#automated data lineage
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has been providing a Korean-language service since 2013.
Text
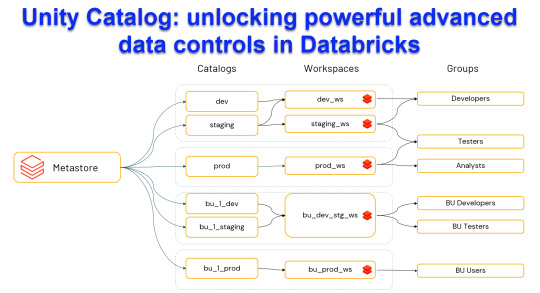
Unity Catalog: Unlocking Powerful Advanced Data Control in Databricks
Harness the power of Unity Catalog within Databricks and elevate your data governance to new heights. Our latest blog post, "Unity Catalog: Unlocking Advanced Data Control in Databricks," delves into the cutting-edge features
View On WordPress
#Advanced Data Security#Automated Data Lineage#Cloud Data Governance#Column Level Masking#Data Discovery and Cataloging#Data Ecosystem Security#Data Governance Solutions#Data Management Best Practices#Data Privacy Compliance#Databricks Data Control#Databricks Delta Sharing#Databricks Lakehouse Platform#Delta Lake Governance#External Data Locations#Managed Data Sources#Row Level Security#Schema Management Tools#Secure Data Sharing#Unity Catalog Databricks#Unity Catalog Features
0 notes
Text
DataOps: From Data to Decision-Making
In today’s complex data landscapes, where data flows ceaselessly from various sources, the ability to harness this data and turn it into actionable insights is a defining factor for many organization’s success. With companies generating over 50 times more data than they were just five years ago, adapting to this data deluge has become a strategic imperative. Enter DataOps, a transformative…

View On WordPress
#automated data lineage#big data challenges#business agility#data integration#data pipeline#DataOps#decision-making#whitepaper
0 notes
Note
I'm surprised youre pro-Z lib but against AI. If you dont mind could you explain why?
sure - zlib is a crucial way readers access books when that access is otherwise difficult/unavailable. as a writer, this is beneficial to me! it helps more people find my book/helps my words reach more readers, which is the goal of writing.
pushes by publishing et al to incorporate AI are chiefly concerned with replacing human writers in the name of 'efficiency,' as is the inevitable result of automation + capitalism. further, and perhaps even more distressingly, the creation of what some call "AI slop" requires a mixing of a huge number of peoples' creative work without citation + acknowledgement of lineage.
a crucial part of making art + writing is citation, whether literally in a bibliography or via an intentional craft practice of reading / viewing / practicing / thinking with the work of our foreparents and peers. our works are informed by our lived experiences writ large, but especially encounters both chance and planned with others' work.
creative practice requires a degree of collaboration, and, ethically, an acknowledgement that we do not work alone. the usage of AI, trained oftentimes on data scraped non-consensually and stripped of lineage, makes that process impossible. further, again, the push to "facilitate" writing / art with AI can't be divorced from reactionary anti- arts/humanities ideologies, which seeks not only to demonize these disciplines + their perceived "unproductivity" but also render their practitioners obsolete.
10 notes
·
View notes
Text
Harnessing the Power of Data Engineering for Modern Enterprises
In the contemporary business landscape, data has emerged as the lifeblood of organizations, fueling innovation, strategic decision-making, and operational efficiency. As businesses generate and collect vast amounts of data, the need for robust data engineering services has become more critical than ever. SG Analytics offers comprehensive data engineering solutions designed to transform raw data into actionable insights, driving business growth and success.
The Importance of Data Engineering
Data engineering is the foundational process that involves designing, building, and managing the infrastructure required to collect, store, and analyze data. It is the backbone of any data-driven enterprise, ensuring that data is clean, accurate, and accessible for analysis. In a world where businesses are inundated with data from various sources, data engineering plays a pivotal role in creating a streamlined and efficient data pipeline.
SG Analytics’ data engineering services are tailored to meet the unique needs of businesses across industries. By leveraging advanced technologies and methodologies, SG Analytics helps organizations build scalable data architectures that support real-time analytics and decision-making. Whether it’s cloud-based data warehouses, data lakes, or data integration platforms, SG Analytics provides end-to-end solutions that enable businesses to harness the full potential of their data.
Building a Robust Data Infrastructure
At the core of SG Analytics’ data engineering services is the ability to build robust data infrastructure that can handle the complexities of modern data environments. This includes the design and implementation of data pipelines that facilitate the smooth flow of data from source to destination. By automating data ingestion, transformation, and loading processes, SG Analytics ensures that data is readily available for analysis, reducing the time to insight.
One of the key challenges businesses face is dealing with the diverse formats and structures of data. SG Analytics excels in data integration, bringing together data from various sources such as databases, APIs, and third-party platforms. This unified approach to data management ensures that businesses have a single source of truth, enabling them to make informed decisions based on accurate and consistent data.
Leveraging Cloud Technologies for Scalability
As businesses grow, so does the volume of data they generate. Traditional on-premise data storage solutions often struggle to keep up with this exponential growth, leading to performance bottlenecks and increased costs. SG Analytics addresses this challenge by leveraging cloud technologies to build scalable data architectures.
Cloud-based data engineering solutions offer several advantages, including scalability, flexibility, and cost-efficiency. SG Analytics helps businesses migrate their data to the cloud, enabling them to scale their data infrastructure in line with their needs. Whether it’s setting up cloud data warehouses or implementing data lakes, SG Analytics ensures that businesses can store and process large volumes of data without compromising on performance.
Ensuring Data Quality and Governance
Inaccurate or incomplete data can lead to poor decision-making and costly mistakes. That’s why data quality and governance are critical components of SG Analytics’ data engineering services. By implementing data validation, cleansing, and enrichment processes, SG Analytics ensures that businesses have access to high-quality data that drives reliable insights.
Data governance is equally important, as it defines the policies and procedures for managing data throughout its lifecycle. SG Analytics helps businesses establish robust data governance frameworks that ensure compliance with regulatory requirements and industry standards. This includes data lineage tracking, access controls, and audit trails, all of which contribute to the security and integrity of data.
