#IPFS error
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
If you dial 1-866-584-6757, you can leave an audio post for your followers.
Text
Unlocking the Future with a Web3 Development Company
In a world that’s rapidly shifting from centralized systems to decentralized, trustless, and more transparent technologies, Web3 is not just a buzzword—it’s the future of the internet. At the heart of this transformation are specialized Web3 development companies that are building the infrastructure and applications driving this next-gen digital revolution.
Whether you're a startup exploring blockchain integrations or an enterprise seeking to adopt smart contracts, choosing the right Web3 development partner can be the difference between leading innovation or playing catch-up.
What is a Web3 Development Company?
A Web3 development company specializes in building decentralized applications (dApps), smart contracts, blockchain platforms, crypto wallets, and other products that rely on Web3 technology. Unlike Web2 development (which focuses on centralized applications), Web3 developers build systems that enable user ownership, security, and transparency by leveraging technologies like Ethereum, IPFS, and smart contracts.
These companies often offer services such as:
Custom blockchain development
Smart contract creation and auditing
NFT marketplace development
DAO creation
Tokenization services
dApp design and development
Why Businesses Need Web3 Solutions
As data privacy, digital ownership, and decentralized finance (DeFi) gain traction, Web3 presents new ways to build digital trust and user engagement. Businesses from various sectors—finance, healthcare, gaming, real estate, and more—are turning to Web3 to:
Cut out middlemen and reduce transaction costs
Create transparent systems that foster user trust
Empower users through token economies
Build global, community-driven platforms
How to Choose the Right Web3 Development Partner
Finding a trustworthy Web3 development company is crucial. Here’s what to look for:
1. Technical Expertise
The blockchain world is vast and rapidly evolving. Your development partner should have proven experience in blockchain protocols like Ethereum, Solana, Polygon, and others.
2. Security & Auditing
Smart contracts, once deployed, can’t be changed easily. Any loophole can lead to disastrous consequences. Choose a company with a strong focus on security, auditing, and error-free deployment.
3. End-to-End Services
A reliable firm will provide complete services from strategy to design, development, deployment, and maintenance—ensuring you don’t need to coordinate across multiple vendors.
4. Innovation-Driven Approach
Web3 is still young and evolving. Companies that also offer AI product development or work closely with SaaS experts often bring more innovation to your product roadmap.
The Role of AI in Web3 Product Development
Combining Web3 and AI product development is the new frontier. Imagine decentralized marketplaces powered by AI algorithms that personalize experiences, or smart contracts that evolve based on machine learning inputs. Web3 companies that integrate AI into their development process help you stay ahead of the curve.
Whether it's AI-generated NFT assets or self-improving DeFi protocols, the synergy between AI and Web3 is unleashing incredible possibilities. An experienced Web3 development company with AI capabilities can design smart, scalable, and autonomous solutions for tomorrow’s digital economy.
Web3 and SaaS – A Game-Changing Combo
Many modern Web3 companies now incorporate SaaS (Software-as-a-Service) models into their offerings. This allows for decentralized apps with cloud-like accessibility. SaaS enables easy onboarding, faster development, and subscription-based monetization—combined with Web3's benefits like decentralization and transparency.
If you're looking to build a decentralized SaaS product or upgrade your current SaaS offering with Web3 capabilities, make sure your development partner includes SaaS experts who understand both cloud and blockchain environments.
Why Hiring the Right Developers Matters
You can have a great idea, but without the right people to build it, it stays just an idea. The best Web3 projects are built by skilled, passionate, and experienced developers. This is why many businesses prefer to hire developers from reputable Web3 agencies rather than rely on fragmented freelancer efforts.
From Solidity smart contracts to cross-chain integrations and full-stack blockchain development, a competent in-house or remote development team can dramatically reduce development time and increase success rates.
Some Web3 companies offer flexible hiring models, including:
Dedicated development teams
On-demand developer hiring
Project-based hiring
CTO-as-a-Service for startups
These flexible models allow businesses to scale efficiently without compromising quality.
The Future is Decentralized
From finance to supply chain to digital identity, the Web3 landscape is evolving faster than ever. More companies, governments, and users are leaning into decentralized models to reclaim control over data, assets, and interactions.
Partnering with an experienced Web3 development company ensures you're not just adopting a trend, but future-proofing your business for the digital economy. Whether you're building a new dApp, exploring token economics, or transforming your SaaS into a decentralized platform—make your next move wisely.
Final Thoughts
Web3 isn’t just about technology; it’s about rethinking the internet for a more open, fair, and user-controlled future. With the right partner who understands blockchain, AI product development, SaaS architecture, and offers a reliable team of developers for hire, you’ll be ready to lead this transformation—not just participate in it. Need a trusted partner to build your next-gen decentralized product? Explore ioweb3.io — where innovation meets execution in the Web3 space.
0 notes
Text
One-Stop Solution for All Your Financial, Legal, and Business Needs - By ANISHA SHARMA & ASSOCIATES
Your partner in comprehensive financial and legal solutions with ANISHA SHARMA & ASSOCIATES

For the third consecutive time, ASA is a distinguished consultancy firm offering a one-stop solution suite in financial, legal, and business domains to help its clients navigate the complex world of finance and compliance. ASA stands out from core financial service provision, be it accounting and auditing to high-end legal consultancy and digital advisory, for its high standard of excellence and client satisfaction. Staffed with experienced professionals presenting a tailored approach with every project, ASA assures thorough and professional service for any kind of clients, however small or big the business is.
Core services help cover all those critical business needs at ASA. These include Accounting and Auditing solutions that aid businesses in maintaining clean, error-free financial records. ASA helps businesses safeguard their intellectual property rights through the services of Trademark Registration and Registrar of Companies (ROC). The firm also streamlines the process of License & Registration, thereby making access to permissions easy for businesses. For clients that need capital, ASA assists them on Loans in identifying and acquiring funding options. Income Tax and Goods & Services Tax (GST) management would be very useful in keeping the client tax-compliant. Specialized services ASA offers include Insurance Consulting, Outsourcing, Digital Signature Certificate (DSC) & Token, and Business Software for effective operations, securing data, and digital transformation.
Furthermore, besides the above, ASA has developed a bouquet of specialized services that catapult it into the arena of excellence in consultancy service provision. Their Stock Broking and Investment Advisory presents clients with the acumen for smart, strategic investment decisions. Further, ASA's Website Development and Digital Marketing ensures that businesses provide an adequate online presence, which is probably key to efficiently engaging with customers. The ASA Real Estate sector provides deep market knowledge and consulting for effective investment entry into the sector. ASA also provides Placement Consulting where the firm connects a client with powerful professionals to ensure smooth proper recruitment channels. Experienced clients receive intelligent legal counsel on matters such as compliance with IPF & ESI to other services like Civil & Criminal Law. Whether it is representation in legal matters or consulting for regulatory compliance, the legal team at ASA is devotedly here to help.
The firm would suit anyone looking for a reliable yet versatile and highly professional consultancy partner. A mixture of core and specialized services makes Anisha Sharma & Associates a one-stop solution for businesses seeking financial management, legal advice, and digital transformation. Thus, ASA's technical experts allow each client to achieve that business and financial objective more easily. That is: when you choose an ASA, you get a reassuring advising professional sincerely invested in your success.
Check our official website : http://www.bpspl.com/
[Some of the above mentioned information has been taken from the internet]
0 notes
Text
The essence of games is entertainment.
The essence of games is entertainment. Traditional web2 games are very different from web3 games, because GameFi will not only provide players with token incentives, but also give players ownership of game assets, creating game projects with the characteristics of crypto economy and decentralization. However, the current blockchain game market is mixed, and it is difficult to distinguish between true and false. There are endless tricks and many pitfalls. GameFi is facing many security vulnerabilities and hacker attacks in its development. These threats not only pose a serious threat to the security of users' assets, but also have a serious negative impact on the healthy development of the entire GameFi ecosystem.
On-chain security challenges include:
Token contract vulnerability
GameFi projects typically use one or more tokens for in-game purchases and rewards. The token contract is responsible for managing the minting, trading, and destruction of tokens. If there are vulnerabilities, it may seriously affect the game economy. Token contracts often face centralization risks. Contract owners or administrators have too much authority and may modify transaction fees, restrict transactions, issue additional tokens, or adjust account balances.
Business contract loopholes
The business contracts in the GameFi project are responsible for implementing the gameplay and reward distribution. Developers usually design them as upgradeable contracts. The ChainSource security team's security recommendations for upgradeable contracts include:
Initialize contracts and dependencies: Forgetting to initialize them at deployment time can lead to serious vulnerabilities.
Be aware of storage conflicts: When upgrading a contract, modifying storage may cause conflicts, leading to data errors or fund losses.
Permission control: Limit the contract upgrade permissions to prevent attackers from obtaining upgrade permissions through private key theft or governance attacks.
NFT Vulnerabilities
NFTs are used in GameFi to represent player assets, and their value is guaranteed by quantity and rarity. Improper implementation may bring security risks, especially randomness generation. GameFi projects should use reliable information sources, such as blind boxes and random reward activities, to reduce prediction and manipulation risks. In addition, project parties should securely store NFT metadata and IPFS hash values to prevent metadata from being leaked in advance. Operators need to carefully distinguish between ERC-1155 and ERC-721 tokens. ERC-1155 supports batch transfers, while ERC-721 requires multiple transfers. Previously, TreasureDAO on the Arbitrum chain was attacked for not distinguishing between the two tokens.
Cross-chain bridge vulnerability
The cross-chain bridge is used to synchronize game assets between different blockchain networks and is an important component to improve the liquidity of the GameFi project. The danger lies in the fact that contract loopholes may cause assets to be out of sync on the connected chains. The cross-chain bridge verification node is also a potential risk. It is recommended to add verification nodes and store private keys securely.
Off-chain security challenges include:
Most GameFi projects rely on off-chain centralized servers to handle some backend logic and interfaces. These servers store critical information, including game logic and player account data, and are vulnerable to malicious attacks. For example:
Tampering with NFT data
The metadata of game NFTs is critical, but many GameFi projects tend to store them on centralized servers rather than decentralized facilities like Arweave, which increases the risk of internal or external attackers tampering with the data and affecting the ownership and interests of players' assets.
Phishing Attacks
Attackers use phishing to obtain sensitive information from project owners, such as private keys to game vaults or GitHub accounts, which may trigger supply chain attacks, expand the scale of attacks, and cause more losses.
The road to shaping the future of Web3 games is full of opportunities and challenges. Through some new technological developments, we see new hope in maintaining fairness, security, and innovation in games, and we have also learned valuable lessons from successful cases such as Black Myth: Wukong: high-quality content and excellent gaming experience are still the core of attracting players. However, game developers must be vigilant about potential security threats, especially in the implementation of on-chain and off-chain technologies. By strengthening technical protection, improving the sustainability of economic models, and promoting broader community participation in the industry, Web3 games are expected to achieve stronger growth and deeper player connections in the future, ultimately driving the positive development of the entire GameFi industry.
Lianyuan Technology is a company focused on blockchain security. Our core work includes blockchain security research, on-chain data analysis, and asset and contract vulnerability rescue. We have successfully recovered many stolen digital assets for individuals and institutions. At the same time, we are committed to providing project security analysis reports, on-chain traceability, and technical consulting/support services to industry organizations.
Thank you for your reading. We will continue to focus on and share blockchain security content.
How to buy LIDO
How to buy cryptocurrency on an exchange
Invest in LIDO It has never been easier! Registering on an exchange, verifying your account, and paying by bank transfer, debit or credit card, with a secure cryptocurrency wallet, is the most widely accepted method of acquiring cryptocurrencies. Here is a step-by-step guide on how to buy cryptocurrency on an exchange.
Step 1: Register OKX (click the link to register)
You can register by email or phone number, then set a password and complete the verification to pass the registration.
Step 2: Identity verification - Submit KYC information to verify your identity
Please verify your identity to ensure full compliance and enhance your experience with full identity verification. You can go to the identity verification page, fill in your country, upload your ID, and submit your selfie. You will receive a notification once your ID has been successfully verified, bind your bank card or credit card and start transactions.
How to exchange USDT with a credit card and then convert it to LIDO
Step 1: Click Buy Coins, first select your country , then click Card
Step 2: Click My Profile in the upper right corner
Step 3: Select Add Payment Method in the lower right corner and select a credit card that is suitable for you to fill in the information and bind, such as Wise, Visa, etc.
Step 4: Click P2P transaction again, select the corresponding payment method and choose the appropriate merchant to complete the transaction.
Step 5: After the transaction is completed, your amount will be converted into USDT (USDT is a stable currency of US dollar, 1:1 with US dollar) and stored in your account. Click on the transaction and search for LIDO , buy its tokens.
How to buy USDT with a savings card and convert it into LIDO
Step 1: Click Buy Coins, click P2P
Step 2: Select My Profile in the upper right corner
Step 3: Select Add Payment Method in the lower right corner, and select the savings card that applies to you to fill in the information and bind it, such as: Payeer, ABA bank, TowerBank, etc.
Step 4: Click P2P transaction again, select the corresponding payment method and choose the appropriate merchant to complete the transaction.
Step 5: After the transaction is completed, your amount will be converted into USDT (USDT is a stable currency of US dollar, 1:1 with US dollar) and stored in your account. Click on the transaction and search for LIDO , buy its tokens.
Use the shortcut to buy USDT and convert it into LIDO
Step 1: Click [Buy Coins]-[Quick Buy Coins] in the top navigation bar to place your order.
Step 2: Enter the LIDO you want quantity
Step 3: Select your payment method, click Next and complete the purchase
Step 4: Click on Trade and search for LIDO , buy its tokens.
1 note
·
View note
Text
The meaning of the birth of IPFS: End high maintenance costs.
In the 2019 data breach cost report study, the average maintenance cost of each piece of compromised data was US$150, and the average total cost of data breaches in 2019 also increased by 1.5% compared to 2018.In the six years since 2014, the average total cost of a data breach has increased by 12% from $3.5 million to $3.92 million.In this regard, IPFS is a new solution.Using IPFS for downloading can save nearly 60% of bandwidth. IPFS divides files into small blocks and downloads them from multiple servers at the same time, which is very fast.At the same time, IPFS provides the historical version of the file backtracking function, you can easily view the historical version of the file, the data can be permanently saved, so that there will be no more 404 errors on HTTP web pages.
Our existing Internet is a highly centralized network. The Internet is a great invention of mankind and an accelerator of technological innovation. However, the centralization of the Internet will lead to various Internet monitoring and privacy leakage problems, and IPFS can overcome these shortcomings of the network.IPFS is not only to speed up the web, but to eventually replace the HTTP protocol and make the Internet a better place. Currently, IPFS has mature applications and a large amount of storage space.
Gavin Wood, author of "Ethereum White Paper" and "Ethereum Yellow Paper" and founder of Polkadot: "We are looking for an initial storage solution similar to a parachain.But no matter what we do, IPFS technology is likely to be integrated in the end. I hope that when Filecoin goes live, we can bridge with it. "
2020 may be the year of the outbreak of the IPFS ecosystem.Based on the projects applied on IPFS, the main areas are social content, audiovisual, scientific research and education, practical tools, storage platforms, shopping, finance, commerce, etc.
The early development of the Internet required infrastructure construction, product development, demand exploration, ecological gathering, etc. It required a long and confusing process.IPFS is an iterative upgrade of technology based on mature Internet technologies and clear product functions, and it builds products, applications, platforms, systems, and ecology in one step. In the future, competition may be achieved overnight and full of firepower.
The Internet is a pioneer in the online world, and IPFS/Filecoin is a fast-developing giant on the shoulders of Internet technology. Let us wait and see! !
2 notes
·
View notes
Text
H O R I Z O N
Chapter 6: Error: Communication Failure

