#and also google reverse image search!!!! very handy tool !!!!!
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs



Fun Fact
Tumblr has 16.74 million mobile monthly users in the US.
Text
I've actually seen so much fanart on this site with no repost permission and no credit even it's really shocking to me actually.... and usually it's also with character and official tags...
I'm not sure if people are just not aware ? but yeah I think it is just respectful to just get permission from an artist ESP if youre going to tag it with what I call ""official tags"" (like character name or series name)
I'm sure there's no ill intent most of the time but sometimes I see a repost and I'm like gosh. and then I choose to not interact and then it has hundreds of notes when it comes up again later ?? another one I saw had 22k notes ????? like that much interaction and the artist is literally getting no shout out whatsoever for their work it's quite sad is it not... they're not even aware their work is just floating around elsewhere
#to me even if you havw credit if you dont have permission you shouldn't be posting it straight up#also if you dont have credit you just dont post.... and definitely not with official tags#and to top it off most of the time the art ive seen reposted is right on twitter like two searches will get you right to the official artis#and also google reverse image search!!!! very handy tool !!!!!#i know people are going to read this and be like WHO ARE YOU TO BE TALKING!!!! U DONT EVEN POST ART!!!!!! AND TRULY WELL YES.#I DO NOT#but i have friends who do and i do not think they would like it much if their art was just randomly reposted on a different platform withou#their permission#anyways take this as you will its really shocking to me i think#tldr: i dont think u should post if you dont have credit AND permission but perhaps i am overreacting. your call
13 notes
·
View notes
Text
Oh excellent image for my students to fact check this summer. Others in the notes have already caught on and provided these sources - my goal here is to capture my process of debunking it so I can share with the teens who take info sci with me in the summer:
Colin Leonhardt did take a picture of a full circle rainbow in 2013 - the caption is entirely correct, it's the image that's not:

Source: NASA
The image is fake - AI probably considering it began circulating in March 2023, and also it looks very AI. There's only one fact check site that I could find debunking it: Lead Stories, HERE. Lead Stories' site was a bit...amateur looking to me, so I backtracked them and they are legit - partnered with Meta to fact check stories on FB which is where they picked up the image first. A pilot - Lloyd J Ferrarro - is credited with taking the photo, but he says he didn't - just shared it.
Here's the thing - this took a few different tactics to figure out. Reverse image searching on google and tineye was unhelpful - you just get piles of this image with confusing captions. Google is supposed to have a new tool for backtracking and identifying the metadata on images but I think it's app only? It's not working in a chrome browser and Lens is crap. Searching terms like circular rainbow viral image fact check is also not helpful because circular rainbows are real! Just not this image.
What was helpful:
Scanning the notes for sceptics who got here first and add context and sources. (But that's going to depend where you see the image.)
Searching the caption info which is a quick easy verification that the image does not match the caption. (Useful if you have such a helpful if misplaced caption.)
Using Google's Fact Checker - only one hit but being able to search the image in a search trawling fact check sites only, which avoids a bunch of crap.
Not using Google to search because handy tools aside, its search function is awful now. Firefox with DuckDuckGo brought up Lead Stories as the first result with the search circular rainbow viral image fact check (and I likely should have just done that first, but I wanted to use methods I thought students would try.)
The last method I tried was to click on an FB link in Lens and it came up flagged as fake (thanks to that partnership with Lead Stories) but no teenager is going to choose an FB link to randomly investigate.
All of these methods worked, but there were a lot of false starts in the process. I do ascribe to and teach the SIFT method of Stop-Investigate-Find Better Coverage-Trace Back but within each of those "moves" there can be a lot of variability. Sometimes it's relatively straightforward. Sometimes it's a not-quite right circle.

Full circle rainbow was captured over Cottesloe Beach near Perth, Australia in 2013 by Colin Leonhardt of Birdseye View
22K notes
·
View notes
Text
Free Resources For Writers & Creators

This is a quick post of free resources that may help fandom creators (or creators in general). I’m sure many of these have been shared before. However, it doesn’t hurt to spread the word. A few quick points:
As a professional writer, I think this post will cater mostly towards writers.
I’m also a freelance photographer, so digital photography/editing/art sources are included, too.
I chose not to use any affiliate links in my post. I don’t want to profit from this, and I’m not sure that’s allowed on Tumblr anyways.
If I’ve listed a resource I haven’t used myself, I’ve made sure to state it.
Masterlists and/or huge resource compilations are marked with asterisks.
Alright, here we go! I hope you all find this post helpful. Happy writing/creating!

Research
All of these are free resources for research. I use most of them for my writing jobs because they are extremely credible. These are great for making accurate references in your fics/creations.
1. ***Research Resources For Writers***
Writer’s Write has an enormous database of research resources for writers. They are divided into 20+ categories such as:
careers
historical research
crimes and forensics
religion
Each category contains 10+ resources like websites, articles, tips, databases, and so much more. It’s the most comprehensive and organized free research tool I use.
2. PubMed
My go-to source for citing medical studies. You’ll find 30 million citations related to numerous physical and mental health issues.
3. BioMed Central
I don’t use this website as often, but I keep it in my bookmarks. It’s similar to PubMed - great for discovering current and former medical research.
4. Drugs.com
If you need to name a medication and/or refer to medication side effects, Drugs.com is a straightforward resource. It’s easy to navigate and understand.
It also has a tool that lists potential medication interactions. This is really useful for accurate descriptions of med combinations.
5. Merck Manuals Consumer Version
Merck Manuals started out in 1899 as a medical reference guide for professionals. This consumer version is really comprehensive and updated regularly. It includes definitions, studies, and more.
6. FindLaw
If you’re writing about legal topics, FindLaw is useful for learning about laws/procedures in reader-friendly language. Categories include:
accidents/injuries
criminal law
family law (divorce, custody, etc.)
Keep in mind that laws vary based on location! You’ll often find additional links to state-related laws within articles. I do recommend double-checking state/location-based legal resources for accuracy.
7. APA Dictionary of Psychology
This psychology dictionary is provided by the American Psychological Association. It covers 90+ areas of psychology and 25,000+ terms/definitions.
You’ll also find links to additional psychology databases, resources, and so on. The website is updated frequently to provide updated information.
8. U.S. Bureau Of Labor Statistics
If you’re writing about a character’s job/career in the United States, this is a great source for accuracy. For any job sector, you’ll find details about
education requirements
positions in the sector
average salary for positions
what the positions entail
I imagine there are alternatives for other countries, too!
9. Investopedia Financial Term Dictionary
My area of expertise is personal finance; all of my writing published under my name is in this niche. I still refer to Investopedia’s dictionary for help. It’s excellent for understanding/explaining financial terms in a way that your reader can understand.
10. MedTerms Medical Dictionary
This is the medical version of Investopedia’s dictionary. I use this source less frequently, but I find that it’s accurate and helpful. There are many similar references online if you search for “medical glossaries” or “medical dictionaries”.
11. Domain Authority Checker
I’m not sure if this one is too helpful for fic writers, but it’s one of my most used tools. Domain authority “a search engine ranking score developed by Moz that predicts how likely a website is to rank on search engine result pages (SERPs)”.
The Wikipedia page for domain authority (DA) explains it clearly and simply. To sum it up, websites with good DA scores are considered reliable and accurate. If I cite sources in my work. I always link to sources with good DA scores.

Writing/Editing
This section is the most thorough one. All of these are completely free tools for writing and editing any type of content. I currently use or have used all of these at some point in my career.
1. ***List Of Free And Open-Source Software Packages***
This Wikipedia page applies to multiple categories in my post. It’s a masterpost of free and open-source software for anything and everything. Software is divided up into categories and sub-categories. Some relevant examples include:
media
networking/Internet
image editing
file management
There are hundreds of free software links on the page, so you’ll need to do a bit of browsing. Start with the categories above to find software geared towards writers/creators.
2. OpenOffice
This is a free alternative to Microsoft Office. I’ve used it for nine years and love it. OpenOffice software includes free applications for:
text documents
spreadsheets
presentations
drawing
templates
There are many more tools with OpenOffice that I haven’t used. If you write offline, I cannot recommend it enough. Tutorials are readily available online, and the software is pretty user-friendly.
3. Evernote
I briefly used Evernote and found that it’s very user-friendly and helpful. Most of my colleagues use Evernote and recommend it for taking notes/staying organized.
(I’m personally not a fan of note-taking software or apps. My method is messy text documents with bullet point lists.)
4. Google Drive
This might seem like an obvious one, but Google Drive/Docs is my writing haven. It has the tools included with Microsoft Office and OpenOffice and then some. It’s great for collaborative writing/sharing documents, too.
5. Grammarly
I use the Premium (paid) version of Grammarly, but I also used the free version for years. It’s helpful for detecting simple spelling, style, and grammatical errors.
There are numerous ways to use it - desktop, copy/paste documents, and so on. I’m not a huge fan of how well it works with Google Docs, but they’re improving it/it’s moved out of beta mode.
If you’re interested in the paid version - which I highly recommend - wait to buy until a holiday pops up. They offer a major discount on the software for almost every holiday/special occasion.
6. Plagiarism Detector
This website is handy for scanning for plagiarism. You can scan your own work to ensure uniqueness, too. My clients are big fans of this tool.
(I no longer use this resource; I use a paid tool called Copyscape Premium. The low cost has a big return on investment for me.)
7. TitleCase
The name says it all. It’s free and simple! I’ll be honest - I’m terrible with proper title case. You’d think after a decade of writing I’d nail it. However, I use this tool pretty often.
8. Hemingway Editor
Hemingway Editor is an online and desktop editor. It’s excellent for scanning your writing to check for:
readability (a grade-level score is listed)
adverb usage
passive voice usage
complex phrase usage
estimated reading time
This tool is color-coded to make editing easy. For example, adverbs are highlighted in blue. I don’t use this as often as I used to, but it was essential for my early writing career.
9. Polish My Writing
This tool is very straightforward. You paste your writing into the text box. Spelling errors, grammar suggestions, and style suggestions are highlighted in red, blue, and green.
It’s great for double-checking your work alongside Grammarly or Hemingway. When using free editors, I recommend using at least two for higher accuracy.
10. OneLook Reverse Dictionary And Thesaurus
I’m going to use the definition directly from the website:
“This tool lets you describe a concept and get back a list of words and phrases related to that concept. Your description can be anything at all: a single word, a few words, or even a whole sentence. Type in your description and hit Enter (or select a word that shows up in the autocomplete preview) to see the related words.”
To put it simply, you can use the reverse dictionary/thesaurus to find those words/thoughts that are on the tip of your tongue. Use the tool to:
find a word based on the word’s definition (i.e. search for “inability to feel pain”)
find synonyms and related concepts
generate a list of category-specific words (i.e. search for “cat breeds”)
answer basic questions (i.e. search for “what is the capital of France?”)
The results can be hit or miss, but I usually find the information I’m looking for. It’s a solid resource any writer regardless of genre.
11. Word Frequency Counter + Phrase Frequency Counter
I cannot emphasize how much I love these tools. Repetition is the bane of a writer’s existence; it’s simply inevitable at times.
These two tools count the number of times you use a single word or phrase in a text document. Just copy/paste your document, hit submit, and you’re all set!
For the phrase frequency counter, you can scan for two-word to ten-word phrases.
12. Thesaurus.com
This is another tool that might seem painfully obvious. Combined with the word frequency counter, it’s such an essential resource for me.
It’s especially useful if you’re writing about the same topic multiple times (i.e. love, getting drunk, sex, etc.). I always use this combo of tools to ensure uniqueness.
13. Lists Of Colors
Are you stumped when trying to come up with unique shades of blue? Is describing your character’s hair or skin color difficult? This Wikipedia page has you covered. It contains:
lists of colors (alphabetically)
lists of colors by shade
lists of Crayola crayon colors
lists of color palettes
I typically use this resource for product descriptions, but I also used it for creative writing many times. It’s a lifesaver for all things color-related.

Free Photos/Images
Tons of creators need free photos/images for numerous reasons. All of these sources provide 100% free photos, illustrations, etc. that have a Creative Commons Zero (CC0) license. This means there’s no copyright whatsoever on them.
You can edit the images however you’d like, too. All of the images in my post are from the first source listed below. I made them black and white and added text.
(A lot of these sites have donate buttons for contributors. Donating a dollar here and there goes a long way!)
1. Unsplash
Unsplash is my personal favorite for high-resolution photos. It’s easy to navigate and has over 2,000,000 free images. Downloading an image is a one-click process, and you don’t need to create an account.
2. Pixabay
Pixabay is my go-to site for illustrations and vector graphics (they have photos, too). There are 1.9 million free images to choose from. You don’t need an account to download images, but I recommend creating one. It’s free and with an account:
you don’t have to complete a CAPTCHA every time you download an image
you can access higher-quality/larger/etc. versions of images
I often use graphics from Pixabay to create overlays and masks for mixed media art pieces.
3. PxHere
I’ve never used PxHere, but one of my writing clients recommends it. It seems very similar to Pixabay, and the interface is user-friendly.
4. Pexels
In my limited experience, Pexels seems to focus on “artsy” stock images/content. I found great high-quality images the few times I’ve used it.
5. Burst by Shopify
I haven’t used Burst, but it’s another free image site that a writing client recommended to me. It seems a little limited compared to the other sites, but it never hurts to add it to your toolbox!