Enhancing Data Analytics with Natural Language Processing Services
In today’s data-driven world, businesses are increasingly turning to advanced analytics techniques to extract deeper insights from their data. One such technique is natural language processing (NLP), a branch of artificial intelligence that enables computers to understand, interpret, and generate human language.
SG Analytics offers cutting-edge natural language processing services as part of its data engineering portfolio. By integrating NLP into data pipelines, SG Analytics helps businesses analyze unstructured data, such as text, social media posts, and customer reviews, to uncover hidden patterns and trends. This capability is particularly valuable in industries like healthcare, finance, and retail, where understanding customer sentiment and behavior is crucial for success.
NLP services can be used to automate various tasks, such as sentiment analysis, topic modeling, and entity recognition. For example, a retail business can use NLP to analyze customer feedback and identify common complaints, allowing them to address issues proactively. Similarly, a financial institution can use NLP to analyze market trends and predict future movements, enabling them to make informed investment decisions.
By incorporating NLP into their data engineering services, SG Analytics empowers businesses to go beyond traditional data analysis and unlock the full potential of their data. Whether it’s extracting insights from vast amounts of text data or automating complex tasks, NLP services provide businesses with a competitive edge in the market.
Driving Business Success with Data Engineering
The ultimate goal of data engineering is to drive business success by enabling organizations to make data-driven decisions. SG Analytics’ data engineering services provide businesses with the tools and capabilities they need to achieve this goal. By building robust data infrastructure, ensuring data quality and governance, and leveraging advanced analytics techniques like NLP, SG Analytics helps businesses stay ahead of the competition.
In a rapidly evolving business landscape, the ability to harness the power of data is a key differentiator. With SG Analytics’ data engineering services, businesses can unlock new opportunities, optimize their operations, and achieve sustainable growth. Whether you’re a small startup or a large enterprise, SG Analytics has the expertise and experience to help you navigate the complexities of data engineering and achieve your business objectives.
5 notes
·
View notes
Text
From Principles to Playbook: Build an AI-Governance Framework in 30 Days | Nate Patel

The gap between aspirational AI principles and operational reality is where risks fester — ethical breaches, regulatory fines, brand damage, and failed deployments. Waiting for perfect legislation or the ultimate governance tool isn’t a strategy; it’s negligence. The time for actionable governance is now.
This isn’t about building an impenetrable fortress overnight. It’s about establishing a minimum viable governance (MVG) framework — a functional, adaptable system — within 30 days. This article is your tactical playbook to bridge the principles-to-practice chasm, mitigate immediate risks, and lay the foundation for robust, scalable AI governance.
Why 30 Days? The Urgency Imperative
Accelerating Adoption: AI use is exploding organically across departments. Without guardrails, shadow AI proliferates.
Regulatory Tsunami: From the EU AI Act and US Executive Orders to sector-specific guidance, compliance deadlines loom.
Mounting Risks: Real-world incidents (biased hiring tools, hallucinating chatbots causing legal liability, insecure models leaking data) demonstrate the tangible costs of inaction.
Competitive Advantage: Demonstrating trustworthy AI is becoming a market differentiator for customers, partners, and talent.
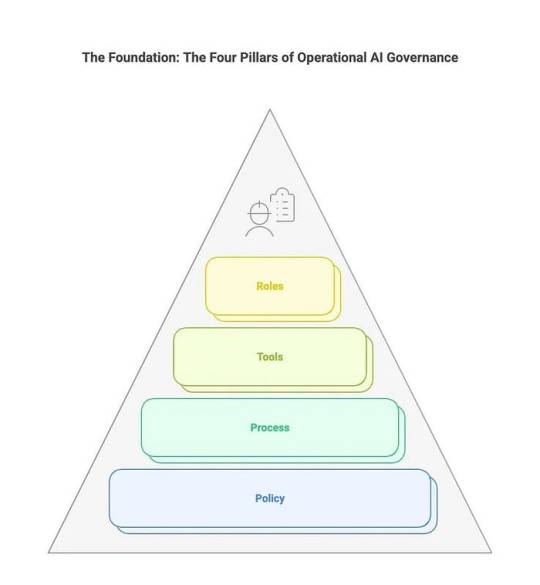
The Foundation: The Four Pillars of Operational AI Governance
An effective MVG framework isn’t a single document; it’s an integrated system resting on four critical pillars. Neglect any one, and the structure collapses.

Policy Pillar: The “What” and “Why” — Setting the Rules of the Road
Purpose: Defines the organization’s binding commitments, standards, and expectations for responsible AI development, deployment, and use.
Core Components:
Risk Classification Schema: A clear system for categorizing AI applications based on potential impact (e.g., High-Risk: Hiring, Credit Scoring, Critical Infrastructure; Medium-Risk: Internal Process Automation; Low-Risk: Basic Chatbots). This dictates the level of governance scrutiny. (e.g., Align with NIST AI RMF or EU AI Act categories).
Core Mandatory Requirements: Specific, non-negotiable obligations applicable to all AI projects. Examples:
Human Oversight: Define acceptable levels of human-in-the-loop, on-the-loop, or review for different risk classes.
Fairness & Bias Mitigation: Requirements for impact assessments, testing metrics (e.g., demographic parity difference, equal opportunity difference), and mitigation steps.
Transparency & Explainability: Minimum standards for model documentation (e.g., datasheets, model cards), user notifications, and explainability techniques required based on risk.
Robustness, Safety & Security: Requirements for adversarial testing, accuracy thresholds, drift monitoring, and secure development/deployment practices (e.g., OWASP AI Security & Privacy Guide).
Privacy: Compliance with relevant data protection laws (GDPR, CCPA, etc.), data minimization, and purpose limitation for training data.
Accountability & Traceability: Mandate for audit trails tracking model development, data lineage, decisions, and changes.
Read More: From Principles to Playbook: Build an AI-Governance Framework in 30 Days
- Nate Patel
Read More Articles:
Building Your AI Governance Foundation
AI Governance: Why It’s Your Business’s New Non-Negotiable
0 notes
Text
Future-Proofing BI: How AI-Powered Migration Sets the Foundation for GenAI in Analytics
In today’s rapidly evolving data landscape, traditional business intelligence (BI) platforms are reaching their limitations. As organizations increasingly adopt generative AI (GenAI) to gain deeper insights and drive smarter decisions, modernizing the BI foundation becomes non-negotiable. This transformation starts with an AI-powered migration—especially from legacy tools like Tableau to scalable, future-ready platforms like Power BI.
