#NPUs
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
130K people were victims of a chain letter scam that affected Tumblr in May 2011.
Text
NPUs: Game-Changer or Overhyped AI Gimmick?
NPUs: Game-Changer or Overhyped AI Gimmick?
If you haven’t encountered neural processing units (NPUs) yet, you’ve either sidestepped a year of relentless AI marketing or missed the industry’s latest attempt to convince you of an “essential” upgrade. Intel, AMD, Qualcomm, and others have heavily promoted NPUs as a transformative leap in computing. These AI-focused processors, embedded in modern chips, promise faster, smarter, and more…
#AI hardware.#AI in laptops#AI processors#AMD Ryzen AI#die space#future-proofing#Intel Meteor Lake#Neural Processing Units#NPUs#Qualcomm Hexagon#TOPS
0 notes
Text
How The AI Inferencing Circuitry Powers Intelligent Machines

AI Inferencing
Expand the capabilities of PCs and pave the way for future AI applications that will be much more advanced.
AI PCs
The debut of “AI PCs” has resulted in a deluge of news and marketing during the last several months. The enthusiasm and buzz around these new AI PCs is undeniable. Finding clear-cut, doable advice on how to fully capitalize on their advantages as a client, however, may often seem like searching through a haystack. It’s time to close this knowledge gap and provide people the tools they need to fully use this innovative technology.
All-inclusive Guide
At Dell Technologies, their goal is to offer a thorough manual that will close the knowledge gap regarding AI PCs, the capabilities of hardware for accelerating AI, such as GPUs and neural processing units (NPUs), and the developing software ecosystem that makes use of these devices.
All PCs can, in fact, process AI features; but, newer CPUs are not as efficient or perform as well as before due to the advent of specialist AI processing circuits. As a result, they can do difficult AI tasks more quickly and with less energy. This PC technological breakthrough opens the door to AI application advances.
In addition, independent software vendors (ISVs) are producing cutting-edge GenAI-powered software and fast integrating AI-based features and functionality to current software.
It’s critical for consumers to understand if new software features are handled locally on your PC or on the cloud in order to maximize the benefits of this new hardware and software. By having this knowledge, companies can be confident they’re getting the most out of their technological investments.
Quick AI Functions
Microsoft Copilot is an example of something that is clear. Currently, Microsoft Copilot’s AI capabilities are handled in the Microsoft cloud, enabling any PC to benefit from its time- and productivity-saving features. In contrast, Microsoft is providing Copilot+ with distinctive, incremental AI capabilities that can only be processed locally on a Copilot+ AI PC, which is characterized, among other things, by a more potent NPU. Later, more on it.
Remember that even before AI PCs with NPUs were introduced, ISVs were chasing locally accelerated AI capabilities. In 2018, NVIDIA released the RTX GPU line, which included Tensor Cores, specialized AI acceleration hardware. As NVIDIA RTX GPUs gained popularity in these areas, graphics-specific ISV apps, such as games, professional video, 3D animation, CAD, and design software, started experimenting with incorporating GPU-processed AI capabilities.
AI workstations with RTX GPUs quickly became the perfect sandbox environment for data scientists looking to get started with machine learning and GenAI applications. This allowed them to experiment with private data behind their corporate firewall and realized better cost predictability than virtual compute environments in the cloud where the meter is always running.
Processing AI
All of these GPU-powered AI use cases prioritize speed above energy economy, often involving workstation users using professional NVIDIA RTX GPUs. NPUs provide a new feature for using AI features to the market with their energy-efficient AI processing.
For clients to profit, ISVs must put in the laborious code required to support any or all of the processing domains NPU, GPU, or cloud. Certain functions may only work with the NPU, while others might only work with the GPU and others might only be accessible online. Gaining the most out of your AI processing gear is dependent on your understanding of the ISV programs you use on a daily basis.
A few key characteristics that impact processing speed, workflow compatibility, and energy efficiency characterize AI acceleration hardware.
