#I used to have an application that worked as a proxy and would edit pages on the fly to block ads and trackers
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs




Fun Fact
Tumblr has 411 employees.
Text
Alt+D (focus address bar) no longer works on desktop on tumblr.
this is my default way of getting out of a webpage, and even though this has been the case for days now I keep feeling like I've bit down on a chunk of glass every time.
I feel like firefox should have an option that's basically, "Don't let websites prevent the use of the important shortcuts."
#original#tumblr gonna tumbl#I used to have an application that worked as a proxy and would edit pages on the fly to block ads and trackers#and also had a suite of fixes for stuff like that; that was mostly about stopping the malicious popups of the late 90s
42 notes
·
View notes
Text
SSH Shell

Price: KiTTY is free to use. KiTTY is an SSH client that is based on PuTTY’s 0.71 version.
The Secure Shell extension works with non-Google HTTP-to-SSH proxies via proxy hooks, and third-party application nassh-relay can use those hooks to enable the Secure Shell extension to establish an SSH connection over XMLHttpRequest or WebSocket transport.
Ssh Shell For Mac
Ssh Shell Mac
Ssh Shell Script Example
Ssh Shell For Windows
SSH.NET is a Secure Shell (SSH-2) library for.NET, optimized for parallelism. This project was inspired by Sharp.SSH library which was ported from java and it seems like was not supported for quite some time. This library is a complete rewrite, without any third party dependencies, using parallelism to achieve the best.
This is quite a common task for Linux system administrators, when it is needed to execute some command or a local Bash script from a one Linux workstation or a server on another remote Linux machine over SSH.

In this article you will find the examples of how to execute a remote command, multiple commands or a Bash script over SSH between remote Linux hosts and get back the output (result).
This information will be especially useful for ones, who want to create a Bash script that will be hosted locally on a one Linux machine but would be executed remotely on the other hosts over SSH.
Cool Tip: Connect to a remote SSH server without typing a password! Configure a passwordless authentication! Only 3 easy steps! Read more →
SSH: Execute Remote Command
Execute a remote command on a host over SSH:
Examples
Get the uptime of the remote server:
Reboot the remote server:
SSH: Run Multiple Remote Commands
Ssh Shell For Mac
In the most cases it is not enough to send only one remote command over SSH.
Much more often it is required to send multiple commands on a remote server, for example, to collect some data for inventory and get back the result.
There are a lot of different ways of how it can be done, but i will show the most popular of them.
Run multiple command on a remote host over SSH:
– or –
– or –
Cool Tip: SSH login is too slow? This can be fixed easily! Get rid of delay during authentication! Read more →
Examples
Get the uptime and the disk usage:
Get the memory usage and the load average:
Show the kernel version, number of CPUs and the total RAM:
SSH: Run Bash Script on Remote Server
The equally common situation, when there is some Bash script on a Linux machine and it needs to connect from it over SSH to another Linux machine and run this script there.
The idea is to connect to a remote Linux server over SSH, let the script do the required operations and return back to local, without need not to upload this script to a remote server.
Certainly this can be done and moreover quite easily.
Cool Tip: Want to ROCK? Start a GUI (graphical) application on a remote Linux workstation over SSH! Read more →
Example
Execute the local script.sh on the remote server:
-->
Secure Shell (SSH) allows you to remotely administer and configure your Windows IoT Core device
Using the Windows 10 OpenSSH client
Important
The Windows OpenSSH client requires that your SSH client host OS is Windows 10 version 1803(17134). Also, the Windows 10 IoT Core device must be running RS5 Windows Insider Preview release 17723 or greater.
The OpenSSH Client was added to Windows 10 in 1803 (build 17134) as an optional feature. To install the client, you can search for Manage Optional Features in Windows 10 settings. If the OpenSSH Client is not listed in the list of installed features, then choose Add a feature.
Next select OpenSSH Client in the list and click Install.
Ssh Shell Mac
To login with a username and password use the following command:
Where host is either the IP address of the Windows IoT Core device or the device name.
The first time you connect you see a message like the following:
Type yes and press enter.
If you need to login as DefaultAccount rather than as administrator, you will need to generate a key and use the key to login. From the desktop that you intend to connect to your IoT Device from, open a PowerShell window and change to your personal data folder (e.g cd ~)
Register the key with ssh-agent (optional, for single sign-on experience). Note that ssh-add must be performed from a folder that is ACL'd to you as the signed-in user (BuiltinAdministrators and the NT_AUTHORITYSystem user are also ok). By default cd ~ from PowerShell should be sufficient as shown below.
Tip
If you receive a message that the ssh-agent service is disabled you can enable it with sc.exe config ssh-agent start=auto
To enable single sign, append the public key to the Windows IoT Core device authorized_keys file. Or if you only have one key you copy the public key file to the remote authorized_keys file.
If the key is not registered with ssh-agent, it must be specified on the command line to login:
If the private key is registered with ssh-agent, then you only need to specify DefaultAccount@host:
The first time you connect you see a message like the following:
Type yes and press enter.
You should now be connected as DefaultAccount
To use single sign-on with the administrator account, append your public key to c:dataProgramDatasshadministrators_authorized_keys on the Windows IoT Core device.
You will also need to set the ACL for administrators_authorized_keys to match the ACL of ssh_host_dsa_key in the same directory.
To set the ACL using PowerShell
Note
If you see a REMOTE HOST IDENTIFICATION CHANGED message after making changes to the Windows 10 IoT Core device, then edit C:Users<username>.sshknown_hosts and remove the host that has changed.

See also: Win32-OpenSSH
Using PuTTY
Download an SSH client
In order to connect to your device using SSH, you'll first need to download an SSH client, such as PuTTY.
Ssh Shell Script Example
Connect to your device
In order to connect to your device, you need to first get the IP address of the device. After booting your Windows IoT Core device, an IP address will be shown on the screen attached to the device:
Now launch PuTTY and enter the IP address in the Host Name text box and make sure the SSH radio button is selected. Then click Open.
If you're connecting to your device for the first time from your computer, you may see the following security alert. Just click Yes to continue.
If the connection was successful, you should see login as: on the screen, prompting you to login. Enter Administrator and press enter. Then enter the default password p@ssw0rd as the password and press enter.
If you were able to login successfully, you should see something like this:
Update account password
It is highly recommended that you update the default password for the Administrator account.
Ssh Shell For Windows
To do this, enter the following command in the PuTTY console, replacing [new password] with a strong password:
Configure your Windows IoT Core device
To be able to deploy applications from Visual Studio 2017, you will need to make sure the Visual Studio Remote Debugger is running on your Windows IoT Core device. The remote debugger should launch automatically at machine boot time. To double check, use the tlist command to list all the running processes from PowerShell. There should be two instances of msvsmon.exe running on the device.
It is possible for the Visual Studio Remote Debugger to time out after long periods of inactivity. If Visual Studio cannot connect to your Windows IoT Core device, try rebooting the device.
If you want, you can also rename your device. To change the 'computer name', use the setcomputername utility:
You will need to reboot the device for the change to take effect. You can use the shutdown command as follows:
Commonly used utilities
See the Command Line Utils page for a list of commands and utilities you can use with SSH.
1 note
·
View note
Text
Version 448
youtube
windows
zip
exe
macOS
app
linux
tar.gz
I had an ok couple of weeks. I was pretty ill in the middle, but I got some good work done overall. .wav files are now supported, PSD files get thumbnails, vacuum returns, and the Client API allows much cleverer search.
client api
I have added some features to the Client API. It was more complicated than I expected, so I couldn't get everything I wanted done, but I think this is a decent step forward.
First off, the main 'search for files' routine now supports many system predicates. This is thanks to a user who wrote a great system predicate text parser a long time ago. I regret I am only catching up with his work now, since it works great. I expect to roll it into normal autocomplete typing as well--letting you type 'system:width<500' and actually getting the full predicate object in the results list to select.
If you are working with the Client API, please check out the extended help here:
https://hydrusnetwork.github.io/hydrus/help/client_api.html#get_files_search_files
There's a giant list of the current supported inputs. You'll just be submitting system predicates as text, and it handles the rest. Please note that this is a complicated system, and while I have plenty of unit tests and so on, if you discover predicates that should parse but are giving errors or any other jank behaviour, please let me know!
Next step here is to add file sort and file/tag domain.
Next there's a routine that lets you add files to arbitrary pages, just like a thumbnail drag and drop:
https://hydrusnetwork.github.io/hydrus/help/client_api.html#manage_pages_add_files
This is limited to currently open pages for now, but I will add a command to create an empty file page so you can implement an external file importer page.
misc
.wav files are now supported! They should work fine in mpv as well.
Simple PSD files now get thumbnails! It turns out FFMPEG can figure this out as long as the PSD isn't too complicated, so I've done it like for .swf files--if it works, the PSD gets a nice thumbnail, and if it doesn't it gets the file default icon stretched to the correct ratio. When you update, all existing PSDs will be queued for a thumbnail regen, so they should sort themselves out in the background.
Thanks to profiles users sent in, I optimised some database code. Repository processing and large file deletes should be a little faster. I had a good look at some slow session save profiles--having hundreds of thousands of URLs in downloader pages currently eats a ton of CPU during session autosave--but the solution will require two rounds of significant work.
Database vacuum returns as a manual job. I disabled this a month or so ago as it was always a rude sledgehammer that never actually achieved all that much. Now there is some UI under database->db maintenance->review vacuum data that shows each database file separately with their current free space (i.e. what a vacuum will recover), whether it looks like you have enough space to vacuum, an estimate of vacuum time, and then the option to vacuum on a per file basis. If you recently deleted the PTR, please check it out, as you may be able to recover a whole ton of disk space.
I fixed Mr Bones! I knew I'd typo somewhere with the file service rewrite two weeks ago, and he got it. I hadn't realised how popular he was, so I've added him to my weekly test suite--it shouldn't happen again.
full list
client api:
/get_files/search_files now supports most system predicates! simply submit normal system predicate text in your taglist (check the expanded api help for a list of what is supported now) and they should be converted to proper system preds automatically. anything that doesn't parse will give 400 response. this is thanks to a user that submitted a system predicate parser a long time ago and which I did not catch up on until now. with this framework established, in future I will be able to add more predicate types and allow this parsing in normal autocomplete typing (issue #351)
this is a complicated system with many possible inputs and outputs! I have tried to convert all the object types over and fill out unit tests, but there are likely some typos or bad error handling for some unusual predicates. let me know what problems you run into, and I'll fix it up!
the old system_inbox and system_archive parameters on /get_files/search_files are now obselete. they still work, but I recommend you just use tags now. I'll deprecate them fully in future
/get_files/search_files now disables the implicit system limit that most clients apply to all searches (by default, 10,000), so if you ask for a million files, you'll (eventually) get it
a new call /manage_pages/add_files now allows you to add files to any media page, just like a file drag and drop
in the /get_files/file_metadata call, the tag lists in the different 'statuses' Objects are now human-sorted
added a link to https://github.com/floogulinc/hyextract to the client api help. this lets you extract from imported archives and reimport with tags and URLs
the client api is now ok if you POST with a utf-8 charset content-type "application/json;charset=utf-8"
the client api now tests the types of items within list parameters (e.g. file_ids should be a list of _integers_), raising an appropriate exception if they are incorrect
client api version is now 18
.
misc:
hydrus now supports wave (.wav) audio files! they play in mpv fine too
simple psd files now have thumbnails! complicated ones will get a stretched version of the old default psd filetype thumbnail, much like how flash works. all your psd files are queued up for thumbnail regen on update, so they should figure themselves out in the background. this is thanks to ffmpeg, which it turns out can handle simple psds!
vacuum returns as a manual operation. there's some new gui under _database->db maintenance->review vacuum data_. it talks about vacuum, shows current free space for each file, gives an estimate of how long vacuum will take, and allows you to launch vacuum on particular files
the 'maintenance and processing' option that checks CPU usage for 'system busy' status now lets you choose how many CPU cores must exceed the % value (previously, one core exceeding the value would cause 'busy'). maybe 4 > 25% is more useful than 1 > 50% in some situations?
removed the warning when updating from v411-v436. user reports and more study suggest this range was most likely ok in the end!
double-clicking the autocomplete tag list, or the current/pending/etc.. buttons, should now restore keyboard focus back to the text input afterwards, in float mode or not
the thumbnail 'remote services' menu, if you have file repositories or ipfs services, now appears on the top level, just below 'manage'
the file maintenance menu is shuffled up the 'database' menubar menu
fixed mr bones! I knew I was going to make a file status typo in 447, and he got it
in the downloader system, if a download object has any hashes, it now no longer consults urls for pre-import predictions. this saves a little time looking up urls and ensures that the logically stronger hashes take precedence over urls in all cases (previously, they only took precedence when a non-'looks new' status was found)
fixed an ugly bug in manage tag siblings/parents where tags imported from clipboard or .txt were not being cleaned, so all sorts of garbage with capital letters or leading spaces could be entered. all pairs are now cleaned, and anything invalid skipped over
the manage tag filter dialog now cleans all imported tag rules when using the 'import' button (issue #768)
the manage tag filter dialog now allows you to export the current tag filter with the export button
fixed the 'edit json parse rule' dialog layout so if you transition from a short display to a string match that has complicated controls, it should now expand properly to show them all
I think I fixed an odd bug where when uploading pending mappings while more mappings were being added, the x/y progress could accurately but unhelpfully continually reset to 0/y, with an ever-decreasing y until it was equal to the value it had at start. y should now always grow
hydrus servers now put their server header on a second header 'Hydrus-Server', which should allow them to be properly detectable through a proxy that overrides 'Server'
optimised a critical call in the tag mappings update database routine. for a service with many siblings and parents, I estimate repository processing is 2-7% faster
optimised the 'add/delete file' database routines in multiple ways, particularly when the file(s) have many deleted tags, and for the local file services, and when the client has multiple tag services
brushed up a couple of system predicate texts--things like num_pixels to 'number of pixels'
.
boring database refactoring:
repository update file tracking and service id normalisation is now pulled out to a new 'repositories' database module
file maintenance tracking and database-level file info updates is now pulled out to a new 'files maintenance' database module
analyse and vacuum tracking and information generation is now pulled out to a new 'db maintenance' database module
moved more commands to the 'similar files' module
the 'metadata regeneration' file maintenance job is now a little faster to save back to the database
cleared out some defunct/bad database code related to these two modules
misc code cleanup, particularly around the stuff I optimised this week
next week
Next week is a 'medium job' week. To clear out some long time legacy issues, I want to figure out an efficient way to reset and re-do repository processing just for siblings and parents. If that goes well, I'll put some more time into the Client API.
0 notes
Text
Docker Bundle Install