Why Traditional BI Falls Short in the GenAI Era
Traditional BI systems are often rigid, siloed, and heavily reliant on manual configurations. These systems struggle to scale with real-time data demands or support advanced AI integration. As GenAI becomes integral to business strategy—enabling auto-generated insights, narrative reports, and predictive forecasting—organizations require a BI foundation that can support automation, flexibility, and dynamic data interpretation.
That’s where AI-powered migration steps in.
AI-Powered Migration: More Than Just a Transfer
Unlike basic data migration, AI-powered migration uses machine learning and intelligent automation to translate dashboards, DAX calculations, data models, and business logic with minimal manual rework. Tools like Pulse Convert—developed by OfficeSolution—intelligently map Tableau objects to Power BI, preserving data integrity and logic while optimizing performance for the new environment.
This not only accelerates the migration process but also prepares the infrastructure for GenAI integration. With AI doing the heavy lifting, teams can focus on value creation rather than technical translation.
Laying the Groundwork for GenAI in Analytics
A successful migration to Power BI, driven by AI, sets the stage for GenAI in multiple ways:
Semantic Layer Optimization: AI ensures your data models are structured and standardized, which is essential for GenAI tools to interpret and respond accurately to natural language queries.
Performance Enhancements: GenAI needs a high-speed analytical backend. AI-powered migration ensures optimized DAX expressions and dataflows to support fast, responsive querying.
Data Governance Alignment: AI-driven migration supports tagging, lineage, and documentation—crucial for GenAI applications that rely on governed and contextualized datasets.
Scalable Architecture: Once migrated, organizations can integrate Power BI with Azure AI, Copilot, and custom GenAI solutions for conversational analytics, predictive models, and more.
Future-Proofing with Confidence
AI-powered migration is not just about switching platforms—it’s about preparing your data ecosystem for what’s next. It’s a strategic step that aligns your BI environment with the capabilities of GenAI, giving your analysts, executives, and data teams tools that think, learn, and generate with human-like understanding.
By future-proofing your BI with OfficeSolution’s Pulse Convert, your organization not only modernizes its reporting infrastructure but also unlocks the transformative potential of generative AI.
Ready to evolve your BI strategy? Explore AI-powered migration at https://tableautopowerbimigration.com and lay the foundation for GenAI-driven analytics today.
0 notes
Text
How Data Fabric and Data Mesh Democratize Data Access for Enterprise AI

As of mid-2025, the digital transformation journey for enterprises, especially those heavily investing in AI, is increasingly defined by how effectively they can leverage their data. For far too long, data has remained locked in silos, fragmented across disparate systems, and accessible only to a select few technical experts. This "data scarcity," despite its abundance, has been a major bottleneck for enterprise AI initiatives.
Enter Data Fabric and Data Mesh – two powerful architectural philosophies that are rapidly gaining traction for their ability to democratize data access, making it readily available, understandable, and trustworthy for every data consumer, from business analysts to AI/ML engineers.
The AI Imperative and the Data Access Challenge
Artificial Intelligence and Machine Learning models are insatiably hungry for data. They thrive on large, diverse, high-quality datasets to train, validate, and perform accurate predictions or complex reasoning. However, in many traditional enterprise environments:
Data is siloed: Residing in legacy databases, cloud applications, SaaS platforms, and data lakes, often managed by different teams.
Access is manual and slow: Data consumers frequently rely on centralized IT or data engineering teams to extract, transform, and load data, leading to significant delays and bottlenecks.
Data quality is inconsistent: Without clear ownership or unified governance, data integrity can suffer, leading to unreliable AI outputs.
Context is lost: Business users and data scientists struggle to understand data definitions, lineage, and trustworthiness, hindering data exploration and model development.
These challenges directly impede the agility and speed required for developing and deploying AI applications at scale, stifling innovation and delaying time-to-value.
Data Fabric: The Unified, Intelligent Overlay
Imagine a sophisticated, interconnected fabric woven across all your disparate data sources. That's the essence of a Data Fabric. It's a technology-centric architectural pattern that creates a unified, virtual access layer over your existing data landscape, critically, without physically moving or replicating the data.
When a data consumer (an AI model, an analytics dashboard, a business application) queries the Data Fabric, it:
Connects to various underlying data repositories (on-premises, multi-cloud, edge devices, streaming feeds).
Understands the diverse structures and metadata of these sources.
Translates the query into commands specific to each source.
Retrieves only the necessary data from its original location in real-time.
Combines and transforms the results virtually, presenting a cohesive, logical view to the requesting entity.
How Data Fabric Democratizes Data for AI:
Unified Access & Abstraction: It provides a single, simplified point of access, abstracting away the underlying complexities of data location, storage technology, or format. Data scientists can query a "virtual table" that seamlessly integrates data from an ERP, a cloud CRM, and a live IoT stream, as if it were one dataset.
Real-time Insights: By connecting directly to sources and processing data on demand, Data Fabric delivers the freshest data, essential for real-time AI inference in applications like fraud detection, dynamic pricing, or hyper-personalized recommendations.
AI-Driven Automation & Augmentation: Many modern Data Fabric solutions leverage AI and Machine Learning within themselves to automate data discovery, metadata management, data quality checks, and even integration processes. This "AI for data management" dramatically reduces manual effort in data preparation, freeing up data scientists for model building.
Enhanced Governance & Security: With a centralized virtual layer, robust data governance policies, security controls, and access management can be applied consistently across all underlying data sources, ensuring compliance and protecting sensitive data used in AI workloads.
Self-Service Analytics & Exploration: By providing intuitive interfaces and a semantic layer, Data Fabric empowers business analysts and even citizen data scientists to discover, understand, and combine datasets independently, accelerating self-service analytics that can directly fuel AI model development and validation.
Data Mesh: The Decentralized, Product-Oriented Paradigm
While Data Fabric focuses on the technical integration layer, Data Mesh is a more decentralized, organizational, and cultural paradigm shift. It rethinks how data is owned, managed, and consumed, applying principles from product development and domain-driven design to data.
How Data Mesh Democratizes Data for AI:
Domain-Oriented Ownership: Data Mesh decentralizes data ownership to the business domains that inherently understand their data best (e.g., Marketing, Sales, Finance, Supply Chain). Each domain becomes fully responsible for its data, eliminating the bottlenecks of a central data team. This means data scientists embedded within a domain can work directly with the data they understand deeply.