San’s entire arm is numb when he opens his eyes to see the ceiling of the medical bay. Wooyoung’s head pops into his vision and Yunho’s appears a moment later.
“What’s… going on?” San slurs, and the two heads look at each other, concerned.
“You were drugged and brought here after you fell,” Wooyoung explains slowly. “You don’t remember?”
As he’s speaking, the memories return. He had been thrown through a window, his arm had been throbbing with pain, and Wooyoung had injected him with a sedative to numb him. Now he was here to recover and he still didn’t know if—
“Did we win?”
Wooyoung avoids his eyes and so San looks over to see Hongjoong sitting up in the bed next to his while a nurse bandages a minor burn on his shoulder. He flinches at the contact, but it doesn’t show on his face, deep thought etched into his features instead.
“I’m sorry,” he finally says, turning to face San. “We lost.”
“I didn’t mean to throw you out the window,” Yunho mutters nervously, bringing San’s attention back over to him. “It was just hard to breathe or see what I was doing—”
San places a hand on Yunho’s arm. “Don’t be sorry,” he insists. “None of us can change what happened, it is what it is.”
A thought that San himself will have to come to terms with some time before the next round of Dome training.
“You did your best, San,” Hongjoong encourages with a small smile. “I shouldn’t have underestimated Seong--”
Just as he’s about to say his name, Seonghwa suddenly appears in the doorway and everything goes quiet.
“Everyone alright?” He asks, still standing in the doorway, and when the nurse answers affirmatively he approaches Yunho.
“Mingi and Jongho offered their room for our team to hang out and eat snacks,” Seonghwa informs him. “You can join us if you’d like.”
Yunho squeezes San’s hand once before grabbing his things to leave. He must have been there waiting for him to wake up for a while, San realises. But alas, he’s been invited to a celebratory party and San, naturally, has not.
“Who shot him?” San asks a strangely quiet Wooyoung, indicating Hongjoong, before Wooyoung coughs and tosses his head in Seonghwa’s direction. “Oh, I see.”
They wait until their rivals have left to discuss a course of action.
“We really should get practicing, shouldn’t we?” San sighs, ready to get out of bed. He’s already cost them precious time, and he’s determined not to be the weak link of Team A.
“No, hang on, you’re still recovering!” Wooyoung protests, pushing him back down. “Heal first, practice later. That goes for you too, Hongjoong.”
Hongjoong rolls his eyes from his position, already halfway out of the bed, before pulling up his wristband and accessing class materials. He might as well get some homework done while he’s down. “It’s just a burn, it’ll be healed in thirty minutes tops,” he grumbles, silently thanking IPF’s world class medical technology. “But if you get the chance, Wooyoung, would you find Junyoung and see how he is? I’ve heard stun freeze can be a bit disorienting.”
Wooyoung nods and heads for the door, hesitating while his hand hovers above the opening switch.
“You know, we don’t blame you,” he tells Hongjoong, turning to face him. “None of us knew they’d play dirty.”
“I don’t blame you two either,” Hongjoong responds, jaw set. “But we’re going to have to think faster next time if that’s how it’s going to be.”
San lays back on the pillows and watches Wooyoung leave.
Hongjoong is absorbed in typing away at his holographic keyboard and San is suddenly afraid he’ll finish up and leave him alone in the medlab.
“What did you mean about underestimating Seonghwa?” San asks quietly, fingers tangling in the edge of his blanket.
Hongjoong doesn’t look up from his work but pauses briefly before answering. “You know, we aren’t supposed to be rivals forever. We’re going to be one team eventually, all ten of us.”
“You wanted to stay on good terms,” San finishes out loud. He has to agree, because he wanted the same thing initially. To make friends with everyone. To be an irreplaceable team member. To be a success.
“But to get there we have to toughen up and complete this training process. Even though it’s one that pits us against each other,” Hongjoong explains, giving San a half-hearted smile. “We can do it. We just need to be two steps ahead this time.”
Shake off the loss and keep going. It’s what San’s always done, there’s nothing new about the process. He tests his arm and realises sensations are returning to him, even a bit of pain.
“Maybe you shouldn’t do that…” Hongjoong mutters nervously, about to summon a nurse but distracted by a call suddenly emitting from his wristband. “Oh, it’s my mother. If you’ll excuse me.”
So, he takes his call outside and San is alone.
A row of empty beds faces him, and to his left and right are more. Every day, more Horizon teams are preparing to blast off for the Citadel and fewer and fewer occupy the spaces Team ATZ frequent.
Even the nurses milling about look distracted and disinterested and San wonders how many severe Dome-related wounds they’ve treated over the course of the Horizon Project. Certainly more than a sprained arm and some minor burning.
The whole place is sterile and bright, with that weird hospital smell San already hates and he’d just as soon be out and about, working on his lessons or training for simulations.
All he can do is bide his time, and hope he isn’t falling behind as early as Week One.
When he’s alone with his thoughts he’s right back where he began, the starting line of the race to measure up.
___
Yeosang finishes his can of soda and gathers his studying materials, to see that the rest of his team is already tired out from their celebrations and not at all ready for their afternoon engagements.
They were all excused from the morning class, seeing as how it was the day after their first match, but apparently the exhaustion carried over anyway.
“Where are you going?” Seonghwa jerks awake, tightening his grip on Yeosang’s arm instinctively from where he had been holding onto him while he dozed off before becoming flustered and letting him go. “Sorry, is it that time already?”
Yeosang nods and ignores the giggles of Yunho, Mingi, and Jongho, stepping out through the hall and into the elevator.
Everything about this is conflicting, and Yeosang doesn’t think he can relax and enjoy the victory he’s earned until the whole competition is over and he’s blasted off into space.
He’s thinking about the confrontation with Wooyoung that has yet to occur when he gets off the tram for the medical facilities, and sure enough, runs into Wooyoung while he’s distracted with his worries.
“What are you doing here?” His roommate snaps, mostly out of surprise, but Yeosang is quick to defend himself anyway.
“I work in the medlab in the afternoons...”
“Oh, right, sorry, of course,” Wooyoung splutters. “I forgot.”
“I’m not intruding on anything confidential, am I?” Yeosang rushes to say, peeking inside again.
“No, not really,” Wooyoung sighs. “I was just on my way back from lunch with Junyoung and Youngseok, to keep San company.”
Of course, the conversation always loops back to San somehow.
“How is he?”
Wooyoung’s expression tightens and he chews his lip in thought before deeming Yeosang trustworthy enough to say, “Improving. He’ll be fine by tomorrow.”
Yeosang hates it. He hates the way Wooyoung has to second guess himself before divulging his thoughts or sharing his secrets now.
But he supposes it’s only fair. At least it’s only temporary.
And it’s not like Yeosang didn’t bring it on himself anyway.
When they reach the recovery wing Yeosang is confronted again by something else. Hongjoong pacing the hallway, on a call with his mother.
It seems he’s always on a call with her, and Yeosang’s only ever really seen him a few times outside of class until now, which baffles him even more.
Honestly it’s starting to grind his gears that he apparently can’t go two seconds without crying to her about something, as if that will help, when Yeosang is still stuck debating with himself every night whether he should attempt to reach out to his own mother.
Would she even care what he had to say? She was in PR heaven promoting his Horizon team position, what did she care if he had thoughts or feelings to express and years of neglect to put right.
Yeosang realises he’s staring and moves on. Where all this jealousy came from in the span of a few days is a mystery to him.
He watches through an adjoining window while Wooyoung and San play some kind of game on their wristbands until his nurse supervisor scolds him and returns his attention to his lesson.
The dummy he’s supposed to be reviving dies a dozen times over while he’s distracted, until he forces back the stress of his dissolving friendship.
Horizon Project first, Wooyoung later.
___
The shadow of the Dome lies heavy on them, even in the most casual of situations. A couple of days pass quickly, full of work and training of various kinds, with what camaraderie and respite they could take.
Wooyoung finds himself trying to bridge a gap, reprimanding San when he spends too long in the gym but also getting along with him while they make repairs to an old engine for an assignment, and keeping an eye on Yeosang late at night in case he drops hints of the other team’s plan while also listening to and reassuring him when he worries about home or the Project or any of the plethora of things that he might be worrying about at any one time.
He’s much more successful in the first category. And so, feeling like his relationship with Yeosang is hanging by a thread after a heart-wrenching evening in which the former didn’t even save him his seat in the cafeteria at dinner in favour of Seonghwa, Wooyoung devises a plan and seeks out some help.
Colourful sparks leap out into the air from the recreational space he and San have commandeered for themselves and none of his knocks are answered, so he waves his wristband and opens the door.
“Told you to leave me alone when I’m welding!” San calls out, voice muffled by the metal safety mask he’s wearing. The sparks halt as he looks up and sees Wooyoung, flipping up his mask and flashing a grin. “Oh, it’s you. Thought you were Yunho.”
“You always weld in silence?” Wooyoung jabs cheekily, closing the door behind him.
San shrugs. He never had any reason to do otherwise. “Yeah. What’s up?”
“Ah, it’s just Yeosang. He’s kind of upset because he wanted my help with his drone project but I’ve been busy and, to-to be honest, it’s not really my kind of thing...”
San raises an eyebrow. “How so?”
Wooyoung coughs with embarrassment and smacks his lips. “I can’t get it to fly.”
San snorts out a laugh and sits back. “So that’s what it is. I wondered when it would become clear where our weaknesses are...” he smirks and wiggles his eyebrows at a tomato-faced Wooyoung. “Found yours!”
“Look, I got into this project without studying materials,” Wooyoung defends himself. “I just tinker around until the thing functions, if it won’t budge then I don’t know what to do next. And, yeah, I really don’t know which propellers to use.”
“Don’t worry, I’m just teasing,” San reassures him as he wraps up his work and puts things away. “Design is my strong suit anyway, we compliment each other.”
“So you’ll help?”
“Yeah, of course! Been meaning to get to know Yeosang better anyway.”
Wooyoung rubs the back of his neck nervously as they leave the room. If only he could speak for Yeosang that he felt the same way.
___
It’s been a week since the first Dome fight and Seonghwa is still on edge.
He enjoyed the spoils of success while he could but now a pressure to live up to his own precedent weighs heavily on him.
Bonding as a group has been going well for Team Z, the five of them becoming more and more accustomed to working with each other and covering each other’s blind spots.
However, the other half of their Project group feels as alienated as ever to him. Jongho may get along with San perfectly well and Yeosang might be content to spend time with Youngseok, but anyone outside his own small circle is a threat to Seonghwa. Even then, he’s not eager to overshare with his own team.
He knows he’s being too paranoid but there’s too many ways his position could be jeopardised and the day Hongjoong or even Wooyoung gets a little too suspicious, it’s over for him.
As such, when the command comes for all ten members to report to the pool for astronaut training, he can’t help but feel a little bit reluctant.
Seonghwa doesn’t have to worry about waking Hongjoong up for the appointment this time, since the latter drags himself out of bed and gets dressed without his help.
The attire as ordered by the schedule is wetsuits, and Seonghwa fights the urge to wriggle around and adjust his tight-fitting outfit as all ten of them stand in the elevator in awkward silence. Junyoung says what’s on all of their minds.