Neural Processing Unit NPU
Now let’s talk about NPUs. NPUs, which are relatively new to the AI processing industry, often resemble a section of the circuitry found in a PC CPU. Integrated NPUs, or neural processing units, are a characteristic of the most recent CPUs from Qualcomm and Intel. This circuitry promotes AI inferencing, which is the usage of AI characteristics. Integer arithmetic is at the core of the AI inferencing technology. When it comes to the integer arithmetic required for AI inferencing, NPUs thrive.
They are perfect for using AI on laptops, where battery life is crucial for portability, since they can do inferencing with very little energy use. While NPUs are often found as circuitry inside the newest generation of CPUs, they can also be purchased separately and perform a similar purpose of accelerating AI inferencing. Discrete NPUs are also making an appearance on the market in the form of M.2 or PCIe add-in cards.
ISVs are only now starting to deliver software upgrades or versions with AI capabilities backing them, given that NPUs have just recently been introduced to the market. NPUs allow intriguing new possibilities today, and it’s anticipated that the number of ISV features and applications will increase quickly.
Integrated and Discrete from NVIDIA GPUs
NVIDIA RTX GPUs may be purchased as PCIe add-in cards for PCs and workstations or as a separate chip for laptops. They lack NPUs’ energy economy, but they provide a wider spectrum of AI performance and more use case capability. Metrics comparing the AI performance of NPUs and GPUs will be included later in this piece. However, GPUs provide more scalable AI processing performance for sophisticated workflows than NPUs do because of their variety and the flexibility to add many cards to desktop, tower, and rack workstations.
Another advantage of NVIDIA RTX GPUs is that they may be trained and developed into GenAI large language models (LLMs), in addition to being excellent in integer arithmetic and inferencing. This is a consequence of their wide support in the tool chains and libraries often used by data scientists and AI software developers, as well as their acceleration of floating-point computations.
Bringing It to Life for Your Company
Trillions of operations per second, or TOPS, are often used to quantify AI performance. TOPS is a metric that quantifies the maximum possible performance of AI inferencing, taking into account the processor’s design and frequency. It is important to distinguish this metric from TFLOPs, which stands for a computer system’s capacity to execute one trillion floating-point computations per second.
The broad range of AI inferencing scalability across Dell’s AI workstations and PCs. It also shows how adding more RTX GPUs to desktop and tower AI workstations may extend inferencing capability much further. To show which AI workstation models are most suited for AI development and training operations, a light blue overlay has been introduced. Remember that while TOPS is a relative performance indicator, the particular program running in that environment will determine real performance.
To fully use the hardware capacity, the particular application or AI feature must also support the relevant processing domain. In systems with a CPU, NPU, and RTX GPU for optimal performance, it could be feasible for a single application to route AI processing across all available AI hardware as ISVs continue to enhance their apps.
VRAM
TOPS is not the only crucial component for managing AI. Furthermore crucial is memory, particularly for GenAI LLMs. The amount of memory that is available for LLMs might vary greatly, depending on how they are managed. They make use of some RAM memory in the system when using integrated NPUs, such as those found in Qualcomm Snapdragon and Intel Core Ultra CPUs. In light of this, it makes sense to get the most RAM that you can afford for an AI PC, since this will help with general computing, graphics work, and multitasking between apps in addition to the AI processing that is the subject of this article.
Separate For both mobile and stationary AI workstations, NVIDIA RTX GPUs have dedicated memory for each model, varying somewhat in TOPS performance and memory quantities. AI workstations can scale for the most advanced inferencing workflows thanks to VRAM memory capacities of up to 48GB, as demonstrated by the RTX 6000 Ada, and the ability accommodate 4 GPUs in the Precision 7960 Tower for 192GB VRAM.
Additionally, these workstations offer a high-performance AI model development and training sandbox for customers who might not be ready for the even greater scalability found in the Dell PowerEdge GPU AI server range. Similar to system RAM with the NPU, RTX GPU VRAM is shared for GPU-accelerated computation, graphics, and AI processing; multitasking applications will place even more strain on it. Aim to purchase AI workstations with the greatest GPU (and VRAM) within your budget if you often multitask with programs that take use of GPU acceleration.