Data as a Product: Data within each domain is treated as a "data product." This necessitates that data assets are discoverable, addressable, trustworthy, self-describing (with rich metadata), and interoperable. For AI teams, this translates into readily available, high-quality, well-documented datasets (data products) that are "fit for purpose" for specific AI use cases, drastically reducing data discovery time.
Self-Service Data Platform: A Data Mesh provides a self-service platform that offers the tools and infrastructure for domain teams to manage and serve their data products independently. This empowers data scientists and analysts to provision, transform, and access data without relying on a centralized bottleneck.
Federated Computational Governance: Instead of a rigid, centralized governance body, Data Mesh advocates for federated governance. Centralized standards (e.g., data quality metrics, security protocols) are defined, but each domain has the autonomy to implement them in a way that suits their specific data products, ensuring consistent quality and compliance across the distributed landscape.
Improved Data Quality for AI: Because domain experts directly own and curate their data products, they have a vested interest in ensuring high data quality and accuracy. This direct ownership translates to more reliable and trustworthy data for AI model training, significantly reducing issues like data drift and enhancing overall model performance.
Complementary Powerhouses for Enterprise AI
It's crucial to understand that Data Fabric and Data Mesh are not mutually exclusive; in fact, they are often complementary.
Data Fabric is primarily a technology solution focused on integrating and delivering data virtually across disparate sources. It solves the technical challenge of connectivity, real-time access, and unified semantic views.
Data Mesh is primarily an organizational and cultural shift focused on decentralizing data ownership and treating data as a product. It solves the people and process challenges of data silos and slow delivery.
Many forward-thinking enterprises are exploring a hybrid approach. They leverage a Data Fabric as the underlying technical framework to enable the principles of a Data Mesh. The fabric can provide the automated, unified access layer and robust governance, while the mesh principles guide how domains organize, own, and deliver their data products via that fabric. This synergy creates a truly scalable, agile, and democratized data ecosystem.
The Tangible Impact on Enterprise AI
By strategically implementing Data Fabric and Data Mesh principles, organizations can witness transformative impacts on their AI initiatives:
Accelerated AI Development: Data scientists spend significantly less time on cumbersome data wrangling (often cited as 80% of their work) and more time on high-value activities like model building, experimentation, and innovation.
Improved Model Performance & Reliability: Consistent access to fresh, high-quality, and context-rich data leads to more accurate, robust, and reliable AI models, reducing risks of bias and improving business outcomes.
True Data Democratization & AI Adoption: Data becomes a self-service asset, accessible to a wider range of users across the organization, including business analysts and citizen data scientists. This fosters a more data-driven culture and accelerates AI adoption beyond specialist teams.
Enhanced Data Governance & Compliance: Centralized policy enforcement (Data Fabric) combined with decentralized ownership and accountability (Data Mesh) ensures stronger data security, privacy, and compliance across complex, distributed environments.
Unprecedented Agility and Innovation: The ability to rapidly integrate new data sources and develop new AI applications in response to evolving business needs becomes a core competency, enabling quicker adaptation to market changes and competitive advantage.
As the digital economy continues its rapid expansion, fueled by massive data generation, the adoption of Data Fabric and Data Mesh will be pivotal for enterprises across sectors like finance, e-commerce, manufacturing, and healthcare. These architectural strategies are not just about managing data more efficiently; they are about fundamentally reimagining how data powers intelligence, ensuring that enterprises are truly future-proofed for the AI-driven era.
0 notes
Text
Legal Accountability Through AI Audit Trails

In 2025, a major financial institution faced a regulatory investigation after an AI system made automated trading decisions that led to market disruption and significant losses. The firm is unable to provide sufficient audit trails to explain the logic behind the decisions, highlighting a point robust AI audit trails are now a legal and operational necessity. As AI increasingly impacts regulated industries such as finance and healthcare, the need for transparency and legal accountability has become crucial for compliance. The emergence of AI audit trails is now essential for managing risk, oversight, and trust within organizations.
The Importance of Audit Trails Matter in AI Systems
Traditionally, audit trails are essential in sectors such as cybersecurity and finance as maintaining secure, time-stamped records of system activity is crucial in AI, especially under evolving regulatory frameworks, for creating audit trails.
Transparency: Clarifying AI-driven decisions for stakeholders.
Traceability: Documenting data flow, and decision making.
Accountability: Identifying responsibility for errors and violations
Compliance: Supporting audits and regulatory assessments.
Regulatory Factors Behind the EU AI Act
These align with industry guidance and regulatory proposals expected to become binding in the near future.
Documentation with capabilities (Annex IV).
Monitorable risk management procedures (Article 17).
Post-market obligations using accessible audit logs (Article 61).
In the U.S, regulators like the SEC and FTC are increasing scrutiny of AI use in making decisions, expected requirements include:
Tracking data lineage sources to model inputs.
Documentation of data version histories
Explainable justification for AI-based decisions
This aligns with industry guidelines and upcoming mandatory proposals.
Components of AI Audit Trail
A comprehensive AI audit trail should capture the following elements:
User interactions: Who accessed the AI system, when, and why.
Model usage: Which models were invoked, with what inputs and resulting outputs.
Data flow: How data was ingested, processed, transformed, and utilized.
Model evolution: Retraining events, tuning, and version control histories.
Policy enforcement: Logging of security events, exceptions, or compliance breaches.
What are the Operational and Legal Benefits
AI audit trails provide significant benefits more than just a compliance tool, including:
Alignment with regulations, including with EU AI Act, GDPR, and U.S. financial laws.
Risk mitigation and prevention of misusing the model.
Faster response and effective resolution of failures.
Increased trust with regulators and customer transparency.
Legal Accountability and Third Party Auditing
There is consensus on the need for independent oversight of AI systems. Current proposals include:
AI incident reporting system to prioritize audits.
Independent boards to certify AI auditors.
Legal protections for certified auditors to promote transparency.
Conclusion In this new era of transparent and accountable AI, Ricago empowers organizations to meet regulatory expectations. With built-in audit trail capabilities, customizable compliance workflows, and deep integration with governance frameworks, Ricago ensures your AI systems are both explainable and fully traceable. Its intelligent dashboards, automated logging, and real-time compliance monitoring make it the ideal solution for regulated entities seeking operational resilience and ethical AI. Choose Ricago not just to comply, but to lead with trust.