“I feel like I look stupid.”
“It’s alright,” Mingi laughs. “We all look stupid.”
Seonghwa and Hongjoong naturally gravitate to the front of the pack, but halt when they reach the rec facilities. Hongjoong is clearly unsure which direction to go, so Seonghwa points it out for him.
“It’s this one.”
“How are you so sure? You haven’t trained here before, have you?” It sounds like he’s poking fun but it’s not very clear.
Seonghwa isn’t sure how to respond so he doesn’t, and he doesn’t need to for all Hongjoong continues to prattle on.
“I didn’t even know we had more than one pool. You don’t think there’s a hot tub anywhere, do you? Mingi would probably like that. Hey, Mingi...”
He wanders away and it’s easy to tell that he doesn’t really want to talk with Seonghwa, besides having this new bristled attitude toward him that only feeds Seonghwa’s desire to go stand somewhere else.
Soojin welcomes them, briefs them, and sets them to work, Seonghwa going through the motions and helping Jongho secure his helmet properly before they’re submerged and sent underwater with a few safety divers to practice navigating zero gravity and simulate spacewalks.
It’s a quiet and weightless world, even being surrounded by so many others, and Seonghwa quickly grows bored. He creates a private link with Yeosang and tries to strike up a conversation.
“How are things with you and Wooyoung?”
“Fine,” Yeosang answers just a bit too quickly. “Why?”
“Well, you’re roommates, I’m sure you’re tempted to tell him everything.”
“Oh no, not at all,” Yeosang rushes to say. Seonghwa realises he must think he was accusing him because he offers excuses. “We get along fine but team secrets stay secrets, don’t worry. Yunho and San are the same way.”
Seonghwa laughs nervously, not sure how to explain that he was curious for another reason, but Yeosang catches on.
“You must be in a similar situation with Hongjoong,” he hums quietly. “It’s normal if you’re struggling with him. I don’t even think his team sees much of him either.”
“A little less chatter please, boys,” Soojin scolds over the comm link. “You’re supposed to be conserving oxygen, remember?”
Immediately both of them blush, realising their conversation is being monitored.
Seonghwa’s thankful at least the rest of the trainees didn’t hear it and focuses on his work.
Practicing an external spaceship repair is much more difficult than an internal one, but Seonghwa has studied hard to keep up. After all, it’s knowledge everyone should know. The entire morning is consumed by the tedious work and Seonghwa’s mind is emptied of worries over Dome battles and starcharting homework until lunch.
He steps out of the shower, having washed away the rubbery wetsuit smell that lingered on him and checks his wristband.
What he sees makes his heart drop to his stomach.
A dozen pictures of his parents, in every context from home to workplace, sent from an untraceable source. They’re accompanied with the message, Proof of the destruction of the documents or poof go your parents. You choose.
Seonghwa spins around to retch into the toilet until all that’s left are dry heaves and splashes his face with water until his hands are red.
He can only stare at his reflection in the mirror in motionless horror as it washes over him just how deeply he’s landed himself.
When Wooyoung asks if he’s okay while he spoons his unwanted cucumbers onto Seonghwa’s plate, he nods and keeps his head down. He can’t keep sitting here like everything is fine. It’s his choice whether his parents live or die, and a single misstep could cost him everything.
Somehow he’d forgotten the most fundamental truth in his first month at the IPF, lulled into false security by the shiny skyscrapers and expensive tech. If his family is being watched, he’s certainly being watched as well.
He’s always being watched.
___
Mingi has a hard time keeping things to himself. Usually, he would shove his japchae into his mouth and suck it up, but Jongho has sent him down a rabbit trail from which there is no return. Hongjoong happens to be sitting next to him.
“I was doing some research on mysterious Project member disappearances historically because, uh, I was bored,” Mingi starts off, quickly thinking of excuses. “And I found something that might interest you.”
Hongjoong raises his eyebrows and nods him on, slurping his noodles.
“Sung Taejin, the Horizon pilot who first landed on Naeng, the fourth moon of Yangeum, didn’t actually go missing.”
“He… what?” Hongjoong lowers his voice and the rushed whispers catch Jongho’s attention from across the table where he pretends to be engrossed in his sandwich.
“He’s alive and lives on the Citadel, under another name,” Mingi stifles a giggle, so extremely proud of his work that he can’t help but share it.
“How do you know?” Jongho hisses, abandoning the sandwich altogether.
“There’s an online database full of Citadel promotional footage, for people who want to move there,” Mingi explains. “I stumbled across it while I was doing, uh, homework… and I noticed this familiar looking man in the background of one of the videos. Ran him through facial recognition and it’s him. It’s Sung Taejin.”
“No way,” Hongjoong gasps, leaning back wide-eyed. “Isn’t the facial recognition system restricted access?”
Mingi chuckles nervously and shoves more japchae into his mouth before he says something stupid.
“Do you know the dates for both Sung’s disappearance and reappearance?” Jongho asks, giving him an intense stare until Mingi caves and tells him.
Jongho stands immediately and hurries off towards the dorms. “Thank you,” he shouts back. “This is all really helpful.”
Hongjoong blinks, surprised. “Why does he care?” He mumbles in confusion.
Mingi smiles back at him. “He’s also interested in Horizon Project history,” he fibs. “You know, casually.”
Hongjoong doesn’t question it and finishes up his meal.
Mingi is the last to be done eating, but he doesn’t have Yunho to sit with him and keep him company this time. He cleans his bowl and grabs an extra, taking it to the gun range where he knows Yunho will be practicing.
By now, it’s obvious that Yunho hates his teacher.
“Apparently my reaction time is too slow,” he gripes, setting up some moving targets through a holographic console.
Mingi resists the urge to dig into Yunho’s japchae himself and lets him rant.
“Even Yeosang gets along with that soulless military nurse who teaches him echo-cardiography or whatever. It’s just not fair.”
“I’m starting to think a lot about the Horizon Project isn’t fair,” Mingi says quietly. “But I also think that’s the point.”
Yunho pauses and raises an eyebrow at him. “Professor Pyo wanted you to come here and push yourself. He wouldn’t have insulted your skills otherwise.”
“Well, good for him,” Yunho growls, aiming and firing again. “Because that’s exactly what I’ll do until I can beat him.”
“Alright, maybe he wants you to keep practicing but I don’t,” Mingi sighs, standing between Yunho and his targets. “If I know you at all, I know it’s the lack of sleep and food that’s affecting your reaction time. Come get some lunch before class.”
“Oh you think my reaction time is bad too, huh?” Yunho smirks, switching his settings to a harmless light ray and firing at Mingi’s feet. “Let’s see how fast you can be.”
With a squeak, Mingi runs away, leading Yunho back to the cafeteria while he fires the occasional shot at him jokingly. They would definitely get in trouble for this later, but Yunho was happier than Mingi had seen him all day.
It was a win in his books.
___
The first few weeks of the Horizon Project have been hard, but sharing a room with his new worst enemy has to be the crown of Hongjoong’s experience so far.
It wasn’t all that bad to start with, and he honestly wanted to be friends with Seonghwa when he met him, but some things can never be reversed.
Seonghwa’s paranoia is one of those things.
Hongjoong’s absorbed in some interplanetary flight path calculations after supper when Seonghwa suddenly enters the room, antsy, and starts throwing accusations.
“We’ve only been here a couple weeks and you’re already trying to make fun of me?”
Hongjoong blinks rapidly in surprise before snorting out a question, “What are you talking about?”
“Mingi made a joke that I seem like I’ve been here before and must have been thrown out of a previous Horizon Project.” Seonghwa looks pointedly at him as if he should know why he’s distressed. “Sounds a bit familiar to something you said this morning, doesn’t it? Don’t think I didn’t notice you two chatting at lunch.”
“About old astronauts, not you! Mingi doesn’t have a filter, you know he wasn’t trying to make fun of you. It was harmless.”
“And?” Seonghwa scoffs, throwing his hands into the air. Hongjoong’s never seen him this bent out of shape and he immediately doesn’t like it. “That somehow gives all of you a reason to speculate about me? I know we’re pitted against each other but it’s just low that you think you can—”
“What happened to ‘no hard feelings’?” Hongjoong finally interrupts, getting out of his chair and doing his best to stand up to him. “I can’t believe you’re jumping to conclusions like this. And what is it you’ve got to hide anyway?”
“I’m going to say this one time only,” Seonghwa’s voice drops dangerously low. “I don’t care if you come from a perfect family and you’re top of your class. Some of us are less fortunate and would really appreciate it if you kept your nose out of our business.”
“You don’t know what you’re talking about,” Hongjoong says darkly. He’s had enough of this conversation.
He scoops up his wristband off the bed and marches out. Seonghwa can cool off on his own for the night.
The rest of the dormitory has settled into sleep, save for one young member grabbing a midnight snack and then watching Hongjoong struggle to get comfortable.
“Sleeping on the couch?” Youngseok whispers, glass of milk in hand. “It’s that bad with him?”
Hongjoong nods with a sigh and flops on his side. “You have no idea.”
It’s the first night of many in the same fashion.
“No hard feelings” turns into blatant avoidance and sharp words when the pair’s wild schedules do happen to overlap, making every effort not to interact despite living on top of each other, a fact that gives them that much more incentive to argue. It’s a vicious cycle of ignoring and bickering and none of the others have the first idea what to do about it.
While Hongjoong spends most of his time in the hangars or simulation rooms working and studying in the late hours of the night, Seonghwa sticks to the dorms and takes an immediate distaste to the way Hongjoong’s natural untidiness bleeds over into his half.
When sarcasm and snark fall through, Seonghwa retaliates by inviting his team over on nights when Hongjoong stays out, trashing the room in their festivities and then not bothering to clean it up to give him a taste of his own medicine.
Hongjoong doesn’t take the bait as it’s clear Seonghwa just wants to pick a fight with him, but Yunho with his heart of gold comes to help clean the mess and convince the two to patch things up.
It only works until the next day when Hongjoong catches Seonghwa insulting him in Russian (at least, he’s pretty sure that’s what he was doing) and then the two are at each other’s throats all over again.
Hongjoong finds himself on the couch once more after a blowup over sparring pad reservations lands him outside of his own room when the light of his wristband blinks awake, stirring him from his shallow sleep.
For once, his alarm system works properly.
A natural disaster alert is blinking on the screen and he squints at it to see the words: FLASH FLOOD APPROACHING.
It had been too long without an incident, it only figures that one should happen now.
But this is a flash flood, which means emergency evacuations instead of hiding in a bunker.
Hongjoong can hear the others shuffling out into the hallway quickly and scaling the staircase for roof access and switches off the alert to join them, flashing his wristband at the display by the door.
The door doesn’t open.
He lets out an irritated huff and tries again, and again, and again before realising what’s going on.
The door won’t open.
A creeping feeling snakes up from the pit of his stomach that Seonghwa has locked him in.
It wouldn’t be the first time he got fed up with Hongjoong’s constant coming and going, forcing him into one place to grant himself a full night’s sleep.
But in this situation, it just might be the end of him.
A window suddenly breaks and Hongjoong squeaks in surprise.
Rain is battering the dorm sideways and water floods up at an alarming rate.
All Hongjoong can do is yell and hope someone hears him.
The retreating steps suddenly halt and return to him. Yeosang’s voice is surprised and muffled through the door. “Hongjoong, are you in there?”
