#Nvidia HGX
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has 16.74 million mobile monthly users in the US.
Text
Nvidia HGX vs DGX: Key Differences in AI Supercomputing Solutions

Nvidia HGX vs DGX: What are the differences?
Nvidia is comfortably riding the AI wave. And for at least the next few years, it will likely not be dethroned as the AI hardware market leader. With its extremely popular enterprise solutions powered by the H100 and H200 “Hopper” lineup of GPUs (and now B100 and B200 “Blackwell” GPUs), Nvidia is the go-to manufacturer of high-performance computing (HPC) hardware.
Nvidia DGX is an integrated AI HPC solution targeted toward enterprise customers needing immensely powerful workstation and server solutions for deep learning, generative AI, and data analytics. Nvidia HGX is based on the same underlying GPU technology. However, HGX is a customizable enterprise solution for businesses that want more control and flexibility over their AI HPC systems. But how do these two platforms differ from each other?




Nvidia DGX: The Original Supercomputing Platform
It should surprise no one that Nvidia’s primary focus isn’t on its GeForce lineup of gaming GPUs anymore. Sure, the company enjoys the lion’s share among the best gaming GPUs, but its recent resounding success is driven by enterprise and data center offerings and AI-focused workstation GPUs.
Overview of DGX
The Nvidia DGX platform integrates up to 8 Tensor Core GPUs with Nvidia’s AI software to power accelerated computing and next-gen AI applications. It’s essentially a rack-mount chassis containing 4 or 8 GPUs connected via NVLink, high-end x86 CPUs, and a bunch of Nvidia’s high-speed networking hardware. A single DGX B200 system is capable of 72 petaFLOPS of training and 144 petaFLOPS of inference performance.
Key Features of DGX
AI Software Integration: DGX systems come pre-installed with Nvidia’s AI software stack, making them ready for immediate deployment.
High Performance: With up to 8 Tensor Core GPUs, DGX systems provide top-tier computational power for AI and HPC tasks.
Scalability: Solutions like the DGX SuperPOD integrate multiple DGX systems to form extensive data center configurations.
Current Offerings
The company currently offers both Hopper-based (DGX H100) and Blackwell-based (DGX B200) systems optimized for AI workloads. Customers can go a step further with solutions like the DGX SuperPOD (with DGX GB200 systems) that integrates 36 liquid-cooled Nvidia GB200 Grace Blackwell Superchips, comprised of 36 Nvidia Grace CPUs and 72 Blackwell GPUs. This monstrous setup includes multiple racks connected through Nvidia Quantum InfiniBand, allowing companies to scale thousands of GB200 Superchips.
Legacy and Evolution
Nvidia has been selling DGX systems for quite some time now — from the DGX Server-1 dating back to 2016 to modern DGX B200-based systems. From the Pascal and Volta generations to the Ampere, Hopper, and Blackwell generations, Nvidia’s enterprise HPC business has pioneered numerous innovations and helped in the birth of its customizable platform, Nvidia HGX.
Nvidia HGX: For Businesses That Need More
Build Your Own Supercomputer
For OEMs looking for custom supercomputing solutions, Nvidia HGX offers the same peak performance as its Hopper and Blackwell-based DGX systems but allows OEMs to tweak it as needed. For instance, customers can modify the CPUs, RAM, storage, and networking configuration as they please. Nvidia HGX is actually the baseboard used in the Nvidia DGX system but adheres to Nvidia’s own standard.
Key Features of HGX
Customization: OEMs have the freedom to modify components such as CPUs, RAM, and storage to suit specific requirements.
Flexibility: HGX allows for a modular approach to building AI and HPC solutions, giving enterprises the ability to scale and adapt.
Performance: Nvidia offers HGX in x4 and x8 GPU configurations, with the latest Blackwell-based baseboards only available in the x8 configuration. An HGX B200 system can deliver up to 144 petaFLOPS of performance.
Applications and Use Cases
HGX is designed for enterprises that need high-performance computing solutions but also want the flexibility to customize their systems. It’s ideal for businesses that require scalable AI infrastructure tailored to specific needs, from deep learning and data analytics to large-scale simulations.
Nvidia DGX vs. HGX: Summary
Simplicity vs. Flexibility
While Nvidia DGX represents Nvidia’s line of standardized, unified, and integrated supercomputing solutions, Nvidia HGX unlocks greater customization and flexibility for OEMs to offer more to enterprise customers.
Rapid Deployment vs. Custom Solutions
With Nvidia DGX, the company leans more into cluster solutions that integrate multiple DGX systems into huge and, in the case of the DGX SuperPOD, multi-million-dollar data center solutions. Nvidia HGX, on the other hand, is another way of selling HPC hardware to OEMs at a greater profit margin.
Unified vs. Modular
Nvidia DGX brings rapid deployment and a seamless, hassle-free setup for bigger enterprises. Nvidia HGX provides modular solutions and greater access to the wider industry.
FAQs
What is the primary difference between Nvidia DGX and HGX?
The primary difference lies in customization. DGX offers a standardized, integrated solution ready for deployment, while HGX provides a customizable platform that OEMs can adapt to specific needs.
Which platform is better for rapid deployment?
Nvidia DGX is better suited for rapid deployment as it comes pre-integrated with Nvidia’s AI software stack and requires minimal setup.
Can HGX be used for scalable AI infrastructure?
Yes, Nvidia HGX is designed for scalable AI infrastructure, offering flexibility to customize and expand as per business requirements.
Are DGX and HGX systems compatible with all AI software?
Both DGX and HGX systems are compatible with Nvidia’s AI software stack, which supports a wide range of AI applications and frameworks.
Final Thoughts
Choosing between Nvidia DGX and HGX ultimately depends on your enterprise’s needs. If you require a turnkey solution with rapid deployment, DGX is your go-to. However, if customization and scalability are your top priorities, HGX offers the flexibility to tailor your HPC system to your specific requirements.
Muhammad Hussnain Facebook | Instagram | Twitter | Linkedin | Youtube
0 notes
Text
Exploring the Key Differences: NVIDIA DGX vs NVIDIA HGX Systems

