#SQL Select Statement
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
China blocked Tumblr because of pornography and censorship problems in 2013.
Text
Using CASE Statements for Conditional Logic in SQL Server like IF THEN
In SQL Server, you can use the CASE statement to perform IF…THEN logic within a SELECT statement. The CASE statement evaluates a list of conditions and returns one of multiple possible result expressions. Here’s the basic syntax for using a CASE statement: SELECT column1, column2, CASE WHEN condition1 THEN result1 WHEN condition2 THEN result2 ... ELSE default_result END AS…
View On WordPress
#conditional SELECT SQL#dynamic SQL queries#managing SQL data#SQL Server CASE statement#SQL Server tips
0 notes
Text
I tried to train/teach like 3 people on sql and they all stopped me almost immediately saying stuff like "that's a lot. do I have to know all that?" when I had only gotta to like the required order of statements and what is/isn't comma separated so my answer was always "no". it literally starts with just a bunch of rules you have to know and you for real have to learn them. stop getting mad that you get red underlines when you don't put any commas in your select statement and just remember to put the commas in there.
28 notes
·
View notes
Text
SQL Injection in RESTful APIs: Identify and Prevent Vulnerabilities
SQL Injection (SQLi) in RESTful APIs: What You Need to Know
RESTful APIs are crucial for modern applications, enabling seamless communication between systems. However, this convenience comes with risks, one of the most common being SQL Injection (SQLi). In this blog, we’ll explore what SQLi is, its impact on APIs, and how to prevent it, complete with a practical coding example to bolster your understanding.

What Is SQL Injection?
SQL Injection is a cyberattack where an attacker injects malicious SQL statements into input fields, exploiting vulnerabilities in an application's database query execution. When it comes to RESTful APIs, SQLi typically targets endpoints that interact with databases.
How Does SQL Injection Affect RESTful APIs?
RESTful APIs are often exposed to public networks, making them prime targets. Attackers exploit insecure endpoints to:
Access or manipulate sensitive data.
Delete or corrupt databases.
Bypass authentication mechanisms.
Example of a Vulnerable API Endpoint
Consider an API endpoint for retrieving user details based on their ID:
from flask import Flask, request import sqlite3
app = Flask(name)
@app.route('/user', methods=['GET']) def get_user(): user_id = request.args.get('id') conn = sqlite3.connect('database.db') cursor = conn.cursor() query = f"SELECT * FROM users WHERE id = {user_id}" # Vulnerable to SQLi cursor.execute(query) result = cursor.fetchone() return {'user': result}, 200
if name == 'main': app.run(debug=True)
Here, the endpoint directly embeds user input (user_id) into the SQL query without validation, making it vulnerable to SQL Injection.
Secure API Endpoint Against SQLi
To prevent SQLi, always use parameterized queries:
@app.route('/user', methods=['GET']) def get_user(): user_id = request.args.get('id') conn = sqlite3.connect('database.db') cursor = conn.cursor() query = "SELECT * FROM users WHERE id = ?" cursor.execute(query, (user_id,)) result = cursor.fetchone() return {'user': result}, 200
In this approach, the user input is sanitized, eliminating the risk of malicious SQL execution.
How Our Free Tool Can Help
Our free Website Security Checker your web application for vulnerabilities, including SQL Injection risks. Below is a screenshot of the tool's homepage:
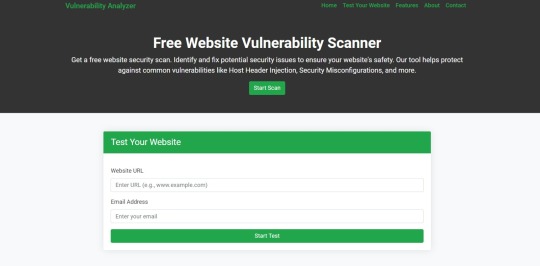
Upload your website details to receive a comprehensive vulnerability assessment report, as shown below:
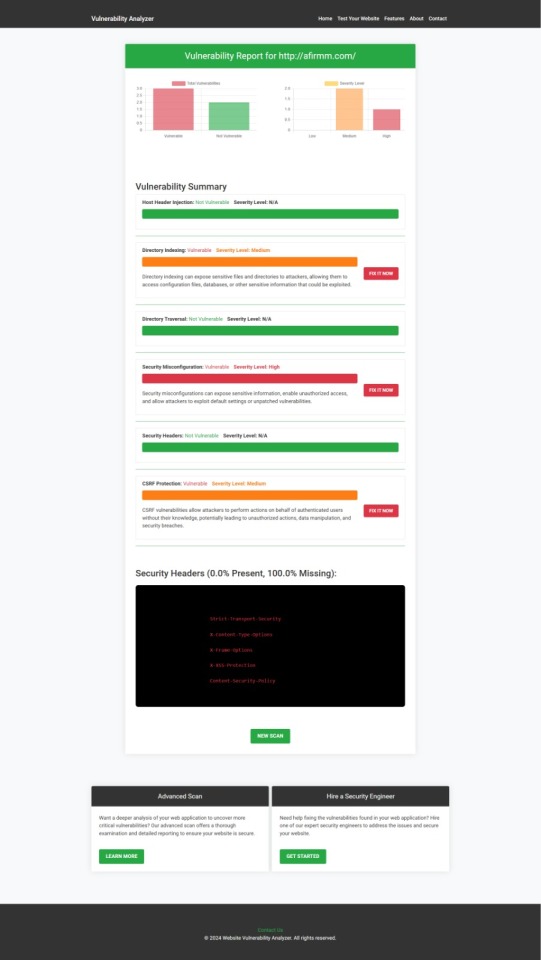
These tools help identify potential weaknesses in your APIs and provide actionable insights to secure your system.
Preventing SQLi in RESTful APIs
Here are some tips to secure your APIs:
Use Prepared Statements: Always parameterize your queries.
Implement Input Validation: Sanitize and validate user input.
Regularly Test Your APIs: Use tools like ours to detect vulnerabilities.
Least Privilege Principle: Restrict database permissions to minimize potential damage.
Final Thoughts
SQL Injection is a pervasive threat, especially in RESTful APIs. By understanding the vulnerabilities and implementing best practices, you can significantly reduce the risks. Leverage tools like our free Website Security Checker to stay ahead of potential threats and secure your systems effectively.
Explore our tool now for a quick Website Security Check.
#cyber security#cybersecurity#data security#pentesting#security#sql#the security breach show#sqlserver#rest api
2 notes
·
View notes
Text
SQL injection

we will recall SQLi types once again because examples speak louder than explanations!
In-band SQL Injection
This technique is considered the most common and straightforward type of SQL injection attack. In this technique, the attacker uses the same communication channel for both the injection and the retrieval of data. There are two primary types of in-band SQL injection:
Error-Based SQL Injection: The attacker manipulates the SQL query to produce error messages from the database. These error messages often contain information about the database structure, which can be used to exploit the database further. Example: SELECT * FROM users WHERE id = 1 AND 1=CONVERT(int, (SELECT @@version)). If the database version is returned in the error message, it reveals information about the database.
Union-Based SQL Injection: The attacker uses the UNION SQL operator to combine the results of two or more SELECT statements into a single result, thereby retrieving data from other tables. Example: SELECT name, email FROM users WHERE id = 1 UNION ALL SELECT username, password FROM admin.
