#Merkle-Damgard
Text
Hashes
So hashes are great. They can be used to hide passwords and also to verify original documents. They take any length of message and turn it into a fixed length. Ideally, changing a single bit in the original message results in half the bits used in the hashed value. This is to stop people from easily determining what similar initial values are from their hashes.
SHA2 and some others uses the below pattern, taking an initialisation vector and combining it with the first portion of the message with the hashing function. This hashed value is then used as the initialisation vector for the next section of the message. When the message isn’t perfectly divisible by the size of the blocks, extra padding is added on to the last message block.
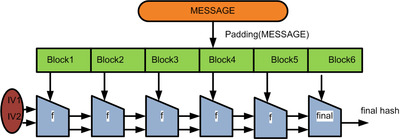
The two initialisation vector are used to stop length extension attacks. It works with the following formula.
H = h( k_2⋅h( k_1⋅p ) )
When used for password storage, they limit how secure your password can be. Consider that if your password has more of bits than the hash, the hash will make your password shorter bit wise. The only difference is that if your password is predictable at that length, a long password might be easier to break than brute forcing it with a different password that is likely gibberish that also produces the same hash, but it’s unlikely since most non brute forcing programs only consider shorter length passwords at the moment. That may change.
But don’t use MD5 or SHA1, they’ve been broken. You can google a hash and get back original passwords. These hashes are too short to use. A colliding result, where two inputs result in the same hash can be found at roughly the squareroot of the total space, which is half the bits. 128 bits may seem like a lot, but you only need to do 64 bits of work to get a collision to break it.
Now, hashes can be used to verify legitimate documents. This works since a company will release both the document and the hash. If the document when hashed doesn’t match the hash, it’s not the real one.
Problems arise if you can find a document that hashes to the same string. So you still need a good long hash.
Sometime in the future, there may come a time where signing something with your RSA is a good as a handwritten signature. But since RSA is slow, it would be easier to do that on something smaller, like a hash of a document. Simply encrypt it with your private key, and if it become the true hash when decrypted with the public key, it can be verified.
Just be careful what you sign. If you don’t modify the document, then it is possible that the sender found a collision for that document with another document they actually want you to sign. They do this by playing with whitespace. They only need to play with half the number of bits of the hash result in whitespace to make enough changes to create a collision with their own document, playing with both sides. If you change the whitespace on a document before you sign it in a different way than an attacker might, then you can sign it and not worry about any nefarious document they actually wanted you to sign. They likely wouldn’t have a matching hashed document for the new document you created. It would take the full amount of work to match your document.
#lectures#wk5#hashes#crypography#security#security engineering#cyber security#WEP#MD5#SHA#XOR#Merkle-Damgard
2 notes
·
View notes
Text
Lectures - Week 6
One Time Pads
This is basically an encryption method that cannot be cracked, provided the secret key is ‘random’ enough and is not reused. The idea is to XOR each bit in the ciphertext with a corresponding bit in the key; the main caveat is the key must be at least as long as the plaintext. They are still used a fair bit today, but were more extensively used historically during wartime communications utilising codebooks and number stations.
Threat / Attack Tree
One part of building a threat model can be through an attack tree - the idea is that you list all the assets as nodes. The branches from each of these nodes are threats and the causes for each of these can be listed as sub-branches. You can then expand out on any of the causes, if there are multiple ways it can occur.
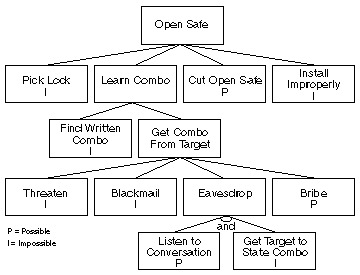
It’s important to consider disasters and potential periods of turmoil in your analysis of threats as well. Organisational changes such as the introduction of new systems are ‘prime’ periods for attack.
Types of Attackers
Three main types of attackers:
Casual - doesn’t target the victim specifically and does so while checking out numerous other targets
Determined - targets the victim, has a motive and tries to find specific vulnerabilities of the victim
Funded - similar to determined except performs lots of recon on top of hiring people and equipment to perform the attack
Initialisation Vectors
More broadly IVs are simply used as initialisation values to an iterative process. They are used in cryptographic hash functions such as the Merkle-Damgard construction as constants at the beginning, in the compression with the first message block. There are also times when they are required to be random such as in block ciphers - the purpose of this is so that different messages are encrypted differently. This means that an attacker seeing two messages encrypted with the same key doesn’t give them any more information than the whole message sent together.
Let us consider the usage of the IV in a protocol such as WEP - it uses a 64-bit key where the user is responsible for picking the first 40 bits and the final 24 bits are generated randomly. Since the IV is publicly known as is only 24 bits, it only takes 2^12=4096 different generated IVs before an older one is reused. This defeats the whole purpose of not giving the attacker extra info (described above) and allows the whole key to then be cracked. This is because the user-generated component has fairly low entropy - it only permits 5 character user inputs (with 64 combinations - 0->10, a->z, A->Z) which only represents an 8% subset of all bit combinations - 2^40.
Mixing Data & Control
I’ve discussed this topic at length in previous blog posts, although I did find Richard’s example with the postal stamps quite interesting. Basically he sent himself a heap of ‘expensive’ express postal stamps from within the post office - so the ‘data’ was the stamps and the ‘control’ was the ability to exit the store with them.
I also had another interesting thought regarding this in the tutorial the other week with autonomous cars. If every self-driving car is providing driving data back to their company servers, which is then used in improving their fleet of cars’ autonomous capabilities, isn’t this also technically an example of mixing data and control? For example, if you fed faulty data from hundreds of locations back to the servers which then was distributed back to the users, it could be problematic.
Harvard Architecture
There are two main types of architectures used in microcontrollers: Von Neumann and Harvard. Von Neumann basically has all the memory in one location, with instruction and data using the same bus. Harvard overcomes the data and control issue by having code and data on separate buses; this actually results in an improved performance as they can loaded at the same time.