A frequent topic of inquiry we encounter involves understanding the distinctions between the NVIDIA DGX and NVIDIA HGX platforms. Despite the resemblance in their names, these platforms represent distinct approaches NVIDIA employs to market its 8x GPU systems featuring NVLink technology. The shift in NVIDIA’s business strategy was notably evident during the transition from the NVIDIA P100 “Pascal” to the V100 “Volta” generations. This period marked the significant rise in prominence of the HGX model, a trend that has continued through the A100 “Ampere” and H100 “Hopper” generations.
NVIDIA DGX versus NVIDIA HGX What is the Difference
Focusing primarily on the 8x GPU configurations that utilize NVLink, NVIDIA’s product lineup includes the DGX and HGX lines. While there are other models like the 4x GPU Redstone and Redstone Next, the flagship DGX/HGX (Next) series predominantly features 8x GPU platforms with SXM architecture. To understand these systems better, let’s delve into the process of building an 8x GPU system based on the NVIDIA Tesla P100 with SXM2 configuration.

DeepLearning12 Initial Gear Load Out
Each server manufacturer designs and builds a unique baseboard to accommodate GPUs. NVIDIA provides the GPUs in the SXM form factor, which are then integrated into servers by either the server manufacturers themselves or by a third party like STH.
DeepLearning12 Half Heatsinks Installed 800
This task proved to be quite challenging. We encountered an issue with a prominent server manufacturer based in Texas, where they had applied an excessively thick layer of thermal paste on the heatsinks. This resulted in damage to several trays of GPUs, with many experiencing cracks. This experience led us to create one of our initial videos, aptly titled “The Challenges of SXM2 Installation.” The difficulty primarily arose from the stringent torque specifications required during the GPU installation process.

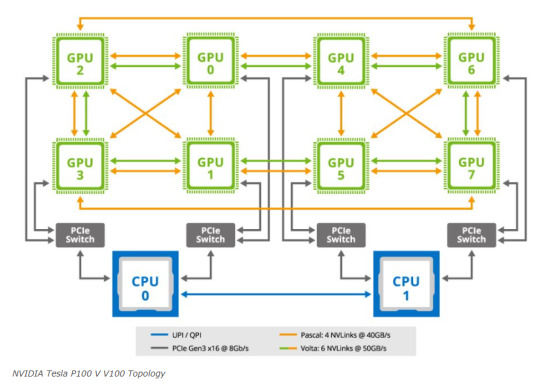
NVIDIA Tesla P100 V V100 Topology
During this development, NVIDIA established a standard for the 8x SXM GPU platform. This standardization incorporated Broadcom PCIe switches, initially for host connectivity, and subsequently expanded to include Infiniband connectivity.
Microsoft HGX 1 Topology
It also added NVSwitch. NVSwitch was a switch for the NVLink fabric that allowed higher performance communication between GPUs. Originally, NVIDIA had the idea that it could take two of these standardized boards and put them together with this larger switch fabric. The impact, though, was that now the NVIDIA GPU-to-GPU communication would occur on NVIDIA NVSwitch silicon and PCIe would have a standardized topology. HGX was born.

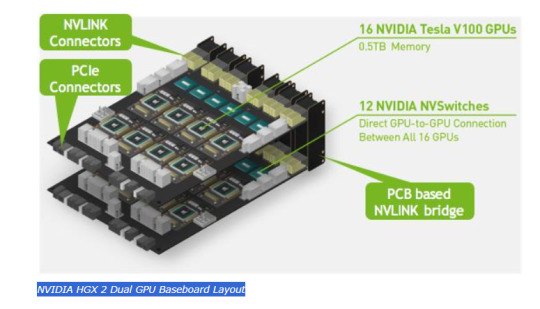
NVIDIA HGX 2 Dual GPU Baseboard Layout
Let’s delve into a comparison of the NVIDIA V100 setup in a server from 2020, renowned for its standout color scheme, particularly in the NVIDIA SXM coolers. When contrasting this with the earlier P100 version, an interesting detail emerges. In the Gigabyte server that housed the P100, one could notice that the SXM2 heatsinks were without branding. This marked a significant shift in NVIDIA’s approach. With the advent of the NVSwitch baseboard equipped with SXM3 sockets, NVIDIA upped its game by integrating not just the sockets but also the GPUs and their cooling systems directly. This move represented a notable advancement in their hardware design strategy.
Consequences
The consequences of this development were significant. Server manufacturers now had the option to acquire an 8-GPU module directly from NVIDIA, eliminating the need to apply excessive thermal paste to the GPUs. This change marked the inception of the NVIDIA HGX topology. It allowed server vendors the flexibility to customize the surrounding hardware as they desired. They could select their preferred specifications for RAM, CPUs, storage, and other components, while adhering to the predetermined GPU configuration determined by the NVIDIA HGX baseboard.
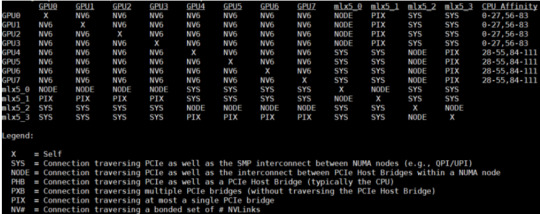
Inspur NF5488M5 Nvidia Smi Topology
This was very successful. In the next generation, the NVSwitch heatsinks got larger, the GPUs lost a great paint job, but we got the NVIDIA A100. The codename for this baseboard is “Delta”. Officially, this board was called the NVIDIA HGX.
Inspur NF5488A5 NVIDIA HGX A100 8 GPU Assembly 8x A100 And NVSwitch Heatsinks Side 2
NVIDIA, along with its OEM partners and clients, recognized that increased power could enable the same quantity of GPUs to perform additional tasks. However, this enhancement came with a drawback: higher power consumption led to greater heat generation. This development prompted the introduction of liquid-cooled NVIDIA HGX A100 “Delta” platforms to efficiently manage this heat issue.

