#approaches of ETL testing
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The Tumblr office adopted Tommy, an 11-year-old Pomeranian.
Text
Approaches to ETL Testing: Ensuring Data Quality and Reliability
ETL TESTING
ETL testing (Extract, Transform, Load) is critical in data management and warehousing. It is the process of verifying the accuracy, completeness, and reliability of data as it moves through the ETL pipeline. ETL testing aims to identify any issues, inconsistencies, or errors in data, ensuring that the final data in the target system or data warehouse is of high quality and can be relied upon for decision-making.
The Importance of Different Approaches of ETL Testing
In the world of data management, where data is often the lifeblood of organizations, different approaches of ETL testing have a critical role to play. These approaches encompass a range of testing methodologies, each serving specific purposes and offering unique benefits. They are designed to scrutinize the accuracy, completeness, and consistency of data as it traverses through the ETL pipeline, ensuring that the final data in the target system or data warehouse is of the highest quality and can be trusted for making informed decisions.
Manual Testing: One of the Fundamental Approaches of ETL Testing
Manual testing is one of the fundamental approaches of ETL testing. In manual testing, human testers execute predefined test cases and meticulously validate ETL processes through visual inspection and comparisons. This approach is ideal for smaller ETL projects or the initial testing phases, where automation may not be cost-effective. Manual testing offers the flexibility to adapt to evolving ETL pipelines and is invaluable for exploratory testing, allowing testers to explore the ETL process without predefined test cases.
Automation Testing: Harnessing Automation as One of the Approaches of ETL Testing
Automation testing is another of the fundamental approaches of ETL testing. This approach involves the use of ETL testing tools and scripts to automate the execution of test cases and the validation of ETL processes. Automation testing is highly efficient for large and complex ETL pipelines, where manual testing is impractical. It saves time and reduces the risk of human error, making it ideal for repetitive testing tasks, regression testing, and ensuring that ETL processes work consistently.
Incremental Testing: A Focused Approach of ETL Testing
Incremental testing is a focused approach of ETL testing that concentrates on testing only the new or changed data within the ETL process. Instead of retesting the entire dataset, testers zero in on the data that has been added or modified since the last ETL process run. This approach is beneficial in scenarios where source data experiences frequent changes, optimizing testing efforts and speeding up the testing cycle.
Data Sampling: A Pragmatic Approach of ETL Testing
Data sampling is a pragmatic approach of ETL testing that involves selecting a subset of data from the source and target systems for testing. This approach is particularly useful when dealing with exceptionally large datasets, where testing the entire dataset is impractical. Data sampling provides a snapshot of data quality without the need for exhaustive testing.
End-to-End Testing: A Holistic Approach of ETL Testing
End-to-End testing is a holistic approach of ETL testing that validates the complete ETL pipeline. It encompasses testing data extraction, transformation, and loading. This approach ensures that all components of the ETL process work together seamlessly, verifying that data is correctly extracted, transformed, and loaded without any issues. It is critical for achieving comprehensive ETL process validation.
Data Profiling: Unearthing Insights Through Another Approach of ETL Testing
Data profiling is a highly insightful approach of ETL testing that involves analyzing data to identify patterns, anomalies, and data quality issues. It helps testers gain a deep understanding of the characteristics of the data, enabling the creation of meaningful test scenarios. Data profiling is invaluable for understanding data quality, identifying potential issues, and developing effective test cases.
Integration Testing: Ensuring Interoperability Through Another Approach of ETL Testing
Integration testing is an approach of ETL testing that verifies the integration of the ETL process with other systems, databases, and applications. In complex ETL environments where the ETL process interacts with multiple systems, integration testing ensures that data flows smoothly between systems. It is critical for identifying and addressing integration issues.
Performance Testing: Ensuring Efficiency Through Another Approach of ETL Testing
Performance testing is an approach of ETL testing that focuses on evaluating the efficiency, scalability, and response times of the ETL process. It is essential when dealing with large volumes of data, ensuring that the ETL process meets performance requirements and identifying performance bottlenecks.
Regression Testing: Safeguarding Stability Through Another Approach of ETL Testing
Regression testing is an approach of ETL testing that involves retesting the entire ETL process after making changes or enhancements. This approach ensures that new modifications do not introduce defects or disrupt existing functionality. Regression testing safeguards the stability of the ETL process as it evolves, preventing unintended issues and maintaining data quality.
conclusion
different approaches of ETL testing are the cornerstone of data quality and reliability in the realm of data management and data warehousing. By comprehending these various testing methodologies, organizations can implement effective ETL testing strategies that align with their specific needs, ensuring that their data is reliable and trustworthy for informed decision-making
0 notes
Text
Essential Predictive Analytics Techniques
With the growing usage of big data analytics, predictive analytics uses a broad and highly diverse array of approaches to assist enterprises in forecasting outcomes. Examples of predictive analytics include deep learning, neural networks, machine learning, text analysis, and artificial intelligence.
Predictive analytics trends of today reflect existing Big Data trends. There needs to be more distinction between the software tools utilized in predictive analytics and big data analytics solutions. In summary, big data and predictive analytics technologies are closely linked, if not identical.
Predictive analytics approaches are used to evaluate a person's creditworthiness, rework marketing strategies, predict the contents of text documents, forecast weather, and create safe self-driving cars with varying degrees of success.
Predictive Analytics- Meaning
By evaluating collected data, predictive analytics is the discipline of forecasting future trends. Organizations can modify their marketing and operational strategies to serve better by gaining knowledge of historical trends. In addition to the functional enhancements, businesses benefit in crucial areas like inventory control and fraud detection.
Machine learning and predictive analytics are closely related. Regardless of the precise method, a company may use, the overall procedure starts with an algorithm that learns through access to a known result (such as a customer purchase).
The training algorithms use the data to learn how to forecast outcomes, eventually creating a model that is ready for use and can take additional input variables, like the day and the weather.
Employing predictive analytics significantly increases an organization's productivity, profitability, and flexibility. Let us look at the techniques used in predictive analytics.
Techniques of Predictive Analytics
Making predictions based on existing and past data patterns requires using several statistical approaches, data mining, modeling, machine learning, and artificial intelligence. Machine learning techniques, including classification models, regression models, and neural networks, are used to make these predictions.
Data Mining
To find anomalies, trends, and correlations in massive datasets, data mining is a technique that combines statistics with machine learning. Businesses can use this method to transform raw data into business intelligence, including current data insights and forecasts that help decision-making.
Data mining is sifting through redundant, noisy, unstructured data to find patterns that reveal insightful information. A form of data mining methodology called exploratory data analysis (EDA) includes examining datasets to identify and summarize their fundamental properties, frequently using visual techniques.
EDA focuses on objectively probing the facts without any expectations; it does not entail hypothesis testing or the deliberate search for a solution. On the other hand, traditional data mining focuses on extracting insights from the data or addressing a specific business problem.
Data Warehousing
Most extensive data mining projects start with data warehousing. An example of a data management system is a data warehouse created to facilitate and assist business intelligence initiatives. This is accomplished by centralizing and combining several data sources, including transactional data from POS (point of sale) systems and application log files.
A data warehouse typically includes a relational database for storing and retrieving data, an ETL (Extract, Transfer, Load) pipeline for preparing the data for analysis, statistical analysis tools, and client analysis tools for presenting the data to clients.
Clustering
One of the most often used data mining techniques is clustering, which divides a massive dataset into smaller subsets by categorizing objects based on their similarity into groups.
When consumers are grouped together based on shared purchasing patterns or lifetime value, customer segments are created, allowing the company to scale up targeted marketing campaigns.
Hard clustering entails the categorization of data points directly. Instead of assigning a data point to a cluster, soft clustering gives it a likelihood that it belongs in one or more clusters.
Classification
A prediction approach called classification involves estimating the likelihood that a given item falls into a particular category. A multiclass classification problem has more than two classes, unlike a binary classification problem, which only has two types.
Classification models produce a serial number, usually called confidence, that reflects the likelihood that an observation belongs to a specific class. The class with the highest probability can represent a predicted probability as a class label.
Spam filters, which categorize incoming emails as "spam" or "not spam" based on predetermined criteria, and fraud detection algorithms, which highlight suspicious transactions, are the most prevalent examples of categorization in a business use case.