Inferential (Blind) SQL Injection
Inferential SQL injection does not transfer data directly through the web application, making exploiting it more challenging. Instead, the attacker sends payloads and observes the application’s behaviour and response times to infer information about the database. There are two primary types of inferential SQL injection:
Boolean-Based Blind SQL Injection: The attacker sends an SQL query to the database, forcing the application to return a different result based on a true or false condition. By analysing the application’s response, the attacker can infer whether the payload was true or false. Example: SELECT * FROM users WHERE id = 1 AND 1=1 (true condition) versus SELECT * FROM users WHERE id = 1 AND 1=2 (false condition). The attacker can infer the result if the page content or behaviour changes based on the condition.
Time-Based Blind SQL Injection: The attacker sends an SQL query to the database, which delays the response for a specified time if the condition is true. By measuring the response time, the attacker can infer whether the condition is true or false. Example: SELECT * FROM users WHERE id = 1; IF (1=1) WAITFOR DELAY '00:00:05'--. If the response is delayed by 5 seconds, the attacker can infer that the condition was true.
Out-of-band SQL Injection
Out-of-band SQL injection is used when the attacker cannot use the same channel to launch the attack and gather results or when the server responses are unstable. This technique relies on the database server making an out-of-band request (e.g., HTTP or DNS) to send the query result to the attacker. HTTP is normally used in out-of-band SQL injection to send the query result to the attacker's server. We will discuss it in detail in this room.
Each type of SQL injection technique has its advantages and challenges.
3 notes
·
View notes
Text
SQL Temporary Table | Temp Table | Global vs Local Temp Table
Q01. What is a Temp Table or Temporary Table in SQL? Q02. Is a duplicate Temp Table name allowed? Q03. Can a Temp Table be used for SELECT INTO or INSERT EXEC statement? Q04. What are the different ways to create a Temp Table in SQL? Q05. What is the difference between Local and Global Temporary Table in SQL? Q06. What is the storage location for the Temp Tables? Q07. What is the difference between a Temp Table and a Derived Table in SQL? Q08. What is the difference between a Temp Table and a Common Table Expression in SQL? Q09. How many Temp Tables can be created with the same name? Q10. How many users or who can access the Temp Tables? Q11. Can you create an Index and Constraints on the Temp Table? Q12. Can you apply Foreign Key constraints to a temporary table? Q13. Can you use the Temp Table before declaring it? Q14. Can you use the Temp Table in the User-Defined Function (UDF)? Q15. If you perform an Insert, Update, or delete operation on the Temp Table, does it also affect the underlying base table? Q16. Can you TRUNCATE the temp table? Q17. Can you insert the IDENTITY Column value in the temp table? Can you reset the IDENTITY Column of the temp table? Q18. Is it mandatory to drop the Temp Tables after use? How can you drop the temp table in a stored procedure that returns data from the temp table itself? Q19. Can you create a new temp table with the same name after dropping the temp table within a stored procedure? Q20. Is there any transaction log created for the operations performed on the Temp Table? Q21. Can you use explicit transactions on the Temp Table? Does the Temp Table hold a lock? Does a temp table create Magic Tables? Q22. Can a trigger access the temp tables? Q23. Can you access a temp table created by a stored procedure in the same connection after executing the stored procedure? Q24. Can a nested stored procedure access the temp table created by the parent stored procedure? Q25. Can you ALTER the temp table? Can you partition a temp table? Q26. Which collation will be used in the case of Temp Table, the database on which it is executing, or temp DB? What is a collation conflict error and how you can resolve it? Q27. What is a Contained Database? How does it affect the Temp Table in SQL? Q28. Can you create a column with user-defined data types (UDDT) in the temp table? Q29. How many concurrent users can access a stored procedure that uses a temp table? Q30. Can you pass a temp table to the stored procedure as a parameter?
#sqlinterview#sqltemptable#sqltemporarytable#sqltemtableinterview#techpointinterview#techpointfundamentals#techpointfunda#techpoint#techpointblog
4 notes
·
View notes
Text
In the early twenty-first century, SQL injection is a common (and easily preventable) form of cyber attack. SQL databases use SQL statements to manipulate data. For example (and simplified), "Insert 'John' INTO Enemies;" would be used to add the name John to a table that contains the list of a person's enemies. SQL is usually not done manually. Instead it would be built into a problem. So if somebody made a website and had a form where a person could type their own name to gain the eternal enmity of the website maker, they might set things up with a command like "Insert '<INSERT NAME HERE>' INTO Enemies;". If someone typed 'Bethany' it would replace <INSERT NAME HERE> to make the SQL statement "Insert 'Bethany' INTO Enemies;"
The problem arises if someone doesn't type their name. If they instead typed "Tim' INTO Enemies; INSERT INTO [Friends] SELECT * FROM [Powerpuff Girls];--" then, when <INSERT NAME HERE> is replaced, the statement would be "Insert 'Tim' INTO Enemies; INSERT INTO [Friends] SELECT * FROM [Powerpuff Girls];--' INTO Enemies;" This would be two SQL commands: the first which would add 'Tim' to the enemy table for proper vengeance swearing, and the second which would add all of the Powerpuff Girls to the Friend table, which would be undesirable to a villainous individual.
SQL injection requires knowing a bit about the names of tables and the structures of the commands being used, but practically speaking it doesn't take much effort to pull off. It also does not take much effort to stop. Removing any quotation marks or weird characters like semicolons is often sufficient. The exploit is very well known and many databases protect against it by default.
People in the early twenty-first century probably are not familiar with SQL injection, but anyone who works adjacent to the software industry would be familiar with the concept as part of barebones cybersecurity training.
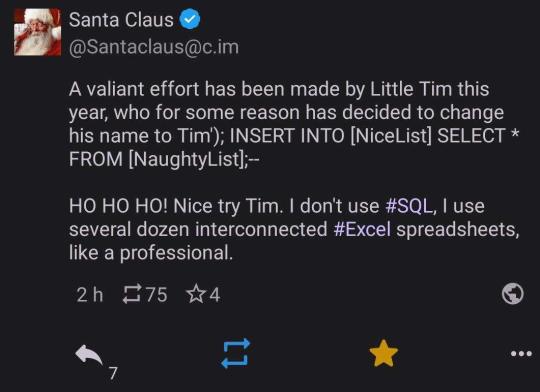
#period novel details#explaining the joke ruins the joke#not explaining the joke means people 300 years from now won't understand our culture#hacking is usually much less sophisticated than people expect#lots of trial and error#and relying on other people being lazy
20K notes
·
View notes
Text
Speed Matters: Best Practices for Optimizing Database Queries in Web Applications

In the modern era of web development, optimizing the performance of a database web application is essential to deliver fast, seamless, and efficient user experiences. As businesses increasingly rely on web applications to interact with customers, process transactions, and store data, the performance of these applications—especially database queries—becomes a critical factor in overall system efficiency. Slow or inefficient database queries can result in long loading times, frustrated users, and, ultimately, lost revenue. This blog will explore the importance of optimizing database queries and how this can directly impact the performance of your web application.
Understanding Database Query Optimization
A database query is a request for data from a database, typically structured using SQL (Structured Query Language). Web applications rely on these queries to retrieve, modify, or delete data stored in a database. However, when these queries are not optimized, they can become a bottleneck, slowing down the entire web application.