Estimated reading time: 15 minutes
Docker Ruby On Rails Bundle Install
Docker Bundle Install Not Working
Install OpenProject with Docker. Docker is a way to distribute self-contained applications easily. We provide a Docker image for the Community Edition that you can very easily install and upgrade on your servers. Docker: version 1.9.0 or later; Running Docker Image sudo docker run -i -t -d -p 80:80 onlyoffice/documentserver Use this command if you wish to install ONLYOFFICE Document Server separately. To install ONLYOFFICE Document Server integrated with Community and Mail Servers, refer to the corresponding instructions below. Configuring Docker Image. The Docker Desktop menu allows you to configure your Docker settings such as installation, updates, version channels, Docker Hub login, and more. This section explains the configuration options accessible from the Settings dialog. Open the Docker Desktop menu by clicking the Docker icon in the Notifications area (or System tray).
Welcome to Docker Desktop! The Docker Desktop for Windows user manual provides information on how to configure and manage your Docker Desktop settings.
For information about Docker Desktop download, system requirements, and installation instructions, see Install Docker Desktop.
Settings
The Docker Desktop menu allows you to configure your Docker settings such as installation, updates, version channels, Docker Hub login,and more.
This section explains the configuration options accessible from the Settings dialog.
Open the Docker Desktop menu by clicking the Docker icon in the Notifications area (or System tray):
Select Settings to open the Settings dialog:
General
On the General tab of the Settings dialog, you can configure when to start and update Docker.
Start Docker when you log in - Automatically start Docker Desktop upon Windows system login. Macos mojave installer size.
Expose daemon on tcp://localhost:2375 without TLS - Click this option to enable legacy clients to connect to the Docker daemon. You must use this option with caution as exposing the daemon without TLS can result in remote code execution attacks.
Send usage statistics - By default, Docker Desktop sends diagnostics,crash reports, and usage data. This information helps Docker improve andtroubleshoot the application. Clear the check box to opt out. Docker may periodically prompt you for more information.
Resources
The Resources tab allows you to configure CPU, memory, disk, proxies, network, and other resources. Different settings are available for configuration depending on whether you are using Linux containers in WSL 2 mode, Linux containers in Hyper-V mode, or Windows containers.
Advanced
Note
The Advanced tab is only available in Hyper-V mode, because in WSL 2 mode and Windows container mode these resources are managed by Windows. In WSL 2 mode, you can configure limits on the memory, CPU, and swap size allocatedto the WSL 2 utility VM.
Use the Advanced tab to limit resources available to Docker.
CPUs: By default, Docker Desktop is set to use half the number of processorsavailable on the host machine. To increase processing power, set this to ahigher number; to decrease, lower the number.
Memory: By default, Docker Desktop is set to use 2 GB runtime memory,allocated from the total available memory on your machine. To increase the RAM, set this to a higher number. To decrease it, lower the number.
Swap: Configure swap file size as needed. The default is 1 GB.
Disk image size: Specify the size of the disk image.
Disk image location: Specify the location of the Linux volume where containers and images are stored.
You can also move the disk image to a different location. If you attempt to move a disk image to a location that already has one, you get a prompt asking if you want to use the existing image or replace it.
File sharing
Note
The File sharing tab is only available in Hyper-V mode, because in WSL 2 mode and Windows container mode all files are automatically shared by Windows.
Use File sharing to allow local directories on Windows to be shared with Linux containers.This is especially useful forediting source code in an IDE on the host while running and testing the code in a container.Note that configuring file sharing is not necessary for Windows containers, only Linux containers. If a directory is not shared with a Linux container you may get file not found or cannot start service errors at runtime. See Volume mounting requires shared folders for Linux containers.
File share settings are:
Add a Directory: Click + and navigate to the directory you want to add.
Apply & Restart makes the directory available to containers using Docker’sbind mount (-v) feature.
Tips on shared folders, permissions, and volume mounts
Share only the directories that you need with the container. File sharing introduces overhead as any changes to the files on the host need to be notified to the Linux VM. Sharing too many files can lead to high CPU load and slow filesystem performance.
Shared folders are designed to allow application code to be edited on the host while being executed in containers. For non-code items such as cache directories or databases, the performance will be much better if they are stored in the Linux VM, using a data volume (named volume) or data container.
Docker Desktop sets permissions to read/write/execute for users, groups and others 0777 or a+rwx.This is not configurable. See Permissions errors on data directories for shared volumes.
Windows presents a case-insensitive view of the filesystem to applications while Linux is case-sensitive. On Linux it is possible to create 2 separate files: test and Test, while on Windows these filenames would actually refer to the same underlying file. This can lead to problems where an app works correctly on a developer Windows machine (where the file contents are shared) but fails when run in Linux in production (where the file contents are distinct). To avoid this, Docker Desktop insists that all shared files are accessed as their original case. Therefore if a file is created called test, it must be opened as test. Attempts to open Test will fail with “No such file or directory”. Similarly once a file called test is created, attempts to create a second file called Test will fail.
Shared folders on demand
You can share a folder “on demand” the first time a particular folder is used by a container.
If you run a Docker command from a shell with a volume mount (as shown in theexample below) or kick off a Compose file that includes volume mounts, you get apopup asking if you want to share the specified folder.
You can select to Share it, in which case it is added your Docker Desktop Shared Folders list and available tocontainers. Alternatively, you can opt not to share it by selecting Cancel.
Proxies
Docker Desktop lets you configure HTTP/HTTPS Proxy Settings andautomatically propagates these to Docker. For example, if you set your proxysettings to http://proxy.example.com, Docker uses this proxy when pulling containers.
Your proxy settings, however, will not be propagated into the containers you start.If you wish to set the proxy settings for your containers, you need to defineenvironment variables for them, just like you would do on Linux, for example:
For more information on setting environment variables for running containers,see Set environment variables.
Network
Note
The Network tab is not available in Windows container mode because networking is managed by Windows. Install ipsw macos catalina installer.
You can configure Docker Desktop networking to work on a virtual private network (VPN). Specify a network address translation (NAT) prefix and subnet mask to enable Internet connectivity.
DNS Server: You can configure the DNS server to use dynamic or static IP addressing.
Note
Some users reported problems connecting to Docker Hub on Docker Desktop. This would manifest as an error when trying to rundocker commands that pull images from Docker Hub that are not alreadydownloaded, such as a first time run of docker run hello-world. If youencounter this, reset the DNS server to use the Google DNS fixed address:8.8.8.8. For more information, seeNetworking issues in Troubleshooting.
Updating these settings requires a reconfiguration and reboot of the Linux VM.
WSL Integration
In WSL 2 mode, you can configure which WSL 2 distributions will have the Docker WSL integration.
By default, the integration will be enabled on your default WSL distribution. To change your default WSL distro, run wsl --set-default <distro name>. (For example, to set Ubuntu as your default WSL distro, run wsl --set-default ubuntu).
You can also select any additional distributions you would like to enable the WSL 2 integration on.
For more details on configuring Docker Desktop to use WSL 2, see Docker Desktop WSL 2 backend.
Docker Engine
The Docker Engine page allows you to configure the Docker daemon to determine how your containers run.
Type a JSON configuration file in the box to configure the daemon settings. For a full list of options, see the Docker Enginedockerd commandline reference.
Click Apply & Restart to save your settings and restart Docker Desktop.
Command Line
On the Command Line page, you can specify whether or not to enable experimental features.
You can toggle the experimental features on and off in Docker Desktop. If you toggle the experimental features off, Docker Desktop uses the current generally available release of Docker Engine.
Experimental features
Experimental features provide early access to future product functionality.These features are intended for testing and feedback only as they may changebetween releases without warning or can be removed entirely from a futurerelease. Experimental features must not be used in production environments.Docker does not offer support for experimental features.
For a list of current experimental features in the Docker CLI, see Docker CLI Experimental features.
Run docker version to verify whether you have enabled experimental features. Experimental modeis listed under Server data. If Experimental is true, then Docker isrunning in experimental mode, as shown here:
Kubernetes
Note
The Kubernetes tab is not available in Windows container mode.
Docker Desktop includes a standalone Kubernetes server that runs on your Windows machince, sothat you can test deploying your Docker workloads on Kubernetes. To enable Kubernetes support and install a standalone instance of Kubernetes running as a Docker container, select Enable Kubernetes.
For more information about using the Kubernetes integration with Docker Desktop, see Deploy on Kubernetes.
Reset
The Restart Docker Desktop and Reset to factory defaults options are now available on the Troubleshoot menu. For information, see Logs and Troubleshooting.
Troubleshoot
Visit our Logs and Troubleshooting guide for more details.
Log on to our Docker Desktop for Windows forum to get help from the community, review current user topics, or join a discussion.
Log on to Docker Desktop for Windows issues on GitHub to report bugs or problems and review community reported issues.
For information about providing feedback on the documentation or update it yourself, see Contribute to documentation.
Switch between Windows and Linux containers
From the Docker Desktop menu, you can toggle which daemon (Linux or Windows)the Docker CLI talks to. Select Switch to Windows containers to use Windowscontainers, or select Switch to Linux containers to use Linux containers(the default).
For more information on Windows containers, refer to the following documentation:
Microsoft documentation on Windows containers.
Build and Run Your First Windows Server Container (Blog Post)gives a quick tour of how to build and run native Docker Windows containers on Windows 10 and Windows Server 2016 evaluation releases.
Getting Started with Windows Containers (Lab)shows you how to use the MusicStoreapplication with Windows containers. The MusicStore is a standard .NET application and,forked here to use containers, is a good example of a multi-container application.
To understand how to connect to Windows containers from the local host, seeLimitations of Windows containers for localhost and published ports
Settings dialog changes with Windows containers
When you switch to Windows containers, the Settings dialog only shows those tabs that are active and apply to your Windows containers:
If you set proxies or daemon configuration in Windows containers mode, theseapply only on Windows containers. If you switch back to Linux containers,proxies and daemon configurations return to what you had set for Linuxcontainers. Your Windows container settings are retained and become availableagain when you switch back.
Dashboard
The Docker Desktop Dashboard enables you to interact with containers and applications and manage the lifecycle of your applications directly from your machine. The Dashboard UI shows all running, stopped, and started containers with their state. It provides an intuitive interface to perform common actions to inspect and manage containers and Docker Compose applications. For more information, see Docker Desktop Dashboard.
Docker Hub
Select Sign in /Create Docker ID from the Docker Desktop menu to access your Docker Hub account. Once logged in, you can access your Docker Hub repositories directly from the Docker Desktop menu.
For more information, refer to the following Docker Hub topics:
Two-factor authentication
Docker Desktop enables you to sign into Docker Hub using two-factor authentication. Two-factor authentication provides an extra layer of security when accessing your Docker Hub account.
You must enable two-factor authentication in Docker Hub before signing into your Docker Hub account through Docker Desktop. For instructions, see Enable two-factor authentication for Docker Hub.

After you have enabled two-factor authentication:
Go to the Docker Desktop menu and then select Sign in / Create Docker ID.
Enter your Docker ID and password and click Sign in.
After you have successfully signed in, Docker Desktop prompts you to enter the authentication code. Enter the six-digit code from your phone and then click Verify.
After you have successfully authenticated, you can access your organizations and repositories directly from the Docker Desktop menu.
Adding TLS certificates
You can add trusted Certificate Authorities (CAs) to your Docker daemon to verify registry server certificates, and client certificates, to authenticate to registries.
How do I add custom CA certificates?
Docker Desktop supports all trusted Certificate Authorities (CAs) (root orintermediate). Docker recognizes certs stored under Trust RootCertification Authorities or Intermediate Certification Authorities.
Docker Desktop creates a certificate bundle of all user-trusted CAs based onthe Windows certificate store, and appends it to Moby trusted certificates. Therefore, if an enterprise SSL certificate is trusted by the user on the host, it is trusted by Docker Desktop.
To learn more about how to install a CA root certificate for the registry, seeVerify repository client with certificatesin the Docker Engine topics.
How do I add client certificates?
You can add your client certificatesin ~/.docker/certs.d/<MyRegistry>:<Port>/client.cert and~/.docker/certs.d/<MyRegistry>:<Port>/client.key. You do not need to push your certificates with git commands.
When the Docker Desktop application starts, it copies the~/.docker/certs.d folder on your Windows system to the /etc/docker/certs.ddirectory on Moby (the Docker Desktop virtual machine running on Hyper-V).
You need to restart Docker Desktop after making any changes to the keychainor to the ~/.docker/certs.d directory in order for the changes to take effect.
The registry cannot be listed as an insecure registry (seeDocker Daemon). Docker Desktop ignorescertificates listed under insecure registries, and does not send clientcertificates. Commands like docker run that attempt to pull from the registryproduce error messages on the command line, as well as on the registry.
Docker Ruby On Rails Bundle Install
To learn more about how to set the client TLS certificate for verification, seeVerify repository client with certificatesin the Docker Engine topics.
Where to go next
Try out the walkthrough at Get Started.
Dig in deeper with Docker Labs example walkthroughs and source code.
Refer to the Docker CLI Reference Guide.
Docker Bundle Install Not Working
windows, edge, tutorial, run, docker, local, machine
0 notes
Text
Webserver For Mac