1 note
·
View note
Text
How DataFlip Is Powering the Next Wave of Real‑Time Intelligence

The modern enterprise no longer waits for end‑of‑month spreadsheets. Competitive advantage depends on spotting patterns the moment they emerge, whether that means detecting a supply‑chain hiccup or capitalizing on a viral social‑media trend. Achieving such responsiveness requires more than faster processors; it demands an inversion of the entire data‑flow sequence. That inversion is embodied in dataflip, a paradigm introduced and perfected by analytics pioneer DataFlip, which moves insight upstream in seconds, not hours.
For decades, information pipelines have treated data like cargo on a slow conveyor belt: collect, clean, store, and finally analyze. The data‑flip mindset reverses that order. Operating on a cloud‑native, server‑less fabric, DataFlip applies lightweight machine‑learning models the instant each event lands, attaches context and confidence scores, and then writes only enriched records to an adaptive lakehouse. It is the operational equivalent of tagging luggage while it is still on the airplane instead of after it tumbles onto the carousel—nothing misplaced and nothing delayed.
Speed means little without trust, so governance is woven directly into every stage. Fine‑grained lineage mapping, role‑based encryption, and automated compliance checks ensure auditors can trace any KPI back to its original source within seconds. Because raw and refined facts remain tightly linked, regulators gain transparency while business teams gain the freedom to iterate quickly, confident that obligations under GDPR, HIPAA, and ISO 27001 are continuously met. That peace of mind is invaluable when every second counts.
Read More:-power bi report examples
The ripple effects reach every corner of the organization. Marketing teams launch hyper‑personalized campaigns minutes after a spike in customer interest. Operations reroute inventory on the fly when weather threatens a distribution hub. Finance leaders run scenario analyses continuously rather than once a quarter. By lowering the barrier between raw signals and strategic action, DataFlip creates a common language that unites technical and non‑technical stakeholders alike.
Consider a global retailer that migrated to a dataflip pipeline last year. Dashboard latency fell from six hours to under thirty seconds, and inventory write‑offs dropped by eighteen percent. Engineers reported a forty‑percent decline in maintenance tickets because anomaly alerts surfaced root causes before downstream systems failed. By translating raw technical speed into measurable business results, the DataFlip approach paid for itself within a single fiscal quarter.
Looking ahead, the company is weaving generative AI directly into its streaming layer, enabling dashboards to surface narrative explanations alongside statistical charts. When an irregular pattern appears, the system will not only flag it but also describe its probable root cause and suggest mitigation steps—all in everyday language. This capability captures the true promise of dataflip: turning torrents of numbers into conversations that anyone can join.
Visit Here
In a marketplace where tomorrow’s leaders are decided today, adopting a dataflip framework is no longer optional—it is a strategic imperative. With proven technology, expert support, and a vibrant community, DataFlip stands ready to make the transition swift and sustainable. Executives who act now will steer their industries, not chase them, as the cadence of change accelerates.
0 notes
Text
AI in Industrial Data Management: How Artificial Intelligence is Revolutionizing Data Systems
Artificial Intelligence (AI) is rapidly transforming industrial data management, unlocking new levels of efficiency, accuracy, and insight across sectors such as manufacturing, energy, transportation, and logistics. As the volume, velocity, and variety of industrial data continue to grow, traditional data management systems are struggling to keep pace. AI is stepping in to revolutionize how this data is collected, processed, analyzed, and used—making industrial operations smarter, more agile, and more competitive.
One of the most significant contributions of AI in industrial data management is automated data processing. Industrial environments generate enormous volumes of real-time data from sensors, machinery, control systems, and enterprise platforms. Manual processing of such data is labor-intensive and error-prone. AI algorithms, especially machine learning models, can automatically clean, organize, and standardize this data, significantly reducing the time required for analysis. They can detect duplicates, fill in missing values, identify anomalies, and ensure data consistency across systems.
Download PDF Brochure @ https://www.marketsandmarkets.com/pdfdownloadNew.asp?id=150678178
AI also brings intelligent data classification and contextualization to the table. In complex industrial setups, raw data often lacks context—such as time, location, or the status of connected systems. AI can tag data with relevant metadata, group it based on operational relevance, and link it to specific assets or processes. This contextualization transforms meaningless numbers into actionable information, enabling engineers, operators, and executives to make faster and more informed decisions.
One of the most transformative applications of AI in industrial data management is in predictive analytics. By learning from historical and real-time data, AI models can predict equipment failures, quality defects, or supply chain disruptions before they occur. This allows organizations to shift from reactive to proactive operations. Predictive maintenance, in particular, has become a cornerstone of industrial AI, helping companies minimize unplanned downtime, extend asset life, and reduce maintenance costs.
In addition to prediction, AI supports prescriptive analytics, where it not only anticipates future events but also suggests optimal actions. For instance, an AI system monitoring a production line might recommend adjusting machine parameters to avoid defects or rerouting tasks to balance workloads. These insights go beyond traditional dashboards and reports, providing direct input into operational decision-making.
AI is also enhancing data security and governance in industrial environments. With growing concerns around data privacy, compliance, and cyber threats, AI can monitor access patterns, detect unusual behavior, and enforce data governance policies. By automating data lineage tracking and compliance reporting, AI reduces the burden on IT and compliance teams while ensuring that sensitive industrial data is handled appropriately.
Another important area where AI is making a significant impact is in natural language processing (NLP) and user interfaces. Modern industrial data platforms now incorporate AI-driven conversational interfaces that allow users to query systems using everyday language. This democratizes access to data analytics, enabling operators, engineers, and non-technical staff to retrieve insights without needing advanced data skills. AI makes data more accessible and usable across the entire organization.
As edge computing continues to grow, AI is also being deployed at the edge of the network, closer to machines and devices. Edge AI allows for real-time data processing without relying on cloud connectivity. This is crucial for time-sensitive applications such as quality inspection, machine control, and safety monitoring. Edge AI ensures that data is processed and acted upon instantly, enabling ultra-responsive operations in even the most remote or bandwidth-constrained industrial settings.