Supermicro Liquid Cooling Supermicro
The HGX A100 assembly was initially introduced with its own brand of air cooling systems, distinctively designed by the company.
In the newest “Hopper” series, the cooling systems were upscaled to manage the increased demands of the more powerful GPUs and the enhanced NVSwitch architecture. This upgrade is exemplified in the NVIDIA HGX H100 platform, also known as “Delta Next”.
NVIDIA DGX H100
NVIDIA’s DGX and HGX platforms represent cutting-edge GPU technology, each serving distinct needs in the industry. The DGX series, evolving since the P100 days, integrates HGX baseboards into comprehensive server solutions. Notable examples include the DGX V100 and DGX A100. These systems, crafted by rotating OEMs, offer fixed configurations, ensuring consistent, high-quality performance.
While the DGX H100 sets a high standard, the HGX H100 platform caters to clients seeking customization. It allows OEMs to tailor systems to specific requirements, offering variations in CPU types (including AMD or ARM), Xeon SKU levels, memory, storage, and network interfaces. This flexibility makes HGX ideal for diverse, specialized applications in GPU computing.


Conclusion
NVIDIA’s HGX baseboards streamline the process of integrating 8 GPUs with advanced NVLink and PCIe switched fabric technologies. This innovation allows NVIDIA’s OEM partners to create tailored solutions, giving NVIDIA the flexibility to price HGX boards with higher margins. The HGX platform is primarily focused on providing a robust foundation for custom configurations.
In contrast, NVIDIA’s DGX approach targets the development of high-value AI clusters and their associated ecosystems. The DGX brand, distinct from the DGX Station, represents NVIDIA’s comprehensive systems solution.
Particularly noteworthy are the NVIDIA HGX A100 and HGX H100 models, which have garnered significant attention following their adoption by leading AI initiatives like OpenAI and ChatGPT. These platforms demonstrate the capabilities of the 8x NVIDIA A100 setup in powering advanced AI tools. For those interested in a deeper dive into the various HGX A100 configurations and their role in AI development, exploring the hardware behind ChatGPT offers insightful perspectives on the 8x NVIDIA A100’s power and efficiency.
M.Hussnain Visit us on social media: Facebook | Twitter | LinkedIn | Instagram | YouTube TikTok
#nvidia#nvidia dgx h100#nvidia hgx#DGX#HGX#Nvidia HGX A100#Nvidia HGX H100#Nvidia H100#Nvidia A100#Nvidia DGX H100#viperatech
0 notes
Text
Elon Musk'ın 100.000 GPU'lu Süper Bilgisayarı İlk Kez Görüntülendi [Video]
Elon Musk’ın montajı 122 gün süren 100.000 GPU’lu süper bilgisayarı xAI Colossus, ilk kez kapılarını açtı. Bir YouTuber, tesisi gezerek görüntülerini paylaştı. Elon Musk’ın yeni projesi xAI Colossus süper bilgisayarı, 100,000 GPU ile donatılmış devasa bir yapay zeka bilgisayarı olarak ilk kez detaylı bir şekilde kameraların önüne çıkarıldı. YouTuber ServeTheHome, süper bilgisayarın…
0 notes
Text
NVIDIA HGX H200 - HBM3e

A NVIDIA anunciou a disponibilização de uma nova plataforma de computação com a designação de HGX H200. Esta nova plataforma é baseada na arquitectura NVIDIA Hopper e utiliza memória HBM3e (um modelo avançado de memória com mais largura de banda e maior capacidade de memória utilizável).
Este é o primeiro modelo a utilizar memória HBM3e, introduzindo outras novidades tecnológicas no processador e na GPU que vão ao encontro das exigências dos mais recentes “modelos de linguagem” complexos e dos projectos de “deep learning”.
A plataforma está optimizada para utilização em Datacenters (centros de dados) e estará comercialmente disponível no segundo semestre de 2024.
Saiba tudo em detalhe na página oficial da NVIDIA localizada em: https://nvidianews.nvidia.com/news/nvidia-supercharges-hopper-the-worlds-leading-ai-computing-platform
______ Direitos de imagem: © NVIDIA Corporation (via NVIDIA Newsroom).
#NVIDIA#AI#IA#processor#processado#gpu#placagrafica#supercomputer#supercomputador#hgx#h200#computing#computacao#platform#plataforma#HBM3e#hmb#llm#deeplearning#learning#languagemodel#modelodelinguagem#language#linguagem#science#ciencia#datacenter#centrodedados
1 note
·
View note
Text
Dell PowerEdge XE9680L Cools and Powers Dell AI Factory