“Yes,” Hongjoong answers quickly. “The door— I can’t open it!”
Yeosang calls San and Wooyoung over to him and for a few heart-pounding seconds, the trio is quiet.
“It’s been jammed electronically, like something hit the mechanism,” San’s voice explains. “I’m going to try to fix it, but you’ll need to sit tight for a minute.”
The water is reaching his ankles. “I don’t know if I have a minute.”
Gasps from the other side indicate that the water has reached them too, probably through the staircase.
There’s a splash that sounds like someone has fallen and bursts of coughing follow. “Is everything alright out there?”
“Wooyoung slipped, but we’re all okay,” San rushes to reassure him, before his voice turns away, presumably addressing the others. “You should both get to safety, there’s no use standing around here.”
“We’re not leaving you,” Yeosang’s voice retorts, and the sound of dialing comes after. “Keep working, I’ll call help.”
Hongjoong is suddenly very glad that all the furniture is bolted down and not in danger of floating at him, but his mask is back in his room and the hole in the window is getting wider and wider.
A sudden scream from the other side makes him jump out of his skin.
“Stand back!” San yells, and the buzzing sound of electricity follows. Flying sparks and water are a horribly bad combination, and Hongjoong is afraid all three of them have been knocked unconscious when the door suddenly hisses open and he stumbles out with the rushing water.
“I’ve lost connection,” Yeosang whines, holding his sparking wristband at arm’s length while Wooyoung cowers behind him.
“No time, we need to get to the roof now,” Hongjoong pants, hauling San along from where he sloshes through the water and making sure Wooyoung and Yeosang are following.
Junyoung is waiting for them a floor up, and when they reach the roof, all the other building residents are there in groups, a glass dome extended over them for protection.
The rest of the team rushes over to check that they’re alright, but Hongjoong’s blood boils the moment he sees Seonghwa’s concerned face.
He already knows what he’s guilty of.
Swatting hands away and ignoring the way his voice shakes, Hongjoong marches right up to Seonghwa and explodes at him.
“You— I could’ve... What were you thinking?!”
Mingi senses the trembling of his legs and offers an arm to lean on.
“It was an accident, Hongjoong, I wasn’t—”
“An accident? No, this... this is sabotage altogether! All four of us could have died all because you thought it would be a funny joke to lock me in again—“
“He didn’t lock you in, Hongjoong,” Yeosang interjects. “The door was jammed because I crashed a test drone into it yesterday. It was an accident.”
Hongjoong tears his hands through his hair in frustration and takes a few gasping breaths, looking up at the way the raindrops flatten and slide down the glass roof to calm himself down.
“I-- Sorry, I’m just…” he trails off and lets Yunho rail him with questions about whether he’s okay or needs to sit down, but keeps his eyes on Seonghwa. “I’m sorry I assumed. But it wouldn’t be the first time…”
Hongjoong directs a dark glare at him, which Seonghwa simply absorbs before looking away.
It wouldn’t be the first time his trust in Seonghwa was broken.
___
Jongho tries to be thankful for his life, and the lives of his teammates, all of whom have already managed to get under his skin and planted themselves in his life, but his call to his parents isn’t going through.
“Maybe their connection is shot,” San tries to reassure him, just having gotten off the phone himself with his own parents, safe and sound in the countryside, to let them know he was unharmed.
Wondering if it happens to be a citywide issue, Jongho looks to Yeosang and Wooyoung for hope. Both of their calls have been approved and evidently reached their sources. Even though the two look uncomfortable to be speaking with what are most likely distant families, there’s a measure of relief in their expressions that Jongho craves for himself.
Junyoung’s call goes through, and then Youngseok’s, then Hongjoong’s, then Mingi’s, then Seonghwa’s, then Yunho’s and Jongho is left sitting there nervously while a chopper is sent to pick them and the other displaced teams up, watching an outgoing call fail to connect. And fail again. And fail again.
He wouldn’t jump to conclusions but his house was always situated in the lower rings of the city, and the alerts were always spotty, and if no one’s picking up--
Jongho chokes on tears and turns away, ashamed. He lays, throat tight with worry, in a mound of blankets on the highest floor of the main office with all of his fellow project members while IPF staff drains the flood water from their dorms.
Every time an error message pops up, he can feel a little bit of his faith drip down the drain.
And everything had been going so well until today.
___
Taglist: (Let me know if you would like to be added): @mooneylooney1 @hwashinestar @delphinium3000 @kpop-choco
Recommended listening: uhgood by RM
A/N: Here we are with another Horizon chapter! It was a slower one comparatively but expect more action and more angst in the future ;) Don't forget to leave some reblogs and comments if you liked it, and have a great day~
← Previous | Masterlist | Next →
#ateez#ateez fanfiction#atzeditors#atzinc#ateez fanfic#ateez fic#ateez au#ateez series#ateez imagines#ateez scenarios#ateez angst#ateez fluff#ateez writers#ateez writing#ateez writer#ateez space au#sci fi elements#ender's game inspired#horizon#horizon project#ch.6 error: communication failure#tokki writes
15 notes
·
View notes
Text
Version 409
youtube
windows
zip
exe
macOS
app
linux
tar.gz
source
tar.gz
I had a great week fixing some bugs and optimising the new tag siblings cache. The new code works much faster now.
siblings
I am very happy that there do not seem to have been any obvious errors with the new sibling database cache. Unfortunately, a couple of areas were working inefficiently, which IRL testing helped to diagnose. I put a lot of time into this this week and was very successful - some sections take 10% less time, some 90%, and one critical query now takes 99% less time. It depends on many factors, but many things are faster overall. In particular, tag processing speed, which took a real hit, is back up to good speed, and setting new tag sibling application rules now only needs to regenerate for ''changed'' siblings, so if you add (or remove) your own five 'my tags' siblings onto the PTR, the client now only has to do two seconds of work, not ten minutes.
I made some progress on the final awkward things to migrate. Most autocomplete results you see are now able to give themselves the 'will display as xxx' label when needed and match against sibling input (e.g. having an input of 'lotr' match 'series:lord of the rings' due to siblings) on their own, which should save some CPU time when typing. There is still more to do, so I'll keep hammering at it for the next two weeks and see if I can get rid of 'loading tag siblings' on boot before I start on parents db cache.
If you have been waiting for faster code before you update, you might want to wait another week. I just did a test re-do of the 407->408 update step in IRL conditions, and it was not as fast as I wanted it. I'll keep pushing at this.
I am increasingly looking forward to doing that parents db cache, which will extend this work in a new dimension. That will be v412, which I am very confident will be another two-week release. This is some of the most intricate work I have done.
full list
siblings:
the slowest of the new sibling regen & update code has received a full optimisation pass. some sections take 10% less time, some 90%, and one critical query takes 99% less time. overall, several big jobs work much faster, and ptr processing, which slowed significantly for many users, should be back up to a good speed. uploading pending tags (which tend to be for local files) should be much faster in particular. let's do another round of IRL observation and profiling this week, and I'll keep at it
the various 'display' regeneration routines now provide more progress status text, drilling down to the x/y siblings being collapse-counted, or number of files added to a cache, and generally all tag sibling regen got a status update polish pass
optimised the way tag sibling application is set--now, only the tag siblings that are changed need to have their counts regenerated. hence, if you just apply (or remove) your own five 'my tags' siblings onto the PTR, the client now only has to do two seconds of work, not ten minutes
.
the rest:
fixed the annoying issue with media viewer mouseovers stealing focus/activation from the manage tags dialog. this can now only happen if current focus is on a hover window. sorry for the delay!
updated manage tag parents dialog to state the pairs being petitioned on the 'petition reason entry' dialog
updated manage tag parents and siblings dialogs to have appropriate 'reason' suggestions for petitions (previously, they were inheriting the same suggestions as for add)
ipfs network jobs now have a minimum 'reply' connection timeout of two hours (so giganto directory pushes won't throw an error). connection timeout remains the same, so if the server is hanging on that, it'll still notice
fixed the 'test address' button on the IPFS manage services panel
petitioning an IPFS file when there is no IPFS multihash entry in the db no longer causes an error. now, in this case, the file entry is removed with no change made.
when pending to or petitioning from a file service, a quick filter is now applied to discard invalid files (i.e. (not) already in the service). any weird logical holes where this might occur should now be fixed
export folders now catch and report missing file errors more nicely
export folders now remember the last error they encountered and report that in the edit export folders dialog
.
boring tag siblings optimisations:
optimised the tag manager generation routine to use any common file domains for fast cache lookup for any subset of the files available, rather than falling back to 'all known files' domain when there is no single common file domain
optimised the new 'all known files' display autocomplete cache to use similar faster specific files cache lookups when available
optimised how the 'all known files' display cache regenerates tag sibling chains. it now takes a shortcut when given non-sibling tags and tags where all but one sibling member have zero count, and it can count current and pending counts separately according to the most efficient counting method (e.g. most pre-display pending counts are 0 across the board, so even if current count is a million, the pending count can often be assumed without lookup overhead). furthermore, the 'clever' count has better query planning and less non-sqlite data overhead, and with experimental data is now chosen more carefully. what was previously a 22s job on a test database now takes 5s
deduplicated how new mappings are filtered to all the specific cache domains, significantly reducing overhead
massively optimised a critical - and the slowest - part of the new 'combined' cache that handles add/pend mappings pre-insert presence testing, speeding up the core query about 100x!
reduced some overhead when doing file service_id normalisation in repository processing
split up specific chain regen into groups to reduce memory usage
optimised specific display tag cache 'add file' updates, and thereby basic cache regeneration, to be just a little faster for files that have multiple sibling tags
all predicates made in the database are now populated with ideal and chain sibling information, and this is used for '(will display as xxx)' labels and autocomplete tag search filtering (e.g. you type in 'lotr', it matches an autocomplete result of 'lord of the rings'). there are still some ui-made predicates to figure out, so the old system remains as a fallback
related tags lookup is a tiny bit faster and now populates its predicates with ideal and chain sibling info at the db level
cleaned up some 'fetch related tags' code, might make it a bit faster for large tag counts
cleaned up the way some mapping tables are fetched
unified table/table_name nomenclature in the db code
updated an old data->ui status presentation method (it typically does stuff like "regenning some stuff: 500/10,000"), to not hog so much UI time and not yield worker threads so often when new statuses are coming in real fast
several late optimisations based on IRL testing
next week
Next week would normally be 'cleanup', but all the optimisation I did here kind of counts as that, so I'll make sure to do some small jobs, just so I am not neglecting other things. Github issues and other non-sibling work.
1 note
·
View note
Text
#1yrago Facebook Domination vs. Self-Determination