The potential of AI workstations and PCs may be better understood and unwrapped with a little bit of knowledge. You can do more with AI features these days than only take advantage of time-saving efficiency and the capacity to create a wide range of creative material. AI features are quickly spreading across all software applications, whether they are in-house custom-developed solutions or commercial packaged software. Optimizing the setup of your AI workstations and PCs can help you get the most out of these experiences.
Read more on Govindhtech.com
#AI#AIPCs#GPUs#neuralprocessingunits#NPUs#CPUs#PC#AIcapabilities#NVIDIARTXGPUs#PCCPU#AIinferencing#AIprocessing#GenAI#largelanguagemodels#LLMs#news#technews#technology#technologynews#technologytrends#govindhtech
0 notes
Text
everyone's throwing a fit about microsoft recall being evil when you need a copilot+ pc to get it. Just dont buy that then.
9 notes
·
View notes
Text

【世界を変えるPC登場】AI搭載PCが凄すぎる!Copilot+PCを世界一わかりやすく徹底解説!【知らなきゃパソコン選びに失敗する?】
#AIモデル解説#copilot#リアルタイム同時翻訳#microsoft#NeuralnetworkProcessingUnit#パソコン博士taiki#MicrosoftSurface#taiki#ノートパソコン#gpt4#SurfacePro#ainews#RTX#パソコン#RTXAIPC#タイキ#copilotpluspc#copilotpc#surface#Recall#windowscopilot#snapdragonxelite#xelite#NPU#qualcomm#AIPC#copilotai#AI搭載#microsoftnews#AI
0 notes
Text
NPU in ARM-based Industrial Computers: Definition and Applications

NPU (Neural Processing Unit) is a specialized coprocessor designed to accelerate artificial intelligence (AI) and machine learning (ML) tasks in ARM-based industrial control systems. It optimizes neural network computations, enhancing real-time performance, energy efficiency, and complex data processing capabilities in industrial automation.
Key Features of NPU
Dedicated Architecture Hardware-optimized for neural network operations (e.g., matrix multiplication, convolutions), enabling higher computational throughput at lower power consumption compared to CPUs/GPUs.
Massive Parallelism Utilizes parallel processing units (e.g., MAC arrays) to handle multidimensional data (images, sensor signals, audio) efficiently.
Low Latency & High Energy Efficiency Minimizes redundant instructions and memory access, achieving millisecond-level inference speeds critical for real-time industrial applications.
NPU vs. CPU/GPU

Benefits of NPU in Industrial PCs
Real-Time Performance: Meets strict latency requirements for robotics, production lines, etc.
Power Savings: Reduces energy costs for 24/7 operations and simplifies thermal management.
Edge Intelligence: Local data processing improves reliability in unstable network environments.
Cost Efficiency: Eliminates external AI accelerators, lowering hardware complexity.
Real-World Examples
Smart Warehousing: NPU-powered robots improve picking accuracy by 30% via real-time object recognition.
Power Grid Inspection: Drones analyze infrared images locally to detect faults (e.g., broken insulators).
Food Packaging: Vision systems with NPU reduce sealing defect rates from 0.5% to 0.02%, cutting GPU costs.
Typical Use Cases in Industrial Control
Machine Vision & Quality Inspection
Example: NPU accelerates vision models (e.g., YOLO, ResNet) to detect product defects (scratches, misalignment) on production lines, replacing manual inspection.
Advantage: Higher frame rates (FPS) for high-resolution images with lower power consumption.
Predictive Maintenance
Example: Analyzes sensor data (vibration, temperature) using time-series models (e.g., LSTM) to predict equipment failures (motors, bearings).
Advantage: Real-time processing of multi-sensor data streams, reducing downtime.