When It Comes to Cooling and Powering Your AI Factory, Think Dell. As part of the Dell AI Factory initiative, the company is thrilled to introduce a variety of new server power and cooling capabilities.
Dell PowerEdge XE9680L Server
As part of the Dell AI Factory, they’re showcasing new server capabilities after a fantastic Dell Technologies World event. These developments, which offer a thorough, scalable, and integrated method of imaplementing AI solutions, have the potential to completely transform the way businesses use artificial intelligence.
These new capabilities, which begin with the PowerEdge XE9680L with support for NVIDIA B200 HGX 8-way NVLink GPUs (graphics processing units), promise unmatched AI performance, power management, and cooling. This offer doubles I/O throughput and supports up to 72 GPUs per rack 107 kW, pushing the envelope of what’s feasible for AI-driven operations.
Integrating AI with Your Data
In order to fully utilise AI, customers must integrate it with their data. However, how can they do this in a more sustainable way? Putting in place state-of-the-art infrastructure that is tailored to meet the demands of AI workloads as effectively as feasible is the solution. Dell PowerEdge servers and software are built with Smart Power and Cooling to assist IT operations make the most of their power and thermal budgets.
Astute Cooling
Effective power management is but one aspect of the problem. Recall that cooling ability is also essential. At the highest workloads, Dell’s rack-scale system, which consists of eight XE9680 H100 servers in a rack with an integrated rear door heat exchanged, runs at 70 kW or less, as we disclosed at Dell Technologies World 2024. In addition to ensuring that component thermal and reliability standards are satisfied, Dell innovates to reduce the amount of power required to maintain cool systems.
Together, these significant hardware advancements including taller server chassis, rack-level integrated cooling, and the growth of liquid cooling, which includes liquid-assisted air cooling, or LAAC improve heat dissipation, maximise airflow, and enable larger compute densities. An effective fan power management technology is one example of how to maximise airflow. It uses an AI-based fuzzy logic controller for closed-loop thermal management, which immediately lowers operating costs.
Constructed to Be Reliable
Dependability and the data centre are clearly at the forefront of Dell’s solution development. All thorough testing and validation procedures, which guarantee that their systems can endure the most demanding situations, are clear examples of this.
A recent study brought attention to problems with data centre overheating, highlighting how crucial reliability is to data centre operations. A Supermicro SYS‑621C-TN12R server failed in high-temperature test situations, however a Dell PowerEdge HS5620 server continued to perform an intense workload without any component warnings or failures.
Announcing AI Factory Rack-Scale Architecture on the Dell PowerEdge XE9680L
Dell announced a factory integrated rack-scale design as well as the liquid-cooled replacement for the Dell PowerEdge XE9680.
The GPU-powered Since the launch of the PowerEdge product line thirty years ago, one of Dell’s fastest-growing products is the PowerEdge XE9680. immediately following the Dell PowerEdge. Dell announced an intriguing new addition to the PowerEdge XE product family as part of their next announcement for cloud service providers and near-edge deployments.
AI computing has advanced significantly with the Direct Liquid Cooled (DLC) Dell PowerEdge XE9680L with NVIDIA Blackwell Tensor Core GPUs. This server, shown at Dell Technologies World 2024 as part of the Dell AI Factory with NVIDIA, pushes the limits of performance, GPU density per rack, and scalability for AI workloads.
The XE9680L’s clever cooling system and cutting-edge rack-scale architecture are its key components. Why it matters is as follows:
GPU Density per Rack, Low Power Consumption, and Outstanding Efficiency
The most rigorous large language model (LLM) training and large-scale AI inferencing environments where GPU density per rack is crucial are intended for the XE9680L. It provides one of the greatest density x86 server solutions available in the industry for the next-generation NVIDIA HGX B200 with a small 4U form factor.
Efficient DLC smart cooling is utilised by the XE9680L for both CPUs and GPUs. This innovative technique maximises compute power while retaining thermal efficiency, enabling a more rack-dense 4U architecture. The XE9680L offers remarkable performance for training large language models (LLMs) and other AI tasks because it is tailored for the upcoming NVIDIA HGX B200.
More Capability for PCIe 5 Expansion
With its standard 12 x PCIe 5.0 full-height, half-length slots, the XE9680L offers 20% more FHHL PCIe 5.0 density to its clients. This translates to two times the capability for high-speed input/output for the North/South AI fabric, direct storage connectivity for GPUs from Dell PowerScale, and smooth accelerator integration.
The XE9680L’s PCIe capacity enables smooth data flow whether you’re managing data-intensive jobs, implementing deep learning models, or running simulations.
Rack-scale factory integration and a turn-key solution
Dell is dedicated to quality over the XE9680L’s whole lifecycle. Partner components are seamlessly linked with rack-scale factory integration, guaranteeing a dependable and effective deployment procedure.
Bid farewell to deployment difficulties and welcome to faster time-to-value for accelerated AI workloads. From PDU sizing to rack, stack, and cabling, the XE9680L offers a turn-key solution.
With the Dell PowerEdge XE9680L, you can scale up to 72 Blackwell GPUs per 52 RU rack or 64 GPUs per 48 RU rack.
With pre-validated rack infrastructure solutions, increasing power, cooling, and AI fabric can be done without guesswork.
AI factory solutions on a rack size, factory integrated, and provided with “one call” support and professional deployment services for your data centre or colocation facility floor.
Dell PowerEdge XE9680L
The PowerEdge XE9680L epitomises high-performance computing innovation and efficiency. This server delivers unmatched performance, scalability, and dependability for modern data centres and companies. Let’s explore the PowerEdge XE9680L’s many advantages for computing.
Superior performance and scalability
Enhanced Processing: Advanced processing powers the PowerEdge XE9680L. This server performs well for many applications thanks to the latest Intel Xeon Scalable CPUs. The XE9680L can handle complicated simulations, big databases, and high-volume transactional applications.
Flexibility in Memory and Storage: Flexible memory and storage options make the PowerEdge XE9680L stand out. This server may be customised for your organisation with up to 6TB of DDR4 memory and NVMe, SSD, and HDD storage. This versatility lets you optimise your server’s performance for any demand, from fast data access to enormous storage.
Strong Security and Management
Complete Security: Today’s digital world demands security. The PowerEdge XE9680L protects data and system integrity with extensive security features. Secure Boot, BIOS Recovery, and TPM 2.0 prevent cyberattacks. Our server’s built-in encryption safeguards your data at rest and in transit, following industry standards.
Advanced Management Tools
Maintaining performance and minimising downtime requires efficient IT infrastructure management. Advanced management features ease administration and boost operating efficiency on the PowerEdge XE9680L. Dell EMC OpenManage offers simple server monitoring, management, and optimisation solutions. With iDRAC9 and Quick Sync 2, you can install, update, and troubleshoot servers remotely, decreasing on-site intervention and speeding response times.
Excellent Reliability and Support
More efficient cooling and power
For optimal performance, high-performance servers need cooling and power control. The PowerEdge XE9680L’s improved cooling solutions dissipate heat efficiently even under intense loads. Airflow is directed precisely to prevent hotspots and maintain stable temperatures with multi-vector cooling. Redundant power supply and sophisticated power management optimise the server’s power efficiency, minimising energy consumption and running expenses.
A proactive support service
The PowerEdge XE9680L has proactive support from Dell to maximise uptime and assure continued operation. Expert technicians, automatic issue identification, and predictive analytics are available 24/7 in ProSupport Plus to prevent and resolve issues before they affect your operations. This proactive assistance reduces disruptions and improves IT infrastructure stability, letting you focus on your core business.
Innovation in Modern Data Centre Design Scalable Architecture
The PowerEdge XE9680L’s scalable architecture meets modern data centre needs. You can extend your infrastructure as your business grows with its modular architecture and easy extension and customisation. Whether you need more storage, processing power, or new technologies, the XE9680L can adapt easily.
Ideal for virtualisation and clouds
Cloud computing and virtualisation are essential to modern IT strategies. Virtualisation support and cloud platform integration make the PowerEdge XE9680L ideal for these environments. VMware, Microsoft Hyper-V, and OpenStack interoperability lets you maximise resource utilisation and operational efficiency with your visualised infrastructure.
Conclusion
Finally, the PowerEdge XE9680L is a powerful server with flexible memory and storage, strong security, and easy management. Modern data centres and organisations looking to improve their IT infrastructure will love its innovative design, high reliability, and proactive support. The PowerEdge XE9680L gives your company the tools to develop, innovate, and succeed in a digital environment.
Read more on govindhtech.com
#DellPowerEdge#XE9680LCools#DellAiFactory#coolingcapabilities#artificialintelligence#NVIDIAB200#DellPowerEdgeservers#PowerEdgeb#DellTechnologies#AIworkloads#cpu#gpu#largelanguagemodel#llm#PCIecapacity#IntelXeonScalableCPU#DDR4memory#memorystorage#Cloudcomputing#technology#technews#news#govindhtech
2 notes
·
View notes
Text
NVIDIA pierde 5.500 millones por restricciones de EE.UU
La tensión comercial entre Estados Unidos y China ha golpeado fuerte a NVIDIA, que reportará una pérdida de 5.500 millones de dólares en el primer trimestre fiscal de 2026. El motivo es la prohibición de exportar sus GPU H20 HGX a China, impuesta por el Departamento de Comercio de EE.UU., que considera que estas GPU podrían ser utilizadas en supercomputadoras, una posibilidad que el país busca…
0 notes
Text
NVIDIA pierde 5.500 millones por restricciones de EE.UU
La tensión comercial entre Estados Unidos y China ha golpeado fuerte a NVIDIA, que reportará una pérdida de 5.500 millones de dólares en el primer trimestre fiscal de 2026. El motivo es la prohibición de exportar sus GPU H20 HGX a China, impuesta por el Departamento de Comercio de EE.UU., que considera que estas GPU podrían ser utilizadas en supercomputadoras, una posibilidad que el país busca…
0 notes
Photo