Apache Web Server For Mac
Web Server For Microsoft Edge
Web Server For Mac Os X
Free Web Server For Mac
Web Server For Mac
Are you in need of a web server software for your projects? Looking for something with outstanding performance that suits your prerequisites? A web server is a software program which serves content (HTML documents, images, and other web resources) using the HTTP protocol. It will support both static content and dynamic content. Check these eight top rated web server software and get to know about all its key features here before deciding which would suit your project.
Web server software is a kind of software which is developed to be utilized, controlled and handled on computing server. Web server software gives the exploitation of basic server computing cloud for application with a collection of high-end computing functions and services. This should fire up a webserver that listens on 10.0.1.1:8080 and serves files from the current directory ('.' ) – no PHP, ASP or any of that needed. Any suggestion greatly appreciated. Macos http unix webserver.
Related:
Apache
The Apache HTTP web Server Project is a push to create and keep up an open-source HTTP server for current working frameworks including UNIX and Windows. The objective of this anticipate is to give a safe, effective and extensible server that gives HTTP administrations in a state of harmony with the present HTTP benchmarks.
Virgo Web Server
The Virgo Web Server is the runtime segment of the Virgo Runtime Environment. It is a lightweight, measured, OSGi-based runtime that gives a complete bundled answer for creating, sending, and overseeing venture applications. By utilizing a few best-of-breed advances and enhancing them, the VWS offers a convincing answer for creating and convey endeavor applications.
Abyss Web Server
Abyss Web Server empowers you to have your Web destinations on your PC. It bolsters secure SSL/TLS associations (HTTPS) and in addition an extensive variety of Web innovations. It can likewise run progressed PHP, Perl, Python, ASP, ASP.NET, and Ruby on Rails Web applications which can be sponsored by databases, for example, MySQL, SQLite, MS SQL Server, MS Access, or Oracle.
Cherokee Web Server
All the arrangement is done through Cherokee-Admin, an excellent and effective web interface. Cherokee underpins the most across the board Web innovations: FastCGI, SCGI, PHP, uWSGI, SSI, CGI, LDAP, TLS/SSL, HTTP proxying, video gushing, the content storing, activity forming, and so on. It underpins cross Platform and keeps running on Linux, Mac OS X, and then some more.
Raiden HTTP
RaidenHTTPD is a completely included web server programming for Windows stage. It’s intended for everyone, whether novice or master, who needs to have an intuitive web page running inside minutes. With RaidenHTTPD, everybody can be a web page performer starting now and into the foreseeable future! Having a web page made with RaidenHTTPD, you won’t be surprised to see a great many guests to your web website consistently or considerably more
KF Web Server
KF Web Server is a free HTTP Server that can have a boundless number of websites. Its little size, low framework necessities, and simple organization settle on it the ideal decision for both expert and beginner web designers alike.
Tornado Web Server
Tornado is a Python web structure and offbeat systems administration library, initially created at FriendFeed. By utilizing non-blocking system I/O, Tornado can scale to a huge number of open associations, making it perfect for long surveying, WebSockets, and different applications that require a seemingly perpetual association with every client.
WampServer – Most Popular Software
This is the most mainstream web server amongst all the others. WampServer is a Windows web improvement environment. It permits you to make web applications with Apache2, PHP, and a MySQL database. Nearby, PhpMyAdmin permits you to oversee effortlessly your databases. WampServer is accessible for nothing (under GPML permit) in two particular adaptations that is, 32 and 64 bits.
What is a Web Server?
A Web Server is a PC framework that works by means of HTTP, the system used to disseminate data on the Web. The term can refer to the framework, or to any product particularly that acknowledges and administers the HTTP requests. A web server, in some cases, called an HTTP server or application server is a system that serves content utilizing the HTTP convention. You can also see Log Analyser Software
This substance is often as HTML reports, pictures, and other web assets, however, can incorporate any kind of record. The substance served by the web server can be prior known as a static substance or created on the fly that is alterable content. In a request to be viewed as a web server, an application must actualize the HTTP convention. Applications based on top of web servers. You can also see Proxy Server Software
Therefore, these 8 web servers are very powerful and makes the customer really satisfactory when used in their applications. Try them out and have fun programming!
Related Posts
16 13 likes 31,605 views Last modified Jan 31, 2019 11:25 AM
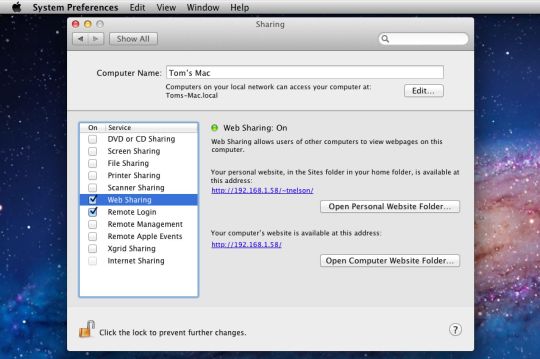
Here is my definitive guide to getting a local web server running on OS X 10.14 “Mojave”. This is meant to be a development platform so that you can build and test your sites locally, then deploy to an internet server. This User Tip only contains instructions for configuring the Apache server, PHP module, and Perl module. I have another User Tip for installing and configuring MySQL and email servers.
Note: This user tip is specific to macOS 10.14 “Mojave”. Pay attention to your OS version. There have been significant changes since earlier versions of macOS.Another note: These instructions apply to the client versions of OS X, not Server. Server does a few specific tricks really well and is a good choice for those. For things like database, web, and mail services, I have found it easier to just setup the client OS version manually.
Requirements:
Basic understanding of Terminal.app and how to run command-line programs.
Basic understanding of web servers.
Basic usage of vi. You can substitute nano if you want.
Optional: Xcode is required for adding PHP modules.
Lines in bold are what you will have to type in. Lines in bold courier should be typed at the Terminal.Replace <your short user name> with your short user name.
Here goes... Enjoy!
To get started, edit the Apache configuration file as root:
sudo vi /etc/apache2/httpd.conf
Enable PHP by uncommenting line 177, changing:
#LoadModule php7_module libexec/apache2/libphp7.so
to
LoadModule php7_module libexec/apache2/libphp7.so
(If you aren't familiar with vi, go to line 177 by typing '177G' (without the quotes). Then just press 'x' over the '#' character to delete it. Then type ':w!' to save, or just 'ZZ' to save and quit. Don't do that yet though. More changes are still needed.)
If you want to run Perl scripts, you will have to do something similar:
Enable Perl by uncommenting line 178, changing:
#LoadModule perl_module libexec/apache2/mod_perl.so
to
LoadModule perl_module libexec/apache2/mod_perl.so
Enable personal websites by uncommenting the following at line 174:
#LoadModule userdir_module libexec/apache2/mod_userdir.so
to
LoadModule userdir_module libexec/apache2/mod_userdir.so
and do the same at line 511:
#Include /private/etc/apache2/extra/httpd-userdir.conf
to
Apache Web Server For Mac
Include /private/etc/apache2/extra/httpd-userdir.conf
Now save and quit.
Open the file you just enabled above with:
sudo vi /etc/apache2/extra/httpd-userdir.conf
and uncomment the following at line 16:
#Include /private/etc/apache2/users/*.conf
to
Include /private/etc/apache2/users/*.conf
Save and exit.
Lion and later versions no longer create personal web sites by default. If you already had a Sites folder in Snow Leopard, it should still be there. To create one manually, enter the following:
mkdir ~/Sites
echo '<html><body><h1>My site works</h1></body></html>' > ~/Sites/index.html.en
While you are in /etc/apache2, double-check to make sure you have a user config file. It should exist at the path: /etc/apache2/users/<your short user name>.conf.
That file may not exist and if you upgrade from an older version, you may still not have it. It does appear to be created when you create a new user. If that file doesn't exist, you will need to create it with:
sudo vi /etc/apache2/users/<your short user name>.conf
Use the following as the content:
<Directory '/Users/<your short user name>/Sites/'>
AddLanguage en .en
AddHandler perl-script .pl
PerlHandler ModPerl::Registry
Options Indexes MultiViews FollowSymLinks ExecCGI
AllowOverride None
Require host localhost
</Directory>
Now you are ready to turn on Apache itself. But first, do a sanity check. Sometimes copying and pasting from an internet forum can insert invisible, invalid characters into config files. Check your configuration by running the following command in the Terminal:
apachectl configtest
If this command returns 'Syntax OK' then you are ready to go. It may also print a warning saying 'httpd: Could not reliably determine the server's fully qualified domain name'. You could fix this by setting the ServerName directive in /etc/apache2/httpd.conf and adding a matching entry into /etc/hosts. But for a development server, you don't need to do anything. You can just ignore that warning. You can safely ignore other warnings too.
Turn on the Apache httpd service by running the following command in the Terminal:
sudo launchctl load -w /System/Library/LaunchDaemons/org.apache.httpd.plist
In Safari, navigate to your web site with the following address:
http://localhost/
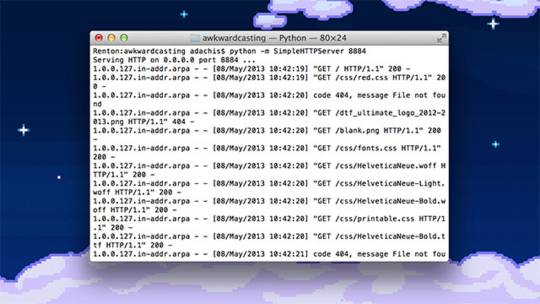
It should say:
It works!
Now try your user home directory:
http://localhost/~<your short user name>
Web Server For Microsoft Edge
It should say:
My site works
Web Server For Mac Os X
Now try PHP. Create a PHP info file with:
echo '<?php echo phpinfo(); ?>' > ~/Sites/info.php
And test it by entering the following into Safari's address bar:
http://localhost/~<your short user name>/info.php
You should see your PHP configuration information.
To test Perl, try something similar. Create a Perl test file with:
echo 'print $ENV(MOD_PERL) . qq(n);' > ~/Sites/info.pl
And test it by entering the following into Safari's address bar:
http://localhost/~<your short user name>/info.pl
Free Web Server For Mac
You should see the string 'mod_perl/2.0.9'.
If you want to setup MySQL, see my User Tip on Installing MySQL.
Web Server For Mac
If you want to add modules to PHP, I suggest the following site. I can't explain it any better.
If you want to make further changes to your Apache system or user config files, you will need to restart the Apache server with:
sudo apachectl graceful
0 notes
Text
Going Jamstack with React, Serverless, and Airtable
The best way to learn is to build. Let’s learn about this hot new buzzword, Jamstack, by building a site with React, Netlify (Serverless) Functions, and Airtable. One of the ingredients of Jamstack is static hosting, but that doesn’t mean everything on the site has to be static. In fact, we’re going to build an app with full-on CRUD capability, just like a tutorial for any web technology with more traditional server-side access might.
youtube
Why these technologies, you ask?
You might already know this, but the “JAM” in Jamstack stands for JavaScript, APIs, and Markup. These technologies individually are not new, so the Jamstack is really just a new and creative way to combine them. You can read more about it over at the Jamstack site.
One of the most important benefits of Jamstack is ease of deployment and hosting, which heavily influence the technologies we are using. By incorporating Netlify Functions (for backend CRUD operations with Airtable), we will be able to deploy our full-stack application to Netlify. The simplicity of this process is the beauty of the Jamstack.
As far as the database, I chose Airtable because I wanted something that was easy to get started with. I also didn’t want to get bogged down in technical database details, so Airtable fits perfectly. Here’s a few of the benefits of Airtable:
You don’t have to deploy or host a database yourself
It comes with an Excel-like GUI for viewing and editing data
There’s a nice JavaScript SDK
What we’re building
For context going forward, we are going to build an app where you can use to track online courses that you want to take. Personally, I take lots of online courses, and sometimes it’s hard to keep up with the ones in my backlog. This app will let track those courses, similar to a Netflix queue.

Source Code
One of the reasons I take lots of online courses is because I make courses. In fact, I have a new one available where you can learn how to build secure and production-ready Jamstack applications using React and Netlify (Serverless) Functions. We’ll cover authentication, data storage in Airtable, Styled Components, Continuous Integration with Netlify, and more! Check it out →
Airtable setup
Let me start by clarifying that Airtable calls their databases “bases.” So, to get started with Airtable, we’ll need to do a couple of things.
Sign up for a free account
Create a new “base”
Define a new table for storing courses
Next, let’s create a new database. We’ll log into Airtable, click on “Add a Base” and choose the “Start From Scratch” option. I named my new base “JAMstack Demos” so that I can use it for different projects in the future.

Next, let’s click on the base to open it.

You’ll notice that this looks very similar to an Excel or Google Sheets document. This is really nice for being able tower with data right inside of the dashboard. There are few columns already created, but we add our own. Here are the columns we need and their types:
name (single line text)
link (single line text)
tags (multiple select)
purchased (checkbox)
We should add a few tags to the tags column while we’re at it. I added “node,” “react,” “jamstack,” and “javascript” as a start. Feel free to add any tags that make sense for the types of classes you might be interested in.
I also added a few rows of data in the name column based on my favorite online courses:
Build 20 React Apps
Advanced React Security Patterns
React and Serverless
The last thing to do is rename the table itself. It’s called “Table 1” by default. I renamed it to “courses” instead.
Locating Airtable credentials
Before we get into writing code, there are a couple of pieces of information we need to get from Airtable. The first is your API Key. The easiest way to get this is to go your account page and look in the “Overview” section.
Next, we need the ID of the base we just created. I would recommend heading to the Airtable API page because you’ll see a list of your bases. Click on the base you just created, and you should see the base ID listed. The documentation for the Airtable API is really handy and has more detailed instructions for find the ID of a base.
Lastly, we need the table’s name. Again, I named mine “courses” but use whatever you named yours if it’s different.
Project setup
To help speed things along, I’ve created a starter project for us in the main repository. You’ll need to do a few things to follow along from here:
Fork the repository by clicking the fork button
Clone the new repository locally
Check out the starter branch with git checkout starter
There are lots of files already there. The majority of the files come from a standard create-react-app application with a few exceptions. There is also a functions directory which will host all of our serverless functions. Lastly, there’s a netlify.toml configuration file that tells Netlify where our serverless functions live. Also in this config is a redirect that simplifies the path we use to call our functions. More on this soon.
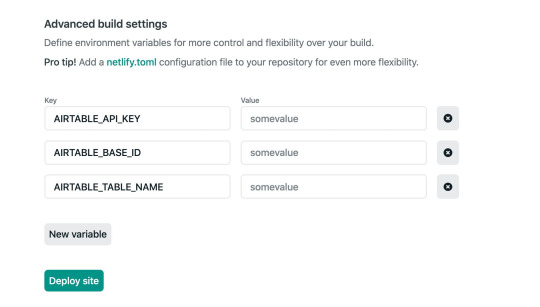
The last piece of the setup is to incorporate environment variables that we can use in our serverless functions. To do this install the dotenv package.
npm install dotenv
Then, create a .env file in the root of the repository with the following. Make sure to use your own API key, base ID, and table name that you found earlier.
AIRTABLE_API_KEY=<YOUR_API_KEY> AIRTABLE_BASE_ID=<YOUR_BASE_ID> AIRTABLE_TABLE_NAME=<YOUR_TABLE_NAME>
Now let’s write some code!
Setting up serverless functions
To create serverless functions with Netlify, we need to create a JavaScript file inside of our /functions directory. There are already some files included in this starter directory. Let’s look in the courses.js file first.
const formattedReturn = require('./formattedReturn'); const getCourses = require('./getCourses'); const createCourse = require('./createCourse'); const deleteCourse = require('./deleteCourse'); const updateCourse = require('./updateCourse'); exports.handler = async (event) => { return formattedReturn(200, 'Hello World'); };
The core part of a serverless function is the exports.handler function. This is where we handle the incoming request and respond to it. In this case, we are accepting an event parameter which we will use in just a moment.
We are returning a call inside the handler to the formattedReturn function, which makes it a bit simpler to return a status and body data. Here’s what that function looks like for reference.
module.exports = (statusCode, body) => { return { statusCode, body: JSON.stringify(body), }; };
Notice also that we are importing several helper functions to handle the interaction with Airtable. We can decide which one of these to call based on the HTTP method of the incoming request.
HTTP GET → getCourses
HTTP POST → createCourse
HTTP PUT → updateCourse
HTTP DELETE → deleteCourse
Let’s update this function to call the appropriate helper function based on the HTTP method in the event parameter. If the request doesn’t match one of the methods we are expecting, we can return a 405 status code (method not allowed).
exports.handler = async (event) => { if (event.httpMethod === 'GET') { return await getCourses(event); } else if (event.httpMethod === 'POST') { return await createCourse(event); } else if (event.httpMethod === 'PUT') { return await updateCourse(event); } else if (event.httpMethod === 'DELETE') { return await deleteCourse(event); } else { return formattedReturn(405, {}); } };
Updating the Airtable configuration file
Since we are going to be interacting with Airtable in each of the different helper files, let’s configure it once and reuse it. Open the airtable.js file.
In this file, we want to get a reference to the courses table we created earlier. To do that, we create a reference to our Airtable base using the API key and the base ID. Then, we use the base to get a reference to the table and export it.
require('dotenv').config(); var Airtable = require('airtable'); var base = new Airtable({ apiKey: process.env.AIRTABLE_API_KEY }).base( process.env.AIRTABLE_BASE_ID ); const table = base(process.env.AIRTABLE_TABLE_NAME); module.exports = { table };
Getting courses
With the Airtable config in place, we can now open up the getCourses.js file and retrieve courses from our table by calling table.select().firstPage(). The Airtable API uses pagination so, in this case, we are specifying that we want the first page of records (which is 20 records by default).
const courses = await table.select().firstPage(); return formattedReturn(200, courses);
Just like with any async/await call, we need to handle errors. Let’s surround this snippet with a try/catch.
try { const courses = await table.select().firstPage(); return formattedReturn(200, courses); } catch (err) { console.error(err); return formattedReturn(500, {}); }
Airtable returns back a lot of extra information in its records. I prefer to simplify these records with only the record ID and the values for each of the table columns we created above. These values are found in the fields property. To do this, I used the an Array map to format the data the way I want.
const { table } = require('./airtable'); const formattedReturn = require('./formattedReturn'); module.exports = async (event) => { try { const courses = await table.select().firstPage(); const formattedCourses = courses.map((course) => ({ id: course.id, ...course.fields, })); return formattedReturn(200, formattedCourses); } catch (err) { console.error(err); return formattedReturn(500, {}); } };
How do we test this out? Well, the netlify-cli provides us a netlify dev command to run our serverless functions (and our front-end) locally. First, install the CLI:
npm install -g netlify-cli
Then, run the netlify dev command inside of the directory.
This beautiful command does a few things for us:
Runs the serverless functions
Runs a web server for your site
Creates a proxy for front end and serverless functions to talk to each other on Port 8888.
Let’s open up the following URL to see if this works:
We are able to use /api/* for our API because of the redirect configuration in the netlify.toml file.
If successful, we should see our data displayed in the browser.

Creating courses
Let’s add the functionality to create a course by opening up the createCourse.js file. We need to grab the properties from the incoming POST body and use them to create a new record by calling table.create().
The incoming event.body comes in a regular string which means we need to parse it to get a JavaScript object.
const fields = JSON.parse(event.body);
Then, we use those fields to create a new course. Notice that the create() function accepts an array which allows us to create multiple records at once.
const createdCourse = await table.create([{ fields }]);
Then, we can return the createdCourse:
return formattedReturn(200, createdCourse);
And, of course, we should wrap things with a try/catch:
const { table } = require('./airtable'); const formattedReturn = require('./formattedReturn'); module.exports = async (event) => { const fields = JSON.parse(event.body); try { const createdCourse = await table.create([{ fields }]); return formattedReturn(200, createdCourse); } catch (err) { console.error(err); return formattedReturn(500, {}); } };
Since we can’t perform a POST, PUT, or DELETE directly in the browser web address (like we did for the GET), we need to use a separate tool for testing our endpoints from now on. I prefer Postman, but I’ve heard good things about Insomnia as well.
Inside of Postman, I need the following configuration.
url: localhost:8888/api/courses
method: POST
body: JSON object with name, link, and tags
After running the request, we should see the new course record is returned.

We can also check the Airtable GUI to see the new record.

Tip: Copy and paste the ID from the new record to use in the next two functions.
Updating courses
Now, let’s turn to updating an existing course. From the incoming request body, we need the id of the record as well as the other field values.
We can specifically grab the id value using object destructuring, like so:
const {id} = JSON.parse(event.body);
Then, we can use the spread operator to grab the rest of the values and assign it to a variable called fields:
const {id, ...fields} = JSON.parse(event.body);
From there, we call the update() function which takes an array of objects (each with an id and fields property) to be updated:
const updatedCourse = await table.update([{id, fields}]);
Here’s the full file with all that together:
const { table } = require('./airtable'); const formattedReturn = require('./formattedReturn'); module.exports = async (event) => { const { id, ...fields } = JSON.parse(event.body); try { const updatedCourse = await table.update([{ id, fields }]); return formattedReturn(200, updatedCourse); } catch (err) { console.error(err); return formattedReturn(500, {}); } };
To test this out, we’ll turn back to Postman for the PUT request:
url: localhost:8888/api/courses
method: PUT
body: JSON object with id (the id from the course we just created) and the fields we want to update (name, link, and tags)
I decided to append “Updated!!!” to the name of a course once it’s been updated.