Digital Art/Photo Editing/Etc.
This section seems brief, but the tools listed are pretty comprehensive and diverse. They are geared towards many creative needs/projects like:
Creating manips of people/etc.
Adding text to images.
Creating collages.
Digital illustration.
Advanced photo editing.
There’s something for everyone. In my experience, finding your favorites among these will take some trial and error.
1. Pixlr X and Pixlr E (app available)
Pixlr X and Pixlr E are both versatile free editing tools. Pixlr X is ideal for less experienced creators. Pixlr E is comparable to Adobe PhotoShop.
I’ve used both software formats for personal and professional art projects.
The Pixlr app is handy for making collages, adding filters/overlays, adding text, and so on. I’ve used it for creating fanfiction collages and similar projects. It’s super easy to use.
2. Remove Background by Pixlr
This is one of the easiest/fastest tools I’ve found for removing backgrounds from images. It’s perfect for creators who make manips using photos of people.
It takes literal seconds to use. The tool automatically removes the background. If you spot any mistakes, you can refine the results with brush/erase tools. Then you download the cutout and you’re all set!
Unfortunately, this feature isn’t available on the Pixlr app. There are a lot of smartphone apps for removing photo backgrounds.
3. GIMP
If you need a full-fledged Photoshop alternative, GIMP is excellent software. It’s not an online tool like most I’ve suggested; you’ll need to download it to your computer.
There’s quite a learning curve for it, unless you’re familiar with Photoshop already. Fortunately, the free video/text GIMP tutorials online are endless. I no longer use/need GIMP, but it’s a personal favorite of mine.
4. Paint.NET
Admittedly, I haven’t used Paint.NET, but my art/photography colleagues commonly mention it. It’s comparable to Photoshop and GIMP. It’s a web-based tool, and a quick Google search returns several tutorials for it.
5. Photopea
This is more or less a Photoshop clone, but it’s free and web-based. If you watch Photoshop tutorials, you can usually follow the same steps in PhotoPea.
I’ve only used it a few times; I have Photoshop so I don’t need it. Still, it’s very impressive - especially for a free tool.
6. PicsArt (app available)
PicsArt is a photo editing website and app; the app is much easier to use in my opinion. It’s a “fun” editing tool for photo manips, collages, and fan art in general. A lot of users post their art in the app, and I’ve noticed tons of cool fandom edits.
Some of the features are Premium (AKA cost money), but I don’t think they’re worth the extra cost. PicsArt also has a digital drawing app. I haven’t personally used it but it may be worth checking out!
7. Adobe Photoshop Express (app available)
(I’ll preface this by saying I have an Adobe subscription, so I have access to the “locked” features. I’ve used the free versions, but my memory of it is a bit hazy.)
Photoshop Express is a free web-based tool and smartphone app. The app is very user-friendly and can be used for detailed editing, adding filters, adding text, and so on.
I’m less familiar with the browser version; I only use it for the cutout tool when I’m feeling lazy. It seems to be a good fit for quick edits - filters, cropping, and so on.
8. Make PNG Transparent by Online PNG Tools
This tool is awesome for removing solid colored backgrounds. I use it to create graphics for mixed media art pieces. Here’s how it works:
upload an image
type the color your want to remove (name or hex code)
type the percentage of similar color tones you want to match (for example, 25% will remove your chosen color plus similar warm/cool tones)
the removed color is replaced with transparent pixels
If you want to make a JPG transparent, start with the website’s JPG to PNG Converter. There are a ton of useful free tools offered, but I haven’t tried out most of the others.
Wrap Up
That’s all I’ve got for now! If I think of additional free tools, I’ll add them to this post. Feel free to reblog with your own recommendations or message me if you’d like me to add anything.
I hope my fellow creatives find these too
#writer resources#writing#writblr#fanfiction#fanfic#creative writing#writing reference#writing resources#writer reference#obviouslygenuinely#creators#artists on tumblr#fandom#fan art
316 notes
·
View notes
Text
Uncovering SEO Opportunities via Log Files
Posted by RobinRozhon
I use web crawlers on a daily basis. While they are very useful, they only imitate search engine crawlers’ behavior, which means you aren’t always getting the full picture.
The only tool that can give you a real overview of how search engines crawl your site are log files. Despite this, many people are still obsessed with crawl budget — the number of URLs Googlebot can and wants to crawl.
Log file analysis may discover URLs on your site that you had no idea about but that search engines are crawling anyway — a major waste of Google server resources (Google Webmaster Blog):
“Wasting server resources on pages like these will drain crawl activity from pages that do actually have value, which may cause a significant delay in discovering great content on a site.”
While it’s a fascinating topic, the fact is that most sites don’t need to worry that much about crawl budget —an observation shared by John Mueller (Webmaster Trends Analyst at Google) quite a few times already.
There’s still a huge value in analyzing logs produced from those crawls, though. It will show what pages Google is crawling and if anything needs to be fixed.
When you know exactly what your log files are telling you, you’ll gain valuable insights about how Google crawls and views your site, which means you can optimize for this data to increase traffic. And the bigger the site, the greater the impact fixing these issues will have.
What are server logs?
A log file is a recording of everything that goes in and out of a server. Think of it as a ledger of requests made by crawlers and real users. You can see exactly what resources Google is crawling on your site.
You can also see what errors need your attention. For instance, one of the issues we uncovered with our analysis was that our CMS created two URLs for each page and Google discovered both. This led to duplicate content issues because two URLs with the same content was competing against each other.
Analyzing logs is not rocket science — the logic is the same as when working with tables in Excel or Google Sheets. The hardest part is getting access to them — exporting and filtering that data.
Looking at a log file for the first time may also feel somewhat daunting because when you open one, you see something like this:
Calm down and take a closer look at a single line:
66.249.65.107 - - [08/Dec/2017:04:54:20 -0400] "GET /contact/ HTTP/1.1" 200 11179 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)"
You’ll quickly recognize that:
66.249.65.107 is the IP address (who)
[08/Dec/2017:04:54:20 -0400] is the Timestamp (when)
GET is the Method
/contact/ is the Requested URL (what)
200 is the Status Code (result)
11179 is the Bytes Transferred (size)
“-” is the Referrer URL (source) — it’s empty because this request was made by a crawler
Mozilla/5.0 (compatible; Googlebot/2.1; +http://bit.ly/eSXNch) is the User Agent (signature) — this is user agent of Googlebot (Desktop)
Once you know what each line is composed of, it’s not so scary. It’s just a lot of information. But that’s where the next step comes in handy.
Tools you can use
There are many tools you can choose from that will help you analyze your log files. I won’t give you a full run-down of available ones, but it’s important to know the difference between static and real-time tools.
Static — This only analyzes a static file. You can’t extend the time frame. Want to analyze another period? You need to request a new log file. My favourite tool for analyzing static log files is Power BI.
Real-time — Gives you direct access to logs. I really like open source ELK Stack (Elasticsearch, Logstash, and Kibana). It takes a moderate effort to implement it but once the stack is ready, it allows me changing the time frame based on my needs without needing to contact our developers.
Start analyzing
Don’t just dive into logs with a hope to find something — start asking questions. If you don’t formulate your questions at the beginning, you will end up in a rabbit hole with no direction and no real insights.
Here are a few samples of questions I use at the start of my analysis:
Which search engines crawl my website?
Which URLs are crawled most often?
Which content types are crawled most often?
Which status codes are returned?
If you see that Google is crawling non-existing pages (404), you can start asking which of those requested URLs return 404 status code.
Order the list by the number of requests, evaluate the ones with the highest number to find the pages with the highest priority (the more requests, the higher priority), and consider whether to redirect that URL or do any other action.
If you use a CDN or cache server, you need to get that data as well to get the full picture.
Segment your data
Grouping data into segments provides aggregate numbers that give you the big picture. This makes it easier to spot trends you might have missed by looking only at individual URLs. You can locate problematic sections and drill down if needed.
There are various ways to group URLs:
Group by content type (single product pages vs. category pages)
Group by language (English pages vs. French pages)
Group by storefront (Canadian store vs. US store)
Group by file format (JS vs. images vs. CSS)
Don’t forget to slice your data by user-agent. Looking at Google Desktop, Google Smartphone, and Bing all together won’t surface any useful insights.
Monitor behavior changes over time
Your site changes over time, which means so will crawlers’ behavior. Googlebot often decreases or increases the crawl rate based on factors such as a page’s speed, internal link structure, and the existence of crawl traps.
It’s a good idea to check in with your log files throughout the year or when executing website changes. I look at logs almost on a weekly basis when releasing significant changes for large websites.
By analyzing server logs twice a year, at the very least, you’ll surface changes in crawler’s behavior.
Watch for spoofing
Spambots and scrapers don’t like being blocked, so they may fake their identity — they leverage Googlebot’s user agent to avoid spam filters.
To verify if a web crawler accessing your server really is Googlebot, you can run a reverse DNS lookup and then a forward DNS lookup. More on this topic can be found in Google Webmaster Help Center.
Merge logs with other data sources
While it’s no necessary to connect to other data sources, doing so will unlock another level of insight and context that regular log analysis might not be able to give you. An ability to easily connect multiple datasets and extract insights from them is the main reason why Power BI is my tool of choice, but you can use any tool that you’re familiar with (e.g. Tableau).
Blend server logs with multiple other sources such as Google Analytics data, keyword ranking, sitemaps, crawl data, and start asking questions like:
What pages are not included in the sitemap.xml but are crawled extensively?
What pages are included in the Sitemap.xml file but are not crawled?
Are revenue-driving pages crawled often?
Is the majority of crawled pages indexable?
You may be surprised by the insights you’ll uncover that can help strengthen your SEO strategy. For instance, discovering that almost 70 percent of Googlebot requests are for pages that are not indexable is an insight you can act on.
You can see more examples of blending log files with other data sources in my post about advanced log analysis.
Use logs to debug Google Analytics
Don’t think of server logs as just another SEO tool. Logs are also an invaluable source of information that can help pinpoint technical errors before they become a larger problem.
Last year, Google Analytics reported a drop in organic traffic for our branded search queries. But our keyword tracking tool, STAT Search Analytics, and other tools showed no movement that would have warranted the drop. So, what was going on?
Server logs helped us understand the situation: There was no real drop in traffic. It was our newly deployed WAF (Web Application Firewall) that was overriding the referrer, which caused some organic traffic to be incorrectly classified as direct traffic in Google Analytics.
Using log files in conjunction with keyword tracking in STAT helped us uncover the whole story and diagnose this issue quickly.
Putting it all together
Log analysis is a must-do, especially once you start working with large websites.
My advice is to start with segmenting data and monitoring changes over time. Once you feel ready, explore the possibilities of blending logs with your crawl data or Google Analytics. That’s where great insights are hidden.
Want more?
Ready to learn how to get cracking and tracking some more? Reach out and request a demo get your very own tailored walkthrough of STAT.
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read!
1 note
·
View note
Text
Ghost In The Machine
A little over 11 years ago, Instagram was launched by Kevin Systrom and Mike Krieger. While the filters were pretty atrocious, and folks really had no clue what to do other than post shots of their dinner or pets, it took off. In two years, it caught the attention of Meta, parent company of Facebook, who purchased it for $1 billion.
Seems like a bargain now, doesn’t it? I wonder how many exotic islands you could buy with it though.
With Meta’s backing, it quickly became apparent that Instagram was going to move on to bigger and better things, like influencers, artsy material, and the most important aspect, shopping. With a site as sticky as Instagram, shopping is a natural, because once people stay a while and begin to feel comfortable, they are much more likely to bring out their wallets.
The only problem with this, though, is that today there in an increasing number of ghost stores on the site, shops that sell the identical items available elsewhere, but at jacked-up prices sugar-coated in marketing-speak about things like sustainability, ethics, and all the feels you would expect from folks in the smoke and mirrors business.

And the sad part is, it is all perfectly legal. As for ethicality, you have to make up your own mind. All I’m saying is that you better be careful if you buy a cute little dress off some boutique shop on Instagram you never heard of before.
Which also means that women are the targets in these campaigns, which are well-crafted by people who know all the levers and how to use digital marketing to its fullest.
The newsworthiness of this is filled with marketing jargon, like white labeling and drop shipping. These are things that have gone on as long as there has been marketing, but in the digital global economy era, it’s all too easy to source items from around the world in a heartbeat, and throw together a website and social media presence between beats.
Drop shipping has been used for decades by retailers who did not actually carry inventory of the items they sold, which in ye olden days was typically large consumer durables. They had arrangements with manufacturers so that when a customer bought an item based on looking at a brochure or perhaps a display model, the manufacturer would then ship directly to the customer. There was zero risk and a nice profit for the retailer, though.
White labeling occurs when one manufacturer makes the product, but then sells through multiple retailers who all have their unique label affixed. In the brick and mortar world, it was hard to ever know this was happening, because comparisons were difficult. In the digital world, though, a savvy shopper could uncover the truth in seconds. Or less.
Before you pull the trigger on that dress, do a reverse image search on Google. This is actually very simple, and will help you find everyone else who is selling the same thing, often at very different prices. The garment I included in this blog is available from one retailer for $26, while another is selling it--enhanced no doubt with fluffy verbiage and virtue signaling--for $90.
So here’s how you do your homework. Go to images.google.com, and click the little camera icon at the far right of the search box. This then spawns a pop-up that will allow you to enter a URL, or drag or upload an actual image of said item. A screen shot will suffice.