The scalability and adaptability of AI-powered data management systems make them ideal for complex, evolving industrial environments. As new machines, sensors, and systems are added, AI can quickly learn new data patterns, adapt to changing operational contexts, and continuously optimize performance. This makes AI a future-proof solution for industrial organizations seeking to remain competitive in a fast-paced digital economy.
0 notes
Text
Governance Without Boundaries - CP4D and Red Hat Integration

The rising complexity of hybrid and multi-cloud environments calls for stronger and more unified data governance. When systems operate in isolation, they introduce risks, make compliance harder, and slow down decision-making. As digital ecosystems expand, consistent governance across infrastructure becomes more than a goal, it becomes a necessity. A cohesive strategy helps maintain control as platforms and regions scale together.
IBM Cloud Pak for Data (CP4D), working alongside Red Hat OpenShift, offers a container-based platform that addresses these challenges head-on. That setup makes it easier to scale governance consistently, no matter the environment. With container orchestration in place, governance rules stay enforced regardless of where the data lives. This alignment helps prevent policy drift and supports data integrity in high-compliance sectors.
Watson Knowledge Catalog (WKC) sits at the heart of CP4D’s governance tools, offering features for data discovery, classification, and controlled access. WKC lets teams organize assets, apply consistent metadata, and manage permissions across hybrid or multi-cloud systems. Centralized oversight reduces complexity and brings transparency to how data is used. It also facilitates collaboration by giving teams a shared framework for managing data responsibilities.
Red Hat OpenShift brings added flexibility by letting services like data lineage, cataloging, and enforcement run in modular, scalable containers. These components adjust to different workloads and grow as demand increases. That level of adaptability is key for teams managing dynamic operations across multiple functions. This flexibility ensures governance processes can evolve alongside changing application architectures.
Kubernetes, which powers OpenShift’s orchestration, takes on governance operations through automated workload scheduling and smart resource use. Its automation ensures steady performance while still meeting privacy and audit standards. By handling deployment and scaling behind the scenes, it reduces the burden on IT teams. With fewer manual tasks, organizations can focus more on long-term strategy.
A global business responding to data subject access requests (DSARs) across different jurisdictions can use CP4D to streamline the entire process. These built-in tools support compliant responses under GDPR, CCPA, and other regulatory frameworks. Faster identification and retrieval of relevant data helps reduce penalties while improving public trust.
CP4D’s tools for discovering and classifying data work across formats, from real-time streams to long-term storage. They help organizations identify sensitive content, apply safeguards, and stay aligned with privacy rules. Automation cuts down on human error and reinforces sound data handling practices. As data volumes grow, these automated capabilities help maintain performance and consistency.
Lineage tracking offers a clear view of how data moves through DevOps workflows and analytics pipelines. By following its origin, transformation, and application, teams can trace issues, confirm quality, and document compliance. CP4D’s built-in tools make it easier to maintain trust in how data is handled across environments.
Tight integration with enterprise identity and access management (IAM) systems strengthens governance through precise controls. It ensures only the right people have access to sensitive data, aligning with internal security frameworks. Centralized identity systems also simplify onboarding, access changes, and audit trails.
When governance tools are built into the data lifecycle from the beginning, compliance becomes part of the system. It is not something added later. This helps avoid retroactive fixes and supports responsible practices from day one. Governance shifts from a task to a foundation of how data is managed.
As regulations multiply and workloads shift, scalable governance is no longer a luxury. It is a requirement. Open, container-driven architectures give organizations the flexibility to meet evolving standards, secure their data, and adapt quickly.
0 notes
Text
EUC Insight Discovery CIMCON Software
EUC Insight Discovery helps enterprises inventory high-risk files, assess risks and errors, detect PII/PCI data, and visualize enterprise data lineage. Scan network drives, fix broken links, and automate file cleanup with powerful add-on services.
Visit: https://part11solutions.com/euc-insight-discovery/
0 notes
Text
From Principles to Playbook: Build an AI-Governance Framework in 30 Days | Nate Patel

The gap between aspirational AI principles and operational reality is where risks fester — ethical breaches, regulatory fines, brand damage, and failed deployments. Waiting for perfect legislation or the ultimate governance tool isn’t a strategy; it’s negligence. The time for actionable governance is now.
This isn’t about building an impenetrable fortress overnight. It’s about establishing a minimum viable governance (MVG) framework — a functional, adaptable system — within 30 days. This article is your tactical playbook to bridge the principles-to-practice chasm, mitigate immediate risks, and lay the foundation for robust, scalable AI governance.
Why 30 Days? The Urgency Imperative
Accelerating Adoption: AI use is exploding organically across departments. Without guardrails, shadow AI proliferates.
Regulatory Tsunami: From the EU AI Act and US Executive Orders to sector-specific guidance, compliance deadlines loom.
Mounting Risks: Real-world incidents (biased hiring tools, hallucinating chatbots causing legal liability, insecure models leaking data) demonstrate the tangible costs of inaction.
Competitive Advantage: Demonstrating trustworthy AI is becoming a market differentiator for customers, partners, and talent.
The Foundation: The Four Pillars of Operational AI Governance
An effective MVG framework isn’t a single document; it’s an integrated system resting on four critical pillars. Neglect any one, and the structure collapses.
Policy Pillar: The “What” and “Why” — Setting the Rules of the Road
Purpose: Defines the organization’s binding commitments, standards, and expectations for responsible AI development, deployment, and use.
Core Components:
Risk Classification Schema: A clear system for categorizing AI applications based on potential impact (e.g., High-Risk: Hiring, Credit Scoring, Critical Infrastructure; Medium-Risk: Internal Process Automation; Low-Risk: Basic Chatbots). This dictates the level of governance scrutiny. (e.g., Align with NIST AI RMF or EU AI Act categories).
Core Mandatory Requirements: Specific, non-negotiable obligations applicable to all AI projects. Examples:
Human Oversight: Define acceptable levels of human-in-the-loop, on-the-loop, or review for different risk classes.
Fairness & Bias Mitigation: Requirements for impact assessments, testing metrics (e.g., demographic parity difference, equal opportunity difference), and mitigation steps.
Transparency & Explainability: Minimum standards for model documentation (e.g., datasheets, model cards), user notifications, and explainability techniques required based on risk.