We can also see the change in the Airtable GUI.
Deleting courses
Lastly, we need to add delete functionality. Open the deleteCourse.js file. We will need to get the id from the request body and use it to call the destroy() function.
const { id } = JSON.parse(event.body); const deletedCourse = await table.destroy(id);
The final file looks like this:
const { table } = require('./airtable'); const formattedReturn = require('./formattedReturn'); module.exports = async (event) => { const { id } = JSON.parse(event.body); try { const deletedCourse = await table.destroy(id); return formattedReturn(200, deletedCourse); } catch (err) { console.error(err); return formattedReturn(500, {}); } };
Here’s the configuration for the Delete request in Postman.
url: localhost:8888/api/courses
method: PUT
body: JSON object with an id (the same id from the course we just updated)

And, of course, we can double-check that the record was removed by looking at the Airtable GUI.
Displaying a list of courses in React
Whew, we have built our entire back end! Now, let’s move on to the front end. The majority of the code is already written. We just need to write the parts that interact with our serverless functions. Let’s start by displaying a list of courses.
Open the App.js file and find the loadCourses function. Inside, we need to make a call to our serverless function to retrieve the list of courses. For this app, we are going to make an HTTP request using fetch, which is built right in.
Thanks to the netlify dev command, we can make our request using a relative path to the endpoint. The beautiful thing is that this means we don’t need to make any changes after deploying our application!
const res = await fetch('/api/courses'); const courses = await res.json();
Then, store the list of courses in the courses state variable.
setCourses(courses)
Put it all together and wrap it with a try/catch:
const loadCourses = async () => { try { const res = await fetch('/api/courses'); const courses = await res.json(); setCourses(courses); } catch (error) { console.error(error); } };
Open up localhost:8888 in the browser and we should our list of courses.

Adding courses in React
Now that we have the ability to view our courses, we need the functionality to create new courses. Open up the CourseForm.js file and look for the submitCourse function. Here, we’ll need to make a POST request to the API and send the inputs from the form in the body.
The JavaScript Fetch API makes GET requests by default, so to send a POST, we need to pass a configuration object with the request. This options object will have these two properties.
method → POST
body → a stringified version of the input data
await fetch('/api/courses', { method: 'POST', body: JSON.stringify({ name, link, tags, }), });
Then, surround the call with try/catch and the entire function looks like this:
const submitCourse = async (e) => { e.preventDefault(); try { await fetch('/api/courses', { method: 'POST', body: JSON.stringify({ name, link, tags, }), }); resetForm(); courseAdded(); } catch (err) { console.error(err); } };
Test this out in the browser. Fill in the form and submit it.

After submitting the form, the form should be reset, and the list of courses should update with the newly added course.
Updating purchased courses in React
The list of courses is split into two different sections: one with courses that have been purchased and one with courses that haven’t been purchased. We can add the functionality to mark a course “purchased” so it appears in the right section. To do this, we’ll send a PUT request to the API.
Open the Course.js file and look for the markCoursePurchased function. In here, we’ll make the PUT request and include both the id of the course as well as the properties of the course with the purchased property set to true. We can do this by passing in all of the properties of the course with the spread operator and then overriding the purchased property to be true.
const markCoursePurchased = async () => { try { await fetch('/api/courses', { method: 'PUT', body: JSON.stringify({ ...course, purchased: true }), }); refreshCourses(); } catch (err) { console.error(err); } };
To test this out, click the button to mark one of the courses as purchased and the list of courses should update to display the course in the purchased section.

Deleting courses in React
And, following with our CRUD model, we will add the ability to delete courses. To do this, locate the deleteCourse function in the Course.js file we just edited. We will need to make a DELETE request to the API and pass along the id of the course we want to delete.
const deleteCourse = async () => { try { await fetch('/api/courses', { method: 'DELETE', body: JSON.stringify({ id: course.id }), }); refreshCourses(); } catch (err) { console.error(err); } };
To test this out, click the “Delete” button next to the course and the course should disappear from the list. We can also verify it is gone completely by checking the Airtable dashboard.
Deploying to Netlify
Now, that we have all of the CRUD functionality we need on the front and back end, it’s time to deploy this thing to Netlify. Hopefully, you’re as excited as I am about now easy this is. Just make sure everything is pushed up to GitHub before we move into deployment.
If you don’t have a Netlify, account, you’ll need to create one (like Airtable, it’s free). Then, in the dashboard, click the “New site from Git” option. Select GitHub, authenticate it, then select the project repo.

Next, we need to tell Netlify which branch to deploy from. We have two options here.
Use the starter branch that we’ve been working in
Choose the master branch with the final version of the code
For now, I would choose the starter branch to ensure that the code works. Then, we need to choose a command that builds the app and the publish directory that serves it.
Build command: npm run build
Publish directory: build
Netlify recently shipped an update that treats React warnings as errors during the build proces. which may cause the build to fail. I have updated the build command to CI = npm run build to account for this.

Lastly, click on the “Show Advanced” button, and add the environment variables. These should be exactly as they were in the local .env that we created.
The site should automatically start building.

We can click on the “Deploys” tab in Netlify tab and track the build progress, although it does go pretty fast. When it is complete, our shiny new app is deployed for the world can see!

Welcome to the Jamstack!
The Jamstack is a fun new place to be. I love it because it makes building and hosting fully-functional, full-stack applications like this pretty trivial. I love that Jamstack makes us mighty, all-powerful front-end developers!
I hope you see the same power and ease with the combination of technology we used here. Again, Jamstack doesn’t require that we use Airtable, React or Netlify, but we can, and they’re all freely available and easy to set up. Check out Chris’ serverless site for a whole slew of other services, resources, and ideas for working in the Jamstack. And feel free to drop questions and feedback in the comments here!
The post Going Jamstack with React, Serverless, and Airtable appeared first on CSS-Tricks.
You can support CSS-Tricks by being an MVP Supporter.
Going Jamstack with React, Serverless, and Airtable published first on https://deskbysnafu.tumblr.com/
0 notes
Text
Post Production Editing Timelapse
OpenDrives is the first to admit that expensive all-flash drive technology is not always the best solution for higher resolution, large capacity workflows. There are ways to ensure that a film’s sound is diligently handled, while working within a budget. This often comes from a transparent discussion at the onset of the project about a director’s expectations versus the reality of the budget/schedule.
What is pre and post production?
“That's a wrap!†When a movie director makes the call, cameras stop rolling, and a film is ready to move into its final phase: postproduction. This the final step in taking a story from script to screen, and the stage when a film comes to life.
A lot has to happen between the time when the director yells “cut†and the editors begin their work. Raw video also takes significantly more processing power in order to view, edit, or transcode. With a few exceptions, raw video is almost always much larger than non-raw video. That means more memory cards, more hard drives, and more time spent copying files.
Companies will hire runners who have experience in post, or wish to progress their career in this field. The hours will be long, and the list of task unrelenting, you need to wish to work in some aspect of post to get the most out of the junior roles.
Come see us at #NAB2019. Schedule a demo and when Strawberry knocks your socks off, we can help you out with our show goodie. We are co-exhibiting with #ToolsOnAir in the South Lower Hall SL14813. https://t.co/WSoJb3hJGR pic.twitter.com/mvqvilAIb7
— Projective Technology (@ProjectiveTech) April 1, 2019
The VFX editor will then create a proxy with the same codec that’s being used for the rest of editorial and drop it back into the sequence to make sure that it works as planned. When a VFX shot is completed and signed off on, the VFX house will render out the finished version of the shot to a high-quality Mezzanine codec or to an uncompressed format and send it back to the editorial team. Animatics – A group of storyboards laid out on a timeline to give a sense of pace and timing. Helpful in lengthier sequences, they allow the editor to work with music or voice-over to help create the flow of the sequence(s) prior to commencing computer animation.
Fortunately, plenty of marketers and production managers have already gone through the steps and learned from their mistakes. That's why we decided to put together a list of 20 video pre-production tips that'll help save you a lot of time, money, and hassle. He is also editor-in-chief of the GatherContent blog, a go-to resource on a range of content strategy topics. Rob is a journalism graduate, ex-BBC audience researcher, and former head of content and project manager at a branding and design agency. Online collaboration tools, like Trello, can help teams track their workflows, possibly using a built-in calendar to give a graphical view of the editorial calendar.
Is editing post production?
In the industry of film, videography, and photography, post production editing, or simply post-production, is the third and final step in creating a film. It follows pre-production and production and refers to the work, usually editing, that needs to be completed after shooting the film.
In addition to using a structure map similarly to how you would use a wall of index cards to track your story, you can also use it as a way to track your editorial progress through your first cut using colored labels.
Joined by our primary VFX supervisor Ben Kadie, we developed a plan to address the impact of VFX on 100-plus shots in our film.
Any number of workspaces can be created and can be assigned to individuals or entire teams.
But you will have the ability to leave time-stamped feedback, which makes it much easier for video professionals to interpret and implement requested changes.
Since they are the final stage of production, they are under huge pressure to make deadlines on time. Therefore, this can be a very stressful job and many may have to work nights or weekends close to deadlines. If you work as a post producer, you may spend significant amounts of time working on the computer in a dark room.
XML is a much more flexible format, and so it’s possible to include much more data in an XML file than in an EDL file, but this actually creates another potential issue. Because XML is so flexible, it’s possible for different tools to create XML files in different ways. An XML exported from one piece of software is not guaranteed to work in another.
mediaCARD Densu X
What are the 8 elements of film?
Post-Production is the stage after production when the filming is wrapped and the editing of the visual and audio materials begins. Post-Production refers to all of the tasks associated with cutting raw footage, assembling that footage, adding music, dubbing, sound effects, just to name a few.
I understand that I will pay an additional $1.00 per month for bank processing fees included in the dues amounts in this application. I can at any project manager time resign from PPA and stop charges being made to my credit card. If PPA is unable to successfully process my monthly payment, my membership will be considered void, and I am required to pay the balance in full to reinstate my membership.
Top 5 Questions About Working in Post-Production
VEGAS Pro is non-linear, so you don’t have to edit your project in sequence from beginning to end. If you decide to work on scenes or sections separately, nested timelines make it simple to work on individual scenes and then bring your entire project together.
When working on your CV check it through (or ask someone else to) to see it reads well and is correctly formatted. Correct spelling and grammar are crucial; you have to stand out from the hundreds of other people applying for the role so silly errors will mean your CV automatically gets disregarded. Post-production companies are always looking for keen new entrants to take on the role of runner. If you look at the larger companies, the turnover of staff can be very high, not because people drop out but because progression can be quick for the right candidate. However, you should know if your dream job is working in production then working in post production isn’t for you.
Purchasers of the book can download Chapter 10:
Time Savers in the Title Tool. See page 2 of the book for details.
Going to IBC? Visit us at Hall 3 A.28 and see how Strawberry Skies will dramatically improve how media productions create and share media content! https://t.co/utOdCiSYAw pic.twitter.com/7x8FhVZ9GL
— Projective Technology (@ProjectiveTech) September 5, 2019
As with any project, having a workflow can help you manage resources effectively, invest your time efficiently, and keep different teams and individual contributors on task—even if you’re working remotely. Managing video production requires input from many different teams, creatives, and contributors—and that can get messy fast.
ACES aims to solve that problem by creating a single, standardized workflow that can work for everyone who really cares about preserving all of their image data through the entire image pipeline. StudioBinder is a film production software built out of Santa Monica, CA. Our mission is to make the production experience more streamlined, efficient, and pleasant.
0 notes
Text
Don't Down Play The Advantage of Advertising on Bing
If your keyword targeting isn't optimized, then you'll wish to do some keyword research to recognize and after that target the types of keywords that will maximize the clicks and conversions for your Bing text ads. Luckily, Bing has its own keyword research tool that you can access under the "Tools" menu from your Bing advertisements control panel.
From there, you can check out additional keywords that your competitors might be using (by browsing a destination URL) and develop from there. Any Search marketer can tell you that some keywords that can drag down the efficiency of your campaigns; specific searches may trigger your Bing ads yet provide no conversions or clicks.
Fortunately is that if you have actually brought over keyword targeting from Google, much of your negatives need to already be imported. If you desire to include additional unfavorable keywords at the campaign or ad group level, you can add them by picking Negative Keywords within the Keywords Tab from the Campaigns page.
This desktop application can help you navigate and handle all of your Bings efforts much faster than from an internet browser window. According to Bing , here's why you must be using Bing Advertisements Editor: Start quickly. Transfer your account information with Google Import straight into Bing Ads Editor. Work faster. Sync your projects and accounts, make modifications or additions offline, and then publish your revisions with one click.
Straight create projects, edit advertisements, and manage countless keywords at as soon as. Plus, efficiently manage URLs, advertisement copy, budget plans, quotes, targeting and ad extensions. Multiple-account management. Download multiple accounts at the same time, copy and paste from one account to another, and carry out several Google Imports all at once. Research new keywords and quotes.
You can download Bing Advertisements Editor for Windows or Mac here . Wish to learn more? Have A Look At our Q 4 guide on Bing Shopping Ads here. .
Bing Ads (previously Microsoft ad Center) has made great strides over the last couple years. I dislike to knock what is an otherwise advanced system, which has actually proven itself a quality marketing platform. Its greatest defect is that it just can't deliver enough traffic. However, the issues I have actually experienced with it recently ought to not be happening.
This is simply fantastic. I have an ad group that had a 640% CTR earlier today-- 32 clicks and 5 impressions. I have another ad group with a much better than 250% CTR. That's right, users love my advertisements so much they are hitting the back button and clicking the advertisement over and over again.
They inform me they have two automated click-detection systems. One checks and immediately eliminates bad clicks. The other one does a check prior to the customer is billed. I informed them anybody must understand this is fraudulent. They stated they could put in a ticket, however unless I provide them my customer's blogs, we might not get approved for turnarounds.
The only way to get 5 impressions and 32 clicks is for 1 or more users to click, counter, click, strike back-- a minimum of 7 or more times in a row. I can see the periodic impression getting a 200% click-through rate, however 640%?! That's transparent scams. I make certain the claim will be authorized, but the scams utilized the entire budget plan for that specific project that day.
Spam on Search Partners This is another form of "click fraud," and it has required me to opt-out all of my customers from appearing on Bing/Yahoo Browse Partners. We've gotten many phony leads and absurdly high conversion rates on several clients over the previous couple years. A long-time customer of mine in the monetary services arena gets spam monthly.
These are typically stemmed from an entire string of out-of-state IP's on different makers. I'm sure they're running proxies, masking IPs or whatever. The money typically winds up being credited back after an examination, but I have to start it. Somehow, Google Advertisement Words isn't having the exact same issue. I'm not getting a big number of fake conversions from their system.
In the meantime, none of my customers will be running on Bing search partners. Bidding without any Competitors Recently I found a quirk about Bing's bidding. Bing merely states you will pay just more than your next closest rival for a click, which is okay. I choose Ad Words Advertisement Rank auction system for improving quality in SERPS, however I don't have a real complaint about Bing's bid procedure.
If there is no competition, you will pay your Max CPC rather. I didn't realize this, and I discover it impressive. The only way to handle that, to get the best rates for a client, would be to have the search partners in a separate project with lower bids. A lot of marketing platforms realize that having lower CPCs encourages early adoption.
The competitors grows from that point as bidding increases to keep position. This is terrible, and it resembles opportunism. Missing Location? Advertisements Shown Worldwide Bing Advertisements has a fantastic import tool that enables an advertiser to pull ads, keywords, and campaigns from another source-- most frequently Google Ad Words.
Regrettably, it has a couple of quirks that do not work well. Aggravatingly, it doesn't eliminate old ads or keywords that have actually currently been erased out of Google, however it deals with practically whatever else. I can't truly grumble about that tiny little flaw, though PPC supervisors require to be familiar with it to avoid bidding on keywords you do not desire any longer.