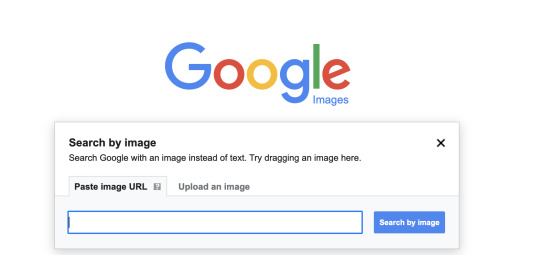
See? I told you a few weeks ago that visual search was for real, and what a handy tool it is. It is now your best friend.
The problem is further complicated by these nefarious retailers who are aggregating inventory by hook or crook, possibly buying in large volume from Shein, or just using the same contract manufacturer in China. The important thing to remember is that in the world of fast fashion, Shein is the price point setter. These are garments meant to be worn not for a season, but maybe only a few weeks before the next next thing hits the streets. Then they self-destruct.
And like I said earlier, no laws have been broken. It’s all perfectly legal. If these sheisters ever start feeling heat, they can shut down and reappear tomorrow with a completely different name and look. Or, have multiple outlets at the same time. It’s like going to a virtual flea market, but instead of knockoffs, they are selling the exact same thing, and typically at hyper-inflated social justice-oozing prices.
It’s a shame that the portal Systrom and Krieger developed has evolved into such a minefield of downright shady behavior. It’s almost enough to make you want to go back to seeing what your friends had for dinner last night. Or stupid pet tricks. At least you don’t waste your money that way.
Dr “Hang On To Your Wallet“ Gerlich
Audio Blog
0 notes
Text
Information Architecture
Have a look...
Too many choices, isn’t it?The design of the website is cramped making it hard to identify all the options available. Now let’s take a look at another webpage.
A clear and useful page for the user. So why the difference?
The answer is Information Architecture. Information architecture is the process of categorizing and organizing information to create structure and meaning. Information architecture is the creation of a structure for a website, application, or other project.We are living in a world exploding with information, but how do we find what is relevant to us at the time that we need it? I believe that good information architecture is key to helping us navigate through the mountains of data and information we have created for ourselves.
What Is Information Architecture And Why Is It Important?
“Information architecture is the practice of deciding how to arrange the parts of something to be understandable.” —
The Information Architecture Institute
A good information architecture (IA) uses scalable hierarchy and familiar nomenclature to make content easy to find. An effective information architecture enables people to step logically through a system confident they are getting closer to the information they require.Most people only notice information architecture when it is poor and stops them from finding the information they require.Information architecture is considered to have been founded by Richard Saul Wurman. Today there is a growing network of active IA specialists who constitute the Information Architecture Institute.
USES
Benefits of good information architecture:
For users, information architecture solves the most basic problems of finding relevant information to them at any given point, in an intuitive way.
· Reduces cognitive loadToo much information on a screen with no clear navigation can make it difficult for a user to focus. Too many options can overwhelm where a user chooses not to make a decision at all.
· Right information, quickerIA creates a spotlight on the required information and the user make choices faster.
· Focus on the task If the user is provided with a clear path of navigation, they will find it easier to accomplish their goal without too many distractions.
· Reduces frustration If the webpage contains information in an organized manner, then the user will complete their task on their own. Or else they may contact the supplier due to frustration.
FOR A BUSINESS:
Keeps customers on their website for longer.
Increases the chance of customer conversion.
Reduces risk of customers going to a competitor.
Reduces cost of support when a user can’t find something.
Search Vs Navigation
How To Do It The RIGHT Way?
Here is a brief list of considerations and processes to use when you are designing the information architecture for a product or service.
Define the company goals and users goals
Identify what tasks they are trying to achieve Try to create a hierarchy with minimal sub-levels. If you can achieve this, then the user can access any information on your site with a maximum of two clicks.
Map out your site navigation to see if you can organise into a minimal number of sub-levels or categories.
Don’t use jargon in the navigation language. Understand the language of your audience. Test with your users to ensure they understand the correct meaning of the language used.
Always indicate to the user exactly where they are within the site
so they can easily navigate back to a previous page. Breadcrumb navigation is one example of how to do this effectively Use hierarchy For example, a top-level hierarchy heading may be displayed with a larger font size. These visual differences can guide the user’s eye to more important information first. It can also be the job of the visual designer to help differentiate these areas.
Methods To Test Your Navigation:
CARD SORTING
Card sorting is a generative UX research method that reveals users’ mental models by having them arrange topics into groups that make sense to them.
Card sorting sessions can be classified as one of two types — open or closed. Open card sorting is the more flexible option of the two. Here, users are free to organize the cards you supply into groups that make sense to them, and then come up with their own names for these groups. They are also free to rename cards or make their own suggestions for new cards if they wish. This type is best when you want to understand how users would group your content. Gathering their ideas and suggestions for names and labels goes a long way to making your website more intuitive. The alternative method, closed card sorting, is where the categories or labels are fixed. This is useful when you want to understand how users fit content into an existing structure. It’s also used when new content needs to be added to a website. As an example, consider an e-commerce website and the top-level categories they might have for their products, such as technology, home and garden, and sports and leisure. Now suppose that the store has started stocking a new range of products that have just been launched. Which top-level category on the website should these products be added to? Involving users in a closed card sort could help you to arrive at an answer.
SCENARIO TESTING
By using a wireframe or prototype, ask participants to complete a specific task by navigating through the site. You can use a clickable wireframe to test this by observing how clear it is for a user to carry out the activity. An example task (refer to the wireframe below) might be to register on the website and then make a booking for a single event and publish it.
TREE TESTING
Tree testing is a usability technique for evaluating the findability of topics in a website. It is also known as reverse card sorting or card-based classification. A large website is typically organized into a hierarchy (a "tree") of topics and subtopics. Tree testing provides a way to measure how well users can find items in this hierarchy.
USABILITY TESTING
The test is used to determine how and why users use a website (or a product). It is one of the qualitative testing techniques. The answer to the question ‘why?’ is such valuable information that can help you design and get better results. TOOLS
1. Treejack is a tool that allows you to validate your navigation structure. It asks the participants to indicate where they would look to find specific information and provides you with insightful actions.
2. dynomapper.com/This visual sitemap generator is more than just that—sure you can create, customize, edit, and share your interactive sitemaps, but you will also be able to take care of your content inventory, content audit, and keyword tracking. Integrated with Google Analytics, display and share all of the most important data related to your website.
3. For you Mac fans, xSort enables creating and grouping various content listings using a computer version of the tried-and-true 3×5 index cards on a table theme. Handy for use when conducting card-sorts, it’s easy enough to use for almost all your participants and will help identify from the user’s perspective the proper grouping of content items.
4. WebSort.net and PlainFrame.com – while these sites also offer paid licensing, there are free versions of the studies that you can run and gather some great feedback on your IA.Apart from these, a simple piece of paper and pen or pencil can be is simple to use, fast and effective for IA. Listing out content items, then asking others to draw circles around similar groupings is a great way to facilitate information architecture analysis and optimization. Online white boards, Excel sheets and powerpoint are simple tools that can be used for organising information.
Why is IA Important?
We live in a time where our access to information is unprecedented. It is instantaneous, it is global, it is everywhere, it is the Internet. News stories are broadcast as they unfold, communication with friends and family in other parts of the world has never been easier, and Google has become our personal library of virtually limitless topics. Information is king and queen.
A Final note,
While creating a new website or developing an existing one, the effective structure and organisation of information across the site is essential. Information architecture can be best understood by comparing these two images:
Organizing books doesn’t just make it easier to find what you’re looking for — it also makes you more likely to actually pick up a book and read. In the similar way, a well structured website appeals the user more and results in a good profit for the company.
Crafting content and structure with the user in mind should be a primary consideration.Information architecture is about putting the user at the heart of the design process to ensure that the site is being built for them. A good website structure that intuitively works for users is much more likely to be valued by any search engine.
We will be happy to answer your questions on designing, developing, and deploying comprehensive enterprise web, mobile apps and customized software solutions that best fit your organization needs. As a reputed Software Solutions Developer we have expertise in providing dedicated remote and outsourced technical resources for software services at very nominal cost. Besides experts in full stacks We also build web solutions, mobile apps and work on system integration, performance enhancement, cloud migrations and big data analytics. Don’t hesitate to
get in touch with us!
0 notes
Text
Information Architecture
Have a look...
Too many choices, isn’t it?The design of the website is cramped making it hard to identify all the options available. Now let’s take a look at another webpage.
A clear and useful page for the user. So why the difference?
The answer is Information Architecture. Information architecture is the process of categorizing and organizing information to create structure and meaning. Information architecture is the creation of a structure for a website, application, or other project.We are living in a world exploding with information, but how do we find what is relevant to us at the time that we need it? I believe that good information architecture is key to helping us navigate through the mountains of data and information we have created for ourselves.
What Is Information Architecture And Why Is It Important?
“Information architecture is the practice of deciding how to arrange the parts of something to be understandable.” —
The Information Architecture Institute
A good information architecture (IA) uses scalable hierarchy and familiar nomenclature to make content easy to find. An effective information architecture enables people to step logically through a system confident they are getting closer to the information they require.Most people only notice information architecture when it is poor and stops them from finding the information they require.Information architecture is considered to have been founded by Richard Saul Wurman. Today there is a growing network of active IA specialists who constitute the Information Architecture Institute.
USES
Benefits of good information architecture:
For users, information architecture solves the most basic problems of finding relevant information to them at any given point, in an intuitive way.
· Reduces cognitive loadToo much information on a screen with no clear navigation can make it difficult for a user to focus. Too many options can overwhelm where a user chooses not to make a decision at all.
· Right information, quickerIA creates a spotlight on the required information and the user make choices faster.
· Focus on the task If the user is provided with a clear path of navigation, they will find it easier to accomplish their goal without too many distractions.
· Reduces frustration If the webpage contains information in an organized manner, then the user will complete their task on their own. Or else they may contact the supplier due to frustration.
FOR A BUSINESS:
Keeps customers on their website for longer.
Increases the chance of customer conversion.
Reduces risk of customers going to a competitor.
Reduces cost of support when a user can’t find something.
Search Vs Navigation
How To Do It The RIGHT Way?
Here is a brief list of considerations and processes to use when you are designing the information architecture for a product or service.
Define the company goals and users goals
Identify what tasks they are trying to achieve Try to create a hierarchy with minimal sub-levels. If you can achieve this, then the user can access any information on your site with a maximum of two clicks.
Map out your site navigation to see if you can organise into a minimal number of sub-levels or categories.
Don’t use jargon in the navigation language. Understand the language of your audience. Test with your users to ensure they understand the correct meaning of the language used.
Always indicate to the user exactly where they are within the site
so they can easily navigate back to a previous page. Breadcrumb navigation is one example of how to do this effectively Use hierarchy For example, a top-level hierarchy heading may be displayed with a larger font size. These visual differences can guide the user’s eye to more important information first. It can also be the job of the visual designer to help differentiate these areas.
Methods To Test Your Navigation:
CARD SORTING
Card sorting is a generative UX research method that reveals users’ mental models by having them arrange topics into groups that make sense to them.
Card sorting sessions can be classified as one of two types — open or closed. Open card sorting is the more flexible option of the two. Here, users are free to organize the cards you supply into groups that make sense to them, and then come up with their own names for these groups. They are also free to rename cards or make their own suggestions for new cards if they wish. This type is best when you want to understand how users would group your content. Gathering their ideas and suggestions for names and labels goes a long way to making your website more intuitive. The alternative method, closed card sorting, is where the categories or labels are fixed. This is useful when you want to understand how users fit content into an existing structure. It’s also used when new content needs to be added to a website. As an example, consider an e-commerce website and the top-level categories they might have for their products, such as technology, home and garden, and sports and leisure. Now suppose that the store has started stocking a new range of products that have just been launched. Which top-level category on the website should these products be added to? Involving users in a closed card sort could help you to arrive at an answer.
SCENARIO TESTING
By using a wireframe or prototype, ask participants to complete a specific task by navigating through the site. You can use a clickable wireframe to test this by observing how clear it is for a user to carry out the activity. An example task (refer to the wireframe below) might be to register on the website and then make a booking for a single event and publish it.
TREE TESTING
Tree testing is a usability technique for evaluating the findability of topics in a website. It is also known as reverse card sorting or card-based classification. A large website is typically organized into a hierarchy (a "tree") of topics and subtopics. Tree testing provides a way to measure how well users can find items in this hierarchy.
USABILITY TESTING
The test is used to determine how and why users use a website (or a product). It is one of the qualitative testing techniques. The answer to the question ‘why?’ is such valuable information that can help you design and get better results. TOOLS
1. Treejack is a tool that allows you to validate your navigation structure. It asks the participants to indicate where they would look to find specific information and provides you with insightful actions.
2. dynomapper.com/This visual sitemap generator is more than just that—sure you can create, customize, edit, and share your interactive sitemaps, but you will also be able to take care of your content inventory, content audit, and keyword tracking. Integrated with Google Analytics, display and share all of the most important data related to your website.
3. For you Mac fans, xSort enables creating and grouping various content listings using a computer version of the tried-and-true 3×5 index cards on a table theme. Handy for use when conducting card-sorts, it’s easy enough to use for almost all your participants and will help identify from the user’s perspective the proper grouping of content items.
4. WebSort.net and PlainFrame.com – while these sites also offer paid licensing, there are free versions of the studies that you can run and gather some great feedback on your IA.Apart from these, a simple piece of paper and pen or pencil can be is simple to use, fast and effective for IA. Listing out content items, then asking others to draw circles around similar groupings is a great way to facilitate information architecture analysis and optimization. Online white boards, Excel sheets and powerpoint are simple tools that can be used for organising information.
Why is IA Important?
We live in a time where our access to information is unprecedented. It is instantaneous, it is global, it is everywhere, it is the Internet. News stories are broadcast as they unfold, communication with friends and family in other parts of the world has never been easier, and Google has become our personal library of virtually limitless topics. Information is king and queen.
A Final note,
While creating a new website or developing an existing one, the effective structure and organisation of information across the site is essential. Information architecture can be best understood by comparing these two images:
Organizing books doesn’t just make it easier to find what you’re looking for — it also makes you more likely to actually pick up a book and read. In the similar way, a well structured website appeals the user more and results in a good profit for the company.
Crafting content and structure with the user in mind should be a primary consideration.Information architecture is about putting the user at the heart of the design process to ensure that the site is being built for them. A good website structure that intuitively works for users is much more likely to be valued by any search engine.
We will be happy to answer your questions on designing, developing, and deploying comprehensive enterprise web, mobile apps and customized software solutions that best fit your organization needs. As a reputed Software Solutions Developer we have expertise in providing dedicated remote and outsourced technical resources for software services at very nominal cost. Besides experts in full stacks We also build web solutions, mobile apps and work on system integration, performance enhancement, cloud migrations and big data analytics. Don’t hesitate to
get in touch with us!
0 notes
Text
The Web – Savior of Small Businesses