Query optimization is the process of improving the performance of database queries to ensure faster execution and better utilization of server resources. The goal of optimization is not only to reduce the time it takes for a query to execute but also to minimize the load on the database server, making the application more scalable and responsive.
In the context of a database web application, performance is key. A slow web application—due to poor query performance—can cause users to abandon the site or app, which ultimately affects business success. Optimizing database queries is therefore an essential step in the web app development process, ensuring that your web application can handle large volumes of data and multiple users without lag.
Key Techniques for Optimizing Database Queries
There are several techniques that developers can use to optimize database queries and ensure faster web application performance. Here are some of the most effective ones:
1. Use Proper Indexing
Indexing is one of the most powerful tools for optimizing database queries. An index is a data structure that improves the speed of data retrieval operations on a database table. By creating indexes on frequently queried columns, you allow the database to quickly locate the requested data without scanning every row in the table.
However, it is important to balance indexing carefully. Too many indexes can slow down data insertion and updates, as the index must be updated each time a record is added or modified. The key is to index the columns that are most frequently used in WHERE, JOIN, and ORDER BY clauses.
2. Optimize Queries with Joins
Using joins to retrieve data from multiple tables is a common practice in relational databases. However, poorly written join queries can lead to performance issues. To optimize joins, it is important to:
Use INNER JOINs instead of OUTER JOINs when possible, as they typically perform faster.
Avoid using unnecessary joins, especially when retrieving only a small subset of data.
Ensure that the fields used in the join conditions are indexed.
By optimizing join queries, developers can reduce the number of rows processed, thus speeding up query execution.
3. Limit the Use of Subqueries
Subqueries are often used in SQL to retrieve data that will be used in the main query. While subqueries can be powerful, they can also lead to performance issues if used incorrectly, especially when nested within SELECT, INSERT, UPDATE, or DELETE statements.
To optimize queries, it is better to use JOINs instead of subqueries when possible. Additionally, consider breaking complex subqueries into multiple simpler queries and using temporary tables if necessary.
4. Use Caching to Reduce Database Load
Caching is a technique where the results of expensive database queries are stored temporarily in memory, so that they don’t need to be re-executed each time they are requested. By caching frequently accessed data, you can significantly reduce the load on your database and improve response times.
Caching is particularly effective for data that doesn’t change frequently, such as product listings, user profiles, or other static information. Popular caching systems like Redis and Memcached can be easily integrated into your web application to store cached data and ensure faster access.
5. Batch Processing and Pagination
For applications that need to retrieve large datasets, using batch processing and pagination is an effective way to optimize performance. Instead of loading large sets of data all at once, it is more efficient to break up the data into smaller chunks and load it incrementally.
Using pagination allows the database to return smaller sets of results, which significantly reduces the amount of data transferred and speeds up query execution. Additionally, batch processing can help ensure that the database is not overwhelmed with requests that would otherwise require processing large amounts of data in one go.
6. Mobile App Cost Calculator: Impact on Query Optimization
When developing a mobile app or web application, it’s essential to understand the associated costs, particularly in terms of database operations. A mobile app cost calculator can help you estimate how different factors—such as database usage, query complexity, and caching strategies—will impact the overall cost of app development. By using such a calculator, you can plan your app’s architecture better, ensuring that your database queries are optimized to stay within budget without compromising performance.
If you're interested in exploring the benefits of web app development services for your business, we encourage you to book an appointment with our team of experts.
Book an Appointment
Conclusion: The Role of Web App Development Services
Optimizing database queries is a critical part of ensuring that your web application delivers a fast and efficient user experience. By focusing on proper indexing, optimizing joins, reducing subqueries, and using caching, you can significantly improve query performance. This leads to faster load times, increased scalability, and a better overall experience for users.
If you are looking to enhance the performance of your database web application, partnering with professional web app development services can make a significant difference. Expert developers can help you implement the best practices in database optimization, ensuring that your application is not only fast but also scalable and cost-effective. Book an appointment with our team to get started on optimizing your web application’s database queries and take your web app performance to the next level.
0 notes
Text
SQL Basics: How to Query and Manage Data in DBMS
Structured Query Language (SQL) is the backbone of database management systems (DBMS). It enables users to interact with, manipulate, and retrieve data stored in databases. Whether you're managing a small database for a personal project or working with large-scale enterprise systems, SQL is an invaluable tool. This comprehensive guide introduces you to essential SQL commands, such as SELECT, INSERT, UPDATE, DELETE, and JOINs, empowering you to manage and query data effectively.
How to Query and Manage Data
Understanding Databases and Tables
Before diving into SQL commands, it's crucial to understand the basic structure of databases. A database is an organized collection of data, typically stored and accessed electronically from a computer system. Within a database, data is arranged in tables, which consist of rows and columns. Each column represents a data field, while each row corresponds to a record.
Example of a Table
Consider a simple Customers table:
CustomerID
Name
Email
Age
1
Jane Doe
30
2
John Smith
25
3
Alice Lee
40
Essential SQL Commands
SELECT: Retrieving Data
The SELECT statement is used to query and retrieve data from a database. It allows you to specify the columns you want to view and apply filters to narrow down results.
Syntax:
SELECT column1, column2, ... FROM table_name WHERE condition;
Example:
To retrieve all customer names and emails from the Customers table:
SELECT Name, Email FROM Customers;
To get customers above the age of 30:
SELECT Name, Email FROM Customers WHERE Age > 30;
INSERT: Adding New Data
The INSERT statement allows you to add new records to a table.
Syntax:
INSERT INTO table_name (column1, column2, ...) VALUES (value1, value2, ...);
Example:
To add a new customer to the Customers table:
INSERT INTO Customers (Name, Email, Age) VALUES ('Robert Brown', '[email protected]', 28);
UPDATE: Modifying Existing Data
The UPDATE statement is used to modify existing records in a table.
Syntax:
UPDATE table_name SET column1 = value1, column2 = value2, ... WHERE condition;
Example:
To update the email of a customer with CustomerID 1:
UPDATE Customers SET Email = '[email protected]' WHERE CustomerID = 1;
DELETE: Removing Data
The DELETE statement is used to remove records from a table.
Syntax:
DELETE FROM table_name WHERE condition;
Example:
To delete a customer with CustomerID 3:
DELETE FROM Customers WHERE CustomerID = 3;
JOINs: Combining Tables
JOINs are used to combine rows from two or more tables based on a related column between them. There are several types of JOINs, including INNER JOIN, LEFT JOIN, RIGHT JOIN, and FULL JOIN.
INNER JOIN:
Returns records that have matching values in both tables.
Syntax:
SELECT columns FROM table1 INNER JOIN table2 ON table1.column = table2.column;
Example:
Consider an Orders table:
OrderID
CustomerID
OrderDate
101
1
2023-10-01
102
2
2023-10-05
To find all orders along with customer names:
SELECT Customers.Name, Orders.OrderDate FROM Customers INNER JOIN Orders ON Customers.CustomerID = Orders.CustomerID;
LEFT JOIN:
Returns all records from the left table and matched records from the right table. If no match is found, NULL values are returned for columns from the right table.
Syntax:
SELECT columns FROM table1 LEFT JOIN table2 ON table1.column = table2.column;
Example:
To include all customers, even those with no orders:
SELECT Customers.Name, Orders.OrderDate FROM Customers LEFT JOIN Orders ON Customers.CustomerID = Orders.CustomerID;
SQL Commands
Best Practices for Using SQL
Use Aliases: Use aliases to make your queries more readable.