Regression Model
When a company needs to forecast a numerical number, such as how long a potential customer will wait to cancel an airline reservation or how much money they will spend on auto payments over time, they can use a regression method.
For instance, linear regression is a popular regression technique that searches for a correlation between two variables. Regression algorithms of this type look for patterns that foretell correlations between variables, such as the association between consumer spending and the amount of time spent browsing an online store.
Neural Networks
Neural networks are data processing methods with biological influences that use historical and present data to forecast future values. They can uncover intricate relationships buried in the data because of their design, which mimics the brain's mechanisms for pattern recognition.
They have several layers that take input (input layer), calculate predictions (hidden layer), and provide output (output layer) in the form of a single prediction. They are frequently used for applications like image recognition and patient diagnostics.
Decision Trees
A decision tree is a graphic diagram that looks like an upside-down tree. Starting at the "roots," one walks through a continuously narrowing range of alternatives, each illustrating a possible decision conclusion. Decision trees may handle various categorization issues, but they can resolve many more complicated issues when used with predictive analytics.
An airline, for instance, would be interested in learning the optimal time to travel to a new location it intends to serve weekly. Along with knowing what pricing to charge for such a flight, it might also want to know which client groups to cater to. The airline can utilize a decision tree to acquire insight into the effects of selling tickets to destination x at price point y while focusing on audience z, given these criteria.
Logistics Regression
It is used when determining the likelihood of success in terms of Yes or No, Success or Failure. We can utilize this model when the dependent variable has a binary (Yes/No) nature.
Since it uses a non-linear log to predict the odds ratio, it may handle multiple relationships without requiring a linear link between the variables, unlike a linear model. Large sample sizes are also necessary to predict future results.
Ordinal logistic regression is used when the dependent variable's value is ordinal, and multinomial logistic regression is used when the dependent variable's value is multiclass.
Time Series Model
Based on past data, time series are used to forecast the future behavior of variables. Typically, a stochastic process called Y(t), which denotes a series of random variables, are used to model these models.
A time series might have the frequency of annual (annual budgets), quarterly (sales), monthly (expenses), or daily (daily expenses) (Stock Prices). It is referred to as univariate time series forecasting if you utilize the time series' past values to predict future discounts. It is also referred to as multivariate time series forecasting if you include exogenous variables.
The most popular time series model that can be created in Python is called ARIMA, or Auto Regressive Integrated Moving Average, to anticipate future results. It's a forecasting technique based on the straightforward notion that data from time series' initial values provides valuable information.
In Conclusion-
Although predictive analytics techniques have had their fair share of critiques, including the claim that computers or algorithms cannot foretell the future, predictive analytics is now extensively employed in virtually every industry. As we gather more and more data, we can anticipate future outcomes with a certain level of accuracy. This makes it possible for institutions and enterprises to make wise judgments.
Implementing Predictive Analytics is essential for anybody searching for company growth with data analytics services since it has several use cases in every conceivable industry. Contact us at SG Analytics if you want to take full advantage of predictive analytics for your business growth.
2 notes
·
View notes
Text
Empowering Data Science Teams for Accelerated AI Application Development

In today's hyper-competitive landscape, Artificial Intelligence (AI) is no longer a futuristic concept; it's a present-day imperative for innovation, efficiency, and market leadership. At the heart of this AI revolution are data science teams, the architects and engineers who translate raw data into intelligent solutions. However, their journey from ideation to deployed AI application is often fraught with hurdles – from data quality woes and communication breakdowns to lengthy model deployment cycles.
To truly accelerate AI application development and unlock its full potential, organizations must shift their focus from merely hiring data scientists to empowering these critical teams. When equipped with the right tools, processes, and culture, data science teams can move faster, innovate more effectively, and deliver AI solutions that drive tangible business value.
So, how can we empower data science teams to become true catalysts for accelerated AI application development?
1. Foster a Culture of Continuous Learning and Experimentation
The AI landscape evolves at a blistering pace. What was cutting-edge yesterday might be commonplace tomorrow.
Invest in Upskilling: Provide access to continuous learning resources – online courses, certifications, workshops, and conferences – on new algorithms, frameworks (like PyTorch, TensorFlow, JAX), MLOps tools, and ethical AI practices.
Encourage Experimentation: Create a safe environment where data scientists can test new ideas, explore novel approaches, and even "fail fast" without fear of reprisal. Dedicated sandbox environments and hackathons can be excellent avenues for this. This fosters innovation and allows teams to discover unexpected solutions.
Knowledge Sharing: Implement mechanisms for internal knowledge sharing, such as regular tech talks, internal wikis, or communities of practice. When data scientists can easily share successes, failures, and learnings, the entire team grows.
2. Streamline Data Access and Management
Data is the lifeblood of AI, but often, data scientists spend a disproportionate amount of time simply finding, accessing, cleaning, and preparing it.
Unified Data Platforms: Invest in robust data platforms (like data lakes, data warehouses, or data fabrics) that provide centralized, governed access to diverse data sources.
Automate Data Pipelines: Implement automated data pipelines (ETL/ELT) and data quality checks. This reduces manual effort, ensures data freshness, and frees up data scientists to focus on modeling.
Self-Service Data Access: Empower data scientists with self-service tools for data exploration, querying, and feature engineering, while maintaining necessary governance and security guardrails. Tools that allow them to easily pull data from various sources (structured, unstructured, streaming) are crucial.
3. Provide Robust MLOps and Development Infrastructure
The gap between a promising model and a production-ready AI application is often vast. MLOps (Machine Learning Operations) bridges this gap.
Automate MLOps Workflows: Implement MLOps platforms and practices that automate model training, versioning, testing, deployment, monitoring, and retraining. This includes CI/CD pipelines specifically tailored for machine learning.
Standardized Environments: Provide standardized, reproducible development environments (e.g., Docker containers, cloud-based notebooks) to eliminate "it works on my machine" issues and ensure consistent deployments.
Scalable Compute Resources: Ensure easy access to scalable computational resources (GPUs, TPUs) in the cloud or on-premises, allowing data scientists to train complex models without bottlenecks.
4. Foster Cross-Functional Collaboration and Communication
Data science projects are rarely solitary endeavors. They require deep collaboration with business stakeholders, engineers, and product managers.
Clear Problem Definition: Ensure data science teams are involved early in defining the business problem. Misunderstanding the core problem is a leading cause of AI project failure. Leaders must help define clear objectives and success metrics.
Bridging the "Last Mile": Break down silos between data science, data engineering, and software development teams. Encourage hybrid roles (like ML Engineers) and establish clear communication channels to ensure models can be seamlessly integrated into existing applications and workflows.
Manage Expectations: Help data scientists communicate the limitations and probabilities of AI models to non-technical stakeholders effectively. Transparency builds trust.
5. Prioritize Impact and Business Value
Data science teams are most empowered when they see the tangible impact of their work.
Focus on Business Outcomes: Orient projects around clear business objectives and measurable impact. Prioritize initiatives that align with strategic goals and can deliver significant value.
Celebrate Successes: Recognize and celebrate the achievements of data science teams, showcasing how their models are driving real-world improvements, whether it's optimizing operations, enhancing customer experience, or generating new revenue streams.
Autonomy with Accountability: Grant teams autonomy in choosing their methodologies and tools while holding them accountable for delivering on agreed-upon objectives and impact.
6. Address Ethical AI and Responsible Development
As AI becomes more powerful, ethical considerations become paramount. Empowering teams means equipping them to build AI responsibly.
Ethical AI Guidelines: Provide clear ethical guidelines and frameworks for AI development, addressing issues like bias, fairness, privacy, and transparency.
Tools for Explainability & Bias Detection: Equip teams with tools and techniques for model interpretability (XAI) and bias detection/mitigation.
Continuous Education: Regularly educate teams on emerging ethical challenges and best practices in responsible AI.
The Accelerator Effect
Empowering data science teams is not just about making them happier; it's a strategic investment that directly translates into faster AI application development cycles, higher quality models, and a greater return on AI investments. By focusing on culture, data infrastructure, MLOps, collaboration, and ethical practices, organizations can transform their data science teams into dynamic engines of innovation, propelling their digital transformation forward at an accelerated pace.