We're months removed from the Cambridge Analytica scandal and the public outrage of #DeleteFacebook, and new information continues to surface about Facebook's sloppy handling of data and hunger for surveillance. Last month, we learned about an Orwellian patent that might allow Facebook to track you via mobile microphone. Though some have cast doubt on the reports, mobile spyware like the now-infamous Alphonso do track mobile devices via sound emitted by TVs.
Yale Privacy Lab has been warning about proximity tracking via mobile sensors and microphones, and Exodus Privacy's excellent scanner will help you find nasty trackers that utilize similar spy methods. The only way to really dodge Facebook's lidless eye, however, is jumping ship from the social network to a privacy-respecting replacement.
There is no shortage of alternatives, but you won't find surveillance sanctuary in Facebook-owned Instagram or ad-powered, centralized networks like Nextdoor. Instead, you'll have to jump into the "Fediverse", a constellation of Free and Open-Source Software (FOSS) replacements.
Mastodon is the fastest-growing of the FOSS social stars, and its links to the rest of the Fediverse are strengthened by the new ActivityPub standard. In a recent blog post, lead developer Eugen Rochko (@Gargron) sums it up nicely: "The social network that is Mastodon isn't really Mastodon. It's bigger. It's any piece of software that implements ActivityPub. That software can be wildly different in how it looks and what it does! But the social graph - what we call the people and their connections - is the same."
Are we really witnessing the origin of an all-new, all-different social Web? For deeper insight into the Fediverse, read my short interview with Eugen, below.
What is Mastodon and how is it different from social networks such as Facebook and Twitter?
Mastodon is a decentralized social network that uses standard interoperability protocols and is completely [FOSS]. What this means is that anyone can run a Mastodon server, and the users of those servers can talk to each other. More than that, non-Mastodon servers are also part of this network if they conform to the same protocols. This means that Mastodon is more future-proof than Facebook or Twitter: Even if Mastodon-the-software falls out of fashion, the network can be simply continued by other interoperable software. You don't have to tear out your entire social graph to have all friends migrate to something new if that happens. Furthermore, Mastodon allows self-determination and control. When you run a server, it's yours. Your rules, your community, hosted on your hardware... you don't depend on anybody, definitely not on a [Silicon Valley headquarters]. There are a lot of other differences to Facebook and Twitter too.
Where did Facebook go wrong as far as privacy is concerned? How can federated social networks do better?
Facebook is a vacuum for private information. It uses dark UX patterns to solicit every detail of your life from you, but also from your friends. It also builds shadow profiles about people even if they don't use the platform, through e.g. the contact books that people let it access, or from social sharing buttons on random websites. It's quite easy NOT to do that. If you don't intend to advertise to people then you don't need to know everything about them. Mastodon lets you broadcast messages to the public and to your friends, but there is no incentive to convince you to reveal more than necessary. The format of Mastodon is a lot closer to Twitter and Instagram than Facebook specifically, but I think that's a detail of decoration. Facebook replaced MySpace, and they were different formats as well. It doesn't have to be the same thing to be an alternative.
What is unique about federated social networks? Where can they improve upon Facebook and the traditional social networking models?
Federation is key. In my opinion it's one of the most ideal forms of decentralization, and it can be found in many real-world institutions. There is no single point of failure and top-down authority like in a centralized system, communities can spring up by themselves, just like in the old days of the Internet... except now they are interoperable, so content can travel freely between them. And unlike peer-to-peer solutions of decentralization, some issues are avoided, such as having to encounter and moderate all bad content on your own (instead, servers have mods, and your server neighbours can help with reports), or having to be online to receive messages (the server is the one being online), or synchronization between devices.
What can we do about audio, video, and multimedia, to make publishing and sharing of these formats federated and decentralized?
Mastodon allows images and videos up to a certain size limit. The servers cache this content so end-users are not hotlinked to another server, this saves the origin server's bandwidth and protects end-users from leaking their IP address to a different server. Of course, this approach brings challenges when file sizes grow. PeerTube, a federated video sharing platform, takes a different approach by using WebTorrent (BitTorrent over the browser). This does reveal the end-users' IP addresses to other end-users who are watching the video, but bandwidth costs for the origin server are lowered and other servers don't have to download and cache large files. A very similar approach to that is using IPFS. With IPFS, servers can cache large files (essentially also using a form of the BitTorrent protocol), and end-users can either peer with the IPFS network directly or use a gateway server to view the content.
How has the Facebook "scandal" affected federated social networks so far?
With growth and press attention, so quite positively. Privacy-minded people have been ringing the alarm bells about Facebook for years, but right now is when this idea is entering the mainstream.
Can Mastodon avoid the same pitfalls/errors as Facebook?
I think so, and I wouldn't be here otherwise. We have to be careful and thoughtful about our design decisions, but many of the fundamental differences between the platforms are reassuring.
How does Mastodon stand out, improve upon, or interop with the various social media projects of the past (StatusNet/GNU Social, Diaspora, Friendica, etc.)?
Mastodon begun as an OStatus implementation (this is the protocol that StatusNet/GNU Social implement), but it was quite dated and lacking in features, and OStatus never left the draft stage to become an official standard. So halfway through 2017 we performed an upgrade to the newer ActivityPub, which would, after our implementation, become a W3C-recommended standard. PeerTube, Hubzilla, Friendica and MissKey are some of the other softwares that implement ActivityPub. Support for ActivityPub in GNU Social has been planned, as far as I am aware. Furthermore, people are working on other implementations, such as Kroeg, Rustodon and Funkwhale.
Mastodon differents from GNU Social in having more privacy-oriented features, more moderation tools, a simpler/elegant API for client apps, a real-time streaming API, better content discovery mechanisms, and a more attractive user experience. Friendica and Hubzilla have a quite different user experience to Mastodon. Diaspora is the one big-name project that is completely incompatible with Mastodon because they use their own protocol rather than ActivityPub.
Where do we go from here (standards, interoperability, etc.)?
ActivityPub is already a W3C-recommended standard! And I am proud to see more and more implementations spring up. It's a really generic protocol that can support many different use cases of social networks. Microblogging, photo sharing, event planning, video hosting, it's all possible and beautifully interoperable. Ironically, perhaps ActivityPub is the thing that will truly "connect the world", rather than Facebook who that catchphrase belongs to.
https://boingboing.net/2018/07/18/platform-independence.html
22 notes
·
View notes
Text
IPFS error "flatfs: too many open files"
If you have followed my previous tutorial on how to batch import your pinned files, you could have easily incurred on this "flatfs: too many open files" error. Here a practical solution for your Linux OS: Enter the following folder as superuser via your editor of preference, I'm using nano:
sudo nano /etc/security/limits.conf
add these 2 lines at the end of the file: . . . * hard nofile 4096 * soft nofile 40960 # End of file
Log out and log in again > retry =) 4096 and 40960 should be enough, just in case you can always augment these values! ^^
Thank You for reading!
donation area: https://ift.tt/2txWNwA (it helps me to keep servers running ipfs nodes) → https://ift.tt/2lsYtUq
0 notes
Text
what’s IPFS anyway?
So as I learned today... IPFS is a proposal for a new network protocol, designed to replace direct HTTP connections with a peer to peer distribution system. Instead of running a large server to send files to everyone who accessed your site, you would put your content up on the IPFS network and let it be fetched from the nearest IPFS node that has it.
Of course, to some degree the internet already does this, through caching - both at data centres and on your computer. If you say ‘I want resource x’, your browser might say ‘oh we already have that’, or perhaps a data centre somewhere between you and the target server can be like ‘oh I already have that’ and not need to request it anew from the starting server.
The major problem of caching is ‘cache invalidation’ - suppose I change the resource hosted on my server. The downstream server doesn’t necessarily immediately realise, so it might send you a stale version.
(there’s an old joke that goes “the two hard problems of computer science are naming, cache invalidation, and off-by-one errors” incidentally)
So IPFS gets around this by having each IPFS address be a cryptographic hash. A hash essentially generates a new, seemingly random string of bits from all the data of an object. In theory, it’s astronomically unlikely to have a ‘hash collision’ where two objects end up having the same hash. Every time an object changes, it gets a new hash. So an IPFS ‘address’ will always point to the same file, a cache will never get stale.
IPFS sounds pretty similar to BitTorrent, in terms of identifying content by hash and collecting chunks of data from peers. That’s a good thing, I think! BitTorrent was, still is, a great idea. The main reason it’s still pretty marginal is of course that it’s very hard to restrict copying only to ‘authorised’ users, and in an economic system that depends on scarcity and forcing people to sell something or starve. If a copyright owner can’t prevent people from copying something they have ‘ownership’ over until they meet your terms (e.g. until they pay you for the right to copy it), they will potentially make a lot less money from it.
If Netflix released a torrent, they could never stop a non-paid Netflix user from accessing all the videos on their site. Instead, Netflix videos must be downloaded from Netflix’s servers. If my housemate and I watch the same show, I can’t just download the data from them, I have to go to Netflix. To allow this kind of capital accumulation to take place, the state protects ‘intellectual property’ rights and will deploy violence to stop people copying the wrong stuff.
Yeah yeah, the answer to piracy is communism, soapbox over.
The comparison to BitTorrent leads me to some questions. In basic BitTorrent, there is still a centralised element because you need to know where to get the thing you want. Everyone has to connect to one or more ‘trackers’ and declare which files they have (identified by their hash), and which ones they’re looking for. The tracker then tells you which other people either have or want that same file, allowing the BitTorrent protocol to set up a connection and send or receive the ‘chunks’ of the file.
(Most torrents on public pirate sites will use ‘public’ trackers which anyone can connect to, but there are also ‘private’ trackers which restrict entry, and monitor their users’ seed ratios to ensure they’re ‘giving back to’ the network as much as they take! The idea being that for the members of the private tracker, they can rely on always having seeds for the stuff they want.)
Of course, BitTorrent has this ‘where is the thing I want’ problem in common with the internet at large - you need to know where to get a web page just as much! Presently there are a handful of ‘domain name system’ servers around the world, and your computer is configured to use a particular one. If I type, say, “https://canmom.github.io” into my browser, it will first send a request to one of the DNS servers, which will reply with the IP address of the server I want the file from. Then, my browser puts a packet saying ‘I want this resource at this IP address’ on the network, and the IP address is used to route the packet to the desired server (assuming it exists), which sends a message back the same way.
How’s that different from a tracker? The difference: an IP address points to a specific computer on a network, and the rest of a URI is saying ‘hey, server, give me this file’; the server can send back whatever it wants. In BitTorrent, an address is a hash pointing to a specific resource, which could be in many places. The tracker tells you all of the different IP address where you could get the file, and then your torrent client goes down the list and picks some to ask for small bits of it. Whichever computer ends up answering has to give you back something with the same hash.
(The hashes allow P2P to work safely; even if someone shady wanted to give you a fake version of whatever file you’re asking for, unless they can match the hash, they won’t be able to get away with it.)
Later versions of BitTorrent introduced new techniques, such as ‘Distributed Hash Tables’, to sidestep the need for a tracker. A DHT involves some pretty clever maths to form a kind of mini-network which stores the information that would be held by a tracker; in effect it allows you to ask the other computers on the network where you can get the bits of a file, or ‘which way to go’ to find someone who knows this info. This is handy if, say, a torrent is set to use a tracker that was since shut down; you might still be able to find torrent clients with the file through the DHT. In BitTorrent’s case, it’s specifically implemented as ‘mainline’, which is now supported by most torrent clients.
So how does IPFS handle this ‘finding the thing you want’ problem?
The IPFS website kind of goes really hard on hype and less so on technical details, but digging in a bit gets to this concepts page.
So first of all, it allows you to use the domain name system to directly map a domain name to a hash. You can do this on the traditional DNS servers. But every time you update a website, you have to change your entry on the DNS servers.
The alternative is the “Interplanetary Name System”, which uses... more cryptography, oh boy.
So this time we’re using public key/private key crypto. The IPNS is a hash of a public key, and it’s ‘associated with’ a cryptographically signed record that links to the most up to date version of a file. I’m not sure I fully understand that ‘association’, or how it’s updated... looking at the instructions for setting it up for a website, it seems that maybe the IPNS will just tell the person who accesses it to connect to a specific peer, at which point your computer will tell them the hashes of the file they should download? I don’t think I understand this bit yet.
Anyway I want to try this out, I’m curious how well it works in practice. I’m going to see if I can publish my website - currently hosted on Github Pages - onto IPFS. Using a static site generator, such as Jekyll, should be ideal for IPFS. Unfortunately I don’t have my own domain name registration. I wonder if I can publish stuff anyway? Will update when I find out...
17 notes
·
View notes
Text
Sparkster source code review
Sparkster has finally opened its code repositories to the public, and as the project has been somewhat in the centre of discussion in the crypto community, as well as marketed by one of the high profile crypto influencers, we have been quite curious to see the result of their efforts.