SELECT c.Name, o.OrderDate FROM Customers c INNER JOIN Orders o ON c.CustomerID = o.CustomerID;
*Avoid SELECT : Instead of retrieving all columns with SELECT *, specify the columns you need.
Use Comments: Add comments for complex queries to explain the logic.
SELECT Name, Email /* Retrieve customer details */ FROM Customers;
Test Queries: Always test your queries with a subset of data before running them on the entire database.
Backup Data: Regularly backup your database to prevent data loss.
Common SQL Functions
SQL includes a variety of built-in functions to perform calculations on data:
Aggregate Functions: Such as COUNT(), SUM(), AVG(), MIN(), and MAX().
String Functions: Such as CONCAT(), SUBSTRING(), LENGTH().
Date Functions: Such as NOW(), CURDATE(), DATEDIFF().
Example:
To find the total number of customers:
SELECT COUNT(*) AS TotalCustomers FROM Customers;
SQL and Data Integrity
Maintaining data integrity is crucial in database management. SQL supports various constraints to ensure data integrity:
PRIMARY KEY: Uniquely identifies each record.
FOREIGN KEY: Ensures referential integrity between tables.
NOT NULL: Ensures a column cannot have a NULL value.
UNIQUE: Ensures all values in a column are different.
Example:
Creating a Customers table with constraints:
CREATE TABLE Customers ( CustomerID INT PRIMARY KEY, Name VARCHAR(255) NOT NULL, Email VARCHAR(255) UNIQUE, Age INT );
SQL in Real-World Applications
SQL is widely used in various applications, from web development to data analysis. It serves as the foundation for many popular database systems, including MySQL, PostgreSQL, Oracle, and SQL Server.
SQL for Web Development
In web applications, SQL is typically used in the back-end to manage user data, content, and transactions. It enables developers to create dynamic and interactive websites.
SQL for Data Analysis
SQL is a powerful tool for data analysis, allowing analysts to query large datasets efficiently. It is often used in conjunction with data visualization tools to gain insights and make data-driven decisions.
SQL in Real-World Applications
Conclusion
Mastering SQL is essential for anyone working with databases. By understanding and applying the basic commands covered in this guide, you'll be well-equipped to manage and query data effectively. As you become more comfortable with SQL, you can explore advanced topics and techniques to further enhance your database management skills.
FAQs
What is SQL used for? SQL is used for managing and querying data in databases. It allows users to retrieve, insert, update, and delete data, as well as perform complex queries involving multiple tables.
What is the difference between a primary key and a foreign key? A primary key uniquely identifies each record in a table, while a foreign key is a reference to a primary key in another table, ensuring referential integrity between the two tables.
Can SQL be used with non-relational databases? SQL is specifically designed for relational databases. However, some non-relational databases, like NoSQL, offer SQL-like querying capabilities.
What are JOINs in SQL? JOINs are used to combine rows from two or more tables based on a related column. They allow you to retrieve data from multiple tables in a single query.
How can I improve my SQL skills? Practice regularly, work on real-world projects, and explore online resources and tutorials. Joining communities and forums can also provide valuable insights and learning opportunities.
HOME
#SQLBasics#LearnSQL#SQLQueries#DBMS#DatabaseManagement#DataManipulation#SQLForBeginners#TechForStudents#InformationTechnology#DatabaseSkills#AssignmentHelp#AssignmentOnClick#assignment help#assignment service#aiforstudents#machinelearning#assignmentexperts#assignment#assignmentwriting
1 note
·
View note
Text
Understanding Standard SQL and Legacy SQL in BigQuery
BigQuery SQL Explained: Legacy SQL vs Standard SQL Made Simple In Google BigQuery, understanding the difference Standar Standard SQL and Legacy SQL in BigQuery – into between Legacy SQL and Standard SQL isn’t just about syntax it’s the key to unlocking the platform’s full potential. Whether you’re writing simple SELECT statements or designing complex analytics pipelines, the SQL dialect you…
0 notes
Text
10 Must-Have Skills for Data Engineering Jobs

In the digital economy of 2025, data isn't just valuable – it's the lifeblood of every successful organization. But raw data is messy, disorganized, and often unusable. This is where the Data Engineer steps in, transforming chaotic floods of information into clean, accessible, and reliable data streams. They are the architects, builders, and maintainers of the crucial pipelines that empower data scientists, analysts, and business leaders to extract meaningful insights.
The field of data engineering is dynamic, constantly evolving with new technologies and demands. For anyone aspiring to enter this vital domain or looking to advance their career, a specific set of skills is non-negotiable. Here are 10 must-have skills that will position you for success in today's data-driven landscape:
1. Proficiency in SQL (Structured Query Language)
Still the absolute bedrock. While data stacks become increasingly complex, SQL remains the universal language for interacting with relational databases and data warehouses. A data engineer must master SQL far beyond basic SELECT statements. This includes:
Advanced Querying: JOIN operations, subqueries, window functions, CTEs (Common Table Expressions).
Performance Optimization: Writing efficient queries for large datasets, understanding indexing, and query execution plans.
Data Definition and Manipulation: CREATE, ALTER, DROP tables, and INSERT, UPDATE, DELETE operations.
2. Strong Programming Skills (Python & Java/Scala)
Python is the reigning champion in data engineering due to its versatility, rich ecosystem of libraries (Pandas, NumPy, PySpark), and readability. It's essential for scripting, data manipulation, API interactions, and building custom ETL processes.
While Python dominates, knowledge of Java or Scala remains highly valuable, especially for working with traditional big data frameworks like Apache Spark, where these languages offer performance advantages and deeper integration.
3. Expertise in ETL/ELT Tools & Concepts
Data engineers live and breathe ETL (Extract, Transform, Load) and its modern counterpart, ELT (Extract, Load, Transform). Understanding the methodologies for getting data from various sources, cleaning and transforming it, and loading it into a destination is core.
Familiarity with dedicated ETL/ELT tools (e.g., Apache Nifi, Talend, Fivetran, Stitch) and modern data transformation tools like dbt (data build tool), which emphasizes SQL-based transformations within the data warehouse, is crucial.
4. Big Data Frameworks (Apache Spark & Hadoop Ecosystem)
When dealing with petabytes of data, traditional processing methods fall short. Apache Spark is the industry standard for distributed computing, enabling fast, large-scale data processing and analytics. Mastery of Spark (PySpark, Scala Spark) is vital for batch and stream processing.
While less prominent for direct computation, understanding the Hadoop Ecosystem (especially HDFS for distributed storage and YARN for resource management) still provides a foundational context for many big data architectures.
5. Cloud Platform Proficiency (AWS, Azure, GCP)
The cloud is the default environment for modern data infrastructures. Data engineers must be proficient in at least one, if not multiple, major cloud platforms:
AWS: S3 (storage), Redshift (data warehouse), Glue (ETL), EMR (Spark/Hadoop), Lambda (serverless functions), Kinesis (streaming).
Azure: Azure Data Lake Storage, Azure Synapse Analytics (data warehouse), Azure Data Factory (ETL), Azure Databricks.
GCP: Google Cloud Storage, BigQuery (data warehouse), Dataflow (stream/batch processing), Dataproc (Spark/Hadoop).
Understanding cloud-native services for storage, compute, networking, and security is paramount.
