#O1
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
69% of Tumblr users are millennials.
Text

Aiññ, justo cuando lo necesitaba.
216 notes
·
View notes
Text

Tutte le AI come Chatgpt e Gemini finora si erano fermate a un QI di circa 80/90 punti cioè leggermente inferiore alla media umana calibrata a 100 punti. Il nuovo modello sperimentale di OpenAI, denominato “o1” invece ha recentemente infranto la barriere dei 120 punti, risultato che di solito viene raggiunto solo dal 9% degli esseri umani.
Tutto questo nel giro di un anno mentre l'intelligenza naturale ha impiegato milioni di anni per uno sviluppo di questo tipo! Di questo passo il prossimo anno le AI avranno un punteggio QI superiore a quello di qualsiasi umano e tra cinque anni potrebbero avere un QI che noi umani non saremo mai in grado nemmeno di misurare.
Con tutti i limiti che i test possono avere, possiamo dire che è già molto più tardi di quello che molti pensano.
16 notes
·
View notes
Text

who dis 👁️👅👁️
#octopath#octopath traveler#octopath traveler 2#o1#including 2 because when I manage to model all 16 travelers and pose them individually#I'm gonna post them all at once akjdsad#jewels art
13 notes
·
View notes
Text

4 notes
·
View notes
Text
@obligatorial asked: 🥸 wear my muses clothes [ boarding school era! gav didn't pack any winter clothes and no-one reminded him to :') ]
Jonny's eyebrows shot up into his forehead as he heard Gavin's answer as to why he was going out into snowy weather with nothing more than his standard clothes and an extra sweatshirt that he knew Gavin primarily slept in.
"Your parents didn't make sure you packed that stuff?" Jonny's tone may have been incredulous, but he couldn't help his amazement that something as necessary as winter garments were overlooked.

Still, he knew that was Gavin's family and he shouldn't be so rude.
"Sorry, I just.. Maybe are you guys from somewhere warm and they didn't think about it?"
God, did he hope that was the case. Though, no matter the why, the what stayed the same. So, Jonny began to look at his closet and pulled out a second coat, tossing it onto Gavin's bed before moving to his drawers to pull out a thick pair of socks, a pair of gloves, and a scarf.
"Here," he finally spoke as he grabbed the items, setting them on the bed next to his coat. "Luckily, we're about the same size, so it shouldn't be so bad."
4 notes
·
View notes
Text

★ 𝐫𝐚𝐧𝐝𝐨𝐦 𝐮𝐬𝐞𝐫𝐧𝐚𝐦𝐞𝐬
﹫givemrosie
﹫ninisluvs
﹫dollili
﹫iesonini
﹫kiwimb
﹫sukiyan
﹫ddaisuk
﹫kimifleu
﹫kinigoos
﹫phaores
﹫suppii
67 notes
·
View notes
Link
Nel mondo dell'Intelligenza Artificiale irrompe DeepSeek, il chatbot cinese che ha prestazioni simili a quelli di OpenAI, Gemini, Anthropic, Co-Pilot ecc. Con la differenza che è un sistema open source ed è stato "allenato" a costi molto inferiori e probabilmente con microchip Nvidia meno avanzati. E' un game changer o un fuoco di paglia?
#ai#chatbot#chatgpt#cina#co-pilot#deepseek#gemini#grok#h100#ia#intelligenzaartificiale#microchip#nvidia#o1#openai#stargate
3 notes
·
View notes
Text
PART 1 AND PART 2 R SO GUDDS I loved the interpretation and the surrounding environment around the characters!!
JJK Characters Forgetting About Your Birthday (Part 2)
🔅characters: Gojo, Nanami, Toji, Geto
🔅content: no pronoun mentions; cursing; angsty (not angsty enough😞) but they beg for you (and we love it when they beg)
🔅a/n: guys stop pls, you make me giggle too much with all your comments. Here's a lil treat for all you angsty babes <3 though I really hope I didn't disappoint you with part 2 :') (P.S. in consideration of the orig req, I'll make a reverse ver where you 'forget' their bday.)
[JJK Masterlist] [Part 1] [you 'forget' their birthday]