Buffer Overflows
We had already looked at these overflows in the tutorials a bit, so looking at them in the lecture wasn’t too unfamiliar. The basic idea is that you feed in too much user input to some shonky code which doesn’t validate the length to the size of the buffer. This results in overwriting neighbouring data to the buffer - if this is within a function, it means registers on the stack get overwritten. This may include other variables (affecting control flow within the function) or the return address itself (affecting control flow after the function). Attackers can basically use this to write their code into the buffer and then overwrite the return address to the start of the buffer. (and their code starts executing!)
Most modern programming languages have checks in place to prevent buffer overflows on the stack. (the heap is another gold mine) Canaries in the stack can also be used to detect when they occur - before jumping to the return address, they check a small integer value (of known value beforehand) just before the return address. Although, if you were able to find an exploit to read the variables on the stack beforehand, you could potentially dodge the canary still.
Proof of Work
I’m going to write an article to discuss this in more detail later with regards to the extended cryptocurrency talk. The basic idea is that miners are searching for a SHA-256 hash (with leading 0s depending on ‘difficulty’) which incorporates the previous block and current transactions as part of a header. They search through the hash combinations by changing a ‘nonce’ value within the header which leads to changes in the overall hash. You have to do a lot of work in order to find this hash which provides the security for proof-of-work networks such as Bitcoin.
Moore’s Law
This law is an interesting consideration when talking about how many bits of security we need in certain applications. It basically observed that the number of transistors in an IC doubles every two years - i.e. what we think is ‘safe’ should be 1 bit of security higher every 2 years. The problem is we’ve reached a point where it is getting ridiculously hard to reduce the size even more, so I don’t think it will continue to hold true. However if we find completely different methods (i.e. quantum computing) we could achieve an even more significant ‘sudden’ increase.
Disk Encryption and Cold Boot Attacks
Encryption intends to generate a key based on a user-given password which is then used to encrypt the hard drive contents with a block cipher such as AES (used in Bitlocker). The Master Boot Record (MBR) is typically not encrypted without other hardware-based solutions. The problem with these forms of encryptions is that they are vulnerable to cold boot attacks - the keys used in the decryption may be left in memory when the computer is turned off. This means an attacker with physical access may be able to boot the machine with an OS (on a USB say) and then take a dump of all the memory.
They can then analyse this to look for the key or other user data. Typically the attack is possible if it occurs within 90 minutes of the memory losing power, however this window can be extended in some cases by cooling the modules. Even if some of the data disappears from the memory, the process is somewhat predictable and the missing bits can be rebuilt to an extent.
Brief History of Ciphers
Security by obscurity pretty much dominated the encryption scene up until the 1970s - banks used to ‘roll their own crypto’ and this was an awful idea. It wasn’t until the 1970s when NIST began releasing password and encryption standards. They started a competition to develop a standard data encryption method which was eventually won by IBM who developed the block cipher Lucifer. This method was modified by the NSA to be resistant against differential cryptanalysis, a reduced cipher size of 56 bits and a reduced block size of 64 bits - it became the standard and was known as DES.
It wasn’t long before it was realised how weak DES in terms of the fact it was vulnerable to brute force search - this occurred due to a number of export laws which ensured the use of ‘breakable’ ciphers. (absolutely hilarious) Eventually the NIST underwent another process to find a replacement from 1997 which was a lot more transparent, and resulted in the Advanced Encryption Standard (AES256). Currently there are no good ‘known’ methods to crack AES in a significantly fast enough time (provided a random enough key is used). The main forms of attacks against it are a bit unrelated - they are side-channel attacks such as cache-timing which involve monitoring the CPU to determine the key.
Issue of Authentication
I think solving the problem of authentication is one of the biggest in cyber security - it revolves around the fact that any data a computer system may use for authentication relies on a small piece of information which ‘summarises you as an individual’. For example, it may be an image of your face or it could be a password that only you know. The ability to authenticate a person can only be a good as the ability to keep all these components from an attacker’s hands.
The main strategy (which I think I’ve touched on) we use today in authentication is defense in depth - we try to use as many factors as we can to verify you as an individual. The more factors required, the harder it is for an attacker to spoof your identity; the main factors we typically use are:
Something you know - i.e. password
Something you have - i.e. message to phone
Something you are - i.e. physical identity (picture)
Being able to know that these factors are secure is difficult too - we are only good at proving when information is known as opposed to secret. We may think that measures such as biometrics are difficult to fake, but at the end of the day, we have to remember that computer systems are based on binary. If you know the binary input that will open that door (i.e. how their fingerprint is represented), you can open the door.
Web Security - Extended
I already knew a fair bit about the different attacks due to some experiences in web development and my something awesome. However I will go over some of the key talking points. The basic idea is a HTML page will define the elements on a page, and within this we sometimes have control logic with Javascript which defines how these structures may behave or how a user can interact with them. A lot of the flaws in web revolve around the fact that data (the elements on the page) and control (the Javascript) are mixed in the same location.
The other main thing you need to know is that cookies are stored in a browser for each website you visit. A lot of the time it involves preferences for the sites, but they are also commonly used for persistence in logins; i.e. a unique ID to associated you with a user on the server-side. Sessions are pretty much cookies except they are destroyed when you close your browser and only contain IDs which link to a session file that is stored on the server.
XSS attacks for example rely on someone injecting Javascript into the user input of a website, which is then displayed to other users of the site. Their browsers will then execute the code, which could potentially do something malicious like hijacking their cookies. You can read more about them in my OWASP article on them here. Cross-site request forgery is somewhat similar to these - basically it relies on an authorised individual clicking on an image or link which executes some Javascript which uses their authority on a site for malicious purposes.
The Samy XSS worm was a good example of this - anyone who viewed a profile infected with the worm would execute the script and become infected themselves. This meant they would send Samy a friend request, and if any of their friends viewed their profile they would also be infected. Over 1 million users were infected with the worm on MySpace within 20 hours.
The other main problem associated with web is injection in the server itself. SQL injection is the main source; it involves including SQL code in a user input which (if not escaped) will execute on the server resulting in outputting unintended data or making changes to the database. Without proper protections, it means you can bypass authentication forms and steal all the data from the database.
Web Security - Cryptocurrency
I was part of this presentation and I will give a more detailed writeup on it soon.
6 notes
·
View notes
Text
Week 6 Lectures
Cryptographic protocols
initialization vector (IV)
avalanche effect
protect whole document
have whole hash on one block, another hash on another block
merkle damgard
hash previous hash and new block
if first time, no previous hash, need something to start it off, hence IV
WEP
Recall 40bit key and 24 bit IV
Vulnerabilities arise partly due to problems of data vs control mixed into one channel
buffer and overflow
Phrack magazine - Smashing the stack for fun
Proof of work
Used by cryptocurrencies such as bitcoin
The “work” required to compute hashes is the friction of cryptography. Working out a certain hash must be brute forced and can be quantified to take a certain amount of time hence proof of work.
Moore’s law
The exponential growth of computing power means the bits of secuirty of attackers improve over time
Disk encryption
Threat model is someone who has physical access to disk
Disk generates a random key, that has encyrpted key
That key is then encrypted with user password
Cold boot attacks
Every contact leaves a trace
things written in ram dont immediately disappear after turning computers off
Disappearing information has to do with temperature
Forensic people, if machine is still logged on, get what they can from active memory, another way is turn computer off, open up computer, spray RAM and reboot from forensic operating system
Make sure that the data in the hardware itself cannot be compromised by encrypting it all
Windows’s bitlocker system had a flaw in encryption
Ciphers after WW2 but before RSA
Currently
RSA used for initial handshake, based on hard mathematical problem that is a trapdoor function (easy one way, hard the other way)
Other ciphers used for heavy work
Back then, everyone rolled their own ciphers, relied on security by obscurity until mid 70s. No one knew best practices.
NIST
At some point, people decided to make standard,
No one knew much about encryption back then
Held a competition which a few people lodged applications to
The best thing that came about was Lucifer from IBM, which became a new standard for data encryption
The NSA came in and advised to reduced the key length of the algorithm, which later turned out that this was because NSA had a way to crack the algorithm which they tried to hide.