6. Data Warehousing & Data Lake Concepts
A deep understanding of how to structure and manage data for analytical purposes is critical. This includes:
Data Warehousing: Dimensional modeling (star and snowflake schemas), Kimball vs. Inmon approaches, fact and dimension tables.
Data Lakes: Storing raw, unstructured, and semi-structured data at scale, understanding formats like Parquet and ORC, and managing data lifecycle.
Data Lakehouses: The emerging architecture combining the flexibility of data lakes with the structure of data warehouses.
7. NoSQL Databases
While SQL handles structured data efficiently, many modern applications generate unstructured or semi-structured data. Data engineers need to understand NoSQL databases and when to use them.
Familiarity with different NoSQL types (Key-Value, Document, Column-Family, Graph) and examples like MongoDB, Cassandra, Redis, DynamoDB, or Neo4j is increasingly important.
8. Orchestration & Workflow Management (Apache Airflow)
Data pipelines are often complex sequences of tasks. Tools like Apache Airflow are indispensable for scheduling, monitoring, and managing these workflows programmatically using Directed Acyclic Graphs (DAGs). This ensures pipelines run reliably, efficiently, and alert you to failures.
9. Data Governance, Quality & Security
Building pipelines isn't enough; the data flowing through them must be trustworthy and secure. Data engineers are increasingly responsible for:
Data Quality: Implementing checks, validations, and monitoring to ensure data accuracy, completeness, and consistency. Tools like Great Expectations are gaining traction.
Data Governance: Understanding metadata management, data lineage, and data cataloging.
Data Security: Implementing access controls (IAM), encryption, and ensuring compliance with regulations (e.g., GDPR, local data protection laws).
10. Version Control (Git)
Just like software developers, data engineers write code. Proficiency with Git (and platforms like GitHub, GitLab, Bitbucket) is fundamental for collaborative development, tracking changes, managing different versions of pipelines, and enabling CI/CD practices for data infrastructure.
Beyond the Technical: Essential Soft Skills
While technical prowess is crucial, the most effective data engineers also possess strong soft skills:
Problem-Solving: Identifying and resolving complex data issues.
Communication: Clearly explaining complex technical concepts to non-technical stakeholders and collaborating effectively with data scientists and analysts.
Attention to Detail: Ensuring data integrity and pipeline reliability.
Continuous Learning: The data landscape evolves rapidly, demanding a commitment to staying updated with new tools and technologies.
The demand for skilled data engineers continues to soar as organizations increasingly rely on data for competitive advantage. By mastering these 10 essential skills, you won't just build data pipelines; you'll build the backbone of tomorrow's intelligent enterprises.
0 notes
Text
10 Advanced SQL Queries You Must Know for Interviews.
1️. Window Functions These let you rank or number rows without losing the entire dataset. Great for things like ranking employees by salary or showing top results per group.

2️. CTEs (Common Table Expressions) Think of these as temporary tables or “to-do lists” that make complex queries easier to read and manage.
3️.Recursive Queries Used to work with hierarchical data like organizational charts or nested categories by processing data layer by layer.
4️. Pivoting Data This means turning rows into columns to better summarize and visualize data in reports.
5️. COALESCE A handy way to replace missing or null values with something meaningful, like “No Phone” instead of blank.
6️. EXISTS & NOT EXISTS Quick ways to check if related data exists or doesn’t, without retrieving unnecessary data.
7️. CASE Statements Add conditional logic inside queries, like “if this condition is true, then do that,” to categorize or transform data on the fly.
8️. GROUP BY + HAVING Summarize data by groups, and filter those groups based on conditions, like departments with more than a certain number of employees.
9️. Subqueries in SELECT Embed small queries inside bigger ones to calculate additional info per row, such as an average salary compared to each employee’s salary.
EXPLAIN A tool to analyze how your query runs behind the scenes so you can spot and fix performance issues.
Mastering these concepts will make you stand out in interviews and help you work smarter with data in real life.
0 notes
Text
Master the Database Game: Why an Advanced SQL Training Course is Your Next Smart Move
Every time you stream a show, buy a product, or log in to an app, a SQL query is working behind the scenes. Basic SQL gets you into the game, but to truly compete in today’s data-driven landscape, an advanced SQL training course gives you the edge. It helps you move from writing simple SELECT statements to building complex queries, optimizing performance, and solving real-world business problems.
In today’s job market, employers aren’t just looking for “SQL knowledge”—they want people who can write efficient queries, understand indexing, and even perform data engineering tasks. Advanced SQL isn’t just for database administrators anymore. If you’re a data analyst, backend developer, or aspiring data scientist, it’s the difference between being average and becoming indispensable.
What Sets Advanced SQL Apart
So what makes an advanced SQL training course so different from beginner tutorials? One word: depth. You’ll learn to write recursive queries, use window functions like ROW_NUMBER and RANK, and master Common Table Expressions (CTEs). These tools allow you to manipulate data with surgical precision and write cleaner, more scalable code.
Moreover, advanced SQL introduces you to query optimization—learning how the database engine thinks. You’ll explore execution plans, indexes, and strategies for reducing query time from minutes to milliseconds. This kind of performance tuning is critical when working with large datasets, especially in enterprise-level applications.
Real Projects, Real Impact
The best advanced SQL training course doesn’t rely on textbook data like “employees” or “orders.” Instead, it immerses you in real-world scenarios. You’ll build queries that support sales pipelines, analyze customer churn, or power financial dashboards. These exercises mimic the pressure and complexity you’ll face on the job.
Not only does this make the learning experience richer, but it also builds your portfolio. Completing hands-on assignments means you’ll leave the course with code samples to show future employers, and more importantly, the confidence to tackle data challenges independently.
Choosing the Right Course
With so many courses online, how do you pick the right one? Start by checking the syllabus. A high-quality advanced SQL training course covers subqueries, joins optimization, indexing strategies, and advanced filtering using analytic functions. Bonus points if it includes real-time assignments or live sessions with industry mentors.
Also, consider the learning platform. Is there a community forum or mentor support? Are you getting just videos or interactive labs too? Reviews and alumni feedback also speak volumes. Remember, the best course is the one that keeps you engaged, challenges you, and provides practical value.
Your Career After Mastering Advanced SQL
SQL is often underestimated, yet it’s the backbone of most modern tech stacks. After completing an advanced SQL training course, you become eligible for more specialized roles—think Data Engineer, Database Developer, or BI Analyst. Many professionals even use it as a springboard into fields like machine learning or big data analytics.
In short, investing in SQL is a long-term career bet. You’re not just learning syntax—you’re becoming a data problem solver. That’s a skill that transcends job titles and opens doors across industries, from tech startups to global banks.
0 notes
Text
In today’s digital era, database performance is critical to the overall speed, stability, and scalability of modern applications. Whether you're running a transactional system, an analytics platform, or a hybrid database structure, maintaining optimal performance is essential to ensure seamless user experiences and operational efficiency.
In this blog, we'll explore effective strategies to improve database performance, reduce latency, and support growing data workloads without compromising system reliability.
1. Optimize Queries and Use Prepared Statements
Poorly written SQL queries are often the root cause of performance issues. Long-running or unoptimized queries can hog resources and slow down the entire system. Developers should focus on:
Using EXPLAIN plans to analyze query execution paths
Avoiding unnecessary columns or joins
Reducing the use of SELECT *
Applying appropriate filters and limits
Prepared statements can also boost performance by reducing parsing overhead and improving execution times for repeated queries.