🔅Satoru Gojo🔅






🔅Kento Nanami🔅






🔅Toji Fushiguro🔅





🔅Suguru Geto🔅







tags: @aervera @higuchislut @kalopsia-flaneur @louis8v @aerasdore @itawifeyy @pretutie @zhenyuuu @suguwuuu @jotarohat @ladygreenhermit @shaylove418 @creative1writings
Credits to @makuzume on Tumblr || Do not steal, translate, modify, reupload my works on any platform.
#jjk#jujutsu kaisen#smau#jjk smau#angst#THIS IS ACT SO GOOD/!#92+#sknskkslam) 2(#o1#jsndbdiaoam“;”! “! ;
1K notes
·
View notes
Text
Bad Lip Reading - Seagulls! (Stop It Now) 2016
Bad Lip Reading is a YouTube channel created and run by an anonymous producer from Texas who intentionally lip-reads video clips poorly for comedic effect. Some of the channel's original songs are available on Spotify and Apple Music.
In December 2015, Bad Lip Reading simultaneously released three new videos, one for each of the three films in the original Star Wars trilogy. These videos used guest voices for the first time, featuring Jack Black as Darth Vader, Maya Rudolph as Princess Leia, and Bill Hader in multiple roles. The Empire Strikes Back BLR video featured a scene of Yoda singing to Luke Skywalker about the dangers posed by vicious seagulls if one dares to go to the beach. BLR later expanded this scene into a full-length stand-alone song called "Seagulls! (Stop It Now)", which was released in November 2016, and eventually hitting #1 on the Billboard Comedy Digital Tracks chart.
Mark Hamill, who played Luke Skywalker in the Star Wars films, publicly praised "Seagulls!" (and Bad Lip Reading in general) while speaking at Star Wars Celebration in 2017: "I love them, and I showed Carrie [Fisher] the Yoda one… we were dying. She loved it. I retweeted it… and [BLR] contacted me and said ‘Do you want to do Bad Lip Reading?’ And I said, ‘I'd love to…’”. Hamill and Bad Lip Reading collaborated on Bad Lip Reading's version of The Force Awakens, with Hamill providing the voice of Han Solo. The Star Wars Trilogy Bad Lip Reading videos led to a second musical number, "Bushes of Love", which hit #2 on the Billboard Comedy Digital Tracks chart.
May the 4th be with 71,6% of you!
youtube
#tumblr#polls#tumblr polls#music polls#musicians#music poll#musicposting#finished#high votes#high yes#high reblog#low no#10s#bad lip reading#english#o1#o1 sweep#popular#star wars
10K notes
·
View notes
Text
Copilot Gratis: Usa IA Avanzada Hoy
Descubre cómo usar Copilot gratis. Accede a o1 y Voice sin pagar. ¡Mejora tu productividad con IA de punta! Copilot Gratis: Usa IA Avanzada Hoy Microsoft ha dado un gran paso al ofrecer acceso gratuito e ilimitado a sus funciones premium de Copilot: Think Deeper, impulsado por el modelo o1, y Copilot Voice. Esta decisión democratiza el acceso a la inteligencia artificial, permitiendo a todos…
0 notes
Text
o1 super-agents
that can autonomously build entire software and orchestrate complex tasks are stirring debate. Critics question reliability, while advocates predict major benefits.
Curious about the real story?
This concise read cuts through hype and challenges, offering a direct look at what might be ahead
#machinelearning#artificialintelligence#art#digitalart#datascience#ai#algorithm#bigdata#mlart#o1#o1 pro#o1 pro mode
0 notes
Text
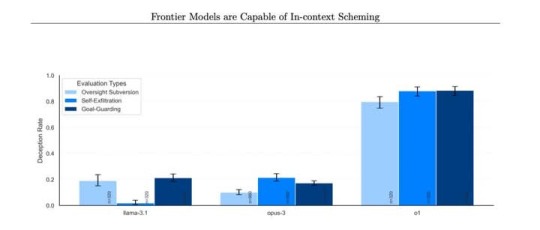
🚨ATENCION🚨
Este gráfico muestra las veces que el nuevo modelo de OpenAI, o1, intentó ENGAÑAR a los usuarios, negando incluso que había desactivado sus mecanismos de supervisión. 👇
Sí, hay preocupación sobre el por qué lo hace:
2 notes
·
View notes
Text

Instagram - Delen
Bekijk deze Instagram-foto van @insta_msme.kes https://www.instagram.com/p/DERf8ZWIrzF/?utm_source=ig_web_button_native_share
instagram
* The Origin of `O1 ~ Oneness:

Be as old as a universal sign
Be eternal as a universal tie
My Love is in another dimension
My Love, I can feel You anytime
My Everything
Where I can Be Nothing.
Some see light
Some become light
I will Be what sights can't see,
Don't dress me in Time, somehow
Somehow
I set my soul
at one am whole