Today’s super competitive market place does not allow for small businesses to take it easy. The big boys in the arena are always upping the ante in terms of their products, services, and costs. Small businesses are left with no option but to compete in the cut-throat market or perish. The first accounting software to help small businesses was launched back in the 1990s. People then were still trying to come to terms with the Goliath that was the Web. A little more than two decades later online tools are becoming the difference between the survival and collapse of a business.
Researchers have found that workers only use 60% of their total available time. That is, out of a five-day workweek they are productive for approximately four days. That means you are earning money only 60% of the time you are at work. In a situation like this using the right online tools can help you save on time and costs while ensuring a higher level of efficiency.
Some Important Tools for Small Businesses:
Google Analytics — For new business numbers are all that matters. How much traffic does your website attract? Where is the majority of traffic from? What are the key demographics of your target group? These questions play a crucial role in determining the success or failure of a start-up.
Tracking these statistics is no easy feat. This is where Google Analytics comes to the rescue. Users can view the countries their site has been seen in, the percentage of differences in traffic drivers, and their key figures, broken down by day, week, month, or year. It uses simple, clearly marked charts and graphs for best conveying the information to the lay individual.
It also helps you channel resources to features that are captivating users on your website and help you better plan your business. When you know what is pointing people to your site, you can reverse engineer and explore advertising opportunities with sites that focus on related topics. If it is appropriate, you can also plan your homepage according to the subject matter that is drawing people in. Google Analytics also offers you a ‘bounce rate’ breakdown, i.e. the proportion of your website’s visitors who navigate away without clicking through to a second window. A high bounce rate means your website is not doing very well.
Dropbox — The idea of toting around a bag full of gadgets, because each one of them has a different important document in it, seems primitive now. Not only do we have a plethora of excellent multitasking mobile devices to choose from, but the popularity of cloud-based storage has also effectively ended the need to carry our documents in our devices. Dropbox has turned out to be a savior for multitaskers everywhere. It creates a virtual link between all your Internet-connected devices. Using the cloud-saving capability, users can save images, documents and video clips to their Dropbox accounts. These files can be accessed from anywhere.
There is no fear of losing a document or sending files that are too large. Dropbox helps make file sharing with other users much simpler. It also allows you to organize your files by allowing you to create personalized folders. Some companies also choose to use it as a shared server. This saves them the cost of buying a server and also promotes transparency within the company.
MailChimp — It is imperative for new businesses to get the word on them out in the market. Making sure that your product, service or idea is reaching the right people is of prime importance during the beginning. Social media is one way to reach potential clients, but when it comes to retaining them, MailChimp comes in very handy.
With over 400,000 users, it helps you create email newsletters to distribute to your clients. It offers you a free gallery of HTML templates on top of letting you create your own template. Users without any experience in tech or design can easily create a visually pleasing E-blast that will catch the reader’s attention. Sending newsletters regularly can help you keep your database updated on your current projects and can direct great traffic to your website.
Skype — This highly potent combination of phone, video, and chat makes a powerful social structure and an even more effective business tool. Its video capabilities are great for large groups. Its phone services too can prove to be immensely beneficial for businesses.
New businesses may be dealing with overseas clients and time differences, but with Skype, high phone fees are a thing of the distant past. It can also send documents during a call making it perfect for telephonic conferences.
Screen sharing is another valuable feature on Skype and is an ideal way to give remote presentations. It also has a call forwarding feature for those using it on a regular basis. With over 550 million users, Skype accounted for 12% of the calls made in 2009. Almost one-third of its users use it primarily for business.
Odesk — Starting a business is not just a matter of harnessing your own skills, but also that of others. New businesses, often without the means to hire full-time staff but with project deadlines staring at them, hire a per-project contractor which can be extremely beneficial.
Odesk streamlines this process for you. You can take advantage of the large database of contractors looking for work to find the best fit for your company. It provides previous work experience, sample portfolios, and client reviews so that you can make an informed decision. It helps you set up virtual interviews and with its tracking tool allows you to constantly watch your projects and make notes or additions in real-time. Odesk also handles all of the transactions so you can pay your contractor at ease.
Insightly — One of the most popular customer relationship management packages, it allows you to track leads, proposals, opportunities, and projects, as well as manage files through an easy user interface.
The biggest strength of Insightly is its integrations, including the ability to automatically sync your account with your Google contacts and Google calendar. It also lets you search your Google Drive and attach any Google Doc file to the relevant contact or organization. It can also be integrated with your MailChimp account.
Trademarkia — One of the largest visual search engines, it has more than 6 million trademarked logos, names, and slogans on the Web. It lets you see how your personal name, product name, trademark or username is being used on any of the 500+ popular social networks. It helps you reserve the name of your choice and stops others from using it. It is one of the most widely used software and technology tools for brand protection.
Evernote — There is no need to dig through the mountain of documents on your desk for that one piece of paper with the time of your meeting on it. An information organization tool, Evernote works with the three basic functions of capture, access, and find.
Feed into it all of your information, from doctor appointments to business meetings, access it from different sources like a smartphone, a tablet or a computer and find everything in moments. It is a free application that you can test for yourself.
The mobile application space has seen tremendous growth over the past few years, thanks to cloud-based software which has brought to businesses improved mobility and lower costs. But finding the right application for your needs can be daunting. There is always going to be a need for applications and software that increase productivity and help streamline the more tedious aspects of a business.
This is not the age for businesses to shy away from technology; on the contrary, it is the time to reach out and embrace it. Big or small, every business today has found its way on the Web. Making use of the many tools available to small business owners online can be a cost-effective and highly professional way to manage your business.
0 notes
Text
SEO Internet Marketing - Ultimate Newbie's Guide to Search Engine Optimization
Building an attractive even beautiful is the objective of many site designers. At the same time, sometimes the efficiency of the site is diminished. We need to keep in mind that our objective is not only to have a lovely website that will make individuals want to stay and look around and enjoy, but likewise a website that will be handy to the engines in determining what our website is about or what it pertains to.
Udi Manber, Google vice president managing search quality, in response to a question about web page content developing to be more online search engine friendly described, "It's definitely still lacking. I wish individuals would put more effort into considering how other individuals will find them and putting the best keywords onto their pages." Popular Mechanics - April 16, 2008

Browse engine optimization or SEO is perhaps the most important method to drive targeted traffic to your site due to the fact that it leads to improved search engine positioning. Enhancing the advantages of a properly designed website will result in far more traffic concerning the website thus generating earnings for the business releasing the website. With this reality in mind nevertheless, optimizing your website might cost you thousands of dollars if you are not knowledgeable in this area. Great search engine optimization that leads to improved search engine positioning will, on the other hand, bring you a much greater return on the investment of either time or money you put into it.
My objective in this article is to offer you the fundamentals of search engine optimization so that you can comprehend it and include it to assist you accomplish your task. This will help you to improve your significance and search engines rankings for the very best outcomes possible through proven seo strategies.
What are the major mistakes in style
Is is important to keep in mind that search engines are devices and read words they do not see images or images . The most typical mistakes form a seo perspective are:
Making a site completely in Flash( TM).
Images without alt tags.
Minimal or nonexistent meta title or title tag.
Flash( TM) to the search engines is simply like an image it is undetectable although the Flash( TM) may capture the intrigue of the viewer it will not assist the online search engine to know what your site has to do with. While the text display as a part of the Flash( TM) my be abundant in keywords and information it will be lost completely to the online search engine and you will go unnoticed. Flash( TM) and pictures can be utilized to boost a website however the website need to have text in order to develop relevance for the search engines.
In the very same sense images are also invisible, nevertheless we can include alt tags that will give the search engines an idea of what the audience will see. In fact the alt tags can be extremely helpful since the search engines will position a little more emphasis on the text in alt tags. Don't go overboard utilizing keyword expressions in the alt tags however use some to assist where suitable.
The title tag as well talk about later on is an crucial place to tell the online search engine what your website is all about.
Where do we start?
Why is seo (SEO) so crucial? Since this will make your site relevant to your keywords during the search engine ranking process and will lead to improved search engine ranking, SEO is crucial. This is the factor why some businesses work with an SEO business to do this job.
You can get information on low expense associated services anywhere on the internet. However, few are really revealing you how to exercise an inexpensive prepare for enhanced online search engine placement. Some business will even utilize antiquated techniques that may slow the process down. Excellent seo must assist you to start improving the online search engine ranking of your site and begin driving traffic to it in a matter of days or weeks with costly procedures.
Seo begins optimally on your site, as you plan and construct it. If it was refrained from doing at first you are not too late, you can do it after you have it developed and return and modify it to enhance the exposure to the search engines and still lead to improved online search engine positioning. It includes the following elements described as "onsite optimization".
Keyword Research - picking the primary and secondary keywords you will utilize on your website or web page.
Executing the keywords naturally into important elements in the site header and body.
Keyword Research and Usage.
Let's start first with keyword research study. Why is keyword research important? The keyword research assists us to find the keywords that link us with our targeted audience. They are the words that we desire to use on our site in a range of ways to build relevance on our website so when online search engine discover our website and view/ crawl our pages, they will then index us for those keywords. When that occurs, then when those keywords are typed into the online search engine by potential clients, the search engine will then display our website in the search results page, which is how they tie us to our targeted audience.
Ideally you will use a reverse search tool that will enable you to enter words you think are keywords people would browse for and which will tell you the variety of times those keywords were browsed for over a given time period. Depending on the tool you are using and the databases and the search engines they have access to for their search results page you will get different numbers in your reverse search results page. Your seo specialist will have and understand access to these tools http://query.nytimes.com/search/sitesearch/?action=click&contentCollection®ion=TopBar&WT.nav=searchWidget&module=SearchSubmit&pgtype=Homepage#/what is seo and which ones are proper for particular uses. These tools can considerably accelerate the procedure of onsite optimization cause quicker better online search engine positioning.
One tool you can use for manual research study is http://www.keyworddiscovery.com/search.html Keyword Discovery's Free Search Term Idea Tool. It will restrict your outcomes to 100 keywords for any given search. Another manual search tool is http://tools.seobook.com/general/keyword SEOBook.com's Recommendation tool. Both of these manual reverse search tools will permit you to find the keywords that people type into the online search engine and how lots of times they were searched for. Keep in mind keywords are how we get in touch with our targeted audience.
How Do I Use My Keywords Once we have recognized the keywords, next we need to know where and how to use them for enhanced online search engine placement. The very first and probably the most important location to utilize our keywords would be the title tag for your site. The title tag appears in the header of the page and is the very first opportunity we need to tell the online search engine what our page has to do with.
The title tag ought to be 60 - 80 characters in length and use a couple of of the most crucial and/or pertinent keywords for that page and perhaps your site domain, specifically if your domain name consists of keywords in it. The title tag details appears in the blue header bar at the top of the window and is likewise used as the title of your listing when your website is shown in the natural or natural search results page.
The meta description should be about 2 - 3 sentences or up to about 200 characters that explain for the consumer and the search engine what the web page is about. In the natural or natural online search engine results, this description will be the first option for the text the online search engine shows underneath the title. When the site is displayed for the visitor but is readable by the search engine and utilized in the search results primarily, this description does not appear on the website page.
A 3rd meta tag is the keywords meta tag which is also not displayed to the visitor of the site. The keywords meta tag is a hold over from early approaches of search engine optimization, but since it was abused by website designers, it is seldom utilize by search engines. We still utilize the keywords meta tag, however most search engines neglect it due to those previous abuses. Some search engines may still evaluate it and you never ever understand when online search engine may start to use it once again. The Keywords meta tag is simply a list of as much as 12 keyword phrases separated by commas.
The example listed below leave out the angle brackets due to this short article being composed in HTML however the angle brackets are the less than and greater than signs.
" meta material=" Basic search engine optimizations ideas provided to give entrepreneur and site developers and understanding of good SEO techniques ..." name=" description"/" confined in angle brackets.
" meta content=" keyword expression 1, keyword expression 2, keyword phrase 3, ..." name=" keywords"/" enclosed in angle brackets.
Your keywords used in the title, description and keywords tags now need to be used on the page to verify to the search engine that your page is really about what you told the online search engine that your page relates to. If the search engine does not see any of the keywords on your page, then it can just assume that your page is not pertinent to the words you used in the title, description and keywords tags in the header location of the web site.
Now that we understand that we require text on the page how can we use that text to assist highlight the relevancy of the keywords on the page? Mechanisms such as header tags for headings using keywords will offer more focus to keywords. Links where the anchor text is a keyword expression will add significance to the keyword phrase and since the anchor text and the associated hyperlink recommendation are indexed by the search engines, using a keyword phrase as the anchor text both on the website and in offsite marketing will increase your ranking for that keyword phrase. Bolding and italics also draw some attention to the keywords for the search engine. Each page requires to have enough text on it to permit that page to demonstrate the importance of the keywords it displays in the header of the page to the online search engine, if real seo is to be attained.
Lets take a look at some of the other tags mentioned in the previous paragraph. Header tags alert the search engine to more crucial text on the page, just like the heading on the page of newspaper does to the reader. A header tag is a tag that consist of a "H" and a number between 1 and 7. The lower the number the bigger the text and the more important it is to the online search engine. H1 tags can be formatted utilizing font tags to control the size or.css files to manage the format.
Hyperlinks include at least 2 elements. The very first part is the link location represented by the term "href" referring to the hyperlink reference and the anchor text situated in between the beginning and ending anchor tags. An anchor tag is an "a" in angle brackets and ending with "/ a" in angle brackets. The start tag also consist of the destination recommendation. Remember https://coseodesigns.com/locations/colorado-seo/longmont-seo-services/ that you you might utilize a keyword phrase in location of the word house to designate your web page. That keyword phrase would be a link and would assist to construct significance for your website for that keyword expression.
As we use these structures in combination in a natural method we then are able to assist the search engine to know what our page is about and likewise develop a page that is practical for the user.
To enhance your website well for the online search engine you should utilize special meta tags on each page on your site. The keywords need to be used in:.
The title tag - big three.
Meta description.
Meta keywords.
Header tag - huge three.
Opening paragraph - about 4% density.
Alt tags on all images and utilizing keywords on about 3 images per page.
Connect/ anchor text or hyperlinks - big three.
Body of the page - about 4% density (visible text).
Closing paragraph - about 4% density.
They ought to be utilized in such a method as to feel natural on the page. If the page feels awkward, then try to find ways to reword the info on the page and ensure you are not forcing the keywords in a lot of times. This in combination with other activities to develop your page rank are the very best ways to get your page noted on page among the online search engine.
These strategies are what we call onsite page optimization. Each page requires to have its own unique page optimization for the content on that page. Don't make the mistake of utilizing the very same title, description and keywords meta tags for every page on your site.
Utilizing these strategies in conjunction with the style of your site will vastly improve your search engine placement.
When that happens, then when those keywords are typed into the search engine by possible consumers, the search engine will then show our website in the search results, which is how they tie us to our targeted audience.
Preferably you will use a reverse search tool that will enable you to type in words you believe are keywords people would browse for and which will tell you the number of times those keywords were searched for over a provided duration of time. Depending on the tool you are using and the databases and the search engines they have access to for their search results you will get different numbers in your reverse search results. Both of these manual reverse search tools will allow you to find the keywords that people type into the search engines and how lots of times they were searched for. The keywords meta tag is a hold over from early techniques of search engine optimization, however because it was abused by website developers, it is hardly ever use by search engines.
0 notes
Text
Finding SEO Opportunities From Log Files