Robustness, Safety & Security: Requirements for adversarial testing, accuracy thresholds, drift monitoring, and secure development/deployment practices (e.g., OWASP AI Security & Privacy Guide).
Privacy: Compliance with relevant data protection laws (GDPR, CCPA, etc.), data minimization, and purpose limitation for training data.
Accountability & Traceability: Mandate for audit trails tracking model development, data lineage, decisions, and changes.
Read More: From Principles to Playbook: Build an AI-Governance Framework in 30 Days
- Nate Patel
Read More Articles:
Building Your AI Governance Foundation
AI Governance: Why It’s Your Business’s New Non-Negotiable
0 notes
Text
Top Benefits of Informatica Intelligent Cloud Services: Empowering Scalable and Agile Enterprises

Introduction In an increasingly digital and data-driven landscape, enterprises are under pressure to unify and manage vast volumes of information across multiple platforms—whether cloud, on-premises, or hybrid environments. Traditional integration methods often result in data silos, delayed decision-making, and fragmented operations. This is where Informatica Intelligent Cloud Services (IICS) makes a transformative impact—offering a unified, AI-powered cloud integration platform to simplify data management, streamline operations, and drive innovation.
IICS delivers end-to-end cloud data integration, application integration, API management, data quality, and governance—empowering enterprises to make real-time, insight-driven decisions.
What Are Informatica Intelligent Cloud Services?
Informatica Intelligent Cloud Services is a modern, cloud-native platform designed to manage enterprise data integration and application workflows in a secure, scalable, and automated way. Built on a microservices architecture and powered by CLAIRE®—Informatica’s AI engine—this solution supports the full spectrum of data and application integration across multi-cloud, hybrid, and on-prem environments.
Key capabilities of IICS include:
Cloud data integration (ETL/ELT pipelines)
Application and B2B integration
API and microservices management
Data quality and governance
AI/ML-powered data discovery and automation
Why Informatica Cloud Integration Matters
With growing digital complexity and decentralized IT landscapes, enterprises face challenges in aligning data access, security, and agility. IICS solves this by offering:
Seamless cloud-to-cloud and cloud-to-on-prem integration
AI-assisted metadata management and discovery
Real-time analytics capabilities
Unified governance across the data lifecycle
This enables businesses to streamline workflows, improve decision accuracy, and scale confidently in dynamic markets.
Core Capabilities of Informatica Intelligent Cloud Services
1. Cloud-Native ETL and ELT Pipelines IICS offers powerful data integration capabilities using drag-and-drop visual designers. These pipelines are optimized for scalability and performance across cloud platforms like AWS, Azure, GCP, and Snowflake. Benefit: Fast, low-code pipeline development with high scalability.
2. Real-Time Application and Data Synchronization Integrate applications and synchronize data across SaaS tools (like Salesforce, SAP, Workday) and internal systems. Why it matters: Keeps enterprise systems aligned and always up to date.
3. AI-Driven Metadata and Automation CLAIRE® automatically detects data patterns, lineage, and relationships—powering predictive mapping, impact analysis, and error handling. Pro Tip: Reduce manual tasks and accelerate transformation cycles.
4. Unified Data Governance and Quality IICS offers built-in data quality profiling, cleansing, and monitoring tools to maintain data accuracy and compliance across platforms. Outcome: Strengthened data trust and regulatory alignment (e.g., GDPR, HIPAA).
5. API and Microservices Integration Design, deploy, and manage APIs via Informatica’s API Manager and Connectors. Result: Easily extend data services across ecosystems and enable partner integrations.
6. Hybrid and Multi-Cloud Compatibility Support integration between on-prem, private cloud, and public cloud platforms. Why it helps: Ensures architectural flexibility and vendor-neutral data strategies.
Real-World Use Cases of IICS
🔹 Retail Synchronize POS, e-commerce, and customer engagement data to personalize experiences and boost revenue.
🔹 Healthcare Unify patient data from EMRs, labs, and claims systems to improve diagnostics and reporting accuracy.
🔹 Banking & Finance Consolidate customer transactions and risk analytics to detect fraud and ensure compliance.
🔹 Manufacturing Integrate supply chain, ERP, and IoT sensor data to reduce downtime and increase production efficiency.
Benefits at a Glance
Unified data access across business functions
Real-time data sharing and reporting
Enhanced operational agility and innovation
Reduced integration costs and complexity
Automated data governance and quality assurance
Cloud-first architecture built for scalability and resilience
Best Practices for Maximizing IICS
✅ Standardize metadata formats and data definitions ✅ Automate workflows using AI recommendations ✅ Monitor integrations and optimize pipeline performance ✅ Govern access and ensure compliance across environments ✅ Empower business users with self-service data capabilities
Conclusion
Informatica Intelligent Cloud Services is more than a data integration tool—it’s a strategic enabler of business agility and innovation. By bringing together disconnected systems, automating workflows, and applying AI for smarter decisions, IICS unlocks the full potential of enterprise data. Whether you're modernizing legacy systems, building real-time analytics, or streamlining operations, Prophecy Technologies helps you leverage IICS to transform your cloud strategy from reactive to intelligent.
Let’s build a smarter, integrated, and future-ready enterprise—together.
0 notes
Text
Fixing the Foundations: How to Choose the Right Data Engineering Service Provider to Scale with Confidence
Introduction
What do failed AI pilots, delayed product launches, and sky-high cloud costs have in common? More often than not, they point to one overlooked culprit: broken or underdeveloped data infrastructure.
You’ve likely invested in analytics, maybe even deployed machine learning. But if your pipelines are brittle, your data governance is an afterthought, and your teams are drowning in manual ETL — scaling is a fantasy. That’s where data engineering service providers come in. Not just to patch things up, but to re-architect your foundation for growth.
This post isn’t a checklist of "top 10 vendors." It’s a practical playbook on how to evaluate, engage, and extract value from data engineering service providers — written for those who’ve seen what happens when things go sideways. We’ll tackle:
Key red flags and hidden risks in typical vendor engagements
Strategic decisions that differentiate a good provider from a transformative one
Actionable steps to assess capabilities across infrastructure, governance, and delivery
Real-world examples of scalable solutions and common pitfalls
By the end, you’ll have a smarter strategy to choose a data engineering partner that scales with your business, not against it.