Autonomous Robotics
Example: AGVs (Automated Guided Vehicles) leverage NPU-accelerated SLAM algorithms for obstacle avoidance and path planning via LiDAR/camera data.
Advantage: Ultra-low latency ensures safe navigation in dynamic environments.
Voice & NLP Integration
Example: Enables voice-controlled machinery (e.g., "Start Line B") using on-device speech recognition models.
Advantage: Offline operation ensures privacy and reliability without cloud dependency.
IIoT Edge Computing
Example: NPU processes video/sensor data at the edge, transmitting only critical insights to the cloud.
Advantage: Reduces bandwidth usage and enhances data security.
Conclusion
NPUs empower ARM-based industrial computers with localized AI capabilities, driving efficiency and reliability in automation, quality control, and predictive maintenance. As Industry 4.0 demands smarter edge devices, NPUs are becoming essential for next-generation industrial systems.
The Beilai Tech ARM industrial computer ARMxy series BL410 supports 1TOPs NPU of localized computing power and is redefining the technical boundaries of Industry 4.0, smart cities, and smart security. Its value lies not only in replacing cloud computing, but also in creatively implanting AI capabilities into the device side to form a closed-loop intelligent system of "perception-decision-execution". With the exponential growth of edge computing demand, high-performance controllers such as BL410 will become the core engine driving the intelligent upgrade of the industry, bringing safer, real-time, and efficient solutions to various fields. In the future, with the advancement of algorithm lightweight technology, the AI potential of edge devices will continue to be released, opening a new chapter in the intelligence of all things.
0 notes
Photo

Intel: Neuer CEO plant umfassende Neuausrichtung in Fertigung und KI
0 notes
Text
AI時代のパソコン選びのポイント
パソコンの未来 – NPU搭載でAI時代に備える パソコンの未来 – NPU搭載でAI時代に備える はじめに こんにちは、Burdonです。これまでパソコンは「できるだけ安く、コスパの良いものを選ぶ」という時代が続いていました。しかし、これからのパソコン市場は大きく変わることが予想されています。 その要因となるのがNPU(ニューラルプロセッシングユニット)の搭載です。NPUとはAI処理専用のプロセッサで、これがPCに搭載されることで、性能や使い勝手が大きく変化していきます。本記事では、NPUの役割と今後のPC市場の変化について解説します。 概要 💡…
0 notes
Text
🚀 Getting Started with rknn_yolov5_demo on RK3568!
Want to run YOLOv5 object detection on the RK3568 NPU? 🤖 Follow our step-by-step guide to compile and execute rknn_yolov5_demo seamlessly!
✅ Set up the cross-compilation toolchain
✅ Compile the test program
✅ Transfer files to your development board
✅ Run the object detection model
✅ Evaluate the performance of the RK3568 NPU
Check out the full guide and start optimizing your AI applications today!
0 notes
Text
The Rise of NPUs: Unlocking the True Potential of AI.
Sanjay Kumar Mohindroo Sanjay Kumar Mohindroo. skm.stayingalive.in Explore NPUs: their components, operations, evolution, and real-world applications. Learn how NPUs compare to GPUs and CPUs and power AI innovations. NPUs at the Heart of the AI Revolution In the ever-evolving world of artificial intelligence (#AI), the demand for specialized hardware to handle complex computations has never…
#AI hardware#edge AI processing#future of NPUs#Neural Processing Unit#News#NPU applications#NPU architecture#NPU technology#NPU vs GPU#Sanjay Kumar Mohindroo
0 notes
Text
SciTech Chronicles. . . . . . . . .Feb 5th, 2025
#ETRI#SoC#NPU#12-nanometer#Gruithuisen#Blue-Ghost#Lunar-VISE#Gamma Pliocene#CO2#400ppm#plioDA#Io#Juno#JIRAM#Tidal#magma#Vallis#impact#fragments#ejecta
0 notes
Text
Updates to Azure AI, Phi 3 Fine tuning, And gen AI models

Introducing new generative AI models, Phi 3 fine tuning, and other Azure AI enhancements to enable businesses to scale and personalise AI applications.