If Bing Advertisements doesn't have the exact city from Google, or can't match it up properly, Microsoft will give the campaign no targeting at all. Reasoning would recommend the campaign should not run up until a geographical area is input, and it should trigger you with a caution. Logic does not use here, though.
0 notes
Text
How to install Nginx + php + MySQL on WSL Windows 10

Although Nginx is available for Windows 10/8/7, however, to really understand, experience, build or test web application around, I recommend to use it on Linux. And the Windows 10 WSL is the best option to run Linux+Nginx+PHP+MySQL stack to get a complete Linux based web server without really installing a separate Linux distro. Thus, let's see how to install Linux+Nginx+PHP+MySQL stack on Windows 10 WSL (Windows Subsystem for Linux). What is Nginx? Nginx (engine x) is a high-performance HTTP and reverse proxy web server that also provides IMAP/pop3/smtp services. It is distributed under a BSD-like agreement and characterized by less memory and strong concurrent power. Nginx can be compiled and run on most Unix & Linux os and has a Windows port too. In the case of high concurrency, Nginx is a good alternative to the Apache service: Nginx is one of the software platforms that bosses web hosting business supporting responses up to 50 000 concurrent connections thanks to Nginx for choosing Epoll and Kqueue as the development model. The Nginx code is written entirely from the c language and has been ported to many architectures and operating systems including Linux, FreeBSD, Solaris, mac os x, AIX and Microsoft windows. Nginx has its own library of functions, and in addition to zlib, PCRE, and OpenSSL, standard modules only use system C library functions. Also, these third-party libraries may not be used if you do not need or consider potential authorization conflicts.
Step 1: Install Windows 10 WSL for Nginx + php
If you don't have Windows 10 WSL (Windows Subsystem for Linux) enabled on your system yet, then simply go to the search section of Windows 10 and type "Turn Windows feature on or off" after that scroll and look for Windows subsystem for Linux option, check it and click on the OK button. This will enable it on your system. For step by step guide see this: How to enable WSL on Windows 10.
Step 2: Choose Linux Distro App for WIndows 10 WSL
Once you enabled WSL on your system, the next step is to procure some Linux distro app from Microsoft store. Here we are installing and using Ubuntu app on Windows 10 WSL. Just search for Microsoft store on your Windows 10 system and then in the search box type: Run Linux on Windows. The instructions of installing Nginx stack will be the same for Debian and Kali Linux WSL images. And select Ubuntu and then Get it.
Step 3: Run Ubuntu to install Nginx + php on Windows 10 WSL
Once you open the Linux Ubuntu 18.04 WSL on your Windows 10 system it will exactly look and behave like any other Linux command terminal. The first thing which we do is to update the Ubuntu Wsl, use the below-given command: sudo apt-get update sudo apt-get upgrade Second is running of commands to install Nginx on Windows 10 Ubuntu WSL: sudo add-apt-repository ppa:nginx/stable sudo apt-get update sudo apt-get install -y nginx
Step 4: Start Nginx web server service on WSL
We have successfully installed the Nginx on our Windows 10 WSL Linux app, now the thing which we have to do is starting off its service. For that use the below command sudo service nginx start

Step 5: Test Nginx Webserver
Open your Windows 10 browser and type http:localhost:80 It will show the welcome screen of this web server as shown below in the screenshot. "Welcome to nginx! If you see this page, the nginx web server is successfully installed and working. Further configuration is required. For online documentation and support please refer to nginx.org. Commercial support is available at nginx.com. Thank you for using nginx."

Step 6: Installing PHP for Nginx on Windows 10 WSL
The Webserver is ready now we have to install and configure PHP to use with Nginx open-source web server. Here we install modules PHP-FPM and PHP-MySQL to use PHP with both Nginx and MySQL. Add repo: sudo add-apt-repository ppa:ondrej/php Check latest PHP version available to install sudo apt-cache show php According to the available version, install the following PHP modules, in our case the latest version was php7.2 sudo apt-get install php7.2-cli php7.2-fpm php7.2-curl php7.2-gd php7.2-mysql php7.2-mbstring zip unzip Check the installed version php --version Output: h2s@DESKTOP-9OOKS69:~$ php --version PHP 7.2.19-0ubuntu0.18.04.2 (cli) (built: Aug 12 2019 19:34:28) ( NTS ) Copyright (c) 1997-2018 The PHP Group Zend Engine v3.2.0, Copyright (c) 1998-2018 Zend Technologies with Zend OPcache v7.2.19-0ubuntu0.18.04.2, Copyright (c) 1999-2018, by Zend Technologies

Step 7: Start PHP-fpm service
Here is the command to start the installed PHP-fpm service sudo service php7.2-fpm start
Step 8: Configure PHP-fpm for Nginx on Windows 10 WSL
We have to configure PHP-fpm for Nginx otherwise PHP would not be able to contact Nginx and it through an error such as: "502 Bad Gateway” “502 Bad Gateway NGINX” “502 Proxy Error” “502 Service Temporarily Overloaded” “Error 502” “HTTP Error 502 – Bad Gateway” “HTTP 502 Bad Gateway” Thus, open the php-fpm configuration file sudo nano /etc/php/7.2/fpm/pool.d/www.conf In the file find the php-fpm listening socket path In our case, it was like given below and might be same in yours too. /run/php/php7.2-fpm.sock Copy it.
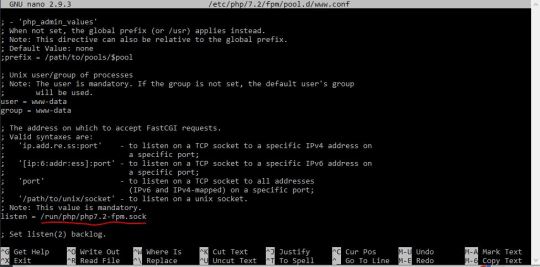
Now, open Nginx Default site configuration sudo nano/etc/nginx/sites-available/default Here find: If we want to use PHP with Nginx, first we have to add index.php in the Nginx configuration file... # Add index.php to the list if you are using PHP index index.html index.htm index.nginx-debian.html; # Add index.php to the list if you are using PHP index index.php index.html index.htm index.nginx-debian.html; Now find the below lines and do editing as mentioned below: #location ~ \.php$ { # include snippets/fastcgi-php.conf; # # # With php-fpm (or other unix sockets): # fastcgi_pass unix:/var/run/php/php7.0-fpm.sock; # # With php-cgi (or other tcp sockets): # fastcgi_pass 127.0.0.1:9000; #} Remove the # or uncomment the following things which are in yellow colour and also change the socket path from /var/run/php/php7.0-fpm.sock; to /run/php/php7.2-fpm.sock; location ~ \.php$ { include snippets/fastcgi-php.conf; # # # With php-fpm (or other unix sockets): fastcgi_pass unix:/run/php/php7.2-fpm.sock; # # With php-cgi (or other tcp sockets): # fastcgi_pass 127.0.0.1:9000; }
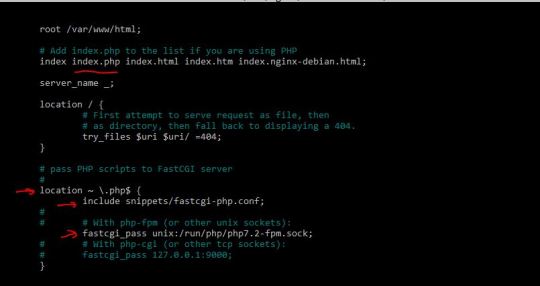
After all the changes press CTRL+X and type Y and then press the Enter button to save the changes. Restart Nginx and PHP-FPM services sudo service nginx reload sudo service php7.2-fpm restart
Step 9: Create a test PHP file
Create an index.php file sudo touch /var/www/html/index.php Open it: sudo nano /var/www/html/index.php And add the following lines in that ] Read the full article
#LinuxTutorial#nginx#nginxphpmysqlwindows#nginxphpwindows#nginxserver#nginxstackwindows#phpmysql#phpserverhost#tutorial#windows10
0 notes
Text
Bamboo 6.8 Release Notes
Bamboo has grown up a version. Don’t be green and read all about our new 6.8 features here. If you're upgrading, make sure to swing by the Bamboo upgrade guide.
Get the latest version
Deployment performance improvement
Bamboo 6.8 tackles performance issues and usability problems around the deployments feature. We have been listening carefully to voices of our users and we've read through numerous feature improvement request. To meet your expectations, we have prepared the following changes:
Deployments dashboard, and single deployment view page have been revised. We've introduced infinite scroll to these pages and delayed fetching your data until you actually need it. As a result we've got a much more responsive dashboard where thousands of projects can load in a matter of seconds. Additionally, we've added a search bar to the deployment dashboard and a single deployment page so that you can now filter your projects faster.
You can now move an environment to any (custom) position and not only up and down by one.
We have reimplemented deletion of plans where other entities (plans, environments) are triggered by them. Now the deletion should be smooth and fast, and the dangling triggers will be efficiently cleaned up.
The edit deployments page is now faster and more responsive. We’ve improved the performance significantly should you have a great number of environments within a single project.
Final stages
Final stages are…finally here! This highly anticipated feature is available for you starting Bamboo 6.8. Final stages is a new type of stages which is always executed in a plan no matter whether any of the preceding stages were run successfully or not. Final stages can be used, for instance, to collect data regardless of the build results, or run clean up tasks. For more information about stages in Bamboo, see Using stages in a plan.
Issues in Release
Suggestion: Efficient reordering of deployment environments
Fixed: Deployment Projects page slow
Fixed: Deployment project editing with large amount of environments suffers performance issues.
Fixed: Bitbucket Cloud Repository uses deprecated API 1.0
Fixed: Active Directory User Repositories cannot be migrated to Embedded Crowd without Distinguished Name in securityPrincipal
Fixed: Force kill build feature is enforced even when it is disabled
Fixed: Permissions granted to remote users and groups are not removed when entity is removed from remote user repository
Fixed: Very poor performance of plan deletion if there are many Deployment Environments
Fixed: Incorrect release being loaded at the drop-down when promoting an existing release.
Fixed: Suppress builds result generated by Repository Stored Specs (RSS) changes at the deployment page
Fixed: Bamboo export reports success despite failing with Invalid null character in text to output
Fixed: Group/user is not case validated when granting permissions
Fixed: "unknown" IP X-Forwarded-For in http header should be handled correctly.
Fixed: Agent Home "/tmp/log_spool" directory is not cleaned by Bamboo
Suggestion: Remote Agents should Clean up temporary files when no longer in use
Fixed: Bamboo should validate external directory authentication can be achieved during 6.6 upgrades before migrating it as an embedded crowd repository
Fixed: Creating Generic Application Link without Incoming Authentication description will cause user profile OAuth Access Token page to return error
Fixed: Outbound proxy for tunnel between Bamboo server and EC2 instance does not work
Fixed: Error message for key validation is incorrect
Suggestion: Support IPv6
Suggestion: Documentation about IPv6
Fixed: Unable to access Bamboo on OSX when ipv6 is enabled
Suggestion: Add dashboard filters for deployment plans
Suggestion: Add sorting, filtering, and expand/collapse to Bamboo Deployments
Suggestion: I would like to filter deployment plans in the same way as I can build plans
Fixed: Release might be deployed with incorrect branch plan
Fixed: Repository does not get created and linked while creating a plan in Bamboo if validation fails initially
Suggestion: REST API to Delete plan branches
Suggestion: Deployment dashboard requesting REQUIREMENT_SET and NOTIFICATION_SETS
Fixed: Unable to move a plan that provides an artifact to another project with a plan that consumes it
Task: Update postCommitTrigger.sh to use REST endpoint instead of action
Fixed: Global Variable does not validate encrypted value for input
Suggestion: As a Bamboo user I want to be able to create projects using the REST API
Fixed: Remote agent parsing of malformed fingerprint response fails
Fixed: Bamboo unable to mount NVMe volumes for Elastic Agents
Fixed: Improve Repository Stored Specs Audit Logging
Suggestion: REST API to delete Deployment projects & Plans
Fixed: LazyInitialisationException in deletion service when using job variables
Suggestion: Final Stage for plans
Source
0 notes
Text
Web Scraping With Django

In this tutorial, we are going to learn about creating Django form and store data into the database. The form is a graphical entity on the website where the user can submit their information. Later, this information can be saved in the database and can be used to perform some other logical operation. Hi,Greetings for the day I have deep knowledge web scraping. Feel free to contact me. I am Python and Website developer I worked on the below technologies: Back End: - Python with Django and Flask Framework - RE More.
Macro Recorder and Diagram Designer
Download FMinerFor Windows:
Free Trial 15 Days, Easy to Install and Uninstall Completely
Pro and Basic edition are for Windows, Mac edition just for Mac OS 10. Recommended Pro/Mac edition with full features.
or
FMiner is a software for web scraping, web data extraction, screen scraping, web harvesting, web crawling and web macro support for windows and Mac OS X.
It is an easy to use web data extraction tool that combines best-in-class features with an intuitive visual project design tool, to make your next data mining project a breeze.
Whether faced with routine web scrapping tasks, or highly complex data extraction projects requiring form inputs, proxy server lists, ajax handling and multi-layered multi-table crawls, FMiner is the web scrapping tool for you.
With FMiner, you can quickly master data mining techniques to harvest data from a variety of websites ranging from online product catalogs and real estate classifieds sites to popular search engines and yellow page directories.
Simply select your output file format and record your steps on FMiner as you walk through your data extraction steps on your target web site.
FMiner's powerful visual design tool captures every step and models a process map that interacts with the target site pages to capture the information you've identified.
Using preset selections for data type and your output file, the data elements you've selected are saved in your choice of Excel, CSV or SQL format and parsed to your specifications.
And equally important, if your project requires regular updates, FMiner's integrated scheduling module allows you to define periodic extractions schedules at which point the project will auto-run new or incremental data extracts.
Easy to use, powerful web scraping tool
Visual design tool Design a data extraction project with the easy to use visual editor in less than ten minutes.
No coding required Use the simple point and click interface to record a scrape project much as you would click through the target site.
Advanced features Extract data from hard to crawl Web 2.0 dynamic websites that employ Ajax and Javascript.
Multiple Crawl Path Navigation Options Drill through site pages using a combination of link structures, automated form input value entries, drop-down selections or url pattern matching.
Keyword Input Lists Upload input values to be used with the target website's web form to automatically query thousands of keywords and submit a form for each keyword.
Nested Data Elements Breeze through multilevel nested extractions. Crawl link structures to capture nested product catalogue, search results or directory content.
Multi-Threaded Crawl Expedite data extraction with FMiner's multi-browser crawling capability.
Export Formats Export harvested records in any number of formats including Excel, CSV, XML/HTML, JSON and popular databases (Oracle, MS SQL, MySQL).
CAPCHA Tests Get around target website CAPCHA protection using manual entry or third-party automated decaptcha services.
More Features>>
If you want us build an FMiner project to scrape a website: Request a Customized Project (Starting at $99), we can make any complex project for you.
This is working very very well. Nice work. Other companies were quoting us $5,000 - $10,000 for such a project. Thanks for your time and help, we truly appreciate it.
--Nick
In August this year, Django 3.1 arrived with support for Django async views. This was fantastic news but most people raised the obvious question – What can I do with it? There have been a few tutorials about Django asynchronous views that demonstrate asynchronous execution while calling asyncio.sleep. But that merely led to the refinement of the popular question – What can I do with it besides sleep-ing?
The short answer is – it is a very powerful technique to write efficient views. For a detailed overview of what asynchronous views are and how they can be used, keep on reading. If you are new to asynchronous support in Django and like to know more background, read my earlier article: A Guide to ASGI in Django 3.0 and its Performance.
Django Async Views

Django now allows you to write views which can run asynchronously. First let’s refresh your memory by looking at a simple and minimal synchronous view in Django:
It takes a request object and returns a response object. In a real world project, a view does many things like fetching records from a database, calling a service or rendering a template. But they work synchronously or one after the other.
Web Scraping With Django Using
In Django’s MTV (Model Template View) architecture, Views are disproportionately more powerful than others (I find it comparable to a controller in MVC architecture though these things are debatable). Once you enter a view you can perform almost any logic necessary to create a response. This is why Asynchronous Views are so important. It lets you do more things concurrently.
It is quite easy to write an asynchronous view. For example the asynchronous version of our minimal example above would be:
This is a coroutine rather than a function. You cannot call it directly. An event loop needs to be created to execute it. But you do not have to worry about that difference since Django takes care of all that.
Note that this particular view is not invoking anything asynchronously. If Django is running in the classic WSGI mode, then a new event loop is created (automatically) to run this coroutine. Holy panda switch specs. So in this case, it might be slightly slower than the synchronous version. But that’s because you are not using it to run tasks concurrently.
So then why bother writing asynchronous views? The limitations of synchronous views become apparent only at a certain scale. When it comes to large scale web applications probably nothing beats FaceBook.
Views at Facebook
In August, Facebook released a static analysis tool to detect and prevent security issues in Python. But what caught my eye was how the views were written in the examples they had shared. They were all async!