0 notes
Text
The Role of Data Migration Software in SAP BTP Integration

In today's fast-paced business world, effective data management plays a crucial role in achieving seamless workflows, informed decision-making, and increased operational efficiency. Organizations are increasingly turning to cloud-based solutions to ensure that their data migration and management processes are optimized for success. In this context, data migration software has become indispensable, particularly for businesses that leverage SAP BTP integration and SAP Data Migration solutions.
At CBS Consulting, we specialize in helping businesses navigate their data migration journeys, ensuring a smooth transition to SAP's innovative tools, including SAP Data Quality solutions. In this article, we examine the key aspects of data migration within the SAP ecosystem, emphasizing its significance for business transformation.
What is Data Migration Software?
Data Migration Software refers to the tools and technologies designed to facilitate the transfer of data from one system to another. Whether you're upgrading to a new ERP, consolidating multiple databases, or moving to the cloud, effective data migration ensures that your business can continue operating seamlessly throughout the transition.
For companies using SAP solutions, data migration becomes a crucial component of their digital transformation. Whether the goal is to migrate legacy systems to SAP's public cloud or to integrate SAP with existing business applications, using the correct data migration software ensures accuracy, consistency, and security throughout the process.
The Importance of SAP BTP Integration in Data Migration
SAP's Business Technology Platform (BTP) is a powerful tool that enables organizations to seamlessly integrate their data, applications, and processes across cloud and on-premise environments. The integration of SAP BTP with data migration software allows businesses to access a unified solution that enhances connectivity, reduces operational silos, and increases data accuracy.
When SAP BTP integration is implemented alongside SAP Data Migration, businesses gain the ability to ensure that data flows seamlessly across multiple systems, eliminating redundancies and errors. This integration is crucial for organizations seeking to leverage SAP's advanced analytics, AI, and machine learning capabilities, which rely on high-quality data for accurate insights.
The Role of SAP Data Migration in Business Transformation
SAP Data Migration is the process of transferring data from legacy systems into SAP applications. This migration involves data extraction, transformation, and loading (ETL) from older systems into the new SAP system. This process can be complex and time-consuming, requiring the expertise of professionals who understand both the technical and business aspects of data migration.
CBS Consulting's team of experts ensures that businesses using SAP Data Migration tools maintain data integrity, security, and compliance during the migration process. Our approach encompasses meticulous planning, robust testing, and a thorough analysis of both the source and target systems to ensure a seamless transition.
Ensuring SAP Data Quality
Data quality is paramount for businesses adopting SAP solutions. Poor data quality can lead to inaccurate reporting, compliance issues, and operational inefficiencies. With SAP Data Quality tools, companies can clean, standardize, and enrich their data, ensuring that it meets the highest standards of accuracy and consistency.
Effective SAP Data Quality tools are integrated with migration solutions, ensuring that only high-quality data is migrated to SAP systems. This ensures that businesses not only move their data efficiently but also improve its reliability and usability. Data profiling, cleansing, and validation are key components of SAP's data quality solution, ensuring the overall success of data migration initiatives.
SAP Public Cloud: The Future of Data Management
As businesses increasingly move their workloads to the cloud, SAP Public Cloud offers an ideal environment for managing and processing large volumes of data. The cloud offers scalability, flexibility, and advanced features such as AI and machine learning, which can unlock greater value from the data migrated into the system.
The use of SAP Public Cloud in data migration enables businesses to modernize their IT infrastructure, enhance data accessibility, and reduce costs. Migrating to the SAP cloud also provides enhanced security features and compliance with global regulations, ensuring that businesses meet the highest standards for data protection and security.
Conclusion
In conclusion, data migration software is crucial for businesses undergoing digital transformation, particularly those integrating SAP solutions, such as SAP BTP, SAP Data Migration, and SAP Data Quality. By utilizing the right tools and expertise, businesses can achieve a seamless migration experience, enhancing data accessibility, security, and usability across their systems. At CBS Consulting, we are committed to providing businesses with the right solutions for data migration, ensuring that their journey to SAP's public cloud is smooth, efficient, and successful.
1 note
·
View note
Text
Managed Data Migration: Which businesses should consider
As organizations handle increasing versions of structured and unnecessary data, managed data has become a key task for achieving effective data management. Whether transferred from EDW to data lake or reinforcing the computer system for better analysis, companies should weigh more factors before continuing with ETL/ELT modernization and migration.
Understanding the need for migration Legacy system can slow down commercial operations due to high maintenance costs, scalability issues and limited integration capabilities. ETL migrations and ELT modernization enable businesses to handle large datasets more efficiently, supporting businesses near real-time analytics.
Modernizing your data architecture also involves transition to flexible storage environment such as data lakes, which are ideal for handling various data types. This change supports future AI, ML and BI capabilities by enabling better data access and advanced processing.
Important ideas before starting migration Before starting a managed data project, companies should consider the following:
Data Inventory: Identify and list current data sources to avoid repetition and ensure relevance. Compliance readiness: Compliance with data security should be maintained through the migration process. Adaptation of business goals: Make sure the new environment supports organizational goals as faster insights or cost savings. Workload assessment: Choose between batch treatment or data flow in real time depending on operating needs.
A clearly defined strategy will prevent common pitfalls such as loss of data, downtime or inconsistent reporting.
Choosing the Right Migration Path There are two widely adopted approaches to data movement: ETL Migration: Extract, Transform, Load processes are better for complex transformations before data reaches its destination. ELT Modernization: Extract, Load, Transform allows the target system to handle transformations, offering faster ingestion and scalability.
Role of Data Integration Services A successful migration demands expert handling of source and target compatibility. These services also support data pipeline automation, which improves processing speed and reduces errors from repetitive tasks.
Automated pipelines enable continuous data flow between legacy systems and modern platforms, allowing incremental testing and validation during the process.
Safety and compliance measures Migration opens several access points, increase in contact with data breech. Businesses have to be implemented:
Role-based access control.
End-to-end encryption.
Compliance checks formed with industry standards like GDPR or Hipaa.
Monitoring tools can further help track migration progress and give flags to discrepancies in real time.
Partner with Celebal Technologies In Celebal Technologies, we offer special ETL/ELT modernization and migration solutions for enterprise scalability. From EDW to Data Lake migration, to data pipeline automation and data security compliance, our expert-led approaches ensure a smooth transition with minimal risk. Choose the Celebal Technologies as your partner in management of mass migration with efficiency, accuracy and accuracy.
#ETL migration#ELT modernization#data integration services#EDW to Data Lake#managed data migration#data pipeline automation#data security compliance
0 notes
Text
Legacy Software Modernization Services In India – NRS Infoways
In today’s hyper‑competitive digital landscape, clinging to outdated systems is no longer an option. Legacy applications can slow innovation, inflate maintenance costs, and expose your organization to security vulnerabilities. NRS Infoways bridges the gap between yesterday’s technology and tomorrow’s possibilities with comprehensive Software Modernization Services In India that revitalize your core systems without disrupting day‑to‑day operations.
Why Modernize?
Boost Performance & Scalability
Legacy architectures often struggle under modern workloads. By re‑architecting or migrating to cloud‑native frameworks, NRS Infoways unlocks the flexibility you need to scale on demand and handle unpredictable traffic spikes with ease.
Reduce Technical Debt
Old codebases are costly to maintain. Our experts refactor critical components, streamline dependencies, and implement automated testing pipelines, dramatically lowering long‑term maintenance expenses.
Strengthen Security & Compliance
Obsolete software frequently harbors unpatched vulnerabilities. We embed industry‑standard security protocols and data‑privacy controls to safeguard sensitive information and keep you compliant with evolving regulations.
Enhance User Experience
Customers expect snappy, intuitive interfaces. We upgrade clunky GUIs into sleek, responsive designs—whether for web, mobile, or enterprise portals���boosting user satisfaction and retention.
Our Proven Modernization Methodology
1. Deep‑Dive Assessment
We begin with an exhaustive audit of your existing environment—code quality, infrastructure, DevOps maturity, integration points, and business objectives. This roadmap pinpoints pain points, ranks priorities, and plots the most efficient modernization path.
2. Strategic Planning & Architecture
Armed with data, we design a future‑proof architecture. Whether it’s containerization with Docker/Kubernetes, serverless microservices, or hybrid-cloud setups, each blueprint aligns performance goals with budget realities.
3. Incremental Refactoring & Re‑engineering
To mitigate risk, we adopt a phased approach. Modules are refactored or rewritten in modern languages—often leveraging Java Spring Boot, .NET Core, or Node.js—while maintaining functional parity. Continuous integration pipelines ensure rapid, reliable deployments.