2. Leverage Indexing Strategically
Indexes are powerful tools for speeding up data retrieval, but improper use can lead to overhead during insert and update operations. Indexes should be:
Applied selectively to frequently queried columns
Monitored for usage and dropped if rarely used
Regularly maintained to avoid fragmentation
Composite indexes can also be useful when multiple columns are queried together.
3. Implement Query Caching
Query caching can drastically reduce response times for frequent reads. By storing the results of expensive queries temporarily, you avoid reprocessing the same query multiple times. However, it's important to:
Set appropriate cache lifetimes
Avoid caching volatile or frequently changing data
Clear or invalidate cache when updates occur
Database proxy tools can help with intelligent query caching at the SQL layer.
4. Use Connection Pooling
Establishing database connections repeatedly consumes both time and resources. Connection pooling allows applications to reuse existing database connections, improving:
Response times
Resource management
Scalability under load
Connection pools can be fine-tuned based on application traffic patterns to ensure optimal throughput.
5. Partition Large Tables
Large tables with millions of records can suffer from slow read and write performance. Partitioning breaks these tables into smaller, manageable segments based on criteria like range, hash, or list. This helps:
Speed up query performance
Reduce index sizes
Improve maintenance tasks such as vacuuming or archiving
Partitioning also simplifies data retention policies and backup processes.
6. Monitor Performance Metrics Continuously
Database monitoring tools are essential to track performance metrics in real time. Key indicators to watch include:
Query execution time
Disk I/O and memory usage
Cache hit ratios
Lock contention and deadlocks
Proactive monitoring helps identify bottlenecks early and prevents system failures before they escalate.
7. Ensure Hardware and Infrastructure Support
While software optimization is key, underlying infrastructure also plays a significant role. Ensure your hardware supports current workloads by:
Using SSDs for faster data access
Scaling vertically (more RAM/CPU) or horizontally (sharding) as needed
Optimizing network latency for remote database connections
Cloud-native databases and managed services also offer built-in scaling options for dynamic workloads.
8. Regularly Update and Tune the Database Engine
Database engines release frequent updates to fix bugs, enhance performance, and introduce new features. Keeping your database engine up-to-date ensures:
Better performance tuning options
Improved security
Compatibility with modern application architectures
Additionally, fine-tuning engine parameters like buffer sizes, parallel execution, and timeout settings can significantly enhance throughput.
0 notes
Text
SQL Injection
perhaps, the direct association with the SQLi is:
' OR 1=1 -- -
but what does it mean?
Imagine, you have a login form with a username and a password. Of course, it has a database connected to it. When you wish a login and submit your credentials, the app sends a request to the database in order to check whether your data is correct and is it possible to let you in.
the following PHP code demonstrates a dynamic SQL query in a login from. The user and password variables from the POST request is concatenated directly into the SQL statement.
$query ="SELECT * FROM users WHERE username='" +$_POST["user"] + "' AND password= '" + $_POST["password"]$ + '";"
"In a world of locked rooms, the man with the key is king",
and there is definitely one key as a SQL statement:
' OR 1=1-- -
supplying this value inside the name parameter, the query might return more than one user.
most applications will process the first user returned, meaning that the attacker can exploit this and log in as the first user the query returned
the double-dash (--) sequence is a comment indicator in SQL and causes the rest of the query to be commented out
in SQL, a string is enclosed within either a single quote (') or a double quote ("). The single quote (') in the input is used to close the string literal.
If the attacker enters ' OR 1=1-- - in the name parameter and leaves the password blank, the query above will result in the following SQL statement:
SELECT * FROM users WHERE username = '' OR 1=1-- -' AND password = ''
executing the SQL statement above, all the users in the users table are returned -> the attacker bypasses the application's authentication mechanism and is logged in as the first user returned by the query.
The reason for using -- - instead of -- is primarily because of how MySQL handles the double-dash comment style: comment style requires the second dash to be followed by at least one whitespace or control character (such as a space, tab, newline, and so on). The safest solution for inline SQL comment is to use --<space><any character> such as -- - because if it is URL-encoded into --%20- it will still be decoded as -- -.
4 notes
·
View notes
Text
WordPress aufräumen: So entlarvst du ungenutzte Dateien mit Python

In diesem Beitrag möchte ich dir gerne einen Weg aufzeigen, wie du sehr einfach und ebenso sicher nicht verwendete Dateien in deiner WordPress-Instanz finden kannst. Du benötigst dafür ein wenig technisches Verständnis – aber keine Sorge: Ich nehme dich an die Hand und führe dich Schritt für Schritt durch den gesamten Prozess. https://youtu.be/T3iVrIGbtl8 Der Bedarf für diese Lösung entstand aus einem ganz praktischen Grund: Mein eigener Blog hat mittlerweile satte 174.000 Dateien angesammelt – da wird es höchste Zeit, etwas auszumisten und wieder Platz auf dem Server zu schaffen. Für das Finden von nicht benötigten Dateien unter WordPress gibt es diverse Plugins. Diese haben jedoch alle den Nachteil, dass sie direkt auf der WordPress-Instanz laufen, Systemressourcen verbrauchen und – wie viele Kommentare zeigen – nicht immer zuverlässig oder sicher funktionieren. Daher habe ich mir folgenden Weg überlegt: Ich exportiere die WordPress-Beiträge als JSON-Datei mit den wichtigsten Feldern (ID, Titel, Inhalt). Anschließend lade ich das Upload-Verzeichnis herunter und lasse ein Python-Skript prüfen, ob die Dateien in den Beiträgen referenziert werden. Alle nicht gefundenen Dateien können theoretisch als ungenutzt eingestuft und anschließend überprüft oder gelöscht werden. ⚠️ Wichtiger Hinweis: Ich empfehle dir dringend, vor dem Löschen von Dateien ein vollständiges Backup deiner WordPress-Instanz anzulegen. Idealerweise testest du die Löschung zunächst in einer Staging-Umgebung oder auf einer Kopie deiner Seite. In seltenen Fällen kann es vorkommen, dass Dateien fälschlich als ungenutzt erkannt werden – insbesondere wenn sie über PageBuilder, Custom Fields oder Medien-IDs referenziert werden.
Warum bestehende Plugins nicht immer zuverlässig arbeiten
Es gibt diverse Plugins wie Media Cleaner, DNUI (Delete Not Used Image) oder ähnliche, die versprechen, ungenutzte Mediendateien automatisch zu erkennen und zu löschen. Grundsätzlich eine praktische Idee – doch in den Kommentaren dieser Plugins häufen sich Berichte über falsch gelöschte Dateien, die offenbar doch noch in Verwendung waren. Die Wiederherstellung solcher Dateien ist oft aufwendig und erfordert entweder Backups oder manuelle Nacharbeit. Meine Lösung setzt daher auf einen anderen Ansatz: Sie analysiert die Inhalte kontrolliert und nachvollziehbar außerhalb des WordPress-Systems – und ist damit deutlich sicherer und transparenter.