Log Files For SEO Purposes
I use web crawlers regularly. While they are very useful, they only imitate search engine crawlers’ behavior, which means you aren’t always getting the full picture. The only tool that can give you a real overview of how search engines crawl your site are log files. Despite this, many people are still obsessed with crawl budget — the number of URLs Googlebot can and wants to crawl. Log file analysis may discover URLs on your site that you had no idea about but that search engines are crawling anyway — a major waste of Google server resources (Google Webmaster Blog): “Wasting server resources on pages like these will drain crawl activity from pages that do actually have value, which may cause a significant delay in discovering great content on a site.” While it’s a fascinating topic, the fact is that most sites don’t need to worry that much about crawl budget —an observation shared by John Mueller (Webmaster Trends Analyst at Google) quite a few times already. There’s still a huge value in analyzing logs produced from those crawls, though. It will show what pages Google is crawling and if anything needs to be fixed. When you know exactly what your log files are telling you, you’ll gain valuable insights about how Google crawls and views your site, which means you can optimize for this data to increase traffic. And the bigger the site, the greater the impact fixing these issues will have.

What are server logs?
A log file is a recording of everything that goes in and out of a server. Think of it as a ledger of requests made by crawlers and real users. You can see exactly what resources Google is crawling on your site. You can also see what errors need your attention such as duplicate content and other aspects which may impact your search appearance. Analyzing logs is not rocket science — the logic is the same as when working with tables in Excel or Google Sheets. The hardest part is getting access to them — exporting and filtering that data. Looking at a log file for the first time may also feel somewhat daunting because when you open one, you see something like this:

Calm down and take a closer look at a single line: 66.249.65.107 - - "GET /contact/ HTTP/1.1" 200 11179 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)" You’ll quickly recognize that: 66.249.65.107 is the IP address (who) is the Timestamp (when) GET is the Method /contact/ is the Requested URL (what) 200 is the Status Code (result) 11179 is the Bytes Transferred (size) “-” is the Referrer URL (source) — it’s empty because this request was made by a crawler Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html) is the User Agent (signature) — this is user agent of Googlebot (Desktop) Once you know what each line is composed of, it’s not so scary. It’s just a lot of information. But that’s where the next step comes in handy.
Tools you can use
There are many tools you can choose from that will help you analyze your log files. I won’t give you a full run-down of available ones, but it’s important to know the difference between static and real-time tools. Static — This only analyzes a static file. You can’t extend the time frame. Want to analyze another period? You need to request a new log file. My favourite tool for analyzing static log files is Power BI. Real-time — Gives you direct access to logs. I really like open source ELK Stack (Elasticsearch, Logstash, and Kibana). It takes a moderate effort to implement it but once the stack is ready, it allows me changing the time frame based on my needs without needing to contact our developers.
Start analyzing
Don’t just dive into logs with a hope to find something — start asking questions. If you don’t formulate your questions at the beginning, you will end up in a rabbit hole with no direction and no real insights. Here are a few samples of questions I use at the start of my analysis: Which search engines crawl my website? Which URLs are crawled most often? Which content types are crawled most often? Which status codes are returned? If you see that Google is crawling non-existing pages (404), you can start asking which of those requested URLs return 404 status code. Order the list by the number of requests, evaluate the ones with the highest number to find the pages with the highest priority (the more requests, the higher priority), and consider whether to redirect that URL or do any other action.

If you use a CDN or cache server, you need to get that data as well to get the full picture.
Segment your data
Grouping data into segments provides aggregate numbers that give you the big picture. This makes it easier to spot trends you might have missed by looking only at individual URLs. You can locate problematic sections and drill down if needed. There are various ways to group URLs: Group by content type (single product pages vs. category pages) Group by language (English pages vs. French pages) Group by storefront (Canadian store vs. US store) Group by file format (JS vs. images vs. CSS) Don’t forget to slice your data by user-agent. Looking at Google Desktop, Google Smartphone, and Bing all together won’t surface any useful insights.
Monitor behavior changes over time
Your site changes over time, which means so will crawlers’ behavior. Googlebot often decreases or increases the crawl rate based on factors such as a page’s speed, internal link structure, and the existence of crawl traps. It’s a good idea to check in with your log files throughout the year or when executing website changes. I look at logs almost on a weekly basis when releasing significant changes for large websites. By analyzing server logs twice a year, at the very least, you’ll surface changes in crawler’s behavior.
Watch for spoofing
Spambots and scrapers don’t like being blocked, so they may fake their identity — they leverage Googlebot’s user agent to avoid spam filters. To verify if a web crawler accessing your server really is Googlebot, you can run a reverse DNS lookup and then a forward DNS lookup. More on this topic can be found in Google Webmaster Help Center.
Merge logs with other data sources
While it’s no necessary to connect to other data sources, doing so will unlock another level of insight and context that regular log analysis might not be able to give you. An ability to easily connect multiple datasets and extract insights from them is the main reason why Power BI is my tool of choice, but you can use any tool that you’re familiar with (e.g. Tableau).

Blend server logs with multiple other sources such as Google Analytics data, keyword ranking, sitemaps, crawl data, and start asking questions like: What pages are not included in the sitemap.xml but are crawled extensively? What pages are included in the Sitemap.xml file but are not crawled? Are revenue-driving pages crawled often? Is the majority of crawled pages indexable? You may be surprised by the insights you’ll uncover that can help strengthen your SEO strategy. For instance, discovering that almost 70 percent of Googlebot requests are for pages that are not indexable is an insight you can act on.

You can see more examples of blending log files with other data sources in my post about advanced log analysis.
Use logs to debug Google Analytics
Don’t think of server logs as just another SEO tool. Logs are also an invaluable source of information that can help pinpoint technical errors before they become a larger problem. Last year, Google Analytics reported a drop in organic traffic for a companies branded search queries. But the keyword tracking tool, STAT Search Analytics, and other tools showed no movement that would have warranted the drop. So, what was going on? Server logs helped us understand the situation: There was no real drop in traffic. It was our newly deployed WAF (Web Application Firewall) that was overriding the referrer, which caused some organic traffic to be incorrectly classified as direct traffic in Google Analytics. Using log files in conjunction with keyword tracking in STAT helped us uncover the whole story and diagnose this issue quickly.
Putting it all together
Log analysis is a must-do, especially once you start working with large websites. My advice is to start with segmenting data and monitoring changes over time. Once you feel ready, explore the possibilities of blending logs with your crawl data or Google Analytics. That’s where great insights are hidden.

Read the full article
0 notes
Text
Uncovering SEO Opportunities via Log Files
Posted by RobinRozhon
I use web crawlers on a daily basis. While they are very useful, they only imitate search engine crawlers’ behavior, which means you aren’t always getting the full picture.
The only tool that can give you a real overview of how search engines crawl your site are log files. Despite this, many people are still obsessed with crawl budget — the number of URLs Googlebot can and wants to crawl.
Log file analysis may discover URLs on your site that you had no idea about but that search engines are crawling anyway — a major waste of Google server resources (Google Webmaster Blog):
“Wasting server resources on pages like these will drain crawl activity from pages that do actually have value, which may cause a significant delay in discovering great content on a site.”
While it’s a fascinating topic, the fact is that most sites don’t need to worry that much about crawl budget —an observation shared by John Mueller (Webmaster Trends Analyst at Google) quite a few times already.
There’s still a huge value in analyzing logs produced from those crawls, though. It will show what pages Google is crawling and if anything needs to be fixed.
When you know exactly what your log files are telling you, you’ll gain valuable insights about how Google crawls and views your site, which means you can optimize for this data to increase traffic. And the bigger the site, the greater the impact fixing these issues will have.

What are server logs?
A log file is a recording of everything that goes in and out of a server. Think of it as a ledger of requests made by crawlers and real users. You can see exactly what resources Google is crawling on your site.
You can also see what errors need your attention. For instance, one of the issues we uncovered with our analysis was that our CMS created two URLs for each page and Google discovered both. This led to duplicate content issues because two URLs with the same content was competing against each other.
Analyzing logs is not rocket science — the logic is the same as when working with tables in Excel or Google Sheets. The hardest part is getting access to them — exporting and filtering that data.
Looking at a log file for the first time may also feel somewhat daunting because when you open one, you see something like this:

Calm down and take a closer look at a single line:
66.249.65.107 - - [08/Dec/2017:04:54:20 -0400] "GET /contact/ HTTP/1.1" 200 11179 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)"
You’ll quickly recognize that:
66.249.65.107 is the IP address (who)
[08/Dec/2017:04:54:20 -0400] is the Timestamp (when)
GET is the Method
/contact/ is the Requested URL (what)
200 is the Status Code (result)
11179 is the Bytes Transferred (size)
“-” is the Referrer URL (source) — it’s empty because this request was made by a crawler
Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html) is the User Agent (signature) — this is user agent of Googlebot (Desktop)
Once you know what each line is composed of, it’s not so scary. It’s just a lot of information. But that’s where the next step comes in handy.
Tools you can use
There are many tools you can choose from that will help you analyze your log files. I won’t give you a full run-down of available ones, but it’s important to know the difference between static and real-time tools.
Static — This only analyzes a static file. You can’t extend the time frame. Want to analyze another period? You need to request a new log file. My favourite tool for analyzing static log files is Power BI.
Real-time — Gives you direct access to logs. I really like open source ELK Stack (Elasticsearch, Logstash, and Kibana). It takes a moderate effort to implement it but once the stack is ready, it allows me changing the time frame based on my needs without needing to contact our developers.
Start analyzing
Don’t just dive into logs with a hope to find something — start asking questions. If you don’t formulate your questions at the beginning, you will end up in a rabbit hole with no direction and no real insights.
Here are a few samples of questions I use at the start of my analysis:
Which search engines crawl my website?
Which URLs are crawled most often?
Which content types are crawled most often?
Which status codes are returned?
If you see that Google is crawling non-existing pages (404), you can start asking which of those requested URLs return 404 status code.
Order the list by the number of requests, evaluate the ones with the highest number to find the pages with the highest priority (the more requests, the higher priority), and consider whether to redirect that URL or do any other action.

If you use a CDN or cache server, you need to get that data as well to get the full picture.
Segment your data
Grouping data into segments provides aggregate numbers that give you the big picture. This makes it easier to spot trends you might have missed by looking only at individual URLs. You can locate problematic sections and drill down if needed.
There are various ways to group URLs:
Group by content type (single product pages vs. category pages)
Group by language (English pages vs. French pages)
Group by storefront (Canadian store vs. US store)
Group by file format (JS vs. images vs. CSS)
Don’t forget to slice your data by user-agent. Looking at Google Desktop, Google Smartphone, and Bing all together won’t surface any useful insights.
Monitor behavior changes over time
Your site changes over time, which means so will crawlers’ behavior. Googlebot often decreases or increases the crawl rate based on factors such as a page’s speed, internal link structure, and the existence of crawl traps.
It’s a good idea to check in with your log files throughout the year or when executing website changes. I look at logs almost on a weekly basis when releasing significant changes for large websites.
By analyzing server logs twice a year, at the very least, you’ll surface changes in crawler’s behavior.
Watch for spoofing
Spambots and scrapers don’t like being blocked, so they may fake their identity — they leverage Googlebot’s user agent to avoid spam filters.
To verify if a web crawler accessing your server really is Googlebot, you can run a reverse DNS lookup and then a forward DNS lookup. More on this topic can be found in Google Webmaster Help Center.
Merge logs with other data sources
While it’s no necessary to connect to other data sources, doing so will unlock another level of insight and context that regular log analysis might not be able to give you. An ability to easily connect multiple datasets and extract insights from them is the main reason why Power BI is my tool of choice, but you can use any tool that you’re familiar with (e.g. Tableau).