4. Data Migration & Integration
Smooth, loss‑less data transfer is critical. Our team employs advanced ETL processes and secure APIs to migrate databases, synchronize records, and maintain interoperability with existing third‑party solutions.
5. Rigorous Quality Assurance
Automated unit, integration, and performance tests catch issues early. Penetration testing and vulnerability scans validate that the revamped system meets stringent security and compliance benchmarks.
6. Go‑Live & Continuous Support
Once production‑ready, we orchestrate a seamless rollout with minimal downtime. Post‑deployment, NRS Infoways provides 24 × 7 monitoring, performance tuning, and incremental enhancements so your modernized platform evolves alongside your business.
Key Differentiators
Domain Expertise: Two decades of transforming systems across finance, healthcare, retail, and logistics.
Certified Talent: AWS, Azure, and Google Cloud‑certified architects ensure best‑in‑class cloud adoption.
DevSecOps Culture: Security baked into every phase, backed by automated vulnerability management.
Agile Engagement Models: Fixed‑scope, time‑and‑material, or dedicated team options adapt to your budget and timeline.
Result‑Driven KPIs: We measure success via reduced TCO, improved response times, and tangible ROI, not just code delivery.
Success Story Snapshot
A leading Indian logistics firm grappled with a decade‑old monolith that hindered real‑time shipment tracking. NRS Infoways migrated the application to a microservices architecture on Azure, consolidating disparate data silos and introducing RESTful APIs for third‑party integrations. The results? A 40 % reduction in server costs, 60 % faster release cycles, and a 25 % uptick in customer satisfaction scores within six months.
Future‑Proof Your Business Today
Legacy doesn’t have to mean liability. With NRS Infoways’ Legacy Software Modernization Services In India, you gain a robust, scalable, and secure foundation ready to tackle tomorrow’s challenges—whether that’s AI integration, advanced analytics, or global expansion.
Ready to transform?
Contact us for a free modernization assessment and discover how our Software Modernization Services In India can accelerate your digital journey, boost operational efficiency, and drive sustainable growth.
0 notes
Text
Power BI Ecosystem Deep Dive: What Tableau Users Should Know
As organizations explore alternatives to Tableau, many are turning to Microsoft's Power BI for its seamless integration with the broader Microsoft ecosystem and cost-effectiveness. But transitioning to Power BI isn't just about learning a new tool—it requires understanding its entire ecosystem. At OfficeSolution, we've guided numerous clients through their Tableau to Power BI migration journey using our purpose-built tool, Pulse Convert, and we know that success starts with knowing what to expect.
Here’s a deep dive into the Power BI ecosystem for Tableau users.
1. The Architecture: Power BI Service, Desktop, and Mobile
Unlike Tableau, which distinguishes between Tableau Desktop, Server, and Online, Power BI operates with three key components:
Power BI Desktop: The primary authoring tool for building reports and dashboards.
Power BI Service (PowerBI.com): A cloud-based platform where reports are published, shared, and consumed.
Power BI Mobile: A native mobile experience to access insights on the go.
This streamlined structure enables a more integrated development and deployment cycle.
2. Data Modeling with DAX and Power Query
Power BI leans heavily on DAX (Data Analysis Expressions) for calculations and Power Query (M language) for data transformation. While Tableau users are accustomed to calculated fields and LOD (Level of Detail) expressions, DAX introduces a more formula-based approach with different context rules (row vs. filter context). Power Query, on the other hand, handles ETL-like operations inside Power BI itself—something Tableau typically leaves to external tools or Tableau Prep.
3. Integration with Microsoft Stack
Power BI's integration with the Microsoft stack is unparalleled. If your organization already uses Azure, Excel, Teams, or SharePoint, you'll find a deeply connected experience. Embedding Power BI in Teams chats or pushing reports via Power Automate are common workflows that streamline collaboration. For Tableau users unfamiliar with Microsoft-centric environments, this level of integration opens new possibilities.
4. Licensing and Cost Efficiency
One major motivator for Tableau to Power BI migration is cost efficiency. Power BI Pro and Power BI Premium offer flexible, user-based, and capacity-based models. Compared to Tableau’s licensing, Power BI often provides more value—especially for organizations already invested in Microsoft 365.
5. Governance and Deployment Pipelines
Tableau users accustomed to version control via Tableau Server will find Power BI's Deployment Pipelines a modern alternative. These pipelines allow for dev-test-prod staging within the Power BI Service, with controlled releases and rollback options—ideal for enterprise-grade governance.
Final Thoughts
Power BI isn't just another visualization tool—it's an ecosystem with unique advantages and approaches. For Tableau users making the switch, understanding these differences can accelerate adoption and minimize friction.
At OfficeSolution, our tool Pulse Convert simplifies your Tableau to Power BI migration, converting dashboards and logic while preserving your analytical intent. Visit us at https://tableautopowerbimigration.com/ to learn how we can support your journey from Tableau to Power BI—seamlessly and efficiently.
0 notes
Text
ETL Testing: How to Validate Your Python ETL Pipelines
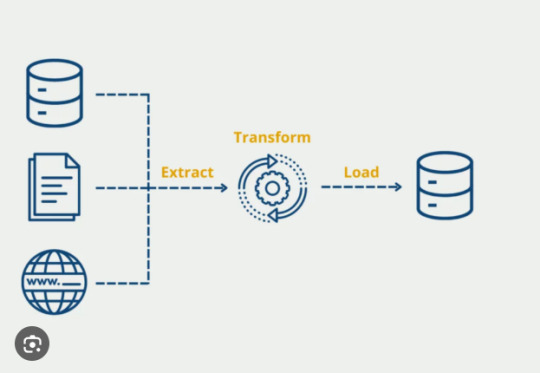
In the world of data engineering, building a strong Extract Transform Load (ETL) process is only half the battle. Ensuring that your ETL pipelines are reliable, accurate, and efficient is just as crucial. When working with Extract Transform Load Python workflows, proper ETL testing is essential to maintain data quality, catch errors early, and guarantee trustworthy outputs for downstream applications. In this article, we'll explore why ETL testing matters and how to effectively validate your Python ETL pipelines.
Why ETL Testing Is Critical
ETL processes move and transform data between systems — often at massive scales. A small mistake during extraction, transformation, or loading can result in significant business consequences, from incorrect analytics to failed reporting. Especially when using Extract Transform Load Python pipelines, where flexibility is high and custom scripts are common, thorough testing helps to:
Detect data loss or corruption
Ensure transformations are applied correctly
Validate that data is loaded into the target system accurately
Confirm that performance meets expectations
Maintain data consistency across different stages
Without systematic ETL testing, you risk pushing flawed data into production, which could impact decision-making and operations.
Key Types of ETL Testing
When validating Extract Transform Load Python pipelines, several types of testing should be performed:
1. Data Completeness Testing
This ensures that all the expected data from the source system is extracted and made available for transformation and loading. You might use row counts, checksum comparisons, or aggregate validations to detect missing or incomplete data.
2. Data Transformation Testing
In this step, you verify that transformation rules (like calculations, data type changes, or standardizations) have been correctly applied. Writing unit tests for transformation functions is a best practice when coding ETL logic in Python.
3. Data Accuracy Testing
Data must be correctly inserted into the target system without errors. Validation includes checking field mappings, constraints (like foreign keys), and ensuring values match expectations after loading.
4. Performance Testing
An efficient Extract Transform Load Python pipeline should process data within acceptable timeframes. Performance testing identifies slow stages and bottlenecks in your ETL workflow.
5. Regression Testing
Whenever changes are made to the ETL code, regression testing ensures that new updates don't break existing functionality.
How to Perform ETL Testing in Python
Python provides a wide range of tools and libraries that make ETL testing approachable and powerful. Here’s a practical roadmap:
1. Write Unit Tests for Each Stage
Use Python’s built-in unittest framework or popular libraries like pytest to create test cases for extraction, transformation, and loading functions individually. This modular approach ensures early detection of bugs.
2. Validate Data with Pandas
Pandas is excellent for comparing datasets. For example, after extracting data, you can create Pandas DataFrames and use assertions like:
python
CopyEdit
import pandas as pd
3. Create Test Data Sets
Set up controlled test databases or files containing predictable datasets. Using mock data ensures that your Extract Transform Load Python process can be tested repeatedly under consistent conditions.