Schritt 1 – Export der Tabelle wp_posts als JSON
Als Erstes werden die Spalten ID, post_title und post_content aus der WordPress-Tabelle wp_posts exportiert. Der Tabellenpräfix wp_ kann bei dir abweichen – diesen findest du in der Datei wp-config.php unter: $table_prefix = 'wp_'; In manchen Fällen sind mehrere WordPress-Instanzen in einer Datenbank vorhanden. Achte also darauf, den richtigen Präfix zu verwenden. Der Export über phpMyAdmin ist dabei besonders einfach: Du führst lediglich ein SELECT-Statement aus, das dir die relevanten Inhalte liefert. Der eigentliche Export als JSON erfolgt über die integrierte Exportfunktion. SQL-Statement: SELECT ID as "id", post_title as 'Titel', post_content as 'Content' FROM wp_posts WHERE post_type in ('page', 'post'); Wenn du dieses SQL-Statement in phpMyAdmin ausführst, erscheint eine Tabelle mit den Ergebnissen. Scrolle nun ganz nach unten – dort findest du den Link „Exportieren“. Ein Klick darauf öffnet eine neue Seite, auf der du den Exporttyp von SQL auf JSON umstellst. Danach nur noch mit OK bestätigen, und der Export startet.


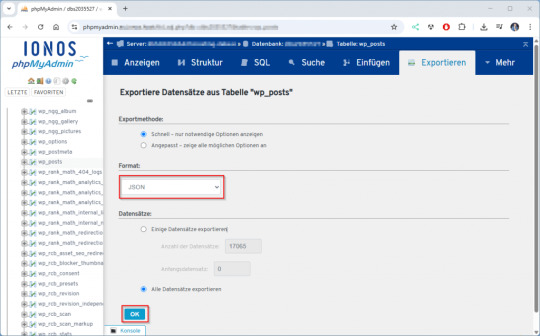
Je nach Anzahl der Beiträge kann der Download ein paar Sekunden dauern.
Schritt 2 – Download des Upload-Verzeichnisses
Im zweiten Schritt wird das komplette Upload-Verzeichnis deiner WordPress-Installation heruntergeladen. Dieses befindet sich standardmäßig unter: /wp-content/uploads/ Ich verwende dafür das kostenlose Tool WinSCP, das eine einfache und übersichtliche Oberfläche bietet. Du benötigst lediglich die SFTP-Zugangsdaten zu deinem Webspace. Diese findest du in der Regel im Kundenbereich deines Hosting-Anbieters. Falls dir kein direkter Zugriff per SFTP möglich ist, bieten viele Hoster eine alternative Lösung an: Du kannst das Verzeichnis online als ZIP-Archiv erstellen und anschließend herunterladen. 💡 Tipp: Achte darauf, die Ordnerstruktur beizubehalten – das Python-Skript analysiert später jede Datei im Originalpfad.
Schritt 3 – Ausführen des Python-Skripts zur Suche nach verwaisten Bildern
Für das Skript wird lediglich Python 3 benötigt – weitere externe Bibliotheken sind nicht erforderlich. Das Skript kann direkt über die Kommandozeile im Projektverzeichnis ausgeführt werden: python3 findunusedfiles.py Während der Ausführung listet das Skript alle Bilder aus dem Upload-Verzeichnis auf und zeigt direkt in der Konsole an, ob sie verwendet (✅) oder nicht verwendet (❌) wurden. Die Laufzeitausgabe sieht zum Beispiel so aus:

Nach Abschluss wird eine Datei namens unused_images.txt erzeugt. Darin enthalten ist eine Liste aller Bildpfade, die im Export der WordPress-Datenbank (siehe Schritt 1) nicht referenziert wurden.
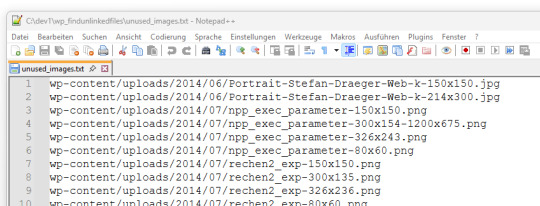
Diese Datei dient als Grundlage zur manuellen Prüfung oder zum späteren Löschen der nicht verwendeten Dateien. 🔗 Hinweis: Das hier verwendete Skript findunusedfiles.py sowie ein Beispiel-SQL-Generator findest du ebenfalls auf GitHub: github.com/StefanDraeger/wp-unused-files-cleaner Python Skript zur Suche nach nicht benutzen Bildern in wordPressHerunterladen Quellcode #!/usr/bin/env python3 # -*- coding: utf-8 -*- """ Titel: WordPress Upload-Verzeichnis auf ungenutzte Dateien prüfen Beschreibung: Dieses Skript durchsucht das lokale Upload-Verzeichnis einer WordPress-Installation nach Bilddateien und vergleicht diese mit den Inhalten aller Beiträge und Seiten, die zuvor als JSON-Datei aus der Tabelle `wp_posts` exportiert wurden. Dateien, die in keinem Beitrag referenziert sind, werden als potenziell ungenutzt gelistet. Autor: Stefan Draeger Webseite: https://draeger-it.blog """ import os import json import sys # Konfiguration UPLOADS_DIR = './wp-content/uploads' JSON_FILE = './wp_posts.json' IMAGE_EXTENSIONS = ('.jpg', '.jpeg', '.png', '.tiff', '.bmp') def format_size(bytes_value): if bytes_value < 1024: return f"{bytes_value} Bytes" elif bytes_value < 1024 ** 2: return f"{bytes_value / 1024:.2f} KB" elif bytes_value < 1024 ** 3: return f"{bytes_value / (1024 ** 2):.2f} MB" else: return f"{bytes_value / (1024 ** 3):.2f} GB" def load_json_data(json_file): if not os.path.isfile(json_file): print(f"❌ Fehler: Datei '{json_file}' nicht gefunden.") sys.exit(1) try: with open(json_file, 'r', encoding='utf-8') as file: raw_json = json.load(file) except json.JSONDecodeError: print(f"❌ Fehler: Datei '{json_file}' ist kein gültiges JSON.") sys.exit(1) for obj in raw_json: if obj.get('type') == 'table' and obj.get('name') == 'wp_posts': return obj.get('data', ) print("❌ Fehler: Keine Daten zur Tabelle 'wp_posts' gefunden.") sys.exit(1) def scan_uploads(content_list): if not os.path.isdir(UPLOADS_DIR): print(f"❌ Fehler: Upload-Verzeichnis '{UPLOADS_DIR}' nicht gefunden.") sys.exit(1) unused_files = checked_count = 0 for root, dirs, files in os.walk(UPLOADS_DIR): for file_name in files: if file_name.lower().endswith(IMAGE_EXTENSIONS): full_path = os.path.join(root, file_name) relative_path = os.path.relpath(full_path, '.').replace('', '/') checked_count += 1 found = False for i in range(len(content_list)): if relative_path in content_list: content_list = content_list.replace(relative_path, '') found = True if found: content_list = print(f"✅ Verwendet: {relative_path}") else: unused_files.append(relative_path) print(f"❌ Nicht verwendet: {relative_path}") return unused_files, checked_count def write_unused_list(unused_files): with open('unused_images.txt', 'w', encoding='utf-8') as f: for path in unused_files: f.write(path + 'n') print("📝 Datei 'unused_images.txt' wurde erstellt.") def write_sql_files(unused_files): with open('delete_attachments.sql', 'w', encoding='utf-8') as del_out: del_out.write("-- SQL-Befehl zum Löschen verwaister Medien aus wp_posts (Typ: attachment)nn") del_out.write("DELETE FROM wp_postsnWHERE post_type = 'attachment'nAND guid IN (n") for i, path in enumerate(unused_files): end = ",n" if i < len(unused_files) - 1 else "n" del_out.write(f" '{path}'{end}") del_out.write(");n") print("🗑️ Datei 'delete_attachments.sql' wurde erzeugt.") with open('select_attachments.sql', 'w', encoding='utf-8') as sel_out: sel_out.write("-- SQL-Befehl