The fundamental idea of the project is to provide a high-throughput decentralized cloud computing platform, with software developer kit (SDK) on top with no requirement for programming expertise (coding is supposed to be done in plain English). The idea of plain English coding is far from new and has been emerging more than a few times over the years, but never gotten any widespread traction. The reason in our opinion is that professional developers are not drawn to simplified drag & drop plain language programming interfaces, and non-developers (which is one of the potential target groups for Sparkster) are, well, most probably just not interested in software development altogether.
However the focus of this article is not to scrutinize the use case scenarios suggested by Sparkster (which do raise some question marks) but rather to take a deep look into the code they have produced. With a team counting 14 software developers and quite a bit of runway passed since their ICO in July 2018, our expectations are high.
Non-technical readers are advised to skip to the end for conclusions.
Source code review Sparkster initially published four public repositories in their github (of which one (Sparkster) was empty). We noticed a lack of commit history which we assume is due to a transfer of the repos from a private development environment into github. Three of the above repositories were later combined into a single one containing subfolders for each system element.
The first impression from browsing the repositories is decent after recent cleanups by the team. Readme has been added to the main repository with information on the system itself and installation instructions (Windows x64 only, no Linux build is available yet)
However, we see no copyright notes anywhere in the code developed by Sparkster, which is quite unusual for an open source project released to the public.
Below is a walk-thru of the three relevant folders containing main system components under the Decentralized-Cloud repository and a summary of our impression.
Master-Node folder The source code is written in C++. Everything we see is very basic. In total there are is not a lot of unique code (we expected much more given the development time spent) and a lot of the recently added code is GNU/forks from other projects (all according to the copyright notes for these parts).
An interesting part is, that if this master node spawned the compute node for this transaction, the master node will request the compute node to commit the transaction. The master nodes takes the control over more or less all communication to stakeholders such as clients. The master node will send a transaction to 20 other master nodes.
The lock mechanism during voting is standard: nodes booting in the middle of voting are locked and cannot participate to avoid incorrect results.
We cannot see anything in the code that differentiates the node and makes it special in any way, i.e. this is blockchain 101.
Compute-Node folder All source files sum up to a very limited amount of code. As the master node takes over a lot of control, the compute node focuses on the real work. A minimalistic code is generally recommended in a concept like this, but this is far less than expected.
We found the “gossip” to 21 master nodes before the memory gets erased and the compute node falls back to listen mode.
The concept of 21 master nodes is defined in the block producer. Every hour a new set of 21 master nodes become the master node m21.
“At any given point in time, 21 Master Nodes will exist that facilitate consensus on transactions and blocks; we will call these master nodes m21. The nodes in m21 are selected every hour through an automated voting process”
(Source: https://github.com/sparkster-me/Decentralized-Cloud)
The compute node is somewhat the heart of the project but is yet again standard without any features giving it high performance capability.
Storage-Node folder The source code is again very basic. Apart from this, the code is still at an experimental stage with e.g. buffer overflow disabling being utilized, something that should not be present at this stage of development.
Overall the storage uses json requests and supports/uses the IPFS (InterPlanetary File System). IPFS is an open source project and used for storing and sharing hypermedia in a distributed file system. The storage node not only handles the storage of data, it also responds to some client filter requests.
Conclusion In total Sparkster has produced a limited amount of very basic code, with a team of 14 developers at their disposal. As their announcement suggests that this is the complete code for their cloud platform mainnet, we must assume that the productivity of the team has been quite low over the months since funds were raised, since none of the envisioned features for high performance are yet implemented.
The current repository is not on par with standards for a mainnet release and raises some serious question marks about the intention of the project altogether. The impression is that the team has taken a very basic approach and attempted to use short cuts in order to keep their timelines towards the community, rather than develop something that is actually unique and useful. This is further emphasized by the fact that the Sparkster website and blockchain explorer is built on stock templates. We don’t see any sign of advanced development capability this far.
Based on what we see in this release Sparkster is currently not a platform for ”full scale support to build AI powered apps” as their roadmap suggest and we are puzzled by the progress and lack of provisioning of any type of SDK plugin. The Sparkster team has a lot to work on to even be close to their claims and outlined roadmap.
Note: we have been in contact with the Sparkster team prior to publishing this review, in order to provide opportunity for them to comment on our observations. Their answers are listed below but doesn’t change our overall conclusions of the current state of Sparkster development.
“We use several open source libraries in our projects. These include OpenDHT, WebSocket++, Boost, and Ed25519. In other places, we’ve clearly listed where code is adapted from in the cases where we’ve borrowed code from other sources. We’ve used borrowed code for things like getting the time from a time server: a procedure that is well documented and for which many working code examples already exist, so it is not necessary for us to reinvent the wheel. However, these cases cover a small portion of our overall code base.
Our alpha net supports one cell, and our public claims are that one cell can support 1,000 TPS. These are claims that we have tested and validated, so the mainnet is in spec. You will see that multi cell support is coming in our next release, as mentioned in our readme. Our method of achieving multi cell support is with a well understood and documented methodology, specifically consistent hashing. However, an optimization opportunity, we’re investiging LSH over CS. This is an optimization that was recommended by a member of our Tech Advisory Board, who is a PHD in Computer Science at the University of Cambridge.
Our code was made straightforward on purpose. Most of its simplicity comes from its modular design: we use a common static library in which we’ve put common functionality, and this library is rightfully called BlockChainCommon.lib. This allows us to abstract away from the individual nodes the inner workings of the core components of our block chain, hence keeping the code in the individual nodes small. This allows for a high level of code reusability. In fact, in some cases this modular design has reduced a node to a main function with a series of data handlers, and that’s all there is to it. It allows us to design a common behavior pattern among nodes: start up OpenDHT, register data handlers using a mapping between the ComandType command and the provided lambda function, call the COMM_PROTOCOL_INIT macro, enter the node’s forever loop. This way, all incoming data packets and command processors are handled by BlockChainCommon, and all nodes behave similarly: wait for a command, act on the command. So while this design gives the impression of basic code, we prefer simplicity over complexity because it allows us to maintain the code and even switch out entire communications protocols within a matter of days should we choose to do so. As far as the Compute Node is concerned, we use V8 to execute the javascript which has a proven track record of being secure, fast and efficient.
We’ve specifically disabled warning 4996 because we are checking for buffer overflows ourselves, and unless we’re in debug mode, we don’t need the compiler to warn about these issues. This also allows our code to be portable, since taking care of a lot of these warnings the way the VCC compiler wants us to will mean using Microsoft-specific functions are portable (other platforms don’t provide safe alternatives with the _s suffix, and even Microsoft warns about this fact here: https://docs.microsoft.com/en-us/cpp/error-messages/compiler-warnings/compiler-warning-level-3-c4996?view=vs-2017.) To quote: “However, the updated names are Microsoft-specific. If you need to use the existing function names for portability reasons, you can turn these warnings off.”
1 note
·
View note
Text
donkey ears chrome extension + blockchain +react 개발
https://youtu.be/8OCEfOKzpAw
react+ chrome extension 개발 세팅설명 매우 좋은 설명
.
npm install --save react react-dom
npm install --save-dev webpack webpack-cli
npm install --save-dev babel-loader @babel/core @babel/preset-env @babel/preset-react
.
.
아래 과정은 django + django rest framework 세팅 과정
https://vomtom.at/how-to-use-uniswap-v2-as-a-developer/virtual env설치
pip install virtualenv
python3 -m venv venv
venv/Scripts/activate
requirements.txt만들어서 django 와 djangorestframework를 타입
pip install -r requirements.txt를 통해 설치
내용은 아래 그림과 같이 설치할 라이브러리를 파일안에 기입
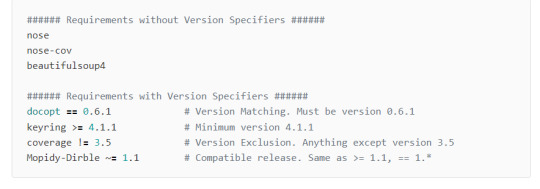
django-admin startproject donkey_ears
django-admin startapp api
python manage.py migrate
python manage.py makemigrations
python manage.py createsuperuser
.
npm install --save react-router-dom
npm install --save semantic-ui-react.
.
.
npm install --save cryptico
.
npm install --save bip39
bip 39을 이용하여 mnemonic phrase를 얻으려 했으나 chrome extension에서는 사용하려면 자꾸 에러 발생
npm install --save bitcore-mnemonic
npm install --save url
를 대신 사용
사용법 https://www.npmjs.com/package/bitcore-mnemonic
.
npm install --save ethereum-hdwallet
npm install --save crypto
npm install --save assert
npm install --save crypto-browserify
npm install --save stream
.
.
error solution
설치후에 계속 Module not found: Error: Can't resolve 'crypto' 에러 발생 해결은 아래와 같이 했다.
https://stackoverflow.com/a/67076572
*******************************************************************
react + web3, ethers
기본적으로 react를 사용할때 function , class스타일 두가지로 이용가능하다.