4. Automate ETL Test Workflows
Incorporate your ETL testing into automated CI/CD pipelines. Tools like GitHub Actions, Jenkins, or GitLab CI can trigger tests automatically whenever new code is pushed.
5. Use Data Validation Libraries
Libraries like great_expectations can make ETL testing even more robust. They allow you to define "expectations" for your data — such as field types, allowed ranges, and value uniqueness — and automatically validate your data against them.
Common ETL Testing Best Practices
Always test with real-world data samples when possible.
Track and log all test results to maintain visibility into pipeline health.
Isolate failures to specific ETL stages to debug faster.
Version-control both your ETL code and your test cases.
Keep test cases updated as your data models evolve.
Final Thoughts
Validating your Extract Transform Load Python pipelines with thorough ETL testing is vital for delivering trustworthy data solutions. From unit tests to full-scale validation workflows, investing time in testing ensures your ETL processes are accurate, reliable, and scalable. In the fast-paced world of data-driven decision-making, solid ETL testing isn't optional — it’s essential.
0 notes
Text
h
Technical Skills (Java, Spring, Python)
Q1: Can you walk us through a recent project where you built a scalable application using Java and Spring Boot? A: Absolutely. In my previous role, I led the development of a microservices-based system using Java with Spring Boot and Spring Cloud. The app handled real-time financial transactions and was deployed on AWS ECS. I focused on building stateless services, applied best practices like API versioning, and used Eureka for service discovery. The result was a 40% improvement in performance and easier scalability under load.
Q2: What has been your experience with Python in data processing? A: I’ve used Python for ETL pipelines, specifically for ingesting large volumes of compliance data into cloud storage. I utilized Pandas and NumPy for processing, and scheduled tasks with Apache Airflow. The flexibility of Python was key in automating data validation and transformation before feeding it into analytics dashboards.
Cloud & DevOps
Q3: Describe your experience deploying applications on AWS or Azure. A: Most of my cloud experience has been with AWS. I’ve deployed containerized Java applications to AWS ECS and used RDS for relational storage. I also integrated S3 for static content and Lambda for lightweight compute tasks. In one project, I implemented CI/CD pipelines with Jenkins and CodePipeline to automate deployments and rollbacks.
Q4: How have you used Docker or Kubernetes in past projects? A: I've containerized all backend services using Docker and deployed them on Kubernetes clusters (EKS). I wrote Helm charts for managing deployments and set up autoscaling rules. This improved uptime and made releases smoother, especially during traffic spikes.
Collaboration & Agile Practices
Q5: How do you typically work with product owners and cross-functional teams? A: I follow Agile practices, attending sprint planning and daily stand-ups. I work closely with product owners to break down features into stories, clarify acceptance criteria, and provide early feedback. My goal is to ensure technical feasibility while keeping business impact in focus.
Q6: Have you had to define technical design or architecture? A: Yes, I’ve been responsible for defining the technical design for multiple features. For instance, I designed an event-driven architecture for a compliance alerting system using Kafka, Java, and Spring Cloud Streams. I created UML diagrams and API contracts to guide other developers.
Testing & Quality
Q7: What’s your approach to testing (unit, integration, automation)? A: I use JUnit and Mockito for unit testing, and Spring’s Test framework for integration tests. For end-to-end automation, I’ve worked with Selenium and REST Assured. I integrate these tests into Jenkins pipelines to ensure code quality with every push.
Behavioral / Cultural Fit
Q8: How do you stay updated with emerging technologies? A: I subscribe to newsletters like InfoQ and follow GitHub trending repositories. I also take part in hackathons and complete Udemy/Coursera courses. Recently, I explored Quarkus and Micronaut to compare their performance with Spring Boot in cloud-native environments.
Q9: Tell us about a time you challenged the status quo or proposed a modern tech solution. A: At my last job, I noticed performance issues due to a legacy monolith. I advocated for a microservices transition. I led a proof-of-concept using Spring Boot and Docker, which gained leadership buy-in. We eventually reduced deployment time by 70% and improved maintainability.
Bonus: Domain Experience
Q10: Do you have experience supporting back-office teams like Compliance or Finance? A: Yes, I’ve built reporting tools for Compliance and data reconciliation systems for Finance. I understand the importance of data accuracy and audit trails, and have used role-based access and logging mechanisms to meet regulatory requirements.
0 notes
Text
Biggest Challenges of Migrating Legacy Applications to the Cloud

Migrating legacy applications to the cloud offers scalability and cost benefits, but it comes with several challenges:
1. Compatibility & Modernization Issues
❌ Challenge: Legacy applications may not be cloud-ready due to outdated architectures, dependencies, or lack of APIs. ✅ Solution: Use re-platforming (minor modifications) or re-architecting (major changes) to ensure cloud compatibility.
2. Performance & Latency Concerns
❌ Challenge: Cloud-based applications might experience higher latency than on-premise setups, especially for high-performance computing (HPC) workloads. ✅ Solution: Use edge computing, CDN, and optimized cloud regions to reduce latency.
3. Security & Compliance Risks
❌ Challenge: Legacy applications may lack modern security measures or fail to meet industry compliance requirements (e.g., GDPR, HIPAA). ✅ Solution: Implement cloud-native security tools, encrypt data, and choose a compliant cloud provider.
4. Data Migration Complexity
❌ Challenge: Migrating large volumes of data with minimal downtime is difficult. ✅ Solution: Use incremental migration, cloud-based ETL tools, or hybrid cloud setups for smooth transitions.
5. Application Downtime & Business Disruptions
❌ Challenge: Migration can lead to temporary downtime, impacting business continuity. ✅ Solution: Implement a phased migration strategy with rollback plans and perform thorough testing before full deployment.
6. Cost Overruns & Budget Planning
❌ Challenge: Cloud migration can exceed budgets if costs aren’t planned properly (e.g., storage, bandwidth, and compute usage). ✅ Solution: Use cost calculators, opt for reserved instances, and monitor cloud expenses with FinOps tools.
7. Lack of Cloud Skills & Expertise
❌ Challenge: Many IT teams lack expertise in cloud architectures, DevOps, and security best practices. ✅ Solution: Invest in cloud training (AWS, Azure, Google Cloud certifications) and hire cloud migration specialists.
8. Vendor Lock-In Risks
❌ Challenge: Choosing a single cloud provider may create dependence on proprietary services. ✅ Solution: Use multi-cloud or hybrid-cloud approaches to maintain flexibility.
9. Application Refactoring Complexity
❌ Challenge: Some legacy apps require complete re-architecture to fit into microservices or containerized environments. ✅ Solution: Evaluate whether re-hosting (lift-and-shift), re-platforming, or rebuilding is necessary.
10. Ensuring Post-Migration Optimization
❌ Challenge: Migrating to the cloud doesn’t automatically improve performance—tuning is required. ✅ Solution: Optimize resources (auto-scaling, caching, monitoring) and continuously test cloud performance.
Final Thoughts
Migrating legacy applications to the cloud requires strategic planning, expertise, and a phased approach. Understanding these challenges upfront can help ensure a smooth, cost-effective, and secure migration.
For more info Check out this blog: - Cloud Migration: Why Companies Are Moving to the Cloud
0 notes
Text
How Data Virtualization Future-Proofs Your Digital Transformation

Digital transformation isn't a one-time project; it's a continuous journey. As businesses strive to become more agile, data-driven, and responsive to market changes, they often face a formidable challenge: the sheer complexity and fragmentation of their data landscape. Data resides in myriad systems – legacy databases, cloud applications, SaaS platforms, data lakes, streaming sources – making it difficult and time-consuming to gain a unified view. This is where Data Virtualization emerges as a critical enabler, providing a robust pathway to future-proof your digital transformation efforts.
The Digital Transformation Imperative
Today, every enterprise is a data enterprise. To innovate, optimize operations, and deliver exceptional customer experiences, organizations need real-time access to accurate, comprehensive data. Traditional data integration methods like Extract, Transform, Load (ETL) often involve physically moving and replicating data into a central data warehouse. While effective for certain use cases, this approach can be slow, costly, rigid, and prone to creating data silos and inconsistencies, making it ill-suited for the rapid pace of modern digital initiatives.
What is Data Virtualization?