The new cipher was published academically and called Data Encryption Standard (DES). The cipher was found too weak eventually, but no replacement was proposed.
Another competition with good shortlist, and the winner Rijndael proposed the Advanced Encryption Standard (AES) which is now 20 years old
The problem with authentication
identify for who? computer or human
computers or humans make decisions
authentication vs identification
what decisions made?
something you know
(password/pin?), shared secret
something you have
confirmation code sms? two factor authentication
something you are
face, fingerprint, retina, dna,
but these thing are easily forged, easily stolen, not a good secret
in the end, authentication all comes down to keeping a secret
All authentication in the end is data, and data is just as good as a secret
1 note
·
View note
Text
Block Modes, SP Boxes and Fiestal Networks
Recall the Merkle-Damgard hash construction and its partitioning of the plaintext and several ‘blocks’ which would be individually hashed and shoved into the next mini hash function to be hashed with the next net cipher block, to give it the following properties of confusion and diffusion.
Confusion and Diffusion are properties meant to ‘thwart the applications of statistics and other methods of cryptanalysis’.
Confusion is the principle of having each bit of a plaintext enciphered by multiple different parts of the key, in order to obscure any straightforward connection between the plaintext and ciphertext.
Diffusion is the avalanche effect property, meaning that if a change a single bit of the plaintext, then half the bits of the cipher text should change.
A method of achieving these two properties, given a straightforward key, is by use of the SP network or SP box. These are a series of mathematical functions linked to one another in arbitrary ways that were inspired by the Enigma code and work in a much similar way. These networks utilise both S-boxes and P-boxes to serve as the ‘mini hash-functions’ in a Merkle-Damgard hash construction i.e. the plaintext will be passed in, the key will be divided into blocks and also passed into the construction and at each step the plaintext will be subject to either the S-box or the P-box, before being spat out into the next S or P box to be enciphered by the next block of the key.
S-boxes substitute a small block of its inputs’ bits by another typically arbitrary block of bits. For example given an input of bits, it may substitute every four bits and those substitutions will be chosen from a fixed table of substitutions that outline which four bits will be mapped to which other arbitrary number of bits. i.e. 1100 may be mapped to 101. These mappings are one-to-one to ensure that they can be reversed/decrypted.
P-boxes permute its bits; taking input and randomly reordering them.
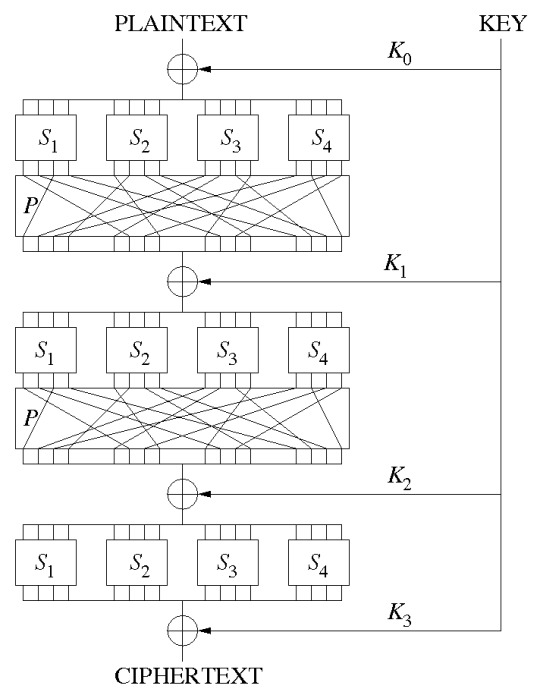
Hence, encrypting the plaintext will look like this: plaintext will be enciphered with a block of the key and outputted into either a S or P box whose output will then be enciphered by the next key block and etc.
How it achieves confusion and diffusion
Thus, changing one bit of the key will result in the section that it will be passed into, to be utterly scrambled as the output of that section will be either permuted or substituted in a pseudorandom way multiple times, and being effectively multiplicatively scrambled which will - if applied correctly - cause half the bits of the final ciphertext to be different: hence avalanche effect/diffusion.
The reasoning for confusion is obvious: the S-boxes will essentially cause different parts of the key to encipher other different parts of the plaintext.
Block Modes
Block enciphering takes multiple blocks/partitions of a plaintext and enciphers each of them with an encryption, in a similar way to the M-D hash construction. These ciphertext blocks will then be chained together in a particular way to form the ciphertext.
The method in which they are chained is known as the block mode.
ECB: Simply chaining them together in left-to-right order. Has serious flaws in that the same plaintext will map to the same ciphertext, and the same bit of the key will map to the same bit of the ciphertext making statistical analysis methods such as frequency analysis fairly simple.
CBC: Tries to solve this problem by XOR’ing the first ciphertext block with the next plaintext block before being plugged into the next cipher function. This is very similar to the Merkle-Damgard hash construction.
CTR: instead of encrypting the plaintext blocks, the CTR mode encrypts a nonce and a counter value which will then be XOR’d with the plaintext to make something really weird and will possess the diffusion and confusion properties. These ciphertext blocks are then chained in left-to-right order.
Feistel Networks
One could think of the Feistel Network as a convoluted version of the above chaining methods to achieve a slightly more convoluted ciphertext i.e. with stronger properties of diffusion and confusion. And they achieve this by performing the following:
The plaintext block is split into two equal pieces L(1) and R(1), where the 1 denotes the current iteration of the cipher. R is shoved into a function F with K(1). the first block of the key, and the output F(K(1),R1(1)) is then XOR’d with L(1) in order to get R(2). L(2) will simply be R(1). This can be summarised succinctly in the following equations.
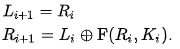
This then repeats with our new values of L(2) and R(2) and then the next, until the desired number of rounds is reached.
This can be decrypted by reversing the above equations for the number of rounds:
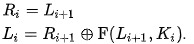
However, one would of course need to know the number of rounds, the F function as well as the corresponding key block for each iteration. Note that these key blocks are often shuffled around and further obscured and the order of R and L, the two partitions, are often arbitrarily swapped around which could lead to a very large number of combinations of swaps once the number of rounds becomes very large.
Block Mode Activity - identifying the block mode
spoiler alert
Cipher 2 is clearly counter-mode, as it’s the only one updating when I enter a new character into the plaintext and that’s what CTR mode does: XOR them as it comes.
The rest is 50/50 between ECB and CBC but we can narrow it down using some advanced Ctrl-F analysis.
Here are the ciphertexts of the plaintext:
ppppppppppppppppppppppppppppppppppppppppppppppppppppppppppppppppppppppppppppppp
for each cipher.
Cipher 1
294744a1c4cd2a9bf6bfe4b048473aa7294744a1c4cd2a9bf6bfe4b048473aa7294744a1c4cd2a9bf6bfe4b048473aa7294744a1c4cd2a9bf6bfe4b048473aa76e9dfd4826a47d16df46400a416c967d
Clearly an ECB block mode. EBC suffers from the problem of the same input providing the same output, meaning that given a long enough string, there WILL be consistent repetitions and if we CTRL-F 4b048473aa72947a1c..., that’s exactly what we find
Cipher 3
c330b8296148fcd5579b64cd63231719edd4c8494f31ea9df99f9c194df9bdc51beb30ed5ea090d0f0c860eb725a872b0c89269e78d739074d0b2ae00b3905d3c1fc8b6c1239251b9c9612bf9945d8fa
No repetitions here, must be CBC.
4.
f659f1491f7c1d7c2f6143999faa9765cdd366379024ff6de1988dfd6efe894729d017b41597f953bf49a214b175200b6bbaa0360933cd3d98fe3bae10db32bb06f3b6601afd37ee96a0d525a48fecd0
CBC, same reason
5.
1fcae373ca6fb1ae0590b5f3d971ad111fcae373ca6fb1ae0590b5f3d971ad111fcae373ca6fb1ae0590b5f3d971ad111fcae373ca6fb1ae0590b5f3d971ad11e9d1c9abf7671d46da742df9203063a8
ECB, same reason
1 note
·
View note
Text
Week 5 Lecture Reflection
This week the lecture discussed concepts of hashes, MAC and HMAC, Key Stretching, and Data control while also having a guest speaker who is a researcher for Woman’s Cancer who discussed about notions of bias during research.
Reflection:
I wasn’t able to make any effective notes for Week 5 mainly because I’ve been busy trying to get my Comp2041 things to work. I feel like the way I’m taking notes and looking back on it might not be very effective. I’ll try to find a way to make some better notes in the future.
Quick Notes:
Wired Equivalent Privacy - Data wasn’t encrypted
Sender and receiver generates a random series of bits using Rc4
Attacker pretends to be website, can trick router in giving info
Bias and Insider attack
Compliance culture
SQL Injection
‘, “, <, > tags in passwords will screw things up.
MD5, SHA0 and SHA1 are broken as they are vulnerable to birthday attacks.
SHA2 and SHA3 are not broken.
SHA2 family consists of SHA256, 224, 384 and 512.
SHA2 is built on Merkle Damgard Strcuture
SHA3 is not vulnerable to length extension attacks which is when an attacker can appends information to the end of a message and create an attacker controlled message and use that to calculate the hash of the original message without ever knowing the original contents.
Merkle Damgard Structure is the method of building a collision Resistant cryptographic hash functions from collision-resistant one way comprehensions.
Bank Message problem demonstrates length extension attacks.
RSA weakness is that it needs people to not be able to factorise large numbers.
Key Stretching-
Online attacks: You can potentially be locked out of the account if too many failed attempts
Offline attacks: Steal the offline file of all hashed passwords and try to decrypt locally.
Salting will help as it will increase the time it takes to decrypt each hash.
1 note
·
View note
Text
Lecture5
- the motto of last week: "every contact leaves a trace"
- WEP: Wired Equivalent Privacy (So many flaws, a joke)
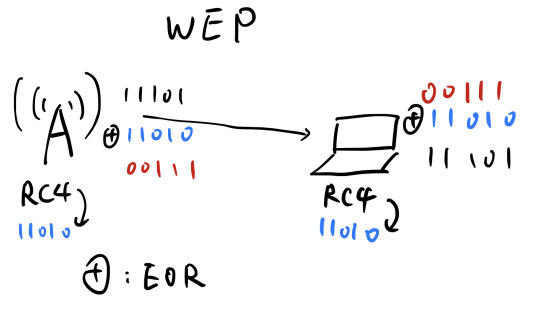
- Exclusive Or:
EOR two same messages will give all 0s
EOR a message with a random number will give a random number as well
- Hash:
MD5 - 1991 - Rivest - 128 bits BROKEN
SHA0 - replaced almost immediately with... BROKEN
SHA1 - 1995 - NSA - 160 bits BROKEN
SHA2 - 2001 - NSA - 224/256/384/512 bits NOT YET
SHA3 - 2015 (standard accepted) - NIST competition (started 2006) - 224/256/384/512 bits NOT YET
Merkle-damgard construction:
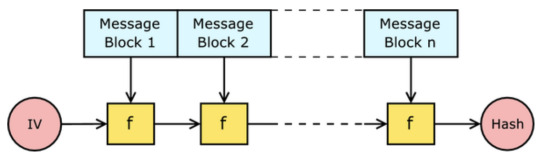
Hash extension attack
Digital Signatures RSA DSA:
Encrypt the message with your private key
Collison attack: can fake you like another person that is trustworthy (hash)
data breaches?
1 note
·
View note
Text
Homework 4 Solution
CBC-MAC
Write the basic construction of CBC-MAC.
Merkle-Damgard
Let h : f0; 1gn+t ! f0; 1gn be a xed-length compression function. Suppose we forgot a few features of Merkle-Damgard and construct H as follows:
Value x is input.
Split x into y0; x1; : : : ; xk. Where y0 is n bits and xi (for i = 1; : : : ; k) is t bits.. The last piece xk may be padded with zeroes.
For i = 1; : : :…