🚨 Breaking News: Nvidia faces a staggering $7.35 billion CAD write-off due to U.S. export restrictions of H20 GPUs to China! 💥 The latest sanctions from the U.S. government have massively impacted Nvidia, as they struggle with unsold H20 HGX inventories. Designed for AI and supercomputing, these GPUs are now stuck in limbo. Why did this happen? 🤔 The U.S. cited concerns over the H20's memory and interconnect bandwidth that could aid China's supercomputer strategies. In parallel, AMD's Instinct MI308 also fell under these new rules, but with less impact. While these GPUs won’t ship to China, Nvidia is confident they will find homes elsewhere. What's next for Nvidia’s inventory challenge? With these sanctions reshaping the tech landscape, could this bring new opportunities for other markets? 🤔 🔍 Share your thoughts: How should Nvidia pivot with this restriction in place? 📈 #Nvidia #TechExport #AIInnovation #GPUs #Geopolitics #TechNews #Innovation #AI #ExportControls #GamingIndustry #H20GPUs #TradingStrategy
0 notes
Link
0 notes
Text
NVIDIA B200 登場!Supermicro AI 伺服器效能狂飆 3 倍,測試資料公開
Nvidia HGX B200 Systems Supermicro 近期發表最新 AI 伺服器,搭載 NVIDIA HGX B200 8-GPU,在 MLPerf Inference v5.0 測試中展現壓倒性優勢,效能比前一代 H200 提升 3 倍以上。 Continue reading NVIDIA B200 登場!Supermicro AI 伺服器效能狂飆 3 倍,測試資料公開
0 notes
Text
Fluidstack implementará clústeres de GPU de exaescala con alta eficiencia energética en Europa en colaboración con Borealis Data Center, Dell Technologies y NVIDIA
Fluidstack, plataforma de IA en la nube, ha anunciado hoy que está implementando y gestionando clústeres a exaescala en Islandia y Europa junto con Borealis Data Center, Dell Technologies y NVIDIA. Los clústeres permitirán a Fluidstack ampliar su oferta de servicios y podrá satisfacer la fuerte demanda de sus soluciones de inteligencia artificial de clientes de todo el mundo.
«Nuestro propósito ha sido siempre respaldar a los laboratorios de IA, investigadores y empresas más destacadas del mundo», dijo César Maklary, cofundador y presidente de Fluidstack. «En colaboración con Borealis, Dell y NVIDIA, estamos en posición de implementar rápidamente superordenadores GPU de alta densidad para clientes de Europa y del resto del mundo, utilizando exclusivamente energía 100 % renovable.»
Crecimiento sostenible con Borealis
Borealis Data Center, líder en infraestructuras de centros de datos respetuosos con el medio ambiente, facilitará a Fluidstack instalaciones operadas con fuentes de energía 100 % renovable. Ubicadas en Islandia y con presencia en los países nórdicos, las instalaciones de Borealis se benefician de un clima frío y del aprovechamiento de energía hidroeléctrica y geotérmica renovables.
«Esta colaboración pone de manifiesto el compromiso compartido de impulsar la IA de próxima generación, al tiempo que reducimos su impacto medioambiental,» destacó Björn Brynjúlfsson, consejero delegado de Borealis.
Colaboración con Dell Technologies para potenciar cargas de IA avanzadas
Fluidstack aprovechará los servidores Dell PowerEdge XE9680, optimizados para cargas de trabajo de IA con NVIDIA HGX H200. Combinados con la red NVIDIA’s Quantum-2 InfiniBand, estos servidores garantizan un rendimiento superior y una máxima fiabilidad para cargas de trabajo de IA.
«Estamos deseando trabajar con Fluidstack, Borealis y NVIDIA para implementar una infraestructura de IA avanzada y sostenible en toda Europa,» apuntó Arun Narayanan, vicepresidente senior de Computación y Redes de Dell Technologies. «Los servidores Dell PowerEdge XE9680, en combinación con las GPU y las redes de NVIDIA, están diseñados específicamente para gestionar eficientemente las crecientes cargas de trabajo de IA, ayudando a los clientes a lograr una eficiencia y escalabilidad sin precedentes, optimizando costes y reduciendo el consumo de energía.»
Construyendo la columna vertebral de la innovación en IA de Europa
Con la proyección de que el mercado europeo de centros de datos de IA alcance los 29,8 mil millones de dólares en 2026, Fluidstack se posiciona a la vanguardia de la investigación e innovación de IA en todo el continente.
Empresas como Poolside y Character.AI confían en Fluidstack para obtener una implementación ágil y un soporte técnico de primer nivel en sus cargas de IA. Jason Warner, consejero delegado de Poolside, concluyó: «Fluidstack ha sido un socio clave para ayudarnos a ampliar nuestras capacidades de IA. Su velocidad, fiabilidad y atención al cliente son insuperables.»
Fluidstack es la plataforma de IA en la nube creada para las empresas de IA líderes en el mundo. Fundada en 2017 en la Universidad de Oxford, respalda laboratorios de IA líderes como Mistral, Character.AI, Poolside y Black Forest Labs. Con más de 100 000 GPU gestionadas, Fluidstack ofrece acceso rápido a la computación a exaescala en cuestión de días, permitiendo ejecutar cargas de trabajo de entrenamiento e inferencia de miles de GPU sin sobresaltos. Para obtener más información, visite www.fluidstack.io.
0 notes
Text
Exploring the Key Differences: NVIDIA DGX vs NVIDIA HGX Systems