Data Virtualization is a modern data management approach that creates a unified, virtual data access layer across disparate data sources without physically moving or replicating the data. Think of it as a sophisticated software layer that sits between your data consumers (applications, analytics tools, business users) and your diverse data sources.
When a query is made, the data virtualization layer:
Connects to various underlying data repositories (on-premises databases, cloud data lakes, SaaS applications, streaming data).
Understands the structure and metadata of these different sources.
Translates the query into commands specific to each source.
Retrieves only the necessary data from its original location in real-time.
Combines and transforms the results virtually, presenting a unified, logical view to the requesting application or user.
The key takeaway: Data remains in its original location, eliminating the need for costly and time-consuming physical data movement and replication.
How Data Virtualization Future-Proofs Your Digital Transformation
Data Virtualization isn't just another integration tool; it's a strategic asset that provides the agility, real-time insights, and flexibility needed to navigate the ever-evolving digital landscape.
Accelerated Time to Insight and Agility:
Real-time Access: Digital transformation demands immediate insights. Data virtualization provides real-time access to the freshest data, enabling instant dashboards, operational analytics, and timely decision-making, unlike batch-oriented ETL processes.
Rapid Prototyping: Business users and data analysts can quickly create new virtual data views, combine datasets, and test hypotheses without waiting for IT to build new physical data pipelines. This accelerates the development and deployment of new data products and services.
Breaking Down Data Silos & Creating a Unified View:
Organizations often have data scattered across dozens, if not hundreds, of disparate systems. Data virtualization acts as a cohesive semantic layer, creating a "single source of truth" by providing a unified, business-friendly view of data, regardless of its physical location or format.
This unified view is crucial for initiatives like Customer 360, comprehensive supply chain visibility, or enterprise-wide performance monitoring.
Cost Efficiency and Reduced Complexity:
Minimize Data Replication: By not physically moving or replicating data, organizations save significantly on storage costs, infrastructure, and the resources (human and computational) required for ETL processes.
Leverage Existing Investments: Data virtualization allows you to extract more value from your existing legacy systems and databases without needing to embark on expensive, disruptive migrations. It abstracts the underlying complexities, allowing for a phased modernization strategy.
Enhanced Data Governance and Security:
With a single, virtual access layer, data governance becomes centralized and simplified. You can apply consistent security policies, access controls, and data quality rules across all underlying sources.
This improves compliance with regulations like GDPR or HIPAA by controlling who accesses what data, without having to replicate sensitive information to multiple uncontrolled locations.
Flexibility for Evolving Technologies (AI, Cloud, Hybrid Environments):
Cloud and Hybrid Agility: As businesses adopt hybrid and multi-cloud strategies, data virtualization acts as a seamless bridge, providing unified access to data whether it resides on-premises or in various cloud environments. This prevents vendor lock-in and facilitates workload migration.
Fueling AI and Machine Learning: AI/ML models thrive on diverse and fresh data. Data virtualization provides an agile data fabric for AI, allowing data scientists to quickly access and combine data from various sources for model training and real-time inference without complex data preparation pipelines.
Microservices and API Economy: It can expose data as consumable data services via APIs, supporting agile application development and microservices architectures.
Challenges to Consider
While powerful, Data Virtualization isn't without its considerations:
Performance for Large Batch Jobs: While excellent for real-time queries, it may not be suitable for extremely large-scale batch processing or deep historical analysis that traditionally benefits from a physically optimized data warehouse.
Initial Setup Complexity: Integrating numerous diverse sources and defining the virtual layer requires careful planning and expertise.
Source System Impact: If queries are not optimized, excessive requests to source systems could potentially impact their operational performance.
Vendor Lock-in (for some solutions): Choosing the right vendor and solution that offers flexibility and open standards is important to avoid future lock-in.
The Future is Virtualized
As we move deeper into the 2020s, the trends in data management – including the rise of data fabrics, data meshes, and the increasing reliance on real-time analytics and AI – all underscore the growing importance of data virtualization. It is seen as a strategic imperative to unify disparate data sources, deliver insights with unprecedented speed, and provide the flexible data access that modern applications and business users demand.
By abstracting data complexities, reducing data movement, and providing a unified, real-time view, Data Virtualization empowers organizations to react swiftly to new demands, integrate emerging technologies, and continuously innovate. It's not just about managing data; it's about unlocking its full potential to drive and future-proof your ongoing digital transformation.
0 notes
Text
How to Ace a Data Engineering Interview: Tips & Common Questions
The demand for data engineers is growing rapidly, and landing a job in this field requires thorough preparation. If you're aspiring to become a data engineer, knowing what to expect in an interview can help you stand out. Whether you're preparing for your first data engineering role or aiming for a more advanced position, this guide will provide essential tips and common interview questions to help you succeed. If you're in Bangalore, enrolling in a Data Engineering Course in Hebbal, Data Engineering Course in Indira Nagar, or Data Engineering Course in Jayanagar can significantly boost your chances of success by providing structured learning and hands-on experience.
Understanding the Data Engineering Interview Process
Data engineering interviews typically consist of multiple rounds, including:
Screening Round – A recruiter assesses your background and experience.
Technical Round – Tests your knowledge of SQL, databases, data pipelines, and cloud computing.
Coding Challenge – A take-home or live coding test to evaluate your problem-solving abilities.
System Design Interview – Focuses on designing scalable data architectures.
Behavioral Round – Assesses your teamwork, problem-solving approach, and communication skills.
Essential Tips to Ace Your Data Engineering Interview
1. Master SQL and Database Concepts
SQL is the backbone of data engineering. Be prepared to write complex queries and optimize database performance. Some important topics include:
Joins, CTEs, and Window Functions
Indexing and Query Optimization
Data Partitioning and Sharding
Normalization and Denormalization
Practice using platforms like LeetCode, HackerRank, and Mode Analytics to refine your SQL skills. If you need structured training, consider a Data Engineering Course in Indira Nagar for in-depth SQL and database learning.
2. Strengthen Your Python and Coding Skills
Most data engineering roles require Python expertise. Be comfortable with:
Pandas and NumPy for data manipulation
Writing efficient ETL scripts
Automating workflows with Python
Additionally, learning Scala and Java can be beneficial, especially for working with Apache Spark.
3. Gain Proficiency in Big Data Technologies
Many companies deal with large-scale data processing. Be prepared to discuss and work with:
Hadoop and Spark for distributed computing
Apache Airflow for workflow orchestration
Kafka for real-time data streaming
Enrolling in a Data Engineering Course in Jayanagar can provide hands-on experience with these technologies.
4. Understand Data Pipeline Architecture and ETL Processes
Expect questions on designing scalable and efficient ETL pipelines. Key topics include:
Extracting data from multiple sources
Transforming and cleaning data efficiently
Loading data into warehouses like Redshift, Snowflake, or BigQuery
5. Familiarize Yourself with Cloud Platforms
Most data engineering roles require cloud computing expertise. Gain hands-on experience with:
AWS (S3, Glue, Redshift, Lambda)
Google Cloud Platform (BigQuery, Dataflow)
Azure (Data Factory, Synapse Analytics)
A Data Engineering Course in Hebbal can help you get hands-on experience with cloud-based tools.
6. Practice System Design and Scalability
Data engineering interviews often include system design questions. Be prepared to:
Design a scalable data warehouse architecture
Optimize data processing pipelines
Choose between batch and real-time data processing
7. Prepare for Behavioral Questions
Companies assess your ability to work in a team, handle challenges, and solve problems. Practice answering:
Describe a challenging data engineering project you worked on.
How do you handle conflicts in a team?
How do you ensure data quality in a large dataset?
Common Data Engineering Interview Questions
Here are some frequently asked questions:
SQL Questions:
Write a SQL query to find duplicate records in a table.
How would you optimize a slow-running query?
Explain the difference between partitioning and indexing.
Coding Questions: 4. Write a Python script to process a large CSV file efficiently. 5. How would you implement a data deduplication algorithm? 6. Explain how you would design an ETL pipeline for a streaming dataset.
Big Data & Cloud Questions: 7. How does Apache Kafka handle message durability? 8. Compare Hadoop and Spark for large-scale data processing. 9. How would you choose between AWS Redshift and Google BigQuery?
System Design Questions: 10. Design a data pipeline for an e-commerce company that processes user activity logs. 11. How would you architect a real-time recommendation system? 12. What are the best practices for data governance in a data lake?
