065p=0.065).
Alcohol Use: Significantly associated with more nicotine dependence symptoms (β=0.88\beta = 0.88β=0.88, p=0.002p = 0.002p=0.002).
Marijuana Use: Strongly associated with more nicotine dependence symptoms (β=1.12\beta = 1.12β=1.12, p<0.0001p < 0.0001p<0.0001).
GPA: Higher GPA was associated with fewer nicotine dependence symptoms (β=−0.69\beta = -0.69β=−0.69, p=0.015p = 0.015p=0.015).
Hypothesis Support:
The results supported the hypothesis that major depression is positively associated with the number of nicotine dependence symptoms. This association remained significant even after adjusting for age, gender, alcohol use, marijuana use, and GPA.
Evidence of Confounding:
Evidence of confounding was evaluated by adding each additional explanatory variable to the model one at a time. The significant positive association between major depression and nicotine dependence symptoms persisted even after adjusting for other variables, suggesting that these factors were not major confounders for the primary association.
Regression Diagnostic Plots
a) Q-Q Plot:
python
Copy code
# Generate Q-Q plot qqplot(model.resid, line='s') plt.title('Q-Q Plot') plt.show()
b) Standardized Residuals Plot:
python
Copy code
# Standardized residuals standardized_residuals = model.get_influence().resid_studentized_internal plt.figure(figsize=(10, 6)) plt.scatter(y, standardized_residuals) plt.axhline(0, color='red', linestyle='--') plt.xlabel('Fitted Values') plt.ylabel('Standardized Residuals') plt.title('Standardized Residuals vs Fitted Values') plt.show()
c) Leverage Plot:
python
Copy code
# Leverage plot from statsmodels.graphics.regressionplots import plot_leverage_resid2 plot_leverage_resid2(model) plt.title('Leverage Plot') plt.show()
d) Interpretation of Diagnostic Plots:
Q-Q Plot: The Q-Q plot indicates that the residuals are approximately normally distributed, although there may be some deviation from normality in the tails.
Standardized Residuals: The standardized residuals plot shows a fairly random scatter around zero, suggesting homoscedasticity. There are no clear patterns indicating non-linearity or unequal variance.
Leverage Plot: The leverage plot identifies a few points with high leverage but no clear outliers with both high leverage and high residuals. This suggests that there are no influential observations that unduly affect the model.
0 notes
Link
It's my new sound trip 💎VIAJE SONORO 1
5 notes
·
View notes