Blend server logs with multiple other sources such as Google Analytics data, keyword ranking, sitemaps, crawl data, and start asking questions like:
What pages are not included in the sitemap.xml but are crawled extensively?
What pages are included in the Sitemap.xml file but are not crawled?
Are revenue-driving pages crawled often?
Is the majority of crawled pages indexable?
You may be surprised by the insights you’ll uncover that can help strengthen your SEO strategy. For instance, discovering that almost 70 percent of Googlebot requests are for pages that are not indexable is an insight you can act on.

You can see more examples of blending log files with other data sources in my post about advanced log analysis.
Use logs to debug Google Analytics
Don’t think of server logs as just another SEO tool. Logs are also an invaluable source of information that can help pinpoint technical errors before they become a larger problem.
Last year, Google Analytics reported a drop in organic traffic for our branded search queries. But our keyword tracking tool, STAT Search Analytics, and other tools showed no movement that would have warranted the drop. So, what was going on?
Server logs helped us understand the situation: There was no real drop in traffic. It was our newly deployed WAF (Web Application Firewall) that was overriding the referrer, which caused some organic traffic to be incorrectly classified as direct traffic in Google Analytics.
Using log files in conjunction with keyword tracking in STAT helped us uncover the whole story and diagnose this issue quickly.
Putting it all together
Log analysis is a must-do, especially once you start working with large websites.
My advice is to start with segmenting data and monitoring changes over time. Once you feel ready, explore the possibilities of blending logs with your crawl data or Google Analytics. That’s where great insights are hidden.
Want more?
Ready to learn how to get cracking and tracking some more? Reach out and request a demo get your very own tailored walkthrough of STAT.
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don’t have time to hunt down but want to read!
from https://dentistry01.wordpress.com/2019/01/23/uncovering-seo-opportunities-via-log-files/
0 notes
Photo