Final Thoughts
Acing a data engineering interview requires a mix of technical expertise, problem-solving skills, and practical experience. By focusing on SQL, coding, big data tools, and cloud computing, you can confidently approach your interview. If you’re looking for structured learning and practical exposure, enrolling in a Data Engineering Course in Hebbal, Data Engineering Course in Indira Nagar, or Data Engineering Course in Jayanagar can provide the necessary training to excel in your interviews and secure a high-paying data engineering job.
0 notes
Text
Harnessing Automated Data Scheduling and REST API Data Automation with Match Data Pro LLC
In today's data-driven world, organizations handle vast amounts of information that require streamlined processing, efficient management, and real-time accessibility. Manual data handling is no longer feasible for businesses aiming to scale operations and maintain accuracy. Enter Match Data Pro LLC, a leader in automated data scheduling and REST API data automation. These cutting-edge solutions empower businesses to manage data workflows seamlessly, ensuring efficiency, security, and precision.
Understanding Automated Data Scheduling
Automated data scheduling is an important feature of contemporary data management that allows companies to run, track, and optimize their data processes automatically. This technology makes sure that data processing operations are run at scheduled times or initiated under certain conditions, greatly improving efficiency.
Advantages of Automated Data Scheduling:
Efficiency – Eliminates manual labor, enabling employees to concentrate on strategic activities.
Accuracy – Reduces errors due to human involvement.
Scalability – Efficiently handles huge amounts of data as companies expand.
Cost Savings – Saves on operational expenses involved in manual data processing.
Timely Execution – Facilitates timely completion of data tasks, enabling real-time decision-making.
Match Data Pro LLC offers robust automated data scheduling solutions that equip businesses with effortless execution and monitoring of data pipelines.
How Automated Data Scheduling Works
Automated data scheduling functions by using sophisticated data pipeline schedulers that run workflows in accordance with specified triggers, time windows, or external events. Such workflows may comprise data extraction, transformation, and loading (ETL), report creation, and system refresh.
In Match Data Pro LLC, the process of automated data scheduling is governed through a formal procedure:
Task Identification – Identifying critical business processes to be automated.
Workflow Design – Designing formal workflows that combine disparate data sources.
Scheduling Execution – Automating tools to run tasks at scheduled intervals.
Monitoring & Optimization – Continuous tracking of performance and error handling.
REST API Data Automation – Automating Data Operations
REST API data automation allows for smooth communication between various systems, applications, and databases through automated API calls. APIs (Application Programming Interfaces) serve as connectors between software components, enabling them to pass data back and forth with ease.
With Match Data Pro LLC, companies can automate their REST API data automation to:
Automate updates and retrieval of data on various platforms.
Connect third-party applications without any human intervention.
Ensure data consistency and synchronization across systems.
Optimize operational efficiency by removing redundant manual processes.
REST API Data Automation Key Features
Seamless Integration – Integrate various software applications for streamlined data management.
Real-Time Data Processing – Updates data on multiple platforms in real time.
Scalability – Manages growing volumes of data without performance decline.
Improved Security – Provides safe data transfer with authentication and encryption mechanisms.
Error Handling & Logging – Detects and fixes data discrepancies effectively.
Putting REST API Data Automation to Work with Match Data Pro LLC
Implementation of REST API data automation is a multi-step process for a smooth shift from manual to automatic processes. Match Data Pro LLC adopts a systematic approach:
Assessment of Business Requirements – Determining precise automation needs.
API Planning for Integration – Creating API endpoints for effective data exchange.
Development of Automation – Executing scripts and tools for automating API interactions.
Testing & Validation – Facilitating seamless data transfer with thorough testing.
Deployment & Monitoring – Deploying automation processes with real-time monitoring.
Real-World Applications of Automated Data Scheduling and REST API Data Automation
Companies in different sectors use automated data scheduling and REST API data automation to automate operations, enhance efficiency, and increase data accuracy. Some of the main uses are:
1. E-commerce Sites
Automated order processing and inventory refresh.
Synchronization of product listings in real-time across multiple channels.
Data-driven marketing campaigns using user behavior analytics.
2. Financial Institutions
Automated transaction processing and fraud detection.
Secure banking API integration for effortless data sharing.
Compliance reporting efficiently through scheduled data extraction.
3. Healthcare & Life Sciences
EHR system integration.
Data exchange between healthcare organizations and insurers automatically.
Patient monitoring and reporting in real-time via networked devices.
4. Medical Resource Planning (ERP)
Auto-synchronization of HR records, financial data, and procurement.
Third-party software integration without gaps for greater workflow automation.
Automated generation of performance reports and data analytics on schedule.
Why Automate with Match Data Pro LLC?
With robust expertise in automated data scheduling and REST API data automation, Match Data Pro LLC is a reliable partner for companies intending to streamline their data management solutions. Here's why companies trust Match Data Pro LLC:
Integrated Data Automation Solutions – Providing full-cycle solutions aligned with business requirements.
State-of-the-Art Technology – Employs the newest automation tools and frameworks.
Scalability & Flexibility – Suitable for businesses of any size and type.
Secure & Reliable – Enforcing industry standards for data security and compliance.
Expert Support & Consultation – Offering live help for smooth implementation of automation.
Conclusion
In the digital age, data scheduling automation and REST API data automation are no longer a choice but a necessity for companies to improve efficiency and data precision. Match Data Pro LLC provides innovative solutions that streamline complicated data processes so that companies can invest in growth and innovation. By leveraging automation, businesses are able to realize streamlined operations, cost savings, and better decision-making, setting themselves up for long-term success.
0 notes
Text
How Databricks Unity Catalog and Datagaps Automate Governance and Validation

Data quality is the backbone of accurate analytics, regulatory compliance, and efficient business operations. As organizations scale their data ecosystems, maintaining high data integrity becomes more challenging.
The seamless integration between Databricks Unity Catalog and Datagaps DataOps Suite provides a powerful framework for automated governance and validation, ensuring that data remains accurate, complete, and compliant at all times.
In our previous discussion, we highlighted how Datagaps enhances metadata management, lineage tracking, and automation within Unity Catalog. This article takes the next step by diving into data quality assurance – a crucial component of enterprise-wide data governance.
By leveraging Datagaps Data Quality Monitor, organizations can implement automated validation strategies, reduce manual effort, and integrate real-time data quality scores into Unity Catalog for proactive governance. Let’s explore how these technologies work together to ensure high-quality, reliable data that drives better decision-making and compliance.
The Growing Need for Automated Data Quality Assurance
Modern enterprises manage vast amounts of structured and unstructured data across multiple platforms. Ensuring data accuracy, completeness, and consistency is no longer just a best practice – it’s a necessity for regulatory compliance and business intelligence.
Databricks Unity Catalog provides a centralized governance framework for managing metadata, access controls, and data lineage across an organization. By integrating with Datagaps Data Quality Monitor, enterprises can automate data validation, reduce errors, and gain deeper insights into data health and integrity.
6 Key Data Quality Dimensions

Effective data quality management revolves around six fundamental dimensions:
Accuracy – Ensuring data reflects real-world values without discrepancies.
Completeness – Verifying that all required fields and records are present.
Consistency – Maintaining uniformity across multiple data sources and systems.
Timeliness – Ensuring data is up-to-date and available when needed.
Uniqueness – Eliminating duplicate records and redundant data entries.
Validity – Enforcing compliance with defined formats, business rules, and constraints.
By addressing these dimensions, organizations can improve the trustworthiness of their data assets, enhance AI/ML outcomes, and comply with industry regulations.
Automating Data Quality Validation with White-Box and Black-Box Testing
Ensuring data integrity at scale requires a systematic approach to validation. Two widely used methodologies are:
1. White-Box Testing
Examines internal data transformations, lineage, and business rules.
Ensures that every step in the ETL (Extract, Transform, Load) process adheres to defined standards.
Provides deeper insights into data processing logic to catch issues at the source.
2. Black-Box Testing
Focuses on output validation by comparing actual results against expected benchmarks.
Useful for detecting anomalies, missing records, and schema mismatches.
Works well for regulatory compliance and end-to-end data pipeline testing.
A hybrid approach combining both techniques ensures robust validation and proactive anomaly detection.