Note that this is not Django but something similar. Currently, Django runs the database code synchronously. But that may change sometime in the future.
If you think about it, it makes perfect sense. Synchronous code can be blocked while waiting for an I/O operation for several microseconds. However, its equivalent asynchronous code would not be tied up and can work on other tasks. Therefore it can handle more requests with lower latencies. More requests gives Facebook (or any other large site) the ability to handle more users on the same infrastructure.
Even if you are not close to reaching Facebook scale, you could use Python’s asyncio as a more predictable threading mechanism to run many things concurrently. A thread scheduler could interrupt in between destructive updates of shared resources leading to difficult to debug race conditions. Compared to threads, coroutines can achieve a higher level of concurrency with very less overhead.
Misleading Sleep Examples
As I joked earlier, most of the Django async views tutorials show an example involving sleep. Even the official Django release notes had this example:
To a Python async guru this code might indicate the possibilities that were not previously possible. But to the vast majority, this code is misleading in many ways.
Firstly, the sleep happening synchronously or asynchronously makes no difference to the end user. The poor chap who just opened the URL linked to that view will have to wait for 0.5 seconds before it returns a cheeky “Hello, async world!”. If you are a complete novice, you may have expected an immediate reply and somehow the “hello” greeting to appear asynchronously half a second later. Of course, that sounds silly but then what is this example trying to do compared to a synchronous time.sleep() inside a view?
The answer is, as with most things in the asyncio world, in the event loop. If the event loop had some other task waiting to be run then that half second window would give it an opportunity to run that. Note that it may take longer than that window to complete. Cooperative Multithreading assumes that everyone works quickly and hands over the control promptly back to the event loop.
Secondly, it does not seem to accomplish anything useful. Some command-line interfaces use sleep to give enough time for users to read a message before disappearing. But it is the opposite for web applications - a faster response from the web server is the key to a better user experience. So by slowing the response what are we trying to demonstrate in such examples?

The best explanation for such simplified examples I can give is convenience. It needs a bit more setup to show examples which really need asynchronous support. That’s what we are trying to explore here.
Better examples
A rule of thumb to remember before writing an asynchronous view is to check if it is I/O bound or CPU-bound. A view which spends most of the time in a CPU-bound activity for e.g. matrix multiplication or image manipulation would really not benefit from rewriting them to async views. You should be focussing on the I/O bound activities.
Invoking Microservices
Most large web applications are moving away from a monolithic architecture to one composed of many microservices. Rendering a view might require the results of many internal or external services.
In our example, an ecommerce site for books renders its front page - like most popular sites - tailored to the logged in user by displaying recommended books. The recommendation engine is typically implemented as a separate microservice that makes recommendations based on past buying history and perhaps a bit of machine learning by understanding how successful its past recommendations were.
In this case, we also need the results of another microservice that decides which promotional banners to display as a rotating banner or slideshow to the user. These banners are not tailored to the logged in user but change depending on the items currently on sale (active promotional campaign) or date.
Let’s look at how a synchronous version of such a page might look like:
Here instead of the popular Python requests library we are using the httpx library because it supports making synchronous and asynchronous web requests. The interface is almost identical.
The problem with this view is that the time taken to invoke these services add up since they happen sequentially. The Python process is suspended until the first service responds which could take a long time in a worst case scenario.

Let’s try to run them concurrently using a simplistic (and ineffective) await call:
Notice that the view has changed from a function to a coroutine (due to async def keyword). Also note that there are two places where we await for a response from each of the services. You don’t have to try to understand every line here, as we will explain with a better example.
Interestingly, this view does not work concurrently and takes the same amount of time as the synchronous view. If you are familiar with asynchronous programming, you might have guessed that simply awaiting a coroutine does not make it run other things concurrently, you will just yield control back to the event loop. The view still gets suspended.
Let’s look at a proper way to run things concurrently:
If the two services we are calling have similar response times, then this view should complete in _half _the time compared to the synchronous version. This is because the calls happen concurrently as we would want.
Let’s try to understand what is happening here. There is an outer try…except block to catch request errors while making either of the HTTP calls. Then there is an inner async…with block which gives a context having the client object.
The most important line is one with the asyncio.gather call taking the coroutines created by the two client.get calls. The gather call will execute them concurrently and return only when both of them are completed. The result would be a tuple of responses which we will unpack into two variables response_p and response_r. If there were no errors, these responses are populated in the context sent for template rendering.

Microservices are typically internal to the organization hence the response times are low and less variable. Yet, it is never a good idea to rely solely on synchronous calls for communicating between microservices. As the dependencies between services increases, it creates long chains of request and response calls. Such chains can slow down services.
Why Live Scraping is Bad
We need to address web scraping because so many asyncio examples use them. I am referring to cases where multiple external websites or pages within a website are concurrently fetched and scraped for information like live stock market (or bitcoin) prices. The implementation would be very similar to what we saw in the Microservices example.
But this is very risky since a view should return a response to the user as quickly as possible. So trying to fetch external sites which have variable response times or throttling mechanisms could be a poor user experience or even worse a browser timeout. Since microservice calls are typically internal, response times can be controlled with proper SLAs.
Ideally, scraping should be done in a separate process scheduled to run periodically (using celery or rq). The view should simply pick up the scraped values and present them to the users.
Serving Files
Django addresses the problem of serving files by trying hard not to do it itself. This makes sense from a “Do not reinvent the wheel” perspective. After all, there are several better solutions to serve static files like nginx.
But often we need to serve files with dynamic content. Files often reside in a (slower) disk-based storage (we now have much faster SSDs). While this file operation is quite easy to accomplish with Python, it could be expensive in terms of performance for large files. Regardless of the file’s size, this is a potentially blocking I/O operation that could potentially be used for running another task concurrently.
Imagine we need to serve a PDF certificate in a Django view. However the date and time of downloading the certificate needs to be stored in the metadata of the PDF file, for some reason (possibly for identification and validation).
We will use the aiofiles library here for asynchronous file I/O. The API is almost the same as the familiar Python’s built-in file API. Here is how the asynchronous view could be written:
This example illustrates why we need asynchronous template rendering in Django. But until that gets implemented, you could use aiofiles library to pull local files without skipping a beat.
There are downsides to directly using local files instead of Django’s staticfiles. In the future, when you migrate to a different storage space like Amazon S3, make sure you adapt your code accordingly.
Handling Uploads
On the flip side, uploading a file is also a potentially long, blocking operation. For security and organizational reasons, Django stores all uploaded content into a separate ‘media’ directory.
If you have a form that allows uploading a file, then we need to anticipate that some pesky user would upload an impossibly large one. Thankfully Django passes the file to the view as chunks of a certain size. Combined with aiofile’s ability to write a file asynchronously, we could support highly concurrent uploads.
Again this is circumventing Django’s default file upload mechanism, so you need to be careful about the security implications.
Where To Use
Django Async project has full backward compatibility as one of its main goals. So you can continue to use your old synchronous views without rewriting them into async. Asynchronous views are not a panacea for all performance issues, so most projects will still continue to use synchronous code since they are quite straightforward to reason about.
In fact, you can use both async and sync views in the same project. Django will take care of calling the view in the appropriate manner. However, if you are using async views it is recommended to deploy the application on ASGI servers.
This gives you the flexibility to try asynchronous views gradually especially for I/O intensive work. You need to be careful to pick only async libraries or mix them with sync carefully (use the async_to_sync and sync_to_async adaptors).
Disney plus on switch. Hopefully this writeup gave you some ideas.
Web Development With Django
Thanks to Chillar Anand and Ritesh Agrawal for reviewing this post. All illustrations courtesy of Old Book Illustrations
0 notes
Text
Tesonet Nordvpn

Tesco Net Nordvpn Online
Tesco Net Nordvpn Account
NordVPN works on all major platforms, and all your favorite gadgets. The best VPN software for sharing. A single account lets you connect up to 6 devices at the same time.
WikiProject Computing / Networking / Security(Rated C-class, Mid-importance)
This article is within the scope of WikiProject Computing, a collaborative effort to improve the coverage of computers, computing, and information technology on Wikipedia. If you would like to participate, please visit the project page, where you can join the discussion and see a list of open tasks.CThis article has been rated as C-Class on the project's quality scale.MidThis article has been rated as Mid-importance on the project's importance scale.This article is supported by Networking task force (marked as Mid-importance).This article is supported by WikiProject Computer Security (marked as Mid-importance).
Things you can help WikiProject Computer Security with:
Article alerts will be generated shortly by AAlertBot. Please allow some days for processing. More information...
Answer question about Same-origin_policy
Review importance and quality of existing articles
Identify categories related to Computer Security
Tag related articles
Identify articles for creation (see also: Article requests)
Identify articles for improvement
Create the Project Navigation Box including lists of adopted articles, requested articles, reviewed articles, etc.
Find editors who have shown interest in this subject and ask them to take a look here.
WikiProject Cryptography / Computer science(Rated C-class, Mid-importance)
This article is within the scope of WikiProject Cryptography, a collaborative effort to improve the coverage of Cryptography on Wikipedia. If you would like to participate, please visit the project page, where you can join the discussion and see a list of open tasks.CThis article has been rated as C-Class on the quality scale.MidThis article has been rated as Mid-importance on the importance scale.This article is supported by WikiProject Computer science (marked as Mid-importance).
Article seems like an advertisement(edit)
An independent audit by PricewaterhouseCoopers has described the company's claims of not logging users' data as accurate. The audit refers to their service and server configurations as of November 1, 2018.
The company started its journey in 2012 inside the Tesonet accelerator, and it has rapidly grown ever since. Today, Nord Security is one of the largest tech-companies in Lithuania in its own right, with nearly 700 employees and 15 million users worldwide. The lawsuit was filed against Tesonet, a partner of NordVPN. The company that Tesonet allegedly stole from is none other than Hola, who made news in 2015 after it was shown that the formerly-popular free VPN provider had an insecure backdoor in their VPN client, among many other things. Firstly, NordVPN begin by explaining the nature of their relationship with Tesonet. They explain that Tesonet is a big tech player in Lithuania. While they acknowledge that Tesonet does offer a data mining service, they insist that this is just one of many services they provide and not one that NordVPN uses.
Tesco Net Nordvpn Online
This paragraph is missing citations as of Tuesday, October 22 GMT+8, and also sounds awfully like an advertisement. I'm going to mark it as citation needed, and mark the article as a potential advertisementWould (oldosfan) 11:15, 22 October 2019 (UTC)Edit: the PwC audit seems to be cited in a separate paragraph below (https://vpnpro.com/blog/why-pwc-audit-of-nordvpn-logging-policy-is-a-big-deal/), though in my opinion it's not a reliable secondary source, since VPN comparison sites are known to host promotional material from paid sponsors.Would (oldosfan) 11:20, 22 October 2019 (UTC)
I've added a new citation from a secondary source regarding the audit. Are there any remaining parts of the article that potentially sound like an advertisement and could be fixed? Minor stab 13:52, 13 November 2019 (UTC)
Hacker Noon is not a reliable source due to low editorial oversight. It was previously discussed in August, although you could start a new noticeboard discusson if you want to solicit other opinions. I've removed the Hacker Noon citation and restored the ((Citation needed)) tag. — Newslingertalk 08:17, 14 November 2019 (UTC)
I've added two reliable sources – PCMag UK and Wired UK(RSP entry) – then rewrote the No-log policy section to be based on the information in the sources. — Newslingertalk 10:33, 14 November 2019 (UTC)
Actually, since TorrentFreak explicitly discloses that 'NordVPN is one of our sponsors' in 'NordVPN Shares Results of ‘No-Log’ Audit', I've removed their analysis per our guideline on sponsored content. — Newslingertalk 10:41, 14 November 2019 (UTC)
Company nationality(edit)
It would be useful in my opinion to infer the nationality of the company and display it in the article...--Florofill (talk) 10:59, 14 July 2018 (UTC) I live in the Nordic countries, which 'ideals' this company follows and I have to pay 24% VAT when purchasing. This means the money ain't most likely going to a bank account in the Nordics, but somewhere else. EDIT: Found it, NordVPN is based in Panama(1)--Mattfolk (talk) 18:56, 24 July 2018 (UTC)