A frequent topic of inquiry we encounter involves understanding the distinctions between the NVIDIA DGX and NVIDIA HGX platforms. Despite the resemblance in their names, these platforms represent distinct approaches NVIDIA employs to market its 8x GPU systems featuring NVLink technology. The shift in NVIDIA’s business strategy was notably evident during the transition from the NVIDIA P100 “Pascal” to the V100 “Volta” generations. This period marked the significant rise in prominence of the HGX model, a trend that has continued through the A100 “Ampere” and H100 “Hopper” generations.
NVIDIA DGX versus NVIDIA HGX What is the Difference
Focusing primarily on the 8x GPU configurations that utilize NVLink, NVIDIA’s product lineup includes the DGX and HGX lines. While there are other models like the 4x GPU Redstone and Redstone Next, the flagship DGX/HGX (Next) series predominantly features 8x GPU platforms with SXM architecture. To understand these systems better, let’s delve into the process of building an 8x GPU system based on the NVIDIA Tesla P100 with SXM2 configuration.

DeepLearning12 Initial Gear Load Out
Each server manufacturer designs and builds a unique baseboard to accommodate GPUs. NVIDIA provides the GPUs in the SXM form factor, which are then integrated into servers by either the server manufacturers themselves or by a third party like STH.
DeepLearning12 Half Heatsinks Installed 800
This task proved to be quite challenging. We encountered an issue with a prominent server manufacturer based in Texas, where they had applied an excessively thick layer of thermal paste on the heatsinks. This resulted in damage to several trays of GPUs, with many experiencing cracks. This experience led us to create one of our initial videos, aptly titled “The Challenges of SXM2 Installation.” The difficulty primarily arose from the stringent torque specifications required during the GPU installation process.
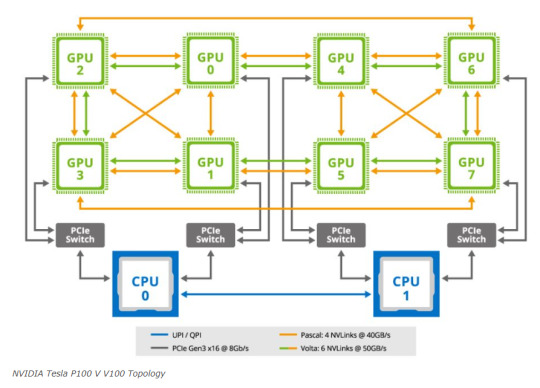
NVIDIA Tesla P100 V V100 Topology
During this development, NVIDIA established a standard for the 8x SXM GPU platform. This standardization incorporated Broadcom PCIe switches, initially for host connectivity, and subsequently expanded to include Infiniband connectivity.
Microsoft HGX 1 Topology
It also added NVSwitch. NVSwitch was a switch for the NVLink fabric that allowed higher performance communication between GPUs. Originally, NVIDIA had the idea that it could take two of these standardized boards and put them together with this larger switch fabric. The impact, though, was that now the NVIDIA GPU-to-GPU communication would occur on NVIDIA NVSwitch silicon and PCIe would have a standardized topology. HGX was born.