1. The Invisible Problem: When Data Engineering Fails Quietly
📌 Most executives don't realize they have a data engineering problem until it's too late. AI initiatives underperform. Dashboards take weeks to update. Engineering teams spend 60% of their time fixing bad data.
Here’s what failure often looks like:
✅ Your cloud bills spike with no clear reason.
✅ BI tools surface outdated or incomplete data.
✅ Product teams can't launch features because backend data is unreliable.
These issues may seem scattered but usually trace back to brittle or siloed data engineering foundations.
What You Need from a Data Engineering Service Provider:
Expertise in building resilient, modular pipelines (not just lifting-and-shifting existing workflows)
A data reliability strategy that includes observability, lineage tracking, and automated testing
Experience working cross-functionally with data science, DevOps, and product teams
Example: A fintech startup we worked with saw a 40% drop in fraud detection accuracy after scaling. Root cause? Pipeline latency had increased due to a poorly designed batch ingestion system. A robust data engineering partner re-architected it with stream-first design, reducing lag by 80%.
Takeaway: Treat your pipelines like production software — and find partners who think the same way.
2. Beyond ETL: What Great Data Engineering Providers Actually Deliver
Not all data engineering service providers are built the same. Some will happily take on ETL tickets. The best? They ask why you need them in the first place.
Look for Providers Who Can Help You With:
✅ Designing scalable data lakes and lakehouses
✅ Implementing data governance frameworks (metadata, lineage, cataloging)
✅ Optimizing storage costs through intelligent partitioning and compression
✅ Enabling real-time processing and streaming architectures
✅ Creating developer-friendly infrastructure-as-code setups
The Diagnostic Test: Ask them how they would implement schema evolution or CDC (Change Data Capture) in your environment. Their answer will tell you whether they’re architects or just implementers.
Action Step: During scoping calls, present them with a real use case — like migrating a monolithic warehouse to a modular Lakehouse. Evaluate how they ask questions, identify risks, and propose a roadmap.
Real-World Scenario: An e-commerce client struggling with peak load queries discovered that their provider lacked experience with distributed compute. Switching to a team skilled in Snowflake workload optimization helped them reduce latency during Black Friday by 60%.
Takeaway: The right provider helps you design and own your data foundation. Don’t just outsource tasks — outsource outcomes.
3. Common Pitfalls to Avoid When Hiring Data Engineering Providers
Even experienced data leaders make costly mistakes when engaging with providers. Here are the top traps:
❌ Vendor Lock-In: Watch for custom tools and opaque frameworks that tie you into their team.
❌ Low-Ball Proposals: Be wary of providers who bid low but omit governance, testing, or monitoring.
❌ Overemphasis on Tools: Flashy slides about Airflow or dbt mean nothing if they can’t operationalize them for your needs.
❌ Siloed Delivery: If they don’t involve your internal team, knowledge transfer will suffer post-engagement.
Fix It With These Steps:
Insist on open standards and cloud-native tooling (e.g., Apache Iceberg, Terraform, dbt)
Request a roadmap for documentation and enablement
Evaluate their approach to CI/CD for data (do they automate testing and deployment?)
Ask about SLAs and how they define “done” for a data project
Checklist to Use During Procurement:
Do they have case studies with measurable outcomes?
Are they comfortable with hybrid cloud and multi-region setups?
Can they provide an observability strategy (e.g., using Monte Carlo, OpenLineage)?
Takeaway: The right provider makes your team better — not more dependent.
4. Key Qualities That Set Top-Tier Data Engineering Service Providers Apart
Beyond technical skills, high-performing providers offer strategic and operational value:
✅ Business Context Fluency: They ask about KPIs, not just schemas.
✅ Cross-Functional Alignment: They involve product owners, compliance leads, and dev teams.
✅ Iterative Delivery: They build in small releases, not 6-month monoliths.
✅ Outcome Ownership: They sign up for business results, not just deliverables.
Diagnostic Example: Ask: “How would you approach improving our data freshness SLA from 2 hours to 30 minutes?” Listen for depth of response across ingestion, scheduling, error handling, and metrics.
Real Use Case: A healthtech firm needed HIPAA-compliant pipelines. A qualified data engineering partner built an auditable, lineage-rich architecture using Databricks, Delta Lake, and Unity Catalog — while training the in-house team in parallel.
Takeaway: Great providers aren’t just engineers. They’re enablers of business agility.
5. Building a Long-Term Engagement That Grows With You
You’re not just hiring for today’s needs. You’re laying the foundation for:
✅ Future ML use cases
✅ Regulatory shifts
✅ New product data requirements
Here’s how to future-proof your partnership:
Structure the engagement around clear phases: Discovery → MVP → Optimization → Handoff
Build in regular architecture reviews (monthly or quarterly)
Set mutual KPIs (e.g., data latency, SLA adherence, team velocity improvements)
Include upskilling workshops for your internal team
Vendor Models That Work:
Pod-based teams embedded with your org
Outcome-based pricing for projects (vs. hourly billing)
SLA-backed support with defined escalation paths
Takeaway: Don’t look for a vendor. Look for a long-term capability builder.
Conclusion
Choosing the right data engineering service provider is not about ticking boxes. It’s about finding a strategic partner who can help you scale faster, move smarter, and reduce risk across your data stack.
From reducing latency in critical pipelines to building governance into the foundation, the right provider becomes a multiplier for your business outcomes — not just a toolsmith.
✅ Start by auditing your current bottlenecks.
✅ Map your needs not to tools, but to business outcomes.
✅ Interview providers with real-world scenarios, not RFIs.
✅ Insist on open architectures, ownership transfer, and iterative value delivery.
Next Step: Start a 1:1 discovery session with your potential provider — not to discuss tools, but to outline your strategic priorities.
And remember: Great data engineering doesn’t shout. But it silently powers everything your business depends on.
#DataEngineering#DataInfrastructure#DataOps#ModernDataStack#ETL#DataPipeline#BigDataSolutions#AIReadyData#CloudDataEngineering#DataGovernance#ScalableData#TechStrategy#DataInnovation#MachineLearningOps#AnalyticsEngineering#DataEngineeringServiceProviders#EnterpriseData#BusinessDataSolutions#DataTransformation#DataArchitecture#DataStrategy#DataDriven#DataQuality#CloudArchitecture#DataPlatform#AdvancedAnalytics#DataIntegration#DataOptimization#SmartData#RealTimeData
0 notes