View On WordPress
0 notes
Text
Message Authentication Codes: Stream Ciphers + HMAC
“In cryptography, a message authentication code (MAC), sometimes known as a tag, is a short piece of information used to authenticate a message—in other words, to confirm that the message came from the stated sender (its authenticity) and has not been changed.” - https://en.wikipedia.org/wiki/Message_authentication_code
MACs are attached to most messages sent across the internet, they are either built into the cipher or are appended to every message that gets sent. They guarantee that the message hasn’t been changed. But what happens when we change the cipher?

On the internet, either block ciphers or stream ciphers are prevalent, with the latter popular for video streaming and mobile communications for their speed advantage. Above is a diagram of a stream cipher. The cipher will use the key to generate a long, pseudo-random key stream, which is then XOR’d (exclusive or logical operator) with the plain text to produce the cipher text.
However, an attacker may simply intercept this stream and flip bits in the cipher text maliciously, effectively changing the plain text input.
A block cipher is impervious to this as the whole block is encrypted as one, resulting in any kind of bit change in the cipher text effectively destroying the output when attempting to decrypt.
In other words, if a message saying Send Bob $300 produces some cipher text obtained from flipping bits, an attacker may intercept this cipher text and flip a bit, resulting in the corresponding ASCII of the decrypted plain text message being changed to Send Bob $900. Obviously this is a problem! So how do we secure stream ciphers?
What about hashing?
We could perhaps hash the message, then append the hash of the message to the message itself, like so:

The problem here is that anyone intercepting could simply change the message and recompute the hash before sending it along to the receiver who hashes the message, sees the hashes match and believes the message to be authentic! This is obviously naive and does not work for networking.
What about a shared key k ? Transmitter and receiver could agree upon this message k, and attach h(k|m) to the message, where h(k|m) is a hash of k appended to the message, like so:

This is better and works okay. However, this MAC is vulnerable to a length extension attack if the length of the shared key is guessed. SHA-1,2 are based around Merkle-Damgard construction, which through a length extension attack means an attacker could potentially append to the message.
So what do we actually use?
The keyed, hashed, message authentication code, HMAC. It is the same as the standard MAC, but uses 2 hashes and 2 keys, making it completely invulnerable to a length extension attack.
To do this, we take a key K and use it to derive 2 subkeys, k1 (outerpad) and k2 (innerpad). They are derived by taking constants and XOR, the process is not wholly important but the keys must have as few bits in common as possible.
We then calculate the hash of k1 appended to our message:
h(k1|m)
Then append that to k2, and hash the result:
h(h(k1|m)|k2)
The length extension attack now cannot be performed on the message as knowledge of the internal state of the hash function after the middle point is not known to an attacker.
We've now secured stream ciphers!
0 notes
Text
Week 5 Recap
Don’t roll your own
Don’t try to make your own cryptographic function
WEP
Some people still use it which is Worrying
Captain Crunch
Phones back in the day mixed data and control. Users should have access to data but not control
Phone tones were exploited used the whistle that came with Captain Crunch cereal
(More) Hashes
MD5, SHA0, SHA1 broken
SHA2, SHA3 unbroken
Merkle-damgard construction
Builds collision-resistant cryptographic functions
How it works:
Break up message into blocks
Start with initialisation vector (IV)
Use hash function with IV and block one, then use output with block 2, block 3, ..., block n
Once finished, that is final hash

Also that one puzzle at the end of the lecture notes
EDIT: This is me from the future to say I never figured out what the code says and I am Annoyed
Guest Lecturer: Dr Lisa Parker
Main topic: Unconcious bias
When wanting to affect change, attack the weakest link - target the one with the power of influence/decision (the root) making rather than spending effort/time/resources on the branches of the proverbial tree
In security, this might mean bribing someone for the needed password instead of cracking a hash function to obtain it
Changing culture/mindset is a key part in bringing change rather than implementing more rules
It is about modelling its affects rather than just talking about them
0 notes
Text
Week 6
++ the stack grows up ++
Don’t mix data and control – v v bad idea, then you have access to everything
AES – advanced encryption standard
The process of selecting a new algorithm was open to the public to allow full analysis and scrutiny. The algorithms were judged based on their ability to
resist attack (most importantly )
their cost – efficient both in terms of computation and memory
their implementation – flexibility, sustainability in hardware and software, simplicity
Rjindael Cipher was chosen
A block cipher used to protect classified information – encryption of electronic data
There are 3 block ciphers each of 128 bits, but with different key lengths – 128, 192, 256 bits
It is a symmetric-key algorithm i.e. the same key is used for encryption and decryption
All of the key lengths are sufficient to protect information up to the “Secret” level (see wk 2 Bell LaPadula) but “Top-Secret” level documents require 192 or 256 bit keys.
Data is storied in an array before being put through a series of rounds consisting of substitution, transposition, mixing of plain text and transformation into cipher text. The number of rounds differs depending the key size.
Substitution table -> shift data rows -> mix columns -> …. -> XOR operation on each column using a different part of the key …
Based on substitution-permutation network

Buffer Overflow Vulns
A buffer overflow is when more data is put into a fixed length buffer than the buffer can handle. The additional data overflows into adjacent memory, overwriting the data stored there. In a buffer overflow attack, the data is intentionally made to overflow into areas where important executable code is stored, where it can be overwritten with malicious code, or altered to change a program’s behaviour.
In C, there is no built-in protection against accessing data outside of certain boundaries, so it is essential to implement boundary checking when dealing with arrays.
Canary -> space deliberately left between buffers which look for actions written into them
DON’T USE gets()
Block Cipher – to secure a msg (encrypt / decrypt)
An algorithm which takes a fixed-length of bits called a block and applies a symmetric key and cryptographic algorithm (rather than applying it to one bit at a time – stream cipher). The previous block is added to the next block so that identical blocks are not encrypted the same. (I think this is not true of all block ciphers but good ones do this - ECB doesn’t that’s why it sucks) An initialisation vector also help prevent identical ciphertexts – they are a randomly generated set of bits, added to the first block and key.
Block Modes – for authentication
An algo that uses a block cipher to provide confidentiality / authenticity. It describes how to repeatedly apply a single-block op to securely transform data greater than the size of a block. They usually require an IV which must be non-repeating. Data greater than a single block is padded to make it a full block size – some modes don’t pad they act more like stream cipher.
ECB – Electronic Codebook: The simplest. Do not use for cryptographic protocol
Each message divided into blocks and encrypted separately -> this means identical plaintext becomes identical ciphertext leaving it vulnerable to pattern searching attacks. It is also susceptible to replay attacks as each block is decrypted the same way