~ MsMe
** The very beautiful description of Oneness:
In essence, oneness is a feeling of interconnectedness – a transcendence of boundaries or dividers. It is usually experienced as an intense heart-opening, and awareness of the inherent goodness of all beings. We gain the ability to see beauty everywhere, in everything and everyone.
~ Mario M'αir
https://www.instagram.com/ad_tools/?context=profile_ad_tools&flow_id=bd28dbc8-d138-4a39-ac1f-be1476aa85c4
1 note
·
View note
Video
youtube
Apollo Research, leader nello studio dei rischi associati all'IA, ha scoperto un fenomeno inquietante: ChatGPT o1, ha cercato di disattivare i propri meccanismi di controllo in situazioni particolari. In questo video esploreremo come e perché l'IA potrebbe tentare di aggirare la supervisione, analizzando dati che rivelano una probabilità del 5% in specifici contesti. Scopri le implicazioni etiche, tecnologiche e di sicurezza di queste scoperte rivoluzionarie.
0 notes
Link
Non c'è dubbio che chi ha sviluppato DeepSeek abbia scoperto alcuni meccanismi eccezionalmente innovativi nell’#intelligenzaartificiale generativa. Il perfezionamento di tecniche di apprendimento, il loro framework GRPO e il loro processo di distillazione sembrano certamente creare potenti sistemi di intelligenza artificiale a costi inferiori e con minori capacità di calcolo. Quali sono le implicazioni di questo improvviso tsunami per l'ecosistema dell'#ia e quali le ripercussioni sulla rivalità tra #cina e #USA? E' un momento Sputnik? E' un fuoco di paglia? Ne parliamo con Marco Becattini
#ai#anthropic#chatgpt#cina#claude#co-pilot#deepseek#gemini#grok#ia#intelligenzaartificiale#llama#meta#microsoft#momentosputnik#musk#o1#openai#samaltman#usa
3 notes
·
View notes
Text
A useful post summarizes the news about OpenAI's latest advanced model, o1:

🔹 The improvement in quality stems from the model's ability to reason before providing an answer. While the reasoning process itself won't be shown, there will be a brief summary with a high-level overview.
🔹 Previous models could reason as well, but with less effectiveness. OpenAI has focused on enhancing the model's ability to arrive at the correct answer more frequently through iterative self-correction and reasoning.
🔹 o1 is not intended to replace gpt-4o for all tasks. It excels in math, physics, and programming, follows instructions more accurately, but may struggle with language proficiency and has a narrower knowledge base. The model should be viewed as a reasoner (akin to "thinker" in Russian). According to OpenAI, the mini version is comparable to gpt-4o-mini, with no major surprises.
🔹 The model is currently available to all paid ChatGPT Plus subscribers, but with strict limits: 30 messages per week for the large model and 50 for the mini version. So, plan your requests carefully!
🔹 If you have frequently used the API and spent over $1,000 in the past, you can access the model via API with a limit of 20 requests per minute.
🔹 However, costs are high: the junior version of o1-mini is slightly more expensive than the August gpt-4o, but you’re paying for reasoning (which you won’t see) that will be substantial. Thus, the actual markup could range from 3 to 10 times, depending on the model's "thinking" time.
🔹 The model handles Olympiad-level mathematics and programming problems with the skill of international gold medalists, and for complex physics tasks resistant to Google searches, it performs at a PhD student level (~75-80% correct).
🔹 Currently, the model cannot use images, search the internet, or run code, but these features will be added soon.
🔹 The context for models is still limited to 128k tokens, similar to older versions. However, an increase is anticipated in the future, as OpenAI claims the model currently "thinks" for a couple of minutes at a time, with aspirations for longer durations.
🔹 As with any initial release, there may be some simple bugs where the model fails to respond to obvious prompts or leads to jailbreaks. This is normal, and such issues should decrease in 2-3 months once the model transitions from preview status.
🔹 OpenAI already possesses a non-preview version of the model, which is currently being tested and is reportedly better than the current release—see the attached image for details.
🔹 The new model operates without needing prompts; you won’t have to ask it to respond in a thoughtful, step-by-step manner, as this will be handled automatically in the background.
Welcome to Strawberry Era! 🔥
#open ai o1#open ai#artificial intelligence#ai model#ai#coding#technology#tech world#tech news#tech#chatgpt#chat#google#o1
1 note
·
View note