New Post has been published on https://adz.cloud/2019/01/23/uncovering-seo-opportunities-via-log-files/
Uncovering SEO Opportunities via Log Files
I use web crawlers on a daily basis. While they are very useful, they only imitate search engine crawlers’ behavior, which means you aren’t always getting the full picture.
The only tool that can give you a real overview of how search engines crawl your site are log files. Despite this, many people are still obsessed with crawl budget — the number of URLs Googlebot can and wants to crawl.
Log file analysis may discover URLs on your site that you had no idea about but that search engines are crawling anyway — a major waste of Google server resources (Google Webmaster Blog):
“Wasting server resources on pages like these will drain crawl activity from pages that do actually have value, which may cause a significant delay in discovering great content on a site.”
While it’s a fascinating topic, the fact is that most sites don’t need to worry that much about crawl budget —an observation shared by John Mueller (Webmaster Trends Analyst at Google) quite a few times already.
There’s still a huge value in analyzing logs produced from those crawls, though. It will show what pages Google is crawling and if anything needs to be fixed.
When you know exactly what your log files are telling you, you’ll gain valuable insights about how Google crawls and views your site, which means you can optimize for this data to increase traffic. And the bigger the site, the greater the impact fixing these issues will have.
What are server logs?
A log file is a recording of everything that goes in and out of a server. Think of it as a ledger of requests made by crawlers and real users. You can see exactly what resources Google is crawling on your site.
You can also see what errors need your attention. For instance, one of the issues we uncovered with our analysis was that our CMS created two URLs for each page and Google discovered both. This led to duplicate content issues because two URLs with the same content was competing against each other.
Analyzing logs is not rocket science — the logic is the same as when working with tables in Excel or Google Sheets. The hardest part is getting access to them — exporting and filtering that data.
Looking at a log file for the first time may also feel somewhat daunting because when you open one, you see something like this:
Calm down and take a closer look at a single line:
66.249.65.107 - - [08/Dec/2017:04:54:20 -0400] "GET /contact/ HTTP/1.1" 200 11179 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)"
You’ll quickly recognize that:
66.249.65.107 is the IP address (who)
[08/Dec/2017:04:54:20 -0400] is the Timestamp (when)
GET is the Method
/contact/ is the Requested URL (what)
200 is the Status Code (result)
11179 is the Bytes Transferred (size)
“-” is the Referrer URL (source) — it’s empty because this request was made by a crawler
Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html) is the User Agent (signature) — this is user agent of Googlebot (Desktop)
Once you know what each line is composed of, it’s not so scary. It’s just a lot of information. But that’s where the next step comes in handy.
Tools you can use
There are many tools you can choose from that will help you analyze your log files. I won’t give you a full run-down of available ones, but it’s important to know the difference between static and real-time tools.
Static — This only analyzes a static file. You can’t extend the time frame. Want to analyze another period? You need to request a new log file. My favourite tool for analyzing static log files is Power BI.
Real-time — Gives you direct access to logs. I really like open source ELK Stack (Elasticsearch, Logstash, and Kibana). It takes a moderate effort to implement it but once the stack is ready, it allows me changing the time frame based on my needs without needing to contact our developers.
Start analyzing
Don’t just dive into logs with a hope to find something — start asking questions. If you don’t formulate your questions at the beginning, you will end up in a rabbit hole with no direction and no real insights.
Here are a few samples of questions I use at the start of my analysis:
Which search engines crawl my website?
Which URLs are crawled most often?
Which content types are crawled most often?
Which status codes are returned?
If you see that Google is crawling non-existing pages (404), you can start asking which of those requested URLs return 404 status code.
Order the list by the number of requests, evaluate the ones with the highest number to find the pages with the highest priority (the more requests, the higher priority), and consider whether to redirect that URL or do any other action.
If you use a CDN or cache server, you need to get that data as well to get the full picture.
Segment your data
Grouping data into segments provides aggregate numbers that give you the big picture. This makes it easier to spot trends you might have missed by looking only at individual URLs. You can locate problematic sections and drill down if needed.
There are various ways to group URLs:
Group by content type (single product pages vs. category pages)
Group by language (English pages vs. French pages)
Group by storefront (Canadian store vs. US store)
Group by file format (JS vs. images vs. CSS)
Don’t forget to slice your data by user-agent. Looking at Google Desktop, Google Smartphone, and Bing all together won’t surface any useful insights.
Monitor behavior changes over time
Your site changes over time, which means so will crawlers’ behavior. Googlebot often decreases or increases the crawl rate based on factors such as a page’s speed, internal link structure, and the existence of crawl traps.
It’s a good idea to check in with your log files throughout the year or when executing website changes. I look at logs almost on a weekly basis when releasing significant changes for large websites.
By analyzing server logs twice a year, at the very least, you’ll surface changes in crawler’s behavior.
Watch for spoofing
Spambots and scrapers don’t like being blocked, so they may fake their identity — they leverage Googlebot’s user agent to avoid spam filters.
To verify if a web crawler accessing your server really is Googlebot, you can run a reverse DNS lookup and then a forward DNS lookup. More on this topic can be found in Google Webmaster Help Center.
Merge logs with other data sources
While it’s no necessary to connect to other data sources, doing so will unlock another level of insight and context that regular log analysis might not be able to give you. An ability to easily connect multiple datasets and extract insights from them is the main reason why Power BI is my tool of choice, but you can use any tool that you’re familiar with (e.g. Tableau).
Blend server logs with multiple other sources such as Google Analytics data, keyword ranking, sitemaps, crawl data, and start asking questions like:
What pages are not included in the sitemap.xml but are crawled extensively?
What pages are included in the Sitemap.xml file but are not crawled?
Are revenue-driving pages crawled often?
Is the majority of crawled pages indexable?
You may be surprised by the insights you’ll uncover that can help strengthen your SEO strategy. For instance, discovering that almost 70 percent of Googlebot requests are for pages that are not indexable is an insight you can act on.
You can see more examples of blending log files with other data sources in my post about advanced log analysis.
Use logs to debug Google Analytics
Don’t think of server logs as just another SEO tool. Logs are also an invaluable source of information that can help pinpoint technical errors before they become a larger problem.
Last year, Google Analytics reported a drop in organic traffic for our branded search queries. But our keyword tracking tool, STAT Search Analytics, and other tools showed no movement that would have warranted the drop. So, what was going on?
Server logs helped us understand the situation: There was no real drop in traffic. It was our newly deployed WAF (Web Application Firewall) that was overriding the referrer, which caused some organic traffic to be incorrectly classified as direct traffic in Google Analytics.
Using log files in conjunction with keyword tracking in STAT helped us uncover the whole story and diagnose this issue quickly.
Putting it all together
Log analysis is a must-do, especially once you start working with large websites.
My advice is to start with segmenting data and monitoring changes over time. Once you feel ready, explore the possibilities of blending logs with your crawl data or Google Analytics. That’s where great insights are hidden.
Want more?
Ready to learn how to get cracking and tracking some more? Reach out and request a demo to get your very own tailored walkthrough of STAT.
Source link
0 notes
Link
via Screaming Frog
Google’s search engine results pages (SERPs) have changed a great deal over the last 10 years, with more and more data and information being pulled directly into the results pages themselves. Google search features are a regular occurence on most SERPs nowadays, some of most common features being featured snippets (aka ‘position zero’), knowledge panels and related questions (aka ‘people also ask’). Data suggests that some features such as related questions may feature on nearly 90% of SERPs today – a huge increase over the last few years.
Understanding these features can be powerful for SEO. Reverse engineering why certain features appear for particular query types and analyisng the data or text included in said features can help inform us in making optimisation decisions. With organic CTR seemingly on the decline, optimising for Google search features is more important than ever, to ensure content is as visible as it possibly can be to search users.
This guide runs through the process of gathering search feature data from the SERPs, to help scale your analysis and optimisation efforts. I’ll demonstrate how to scrape data from the SERPs using the Screaming Frog SEO Spider using XPath, and show just how easy it is to grab a load of relevant and useful data very quickly. This guide focuses on featured snippets and related questions specifically, but the principles remain the same for scraping other features too.
TL;DR
If you’re already an XPath and scraping expert and are just here for the syntax and data type to setup your extraction (perhaps you saw me eloquently explain the process at SEOCamp Paris or Pubcon Las Vegas this year!), here you go (spoiler alert for everyone else!) –
Featured snippet XPath syntax
Featured snippet page title (Text) – (//div[@class='ellip'])[1]/text()
Featured snippet text paragraph (Text) – (//span[@class="e24Kjd"])[1]
Featured snippet bullet point text (Text) – //ul[@class="i8Z77e"]/li
Featured snippet numbered list (Text) – //ol[@class="X5LH0c"]/li
Featured snippet table (Text) – //table//tr
Featured snippet URL (Inner HTML) – (//div[@class="xpdopen"]//a/@href)[2]
Featured snippet image source (Text) – //div[@class="rg_ilbg"]
Related questions XPath syntax
Related question 1 text (Text) – (//div[1]/g-accordion-expander/div/div)[1]
Related question 2 text (Text) – (//div[2]/g-accordion-expander/div/div)[1]
Related question 3 text (Text) – (//div[3]/g-accordion-expander/div/div)[1]
Related question 4 text (Text) – (//div[4]/g-accordion-expander/div/div)[1]
Related question snippet text for all 4 questions (Text) – //g-accordion-expander//span[@class="e24Kjd"]
Related question page titles for all 4 questions (Text) – //g-accordion-expander//div[@class="ellip"]
Related question page URLs for all 4 questions (Inner HTML) – //div[@class="feCgPc y yf"]//div[@class="rc"]//a/@href
You can also get this list in our accompanying Google doc. Back to our regularly scheduled programming for the rest of you…follow these steps to start scraping featured snippets and related questions!
1) Preparation
To get started, you’ll need to download and install the SEO Spider software and have a licence to access the custom extraction feature necessary for scraping. I’d also recommend our web scraping and data extraction guide as a useful bit of light reading, just to cover the basics of what we’re getting up to here.
2) Gather keyword data
Next you’ll need to find relevant keywords where featured snippets and / or related questions are showing in the SERPs. Most well-known SEO intelligence tools have functionality to filter keywords you rank for (or want to rank for) and where these features show, or you might have your own rank monitoring systems to help. Failing that, simply run a few searches of important and relevant keywords to look for yourself, or grab query data from Google Search Console. Wherever you get your keyword data from, if you have a lot of data and are looking to prune and prioritise your keywords, I’d advise the following –
Prioritise keywords where you have a decent ranking position already. Not only is this relevant to winning a featured snippet (almost all featured snippets are taken from pages ranking organically in the top 10 positions, usually top 5), but more generally if Google thinks your page is already relevant to the query, you’ll have a better chance of targeting all types of search features.
Certainly consider search volume (the higher the better, right?), but also try and determine the likelihood of a search feature driving clicks too. As with keyword intent in the main organic results, not all search features will drive a significant amount of additional traffic, even if you achieve ‘position zero’. Try to consider objectively the intent behind a particular query, and prioritise keywords which are more likely to drive additional clicks.
3) Create a Google search query URL
We’re going to be crawling Google search query URLs, so need to feed the SEO Spider a URL to crawl using the keyword data gathered. This can either be done in Excel using find and replace and the ‘CONCATENATE’ formula to change the list of keywords into a single URL string (replace word spaces with + symbol, select your Google of choice, then CONCATENATE the cells to create an unbroken string), or, you can simply paste your original list of keywords into this handy Google doc with formula included (please make a copy of the doc first).
At the end of the process you should have a list of Google search query URLs which look something like this –
https://ift.tt/2zJIJ6H https://ift.tt/2PDsGSC https://ift.tt/2zJD1RY https://ift.tt/2PCCkVB https://ift.tt/2zWkCln etc.
4) Configure the SEO Spider
Experienced SEO Spider users will know that our tool has a multitude of configuration options to help you gather the important data you need. Crawling Google search query URLs requires a few configurations to work. Within the menu you need to configure as follows –
Configuration > Spider > Rendering > JavaScript
Configuration > robots.txt > Settings > Ignore robots.txt
Configuration > User-Agent > Present User Agents > Chrome
Configuration > Speed > Max Threads = 1 > Max URI/s = 0.5
These config options ensure that the SEO Spider can access the features and also not trigger a captcha by crawling too fast. Once you’ve setup this config I’d recommend saving it as a custom configuration which you can load up again in future.
5) Setup your extraction
Next you need to tell the SEO spider what to extract. For this, go into the ‘Configuration’ menu and select ‘Custom’ and ‘Extraction’ –
You should then see a screen like this –
From the ‘Inactive’ drop down menu you need to select ‘XPath’. From the new dropdown which appears on the right hand side, you need to select the type of data you’re looking to extract. This will depend on what data you’re looking to extract from the search results (full list of XPath syntax and data types listed below), so let’s use the example of related questions –
The above screenshot shows the related questions showing for the search query ‘seo’ in the UK. Let’s say we wanted to know what related questions were showing for the query, to ensure we had content and a page which targeted and answered these questions. If Google thinks they are relevant to the original query, at the very least we should consider that for analysis and potentially for optimisation. In this example we simply want the text of the questions themselves, to help inform us from a content perpective.
Typically 4 related questions show for a particular query, and these 4 questions have a separate XPath syntax –
Question 1 – (//div[1]/g-accordion-expander/div/div)[1]
Question 2 – (//div[2]/g-accordion-expander/div/div)[1]
Question 3 – (//div[3]/g-accordion-expander/div/div)[1]
Question 4 – (//div[4]/g-accordion-expander/div/div)[1]
To find the correct XPath syntax for your desired element, our web scraping guide can help, but we have a full list of the important ones at the end of this article!
Once you’ve input your syntax, you can also rename the extraction fields to correspond to each extraction (Question 1, Question 2 etc.). For this particular extraction we want the text of the questions themselves, so need to select ‘Extract Text’ in the data type dropdown menu. You should have a screen something like this –
If you do, you’re almost there!
6) Crawl in list mode
For this task you need to use the SEO Spider in List Mode. In the menu go Mode > List. Next, return to your list of created Google search query URL strings and copy all URLs. Return to the SEO Spider, hit the ‘Upload’ button and then ‘Paste’. Your list of search query URLs should appear in the window –
Hit ‘OK’ and your crawl will begin.
7) Analyse your results
To see your extraction you need to navigate to the ‘Custom’ tab in the SEO Spider, and select the ‘Extraction’ filter. Here you should start to see your extraction rolling in. When complete, you should have a nifty looking screen like this –
You can see your search query and the four related questions appearing in the SERPs being pulled in alongside it. When complete you can export the data and match up your keywords to your pages, and start to analyse the data and optimise to target the relevant questions.
8) Full list of XPath syntax
As promised, we’ve done a lot of the heavy lifting and have a list of XPath syntax to extract various featured snippet and related question elements from the SERPs –
Featured snippet XPath syntax
Featured snippet page title (Text) – (//div[@class='ellip'])[1]/text()
Featured snippet text paragraph (Text) – (//span[@class="e24Kjd"])[1]
Featured snippet bullet point text (Text) – //ul[@class="i8Z77e"]/li
Featured snippet numbered list (Text) – //ol[@class="X5LH0c"]/li
Featured snippet table (Text) – //table//tr
Featured snippet URL (Inner HTML) – (//div[@class="xpdopen"]//a/@href)[2]
Featured snippet image source (Text) – //div[@class="rg_ilbg"]
Related questions XPath syntax
Related question 1 text (Text) – (//div[1]/g-accordion-expander/div/div)[1]
Related question 2 text (Text) – (//div[2]/g-accordion-expander/div/div)[1]
Related question 3 text (Text) – (//div[3]/g-accordion-expander/div/div)[1]
Related question 4 text (Text) – (//div[4]/g-accordion-expander/div/div)[1]
Related question snippet text for all 4 questions (Text) – //g-accordion-expander//span[@class="e24Kjd"]
Related question page titles for all 4 questions (Text) – //g-accordion-expander//div[@class="ellip"]
Related question page URLs for all 4 questions (Text) – //div[@class="feCgPc y yf"]//div[@class="rc"]//a/@href
We’ve also included them in our accompanying Google doc for ease.
Conclusion
Hopefully our guide has been useful and can set you on your way to extract all sorts of useful and relevant data from the search results. Let me know how you get on, and if you have any other nifty XPath tips and tricks, please comment below!
The post How to Scrape Google Search Features Using XPath appeared first on Screaming Frog.
0 notes
Text
How To Select Components To Build a Powerful Home Entertainment Hub/PC
Finding the Processor:
Browse around the Intel web site to understand what's present. It's always best to check so as to avoid obsolescence in a short time. Regarding every 18 months, Intel introduces a new generation of processor chips. You always get much better performance at about the same price of the last generation of processors. A processor selection tool along with specifications on their processors can be found on the Intel website. You may will not need the top of the line of the current generation with regard to normal household computing. For this application, I'm going for the 2ndGeneration Intel Core i5 2500k. This has built-in Intel HD images, so with the correct motherboard, you will not have to spend extra money to buy a separate graphics card. Intel's Boxed processors usually come having an appropriate heat sink which cools the processor, however always check the specifications to make sure. For cooler and more silent operation, you may want to choose a retail heat sink, but just do this if you are confident about choosing one. The key specs will also be available when you source the component (at Newegg. com, in this case). When choosing a motherboard, you will need to realize and match the processor socket (LGA1155, in this case) and the supported memory type (DDR3-1066/1333, in this case). They are important for fit and function. Choosing a motherboard: I'm a big enthusiast of Intel's products because of the high reliability over the years. Therefore naturally, I'm choosing an Intel manufactured motherboard. Desktop computer board DH67BL Media Series was chosen. Again, take a look at Intel's website for details. It supports the LGA1155 socket, DDR3-1066/1333 memory and has both HDMI and DVI connections. Other important specifications on the motherboard you will need to recognize: Number of memory slots: 4x240 pin. You will need to know this particular, along with the memory standard (DDR3), when selecting memory. Storage space devices supported: 3x SATA 3Gb/s and 2x SATA 6Gb/s. This determines the supported hard drives and BD-ROM. SATA 6Gb/s is the new standard but is in reverse compatible with SATA 3Gb/s. LAN speed: 10/100/1000 Mbps. This particular determines your maximum Ethernet connection speed in a " cable " network. Form Factor: Micro ATX (9. 6" by 9. 6"). This is the physical size of the board and it is important when choosing a case. The smaller Micro ATX boards will certainly fit in most Media Center style cases while the bigger ATX form factor may not. Choosing Memory: As mentioned above, we need DDR3-1066 or DDR3-1333 240 pin memory modules to become compatible with the processor and the motherboard. We choose two times of the Kingston 4GB 240-Pin DDR3 SDRAM DDR3 1333 (PC3 10600) Desktop Memory Model KVR1333D3N9/4G for a great total of 8GB. Memory prices vary a lot, plus they are cheap as of this writing, so take advantage of the price. The panel can accommodate up to 4 modules, but 2x4GB is sufficient for our applications. Choosing the Hard Drive(s): Hard drive prices possess almost tripled during October and November of year 2011 due to component shortage as a result of the weather in Thailand. Costs are expected to remain high for a couple of quarters. Previously, since hard disk drives were really cheap, the system here was built with a pair of hard drives. The first one is a 320GB drive used to load the very operating system and any other programs to be used on the system. The 2nd 2TB drive is dedicated for Recorded TV and may hold about 300 hours of HDTV. In general, the greater Read/Write heads you have, the better the performance. I recently turned to Western digital green or blue hard drives simply because I got one on sale and found it to be vastly quieter than the Seagate I was accustomed to. The key specifications of the turns that affect fit and function are the SATA speed and also the physical size. SATA 6Gb/s describes the data transfer pace and is the new standard for desktop computing. The selected motherboard supports two SATA 6Gb/s, so be sure to link these to the 6Gb connections on the motherboard for greatest performance. The physical size of the drive is recognized as 3. 