CBC – Cipher Block Chaining
In cipher block chaining each message is XOR-d with the previous block (kind of like Merkle-Damgard ?) This makes it more secure than ECP mode as you cannot decrypt individual blocks – they are all dependent on the previous block. The initialisation vector is unique for every message, it does not have to be secret but keeping it secret probably adds a bit of extra security

CTR (Counter Mode)
CTR mode changes a block cipher into a stream cipher (i.e every bit is encrypted rather than every block). Kestream blocks are generated by encrypting a nonce with a counter ( I think - come back to this )

Moore’s law
Processor speeds will double every 2 years – i.e. the number of transistors on an affordable CPU double. This was a prediction made in 1965 and despite many others predicting this rate would slow, so far it has been pretty accurate
Cold Boot Attacks
A side channel attack used to gain access to the encryption keys of an OS. The attacker needs physical access to the computer to perform a cold reboot to restart the machine. After a computer is switched off there is a small window where the RAM holds onto data. In a cold boot attack, the contents of the RAM can be copied to an external drive in this time.
Attackers can also lower the temperature, giving them more time before the RAM fades due to lack of electricity. The computer must be forcibly turned off so that the processor does not dismount important data. Most modern systems wipe memory early in a boot process to help prevent these attacks. Of course this attack can be stopped entirely by remaining with your computer for a few minutes after it’s switched off, ensuring no one has access to your machine.
0 notes
Text
Lectures - Week 5 (Mixed)
Vulnerabilities
One of the most fundamental concepts in security is the idea of a vulnerability - a flaw in the design of a system which can be used to compromise (or cause an unintended usage of) the system. A large majority of bugs in programming are a result of memory corruptions which can be abused to take control - the most ubiquitous example of this is the buffer overflow; the idea that you can overwrite other data alongside a variable which can change both data and control of a program. The common case is when programmers fail to validate the length of the input when reading in a string in C. Another fairly common bug relates to the overflow of unsigned integers; failing to protect against the wraparound can have unintended consequences in control flow.
‘NOP Sled’
Richard also mentioned in the 2016 lectures the idea of a NOP sled which I found quite interesting. The idea is that due to run time differences and randomisation of the stack, the address the program will jump to (from the return address) can sometimes be difficult to predict. So to make it more likely it will jump where the attack wants, he converts a large set of memory to NOP (no operation) instructions which will just skip to the next one; then finally after the “NOP sled” his code will execute.
printf(”%s Printf Vulnerabilities”);
One of the most hilarious programming vulnerabilities related to the usage of the printf function. Basically if you have an input which is accepted from the terminal and you plug this (without parsing) into a printf, an attacker could potentially feed in an input such as “%s”. (i.e. the title) Now since you haven’t specified a 2nd argument, it will just keep reading all the variables in memory until you hit a “\0″. In fact you can abuse this even further to overwrite memory with the “%n” format string - it will overwrite an integer with the number of characters written so far.
Handling Bugs
Many of the bugs we know of today are actually reported in online databases such as the National Vulnerability Database or Common Vulnerability & Exposures (CVE) Databases. There is actually lots of pretty cool examples online in these, however most of these have been actually fixed - we call them zero day vulnerabilities if the vendor hasn’t fixed them (and if they are then abused then zero day exploits).
When working in security, it’s important to understand the potential legal consequences associated with publicly releasing damaging vulnerabilities in software. This is where responsible disclosure comes in - the idea that if you find a bug you disclose it to a software vendor first and then give them a reasonable period of time to fix it first. I think I discussed an example from Google’s Project Zero Team a couple weeks ago - however just from a quick look there was a case in March where their team released the details on a flaw in the macOS’s copy-on-write (CoW) after the 90 day period for patching. (it’s important to note they gave them reasonable time to fix it)
OWASP Top 10
This was a pretty cool website we got referred to mainly regarding the top bugs relating to web security (link); I’ll give a brief overview here:
Injection - sends invalid data to get software to produce an unintended flow of control (i.e. SQL injection)
Broken authentication - logic issues in authentication mechanisms
Sensitive data exposure - leaks in privacy of sensitive customer data
XML External Entities (XXE) - parsing XML input with links to external bodies
Broken action control - improper access checks when accessing data
Security misconfigurations - using default configs, failing to patch flaws, unnecessary services & pages, as well as unprotected files
Cross-Site Scripting (XSS) - client injects Javascript into a website which is displayed to another user
Insecure deserialisation - tampering with serialization of user data
Using components with known vulnerabilities - out of date dependencies
Insufficient logging and monitoring - maintaining tabs on unusual or suspicious activity, as well as accesses to secure data
Some Common Bugs
Just a couple of the bugs that were explored in some of the 2016 lecture videos:
Signed vs unsigned integers casts - without proper checks can lead to unintended control flow
Missing parenthesis after if statement - only executes next line and not all within the indentation
Declaring array sizes wrong - buf[040] will be interpreted as base 8
Wrong comparators - accidentally programming ‘=‘ when you intended ‘==‘
A lot of the more common bugs we used to have are getting a lot easier to detect in the compilation process; GCC has a lot of checks built in. Valgrind is also a really awesome tool to make sure your not making any mistakes with memory.
WEP Vulnerability
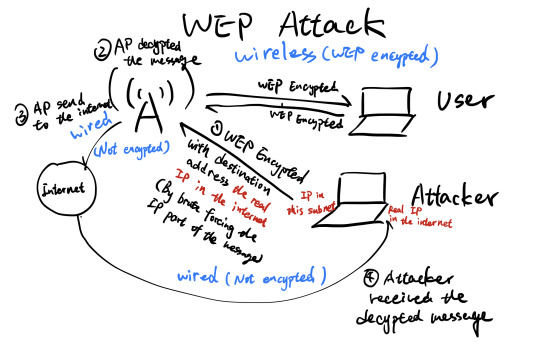
I actually discussed this idea already in the week 1 lectures here - just for the sake of revision I will give a basic overview here. The basic idea is that WEP uses a stream cipher RC4 which XORs the message with a key; however the issue is that we know information about the structure of TCP/IP packets. Within a local network the local IPs are usually of the form A.B.C.D (i.e. 192.168.20.4 for a specific computer) where each letter represents a byte in the range 0-255. (0-255 are usually reserved and not used for computers in the network) Due to subnetting (i.e. with a subnet mask 255.255.255.0 on private network) the last byte D is usually the only one that changes - this means we effectively have 254 combinations.
Since we know where the destination address is located within the packet, an attacker can potentially record a packet and modify this last byte - they can send out all 256 possible combinations to the router (remember it’s encrypted so we can’t limit it to 254). The router will then decrypt the message and then encrypt it with the key used for communications with the attacker - and voila the system is compromised.
Hashes