react 사용시 import하는 내용
.
클래스 스타일로 이용
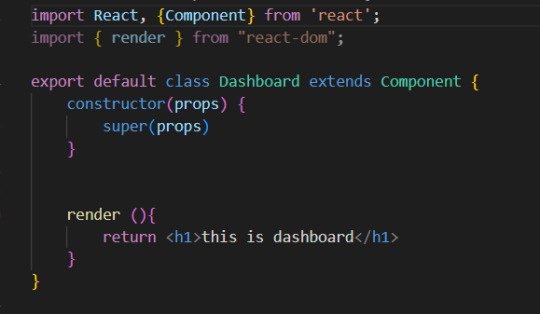
.
함수형태이용

.

Web3.providers.HttpProvder를 통해서 만들어진 provider를 ethers에서도 provider로 사용가능할줄 알았는데 약간 다른 형태의 provider였다.
.
react에서 하위 component에게 데이터 전달하는 방법


.
react 에서 useState사용하는 방법
const [] 에서 첫번째는 state variable 이름이고 다���은 set 함수이름
useState()안은 초기값
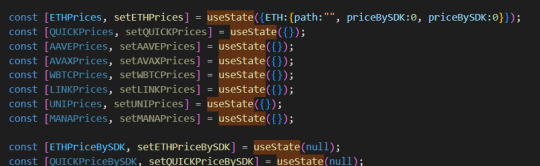
.
componentDidMount과 같은 역활하는 useEffect
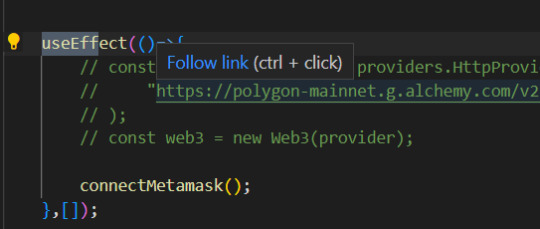
.
window.web3에 값이 할당되면 window.ethereum 에도 비슷한 값이 할당된다.
즉 window.ethereum을 통해서도 window.web3를 통해 하던 데이터를 얻을수 있으나 정확하게 같지는 않다.
window.web3안의 eth값이 있지 않은점이 크게 다른점이다. 그래서 window.ethereum.eth는 불가능하다는 이야기다.
metamask를 이용하는 경우 Web3.providers.HttpProvider()의 작업이 필요하지 않다 metamask안에 자체 provider를 이용한다.
metamask를 이용하는 경우 자동으로 window.ethereum 값이 설정되어있으므로 이를 이용하면 된다.
.
.
.
.
.
***********************************************************************************
***********************************************************************************
redirect 작업을 위해 useNavigate()를 이용하려고 했지만 react router를 사용해야지만 사용할수 있어서 사용하지 않고 window.location.href = '/popup.html?target=CreatePassword'; 와 같은 방법을 사용했다.
https://ncoughlin.com/posts/react-navigation-without-react-router/
.
react router 를 사용하지 못하고 (chrome extension에서는 일반 router기능을 이용할수 없음. 메타메스크의 경우 anchor # 를 이용했다. 아니면 query string을 이용해야 한다.)
.
useState를 통해 주입되는 component 내부에서 useState를 또 사용하는 경우 에러 발생
avubble 프로젝트의 app.js참고해 볼것
.
jsx에서 collection data type을 iterate 하면서 tag만들어내기

.

.
switch를 이용한 경우에 따른 component 삽입

.
chrome storage sync 삭제하기

.
pass parameters executeScript
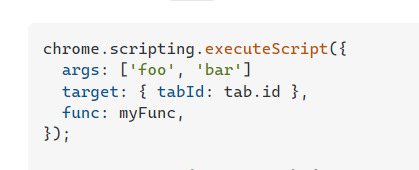
https://stackoverflow.com/a/68640372
.
opensea get sing asset
https://docs.opensea.io/reference/retrieving-a-single-asset-testnets
{ "id": 132352212, "num_sales": 0, "background_color": null, "image_url": "https://i.seadn.io/gae/zNAGqUNWdnYZQDWe9NnswJrQjRAspk8MlwCvRlsdGN6UOPc1Lzc6ZmPliqUMEmyRe1fVyjwm6w-5fr__pfA7hQNC_27RCj5-iLVjNDQ?w=500&auto=format", "image_preview_url": "https://i.seadn.io/gae/zNAGqUNWdnYZQDWe9NnswJrQjRAspk8MlwCvRlsdGN6UOPc1Lzc6ZmPliqUMEmyRe1fVyjwm6w-5fr__pfA7hQNC_27RCj5-iLVjNDQ?w=500&auto=format", "image_thumbnail_url": "https://i.seadn.io/gae/zNAGqUNWdnYZQDWe9NnswJrQjRAspk8MlwCvRlsdGN6UOPc1Lzc6ZmPliqUMEmyRe1fVyjwm6w-5fr__pfA7hQNC_27RCj5-iLVjNDQ?w=500&auto=format", "image_original_url": "https://nftstorage.link/ipfs/bafybeig76mncgmub2f7m7mordkveptk3br4wu6u6j4fhwqznez2ugiskku/0.png", "animation_url": null, "animation_original_url": null, "name": "Test 0", "description": "Test 0", "external_link": null, "asset_contract": { "address": "0xcfaf8eb5546fae192916f73126ea2d5991cb2028", "asset_contract_type": "semi-fungible", "created_date": "2022-09-29T09:41:30.559731", "name": "Example Game ERC 1155", "nft_version": null, "opensea_version": null, "owner": 12540403, "schema_name": "ERC1155", "symbol": "", "total_supply": null, "description": null, "external_link": null, "image_url": null, "default_to_fiat": false, "dev_buyer_fee_basis_points": 0, "dev_seller_fee_basis_points": 0, "only_proxied_transfers": false, "opensea_buyer_fee_basis_points": 0, "opensea_seller_fee_basis_points": 250, "buyer_fee_basis_points": 0, "seller_fee_basis_points": 250, "payout_address": null }, "permalink": "https://testnets.opensea.io/assets/goerli/0xcfaf8eb5546fae192916f73126ea2d5991cb2028/0", "collection": { "payment_tokens": [ { "id": 1507176, "symbol": "ETH", "address": "0x0000000000000000000000000000000000000000", "image_url": "https://openseauserdata.com/files/6f8e2979d428180222796ff4a33ab929.svg", "name": "Ether", "decimals": 18, "eth_price": 1, "usd_price": 1592.29 }, { "id": 1507152, "symbol": "WETH", "address": "0xb4fbf271143f4fbf7b91a5ded31805e42b2208d6", "image_url": "https://openseauserdata.com/files/accae6b6fb3888cbff27a013729c22dc.svg", "name": "Wrapped Ether", "decimals": 18, "eth_price": 1, "usd_price": 1593.2 } ], "primary_asset_contracts": [ { "address": "0xcfaf8eb5546fae192916f73126ea2d5991cb2028", "asset_contract_type": "semi-fungible", "created_date": "2022-09-29T09:41:30.559731", "name": "Example Game ERC 1155", "nft_version": null, "opensea_version": null, "owner": 12540403, "schema_name": "ERC1155", "symbol": "", "total_supply": null, "description": null, "external_link": null, "image_url": null, "default_to_fiat": false, "dev_buyer_fee_basis_points": 0, "dev_seller_fee_basis_points": 0, "only_proxied_transfers": false, "opensea_buyer_fee_basis_points": 0, "opensea_seller_fee_basis_points": 250, "buyer_fee_basis_points": 0, "seller_fee_basis_points": 250, "payout_address": null } ], "traits": {}, "stats": { "one_hour_volume": 0, "one_hour_change": 0, "one_hour_sales": 0, "one_hour_sales_change": 0, "one_hour_average_price": 0, "one_hour_difference": 0, "six_hour_volume": 0, "six_hour_change": 0, "six_hour_sales": 0, "six_hour_sales_change": 0, "six_hour_average_price": 0, "six_hour_difference": 0, "one_day_volume": 0, "one_day_change": 0, "one_day_sales": 0, "one_day_sales_change": 0, "one_day_average_price": 0, "one_day_difference": 0, "seven_day_volume": 0, "seven_day_change": 0, "seven_day_sales": 0, "seven_day_average_price": 0, "seven_day_difference": 0, "thirty_day_volume": 0, "thirty_day_change": 0, "thirty_day_sales": 0, "thirty_day_average_price": 0, "thirty_day_difference": 0, "total_volume": 0, "total_sales": 0, "total_supply": 1, "count": 1, "num_owners": 1, "average_price": 0, "num_reports": 0, "market_cap": 0, "floor_price": 0 }, "banner_image_url": null, "chat_url": null, "created_date": "2022-09-29T09:41:30.933452+00:00", "default_to_fiat": false, "description": null, "dev_buyer_fee_basis_points": "0", "dev_seller_fee_basis_points": "0", "discord_url": null, "display_data": { "card_display_style": "contain", "images": [] }, "external_url": null, "featured": false, "featured_image_url": null, "hidden": false, "safelist_request_status": "not_requested", "image_url": null, "is_subject_to_whitelist": false, "large_image_url": null, "medium_username": null, "name": "Example Game ERC 1155", "only_proxied_transfers": false, "opensea_buyer_fee_basis_points": "0", "opensea_seller_fee_basis_points": "250", "payout_address": null, "require_email": false, "short_description": null, "slug": "example-game-erc-1155", "telegram_url": null, "twitter_username": null, "instagram_username": null, "wiki_url": null, "is_nsfw": false, "fees": { "seller_fees": {}, "opensea_fees": { "0x0000a26b00c1f0df003000390027140000faa719": 250 } }, "is_rarity_enabled": false }, "decimals": null, "token_metadata": "https://nftstorage.link/ipfs/bafybeihfcvvlchgu6wogre4ae3jqwigyey3kgb2ur5o3jajv3zsmyve32q/0.json", "is_nsfw": false, "owner": { "user": null, "profile_img_url": "https://storage.googleapis.com/opensea-static/opensea-profile/1.png", "address": "0x0000000000000000000000000000000000000000", "config": "" }, "seaport_sell_orders": null, "creator": { "user": { "username": null }, "profile_img_url": "https://storage.googleapis.com/opensea-static/opensea-profile/2.png", "address": "0x72cebbf26f93cc5913fd87076c59428b794d6786", "config": "" }, "traits": [ { "trait_type": "Base", "value": "Starfish", "display_type": null, "max_value": null, "trait_count": 0, "order": null }, { "trait_type": "Eye", "value": "Big", "display_type": null, "max_value": null, "trait_count": 0, "order": null } ], "last_sale": null, "top_bid": null, "listing_date": null, "is_presale": false, "supports_wyvern": true, "rarity_data": null, "transfer_fee": null, "transfer_fee_payment_token": null, "related_assets": [], "orders": null, "auctions": [], "top_ownerships": [ { "owner": { "user": { "username": null }, "profile_img_url": "https://storage.googleapis.com/opensea-static/opensea-profile/2.png", "address": "0x72cebbf26f93cc5913fd87076c59428b794d6786", "config": "" }, "quantity": "3", "created_date": "2022-09-29T09:44:15.755541+00:00" } ], "ownership": null, "highest_buyer_commitment": null, "token_id": "0" }
.
solidity development
title generator
https://patorjk.com/
.
spdx license
// SPDX-License-Identifier: MIT
.
mumbai test contract
0x383A22a13D2693ecE63186A594671635a4C163fB
0 notes
Link
0 notes
Text
Radiotracer effective for detection and assessment of lung fibrosis