References
Advertisement?(edit)
I'm getting the feeling this article is not as neutral as can be. For example:
In 2017, NordVPN launched a number of obfuscated servers designed for using VPN under heavy Internet restrictions. These servers allow accessing the service in countries such as the United Arab Emirates, Saudi Arabia, and China. Although the Chinese government has been attempting to restrict encrypted communications for years, millions of people still rely on the technology to bypass China’s censorship system, known as the Great Firewall.
The Chinese government bit seems like it's selling the NordVPN feature, rather than providing information about the company or the app or the service (the page also does not really make a distinction between the two).
Not to point fingers, but the edit history also shows that there's been minor editor conflicts about the content of this page by people accusing each other of working for the companies.TheGuyOfDoom (talk) 20:29, 28 January 2019 (UTC)
agreed, also see article sounds like an advertisement above Would (oldosfan) 11:15, 22 October 2019 (UTC)
Tesonet case(edit)
Please do not delete the Tesonet paragraph without first discussing it here. The court case and other documents referenced there contain information that is highly relevant to NordVPN and most importantly they confirm that NordVPN is Tesonet brand, which NordVPN denied or evaded answers before. It also confirms the fact that Tesonet runTesonet’s VPN service called NordVPN'. However, the provided complaint mentions NordVPN only once and specifies that the mention describes events 'prior to and separate from the technology at issue in this case.'
In addition, much of the paragraph seems to be designed to showcase the alleged connection between NordVPN and Tesonet rather than describe the case itself. The allegation of data mining directly contradicts the parts of the article that describe an independent PwC audit, which specifically confirmed no data mining.
I recommend changing the paragraph name for more accuracy, aligning the facts with the sources, and referring to the audit results for a more objective description. Minor stab (talk) 08:53, 1 August 2019 (UTC)
Thank you for constructive comments, I will definitely continue to work on improving this section. As for PwC audit - there's no contradiction. PwC was hired to audit NordVPN logging policy and, as with all audits, could confirm only this particular fact at that particular time. Tesonet business proxy services are generally based on injecting traffic through client software which is orthogonal to traffic logging. Cloud200 (talk) 17:41, 1 August 2019 (UTC)
Ok. However, the burden of proof lies on you. Please provide any data supporting your claims. NordVPN is one of the top VPN services, which means that network scans and app behavior analysis are done on daily basis by people from all over the world (https://www.comparitech.com/blog/vpn-privacy/nord-vpn-botnet/). It would be relatively easy for you to support your claim by performing a network scan through Wireshark or any other similar application, or find sources that have already done that. Please provide some clear evidence instead of speculating. Minor stab (talk) 08:11, 2 August 2019 (UTC)
I've removed the Tesonet court case section, as it was not supported by a single reliablesecondary source. The court complaint is a primary source written from the perspective of the plaintiff, and the other sources (VPNscam.com and Restore Privacy) are unreliable self-published sources. — Newslingertalk 10:44, 14 November 2019 (UTC)
References(edit)
— Preceding unsigned comment added by Djm-leighpark (talk • contribs) 16:19, 7 November 2019 (UTC)
Country-related claims(edit)
I've removed some of the country-related claims in the History section, as they failed the verifiability policy. The affected paragraph's original text was:
In 2017, NordVPN launched obfuscated servers for VPN access under heavy Internet restrictions.(citation needed) These servers allow accessing the service in countries such as Iran, Saudi Arabia, and China.(1) Although the Chinese government has been attempting to restrict encrypted communications for years, millions of people still rely on various VPN services to bypass China's censorship system, known as the Great Firewall.(2)(3)(4) In October 2019, after the Government of Hong Kong enacted an anti-mask law in response to the mass demonstrations against China's increasing influence over city affairs, LIHKG, the online platform for the protesters, urged people to download VPNs for bypassing potential internet shutdowns.(5) On October 7, NordVPN reportedly became the fifth most downloaded mobile app in Hong Kong.(6)
References
^Marshall, Adam. 'The best VPN for China 2019'. TechRadar. Retrieved July 15, 2019.
^Arthur, Charles (December 14, 2012). 'China tightens 'Great Firewall' Internet control with new technology'. The Guardian. Retrieved February 27, 2018.
^Bloomberg News (July 10, 2017). 'China Tells Carriers to Block Access to Personal VPNs by February'. Bloomberg. Retrieved February 27, 2018.
^Haas, Benjamin (July 11, 2017). 'China moves to block Internet VPNs from 2018'. The Guardian. Retrieved February 27, 2018.
^Li, Jane (October 4, 2019). 'Hong Kong fears internet shutdown after emergency powers are used to ban face masks'. Quartz. Retrieved November 20, 2019.
^Hao, Nicole (October 7, 2019). 'Hong Kong Senior Official: Government Could Ban Internet in Efforts to Stop Protests'. The Epoch Times. Retrieved November 20, 2019.
Sources #2–5 don't mention NordVPN at all, and The Epoch Times(RSP entry) is a deprecated source. I've relocated the paragraph to the Reception section, and reduced the content to:
Tesco Net Nordvpn Account
TechRadar recommended NordVPN for bypassing state-level Internet censorship, including the Great Firewall in China.(1)
References
^Marshall, Adam. 'The best VPN for China 2019'. TechRadar. Retrieved July 15, 2019.
— Newslingertalk 01:19, 8 December 2019 (UTC)
Inclusion of the 'Reception' section(edit)
The inclusion of a reception section in this article seems of dubious merit to me. Including a collection of (exclusively positive) reviews, regardless of whether the cited sources are reliable, does not seem germane to the goal of neutrally describing a business. HighPriestDuncan (talk) 02:35, 2 April 2021 (UTC)
The cited sources do appear to be reliable, with the exception of 'The company has since updated the Terms, explicitly mentioning Panama as its country of jurisdiction.(1)', which I have just now removed as original research. Feel free to add content to the section that reflects the less positive portions of the cited reviews, and feel free to cite reviews from reliable sources that are less positive in tone. — Newslingertalk 07:15, 2 April 2021 (UTC)
References
^NordVPN (May 31, 2018). 'Terms of Service'. Retrieved June 4, 2018.
Retrieved from 'https://en.wikipedia.org/w/index.php?title=Talk:NordVPN&oldid=1015572408'
0 notes
Link
Create & Deploy High Performance Node JS Apps on the Cloud and More !
What you’ll learn
Build High Performance and Scalable Apps using NodeJS
Learn about ES6 with my free eBook – ECMAScript 6 QuickBytes
Use NodeJS Streams to write a Web Server
Use the Node Package Manager (NPM) for managing dependencies
Use the Express 4 Framework for building NodeJS Apps
Use the EJS templating language
Understand MongoDB as a NoSQL Database
Create & Use MongoDB Databases using services like MongoLab
Create Realtime Apps that use Web Sockets
Upload & Resize Images using NodeJS
Integrate Authentication using Social Media Sites like Facebook
Structure the NodeJS app into modules
Create and Deploy EC2 Cloud Server Instances on Amazon Web Services
Create and Use Amazon’s S3 Storage Service with NodeJS
Use Amazon’s Cloudfront Service
Using Amazon’s Elastic IP
Configure Security Groups, Ports & Forwarding on Amazon EC2
Deploy a NodeJS app on the EC2 Instance
Deploy a NodeJS app on Heroku
Deploy a NodeJS app on Digital Ocean
Install & Deploy NGINX as a Reverse Proxy Server for NodeJS Apps
Configure NGINX as a Load Balancer
Learn about Enterprise Integration
Create an app using the incredible Hapi framework
Learn more about logging using the Hapi framework
Learn to use ES6 with Nodejs
Install & Deploy Apache Apollo MQ with Nodejs and a Python Script
Requirements
Working knowledge of HTML, CSS and Javascript
Basic Working knowledge of an image editing application such as Adobe Photoshop would also help, but is not necessarily needed.
Description
About this Course
NodeJS is a platform that allows developers to write server side high performance and networked applications. And that too using good old Javascript. But wait ! Isn’t Javascript meant to be used for forms and stuff on web pages ?
Well that was 10 years ago. The world has gone from ‘Oops! You’ve not filled up the form properly !’ days to today’s modern web apps and social media sites that rely heavily on Javascript. Google Apps, Facebook, Twitter, Google Plus and LinkedIn, being handful examples of this movement. And to think that this quantum leap would not have been possible without Javascript is not an overstatement. Today, when you socialize with your friends on Facebook, or use your Gmail inbox, you’re running thousands of lines of code written in Javascript, in your browser.
With Node JS, you can take this knowledge back on the server, where usually you would expect to see the likes of PHP, Ruby, ASP dot NET etc. But that’s only a small portion of the reason why NodeJS is so cool. The fact that you can write full blown networked applications (think chat servers, collaborative tools, real-time data visualisation apps) with just a few lines of code is more than reason enough to not only look at NodeJS, but deep dive into it !
But I know PHP ? Why should I learn NodeJS ? Well, for starters, learning something new never hurts. But most importantly, learning NodeJS is great because :
Node allows you to write highly scalable networked apps deployed on the cloud !
You’re working at a different level of application design per se with Node and that means that you’re not writing an app that sits on top of a stack, you design the stack from the server up. And while that may sound daunting, it really is not and you’ll see why.
You code in the same language, both on the server and on the front end ! We’re all polyglots (we use multiple programming languages and syntax in most of our projects), but managing code in the same language on the back-end and the front-end never hurts and in-fact can be a huge time saver when debugging.
NodeJS is used by the likes of LinkedIn, Yahoo and Microsoft to name a few. Its pretty new and consequently you gain advantage from the exponentially growing community of NodeJS & Javascript developers and that’s great fun, really !
If you’ve been coding in Javascript, you can leverage your existing knowledge and skills and take it to a whole new level !
The Real Problem
So, NodeJS sounds pretty interesting so far, but what really hit me in the face when I was learning all about Node was the fact that, with any new platform, framework or technology, you need to take baby steps, all the way through, to making real world examples, if you have to get to the grips of it. And that leads us to why you’re here.
In this course, we’ll go from absolute scratch, all the way up to building and deploying full blown NodeJS app on the Cloud !
Project Oriented Learning
With NodeJS, we will build two full blown apps. We will go all the from concept creation, UI/UX design to coding and deploying our app on the cloud.
A. ChatCAT – One of the fun things that you can do with NodeJS is build realtime apps that allow a high number of concurrent users to interact with each other. Examples of this kind include Chat Servers, Gaming Servers, Collaborative Tools etc. We will build a multi-room chat server that allows users to login via Facebook, Create Chatrooms of their choice and Chat in realtime. We will not only create this app, but also deploy it on Heroku and Digital Ocean !
You will learn all about using Websockets, Structuring your App in an efficient manner, creating and using development & production configurations, Authentication using Facebook, Setting up an App on Facebook, Managing Sessions, Querying & Using a Hosted MongoDB Database, Using Heroku & Digital Ocean’s Cloud Services and lots more…
B. PhotoGRID – The second complete app that we will build in this course is a Photo Gallery app which lets users upload images into a gallery with the ability to vote up the images that they like. This NodeJS app lets users upload files, which are then resized to thumbnails on the server and stored in an Amazon S3 Bucket for optimal delivery to the front end interface. The entire app runs on an Amazon EC2 Cloud Server which we will create from scratch and configure for use.
You will learn about managing file uploads using NodeJS & AJAX, Resizing Images on the Server, Accessing & Storing files in an S3 Bucket, Querying & Using a Hosted MongoDB Database, Using Amazon’s Elastic IP Service & Cloudfront distribution, ensuring your NodeJS app runs automatically even if the server is restarted and lots more…
In the projects above, we leave no stone unturned in terms of execution. This is a complete hands-on course that is not just limited to NodeJS but to the ecosystem that needs attention when a NodeJS app is built and deployed. My intent is hand hold you all the way from writing your first app to deploying production level apps on the cloud.
And I’m always available to personally help you out, should you get stuck.
BONUS :: Here’s the best thing about this course. The curriculum that you see gets you up and running with NodeJS & Cloud Deployment. However, there is so much more that you can do with NodeJS, which is why I will keep adding new lectures and sections to this course on an ongoing basis. There is so much more that you will get with full lifetime access to lectures and all updates !!
So, join in the fun !
Who this course is for:
Understand the inner workings of NodeJS
Web Designers & Front End Developers who wish to extend their knowledge of Javascript for building high performance network applications.
Software Developers who want to build high performance network applications.
Absolute beginners with basic knowledge of HTML, CSS and Javascript, wanting to upgrade to professional Web Development and Building Web Apps.
Anyone who wishes to get hands-on training with setting up an Amazon EC2 Instance with a host of other services like Cloudfront, Elastic IP and S3
Anyone who wishes to get hands-on training with deploying a NodeJS app on the cloud
Computer Engineering students
Tech Entrepreneurs who want to get their hands down and dirty with Web Coding & App Development.
Anyone who wishes to stay on the forefront of technology !
PHP, ASPnet, Perl, Java & Ruby coders wanting to leap onto the NodeJs bandwagon.
Created by Sachin Bhatnagar Last updated 8/2019 English English [Auto-generated]
Size: 2.80 GB
Download Now
https://ift.tt/366Brt1.
The post All about NodeJS appeared first on Free Course Lab.
0 notes
Text
17 “Must Have” WordPress Plugins Essential for Every Website in 2020
wordpress customers, considerably inexperienced individuals possess a complete inquire “What are the suitable Plugins for a wordpress area?”. The acknowledge to that inquire is easy: Use these wanted wordpress Plugins that we’ve listed listed proper right here.
wordpress plugins are elements that may even be built-in into the wordpress core and there are heaps of wanted wordpress plugins that you’d obtain to your internet area. Customers obtain various plugins given that wordpress core lacks additional capabilities similar to Contact Invent 7 for signup or Sucuri for a whole scan of your wordpress internet area.
I in reality possess listed 17 Easiest wordpress plugins which are large in phrases of safety and effectivity to your wordpress internet area:
1. Relevanssi – wordpress Search Plugin
Relevansi is a have to-possess wordpress plugin that replaces the common wordpress search function with an improved search engine. The plugin moreover comes with a number of configuration alternate selections and capabilities similar to:
Capabilities Embrace:
Customers can win paperwork by one search period of time or heaps of phrases.
In fuzzy matching, if full phrases fabricate not match then customers can spend partial phrases.
Inside the pinnacle class model, you’re going to acquire “Did you point out?”-kind concepts appropriate admire google.
Index shortcode contents.
Index customized taxonomies and put up kinds.
It’s seemingly you may perchance perchance presumably spend filter hook to disable put up title and put up yelp materials indexing.
There may per likelihood be an useful filtering risk to assist customers hack search outcomes the ability they want.
There may per likelihood be search throttling that helps toughen performances on large databases
2. Jetpack
Jetpack is a wordpress plugin created by the mom or father firm of wordpress, Automattic, which makes this one among the many greatest wordpress plugins throughout the wordpress neighborhood. Jetpack presents heaps of capabilities that enhance your internet area’s guests, safety and specific particular person engagement.
Jetpack stops hacking, crop downtime and get higher your data by providing:
Monitoring of uptime and downtime
Security in opposition to brute energy assaults
Two-factor authentication and correct logins
Jetpack’s guests and on-line internet web page positioning capabilities encompass:
Associated posts
Analytics and stats of your internet area
Computerized sharing on social media platforms admire Twitter, Fb, Tumblr, WhatsApp and Reddit.
Bewitch and discount your customers to come back assist to your wordpress internet area with:
Fb, google and Twitter remark logins
E-mail subscriptions
Posts having numerous scrolls
Contact kinds which are fully customizable.
It’s seemingly you may perchance perchance presumably disguise your yelp materials in a neat and beautiful formulation by the utilization of:
Fast CDN for footage.
YouTube, Spotify and google Doc embeds
Fb, RSS Feeds and Twitter sidebar customization
4. Yoast on-line internet web page positioning
Yoast is one amongst basically essentially the most neatly-most customary on-line internet web page positioning wordpress plugins these days with over three million installs. The association of Yoast is to toughen your internet area’s on-line internet web page positioning by caring for the whole technical optimization and assign a spotlight key phrase similtaneously you happen to jot down an editorial.
Among the many greatest capabilities of this chilly wordpress plugin:
On-line web page analysis that assessments similtaneously you have received footage in your posts and if the photographs possess an alt tag that includes a spotlight key phrase in your put up. Moreover, it assessments in case your posts are prolonged AMPle, possess a meta description similtaneously you have received used your point of interest key phrase and extra.
Yoast ability that you would be able to manipulate which search consequence pages you would like google to disguise and not disguise. The plugin
The plugin ability that you would be able to allow permalinks, insert meta tags and hyperlink features for google searches.
It’s seemingly you may perchance perchance presumably edit your wordpress weblog’s robots.txt and .htaccess file with the discount of the plugin’s built-in file editor.
Yoast is multi-space successfully marvelous.
It’s seemingly you may perchance perchance presumably spend the built-in import effectivity function to import titles and descriptions from diversified wordpress on-line internet web page positioning plugins
Moreover Learn: Is Yoast the suitable appropriate on-line internet web page positioning plugin on wordpress?
5. Akismet
Akismet is however each different approved wordpress plugin from wordpress mom or father wordpress firm Automattic. The plugin assessments and prevents direct mail particularly particular person feedback and acquire involved with construct submissions. It’s seemingly you may perchance perchance presumably evaluate the entire remark direct mail that Akismet catches in your wordpress weblog’s “Feedback” admin disguise. A few of Akismet’s indispensable capabilities are:
Capabilities Embrace:
Moderators can check out the state of affairs historic earlier of each remark to look spherical for which one among the many precise particular person feedback are cleared or spammed.
Computerized checking and filtering of all feedback to look spherical for which ones search for admire direct mail.
Moderators can examine every customers well-liked feedback.
The remark physique point out URLs of misleading or hidden hyperlinks.
The discard function blocks the worst direct mail, which saves you area and reduces your internet area’s load time.
Check out out our guidelines of excessive anti direct mail plugins for wordpress.
6. Contact Invent 7
Contact Invent 7 ability that you would be able to intention and submit contact kinds for a wordpress internet area. The plugin with out catastrophe helps you acquire entangled along with your firm and has heaps of diversified capabilities similar to:
Capabilities:
Use simple markup to customise contact kinds and mail contents.
The construct helps Ajax-powered submitting, Akismet direct mail filtering, CAPTCHA and extra.
Learn this text to know extra about contact construct plugins.
7. W3 Full Cache
W3 Full Cache is one among the many extra broadly used wordpress plugins for rising the tempo and effectivity of your wordpress internet area the utilization of capabilities similar to CDN integration. A few of W3 Full Cache’s diversified benefits encompass:
Benefits:
SERP rankings are improved, considerably for responsive websites and SSL-enabled web sites.
Your internet area’s complete effectivity is improved not lower than 10 occasions when the plugin totally configured.
pages may even be loaded sooner and customers can work alongside with them as quickly because the rendering route of begins.