Richard gave a brief overview of the basis of many of our hash functions which is the Merkle-Damgard construction. The basic idea behind it is to break the message into blocks - the size varies on the hash type and if its not a multiple of the required length then we need to apply a MD-compliant padding function. This usually occurs with Merkle-Damgard strengthening which involves encoding the length of the original message into the padding.
To start the process of hashing we utilise an initialisation vector (number specific to the algorithm) and combine it with the first message block using a certain compression function. The output of this is then combined with the 2nd message block and so forth. When we get to the end we apply a finalisation function which typically involves another compression function (sometimes the same) which will reduce the large internal state to the required hash size and provide a better mixing of the bits in the final hash sum.
Length Extension Attacks
I think after looking at the Merkle-Damgard construction it now becomes pretty obvious why using MACs of the form h(key|data) where the length of the data is known are vulnerable to length-extension attacks. All you need to be able to reverse in the above construction is the finalisation function and the extra padding (which is dependent upon the length which we’re assuming we know); then you can keep adding whatever message blocks you want to the end!
Digital Signatures
The whole idea behind these signatures is providing authentication - the simplest method of this is through asymmetric key encryption (i.e. RSA). If your given a document, you can just encrypt it with your private key - to prove to others that you indeed signed it, they can attempt to decrypt it with your public key. There is a problem with this approach however - encryption takes a lot of computation and when the documents become large it gets even worse. The answer to this is to use our newfound knowledge of hashing for data integrity - if we use a hash (’summary of the document’), we can just encrypt this with our private key as a means of signing it!
Verifying Websites
One of the hardest issues we face with the ‘interwebs’ is that it is very difficult to authenticate an entity on the other end. We’ve sort of scrambled together a solution to this for verifying websites - certificate authorities. (I could go on for ages about the problems with these being ‘single points of failure’ but alas I don’t have time)
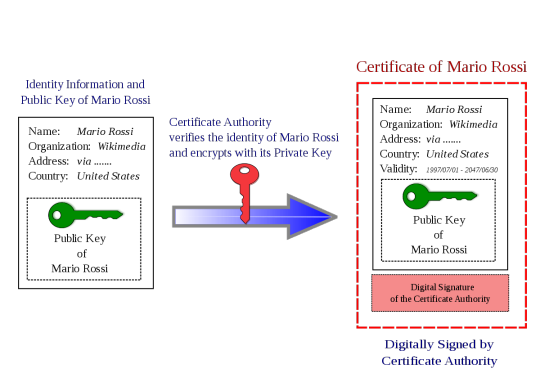
The idea behind these bodies is that a website will register with the entity with a specific public key. The CA will then link this public key (in a “big ol’ secure database”) with the ‘identity’ of the website. To understand how it works its best to consider the example of when you access any website with HTTPS. (i.e. SSL) When you visit www.example.com, they will then provide their public key and a digital signature of key (signed by the cert authority’s private key) in the form of a X.509 certificate. The user will have access to CA’s public key as part of their browser and will then be able to verify the identity of the website. (the cert is encrypted with the CA’s private key - see above image) An attacker is unable to fake it as they don’t know the certificate authorities’ private key.
Attacking Hashed Passwords
Given there is only a limited number of potential hashes for each algorithm, there is a growing number of websites online which provide databases of plaintext and their computed hashes - these are what we refer to as hash tables. We can check a hash very quickly against all the hashes in this database - if we find a match, we either know the password or have found a collision.
Rainbow tables are a little more complex - in order to make one you need a hashing function (the same as the password) and a reduction function; the latter is used to convert the hash into text (i.e. a base64 encode and truncation). These tables are made of a number of ‘chains’ of a specified length (let’s say we choose 1,000,000) - to create a chain you start with a random seed then apply both the above functions to this seed. You then iteratively do this process another 1,000,000 times (chosen length) and store the final seed and value (only these). In order to try and determine a match to the rainbow table, you apply the same two functions to the password for the required length - however, at each step you compare the hash to the result of each of the chains in the table. If you find a match, you can reproduce the password.
Both of the attacks against password hashes described above rely on an attacker doing a large amount of work in advance, which they will hopefully be able to use in cracking many passwords in the future. (it’s basically a space-time tradeoff) An easy way we can destroy all the work they have done is through a process known as salting. Basically what you do is generate a random string which you concatenate with the password when creating a hash - you need to store this alongside the password in order to check it in future. This means an attacker can’t use pre-computed tables on your hash; they have to do all the work again for your particular salt!
Richard discussed another interesting concept called ‘key stretching’ in the lectures - it’s basically the idea that you can grab a ‘weak password hash’ and continuously hash it with a combination of the (’hash’ + ‘password’ + ‘salt’). This process of recursively hashing makes it insanely difficult for an attacker to bruteforce. This is combined with the effects of a ‘salt’ which (on its own) renders rainbow tables (’pre-computed hashes’) useless.
Signing Problems with Weak Hashes
One of the problems with using a hash which is vulnerable to second-preimage attacks is that it becomes a lot easier to sign a fake document. Consider the example of a PDF document certifying that I give you $100. If you wanted you could modify the $100 to $100,000, however this would change the resultant hash. However since it’s a PDF you could modify empty attribute fields or add whitespace such that you can modify the hash an enormous amount of times (i.e. to bruteforce the combinations). Since the hash is vulnerable to second-preimage this means that given an input x (the original signed document) we are able to find an x’ (the fake signed document) such that h(x) = h(x’).
Dr Lisa Parker (guest speaker)
I wasn’t able to make the morning lecture, although I will try and summarise my understanding of the key points from this talk:
More holistic approaches to systems improvement have better outcomes (’grassroots approach’ is just as important as targeted)
Unconscious bias is present across a wide variety of industries (i.e. judges harsher before lunch, doctors prescribing drugs for free lunch)
Codes of conduct intended to reduce corruption; pharmaceuticals try to dodge with soft bribes, advertising, funding research
Transparent reporting reduces malpractice
Enforcing checklists useful for minimising risk
OPSEC Overview (extended)
We traditionally think of OPSEC has been based in the military, however many of the principles can apply in more everyday scenarios:
Identifying critical information
Analysis of threats
Analysis of vulnerabilities
Assessment of risk
Application of appropriate OPSEC measures
A lot of the ideas behind gathering information (recon) revolve around collecting “random data”, which at first may not appear useful, however after managing to piece them together, they are. One of the quotes from Edward Snowden (I think) I found quite interesting, “In every step, in every action, in every point involved, in every point of decision, you have to stop and reflect and think, “What would be the impact if my adversary were aware of my activities?””. I think it’s quite powerful to think about this - however at the same time we don’t want to live with complete unrealistic paranoia and live as a hermit in the hills.
One of the easiest ways to improve your OPSEC is through limiting what you share online, especially with social media sites. Some of the basic tips were:
Don’t share unless you need to
Ensure it can’t be traced (unless you want people to know)
Avoid bringing attention to yourself
You can try and conceal your identity online through things like VPNs and Tor Browser. It is important that in identities you have online that you don’t provide a means to link them in any way (i.e. a common email) if you don’t want someone to be able to develop a “bigger picture” about you. For most people, I think the best advice with regards to OPSEC, is to “blend in”.
Passwords (extended)
I am really not surprised that the usage of common names, dates and pets is as common as it is with passwords. Most people just like to take the lazy approach; that is, the easiest thing for them to remember that will ‘pass the test’. Linking closely with this is the re-use of passwords for convenience - however for security this is absolutely terrible. If your password is compromised on one website and your a ‘worthy target’, then everything is compromised.
HaveIBeenPwned is actually a pretty cool website to see if you’ve been involved in a breach of security. I entered one of my emails, which is more of a ‘throwaway one’ I use for junk-ish accounts on forums and whatnot - it listed that I had been compromised on 11 different websites. I know for a fact that I didn’t use the same password on any of those; secondly for most of them I didn’t care if they got broken.
I think offline password managers are an ‘alright way’ to ensure you have good unique passwords across all the sites you use. (be cautious as they can be a ‘single point of failure’) However when it comes to a number of my passwords which I think are very important - I’ve found just randomly generating them and memorising them works pretty well. Another way is to form long illogical sentences and then morph them with capitalisation, numbers and symbols. You want to maximise the search space for an attacker - for example if your using all 96 possible characters and you have a 16-character password then a bruteforce approach would require you to check 2^105 different combinations (worst-case).
The way websites store our passwords is also important to the overall security - they definitely shouldn’t be stored in plaintext, should use a ‘secure hash function’ (i.e. not MD5) and salted. I’m pretty sure I ranted about a mobile carrier that I had experiences with earlier in my blog, that didn’t do this. This means if the passwords were ‘inevitably’ all stolen from the server, the attacker just gets the hashes, and they can’t use rainbow tables because you hashed them all. Personally, I really like the usage of multi-factor authentication combined with a good password (provided those services don’t get compromised right?). Although, you want to avoid SMS two-factor as it’s vulnerable to SIM hijacking.
4 notes
·
View notes
Text
Job application: Analytical skill
global char *heading = Throughout the term I have constantly analysed relevant security concepts, researched topics in lecture that was not understood fully, and have integrated them into everyday life.
Research:
uint 000001 = For homework activity I researched about average PC life cycle and reflected on my own consumption/technology usage behaviour in here.
uint 000010 = For preparation of case study analysis in week 1 I watched an hour youtube video on the Deep Horizon accident to clear everything up. I blogged about the tutorial discussion later.