IMAGE: A) Axial CT images through the mouse lungs at 7 and 14 days after intratracheal administration of bleomycin or saline (as a control), showing increased lung fibrosis in the bleomycin… see more
Credit: Image developed by CA Ferreira et al., University of Wisconsin-Madison, Madison, WI.
Reston, VA (Embargoed till 4:30 p.m. EDT, Saturday, June 12, 2021)–Positron emission tomography (PET) utilizing a 68Ga-labeled fibroblast activation protein inhibitor (FAPI) can noninvasively recognize and screen lung fibrosis, according to research study provided at the Society of Nuclear Medicine and Molecular Imaging 2021 Annual Meeting. By binding to triggered fibroblasts present in afflicted lungs, FAPI-PET permits for direct imaging of the illness procedure.
Idiopathic lung fibrosis (IPF) triggers significant scarring to the lungs, making it hard for those affected to breathe. It is a considerable cause of morbidity and death in the United States, with more than 40,000 deaths yearly. A significant obstacle in medical diagnosis and treatment of IPF is the absence of a particular diagnostic tool that can noninvasively detect and examine illness activity, which is essential for the management of lung fibrosis clients.
“CT scans can provide physicians with information on anatomic features and other effects of IPF but not its current state of activity. We sought to identify and image a direct noninvasive biomarker for early detection, disease monitoring and accurate assessment of treatment response,” stated Carolina de Aguiar Ferreira, PhD, a research study partner at the University of Wisconsin-Madison in Madison, Wisconsin.
In the research study, scientists targeted the fibroblast activation protein (FAP) that is overexpressed in IPF as a possible biomarker. Two groups of mice—one group with caused lung fibrosis and one control group—were scanned with the FAPI-based PET/CT radiotracer 68Ga-FAPI-46 at numerous time points. Compared to the control group, the mice with caused lung fibrosis had a much greater uptake of the radiotracer, enabling scientists to effectively recognize and examine locations of IPF.
“Further validation of 68Ga-FAPI-46 for the detection and monitoring of pulmonary fibrosis would make this molecular imaging tool the first technique for early, direct, and noninvasive detection of disease. It would also provide an opportunity for molecular imaging to reduce the frequency of lung biopsies, which carry their own inherent risks,” kept in mind Ferreira. “This development will demonstrate that functional imaging can play an invaluable role in evaluation of the disease process.”
Abstract 10. “Targeting Activated Fibroblasts for Non-invasive Detection of Lung Fibrosis,” Carolina Ferreira, Zachary Rosenkrans, Ksenija Bernau, Jeanine Batterton, Christopher Massey, Alan McMillan, Nathan Sandbo, Ali Pirasteh and Reinier Hernandez, University of Wisconsin – Madison, Madison, Wisconsin; and Melissa Moore, Frank Valla and Christopher Drake, Sofie Biosciences, Dulles, Virginia.
###
All 2021 SNMMI Annual Meeting abstracts can be discovered online at https://jnm.snmjournals.org/content/62/supplement_1.
About the Society of Nuclear Medicine and Molecular Imaging
The Society of Nuclear Medicine and Molecular Imaging (SNMMI) is a global clinical and medical company devoted to advancing nuclear medication and molecular imaging, crucial components of accuracy medication that permit medical diagnosis and treatment to be customized to private clients in order to attain the very best possible results.
SNMMI’s members set the requirement for molecular imaging and nuclear medication practice by producing standards, sharing details through journals and conferences and leading advocacy on crucial problems that impact molecular imaging and treatment research study and practice. For more details, see http://www.snmmi.org.
Disclaimer: We can make errors too. Have a great day.
New post published on: https://livescience.tech/2021/06/13/radiotracer-effective-for-detection-and-assessment-of-lung-fibrosis/
0 notes
Text
Version 378
youtube
windows
zip
exe
macOS
app
linux
tar.gz
source
tar.gz
I had a great, simple week. Searches are less likely to be very slow, and system:limit searches now sort.
all misc this week
I identified a database access routine that was sometimes not taking an optimal route. Normally it was fine, but with certain sizes or types of query, it could take a very long time to complete. This mostly affected multi-predicate searches that included certain tags or system:duration and system:known urls, but the routine was used in about 60 different places across the program, including tag and duplicate files processing. I have rewritten this access routine to work in a more 'flat' way that will ensure it is not so 'spiky'.
Also in searching, I managed to push all the 'simple' file sorts down to file searches that have 'system:limit'. If you search with system:limit=256 and are sorting by 'largest files first', you will now see the 256 largest files in the search! Previously, it would give a random sample. All the simple sorts are supported: import time, filesize, duration, width, height, resolution ratio, media views, media viewtime, num pixels, approx bitrate, and modified time. If you want something fun, do a search for just 'system:limit=64' (and maybe system:filetype) and try some different sorts with F5--you can now see the oldest, smallest, longest, widest, whateverest files in your collection much easier.
There are also some fixes: if you had sessions not appearing in the 'pages' menu, they should be back; if you have had trouble with ipfs directory downloads, I think I have the file-selection UI working again; 'remove files when trashed' should work more reliably in downloader pages; and several tag and selection lists should size themselves a bit better.
full list
if a search has system:limit, the current sort is now sent down to the database. if the sort is simple, results are now sorted before system:limit is applied, meaning you will now get the largest/longest/whateverest sample of the search! supported sorts are: import time, filesize, duration, width, height, resolution ratio, media views, media viewtime, num pixels, approx bitrate, and modified time. this does not apply to searches in the 'all known files' file domain.
after identifying a sometimes-unoptimal db access routine, wrote a new more reliable one and replaced the 60-odd places it is used in both client and server. a variety of functions will now have less 'spiky' job time, including certain combinations of regular tag and system search predicates. some jobs will have slightly higher average job time, some will be much faster in all common situations
added additional database analysis to some complicated duplicate file system jobs that adds some overhead but should reduce extreme spikes in job time for very large databases
converted some legacy db code to new access methods
fixed a bug in the new menu generation code that was not showing sessions in the 'pages' menu if there were no backups for these sessions (i.e. they have only been saved once, or are old enough to have been last saved before the backup system was added)
fixed the 'click window close button should back out, not choose the red no button' bug in the yes/no confirmation dialogs for analyze, vacuum, clear orphan, and gallery log button url import
fixed some checkbox select and data retrieval logic in the checkbox tree control and completely cleared out the buggy ipfs directory download workflow. I apologise for the delay
fixed some inelegant multihash->urls resolution in the ipfs service code that would often mean a large folder would lock the client while parsing was proceeding
when the multihash->urls resolution is going on, the popup now exposes the underlying network control. cancelling the whole job mid-parse/download is now also quicker and prettier
when a 'downloader multiple urls' popup is working, it will publish its ongoing presented files to a files button as it works, rather than just once the job is finished
improved some unusual taglist height calculations that were turning up
improved how taglists set their minimum height--the 'selection tags' list should now always have at least 15 rows, even when bunched up in a tall gallery panel
if the system clock is rewound, new objects that are saved in the backup system (atm, gui sessions) will now detect that existing backups are from the future and increase their save time to ensure they count as the newest object
short version: 'remove files from view when trashed' now works on downloader thumbs that are loaded in from a session. long version: downloader thumb pages now force 'my files' file domain for now (previously it was 'all local files')
the downloader/thread watcher right-click menus for 'show all downloaders xxx files' now has a new 'all files and trash' entry. this will show absolutely everything still in your db, for quick access to accidental deletes
the 'select a downloader' list dialog _should_ size itself better, with no double scrollbars, when there are many many downloaders and/or very long-named downloaders. if this layout works, I'll replicated it in other areas
if an unrenderable key enters a shortcut, the shortcut will now display an 'unknown key: blah' statement instead of throwing an error. this affected both the manage shortcuts dialog and the media viewer(!)
SIGTERM is now caught in non-windows systems and will initiate a fast forced shutdown
unified and played with some border styles around the program
added a user-written guide to updating to the 'getting started - installing' help page
misc small code cleanup
next week
I am going to take a few days off for the holiday and make the next release in two weeks, for New Year's Day. I expect to do some small jobs, push more on the database optimisation, continue improving the UI layout code, and perhaps put some time into some space-clearing database maintenance.
𝕸𝖊𝖗𝖗𝖞 𝕮𝖍𝖗𝖎𝖘𝖙𝖒𝖆𝖘!
1 note
·
View note
Text
NFT Market Place Software Developers
For More Details Please Contact
Call / Whatsapp: +(60)-0392121566
Website: www.cryptosoftmalaysia.com
Unit3, Level 22,
The Gardens South Tower,
Mid Valley City,
59200 Kuala Lumpur

NFT Market Place Software Developers
NFT Marketplace Software is an optimal Software Solution, provides sole proprietorship to start an NFT Marketplace platform on any domains like art, music, gaming, and real estate, etc, where users can buy, sell and list NFTs hurdle lessly. With keen concern to provide rich user experience, we have equipped our software package with standard security and storage features including IPFS and Filecoin. It is primarily designed as the developer friendly software promotes instant market launch.
Cryptosoft Malaysia Marketplace Software comes as a customizable package so the business person can pick up things from Blockchain Technology used to additional APIs.
We help you launch your own NFT marketplace and attract the growing community of NFT users. NFT marketplaces built by us are feature-rich, decentralized, and facilitate tokenization of all kinds of assets.
Who We Are?
Being the prominent company in the Crypto Industry, we provide optimal NFT solutions for various industries. With our client centric approach, we always strive for the best to meet the client’s requirements. We also Provides NFT Marketplace Clone Scripts which works exactly as the popular NFT Marketplaces.
Our NFT Marketplace Development Services
NFT Marketplace Design and Development
With in-depth knowledge of ERC-721 and ERC-1155 standards, smart contracts and IPFS protocols, our team designs and builds a user-centric NFT marketplace platform where users can create and trade NFTs.
NFT Smart Contract Development and Audit
We offer NFT smart contract development and audit services to ensure the error-free functioning of the smart contracts, ensuring seamless automation in NFT transactions.
NFT Marketplace Support and Maintenance
We continuously monitor, maintain and offer support for managing third-party upgrades, new OS releases and ensure nodes are always up and running.
NFT Development
Our NFT marketplace development company provides a token creation feature as a service to your NFT marketplace. It allows users on the platform to mint tokens for their assets.
NFT Use Cases Crypto Collectibles
Unique digital assets such as rare baseball cards or a rare whisky bought and sold on the blockchain are crypto collectibles. NFTs verify and record the ownership of crypto collectibles.
Gaming
NFTs help gamers safely transfer in-game assets like a rare skin or avatar and provide proof of authenticity.
Software License Management
NFTs help in managing software licenses. Each license is represented by an NFT that is signed and authenticated by its owner.
Asset Lifecycle Management
By converting an asset into NFT, trading of assets and transferring ownership of assets/tokens become easy and quick.
Trading Marketplace
NFT marketplaces offer a wide range of NFTs, including digital art, domain names, virtual lands and other collectibles to buy, sell and explore exclusive assets.
Music
NFTs enable musicians to tokenize their creations and list them in the market. It not only attracts music lovers on the NFT platform but also eliminates piracy in music.
Components of NFT Marketplace Software
Blockchain Technology: Build on any kinds of Blockchain like Ethereum, Polkadot, Cardano, Solana, etc.
NFT Wallet Integration:NFT Wallet Integration to store NFTs.
Admin Panel Integration:Admin Panel Integration to keep track about website details.
NFT Storage: NFT Storage Integration with IPFS and File coin.
0 notes
Photo

🌈IPFS - Technology that will change the current Internet
🧲IPFS is a distributed system for storing and accessing files, websites, applications, and data.
Why does the Internet need IPFS? 🌟Here's the problem with HTTP: When you visit a website, your browser must be directly connected to the computers that are serving the site, so when their servers are far away, the transmission takes a lot of time and bandwidth.
💥The HTTP protocol is server-dependent. If a link in HTTP transmission is broken for any reason, the entire transmission will fail (I am sure each of us has experienced a “404” error once in our life and it is very difficult!!).
💦IPFS will help the Internet grow into a system capable of connecting everyone around the world (even offline), we are free to express who we are, free to find the information we want (true information), and without fear of being blocked by servers or being taken down by some kind of attack.
🚀IPFS is tightly integrated with the Hora OS blockchain. Building projects using IPFS technology is an important part of Hora OS's mission.
#HoraOs #HoraChain #UfinUk #IPFS
0 notes