NVIDIA HGX 2 Dual GPU Baseboard Layout
Let’s delve into a comparison of the NVIDIA V100 setup in a server from 2020, renowned for its standout color scheme, particularly in the NVIDIA SXM coolers. When contrasting this with the earlier P100 version, an interesting detail emerges. In the Gigabyte server that housed the P100, one could notice that the SXM2 heatsinks were without branding. This marked a significant shift in NVIDIA’s approach. With the advent of the NVSwitch baseboard equipped with SXM3 sockets, NVIDIA upped its game by integrating not just the sockets but also the GPUs and their cooling systems directly. This move represented a notable advancement in their hardware design strategy.
Consequences
The consequences of this development were significant. Server manufacturers now had the option to acquire an 8-GPU module directly from NVIDIA, eliminating the need to apply excessive thermal paste to the GPUs. This change marked the inception of the NVIDIA HGX topology. It allowed server vendors the flexibility to customize the surrounding hardware as they desired. They could select their preferred specifications for RAM, CPUs, storage, and other components, while adhering to the predetermined GPU configuration determined by the NVIDIA HGX baseboard.
Inspur NF5488M5 Nvidia Smi Topology
This was very successful. In the next generation, the NVSwitch heatsinks got larger, the GPUs lost a great paint job, but we got the NVIDIA A100.
The codename for this baseboard is “Delta”.
Officially, this board was called the NVIDIA HGX.
Inspur NF5488A5 NVIDIA HGX A100 8 GPU Assembly 8x A100 And NVSwitch Heatsinks Side 2
NVIDIA, along with its OEM partners and clients, recognized that increased power could enable the same quantity of GPUs to perform additional tasks. However, this enhancement came with a drawback: higher power consumption led to greater heat generation. This development prompted the introduction of liquid-cooled NVIDIA HGX A100 “Delta” platforms to efficiently manage this heat issue.

Supermicro Liquid Cooling Supermicro
The HGX A100 assembly was initially introduced with its own brand of air cooling systems, distinctively designed by the company.
In the newest “Hopper” series, the cooling systems were upscaled to manage the increased demands of the more powerful GPUs and the enhanced NVSwitch architecture. This upgrade is exemplified in the NVIDIA HGX H100 platform, also known as “Delta Next”.
NVIDIA DGX H100
NVIDIA’s DGX and HGX platforms represent cutting-edge GPU technology, each serving distinct needs in the industry. The DGX series, evolving since the P100 days, integrates HGX baseboards into comprehensive server solutions. Notable examples include the DGX V100 and DGX A100. These systems, crafted by rotating OEMs, offer fixed configurations, ensuring consistent, high-quality performance.
While the DGX H100 sets a high standard, the HGX H100 platform caters to clients seeking customization. It allows OEMs to tailor systems to specific requirements, offering variations in CPU types (including AMD or ARM), Xeon SKU levels, memory, storage, and network interfaces. This flexibility makes HGX ideal for diverse, specialized applications in GPU computing.
Conclusion
NVIDIA’s HGX baseboards streamline the process of integrating 8 GPUs with advanced NVLink and PCIe switched fabric technologies. This innovation allows NVIDIA’s OEM partners to create tailored solutions, giving NVIDIA the flexibility to price HGX boards with higher margins. The HGX platform is primarily focused on providing a robust foundation for custom configurations.
In contrast, NVIDIA’s DGX approach targets the development of high-value AI clusters and their associated ecosystems. The DGX brand, distinct from the DGX Station, represents NVIDIA’s comprehensive systems solution.
Particularly noteworthy are the NVIDIA HGX A100 and HGX H100 models, which have garnered significant attention following their adoption by leading AI initiatives like OpenAI and ChatGPT. These platforms demonstrate the capabilities of the 8x NVIDIA A100 setup in powering advanced AI tools. For those interested in a deeper dive into the various HGX A100 configurations and their role in AI development, exploring the hardware behind ChatGPT offers insightful perspectives on the 8x NVIDIA A100’s power and efficiency.
0 notes
Text
DeepSeek-R1がbuild.nvidia.comで利用可能に!NVIDIA HGX H200システム上での高性能な推論処理と、NVIDIA AI Foundryを活用した独自AIエージェントの開発に対応
高性能推論を実現するDeepSeek-R1のアーキテクチャ DeepSeek-R1は、大規模言語モデルの効率的な運用を追求した革新的なアーキテクチャを採用しています。 6,710億個の総パラメータの中から、推論時に必要な370億個のパラメータのみを選択的に活性化させる設計により、高速な推論処理を実現しました。 最適化された推論パフォーマンス NVIDIA HGX H200システム上でDeepSeek-R1は、1秒あたり3,872トークンという高速な推論処理を達成しています。 この処理性能は、NVIDIA Hopper アーキテクチャのFP8 Transformer Engineと、NVLinkによる900 GB/sの高速な帯域幅、MoEエキスパート通信の最適化によって支えられています。 最新鋭のハードウェア構成 NVIDIA HGX H200は、1GPU…
0 notes
Text
ASUS Announces ESC N8-E11 AI Server with NVIDIA HGX H200
New server offering solidifies ASUS leadership in AI, with first deal secured SINGAPORE – Media OutReach Newswire – 3 September 2024 – ASUS today announced the latest marvel in the groundbreaking lineup of ASUS AI servers ― ESC N8-E11, featuring the intensely powerful NVIDIA® HGX™ H200 platform. With this AI titan, ASUS has secured its first industry deal, showcasing the exceptional performance,…
0 notes
Text
Agentic RAG On Dell & NVIDIA Changes AI-Driven Data Access