uint 000011 = For my something awesome project I had no idea what options were there for me to pick, so I did some research to learn about some of the popular hacking gadgets out there.
uint 000100 = In week 4′s lecture Richard brought up MAC and integrity property in cryptography. I had no idea what that was so I did some days of research and blogged about it. See Ways of authentication.
uint 000101 = In week 5′s kahoot there’s a question asking how is SHIM used in lock-picking. I didn’t know the answer so I watched a bunch of lock-picking videos later that week.
uint 000110 = Spectre and meltdown was brought up in lecture when side-channel attack was mentioned. I watched some youtube videos and blogged about it in my lecture reflection that week. It was later briefly talked about during tutorial but not explained in details, so I interpreted the concept in my own way :(
uint 000111 = During midterm and the week after, I noted down all the concepts that I was not familiar with for future research when I had time. After reading several papers I blogged about things that I struggled most with. See Merkle-Damgard Construction/WEP/Diffie-Hellman algorithm.
uint 001000 = For midterm preparation I went to the consultation session on Tuesday and discussed some questions from the practice exam with Caff and Jazz. I didn’t blog about this one because my poor brain was busy being f**ked by midterm preparation, and it was quite late to blog about preparation when the midterm has finished. Main argument between Caff and Jazz revolved around if MAC provides authentication or not (turns out it does because of the shared secret key involved in the hashing process). Main diversion between Jazz and I was if MAC provides non-repudiation or not (a property hadn’t been covered in lecture yet). Jazz’s opinion was that although A and B both know they share the secret that no one else knows, neither of them could prove it to others. I went to do further research and realised he was right.
uint 001001 = Homework activity required background knowledge of Crib dragging, so a bit reading was done.
uint 001010 = Researched about Block Cipher Mode related to lecture content.
Reflection:
Here are some of the reflection that I did after lecture to ensure I fully grasp the relevant ideas and establish my security mindset.
char *Lecture reflection01
char *Lecture reflection02
char *Lecture reflection03-05
char *Lecture reflection05-07
char *CaseStudy01
char *CaseStudy04
char *Type_I_II_Error
Application:
Application of relevant course concept is mainly through strengthening awareness of security issues in daily life.
char *SecurityEverywhere01
char *SecurityEverywhere02
char *SecurityEverywhere03
char *SecurityEverywhere04
0 notes
Text
[COMP6841] Lecture 5
“Don’t Roll Your Own”
Do not try own cryptography
Wired Equivalent Privacy (WEP) - 2 exclusive ors - no change
MAC address - simply change the destination address, let the switcher decode for us
Merkle Damgard construction - linked blocks with initialization vector iv
https://yifanai.tumblr.com/post/186590664651/comp6841-merkledamgård-hash-function
Length extension attack vulnerability
https://yifanai.tumblr.com/post/186590560126/comp6841-length-extension-attack
Key Stretching - adds time complexity to encode and especially decode
https://yifanai.tumblr.com/post/186155254786/comp6841-key-stretching
Salting - to mitigate rainbow table attacks
https://yifanai.tumblr.com/post/186590795841/comp6841-salting