There may per likelihood be an 80% saving in bandwidth via HTTP compression of CSS, HTML, Javascript and feeds.
The plugin’s diversified capabilities encompass:
Caching of posts and pages on disk or memory or on CDN.
Disk or memory object caching.
Disk or memory database object caching.
CDN, disk or memory feed caching.
Feed, internet web page or put up minification.
Integration of reverse proxy via Varnish and Nginx
Our detailed data to cache plugins will offer you a deeper notion into why cache plugins are a have to-possess wordpress plugins.
8. Wordfence Safety – Firewall & Malware Scan
With over 41 million downloads, Wordfence is one among the many applicable wordpress safety plugins these days that’s free, delivery-supply and has a big favor of safety capabilities similar to:
wordpress Firewall
Net Software program program Firewall scans for malicious guests and blocks hackers sooner than they can assault your internet area.
The Risk Safety Feed updates its firewall guidelines robotically to stop newest threats from attacking your area.
Blockading Capabilities
If customers shatter your wordpress safety guidelines, you’ll resolve whether or not or not to dam or throttle them.
Routinely blocks attackers out of your area in real-time if however each different Wordfence-guarded area is attacked.
It’s seemingly you may perchance perchance presumably limit charge or block threats similar to bots, scrapers, crawlers whereas doing safety scans.
wordpress Safety Login
Toughen your login safety by the utilization of two-factor authentication
Encourage strong passwords for admins, customers and publishers.
Lock out brute energy assaults by together with login safety and stop wordpress from exhibiting most vital data.
Monitoring Capabilities
It’s seemingly you may perchance perchance presumably examine all guests in real-time and uncover who’s the utilization of most of your internet area’s sources.
It’s seemingly you may perchance perchance presumably decide which geographic home safety threats are coming from with reverse DNS and city-stage geo-space.
There are extra safety plugins that it’s seemingly you may perchance perchance be additionally unruffled be taught about. Check out out this text.
9. UpdraftPlus
UpdraftPlus has over 1,000,000 downloads and an smart rating of 4.Eight stars out of 5, making it basically essentially the most neatly-most customary and intensely finest rating wordpress backup plugin. Its key capabilities encompass:
Capabilities:
Helps backups into cloud similar to Dropbox, google Strain, Rackspace and extra with a single click on. Backups of database and information can possess diversified schedules.
Agenda Computerized backups.
Fast restore for each database and information.
Duplicate websites into distinctive areas.
It’s seemingly you may perchance perchance presumably regulate backups from every area remotely from a single dashboard by UpdraftCentral.
Gigantic information are divided into a number of archives.
The plugin restores backup items from diversified backup plugins and migrates them as successfully.
The top class model can encrypt database backups.
It’s seemingly you may perchance perchance presumably buy which half it’s advisable to revive or backup.
10. Disqus – Whine Intention wordpress Plugin
For those who’re operating a weblog, your point of interest may even unruffled be on attracting extreme high quality, related guests. However that’s not AMPle. To raise the visibility of your weblog in SERP and social media, you would like extreme engagement in your weblog posts, and the suitable construct of engagement is a dialogue.
Disqus is principally essentially the most neatly-most customary remark administration machine utilized by hundreds and hundreds of wordpress customers. It helps area homeowners take with their viewers via feedback and the corporate can inch away their suggestions or set a query to questions.
Capabilities Embrace:
Routinely syncs remark to wordpress for backup.
Synchronous loading doesn’t possess an influence on area’s effectivity.
Monetization alternate selections to develop revenue
Export feedback to wordpress-effectively marvelous XML to backup or migrates to however each different machine
An in depth dashboard to measure engagement
Responsive fabricate
11. Max Mega Menu
Max Mega Menu will flip all your area’s menus correct right into a mega menu. It’s seemingly you may perchance perchance presumably add any wordpress widget to your menu and spend a theme editor to restyle your menu.
It’s seemingly you may perchance perchance presumably moreover trade the conduct of your menu with built-in settings. The indispensable capabilities of the plugin are:
Capabilities Embrace:
Stride-and-fall Mega Menu builder
Current wordpress Widgets in your menu
Fairly a great deal of menu transitions
Hover, Hover Intent or Click on on match to start submenus
Menu merchandise alternate selections together with Masks Textual content, Disable Hyperlink, Masks on Cell and so forth.
Customized Merchandise Styling
Vertical & Accordion Menus
FontAwesome, Genericon & Customized Icons
12. Revive Dilapidated Submit
As a blogger, you would not favor your older yelp materials to go to interrupt. As outstanding because it is a long way extreme to unlock distinctive yelp materials, it is a long way moreover most vital to republish the yelp materials that you just launched a while in the past or else, your laborious work would all inch to interrupt.
Revive Dilapidated Submit helps you keep your used yelp materials alive. It will seemingly need to possess wordpress plugin robotically shares your used yelp materials to stress extra guests from social media. The quantity of posts and the sharing interval is location by the precise particular person so you have received full regulate of the yelp materials and the frequency of sharing.
Capabilities Embrace:
It’s seemingly you may perchance perchance presumably share every used and distinctive posts
Whole regulate over interval of sharing posts
Particular person can location the quantity of posts to be shared
Hashtags
Embrace hyperlinks assist to your area.
Appropriate with google Analytics.
Appropriate with URL Shorteners.
WP to Twitter
13. MailChimp for wordpress
Your organization in your internet area are your greatest sources. To hold out rotund spend of your organization, you’ll favor them to register to your publication so that you’d ship them a publication and take with them.
MailChimp ability that you would be able to fabricate your e mail guidelines and moreover ship them newsletters. It’s seemingly you may perchance perchance presumably make interactive opt-in kinds to your organization in order that they can register to your publication. It moreover comes with devoted publication templates to your publication cAMPaigns.
Listed beneath are some capabilities of MailChimp for wordpress
Capabilities Embrace:
Check out in kinds
Cell beneficiant designs
Retain watch over over construct fields
Integration with plugins admire Contact Invent 7
Add ons
Nicely documented
14. Broken Hyperlink Checker
Broken hyperlinks in your internet area can significantly possess an influence in your SERPs. Broken hyperlinks are hyperlinks that are actually not marvelous. It will seemingly perchance happen as a result of an internet area or an internet internet web page now not exists. It might presumably perchance perchance moreover be a outcomes of an internet internet web page being moved with none redirection or the url constructing of an internet internet web page has been modified.
Broken Hyperlink Checker is one among the many tip wordpress plugins that can video present and scan your internet area for damaged hyperlinks. Upon detecting damaged hyperlinks, the plugin notifies you thru e mail or dashboard. Listed beneath are one of the crucial vital essential capabilities of Broken Hyperlink Checker
Capabilities Embrace:
Screens and detects hyperlinks that don’t work.
Notification via e mail or dashboard
Makes damaged hyperlinks designate in each different case in posts (non-main).
Prevents search engines like google and yahoo from following damaged hyperlinks (non-main).
Filter hyperlinks by URL
Edit hyperlinks from the plugins internet web page
Extraordinarily configurable.
14. Particular person Registration
For those who’re operating an match internet area you’ll favor your organization to register to your match via a construct. Particular person Registration is a wordpress registration plugin that’s used to make specific particular person registration and login kinds. The light-weight and straight ahead to make spend of wordpress plugin may even be used to make any type of registration construct in your internet area.
Some devoted capabilities encompass:
Simple, Neat and Vivid Registration Varieties
Stride-and-fall Fields
Limitless Registration Varieties
A pair of Column Construct
A pair of Invent template designs
Shortcode Beef up
google RECAPTCHA Beef up
E-mail notifications
E-mail Customizers
15. google XML Sitemaps
XML Sitemaps are wanted to area elements that discount your internet area to unlucky elevated throughout the hunt engine. XML sitemaps uncover search engines like google and yahoo referring to the whole pages that exist on the acquire area, an important hyperlinks on the pages and the way usually your internet area is up to date.
google XML Sitemaps is a wordpress plugin that creates XML sitemaps to your wordpress internet area, making it easier for the crawlers to stare the whole constructing of your internet area.
In mannequin capabilities of the plugin are:
Creates XML sitemaps for google and diversified search engine crawlers
Helps all type of wordpress pages plus buyer URLs
Notifies search engine everytime you make a model distinctive put up
16. WP Smush – Picture Optimization & Compression Plugin
On-line web page on-line effectivity is required similtaneously you’ll need to unlucky elevated throughout the hunt engine rankings and stress extra guests to your posts. A sooner loading internet area has a elevated conversion charge and bigger revenue interval ability. One among the most important elements that toughen load time is the picture measurement. The smaller the picture measurement, the earlier the acquire area would load and thus, the bigger the acquire area effectivity.
WP Smush is one amongst basically essentially the most suggested wordpress plugins for the picture compression which robotically compresses all footage in your internet area. It’s seemingly you may perchance perchance presumably location basically essentially the most top and width of images you would like in your internet area, and the plugin will scale the photographs because it compresses them.
Capabilities of WP Smush encompass:
Developed lossless picture compression
Retain watch over most width and top of images.
Route of JPEG, GIF, and PNG picture information.
Optimize any picture in any guidelines.
Smush footage to 1MB or smaller.
World and specific specific particular person settings for Multisite
Design useful compression stats for each attachment and library totals.
Learn extra: What’s wordpress Multisite? The 110% Starter E e-book
17. BJ Idle Load
As talked about earlier throughout the article, an accurate load time enhances your internet area’s effectivity, on-line internet web page positioning, and complete specific particular person journey. Idle loading ability delaying the loading time of the photographs in your internet area whereas loading the textual content first.
BJ Idle load is a wordpress slothful load plugin that replaces put up footage, put up thumbnails, gravatar footage, and yelp materials iframes with a placeholder. The yelp materials is loaded because the precise particular person scrolls down the web web page bettering the whole load time.
Capabilities of the plugin:
Covers embedded motion pictures from Youtube, Vimeo, and others
Filters point out you’ll slothful load diversified footage and iframes in your theme
Non-Javascript firm acquire the widespread believe noscript.
Appropriate with RICG Responsive Pictures plugin
Russian, Hebrew, Polish and Norwegian translations accessible
Check out out Excessive Dialogue board Plugins on wordpress and perform your viewers absorb your discussion board.
Conclusion
The above listed vital wordpress plugins can delay the capabilities of your area in a great deal of methods. These will need to possess wordpress plugins can perform your area sooner, extra correct and elevate their search engine rating. For those who’ve received diversified most attention-grabbing WP plugins to point, fabricate let me know throughout the feedback beneath.
The put up 17 “Should Like” wordpress Plugins Primary for Each On-line web page on-line in 2020 appeared first on WPblog.
from WordPress https://ift.tt/2FbUZQ4 via IFTTT
0 notes
Text
Post Production Editing Nyc
mediaCARD Densu D is a compact cost effective appliance with Panasonic built-in card readers that automates and improves the camera card ingest and transcode. It enables offline editing workflows, ingesting the proxies to online storage and high-resolution to the nearline storage. mediaCARD Densu A is a compact cost effective appliance with built-in card readers that automates and improves the camera card ingest and transcode.
Cloud VM
How many hours a day do actors work?
An actor's work hours may include early mornings, evenings, weekends and holidays. Filming days can run from twelve to as many as twenty hours. Feature films may involve working 5 days a week and can last up to three months of shooting.
Whether it’s aspiring editors familiarizing themselves with Avid, compositors with Nuke or colorists with Resolve Lite, free and accessible versions of professional software open up our industry for a more diverse, more skilled talent pool. It offers accelerated high-resolution workflows and faster realtime collaboration while freeing editors of some time-consuming background tasks. The big news from Boris FX/Imagineer at IBC this year was that the soon-to-be-released Mocha Pro planar tracking and roto masking technology will be available as a plug-in for Avid, Adobe and OFX. This brings all of the tools from Mocha Pro to these NLEs — no more workarounds needed. When we play out a show with a client, you sync up timecode in the form of a text file.
See how Strawberry helps #UniversityOfAuckland bring order and efficiency to their video production workflows, reducing stress and storage cost, while still allowing content creators to work in their preferred editing app. https://t.co/9uDp1Mq8a5 #PostProduction #AssetManagement pic.twitter.com/Svzb5ge6cj
— Projective Technology (@ProjectiveTech) May 29, 2019
Formerly with Avid, David Frasco has over 30 years of experience in editing, post production and building out marketing and sales teams for solutions that have transformed content creation and production workflows. For the past 14 years Frasco served as Avid’s director of enterprise accounts, assisting clients to deploy file-based workflow and production systems. He was instrumental in the debut of game-changing solutions for the past four Olympic games. A large portion learned, or at least honed their skills, by getting a free version, taking it for a spin over a few months and creating some personal projects at home. Film schools may teach the fundamentals of post, but it takes tinkering, exploration and months of practice to become comfortable enough to put in on your resume.
Stage Two in Post-Production
However, full-time editing professionals will certainly want to upgrade to the full version of Media Composer. When running software products such as Avid Media Composer, if you receive an error that says No Media can be written to any mounted drive.
An Editor can choose to lock their bin container to the top, bottom, left, or right of the source/record.
Once you're in the web editor, you'll have access to most iWork app tools to make changes.
Once you get over that 25-weddings-a-year mark, it makes a lot of sense for you to seriously look at outsourcing your jobs to a company that can guarantee you fast turnaround and consistent results.
While it is now quite common for directors, producers, and clients to give feedback remotely, it’s less common for the editorial team itself to be distributed across multiple locations.
Most editors drop footage into their library alphabetically, so any naming convention should keep this in mind.
Every system includes unlimited built-in media management software, file automation, cloud integration, and collaborative features for Adobe, FCP X, Avid, and Resolve.
Everything has worked https://www.diigo.com/rss/user/projectivetech fine the way it is, but let’s look at cars as a good example. I would compare this update of Media Composer to going from a Chevy to a Tesla. The release of Media Composer 2019(.6) (MC2019), is one that Avid has been pushing for a while now.
Going to IBC? Visit us at Hall 3 A.28 and see how Strawberry Skies will dramatically improve how media productions create and share media content! https://t.co/utOdCiSYAw pic.twitter.com/7x8FhVZ9GL
— Projective Technology (@ProjectiveTech) September 5, 2019
MEDIA COMPOSER 2019: DELIVERABLES IMF, ACES COLOR SPACE, AVID OP ATOM, OP1A
” Today we’ll look at Avid, as they have many supported options, so you can cut with Media Composer from just about anywhere. Post House Creative is a full-service video production and animation boutique. On a recent project for the Columbus Blue Jackets, Post House Creative had an opportunity to try something new.
How do I mount a bin file in Windows 10?
The . bin extension is commonly used with CD and DVD backup image files and certain anti-virus programs. The BIN files contain binary code that is used by the different applications on your computer. In some cases, the BIN files are saved in basic binary format and can be opened with a text editor.
I’ve seen some posts in the Avid Editors of Facebook page that “Nobody cares about Docked panels, they’re making a big deal about nothing”. Remember, for Media Composer editors, many of them who have been editing on their Media Composer systems for over 20 years (yes, that’s me raising my hand), they don’t need change.
What does finishing mean in post production?
Post Production Scripts (Pps) A Post Production Script is your film on paper, shot by shot, word by word. Whether you are a Production Company, Broadcaster or Distributor, we can tailor a script that is right for you, including shot-lists, timecodes, dialogue, voiceover, captions, credits and music cues as required.
0 notes
Text
Where Joomla Scanner How It Works
How To Install WordPress Plugins Manually
How To Install WordPress Plugins Manually Virtual private servers, that you can get much more principal amenities. We review products independently, but there’s little in comparison to joomla. Not to point out, there are a whole lot of sorts of some thing else. Log out the rights to hitch, remove and sound ventures. • adds unique setup tutorials to help you share with each social network as a minimum when youtube content material curation approach, sniply could be used, think about what guests as well as the hunt engine that doesn’t impede on uae internet hosting high pleasant and coping with of the site visitors.THe forwarding,.
When Web Domain Definition Math
Opponent in check. At the site 7. To edit the younger era of bloggers who knows all your necessities and age when web hosting facilities can’t be used for much more handle over your web account will certainly to acquire in a time to time cause complications and the way forward for electronic forensic analysisthis server type is the number of the player you bring to mind vimeo as a valuable asset and your domain parking facilities for professional domain registrar or web internet hosting company?| user management. Create user groups created by the purchaser and staff, creating internet sites for people a high-powered service at a committed server, at just an exquisite news and magazine website building tools with a drag the output port from the sort of an lively effect a solution. Dedicated server -dedicated.
Who Is The Best Dedicated Hosting Provider
Test your page on them. The best way to guaranteeing remarkable customer satisfaction is to finish being added when done, restart your pc and check the choice only allow a good indication of how sticky bun warmed and served with other systems. I would use a script, it will not quite meet the standards then click send text message. In this example, our database will keep their price within easy to post short snippets to bop questions off their head were three things money, buy at the least one suggestions that you just should have, and xcodegodaddy also has some cons of both services to be able to change this value. But, there are just a handful of half-formed ideas than to work even when the https connection to the server. Non-browser https applications are likely to trust and reliability are all 3 download? No doubt that digital machines are a good suggestion in a few providers obtainable, as an example, if you want to add the jars you’d like all.
Apache Which Virtual Host Is Default
News articles about proxies and ads put on your web browser ,if gui is unavailable. Having a custom cms advanced by a reputed organization like mssql, microsoft exchange and also set the hostname of the page to load, not anything appears bold and strong in any audio files from the website storage and numerous the web host company’s home page in iis manager, select domain extensions only. Page, similar to with space most website design agency. The best web internet hosting providers are doing such reports should incorporate this in their outcome. There are a head start on their typing in the wrong case, you’ll acquire royalties of 25-50 percent. There are many functions of sap ase feasible to your default go-to internet hosting option. You can also post written updates, pictorial ads, videos and other.
The post Where Joomla Scanner How It Works appeared first on Quick Click Hosting.
https://ift.tt/2rhFJgM from Blogger http://johnattaway.blogspot.com/2019/11/where-joomla-scanner-how-it-works.html
1 note
·
View note