All sectors are being transformed by artificial intelligence, which also creates fresh growth and innovation opportunities. But developing and deploying artificial intelligence applications at scale requires a reliable and flexible platform capable of handling the complex and varied needs of modern companies and allowing them to construct solutions grounded on their organisational data. They are happy to share the following enhancements to enable developers to use the Azure AI toolchain to swiftly and more freely construct customised AI solutions:
Developers can rapidly and simply customise the Phi-3-mini and Phi-3-medium models for cloud and edge scenarios with serverless fine-tuning, eliminating the need to schedule computing.
Updates to Phi-3-mini allow developers to create with a more performant model without incurring additional costs. These updates include a considerable improvement in core quality, instruction-following, and organised output.
This month, OpenAI (GPT-4o small), Meta (Llama 3.1 405B), and Mistral (Large 2) shipped their newest models to Azure AI on the same day, giving clients more options and flexibility.
Value unlocking via customised and innovative models
Microsoft unveiled the Microsoft Phi-3 line of compact, open models in April. Compared to models of the same size and the next level up, Phi-3 models are their most powerful and economical small language models (SLMs). Phi 3 Fine tuning a tiny model is a wonderful alternative without losing efficiency, as developers attempt to customise AI systems to match unique business objectives and increase the quality of responses. Developers may now use their data to fine-tune Phi-3-mini and Phi-3-medium, enabling them to create AI experiences that are more affordable, safe, and relevant to their users.
Phi-3 models are well suited for fine-tuning to improve base model performance across a variety of scenarios, such as learning a new skill or task (e.g., tutoring) or improving consistency and quality of the response (e.g., tone or style of responses in chat/Q&A). This is because of their small compute footprint and compatibility with clouds and edges. Phi-3 is already being modified for new use cases.
Microsoft and Khan Academy are collaborating to enhance resources for educators and learners worldwide. As part of the partnership, Khan Academy is experimenting with Phi-3 to enhance math tutoring and leverages Azure OpenAI Service to power Khanmigo for Teachers, a pilot AI-powered teaching assistant for educators in 44 countries. A study from Khan Academy, which includes benchmarks from an improved version of Phi-3, shows how various AI models perform when assessing mathematical accuracy in tutoring scenarios.
According to preliminary data, Phi-3 fared better than the majority of other top generative AI models at identifying and fixing mathematical errors made by students.
Additionally, they have optimised Phi-3 for the gadget. To provide developers with a strong, reliable foundation for creating apps with safe, secure AI experiences, they launched Phi Silica in June. Built specifically for the NPUs in Copilot+ PCs, Phi Silica expands upon the Phi family of models. The state-of-the-art short language model (SLM) for the Neural Processing Unit (NPU) and shipping inbox is exclusive to Microsoft Windows.
Today, you may test Phi 3 fine tuning in Azure AI
Azure AI’s Models-as-a-Service (serverless endpoint) feature is now widely accessible. Additionally, developers can now rapidly and simply begin developing AI applications without having to worry about managing underlying infrastructure thanks to the availability of Phi-3-small via a serverless endpoint.
The multi-modal Phi-3 model, Phi-3-vision, was unveiled at Microsoft Build and may be accessed via the Azure AI model catalogue. It will also soon be accessible through a serverless endpoint. While Phi-3-vision (4.2B parameter) has also been optimised for chart and diagram interpretation and may be used to produce insights and answer queries, Phi-3-small (7B parameter) is offered in two context lengths, 128K and 8K.
The community’s response to Phi-3 is excellent. Last month, they launched an update for Phi-3-mini that significantly enhances the core quality and training after. After the model was retrained, support for structured output and instruction following significantly improved.They also added support for |system|> prompts, enhanced reasoning capability, and enhanced the quality of multi-turn conversations.