Buffer overflow attacks
https://yifanai.tumblr.com/post/186590951966/comp6841-buffer-overflow-attacks
Data and control
mixing data and control is risky
data and control should be separated
Passwords
good passwords and bad passwords
I can now interpret Moore’s Law in another way: We loss one bit of security every 18 months.
I can now categorize difference ciphers into symmetric and asymmetric ciphers.
Happy Extended Security Engineering and Cyber Security!
0 notes
Text
Lecture 6
I just remembered that professionalism was part of the portfolio marking criteria so I’ll try to keep it PG in these posts. Meaning that I’m allowed to drop one and only one F-bomb somewhere.
Avalanching
Recall that the Merkle-Damgard hash construction looked like this:
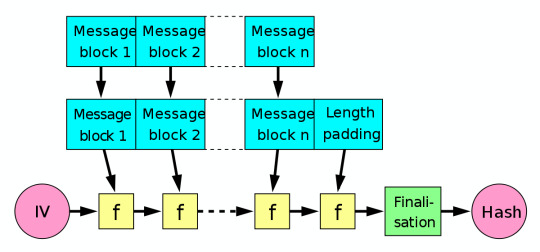
The reason the hash function is segmented into the various f’s you see above, is to allow avalanching to occur; the property that causes good cryptographic hashes to be drastically different from one another, even if the edit distance of the inputs if minimal.
This allows for the semantic meaning of relatively similar inputs to be obfuscated, as one would otherwise be able to perhaps glean information pertaining to the information that had been hashed, through observation of the structure of the hash string and comparison with other similar hashes e.g. if hashing 12345 and 12346 produced hashes of 0xaa0geb212r3r3142q and 0xaa0geb212r3r3131w, then an attacker could probably guess the structure of the input at the very least and perhaps interpolate the inputs by generating other hashes.
Passwords Part II
From the exam, we might have found that the # of bits of security that we get from a random password using the Elephant Apple Golfing principle (or some shit I don’t remember the stupid name) isn’t as many as we would like. It’s naive to say that a password has as many bits as it is long, unless those bits are truly random and the full complement of ASCII characters are actually utilised, such as \0.
Indeed most passwords aren’t that many bits, given that they’re based largely on quotes, names, birthdays etc. etc. and it’s only a matter of time before increases in computing power renders them obsolete.
So yeah, the answer to that question pertaining to the Homophobic Dog Shagger principle is 40-49 bits i.e. the smallest choice. Congratulations if you got it right.
This kind of segues into why WEP keys are terrible:
They’re consisted of a shared 40 bit key, that everyone connected to a network knows, and a 24 bit initialisation vector that was randomly generated locally by the receiver that were combined to form a ‘64′ bit key and this key was used to encrypt every frame.
The obvious issue with this is that it’s trivial to brute force 24 bits, and it’s probably trivial to brute force 40 bits, and it wasn’t too difficult combining all the brute forced combinations to obtain the purported 64 bit key.
Mixing Control and Data - Smashing the Stack for Fun and Profit
http://phrack.org/issues/49/14.html
Mixing control and data is bad, don’t do it.
C lets us do it and although most modern compilers such as gcc and clang have several countermeasures for stack smashing, it remains a useful case study and a common issue in modern software.
Buffer overflows can occur when someone writes shit code and rather than fixing declaring a fixed array size in their loop iteration, they end the array loop once the program hits NULL, allowing a third-party to use a function such as strcpy() - that doesn’t check buffer size - to stuff more in the buffer than has been allocated to memory. There are other methods too but this is the most intuitive to understand.
The Stack and Return Addresses:
Computers switch context lots of times a second to allow them to deal with interrupts from a multitude of sources. When something interrupts them, such as a keyboard entry perhaps, the computer will execute the interrupt and then return to whatever task it was completing before.
How it knows where to return in the code, is by adding the address of that particular point where it stopped - the return address - as well as the miscellaneous parameters that the code needed to execute, onto a LIFO structure known as the stack. These miscellaneous parameters, such as our array, are stored before the pointer and as such, by overflowing the array, we are able to overwrite whatever return address was in stored at the pointer(’s address) which paves the way for all sorts of shenanigans.
Most common of these shenanigans:
- Actually writing code into an overflowed buffer and addressing the pointer to the location of this code
- Getting a shell open
Overflowing the array is most commonly done with a NOP Sled, which is simply consisted of a bunch of NOPs (no operation commands) that serve to pad the buffer up to the memory/stack address containing the return address and your payload which can be either a memory address pointing to your code or pointing to whatever would open up a shell.
This requires us to know the # of NOPs to place into our sled, which can be done in a variety of methods that the course doesn’t require us to know.
*will add more to this section as I read more on it*
NIST and the History of Ciphers
Even after WWII, ciphers were not particularly powerful and for a while there was a ‘crypto black hole’ where no new cryptographic methods were being devised and nobody was aware of any principles one should follow.
This changed with the advent of computers and eventually, groups concerned about security put out a standard known as NIST.
Except noone knew what to put into the standard and so a competition was held which noone except IBM entered into and they won by default.
And so IBM’s DES was adopted and had at the time, only 56 bits.
Then the NSA comes along, looks at DES, breaks it in two seconds using their differential cryptographic methods and says ‘yeah it’s okay keep using it XD’.
Except everyone was like HANG ON, and eventually a successor AES was built. AES was predicated, much like DES, on performing many permutations, transposing and other obfuscating measures, which created an encryption method that was difficult to break feasibly, but had significantly more bits than AES.
XSS (Cross Site Scripting) or why Javascript is awful
Cross Site Scripting
Involved placing Javascript on a webpage, for example in a poorly secured forum, where you know unassuming people would visit. The Javascript will execute upon that page opening and whatever was in the JS will proceed to wreak havoc.
Common attacks include stealing your cookies to impersonate you.
SQL & Command Injections
Webpages that require you to enter your username and password into fields will typically take the characters you entered as your username and password, stick them in an SQL query and execute said query to check your username and password against a preexisting username and password database.
Instead of entering our usernames and passwords, we can enter actual SQL code which will actually execute, due to the nature of PHP converting your input into code. This wouldn’t work in any other language. For example:
Here’s an example query taken off https://www.acunetix.com/websitesecurity/sql-injection/
# Define POST variables uname = request.POST['username'] passwd = request.POST['password'] # SQL query vulnerable to SQLi sql = “SELECT id FROM users WHERE username=’” + uname + “’ AND password=’” + passwd + “’” # Execute the SQL statement database.execute(sql)
Now, we could easily input as the password:
password' OR 1=1
which would cause:
SELECT id FROM users WHERE username='username' AND password='password' OR 1=1'
SELECT id FROM users WHERE username=‘username’ AND password=‘password OR 1=1′
to execute, which would return the first ID of the first user in the database table due to that 1=1 is always true and the query is made complete by the ‘ appended to the word password.
We could easily modify this query to print out the entire table if we wanted to write more code.
Command injections rely on the same concept of writing code into input boxes, but instead we write shell code and grep our way to sensitive data.
Cryptocurrency
Wasn’t really paying attention to this part, I’ll fill it in later
Block Modes
How we combine individually ciphered blocks of a ciphertext, like we did in the Merkle-Damgard hash (recall that the input was split into blocks), to get a whole ciphertext:
- Can concatenate them like in WEP
- Or more commonly, we can use CBC which is really convoluted: here’s some reading if you’re interested, but basically each unciphered block is XOR’d with the previous block.
https://en.wikipedia.org/wiki/Block_cipher_mode_of_operation#Cipher_Block_Chaining_(CBC)
Authentication - WIP
How? What decisions?
Humans are bad at looking at faces
No point in confidentiality, if there is no authentication
Defence in depth
Something you know
Have: let's send someone an SMS when they type their PW WOW.
2FA worked well initially, however, SMS is easy to intercept.
Have single point of weakness, in your phone
Are:
Requires secrets to be confidential, keyloggers, shoulder surfing etc.
Naïve but easy to implement
1 note
·
View note
Text
Week 5 Lecture Takeaways
DON’T ROLL YOUR OWN CRYPTO. JUST DON’T DO IT MATE
WEP is the best example of this
it was meant to make wifi secure but ended up being the most flawed protocol
it was used for years after flaws were discovered
How WEP worked:
There was an access point sending a bit string to a device
Both the point and device encrypt using RC4
RC4 creates another bit string
Bit strings are XOR’d together
XOR’d from the point, then the device decrypts data to get the original
Why it sucked
Passive observing could recover the key in minutes
the single key is shared with EVERYONE
they mixed data and control
The guest speaker, Lisa Parker, had some really interesting points about bias
Bias in evidence: self explanatory
Inherent Bias: natural and unconscious
Observation bias: based on what you see
Systematic bias: I didn’t write a definition but there was the example about how a marketing company for a drug will give out free lunches to doctors and doctors are more likely to recommend that drug as opposed to others based on that lunch
Behavioural/Cultural bias: Basically involves actions because of the “culture” and how it is hard to change
Operational Security:
Great presentation featuring my boy Andrew Nguyen.
Passwords:
Although mostly known, still interesting to hear. The live demo was amazing and really interesting. cup.py seemed like such a powerful tool and exploitable on lesser informed individuals.
More Richard;
Merkle Damgard construction - outlined in other blog post
Password stretching - instead of MD5, a custom function is used to hash passwords. It’s made to be a slow hash function so that the hacker takes way longer. although it is longer for the user, it is multiplicative for the hacker.
Salt - other blog post
0 notes
Text
Block Cipher Modes
Again, Block Cipher Modes are encryption methods that operate on data of fixed length. For example, DES operates on 64 bit data, whilst AES can operate on either 128 or 256 bits. However, you might note that most files are generally LARGER than 64/128/256 bits which is truthfully a small size. Therefore, these algorithms effect on splitting up the data into these fixed sizeable chunks and encrypting that.

ECB (Electronic Code Book)
Now then the simplest variant of this is ECB which is very simply, just splitting the data into 128-bit sized chunks and encrypting them individually. As below, it simply takes the plain-text, combines it with the key and encrypts it. This is however very linear and because of its straightforwardness, carries information inside the cipher-text.

As mentioned before, this is the major flaw in ECB and not at all recommended for encryption. For example, if you compare the following image of Tux encrypted using ECB (second) against AES (last), you can see that all the same coloured blocks have the same encryption (black = black, white = white, yellow = yellow).

CBC (Cipher Block Chaining)
CBC is the solution to EBC’s problem of the same blocks resulting in the same encrypted cipher-text by introducing a chaining methodology which is an iterative process, much like Merkle-Damgard algorithm. In comparison to EBC, CBC initially uses a random initialisation vector (IV) to start of the chain, and the subsequent blocks depend on the cipher-text of the previous block. While more secure, and solving this issue by introducing more complexity, this algorithm is a lot slower because of its dependencies on the previous cipher-text. Due to the chain structure, to finish encrypting, it needs to wait for all the blocks prior to encrypt procedurally. This means that the encryption CANNOT BE DONE IN PARALLEL, which would make it a lot faster.

CTR (Counter Mode)
da best one.
CTR is a unique mode that takes AES block-cipher and turns it into a pseudo-stream cipher. Instead of simply encrypting the plain-text, CTR first encrypts a NONCE together with a counter value (signifying the operative block, so with each new block, the counter value is increased). This is extremely effective due to the Confusion and Diffusion properties of AES originally (small change->big output). Finally, the encrypted block is XOR’d with the plaintext which is super good because XOR is very inexpensive and fast! Altogether this can be done in parallel too because none of them have dependencies.

0 notes
Last Seen Blogs

beneaththebloodriver
Unto Infinity

bellzinha-ofc
Bellzinha-Ofc

dyahworld
Tersimpan Oleh Mulut dan Tertuangkan Oleh Tulisan

bendy-of-ink
Bendy and the ink machine

captaintaco
Untitled