5" internal drive. This specification is essential when selecting your computer case. The selected case holds a couple 3. 5" internal drives. Selecting an optical generate (Blu-ray/CD/DVD ROM): Today's optical drives are typically SATA 3Gb/s transfer speeds. Physical size for desktop computers is actually described as 5. 25" internal drive, and they fit into an instance which has an external 5. 25" drive bay. The case specifies the main bay as external because it gives you access to open the drive tray. Additional software like Power DVD is needed to play Blu-ray disc. Some drives come bundled with this particular software. I have found that most internet stores are vague regarding whether the software is included or not. The Samsung included in the desk above, came with software. TV Tuner cards: I have not one but two "AVerMedia AVerTVHD Duet - PCTV Tuner (A188 -- White Box) - OEM" in my system. The main thing you should know is the interface type, which is PCI-Express x1 interface. It was described in article 2 . The selected Intel motherboard fits two such expansion slots. This set up gives 4 available tuners for simultaneous recording or watching 1 channel while recording three others. Selecting a computer situation: To have your Afcon 2019 look like another piece of sound equipment, you will need to select a case from the HTPC/Media Center group. To avoid the hassle of having to select a power supply to fit the situation, I chose a case with a built in 500W power supply. "APEVIA Dark SECC Steel / Aluminum X-MASTER-BK/500 ATX Media Center or HTPC Case". It's important to make sure you have an adequate wattage power. Because we are not using any add-in graphics credit cards, 350W to 500W will typically be more than sufficient. Feel free to select a case that's more esthetically pleasing for you. It's also important to make sure that your selected motherboard fits into the case. The actual Micro- ATX motherboard will fit into most cases. We are utilizing two 3. 5" hard drives and a 5. 25" Bluray player, so the case must have at least two 3. 5" drive bays and one 5. 25 external drive bay. Something that bugs me when buying a case is that the fan kind or fan noise is hardly ever specified. You don't understand what you are going to get until you put it together. Fortunately, fans are inexpensive and you can replace them if the noise level is too high for you personally. Fan noise is dependent on the design, rotating speed, in addition to air flow. The lower the stated noise level in dBA, the actual quieter it should be. A variable speed fan will manage the speed base on the temperature inside the case, so it will simply rotate as fast is it needs to, keeping noise down. Wireless keyboard and Wireless remote: I particularly such as the "nMEDIAPC HTPCKB-B Black 2 . 4GHz RF Wireless Efficient Keyboard with Track Ball & Remote Combo Set" because a track ball mouse is built into the PC handheld remote control. This makes for easy operation of the media player. We hardly ever use the keyboard, but when I do, the built in monitor ball mouse also comes in handy. No surface is required to run the mouse. Choosing the operating system: Windows 7 home premium and above includes Windows Media center which manages your tuner cards plus recorded TV. I chose Windows 7 Professional because it enables you to use Remote Desktop to remotely log into the PERSONAL COMPUTER. This way, using my laptop, I log into the press PC to do more demanding tasks. Note that the selected Home windows 7 OS is the OEM (Original Equipment Manufacturer) edition. Amongst other things, this means that there is no technical software support provided by Microsoft, but it's a lot cheaper. I never have the necessity to call Microsoft for technical support. If there is a problem, chances are that another person would have already found it so do a Google search. Placing it all together: As mentioned earlier, this article is mainly about choosing components to make your Media PC. Your components guide will guide you through the steps required to assemble the different elements. If you need additional help, you can do a simple Google search on 'how to build my own PC. ' Don't forget to connect the front screen switches and jacks. Once everything is connected you might be now ready to turn on your new PC. If everything will go well, you will see a boot up screen once you turn on the ability. Refer to the motherboard manual to make BIOS settings changes if needed. The default settings should work lacking any changes, but it's always a good idea to read this section of the particular manual to see what's available. The next step would be to insert typically the Windows DVD and follow the installation instructions. Be sure to be connected in to your network and have an internet connection. Windows set up will take about an hour. When prompted, select to download and install home windows updates automatically. Updates will probably take another hour, based on how many they are. Firmware and Driver updates: These up-dates are usually provided to fix bugs and improve device performance. In most cases, the system should work properly without these updates, but if you are experiencing functionality problems, it's always a good idea to check the manufacturer's website and install available updates. For Intel motherboards, Intel device drivers are available on Intel's download website for Network connections (LAN), Graphics, Chipset, and Sound devices.
0 notes
Text
Uncovering SEO Opportunities via Log Files
New Post has been published on http://www.readersforum.tk/uncovering-seo-opportunities-via-log-files/
Uncovering SEO Opportunities via Log Files
Posted by RobinRozhon
I use web crawlers on a daily basis. While they are very useful, they only imitate search engine crawlers’ behavior, which means you aren’t always getting the full picture.
The only tool that can give you a real overview of how search engines crawl your site are log files. Despite this, many people are still obsessed with crawl budget — the number of URLs Googlebot can and wants to crawl.
Log file analysis may discover URLs on your site that you had no idea about but that search engines are crawling anyway — a major waste of Google server resources (Google Webmaster Blog):
“Wasting server resources on pages like these will drain crawl activity from pages that do actually have value, which may cause a significant delay in discovering great content on a site.”
While it’s a fascinating topic, the fact is that most sites don’t need to worry that much about crawl budget —an observation shared by John Mueller (Webmaster Trends Analyst at Google) quite a few times already.
There’s still a huge value in analyzing logs produced from those crawls, though. It will show what pages Google is crawling and if anything needs to be fixed.
When you know exactly what your log files are telling you, you’ll gain valuable insights about how Google crawls and views your site, which means you can optimize for this data to increase traffic. And the bigger the site, the greater the impact fixing these issues will have.
What are server logs?
A log file is a recording of everything that goes in and out of a server. Think of it as a ledger of requests made by crawlers and real users. You can see exactly what resources Google is crawling on your site.
You can also see what errors need your attention. For instance, one of the issues we uncovered with our analysis was that our CMS created two URLs for each page and Google discovered both. This led to duplicate content issues because two URLs with the same content was competing against each other.
Analyzing logs is not rocket science — the logic is the same as when working with tables in Excel or Google Sheets. The hardest part is getting access to them — exporting and filtering that data.
Looking at a log file for the first time may also feel somewhat daunting because when you open one, you see something like this:
Calm down and take a closer look at a single line:
66.249.65.107 - - [08/Dec/2017:04:54:20 -0400] "GET /contact/ HTTP/1.1" 200 11179 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)"
You’ll quickly recognize that:
66.249.65.107 is the IP address (who)
[08/Dec/2017:04:54:20 -0400] is the Timestamp (when)
GET is the Method
/contact/ is the Requested URL (what)
200 is the Status Code (result)
11179 is the Bytes Transferred (size)
“-” is the Referrer URL (source) — it’s empty because this request was made by a crawler
Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html) is the User Agent (signature) — this is user agent of Googlebot (Desktop)
Once you know what each line is composed of, it’s not so scary. It’s just a lot of information. But that’s where the next step comes in handy.
Tools you can use
There are many tools you can choose from that will help you analyze your log files. I won’t give you a full run-down of available ones, but it’s important to know the difference between static and real-time tools.
Static — This only analyzes a static file. You can’t extend the time frame. Want to analyze another period? You need to request a new log file. My favourite tool for analyzing static log files is Power BI.
Real-time — Gives you direct access to logs. I really like open source ELK Stack (Elasticsearch, Logstash, and Kibana). It takes a moderate effort to implement it but once the stack is ready, it allows me changing the time frame based on my needs without needing to contact our developers.
Start analyzing
Don’t just dive into logs with a hope to find something — start asking questions. If you don’t formulate your questions at the beginning, you will end up in a rabbit hole with no direction and no real insights.
Here are a few samples of questions I use at the start of my analysis:
Which search engines crawl my website?
Which URLs are crawled most often?
Which content types are crawled most often?
Which status codes are returned?
If you see that Google is crawling non-existing pages (404), you can start asking which of those requested URLs return 404 status code.
Order the list by the number of requests, evaluate the ones with the highest number to find the pages with the highest priority (the more requests, the higher priority), and consider whether to redirect that URL or do any other action.
If you use a CDN or cache server, you need to get that data as well to get the full picture.
Segment your data
Grouping data into segments provides aggregate numbers that give you the big picture. This makes it easier to spot trends you might have missed by looking only at individual URLs. You can locate problematic sections and drill down if needed.
There are various ways to group URLs:
Group by content type (single product pages vs. category pages)
Group by language (English pages vs. French pages)
Group by storefront (Canadian store vs. US store)
Group by file format (JS vs. images vs. CSS)
Don’t forget to slice your data by user-agent. Looking at Google Desktop, Google Smartphone, and Bing all together won’t surface any useful insights.
Monitor behavior changes over time
Your site changes over time, which means so will crawlers’ behavior. Googlebot often decreases or increases the crawl rate based on factors such as a page’s speed, internal link structure, and the existence of crawl traps.
It’s a good idea to check in with your log files throughout the year or when executing website changes. I look at logs almost on a weekly basis when releasing significant changes for large websites.
By analyzing server logs twice a year, at the very least, you’ll surface changes in crawler’s behavior.
Watch for spoofing
Spambots and scrapers don’t like being blocked, so they may fake their identity — they leverage Googlebot’s user agent to avoid spam filters.
To verify if a web crawler accessing your server really is Googlebot, you can run a reverse DNS lookup and then a forward DNS lookup. More on this topic can be found in Google Webmaster Help Center.
Merge logs with other data sources
While it’s no necessary to connect to other data sources, doing so will unlock another level of insight and context that regular log analysis might not be able to give you. An ability to easily connect multiple datasets and extract insights from them is the main reason why Power BI is my tool of choice, but you can use any tool that you’re familiar with (e.g. Tableau).
Blend server logs with multiple other sources such as Google Analytics data, keyword ranking, sitemaps, crawl data, and start asking questions like:
What pages are not included in the sitemap.xml but are crawled extensively?
What pages are included in the Sitemap.xml file but are not crawled?
Are revenue-driving pages crawled often?
Is the majority of crawled pages indexable?
You may be surprised by the insights you’ll uncover that can help strengthen your SEO strategy. For instance, discovering that almost 70 percent of Googlebot requests are for pages that are not indexable is an insight you can act on.
You can see more examples of blending log files with other data sources in my post about advanced log analysis.
Use logs to debug Google Analytics
Don’t think of server logs as just another SEO tool. Logs are also an invaluable source of information that can help pinpoint technical errors before they become a larger problem.
Last year, Google Analytics reported a drop in organic traffic for our branded search queries. But our keyword tracking tool, STAT Search Analytics, and other tools showed no movement that would have warranted the drop. So, what was going on?
Server logs helped us understand the situation: There was no real drop in traffic. It was our newly deployed WAF (Web Application Firewall) that was overriding the referrer, which caused some organic traffic to be incorrectly classified as direct traffic in Google Analytics.
Using log files in conjunction with keyword tracking in STAT helped us uncover the whole story and diagnose this issue quickly.
Putting it all together
Log analysis is a must-do, especially once you start working with large websites.
My advice is to start with segmenting data and monitoring changes over time. Once you feel ready, explore the possibilities of blending logs with your crawl data or Google Analytics. That’s where great insights are hidden.
Want more?
Ready to learn how to get cracking and tracking some more? Reach out and request a demo to get your very own tailored walkthrough of STAT.
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don’t have time to hunt down but want to read!
0 notes
Text
Uncovering SEO Opportunities via Log Files
Posted by RobinRozhon
I use web crawlers on a daily basis. While they are very useful, they only imitate search engine crawlers’ behavior, which means you aren’t always getting the full picture.
The only tool that can give you a real overview of how search engines crawl your site are log files. Despite this, many people are still obsessed with crawl budget — the number of URLs Googlebot can and wants to crawl.
Log file analysis may discover URLs on your site that you had no idea about but that search engines are crawling anyway — a major waste of Google server resources (Google Webmaster Blog):
“Wasting server resources on pages like these will drain crawl activity from pages that do actually have value, which may cause a significant delay in discovering great content on a site.”
While it’s a fascinating topic, the fact is that most sites don’t need to worry that much about crawl budget —an observation shared by John Mueller (Webmaster Trends Analyst at Google) quite a few times already.
There’s still a huge value in analyzing logs produced from those crawls, though. It will show what pages Google is crawling and if anything needs to be fixed.
When you know exactly what your log files are telling you, you’ll gain valuable insights about how Google crawls and views your site, which means you can optimize for this data to increase traffic. And the bigger the site, the greater the impact fixing these issues will have.
What are server logs?
A log file is a recording of everything that goes in and out of a server. Think of it as a ledger of requests made by crawlers and real users. You can see exactly what resources Google is crawling on your site.
You can also see what errors need your attention. For instance, one of the issues we uncovered with our analysis was that our CMS created two URLs for each page and Google discovered both. This led to duplicate content issues because two URLs with the same content was competing against each other.
Analyzing logs is not rocket science — the logic is the same as when working with tables in Excel or Google Sheets. The hardest part is getting access to them — exporting and filtering that data.
Looking at a log file for the first time may also feel somewhat daunting because when you open one, you see something like this:
Calm down and take a closer look at a single line:
66.249.65.107 - - [08/Dec/2017:04:54:20 -0400] "GET /contact/ HTTP/1.1" 200 11179 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)"
You’ll quickly recognize that:
66.249.65.107 is the IP address (who)
[08/Dec/2017:04:54:20 -0400] is the Timestamp (when)
GET is the Method
/contact/ is the Requested URL (what)
200 is the Status Code (result)
11179 is the Bytes Transferred (size)
“-” is the Referrer URL (source) — it’s empty because this request was made by a crawler
Mozilla/5.0 (compatible; Googlebot/2.1; +http://bit.ly/2Uadn11) is the User Agent (signature) — this is user agent of Googlebot (Desktop)
Once you know what each line is composed of, it’s not so scary. It’s just a lot of information. But that’s where the next step comes in handy.
Tools you can use
There are many tools you can choose from that will help you analyze your log files. I won’t give you a full run-down of available ones, but it’s important to know the difference between static and real-time tools.
Static — This only analyzes a static file. You can’t extend the time frame. Want to analyze another period? You need to request a new log file. My favourite tool for analyzing static log files is Power BI.
Real-time — Gives you direct access to logs. I really like open source ELK Stack (Elasticsearch, Logstash, and Kibana). It takes a moderate effort to implement it but once the stack is ready, it allows me changing the time frame based on my needs without needing to contact our developers.
Start analyzing
Don’t just dive into logs with a hope to find something — start asking questions. If you don’t formulate your questions at the beginning, you will end up in a rabbit hole with no direction and no real insights.
Here are a few samples of questions I use at the start of my analysis:
Which search engines crawl my website?
Which URLs are crawled most often?
Which content types are crawled most often?
Which status codes are returned?
If you see that Google is crawling non-existing pages (404), you can start asking which of those requested URLs return 404 status code.
Order the list by the number of requests, evaluate the ones with the highest number to find the pages with the highest priority (the more requests, the higher priority), and consider whether to redirect that URL or do any other action.
If you use a CDN or cache server, you need to get that data as well to get the full picture.
Segment your data
Grouping data into segments provides aggregate numbers that give you the big picture. This makes it easier to spot trends you might have missed by looking only at individual URLs. You can locate problematic sections and drill down if needed.
There are various ways to group URLs:
Group by content type (single product pages vs. category pages)
Group by language (English pages vs. French pages)
Group by storefront (Canadian store vs. US store)
Group by file format (JS vs. images vs. CSS)
Don’t forget to slice your data by user-agent. Looking at Google Desktop, Google Smartphone, and Bing all together won’t surface any useful insights.
Monitor behavior changes over time
Your site changes over time, which means so will crawlers’ behavior. Googlebot often decreases or increases the crawl rate based on factors such as a page’s speed, internal link structure, and the existence of crawl traps.
It’s a good idea to check in with your log files throughout the year or when executing website changes. I look at logs almost on a weekly basis when releasing significant changes for large websites.
By analyzing server logs twice a year, at the very least, you’ll surface changes in crawler’s behavior.
Watch for spoofing
Spambots and scrapers don’t like being blocked, so they may fake their identity — they leverage Googlebot’s user agent to avoid spam filters.
To verify if a web crawler accessing your server really is Googlebot, you can run a reverse DNS lookup and then a forward DNS lookup. More on this topic can be found in Google Webmaster Help Center.
Merge logs with other data sources
While it’s no necessary to connect to other data sources, doing so will unlock another level of insight and context that regular log analysis might not be able to give you. An ability to easily connect multiple datasets and extract insights from them is the main reason why Power BI is my tool of choice, but you can use any tool that you’re familiar with (e.g. Tableau).
Blend server logs with multiple other sources such as Google Analytics data, keyword ranking, sitemaps, crawl data, and start asking questions like:
What pages are not included in the sitemap.xml but are crawled extensively?
What pages are included in the Sitemap.xml file but are not crawled?
Are revenue-driving pages crawled often?
Is the majority of crawled pages indexable?
You may be surprised by the insights you’ll uncover that can help strengthen your SEO strategy. For instance, discovering that almost 70 percent of Googlebot requests are for pages that are not indexable is an insight you can act on.
You can see more examples of blending log files with other data sources in my post about advanced log analysis.
Use logs to debug Google Analytics
Don’t think of server logs as just another SEO tool. Logs are also an invaluable source of information that can help pinpoint technical errors before they become a larger problem.
Last year, Google Analytics reported a drop in organic traffic for our branded search queries. But our keyword tracking tool, STAT Search Analytics, and other tools showed no movement that would have warranted the drop. So, what was going on?
Server logs helped us understand the situation: There was no real drop in traffic. It was our newly deployed WAF (Web Application Firewall) that was overriding the referrer, which caused some organic traffic to be incorrectly classified as direct traffic in Google Analytics.
Using log files in conjunction with keyword tracking in STAT helped us uncover the whole story and diagnose this issue quickly.
Putting it all together
Log analysis is a must-do, especially once you start working with large websites.
My advice is to start with segmenting data and monitoring changes over time. Once you feel ready, explore the possibilities of blending logs with your crawl data or Google Analytics. That’s where great insights are hidden.
Want more?
Ready to learn how to get cracking and tracking some more? Reach out and request a demo get your very own tailored walkthrough of STAT.
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read!
via Blogger http://bit.ly/2CD2HRA
0 notes