Agentic RAG Changes AI Data Access with Dell & NVIDIA
The secret to successfully implementing and utilizing AI in today’s corporate environment is comprehending the use cases within the company and determining the most effective and frequently quickest AI-ready strategies that produce outcomes fast. There is also a great need for high-quality data and effective retrieval techniques like RAG retrieval augmented generation. The value of AI for businesses is further accelerated at SC24 by fresh innovation at the Dell AI Factory with NVIDIA, which also gets them ready for the future.
AI Applications Place New Demands
GenAI applications are growing quickly and proliferating throughout the company as businesses gain confidence in the results of applying AI to their departmental use cases. The pressure on the AI infrastructure increases as the use of larger, foundational LLMs increases and as more use cases with multi-modal outcomes are chosen.
RAG’s capacity to facilitate richer decision-making based on an organization’s own data while lowering hallucinations has also led to a notable increase in interest. RAG is particularly helpful for digital assistants and chatbots with contextual data, and it can be easily expanded throughout the company to knowledge workers. However, RAG’s potential might still be limited by inadequate data, a lack of multiple sourcing, and confusing prompts, particularly for large data-driven businesses.
It will be crucial to provide IT managers with a growth strategy, support for new workloads at scale, a consistent approach to AI infrastructure, and innovative methods for turning massive data sets into useful information.
Raising the AI Performance bar
The performance for AI applications is provided by the Dell AI Factory with NVIDIA, giving clients a simplified way to deploy AI using a scalable, consistent, and outcome-focused methodology. Dell is now unveiling new NVIDIA accelerated compute platforms that have been added to Dell AI Factory with NVIDIA. These platforms offer acceleration across a wide range of enterprise applications, further efficiency for inferencing, and performance for developing AI applications.
The NVIDIA HGX H200 and NVIDIA H100 NVL platforms, which are supercharging data centers, offer state-of-the-art technology with enormous processing power and enhanced energy efficiency for genAI and HPC applications. Customers who have already implemented the Dell AI Factory with NVIDIA may quickly grow their footprint with the same excellent foundations, direction, and support to expedite their AI projects with these additions for PowerEdge XE9680 and rack servers. By the end of the year, these combinations with NVIDIA HGX H200 and H100 NVL should be available.
Deliver Informed Decisions, Faster
RAG already provides enterprises with genuine intelligence and increases productivity. Expanding RAG’s reach throughout the company, however, may make deployment more difficult and affect quick response times. In order to provide a variety of outputs, or multi-modal outcomes, large, data-driven companies, such as healthcare and financial institutions, also require access to many data kinds.
Innovative approaches to managing these enormous data collections are provided by agentic RAG. Within the RAG framework, it automates analysis, processing, and reasoning through the use of AI agents. With this method, users may easily combine structured and unstructured data, providing trustworthy, contextually relevant insights in real time.
Organizations in a variety of industries can gain from a substantial advancement in AI-driven information retrieval and processing with Agentic RAG on the Dell AI Factory with NVIDIA. Using the healthcare industry as an example, the agentic RAG design demonstrates how businesses can overcome the difficulties posed by fragmented data (accessing both structured and unstructured data, including imaging files and medical notes, while adhering to HIPAA and other regulations). The complete solution, which is based on the NVIDIA and Dell AI Factory platforms, has the following features:
PowerEdge servers from Dell that use NVIDIA L40S GPUs
Storage from Dell PowerScale
Spectrum-X Ethernet networking from NVIDIA
Platform for NVIDIA AI Enterprise software
Together with the NVIDIA Llama-3.1-8b-instruct LLM NIM microservice, NVIDIA NeMo embeds and reranks NVIDIA NIM microservices.
The recently revealed NVIDIA Enterprise Reference Architecture for NVIDIA L40S GPUs serves as the foundation for the solution, which allows businesses constructing AI factories to power the upcoming generation of generative AI solutions cut down on complexity, time, and expense.
A thorough beginning strategy for enterprises to modify and implement their own Agentic RAG and raise the standard of value delivery is provided by the full integration of these components.
Readying for the Next Era of AI
As employees, developers, and companies start to use AI to generate value, new applications and uses for the technology are released on a daily basis. It can be intimidating to be ready for a large-scale adoption, but any company can change its operations with the correct strategy, partner, and vision.
The Dell AI factory with NVIDIA offers a scalable architecture that can adapt to an organization’s changing needs, from state-of-the-art AI operations to enormous data set ingestion and high-quality results.
The first and only end-to-end enterprise AI solution in the industry, the Dell AI Factory with NVIDIA, aims to accelerate the adoption of AI by providing integrated Dell and NVIDIA capabilities to speed up your AI-powered use cases, integrate your data and workflows, and let you create your own AI journey for scalable, repeatable results.
What is Agentic Rag?
An AI framework called Agentic RAG employs intelligent agents to do tasks beyond creating and retrieving information. It is a development of the classic Retrieval-Augmented Generation (RAG) method, which blends generative and retrieval-based models.
Agentic RAG uses AI agents to:
Data analysis: Based on real-time input, agentic RAG systems are able to evaluate data, improve replies, and make necessary adjustments.
Make choices: Agentic RAG systems are capable of making choices on their own.
Dividing complicated tasks into smaller ones and allocating distinct agents to each component is possible with agentic RAG systems.
Employ external tools: To complete tasks, agentic RAG systems can make use of any tool or API.
Recall what has transpired: Because agentic RAG systems contain memory, like as chat history, they are aware of past events and know what to do next.
For managing intricate questions and adjusting to changing information environments, agentic RAG is helpful. Applications for it are numerous and include:
Management of knowledge
Large businesses can benefit from agentic RAG systems’ ability to generate summaries, optimize searches, and obtain pertinent data.
Research
Researchers can generate analyses, synthesize findings, and access pertinent material with the use of agentic RAG systems.
Read more on govindhtech.com
#AgenticRAG#NVIDIAChanges#dell#AIDriven#ai#DataAccess#RAGretrievalaugmentedgeneration#DellAIFactory#NVIDIAHGXH200#PowerEdgeXE9680#NVIDIAL40SGPU#DellPowerScale#generativeAI#RetrievalAugmentedGeneration#rag#technology#technews#news#govindhtech
0 notes