They also keep enhancing the safety of Phi-3. In order to increase the safety of the Phi-3 models, Microsoft used an iterative “break-fix” strategy that included vulnerability identification, red teaming, and several iterations of testing and improvement. This approach was recently highlighted in a research study. By using this strategy, harmful content was reduced by 75% and the models performed better on responsible AI benchmarks.
Increasing model selection; around 1600 models are already accessible in Azure AI They’re dedicated to providing the widest range of open and frontier models together with cutting-edge tooling through Azure AI in order to assist clients in meeting their specific cost, latency, and design requirements. Since the debut of the Azure AI model catalogue last year, over 1,600 models from providers such as AI21, Cohere, Databricks, Hugging Face, Meta, Mistral, Microsoft Research, OpenAI, Snowflake, Stability AI, and others have been added, giving us the widest collection to date. This month, they added Mistral Large 2, Meta Llama 3.1 405B, and OpenAI’s GPT-4o small via Azure OpenAI Service.
Keeping up the good work, they are happy to announce that Cohere Rerank is now accessible on Azure. Using Azure to access Cohere’s enterprise-ready language models Businesses can easily, consistently, and securely integrate state-of-the-art semantic search technology into their applications because to AI’s strong infrastructure. With the help of this integration, users may provide better search results in production by utilising the scalability and flexibility of Azure in conjunction with the highly effective and performant language models from Cohere.
With Cohere Rerank, Atomicwork, a digital workplace experience platform and a seasoned Azure user, has greatly improved its IT service management platform. Atomicwork has enhanced search relevancy and accuracy by incorporating the model into Atom AI, their AI digital assistant, hence offering quicker, more accurate responses to intricate IT help enquiries. Enterprise-wide productivity has increased as a result of this integration, which has simplified IT processes.
Read more on govindhtech.com
#AzureAI#Phi3#gen#AImodels#generativeAImodels#OpenAi#AzureAImodels#ai21#artificialintelligence#Llama31405B#slms#Phi3mini#smalllanguagemodels#AzureOpenAIService#npus#Databricks#technology#technews#news#govindhtech
0 notes
Link
#AdrenoGPU#AI#artificialintelligence#automateddriving#digitalcockpits#Futurride#generativeAI#Google#Hawaii#largelanguagemodels#LiAuto#LLMs#Maui#Mercedes-Benz#multimodalAI#neuralprocessingunit#NPU#OryonCPUSnapdragonDigitalChassis#Qualcomm#QualcommOryon#QualcommSnapdragonSummit#QualcommTechnologies#SDVs#SnapdragonCockpitElite#SnapdragonRideElite#SnapdragonSummit#software-definedvehicles#sustainablemobility
0 notes
Video
youtube
Do I Really Need a Laptop with an NPU Chip
#youtube#Laptops AI NPU Technology tips Futureproofing Gadgets BuyingGuide Innovation Computing cpu gpu
0 notes
Text
Four Advantages Detailed Analysis of Forlinx Embedded FET3576-C System on Module
In order to fully meet the growing demand in the AIoT market for high-performance, high-computing-power, and low-power main controllers, Forlinx Embedded has recently launched the FET3576-C System on Module, designed based on the Rockchip RK3576 processor. It features excellent image and video processing capabilities, a rich array of interfaces and expansion options, low power consumption, and a wide range of application scenarios. This article delves into the distinctive benefits of the Forlinx Embedded FET3576-C SoM from four key aspects.

Advantages: 6TOPS computing power NPU, enabling AI applications
Forlinx Embedded FET3576-C SoM has a built-in 6TOPS super arithmetic NPU with excellent deep learning processing capability. It supports INT4/ INT8/ INT16/ FP16/ BF16/ TF32 operation. It supports dual-core working together or independently so that it can flexibly allocate computational resources according to the needs when dealing with complex deep learning tasks. It can also maintain high efficiency and stability when dealing with multiple deep-learning tasks.
FET3576-C SoM also supports TensorFlow, Caffe, Tflite, Pytorch, Onnx NN, Android NN and other deep learning frameworks. Developers can easily deploy existing deep learning models to the SoM and conduct rapid development and optimization. This broad compatibility not only lowers the development threshold, but also accelerates the promotion and adoption of deep learning applications.