zur Prüfung verwaister Medien aus wp_posts (Typ: attachment)nn") sel_out.write("SELECT ID, guid FROM wp_postsnWHERE post_type = 'attachment'nAND guid IN (n") for i, path in enumerate(unused_files): end = ",n" if i < len(unused_files) - 1 else "n" sel_out.write(f" '{path}'{end}") sel_out.write(");n") print("🔍 Datei 'select_attachments.sql' wurde erzeugt.") def write_log(unused_files, checked_count): total_size_bytes = sum( os.path.getsize(os.path.join('.', path)) for path in unused_files if os.path.isfile(os.path.join('.', path)) ) formatted_size = format_size(total_size_bytes) with open('cleanup_log.txt', 'w', encoding='utf-8') as log: log.write("📄 Ausführungsprotokoll – WordPress Dateiaufräumungn") log.write("==================================================nn") log.write(f"📦 Verarbeitete Dateien: {checked_count}n") log.write(f"🗂️ Ungenutzte Dateien gefunden: {len(unused_files)}n") log.write(f"💾 Speicherverbrauch (gesamt): {formatted_size}nn") log.write("📝 Die folgenden Dateien wurden erstellt:n") log.write("- unused_images.txtn") log.write("- delete_attachments.sqln") log.write("- select_attachments.sqln") print("🧾 Logdatei 'cleanup_log.txt' wurde erstellt.") def main(): entries = load_json_data(JSON_FILE) content_list = unused_files, checked_count = scan_uploads(content_list) print("nAnalyse abgeschlossen.") print(f"Geprüfte Dateien: {checked_count}") print(f"Nicht referenzierte Dateien: {len(unused_files)}n") if unused_files: print("⚠️ Nicht referenzierte Bilddateien:") for path in unused_files: print(path) write_unused_list(unused_files) write_sql_files(unused_files) write_log(unused_files, checked_count) if __name__ == "__main__": main()
Schritt 4 – Aufräumen der WordPress-Datenbank
⚠️ Wichtiger Hinweis vorab: Bevor du Änderungen an deiner Datenbank vornimmst, solltest du ein vollständiges Backup deiner WordPress-Datenbank erstellen. So kannst du im Fall eines Fehlers jederzeit alles wiederherstellen. WordPress speichert alle hochgeladenen Medien – also auch Bilder – in der Tabelle wp_posts. Dabei handelt es sich um Einträge mit dem Post-Typ attachment, wobei in der Spalte guid der Pfad zur Datei gespeichert ist. Wenn du mit dem Python-Skript verwaiste Bilder identifiziert und vielleicht schon gelöscht hast, verbleiben deren Einträge trotzdem in der WordPress-Mediathek. Diese kannst du gezielt aus der Datenbank entfernen. Vorgehen: - Öffne die Datei unused_images.txt, die du im vorherigen Schritt erhalten hast. - Jeder darin aufgeführte Pfad (z. B. wp-content/uploads/2023/08/beispiel.jpg) lässt sich mit einem einfachen SQL-Befehl entfernen: DELETE FROM wp_posts WHERE post_type = 'attachment' AND guid LIKE '%wp-content/uploads/2023/08/beispiel.jpg'; - Um diese Aufgabe bei vielen Dateien zu automatisieren, kannst du folgendes Python-Skript nutzen. Es erstellt dir aus unused_images.txt eine vollständige SQL-Datei mit allen nötigen Löschbefehlen: # generate_delete_sql.py with open('unused_images.txt', 'r', encoding='utf-8') as infile, open('delete_attachments.sql', 'w', encoding='utf-8') as outfile: outfile.write("-- SQL-Befehle zum Löschen verwaister Medien aus wp_posts (Typ: attachment)nn") for line in infile: path = line.strip() if path: outfile.write(f"DELETE FROM wp_posts WHERE post_type = 'attachment' AND guid LIKE '%{path}';n") - Führe die generierte Datei delete_attachments.sql anschließend in phpMyAdmin oder über ein externes SQL-Tool aus. Optional: Erst prüfen, dann löschen Wenn du sicherstellen willst, dass die Statements korrekt sind, kannst du sie vor dem Löschen zunächst mit SELECT testen: SELECT ID, guid FROM wp_posts WHERE post_type = 'attachment' AND guid LIKE '%wp-content/uploads/2023/08/beispiel.jpg'; Mit diesem Schritt entfernst du nicht nur die Bilddateien selbst, sondern auch die dazugehörigen Mediathek-Einträge – für eine wirklich aufgeräumte WordPress-Installation.
Aufräumen via SSH
⚠️ Wichtiger Sicherheitshinweis: Bevor du Dateien vom Server löschst, solltest du unbedingt ein vollständiges Backup deiner WordPress-Installation und der Datenbank anlegen. In seltenen Fällen können Dateien fälschlich als ungenutzt erkannt werden – z. B. wenn sie über PageBuilder, Shortcodes oder Custom Fields eingebunden sind. Teste den Löschvorgang idealerweise zuerst in einer Staging-Umgebung. Wenn du Zugriff auf deinen Webserver per SSH hast, kannst du die ungenutzten Dateien aus der Datei unused_images.txt direkt automatisiert löschen – ohne mühsames Durchklicken per Hand. Voraussetzungen: - Die Datei unused_images.txt befindet sich auf dem Server (z. B. via WinSCP oder scp hochgeladen). - Du befindest dich im WordPress-Stammverzeichnis oder die Pfade in der Datei stimmen relativ zur aktuellen Position. Optional: Dry-Run vor dem Löschen Damit du vorab prüfen kannst, ob die Dateien wirklich existieren: while IFS= read -r file; do if ; then echo "Würde löschen: $file" else echo "❌ Nicht gefunden: $file" fi done < unused_images.txt Dateien sicher löschen (nach manueller Prüfung) while IFS= read -r file; do if ; then rm "$file" echo "✅ Gelöscht: $file" fi done < unused_images.txt Optional: Löschvorgang protokollieren while IFS= read -r file; do if ; then rm "$file" echo "$(date +"%F %T") Gelöscht: $file" >> deleted_files.log fi done < unused_images.txt
Fazit
Ein überfülltes Upload-Verzeichnis ist nicht nur unübersichtlich, sondern kann auch unnötig Speicherplatz und Backup-Zeit kosten. Mit dem hier vorgestellten Ansatz hast du eine sichere, transparente und Plugin-freie Lösung, um gezielt ungenutzte Dateien in deiner WordPress-Installation zu identifizieren und aufzuräumen. Durch die Kombination aus Datenbank-Export, Python-Skript und optionaler Löschung via SSH behältst du die volle Kontrolle – und vermeidest die Risiken automatischer Plugin-Löschungen. Zudem hast du mit den generierten SQL-Dateien und dem Log eine solide Dokumentation deines Bereinigungsprozesses. 💡 Tipp zum Schluss: Behalte die Anzahl deiner Medien im Blick, deaktiviere nicht benötigte Thumbnails und führe diese Art von Aufräumaktion regelmäßig durch – so bleibt dein System langfristig sauber und performant. Read the full article
0 notes