How Unity Catalog and Datagaps Data Quality Monitor Work Together
1. Unified Governance and Automated Validation
Databricks Unity Catalog centralizes metadata management, access control, and lineage tracking.
Datagaps Data Quality Monitor extends these capabilities with automated quality checks, reducing manual efforts.
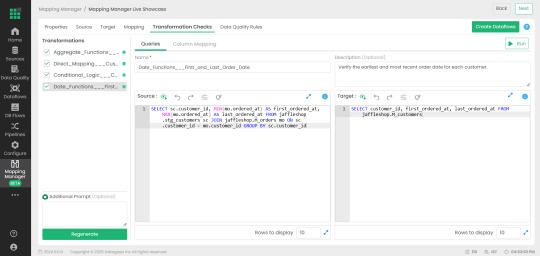
2. Mapping Manager Utility: Simplifying Test Case Automation
One of the standout features of Datagaps Data Quality Monitor is the Mapping Manager Utility, which:
Extracts mapping configurations��from Databricks Unity Catalog.
Automatically generates white-box and black-box test cases.
Reduces the need for manual intervention, increasing efficiency and scalability.
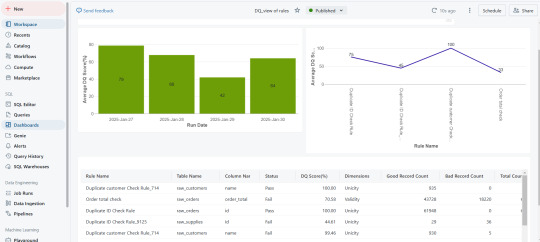
3. Real-Time Data Quality Scores for Proactive Governance
After test execution, a data quality score is generated.
These scores are seamlessly integrated into Databricks Unity Catalog, allowing real-time monitoring.
Organizations can visualize data quality insights through dashboards and take corrective actions before issues impact business operations.
Key Use Cases
ETL and Data Pipeline Validation – Ensuring data transformations adhere to defined business rules.
Regulatory Compliance and Audit Readiness – Mitigating risks associated with inaccurate reporting.
Enterprise Data Lakehouse Governance – Enhancing consistency across distributed datasets.
AI/ML Data Preprocessing – Ensuring clean, high-quality data for better model performance.
Automated Data Quality Checks – Reducing manual data validation efforts for faster, more reliable insights.
Scalability for Large Datasets – Efficiently managing high-volume, high-velocity enterprise data.
Faster QA Cycles – Automating test case execution for rapid turnaround.
Lower Operational Resources – Reducing human intervention, saving time and resources.
The Business Impact: Why This Integration Matters
Enhanced Automation – Eliminates manual quality checks and increases efficiency.
Real-Time Monitoring – Provides instant visibility into data quality metrics.
Stronger Compliance – Supports industry standards and regulations effortlessly.
Scalability – Designed for large-scale, complex data ecosystems.
Cost Efficiency – Reduces operational overhead and improves ROI on data management initiatives.
Ensuring data quality at scale requires a combination of automated governance, real-time monitoring, and seamless integration. The connection between Databricks Unity Catalog and Datagaps Data Quality Monitor provides a comprehensive solution to achieve this goal.
With automated test case generation, continuous data validation, and integrated governance, organizations can ensure their data is always accurate, complete, and compliant—laying the foundation for data-driven decision-making and regulatory confidence.
0 notes
Text
Software Development in Canada: Driving Innovation and Growth

Canada has emerged as a global hub for software development, offering a unique blend of talent, innovation, and a thriving tech ecosystem. With its robust infrastructure, supportive government policies, and a highly skilled workforce, Canada is at the forefront of delivering cutting-edge software solutions that cater to diverse industries. Whether you're a startup, a mid-sized enterprise, or a large corporation, software development Canada provides the expertise and resources needed to transform your ideas into reality.
Why Choose Software Development in Canada?
World-Class Talent PoolCanada is home to some of the brightest minds in the tech industry. The country’s emphasis on STEM education and its welcoming immigration policies have attracted top-tier developers, engineers, and data scientists from around the world. This diverse talent pool ensures that businesses have access to professionals who are not only skilled but also bring fresh perspectives to the table.
Innovation and Technology LeadershipCanadian cities like Toronto, Vancouver, and Montreal are recognized as global tech hubs, fostering innovation and collaboration. The country’s focus on emerging technologies such as artificial intelligence (AI), machine learning (ML), cloud computing, and blockchain has positioned it as a leader in the software development landscape.
Cost-Effective SolutionsCompared to other tech-heavy regions like Silicon Valley, software development in Canada offers a cost-effective alternative without compromising on quality. Businesses can leverage high-quality development services at competitive rates, making it an attractive destination for outsourcing and custom software development.
Strong Focus on Quality and SecurityCanadian software development companies prioritize quality assurance and security. With stringent data protection laws and a commitment to best practices, businesses can trust that their software solutions are not only functional but also secure and compliant with international standards.
Agile and Scalable DevelopmentCanadian developers are well-versed in agile methodologies, ensuring that projects are delivered efficiently and can adapt to changing requirements. This approach allows businesses to scale their software solutions as they grow, ensuring long-term success.
Key Services in Software Development Canada

Custom Enterprise Software DevelopmentCanadian firms specialize in building tailored enterprise solutions that streamline operations, enhance productivity, and drive growth. From ERP systems to CRM platforms, these solutions are designed to meet the unique needs of businesses across industries.
Cloud Migration and DevelopmentWith the increasing adoption of cloud technologies, Canadian developers excel in migrating legacy systems to cloud platforms like AWS, Azure, and Google Cloud. They also build cloud-native applications that leverage the full potential of cloud computing.
Data Science and AutomationCanada’s expertise in data science and system automation enables businesses to harness the power of data. From building ETL pipelines to developing AI-driven automation tools, Canadian developers help organizations make data-driven decisions and optimize processes.
Quality Assurance and TestingEnsuring software reliability and performance is a top priority. Canadian QA teams employ rigorous testing methodologies to identify and resolve issues before deployment, guaranteeing a seamless user experience.
Ongoing Support and MaintenanceSoftware development doesn’t end at deployment. Canadian companies offer dedicated support and maintenance services to ensure that systems remain up-to-date, secure, and efficient.
The Canadian Advantage: A Collaborative Ecosystem
Canada’s software development industry thrives on collaboration. The country’s tech ecosystem is supported by government initiatives, incubators, accelerators, and venture capital funding, creating an environment where innovation flourishes. This collaborative spirit extends to partnerships between businesses and development firms, ensuring that projects are aligned with business goals and deliver measurable results.
Future Trends in Software Development Canada
AI and Machine Learning IntegrationAI and ML are transforming industries, and Canadian developers are at the forefront of integrating these technologies into software solutions. From predictive analytics to intelligent automation, AI-driven software is shaping the future of business.
Increased Adoption of DevOpsDevOps practices are becoming standard in software development, enabling faster delivery and continuous improvement. Canadian firms are embracing DevOps to enhance collaboration between development and operations teams.
Focus on SustainabilityAs businesses prioritize sustainability, Canadian developers are creating eco-friendly software solutions that minimize energy consumption and reduce environmental impact.
Expansion of Remote Work ToolsThe shift to remote work has accelerated the demand for collaboration and productivity tools. Canadian developers are building innovative solutions to support distributed teams and enhance remote work experiences.
Why Partner with a Canadian Software Development Company?
Partnering with a Canadian software development company offers numerous benefits, including access to top talent, cost-effective solutions, and a commitment to quality. Whether you’re looking to build a custom application, migrate to the cloud, or automate your processes, Canadian developers have the expertise to deliver results.
At Peytosoft, we embody the best of software development in Canada. With over 15 years of experience, we specialize in crafting innovative solutions that address complex challenges and drive business growth. Our team of skilled engineers, rigorous training programs, and client-centric approach ensure that we deliver software that exceeds expectations.
Conclusion
Software development in Canada is more than just a service—it’s a partnership that drives innovation, efficiency, and growth. With its world-class talent, cutting-edge technologies, and commitment to quality, Canada is the ideal destination for businesses seeking to transform their digital landscape. Whether you’re a local business or an international organization, partnering with a Canadian software development company like Peytosoft Corporation can help you achieve your goals and stay ahead in a competitive market.
Ready to take your business to the next level? Let’s connect and build something extraordinary together.
1 note
·
View note