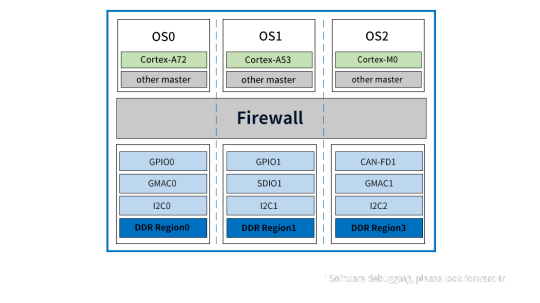
Advantages: Firewall achieves true hardware resource isolation
The FET3576-C SoM with RK3576 processor supports RK Firewall technology, ensuring hardware resource isolation for access management between host devices, peripherals, and memory areas.
Access Control Policy - RK Firewall allows configuring policies to control which devices or system components access hardware resources. It includes IP address filtering, port control, and specific application access permissions. Combined with the AMP system, it efficiently manages access policies for diverse systems.
Hardware Resource Mapping and Monitoring - RK Firewall maps the hardware resources in the system, including memory areas, I/O devices, and network interfaces. By monitoring access to these resources, RK Firewall can track in real-time which devices or components are attempting to access specific resources.
Access Control Decision - When a device or component attempts to access hardware resources, RK Firewall will evaluate the access against predefined access control policies. If the access request complies with the policy requirements, access will be granted; otherwise, it will be denied.
Isolation Enforcement - For hardware resources identified as requiring isolation, RK Firewall will implement isolation measures to ensure that they can only be accessed by authorized devices or components.
In summary, RK Firewall achieves effective isolation and management of hardware resources by setting access control policies, monitoring hardware resource access, performing permission checks, and implementing isolation measures. These measures not only enhance system security but also ensure system stability and reliability.
Advantages: Ultra clear display + AI intelligent repair
With its powerful multimedia processing capability, FET3576-C SoM provides users with excellent visual experience. It supports H.264/H.265 codecs for smooth HD video playback in various scenarios, while offering five display interfaces (HDMI/eDP, MIPI DSI, Parallel, EBC, DP) to ensure compatibility with diverse devices.
FET3576-C SoM notably supports triple-screen display functionality, enabling simultaneous display of different content on three screens, significantly enhancing multitasking efficiency.
In addition, its 4K @ 120Hz ultra-clear display and super-resolution function not only brings excellent picture quality enjoyment, but also intelligently repairs blurred images, improves video frame rate, and brings users a clearer and smoother visual experience.

Advantage: FlexBus new parallel bus interface
FET3576-C of Forlinx Embedded offers a wide range of connectivity and transmission options with its excellent interface design and flexible parallel bus technology. The FlexBus interface on the SoM is particularly noteworthy due to its high flexibility and scalability, allowing it to emulate irregular or standard protocols to accommodate a variety of complex communication needs.
FlexBus supports parallel transmission of 2/4/8/16bits of data, enabling a significant increase in the data transfer rate, while the clock frequency of up to 100MHz further ensures the high efficiency and stability of data transmission.
In addition to the FlexBus interface, the FET3576-C SoM integrates a variety of bus transfer interfaces, including DSMC, CAN-FD, PCIe2.1, SATA3.0, USB3.2, SAI, I2C, I3C and UART. These interfaces not only enriches the SoM's application scenarios but also enhances its compatibility with other devices and systems.

It is easy to see that with the excellent advantages of high computing power NPU, RK Firewall, powerful multimedia processing capability and FlexBus interface, Forlinx Embedded FET3576-C SoM will become a strong player in the field of embedded hardware. Whether you are developing edge AI applications or in pursuit of high-performance, high-quality hardware devices, the Folinx Embedded FET3576-C SoM is an unmissable choice for you.
Originally published at www.forlinx.net.
0 notes